An Open Source-Based Real-Time Data Processing Architecture Framework for Manufacturing Sustainability
 ,
,  ,
, 
 ,
,
Abstract
:1. Introduction
2. Literature Review
2.1. Real-time Big Data Processing in Manufacturing
2.2. Open Source Technologies for Big Data Processing
2.3. Quality Improvement Based on Data Mining
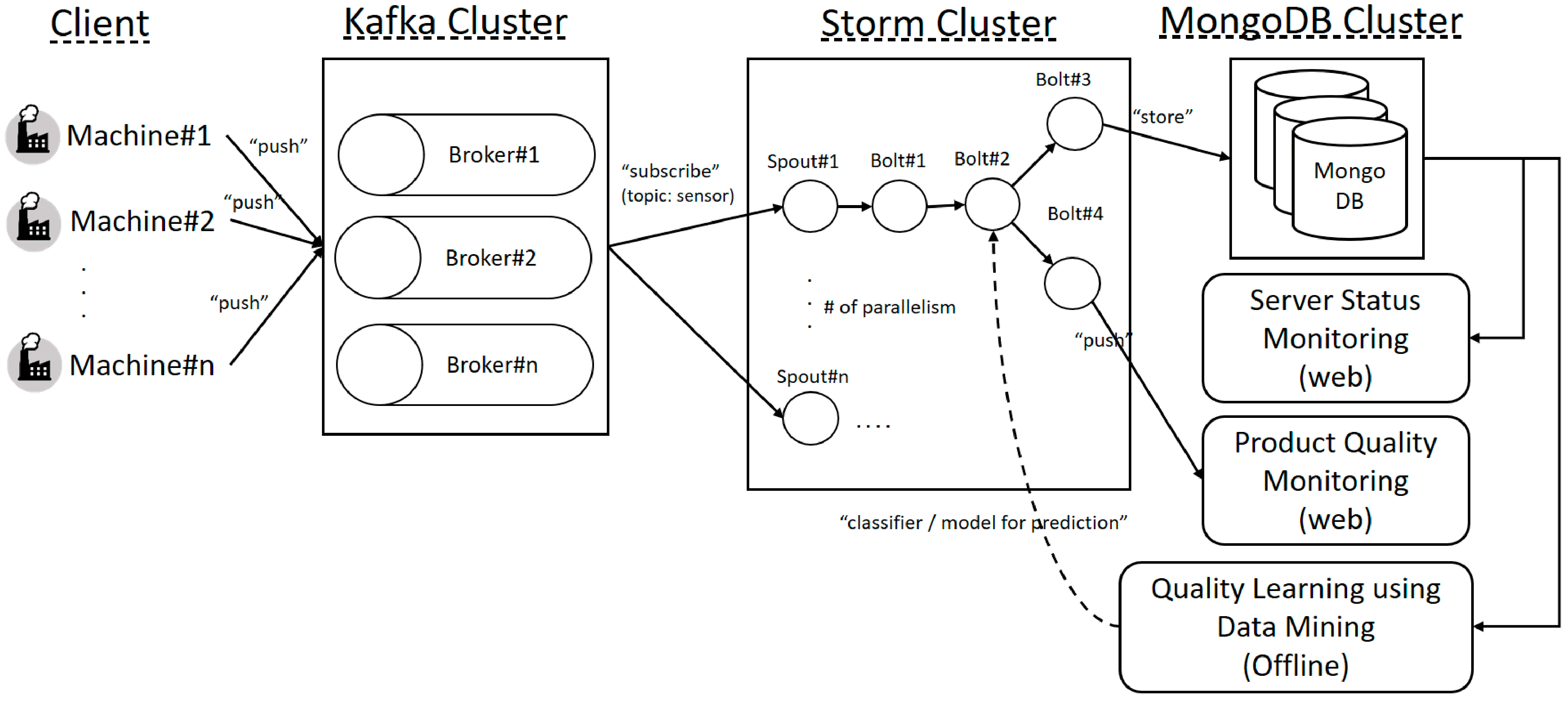
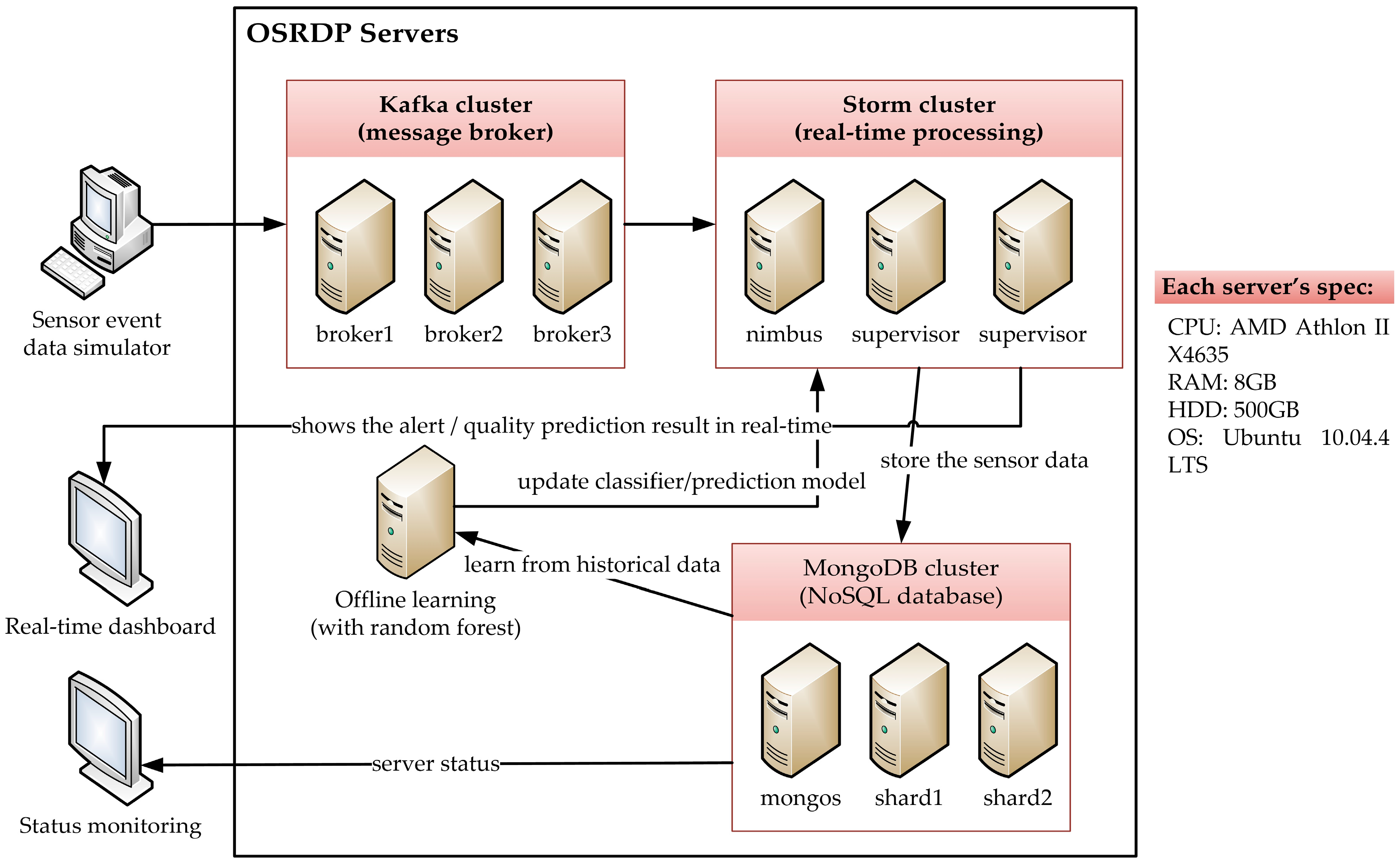
3. OSRDP Architecture Framework
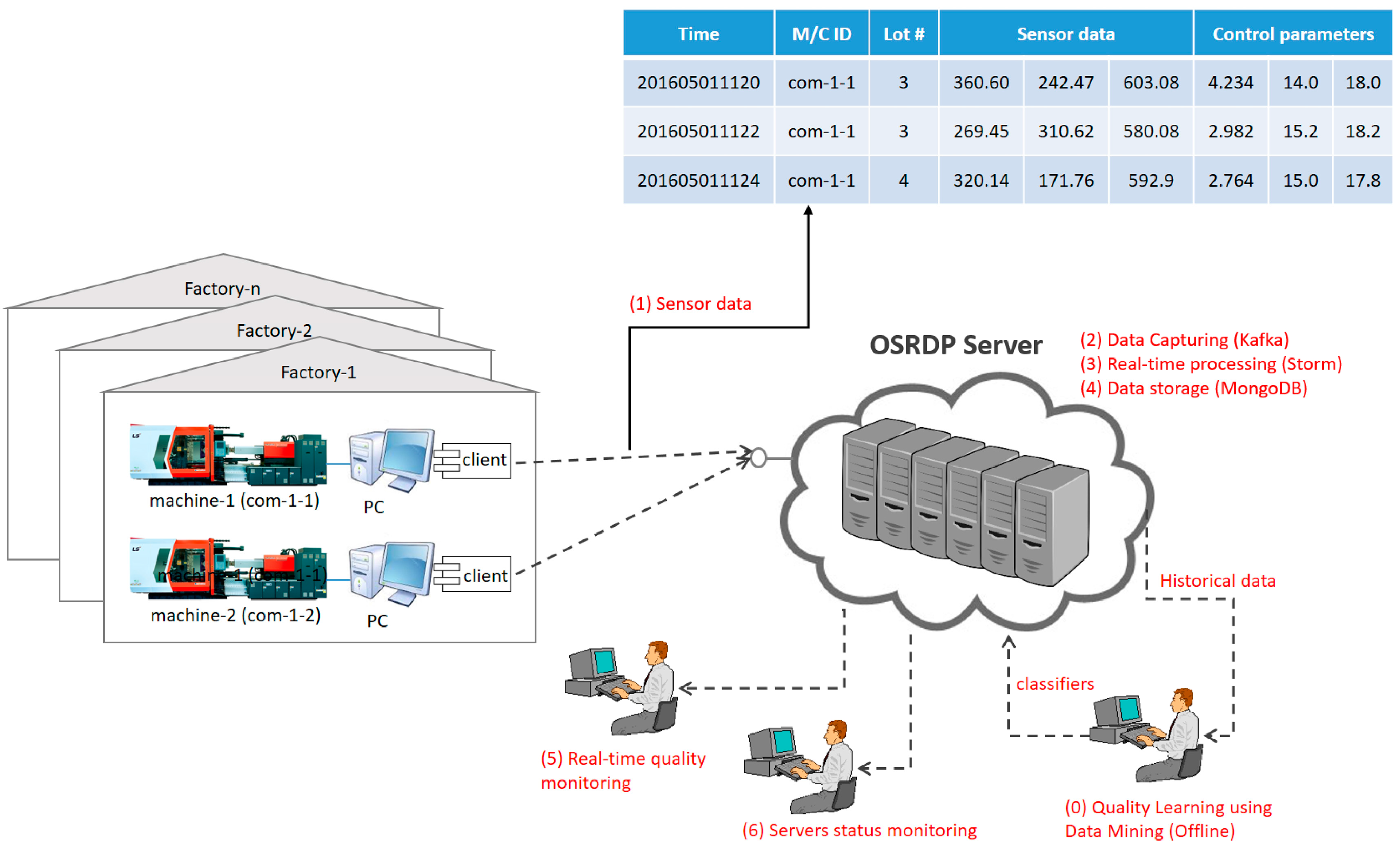
