
Multi-Agent Reinforcement Learning for Traffic Signal Control: A Cooperative Approach




Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution
2. Methodology
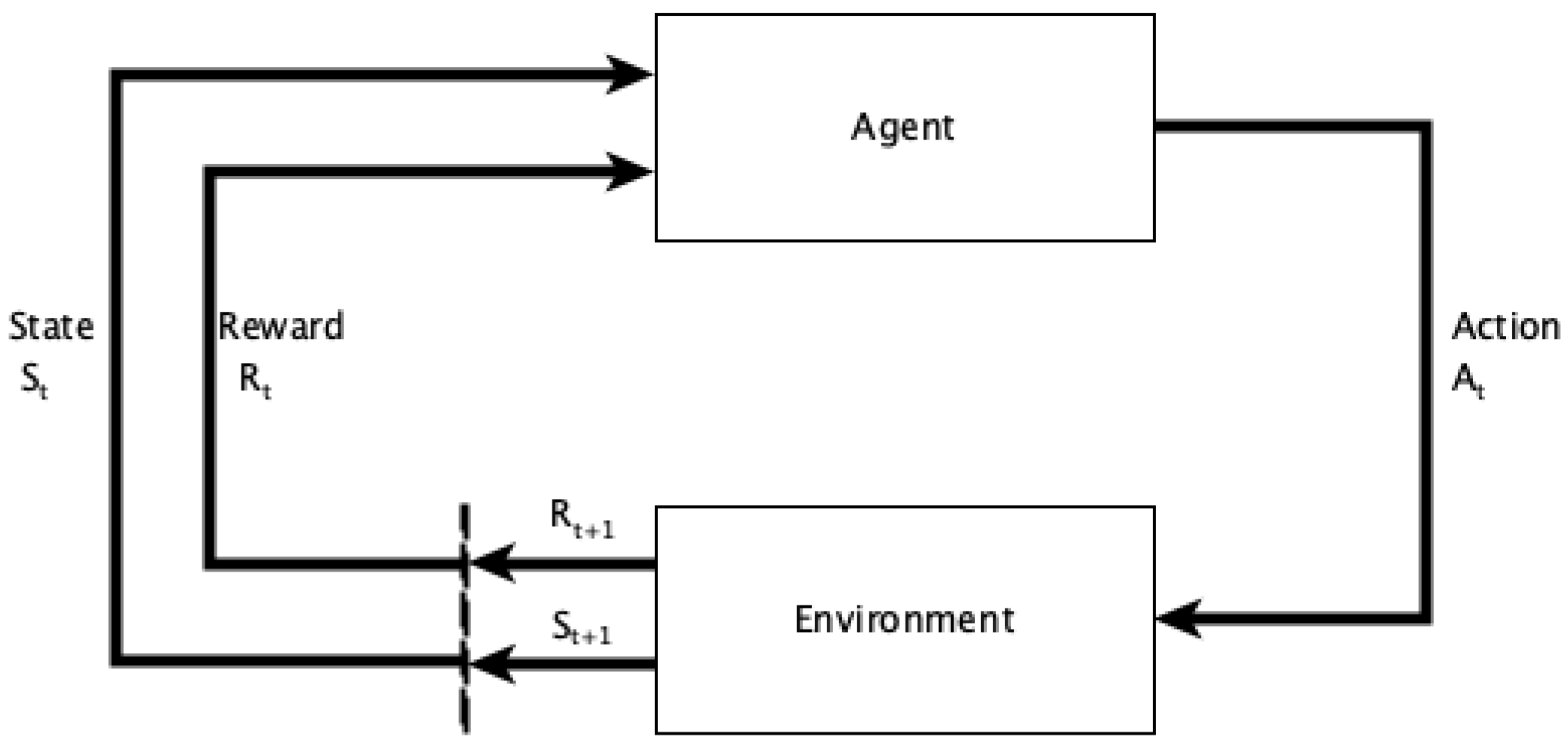
2.1. Reinforcement Learning
- S: Set of observable states;
- A: Set of possible agent actions;
- R: Set of gathered rewards based on the quality of the action;
- P: The policy is to decide which action is selected at a given state.
