
Not Deep Learning but Autonomous Learning of Open Innovation for Sustainable Artificial Intelligence




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Model Building
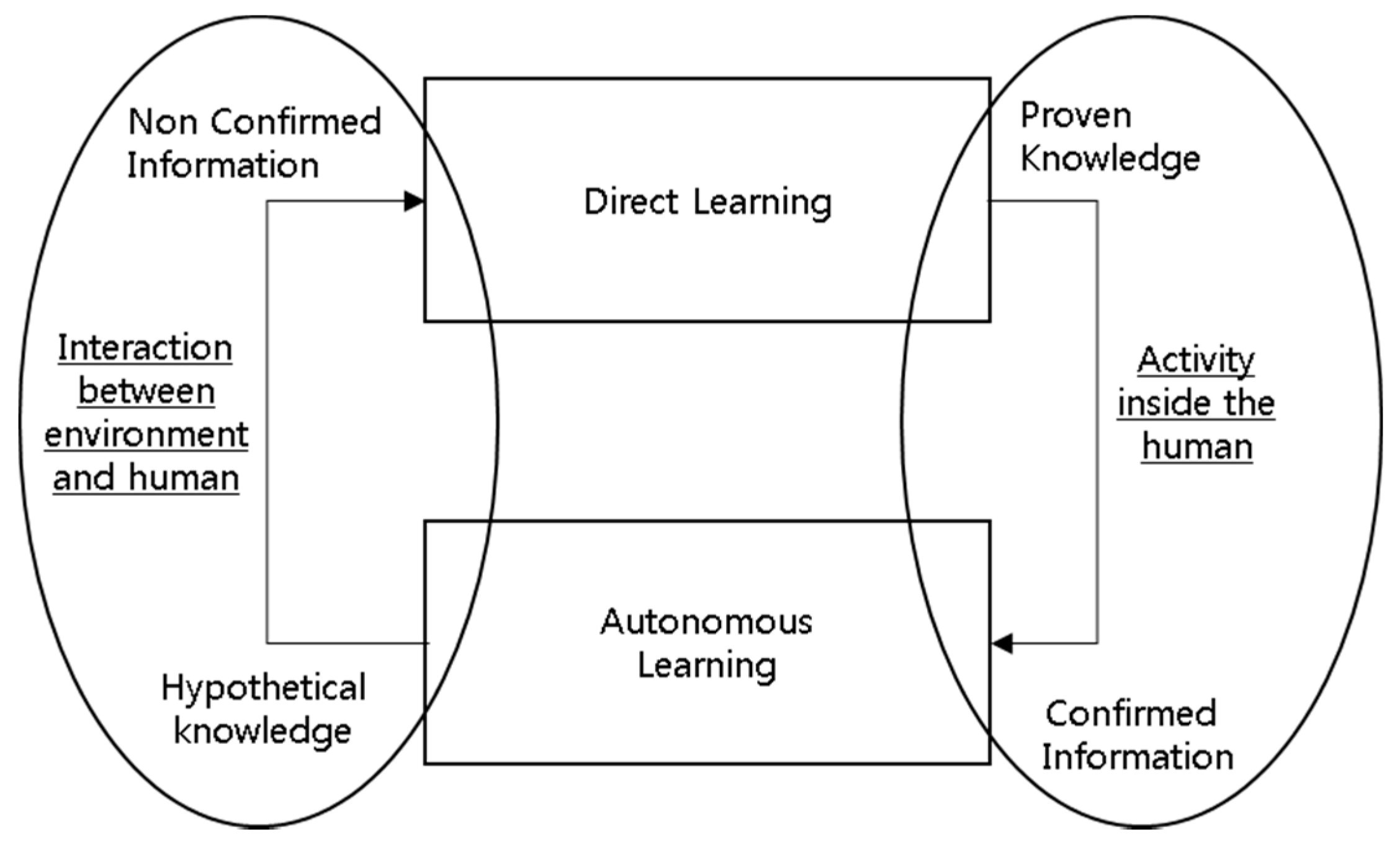
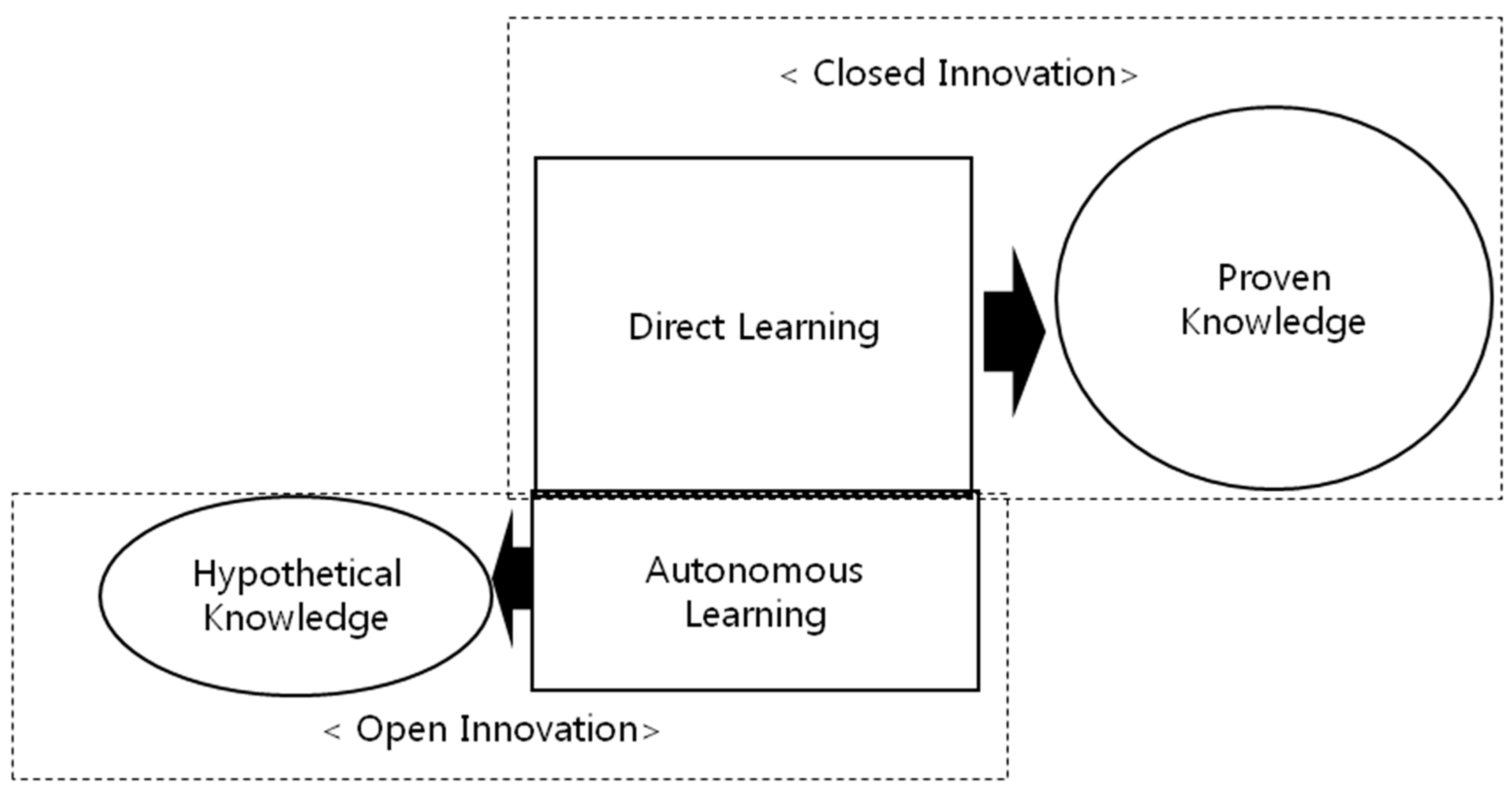
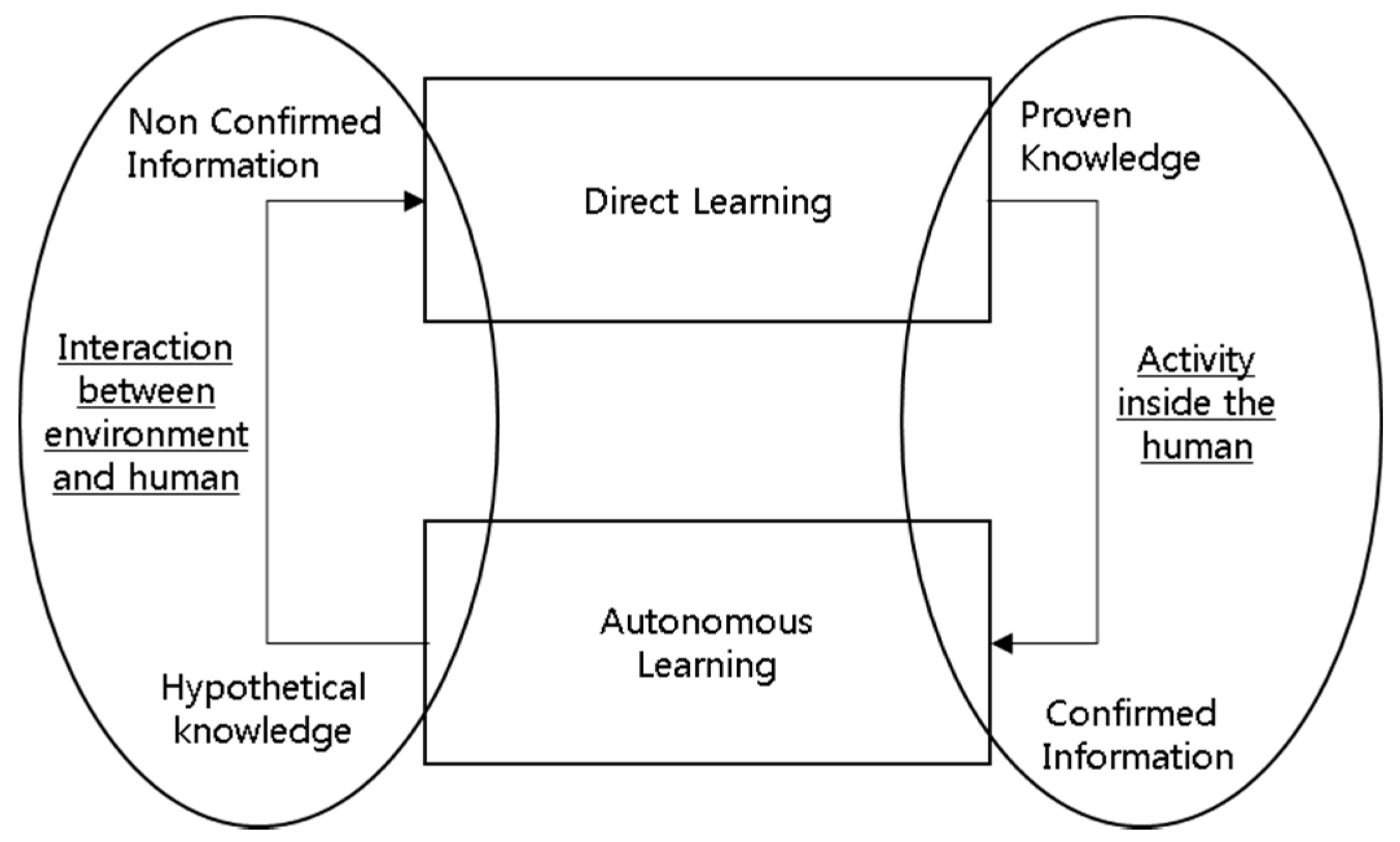
2.1. Basic Concept Modeling of Human and Firm Learning
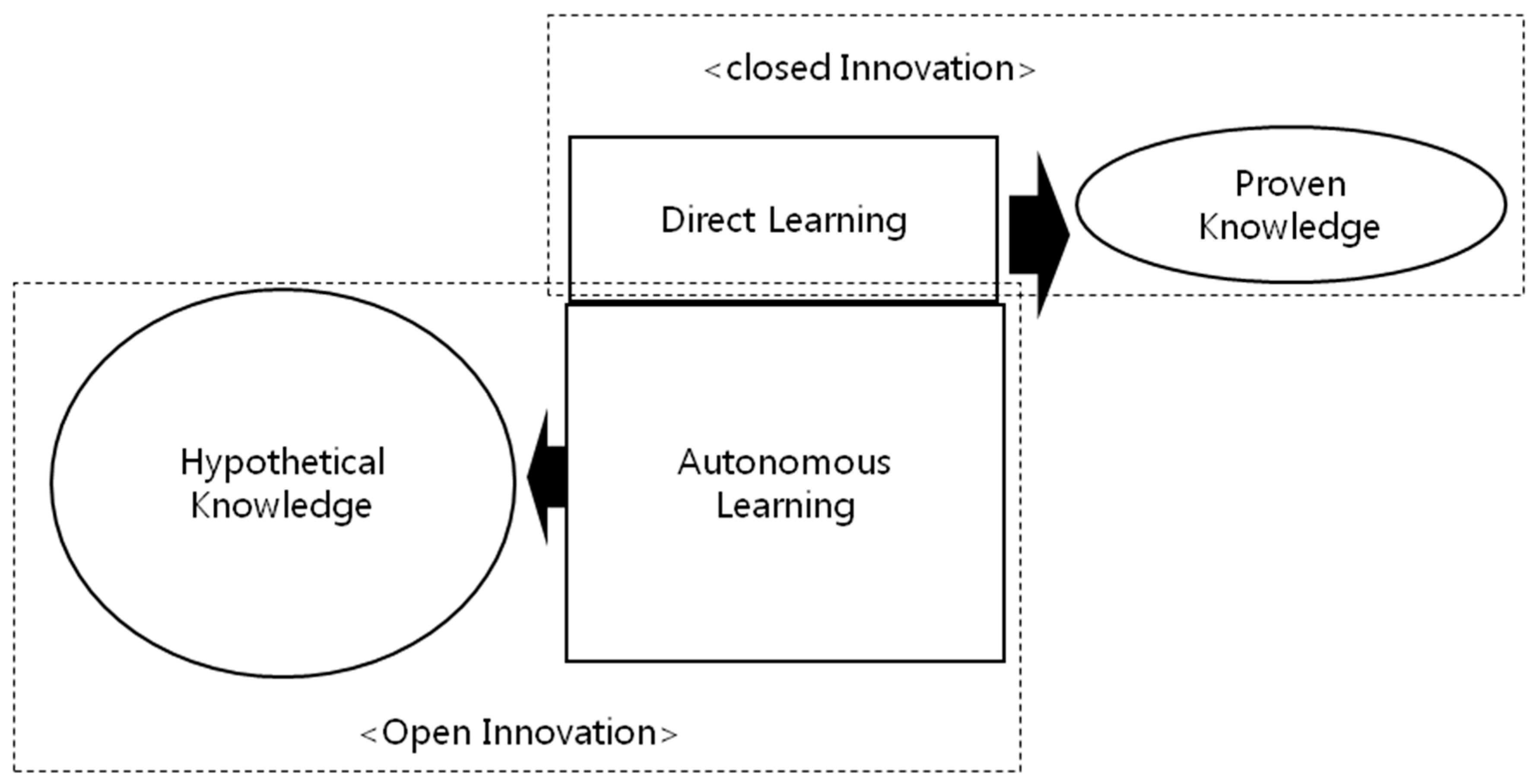
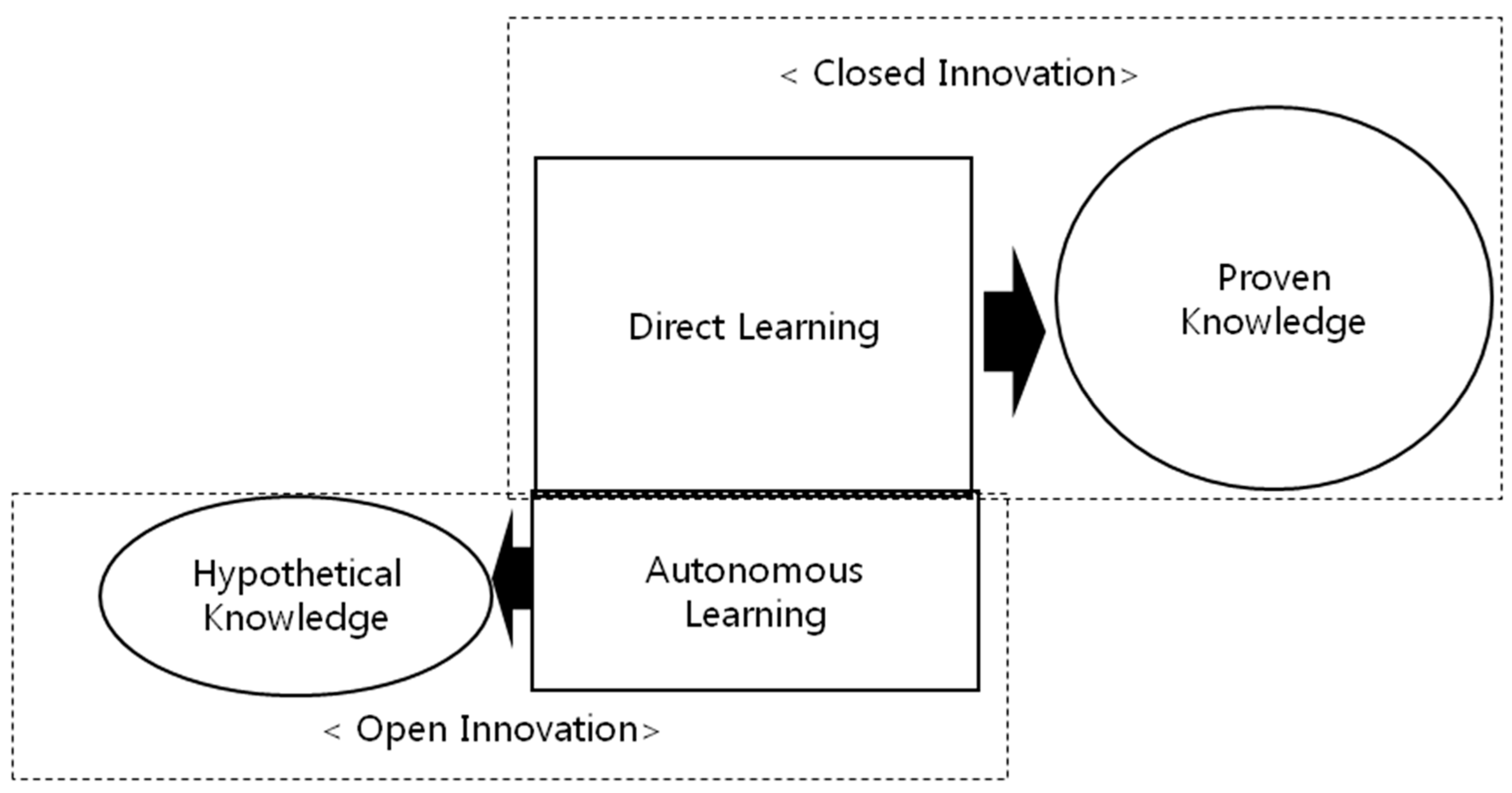
2.2. Open the Black Box of Autonomous Learning
