Creating Sustainable Innovativeness through Big Data and Big Data Analytics Capability: From the Perspective of the Information Processing Theory

Abstract
1. Introduction
2. Theoretical Background and Framework
2.1. Information Processing Theory (IPT)
2.2. Big Data
2.3. Big Data Analytics Capability (BDAC)
2.4. Sustainable Innovativeness
3. Research Hypotheses
4. Methodology and Data Sources
4.1. Empirical Study 1: The United States
4.1.1. Measurement
4.1.2. Data
4.1.3. Analysis and Results
4.2. Empirical Study 2: China
4.2.1. Measurement Validation in Empirical Study 2
4.2.2. Data
4.2.3. Analysis and Results
4.3. Empirical Study 3: Singapore
4.3.1. Measurement Validation
4.3.2. Data
4.3.3. Analysis and Results
4.4. Summary of Hypothesis Testing for All Three Empirical Studies
- In the United States, high-high fit > high-low misfit > low-low fit > low-high misfit (p < 0.01). Therefore, H1 is partially supported because low-low fit < high-low misfit (not > as predicted by H1); and H2 is supported. However, counter to H3, the effect of low-high misfit fit on sustainable innovativeness is less, not higher (as predicted by H3), than High-Low Misfit is.
- In China, high-high fit > low-low fit > low-high misfit > high-low misfit (p < 0.01). Therefore, all three hypotheses are supported as predicted.
- In Singapore, high-high fit > low-high misfit > low-low fit > high-low misfit (p < 0.10). Therefore, H1 is partially supported because low-low fit < low-high misfit (not > as predicted by H1); and both H2 and H3 are supported.
5. Cross-National Comparative Analyses
- (1)
- For effect of high-low misfit on sustainable innovativeness, the effect is less (β = −0.974; p < 0.05), in Singapore than in the U.S. There are no significant differences in the effect between U.S. and China (p > 0.10) and between China and Singapore (p > 0.10).
- (2)
- For effect of high-high fit on sustainable innovativeness, the effect is the largest in the U.S. (β = 6.963), the same in China (−0.215) but it is not significantly different from the U.S. with p > 0.10), and the smallest in Singapore (β = 6.963–0.873= 6.090; p < 0.01). The results in Table 12 suggest that the difference between U.S. and Singapore is significant (p < 0.01). The results in Table 13 indicate that the difference between China and Singapore is significant (p < 0.01).
- (3)
- For effect of low-low fit on sustainable innovativeness, the effect is also the highest in the U.S. (β = 4.179), the same in China (−0.049 but it is not significantly different from the U.S. with p > 0.10), and the lowest in Singapore (β = 4.179–0.963= 3.216; p < 0.01). The results in Table 12 suggest that the difference between U.S. and Singapore is significant (p < 0.01). The results in Table 13 indicate that the difference between China and Singapore is significant (p < 0.01).
- (4)
- For low-high misfit on sustainable innovativeness, the effect is the highest in the U.S. (β = 5.380), second in China (β = 5.380–0.727 = 4.653) and lowest in Singapore (β = 5.380–1.738 = 3.642). The differences are all significant (p < 0.01).
6. Conclusions, Implications, and Future Research
6.1. Conclusions
6.2. Theoretical Implications
6.3. Managerial Implications
6.4. Limitations and Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Study Measures and Sources
- (1)
- We have access to very large, unstructured, or fast-moving data for analysis.
- (2)
- We integrate data from multiple internal sources into a data warehouse or mart for easy access.
- (3)
- We integrate external data with internal to facilitate high-value analysis of our business environment.
- (4)
- Our big data analytics projects are adequately funded.
- (5)
- * Our big data analytics projects are given enough time to achieve their objectives.
- (1)
- (2)
- Our capability to discover relationships and dependencies from the big data is: (0 = no capability; 5 = neutral; 10 = very high level of capability; adopted from Hao et al. [2], which was developed based on field research).
- (3)
- (4)
- (5)
- (1)
- The products and services often incorporate innovative technologies which have never been used in the industry before.
- (2)
- The products and services caused significant changes in the whole industry.
- (3)
- The products and services are one of the first of its kind introduced into the market.
- (4)
- The products and services are highly innovative—totally new to the market.
- (5)
- The products and services are perceived as most innovative in the industry.
