
Assessing Tornado Impacts in the State of Kentucky with a Focus on Demographics and Roadways Using a GIS-Based Approach


Abstract
1. Introduction
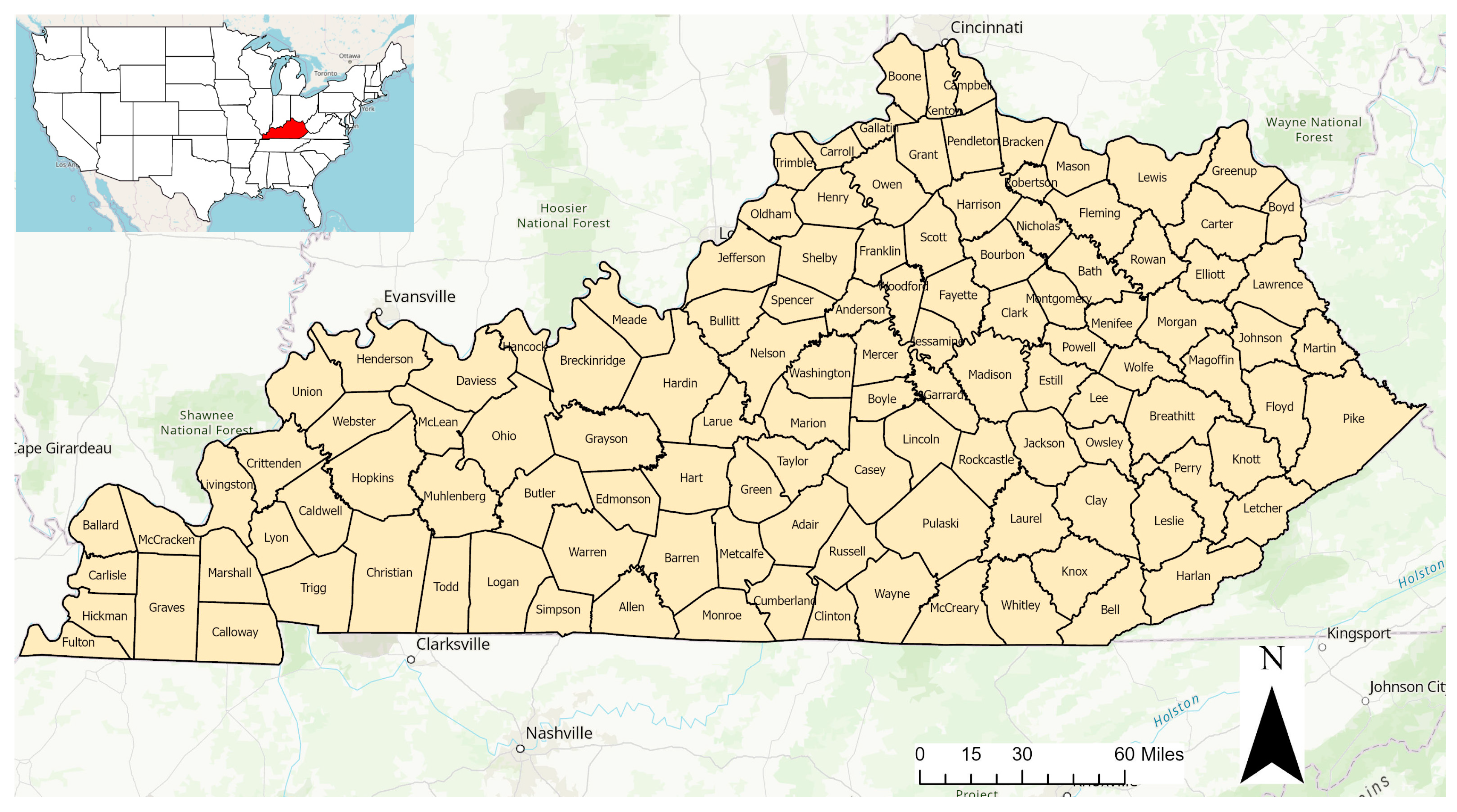
2. Study Area and Data Collection
2.1. TIGER and ACS Dataset
2.2. Smart Location Calculator Dataset
