
Computer-Vision-Based Statue Detection with Gaussian Smoothing Filter and EfficientDet



Abstract
:1. Introduction
- Applying the Gaussian Smoothing filter to improve the performance of the trained models.
- A lightweight object detection model that can be deployed to mobile phones and edge devices was proposed to detect statues efficiently.
- A mobile application with the trained model as a backend was developed to detect the statue and give information about the statue.
2. Related Works
2.1. Two-Stage Detection
2.2. One Stage Detection
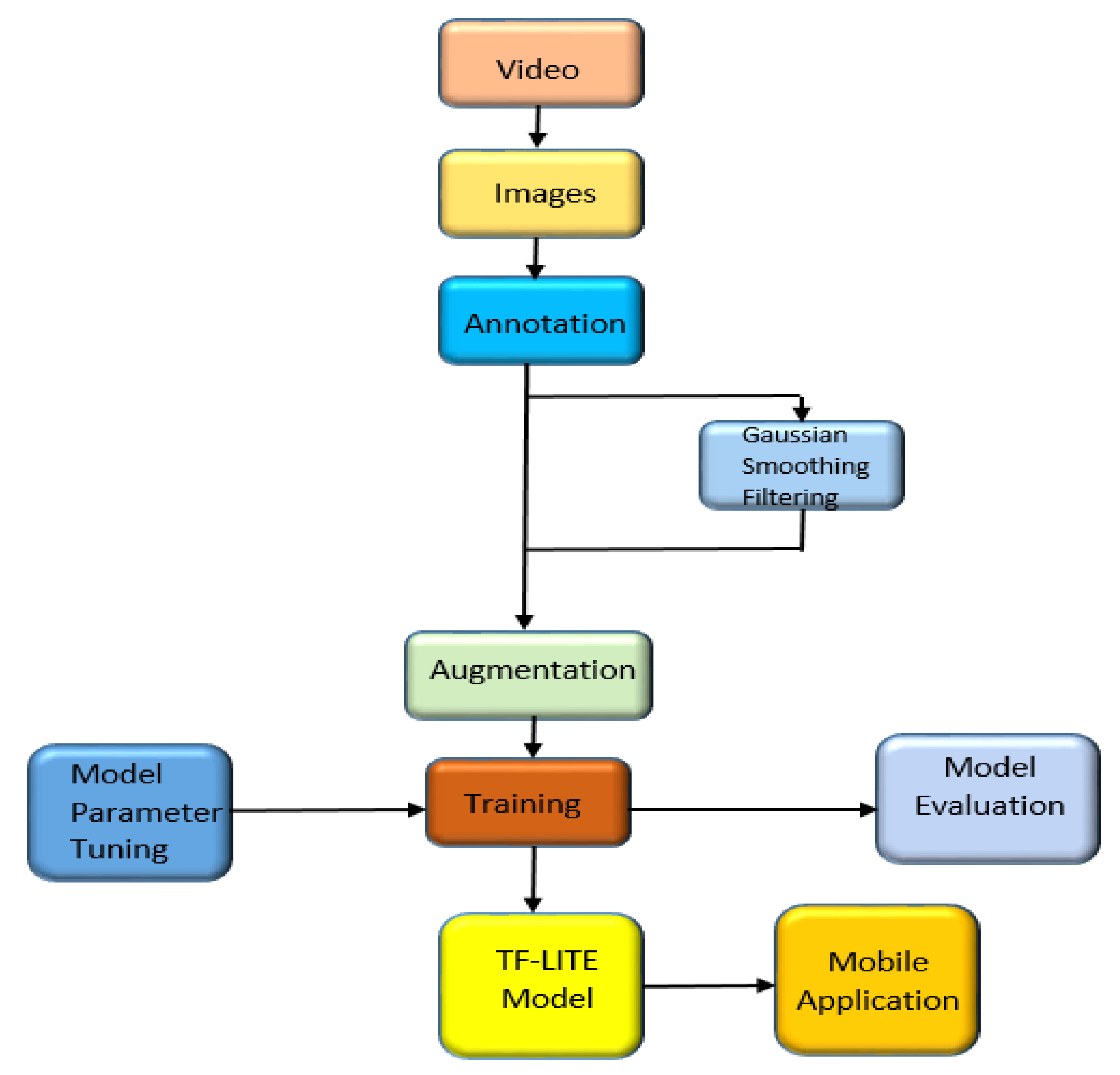
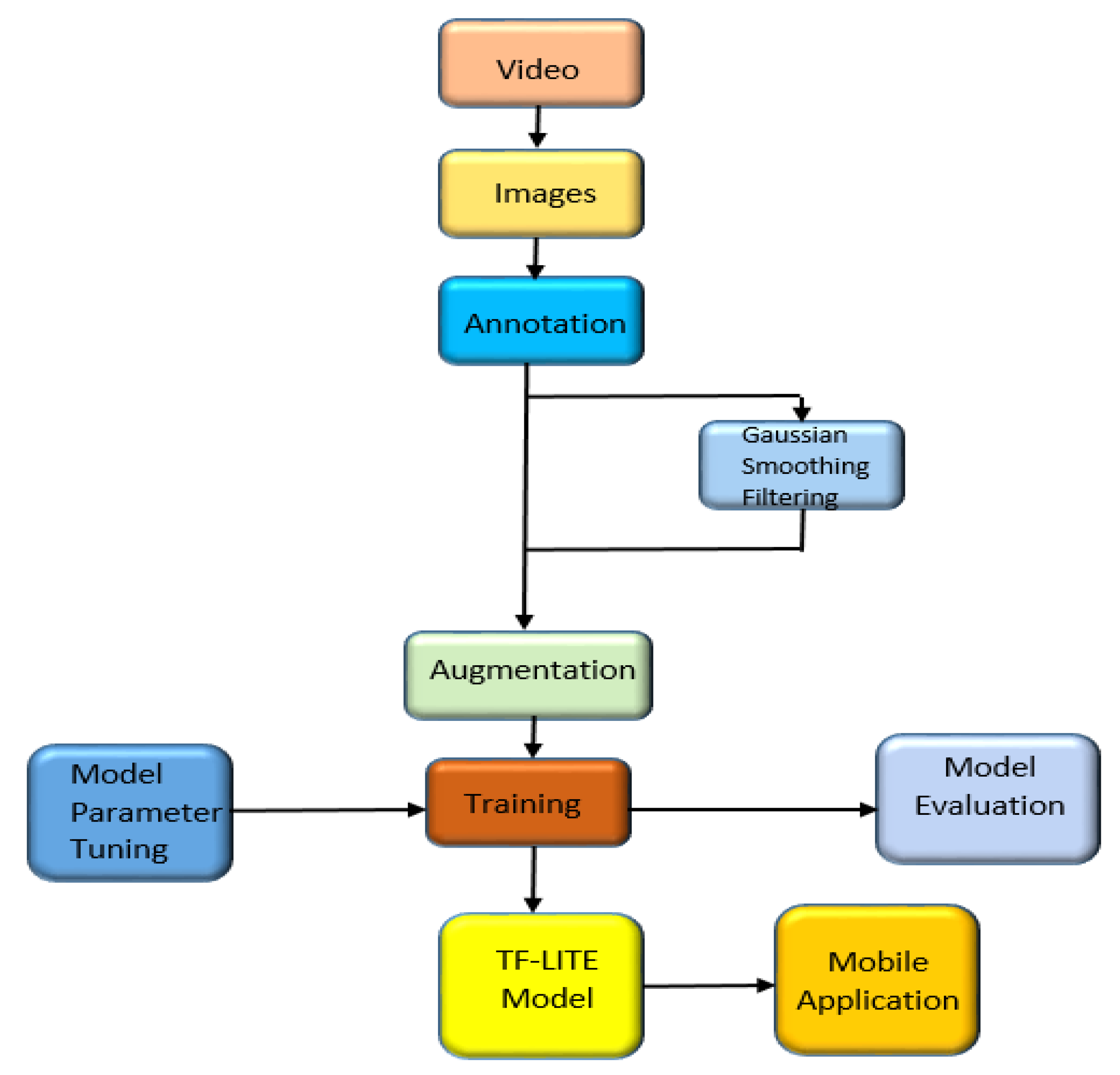
3. Statue Detection
3.1. Dataset and Data Preprocessing
3.2. Gaussian Filtering (Smoothing)
3.3. EfficientDet
3.4. Model Training
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Fritz, F.; Susperregui, A.; Linaza, M.T. Enhancing Cultural Tourism experiences with Augmented Reality Technologies. In Proceedings of the 6th International Symposium on Virtual Reality, Archaeology and Cultural Heritage (VAST), Pisa, Italy, 8–11 November 2005. [Google Scholar]
- Deng, J.; Xuan, X.; Wang, W.; Li, Z.; Yao, H.; Wang, Z. A review of research on object detection based on deep learning. J. Phys. Conf. Ser. 2020, 1684, 012028. [Google Scholar] [CrossRef]