2.2. Multi-Agent Reinforcement Learning
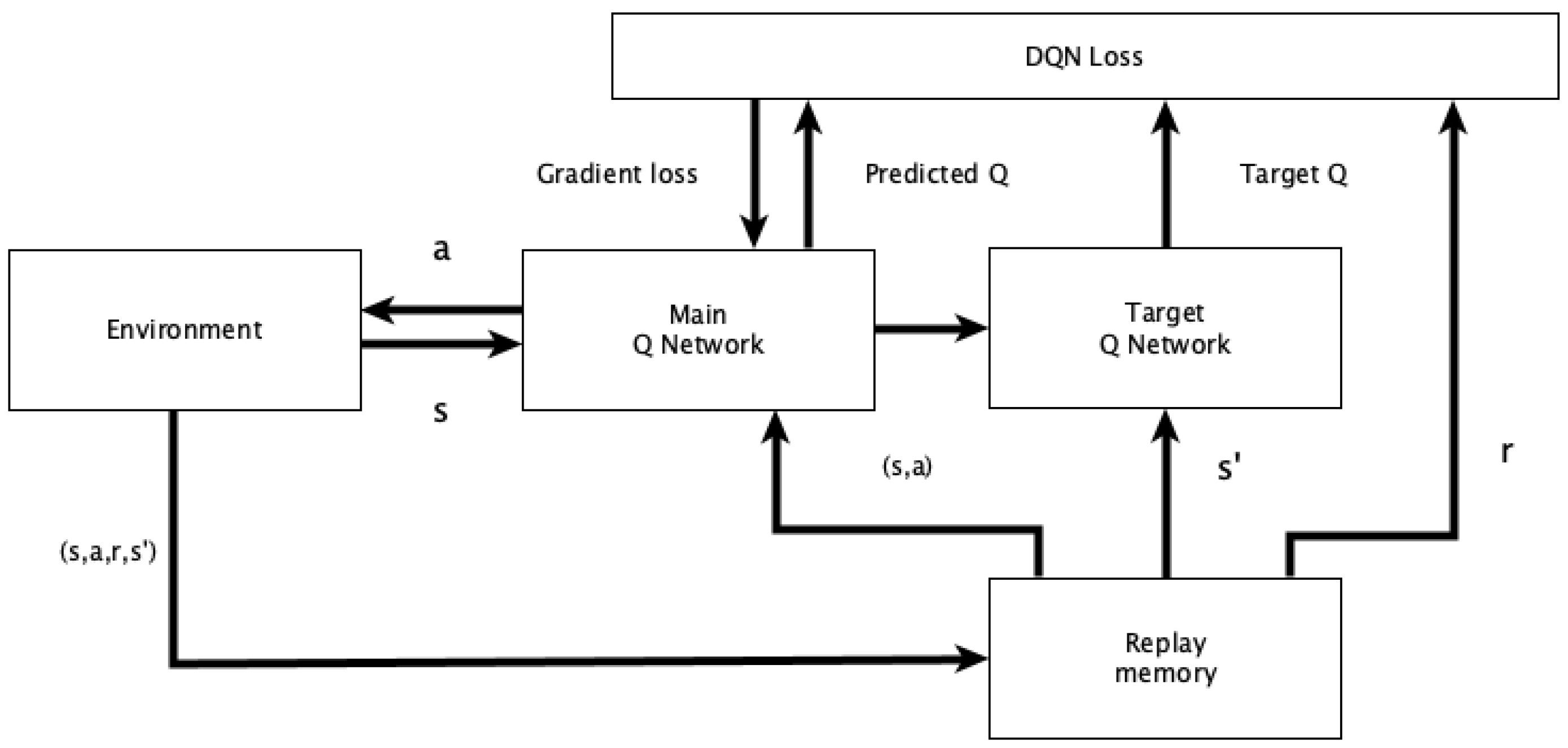
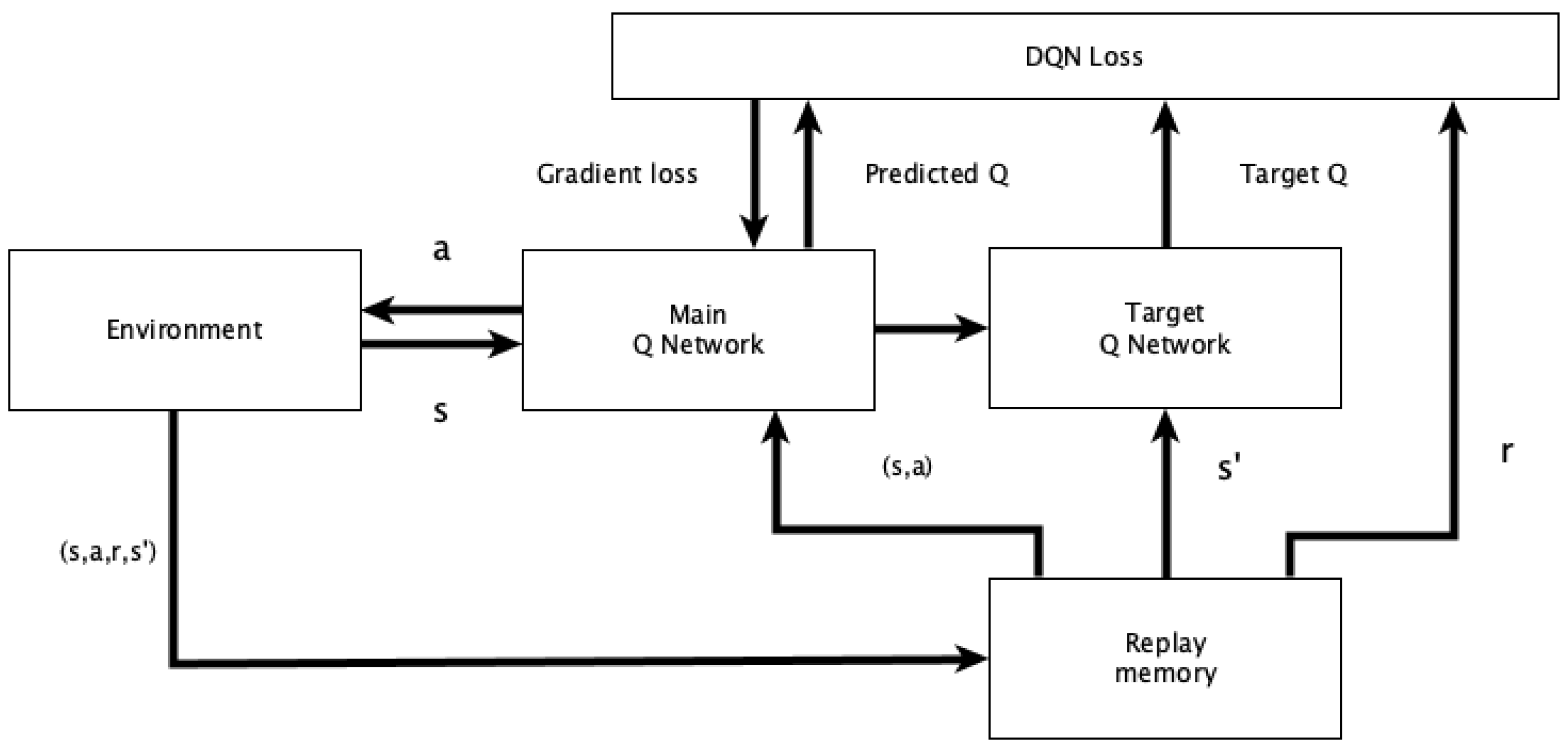
2.3. Deep Q-Learning
2.4. Policy Gradient Algorithm
- The neural network’s weights are initialized at the start of the training. Subsequently, the training starts from an initial state ;
- The interactions between the agent and the environment are saved into the episode history. The interactions continue until a terminal condition is reached;
- After the termination occurs, the cumulated and discounted reward is calculated based on the interactions stored in the episode history;
- Finally, the gradient buffer is extended by the calculated gradient, which is used for updating the neural network’s weights based on the chosen update frequency.