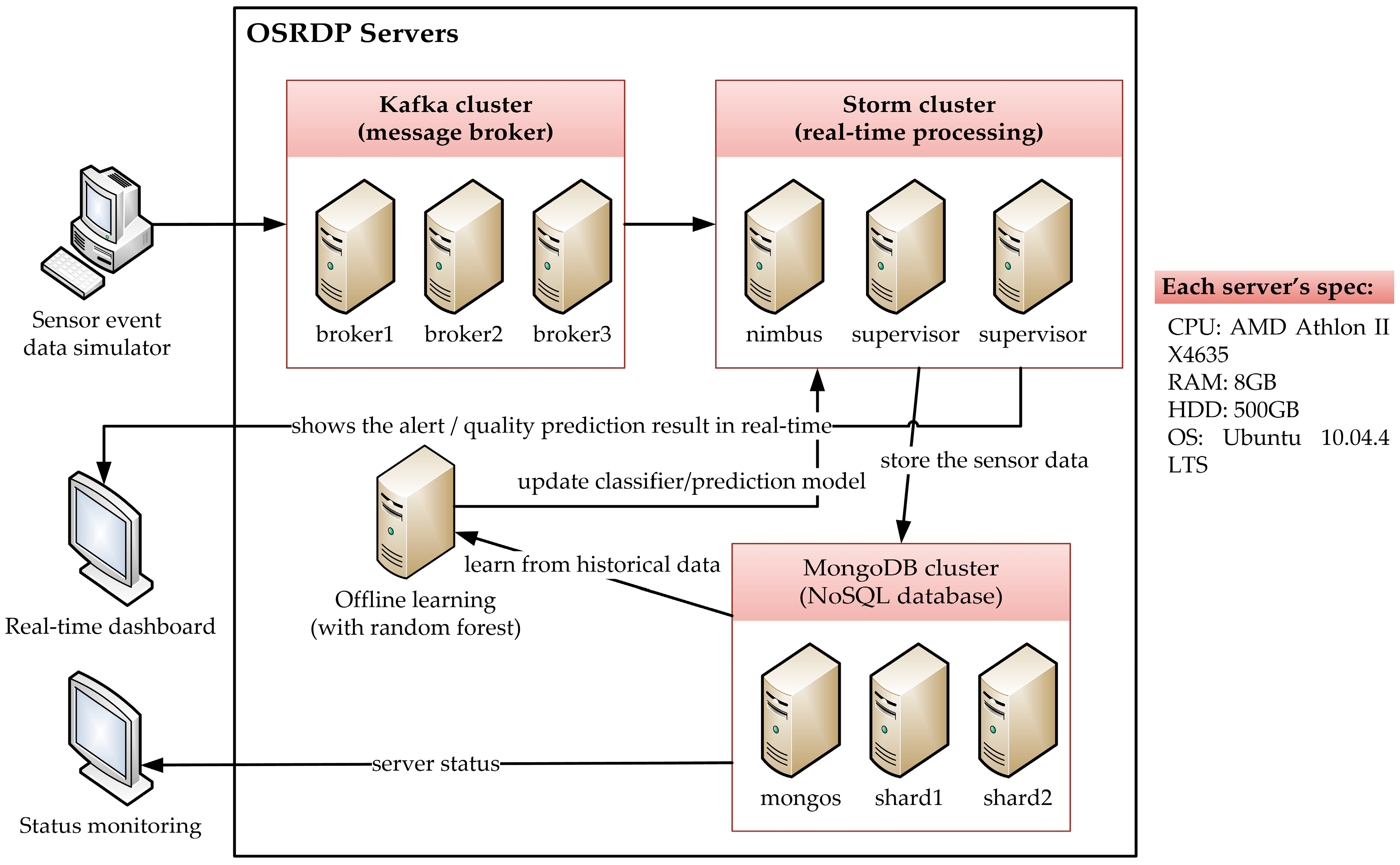
3.1. OSRDP Architecture Framework
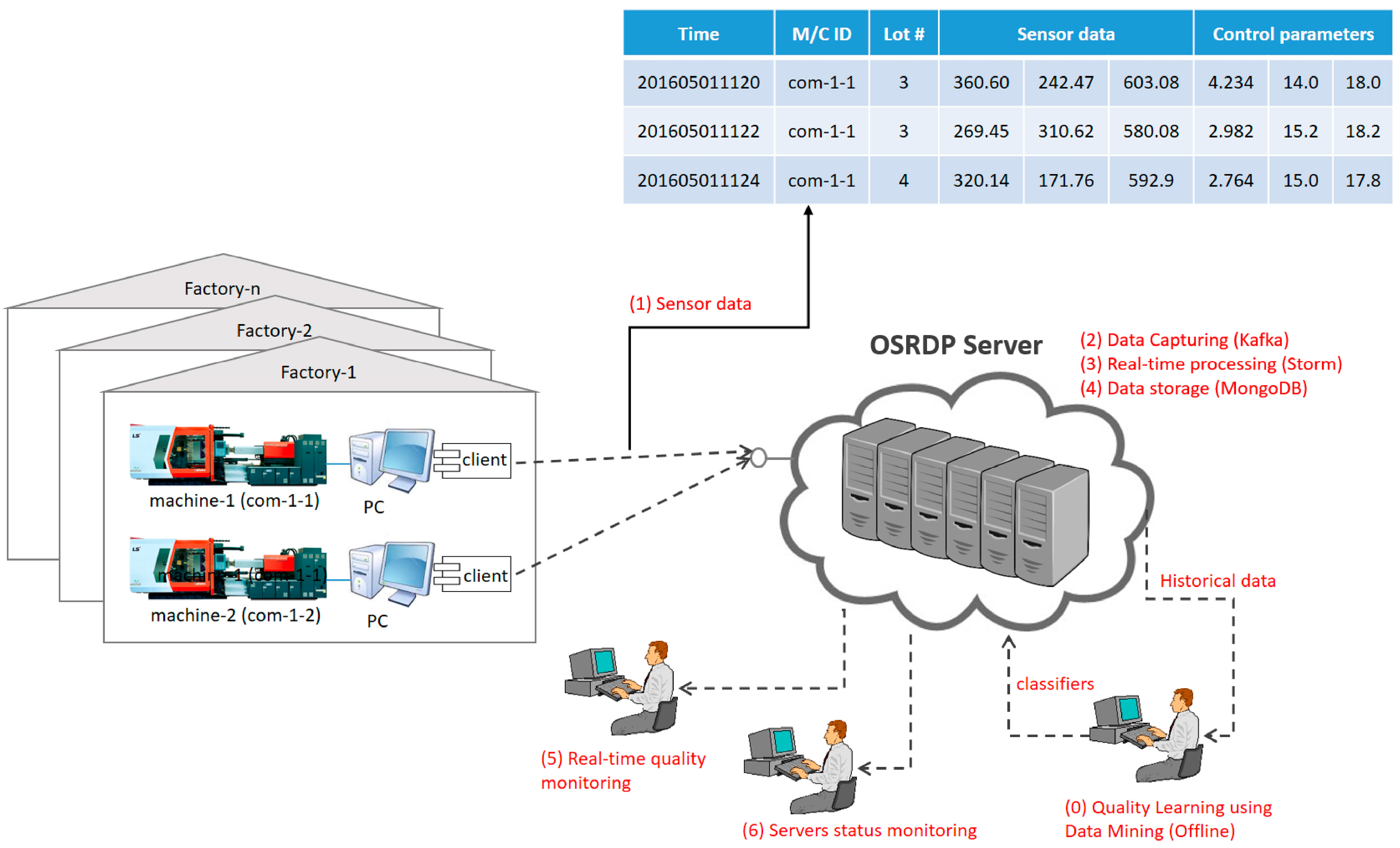
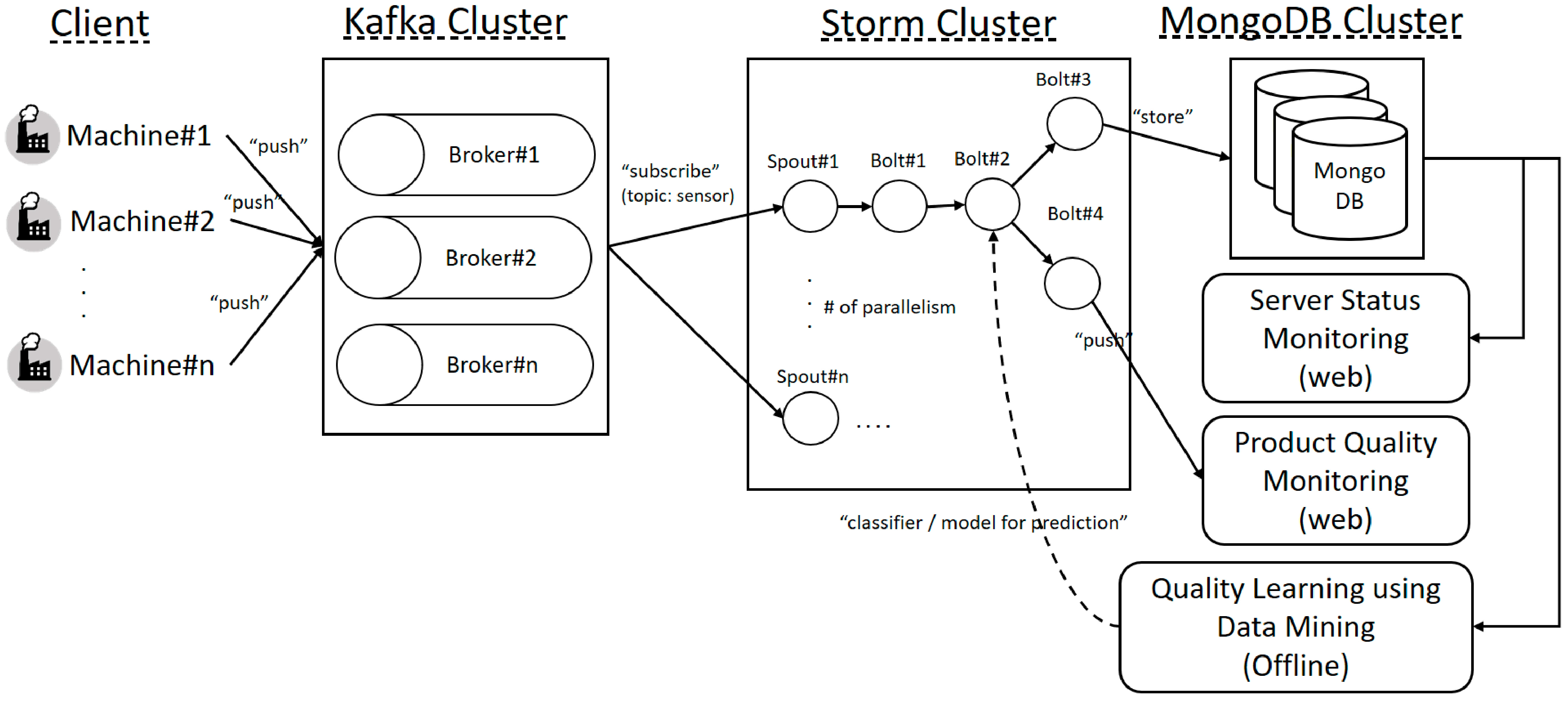
3.2. OSRDP Scenario in the Manufacturing
- (0)
- Pre-Step: Before using the data mining algorithm, we need to engage in offline learning first for quality prediction based on historical quality data. After learning is finished, it will produce the classifier model and will be used for real-time quality prediction in the Bolt of Storm topology.
- (1)
- The injection molding machine will send the sensor data into OSRDP server.
- (2)
- In the OSRDP server, the sensor data will be managed by Kafka and published to Storm.
- (3)
- In the Storm, there are several processes such as preprocessing task, and prediction task.
- (4)
- After the prediction task in the Storm is finished, the sensor data and its prediction result will be stored into MongoDB.