- Zaifri, M.; Azough, A.; El Alaoui, S.O. Experimentation of visual augmented reality for visiting the historical monuments of the medina of Fez. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; IEEE: Manhattan, NY, USA, 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Majidi, B.; Bab-Hadiashar, A. Aerial tracking of elongated objects in rural environments. Mach. Vis. Appl. 2009, 20, 23–34. [Google Scholar] [CrossRef]
- Shamisa, A.; Majidi, B.; Patra, J.C. Sliding-window-based real-time model order reduction for stability prediction in smart grid. IEEE Trans. Power Syst. 2019, 34, 326–337. [Google Scholar] [CrossRef]
- Mansouri, A.; Majidi, B.; Shamisa, A. Metaheuristic neural networks for anomaly recognition in industrial sensor networks with packet latency and jitter for smart infrastructures. Int. J. Comput. Appl. 2021, 43, 257–266. [Google Scholar] [CrossRef]
- Gedraite, E.S.; Hadad, M. Investigation on the effect of a Gaussian Blur in image filtering and segmentation. Proc. Elmar Int. Symp. Electron. Mar. 2011, 393–396. Available online: https://www.semanticscholar.org/paper/Investigation-on-the-effect-of-a-Gaussian-Blur-in-Gedraite-Hadad/6c1144d8705840e075739393a10235fcc4cd0f4b#citing-papers (accessed on 21 June 2022).
