
Dynamic Scheduling Method for Job-Shop Manufacturing Systems by Deep Reinforcement Learning with Proximal Policy Optimization






Abstract
:1. Introduction
2. Preliminary
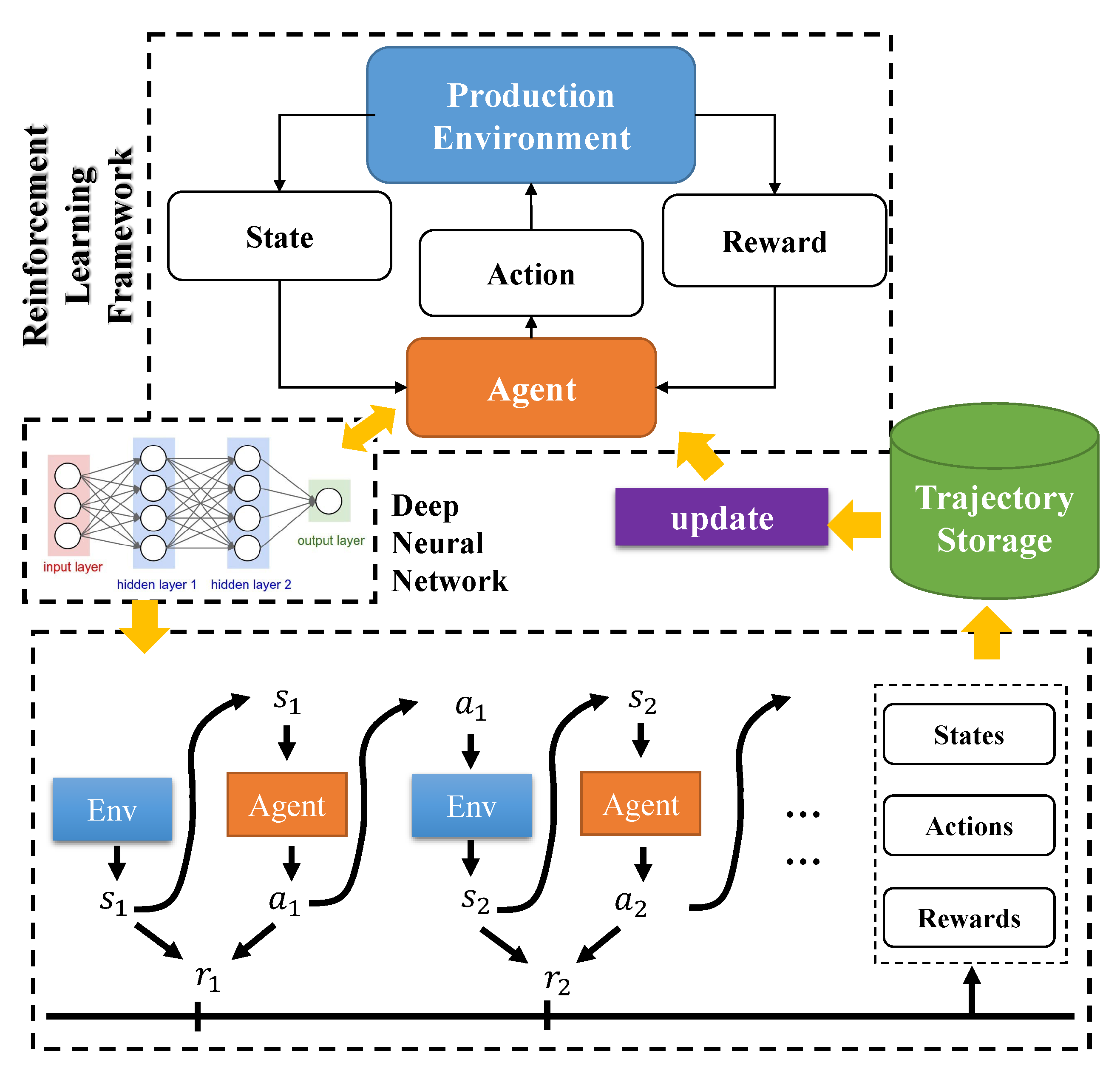
2.1. Markov Decision Process
2.2. Policy Gradient Theorem
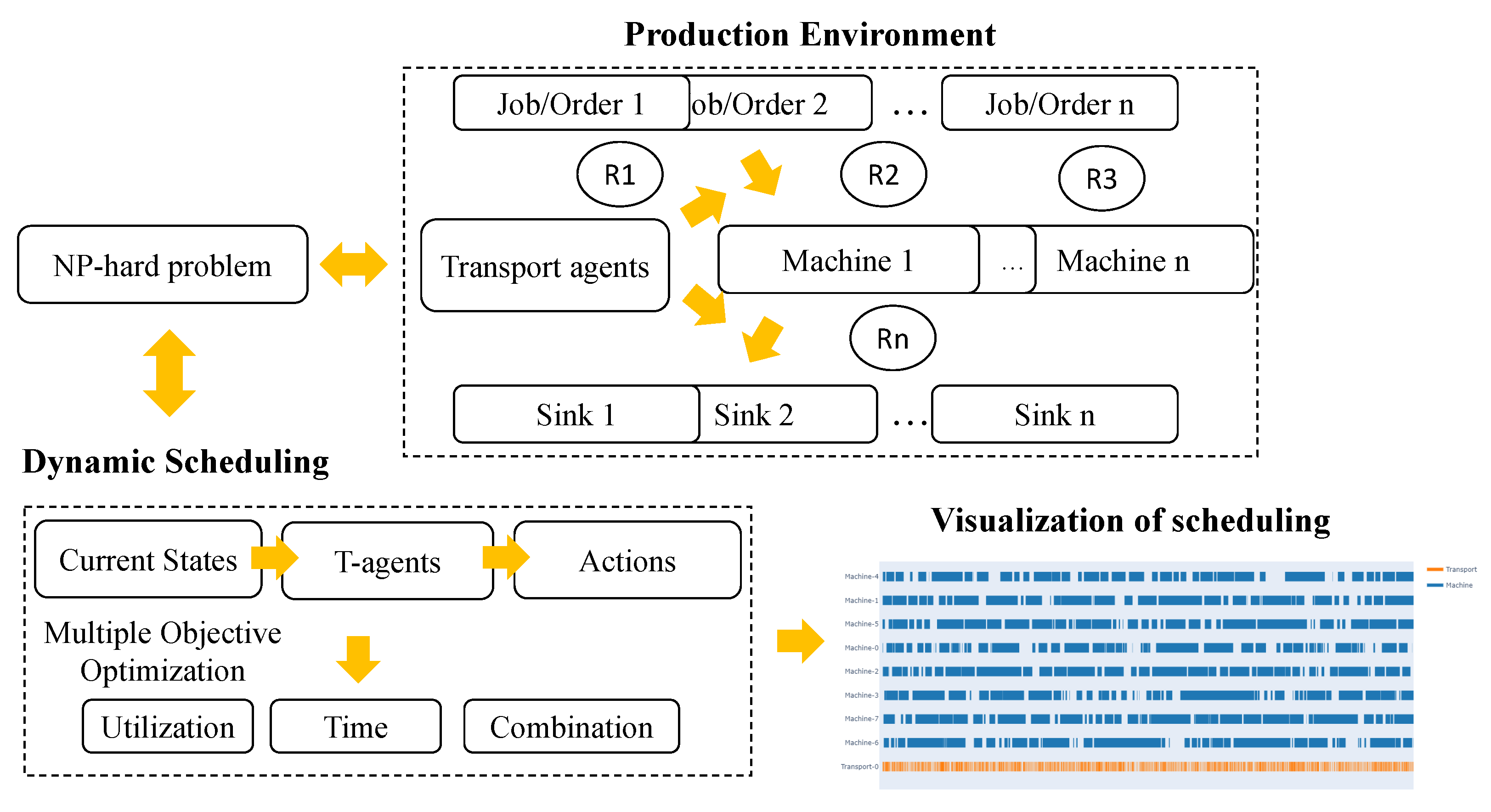
3. Proposed Methods
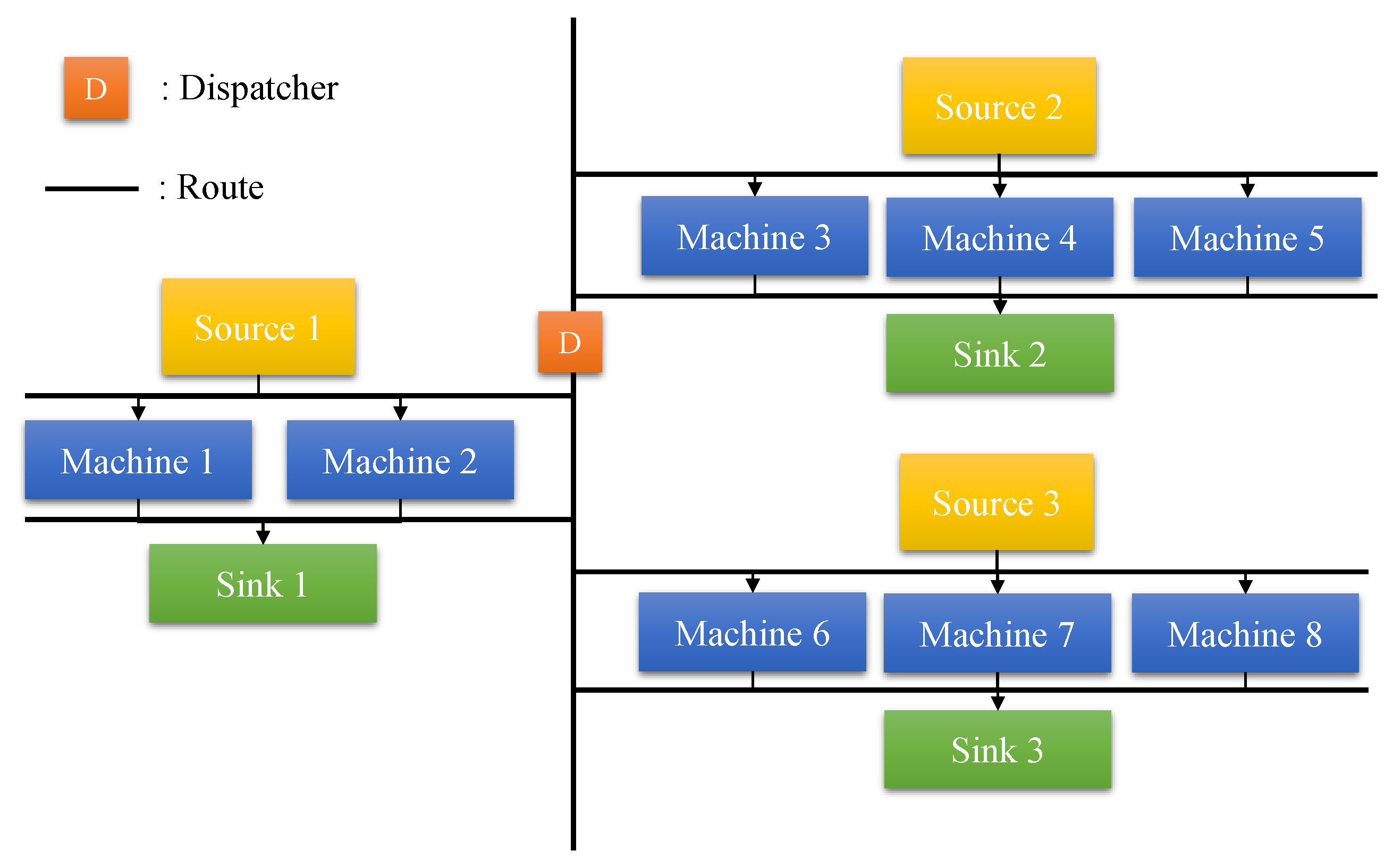
3.1. Dynamic Simulation of Production Environment
- Machines that have similar disposal ability of orders are put into the same group.
- Orders are released by the sources and they are performed according to specific probability.
- The processing time of each order is decided by the predefined probability distribution.
- Machine failures are considered in this environment, which can result in the breakdown of all of the machines. The failure events are random triggered based on the mean time between failure (MTBF) and mean time off-line (MTOL).
3.1.1. Action Module
3.1.2. States
- Firstly, the state of action shows whether the current action is valid or not, and it is defined as:
- The machine breakdown was designed in the simulation, and the state of failure for each machine is also considered, which is defined as:
- The remaining processing time of each machine is defined as:where is the remaining processing time, and is the average processing time at .
- indicates the state information of remaining free buffer spaces of each machine in its entry buffer:where is the number of occupied buffers, and is the capacity of the entry buffer.
- indicates the remaining free buffer space in the exit buffer for each machine :where is the number of occupied buffers, and is the capacity of the exit buffer.
- indicates the waiting times of orders waiting for transport:where is the longest waiting time, and and are the average and standard variation of waiting time of orders.
