
Short-Term Power-Generation Prediction of High Humidity Island Photovoltaic Power Station Based on a Deep Hybrid Model

Abstract
1. Introduction
- Combining CNN’s powerful data-feature extraction ability with BIGRU’s two-way use of time series prediction, the latest heuristic algorithm (POA) is proposed for the first time to optimize CNN-BIGRU hyperparameters;
- To enhance the convergence speed and global optimization ability of the algorithm, the ICMIC chaotic mapping technique is employed to optimize the initialization position of the POA population;
- To address potential overfitting issues during training, the L2-regularization technique is employed, which facilitates rapid convergence of the loss curve for CNN-BIGRU. Furthermore, the optimal L2-regularization coefficient is automatically iteratively optimized using the POA algorithm;
- The prediction performance of the six models under diverse weather conditions is evaluated using six evaluation indicators. K-fold cross-validation is conducted to compare the prediction effects of the three hybrid models on different datasets spanning three consecutive days and five consecutive days. The results demonstrate that the hybrid model proposed in this study exhibits the most superior prediction performance.
2. Materials and Methods
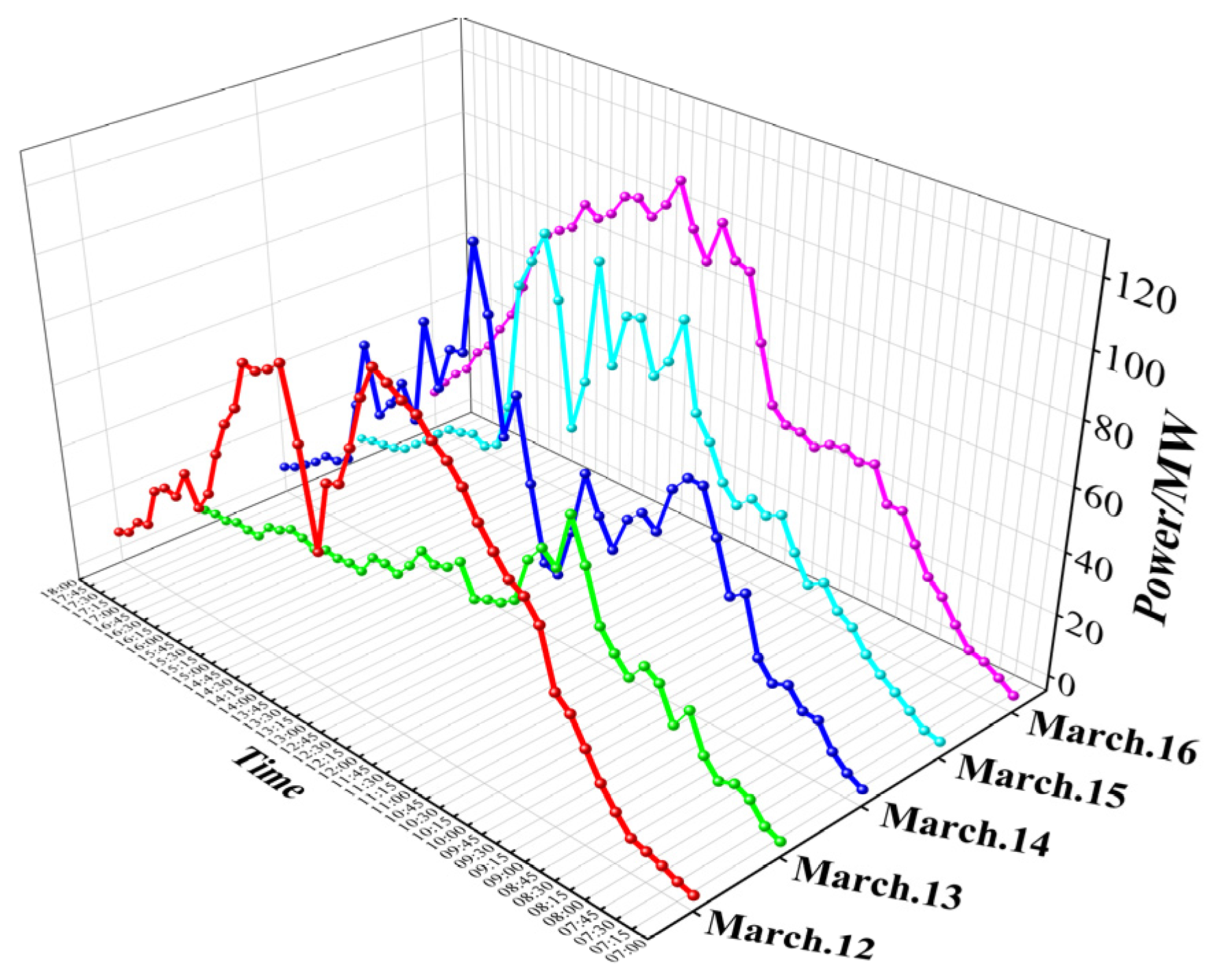
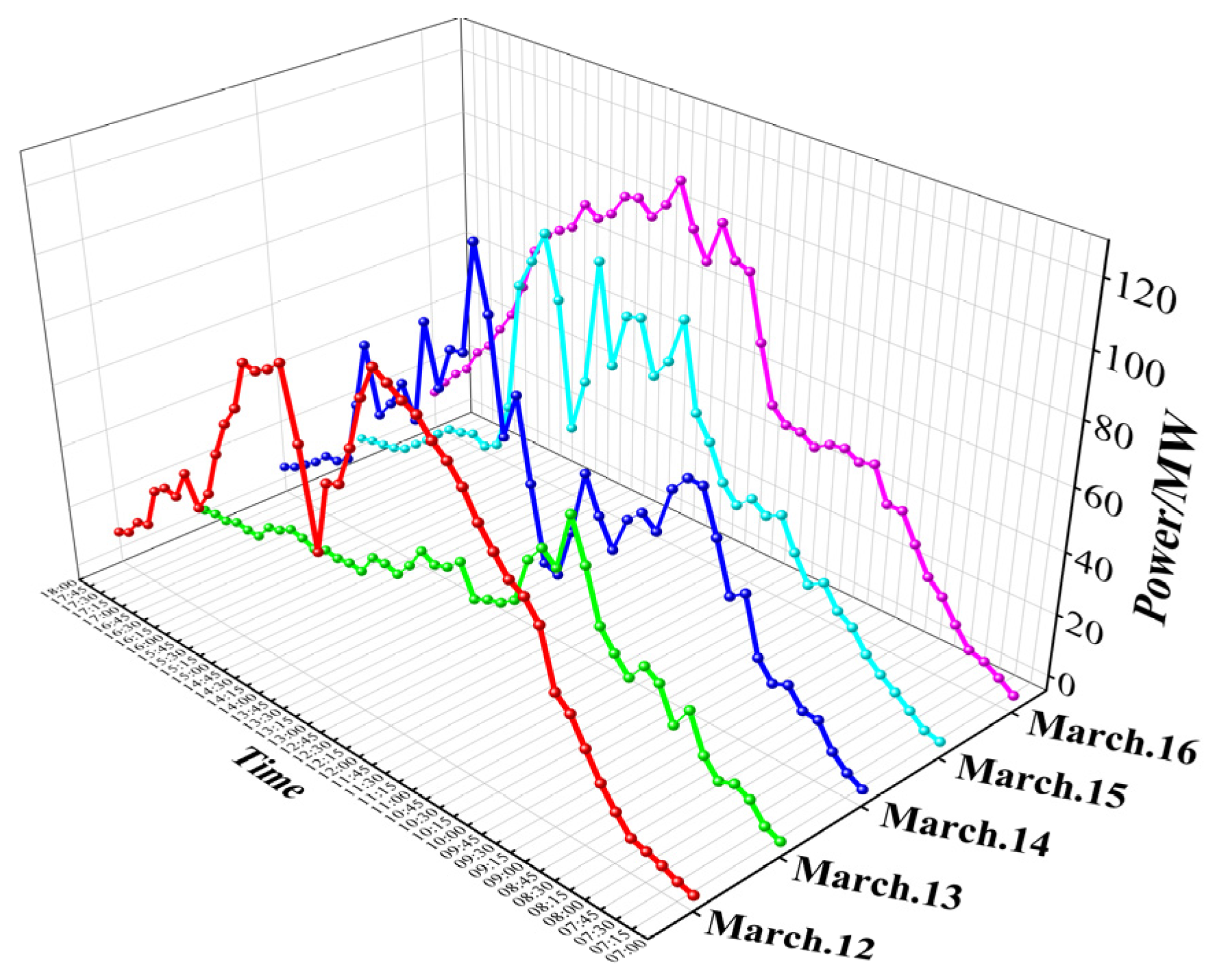
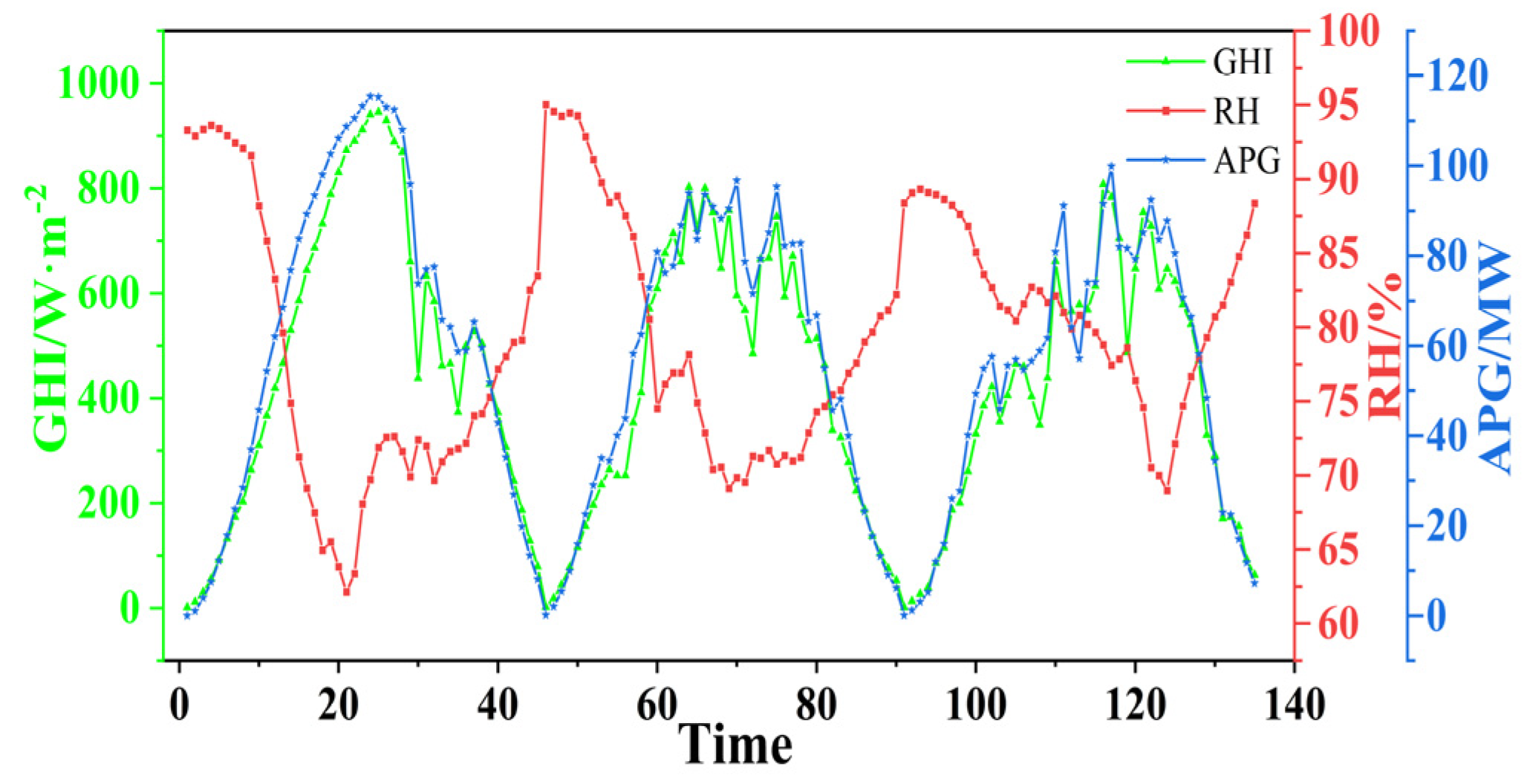
2.1. Data Sources
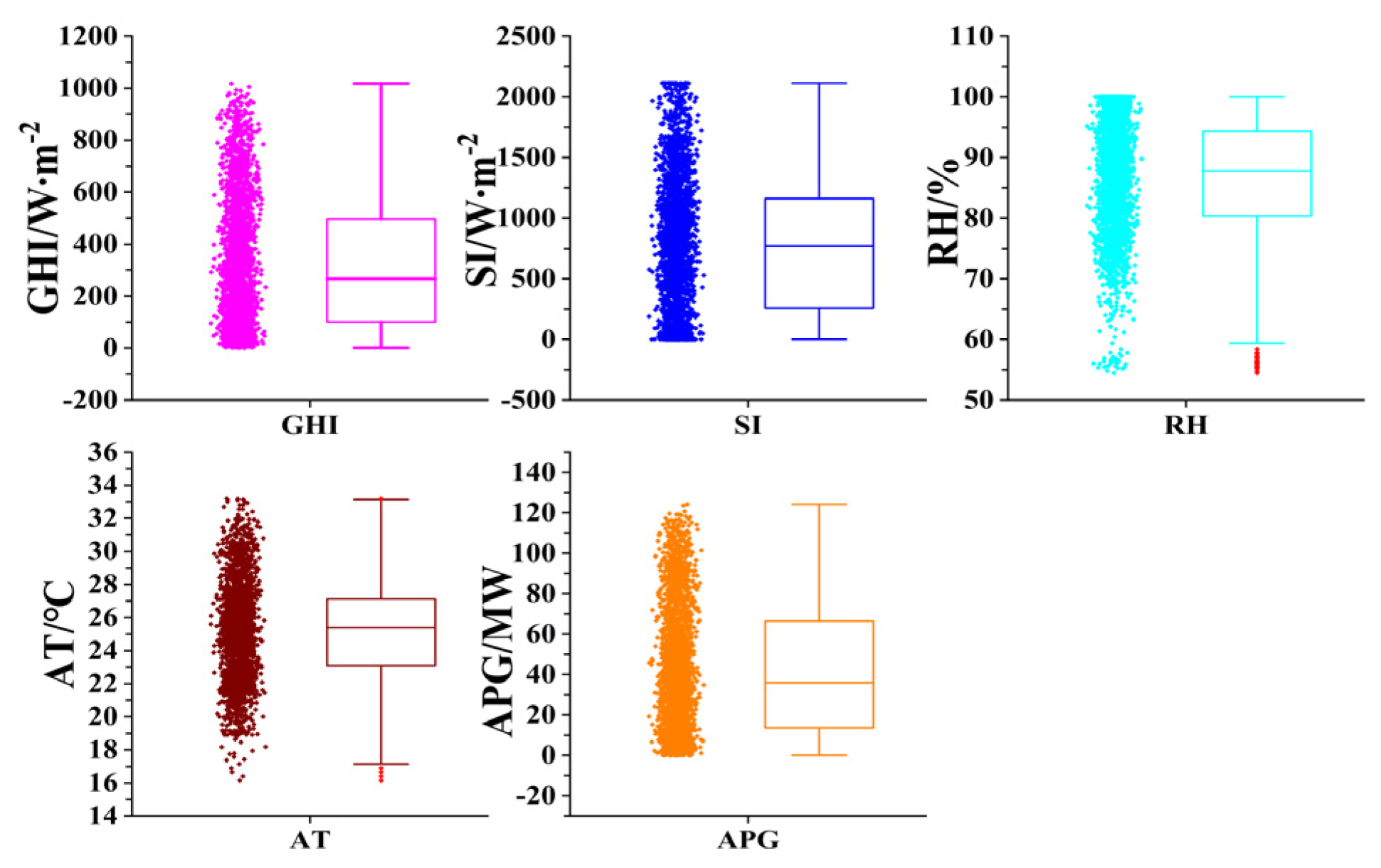
2.2. Data Preprocessing
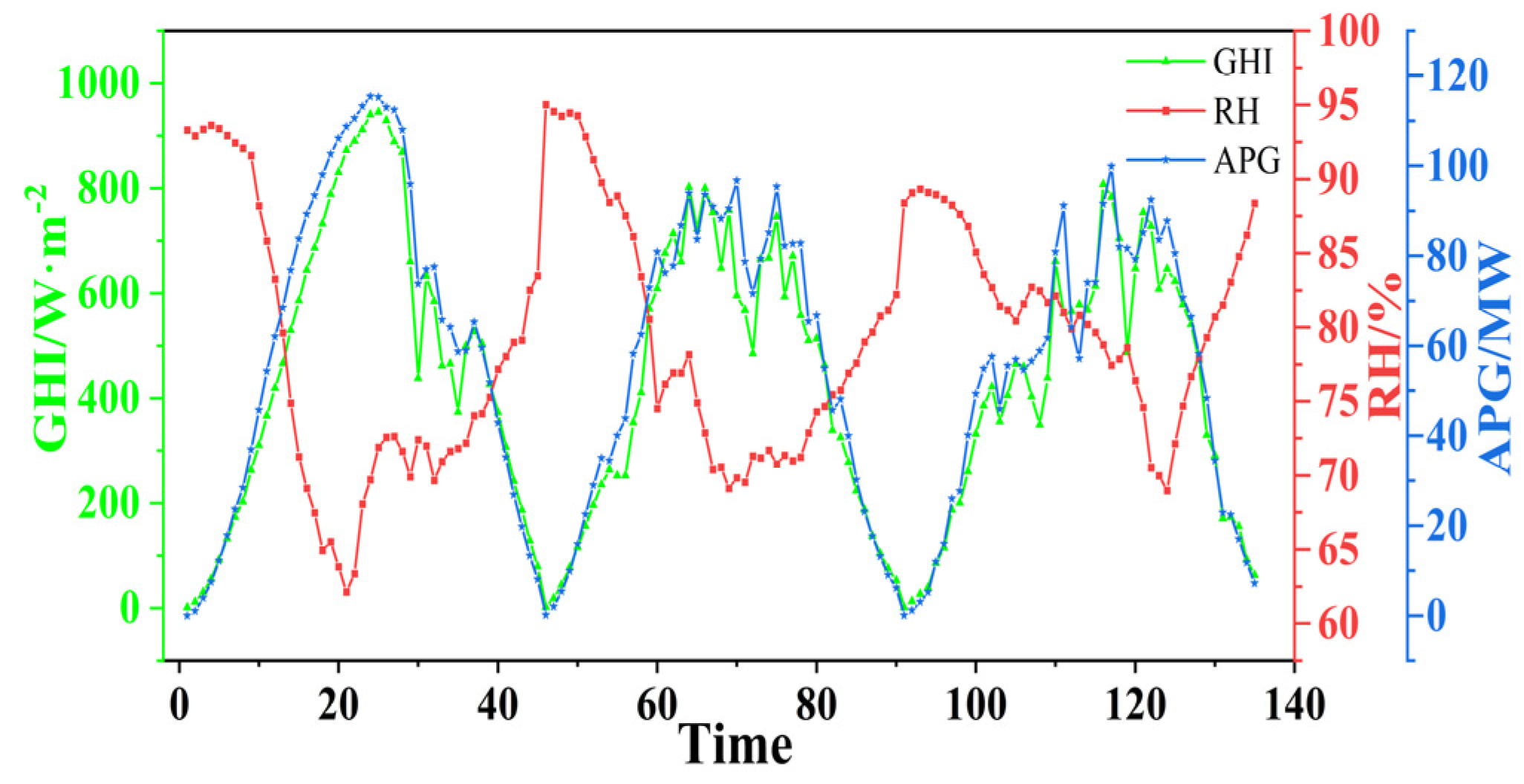
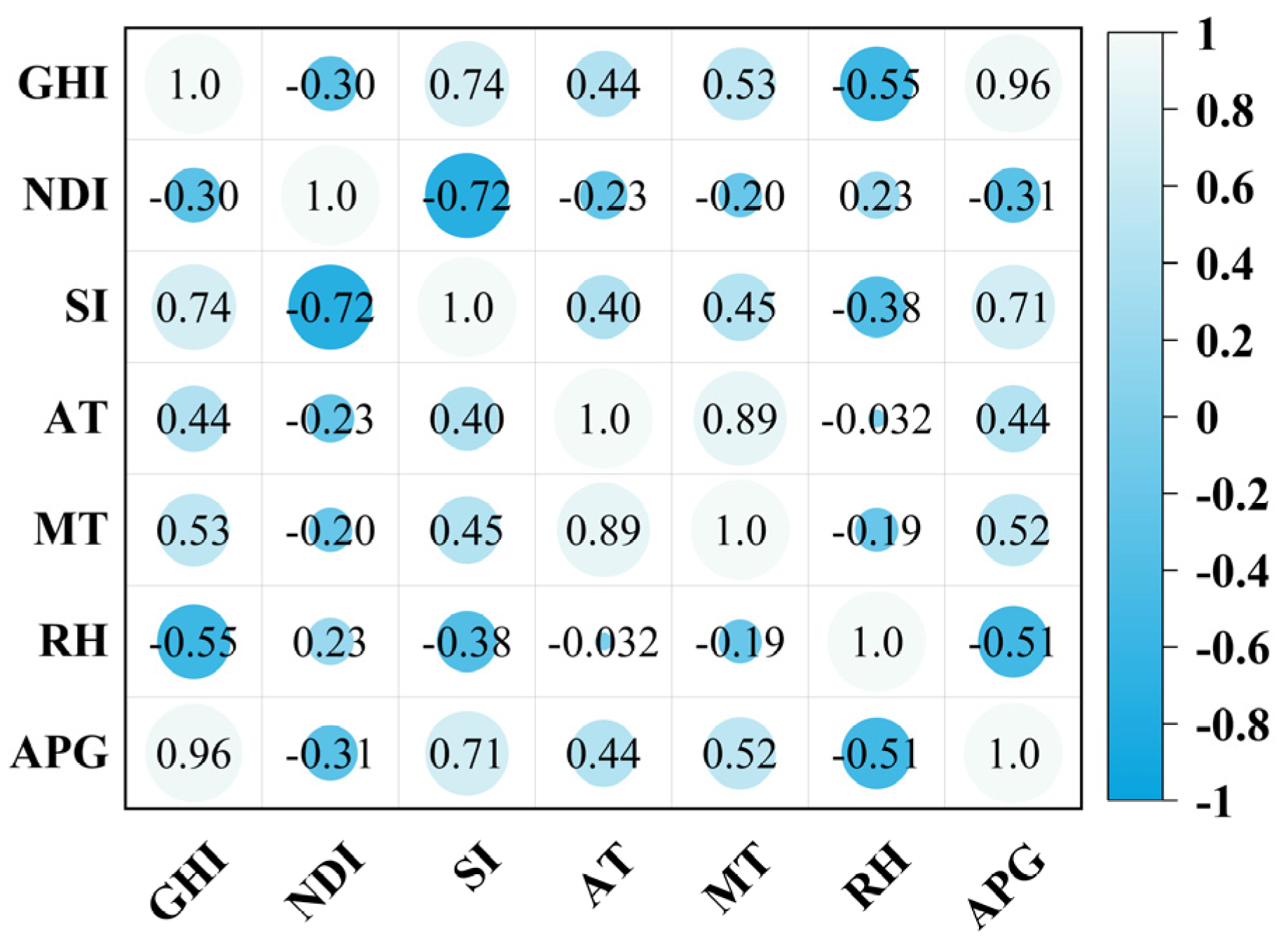
2.2.1. Correlation Analysis
2.2.2. Outlier Processing
2.2.3. Data Normalization
2.3. Prediction Model
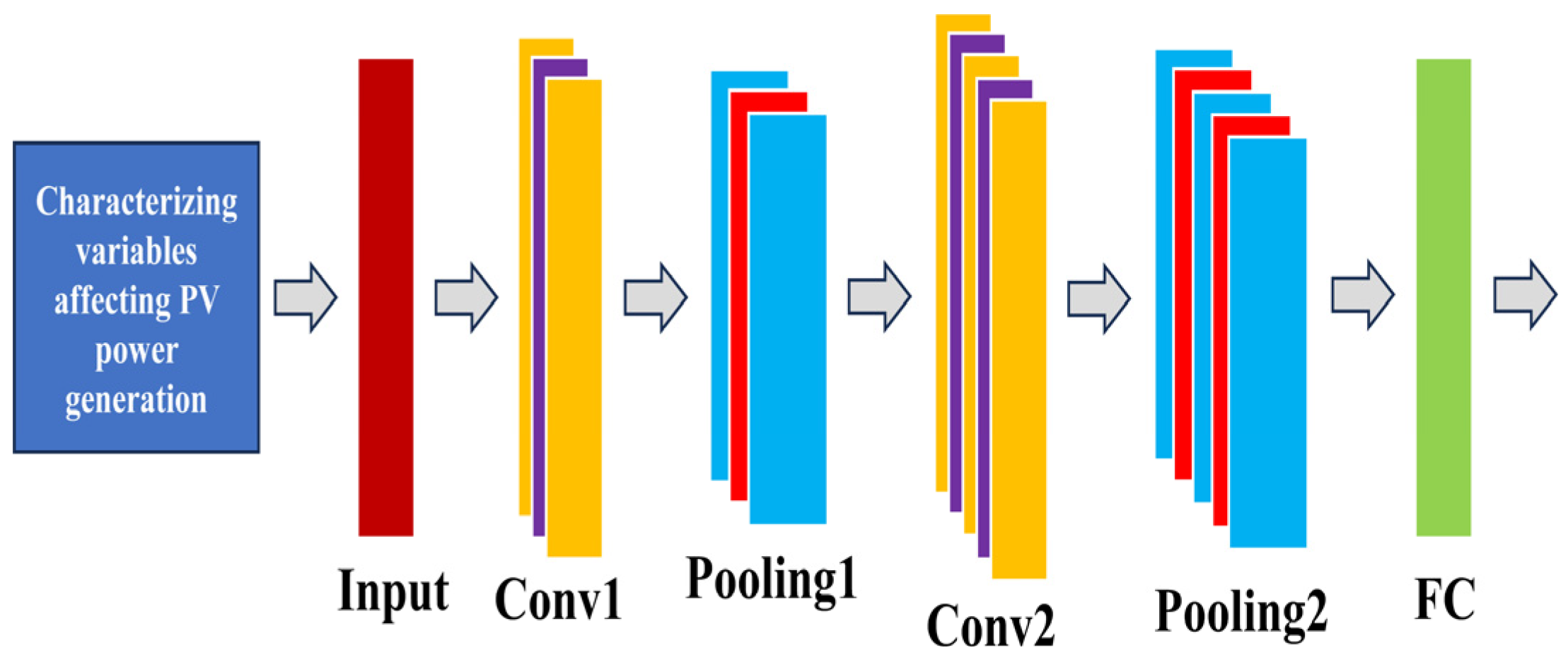
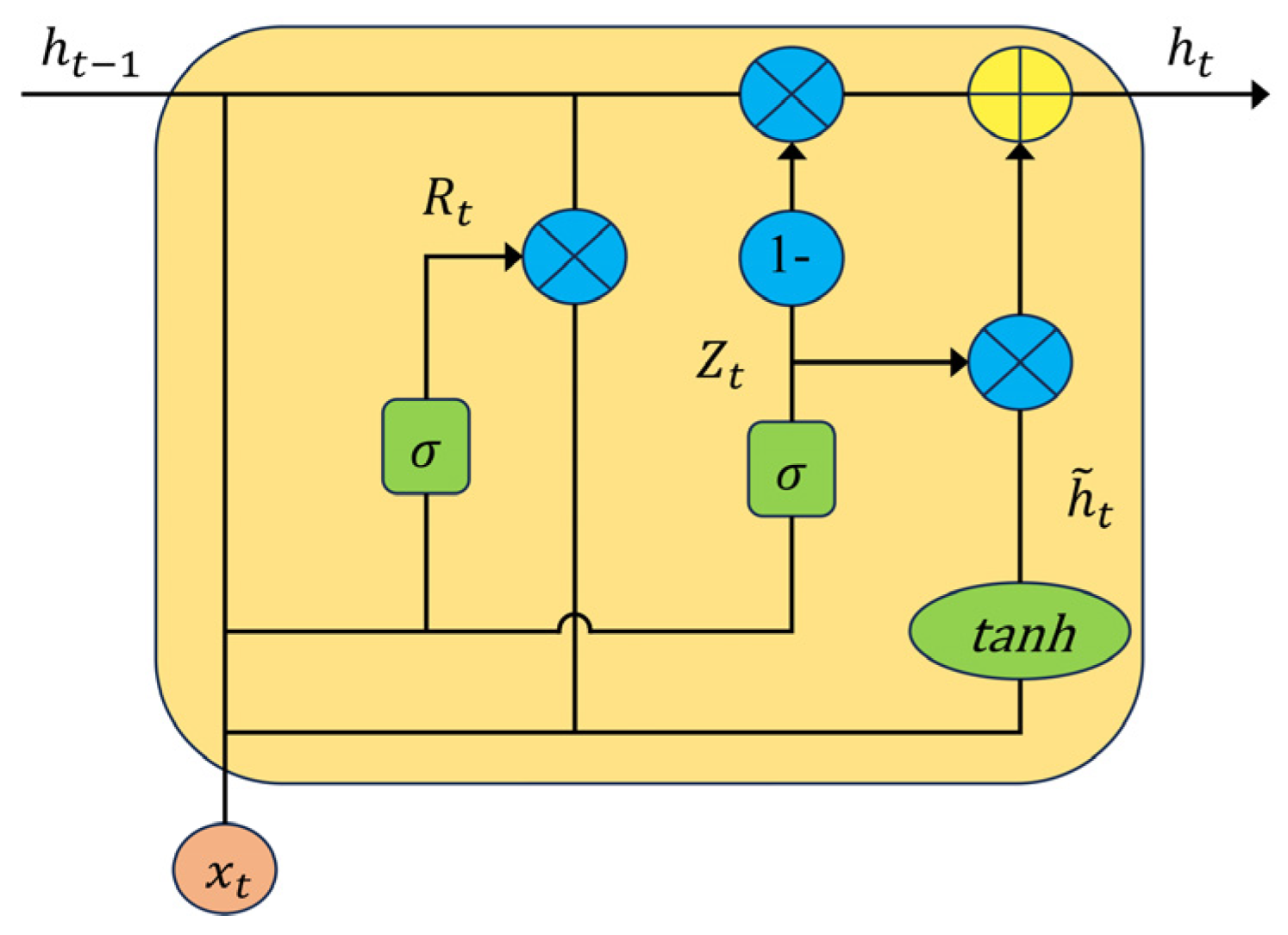
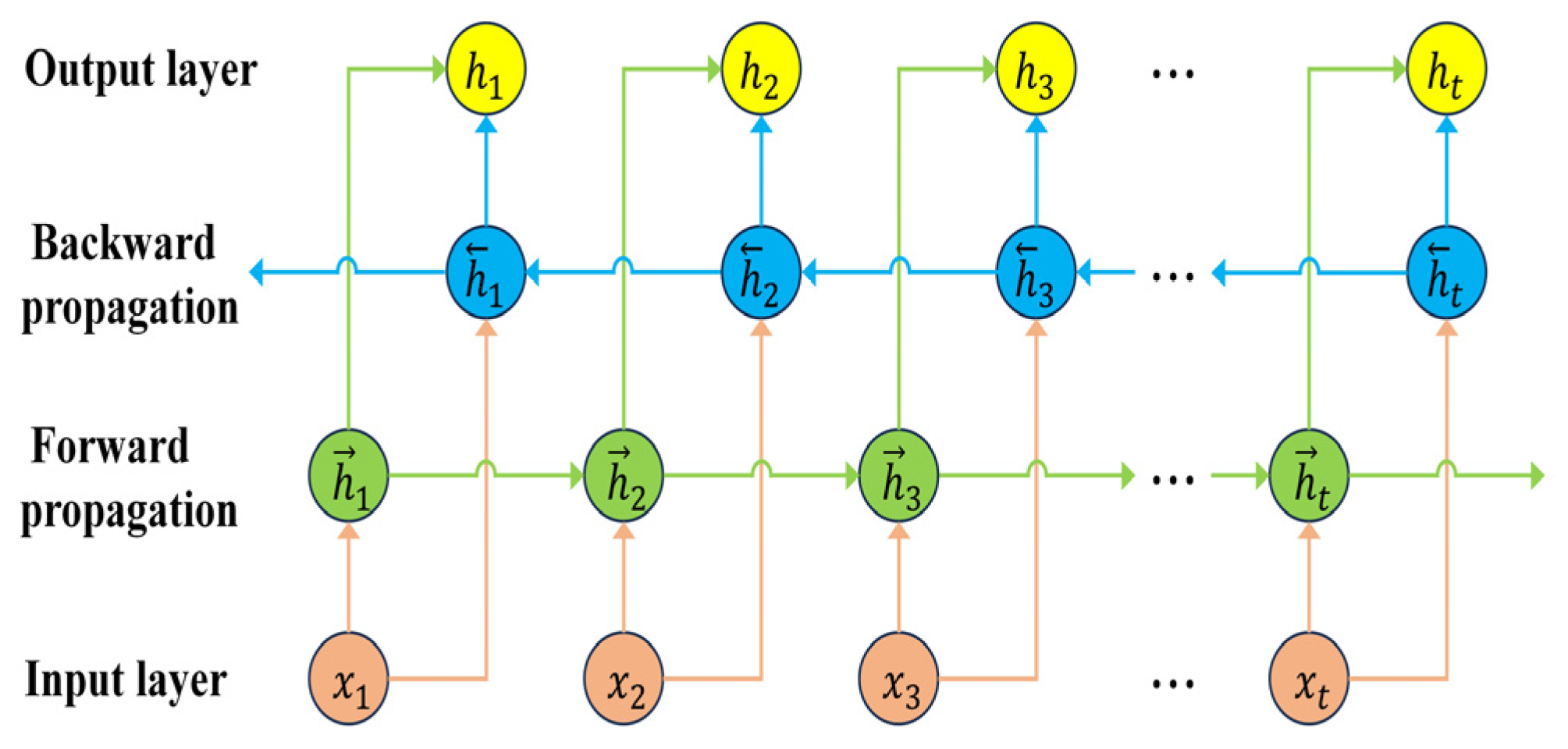
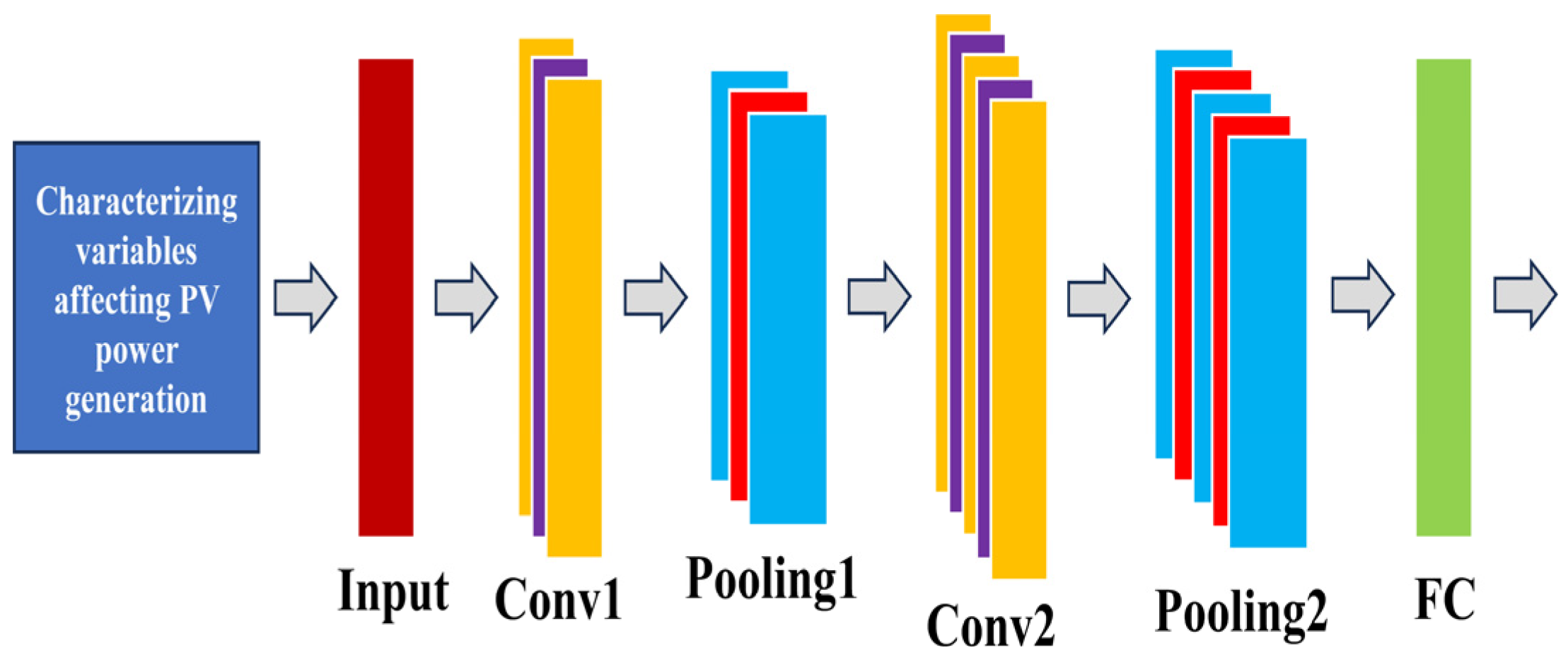
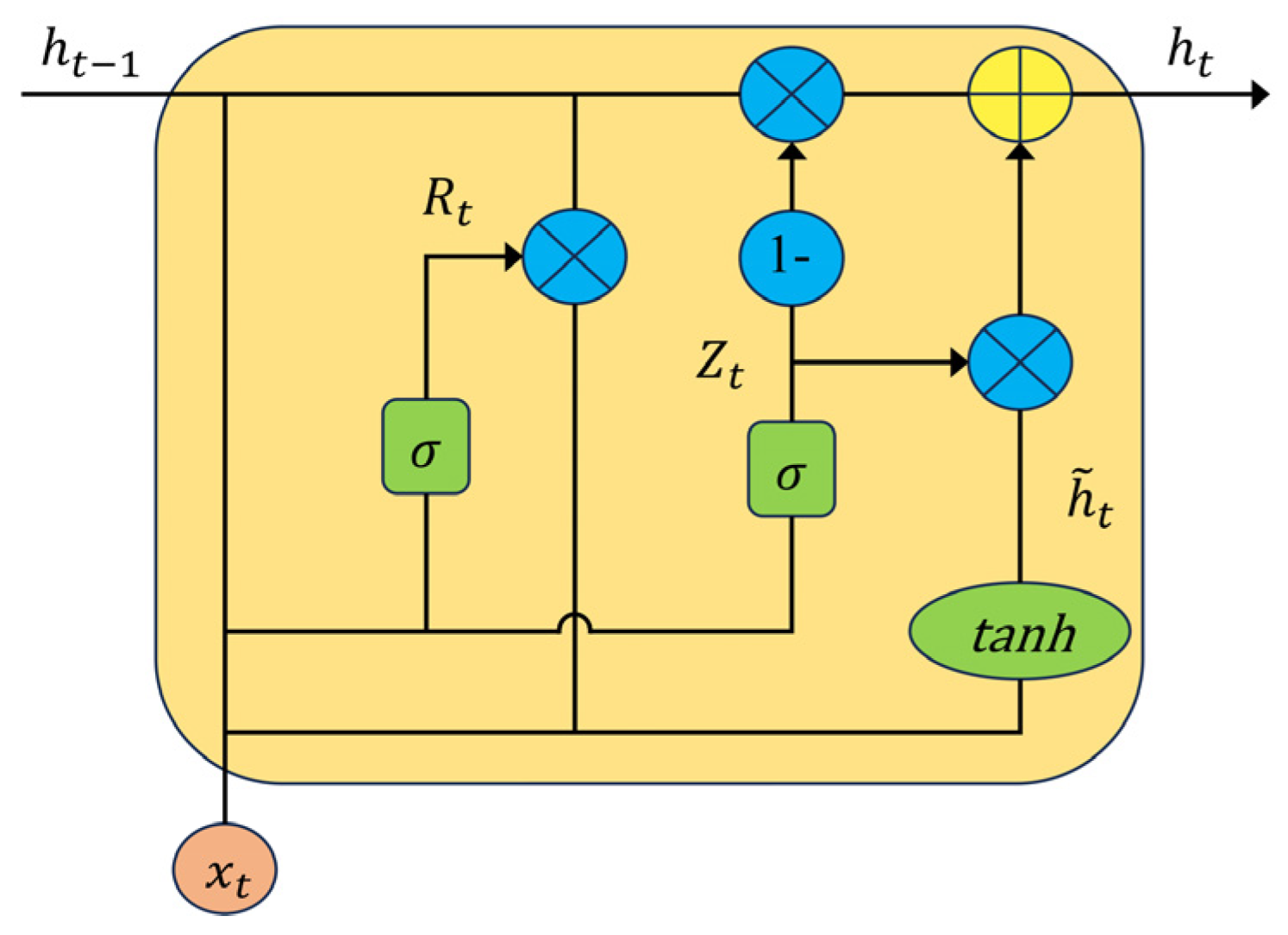
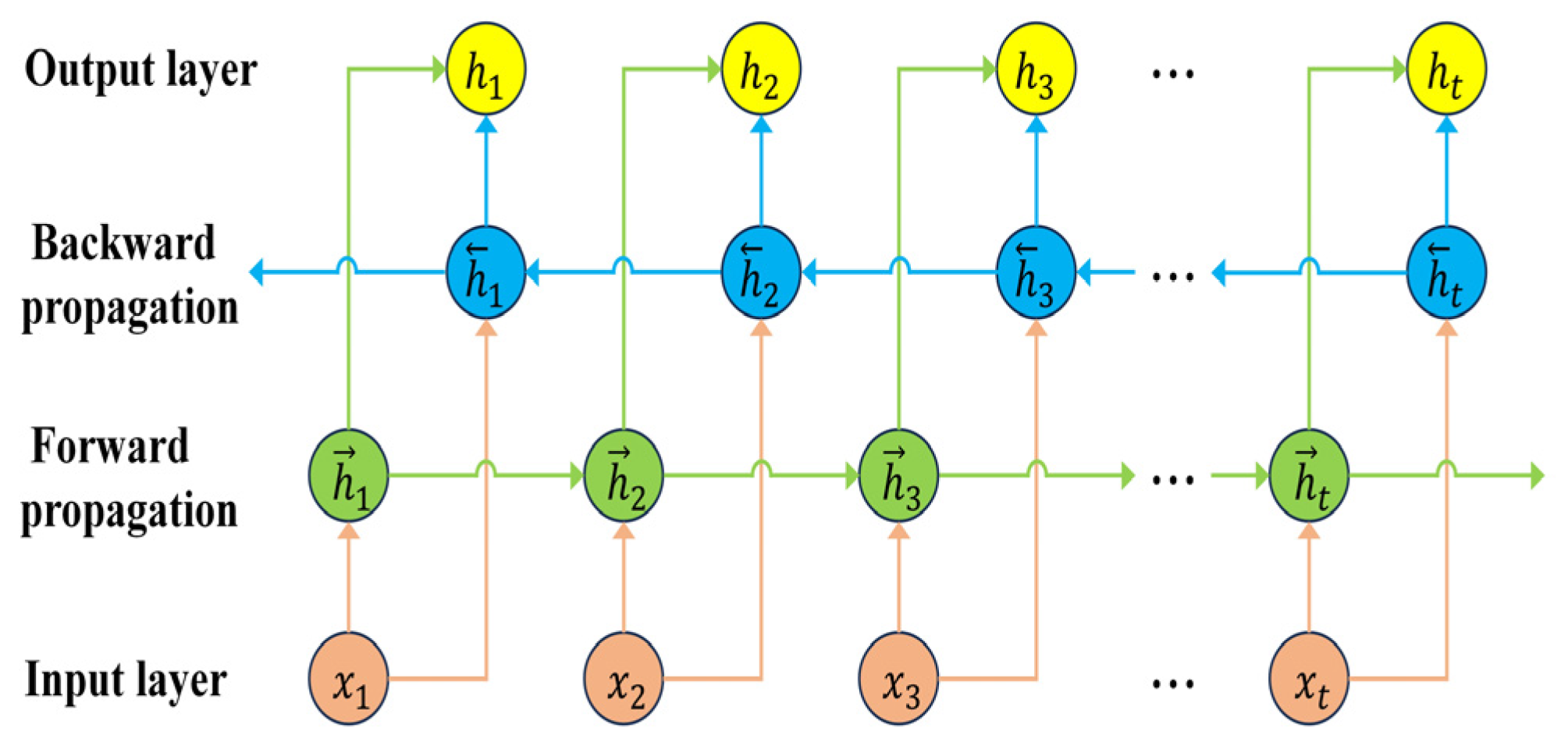
2.3.1. CNN-BIGRU
2.3.2. POA
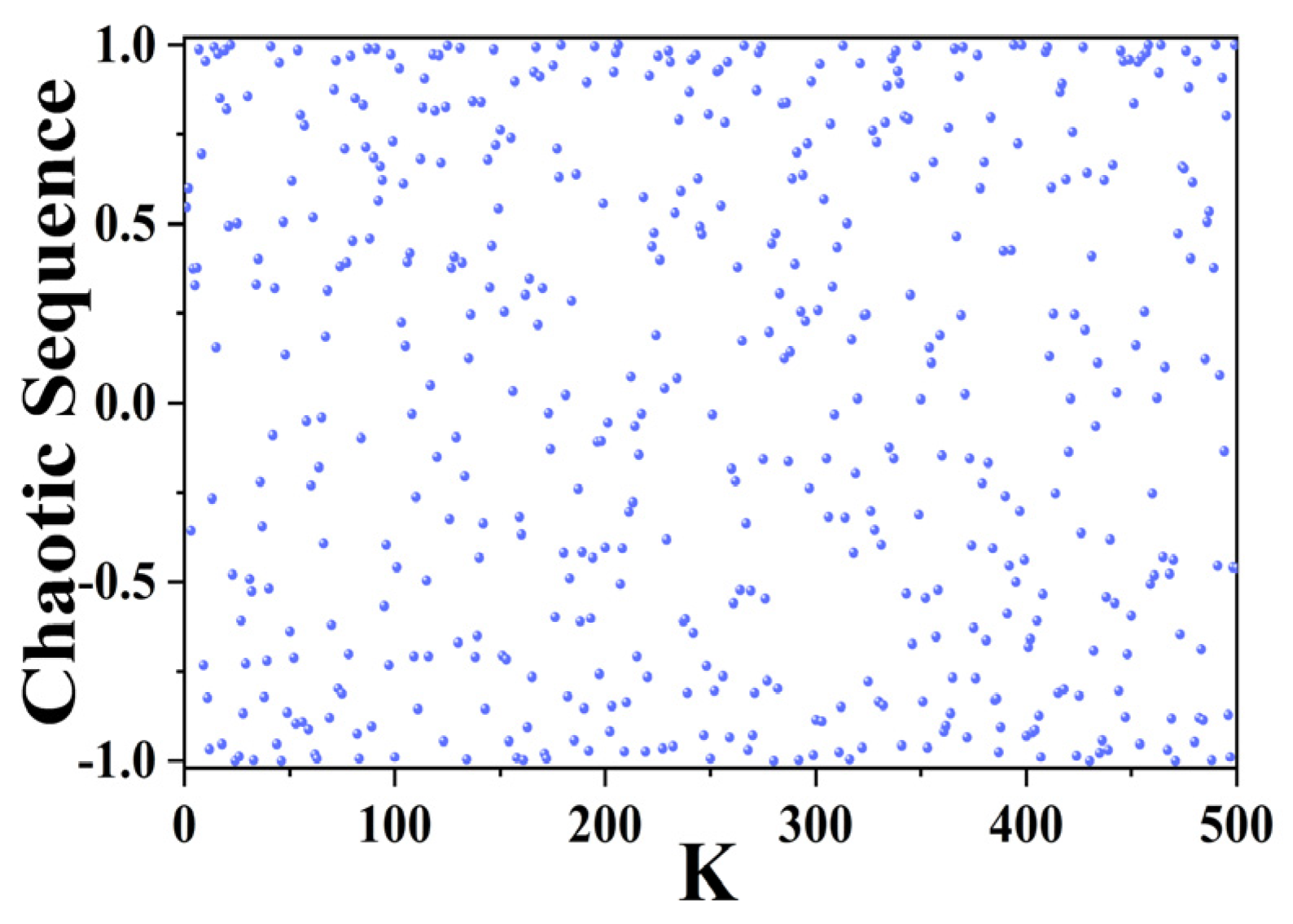
2.3.3. ICMIC Chaotic Mapping
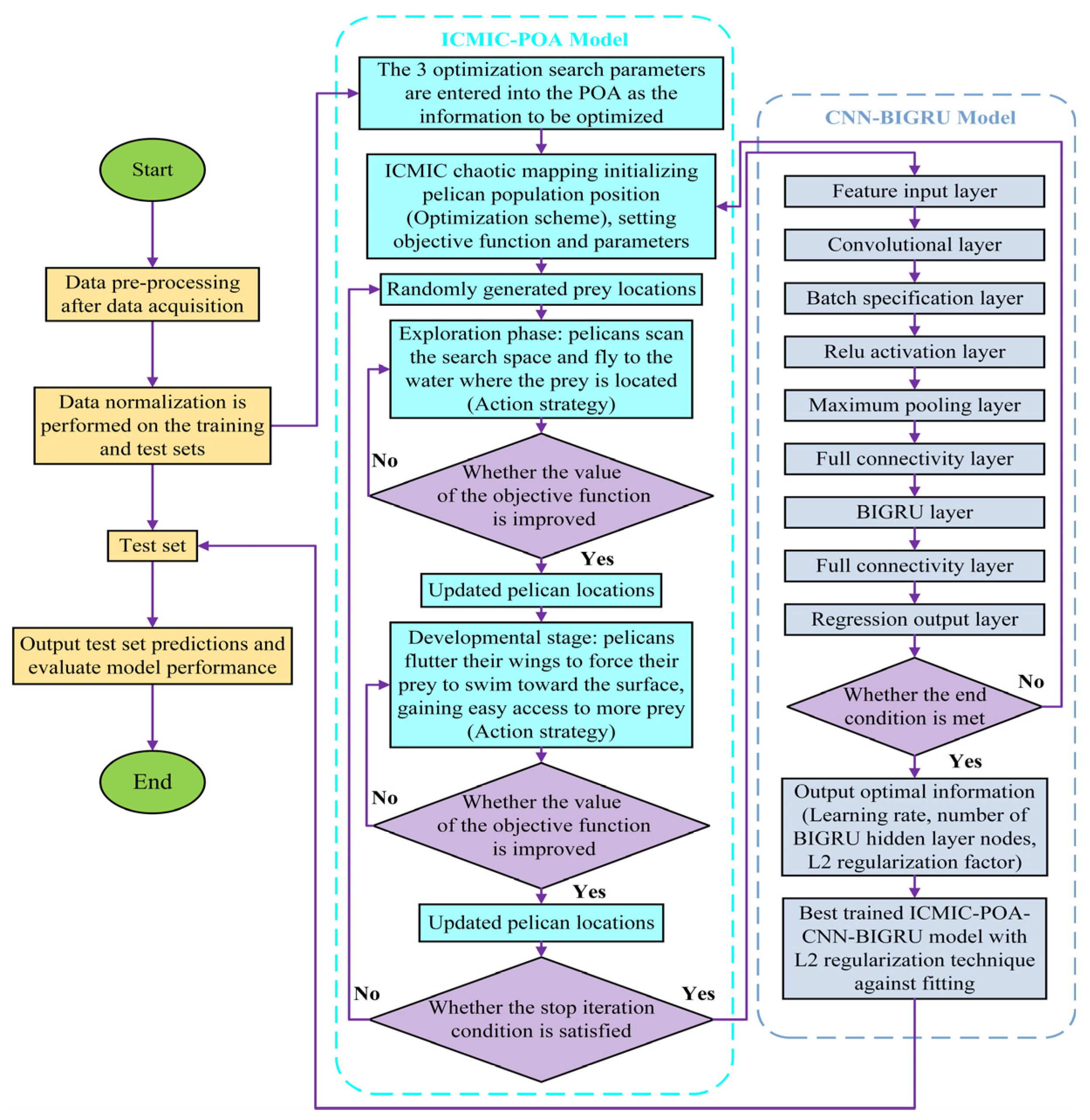
2.4. CNN-BIGRU Prediction Model Based on ICMIC-POA
- The original dataset is partitioned into training and test sets, and the data is normalized;
- Three optimization search parameters are input into the POA as the variables to be optimized;
- The initialization of the pelican population’s position is carried out using the ICMIC chaotic mapping technique. In this study, the three parameters subject to optimization are the learning rate, the number of nodes in the hidden layer of the BIGRU, and the L2-regularization coefficient λ. The fitness function of the POA, which is the mean-square error, serves as the objective function, while the remaining parameters are set accordingly;
