
Carbon-Aware Spatio-Temporal Workload Shifting in Edge–Cloud Environments: A Review and Novel Algorithm

 , ,
, , 
Abstract
1. Introduction
2. Background
2.1. The Growing Energy and Carbon Footprint of Computing
2.2. Operational Carbon of Computing Loads
2.2.1. Electricity Consumption of Computing Loads
2.2.2. Carbon Intensity of Electricity
2.3. Workload Scheduling: Traditional Methods vs. Carbon Footprint Optimization
2.3.1. Traditional Methods
2.3.2. Emergence of Carbon-Aware Methods
2.3.3. Workload Classification Regarding Their Shiftability
2.4. Accounting for Embodied Emissions
2.4.1. Overview of LCA Basics with Focus on Carbon Footprinting
2.4.2. Definition of a Functional Unit
2.4.3. Allocating Hardware Production
2.5. Workload Prediction
3. Literature Review on Carbon-Aware Scheduling Techniques
3.1. Quantitative Analysis
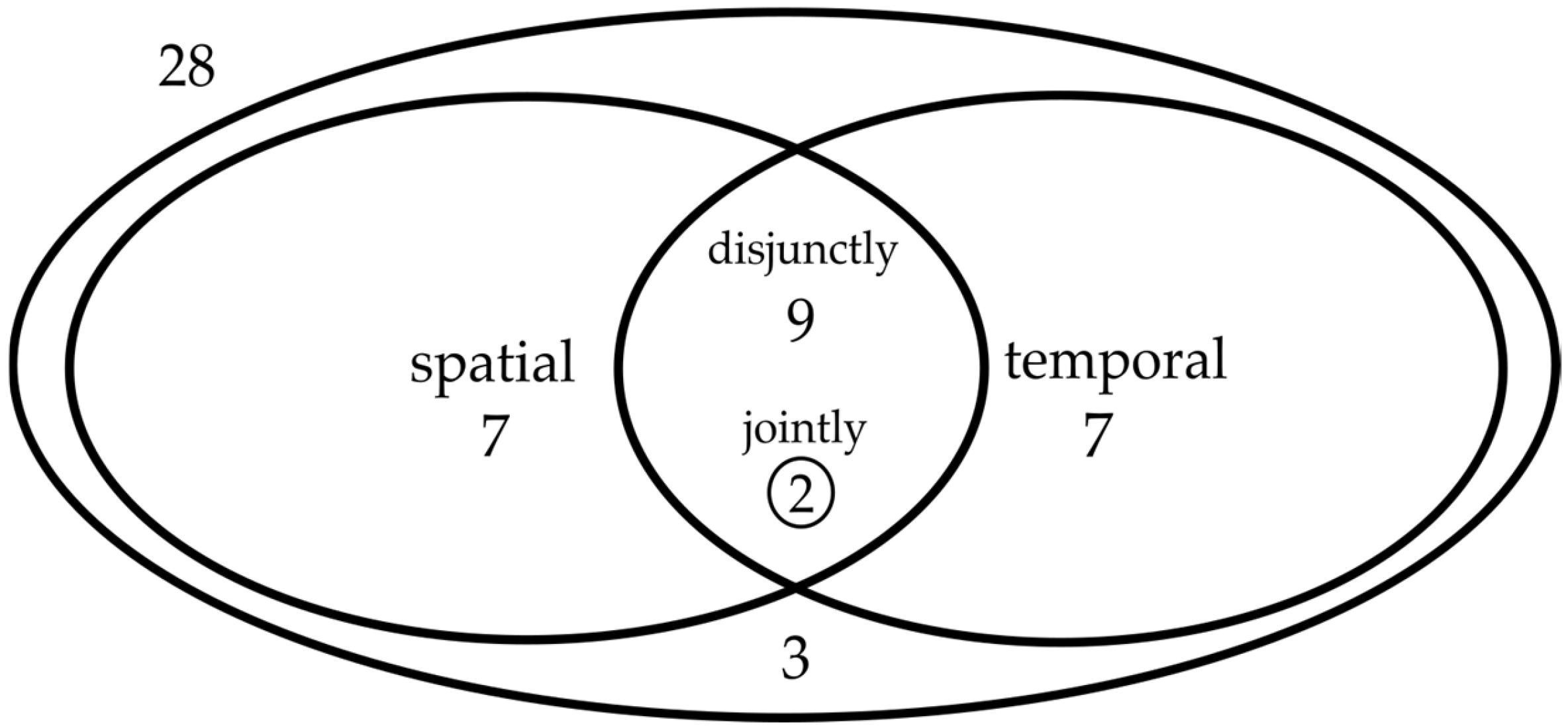
- Temporal Workload Shifting: Analyzed in 18 studies (see also Figure 2), this strategy involves scheduling tasks to times of lower carbon intensity, often coinciding with renewable energy availability.
- Spatial Workload Shifting: Investigated coincidentally also in 18 studies, it focuses on redistributing tasks across geographically diverse data centers, guided by their varying carbon intensities.
- Combined Approaches: A total of 11 of the above studies examined both strategies, suggesting a trend towards integrated approaches for more effective carbon footprint reduction. While in earlier years (i.e., pre-2023), most studies considered either temporal or spatial shifting (13/20 studies, 65%), from the recent literature (i.e., 2024 and 2025), the majority tend to consider both methods (4/5 studies, 80%).
- Beyond Workload Shifting: Five studies proposed different methods for carbon footprint optimization, challenging the sole reliance on workload shifting and indicating a need for diversified strategies.
- Emission Factors: A total of 5 studies used average emission factors, 10 used marginal emission factors, and 10 did not specify their use, highlighting methodological diversity and potential gaps in CI calculation.
- Networking Overhead: Only two studies evaluated the energy requirement due to networking overhead from workload migration, which is generally considered negligible.
- Forecasting: Eight studies employed forecasting techniques, primarily for predicting day-ahead demand or energy prices. However, only two studies detailed their forecasting methods, which raises concerns about methodological transparency and reproducibility.
- Power Mapping: Six studies integrated a mapping of computations to the required power, either by estimation or—for two of them—directly measured, indicating growing interest in accurate energy consumption assessment.