3.2. Deep Reinforcement Learning for Dynamic Scheduling
3.2.1. Optimization Objectives
- The constant reward rewards the valid action with value for , and for is defined as:
- To promote the average utilization U, was designed with exponential function when the agent provides a valid action. The purpose of this reward function is to maximize utilization, and it is defined as:
- To shorten the waiting time of orders, is designed to award the valid action determined by the agent. The reward function also follows the exponential function to accelerate the order leaving the system, which is defined as:
- Combining with and , two complex reward functions are designed as follows:
- For implementing the multiple-objective optimization, the hybrid reward function with and is defined as:
3.2.2. Proximal Policy Optimization
| Algorithm 1 DRL with PPO for dynamic scheduling |
|
4. Experiments
4.1. Case Description
4.2. Implementation Details
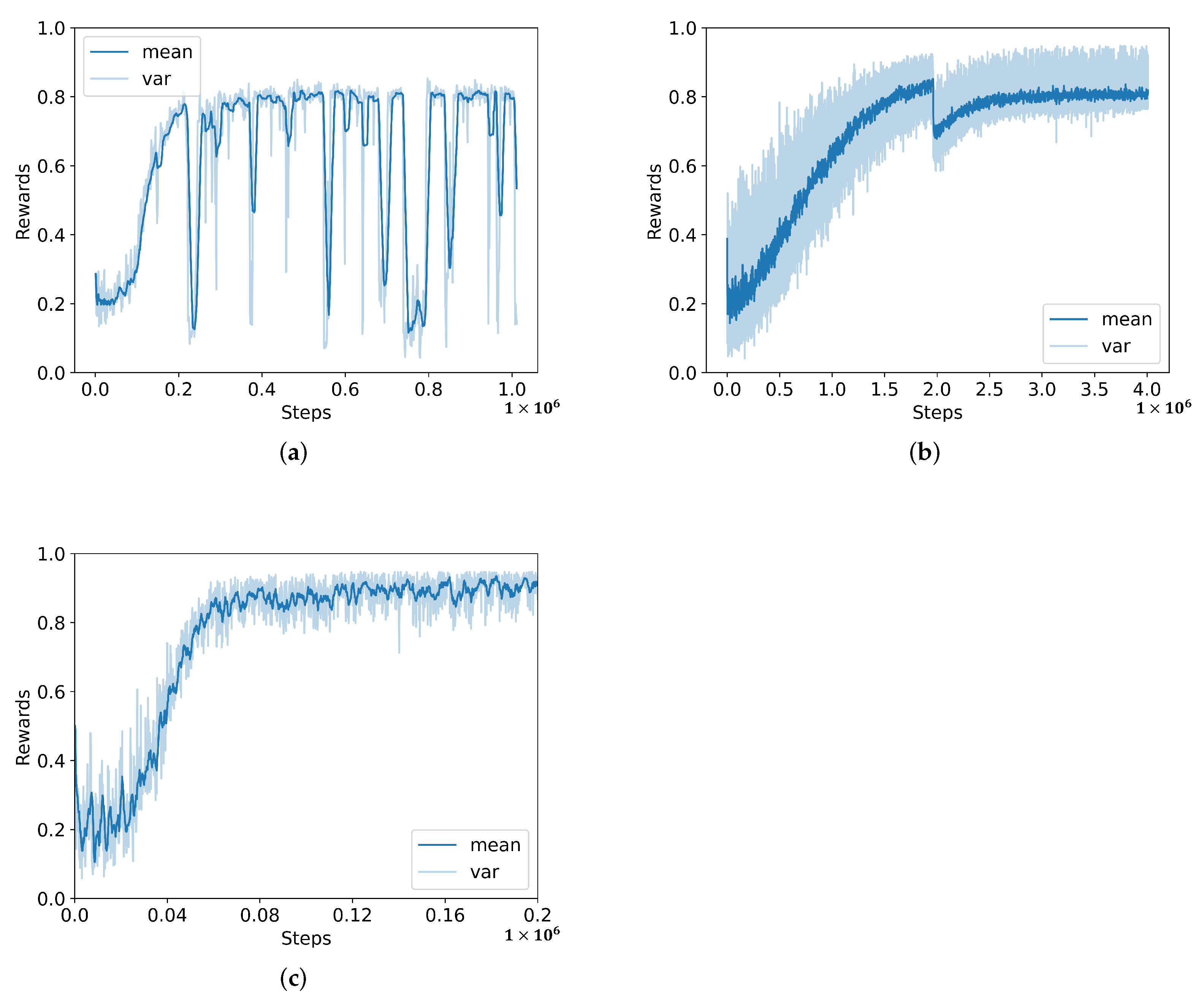
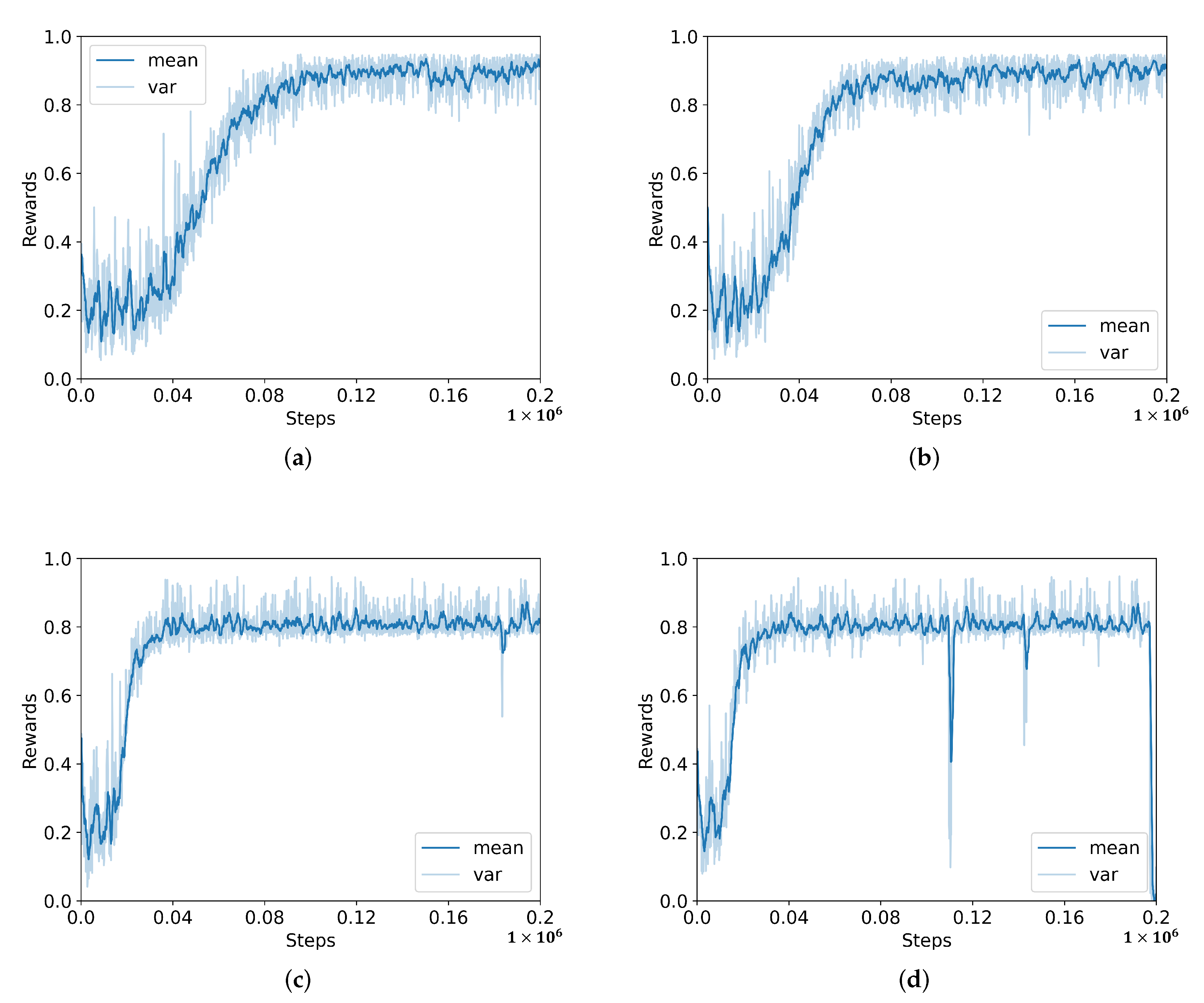
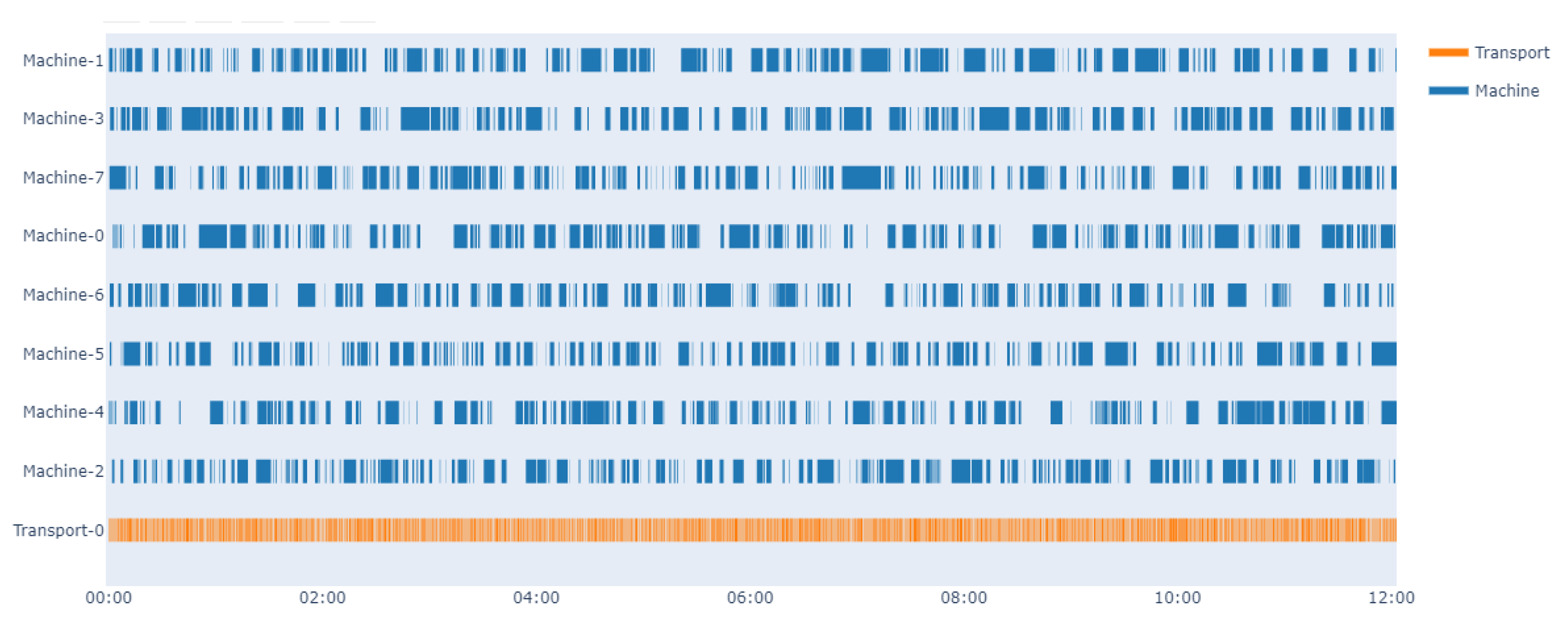
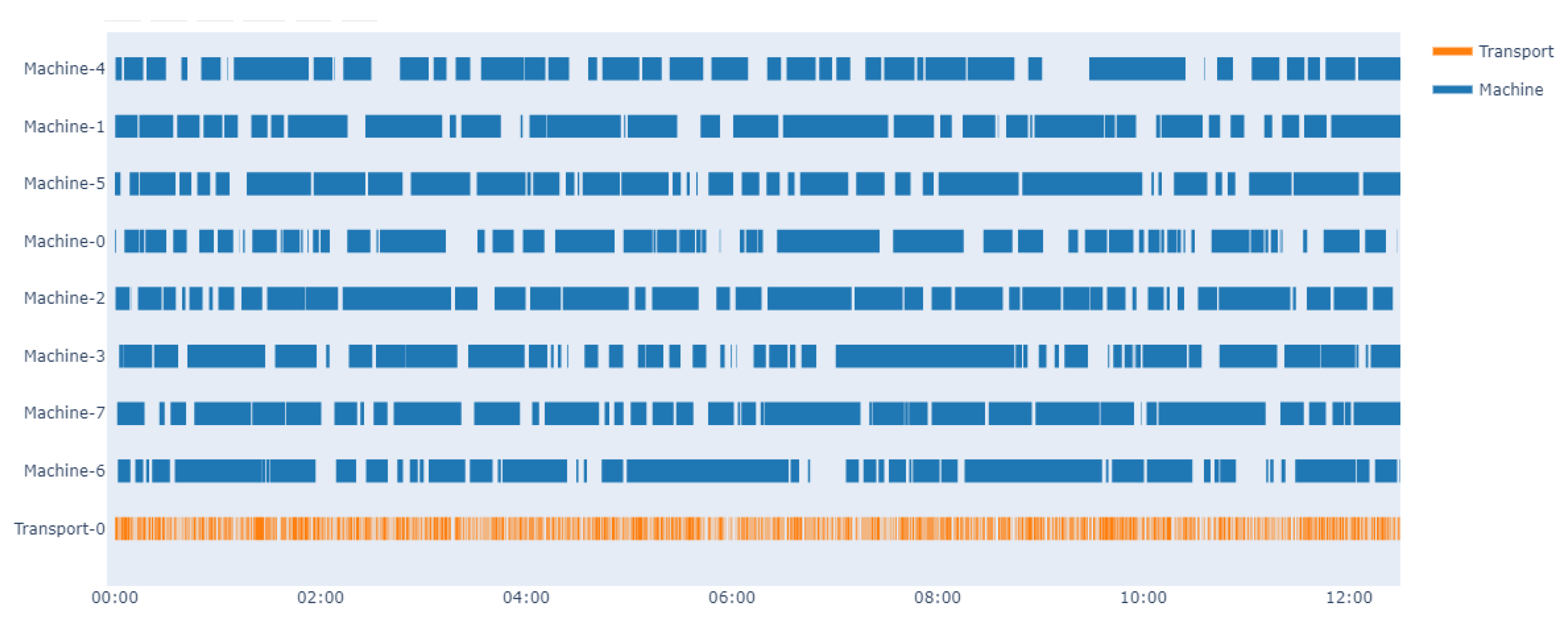
4.3. Results and Analysis
5. Discussion and Conclusions
- The optimal policy is only learned from the massive interaction data with the production environment. Expert knowledge would be considered as a support of further enhancement of efficiency and performance.
- In the current simulation, only one dispatcher is used as the transport agent. However, a dynamic simulation environment with multiple transport agents should be developed in future studies. The proposed deep reinforcement learning framework needs to be improved in multiagent situations.