- Randomly generated prey locations;
- In the exploration phase, pelicans scan the search space and fly to the water where the prey is located (action strategy);
- The objective function of the exploration phase is worth improving and updating the pelican position. Otherwise, return to step (5);
- In the developmental stage, pelicans flutter their wings to force their prey to swim toward the surface, easily gaining more prey (action strategy);
- The objective function of the development phase is worth improving and updating the pelican position. Otherwise, return to step (7);
- Satisfy the stop iteration condition and output to the CNN-BIGRU model. Otherwise, return to step (4);
- CNN deep mines the features of time series variables and inputs them to BIGRU for prediction;
- After the end condition is satisfied, output the optimal 3 parameter values. Otherwise, return to step (3);
- The best-trained ICMIC-POA-CNN-BIGRU model for prediction and performance evaluation of the test set.
3. Result and Discussion
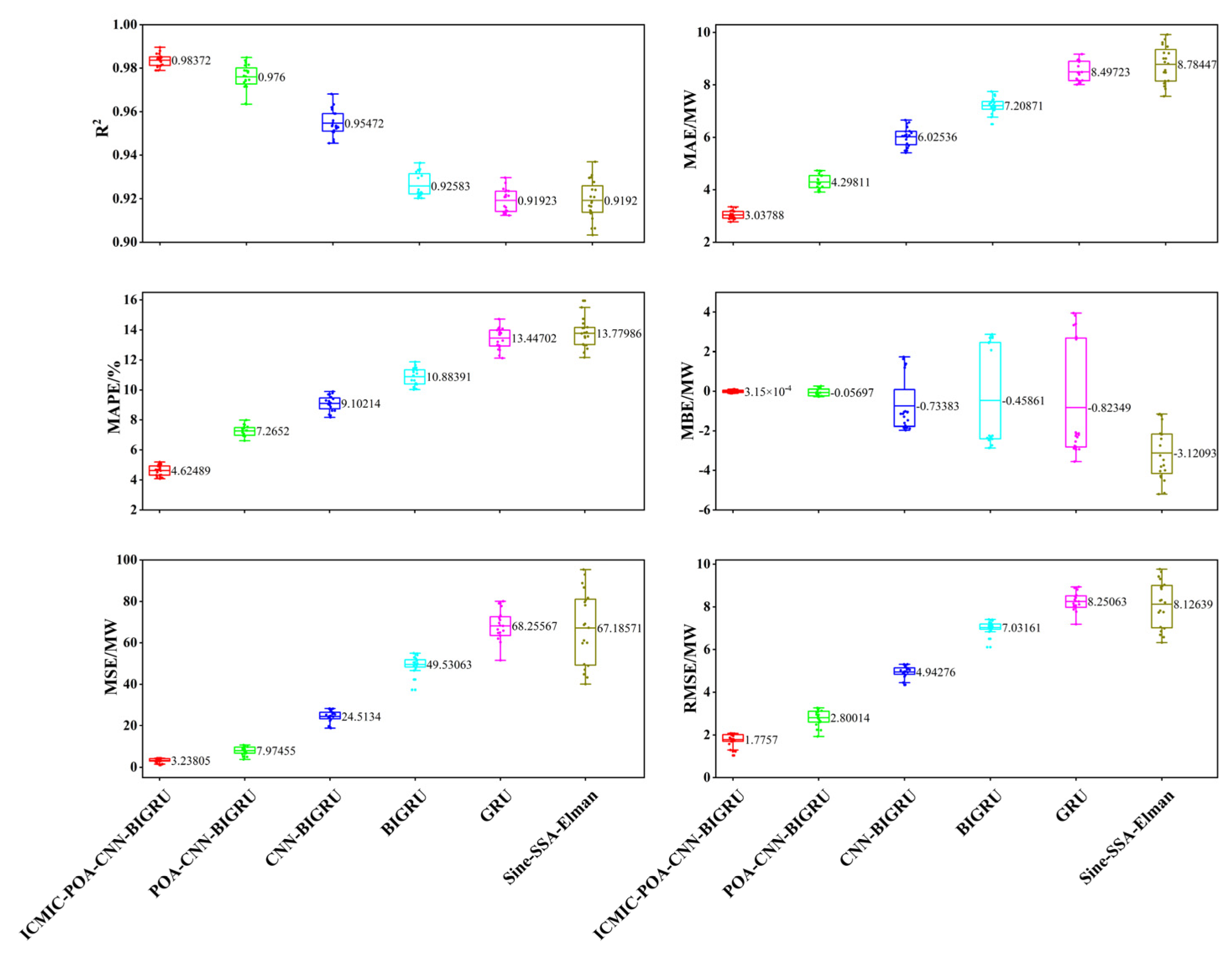
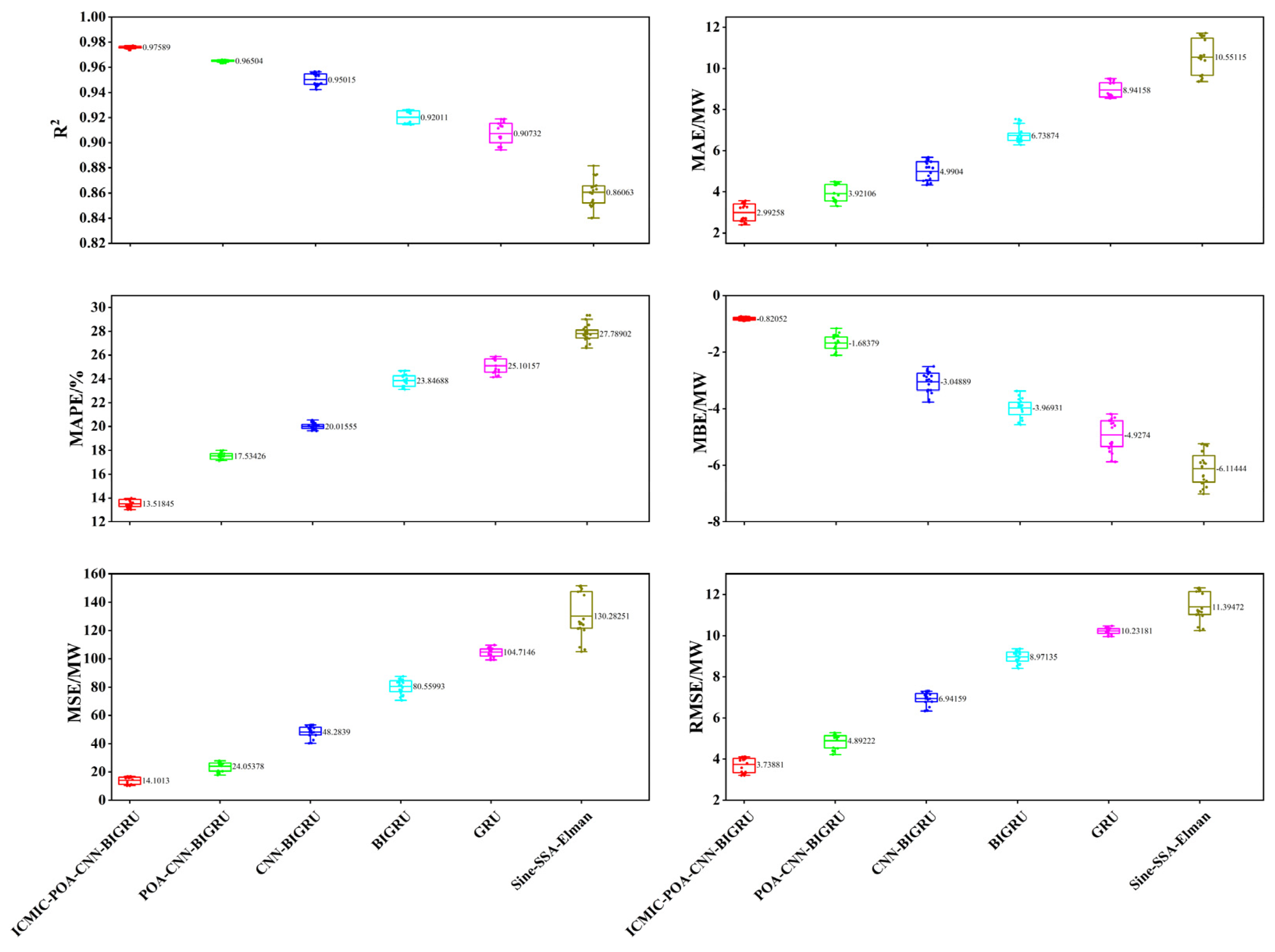
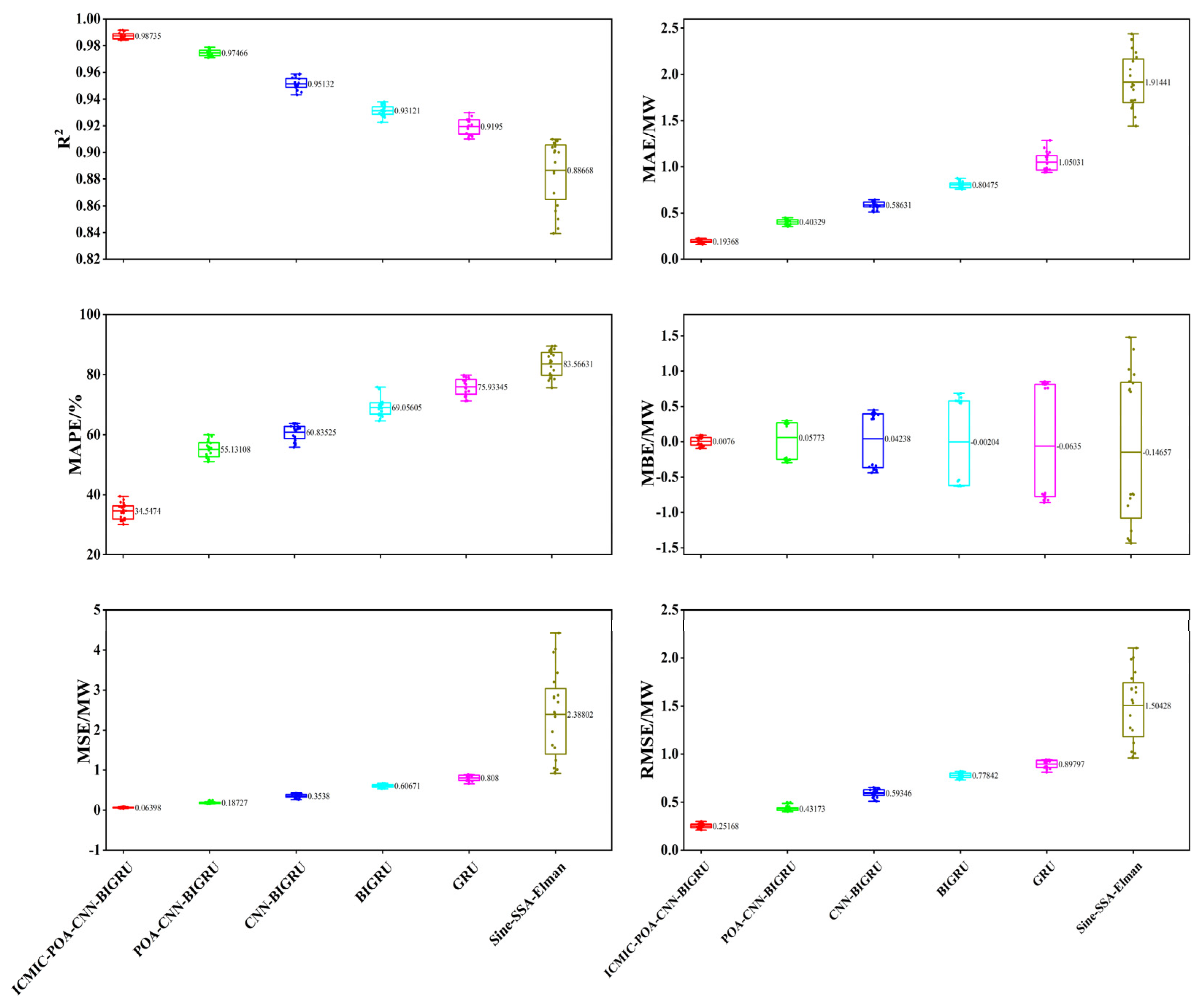
3.1. Evaluation Index
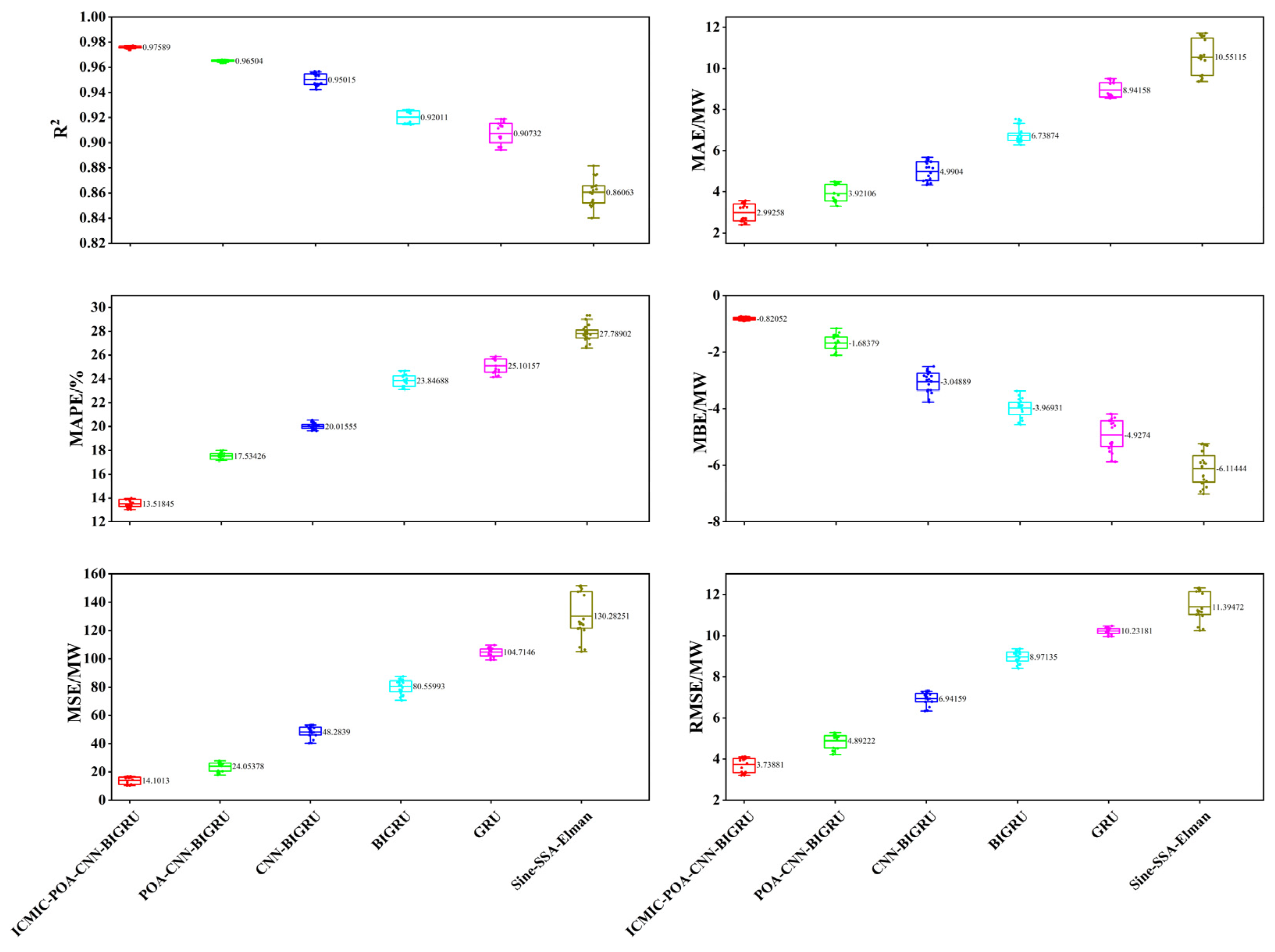
3.2. Prediction Results and Analysis
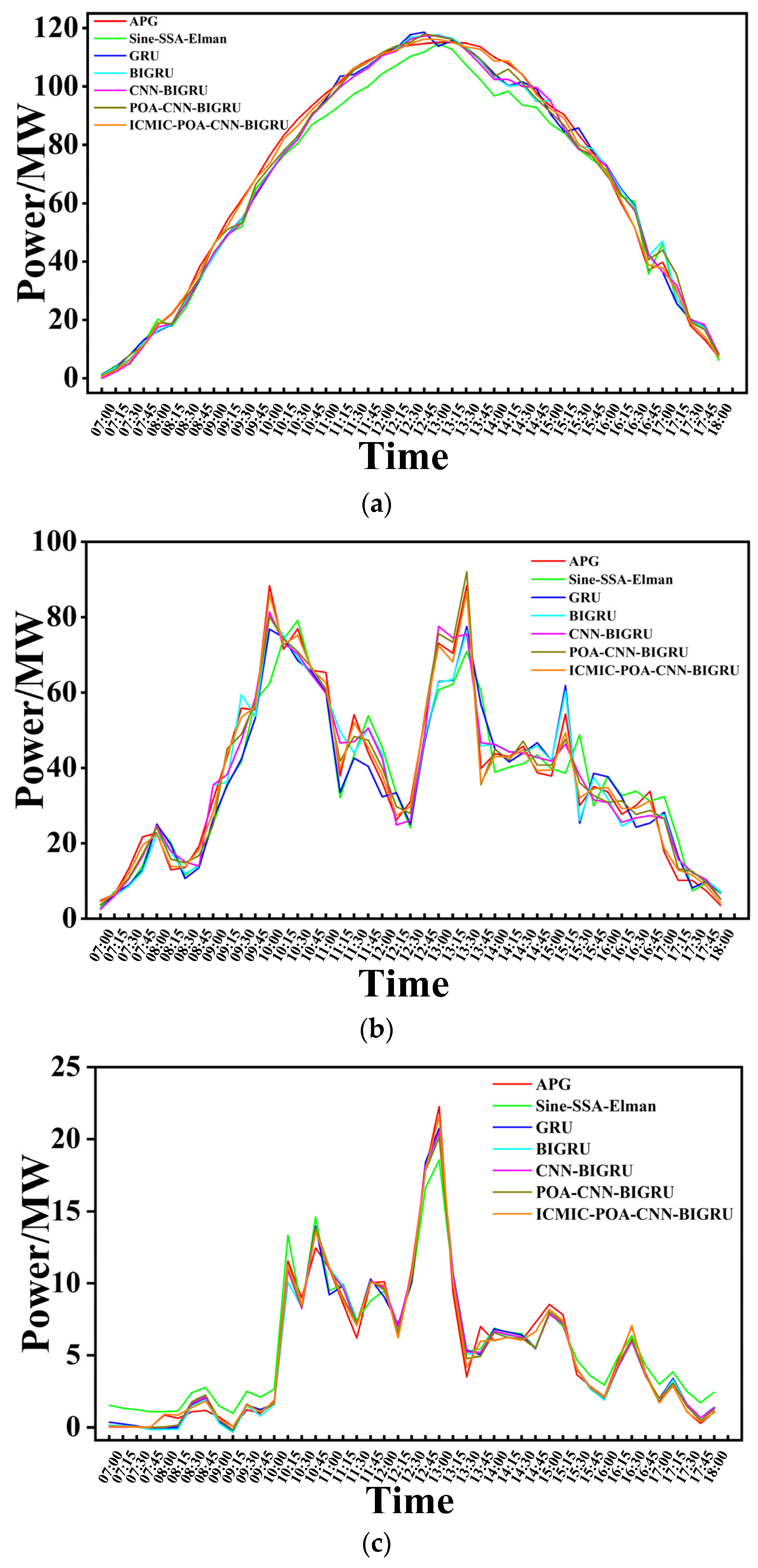
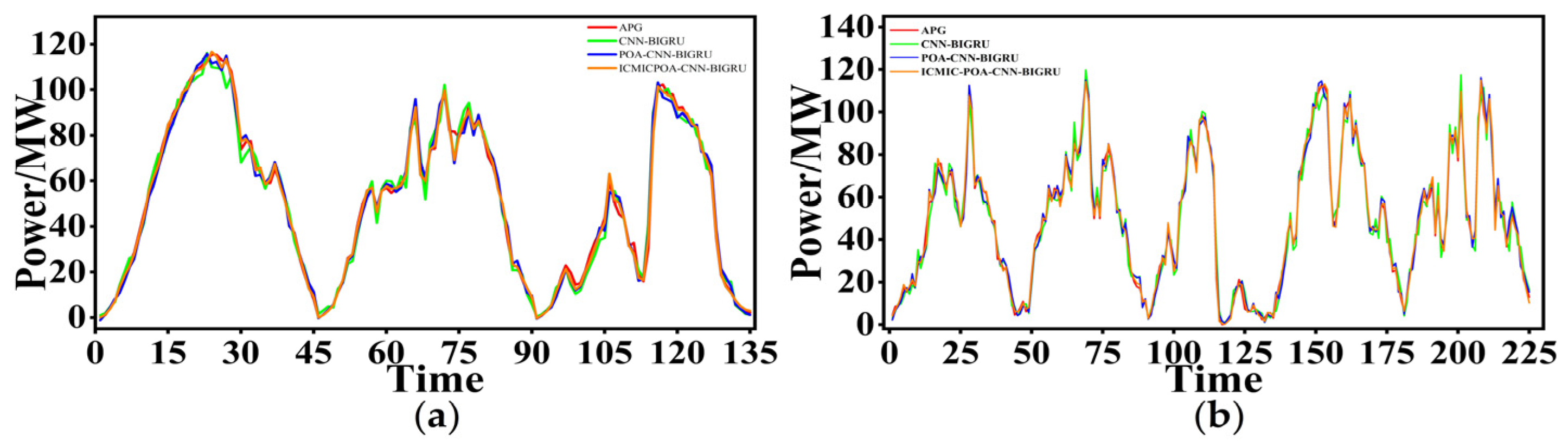
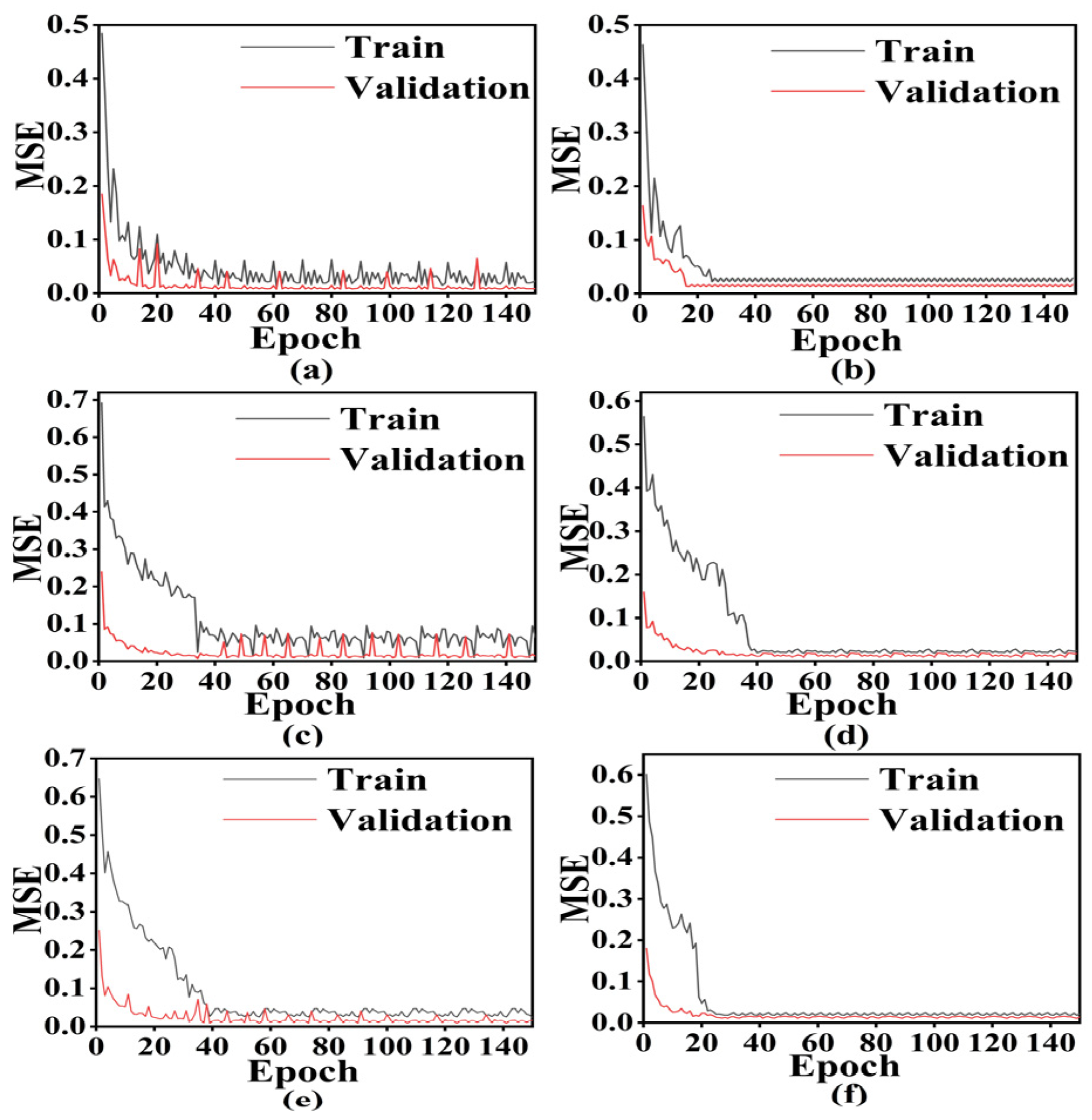
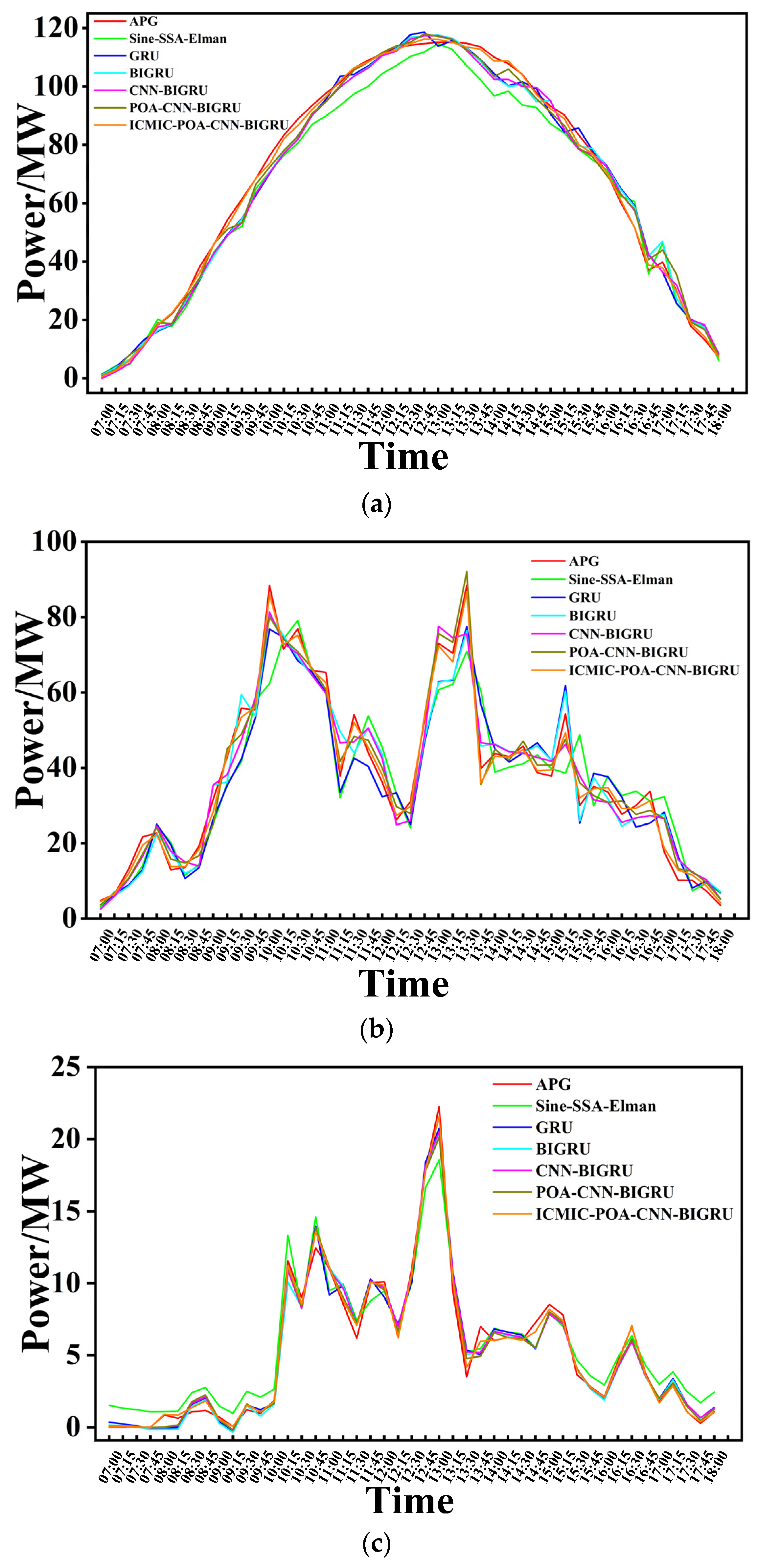
3.2.1. Prediction of Three Typical Days
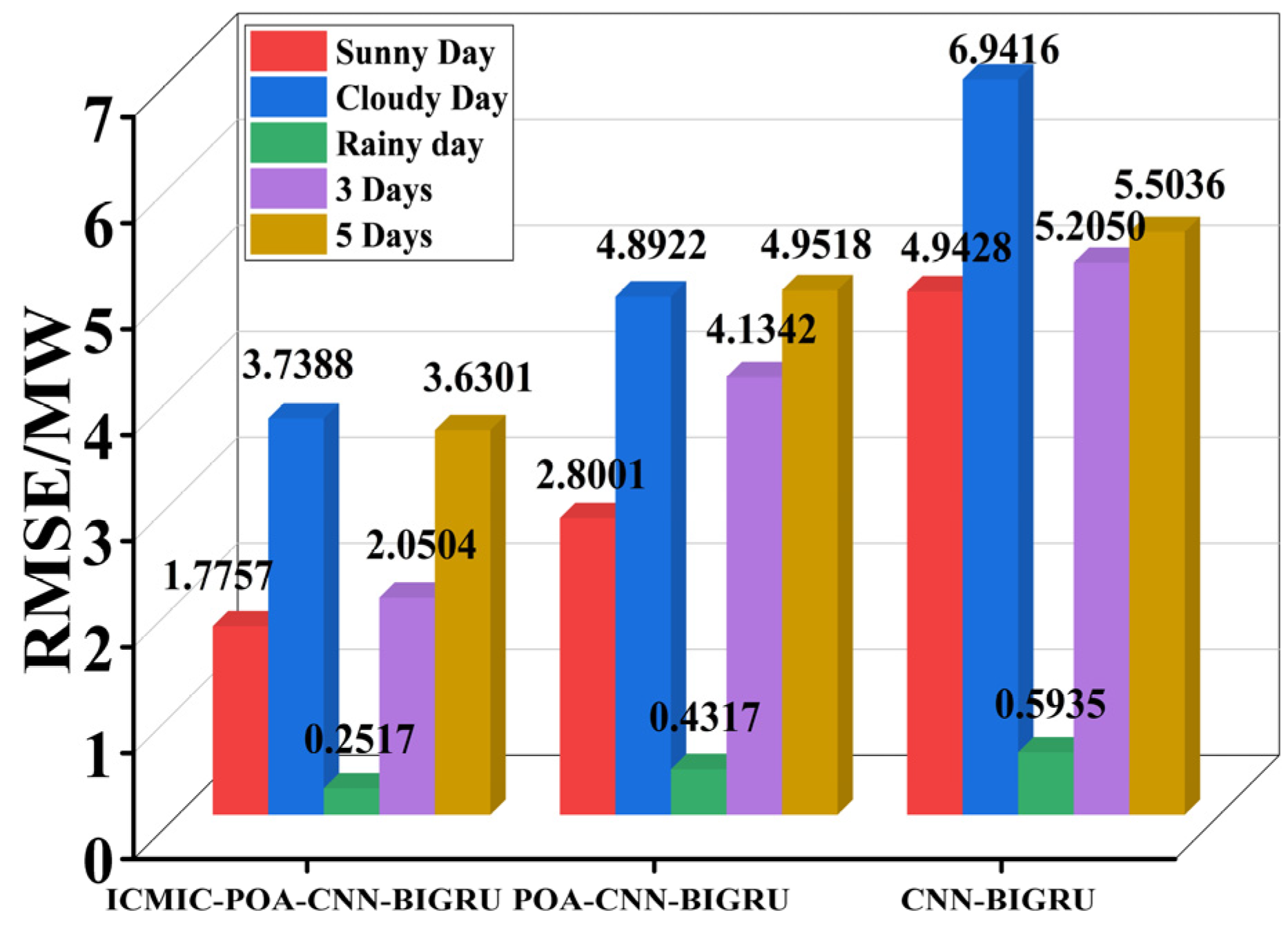
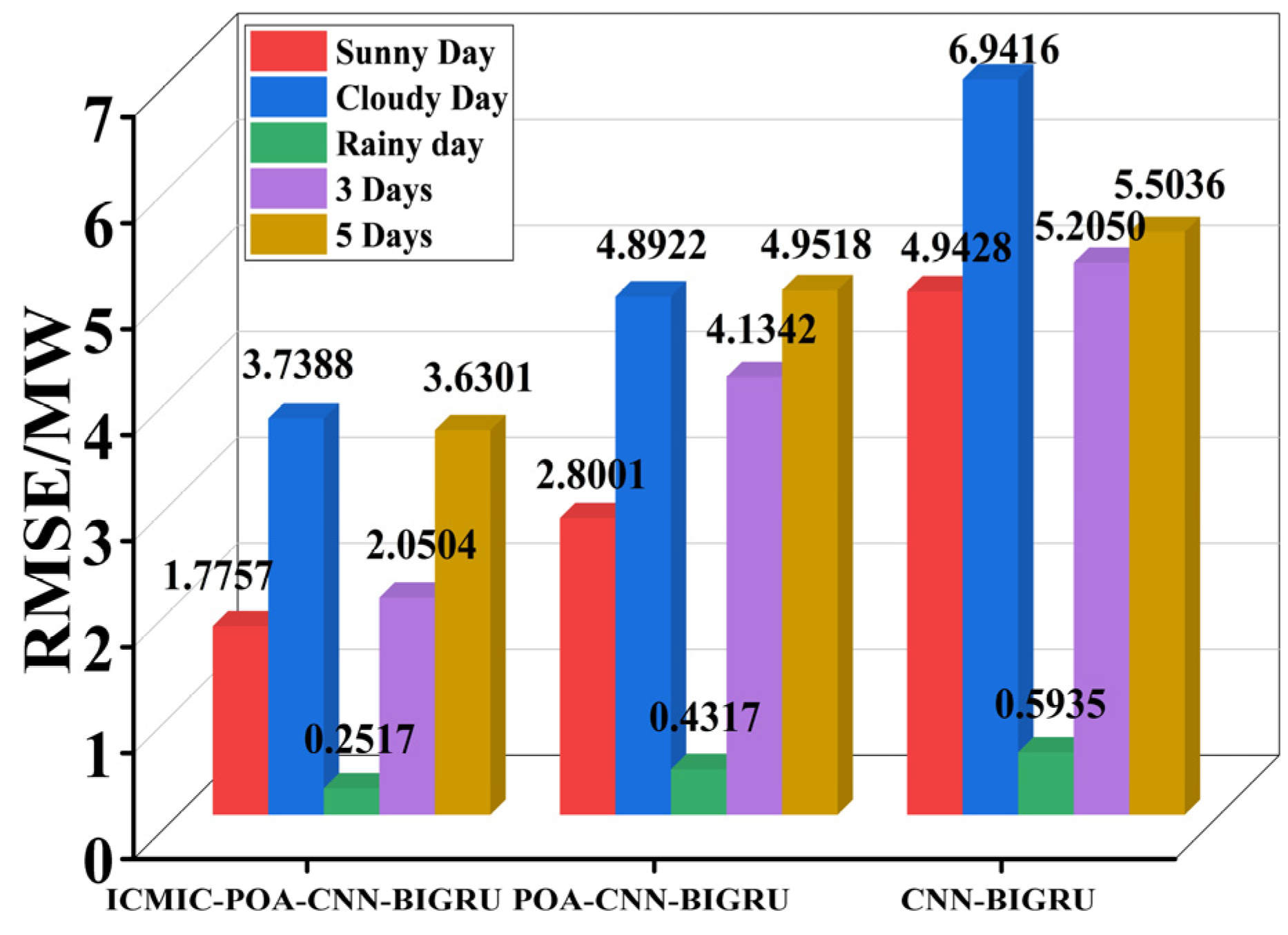
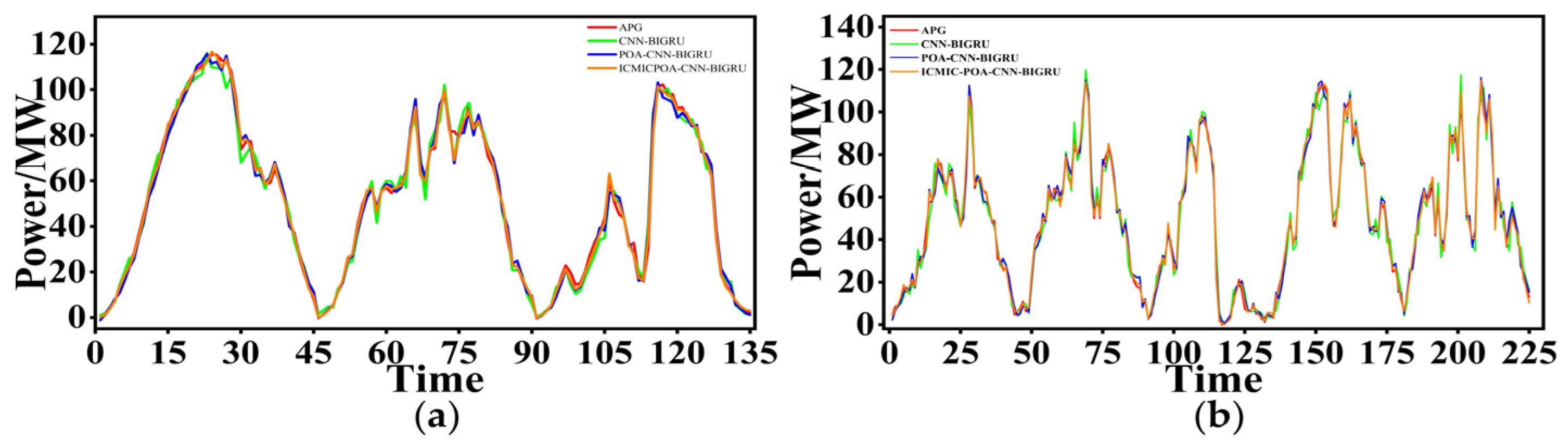
3.2.2. K-Fold Cross-Validation
4. Conclusions
- The latest heuristic algorithm (POA) was used for the first time to search and automatically debug the optimal hyperparameters of CNN-BIGRU and the optimal value of the L2-regularization coefficient, which greatly saved the computational cost and improved the prediction performance of the model;
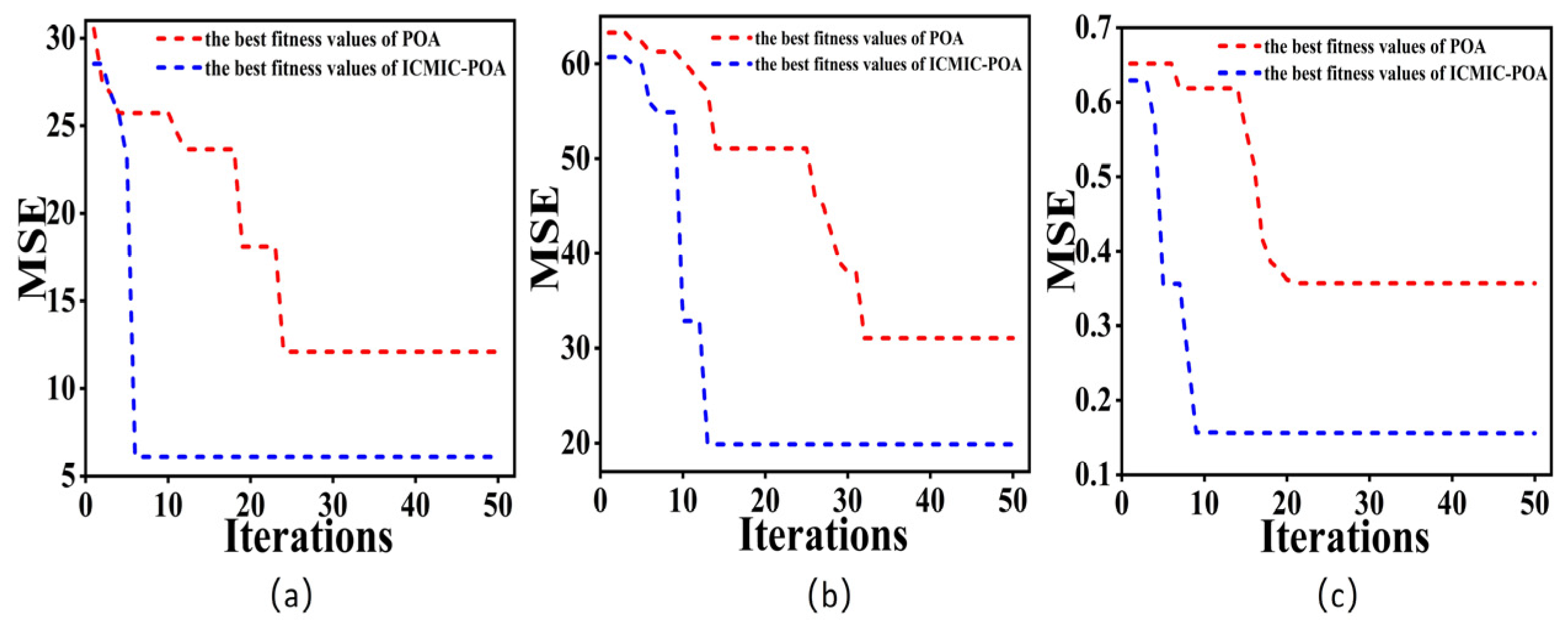
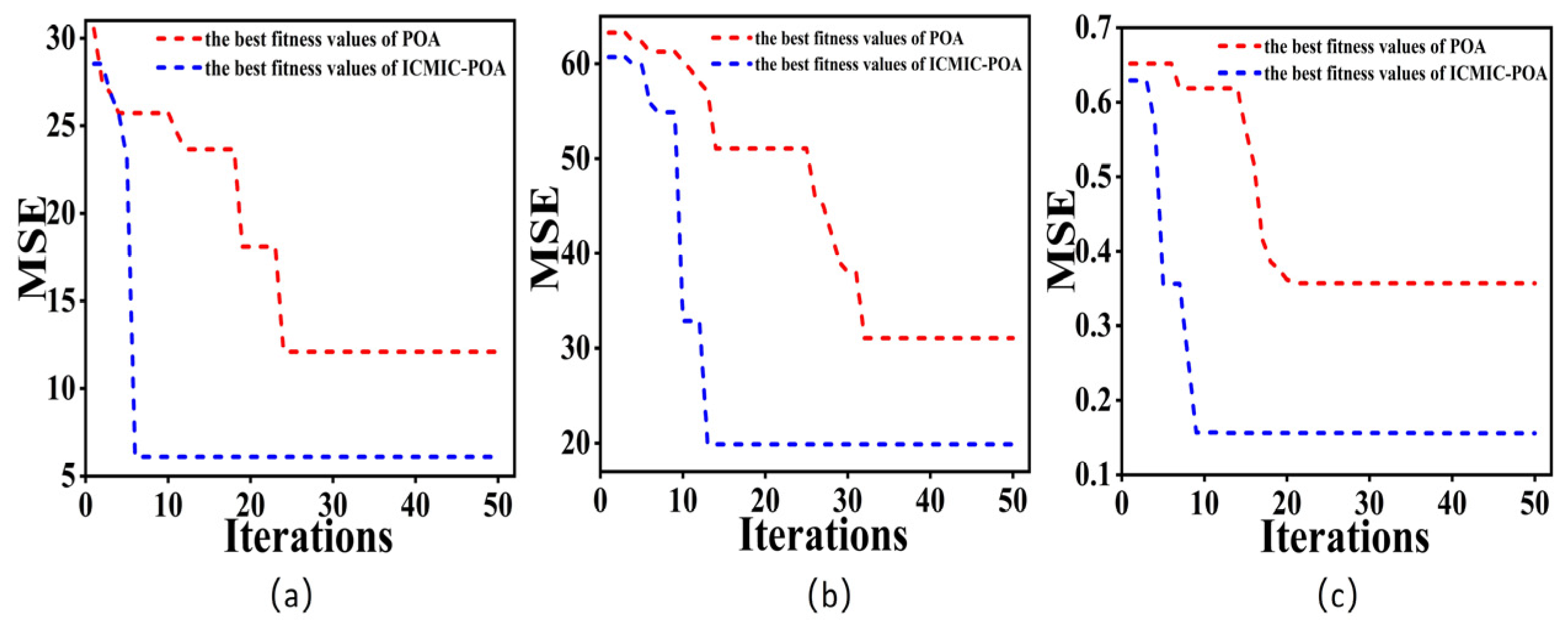
- ICMIC chaotic mapping optimized the initial population position of the POA, increased the randomness of the population distribution, and greatly improved the ergodicity and global search ability of the POA;
- Adding L2-regularization technology could quickly reduce the loss value of the loss function in the deep learning model (CNN-BIGRU), and the convergence was stable in a very small range. It solved the over-fitting problem that easily occurred in the training process;