2.3. The Relationship between Open Innovation and Autonomous Learning
3. Expansion of Autonomous Learning
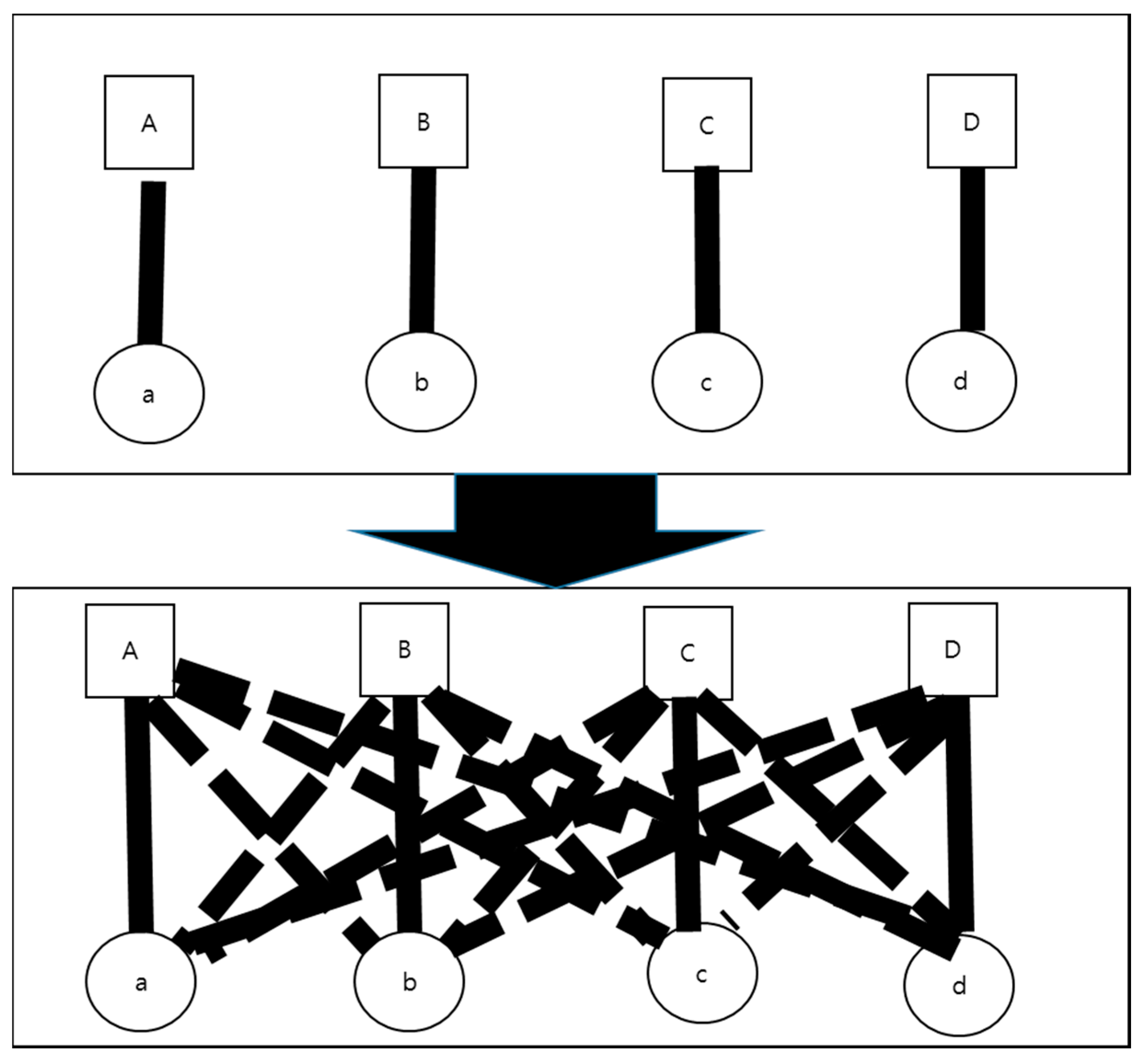
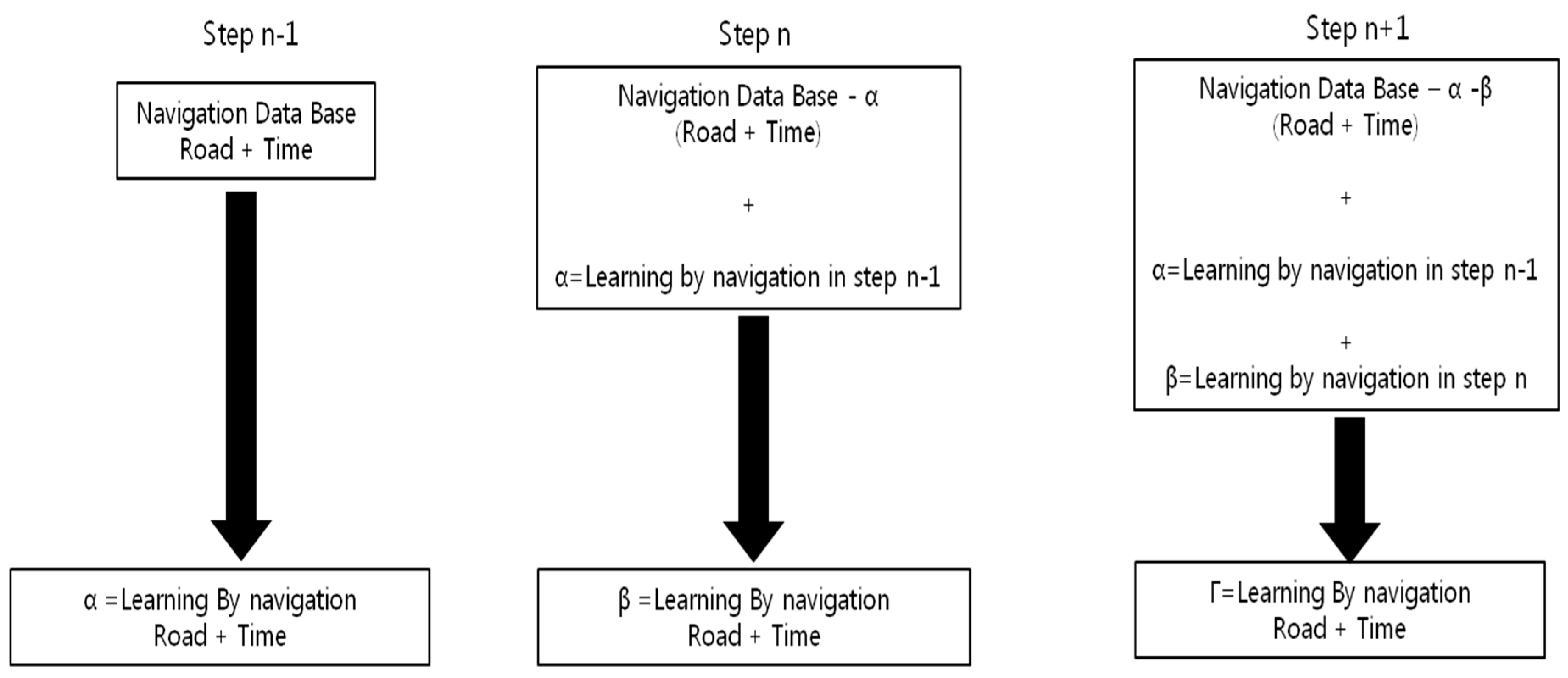
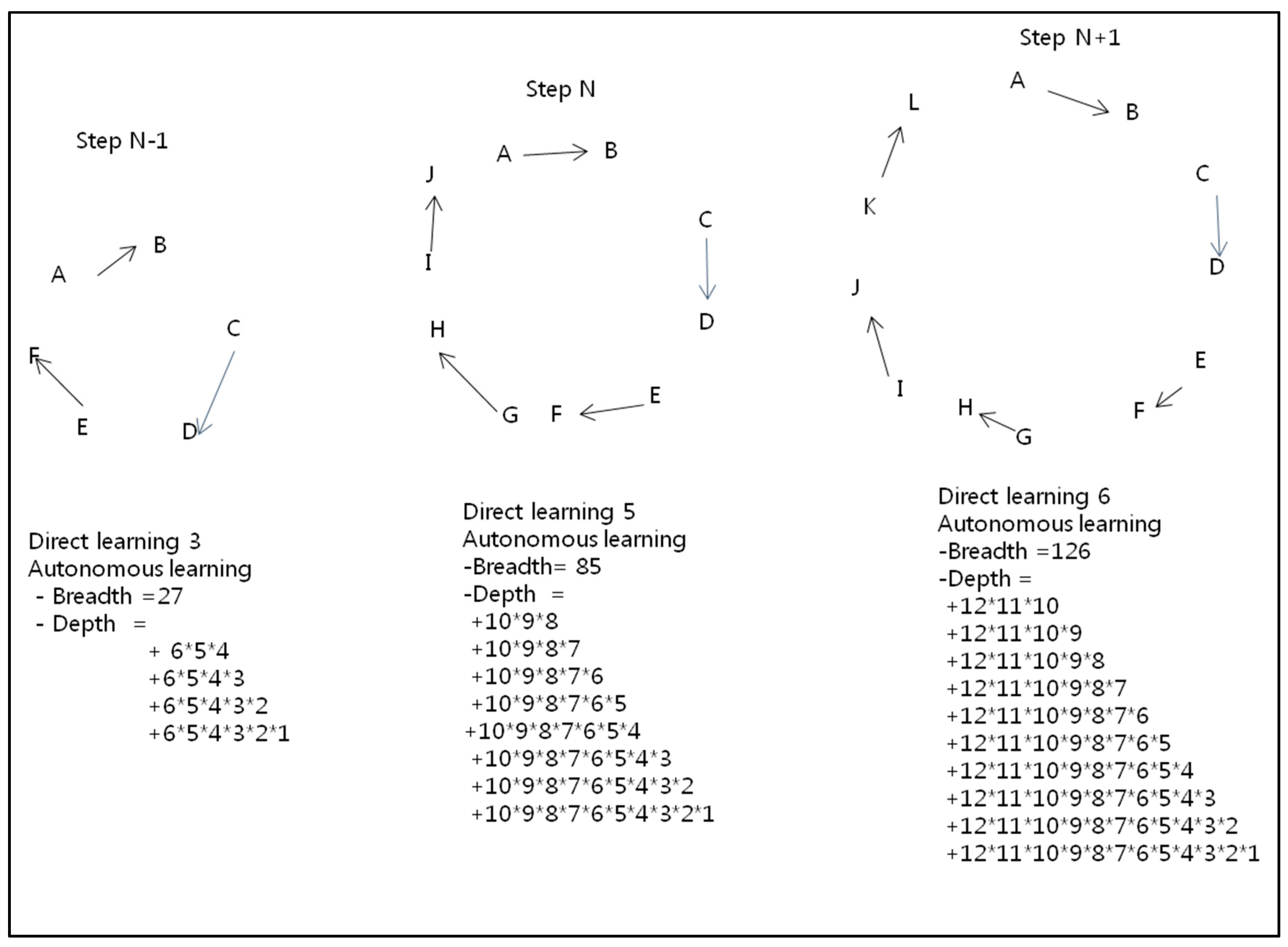
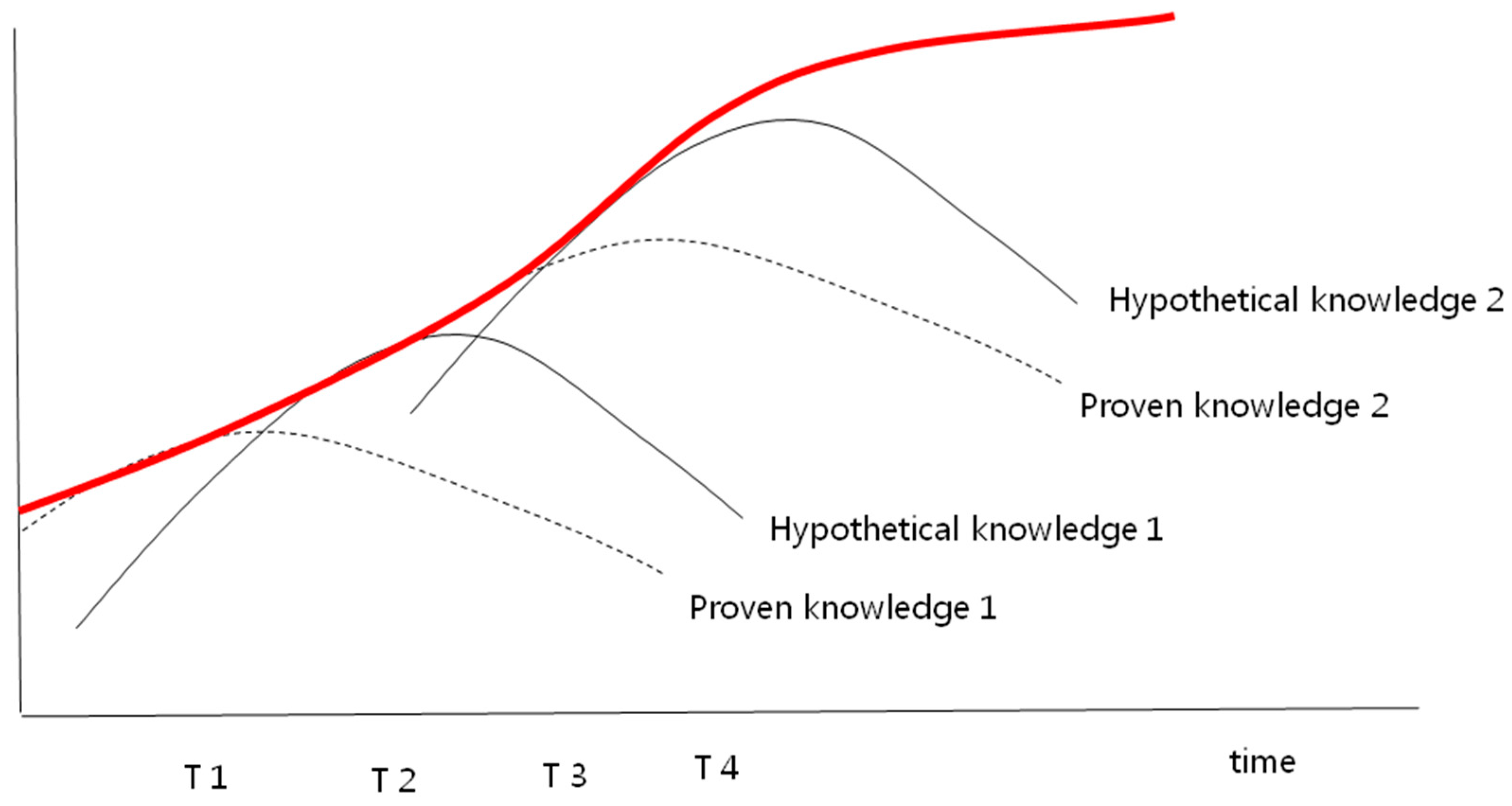
3.1. First Expansion of Autonomous Learning: Denial of Differentiation between Subjects and Predicates
3.2. Second Expansion of Autonomous Learning: Vertical Expansion
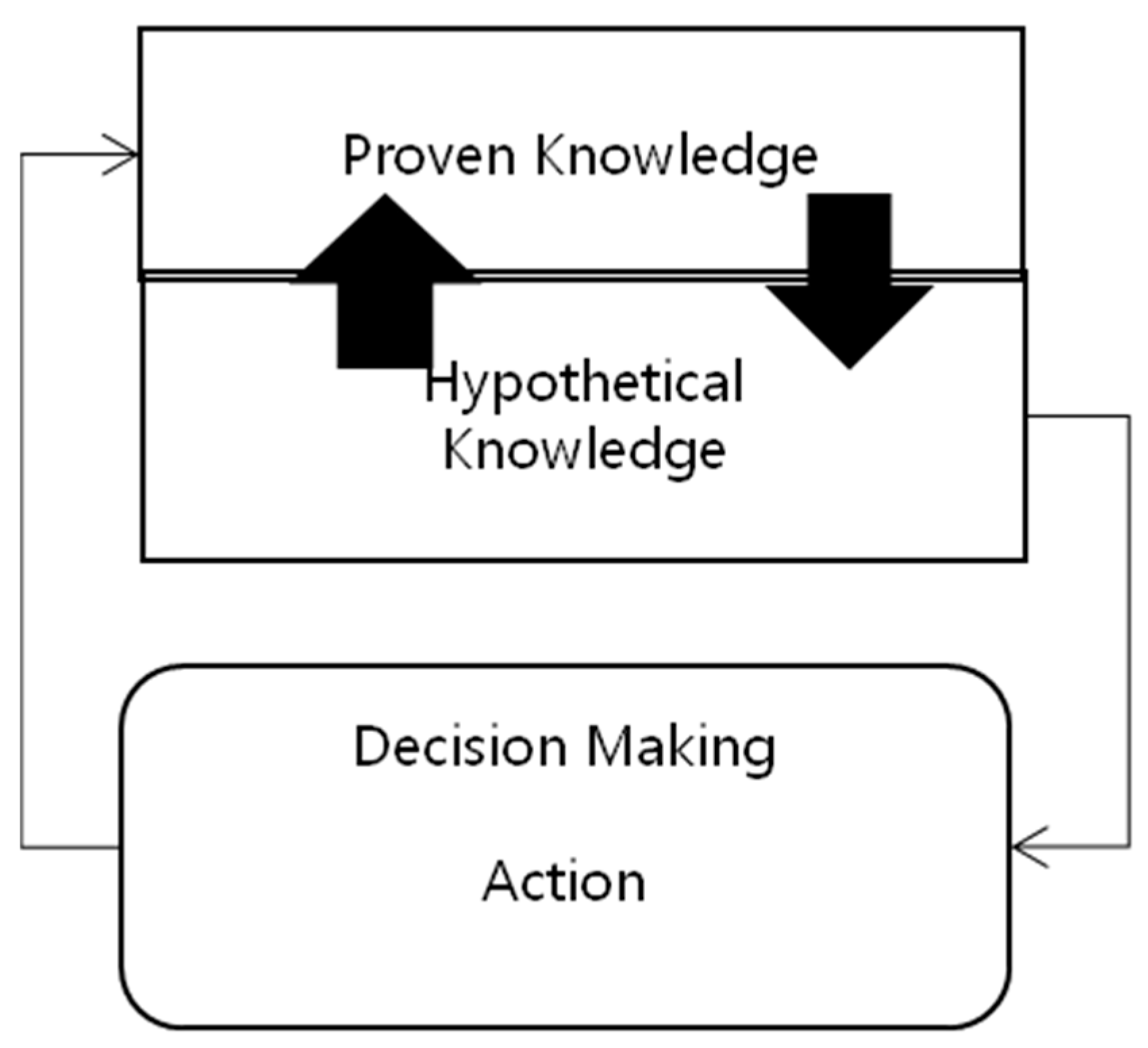
