
Residential Electricity Load Forecasting Based on Fuzzy Cluster Analysis and LSSVM with Optimization by the Fireworks Algorithm

Abstract
:1. Introduction
2. Contributions
- (1)
- Based on support vector machines, this paper proposes a method for short-term load prediction, which effectively reduces the difficulty of prediction by least-squares support vector machines while alleviating the possibility of overfitting and improving the inductive ability of learners and prediction accuracy.
- (2)
- This paper proposes a feature extraction method for data compression through fuzzy cluster analysis and parameter optimization using the fireworks algorithm, which can reduce the redundancy of data more effectively, further improve the prediction effect, and reduce the difficulty of prediction, compared with traditional cluster analysis.
- (3)
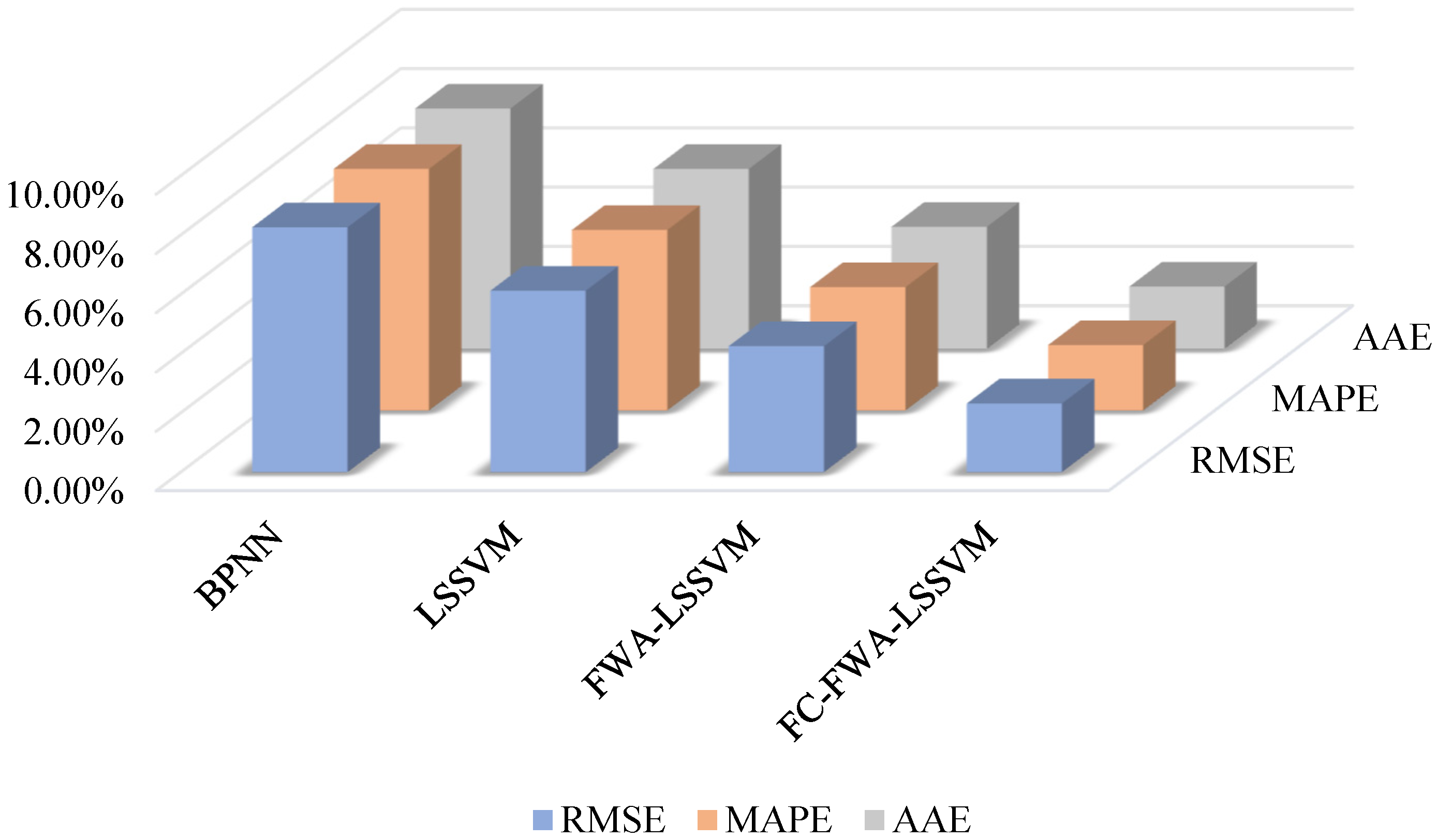
- Based on an empirical analysis of a residential neighborhood in China, this paper validates the effectiveness of the proposed method. Compared with traditional methods, the proposed method in this paper can reduce RMSE to 2.32%, MAPE to 2.21%, and AAE to 2.1%, which is suitable for high accuracy load prediction under large-scale features.