- The model in this paper had the best prediction performance compared with the five prediction models. In the prediction time window of 1 day (sunny, cloudy, and rainy days), 3 days, and 5 days, six evaluation indicators were used to comprehensively evaluate the prediction performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Houran, M.A.; Bukhari, S.M.S.; Zafar, M.H.; Mansoor, M.; Chen, W. COA-CNN-LSTM: Coati optimization algorithm-based hybrid deep learning model for PV/wind power forecasting in smart grid applications. Appl. Energy 2023, 349, 121638. [Google Scholar] [CrossRef]
- Agga, A.; Abbou, A.; Labbadi, M.; Houm, Y.E. Short-term self consumption PV plant power production forecasts based on hybrid CNN-LSTM, ConvLSTM models. Renew. Energy 2021, 177, 101–112. [Google Scholar] [CrossRef]
- Micheli, L.; Talavera, D.L. Economic feasibility of floating photovoltaic power plants: Profitability and competitiveness. Renew. Energy 2023, 211, 607–616. [Google Scholar] [CrossRef]
- Micheli, L.; Talavera, D.L.; Tina, G.M.; Almonacid, F.; Fernández, E.F. Techno-economic potential and perspectives of floating photovoltaics in Europe. Sol. Energy 2022, 243, 203–214. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Goswami, A.; Sadhu, P.K. Design, development and performance analysis of FSPV system for powering sustainable energy based mini micro-grid. Microsyst. Technol. 2023, 29, 1465–1478. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhou, Y.; Li, Z. Hour-ahead photovoltaic generation forecasting method based on machine learning and multi objective optimization algorithm. Appl. Energy 2022, 312, 118725. [Google Scholar] [CrossRef]
- Pierro, M.; Gentili, D.; Liolli, F.R.; Cornaro, C.; Moser, D.; Betti, A.; Moschella, M.; Collino, E.; Ronzio, D.; van der Meer, D. Progress in regional PV power forecasting: A sensitivity analysis on the Italian case study. Renew. Energy 2022, 189, 983–996. [Google Scholar] [CrossRef]
- Markovics, D.; Mayer, M.J. Comparison of machine learning methods for photovoltaic power forecasting based on numerical weather prediction. Renew. Sustain. Energy Rev. 2022, 161, 112364. [Google Scholar] [CrossRef]
- Lauria, D.; Mottola, F.; Proto, D. Caputo derivative applied to very short time photovoltaic power forecasting. Appl. Energy 2022, 309, 118452. [Google Scholar] [CrossRef]