- Magnier, B.; Montesinos, P.; Diep, D. Ridges and valleys detection in images using difference of rotating half smoothing filters. In International Conference on Advanced Concepts for Intelligent Vision Systems; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6915, pp. 261–272. [Google Scholar] [CrossRef]
- Liu, J.; Xu, C.; Zhao, Y. Improvement of Facial Expression Recognition Based on Filtering and Certainty Check. In Proceedings of the 2021 International Conference on Electronic Information Engineering and Computer Science (EIECS), Changchun, China, 23–26 September 2021; IEEE: Manhattan, NY, USA, 2021; pp. 209–213. [Google Scholar] [CrossRef]
- Ke, Q.; Zhang, J.; Song, H.; Wan, Y. Big data analytics enabled by feature extraction based on partial independence. Neurocomputing 2018, 288, 3–10. [Google Scholar] [CrossRef]
- Zhou, B.; Duan, X.; Ye, D.; Wei, W.; Woźniak, M.; Połap, D.; Damaševičius, R. Multi-level features extraction for discontinuous target tracking in remote sensing image monitoring. Sensors 2019, 19, 4855. [Google Scholar] [CrossRef]
- Wei, W.; Poap, D.; Li, X.; Woźniak, M.; Liu, J. Study on Remote Sensing Image Vegetation Classification Method Based on Decision Tree Classifier. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; IEEE: Manhattan, NY, USA, 2019; pp. 2292–2297. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, P.; Peng, X.; Zhu, G.; Song, J.; Wei, W.; Song, H. Simultaneous enhancement and noise reduction of a single low-light image. IET Image Process. 2016, 10, 840–847. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Manhattan, NY, USA, 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Wei, W.; Zhou, B.; Maskeliūnas, R.; Damaševičius, R.; Połap, D.; Woźniak, M. Iterative Design and Implementation of Rapid Gradient Descent Method. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 29 April–3 May 2012; Springer: Cham, Switzerland, 2019; Volume 11508, pp. 530–539. [Google Scholar] [CrossRef]
- Ameen, Z.S.; Saleh Mubarak, A.; Altrjman, C.; Alturjman, S.; Abdulkadir, R.A. C-SVR Crispr: Prediction of CRISPR/Cas12 guideRNA activity using deep learning models. In Proceedings of the 2021 International Conference on Forthcoming Networks and Sustainability in AIoT Era (FoNeS-AIoT), Nicosia, Turkey, 27–28 December 2021; IEEE: Manhattan, NY, USA, 2021; Volume 60, pp. 9–12. [Google Scholar]
- Ameen, Z.S.; Saleh Mubarak, A.; Altrjman, C.; Alturjman, S.; Abdulkadir, R.A. Explainable Residual Network for Tuberculosis Classification in the IoT Era. In Proceedings of the International Conference on Forthcoming Networks and Sustainability in AIoT Era (FoNeS-AIoT), Nicosia, Turkey, 27–28 December 2021; IEEE: Manhattan, NY, USA, 2021; pp. 9–12. [Google Scholar] [CrossRef]
- Van De Sande, K.E.A.; Uijlings, J.R.R.; Gevers, T.; Smeulders, A.W.M. Segmentation as selective search for object recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2021; IEEE: Manhattan, NY, USA, 2011; pp. 1879–1886. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Manhattan, NY, USA, 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Cai, Z.; Saberian, M.; Vasconcelos, N. Learning Complexity-Aware Cascades for Pedestrian Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2195–2211. [Google Scholar] [CrossRef] [PubMed]
- Dai, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. Adv. Neural Inf. Process. Syst. 2016, 29–38. Available online: https://proceedings.neurips.cc/paper/2016/hash/577ef1154f3240ad5b9b413aa7346a1e-Abstract.html (accessed on 21 June 2022).