4. Key Characteristics of IMBDAL: Autonomy Invades Certainty
5. Mathematical Modeling
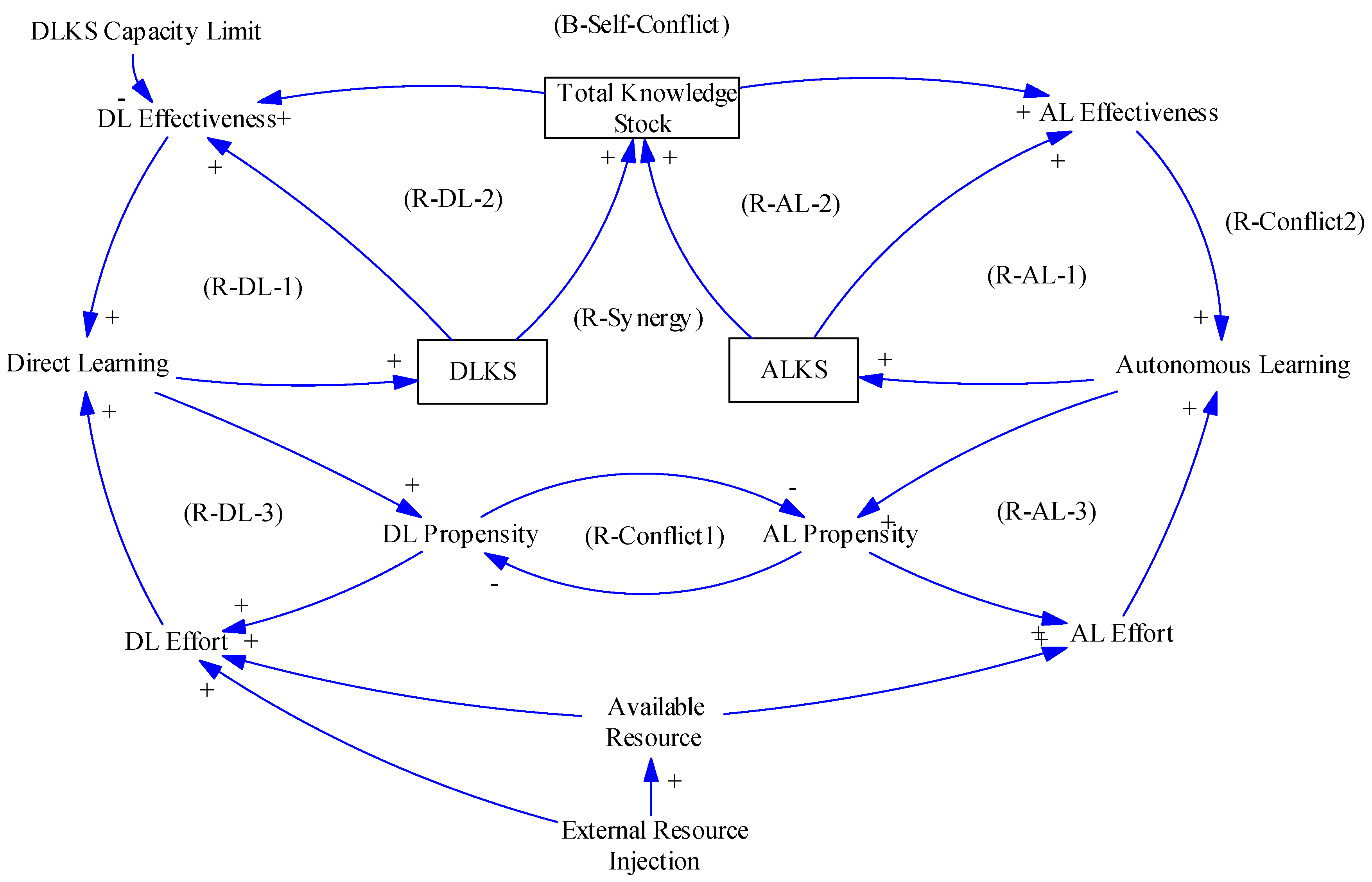
5.1. Causal Modeling of IMBDAL
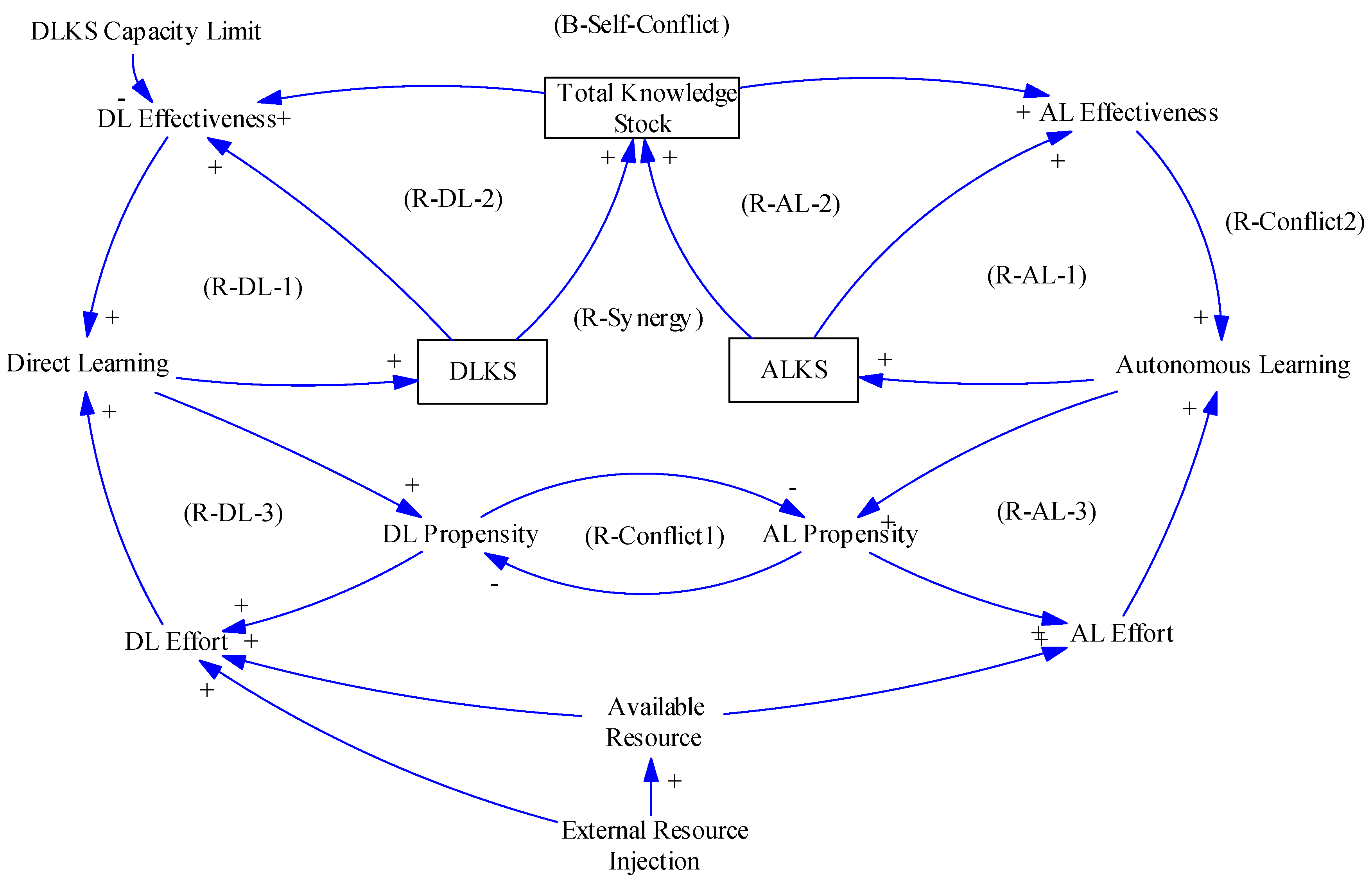
5.1.1. AL and DL Self-Reinforcement and Existence of Capacity Limit
- (Round(R)-DL-1) DL Self-reinforcement from “DLKS” growth: DL↑ ➜ DLKS↑ ➜ DL Effectiveness↑ ➜ DL↑
- (R-DL-2) DL Self-reinforcement from “Total Knowledge Stock”: DL↑ ➜ DLKS↑ ➜ Total KS↑ ➜ DL Effectiveness↑ ➜ DL↑