- (5)
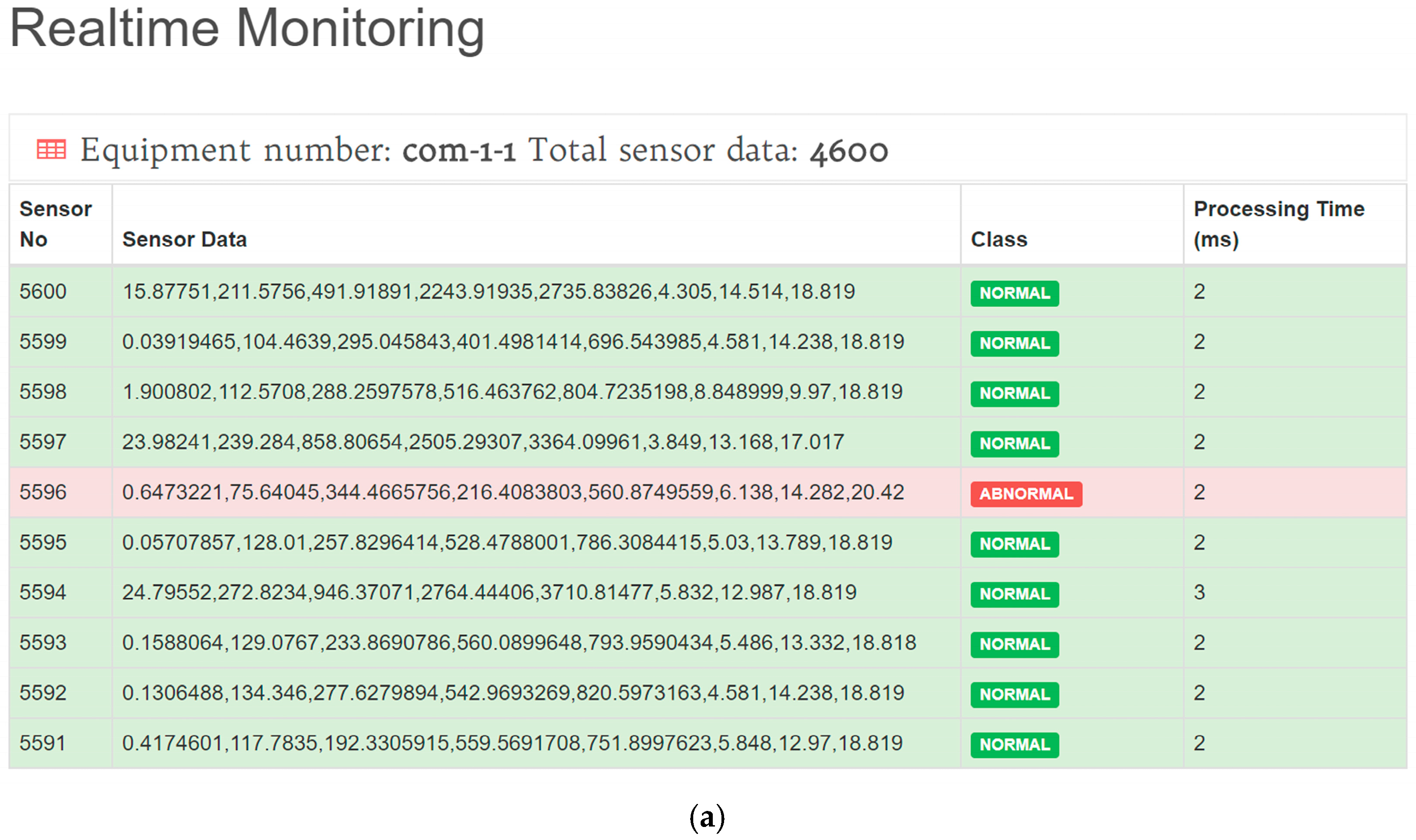
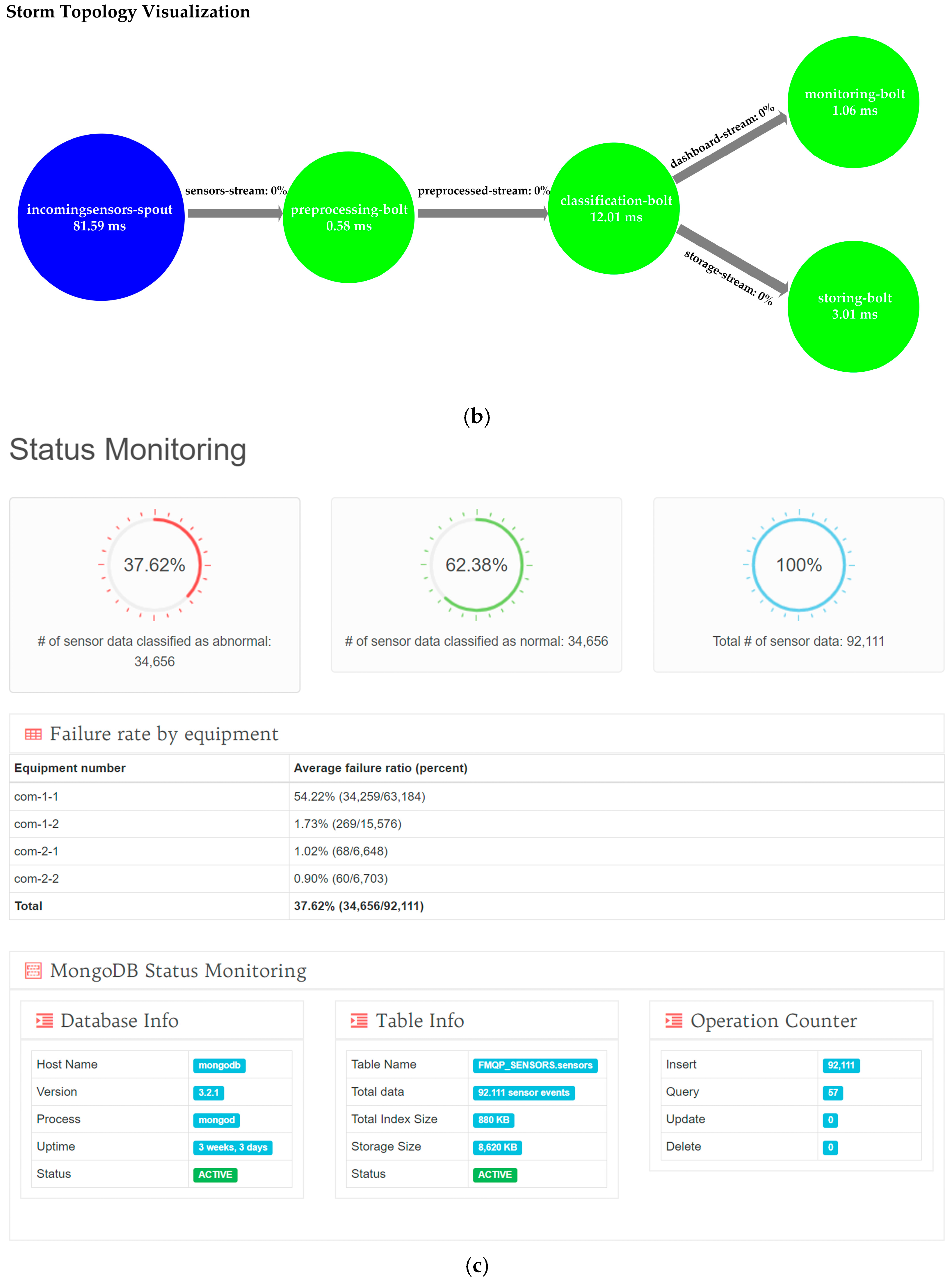
- Storm will also send the result of prediction task into real-time quality monitoring web-page. So, then the manager can see the quality prediction result in real-time.
- (6)
- The admin/manager can also check status of the server by login into server status monitoring web-page.