- Embodied emissions: Five studies mentioned embodied emissions but only one detailed its methodology, underscoring the gap of transparent LCA of ICT hardware.
- Optimization Objectives: Of the 28 studies, 10 prioritized minimizing the carbon footprint, with 5 optimizing for an additional objective and 4 considering three objectives simultaneously. Only one study focused exclusively on carbon, highlighting the trend for multi-objective optimization in carbon-aware computing.
- Platform Utilization: Three studies mentioned Kubernetes, one study discussed running their scheduler as a daemon on Linux distributions, while others did not specify a use case.
- Open-Source Availability: Only eight studies have open-sourced their code, raising questions about study reproducibility and comparability within the field.
3.2. Qualitative Analysis
3.2.1. Embodied Emissions in the Context of Scheduling
3.2.2. Spatio-Temporal Shifting
3.2.3. Algorithm Development Stages
4. Carbon-Aware Spatio-Temporal Workload Shifting: A Novel Algorithm
4.1. Computing a Workload’s Carbon Footprint
4.1.1. Allocating Embodied Carbon
4.1.2. Computing Operational Carbon
4.2. Spatial Scoring
4.3. Temporal Scoring
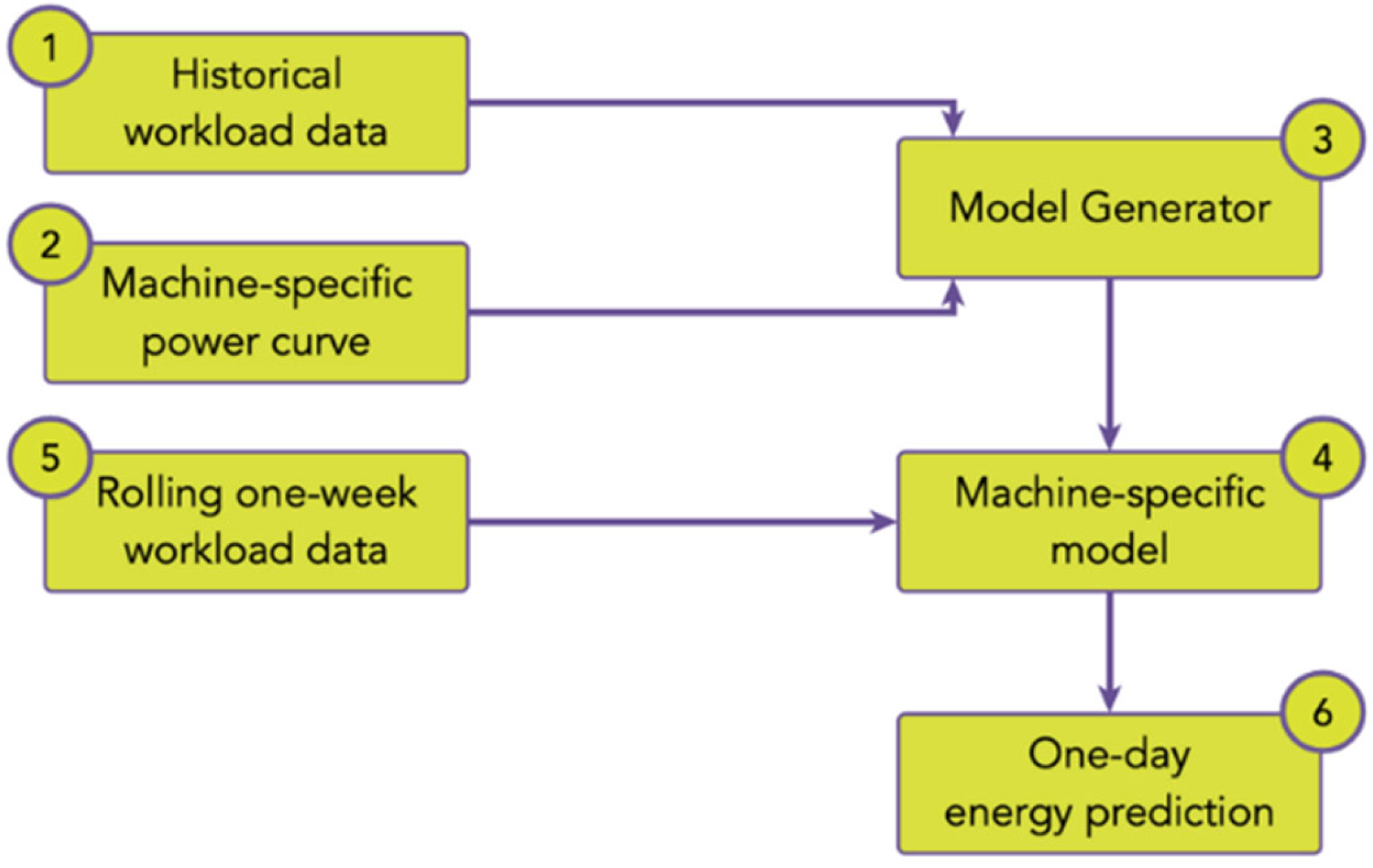
4.4. Workload Prediction Model
4.5. Spatio-Temporal Shifting Algorithm
- Access to CI data (good data available and deployed).
- Pod resource requirements specific to the node (the trickiest assumption; heuristics need to be developed).
- Data on expected lifetimes of hardware (existing but scattered).
- Availability of power curves (good data for DC servers, incipient for edge devices).
