
How Would We Cycle Today If We Had the Weather of Tomorrow? An Analysis of the Impact of Climate Change on Bicycle Traffic


Abstract
:1. Introduction
2. Materials
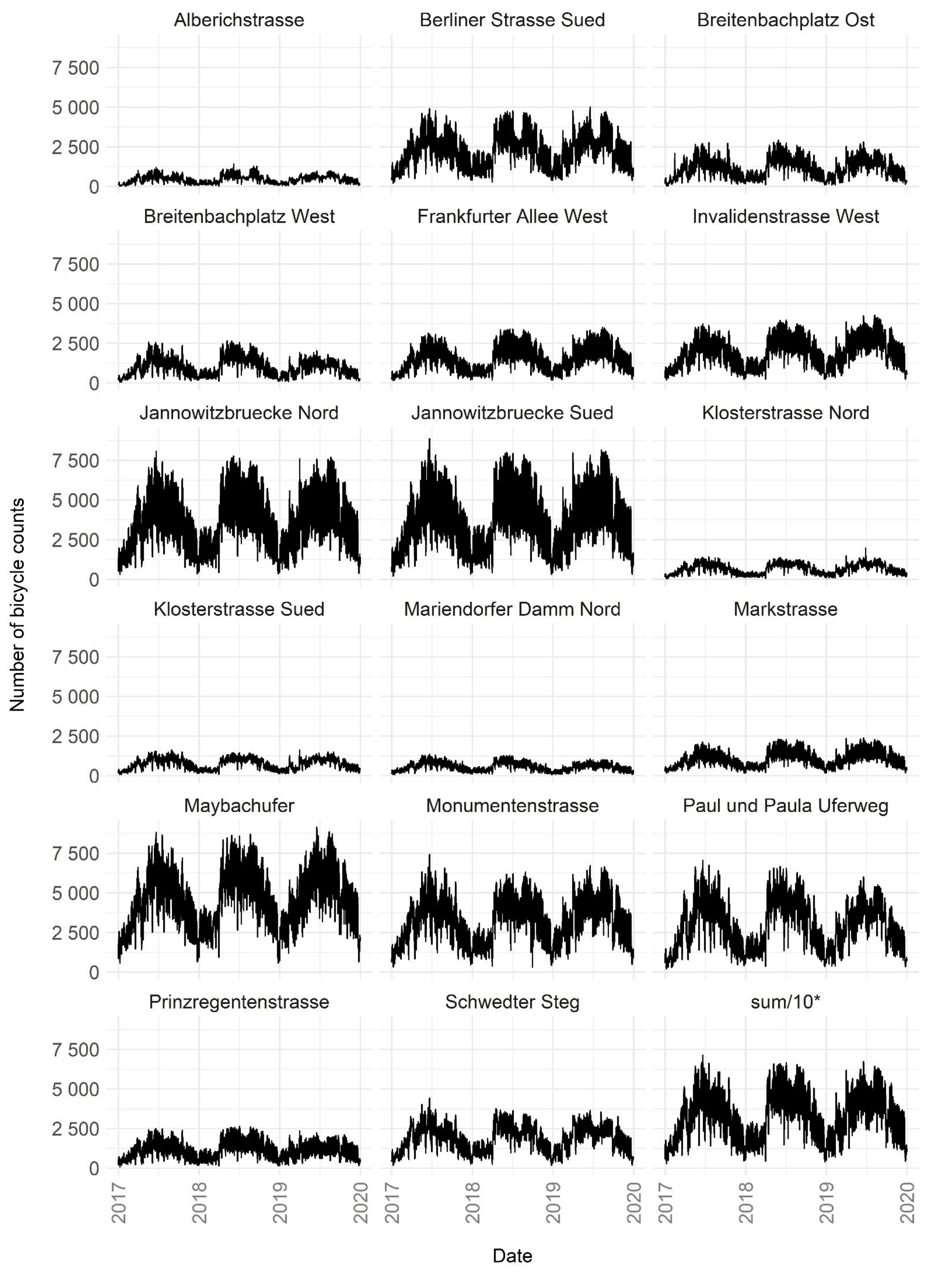
2.1. Bicycle Count Data
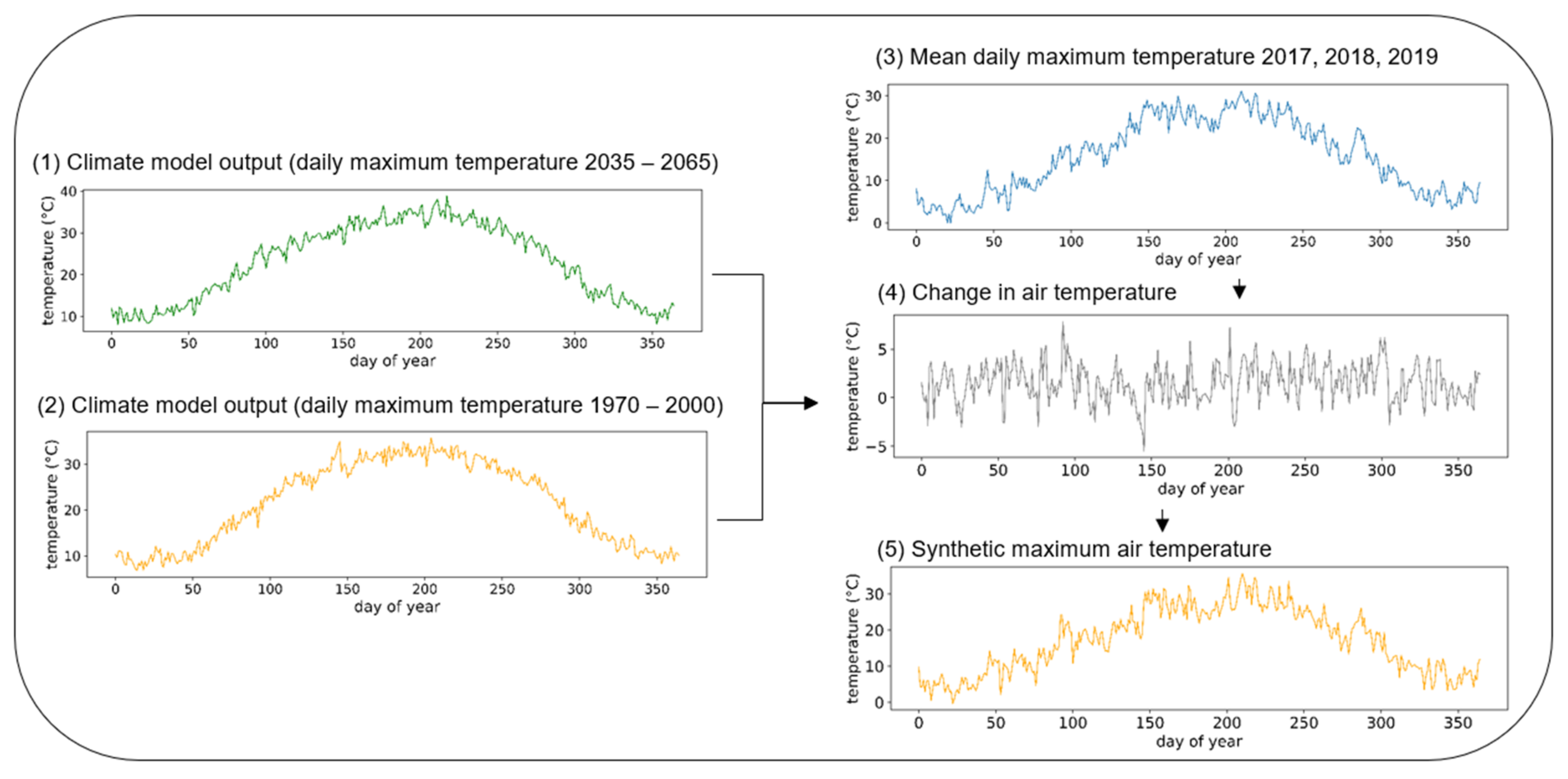
2.2. Using Outputs from Regional Climate Models to Generate Future Weather Scenarios
3. Methods
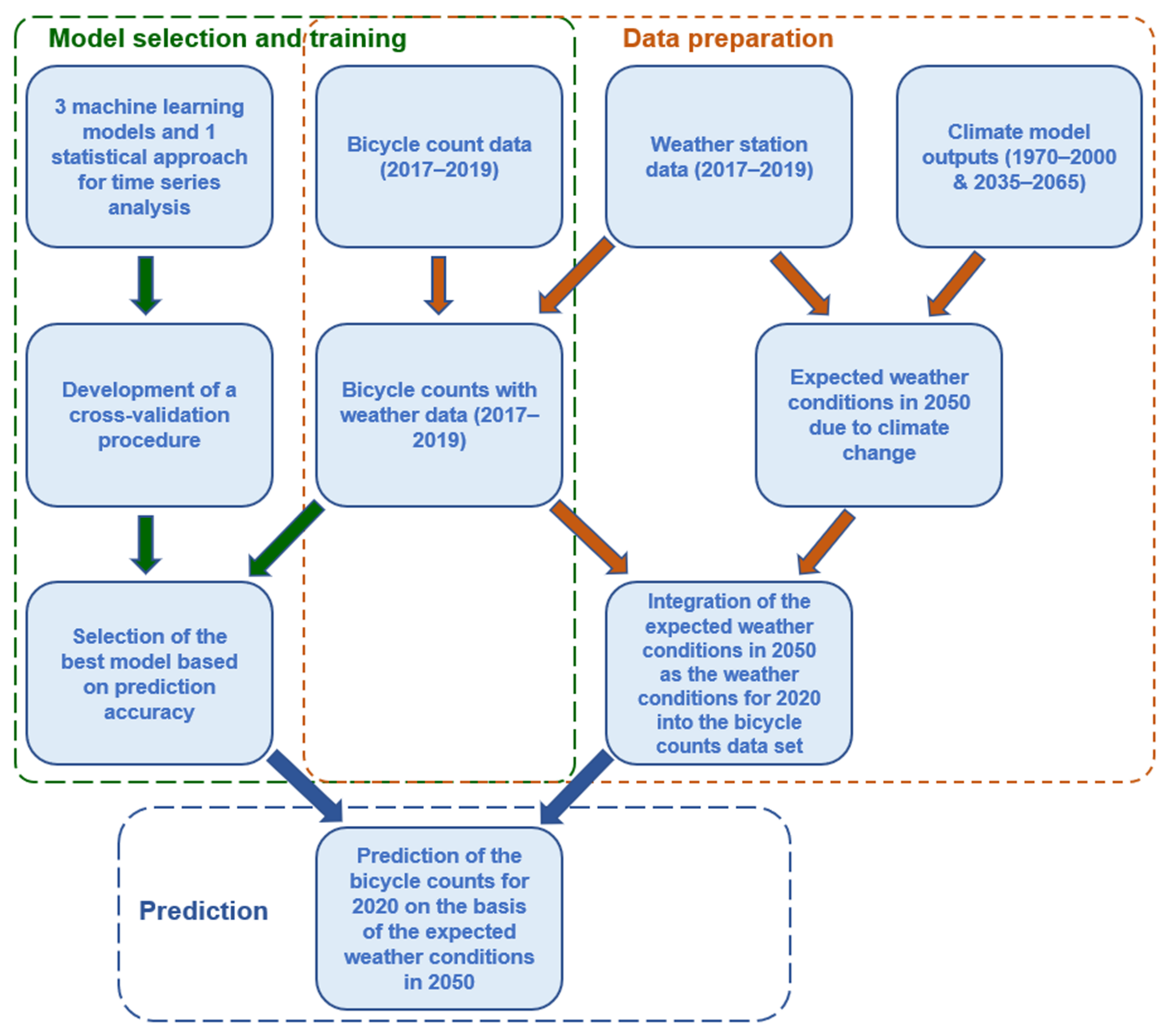
3.1. Research Design
3.2. Forecast Models
3.3. Cross-Validation
3.4. Model Tuning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
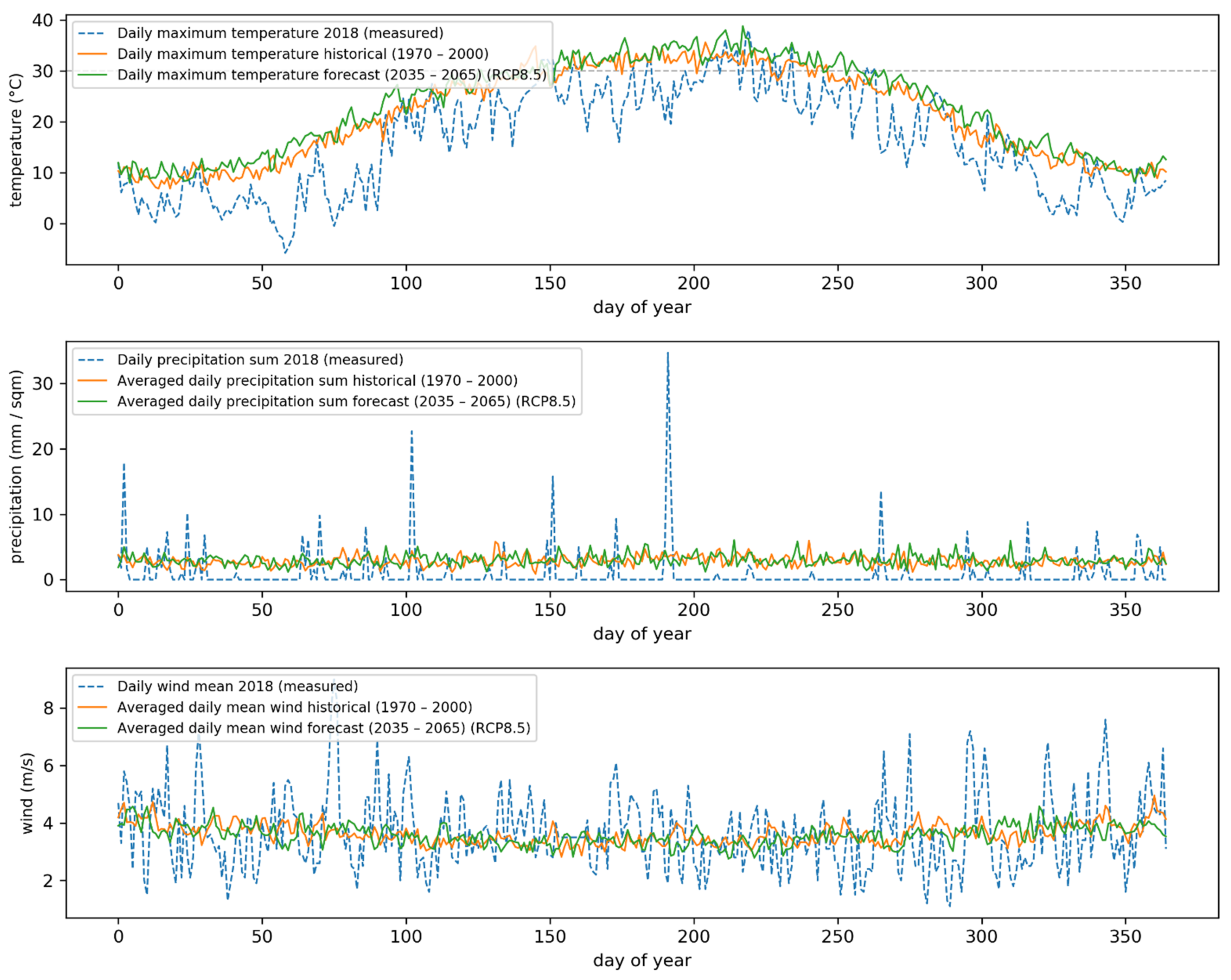
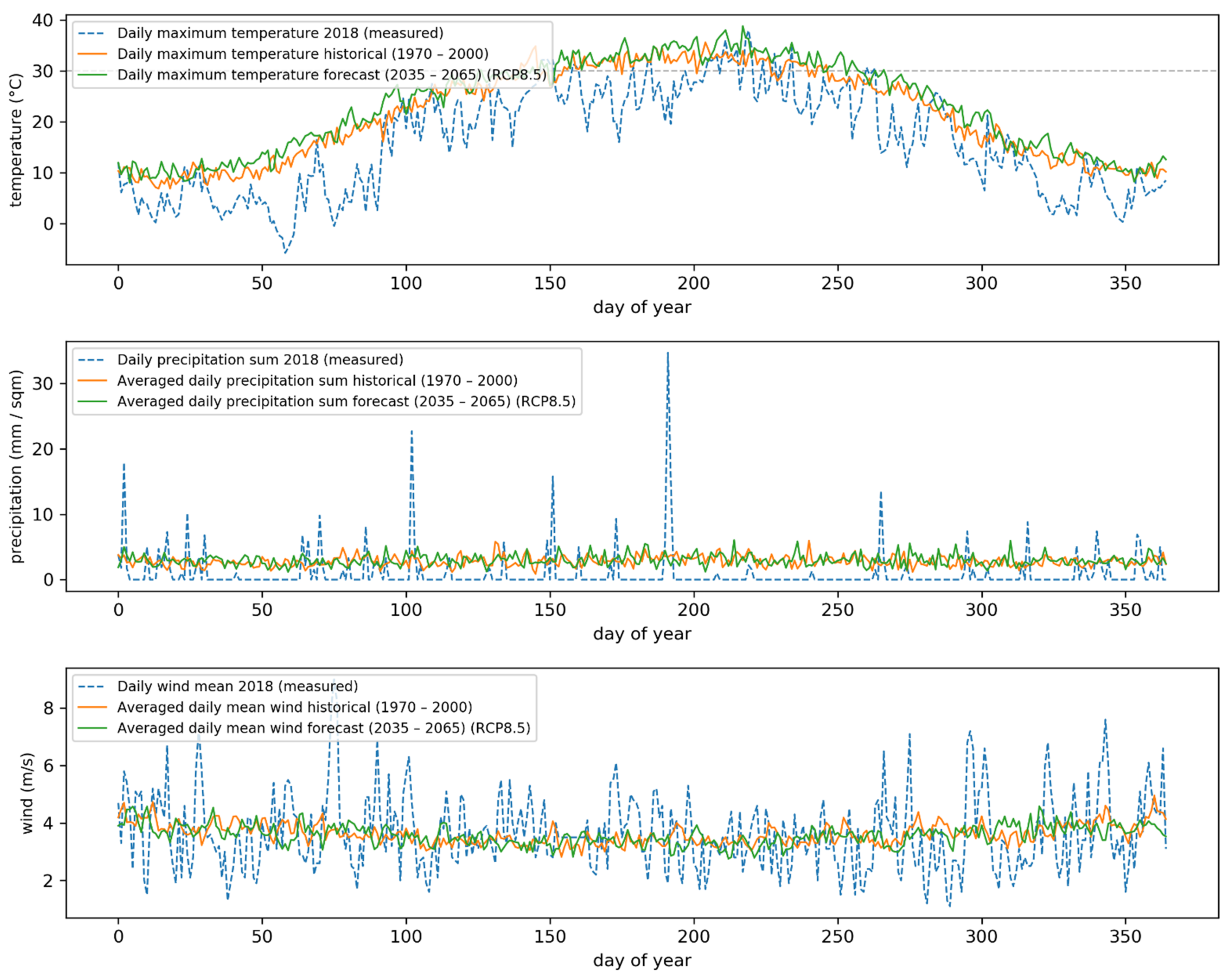{kind=link}
{kind=link}
| Name | Data Type | Unit | Temporal Resolution |
|---|---|---|---|
| Independent variables | |||
| Maximal air temperature | Numeric | ° Celsius | Daily (maximum) |
| Sum of precipitation | Numeric | Millimetres | Daily (sum) |
| Mean wind speed | Numeric | Metre per second | Daily (mean) |
| Day of the week | Categorical | - | Daily |
| Month | Categorical | - | Monthly |
| Year | Categorical | - | Yearly |
| Public holiday | Dummy | - | Daily |
| School holiday | Dummy | - | Daily |
| Dependent variable | |||
| Bicycle counts | Numeric | - | Daily |