2.5. Baseline Controller
2.6. Actuated Controller
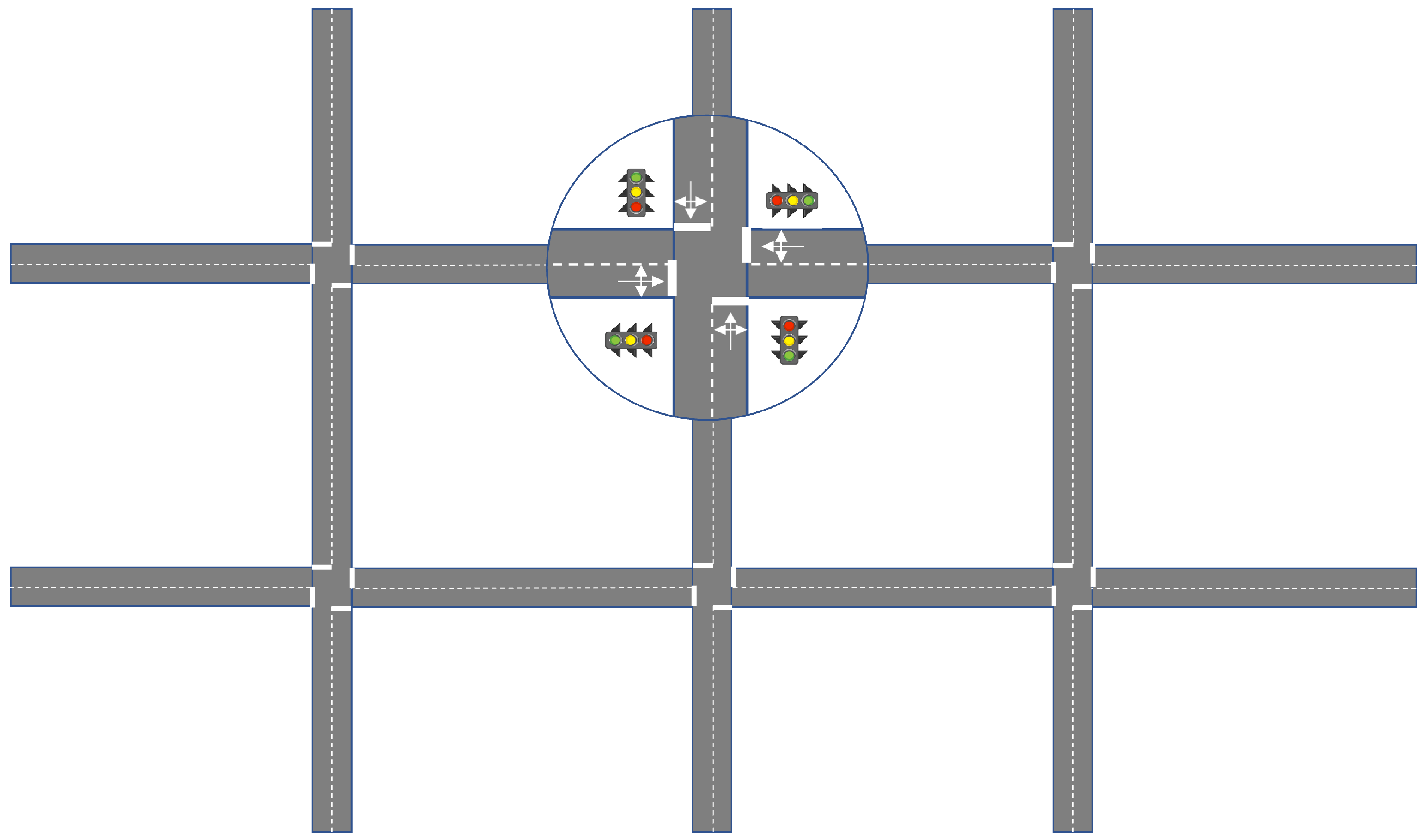
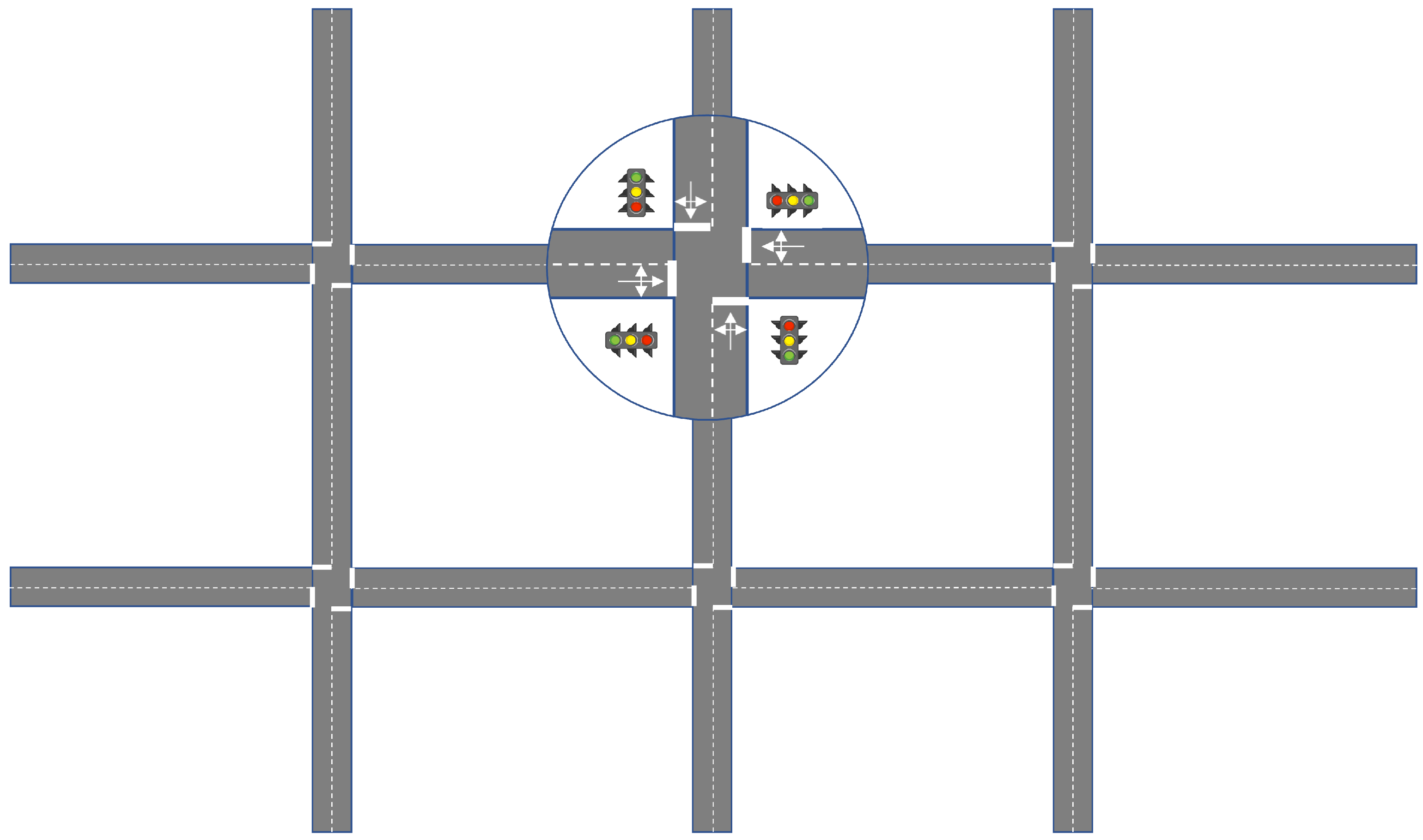
3. Environment
3.1. State Representation
3.2. Action Space
3.3. Reward
3.4. Training
4. Results
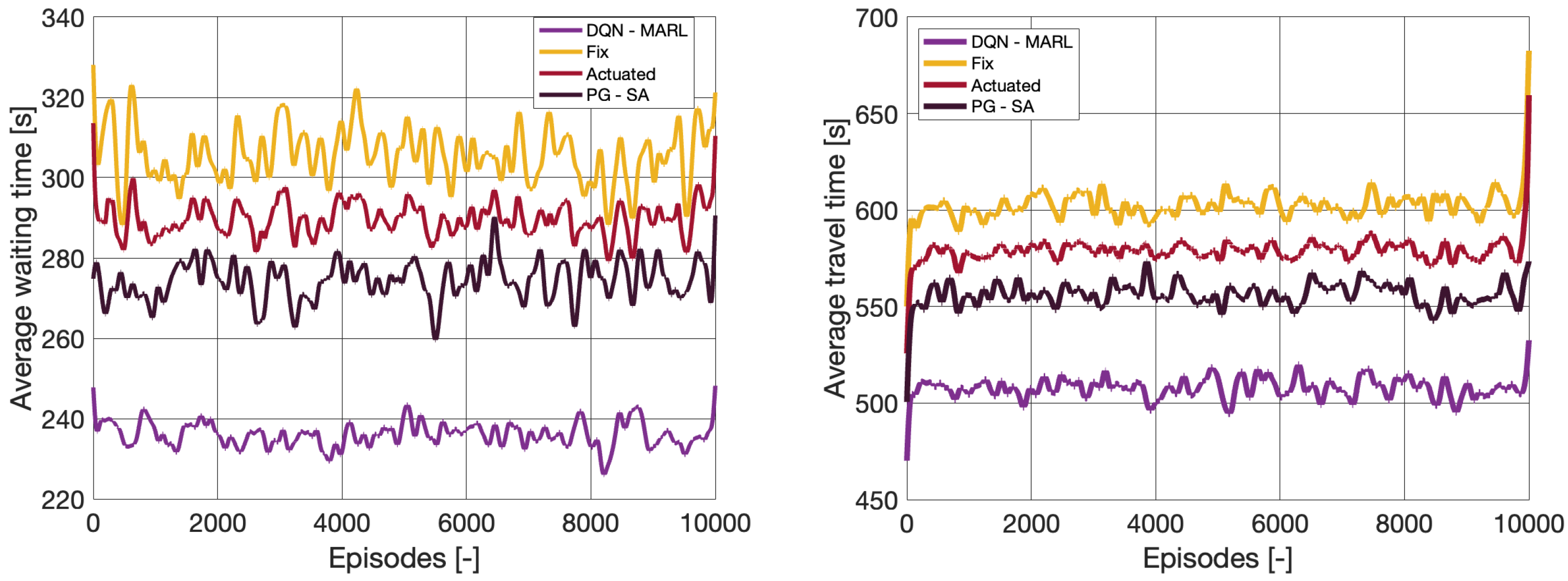
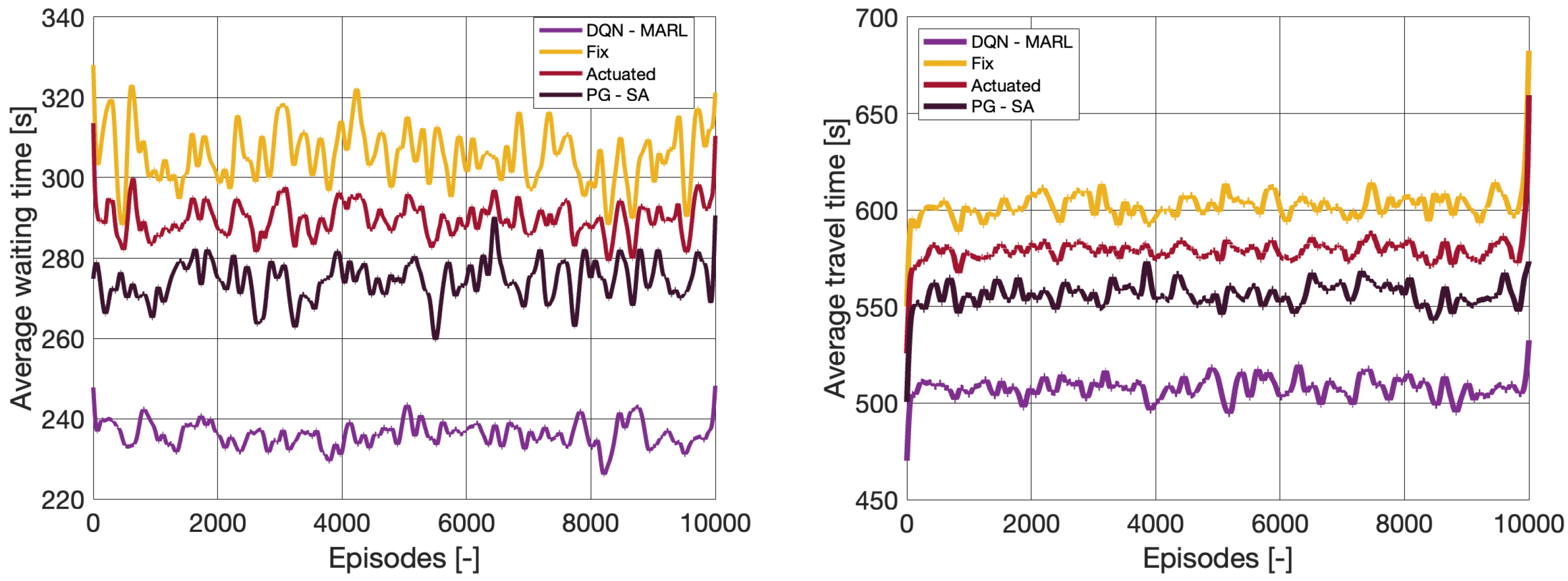
4.1. Training Process
4.2. Classic Performance Measures
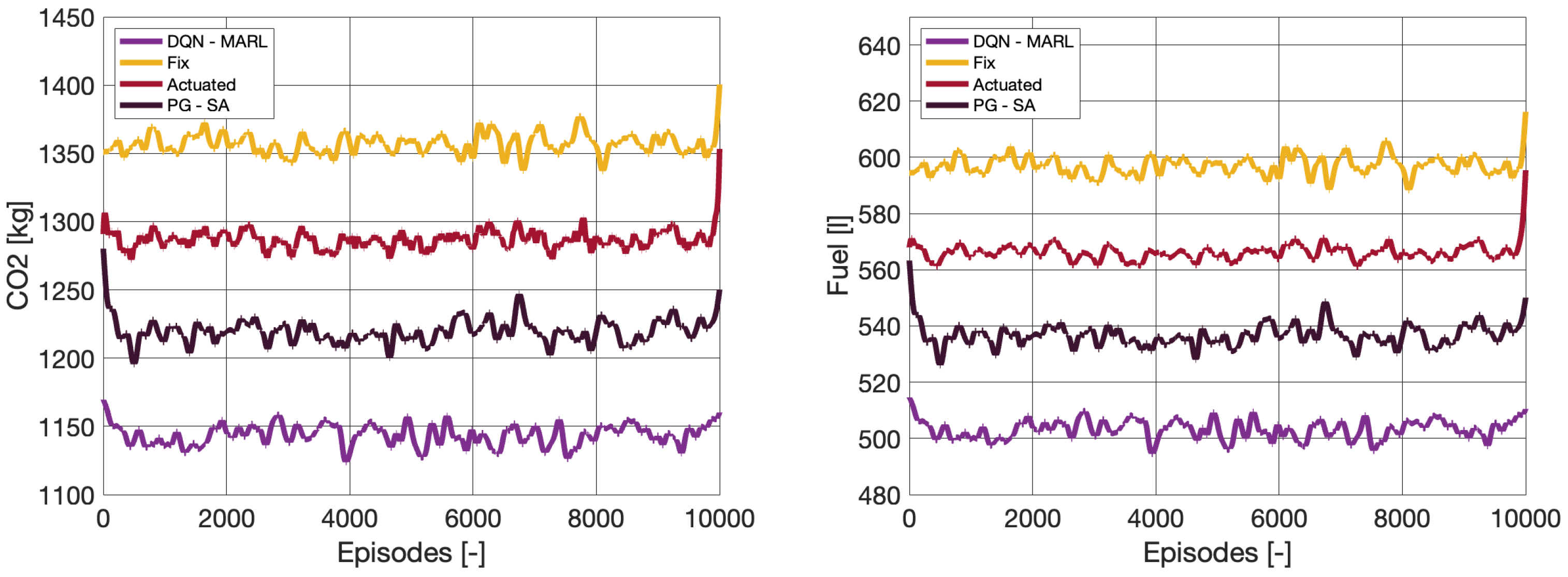
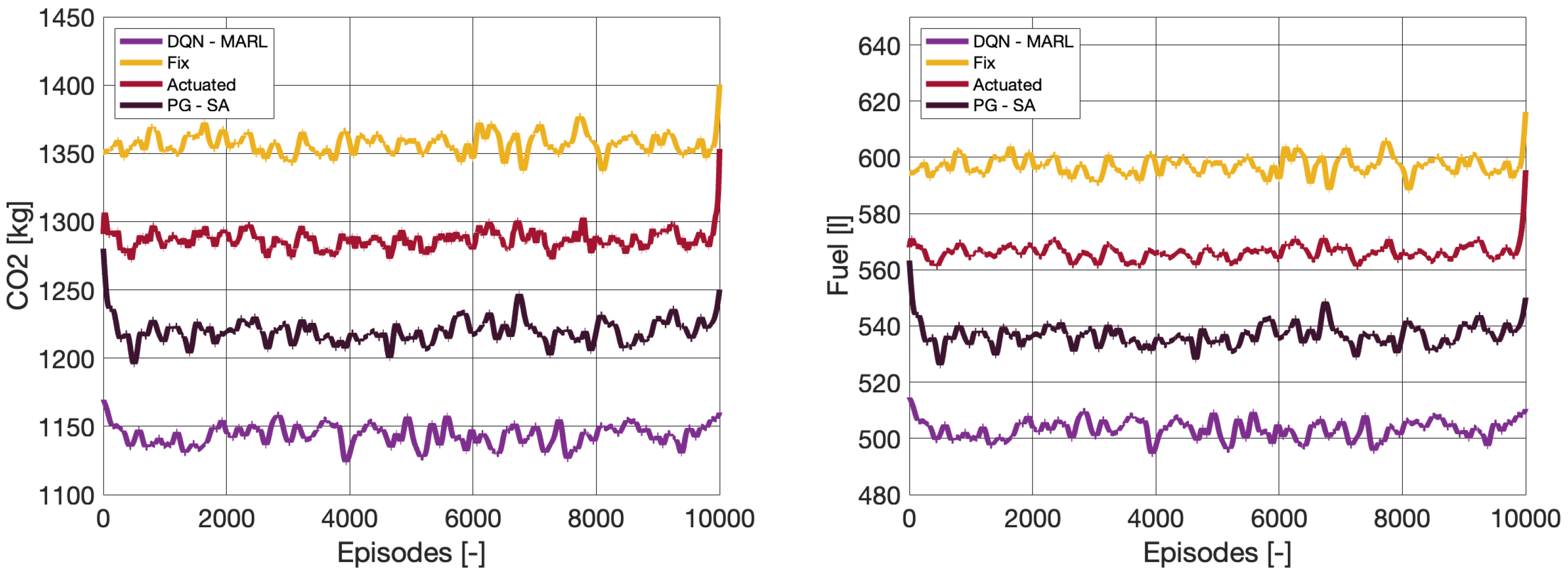
4.3. Sustainability Performance Measures
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ATSC | Adaptive traffic signal control |
| RL | Reinforcement learning |
| SCATS | Sydney coordinated adaptive traffic system |
| CNN | Convolutional neural network |
| GCNN | Graph convolutional neural network |
| MARL | Multi-agent reinforcement learning |
| STMARL | Spatio-temporal multi-agent reinforcement learning |
| PG | Policy gradient |
| DQN | Deep Q-network |
| DRL | Deep reinforcement learning |
| ML | Machine learning |
| MDP | Markov decision process |
| ILs | Independent learners |
| JALs | Joint action learners |
| NN | Neural network |
| SUMO | Simulation of urban mobility |
| TraCI | Traffic control interface |
References
- Goel, R.; Guttikunda, S.K. Evolution of on-road vehicle exhaust emissions in Delhi. Atmos. Environ. 2015, 105, 78–90. [Google Scholar] [CrossRef]
- Mikkonen, S.; Laine, M.; Mäkelä, H.; Gregow, H.; Tuomenvirta, H.; Lahtinen, M.; Laaksonen, A. Trends in the average temperature in Finland, 1847–2013. Stoch. Environ. Res. Risk Assess. 2015, 29, 1521–1529. [Google Scholar] [CrossRef]