- Availability of embodied emissions data (existing, but typically only for categories of devices, not individual products).
| Algorithm 1. Spatio-temporal shifting (ijk represent pod, node, and time slot, respectively, overline denotes pod-related resources, and hat is used to signify predicted variables). |
| Input: Priority queue Q of pods; set of nodes N; set of time slots T; resource requirements and deadlines of pods; predicted average carbon intensities (ACI) and utilization of nodes. |
| Result: Feasible schedule S of pods on nodes and time slots that minimizes total carbon emissions. |
| Initialize empty schedule S |
| Initialize resource availability Rjk for all nodes j ∈ N and time slots k ∈ T |
| Calculate embodied emissions rate for each node j as |
| If new pods arrived then |
| Add new pods to the priority queue Q based on their deadlines |
| End If |
| If hourly update or new pods arrive then |
| For each pod i ∈ Q do |
| Set C* ← ∞; j* ← −1; k* ← −1 |
| For each time slot k ∈ T do |
| If Endk ≤ Deadlinei then |
| For each node j ∈ N do |
| If CPU and RAM constraints are satisfied then |
| If utilization constraint is satisfied then |
| If Ctot < C* then |
| C* ← Ctot; j* ← j; k* ← k |
| End If |
| End If |
| End If |
| End For |
| End If |
| End For |
| If j* ≠ −1 and k* ≠ −1 then |
| Schedule pod i on node j* at time slot k* |
| Update schedule S |
| Remove pod i from Q |
| End If |
| End For |
| End If |
5. Discussion and Limitations
5.1. Algorithm
5.2. Environmental Evaluation
6. Conclusions and Further Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Andrae, A.S.G.; Edler, T. On Global Electricity Usage of Communication Technology: Trends to 2030. Challenges 2015, 6, 117–157. [Google Scholar] [CrossRef]
- Malmodin, J.; Lundén, D. The Energy and Carbon Footprint of the Global ICT and E&M Sectors 2010–2015. Sustainability 2018, 10, 3027. [Google Scholar] [CrossRef]
- Basmadjian, R. Flexibility-Based Energy and Demand Management in Data Centers: A Case Study for Cloud Computing. Energies 2019, 12, 3301. [Google Scholar] [CrossRef]
- Marcel, A.; Cristian, P.; Eugen, P.; Claudia, P.; Cioara, T.; Anghel, I.; Ioan, S. Thermal aware workload consolidation in cloud data centers. In Proceedings of the 2016 IEEE 12th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 8–10 September 2016; IEEE: New York, NY, USA, 2016; pp. 377–384. [Google Scholar] [CrossRef]
- Rong, H.; Zhang, H.; Xiao, S.; Li, C.; Hu, C. Optimizing energy consumption for data centers. Renew. Sustain. Energy Rev. 2016, 58, 674–691. [Google Scholar] [CrossRef]
- Sotos, M.; Didden, M.; Kovac, A.; Ryor, J.; Stevens, A.; Cummis, C. GHG Protocol Scope 2 Guidance; Greenhouse Gas Protocol: Washington, DC, USA, 2015. [Google Scholar]
- Holzapfel, P.; Bach, V.; Finkbeiner, M. Electricity accounting in life cycle assessment: The challenge of double counting. Int. J. Life Cycle Assess 2023, 28, 771–787. [Google Scholar] [CrossRef]
- Biswas, D.; Jahan, S.; Saha, S.; Samsuddoha, M. A succinct state-of-the-art survey on green cloud computing: Challenges, strategies, and future directions. Sustain. Comput. Inform. Syst. 2024, 44, 101036. [Google Scholar] [CrossRef]
- Radovanovic, A.; Koningstein, R.; Schneider, I.; Chen, B.; Duarte, A.; Roy, B.; Xiao, D.; Haridasan, M.; Hung, P.; Care, N.; et al. Carbon-Aware Computing for Datacenters. IEEE Trans. Power Syst. 2021, 38, 1270–1280. Available online: http://arxiv.org/abs/2106.11750 (accessed on 20 July 2023).
- Kubernetes Documentation. Available online: https://kubernetes.io/docs/home/ (accessed on 15 May 2024).
- Hischier, R.; Coroama, V.C.; Schien, D.; Achachlouei, M.A. Grey Energy and Environmental Impacts of ICT Hardware. In ICT Innovations for Sustainability; Hilty, L.M., Aebischer, B., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2015; Volume 310, pp. 171–189. [Google Scholar] [CrossRef]
- Fluidos-Energy-Predictor. 2024. Available online: https://github.com/fluidos-project/fluidos-energy-predictor (accessed on 10 May 2024).
- Fluidos, Creating a Fluid, Dynamic, Scalable, and Trustable Computing Continuum. Available online: https://www.fluidos.eu/ (accessed on 24 July 2024).
- IEA. Electricity 2024: Analysis and Forecast to 2026; IEA: Paris, France, 2024. [Google Scholar]
- OpenAI, ChatGPT. 2024. Available online: https://openai.com/chatgpt (accessed on 18 January 2024).
- Google, Gemini-Chat to Supercharge Your Ideas. 2024. Available online: https://gemini.google.com (accessed on 29 May 2024).
- Meta, Llama 3. 2024. Available online: https://llama.meta.com/llama3/ (accessed on 29 May 2024).
- Wired, The Generative AI Race Has a Dirty Secret. Available online: https://www.wired.com/story/the-generative-ai-search-race-has-a-dirty-secret/ (accessed on 18 January 2024).
- Lin, L.; Chien, A. Adapting Datacenter Capacity for Greener Datacenters and Grid. In Proceedings of the 14th ACM International Conference on Future Energy Systems, Orlando, FL, USA, 16–23 June 2023; pp. 200–213. [Google Scholar] [CrossRef]
- Moore, G.E. Cramming more components onto integrated circuits. Electronics 1965, 38, 114–117. [Google Scholar] [CrossRef]
- Hintemann, R.; Hinterholzer, S. Energy consumption of data centers worldwide. ICT4S. 2019. Available online: https://ceur-ws.org/Vol-2382/ICT4S2019_paper_16.pdf (accessed on 7 July 2025).
- Malmodin, J.; Lövehagen, N.; Bergmark, P.; Lundén, D. ICT sector electricity consumption and greenhouse gas emissions—2020 outcome. Telecommun. Policy 2024, 48, 102701. [Google Scholar] [CrossRef]
- Galantino, S.; Risso, F.; Coroamă, V.C.; Manzalini, A. Assessing the Potential Energy Savings of a Fluidified Infrastructure. Computer 2023, 56, 26–34. [Google Scholar] [CrossRef]
- National Grid Group. What Is Carbon Intensity? Available online: https://web.archive.org/web/20240414132036/https://www.nationalgrid.com/stories/energy-explained/what-is-carbon-intensity (accessed on 9 October 2023).
- Listgarten, S. When to Use Marginal Emissions (and When Not To). Available online: https://web.archive.org/web/*/https://www.paloaltoonline.com/blogs/p/2019/09/29/marginal-emissions-what-they-are-and-when-to-use-them (accessed on 9 October 2023).