4. Results
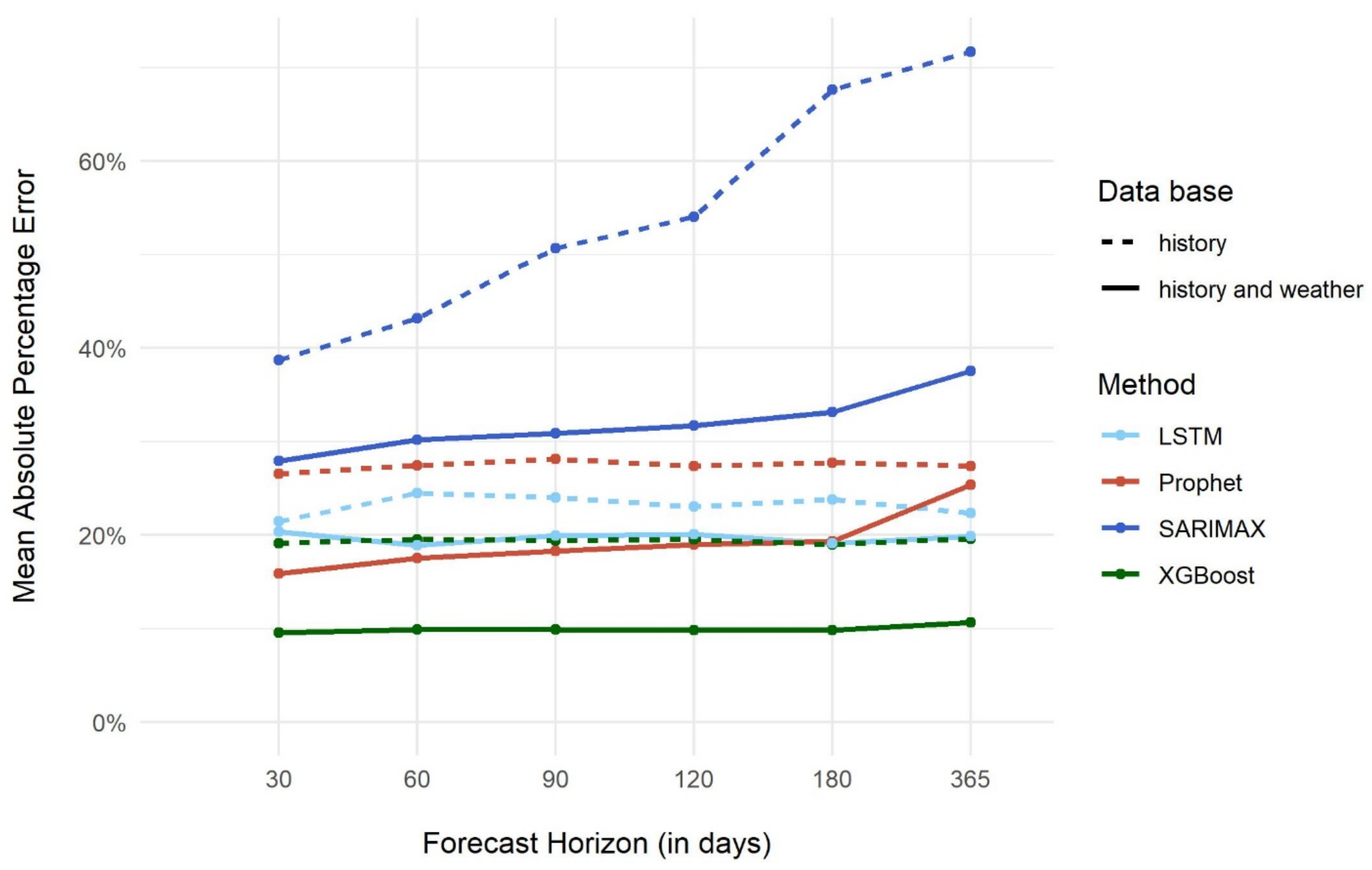
4.1. Model Performance, Comparison and Selection
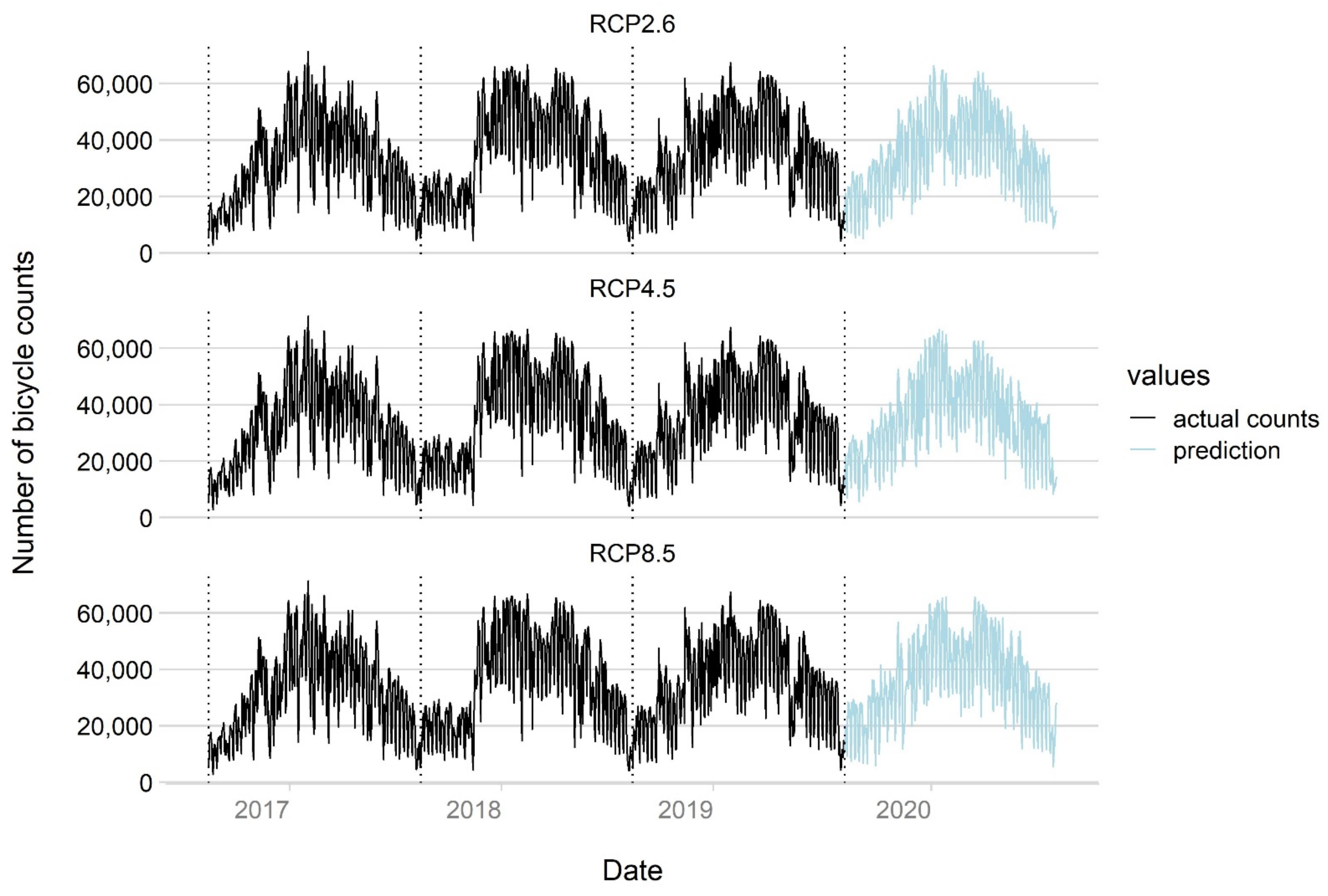
4.2. Predictions
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
References
- Araos, M.; Berrang-Ford, L.; Ford, J.; Austin, S.E.; Biesbroek, R.; Lesnikowski, A. Climate change adaptation planning in large cities: A systematic global assessment. Environ. Sci. Policy 2016, 66, 375–382. [Google Scholar] [CrossRef]
- Raser, E.; Gaupp-Berghausen, M.; Dons, E.; Anaya-Boig, E.; Avila-Palencia, I.; Brand, C.; Castro, A.; Clark, A.; Eriksson, U.; Götschi, T.; et al. European cyclists’ travel behavior: Differences and similarities between seven European (PASTA) cities. J. Transp. Health 2018, 9, 244–252. [Google Scholar] [CrossRef]
- Aldred, R.; Jungnickel, K. Why culture matters for transport policy: The case of cycling in the UK. J. Transp. Geogr. 2014, 34, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Dill, J.; Carr, T. Bicycle Commuting and Facilities in Major U.S. Cities: If You Build Them, Commuters Will Use Them. Transp. Res. Rec. J. Transp. Res. Board 2003, 1828, 116–123. [Google Scholar] [CrossRef]
