
Automatic Vehicle Identification and Classification Model Using the YOLOv3 Algorithm for a Toll Management System


 ,
,  , ,
, ,  , and
, and
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
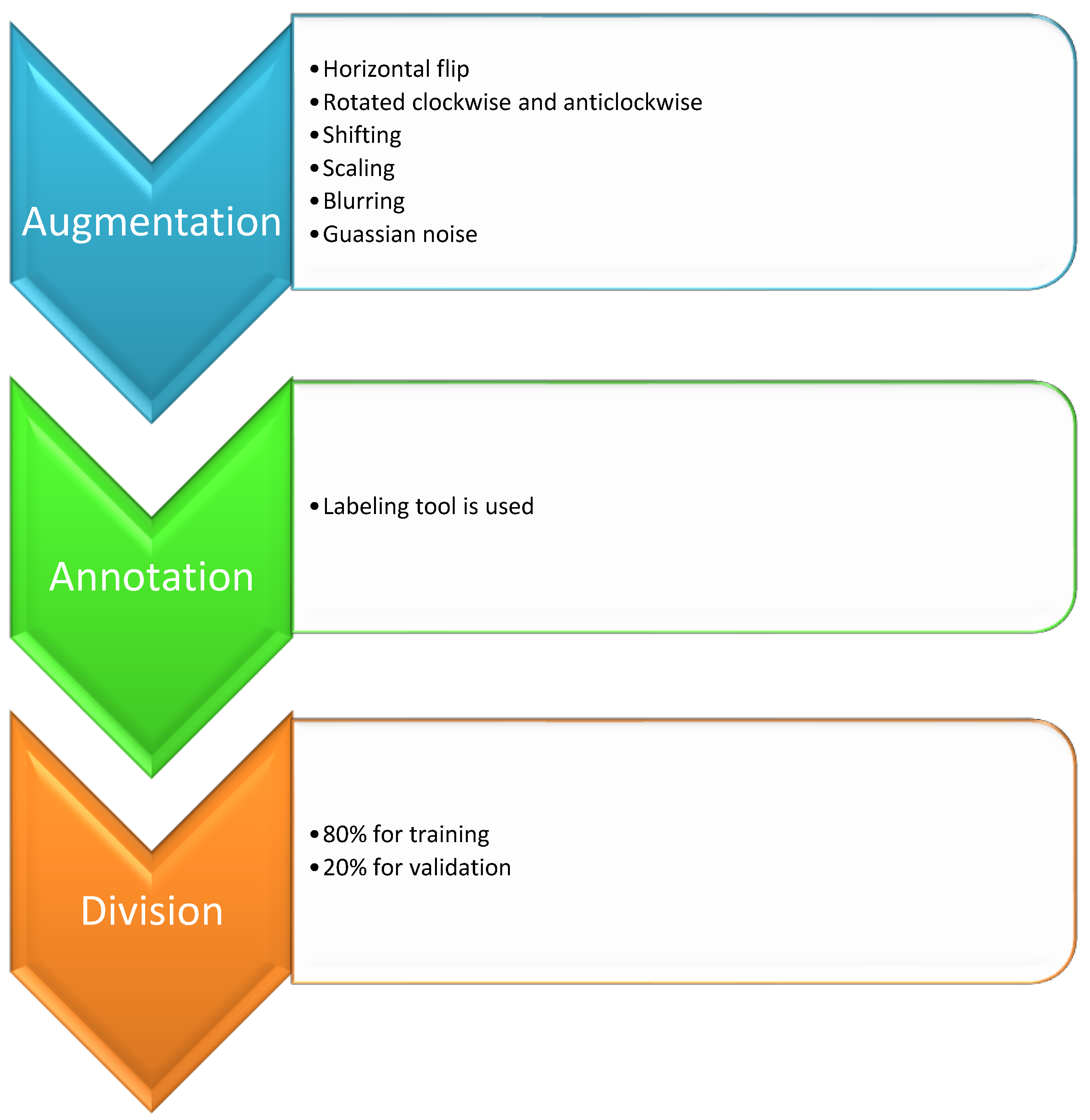
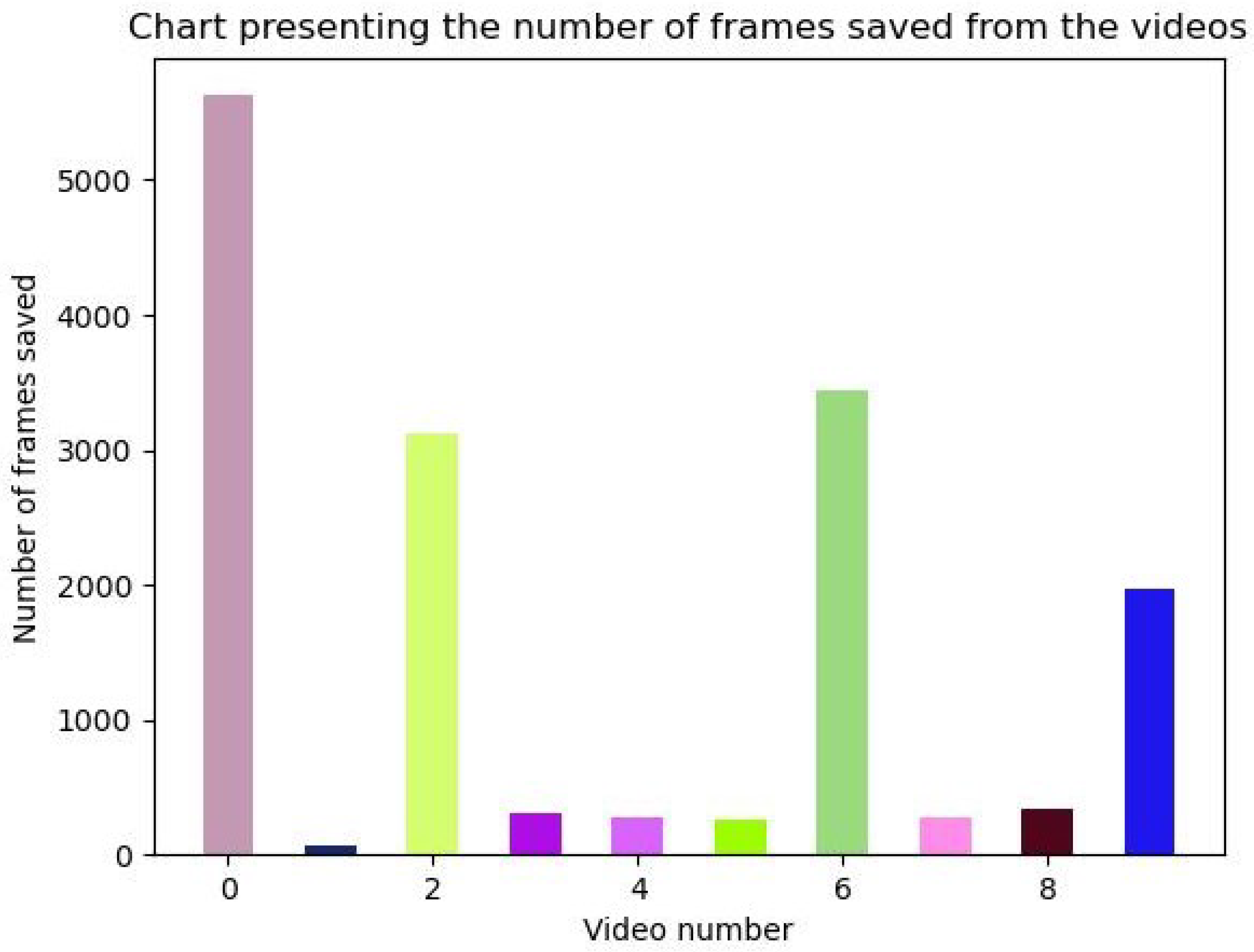
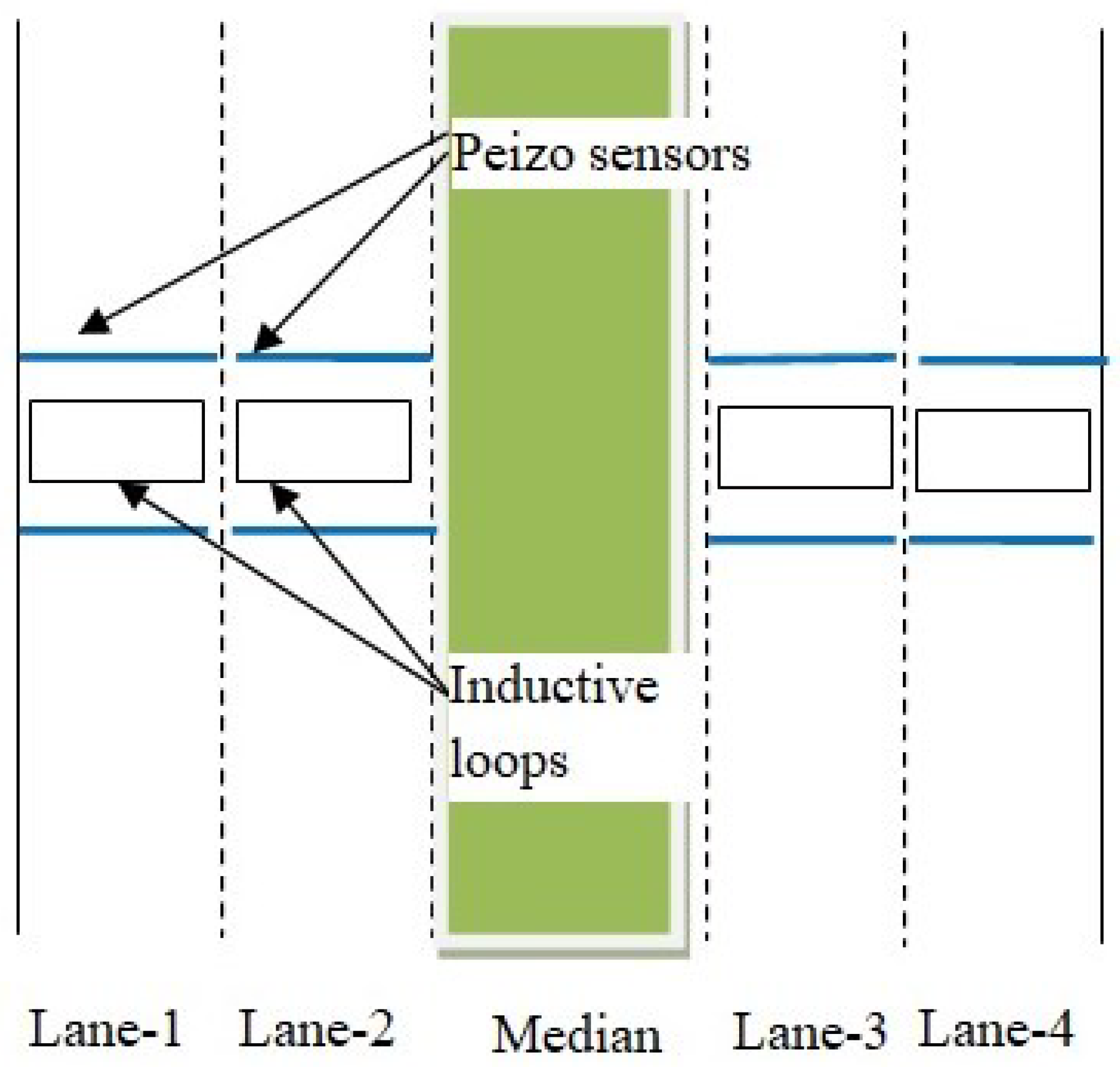
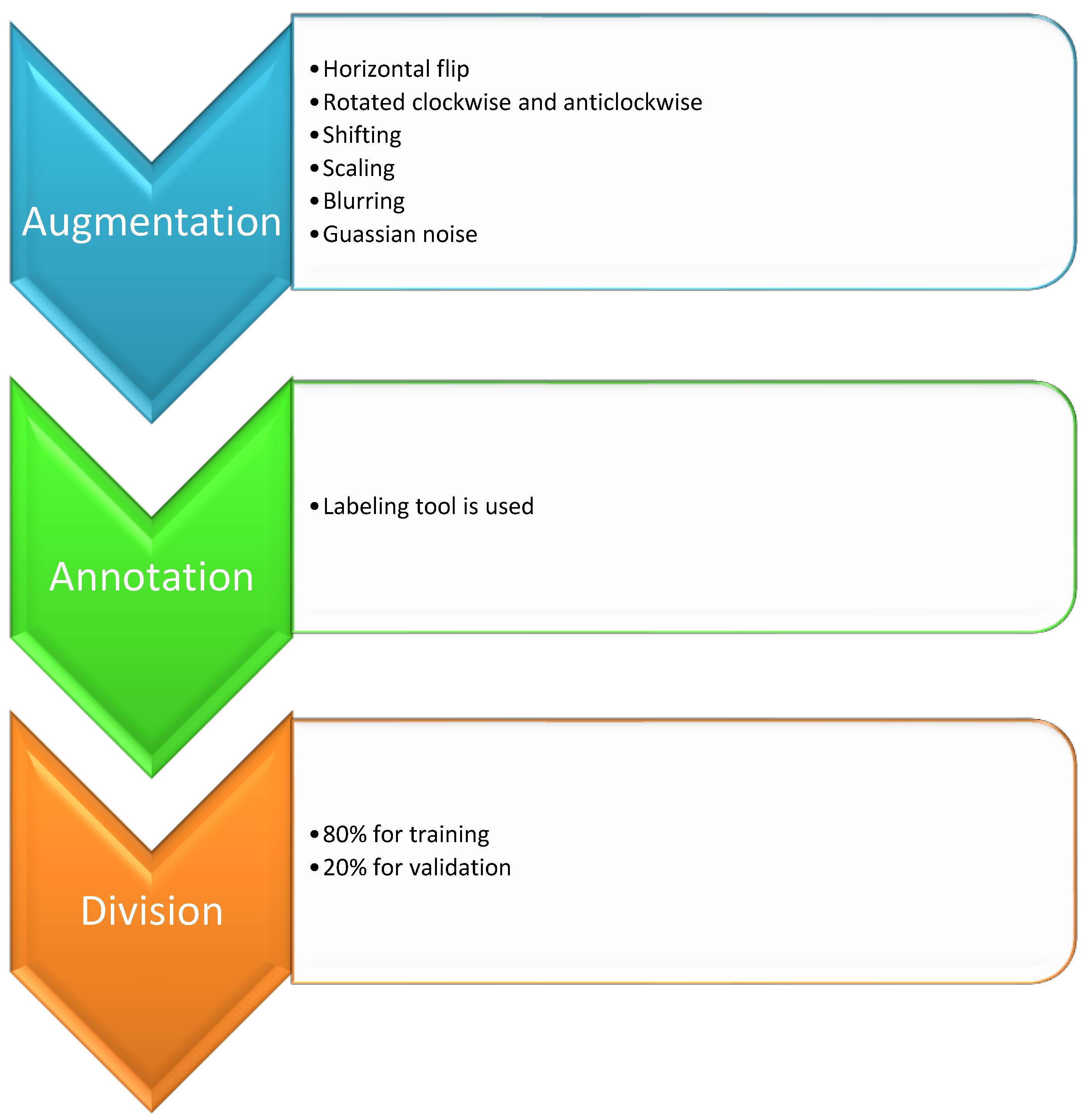
3.1. Dataset and Data Pre-Processing
3.2. Preparing the Darknet Framework and YOLO Configuration File
3.3. Training and Testing
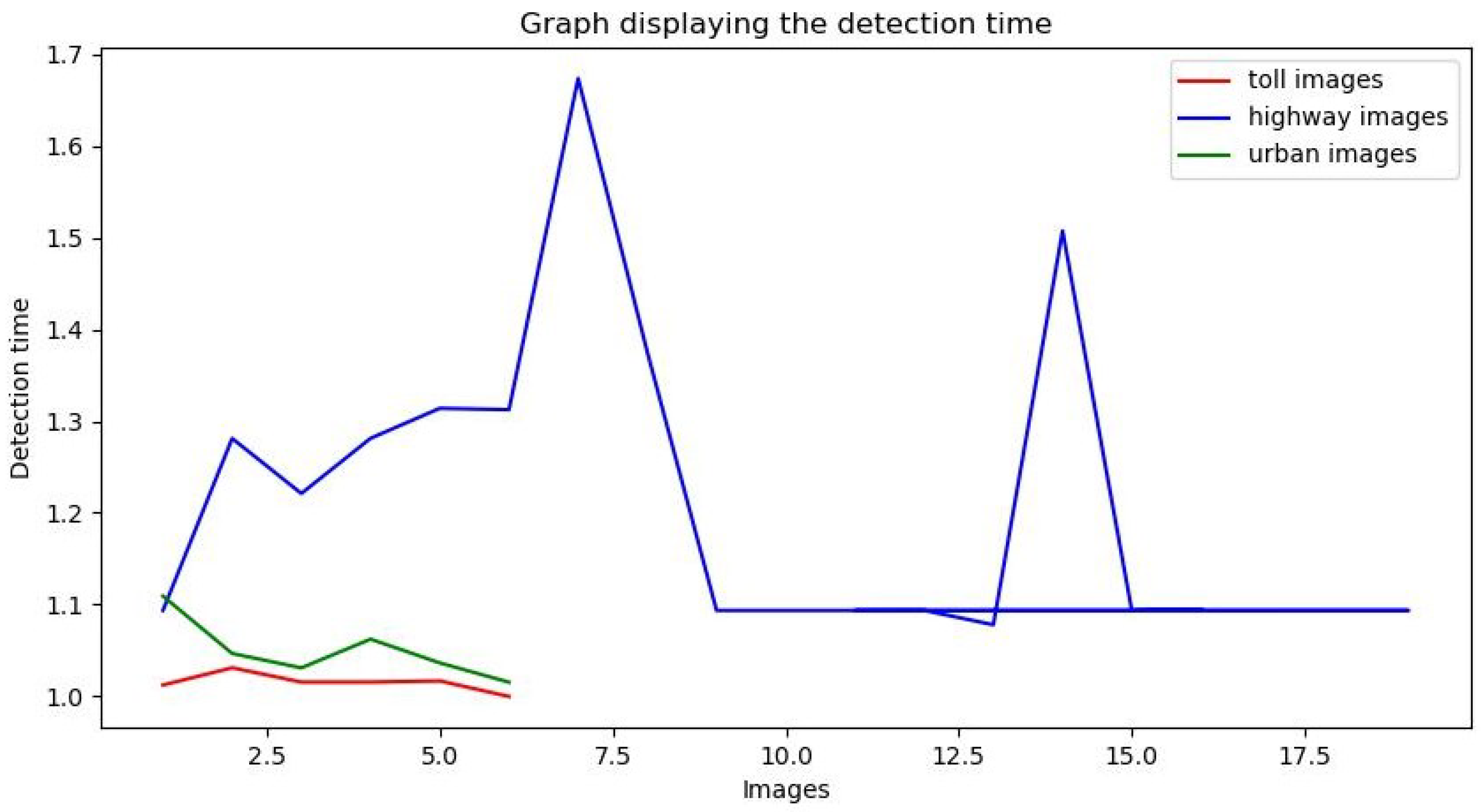
4. Results
5. Discussion
6. Comparison with SOTA
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Win, A.M.; MyatNwe, C.; Latt, K.Z. RFID Based Automated Toll Plaza System. Int. J. Sci. Res. Publ. 2014, 4, 1–7. [Google Scholar]
- John, F.; Khalid, G.; Elibiary, J. AI in Advanced Traffic Management Systems; AAAI Technical Report WS-93-04; AAAI: Palo Alto, CA, USA, 1993. [Google Scholar]