3. Materials and Methods
3.1. Fuzzy Clustering Analysis
- (1)
- Specification of data: Each characteristic indicator has a different scale and order of magnitude and needs to be normalized. The following Equation (3) was used to process the historical data:
- (2)
- Establishing fuzzy similarity relationship matrix: To measure the similarity between the samples that need to be classified, a fuzzy similarity relationship matrix was established. The methods to determine are similarity coefficient method, distance method, closeness method, etc., and the absolute value index method was used in this paper [25].
- (3)
- Dynamic clustering: We had to choose a reasonable threshold L to truncate R*. The size of the clustering level L directly affects the clustering results, and the classification gradually merges from coarse to fine as L decreases from 1 to 0, forming a kinetic gathering plot. The optimal L value can be obtained by using the rate of change of L [26].
3.2. Fireworks Optimization Algorithm
- (1)
- Explosion operator: According to the adaptation value of fireworks, we can calculate the number of sparks produced by each firework blast and the blast radius. The formulas for calculating the number of fireworks and blast radius toward the fireworks are as follows:
- (2)
- Mutation operator: Mutation operators can add to the variety of the sparks population. The variation sparks in FWA are the Gaussian mutation sparks produced by the explosion sparks through Gaussian mutation. When selecting fireworks for Gaussian mutation, the k-dimensional Gaussian mutation exercise is used as , where delegates k-dimensional variation spark, and delegates obeying Gaussian distribution.
- (3)
- Selection strategy: A certain number of individuals need to be selected for the next generation of fireworks in explosion fireworks and mutation sparks, in order to transmit more complete data and information to the next generation of fireworks.
3.3. LSSVM
3.4. Model Construction
4. Example Analysis