- Mertens, L.; Compernolle, S.; Deforche, B.; Mackenbach, J.D.; Lakerveld, J.; Brug, J.; Roda, C.; Feuillet, T.; Oppert, J.-M.; Glonti, K.; et al. Built environmental correlates of cycling for transport across Europe. Health Place 2017, 44, 35–42. [Google Scholar] [CrossRef] [Green Version]
- Nosal, T.; Miranda-Moreno, L.F. The effect of weather on the use of North American bicycle facilities: A multi-city analysis using automatic counts. Transp. Res. Part A Policy Pract. 2014, 66, 213–225. [Google Scholar] [CrossRef]
- Pucher, J.; Buehler, R. Making Cycling Irresistible: Lessons from The Netherlands, Denmark and Germany. Transp. Rev. 2008, 28, 495–528. [Google Scholar] [CrossRef]
- Pucher, J.; Komanoff, C.; Schimek, P. Bicycling renaissance in North America?: Recent trends and alternative policies to promote bicycling. Transp. Res. Part A Policy Pract. 1999, 33, 625–654. [Google Scholar] [CrossRef]
- Thomas, T.; Jaarsma, R.; Tutert, B. Exploring temporal fluctuations of daily cycling demand on Dutch cycle paths: The influence of weather on cycling. Transportation 2012, 40, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Böcker, L.; Uteng, T.P.; Liu, C.; Dijst, M. Weather and daily mobility in international perspective: A cross-comparison of Dutch, Norwegian and Swedish city regions. Transp. Res. Part D Transp. Environ. 2019, 77, 491–505. [Google Scholar] [CrossRef]