- Alassery, F.; Alzahrani, A.; Khan, A.I.; Irshad, K.; Islam, S. An artificial intelligence-based solar radiation prophesy model for green energy utilization in energy management system. Sustain. Energy Technol. Assess. 2022, 52, 102060. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, R.; Ma, M. Research on ultra-short term forecasting technology of wind power output based on various me-teorological factors. Energy Rep. 2022, 8, 1145–1158. [Google Scholar] [CrossRef]
- Fadhel, S.; Diallo, D.; Delpha, C.; Migan, A.; Bahri, I.; Trabelsi, M.; Mimouni, M.F. Maximum power point analysis for partial shading detection and identification in photovoltaic systems. Energy Convers. Manag. 2020, 224, 113374. [Google Scholar] [CrossRef]
- Jia, P.; Zhang, H.; Liu, X.; Gong, X. Short-Term Photovoltaic Power Forecasting Based on VMD and ISSA-GRU. IEEE Access 2021, 9, 105939–105950. [Google Scholar] [CrossRef]
- Niu, D.; Wang, K.; Sun, L.; Wu, J.; Xu, X. Short-term photovoltaic power generation forecasting based on random forest feature selection and CEEMD: A case study. Appl. Soft Comput. 2020, 93, 106389. [Google Scholar] [CrossRef]
- Wang, L.; Liu, Y.; Li, T.; Xie, X.; Chang, C. The Short-Term Forecasting of Asymmetry Photovoltaic Power Based on the Feature Extraction of PV Power and SVM Algorithm. Symmetry 2020, 12, 1777. [Google Scholar] [CrossRef]
- Hajjaj, C.; Ydrissi, M.E.; Azouzoute, A.; Oufadel, A.; Alani, O.E.; Boujoudar, M.; Abraim, M.; Ghennioui, A. Comparing Pho-tovoltaic Power Prediction: Ground-Based Measurements vs. Satellite Data Using an ANN Model. IEEE J. Photovolt. 2023, 13, 998–1006. [Google Scholar] [CrossRef]
- Drałus, G.; Mazur, D.; Kusznier, J.; Drałus, J. Application of Artificial Intelligence Algorithms in Multilayer Perceptron and Elman Networks to Predict Photovoltaic Power Plant Generation. Energies 2023, 16, 6697. [Google Scholar] [CrossRef]
- Ma, W.; Chen, Z.; Zhu, Q. Ultra-Short-Term Forecasting of Photo-Voltaic Power via RBF Neural Network. Electronics 2020, 9, 1717. [Google Scholar] [CrossRef]
- Bozorg, M.; Bracale, A.; Carpita, M.; de Falco, P.; Mottola, F.; Proto, D. Bayesian bootstrapping in real-time probabilistic pho-tovoltaic power forecasting. Sol. Energy 2021, 225, 577–590. [Google Scholar] [CrossRef]
- Wang, H.; Liu, Y.; Zhou, B.; Li, C.; Cao, G.; Voropai, N.; Barakhtenko, E. Taxonomy research of artificial intelligence for de-terministic solar power forecasting. Energy Convers. Manag. 2020, 214, 112909. [Google Scholar] [CrossRef]
- Pan, M.; Li, C.; Gao, R.; Huang, Y.; You, H.; Gu, T.; Qin, F. Photovoltaic power forecasting based on a support vector machine with improved ant colony optimization. J. Clean. Prod. 2020, 277, 123948. [Google Scholar] [CrossRef]
