
Risk Cost Measurement of Value for Money Evaluation Based on Case-Based Reasoning and Ontology: A Case Study of the Urban Rail Transit Public-Private Partnership Projects in China


Abstract
1. Introduction
2. VFM Risk Cost of PPP Project
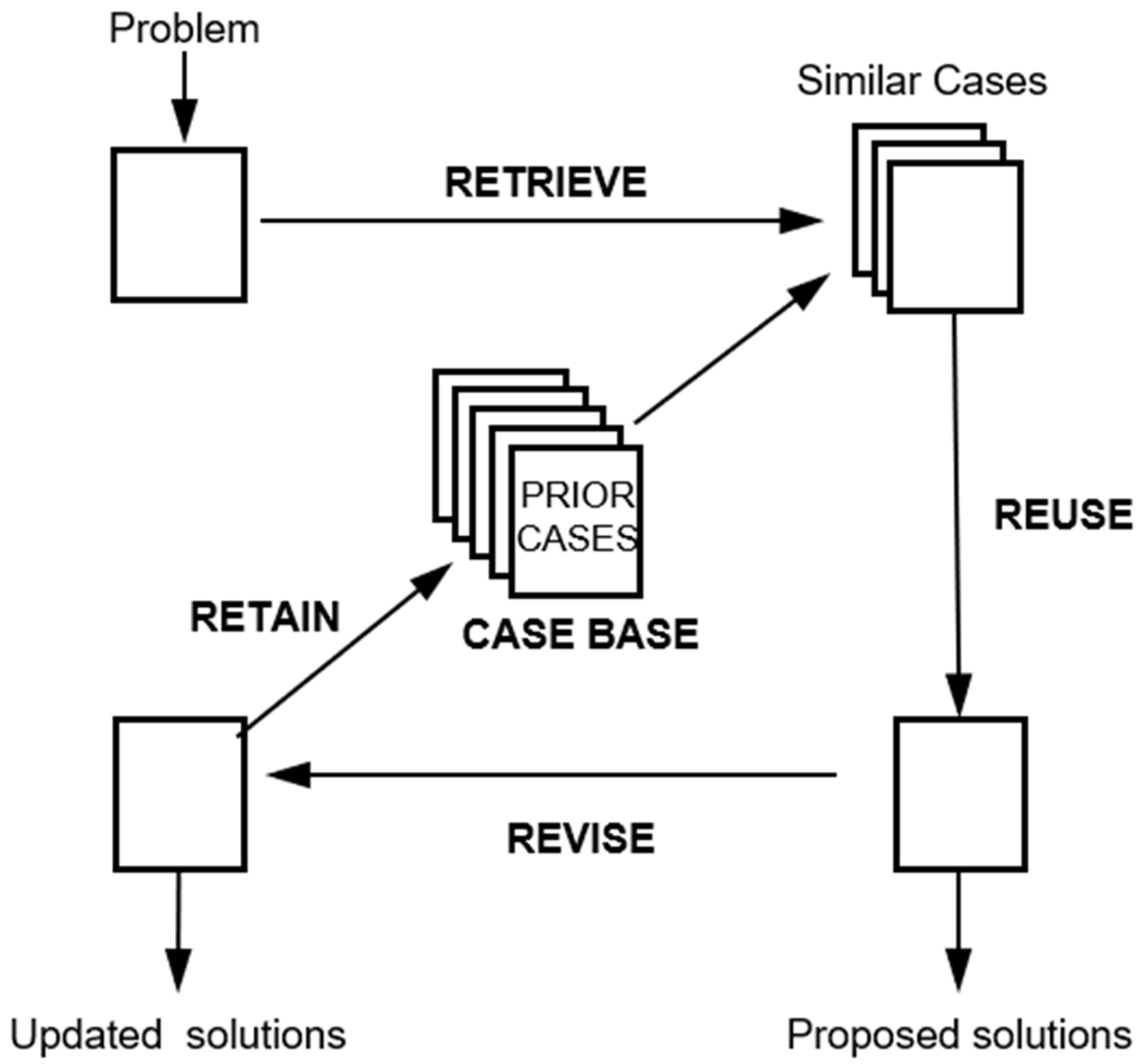
3. Case-Based Reasoning and Ontology