- Gebhart, K.; Noland, R.B. The impact of weather conditions on bikeshare trips in Washington, DC. Transportation 2014, 41, 1205–1225. [Google Scholar] [CrossRef]
- Liu, C.; Susilo, Y.O.; Karlström, A. The influence of weather characteristics variability on individual’s travel mode choice in different seasons and regions in Sweden. Transp. Policy 2015, 41, 147–158. [Google Scholar] [CrossRef]
- Liu, C.; Susilo, Y.O.; Karlström, A. Investigating the impacts of weather variability on individual’s daily activity–travel patterns: A comparison between commuters and non-commuters in Sweden. Transp. Res. Part A Policy Pract. 2015, 82, 47–64. [Google Scholar] [CrossRef]
- Sabir, M. Weather and Travel Behaviour. Ph.D. Thesis, Free University of Amsterdam, Amsterdam, The Netherlands, 2011. [Google Scholar]
- Flynn, B.S.; Dana, G.S.; Sears, J.; Aultman-Hall, L. Weather factor impacts on commuting to work by bicycle. Prev. Med. 2012, 54, 122–124. [Google Scholar] [CrossRef] [PubMed]
- Parkin, J.; Wardman, M.; Page, M. Estimation of the determinants of bicycle mode share for the journey to work using census data. Transportation 2008, 35, 93–109. [Google Scholar] [CrossRef] [Green Version]
- Phung, J.; Rose, G. Temporal variations in usage of Melbourne’s bike paths. In Proceedings of the 30th Australasian Transport Research Forum, Melbourne, VIC, Australia, 25–27 September 2007. [Google Scholar]
- Heinen, E.; Maat, K.; Van Wee, B. Day-to-Day Choice to Commute or Not by Bicycle. Transp. Res. Rec. J. Transp. Res. Board 2011, 2230, 9–18. [Google Scholar] [CrossRef]
- Helbich, M.; Böcker, L.; Dijst, M. Geographic heterogeneity in cycling under various weather conditions: Evidence from Greater Rotterdam. J. Transp. Geogr. 2014, 38, 38–47. [Google Scholar] [CrossRef]
- Saneinejad, S.; Roorda, M.J.; Kennedy, C. Modelling the impact of weather conditions on active transportation travel behaviour. Transp. Res. Part D Transp. Environ. 2012, 17, 129–137. [Google Scholar] [CrossRef] [Green Version]
- Creemers, L.; Wets, G.; Cools, M. Meteorological variation in daily travel behaviour: Evidence from revealed preference data from the Netherlands. Theor. Appl. Clim. 2015, 120, 183–194. [Google Scholar] [CrossRef] [Green Version]