4. Case Analysis with Experiment
4.1. Experimental Environment
4.2. Data Collection
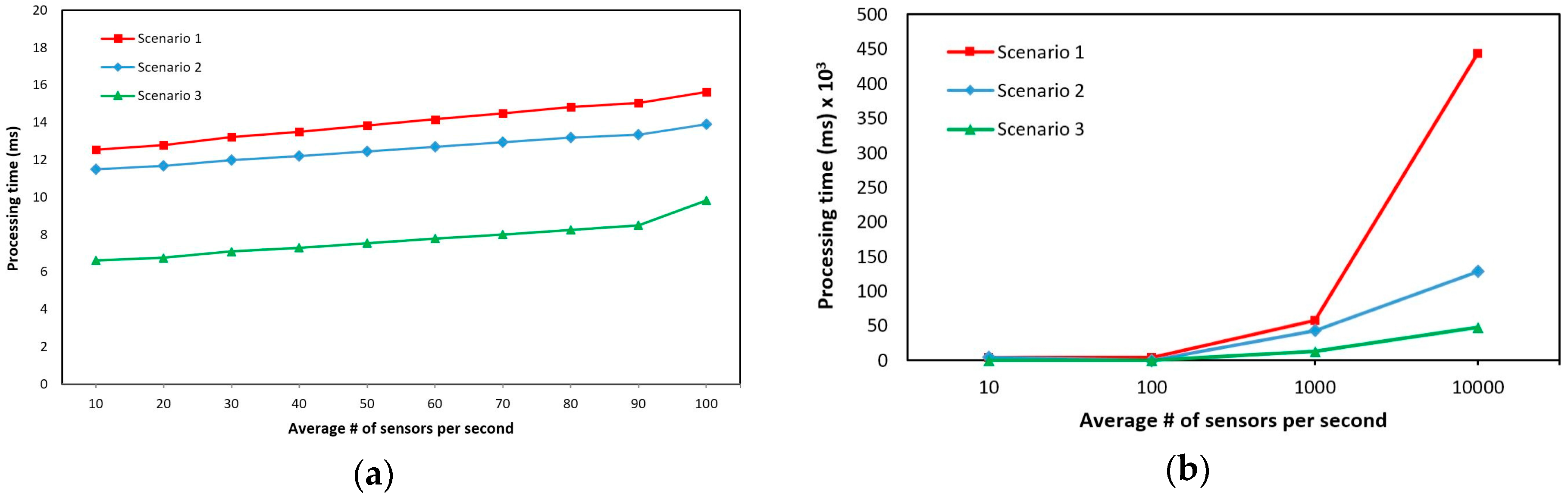
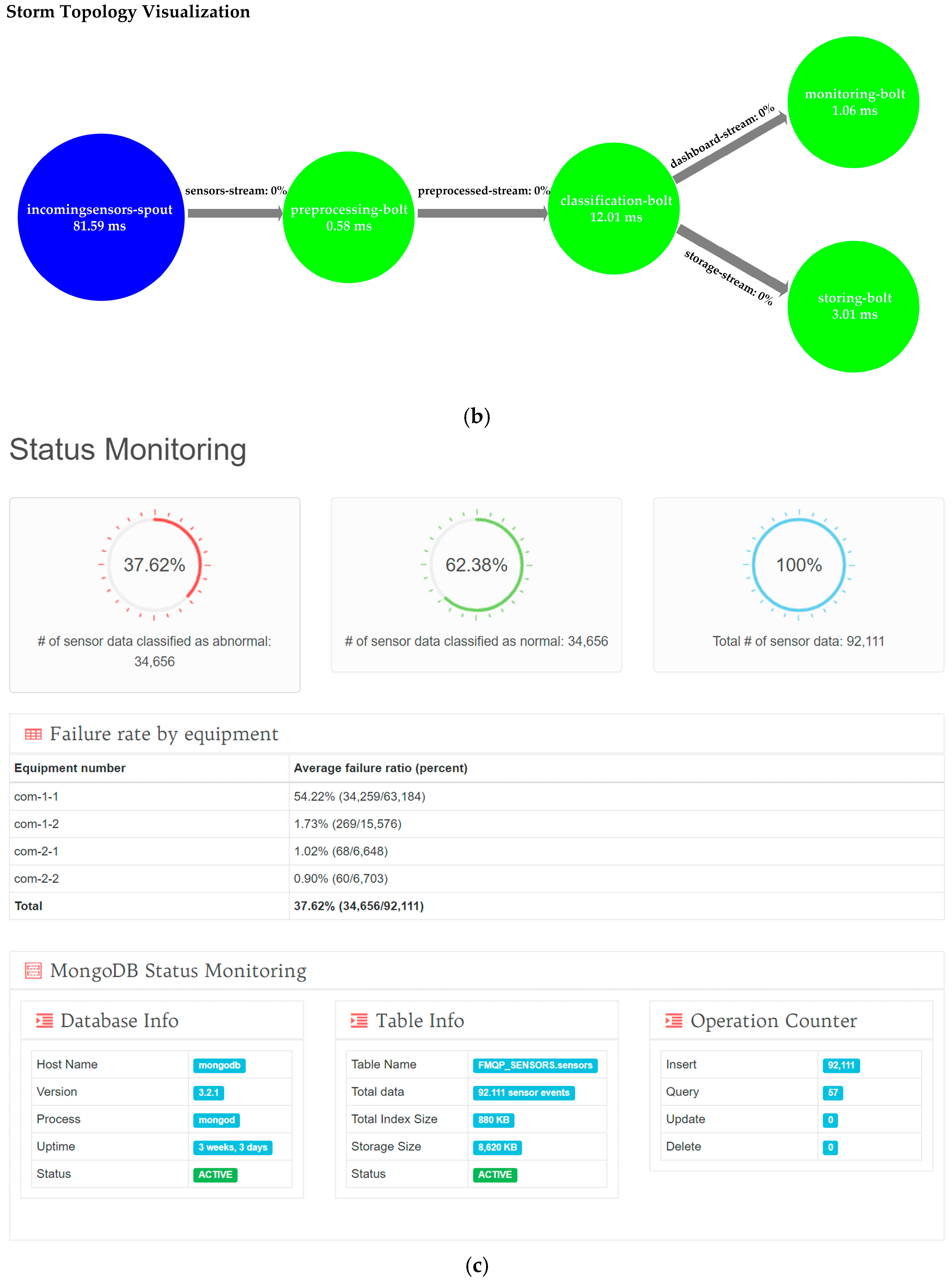
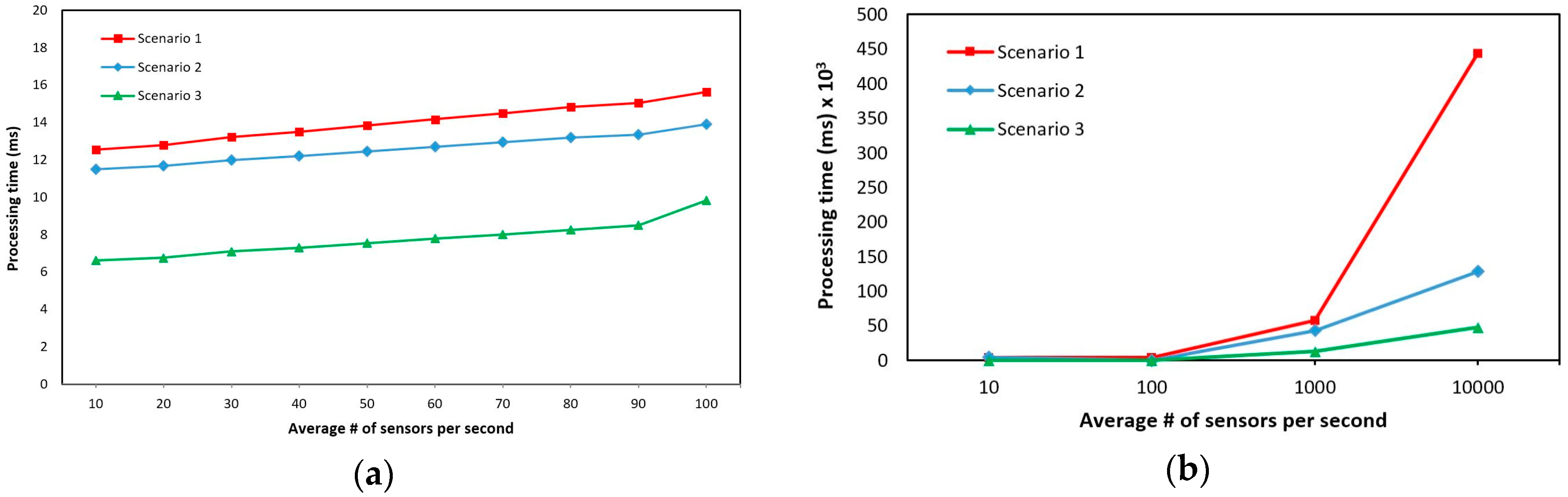
4.3. Performance Evaluation of the OSRDP Architecture Framework
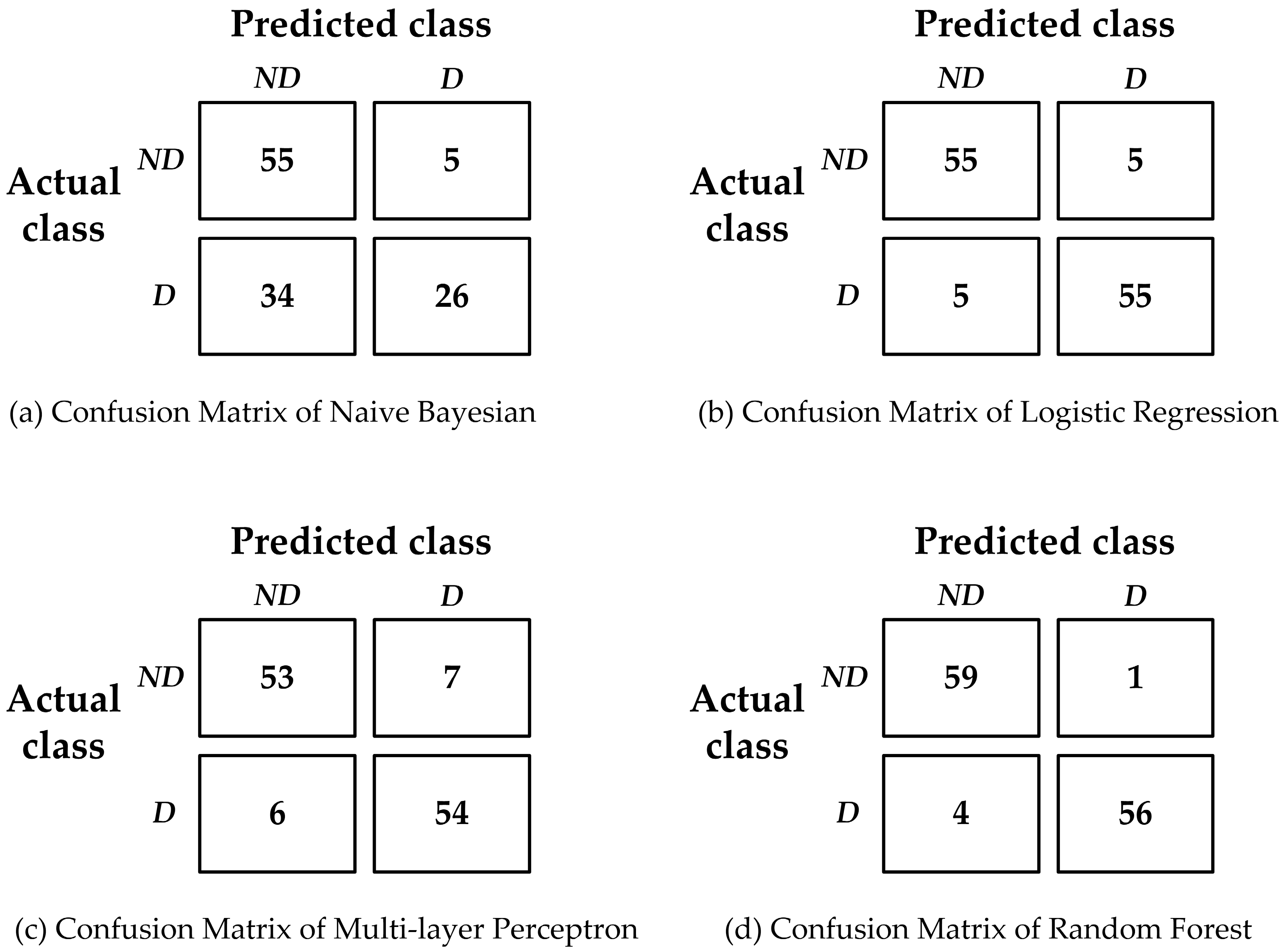
4.4. Performance Comparison of Data Mining Models
5. Discussion
5.1. Cost Analysis to Select an Cost-Effective Integration Solution
- Horizontal Scaling: Horizontal scaling involves distributing workload across many servers in clusters. Those servers usually are commodity hardware that are not high-specification servers. Horizontal scaling also known as “scale-out”, where multiple commodity servers are added together into cluster to improve processing capability. This is usually cost-effective and inexpensive while achieving high processing capability [65].
- Vertical Scaling: Vertical scaling involves adding more processors, more memory and higher specification hardware within one server. It is also known as “scale-up” which by replacing the processor and RAM with higher specification, or buying expensive and high-specification server [64].
5.2. The Impact Analysis of the OSRDP Architecture Framework on the Manufacturing Sustainability
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jovane, F.; Koren, Y.; Boër, C.R. Present and Future of Flexible Automation: Towards New Paradigms. CIRP Ann. 2003, 52, 543–560. [Google Scholar] [CrossRef]
- Koren, Y. The Global Manufacturing Revolution: Product-Process-Business Integration and Reconfigurable Systems; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Goodland, R. The concept of environmental sustainability. Annu. Rev. Ecol. Syst. 1995, 26, 1–24. [Google Scholar] [CrossRef]
- Rosen, M.A.; Kishawy, H.A. Sustainable Manufacturing and Design: Concepts, Practices and Needs. Sustainability 2012, 4, 154–174. [Google Scholar] [CrossRef]
- Garetti, M.; Taisch, M. Sustainable manufacturing: Trends and research challenges. Prod. Plan. Control 2012, 23, 83–104. [Google Scholar] [CrossRef]
- Gunasekaran, A.; Spalanzani, A. Sustainability of manufacturing and services: Investigations for research and applications. Int. J. Prod. Econ. 2012, 140, 35–47. [Google Scholar] [CrossRef]
- Davis, J.; Edgar, T.; Porter, J.; Bernaden, J.; Sarli, M. Smart manufacturing, manufacturing intelligence and demand-dynamic performance. Comput. Chem. Eng. 2012, 47, 145–156. [Google Scholar] [CrossRef]
- Lee, J.; Kao, H.-A.; Yang, S. Service innovation and smart analytics for Industry 4.0 and big data environment. Procedia CIRP 2014, 16, 3–8. [Google Scholar] [CrossRef]
- Hazen, B.T.; Boone, C.A.; Ezell, J.D.; Jones-Farmer, L.A. Data quality for data science, predictive analytics, and big data in supply chain management: An introduction to the problem and suggestions for research and applications. Int. J. Prod. Econ. 2014, 154, 72–80. [Google Scholar] [CrossRef]