- Toward the dynamic job-shop scheduling problem, other well-known algorithms, such as GA, PSO, and TLBO, will be implemented and compared with the deep reinforcement learning framework. With the corresponding benchmark problems developed, we will validate all the algorithms within the dynamic environment.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sanchez, M.; Exposito, E.; Aguilar, J. Autonomic computing in manufacturing process coordination in industry 4.0 context. J. Ind. Inf. Integr. 2020, 19, 100159. [Google Scholar] [CrossRef]
- Csalódi, R.; Süle, Z.; Jaskó, S.; Holczinger, T.; Abonyi, J. Industry 4.0-driven development of optimization algorithms: A systematic overview. Complexity 2021, 2021, 6621235. [Google Scholar] [CrossRef]
- Zenisek, J.; Wild, N.; Wolfartsberger, J. Investigating the potential of smart manufacturing technologies. Procedia Comput. Sci. 2021, 180, 507–516. [Google Scholar] [CrossRef]
- Popov, V.V.; Kudryavtseva, E.V.; Kumar Katiyar, N.; Shishkin, A.; Stepanov, S.I.; Goel, S. Industry 4.0 and Digitalisation in Healthcare. Materials 2022, 15, 2140. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wang, H. Data-driven methods for predictive maintenance of industrial equipment: A survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- Kleindorfer, P.R.; Singhal, K.; Van Wassenhove, L.N. Sustainable operations management. Prod. Oper. Manag. 2005, 14, 482–492. [Google Scholar] [CrossRef]
- Kiel, D.; Müller, J.M.; Arnold, C.; Voigt, K.I. Sustainable industrial value creation: Benefits and challenges of industry 4.0. In Digital Disruptive Innovation; World Scientific: Singapore, 2020; pp. 231–270. [Google Scholar]
- Saxena, P.; Stavropoulos, P.; Kechagias, J.; Salonitis, K. Sustainability assessment for manufacturing operations. Energies 2020, 13, 2730. [Google Scholar] [CrossRef]