- Li, X.; Xing, G.; Qian, X.; Guo, Y.; Wang, W.; Cheng, C. Subway Station Accessibility and Its Impacts on the Spatial and Temporal Variations of Its Outbound Ridership. J. Transp. Eng. Part A Syst. 2022, 148, 04022106. [Google Scholar] [CrossRef]
- Guo, Y.; Qian, X.; Lei, T.; Guo, S.; Gong, L. Modeling the preference of electric shared mobility drivers in choosing charging stations. Transp. Res. Part D: Transp. Environ. 2022, 110, 103399. [Google Scholar] [CrossRef]
- Koonce, P.; Rodegerdts, L. Traffic Signal Timing Manual; Technical Report; United States, Federal Highway Administration: Washington, DC, USA, 2008.
- Roess, R.P.; Prassas, E.S.; McShane, W.R. Traffic Engineering; Pearson/Prentice Hall: New York City, NY, USA, 2004. [Google Scholar]
- Varaiya, P. The max-pressure controller for arbitrary networks of signalized intersections. In Advances in Dynamic Network Modeling in Complex Transportation Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 27–66. [Google Scholar]
- Lowrie, P. Scats-a traffic responsive method of controlling urban traffic. In Sales Information Brochure; Roads & Traffic Authority: Sydney, Australia, 1990. [Google Scholar]
- Van der Pol, E.; Oliehoek, F.A. Coordinated deep reinforcement learners for traffic light control. In Proceedings of the Learning, Inference and Control of Multi-Agent Systems (at NIPS 2016), Barcelona, Spain, 10 December 2016. [Google Scholar]
- Wei, H.; Zheng, G.; Yao, H.; Li, Z. Intellilight: A reinforcement learning approach for intelligent traffic light control. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2496–2505. [Google Scholar]
- Wiering, M.A. Multi-agent reinforcement learning for traffic light control. In Proceedings of the Machine Learning, 17th International Conference (ICML’2000), Stanford, CA, USA, 29 June–2 July 2000; pp. 1151–1158. [Google Scholar]