- Wamba, S.F.; Akter, S.; Edwards, A.; Chopin, G.; Gnanzou, D. How ‘big data’ can make big impact: Findings from a systematic review and a longitudinal case study. Int. J. Prod. Econ. 2015, 165, 234–246. [Google Scholar] [CrossRef]
- Lee, J.; Lapira, E.; Bagheri, B.; Kao, H. Recent advances and trends in predictive manufacturing systems in big data environment. Manuf. Lett. 2013, 1, 38–41. [Google Scholar] [CrossRef]
- Kumar, P.; Dhruv, B.; Rawat, S.; Rathore, V.S. Present and future access methodologies of big data. Int. J. Adv. Res. Sci. Eng. 2014, 3, 541–547. [Google Scholar]
- Chen, C.L.P.; Zhang, C.-Y. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Vera-Baquero, A.; Colomo-Palacios, R.; Molloy, O. Towards a process to guide Big data based decision support systems for business processes. Procedia Technol. 2014, 16, 11–21. [Google Scholar] [CrossRef]
- Ferreiro, S.; Sierra, B.; Irigoien, I.; Gorritxategi, E. Data mining for quality control: Burr detection in the drilling process. Comput. Ind. Eng. 2011, 60, 801–810. [Google Scholar] [CrossRef]
- Harding, J.A.; Shahbaz, M.; Srinivas, S.; Kusiak, A. Data mining in manufacturing: A review. ASME J. Manuf. Sci. Eng. 2005, 128, 969–976. [Google Scholar] [CrossRef]
- Baldwin, H. 4 Reasons Companies Say Yes to Open Source. Available online: http://www.computerworld.com/article/2486991/app-development-4-reasons-companies-say-yes-to-open-source.html (accessed on 9 November 2016).
- Shaikh, M.; Cornford, T. Total Cost of Ownership of Open Source Software: A Report for the UK Cabinet Office Supported by OpenForum Europe; UK Cabinet Office: London, UK, 2011. Available online: http://eprints.lse.ac.uk/39826 (accessed on 9 November 2016).
- Mani, V.; Delgado, C.; Hazen, B.T.; Patel, P. Mitigating Supply Chain Risk via Sustainability Using Big Data Analytics: Evidence from the Manufacturing Supply Chain. Sustainability 2017, 9, 608. [Google Scholar] [CrossRef]
- Malek, Y.N.; Kharbouch, A.; El Khoukhi, H.; Bakhouya, M.; De Florio, V.; El Ouadghiri, D.; Latre, S.; Blondia, C. On the use of IoT and Big Data Technologies for Real-time Monitoring and Data Processing. Procedia Comput. Sci. 2017, 113, 429–434. [Google Scholar] [CrossRef]
- He, Q.P.; Wang, J. Statistical process monitoring as a big data analytics tool for smart manufacturing. J. Process Control 2017. [Google Scholar] [CrossRef]
- Siddique, K.; Akhtar, Z.; Lee, H.-G.; Kim, W.; Kim, Y. Toward Bulk Synchronous Parallel-Based Machine Learning Techniques for Anomaly Detection in High-Speed Big Data Networks. Symmetry 2017, 9, 197. [Google Scholar] [CrossRef]
- Open Source Initiative. Available online: https://opensource.org/definition (accessed on 18 October 2016).