4.1. Input Variable Selection and Processing
- (1)
- Relative error (RE)
- (2)
- Root-mean-squared error (RMSE)
- (3)
- Mean absolute percentage error (MAPE)
- (4)
- Average absolute error (AAE)
4.2. Evaluation Indices of Forecasting Results
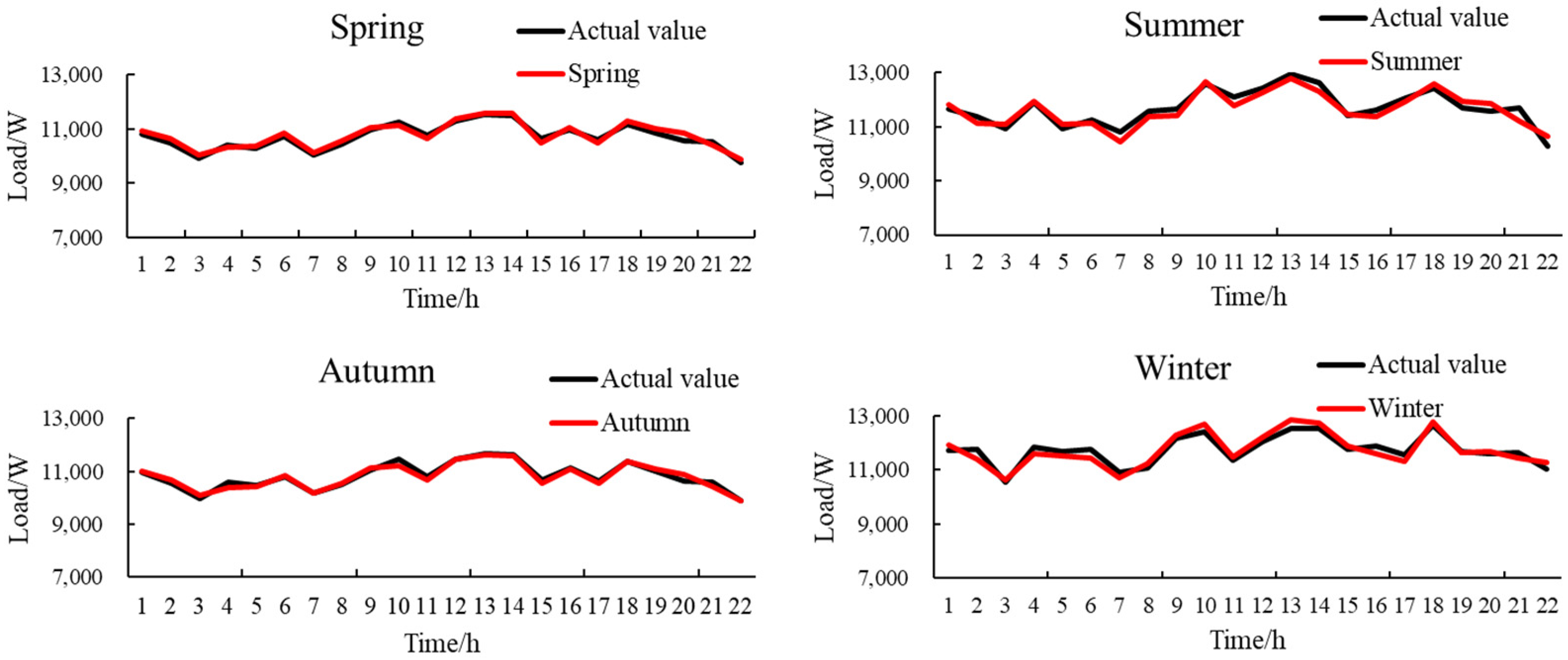
5. Scenario Validation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fan, Y.N.; Chen, C.H.; Xu, J.Y.; Xu, L.; Yu, D. Medium- and long term power load forecasting based on MATLAB gray Elman network. Tech. Autom. Appl. 2021, 40, 93–98. [Google Scholar]
- Chen, J.P.; Hu, Z.J.; Chen, W.N.; Gao, M.; Du, Y.; Lin, M. Load prediction of integrated energy system based on combination of quadratic modal decomposition and deep bidirectional long short-term memory and multiple linear regression. Autom. Electr. Power Syst. 2021, 45, 85–94. [Google Scholar]
- Zhang, H.; Li, S.X.; Shi, J.; Liu, X.; Wang, K.; Sun, X. Short-term load forecasting method based on serial GA-BP. Proc. CSU-EPSA 2021, 33, 97–101. [Google Scholar]
- Li, Z.W.; Hu, J.A.; Liu, X.; Deng, Y.; Tang, P.; Wang, Y. Multi-factor short-term load prediction model based on PCA-DBILSTM. Proc. CSU-EPSA 2020, 32, 32–39. [Google Scholar]
- Bozorg, M.; Bracale, A.; Caramia, P.; Carpinelli, G.; Carpita, M.; De Falco, P. Bayesian bootstrap quantile regression for probabilistic photovoltaic power forecasting. Prot. Control Mod. Power Syst. 2020, 5, 218–229. [Google Scholar] [CrossRef]
- Xi, Y.W.; Wu, J.Y.; Shi, C.; Zhu, X.; Cai, R. A refined load forecasting based on historical data and real-time influencing factors. Power Syst. Prot. Control 2019, 47, 80–87. [Google Scholar]
- Chen, H.; Zhang, J.; Tao, Y.; Tan, F. Asymmetric GARCH type models for asymmetric volatility characteristics analysis and wind power forecasting. Prot. Control Mod. Power Syst. 2019, 4, 29. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C. Improved BP Neural Network Based on Genetic Algorithm for Short-Term Load Forecasting of Power System. Master’s Thesis, Xi’an University of Technology, Xi’an, China, 2020. [Google Scholar]