- Henao, R.; Sarache, W.; Gómez, I. Lean manufacturing and sustainable performance: Trends and future challenges. J. Clean. Prod. 2019, 208, 99–116. [Google Scholar] [CrossRef]
- Rajeev, A.; Pati, R.K.; Padhi, S.S.; Govindan, K. Evolution of sustainability in supply chain management: A literature review. J. Clean. Prod. 2017, 162, 299–314. [Google Scholar] [CrossRef]
- Serrano-Ruiz, J.C.; Mula, J.; Poler, R. Smart manufacturing scheduling: A literature review. J. Manuf. Syst. 2021, 61, 265–287. [Google Scholar] [CrossRef]
- Serrano-Ruiz, J.C.; Mula, J.; Poler, R. Development of a multidimensional conceptual model for job shop smart manufacturing scheduling from the Industry 4.0 perspective. J. Manuf. Syst. 2022, 63, 185–202. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, W. Complex equipment remanufacturing schedule management based on multi-layer graphic evaluation and review technique network and critical chain method. IEEE Access 2020, 8, 108972–108987. [Google Scholar] [CrossRef]
- Yu, J.M.; Lee, D.H. Scheduling algorithms for job-shop-type remanufacturing systems with component matching requirement. Comput. Ind. Eng. 2018, 120, 266–278. [Google Scholar] [CrossRef]
- Cai, L.; Li, W.; Luo, Y.; He, L. Real-time scheduling simulation optimisation of job shop in a production-logistics collaborative environment. Int. J. Prod. Res. 2022, 1–21. [Google Scholar] [CrossRef]
- Satyro, W.C.; de Mesquita Spinola, M.; de Almeida, C.M.; Giannetti, B.F.; Sacomano, J.B.; Contador, J.C.; Contador, J.L. Sustainable industries: Production planning and control as an ally to implement strategy. J. Clean. Prod. 2021, 281, 124781. [Google Scholar] [CrossRef]
- Wang, L.; Hu, X.; Wang, Y.; Xu, S.; Ma, S.; Yang, K.; Liu, Z.; Wang, W. Dynamic job-shop scheduling in smart manufacturing using deep reinforcement learning. Comput. Netw. 2021, 190, 107969. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S.; Sethi, R. The complexity of flowshop and jobshop scheduling. Math. Oper. Res. 1976, 1, 117–129. [Google Scholar] [CrossRef]