- Zhang, G.; Wang, Y.H. Video-Based Vehicle Detection and Classification System for Real-Time Traffic Data Collection Using Uncelebrated Video Cameras. Transp. Res. Rec. J. Transp. Res. Board 2007, 1993, 138–147. [Google Scholar] [CrossRef] [Green Version]
- Pietrzyk, C.M. Interim Evaluation Report-Task Order #1: Automatic Vehicle Classification (AVC) Systems; CUTR Research Reports; CUTR Publications: Tampa, FL, USA, 1997. [Google Scholar]
- Kaewkamnerd, S.; Pongthornseri, R.; Chinrungrueng, J.; Silawan, T. Automatic Vehicle Classification Using Wireless Magnetic Sensor. In Proceedings of the IEEE International Workshop on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Rende, Italy, 21–23 September 2009. [Google Scholar]
- Urazghildiiev, I.; Ragnarsson, R.; Ridderström, P.; Rydberg, A.; Öjefors, E.; Wallin, K.; Enochsson, P.; Ericson, M.; Löfqvist, G. Vehicle Classification Based on the Radar Measurement of Height Profiles. In IEEE Transactions on Intelligent Transportation Systems; IEEE: New York, NY, USA, 2007; Volume 8, pp. 245–253. [Google Scholar]