4. VFM Risk Cost Measurement of a PPP Project Based on CBR and Ontology
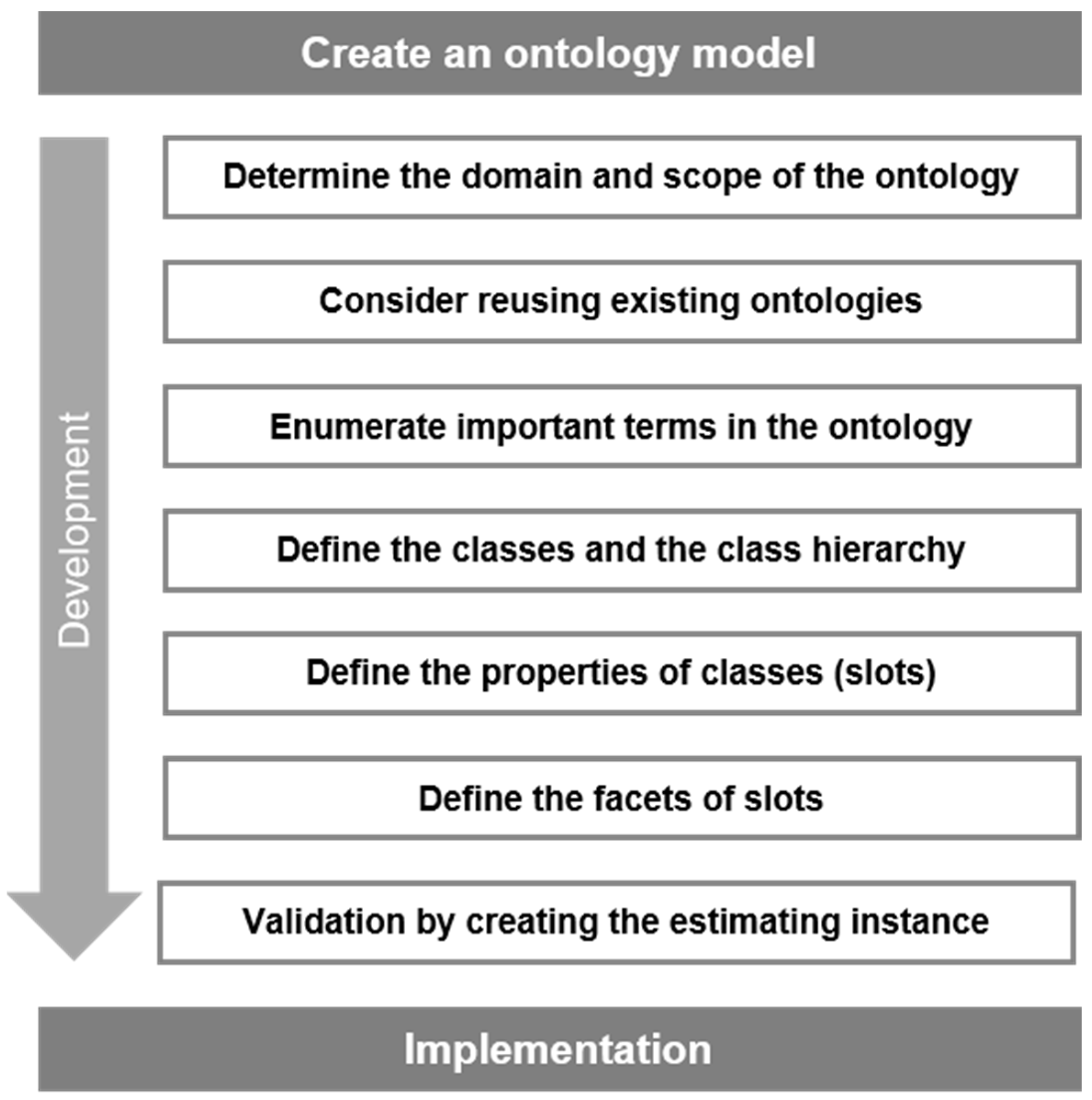
4.1. Ontology Development
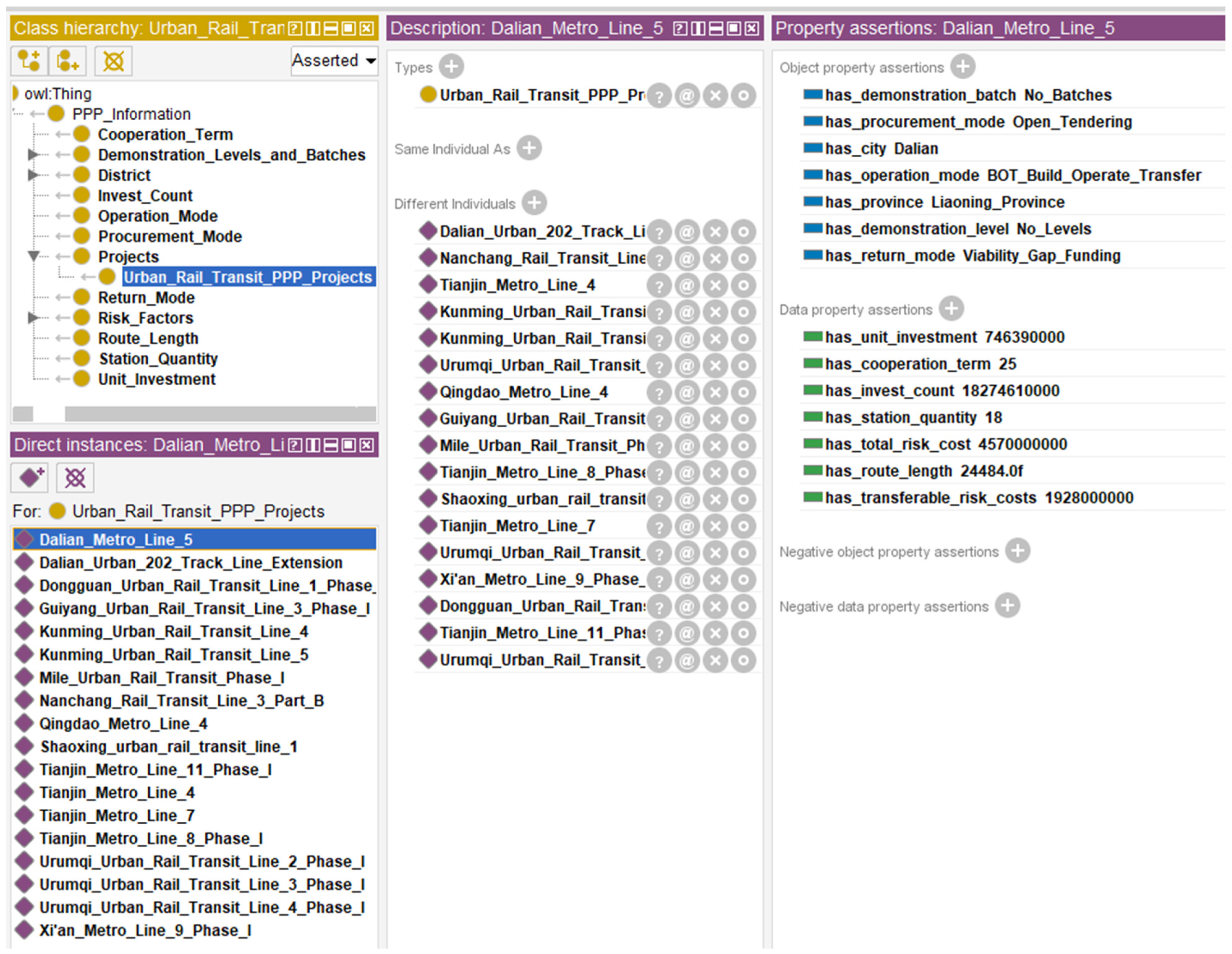
- The domain and scope of the ontology created in this paper was PPP project information, which was derived from the PPP project management database of the China Public–Private Partnerships Center.
- 2.