- Manne, A.S. On the job-shop scheduling problem. Oper. Res. 1960, 8, 219–223. [Google Scholar] [CrossRef] [Green Version]
- Van Laarhoven, P.J.; Aarts, E.H.; Lenstra, J.K. Job shop scheduling by simulated annealing. Oper. Res. 1992, 40, 113–125. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Qing-dao-er-ji, R. A new hybrid genetic algorithm for job shop scheduling problem. Comput. Oper. Res. 2012, 39, 2291–2299. [Google Scholar]
- Sha, D.; Lin, H.H. A multi-objective PSO for job-shop scheduling problems. Expert Syst. Appl. 2010, 37, 1065–1070. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, L.; Wang, S.y.; Liu, M. An effective teaching–learning-based optimization algorithm for the flexible job-shop scheduling problem with fuzzy processing time. Neurocomputing 2015, 148, 260–268. [Google Scholar] [CrossRef]
- Du, Y.; Li, J.q.; Chen, X.l.; Duan, P.y.; Pan, Q.k. Knowledge-Based Reinforcement Learning and Estimation of Distribution Algorithm for Flexible Job Shop Scheduling Problem. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 1–15. [Google Scholar] [CrossRef]
- Mohan, J.; Lanka, K.; Rao, A.N. A review of dynamic job shop scheduling techniques. Procedia Manuf. 2019, 30, 34–39. [Google Scholar] [CrossRef]
- Azadeh, A.; Negahban, A.; Moghaddam, M. A hybrid computer simulation-artificial neural network algorithm for optimisation of dispatching rule selection in stochastic job shop scheduling problems. Int. J. Prod. Res. 2012, 50, 551–566. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, P. Manifold learning based rescheduling decision mechanism for recessive disturbances in RFID-driven job shops. J. Intell. Manuf. 2018, 29, 1485–1500. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, H. Application of machine learning and rule scheduling in a job-shop production control system. Int. J. Simul. Model 2021, 20, 410–421. [Google Scholar] [CrossRef]