- Divvala, S.K.; Hoiem, D.; Hays, J.H.; Efros, A.A.; Hebert, M. An empirical study of context in object detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Manhattan, NY, USA, 2009; pp. 1271–1278. [Google Scholar] [CrossRef]
- Mubarak, A.S.; Sa’id Ameen, Z.; Tonga, P.; Al-Turjman, F. Smart Tourism: A Proof of Concept For Cyprus Museum of Modern Arts In The IoT Era. In Proceedings of the 2021 International Conference on Artificial Intelligence of Things (ICAIoT), Nicosia, Turkey, 3–4 September 2021; IEEE: Manhattan, NY, USA, 2021; pp. 49–53. [Google Scholar] [CrossRef]
- Mubarak, A.S.; Ameen, Z.S.; Tonga, P.; Altrjman, C.; Al-Turjman, F. A Framework for Pothole Detection via the AI-Blockchain Integration. In Proceedings of the 2021 International Conference on Forthcoming Networks and Sustainability in AIoT Era (FoNeS-AIoT), Erbil, Iraq, 28 September 2022; IEEE: Manhattan, NY, USA, 2022; pp. 398–406. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Manhattan, NY, USA, 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Wu, B.; Wan, A.; Iandola, F.; Jin, P.H.; Keutzer, K. SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; IEEE: Manhattan, NY, USA, 2017; pp. 446–454. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger Joseph. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Manhattan, NY, USA, 2017; pp. 187–213. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.; Ai, F.; Doll, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Manhattan, NY, USA, 2017; pp. 2980–2988. [Google Scholar]