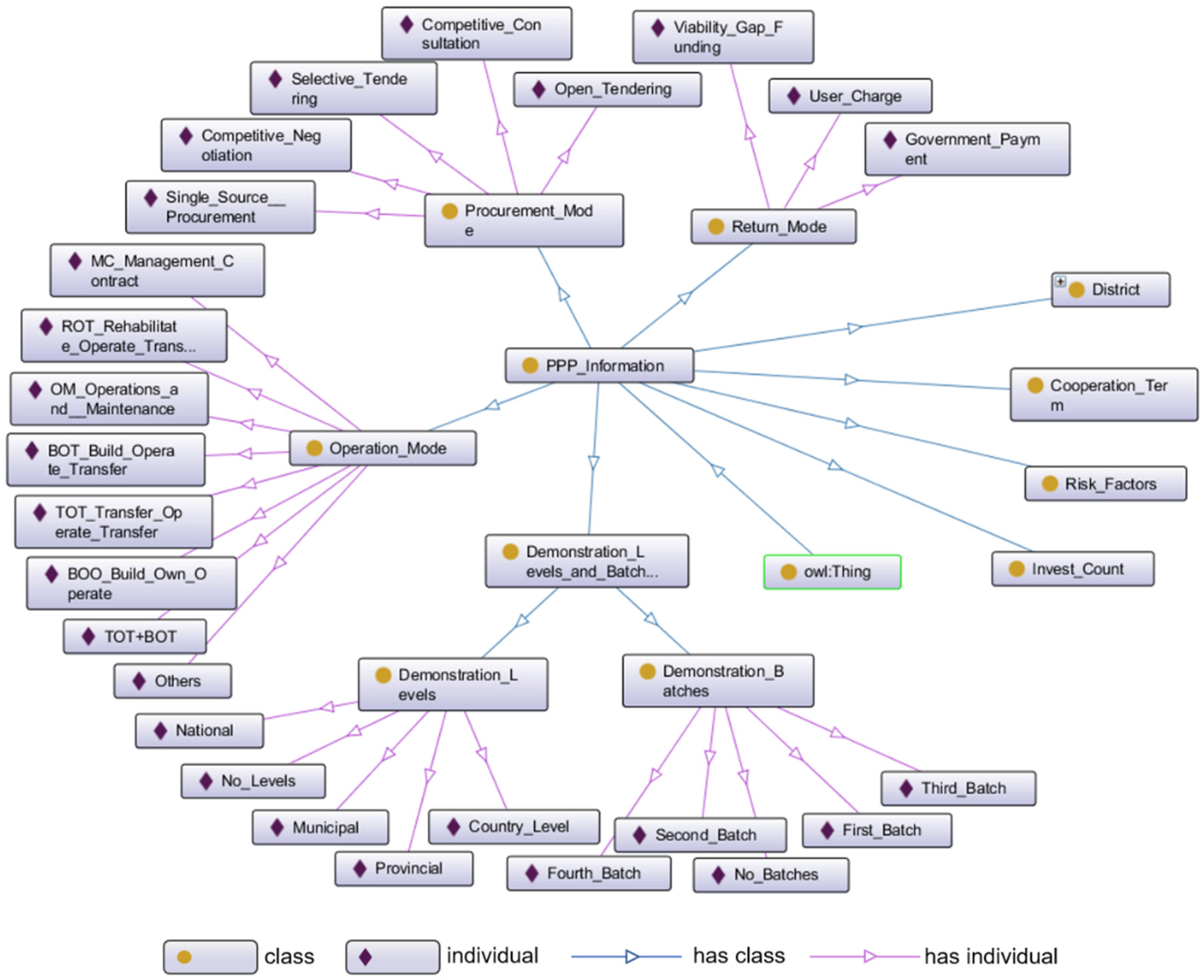
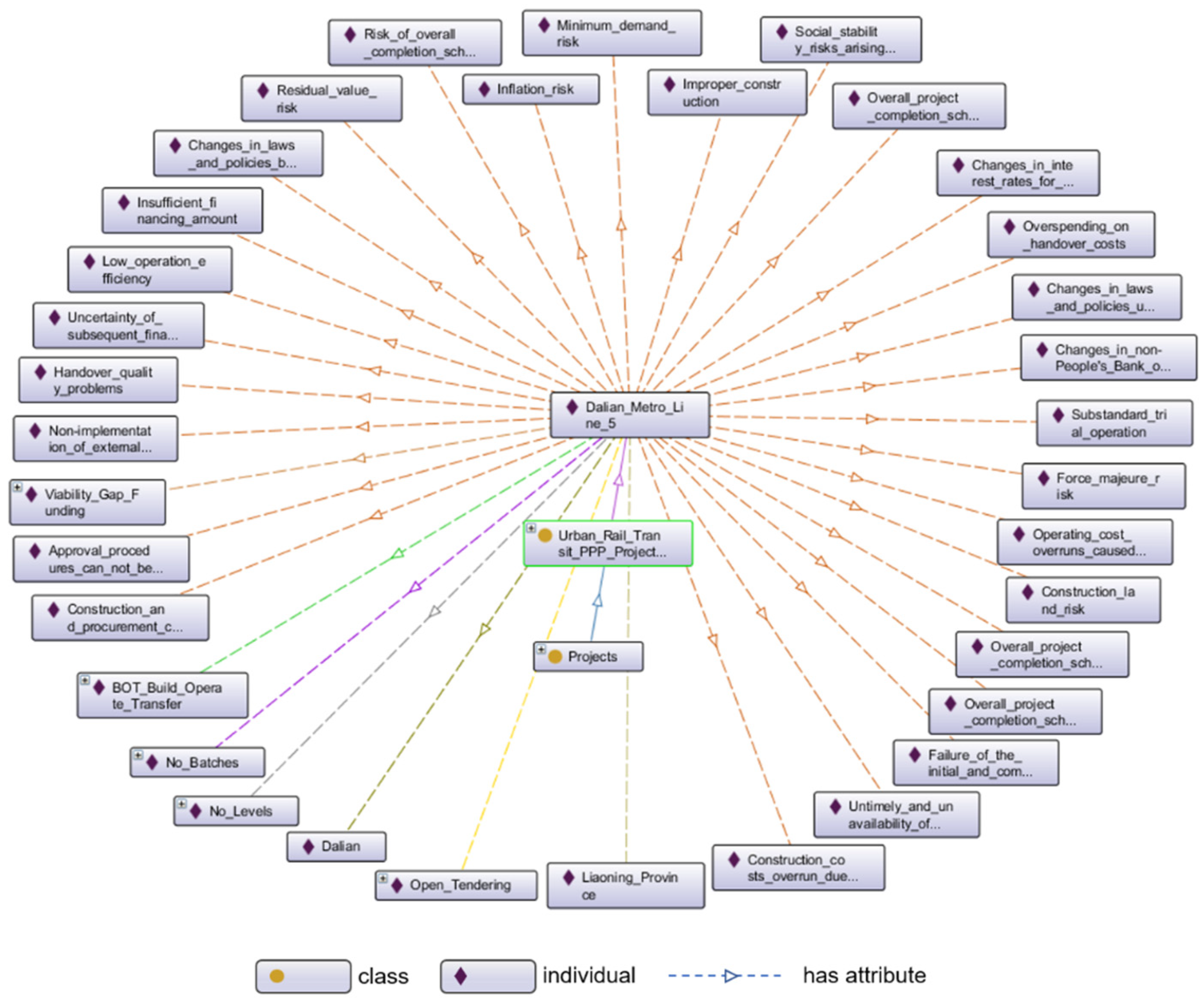
- There are few existing ontologies in the PPP field and no available ontology models that could be used in the VFM evaluation. Thus, we reconstructed an ontology model based on the information from the PPP project management database. According to the information listed in the database, eight major classes were defined, namely “district,” “invest count,” “demonstration levels and batches,” “return mode,” “cooperation term,” “procurement mode,” “operation mode,” and “risk factors.” The above classes were applicable for all PPP industries and were allowed to be further expanded or subtracted according to the actual industries studied.