- Electricity Maps. Marginal vs Average: Which One to Use for Real-Time Decisions? Available online: https://www.electricitymaps.com/blog/marginal-vs-average-real-time-decision-making (accessed on 19 April 2024).
- WattTime. Available online: https://www.watttime.org/ (accessed on 9 October 2023).
- Electricity Maps. Live 24/7 CO2 Emissions of Electricity Consumption. Available online: http://electricitymap.tmrow.co (accessed on 29 May 2024).
- NESO. Carbon Intensity. Available online: https://carbonintensity.org.uk/ (accessed on 9 October 2023).
- EIA. Hourly Electric Grid Monitor. Available online: https://www.eia.gov/electricity/gridmonitor/index.php (accessed on 9 October 2023).
- ENTSO-E. ENTSO-E Transparency Platform. Available online: https://transparency.entsoe.eu/ (accessed on 9 October 2023).
- Kubernetes Carbon Intensity Exporter. (27 September 2023). Go. Microsoft Azure. Available online: https://github.com/Azure/kubernetes-carbon-intensity-exporter (accessed on 5 October 2023).
- Carbon Aware SDK. (29 September 2023). C#. Green Software Foundation. Available online: https://github.com/Green-Software-Foundation/carbon-aware-sdk (accessed on 5 October 2023).
- KEDA. Available online: https://keda.sh/docs/2.13/concepts/ (accessed on 17 February 2024).
- Gao, X.; Liu, R.; Kaushik, A. Hierarchical Multi-Agent Optimization for Resource Allocation in Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 692–707. [Google Scholar] [CrossRef]
- Elhady, G.F.; Tawfeek, M.A. A comparative study into swarm intelligence algorithms for dynamic tasks scheduling in cloud computing. In Proceedings of the 2015 IEEE Seventh International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 12–14 December 2015; IEEE: New York, NY, USA, 2015; pp. 362–369. [Google Scholar] [CrossRef]
- Saxena, R.; Afrin, N. Comparison of Scheduling Algorithms in Cloud Computing. In Proceedings of the National Conference on Computer Security, Image Processing, Graphics, Mobility and Analytics, Telangana, India, 17–18 December 2016; pp. 37–40. [Google Scholar] [CrossRef]
- Pacini, E.; Mateos, C.; Garino, C.G. Balancing throughput and response time in online scientific Clouds via Ant Colony Optimization (SP2013/2013/00006). Adv. Eng. Softw. 2015, 84, 31–47. [Google Scholar] [CrossRef]
- Singh, P.; Dutta, M.; Aggarwal, N. Bi-objective HWDO Algorithm for Optimizing Makespan and Reliability of Workflow Scheduling in Cloud Systems. In Proceedings of the 2017 14th IEEE India Council International Conference (INDICON), Roorkee, India, 15–17 December 2017; IEEE: New York, NY, USA, 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Kaur, T.; Pahwa, S. An Upgraded Algorithm of Resource Scheduling using PSO and SA in Cloud Computing. Int. J. Comput. Appl. 2013, 74, 28–32. [Google Scholar] [CrossRef]
- Wu, W.; Lin, W.; Peng, Z. An intelligent power consumption model for virtual machines under CPU-intensive workload in cloud environment. Soft Comput. 2017, 21, 5755–5764. [Google Scholar] [CrossRef]
- Beegom, A.S.A.; Rajasree, M.S. Integer-PSO: A discrete PSO algorithm for task scheduling in cloud computing systems. Evol. Intell. 2019, 12, 227–239. [Google Scholar] [CrossRef]
- Dubey, H.M.; Pandit, M.; Srivastava, L.; Panigrahi, B.K. (Eds.) Artificial Intelligence and Sustainable Computing: Proceedings of ICSISCET 2020; Springer Nature: Singapore, 2022. [Google Scholar] [CrossRef]
- Zuo, L.; Shu, L.; Dong, S.; Zhu, C.; Hara, T. A Multi-Objective Optimization Scheduling Method Based on the Ant Colony Algorithm in Cloud Computing. IEEE Access 2015, 3, 2687–2699. [Google Scholar] [CrossRef]
- Fard, H.M.; Prodan, R.; Barrionuevo, J.J.D.; Fahringer, T. A Multi-objective Approach for Workflow Scheduling in Heterogeneous Environments. In Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID 2012), Ottawa, ON, Canada, 13–16 May 2012; IEEE: New York, NY, USA, 2012; pp. 300–309. [Google Scholar] [CrossRef]
- Lu, X.; Tang, S. Synchronous Dislocation Scheduling Quantum Algorithm Optimization in Virtual Private Cloud Computing Environment. In Proceedings of the 2022 6th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 25–27 May 2022; pp. 596–599. [Google Scholar] [CrossRef]
- Zandvakili, A.; Mansouri, N.; Javidi, M.M. A Fuzzy based Pathfinder Optimization Technique for Performance-Effective Task Scheduling in Cloud. AUT J. Model. Simul. 2021, 53, 197–216. [Google Scholar] [CrossRef]
- Vinothkumar, K.; Maruthanayagam, D. Comprehensive Study On EDGE-Cloud Collaborative Computing for Optimal Task Scheduling. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2022, 8, 75–90. [Google Scholar] [CrossRef]
- Piroozfard, H.; Wong, K.Y.; Wong, W.P. Minimizing total carbon footprint and total late work criterion in flexible job shop scheduling by using an improved multi-objective genetic algorithm. Resour. Conserv. Recycl. 2018, 128, 267–283. [Google Scholar] [CrossRef]
- Chen, C.; He, B.; Tang, X. Green-aware workload scheduling in geographically distributed data centers. In Proceedings of the 2012 IEEE 4th International Conference on Cloud Computing Technology and Science (CloudCom), Taipei, Taiwan, 3–6 December 2012; IEEE: New York, NY, USA, 2012; pp. 82–89. [Google Scholar] [CrossRef]
- Wiesner, P.; Behnke, I.; Scheinert, D.; Gontarska, K.; Thamsen, L. Let’s Wait Awhile: How Temporal Workload Shifting Can Reduce Carbon Emissions in the Cloud. In Proceedings of the 22nd International Middleware Conference, Quebec City, QC, Canada, 6–10 December 2021; pp. 260–272. [Google Scholar] [CrossRef]
- Khodayarseresht, E.; Shameli-Sendi, A.; Fournier, Q.; Dagenais, M. Energy and carbon-aware initial VM placement in geographically distributed cloud data centers. Sustain. Comput. Inform. Syst. 2023, 39, 100888. [Google Scholar] [CrossRef]
- Rawas, S.; Zekri, A.; El-Zaart, A. LECC: Location, energy, carbon and cost-aware VM placement model in geo-distributed DCs. Sustain. Comput. Inform. Syst. 2021, 33, 100649. [Google Scholar] [CrossRef]
- Yang, T.; Jiang, H.; Hou, Y.; Geng, Y. Carbon Management of Multi-Datacenter Based on Spatio-Temporal Task Migration. IEEE Trans. Cloud Comput. 2023, 11, 1078–1090. [Google Scholar] [CrossRef]
- Acun, B.; Lee, B.; Kazhamiaka, F.; Maeng, K.; Gupta, U.; Chakkaravarthy, M.; Brooks, D.; Wu, C.-J. Carbon Explorer: A Holistic Approach for Designing Carbon Aware Datacenters. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, BC, Canada, 25–29 March 2023; Volume 2, pp. 118–132. [Google Scholar] [CrossRef]
- DIN EN ISO 14044-2006; Environmental Management—Life Cycle Assessment—Requirements and Guidelines. ISO: Geneva, Switzerland, 2006.