- Bisong, E. Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Apress: Berkeley, CA, USA, 2019; pp. 59–64. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; Association for the Advancement of Artificial Intelligence (AAAI): Menlo Park, CA, USA, 2020; Volume 34, pp. 12993–13000. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2014; Volume 8691, pp. 346–361. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. PANet: Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Manhattan, NY, USA, 2018; pp. 8759–8768. [Google Scholar]
- Zhang, D.S.; Li, S.Z.; Wei, W. Visual clustering methods with feature displayed function for self-organizing. In Proceedings of the 2010 The 2nd International Conference on Industrial Mechatronics and Automation, Wuhan, China, 30–31 May 2010; IEEE: Manhattan, NY, USA, 2010; Volume 2, pp. 452–455. [Google Scholar] [CrossRef]
- Liu, W.; Liao, S.; Hu, W.; Liang, X.; Chen, X. Learning Efficient Single-Stage Pedestrian Detectors by Asymptotic Localization Fitting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; Volume 11218, pp. 643–659. [Google Scholar] [CrossRef]
- Mubarak, A.; Said, Z.; Aliyu, R.; Al Turjman, F.; Serte, S.; Ozsoz, M. Deep learning-based feature extraction coupled with multi-class SVM for COVID-19 detection in the IoT era. Int. J. Nanotechnol. 2021, 1, 1. [Google Scholar] [CrossRef]