2.3. H + T Index
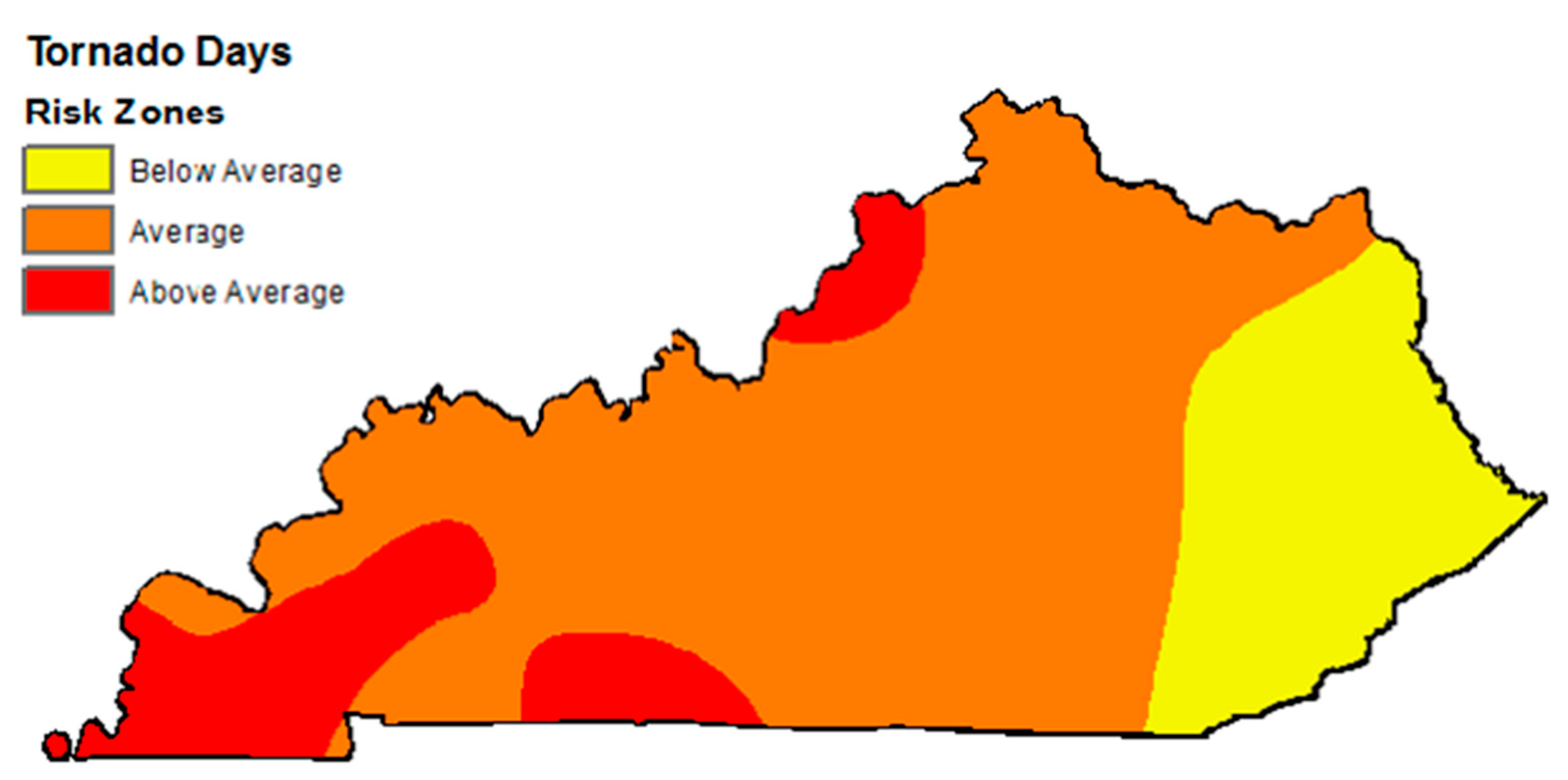
2.4. Tornado Incident Dataset
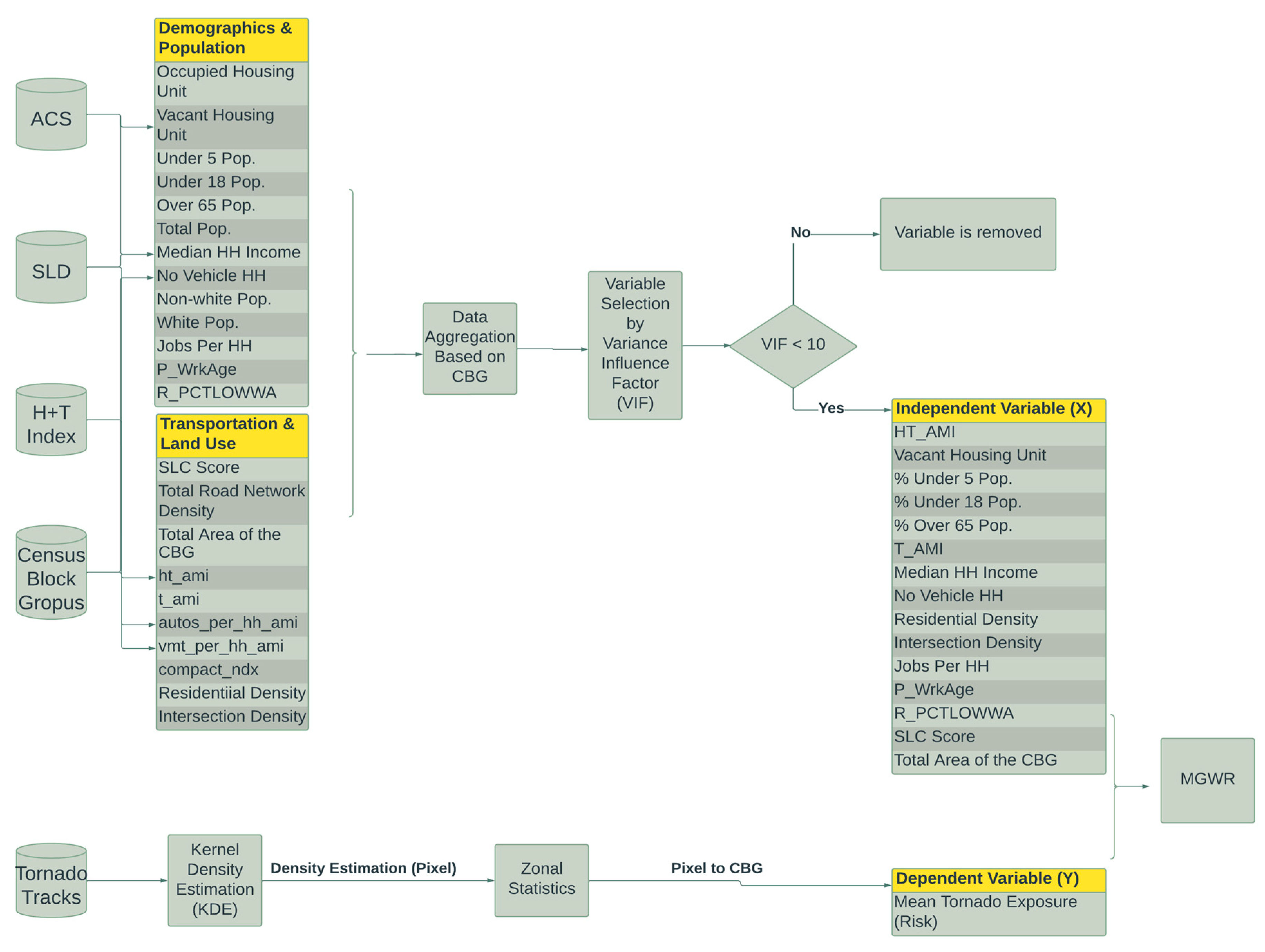
3. Methodology
3.1. Density Estimation
3.2. Variable Selection
3.3. Multiscale Geographically Weighted Regression (MGWR)
4. Results and Discussions