- Genders, W.; Razavi, S. Using a deep reinforcement learning agent for traffic signal control. arXiv 2016, arXiv:1611.01142. [Google Scholar]
- Nishi, T.; Otaki, K.; Hayakawa, K.; Yoshimura, T. Traffic signal control based on reinforcement learning with graph convolutional neural nets. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 877–883. [Google Scholar]
- Wu, Q.; Wu, J.; Shen, J.; Du, B.; Telikani, A.; Fahmideh, M.; Liang, C. Distributed agent-based deep reinforcement learning for large scale traffic signal control. Knowl.-Based Syst. 2022, 241, 108304. [Google Scholar] [CrossRef]
- Fang, Z.; Zhang, F.; Wang, T.; Lian, X.; Chen, M. MonitorLight: Reinforcement Learning-based Traffic Signal Control Using Mixed Pressure Monitoring. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 478–487. [Google Scholar]
- Wang, Y.; Xu, T.; Niu, X.; Tan, C.; Chen, E.; Xiong, H. STMARL: A spatio-temporal multi-agent reinforcement learning approach for cooperative traffic light control. IEEE Trans. Mob. Comput. 2020, 2228–2242. [Google Scholar] [CrossRef]
- Kővári, B.; Pelenczei, B.; Aradi, S.; Bécsi, T. Reward Design for Intelligent Intersection Control to Reduce Emission. IEEE Access 2022, 10, 39691–39699. [Google Scholar] [CrossRef]
- Kohl, N.; Stone, P. Policy gradient reinforcement learning for fast quadrupedal locomotion. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA’04, New Orleans, LA, USA, 26 April–1 May 2004; Volume 3, pp. 2619–2624. [Google Scholar]