- Mubarak, A.S.; Serte, S.; Al-Turjman, F.; Ameen, Z.S.; Ozsoz, M. Local binary pattern and deep learning feature extraction fusion for COVID-19 detection on computed tomography images. Expert Syst. 2021, 39, e12842. [Google Scholar] [CrossRef]
- Haque, A.B.; Rahman, M. Augmented COVID-19 X-ray Images Dataset (Mendely) Analysis using Convolutional Neural Network and Transfer Learning. 2020, 19. Available online: https://www.researchgate.net/publication/340514197_Augmented_COVID-19_X-ray_Images_Dataset_Mendely_Analysis_using_Convolutional_Neural_Network_and_Transfer_Learning?channel=doi&linkId=5e8e0a9592851c2f5288a56e&showFulltext=true (accessed on 21 June 2022). [CrossRef]
- Apostolopoulos, I.D.; Mpesiana, T.A. Covid-19: Automatic detection from X-ray images utilizing transfer learning with convolutional neural networks. Phys. Eng. Sci. Med. 2020, 43, 635–640. [Google Scholar] [CrossRef]
- Hussein, S.; Kandel, P.; Bolan, C.W.; Wallace, M.B.; Bagci, U. Lung and Pancreatic Tumor Characterization in the Deep Learning Era: Novel Supervised and Unsupervised Learning Approaches. IEEE Trans. Med. Imaging 2019, 38, 1777–1787. [Google Scholar] [CrossRef]