References
- Mcafee, A.; Brynjolfsson, E. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar] [PubMed]
- Hao, S.; Zhang, H.; Song, M. Big data, big data analytics capability, and sustainable innovation performance. Sustainability 2019, 11, 7145. [Google Scholar] [CrossRef]
- Tan, K.H.; Zhan, Y. Improving new product development using big data: A case study of an electronics company. R&D Manag. 2016, 47, 570–582. [Google Scholar]
- Isik, Ö. Big Data Capabilities: An Organizational Information Processing Perspective. In Analytics and Data Science. Annals of Information Systems; Deokar, A., Gupta, A., Iyer, L., Jones, M., Eds.; Springer: Berlin, Germany, 2018; pp. 29–40. [Google Scholar]
- George, G.; Osinga, E.C.; Lavie, D.; Scott, B. Big data and data science methods for management research. Acad. Manag. J. 2016, 59, 1493–1507. [Google Scholar] [CrossRef]
- Peng, D.X.; Heim, G.R.; Mallick, D.N. Collaborative product development: The effect of project complexity on the use of information technology tools and new product development practices. Prod. Oper. Manag. 2014, 23, 1421–1438. [Google Scholar] [CrossRef]
- Tushman, M.; Nadler, D. Information processing as an integrating concept in organization design. Acad. Manag. Rev. 1978, 3, 613–624. [Google Scholar]
- Galbraith, J.R. Organization design: An information processing view. Interfaces 1974, 4, 28–36. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Gupta, M.; George, J.F. Toward the development of a big data analytics capability. Inf. Manag. Amst. 2016, 53, 1049–1064. [Google Scholar] [CrossRef]
- Ferraris, A.; Mazzoleni, A.; Devalle, A.; Couturier, J. Big data analytics capabilities and knowledge management: Impact on firm performance. Manag. Deci. 2019, 57, 1923–1936. [Google Scholar] [CrossRef]
- Bumblauskas, D.; Nold, H.; Bumblauskas, P.; Igou, A. Big data analytics: Transforming data to action. Bus. Proc. Manag. J. 2017, 23, 703–720. [Google Scholar] [CrossRef]
- Ghasemaghaei, M.; Ebrahimi, S.; Hassanein, K. Data analytics competency for improving firm decision making performance. J. Strateg. Inf. Syst. 2018, 27, 101–113. [Google Scholar] [CrossRef]
- Akter, S.; Wamba, S.F.; Gunasekaran, A.; Dubey, R.; Childe, S.J. How to improve firm performance using big data analytics capability and business strategy alignment. Int. J. Prod. Econ. 2016, 182, 113–131. [Google Scholar] [CrossRef]
- Jin, D.H.; Kim, H.J. Integrated understanding of big data, big data analysis, and business intelligence: A case study of logistics. Sustainability 2018, 10, 3778. [Google Scholar] [CrossRef]
- Tan, K.H. Managerial perspectives of big data analytics capability towards product innovation. Strateg. Direc. 2018, 34, 33–35. [Google Scholar] [CrossRef]