- (R-DL-3) DL Self-reinforcement from “DL Propensity (or DL Inertia)”: DL↑ ➜ DL Propensity↑ ➜ DL Effort↑ ➜ DL↑
5.1.2. AL and DL Synergy
- (R-Synergy) AL and DL Synergy from “Total KS” Growth: DL↑ ➜ DLKS↑ ➜ Total KS↑ ➜ AL Effectiveness↑ ➜ AL↑ ➜ ALKS↑ ➜ Total KS↑ ➜ DL Effectiveness↑ ➜ DL↑
5.1.3. AL and DL Conflict
- (R-Conflict1) DL↑ ➜ DLP (DL Propensity) ↑ ➜ ALP↓ ➜ AL Effort↓ ➜ AL↓ ➜ ALP↓ ➜ DLP↑ ➜ DL Effort↑ ➜ DL↑ (not through KS but through propensity)
- (R-Conflict1) DL↑ ➜ DLP (DL Propensity) ↑ ➜ ALP↓ ➜ AL Effort↓ ➜ AL↓ ➜ ALP↓ ➜ DLP↑ ➜ DL Effort↑ ➜ DL↑ (not through KS but through propensity)
- (B-Self-Conflict) DL↑ ➜ DLP↑ ➜ ALP↓ ➜ AL Effort↓ ➜ AL↓ ➜ ALKS↓ ➜ Total KS↓ ➜ DL Effectiveness↓ ➜ DL↓ (It also exists the same in the AL part.)
5.1.4. Possibility of External Resource Injection
- DLP (DL propensity) + ALP (AL propensity) = 1
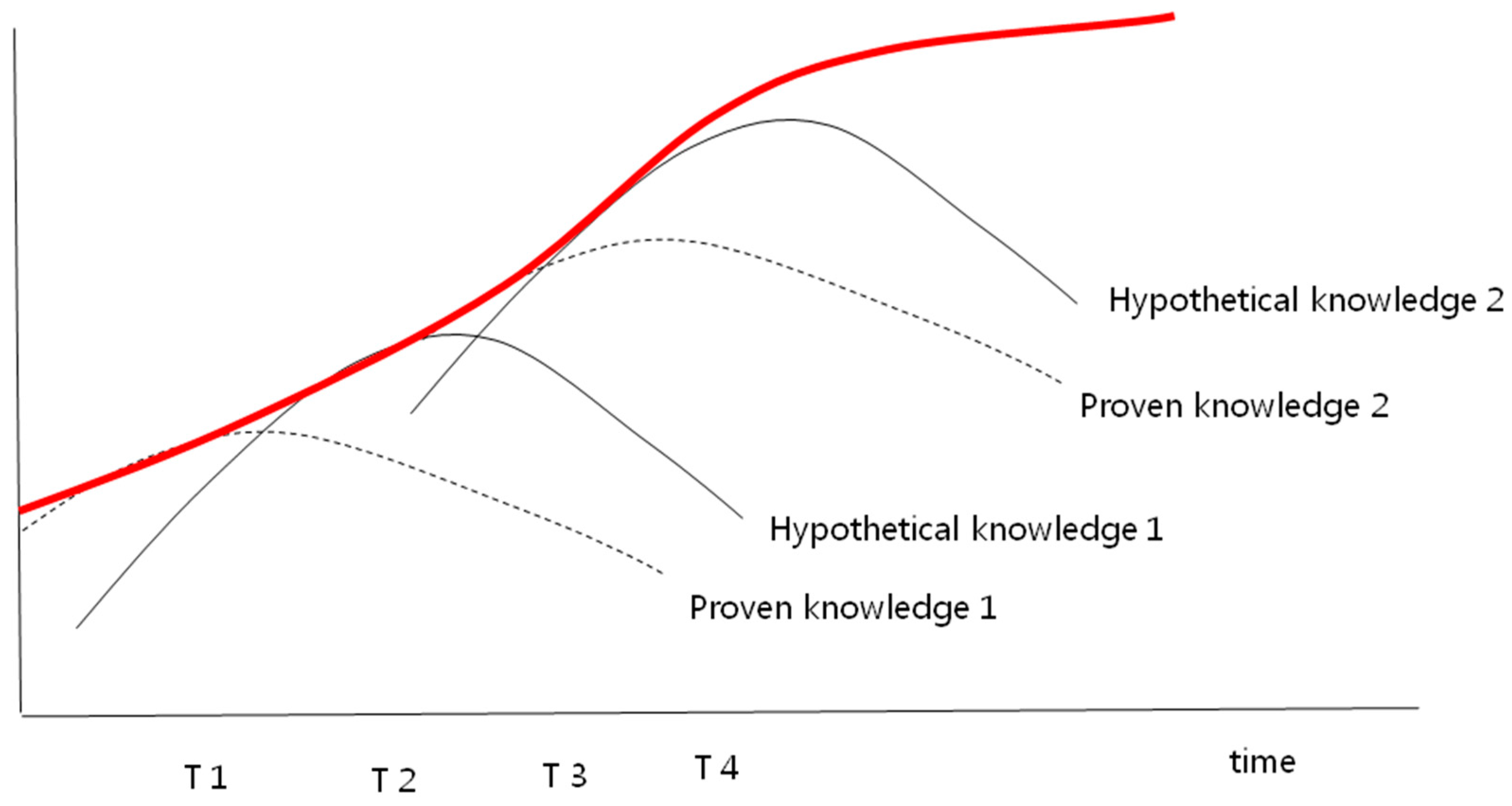
- DL effectiveness is expected to decrease with DLKS (or Total KS) growth (DLKS capacity limit).