- Loey, M.; Smarandache, F.; Khalifa, M.N.E. Within the Lack of Chest COVID-19 X-ray Dataset: A Novel Detection Model Based on GAN and Deep Transfer Learning. Symmetry 2020, 12, 651. [Google Scholar] [CrossRef]
- Mahmud, T.; Rahman, M.A.; Fattah, S.A. CovXNet: A multi-dilation convolutional neural network for automatic COVID-19 and other pneumonia detection from chest X-ray images with transferable multi-receptive feature optimization. Comput. Biol. Med. 2020, 122, 103869. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Zheng, S.; Li, X.; Qin, X. A new image denoising method based on Gaussian filter. In Proceedings of the 2014 International Conference on Information Science, Electronics and Electrical Engineering, Sapporo, Japan, 26–28 April 2014; IEEE: Manhattan, NY, USA, 2014; Volume 1, pp. 163–167. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Manhattan, NY, USA, 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; IEEE: Manhattan, NY, USA, 2019; pp. 6568–6577. [Google Scholar]
- Howard, A.G.; Wang, W. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Manhattan, NY, USA, 2017; pp. 2961–2969. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | Testing |
|---|---|---|
| 6696 | 774 | 774 |
| Models | mAP | mAP-50 | mAP-75 |
|---|---|---|---|
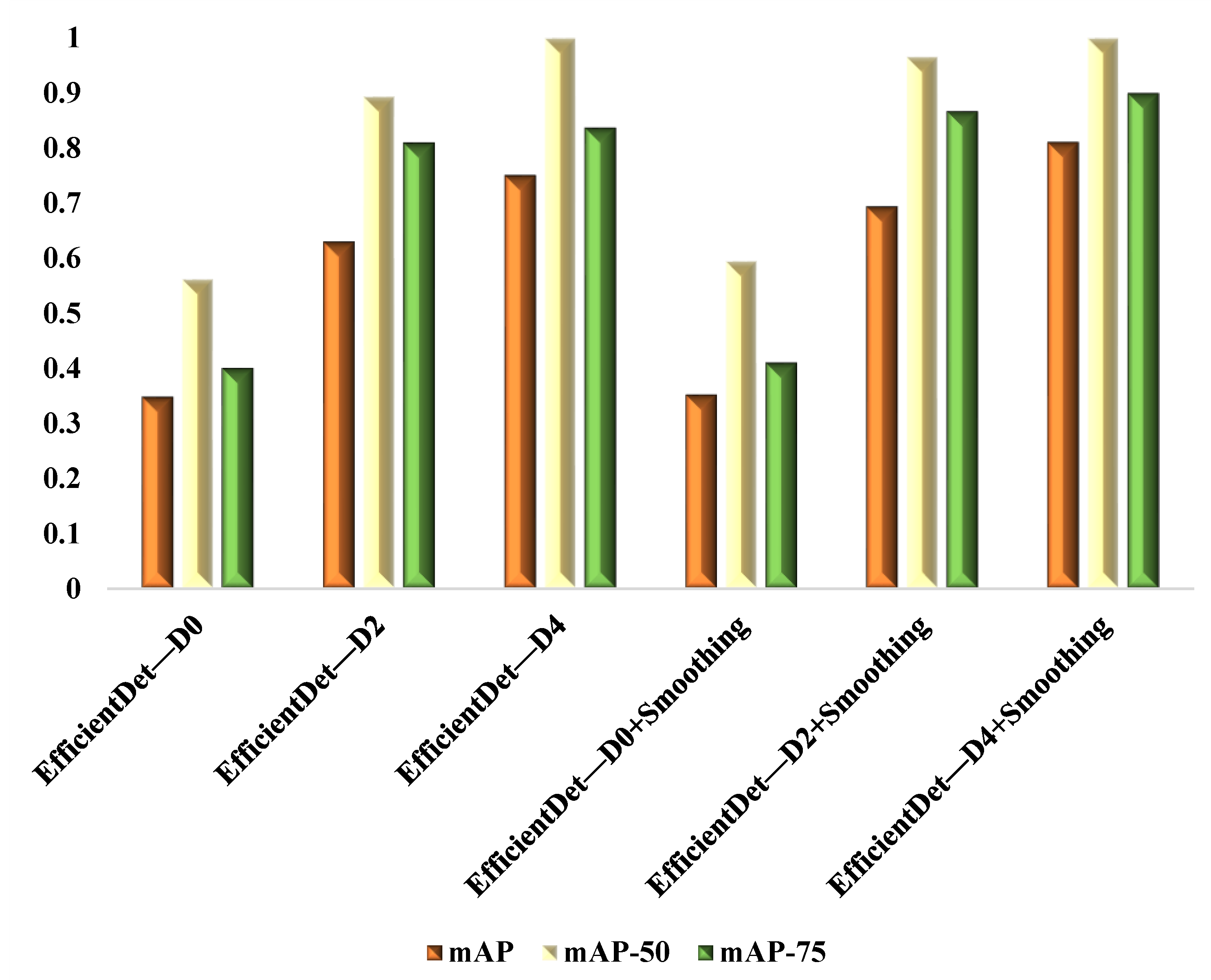
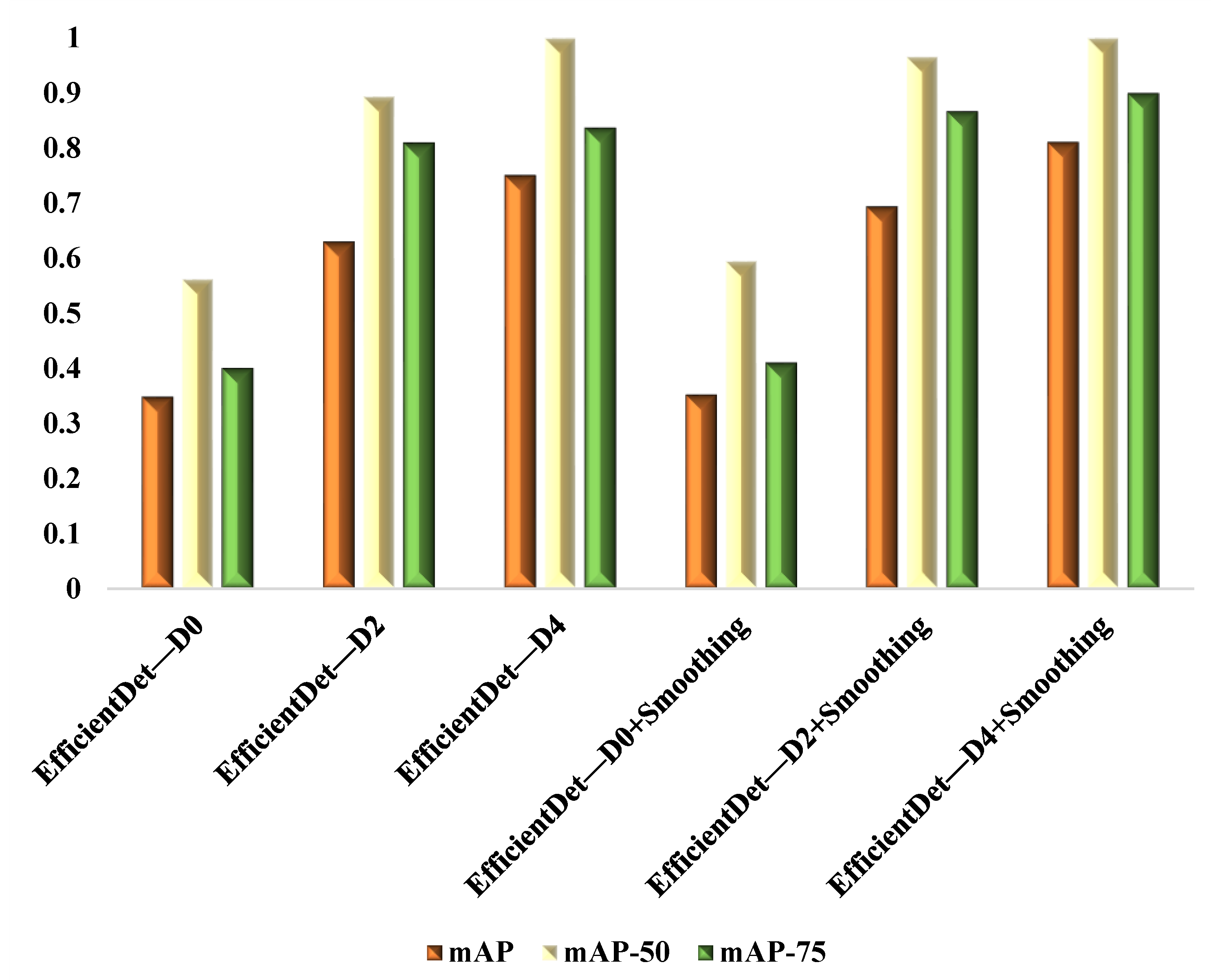
| EfficientDet—D0 | 0.348 | 0.562 | 0.4 |
| EfficientDet—D2 | 0.63 | 0.894 | 0.81 |
| EfficientDet—D4 | 0.751 | 1 | 0.837 |