- Finkbeiner, M. Carbon footprinting—Opportunities and threats. Int. J. Life Cycle Assess. 2009, 14, 91–94. [Google Scholar] [CrossRef]
- Gröger, J.; Liu, R.; Stobbe, L.; Druschke, J.; Richter, N. Green Cloud Computing: Lebenszyklusbasierte Datenerhebung zu Umweltwirkungen des Cloud Computing; Federal Environment Agency: Berlin, Germany, 2021.
- Wäger, P.A.; Hischier, R.; Widmer, R. The Material Basis of ICT. In ICT Innovations for Sustainability; Hilty, L.M., Aebischer, B., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2015; Volume 310, pp. 209–221. [Google Scholar] [CrossRef]
- DIN EN ISO 14040; Environmental Management—Life Cycle Assessment—Principles and Framework. ISO: Geneva, Switzerland, 2006. [CrossRef]
- Weidema, B.; Wenzel, H.; Petersen, C.; Hansen, K. The Product, Functional Unit and Reference Flows in LCA; Danish Environmental Protection Agency: Odense, Denmark, 2004.
- Deng, L.; Williams, E.D. Functionality Versus “Typical Product” Measures of Technological Progress: A Case Study of Semiconductor Manufacturing. J. Ind. Ecol. 2011, 15, 108–121. [Google Scholar] [CrossRef]
- Mars, C.; Nafe, C.; Linnell, J. The Electronics Recycling Landscape Report; The Sustainable Consortium: Tempe, AZ, USA, 2016. [Google Scholar]
- Whitehead, B.; Andrews, D.; Shah, A. Maidment Assessing the environmental impact of data centres part 2: Building environmental assessment methods and life cycle assessment. Build. Environ. 2015, 93, 395–405. [Google Scholar] [CrossRef]
- Makov, T.; Fishman, T.; Chertow, M.R.; Blass, V. What Affects the Secondhand Value of Smartphones: Evidence from eBay. J. Ind. Ecol. 2019, 23, 549–559. [Google Scholar] [CrossRef]
- Grobe, K. Energy Efficiency Limits to ICT Lifetime. In Proceedings of the 23th ITG-Symposium, Berlin, Germany, 18–19 May 2022. [Google Scholar]
- Masanet, E.; Shehabi, A.; Koomey, J. Characteristics of low-carbon data centres. Nat. Clim. Change 2013, 3, 627–630. [Google Scholar] [CrossRef]
- Boavizta/Environmental-Footprint-Data. (20 June 2025). Python. Boavizta. Available online: https://github.com/Boavizta/environmental-footprint-data (accessed on 4 July 2025).
- Dayarathna, M.; Wen, Y.; Fan, R. Data Center Energy Consumption Modeling: A Survey. IEEE Commun. Surv. Tutor. 2016, 18, 732–794. [Google Scholar] [CrossRef]
- Jin, C.; Bai, X.; Yang, C.; Mao, W.; Xu, X. A review of power consumption models of servers in data centers. Appl. Energy 2020, 265, 114806. [Google Scholar] [CrossRef]
- Mosavi, A.; Bahmani, A. Energy Consumption Prediction Using Machine Learning; A Review. Engineering 2019. preprints. [Google Scholar] [CrossRef]
- Depasquale, E.-V.; Davoli, F.; Rajput, H. Dynamics of Research into Modeling the Power Consumption of Virtual Entities Used in the Telco Cloud. Sensors 2022, 23, 255. [Google Scholar] [CrossRef]
- Bohra, A.E.H.; Chaudhary, V. VMeter: Power modelling for virtualized clouds. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW), Atlanta, GA, USA, 19–23 April 2010; IEEE: New York, NY, USA, 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Yin, B.; Guan, L. An Online Power Metering Model for Cloud Environment. In Proceedings of the 2012 IEEE 11th International Symposium on Network Computing and Applications, Cambridge, MA, USA, 23–25 August 2012; pp. 175–180. [Google Scholar] [CrossRef]
- Chen, F.; Schneider, J.-G.; Yang, Y.; Grundy, J.; He, Q. An energy consumption model and analysis tool for Cloud computing environments. In Proceedings of the 2012 First International Workshop on Green and Sustainable Software (GREENS), Zurich, Switzerland, 3 June 2012; IEEE: New York, NY, USA, 2012; pp. 45–50. [Google Scholar] [CrossRef]
- Krishnan, B.; Amur, H.; Gavrilovska, A.; Schwan, K. VM power metering: Feasibility and challenges. ACM Sigmetrics Perform. Eval. Rev. 2011, 38, 56–60. [Google Scholar] [CrossRef]
- Xiao, P.; Hu, Z.; Liu, D.; Yan, G.; Qu, X. Virtual machine power measuring technique with bounded error in cloud environments. J. Netw. Comput. Appl. 2013, 36, 818–828. [Google Scholar] [CrossRef]
- Da Costa, G.; Hlavacs, H. Methodology of measurement for energy consumption of applications. In Proceedings of the 2010 11th IEEE/ACM International Conference on Grid Computing, Brussels, Belgium, 25–28 October 2010; IEEE: New York, NY, USA, 2010; pp. 290–297. [Google Scholar] [CrossRef]
- Kansal, A.; Zhao, F.; Liu, J.; Kothari, N.; Bhattacharya, A.A. Virtual machine power metering and provisioning. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; ACM: New York, NY, USA, 2010; pp. 39–50. [Google Scholar] [CrossRef]