- AL effectiveness is expected to maintain or grow with ALKS (or Total KS) growth.
5.2. Mathematical Model Building
5.2.1. Basic Condition for Mathematical Modeling
- (a)
- We assume that the accumulation of knowledge determines the rewards at each situation, so as the concern about the size of knowledge. Knowledge stock consists of two parts: the sum of PK, i.e., DLKS, as well as the sum of HK, i.e., ALKS. The accumulation of PK also interacts with the accumulation of HK. These are different from the perspective of machine learning in several facts [38].
- (b)
- The increase of DLKS in accordance with direct learning requires cost in that the difference of input resource based on time is allocated automatically by DL propensity. The output of DL is proportional to the input size of DLKS. The increase of DLKS is finite in each time interval because knowledge creation in finite time cannot be infinite. In addition, there is a memory decrease cycle, DL forget coefficient [39], deleting of old DL, which does not fit with changed environment.
- (c)
- ALKS has different aspects with DLKS in several factors. Autonomous learning offers from horizontal and vertical expansion of DLKS. The creation of knowledge by AL is much bigger than that of DL, but the increase of ALKS is finite in each time interval as in DLKS. This process requires cost of injecting resource at each time step which is allocated by AL propensity. DL helps AL since AL increases by proportional to DLKS. In addition, DL conflicts with AL in that DL propensity + AL propensity = 1, which means that if DL propensity increases, then AL propensity decreases. There is also a memory decrease cycle based on AL forget coefficient.
- (d)
- At each time step, resources are divided into two parts by DL propensity and AL propensity whose sum is one. Propensities represent the behavioral inertia which prevents the rapid change from one side to another but continuous success of one side result in the increase of that propensity. Propensities are controlled by the coefficients DL_min and DL_max, which set the minimum and the maximum bound of DL propensity, respectively.
5.2.2. Building up Activating Model
- [DL Effort]_t = DLP_(t-1) × R_t
- [AL]_t = [AL Effectiveness]_(t-1) × [AL Effort]_t
- [AL Effort]_t = [ALP]_(t-1) × R_t
- (DLP_t,ALP_t)= Inertia (∆DL_t,∆AL_t,DLP_(t-1),ALP_(t-1,)Inc_(_min),Inc_(_max),[DL]_(_min), Inc_(_min))
- DLP_t + ALP_t = 1
- [DL]_(_min) ≤ DLP_t ≤ [DL]_(_max)
- 1-[DL]_(_max) ≤ ALP_t ≤ 1 – [DL]_(_min)
- Inc_(_min) ≤ DLP_t-DLP_(t-1) ≤ Inc_(_max)
- [DL Effectiveness]_t = DL Effective(ALKS_t,DL_(_coefficients))
- [AL Effectiveness]_t = AL Effective(DLKS_t,AL_(_coefficients))
- DLt = DL Effectivenesst-1 × DL Effortt
- ALt = AL Effectivenesst-1 × AL Effortt
- [DLKS]_t = [DLKS]_(t-1) × (1-DL_(__forget__coefficient)) + [DL]_t
- [ALKS]_t = [ALKS]_(t-1) × (1-AL_(__forget__coefficient)) + [AL]_t
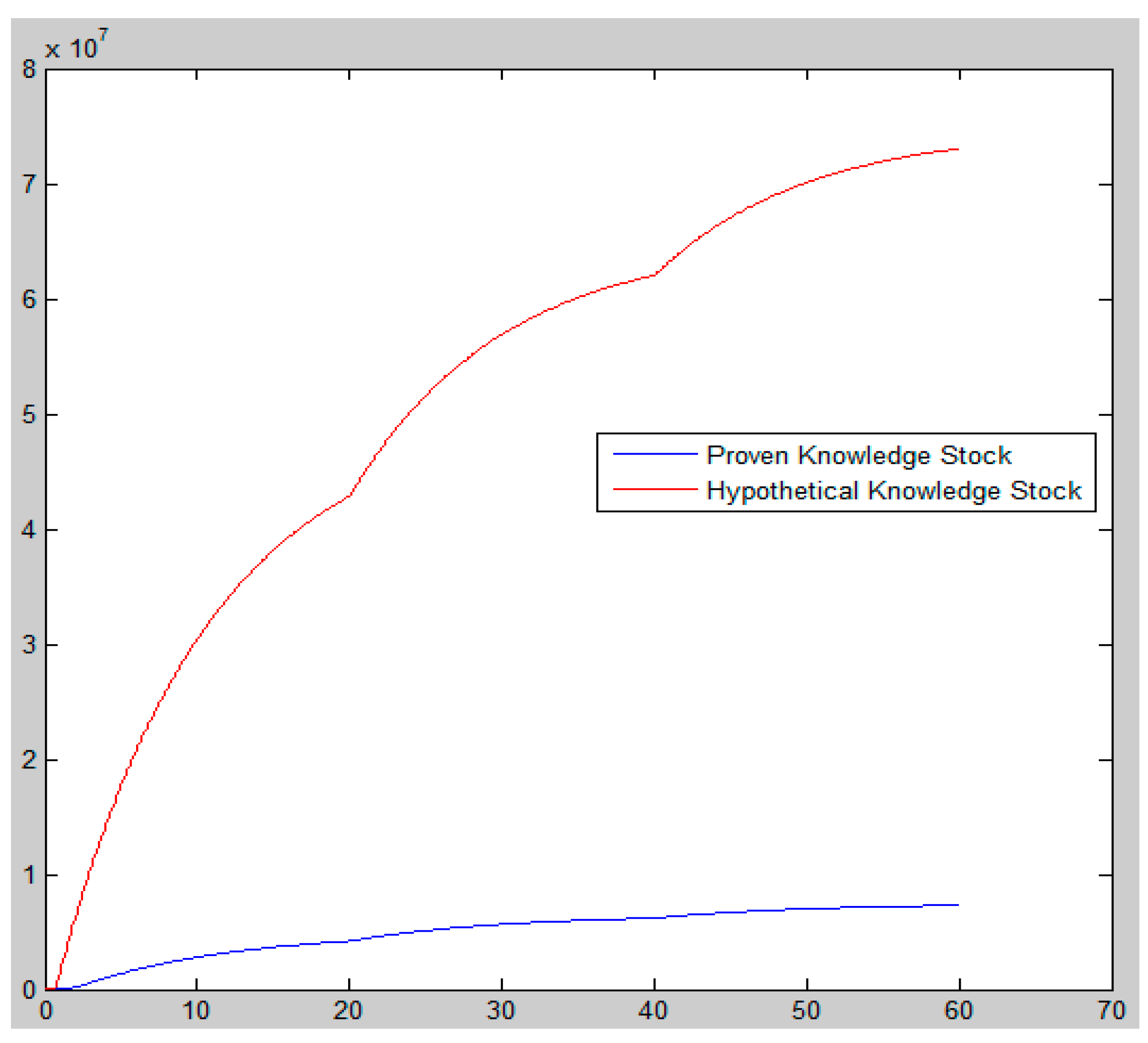
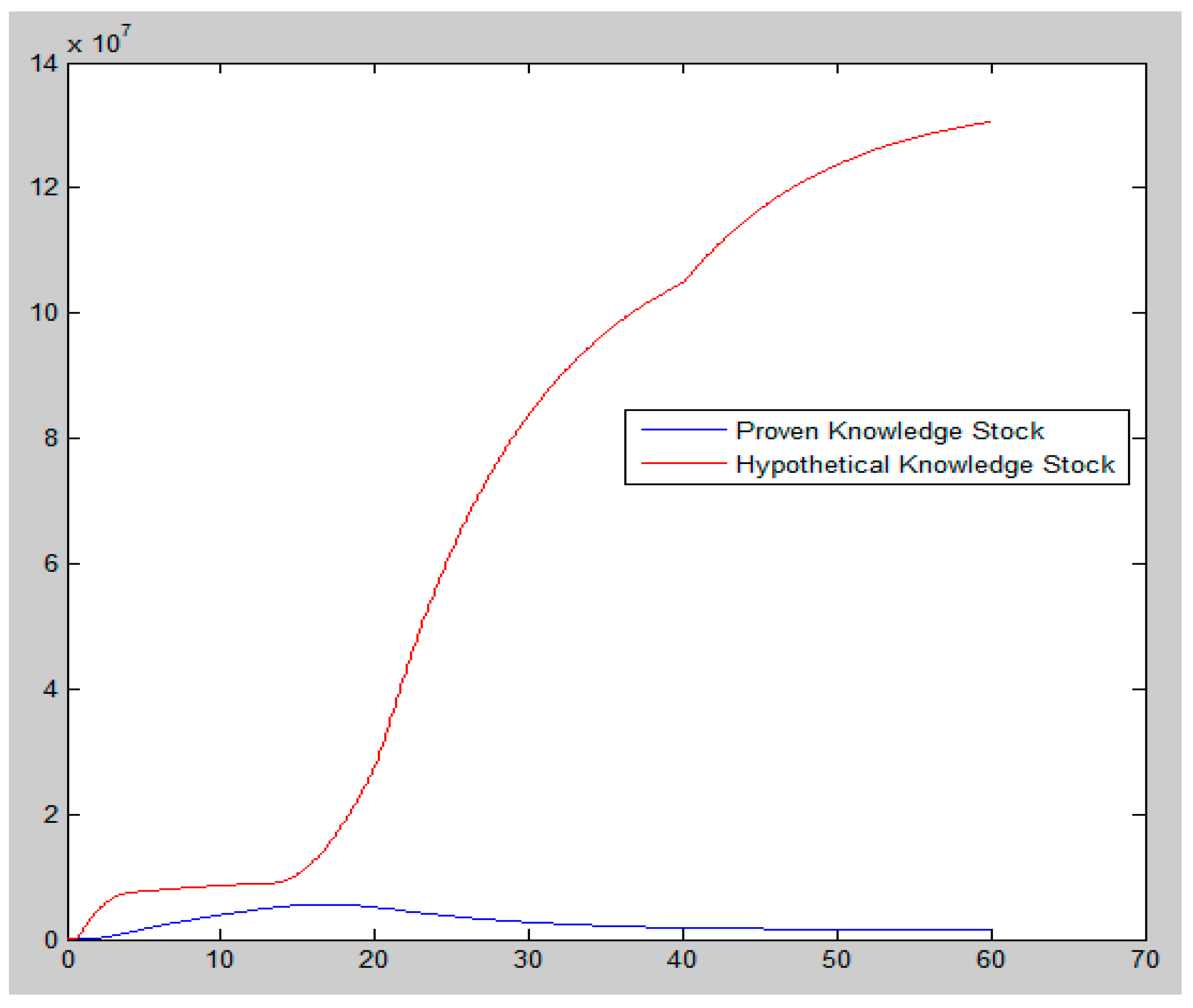
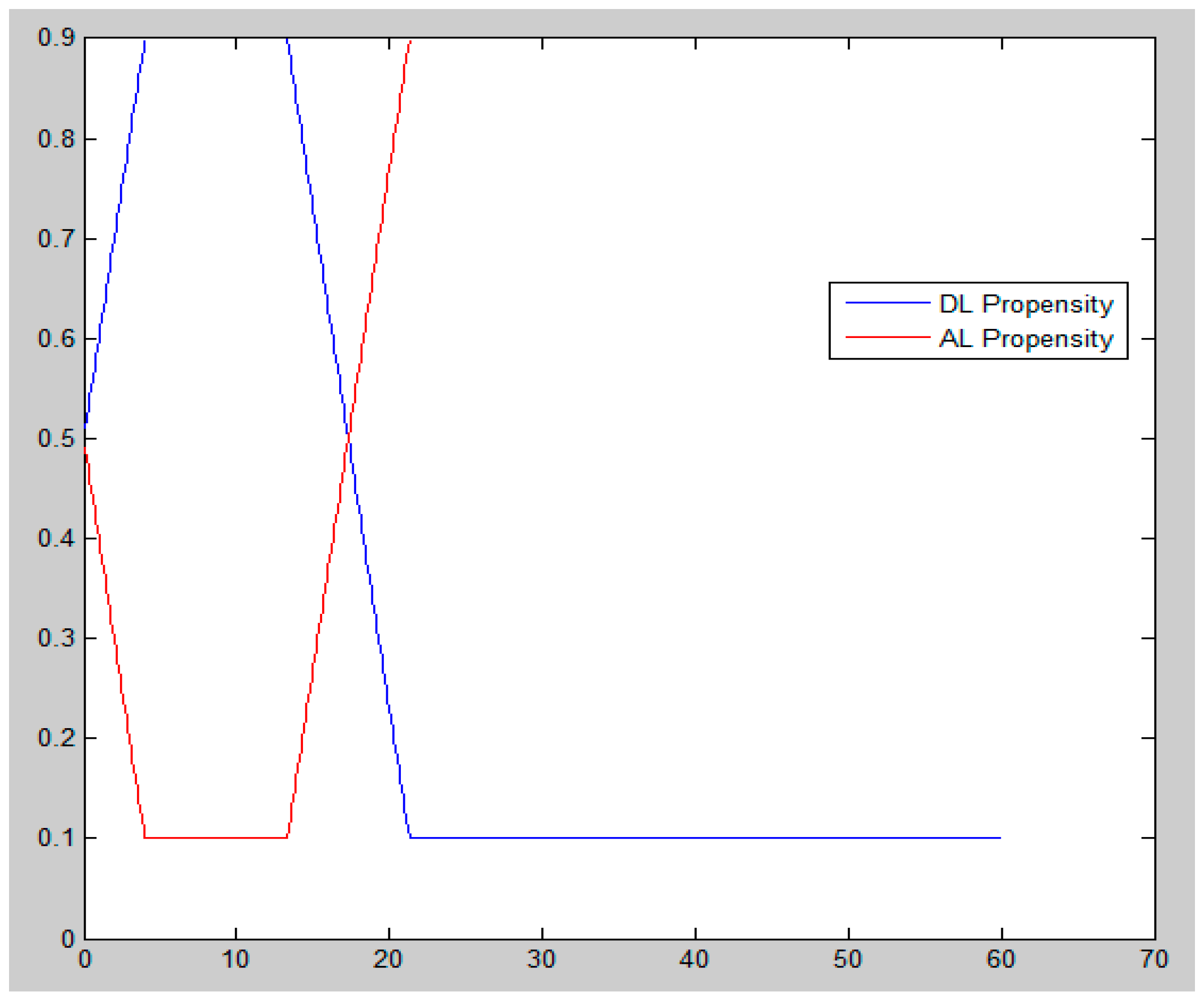
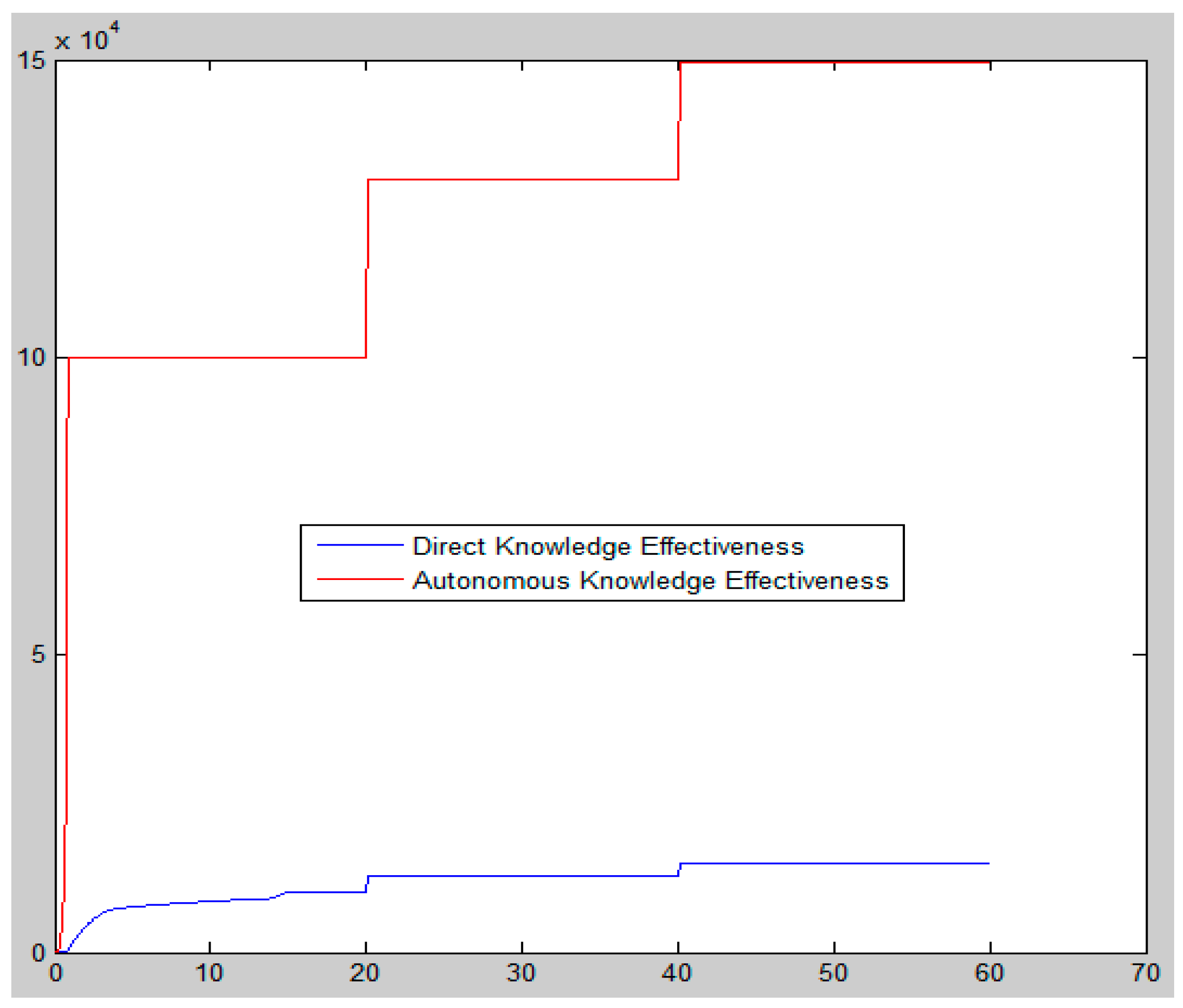
5.2.3. Simulation Results
6. Discussion and Application
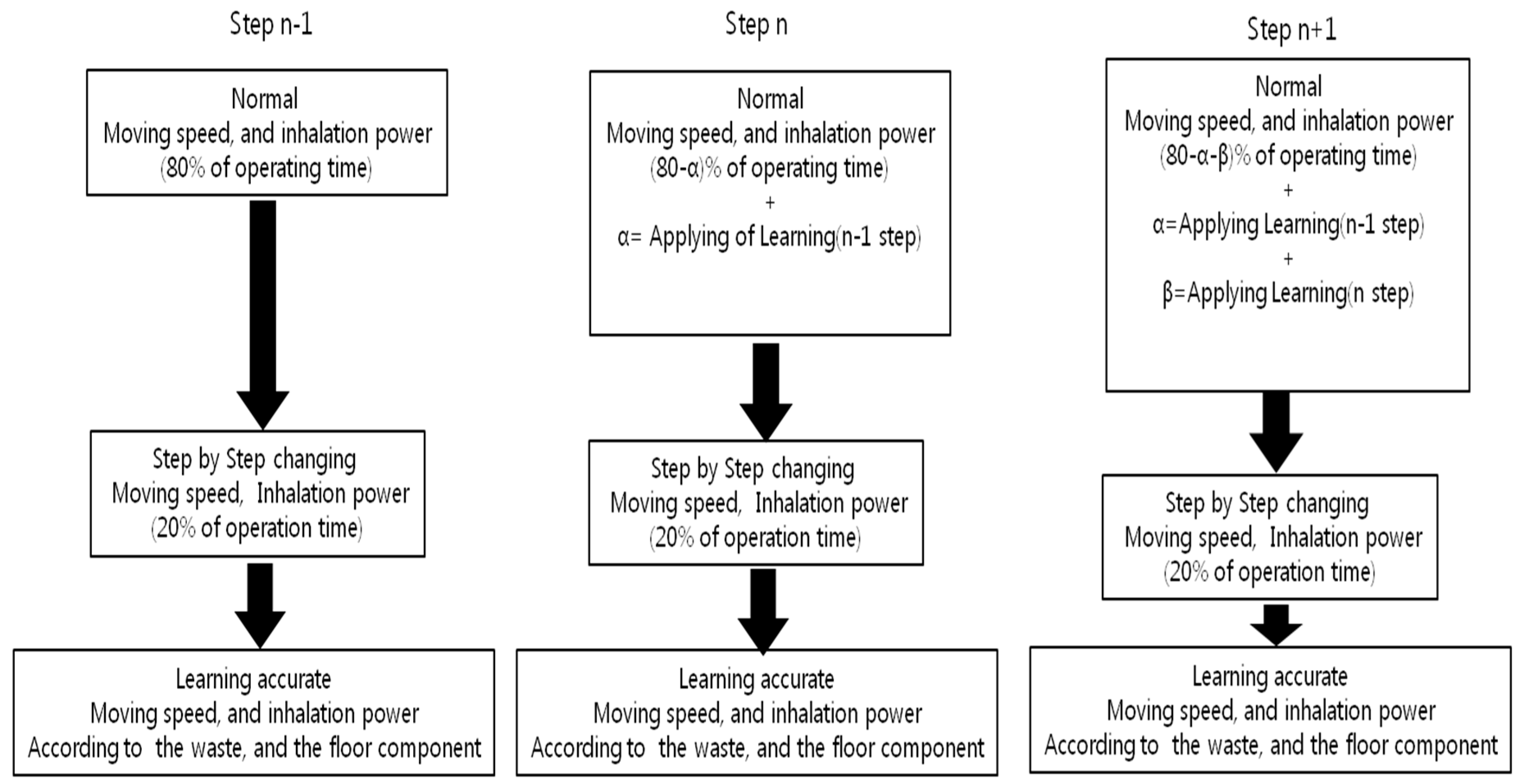
6.1. Application to Machine Learning
6.2. Discussion from Findings at Simulation
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Shen, W.-M. Discovery as autonomous learning from the environment. Mach. Learn. 1993, 12, 143–165. [Google Scholar] [CrossRef]
- Jeon, J.-H.; Kim, S.-K.; Koh, J.-H. Historical review on the patterns of open innovation at the national level: The case of the roman period. J. Open Innov. Technol. Mark. Complex. 2015, 1, 1–17. [Google Scholar] [CrossRef]