- Roberts, J.A.; Hann, I.-H.; Slaughter, S.A. Understanding the motivations, participation, and performance of open source software developers: A longitudinal study of the apache projects. Manag. Sci. 2006, 52, 984–999. [Google Scholar] [CrossRef]
- Panetto, H.; Molina, A. Enterprise integration and interoperability in manufacturing systems: Trends and issues. Comput. Ind. 2007, 59, 641–646. [Google Scholar] [CrossRef]
- Apache Kafka. Available online: https://kafka.apache.org (accessed on 20 October 2016).
- Goodhope, K.; Koshy, J.; Kreps, J.; Narkhede, N.; Park, R.; Rao, J.; Ye, V.Y. Building LinkedIn’s real-time activity data pipeline. IEEE Data Eng. Bull. 2012, 35, 33–45. [Google Scholar]
- Kreps, J.; Narkhede, N.; Rao, J. Kafka: A distributed messaging system for log processing. In Proceedings of the NetDB, Athens, Greece, 12–16 June 2011. [Google Scholar]
- Fernández-Rodríguez, J.Y.; Álvarez-García, J.A.; Fisteus, J.A.; Luaces, M.R.; Magaña, V.C. Benchmarking real-time vehicle data streaming models for a Smart City. Inf. Syst. 2017, 72, 62–76. [Google Scholar] [CrossRef]
- Jain, A.; Nalya, A. Learning Storm; Packt Publishing: Birmingham, UK, 2014. [Google Scholar]
- Nivash, J.P.; Raj, E.D.; Babu, L.D.; Nirmala, M.; Kumar, V.M. Analysis on enhancing storm to efficiently process big data in real time. In Proceedings of the 2014 International Conference on Computing, Communications and Networking Technologies (ICCCNT), Hefei, China, 11–13 July 2014. [Google Scholar]
- De Maio, C.; Fenza, G.; Loia, V.; Orciuoli, F. Distributed online temporal Fuzzy concept analysis for stream processing in smart cities. J. Parallel Distrib. Comput. 2017, 110, 31–41. [Google Scholar] [CrossRef]
- Yang, W.; Liu, X.; Zhang, L.; Yang, L.T. Big data real-time processing based on storm. In Proceedings of the 12th IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Melbourne, VIC, Australia, 16–18 July 2013; pp. 1784–1787. [Google Scholar]
- Banker, K. MongoDB in Action; Manning Publications Co.: Shelter Island, NY, USA, 2011. [Google Scholar]
- Sasaki, T. NoSQL Core Guide for Big Data Era; RoadBook: Seoul, Korea, 2011. [Google Scholar]
- Copeland, R. MongoDB Applied Design Patterns; O’Reilly Media, Inc.: Newton, MA, USA, 2013. [Google Scholar]
- Chodorow, K. MongoDB: The Definitive Guide; O’Reilly Media, Inc.: Newton, MA, USA, 2013. [Google Scholar]
- Nyati, S.S.; Pawar, S.; Ingle, R. Performance evaluation of unstructured NoSQL data over distributed framework. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, 22–25 August 2013; pp. 1623–1627. [Google Scholar]
- Kanade, A.; Gopal, A.; Kanade, A. A study of normalization and embedding in MongoDB. In Proceedings of the 2014 IEEE International on Advance Computing Conference (IACC), Gurgaon, India, 21–22 February 2014; pp. 416–421. [Google Scholar]
- Liu, Y.; Wang, Y.; Jin, Y. Research on the improvement of MongoDB auto-sharding in cloud environment. In Proceedings of the 2012 7th International Conference on Computer Science & Education (ICCSE), Melbourne, VIC, Australia, 14–17 July 2012; pp. 851–854. [Google Scholar]
- Tseng, T.L.B.; Jothishankar, M.C.; Wu, T.T. Quality control problem in printed circuit board manufacturing—An extended rough set theory approach. J. Manuf. Syst. 2004, 23, 56–72. [Google Scholar] [CrossRef]
- Chen, W.C.; Tseng, S.S.; Wang, C.Y. A novel manufacturing defect detection method using association rule mining techniques. Expert Syst. Appl. 2005, 29, 807–815. [Google Scholar] [CrossRef]
- Patel, S.V.; Jokhakar, V.N. A random forest based machine learning approach for mild steel defect diagnosis. In Proceedings of the 2016 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Chennai, India, 15–17 December 2016; pp. 1–8. [Google Scholar]
- Tseng, T.L.; Kwon, Y.; Ertekin, Y.M. Feature-based rule induction in machining operation using rough set theory for quality assurance. Robot. Comput. Integr. Manuf. 2005, 21, 559–567. [Google Scholar] [CrossRef]
- Syn, C.Z.; Mokhtar, M.; Feng, C.J.; Manurung, Y.H.P. Approach to prediction of laser cutting quality by employing fuzzy expert system. Expert Syst. Appl. 2011, 38, 7558–7568. [Google Scholar] [CrossRef]
- Zeaiter, M.; Knight, W.; Holland, S. Multivariate regression modeling for monitoring quality of injection moulding components using cavity sensor technology: Application to the manufacturing of pharmaceutical device components. J. Process Control 2011, 21, 137–150. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, Y.; Mao, T.; Zhou, H. Monitoring and dynamic control of quality stability for injection molding process. J. Mater. Process. Technol. 2017, 249, 358–366. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann: New York, NY, USA, 2016. [Google Scholar]
- Socket.IO. Available online: http://socket.io (accessed on 1 November 2016).
- Höfler, T. Enabling Realtime Collaborative Data-Intensive Web Applications—A case Study Using Server-Side JavaScript. Master’s Thesis, Technical University of Munich, Munich, Germany, 15 May 2013. [Google Scholar]
- Abohashima, H.S.; Aly, M.F.; Mohib, A.; Attia, H.A. Minimization of Defects Percentage in Injection Molding Process using Design of Experiment and Taguchi Approach. Ind. Eng. Manag. 2015, 4. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Germain, P.; Lacasse, A.; Laviolette, F.; Marchand, M.; Roy, J.-F. Risk bounds for the majority vote: From a PAC-Bayesian analysis to a learning algorithm. J. Mach. Learn. Res. 2015, 16, 787–860. [Google Scholar]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Wainberg, M.; Alipanahi, B.; Frey, B.J. Are random forests truly the best classifiers? J. Mach. Learn. Res. 2016, 17, 1–5. [Google Scholar]
- Oneto, L.; Coraddu, A.; Sanetti, P.; Karpenko, O.; Cipollini, F.; Cleophas, T.; Anguita, D. Marine Safety and Data Analytics: Vessel Crash Stop Maneuvering Performance Prediction. In Proceedings of the 26th International Conference on Artificial Neural Networks (ICANN 2017), Alghero, Italy, 11–14 September 2017; Volume 10614, pp. 385–393. [Google Scholar]
- Liu, B. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data; Springer-Verlag: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-validation. In Encyclopedia of Database Systems; Springer: New York, NY, USA, 2009. [Google Scholar]
- Pressure Sensors Injection Molding. Available online: https://www.rjginc.com/sensors/cavity-pressure (accessed on 28 October 2016).
- Cavity Pressure Sensor Price. Available online: https://www.aliexpress.com/price/cavity-pressure-sensor_price.html (accessed on 28 October 2016).
- Dell PowerEdge Servers for Small Business. Available online: http://www.dell.com/us/business/p/servers (accessed on 28 October 2016).