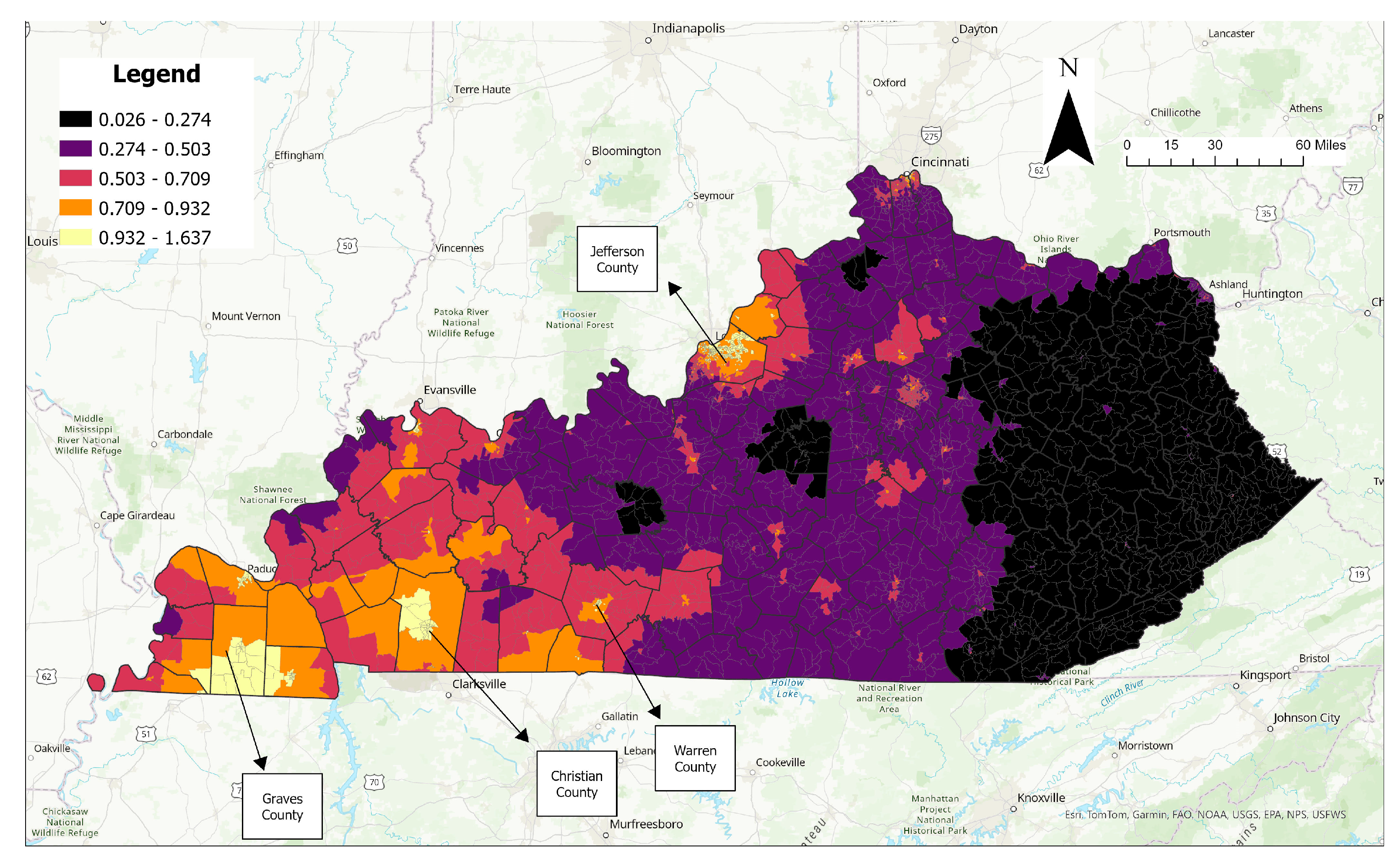
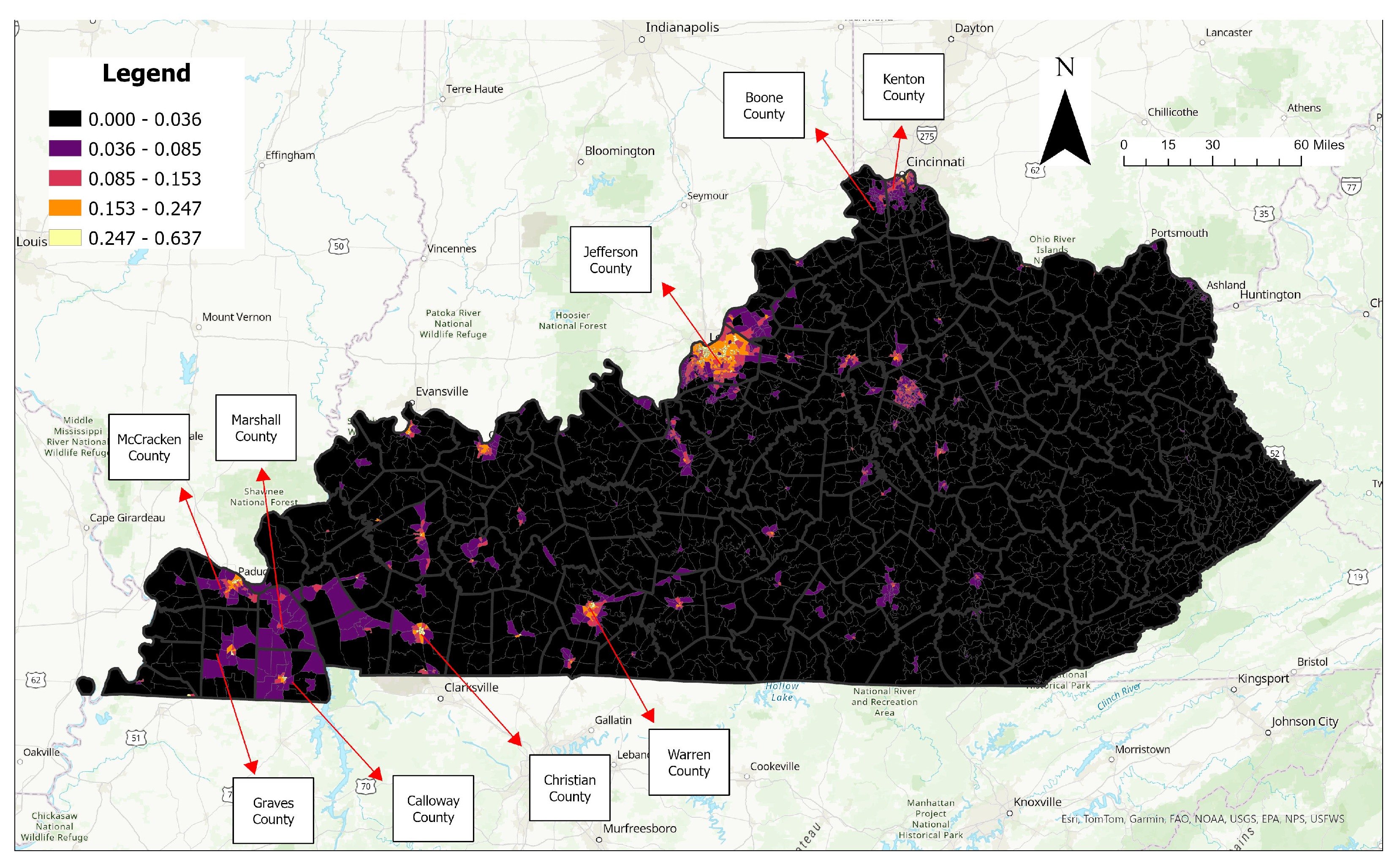
4.1. Spatial Analysis Results
4.2. Statistical Analysis Results
4.2.1. MGWR Model and Its Performance
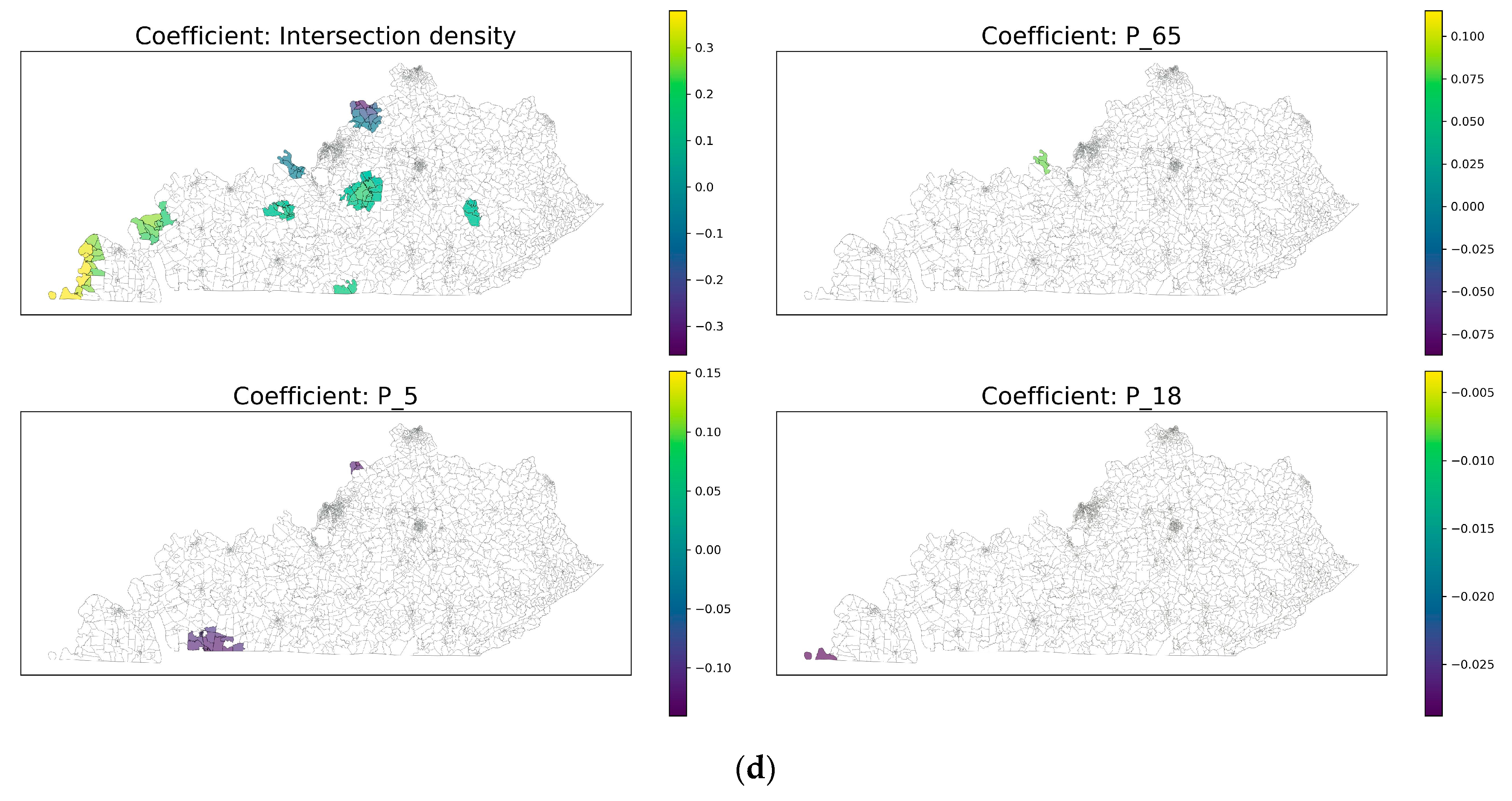
4.2.2. Spatial Distribution of Each Variable
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Changnon, S.A. Tornado Losses in the United States. Nat. Hazards Rev. 2009, 10, 145–150. [Google Scholar] [CrossRef]
- Weather Related Fatality and Injury Statistics. Available online: https://www.weather.gov/hazstat/ (accessed on 28 July 2023).