- Ng, A.Y.; Coates, A.; Diel, M.; Ganapathi, V.; Schulte, J.; Tse, B.; Berger, E.; Liang, E. Autonomous inverted helicopter flight via reinforcement learning. In Experimental Robotics IX; Springer: Berlin/Heidelberg, Germany, 2006; pp. 363–372. [Google Scholar]
- Singh, S.; Litman, D.; Kearns, M.; Walker, M. Optimizing dialogue management with reinforcement learning: Experiments with the NJFun system. J. Artif. Intell. Res. 2002, 16, 105–133. [Google Scholar] [CrossRef]
- Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
- Strehl, A.L.; Li, L.; Wiewiora, E.; Langford, J.; Littman, M.L. PAC model-free reinforcement learning. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 881–888. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Claus, C.; Boutilier, C. The dynamics of reinforcement learning in cooperative multiagent systems. AAAI/IAAI 1998, 1998, 2. [Google Scholar]
- Prashanth, L.; Bhatnagar, S. Reinforcement learning with average cost for adaptive control of traffic lights at intersections. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1640–1645. [Google Scholar]
- Knoblich, G.; Butterfill, S.; Sebanz, N. Psychological research on joint action: Theory and data. Psychol. Learn. Motiv. 2011, 54, 59–101. [Google Scholar]
- Nowé, A.; Vrancx, P.; Hauwere, Y.M.D. Game theory and multi-agent reinforcement learning. In Reinforcement Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 441–470. [Google Scholar]
- Wei, H.; Xu, N.; Zhang, H.; Zheng, G.; Zang, X.; Chen, C.; Zhang, W.; Zhu, Y.; Xu, K.; Li, Z. Colight: Learning network-level cooperation for traffic signal control. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing China, 3–7 November 2019; pp. 1913–1922. [Google Scholar]