- 3.
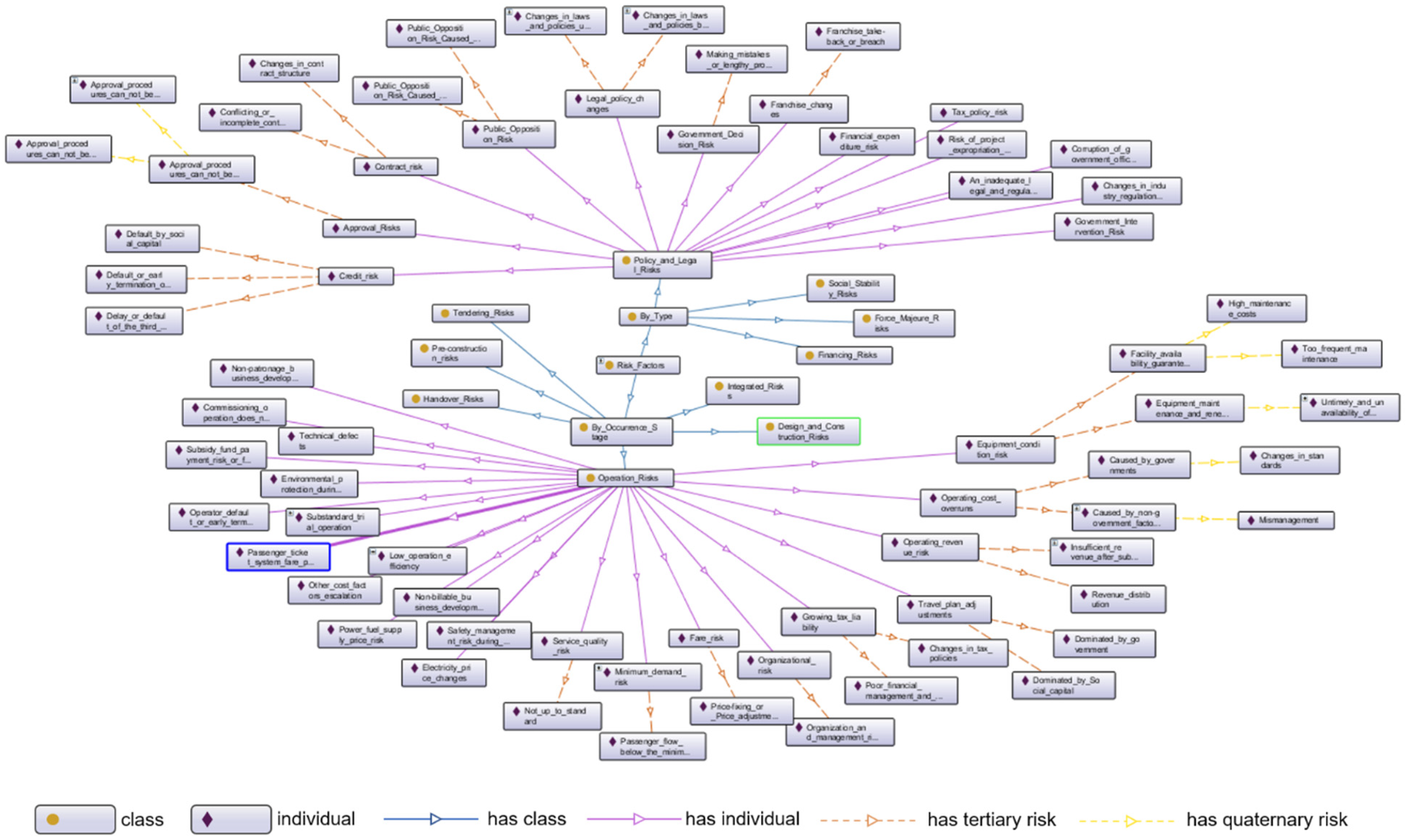
- Define classes and the hierarchy structure. The classes “district,” “return mode,” “demonstration levels and batches,” “operation mode,” and “procurement mode” were commonly perceived attributes in the PPP project management database, and their hierarchies (subclass and individuals) were created based on the different property values they contained. For example, the “procurement mode” consists of open tendering, selective tendering, competitive consultation, competitive negotiation, and single-source procurement, which cannot be further subdivided; therefore, they are regarded as individuals of the “procurement mode.” For the distinctive classes such as “invest count” and “cooperation term,” whose values were different in different PPP projects, hierarchies were created according to every practical case. For “risk factors,” since there was no unified risk factor index system for each industry, this part of the ontology model would be established based on a complete index system that was created according to the actual industry studied; it will be introduced in the validation section.
- 4.
- Define the properties of classes. The role of properties in ontology models is to connect “class to class,” “class to individual,” or “individual to individual.” There is no obvious correlation between the major classes, which were considered mutually exclusive. Each major class and the subclasses (or individuals) are related to each other as “Has” and “Part of.” For “individual to individual,” it must be created according to the actual situation. For example, if the procurement mode of project A is B, then A and B can be connected with the property “has procurement mode.” On this basis, this paper created the hierarchical structure of PPP project information ontology and its relationships. Due to the massive amount of information, only the foundational structure is exemplified, as shown in Figure 3.
4.2. Similar Case Retrieval
4.2.1. Attribute Weighting
4.2.2. Conceptual Semantic Similarity
- (1)
- For quantitative information, the similarity calculation formula is shown below:where = value of an attribute for the target case; = value of an attribute for the -th old case u; and , represent the maximum and minimum values for all the old cases included in the database.
- (2)
- For qualitative information, we used an improved domain ontology similarity algorithm, which integrated a total of four dimensions of semantic similarity: semantic distance, node depth, node density, and semantic coincidence [62]. This algorithm ensured that the calculated value of each influencing factor was between [0, 1] and the combined semantic similarity was always in the range of [0, 1], while the result was always 1 for the similarity calculation of the same node.