| EfficientDet—D0 + Smoothing | 0.352 | 0.595 | 0.41 |
| EfficientDet—D2 + Smoothing | 0.694 | 0.966 | 0.867 |
| EfficientDet—D4 + Smoothing | 0.811 | 1 | 0.9 |
| Model | mAP | mAP-50 | mAP-75 |
|---|---|---|---|
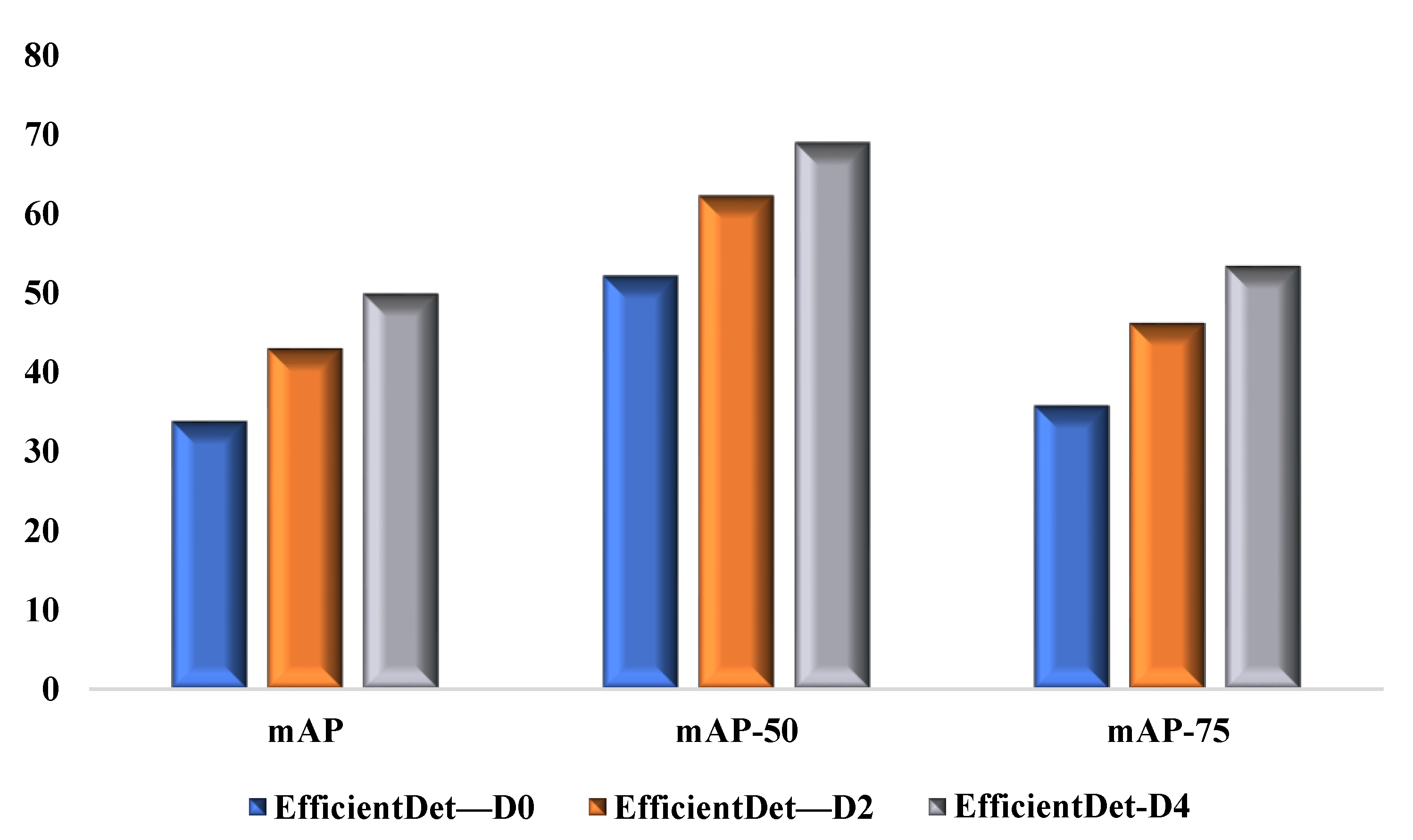
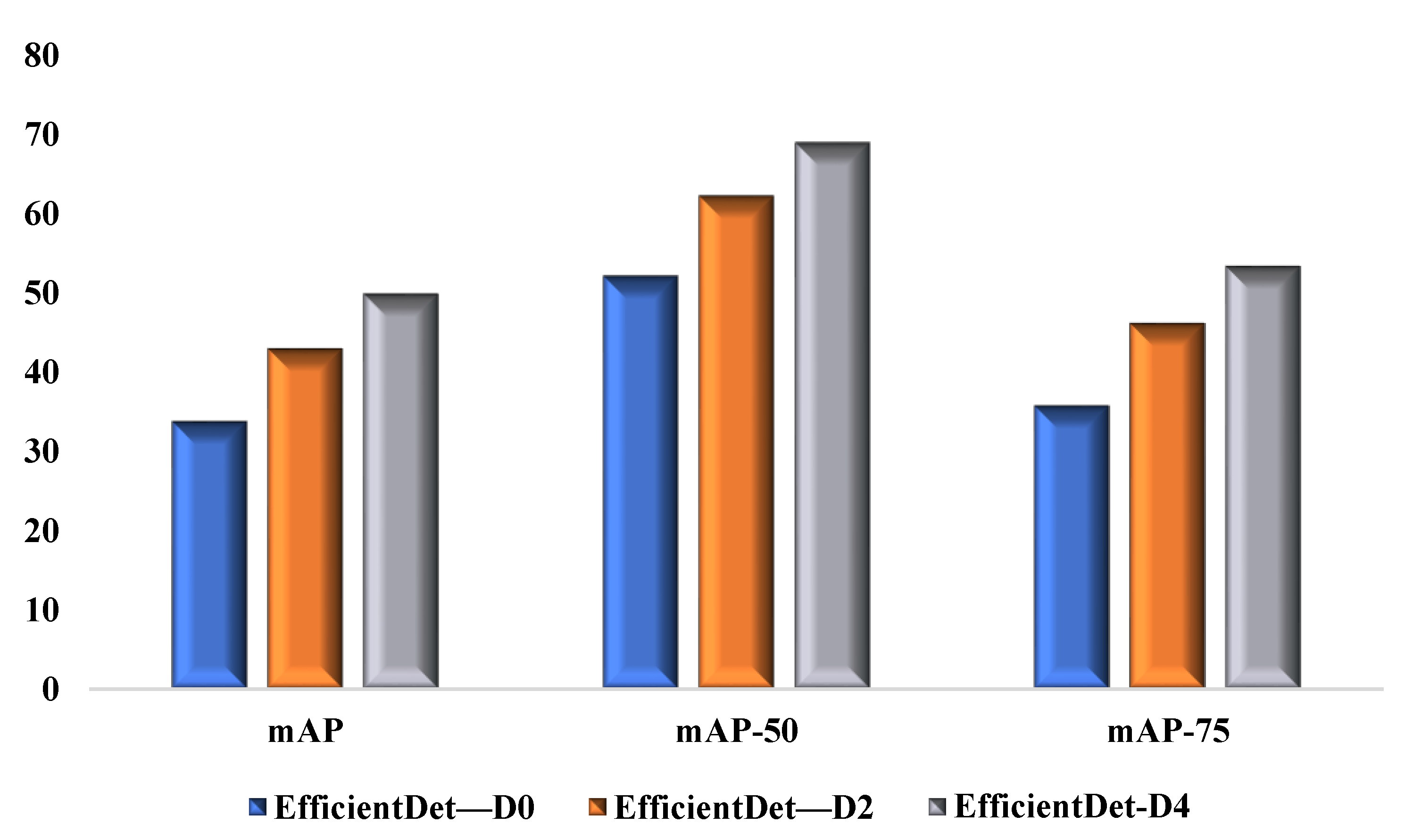
| EfficientDet—D0 | 33.8 | 52.2 | 35.8 |
| EfficientDet—D2 | 43 | 62.3 | 46.2 |
| EfficientDet—D4 | 49.9 | 69 | 53.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saleh, M.A.; Ameen, Z.S.; Altrjman, C.; Al-Turjman, F. Computer-Vision-Based Statue Detection with Gaussian Smoothing Filter and EfficientDet. Sustainability 2022, 14, 11413. https://doi.org/10.3390/su141811413
Saleh MA, Ameen ZS, Altrjman C, Al-Turjman F. Computer-Vision-Based Statue Detection with Gaussian Smoothing Filter and EfficientDet. Sustainability. 2022; 14(18):11413. https://doi.org/10.3390/su141811413
Chicago/Turabian StyleSaleh, Mubarak Auwalu, Zubaida Said Ameen, Chadi Altrjman, and Fadi Al-Turjman. 2022. "Computer-Vision-Based Statue Detection with Gaussian Smoothing Filter and EfficientDet" Sustainability 14, no. 18: 11413. https://doi.org/10.3390/su141811413
APA StyleSaleh, M. A., Ameen, Z. S., Altrjman, C., & Al-Turjman, F. (2022). Computer-Vision-Based Statue Detection with Gaussian Smoothing Filter and EfficientDet. Sustainability, 14(18), 11413. https://doi.org/10.3390/su141811413