- Zhao, P.; Dai, Y.M. Power load forecasting of SVM based on real-time price and weighted grey relational projection algorithm. Power Syst. Technol. 2020, 44, 1325–1332. [Google Scholar]
- Lin, Z.R.; Li, J.C.; Yang, D.Q.; Jun-Yun, W.U. Network traffic prediction based on wavelet neural network with improved differential evolution algorithm. Comput. Eng. Design. 2019, 40, 3413–3418. [Google Scholar]
- Liang, Y.; Wang, H.C.; Hong, W.C. Sustainable Development Evaluation of Innovation and Entrepreneurship Education of Clean Energy Major in Colleges and Universities Based on SPA-VFS and GRNN Optimized by Chaos Bat Algorithm. Sustainability 2021, 13, 5960. [Google Scholar] [CrossRef]
- Yan, C.; Tang, Y.; Dai, J.; Wang, C.; Wu, S. Uncertainty modeling of wind power frequency regulation potential considering distributed characteristics of forecast errors. Prot. Control Mod. Power Syst. 2021, V6, 276–288. [Google Scholar] [CrossRef]
- Wang, Y.L.; Zhou, M.H.; Yao, S.H.; Wei, M.J.; Yang, Y.; Liu, Z.; Hu, M.J. Multi-load cooperative prediction model of integrated energy system based on multi-energy coupling mechanism. J. North China Electr. Power Univ. (Nat. Sci. Ed.) 2021, 1–10. Available online: https://kns.cnki.net/kcms/detail/13.1212.tm.20210705.1544.002.html (accessed on 15 December 2021).
- Hu, L.J.; Guo, C.Z.; Wang, J.S. Short-term Power Load Forecasting Based on ISSA-LSSVM Model. Sci. Technol. Eng. 2021, 21, 9916–9922. [Google Scholar]
- Wang, H.; Liang, Y.; Ding, W.; Niu, D.; Li, S.; Wang, F. The Improved Least Square Support Vector Machine Based on Wolf Pack Algorithm and Data Inconsistency Rate for Cost Prediction of Substation Projects. Math. Probl. Eng. 2020, 2020, 6663006. [Google Scholar] [CrossRef]
- Liu, X.D.; Zou, Y.N.; Xiong, X.D.; Cheng, C.; Yang, H.Y. A regional load forecasting method based on improved Cuckoo Search LSSVM. Inf. Technol. 2021, 45, 41–47. [Google Scholar]