- (3)
- Since the similarity between concept sets in qualitative information, it can be calculated based on the above four dimensions of similarity. Since a PPP project always contains multiple and variable numbers of “risk factors,” the calculation of this attribute’s similarity between two cases is actually a comparison between two sets of concepts of different sizes. In this paper, we use the “mean-maximum” algorithm to calculate the semantic similarity between concept sets, as proposed by Wang et al. [63] in Gene Ontology. It defines the semantic similarity between a concept and a concept set as the maximum semantic similarity between a concept and any concept in the set . That is
4.3. Risk Cost Measurement
4.3.1. Preliminary VFM Risk Cost Calculation
4.3.2. Case Revision
5. Validation
5.1. Data Collection
5.2. Similarity Calculation between Cases
5.2.1. Attribute Weighting
5.2.2. Cases Similarity
- (1)
- For quantitative information, take the “invest count” as an example. The maximum value of total project investment in the historical database was RMB 31,300 million and the minimum was RMB 1457.30 million, while the total project investment of Dalian Metro Line 5 was RMB 17,670.5 million and that of Tianjin Metro Line 4 was RMB 18,274.61 million, then the similarity between the two was .
- (2)
- For qualitative information, all the calculations were based on the conceptual semantic similarity of the ontology.
5.3. Cases Revision and Result
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alonso, J.M.; Clifton, J.; Díaz-Fuentes, D. Did New Public Management Matter? An empirical analysis of the outsourcing and decentralization effects on public sector size. Public Manag. Rev. 2015, 17, 643–660. [Google Scholar] [CrossRef]
- Luo, Z. Application of fuzzy comprehensive evaluation method in risk management of expressway PPP project. J. Traffic Sci. Technol. 2016, 2, 187–190. (In Chinese) [Google Scholar]
- Ke, Y.; Hao, W.; Ding, H.; Wang, Y. Factors Influencing the Private Involvement in Urban Rail Public-Private Partnership Projects in China. Constr. Econ. Build. 2017, 17, 90–106. [Google Scholar] [CrossRef]
- Grimsey, D.; Lewis, M.K. Are Public Private Partnerships value for money?: Evaluating alternative approaches and comparing academic and practitioner views. Account. Forum 2019, 29, 345–378. [Google Scholar] [CrossRef]
- Hu, Z.; Chen, S.; Zhang, X. Value for money and its influential factors: An empirical study of PPP projects in Japan. Built Environ. Proj. Asset Manag. 2014, 4, 166–179. [Google Scholar] [CrossRef]
- Sarmento, J.; Renneboog, L. Public-Private Partnerships: Risk Allocation and Value for Money; TILEC Discussion Paper Volume 2014–017; TILEC: Tilburg, The Netherlands, 2014; Available online: https://ssrn.com/abstract=2411450 (accessed on 16 February 2022).
- Andersen, A.; Enterprise LSE. Value for Money Drivers in the Private Finance Initiative; Arthur Andersen and Enterprise LSE: London, UK, 2000. Available online: www.ogc.gov.uk/pfi/series_1/andersen/7tech_contents.html (accessed on 15 January 2021).
- Andon, P. Accounting-related research in PPPs/PFIs: Present contributions and future opportunities. Account. Audit. Account. J. 2012, 25, 876–924. [Google Scholar] [CrossRef]
- Cheung, E.; Chan, A.P.; Kajewski, S. Enhancing value for money in public private partnership projects. J. Financ. Manag. Prop. Constr. 2009, 14, 7–20. [Google Scholar] [CrossRef]
- Opara, M. Value for Money and Risk Relationships in Public-Private Partnerships: Evaluating Program-based Evidence. Aust. Account. Rev. 2018, 28, 391–404. [Google Scholar] [CrossRef]
- Song, J.; Song, D.; Zhang, X.; Sun, Y. Risk identification for PPP waste-to-energy incineration projects in China. Energy Policy 2013, 61, 953–962. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, Z.; Chai, J.; Kan, Z. Risk Identification and Analysis for PPP Projects of Electric Vehicle Charging Infrastructure Based on 2-Tuple and the DEMATEL Model. World Electr. Veh. J. 2019, 10, 4. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, X.; Xue, H. Identifying critical risks in Sponge City PPP projects using DEMATEL method: A case study of China. J. Clean. Prod. 2019, 226, 949–958. [Google Scholar] [CrossRef]
- Ameyaw, E.E.; Chan, A.P. Risk ranking and analysis in PPP water supply infrastructure projects. Facilities 2015, 33, 428–453. [Google Scholar] [CrossRef]
- Ameyaw, E.E.; Chan, A.P. Identifying public-private partnership (PPP) risks in managing water supply projects in Ghana. J. Facil. Manag. 2013, 11, 152–182. [Google Scholar] [CrossRef]
- Liu, X.; Fang, J. Risk Identification and Evaluation of Urban Underground Pipe Gallery PPP Project Based on Improved AHP. In Proceedings of the International Conference on Construction and Real Estate Management, ICCREM 2019, Banff, AB, Canada, 21–24 May 2019. [Google Scholar] [CrossRef]
- Chan, A.P.C.; Yeung, J.F.Y.; Yu, C.C.; Wang, S.Q.; Ke, Y. Empirical Study of Risk Assessment and Allocation of Public-Private Partnership Projects in China. J. Manag. Eng. 2011, 27, 136–148. [Google Scholar] [CrossRef]
- Wu, Y.; Xu, C.; Li, L.; Wang, Y.; Chen, K.; Xu, R. A risk assessment framework of PPP waste-to-energy incineration projects in China under 2-dimension linguistic environment. J. Clean. Prod. 2018, 183, 602–617. [Google Scholar] [CrossRef]