- Tian, W.; Zhang, H. A dynamic job-shop scheduling model based on deep learning. Adv. Prod. Eng. Manag. 2021, 16, 23–36. [Google Scholar] [CrossRef]
- Tassel, P.; Gebser, M.; Schekotihin, K. A reinforcement learning environment for job-shop scheduling. arXiv 2021, arXiv:2104.03760. [Google Scholar]
- Kuhnle, A.; Schäfer, L.; Stricker, N.; Lanza, G. Design, implementation and evaluation of reinforcement learning for an adaptive order dispatching in job shop manufacturing systems. Procedia CIRP 2019, 81, 234–239. [Google Scholar] [CrossRef]
- Kuhnle, A.; Röhrig, N.; Lanza, G. Autonomous order dispatching in the semiconductor industry using reinforcement learning. Procedia CIRP 2019, 79, 391–396. [Google Scholar] [CrossRef]
- Xia, K.; Sacco, C.; Kirkpatrick, M.; Saidy, C.; Nguyen, L.; Kircaliali, A.; Harik, R. A digital twin to train deep reinforcement learning agent for smart manufacturing plants: Environment, interfaces and intelligence. J. Manuf. Syst. 2021, 58, 210–230. [Google Scholar] [CrossRef]
- Kuhnle, A.; Kaiser, J.P.; Theiß, F.; Stricker, N.; Lanza, G. Designing an adaptive production control system using reinforcement learning. J. Intell. Manuf. 2021, 32, 855–876. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, Y.; Tan, Y.; Zhang, J.; Yu, H. Dynamic Jobshop Scheduling Algorithm Based on Deep Q Network. IEEE Access 2021, 9, 122995–123011. [Google Scholar] [CrossRef]
- Wang, H.; Sarker, B.R.; Li, J.; Li, J. Adaptive scheduling for assembly job shop with uncertain assembly times based on dual Q-learning. Int. J. Prod. Res. 2021, 59, 5867–5883. [Google Scholar] [CrossRef]