- Han, P.P.; Pan, W.; Zhang, N.; Wu, H.; Qiu, R.; Zhang, Z. Optimization method for artificial phase sequence based on load forecasting and non-dominated sorting genetic algorithm. Autom. Electr. Power Syst. 2020, 44, 71–78. [Google Scholar]
- Guan, S.H.; Shen, Y.X. Power load forecasting based on PSO RBF-NN. Transducer Microsyst. Technol. 2021, 40, 128–131. [Google Scholar]
- Erdiwansyah, M.; Husin, H.; Nasaruddin, M.Z.; Muhibbuddin, A. Critical review of the integration of renewable energy sources with various technologies. Prot. Control Mod. Power Syst. 2021, 6, 37–54. [Google Scholar] [CrossRef]
- Wu, Y.; Lei, J.W.; Bao, L.S.; Li, C.Z. Short-term load forecasting based on improved grey correlation analysis and neural network optimized by bat algorithm. Autom. Electr. Power Syst. 2018, 42, 67–72. [Google Scholar]
- Wang, Y.F.; Zheng, Y.P.; Xue, H. Optimal dispatch of mobile energy storage for peak load shifting based on enhanced firework algorithm. Autom. Electr. Power Syst. 2021, 45, 48–56. [Google Scholar]
- Soh, W.; Kim, H.; Yum, B.-J. Application of kernel principal component analysis to multi-characteristic parameter design problems. Ann. Oper. Res. 2018, 263, 69–91. [Google Scholar] [CrossRef]
- Xie, L.; Li, Z.; Zeng, J.; Kruger, U. Block adaptive kernel principal component analysis for nonlinear process monitoring. AIChE J. 2016, 62, 4334–4345. [Google Scholar] [CrossRef]
- Wang, R.; Chen, S.W.; Lu, J. Time-division refined short term load forecasting based on BOA-SVR and Fuzzy Clustering. Eng. J. Wuhan Univ. 2021, 1–10. [Google Scholar]
- Filho, J.B.O.S.; Diniz, P.S.R. A Fixed-Point Online Kernel Principal Component Extraction Algorithm. IEEE Trans. Signal Process. 2017, 65, 6244–6259. [Google Scholar] [CrossRef]
- Omar Noureldeen, I. Hamdan. A novel controllable crowbar based on fault type protection technique for DFIG wind energy conversion system using adaptive neuro-fuzzy inference system. Prot. Control Mod. Power Syst. 2018, 3, 328–339. [Google Scholar]