- Dorigo, M.; Colombetti, M. Robot shaping: Developing autonomous agents through learning. Artif. Intell. 1994, 71, 321–370. [Google Scholar] [CrossRef]
- Oganisjana, K. Promotion of university students’ collaborative skills in open innovation environment. J. Open Innov. Technol. Mark. Complex. 2015, 1, 1–17. [Google Scholar] [CrossRef]
- Figueiredo, M.A.; Jain, A.K. Unsupervised learning of finite mixture models. IEEE Trans. Pattern Anal. 2002, 24, 381–396. [Google Scholar] [CrossRef]
- Niebles, J.C.; Wang, H.; Fei-Fei, L. Unsupervised learning of human action categories using spatial–temporal words. Int. J. Comput. Vis. 2008, 79, 299–318. [Google Scholar] [CrossRef]
- Saul, L.K.; Roweis, S.T. Think globally, fit locally: Unsupervised learning of low dimensional manifolds. J. Mach. Learn. Res. 2003, 4, 119–155. [Google Scholar]
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model. User-Adapt. 1994, 4, 253–278. [Google Scholar] [CrossRef]
- Dianyu, Z. English learning strategies and autonomous learning. Foreign Lang. Educ. 2005, 1, 12. [Google Scholar]
- Dickinson, L. Talking shop aspects of autonomous learning. ELT J. 1993, 47, 330–336. [Google Scholar]
- Jacobs, D.M.; Michaels, C.F. Direct Learning. Ecol. Psychol. 2007, 19, 321–349. [Google Scholar] [CrossRef]
- Nunan, D. Towards autonomous learning: Some theoretical, empirical and practical issues. In Taking Control: Autonomy in Language Learning; Pemberton, R., Li, E.S.L., Or, W.W.F., Pierson, H.D., Eds.; Hong Kong University Press: Hong Kong, China, 1996; pp. 13–26. [Google Scholar]
- Zhou, D.; DeBrunner, V.E. Novel adaptive nonlinear predistorters based on the direct learning algorithm. IEEE Trans. Signal Process. 2007, 55, 120–133. [Google Scholar] [CrossRef]
- Molleman, L.; Van den Berg, P.; Weissing, F.J. Consistent individual differences in human social learning strategies. Nature Communications, 2014, 5, 3570. [Google Scholar] [CrossRef] [PubMed]
- Bonifacio, M.; Bouquet, P.; Cuel, R. Knowledge nodes: The building blocks of a distributed approach to knowledge management. J. Univers. Comput. Sci. 2002, 8, 652–661. [Google Scholar]
- Gil, A.B.; Peñalvo, F.J.G. Learner course recommendation in e-Learning based on swarm intelligence. J. Univers. Comput. Sci. 2008, 14, 2737–2755. [Google Scholar]
- Belussi, F.; Sammarra, A.; Sedita, S.R. Learning at the boundaries in an “Open Regional Innovation System”: A focus on firms’ innovation strategies in the Emilia Romagna life science industry. Res. Policy 2010, 39, 710–721. [Google Scholar] [CrossRef]
- Jacoby, L.L. On interpreting the effects of repetition: Solving a problem versus remembering a solution. J. Verb. Learn. Verb. Behav. 1978, 17, 649–667. [Google Scholar] [CrossRef]
- McGrath, R.G. Exploratory learning, innovative capacity, and managerial oversight. Acad. Manag. J. 2001, 44, 118–131. [Google Scholar] [CrossRef]
- Arthur, W.B. Inductive reasoning and bounded rationality. Am. Econ. Rev. 1994, 84, 406–411. [Google Scholar]
- Gigerenzer, G.; Selten, R. Bounded Rationality: The Adaptive Toolbox; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Simon, H.A. Theories of bounded rationality. In Decision and Organization; McGuire, C.B., Radner, R., Eds.; North-Holland Pub. Co.: Amsterdam, The Netherlands, 1972; Volume 1, pp. 161–176. [Google Scholar]
- Simon, H.A. Models of Bounded Rationality: Empirically Grounded Economic Reason; MIT Press: Cambridge, MA, USA, 1982. [Google Scholar]
- Simon, H.A. Bounded rationality and organizational learning. Organ. Sci. 1991, 2, 125–134. [Google Scholar] [CrossRef]