- Hemanshu, S.; Sunil, K.; Samani, B. Infrared based system for vehicle Axle Counting and Classification. In Proceedings of the 8th IRF International Conference, Pune, India, 4 May 2014. [Google Scholar]
- Filho, A.C.B.d.; Filho, J.P.d.; de Araujo, R.E.; Benevides, C.A. Infrared-based system for vehicle classification. In Proceedings of the 2009 SBMO/IEEE MTT-S International Microwave and Optoelectronics Conference (IMOC), Belem, Brazil, 3–6 November 2009. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks; Communications of the ACM; University of Toronto: Toronto, ON, Canada, 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition; Computer vision and Pattern recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Hill, C.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; Berkeley, U.C. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Kaiming, H.; Zhang, X.; Shaoqing, R.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 2015; pp. 1904–1916. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceddings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016; ECCV 2016. Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef] [PubMed]
- Joshi, B.; Bhagat, K.; Desai, H.; Patel, M.; Parmar, K.J. A Comparative Study of Toll Collection Systems in India. Int. J. Eng. Res. Dev. 2017, 13, 68–71. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jorge, E.; Espinosa, S.; Velastin, A.; Branch, J.W. Vehicle Detection Using AlexNet and Faster R-CNN Deep Learning Models: A Comparative study. In Advances in Visual Informatics; IVIC 2017. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10645. [Google Scholar]
- Aishwarya, C.N.; Mukherjee, R.; Mahato, D.K.; Pundir, A.; Saxena, G.J. Multilayer vehicle classification integrated with single frame optimized object detection framework using CNN based deep learning architecture. In Proceedings of the 2018 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 16–17 March 2018. [Google Scholar]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 51. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, T.; Ma, Y.; Yahya, M.; Ahmad, B.; Nazir, S.; ulHaq, A. Object Detection through Modified YOLO Neural Network. Sci. Program. 2020, 2020, 8403262. [Google Scholar] [CrossRef]
- Gupta, S.; Devi, D.T.U. YOLOv2 based Real Time Object Detection. Int. J. Comput. Sci. Trends Technol. IJCST 2020, 8, 26–30, ISSN 2347-8578. [Google Scholar]
- Wu, Z.; Sang, J.; Zhang, Q.; Xiang, H.; Cai, B.; Xia, X. Multi-Scale Vehicle Detection for Foreground-Background Class Imbalance with Improved YOLOv2. Sensors 2019, 19, 3336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Viraktamath, D.S.V.; Yavagal, M.; Byahatti, R. Object Detection and Classification using YOLOv3. Int. J. Eng. Res. Technol. IJERT 2021, 10. Available online: https://www.academia.edu/download/66162765/object_detection_and_classification_using_IJERTV10IS020078.pdf (accessed on 22 April 2022).