- First, J.M.; Ellis, K.; Held, M.L.; Glass, F. Identifying Risk and Resilience Factors Impacting Mental Health among Black and Latinx Adults Following Nocturnal Tornadoes in the U.S. Southeast. Int. J. Environ. Res. Public Health 2021, 18, 8609. [Google Scholar] [CrossRef]
- Strader, S.M.; Ashley, W.S.; Pingel, T.J.; Krmenec, A.J. Projected 21st Century Changes in Tornado Exposure, Risk, and Disaster Potential. Clim. Chang. 2017, 141, 301–313. [Google Scholar] [CrossRef]
- Wang, C.; Rider, E.; Manning, S.; Fast, J.; Islam, T. Qualitative Analysis of the Lived Experience of Tornado Survivors and Factors Affecting Community Resilience: A Case Study of an EF3 Tornado in Jacksonville, Alabama. Weather Clim. Soc. 2023, 15, 133–144. [Google Scholar] [CrossRef]
- Trujillo-Falcón, J.E.; Gaviria Pabón, A.R.; Reedy, J.; Klockow-Mcclain, K.E. Systemic Vulnerabilities Created an Informal Warning System for U.S. Hispanic and Latinx Immigrants in the 2021 Quad-State Tornado Outbreak. Available online: https://eartharxiv.org/repository/object/4800/download/9556/ (accessed on 7 July 2023).
- Senkbeil, J.C.; Scott, D.A.; Guinazu-Walker, P.; Rockman, M.S. Ethnic and Racial Differences in Tornado Hazard Perception, Preparedness, and Shelter Lead Time in Tuscaloosa. Prof. Geogr. 2014, 66, 610–620. [Google Scholar] [CrossRef]
- Llorente-Marrón, M.; Díaz-Fernández, M.; Méndez-Rodríguez, P.; González Arias, R. Social Vulnerability, Gender and Disasters. The Case of Haiti in 2010. Sustainability 2020, 12, 3574. [Google Scholar] [CrossRef]
- Strader, S.M.; Ashley, W.S. Finescale Assessment of Mobile Home Tornado Vulnerability in the Central and Southeast United States. Weather Clim. Soc. 2018, 10, 797–812. [Google Scholar] [CrossRef]
- Strader, S.; Ash, K.; Wagner, E.; Sherrod, C. Mobile Home Resident Evacuation Vulnerability and Emergency Medical Service Access during Tornado Events in the Southeast United States. Int. J. Disaster Risk Reduct. 2019, 38, 101210. [Google Scholar] [CrossRef]
- Ulak, M.B.; Kocatepe, A.; Konila Sriram, L.M.; Ozguven, E.E.; Arghandeh, R. Assessment of the Hurricane-Induced Power Outages from a Demographic, Socioeconomic, and Transportation Perspective. Nat. Hazards 2018, 92, 1489–1508. [Google Scholar] [CrossRef]
- Karaer, A.; Ulak, M.B.; Abichou, T.; Arghandeh, R.; Ozguven, E.E. Post-Hurricane Vegetative Debris Assessment Using Spectral Indices Derived from Satellite Imagery. In Transportation Research Record; SAGE Publications Ltd.: Thousand Oaks, CA, USA, 2021; Volume 2675, pp. 504–523. [Google Scholar] [CrossRef]
- Dixon, R.W.; Moore, T.W. Tornado Vulnerability in Texas. Weather Clim. Soc. 2012, 4, 59–68. [Google Scholar] [CrossRef]
- Pielke, R.A., Jr.; Pielke, R.A., Sr. Hurricanes: Their Nature and Impact on Society; Wiley: Hoboken, NJ, USA, 1997. [Google Scholar]
- León-Cruz, J.F.; Castillo-Aja, R. A GIS-Based Approach for Tornado Risk Assessment in Mexico. Nat. Hazards 2022, 114, 1563–1583. [Google Scholar] [CrossRef]
- Blinn, M.C. Creation of a Spatial Decision Support System as a Risk Assessment Tool Based on Kentucky Tornado Climatology. Masters Theses Spec. Proj. 2012, 1153. Available online: http://digitalcommons.wku.edu/theses/1153 (accessed on 2 July 2023).