- Netsanet, S.; Dehua, Z.; Wei, Z.; Teshager, G. Short-term PV power forecasting using variational mode decomposition integrated with Ant colony optimization and neural network. Energy Rep. 2022, 8, 2022–2035. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X. A short-term prediction model to forecast power of photovoltaic based on MFA-Elman. Energy Rep. 2022, 8, 495–507. [Google Scholar] [CrossRef]
- Ge, L.; Xian, Y.; Yan, J.; Wang, B.; Wang, Z. A Hybrid Model for Short-term PV Output Forecasting Based on PCA-GWO-GRNN. J. Mod. Power Syst. Clean Energy 2020, 8, 1268–1275. [Google Scholar] [CrossRef]
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 2019, 198, 111799. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, A.; Jiao, J.; Xie, J.; Chen, H. Short-Term PV Power Forecasting Based on CEEMDAN and Ensemble DeepTCN. IEEE Trans. Instrum. Meas. 2023, 27. [Google Scholar] [CrossRef]
- Dairi, A.; Harrou, F.; Sun, Y.; Khadraoui, S. Short-Term Forecasting of Photovoltaic Solar Power Production Using Variational Auto-Encoder Driven Deep Learning Approach. Appl. Sci. 2020, 10, 8400. [Google Scholar] [CrossRef]
- Mishra, S.P.; Rayi, V.K.; Dash, P.K.; Bisoi, R. Multi-objective auto-encoder deep learning-based stack switching scheme for improved battery life using error prediction of wind-battery storage microgrid. Int. J. Energy Res. 2021, 45, 20331–20355. [Google Scholar] [CrossRef]
- Massaoudi, M.; Abu-Rub, H.; Refaat, S.S.; Trabelsi, M.; Chihi, I.; Oueslati, F.S. Enhanced Deep Belief Network Based on Ensemble Learning and Tree-Structured of Parzen Estimators: An Optimal Photovoltaic Power Forecasting Method. IEEE Access 2021, 9, 150330–150344. [Google Scholar] [CrossRef]
- Chang, G.W.; Lu, H.-J. Integrating Gray Data Preprocessor and Deep Belief Network for Day-Ahead PV Power Output Forecast. IEEE Trans. Sustain. Energy 2020, 11, 185–194. [Google Scholar] [CrossRef]
- Akhter, M.N.; Mekhilef, S.; Mokhlis, H.; Ali, R.; Usama, M.; Muhammad, M.A.; Khairuddin, A.S.M. A hybrid deep learning method for an hour ahead power output forecasting of three different photovoltaic systems. Appl. Energy 2022, 307, 118185. [Google Scholar] [CrossRef]
- Garip, Z.; Ekinci, E.; Alan, A. Day-ahead solar photovoltaic energy forecasting based on weather data using LSTM networks: A comparative study for photovoltaic (PV) panels in Turkey. Electr. Eng. 2023, 105, 3329–3345. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y. A Hybrid Neural Network-Based Intelligent Forecasting Approach for Capacity of Photovoltaic Electricity Generation. J. Circuits Syst. Comput. 2023, 32, 2350172. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, X.; Ma, T.; Liu, D.; Wang, H.; Hu, W. A Multi-step ahead photovoltaic power forecasting model based on TimeGAN, Soft DTW-based K-medoids clustering, and a CNN-GRU hybrid neural network. Energy Rep. 2022, 8, 10346–10362. [Google Scholar] [CrossRef]