- Yin, X.; Sasaki, Y.; Wang, W.; Shimizu, K. YOLO and K-Means Based 3D Object Detection Method on Image and Point Cloud. In Proceedings of the JSME Annual Conference on Robotics and Mechatronics (Robomec), online, June 2019; p. 2P1-I01. [Google Scholar]
- Martinez-Alpiste, I.; Golcarenarenji, G.; Wang, Q.; Alcaraz-Calero, J.M. A dynamic discarding technique to increase speed and preserve accuracy for YOLOv3. Neural Comput. Appl. 2021, 33, 9961–9973. [Google Scholar] [CrossRef]
- Chattopadhyay, D.; Rasheed, S.; Yan, L.; Lopez, A.; Farmer, J.; Brown, D.E. Machine Learning for Real-Time Vehicle Detection in All-Electronic Tolling System. In Proceedings of the 2020 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 24 April 2020. [Google Scholar]
- Vehicle Images. (n.d.-b). [Photograph]. Available online: https://www.kaggle.com (accessed on 18 April 2022).
- Vehicle Images. (n.d.-b). [Photograph]. Available online: https://www.google.com (accessed on 27 April 2022).
- Lebellmg. Available online: https://github.com/tzutalin/labelImg (accessed on 22 April 2022).
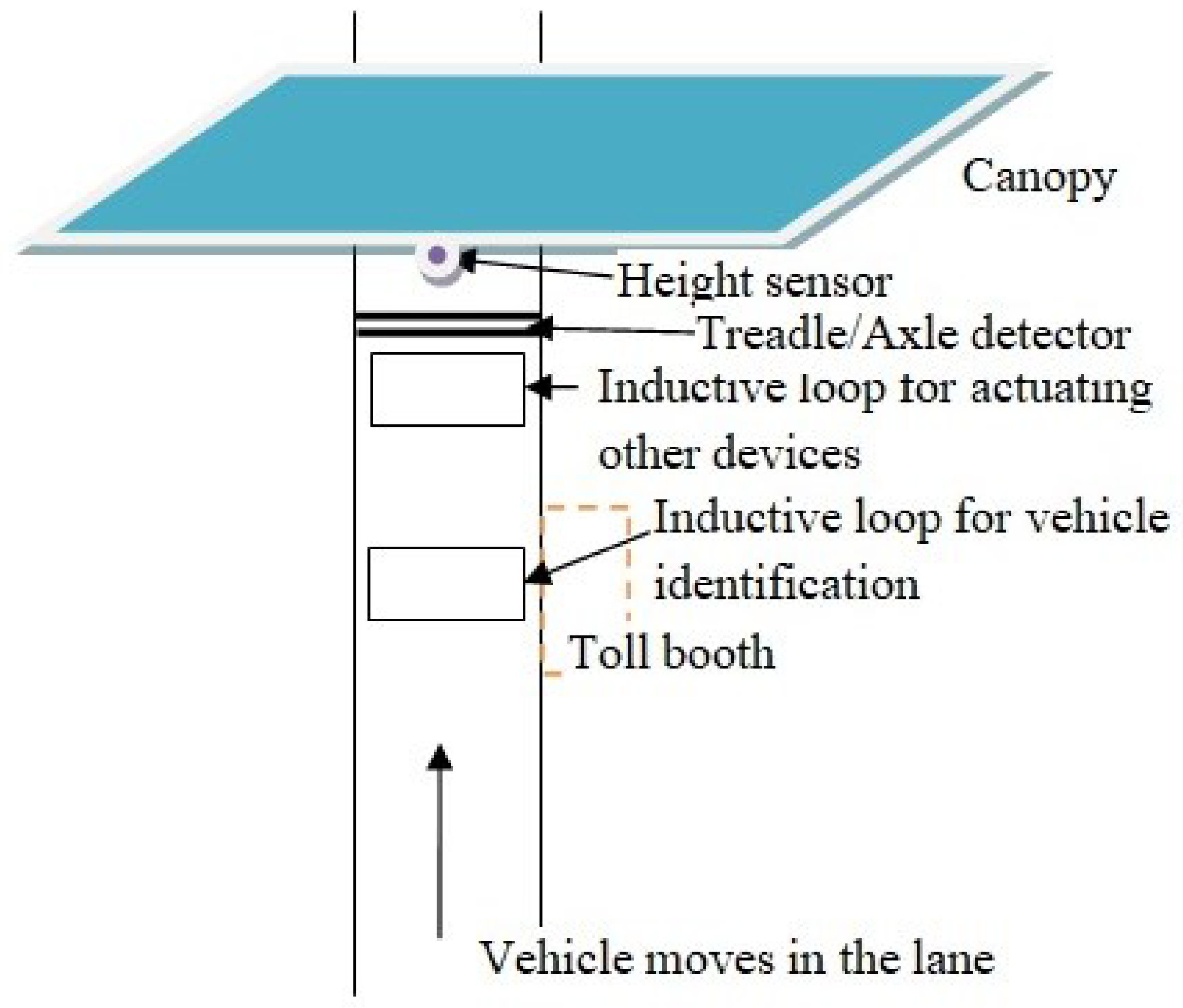
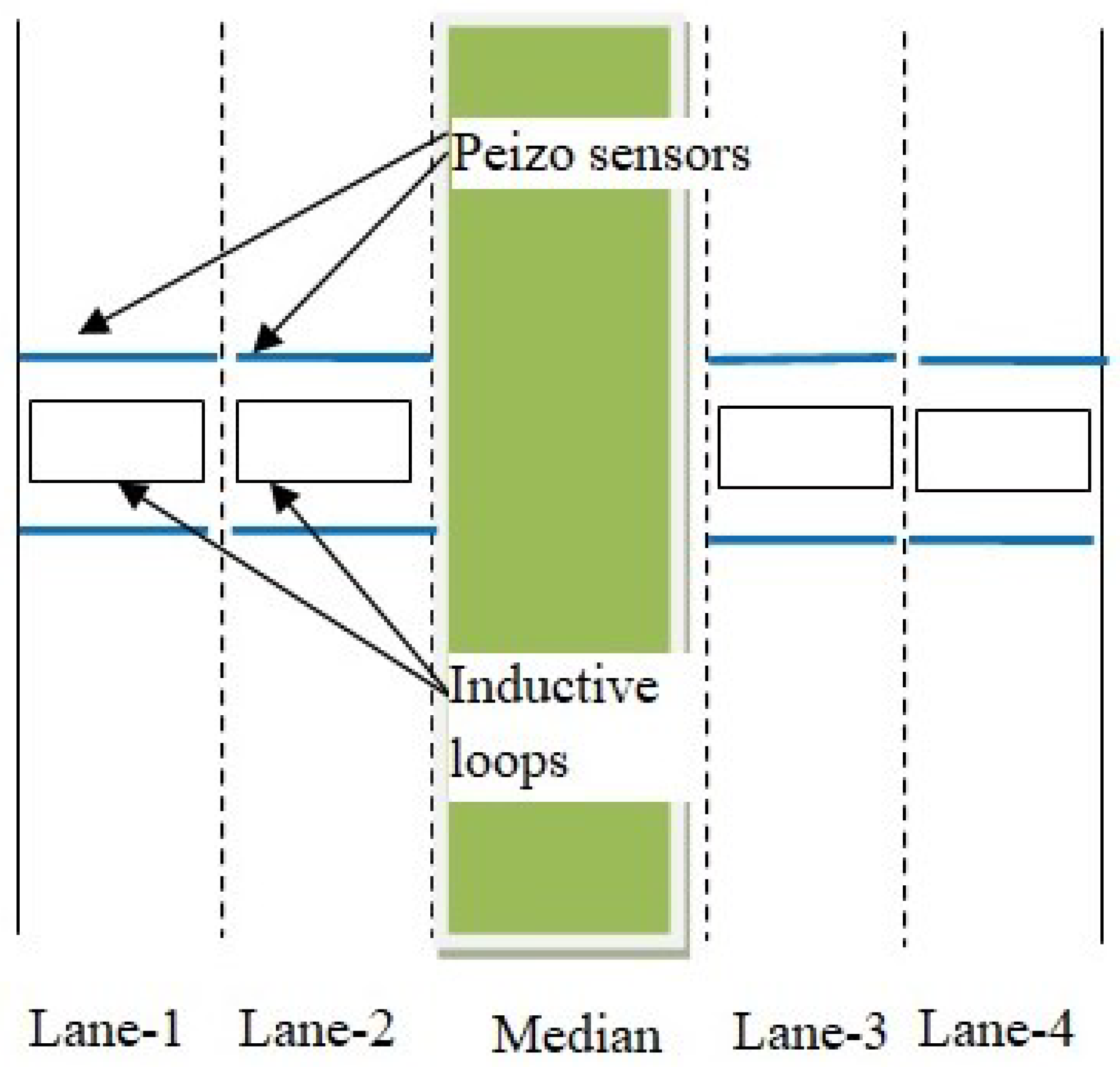






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle Class | Vehicle Types |
|---|---|
| Class-1 | Car/Jeep/van |
| Class-2 | Light commercial vehicle (LCV) |
| Class-3A | 2-axle bus and truck (bus-truck_2A) |
| Class-3B | 3-axle bus and truck (bus-truck_3A) |
| Class-4 | Multi-axle vehicle (MAV) |