- Hwang, S.N.; Meier, K. Tornado Impacts in the US from 1950-2015: A GIS-Based Analysis of Vulnerability and Evolving Risk Zones for Human Casualties. J. Geogr. Inf. Syst. 2023, 15, 563–579. [Google Scholar] [CrossRef]
- Schaefer, J.T.; Galway, J.G. Population Biases in the Tornado Climatology; American Meteorological Society: San Antonio, TX, USA, 1982; pp. 51–54. [Google Scholar]
- Potvin, C.K.; Broyles, C.; Skinner, P.S.; Brooks, H.E.; Rasmussen, E. A Bayesian Hierarchical Modeling Framework for Correcting Reporting Bias in the U.S. Tornado Database. Weather Forecast 2019, 34, 15–30. [Google Scholar] [CrossRef]
- Elsner, J.B.; Michaels, L.E.; Scheitlin, K.N.; Elsner, I.J. The Decreasing Population Bias in Tornado Reports across the Central Plains. Weather Clim. Soc. 2013, 5, 221–232. [Google Scholar] [CrossRef]
- Wang, C.; Du, S.; Wen, J.; Zhang, M.; Gu, H.; Shi, Y.; Xu, H. Analyzing Explanatory Factors of Urban Pluvial Floods in Shanghai Using Geographically Weighted Regression. Stoch. Environ. Res. Risk Assess. 2017, 31, 1777–1790. [Google Scholar] [CrossRef]
- Chun, H.; Chi, S.; Hwang, B.G. A Spatial Disaster Assessment Model of Social Resilience Based on Geographically Weighted Regression. Sustainability 2017, 9, 2222. [Google Scholar] [CrossRef]
- Anselin, L. Exploratory Spatial Data Analysis and Geographic Information Systems. N. Tools Spat. Anal. 1994, 17, 45–54. [Google Scholar]
- Fotheringham, A.S.; Yang, W.; Kang, W. Multiscale Geographically Weighted Regression (MGWR). Ann. Am. Assoc. Geogr. 2017, 107, 1247–1265. [Google Scholar] [CrossRef]
- Abkowitz, M.; Jones, A.; Dundon, L.; Camp, J. Performing A Regional Transportation Asset Extreme Weather Vulnerability Assessment. In Transportation Research Procedia; Elsevier B.V.: Amsterdam, The Netherlands, 2017; Volume 25, pp. 4422–4437. [Google Scholar] [CrossRef]
- Blandford, B.L.; Schurman, S.; Wallace, C.Y.; McCormack, S.M. Transportation System Vulnerability and Resilience to Extreme Weather Events and Other Natural Hazards Report for Pilot Project-KYTC District 1. Ky. Transp. Cent. Res. Rep. 2016, 1554. [Google Scholar] [CrossRef]
- Simpson, D.M.; Human, J.R. Large-Scale Vulnerability Assessments for Natural Hazards. Nat. Hazards 2008, 47, 143–155. [Google Scholar] [CrossRef]
- Gensini, V.A.; Brooks, H.E. Spatial Trends in United States Tornado Frequency. NPJ Clim. Atmos. Sci. 2018, 1, 38. [Google Scholar] [CrossRef]
- Poorest States in the US 2023—Wisevoter. Available online: https://wisevoter.com/state-rankings/poorest-states/ (accessed on 28 July 2023).
- Appalachian Regional Commission. County Economic Status in Appalachia, Fiscal Year 2022. Available online: https://www.arc.gov/map/county-economic-status-in-appalachia-fy-2022/ (accessed on 11 July 2023).
- Masoomi, H.; van de Lindt, J.W. Fatality and Injury Prediction Model for Tornadoes. Nat. Hazards Rev. 2018, 19, 04018009. [Google Scholar] [CrossRef]
- Fricker, T. Tornado-Level Estimates of Socioeconomic and Demographic Variables. Nat. Hazards Rev. 2020, 21, 04020018. [Google Scholar] [CrossRef]
- Ashley, W.S. Spatial and Temporal Analysis of Tornado Fatalities in the United States: 1880–2005. Weather Forecast 2007, 22, 1214–1228. [Google Scholar] [CrossRef]
- Simmons, K.M.; Sutter, D. Tornado Warnings, Lead Times, and Tornado Casualties: An Empirical Investigation. Weather Forecast 2008, 23, 246–258. [Google Scholar] [CrossRef]
- Lim, J.; Loveridge, S.; Shupp, R.; Skidmore, M. Double Danger in the Double Wide: Dimensions of Poverty, Housing Quality and Tornado Impacts. Reg. Sci. Urban. Econ. 2017, 65, 1–15. [Google Scholar] [CrossRef]
- Chapman, J.; Bachman, W.; Frank, L.D.; Thomas, J.; Reyes, A.R. Smart Location Database Technical Documentation and User Guide; US Environmental Protection Agency: Washington, DC, USA, 2021.
- H + T Index. Methods. 2022. Available online: https://htaindex.cnt.org/about/method-2022.pdf (accessed on 9 June 2023).
- Dixon, P.G.; Mercer, A.E.; Choi, J.; Allen, J.S. Tornado Risk Analysis: Is Dixie Alley an Extension of Tornado Alley. Bull. Am. Meteorol. Soc. 2011, 92, 433–441. [Google Scholar] [CrossRef]
- Marsh, P.T.; Brooks, H.E. Comments on “Tornado Risk Analysis: Is Dixie Alley an Extension of Tornado Alley?”. Bull. Am. Meteorol. Soc. 2012, 93, 405–407. [Google Scholar] [CrossRef]
- Smith, B.T.; Thompson, R.L.; Grams, J.S.; Broyles, C.; Brooks, H.E. Convective Modes for Significant Severe Thunderstorms in the Contiguous United States. Part I: Storm Classification and Climatology. Weather Forecast 2012, 27, 1114–1135. [Google Scholar] [CrossRef]
- Wheeler, D.; Tiefelsdorf, M. Multicollinearity and Correlation among Local Regression Coefficients in Geographically Weighted Regression. J. Geogr. Syst. 2005, 7, 161–187. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically Weighted Regression: A Method for Exploring Spatial Nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Fotheringham, A.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships; John Wiley: Hoboken, NJ, USA, 2002; Available online: https://www.researchgate.net/publication/27246972 (accessed on 14 January 2024).
- Oshan, T.M.; Li, Z.; Kang, W.; Wolf, L.J.; Stewart Fotheringham, A. MGWR: A Python Implementation of Multiscale Geographically Weighted Regression for Investigating Process Spatial Heterogeneity and Scale. ISPRS Int. J. Geoinf. 2019, 8, 269. [Google Scholar] [CrossRef]
- Multiscale Geographically Weighted Regression (MGWR) (Spatial Statistics)—ArcGIS Pro|Documentation. Available online: https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/multiscale-geographically-weighted-regression.htm (accessed on 21 July 2023).