- Chen, Q.; Grosso, P.; van der Veldt, K.; de Laat, C.; Hofman, R.; Bal, H. Profiling Energy Consumption of VMs for Green Cloud Computing. In Proceedings of the 2011 IEEE Ninth International Conference on Dependable, Autonomic and Secure Computing, Sydney, Australia, 10–14 December 2011; IEEE: New York, NY, USA, 2011; pp. 768–775. [Google Scholar] [CrossRef]
- Dhiman, G.; Mihic, K.; Rosing, T. A system for online power prediction in virtualized environments using Gaussian mixture models. In Proceedings of the 47th Design Automation Conference, Anaheim, CA, USA, 13–18 June 2010; ACM: New York, NY, USA, 2010; pp. 807–812. [Google Scholar] [CrossRef]
- Yang, H.; Zhao, Q.; Luan, Z.; Qian, D. iMeter: An integrated VM power model based on performance profiling. Futur. Gener. Comput. Syst. 2013, 36, 267–286. [Google Scholar] [CrossRef]
- Song, S.; Su, C.; Rountree, B.; Cameron, K.W. A Simplified and Accurate Model of Power-Performance Efficiency on Emergent GPU Architectures. In Proceedings of the 2013 IEEE International Symposium on Parallel & Distributed Processing (IPDPS), Boston, MA, USA, 20–24 May 2014; pp. 673–686. [Google Scholar] [CrossRef]
- Xu, T.; Li, H.; Bai, Y. An Online Model Integration Framework for Server Resource Workload Prediction. In Proceedings of the 2021 IEEE 21st International Conference on Software Quality, Reliability and Security (QRS), Haikou, China, 6–10 December 2021; pp. 414–421. [Google Scholar] [CrossRef]
- Rong, X.; Zhou, H.; Cao, Z.; Wang, C.; Fan, L.; Ma, J. An Improved Self-Organizing Migration Algorithm for Short-Term Load Forecasting with LSTM Structure Optimization. Math. Probl. Eng. 2022, 2022, 6811401. [Google Scholar] [CrossRef]
- Prevost, J.J.; Nagothu, K.; Kelley, B.; Jamshidi, M. Prediction of cloud data center networks loads using stochastic and neural models. In Proceedings of the 2011 6th International Conference on System of Systems Engineering (SoSE), Albuquerque, NM, USA, 27–30 June 2011; IEEE: New York, NY, USA, 201; pp. 276–281. [Google Scholar] [CrossRef]
- Kumar, J.; Goomer, R.; Singh, A.K. Long Short Term Memory Recurrent Neural Network (LSTM-RNN) Based Workload Forecasting Model For Cloud Datacenters. Procedia Comput. Sci. 2018, 125, 676–682. [Google Scholar] [CrossRef]
- Yadav, M.P.; Pal, N.; Yadav, D.K. Workload Prediction over Cloud Server using Time Series Data. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29 January 2021; pp. 267–272. [Google Scholar] [CrossRef]
- Patel, Y.S.; Jaiswal, R.; Misra, R. Deep learning-based multivariate resource utilization prediction for hotspots and coldspots mitigation in green cloud data centers. J. Supercomput. 2022, 78, 5806–5855. [Google Scholar] [CrossRef]
- Ahvar, E.; Ahvar, S.; Mann, Z.A.; Crespi, N.; Glitho, R.; Garcia-Alfaro, J. DECA: A Dynamic Energy Cost and Carbon Emission-Efficient Application Placement Method for Edge Clouds. IEEE Access 2021, 9, 70192–70213. [Google Scholar] [CrossRef]
- Bahreini, T.; Tantawi, A.; Youssef, A. A Carbon-aware Workload Dispatcher in Cloud Computing Systems. In Proceedings of the 2023 IEEE 16th International Conference on Cloud Computing (CLOUD), Chicago, IL, USA, 2–8 July 2023; IEEE: New York, NY, USA, 2023; pp. 212–218. [Google Scholar] [CrossRef]
- Bahreini, T.; Tantawi, A.N.; Tardieu, O. Caspian: A Carbon-aware Workload Scheduler in Multi-Cluster Kubernetes Environments. In Proceedings of the 2024 32nd International Conference on Modeling, Analysis and Simulation of Computer and Telecommunication Systems (MASCOTS), Krakow, Poland, 21–23 October 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Beena, B.; Csr, P.; Manideep, T.S.S.; Saragadam, S.; Karthik, G. A Green Cloud-Based Framework for Energy-Efficient Task Scheduling Using Carbon Intensity Data for Heterogeneous Cloud Servers. IEEE Access 2025, 13, 73916–73938. [Google Scholar] [CrossRef]
- Bostandoost, R.; Hanafy, W.A.; Lechowicz, A.; Bashir, N.; Shenoy, P.; Hajiesmaili, M. Data-driven Algorithm Selection for Carbon-Aware Scheduling. ACM SIGEnergy Energy Inform. Rev. 2024, 4, 148–153. [Google Scholar] [CrossRef]
- Guo, Y.; Porter, G. Carbon-Aware Inter-Datacenter Workload Scheduling and Placement. Poster Abstract. In Proceedings of the Poster Session of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’23), Boston, MA, USA, 17–19 April 2023; USENIX Association: Berkeley, CA, USA, 2023. [Google Scholar]
- Hanafy, W.A.; Wu, L.; Irwin, D.; Shenoy, P. CarbonFlex: Enabling Carbon-aware Provisioning and Scheduling for Cloud Clusters. arXiv 2025, arXiv:2505.18357. [Google Scholar] [CrossRef]
- James, A.; Schien, D. A Low Carbon Kubernetes Scheduler. ICT4S. 2019. Available online: https://ceur-ws.org/Vol-2382/ICT4S2019_paper_28.pdf (accessed on 7 July 2025).