- Appuswamy, R.; Gkantsidis, C.; Narayanan, D.; Hodson, O.; Rowstron, A. Scale-up vs. scale-out for Hadoop: Time to rethink? In Proceedings of the 4th Annual Symposium on Cloud Computing, Santa Clara, CA, USA, 1–3 October 2013; ACM: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Singh, D.; Reddy, C.K. A survey on platforms for big data analytics. J. Big Data 2015, 2. [Google Scholar] [CrossRef] [PubMed]
- Abbott, M.L.; Fisher, M.T. Scalability Rules: 50 Principles for Scaling Web Sites; Pearson Education, Inc.: Boston, MA, USA, 2011; pp. 35–48. [Google Scholar]
- Walli, S.; Gynn, D.; Von Rotz, B. The Growth of Open Source Software in Organizations; A report; Optaros, Inc.: New York, NY, USA, 2005. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning, 2nd ed.; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Gardner, R.; Bicker, J. Using machine learning to solve tough manufacturing problems. Int. J. Ind. Eng. Theory Appl. Pract. 2000, 7, 359–364. [Google Scholar]
- Kwak, D.-S.; Kim, K.-J. A data mining approach considering missing values for the optimization of semiconductor-manufacturing processes. Expert Syst. Appl. 2012, 39, 2590–2596. [Google Scholar] [CrossRef]
- Pham, D.T.; Afify, A.A. Machine-learning techniques and their applications in manufacturing. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2005, 219, 395–412. [Google Scholar] [CrossRef]
- Susto, G.A.; Schirru, A.; Pampuri, S.; McLoone, S.; Beghi, A. Machine learning for predictive maintenance: A multiple classifier approach. IEEE Trans. Ind. Inf. 2015, 11, 812–820. [Google Scholar] [CrossRef]
- Monostori, L.; Prohaszka, J. A step towards intelligent manufacturing: Modelling and monitoring of manufacturing processes through artificial neural networks. CIRP Ann. Manuf. Technol. 1993, 42, 485–488. [Google Scholar] [CrossRef]
- Apte, C.; Weiss, S.; Grout, G. Predicting defects in disk drive manufacturing: A case study in high dimensional classification. In Proceedings of the IEEE Annual Computer Science Conference on Artificial Intelligence in Application, Orlando, FL, USA, 1–5 March 1993; pp. 212–218. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU | RAM | HDD | OS |
|---|---|---|---|
| 2.9 GHz × 4 | 8 GB | 500 GB | Ubuntu 10.04 LTS |
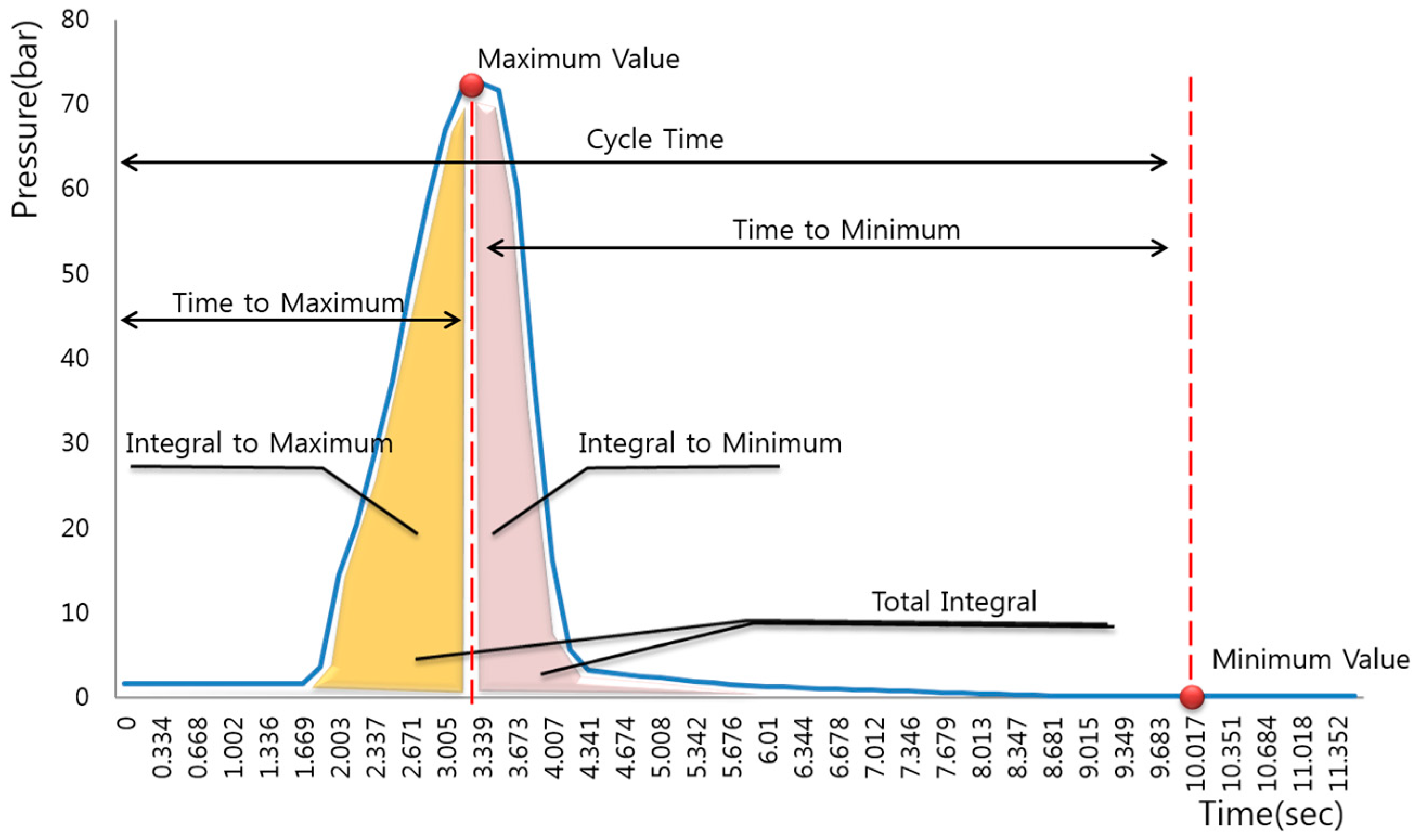
| Feature | Explanation |
|---|---|
| minPressureValue | Minimum pressure value |
| maxPressureValue | Maximum pressure value |
| integralPressureToMax | The pressure integral value from start of cycle to maximum pressure value |
| integralPressureToMin | The pressure integral value from maximum pressure value to end of cycle |
| totalIntegralPressure | Total pressure integral value |
| timeToMaxPressure | Time from start of cycle to maximum pressure value |
| timeToMinPressure | Time from the maximum pressure value to the end of the cycle |
| cycleTime | Cycle time |
| Scenario | Parameter | Measurement |
|---|---|---|
| Scenario 1 | # of parallelism = 1 | Calculate the processing time by increasing the average number of the sensor data sent to the server per second |
| Scenario 2 | # of parallelism = 5 | |
| Scenario 3 | # of parallelism = 10 |
| Classified True | Classified False | |
|---|---|---|
| Actual positive | True Positive (TP) | False Negative (FN) (Type II Error/β-error) |
| Actual negative | False Positive (FP) (Type I Error/α-error) | True Negative (TN) |
| Classifier | Precision (%) | Recall (%) | F-Measure (%) | Accuracy (%) |
|---|---|---|---|---|
| NB | 72.8 | 67.5 | 65.5 | 67.5 |
| LR | 91.7 | 91.7 | 91.7 | 91.67 |
| MLP | 89.2 | 89.2 | 89.2 | 89.17 |
| RF | 95.9 | 95.8 | 95.8 | 95.83 |
| Scaling Type | Advantages | Disadvantages |
|---|---|---|
| Horizontal |
|
|
|
| |
|
| |
| ||
| Vertical |
|
|
|
| |
|
| |
|
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Syafrudin, M.; Fitriyani, N.L.; Li, D.; Alfian, G.; Rhee, J.; Kang, Y.-S. An Open Source-Based Real-Time Data Processing Architecture Framework for Manufacturing Sustainability. Sustainability 2017, 9, 2139. https://doi.org/10.3390/su9112139
Syafrudin M, Fitriyani NL, Li D, Alfian G, Rhee J, Kang Y-S. An Open Source-Based Real-Time Data Processing Architecture Framework for Manufacturing Sustainability. Sustainability. 2017; 9(11):2139. https://doi.org/10.3390/su9112139
Chicago/Turabian StyleSyafrudin, Muhammad, Norma Latif Fitriyani, Donglai Li, Ganjar Alfian, Jongtae Rhee, and Yong-Shin Kang. 2017. "An Open Source-Based Real-Time Data Processing Architecture Framework for Manufacturing Sustainability" Sustainability 9, no. 11: 2139. https://doi.org/10.3390/su9112139
APA StyleSyafrudin, M., Fitriyani, N. L., Li, D., Alfian, G., Rhee, J., & Kang, Y.-S. (2017). An Open Source-Based Real-Time Data Processing Architecture Framework for Manufacturing Sustainability. Sustainability, 9(11), 2139. https://doi.org/10.3390/su9112139