| Class-5 | Over-sized vehicle (OSV) |
| Class | Coordinate (x) | Coordinate (y) | Width (w) | Height (h) |
|---|---|---|---|---|
| 0 | 0.504484 | 0.516556 | 0.919283 | 0.834437 |
| Vehicle Class | Number of Vehicles at Toll Plazas | True Positives | False Positives | False Negatives | Precision | Recall |
|---|---|---|---|---|---|---|
| Class-1 | 55 | 52 | 2 | 3 | 0.963 | 0.945 |
| Class-2 | 9 | 7 | 1 | 2 | 0.875 | 0.778 |
| Class-3 | 60 | 56 | 1 | 4 | 0.982 | 0.933 |
| Class-4 | 35 | 32 | 2 | 3 | 0.941 | 0.914 |
| Class-5 | 5 | 4 | 0 | 1 | 1.000 | 0.800 |
| Class-6 | 20 | 19 | 0 | 1 | 1.000 | 0.950 |
| Class-7 | 12 | 10 | 1 | 2 | 0.909 | 0.833 |
| Class-8 | 8 | 6 | 1 | 2 | 0.857 | 0.750 |
| Averages of precision and recall | 0.941 | 0.863 | ||||
| Vehicle Class | Number of Vehicles on Highways | True Positives | False Positives | False Negatives | Precision | Recall |
|---|---|---|---|---|---|---|
| Class-1 | 80 | 71 | 4 | 9 | 0.947 | 0.888 |
| Class-2 | 5 | 5 | 2 | 0 | 0.714 | 1.000 |
| Class-3 | 92 | 81 | 3 | 11 | 0.964 | 0.880 |
| Class-4 | 87 | 79 | 3 | 8 | 0.963 | 0.908 |
| Class-6 | 36 | 34 | 1 | 2 | 0.971 | 0.944 |
| Averages of precision and recall | 0.912 | 0.924 | ||||
| Algorithm | Technique | Number of Vehicle Classes | Number of Vehicles | Classification Accuracy (%) |
|---|---|---|---|---|
| Treadles + optic sensors | Traditional | All | - | 98–99 |
| Wireless magnetic sensors | Traditional | Four | 130 | 77.69 |
| Axle counters + height sensors | Traditional | Six | 2945 | 87.00 |