- Wang, Y.; Hajli, N. Exploring the path to big data analytics success in healthcare. J. Bus. Res. 2017, 70, 287–299. [Google Scholar] [CrossRef]
- Su, Z.; Ahlstrom, D.; Li, J.; Cheng, D. Knowledge creation capability, absorptive capacity, and product innovativeness. R&D Manag. 2013, 43, 473–485. [Google Scholar]
- Johnson, J.S.; Friend, S.B.; Lee, H.S. Big data facilitation, utilization, and monetization: Exploring the 3Vs in a new product development process. J. Prod. Innov. Manag. 2017, 34, 640–658. [Google Scholar] [CrossRef]
- Urbinati, A.; Bogers, M.; Chiesa, V.; Frattini, F. Creating and capturing value from big data: A multiple-case study analysis of provider companies. Technovation 2019, 84–85, 21–36. [Google Scholar] [CrossRef]
- Bensaou, M.; Venkatraman, N. Configurations of interorganizational relationships: A comparison between U.S. and Japanese automakers. Manag. Sci. 1995, 41, 1471–1492. [Google Scholar] [CrossRef]
- Gómez, J.; Salazar, I.; Vargas, P. Firm boundaries, information processing capacity, and performance in manufacturing firms. J. Manag. Inf. Syst. 2016, 33, 809–842. [Google Scholar] [CrossRef]
- Song, M.; Bij, H.V.D.; Weggeman, M. Determinants of the level of knowledge application: A knowledge-based and information processing perspective. J. Prod. Innov. Manag. 2005, 22, 430–444. [Google Scholar] [CrossRef]
- Moser, R.; Kuklinski, J.W.; Srivastava, M. Information processing fit in the context of emerging markets: An analysis of foreign SBUs in China. J. Bus. Res. 2017, 70, 234–247. [Google Scholar] [CrossRef]
- Venkatraman, N.; Camillus, J.C. Exploring the concept of “fit” in strategic management. Acad. Manag. Rev. 1984, 9, 513–525. [Google Scholar]
- Oncioiu, I.; Bunget, O.C.; Türkeș, M.C.; Căpușneanu, S.; Topor, D.I.; Tamaș, A.S.; Rakoș, I.S.; Hint, M.Ș. The impact of big data analytics on company performance in supply chain management. Sustainability 2019, 11, 4864. [Google Scholar] [CrossRef]
- George, G.; Haas, M.R.; Pentland, A. Big data and management. Acad. Manag. J. 2014, 57, 321–326. [Google Scholar] [CrossRef]
- Hu, F.; Liu, W.; Tsai, S.B.; Gao, J.; Bin, N.; Chen, Q. An empirical study on visualizing the intellectual structure and hotspots of big data research from a sustainable perspective. Sustainability 2018, 10, 667. [Google Scholar] [CrossRef]
- Chen, H.; Chiang, R.H.L.; Storey, V.C. Business intelligence and analytics: From big data to big impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar] [CrossRef]
- Günther, W.A.; Rezazade Mehrizi, M.H.; Huysman, M.; Feldberg, F. Debating big data: A literature review on realizing value from big data. J. Strateg. Inf. Syst. 2017, 26, 191–209. [Google Scholar] [CrossRef]