- Kim, Y.G.; Gupta, U.; McCrabb, A.; Son, Y.; Bertacco, V.; Brooks, D.; Wu, C.-J. GreenScale: Carbon-Aware Systems for Edge Computing. 2023. Available online: http://arxiv.org/abs/2304.00404 (accessed on 25 January 2024).
- Köhler, S.; Herzog, B.; Hofmeier, H.; Vögele, M.; Wenzel, L.; Polze, A.; Hönig, T. Carbon-Aware Memory Placement. In Proceedings of the 2nd Workshop on Sustainable Computer Systems, Boston, MA, USA, 30 June 2025; ACM: New York, NY, USA, 2025; pp. 1–7. [Google Scholar] [CrossRef]
- Lin, W.-T.; Chen, G.; Li, H. Carbon-Aware Load Balance Control of Data Centers with Renewable Generations. IEEE Trans. Cloud Comput. 2023, 11, 1111–1121. [Google Scholar] [CrossRef]
- Lindberg, J.; Lesieutre, B.C.; Roald, L.A. Using Geographic Load Shifting to Reduce Carbon Emissions. arXiv 2022, arXiv:2203.00826. Available online: http://arxiv.org/abs/2203.00826 (accessed on 25 January 2024). [CrossRef]
- Ma, H.; Zhou, Z.; Zhang, X.; Chen, X. Toward Carbon-Neutral Edge Computing: Greening Edge AI by Harnessing Spot and Future Carbon Markets. IEEE Internet Things J. 2023, 10, 16637–16649. [Google Scholar] [CrossRef]
- Perin, G.; Meneghello, F.; Carli, R.; Schenato, L.; Rossi, M. EASE: Energy-Aware Job Scheduling for Vehicular Edge Networks with Renewable Energy Resources. IEEE Trans. Green Commun. Netw. 2023, 7, 339–353. [Google Scholar] [CrossRef]
- Piontek, T.; Haghshenas, K.; Aiello, M. Carbon emission-aware job scheduling for Kubernetes deployments. J. Supercomput. 2023, 80, 549–569. [Google Scholar] [CrossRef]
- Schmidt, A.; Stock, G.; Ohs, R.; Gerhorst, L.; Herzog, B.; Hönig, T. Carbond: An Operating-System Daemon for Carbon Awareness. In Proceedings of the 2nd Workshop on Sustainable Computer Systems, Boston, MA, USA, 30 June 2025; ACM: New York, NY, USA, 2025; pp. 1–6. [Google Scholar] [CrossRef]
- Subramanian, T. Carbon-Aware Scheduling for Serverless Computing. Master’s Thesis, Technical University of Munich, Munich, Germany, February 2023. [Google Scholar]
- Sukprasert, T.; Souza, A.; Bashir, N.; Irwin, D.; Shenoy, P. Quantifying the Benefits of Carbon-Aware Temporal and Spatial Workload Shifting in the Cloud. 2023. Available online: http://arxiv.org/abs/2306.06502 (accessed on 26 September 2023).
- Sukprasert, T.; Souza, A.; Bashir, N.; Irwin, D.; Shenoy, P. On the Limitations of Carbon-Aware Temporal and Spatial Workload Shifting in the Cloud. In Proceedings of the Nineteenth European Conference on Computer Systems, Athens, Greece, 22–25 April 2024; ACM: New York, NY, USA, 2024; pp. 924–941. [Google Scholar] [CrossRef]
- Wang, G.; Zomaya, A.; Martinez, G.; Li, K. (Eds.) Algorithms and Architectures for Parallel Processing. In Proceedings of the 15th International Conference, ICA3PP 2015, Zhangjiajie, China, 18–20 November 2015; Proceedings, Part II Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2015; Volume 9529. [Google Scholar] [CrossRef]
- Wang, P.; Liu, W.; Cheng, M.; Ding, Z.; Wang, Y. Electricity and Carbon-aware Task Scheduling in Geo-distributed Internet Data Centers. In Proceedings of the 2022 IEEE/IAS Industrial and Commercial Power System Asia (I&CPS Asia), Shanghai, China, 8–11 July 2022; IEEE: New York, NY, USA, 2022; pp. 1416–1421. [Google Scholar] [CrossRef]
- Xing, J.; Acun, B.; Sundarrajan, A.; Brooks, D.; Chakkaravarthy, M.; Avila, N.; Wu, C.-J.; Lee, B.C. Carbon Responder: Coordinating Demand Response for the Datacenter Fleet. arXiv 2023, arXiv:2311.08589. Available online: http://arxiv.org/abs/2311.08589 (accessed on 17 January 2024).
- Zhang, C.; Gu, P.; Jiang, P. Low-carbon scheduling and estimating for a flexible job shop based on carbon footprint and carbon efficiency of multi-job processing. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2015, 229, 328–342. [Google Scholar] [CrossRef]
- Gupta, U.; Elgamal, M.; Hills, G.; Wei, G.-Y.; Lee, H.-H.S.; Brooks, D.; Wu, C.-J. ACT: Designing sustainable computer systems with an architectural carbon modeling tool. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–22 June 2022; ACM: New York, NY, USA, 2022; pp. 784–799. [Google Scholar] [CrossRef]
- IBM. IBM CPLEX. Available online: https://dev.ampl.com/solvers/cplex (accessed on 6 February 2024).
- Kumar, R.; Baughman, M.; Chard, R.; Li, Z.; Babuji, Y.; Foster, I.; Chard, K. Coding the Computing Continuum: Fluid Function Execution in Heterogeneous Computing Environments. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 May 2021; IEEE: New York, NY, USA, 2021; pp. 66–75. [Google Scholar] [CrossRef]
- SPECpower_ssj2008. Available online: https://www.spec.org/power_ssj2008/results/res2023q3/power_ssj2008-20230524-01270.html (accessed on 20 December 2023).