- Dong, W.C.; Li, S.H. Reliability sensitivity of wind power system considering correlation of forecast errors based on multivariate NSTPNT method. Prot. Control Mod. Power Syst. 2021, 6, 136–146. [Google Scholar] [CrossRef]
- Shang, L.; Zhu, W.; Li, P.; Guo, H. Maximum power point tracking of PV system under partial shading conditions through flower pollination algorithm. Prot. Control Mod. Power Syst. 2018, 3, 400–406. [Google Scholar] [CrossRef]
- Zheng, D.; Eseye, A.; Zhang, J.; Li, H. Short-term wind power forecasting using a double-stage hierarchical ANFIS approach for energy management in microgrids. Prot. Control Mod. Power Syst. 2017, 2, 136–145. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
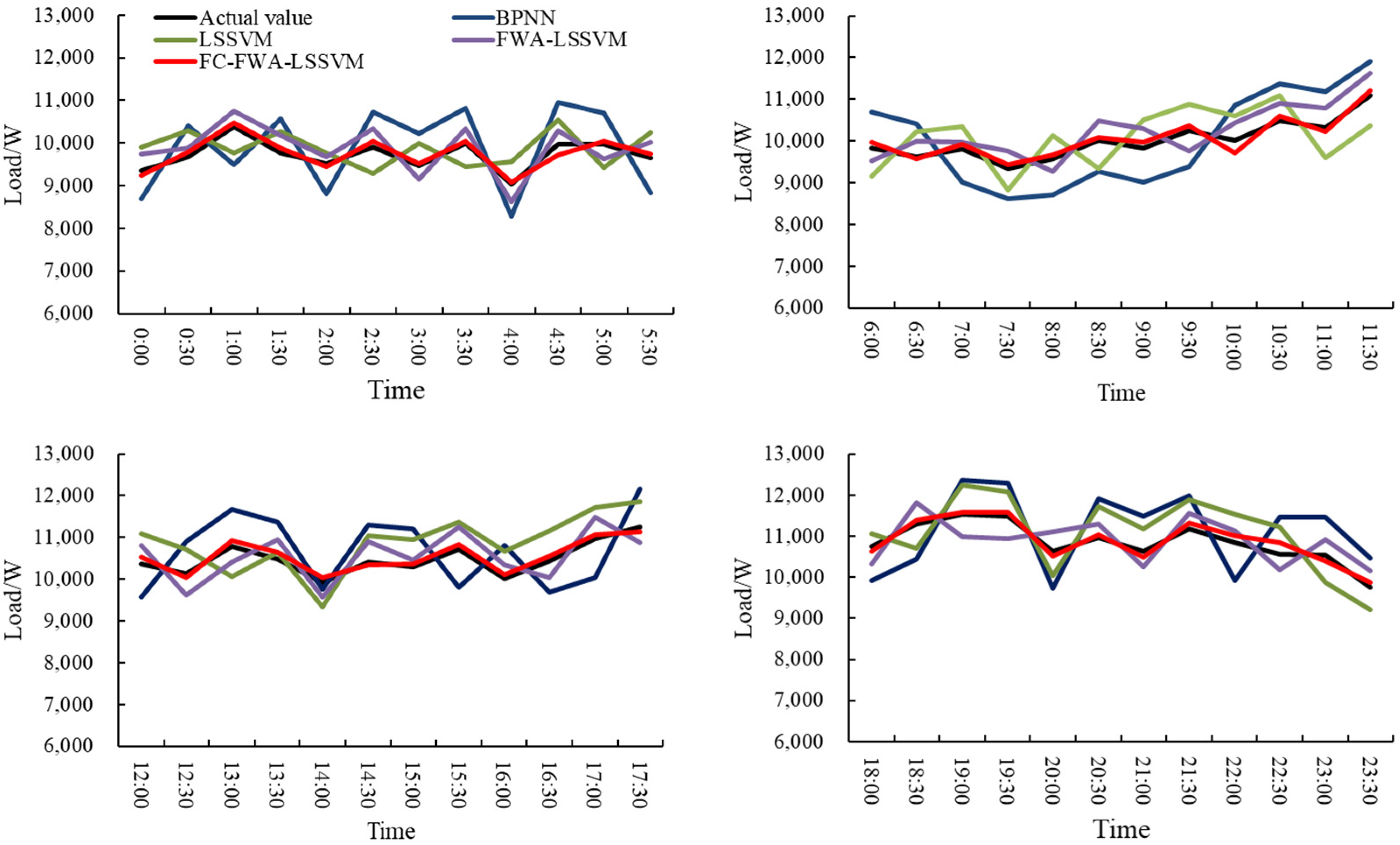
| Time | Actual Value | BPNN | LSSVM | FWA–LSSVM | FC–FWA–LSSVM |
|---|---|---|---|---|---|
| 0:00 | 9357 | 8683 | 9904 | 9743 | 9239 |
| 0:30 | 9676 | 10,418 | 10,296 | 9870 | 9785 |
| 1:00 | 10,373 | 9487 | 9776 | 10,744 | 10,469 |
| 1:30 | 9763 | 10,570 | 10,273 | 10,168 | 9874 |
| 2:00 | 9510 | 8817 | 9765 | 9685 | 9452 |
| 2:30 | 9894 | 10,718 | 9289 | 10,326 | 10,030 |
| 3:00 | 9461 | 10,226 | 9991 | 9161 | 9527 |
| … | … | … | … | … | … |
| 19:00 | 11,524 | 12,369 | 12,235 | 10,976 | 11,582 |
| 19:30 | 11,483 | 12,299 | 12,074 | 10,942 | 11,586 |
| 20:00 | 10,644 | 9720 | 10,049 | 11,107 | 10,503 |
| 20:30 | 10,972 | 11,912 | 11,720 | 11,304 | 11,038 |
| 21:00 | 10,624 | 11,492 | 11,187 | 10,261 | 10,493 |
| 21:30 | 11,173 | 11,979 | 11,897 | 11,568 | 11,310 |
| 22:00 | 10,852 | 9930 | 11,537 | 11,126 | 11,006 |
| 22:30 | 10,559 | 11,455 | 11,214 | 10,173 | 10,856 |
| 23:00 | 10,531 | 11,473 | 9884 | 10,911 | 10,393 |
| 23:30 | 9746 | 10,470 | 9212 | 10,168 | 9879 |
| Time | BPNN (%) | LSSVM (%) | FWA–LSSVM (%) | FC–FWA–LSSVM (%) |
|---|---|---|---|---|
| 0:00 | −7.199 | 5.85 | 4.13 | −1.265 |
| 0:30 | 7.667 | 6.41 | 2.01 | 1.133 |
| 1:00 | −8.546 | −5.757 | 3.575 | 0.924 |
| 1:30 | 8.27 | 5.232 | 4.156 | 1.136 |
| 2:00 | −7.284 | 2.685 | 1.848 | −0.61 |
| 2:30 | 8.321 | −6.115 | 4.368 | 1.376 |
| 3:00 | 8.09 | 5.601 | −3.165 | 0.7 |