- Luo, C.; Ju, Y.; Dong, P.; Gonzalez, E.D.R.S.; Wang, A. Risk assessment for PPP waste-to-energy incineration plant projects in china based on hybrid weight methods and weighted multigranulation fuzzy rough sets. Sustain. Cities Soc. 2021, 74, 103120. [Google Scholar] [CrossRef]
- Ahmadabadi, A.A.; Heravi, G. Risk assessment framework of PPP-megaprojects focusing on risk interaction and project success. Transp. Res. Part A Policy Pract. 2019, 124, 169–188. [Google Scholar] [CrossRef]
- Akcay, E.C. An Analytic Network Process Based Risk Assessment Model for Ppp Hydropower Investments. J. Civ. Eng. Manag. 2021, 27, 268–277. [Google Scholar] [CrossRef]
- Nisar, T.M. Value for money drivers in public private partnership schemes. Int. J. Public Sect. Manag. 2007, 20, 147–156. [Google Scholar] [CrossRef]
- Chung, D.; Hensher, D.A.; Rose, J.M. Toward the betterment of risk allocation: Investigating risk perceptions of Australian stakeholder groups to public–private-partnership tollroad projects. Res. Transp. Econ. 2010, 30, 43–58. [Google Scholar] [CrossRef]
- Froud, J. The Private Finance Initiative: Risk, uncertainty and the state. Account. Organ. Soc. 2003, 28, 567–589. [Google Scholar] [CrossRef]
- Ke, Y.; Wang, S.; Chan, A.; Lam, P.T. Preferred risk allocation in China’s public–private partnership (PPP) projects. Int. J. Proj. Manag. 2010, 28, 482–492. [Google Scholar] [CrossRef]
- Ameyaw, E.E.; Chan, A.P.C. A Fuzzy Approach for the Allocation of Risks in Public–Private Partnership Water-Infrastructure Projects in Developing Countries. J. Infrastruct. Syst. 2016, 22, 04016016. [Google Scholar] [CrossRef]
- Ke, Y.; Wang, S.; Chan, A.P. Risk Allocation in Public-Private Partnership Infrastructure Projects: Comparative Study. J. Infrastruct. Syst. 2010, 16, 343–351. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Wang, Y. Using Bargaining Game Theory for Risk Allocation of Public-Private Partnership Projects: Insights from Different Alternating Offer Sequences of Participants. J. Constr. Eng. Manag. 2017, 143, 04016102. [Google Scholar] [CrossRef]
- Jin, X.-H.; Zhang, G. Modelling optimal risk allocation in PPP projects using artificial neural networks. Int. J. Proj. Manag. 2011, 29, 591–603. [Google Scholar] [CrossRef]
- Jin, X.-H. Neurofuzzy Decision Support System for Efficient Risk Allocation in Public-Private Partnership Infrastructure Projects. J. Comput. Civ. Eng. 2010, 24, 525–538. [Google Scholar] [CrossRef]
- Alireza, V.; Mohammadreza, Y.; Zin, R.M.; Yahaya, N.; Noor, N.M. An enhanced multi-objective optimization approach for risk allocation in public–private partnership projects: A case study of Malaysia. Can. J. Civ. Eng. 2014, 41, 164–177. [Google Scholar] [CrossRef]
- Valipour, A.; Yahaya, N.; Noor, N.M.; Valipour, I.; Tamošaitienė, J. A Swara-Copras Approach to the Allocation of Risk in Water and Sewerage Public–Private Partnership Projects in Malaysia. Int. J. Strat. Prop. Manag. 2019, 23, 269–283. [Google Scholar] [CrossRef]
- Shrestha, A.; Tamošaitienė, J.; Martek, I.; Hosseini, M.R.; Edwards, D.J. A Principal-Agent Theory Perspective on PPP Risk Allocation. Sustainability 2019, 11, 6455. [Google Scholar] [CrossRef]
- Lomoro, A.; Mossa, G.; Pellegrino, R.; Ranieri, L. Optimizing Risk Allocation in Public-Private Partnership Projects by Project Finance Contracts. The Case of Put-or-Pay Contract for Stranded Posidonia Disposal in the Municipality of Bari. Sustainability 2020, 12, 806. [Google Scholar] [CrossRef]
- Kolodner, J. An introduction to case-based reasoning. Artif. Intell. Rev. 1992, 6, 3–34. [Google Scholar] [CrossRef]
- Schank, R. Dynamic Memory: A Theory of Learning in Computers and People; Cambridge University Press: Cambridge, UK, 1982. [Google Scholar]
- De Mantaras, R.L.; Mcsherry, D.; Bridge, D.; Leake, D.; Smyth, B.; Craw, S.; Faltings, B.; Maher, M.L.; Cox, M.T.; Forbus, K.; et al. Retrieval, reuse, revision and retention in case-based reasoning. Knowl. Eng. Rev. 2006, 20, 215–240. [Google Scholar] [CrossRef]
- Yan, A.; Wang, W.; Zhang, C.; Zhao, H. A fault prediction method that uses improved case-based reasoning to continuously predict the status of a shaft furnace. Inf. Sci. 2014, 259, 269–281. [Google Scholar] [CrossRef]
- Liang, Y.; Wang, H.; Xu, A.; Tian, N. A Two-step Case-based Reasoning Method Based on Attributes Reduction for Predicting the Endpoint Phosphorus Content. ISIJ Int. 2015, 55, 1035–1043. [Google Scholar] [CrossRef]
- Kouser, R.R.; Manikandan, T.; Kumar, V.V. Heart Disease Prediction System Using Artificial Neural Network, Radial Basis Function and Case Based Reasoning. J. Comput. Theor. Nanosci. 2018, 15, 2810–2817. [Google Scholar] [CrossRef]
- Chung, E.Y.-H. Identifying evidence to define community-based rehabilitation practice in China using a case study approach with multiple embedded case study design. BMC Health Serv. Res. 2019, 19, 6. [Google Scholar] [CrossRef] [PubMed]
- Fan, Z.-P.; Li, Y.-H.; Zhang, Y. Generating project risk response strategies based on CBR: A case study. Expert Syst. Appl. 2015, 42, 2870–2883. [Google Scholar] [CrossRef]
- Kim, S. Interval Estimation of Construction Cost Using Case-Based Reasoning and Genetic Algorithms. J. Asian Arch. Build. Eng. 2018, 11, 327–334. [Google Scholar] [CrossRef][Green Version]