- Winters, M.; Buehler, R.; Götschi, T. Policies to Promote Active Travel: Evidence from Reviews of the Literature. Curr. Environ. Health Rep. 2017, 4, 278–285. [Google Scholar] [CrossRef]
- Liu, C.; Susilo, Y.O.; Karlström, A. Weather variability and travel behavior—What we know and what we do not know. Transp. Rev. 2017, 37, 715–741. [Google Scholar] [CrossRef]
- Böcker, L.; Prillwitz, J.; Dijst, M. Climate change impacts on mode choices and travelled distances: A comparison of present with 2050 weather conditions for the Randstad Holland. J. Transp. Geogr. 2013, 28, 176–185. [Google Scholar] [CrossRef]
- Wadud, Z. Cycling in a changed climate. J. Transp. Geogr. 2014, 35, 12–20. [Google Scholar] [CrossRef] [Green Version]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.-Y. Traffic Flow Prediction With Big Data: A Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2014, 16, 865–873. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Nobis, C.; Kuhnimhof, T. Mobilität in Deutschland–Tabellarische Grundauswertung, in Studie von Infas, DLR, IVT und Infas 360 im Auftrag des Bundesministers für Verkehr und Digitale Infrastruktur; (FE-Nr. 70.904/15); Bundesministerium für Verkehr und Digitale Infrastruktur: Bonn, Germany, 2018.