- Ghasemaghaei, M. The role of positive and negative valence factors on the impact of bigness of data on big data analytics usage. Int. J. Inf. Manag. 2020, 50, 395–404. [Google Scholar] [CrossRef]
- Ghasemaghaei, M.; Calic, G. Does big data enhance firm innovation competency? The mediating role of data-driven insights. J. Bus. Res. 2019, 104, 69–84. [Google Scholar] [CrossRef]
- Wamba, S.F.; Gunasekaran, A.; Akter, S.; Ren, S.J.; Dubey, R.; Childe, S.J. Big data analytics and firm performance: Effects of dynamic capabilities. J. Bus. Res. 2017, 70, 356–365. [Google Scholar] [CrossRef]
- Dubey, R.; Gunasekaran, A.; Childe, S.J. Big data analytics capability in supply chain agility: The moderating effect of organizational flexibility. Manag. Deci. 2019, 57, 2092–2112. [Google Scholar] [CrossRef]
- Rialti, R.; Zollo, L.; Ferraris, A.; Alon, I. Big data analytics capabilities and performance: Evidence from a moderated multi-mediation model. Technol. Forecast. Soc. Chang. 2019, 149, 1–10. [Google Scholar] [CrossRef]
- Danneels, E.; Kleinschmidtb, E.J. Product innovativeness from the firm’s perspective: Its dimensions and their relation with project selection and performance. J. Prod. Innov. Manag. 2001, 18, 357–373. [Google Scholar] [CrossRef]
- Song, X.M.; Parry, M.E. Challenges of managing the development of breakthrough products in Japan. J. Oper. Manag. 1999, 17, 665–688. [Google Scholar] [CrossRef]
- Song, L.Z.; Song, M.; Di Benedetto, C.A. Resources, supplier investment, product launch advantages, and first product performance. J. Oper. Manag. 2011, 29, 86–104. [Google Scholar] [CrossRef]
- Calantone, R.J.; Chan, K.; Cui, A.S. Decomposing product innovativeness and its effects on new product success. J. Prod. Innov. Manag. 2006, 23, 408–421. [Google Scholar] [CrossRef]
- McNally, R.C.; Cavusgil, E.; Calantone, R.J. Product innovativeness dimensions and their relationships with product advantage, product financial performance, and project protocol. J. Prod. Innov. Manag. 2010, 27, 991–1006. [Google Scholar] [CrossRef]
- Cillo, P.; De Luca, L.M.; Troilo, G. Market information approaches, product innovativeness, and firm performance: An empirical study in the fashion industry. Res. Policy 2010, 39, 1242–1252. [Google Scholar] [CrossRef]
- Tsai, K.H.; Liao, Y.C.; Hsu, T.T. Does the use of knowledge integration mechanisms enhance product innovativeness. Ind. Mark. Manag. 2015, 46, 214–223. [Google Scholar] [CrossRef]
- Song, X.M.; Parry, M.E. What separates Japanese new product winners from losers. J. Prod. Innov. Manag. 1996, 13, 422–439. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Innovativeness | Big Data | BDAC | |