- Love, J.H.; Roper, S.; Vahter, P. Learning from open innovation; CSME Working Paper No. 112; Warwick Business School: Coventry, UK, 2011. [Google Scholar]
- Shanks, D.R.; St John, M.F. Characteristics of dissociable human learning systems. Behav. Brain Sci. 2010, 17, 367–395. [Google Scholar] [CrossRef]
- Yun, J.J.; Won, D.; Park, K. Dynamics from open innovation to evolutionary change. J. Open Innov. Technol. Mark. Complex. 2016, 2, 1–22. [Google Scholar] [CrossRef]
- Kodama, F.; Shibata, T. Demand articulation in the open-innovation paradigm. J. Open Innov. Technol. Mark. Complex. 2015, 1, 1–21. [Google Scholar] [CrossRef]
- Ormrod, J.E.; Davis, K.M. Human Learning; Merrill: Princeton, NC, USA, 2004; pp. 1–5. [Google Scholar]
- Kessler, G.; Bikowski, D. Developing collaborative autonomous learning abilities in computer mediated language learning: Attention to meaning among students in wiki space. Comput. Assist. Lang. Learn. 2010, 23, 41–58. [Google Scholar] [CrossRef]
- Polanyi, M. Personal Knowledge: Towards a Post-Critical Philosophy; University of Chicago Press: Chicago, IL, USA, 2012. [Google Scholar]
- Watanabe, Y.; Nishimura, R.; Okada, Y. Confirmed knowledge acquisition using mails posted to a mailing list. In Proceedings of the 2nd International Joint Conference on Natural Language Processing (IJCNLP), Jeju Island, Korea, 11–13 October 2005; Dale, R., Wong, K., Su, J., Kwong, O.Y., Eds.; Springer-Verlag: Berlin, Germany; pp. 131–142.
- Gluck, M.A.; Bower, G.H. Evaluating an adaptive network model of human learning. J. Mem. Lang. 1988, 27, 166–195. [Google Scholar] [CrossRef]
- Chesbrough, H.W. Open Innovation: The New Imperative for Creating and Profiting from Technology; Harvard Business Press: Boston, MA, USA, 2003. [Google Scholar]
- Chesbrough, H. Open innovation: A new paradigm for understanding industrial innovation. In Open Innovation: Researching a New Paradigm; Chesbrough, H., Vanheverbeke, W., West, J., Eds.; Oxford University Press: Oxford, UK, 2006; pp. 1–12. [Google Scholar]
- Gassmann, O.; Enkel, E. Towards a theory of open innovation: Three core process archetypes. In Proceedings of the R&D Management Conference, Lisbon, Portugal, 6 July 2004.
- Sun, R.; Peterson, T. Autonomous learning of sequential tasks: Experiments and analyses. IEEE Trans. Neural Netw. 1998, 9, 1217–1234. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: A Bradford Book; The MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Lam, K.C.; Donald, L.; Hu, T. Understanding the effect of the learning-forgetting phenomenon to duration of projects construction. Int. J. Proj. Manag. 2001, 19, 411–420. [Google Scholar] [CrossRef]









© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yun, J.J.; Lee, D.; Ahn, H.; Park, K.; Yigitcanlar, T. Not Deep Learning but Autonomous Learning of Open Innovation for Sustainable Artificial Intelligence. Sustainability 2016, 8, 797. https://doi.org/10.3390/su8080797
Yun JJ, Lee D, Ahn H, Park K, Yigitcanlar T. Not Deep Learning but Autonomous Learning of Open Innovation for Sustainable Artificial Intelligence. Sustainability. 2016; 8(8):797. https://doi.org/10.3390/su8080797
Chicago/Turabian StyleYun, JinHyo Joseph, Dooseok Lee, Heungju Ahn, Kyungbae Park, and Tan Yigitcanlar. 2016. "Not Deep Learning but Autonomous Learning of Open Innovation for Sustainable Artificial Intelligence" Sustainability 8, no. 8: 797. https://doi.org/10.3390/su8080797
APA StyleYun, J. J., Lee, D., Ahn, H., Park, K., & Yigitcanlar, T. (2016). Not Deep Learning but Autonomous Learning of Open Innovation for Sustainable Artificial Intelligence. Sustainability, 8(8), 797. https://doi.org/10.3390/su8080797