- Suresh, V.; Janik, P.; Rezmer, J.; Leonowicz, Z. Forecasting Solar PV Output Using Convolutional Neural Networks with a Sliding Window Algorithm. Energies 2020, 13, 723. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A Novel CNN-GRU-Based Hybrid Approach for Short-Term Residential Load Forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Sabri, N.M.; Hassouni, M.E. Accurate photovoltaic power prediction models based on deep convolutional neural networks and gated recurrent units. Energy Source Part A 2022, 44, 6303–6320. [Google Scholar] [CrossRef]
- Wang, F.; Xuan, Z.; Zhen, Z.; Li, K.; Wang, T.; Shi, M. A day-ahead PV power forecasting method based on LSTM-RNN model and time correlation modification under partial daily pattern prediction framework. Energy Convers. Manag. 2020, 212, 112766. [Google Scholar] [CrossRef]
- Limouni, T.; Yaagoubi, R.; Bouziane, K.; Guissi, K.; Baali, E.H. Accurate one step and multistep forecasting of very short-term PV power using LSTM-TCN model. Renew. Energy 2023, 205, 1010–1024. [Google Scholar] [CrossRef]
- Fan, T.; Sun, T.; Liu, H.; Xie, X.; Na, Z. Spatial-Temporal Genetic-Based Attention Networks for Short-Term Photovoltaic Power Forecasting. IEEE Access 2021, 9, 138762–138774. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhou, N.; Gong, L.; Jiang, M. Prediction of photovoltaic power output based on similar day analysis, genetic algorithm and extreme learning machine. Energy 2020, 204, 117894. [Google Scholar] [CrossRef]
- Zhen, H.; Niu, D.; Wang, K.; Shi, Y.; Ji, Z.; Xu, X. Photovoltaic power forecasting based on GA improved Bi-LSTM in microgrid without meteorological information. Energy 2021, 231, 120908. [Google Scholar] [CrossRef]
- Eseye, A.T.; Zhang, J.; Zheng, D. Short-term photovoltaic solar power forecasting using a hybrid Wavelet-PSO-SVM model based on SCADA and Meteorological information. Renew. Energy 2018, 118, 357–367. [Google Scholar] [CrossRef]
- Perera, M.; De Hoog, J.; Bandara, K.; Halgamuge, S. Multi-resolution, multi-horizon distributed solar PV power forecasting with forecast combinations. Expert Syst. Appl. 2022, 205, 117690. [Google Scholar] [CrossRef]