- Senatsverwaltung für Umwelt, Verkehr und Klimaschutz Berlin. Karte: Zählung der Radfahrer. Available online: https://www.berlin.de/senuvk/verkehr/lenkung/vlb/de/karte.shtml (accessed on 3 April 2020).
- Moss, R.H.; Edmonds, J.A.; Hibbard, K.A.; Manning, M.R.; Rose, S.K.; van Vuuren, D.P.; Carter, T.R.; Emori, S.; Kainuma, M.; Kram, T.; et al. The next generation of scenarios for climate change research and assessment. Nat. Cell Biol. 2010, 463, 747–756. [Google Scholar] [CrossRef]
- Jacob, D.; Petersen, J.; Eggert, B.; Alias, A.; Christensen, O.B.; Bouwer, L.M.; Braun, A.; Colette, A.; Déqué, M.; Georgievski, G.; et al. EURO-CORDEX: New high-resolution climate change projections for European impact research. Reg. Environ. Chang. 2014, 14, 563–578. [Google Scholar] [CrossRef]
- Giorgi, F.; Jones, C.; Asrar, G.R. Addressing Climate Information Needs at the Regional Level: The CORDEX Framework. WMO Bull. 2009, 58, 175–183. [Google Scholar]
- Pfeifer, S.; Bülow, K.; Gobiet, A.; Hänsler, A.; Mudelsee, M.; Otto, J.; Rechid, D.; Teichmann, C.; Jacob, D. Robustness of Ensemble Climate Projections Analyzed with Climate Signal Maps: Seasonal and Extreme Precipitation for Germany. Atmosphere 2015, 6, 677–698. [Google Scholar] [CrossRef] [Green Version]
- German Weather Service. Heißer Tag. 2021. Available online: https://www.dwd.de/DE/service/lexikon/Functions/glossar.html?lv2=101094&lv3=101162 (accessed on 6 September 2021).
- German Weather Service. Starkregen. 2021. Available online: https://www.dwd.de/DE/service/lexikon/begriffe/S/Starkregen.html (accessed on 6 September 2021).
- Breiman, L. Statistical Modeling: The Two Cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice, 2nd ed.; OTexts: Melbourne, VIC, Australia, 2018. [Google Scholar]
- Taylor, S.J.; Letham, B. Forecasting at Scale. PeerJ Prepr. 2017, 5, 37–45. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- Aggarwal, C.C. Neural Networks and Deep Learning. A Textbook; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Skansi, S. Introduction to Deep Learning: From Logical Calculus to Artificial Intelligence; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Fan, F.-L.; Xiong, J.; Li, M.; Wang, G. On Interpretability of Artificial Neural Networks: A Survey. IEEE Trans. Radiat. Plasma Med. Sci. 2021. [Google Scholar] [CrossRef]
- Köppen, W.P. Handbuch der Klimatologie: In Fünf Bänden, Allgemeine Klimalehre by W. Borchardt, Das geographische System der Klimate, 1st ed.; Köppen, W., Geiger, R., Eds.; Verlag von Gebrüder Borntraeger: Berlin, Germany, 1936. [Google Scholar]
- Office for Statistics Berlin-Brandenburg. Bevölkerungsstand. 2021. Available online: https://www.statistik-berlin-brandenburg.de/bevoelkerung/demografie/bevoelkerungsstand (accessed on 6 September 2021).
- Jacob, D. A note to the simulation of the annual and inter-annual variability of the water budget over the Baltic Sea drainage basin. Theor. Appl. Clim. 2001, 77, 61–73. [Google Scholar] [CrossRef]