- Akaike, H. A New Look at the Statistical Model Identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- da Silva, A.R.; Fotheringham, A.S. The Multiple Testing Issue in Geographically Weighted Regression. Geogr. Anal. 2016, 48, 233–247. [Google Scholar] [CrossRef]
- Lin, C.-H.; Wen, T.-H. Using Geographically Weighted Regression (GWR) to Explore Spatial Varying Relationships of Immature Mosquitoes and Human Densities with the Incidence of Dengue. Int. J. Environ. Res. Public Health 2011, 8, 2798–2815. [Google Scholar] [CrossRef]
- Hofmann, S.Z. Build Back Better and Long-Term Housing Recovery: Assessing Community Housing Resilience and the Role of Insurance Post Disaster. Sustainability 2022, 14, 5623. [Google Scholar] [CrossRef]
- El-Maissi, A.M.; Argyroudis, S.A.; Nazri, F.M. Seismic Vulnerability Assessment Methodologies for Roadway Assets and Networks: A State-of-the-Art Review. Sustainability 2020, 13, 61. [Google Scholar] [CrossRef]
- Agee, E.; Childs, S. Adjustments in Tornado Counts, F-Scale Intensity, and Path Width for Assessing Significant Tornado Destruction. J. Appl. Meteorol. Climatol. 2014, 53, 1494–1505. [Google Scholar] [CrossRef]
- Tippett, M.K. Changing Volatility of U.S. Annual Tornado Reports. Geophys. Res. Lett. 2014, 41, 6956–6961. [Google Scholar] [CrossRef]
- Anderson, C.J.; Wikle, C.K.; Zhou, Q.; Royle, J.A. Population Influences on Tornado Reports in the United States. Weather Forecast 2007, 22, 571–579. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TIGER and American Community Surveys (ACS) Dataset | |
|---|---|
| Variable | Explanation |
| Occupied Housing Unit | Number of housing units that are occupied |
| Vacant Housing Unit | Number of housing units that are vacant |
| No vehicle household | Number of households that have no access to any vehicle |
| Median household income | Median household income in the past 12 months (2019) |
| Nonwhite pop | Nonwhite population in given CBG |
| White pop | White population in given CBG |
| Under 5 | Population of people who are under the age of five |
| Under 18 | Population of people who are under the age of eighteen |
| Pop 65+ | Population of people who are 65 and over |
| Total pop | Total population in given CBG |
| Smart Location Database (SLD) | |
| Variable | Explanation |
| SLC Score | Smart location score |
| P_WrkAge | Percent of population that is working aged 18 to 64 |
| D2a_JpHH | Jobs per household |
| D3a | Total road network density |
| R_PCTLOWWA(2017) | Percent of low-wage workers in CBG |
| Ac_total | Total geometric area (acres) of the CBG |
| Housing and Transportation Affordability (H+T) Index | |
| Variable | Explanation |
| ht_ami | Housing + transportation costs % income for the regional typical household |
| t_ami | Transportation costs % income for the regional typical household |
| autos_per_hh_ami | Autos per household for the regional typical household |
| vmt_per_hh_ami | Annual vehicle miles traveled per household for the regional typical household |
| compact_ndx | Compact neighborhood score (0–10) |
| res_density | Residential density (households per residential acre) |
| intersection_density | Intersection density in square miles |
| Variable Name | Explanation | VIF_before | VIF_after |
|---|---|---|---|
| Ac_total | Total geometric area (acres) of the CBG | 2.63 | 1.92 |
| P_WrkAGE | Percent of population that is working aged 18 to 64 years | 2.73 | 2.62 |
| R_PCTLOWWA | Percent of low-wage workers in CBG | 1.94 | 1.56 |
| D2a_JpHH | Jobs per household | 1.11 | 1.04 |
| D3a | Total road network density | 11.58 | - |
| SLC Score | SLC Score | 2.71 | 2.23 |
| occ_hou | Number of occupied housing units | 10.73 | - |
| vacant_hou | Number of vacant housing units | 1.22 | 1.16 |
| no_veh_hhs | No vehicle household | 1.98 | 1.61 |
| median_household_income | Median household income | 3.32 | 2.31 |
| total_pop | Total population | 11.1 | - |
| ht_ami | Housing+ transportation costs % income for the regional typical household | 5.16 | 4.71 |
| t_ami | Transportation costs % income for the regional typical household | 8.72 | 6.71 |
| autos_per_hh | Autos per household | 14.25 | - |
| vmt_per_hh | Annual vehicle miles traveled per household | 18.71 | - |
| compact_nd | Compactness index | 11.01 | - |
| res_density | Residential density | 1.75 | 1.72 |
| intersection_density | Intersection density | 6.75 | 2.42 |
| P_65 | Percentage of people who are older than 65 | 3.3 | 2.69 |
| P_5 | Percentage of people who are younger than 5 | 1.49 | 1.47 |
| P_18 | Percentage of people who are younger than 18 | 3.16 | 3.05 |
| P_nwhite | Percentage of nonwhite population | >1000 | - |
| P_white | Percentage of white population | >1000 | - |
| Explanatory Variables | Explanation | Mean | Standard Deviation | Min | Median | Max | |