- Wu, X.; Lai, C.S.; Bai, C.; Lai, L.L.; Zhang, Q.; Liu, B. Optimal Kernel ELM and Variational Mode Decomposition for Probabilistic PV Power Prediction. Energies 2020, 13, 3592. [Google Scholar] [CrossRef]
- Luo, L.; Abdulkareem, S.S.; Rezvani, A.; Miveh, M.R.; Samad, S.; Aljojo, N.; Pazhoohesh, M. Optimal scheduling of a renewable based microgrid considering photovoltaic system and battery energy storage under uncertainty. J. Energy Storage 2020, 28, 101306. [Google Scholar] [CrossRef]
- Rajesh, P.; Shajin, F.H.; Rajani, B.; Sharma, D. An optimal hybrid control scheme to achieve power quality enhancement in micro grid connected system. Int. J. Numer. Model. Electron. Netw. Devices Fields 2022, 35, e3019. [Google Scholar] [CrossRef]
- Trojovský, P.; Dehghani, M. Pelican Optimization Algorithm: A Novel Nature-Inspired Algorithm for Engineering Applications. Sensors 2022, 22, 855. [Google Scholar] [CrossRef]
- Wu, C.; Sun, K.; Xiao, Y. A hyperchaotic map with multi-elliptic cavities based on modulation and coupling. Eur. Phys. J. Spéc. Top. 2021, 230, 2011–2020. [Google Scholar] [CrossRef]
- Wen, J.; Xu, X.; Sun, K.; Jiang, Z.; Wang, X. Triple-image bit-level encryption algorithm based on double cross 2D hyperchaotic map. Nonlinear Dyn. 2023, 111, 6813–6838. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structural Parameter | Parameter Value | Structural Parameter | Parameter Value |
|---|---|---|---|
| Number of pelican populations | 20 | Number of convolution kernels in the first layer | 16 |
| The maximum number of iterations of POA | 50 | Convolution layer activation function | ReLU |
| Single-batch processing samples | 128 | The second-layer convolution kernel size and step size | 4.1 |
| Maximum training iterations | 300 | Number of convolution kernels in the second layer | 32 |
| Optimizer | Adam | Pooling size and step size | 2.1 |
| The first-layer convolution kernel size and step size | 3.1 | BIGRU activation function | Tanh |
| Number of Experiments | Optimal number of Hidden Layer Nodes for BIGRU | Optimal Initial Learning Rate | Optimal L2-Regularization Factor |
|---|---|---|---|
| Range [10,135] | Range [0.001,0.01] | Range [0.0001,0.1] | |
| 1 | 85 | 0.0028 | 0.0014 |
| 2 | 90 | 0.0051 | 0.0056 |
| 3 | 23 | 0.0078 | 0.0067 |
| 4 | 118 | 0.0071 | 0.0060 |
| 5 | 21 | 0.0021 | 0.0052 |
| 6 | 116 | 0.0039 | 0.0024 |
| 7 | 121 | 0.0038 | 0.0089 |
| 8 | 116 | 0.0051 | 0.0122 |
| 9 | 37 | 0.0070 | 0.0019 |
| 10 | 30 | 0.0045 | 0.0054 |
| 11 | 19 | 0.0020 | 0.0039 |
| 12 | 98 | 0.0043 | 0.0212 |
| 13 | 23 | 0.0089 | 0.0077 |
| 14 | 91 | 0.0081 | 0.0267 |