- Nair, A.; Srinivasan, P.; Blackwell, S.; Alcicek, C.; Fearon, R.; De Maria, A.; Panneershelvam, V.; Suleyman, M.; Beattie, C.; Petersen, S.; et al. Massively parallel methods for deep reinforcement learning. arXiv 2015, arXiv:1507.04296. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; pp. 1057–1063. [Google Scholar]
- Egea, A.C.; Howell, S.; Knutins, M.; Connaughton, C. Assessment of reward functions for reinforcement learning traffic signal control under real-world limitations. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 965–972. [Google Scholar]
- Touhbi, S.; Babram, M.A.; Nguyen-Huu, T.; Marilleau, N.; Hbid, M.L.; Cambier, C.; Stinckwich, S. Adaptive traffic signal control: Exploring reward definition for reinforcement learning. Procedia Comput. Sci. 2017, 109, 513–520. [Google Scholar] [CrossRef]
- Keller, M.; Hausberger, S.; Matzer, C.; Wüthrich, P.; Notter, B. HBEFA Version 3.3. Backgr. Doc. Berne 2017, 12. Available online: https://www.hbefa.net/e/index.html (accessed on 10 January 2023).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Minimum Reward | Maximum Reward | ||
|---|---|---|---|
| 0 | 0.1 | 0 | 1 |
| 0.1 | 0.5 | −1 | 0 |
| Parameter | Value |
|---|---|
| Learning rate | 0.0003 |
| Discount factor | 0.95 |
| Batch size | 512 |
| Experience memory size | 15,000 |
| Num. of hidden layers | 2 |
| Num. of neurons | 256,256 |
| Hidden layers activation function | RELU |
| Method | DQN |
| Freq. of weight sharing (in ep.) | 10 |
| Layers | Dense |
| Optimizer | Adam |
| Kernel initializer | Xavier normal |
| Parameter | Value |
|---|---|
| Learning rate | 0.00005 |
| Discount factor | 0.97 |