- Su, Y.; Yang, S.; Liu, K.; Hua, K.; Yao, Q. Developing A Case-Based Reasoning Model for Safety Accident Pre-Control and Decision Making in the Construction Industry. Int. J. Environ. Res. Public Health 2019, 16, 1511. [Google Scholar] [CrossRef]
- Aamodt, A. Explanation-driven case-based reasoning. In Topics in Case-Based Reasoning; Wess, S., Althoff, K., Richter, M., Eds.; Springer: Berlin/Heidelberg, Germany, 1994; pp. 274–288. [Google Scholar]
- Ji, C.; Hong, T.; Hyun, C. CBR Revision Model for Improving Cost Prediction Accuracy in Multifamily Housing Projects. J. Manag. Eng. 2010, 26, 229–236. [Google Scholar] [CrossRef]
- De Soto, B.G.; Adey, B.T. Investigation of the Case-based Reasoning Retrieval Process to Estimate Resources in Construction Projects. Procedia Eng. 2015, 123, 169–181. [Google Scholar] [CrossRef]
- Studer, R.; Benjamins, V.; Fensel, D. Knowledge engineering: Principles and methods. Data Knowl. Eng. 1998, 25, 161–197. [Google Scholar] [CrossRef]
- Costa, R.; Lima, C.; Sarraipa, J.; Jardim-Gonçalves, R. Facilitating knowledge sharing and reuse in building and construction domain: An ontology-based approach. J. Intell. Manuf. 2013, 27, 263–282. [Google Scholar] [CrossRef]
- Gruber, T.R. Toward principles for the design of ontologies used for knowledge sharing? Int. J. Hum. Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef]
- The Gene Ontology Consortium. Expansion of the Gene Ontology knowledgebase and resources. Nucleic Acids Res. 2017, 45, D331–D338. [Google Scholar] [CrossRef]
- Köhler, S.; Carmody, L.; Vasilevsky, N.; Jacobsen, J.O.B.; Danis, D.; Gourdine, J.-P.; Gargano, M.; Harris, N.L.; Matentzoglu, N.; McMurry, J.A.; et al. Expansion of the Human Phenotype Ontology (HPO) knowledge base and resources. Nucleic Acids Res. 2019, 47, D1018–D1027. [Google Scholar] [CrossRef]
- Diehl, A.D.; Meehan, T.F.; Bradford, Y.M.; Brush, M.H.; Dahdul, W.M.; Dougall, D.S.; He, Y.; Osumi-Sutherland, D.; Ruttenberg, A.; Sarntivijai, S.; et al. The Cell Ontology 2016: Enhanced content, modularization, and ontology interoperability. J. Biomed. Semant. 2016, 7, 44. [Google Scholar] [CrossRef]
- Florrence, M. Building a multilingual ontology for education domain using monto method. Comput. Sci. Inf. Technol. 2020, 1, 47–53. [Google Scholar] [CrossRef]
- Constantin, A.; Peroni, S.; Pettifer, S.; Shotton, D.; Vitali, F. The Document Components Ontology (DoCO). Semant. Web 2016, 7, 167–181. [Google Scholar] [CrossRef]
- Zangeneh, P.; McCabe, B. Ontology-based knowledge representation for industrial megaprojects analytics using linked data and the semantic web. Adv. Eng. Inform. 2020, 46, 101164. [Google Scholar] [CrossRef]
- Zhang, S.; Boukamp, F.; Teizer, J. Ontology-Based Semantic Modeling of Safety Management Knowledge. In Proceedings of the International Conference on Computing in Civil and Building Engineering, Orlando, FL, USA, 23–25 June 2014. [Google Scholar] [CrossRef]
- Bilgin, G.; Dikmen, I.; Birgonul, M.T. An ontology-based approach for delay analysis in construction. KSCE J. Civ. Eng. 2017, 22, 384–398. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Zhen, Y.; Zhong, X. An improved conceptual similarity algorithm based on domain ontology tree structure. Highlights Sci. Pap. Online 2017, 10, 1084–1093. (In Chinese) [Google Scholar]
- Wang, J.Z.; Du, Z.; Payattakool, R.; Yu, P.S.; Chen, C.-F. A new method to measure the semantic similarity of GO terms. Bioinformatics 2007, 23, 1274–1281. [Google Scholar] [CrossRef]
- Im, H.; Ha, M.; Kim, D.; Choi, J. Development of an Ontological Cost Estimating Knowledge Framework for EPC Projects. KSCE J. Civ. Eng. 2021, 25, 1578–1591. [Google Scholar] [CrossRef]
- Xiao, J.; Li, X.; Zhang, Z.; Zhang, J. Ontology-Based Knowledge Model to Support Construction Noise Control in China. J. Constr. Eng. Manag. 2018, 144. [Google Scholar] [CrossRef]
- Shunmughavel, V.; Jaganathan, P. Semantic enrichment in ontology mapping using concept similarity computing. In Proceedings of the 4th International Conference on Advanced Computing, Chennai, India, 13–15 December 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Darlington, M.; Culley, S. Investigating ontology development for engineering design support. Adv. Eng. Inform. 2008, 22, 112–134. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Information Gain | Weight |
|---|---|---|
| District | 0.3494 | 0.0230 |
| Invest count | 0.2404 | 0.0158 |
| Unit investment | 0.2404 | 0.0158 |
| Station quantity | 0.2404 | 0.0158 |
| Route length | 0.2404 | 0.0158 |
| Demonstration levels and batches | 0.3767 | 0.0248 |
| Cooperation term | 0.4747 | 0.0312 |
| Procurement mode | 0.1833 | 0.0121 |
| Operation mode | 0.1689 | 0.0111 |
| Risk factors | 12.6859 | 0.8346 |
| No. | Dalian-Qingdao | Qingdao-Dalian | Similarity of “Risk Factor” |
|---|---|---|---|
| 1 | 0.8728 | 0.7299 | (23.4045 + 20.8964)/(28 + 25) = 0.8359 |
| 2 | 0.8728 | 0.7299 | |
| 3 | 0.9134 | 0.7746 | |
| 4 | 0.9134 | 0.8714 | |
| 5 | 0.8714 | 1.0000 | |
| 6 | 0.8120 | 0.8120 | |
| 7 | 0.7767 | 0.7735 | |
| 8 | 1.0000 | 0.7143 | |
| 9 | 0.6657 | 1.0000 | |
| 10 | 0.7819 | 0.7850 | |
| 11 | 0.7819 | 0.7299 | |
| 12 | 0.7102 | 0.7850 | |