- Zeng, Y.; Liao, Z.; Dai, Y.; Wang, R.; Li, X.; Yuan, B. Hybrid intelligence for dynamic job-shop scheduling with deep reinforcement learning and attention mechanism. arXiv 2022, arXiv:2201.00548. [Google Scholar]
- Luo, S.; Zhang, L.; Fan, Y. Dynamic multi-objective scheduling for flexible job shop by deep reinforcement learning. Comput. Ind. Eng. 2021, 159, 107489. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Waschneck, B.; Altenmüller, T.; Bauernhansl, T.; Kyek, A. Production Scheduling in Complex Job Shops from an Industry 4.0 Perspective: A Review and Challenges in the Semiconductor Industry. In Proceedings of the SAMI@ iKNOW, Graz, Austria, 19 October 2016; pp. 1–12. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mönch, L.; Fowler, J.W.; Mason, S.J. Production Planning and Control for Semiconductor Wafer Fabrication Facilities: Modeling, Analysis, and Systems; Springer Science & Business Media: Berlin, Germany, 2012; Volume 52. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Boebel, F.; Ruelle, O. Cycle time reduction program at ACL. In Proceedings of the IEEE/SEMI 1996 Advanced Semiconductor Manufacturing Conference and Workshop. Theme-Innovative Approaches to Growth in the Semiconductor Industry. ASMC 96 Proceedings, Cambridge, MA, USA, 12–14 November 1996; pp. 165–168. [Google Scholar]
- Schoemig, A.K. On the corrupting influence of variability in semiconductor manufacturing. In Proceedings of the 31st Conference on Winter Simulation: Simulation—A Bridge to the Future, Phoenix, AZ, USA, 5–8 December 1999; Volume 1, pp. 837–842. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Type | Description |
|---|---|
| Dispatcher waits at its current position. | |