| Num. of ep. after params are upd. | 20 |
| Num. of hidden layers | 4 |
| Num. of neurons | 128,256,256,128 |
| Hidden layers activation function | RELU |
| Layers | Dense |
| Optimizer | Adam |
| Kernel initializer | Xavier normal |
| Agents | Avg. Waiting Time [s] | Avg. Travel Time [s] |
|---|---|---|
| DQN–MARL | 236.28 | 507.74 |
| PG–SA | 275.72 | 556.26 |
| Actuated | 289.68 | 578.87 |
| Fixed cycle | 307.68 | 602.33 |
| Agents | [kg] | [kg] | [g] | [l] | [g] | [g] |
|---|---|---|---|---|---|---|
| DQN–MARL | 59.77 | 1143.75 | 553.15 | 503.21 | 302.25 | 28.59 |
| PG–SA | 67.32 | 1219.63 | 596.47 | 536.63 | 338.99 | 31.35 |
| Actuated | 70.85 | 1286.81 | 612.39 | 566.19 | 352.68 | 32.36 |
| Fixed cycle | 75.37 | 1356.97 | 651.52 | 597.04 | 378.62 | 34.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kolat, M.; Kővári, B.; Bécsi, T.; Aradi, S. Multi-Agent Reinforcement Learning for Traffic Signal Control: A Cooperative Approach. Sustainability 2023, 15, 3479. https://doi.org/10.3390/su15043479
Kolat M, Kővári B, Bécsi T, Aradi S. Multi-Agent Reinforcement Learning for Traffic Signal Control: A Cooperative Approach. Sustainability. 2023; 15(4):3479. https://doi.org/10.3390/su15043479
Chicago/Turabian StyleKolat, Máté, Bálint Kővári, Tamás Bécsi, and Szilárd Aradi. 2023. "Multi-Agent Reinforcement Learning for Traffic Signal Control: A Cooperative Approach" Sustainability 15, no. 4: 3479. https://doi.org/10.3390/su15043479
APA StyleKolat, M., Kővári, B., Bécsi, T., & Aradi, S. (2023). Multi-Agent Reinforcement Learning for Traffic Signal Control: A Cooperative Approach. Sustainability, 15(4), 3479. https://doi.org/10.3390/su15043479