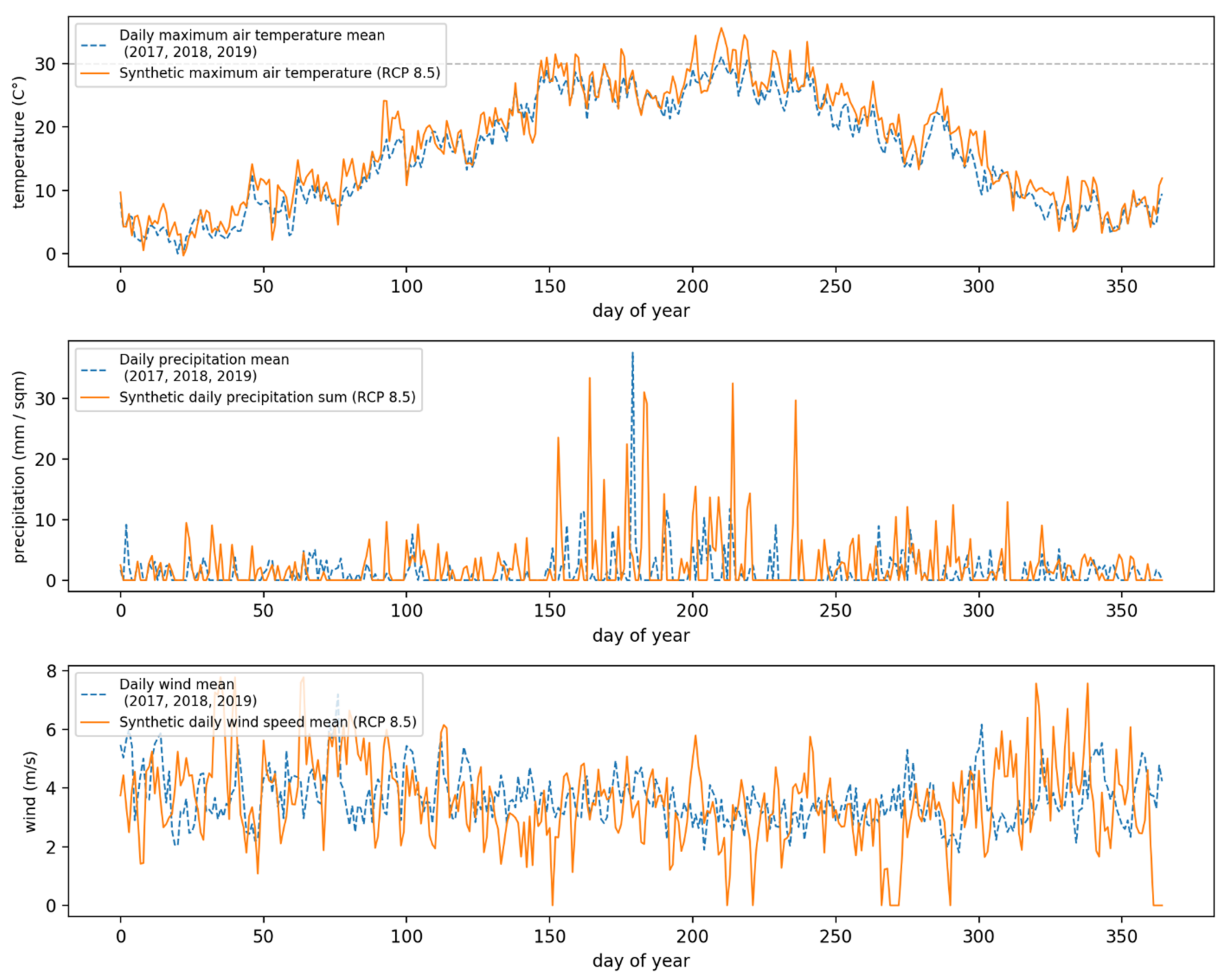
| Season | 2017 | 2018 | 2019 | 2020 (RCP2.6) | 2020 (RCP4.5) | 2020 (RCP8.5) |
|---|---|---|---|---|---|---|
| Maximal daily air temperature in °Celsius (mean) | ||||||
| Spring | 15.35 | 16.38 | 15.21 | 15.94 | 16.34 | 16.98 |
| Summer | 24.18 | 27.19 | 27.30 | 26.43 | 27.65 | 27.92 |
| Autumn | 14.22 | 16.11 | 15.17 | 16.18 | 15.92 | 17.19 |
| Winter | 4.19 | 5.17 | 6.65 | 5.74 | 5.97 | 6.52 |
| Daily precipitation in mm (sum) | ||||||
| Spring | 89.8 | 103.5 | 91 | 120.92 | 116.36 | 129.18 |
| Summer | 400.4 | 97 | 198.6 | 393.33 | 349.76 | 401.68 |
| Autumn | 191.4 | 55.7 | 140.1 | 194.54 | 246.66 | 208.18 |
| Winter | 114.8 | 119.7 | 94.8 | 137.18 | 113.84 | 125.99 |
| Total | 796.4 | 375.9 | 524.5 | 845.86 | 825.61 | 865.01 |
| Daily wind speed in m/s (mean) | ||||||
| Spring | 3.85 | 3.88 | 4.23 | 3.95 | 3.90 | 3.92 |
| Summer | 3.35 | 3.47 | 3.26 | 3.23 | 3.17 | 3.24 |
| Autumn | 3.62 | 3.39 | 3.22 | 3.41 | 3.32 | 3.35 |
| Winter | 3.91 | 3.86 | 3.87 | 3.76 | 3.71 | 3.70 |
| Specific weather events (number of days) | ||||||
| Hot days * (≥30 °C) | 8 | 31 | 26 | 16 | 24 | 26 |
| Dry days * | 171 | 240 | 207 | 213 | 227 | 209 |
| Days with heavy rain * | 22 | 7 | 13 | 20 | 17 | 19 |
| Days with moderate or strong winds * | 40 | 34 | 37 | 37 | 37 | 34 |
| Bicycle counts (sum) | ||||||
| Spring | 3,189,554 | 3,369,275 | 3,301,122 | 3,215,209 | 3,317,420 | 3,340,132 |
| Summer | 4,014,512 | 4,487,628 | 4,386,066 | 4,281,880 | 4,317,930 | 4,377,109 |
| Autumn | 3,004,748 | 3,487,274 | 3,268,441 | 3,285,980 | 3,222,224 | 3,396,897 |
| Winter | 1,450,916 | 1,755,762 | 2,009,325 | 1,931,819 | 1,974,888 | 1,982,382 |
| Total | 11,659,730 | 13,099,939 | 12,964,954 | 12,714,888 | 12,832,461 | 13,096,522 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galich, A.; Nieland, S.; Lenz, B.; Blechschmidt, J. How Would We Cycle Today If We Had the Weather of Tomorrow? An Analysis of the Impact of Climate Change on Bicycle Traffic. Sustainability 2021, 13, 10254. https://doi.org/10.3390/su131810254
Galich A, Nieland S, Lenz B, Blechschmidt J. How Would We Cycle Today If We Had the Weather of Tomorrow? An Analysis of the Impact of Climate Change on Bicycle Traffic. Sustainability. 2021; 13(18):10254. https://doi.org/10.3390/su131810254
Chicago/Turabian StyleGalich, Anton, Simon Nieland, Barbara Lenz, and Jan Blechschmidt. 2021. "How Would We Cycle Today If We Had the Weather of Tomorrow? An Analysis of the Impact of Climate Change on Bicycle Traffic" Sustainability 13, no. 18: 10254. https://doi.org/10.3390/su131810254
APA StyleGalich, A., Nieland, S., Lenz, B., & Blechschmidt, J. (2021). How Would We Cycle Today If We Had the Weather of Tomorrow? An Analysis of the Impact of Climate Change on Bicycle Traffic. Sustainability, 13(18), 10254. https://doi.org/10.3390/su131810254