| … | … | … | … | … |
| 19:00 | 7.335 | 6.168 | −4.754 | 0.501 |
| 19:30 | 7.11 | 5.15 | −4.713 | 0.899 |
| 20:00 | −8.68 | −5.591 | 4.348 | −1.322 |
| 20:30 | 8.573 | 6.821 | 3.029 | 0.603 |
| 21:00 | 8.169 | 5.3 | −3.42 | −1.234 |
| 21:30 | 7.215 | 6.481 | 3.537 | 1.222 |
| 22:00 | −8.496 | 6.306 | 2.526 | 1.418 |
| 22:30 | 8.484 | 6.206 | −3.658 | 2.813 |
| 23:00 | 8.943 | −6.149 | 3.6 | −1.317 |
| 23:30 | 7.427 | −5.475 | 4.325 | 1.367 |
| BPNN | LSSVM | FWA–LSSVM | FC–FWA–LSSVM | |
|---|---|---|---|---|
| RMSE | 8.26% | 6.12% | 4.25% | 2.32% |
| MAPE | 8.15% | 6.09% | 4.16% | 2.21% |
| AAE | 8.11% | 6.07% | 4.12% | 2.10% |
| Season | Index | FC–FWA–LSSVM |
|---|---|---|
| Spring | RMSE | 2.09% |
| MAPE | 2.21% | |
| MAE | 2.03% | |
| Summer | RMSE | 2.01% |
| MAPE | 2.08% | |
| MAE | 2.44% | |
| Autumn | RMSE | 2.21% |
| MAPE | 2.17% | |
| MAE | 2.03% | |
| Winter | RMSE | 2.19% |
| MAPE | 2.32% | |
| MAE | 2.40% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Shen, B.; Lin, L.; Liu, D.; Yan, M.; Li, G. Residential Electricity Load Forecasting Based on Fuzzy Cluster Analysis and LSSVM with Optimization by the Fireworks Algorithm. Sustainability 2022, 14, 1312. https://doi.org/10.3390/su14031312
Zhao X, Shen B, Lin L, Liu D, Yan M, Li G. Residential Electricity Load Forecasting Based on Fuzzy Cluster Analysis and LSSVM with Optimization by the Fireworks Algorithm. Sustainability. 2022; 14(3):1312. https://doi.org/10.3390/su14031312
Chicago/Turabian StyleZhao, Xinyue, Baoxing Shen, Lin Lin, Daohong Liu, Meng Yan, and Gengyin Li. 2022. "Residential Electricity Load Forecasting Based on Fuzzy Cluster Analysis and LSSVM with Optimization by the Fireworks Algorithm" Sustainability 14, no. 3: 1312. https://doi.org/10.3390/su14031312
APA StyleZhao, X., Shen, B., Lin, L., Liu, D., Yan, M., & Li, G. (2022). Residential Electricity Load Forecasting Based on Fuzzy Cluster Analysis and LSSVM with Optimization by the Fireworks Algorithm. Sustainability, 14(3), 1312. https://doi.org/10.3390/su14031312