- Google, Google/Cluster-Data. (Mar. 10, 2023). TeX. Google. Available online: https://github.com/google/cluster-data (accessed on 13 March 2023).
- Fluidos Project. GitHub. Available online: https://github.com/fluidos-project (accessed on 24 July 2024).
- Li, P.; Yang, J.; Islam, M.A.; Ren, S. Making AI Less ‘Thirsty’: Uncovering and Addressing the Secret Water Footprint of AI Models. arXiv 2025, arXiv:2304.03271. [Google Scholar] [CrossRef]
- Morrison, J.; Na, C.; Fernandez, J.; Dettmers, T.; Strubell, E.; Dodge, J. Holistically Evaluating the Environmental Impact of Creating Language Models. arXiv 2025, arXiv:2503.05804. [Google Scholar] [CrossRef]
- KWOK. Available online: https://kwok.sigs.k8s.io/ (accessed on 6 July 2025).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Duration | Scheduled | Ad-Hoc | ||
|---|---|---|---|---|
| Interruptible | Non-Interruptible | Interruptible | Non-Interruptible | |
| Short-running | Moderate (small batch jobs) | Low (nightly CI/CD) | Moderate (FaaS tasks) | Low (CI/CD jobs) |
| Long-running | High (ML training, simulations) | Moderate (backups) | High (ML training) | Moderate (data analysis) |
| Continuously running | Moderate (report generation) | Low (user APIs) | Moderate (blockchain tasks) | Low (blockchain mining) |
| Paper | Shifting Strategy | Emission Factors | Network Energy | Forecast | Power Mapping | Embodied Emissions | Code Available | ||
|---|---|---|---|---|---|---|---|---|---|
| Temporal | Spatial | Average | Marginal | ||||||
| Acun et al., 2023 [55] | X | X | X | X | |||||
| Ahvar et al., 2021 [90] | X | X | X | X | |||||
| Bahreini et al., 2023 [91] | X | X | X | ||||||
| Bahreini et al., 2024 [92] | X | X | X | X | X | ||||
| Beena et al., 2025 [93] | X | X | X | X | X | ||||
| Bostandoost et al., 2024 [94] | X | X | X | ||||||
| Chen et al., 2012 [50] | X | X | X | ||||||
| Guo & Porter, 2023 [95] | X | X | X | ||||||
| Hanafy et al., 2025 [96] | X | X | X | X | X | X | X | ||
| James & Schien, 2019 [97] | X | ||||||||
| Kim et al., 2023 [98] | X | X | X | X | X | ||||
| Köhler et al., 2025 [99] | X | X | X | ||||||
| Lin & Chien, 2023 [19] | X | X | |||||||
| Lin et al., 2023 [100] | X | X | X | ||||||
| Lindberg et al., 2022 [101] | X | X | X | ||||||
| Ma et al., 2023 [102] | X | X | X | ||||||
| Perin et al., 2023 [103] | X | X | |||||||
| Piontek et al., 2023 [104] | X | X | X | X | |||||
| Radovanovic et al., 2021 [9] | X | X | X | X | |||||
| Schmidt et al., 2025 [105] | X | X | |||||||
| Subramanian, 2023 [106] | X | X | X | ||||||
| Sukprasert et al., 2023 [107] | X | X | X | X | |||||
| Sukprasert et al., 2024 [108] | X | X | X | X | |||||
| Wang et al., 2015 [109] | X | ||||||||
| Wang et al., 2022 [110] | X | X | X | ||||||
| Wiesner et al., 2021 [51] | X | X | X | ||||||
| Xing et al., 2023 [111] | X | X | X | X | |||||
| Zhang et al., 2015 [112] | X | ||||||||
| This study | X | X | X | X | X | X | X | ||
| Maturity Tier | Representative Systems | Salient Strengths | Typical Weaknesses and Open Issues |
|---|---|---|---|
| Industrial deployment/production-grade | CICS [9]; CarbonFlex [96] |
|
|
| Prototype systems (real clouds/Kubernetes/edge testbeds) | Caspian [92]; Low-Carbon Scheduler [97]; GreenCourier [106]; carbon-aware K8s extender [104]; PlanShare [19] |
|
|
| Advanced research (simulator or trace-driven studies) | FTL meta-algorithm [94]; MinBrown [75]; TTOA/R3DRA [102]; λCO2-shift [101]; GreenScale [98]; EASE [103]; LC-FJSP/CEA-FJSP [110,112] |
|
|
| Conceptual frameworks and holistic analyses | Carbon Explorer [55]; carbond daemon [105]; Sukprasert et al. [107,108]; Let’sWaitAwhile [51]; Carbon Responder [111] |
|
|
| Given | To Be Estimated |
|---|---|
| Pod CPU reservation () | Node HW lifetime () |
| Pod RAM reservation () Pod runtime () | Pod power consumption () |
| Node power supply ACI () Total embodied emissions of node () Power curve of node |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asadov, N.; Coroamă, V.C.; Franzil, M.; Galantino, S.; Finkbeiner, M. Carbon-Aware Spatio-Temporal Workload Shifting in Edge–Cloud Environments: A Review and Novel Algorithm. Sustainability 2025, 17, 6433. https://doi.org/10.3390/su17146433
Asadov N, Coroamă VC, Franzil M, Galantino S, Finkbeiner M. Carbon-Aware Spatio-Temporal Workload Shifting in Edge–Cloud Environments: A Review and Novel Algorithm. Sustainability. 2025; 17(14):6433. https://doi.org/10.3390/su17146433
Chicago/Turabian StyleAsadov, Nasir, Vlad C. Coroamă, Matteo Franzil, Stefano Galantino, and Matthias Finkbeiner. 2025. "Carbon-Aware Spatio-Temporal Workload Shifting in Edge–Cloud Environments: A Review and Novel Algorithm" Sustainability 17, no. 14: 6433. https://doi.org/10.3390/su17146433
APA StyleAsadov, N., Coroamă, V. C., Franzil, M., Galantino, S., & Finkbeiner, M. (2025). Carbon-Aware Spatio-Temporal Workload Shifting in Edge–Cloud Environments: A Review and Novel Algorithm. Sustainability, 17(14), 6433. https://doi.org/10.3390/su17146433