| 13 | 0.6557 | 0.7850 | |
| 14 | 0.7102 | 0.7850 | |
| 15 | 1.0000 | 1.0000 | |
| 16 | 1.0000 | 0.7102 | |
| 17 | 0.7752 | 0.9336 | |
| 18 | 0.7756 | 1.0000 | |
| 19 | 0.9336 | 0.8120 | |
| 20 | 1.0000 | 0.8120 | |
| 21 | 0.8120 | 0.7819 | |
| 22 | 0.8120 | 0.9134 | |
| 23 | 0.6657 | 0.8728 | |
| 24 | 0.7819 | 1.0000 | |
| 25 | 0.8392 | 0.7850 | |
| 26 | 0.8571 | - | |
| 27 | 1.0000 | - | |
| 28 | 0.8141 | - | |
| Total | 23.4045 | 20.8964 |
| Project | District | Invest Count | Unit Investment | Station Quantity | Route Length | Demonstration Levels and Batches | Cooperation Term | Procurement Mode | Operation Mode | Risk Factors | General Similarity |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Urumqi Urban Rail Transit Line 2 Phase I | 0.6417 | 0.9325 | 0.8899 | 0.619 | 0.8742 | 0.6699 | 0 | 1 | 1 | 0.8323 | 0.8016 |
| Kunming Urban Rail Transit Line 4 | 0.6428 | 0.7196 | 0.6136 | 0.5714 | 0.8415 | 0.6699 | 0.5 | 1 | 1 | 0.8362 | 0.8115 |
| Mile Urban Rail Transit Phase I | 0.6428 | 0.4365 | 0.6854 | 0.5238 | 0.2972 | 1 | 0.5 | 1 | 1 | 0.8425 | 0.8122 |
| Urumqi Urban Rail Transit Line 3 Phase I | 0.6417 | 0.9703 | 0.9267 | 0.9524 | 0.8974 | 0.6699 | 0 | 1 | 1 | 0.84 | 0.8148 |
| Dalian Urban 202 track line extension | 1 | 0.5409 | 0.6749 | 0.8095 | 0.241 | 1 | 1 | 0.7817 | 0.8248 | 0.8189 | 0.8168 |
| Nanchang Rail Transit Line 3 (Part B) | 0.6417 | 0.6265 | 0.9179 | 0.8095 | 0.4051 | 1 | 0.7 | 1 | 1 | 0.8304 | 0.8212 |
| Urumqi Urban Rail Transit Line 4 Phase I | 0.6417 | 0.9321 | 0.9226 | 0.9048 | 0.9537 | 1 | 0 | 1 | 1 | 0.84 | 0.8225 |
| Qingdao Metro Line 4 | 0.6417 | 0.9665 | 0.8872 | 0.8571 | 0.7956 | 0.6699 | 1 | 0.7817 | 1 | 0.8359 | 0.8225 |
| Kunming Urban Rail Transit Line 5 | 0.6428 | 0.9643 | 0.9976 | 0.8571 | 0.9523 | 0.6699 | 0.5 | 1 | 1 | 0.8362 | 0.8277 |
| Xi’an Metro Line 9 Phase I | 0.6417 | 0.853 | 0.9854 | 0.8571 | 0.7659 | 0.6699 | 0.5 | 1 | 1 | 0.8524 | 0.8362 |
| Dongguan Urban Rail Transit Line 1 Phase I | 0.6417 | 0.7305 | 0.3146 | 0.8571 | 0.6492 | 1 | 0.9 | 1 | 0.7097 | 0.8489 | 0.8364 |
| Guiyang Urban Rail Transit Line 3 Phase I | 0.6428 | 0.5635 | 0.6209 | 0.4762 | 0.9774 | 1 | 0.5 | 1 | 1 | 0.8637 | 0.8409 |
| Shaoxing urban rail transit line 1 | 0.6417 | 0.9521 | 0.8504 | 0.7619 | 0.848 | 1 | 0.5 | 1 | 1 | 0.8741 | 0.8618 * |
| Tianjin Metro Line 8 Phase I | 0.7128 | 0.9781 | 0.8797 | 0.9524 | 0.759 | 1 | 0.9 | 1 | 1 | 0.8574 | 0.8645 * |
| Tianjin Metro Line 7 | 0.7128 | 0.9669 | 0.9582 | 0.8571 | 0.9577 | 1 | 0.9 | 1 | 1 | 0.8543 | 0.8645 * |
| Tianjin Metro Line 4 | 0.7128 | 0.9798 | 0.9492 | 0.9524 | 0.9319 | 1 | 0.9 | 1 | 1 | 0.8574 | 0.8683 * |
| Tianjin Metro Line 11 Phase I | 0.7128 | 0.9964 | 0.9615 | 0.8571 | 0.931 | 1 | 0.9 | 1 | 1 | 0.8864 | 0.8915 * |
| Project | Risk Cost | Similarity to Target Case | Weight | Preliminary Risk Cost of Target Case | ||
|---|---|---|---|---|---|---|
| Retained | Total | Retained | Total | |||
| Shaoxing Urban Rail Transit Line 1 | 27.41 | 58.78 | 0.8618 | 0.1981 | ||
| Tianjin Metro Line 8 Phase I | 0.98 | 9.82 | 0.8645 | 0.1987 | ||
| Tianjin Metro Line 7 | 13.10 | 26.35 | 0.8645 | 0.1987 | 11.21 | 32.29 |
| Tianjin Metro Line 4 | 1.07 | 10.62 | 0.8683 | 0.1996 | ||
| Tianjin Metro Line 11 Phase I | 13.51 | 55.35 | 0.8915 | 0.2049 | ||
| Project | Original Risk Cost | PPP | PSC | *PPP | *PSC | Revised Risk Cost | Weight | Risk Cost of Target Case | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Retained | Total | Retained | Total | Retained | Total | ||||||
| Tianjin Metro Line 8 Phase I | 0.98 | 9.82 | 198.48 | 218.73 | 197.50 | 208.91 | 14.98 | 44.08 | 0.1987 | 17.15 | 46.80 |
| Tianjin Metro Line 4 | 1.07 | 10.62 | 223.86 | 243.82 | 222.79 | 233.20 | 16.90 | 49.20 | 0.1996 | ||
| Shaoxing Urban Rail Transit Line 1 | 27.41 | 58.78 | 271.31 | 281.18 | 243.90 | 222.40 | - | - | 0.1981 | ||
| Tianjin Metro Line 7 | 13.10 | 26.35 | 219.33 | 222.36 | 206.23 | 196.01 | - | - | 0.1987 | ||
| Tianjin Metro Line 11 Phase I | 13.51 | 55.35 | 271.12 | 292.22 | 257.61 | 236.87 | - | - | 0.2049 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Lin, Q.; Zhang, Y. Risk Cost Measurement of Value for Money Evaluation Based on Case-Based Reasoning and Ontology: A Case Study of the Urban Rail Transit Public-Private Partnership Projects in China. Sustainability 2022, 14, 5547. https://doi.org/10.3390/su14095547
Wang H, Lin Q, Zhang Y. Risk Cost Measurement of Value for Money Evaluation Based on Case-Based Reasoning and Ontology: A Case Study of the Urban Rail Transit Public-Private Partnership Projects in China. Sustainability. 2022; 14(9):5547. https://doi.org/10.3390/su14095547
Chicago/Turabian StyleWang, Hongqiang, Qiaoyan Lin, and Yingjie Zhang. 2022. "Risk Cost Measurement of Value for Money Evaluation Based on Case-Based Reasoning and Ontology: A Case Study of the Urban Rail Transit Public-Private Partnership Projects in China" Sustainability 14, no. 9: 5547. https://doi.org/10.3390/su14095547
APA StyleWang, H., Lin, Q., & Zhang, Y. (2022). Risk Cost Measurement of Value for Money Evaluation Based on Case-Based Reasoning and Ontology: A Case Study of the Urban Rail Transit Public-Private Partnership Projects in China. Sustainability, 14(9), 5547. https://doi.org/10.3390/su14095547