|---|---|---|---|---|---|---|---|
| A | Intercept | - | −0.062 | 0.779 | −1.565 | −0.111 | 1.992 |
| Ac_total | Total geometric area (acres) of the CBG | 0.012 | 0.071 | −0.228 | 0.016 | 0.250 | |
| P_WrkAge | Percent of population that is working aged 18 to 64 years | 0.007 | 0.034 | −0.246 | 0.012 | 0.181 | |
| R_PCTLOWWA | Percent of low-wage workers in CBG | 0.018 | 0.047 | −0.284 | 0.021 | 0.160 | |
| D2a_JpHH | Jobs per household | 0.001 | 0.002 | −0.001 | 0.001 | 0.028 | |
| SLC Score | SLC score | 0.035 | 0.077 | −0.236 | 0.034 | 0.211 | |
| vacant_hou | Number of vacant housing units | −0.014 | 0.041 | −0.227 | −0.005 | 0.089 | |
| no_veh_hhs | No vehicle household | −0.010 | 0.019 | −0.023 | −0.018 | 0.071 | |
| median_household_income | Median household income | 0.067 | 0.109 | −0.133 | 0.036 | 0.319 | |
| ht_ami | Housing+ transportation costs % income for the regional typical household | 0.049 | 0.098 | −0.278 | 0.070 | 0.372 | |
| t_ami | Transportation costs % income for the regional typical household | −0.188 | 0.333 | −0.920 | −0.131 | 0.474 | |
| res_density | Residential density | 0.002 | 0.116 | −0.443 | 0.008 | 0.445 | |
| intersection_density | Intersection density | 0.005 | 0.063 | −0.363 | −0.020 | 0.380 | |
| P_65 | Percentage of people who are older than 65 | 0.009 | 0.029 | −0.087 | 0.011 | 0.115 | |
| P_5 | Percentage of people who are younger than 5 | −0.004 | 0.025 | −0.141 | −0.003 | 0.152 | |
| P_18 | Percentage of people who are younger than 18 | −0.007 | 0.004 | −0.029 | −0.006 | −0.003 | |
| B | Statistic | GWR | MGWR | ||||
| R-Squared | 0.926 | 0.936 | |||||
| Adjusted R-Squared | 0.911 | 0.929 | |||||
| AICc | 1668.870 | 927.527 | |||||
| Sigma-Squared | 0.089 | 0.071 | |||||
| Sigma-Squared MLE | 0.074 | 0.064 | |||||
| Effective Degrees of Freedom | 2637.060 | 2855.330 |
| Explanatory Variables | Explanation | Bandwidth (% of Extent) | Significance (% of Features) | Effective Number of Parameters | Adjusted Value of Alpha | Adjusted Critical Value of Pseudo-t Statistics |
|---|---|---|---|---|---|---|
| Intercept | - | 38.41 (8.75) | 2446 (77.80) | 19.42 | 0.0026 | 3.0172 |
| Ac_total | Total geometric area (acres) of the CBG | 38.41 (8.75) | 357 (11.35) | 23.93 | 0.0021 | 3.0801 |
| P_WrkAge | Percent of population that is working aged 18 to 64 years | 38.41 (8.75) | 59 (1.88) | 25.41 | 0.0020 | 3.0979 |
| R_PCTLOWWA | Percent of low-wage workers in CBG | 38.41(8.75) | 309 (9.83) | 24.2 | 0.0021 | 3.0833 |
| D2a_JpHH | Jobs per household | 285.97 (65.15) | 0 (0.00) | 1.02 | 0.0490 | 1.9698 |
| SLC Score | SLC score | 38.41 (8.75) | 818 (26.02) | 21.47 | 0.0023 | 3.0475 |
| vacant_hou | Number of vacant housing units | 38.41 (8.75) | 319 (10.15) | 24.03 | 0.0021 | 3.0813 |
| no_veh_hhs | No vehicle household | 141.50 (32.23) | 797 (25.35) | 2.58 | 0.0194 | 2.3392 |
| median_household_income | Median household income | 38.41 (8.75) | 1030 (32.76) | 22.03 | 0.0023 | 3.0553 |
| ht_ami | Housing + transportation costs % income for the regional typical household | 38.41 (8.75) | 1062 (33.78) | 21.10 | 0.0024 | 3.0423 |
| t_ami | Transportation costs % income for the regional typical household | 38.41 (8.75) | 2025 (64.41) | 16.58 | 0.0030 | 2.9688 |
| res_density | Residential density | 38.41 (8.75) | 289 (9.19) | 15.3 | 0.0033 | 2.9439 |
| intersection_density | Intersection density | 38.41 (8.75) | 110 (3.50) | 18.44 | 0.0027 | 3.0013 |
| P_65 | Percentage of people who are older than 65 | 38.41 (8.75) | 2 (0.06) | 25.19 | 0.0020 | 3.0954 |
| P_5 | Percentage of people who are younger than 5 | 38.41 (8.75) | 32 (1.02) | 26.52 | 0.0019 | 3.1106 |
| P_18 | Percentage of people who are younger than 18 | 213.73 (48.69) | 1 (0.03) | 1.43 | 0.0351 | 2.1086 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaya, M.B.; Alisan, O.; Karaer, A.; Ozguven, E.E. Assessing Tornado Impacts in the State of Kentucky with a Focus on Demographics and Roadways Using a GIS-Based Approach. Sustainability 2024, 16, 1180. https://doi.org/10.3390/su16031180
Kaya MB, Alisan O, Karaer A, Ozguven EE. Assessing Tornado Impacts in the State of Kentucky with a Focus on Demographics and Roadways Using a GIS-Based Approach. Sustainability. 2024; 16(3):1180. https://doi.org/10.3390/su16031180
Chicago/Turabian StyleKaya, Mehmet Burak, Onur Alisan, Alican Karaer, and Eren Erman Ozguven. 2024. "Assessing Tornado Impacts in the State of Kentucky with a Focus on Demographics and Roadways Using a GIS-Based Approach" Sustainability 16, no. 3: 1180. https://doi.org/10.3390/su16031180
APA StyleKaya, M. B., Alisan, O., Karaer, A., & Ozguven, E. E. (2024). Assessing Tornado Impacts in the State of Kentucky with a Focus on Demographics and Roadways Using a GIS-Based Approach. Sustainability, 16(3), 1180. https://doi.org/10.3390/su16031180