| Vehicle profile based on infrared sensors | Traditional | All | - | - |
| YOLOv3 | AI-based | Eight | 204 | 94.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajput, S.K.; Patni, J.C.; Alshamrani, S.S.; Chaudhari, V.; Dumka, A.; Singh, R.; Rashid, M.; Gehlot, A.; AlGhamdi, A.S. Automatic Vehicle Identification and Classification Model Using the YOLOv3 Algorithm for a Toll Management System. Sustainability 2022, 14, 9163. https://doi.org/10.3390/su14159163
Rajput SK, Patni JC, Alshamrani SS, Chaudhari V, Dumka A, Singh R, Rashid M, Gehlot A, AlGhamdi AS. Automatic Vehicle Identification and Classification Model Using the YOLOv3 Algorithm for a Toll Management System. Sustainability. 2022; 14(15):9163. https://doi.org/10.3390/su14159163
Chicago/Turabian StyleRajput, Sudhir Kumar, Jagdish Chandra Patni, Sultan S. Alshamrani, Vaibhav Chaudhari, Ankur Dumka, Rajesh Singh, Mamoon Rashid, Anita Gehlot, and Ahmed Saeed AlGhamdi. 2022. "Automatic Vehicle Identification and Classification Model Using the YOLOv3 Algorithm for a Toll Management System" Sustainability 14, no. 15: 9163. https://doi.org/10.3390/su14159163
APA StyleRajput, S. K., Patni, J. C., Alshamrani, S. S., Chaudhari, V., Dumka, A., Singh, R., Rashid, M., Gehlot, A., & AlGhamdi, A. S. (2022). Automatic Vehicle Identification and Classification Model Using the YOLOv3 Algorithm for a Toll Management System. Sustainability, 14(15), 9163. https://doi.org/10.3390/su14159163