| 15 | 95 | 0.0076 | 0.0256 |
| 16 | 75 | 0.0036 | 0.0081 |
| 17 | 45 | 0.0021 | 0.0068 |
| 18 | 52 | 0.0095 | 0.0165 |
| 19 | 96 | 0.0061 | 0.0136 |
| 20 | 95 | 0.0067 | 0.0076 |
| Prediction Intervals | Assessment Indicators | Forecasting Models | ||
|---|---|---|---|---|
| ICMIC-POA-CNN-BIGRU | POA-CNN-BIGRU | CNN-BIGRU | ||
| 3 Days | RMSE/MW | 2.8949 | 4.8083 | 5.1422 |
| 1.3377 | 3.3137 | 4.3971 | ||
| 2.8195 | 4.4362 | 5.5421 | ||
| 2.3524 | 5.0615 | 4.9599 | ||
| 1.2879 | 3.3776 | 3.6108 | ||
| 2.0072 | 5.3213 | 6.1252 | ||
| 0.9581 | 2.9286 | 3.1163 | ||
| 1.2262 | 3.7977 | 5.4232 | ||
| 1.6176 | 3.6883 | 4.2821 | ||
| 1.4799 | 3.9245 | 5.6274 | ||
| 0.8723 | 2.1958 | 4.9951 | ||
| 3.8364 | 5.6568 | 5.8586 | ||
| 3.3353 | 5.8328 | 6.1136 | ||
| 1.3593 | 3.1487 | 5.5886 | ||
| 1.6912 | 3.8669 | 5.3778 | ||
| 2.8984 | 4.4009 | 5.9135 | ||
| 2.8831 | 4.5222 | 6.4113 | ||
| Mean value | 2.0504 | 4.1342 | 5.2050 | |
| Prediction Intervals | Assessment Indicators | Forecasting Models | ||
|---|---|---|---|---|
| ICMIC-POA-CNN-BIGRU | POA-CNN-BIGRU | CNN-BIGRU | ||
| 5 Days | RMSE/MW | 2.9281 | 3.5113 | 4.0149 |
| 3.4851 | 5.0503 | 5.6674 | ||
| 2.2264 | 4.3259 | 5.3498 | ||
| 2.7534 | 3.7559 | 4.9186 | ||
| 5.0063 | 6.2719 | 7.1561 | ||
| 3.3317 | 4.8321 | 5.0249 | ||
| 3.6894 | 4.9451 | 5.4569 | ||
| 4.1103 | 5.4777 | 6.2314 | ||
| 5.4194 | 6.6264 | 5.4731 | ||
| 3.3508 | 4.7218 | 5.7427 | ||
| Mean value | 3.6301 | 4.9518 | 5.5036 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Jia, M.; Li, S.; Chen, K.; Zhang, C.; Song, X.; Zhang, Q. Short-Term Power-Generation Prediction of High Humidity Island Photovoltaic Power Station Based on a Deep Hybrid Model. Sustainability 2024, 16, 2853. https://doi.org/10.3390/su16072853
Wang J, Jia M, Li S, Chen K, Zhang C, Song X, Zhang Q. Short-Term Power-Generation Prediction of High Humidity Island Photovoltaic Power Station Based on a Deep Hybrid Model. Sustainability. 2024; 16(7):2853. https://doi.org/10.3390/su16072853
Chicago/Turabian StyleWang, Jiahui, Mingsheng Jia, Shishi Li, Kang Chen, Cheng Zhang, Xiuyu Song, and Qianxi Zhang. 2024. "Short-Term Power-Generation Prediction of High Humidity Island Photovoltaic Power Station Based on a Deep Hybrid Model" Sustainability 16, no. 7: 2853. https://doi.org/10.3390/su16072853
APA StyleWang, J., Jia, M., Li, S., Chen, K., Zhang, C., Song, X., & Zhang, Q. (2024). Short-Term Power-Generation Prediction of High Humidity Island Photovoltaic Power Station Based on a Deep Hybrid Model. Sustainability, 16(7), 2853. https://doi.org/10.3390/su16072853