| Dispatcher takes an undisposed order from a source to a machine. | |
| Dispatcher takes a disposed order from a machine to a sink. |
| Parameter | Value |
|---|---|
| Learning rate | 0.001 |
| Batch size | 128 |
| Epoch number | 5 |
| Gamma | 0.9 |
| Lamda | 0.95 |
| Clipping | 0.01 |
| Parameter | Default Scenario | Scenario 1 | Scenario 2 |
|---|---|---|---|
| Dispatcher speed factor | 1 | 0.3 | 1 |
| Machine buffer factor | 6 | 0.5 | 1 |
| MTBF | 1000 | 1000 | 1000 |
| MTOL | 200 | 200 | 200 |
| 0.5 | 0.5 | 0.5 | |
| 0.5 | 0.5 | 0.5 |
| Heuristic | Scenario 1 | ||
| Random | |||
| FIFO | |||
| NJF | |||
| Heuristic | Scenario 2 | ||
| Random | |||
| FIFO | |||
| NJF | |||
| PPO | Scenario 1 | ||
| PPO | Scenario 2 | ||
| , | |||
| , | |||
| , | |||
| , | |||
| , |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Lu, Y.; Hu, Y.; Amaitik, N.; Xu, Y. Dynamic Scheduling Method for Job-Shop Manufacturing Systems by Deep Reinforcement Learning with Proximal Policy Optimization. Sustainability 2022, 14, 5177. https://doi.org/10.3390/su14095177
Zhang M, Lu Y, Hu Y, Amaitik N, Xu Y. Dynamic Scheduling Method for Job-Shop Manufacturing Systems by Deep Reinforcement Learning with Proximal Policy Optimization. Sustainability. 2022; 14(9):5177. https://doi.org/10.3390/su14095177
Chicago/Turabian StyleZhang, Ming, Yang Lu, Youxi Hu, Nasser Amaitik, and Yuchun Xu. 2022. "Dynamic Scheduling Method for Job-Shop Manufacturing Systems by Deep Reinforcement Learning with Proximal Policy Optimization" Sustainability 14, no. 9: 5177. https://doi.org/10.3390/su14095177
APA StyleZhang, M., Lu, Y., Hu, Y., Amaitik, N., & Xu, Y. (2022). Dynamic Scheduling Method for Job-Shop Manufacturing Systems by Deep Reinforcement Learning with Proximal Policy Optimization. Sustainability, 14(9), 5177. https://doi.org/10.3390/su14095177