|---|---|---|---|
| Innovativeness | 0.855 | ||
| Big Data | 0.587 *** | 0.918 | |
| BDAC | 0.433 *** | 0.419 *** | 0.803 |
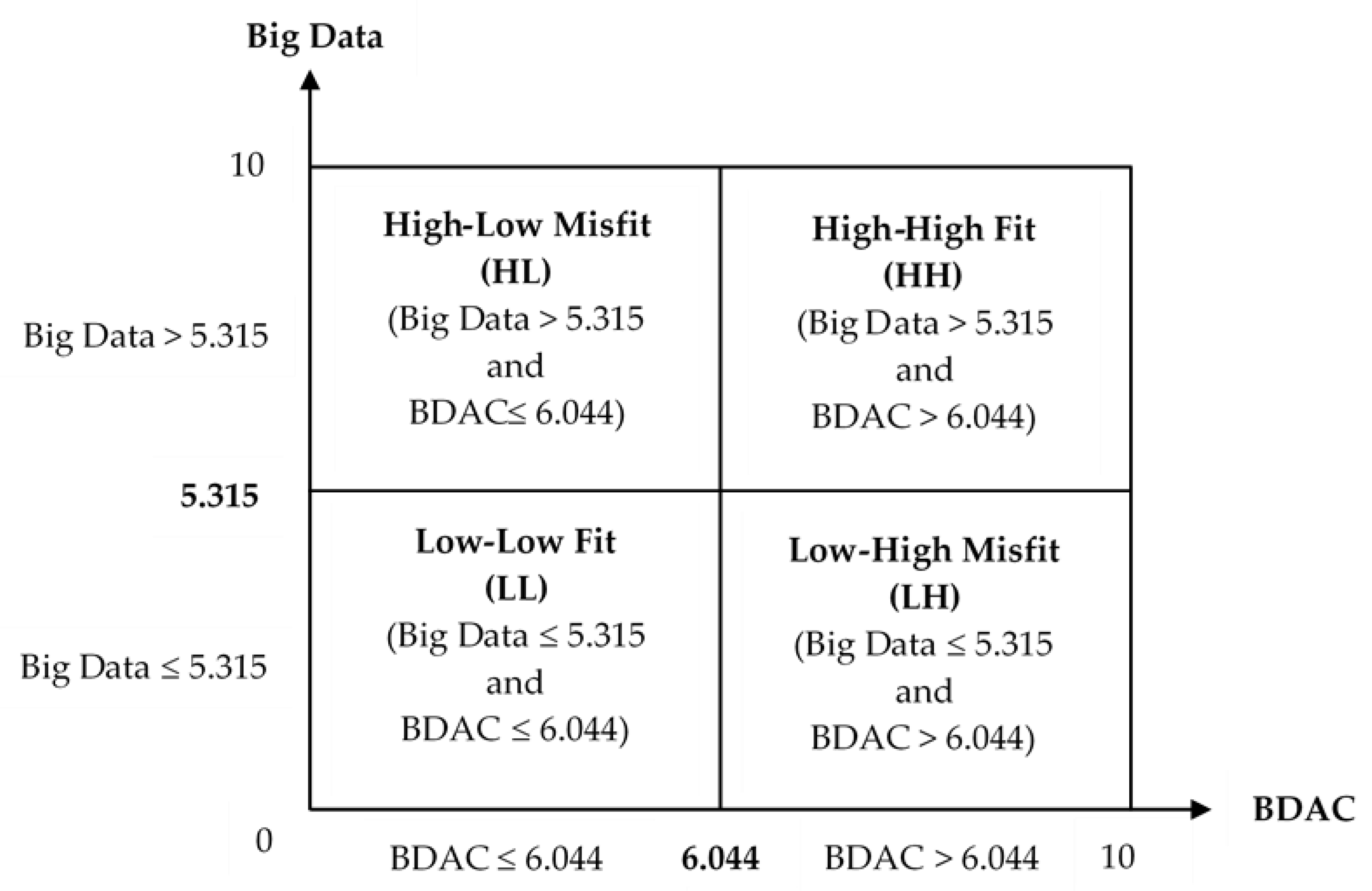
| Mean | 5.717 | 5.315 | 6.044 |
| S.D. | 2.138 | 2.749 | 2.056 |
| Measure Items | Innovativeness | Big Data | BDAC |
|---|---|---|---|
| INNO 1 | 0.833 | 0.187 | 0.190 |
| INNO 4 | 0.772 | 0.229 | 0.086 |
| INNO 2 | 0.723 | 0.260 | 0.125 |
| INNO 3 | 0.722 | 0.178 | 0.238 |
| INNO 5 | 0.671 | 0.272 | 0.181 |
| Big Data 2 | 0.225 | 0.870 | 0.146 |
| Big Data 4 | 0.268 | 0.868 | 0.149 |
| Big Data 1 | 0.329 | 0.813 | 0.121 |
| Big Data 3 | 0.262 | 0.784 | 0.313 |
| BDAC 2 | 0.114 | 0.115 | 0.821 |
| BDAC 1 | 0.135 | 0.162 | 0.759 |
| BDAC 4 | 0.172 | 0.149 | 0.752 |
| BDAC 5 | 0.204 | 0.137 | 0.720 |
| Dependent Variable: Sustainable Innovativeness | |||
|---|---|---|---|
| Parameter Estimate (β) | Standard Error (S.E.) | Standardized Estimate (b) | |
| High-Low Misfit | 6.118 *** | 0.206 | 0.400 |
| High-High Fit | 6.963 *** | 0.134 | 0.701 |
| Low-Low Fit | 4.179 *** | 0.146 | 0.384 |
| Low-High Misfit | 5.380 *** | 0.213 | 0.340 |
| Model F-value | 1263.050 *** | ||
| R-square | 0.914 | ||
| Adjusted R-square | 0.914 | ||
| Innovativeness | Big Data | BDAC | |
|---|---|---|---|
| Innovativeness | 0.869 | ||
| Big Data | 0.588 *** | 0.894 | |
| BDAC | 0.389 *** | 0.506 *** | 0.767 |
| Mean | 5.297 | 4.571 | 6.254 |
| S.D. | 2.192 | 2.585 | 2.085 |
| Measure Items | Innovativeness | Big Data | BDAC |
|---|---|---|---|
| INNO 1 | 0.819 | 0.242 | 0.070 |
| INNO 3 | 0.811 | 0.238 | 0.049 |
| INNO 5 | 0.743 | 0.224 | 0.194 |
| INNO 4 | 0.735 | 0.180 | 0.191 |
| INNO 2 | 0.728 | 0.211 | 0.149 |
| Big Data 1 | 0.243 | 0.865 | 0.159 |
| Big Data 2 | 0.241 | 0.797 | 0.275 |
| Big Data 3 | 0.252 | 0.767 | 0.210 |
| Big Data 4 | 0.377 | 0.752 | 0.200 |
| BDAC 1 | 0.035 | 0.237 | 0.800 |
| BDAC 2 | 0.175 | 0.023 | 0.762 |
| BDAC 5 | 0.066 | 0.241 | 0.730 |
| BDAC 4 | 0.285 | 0.237 | 0.622 |
| Dependent Variable: Sustainable Innovativeness | |||
|---|---|---|---|
| Parameter Estimate (β) | Standard Error (S.E.) | Standardized Estimate (b) | |
| High-Low Misfit | 5.660 *** | 0.224 | 0.329 |
| High-High Fit | 6.748 *** | 0.128 | 0.688 |
| Low-Low Fit | 4.130 *** | 0.126 | 0.427 |
| Low-High Misfit | 4.653 *** | 0.169 | 0.360 |
| Model F-value | 1315.420 *** | ||
| R-square | 0.893 | ||
| Adjusted R-square | 0.893 | ||
| Innovativeness | Big Data | BDAC | |
|---|---|---|---|
| Innovativeness | 0.881 | ||
| Big Data | 0.566 *** | 0.915 | |
| BDAC | 0.393 *** | 0.521 *** | 0.775 |
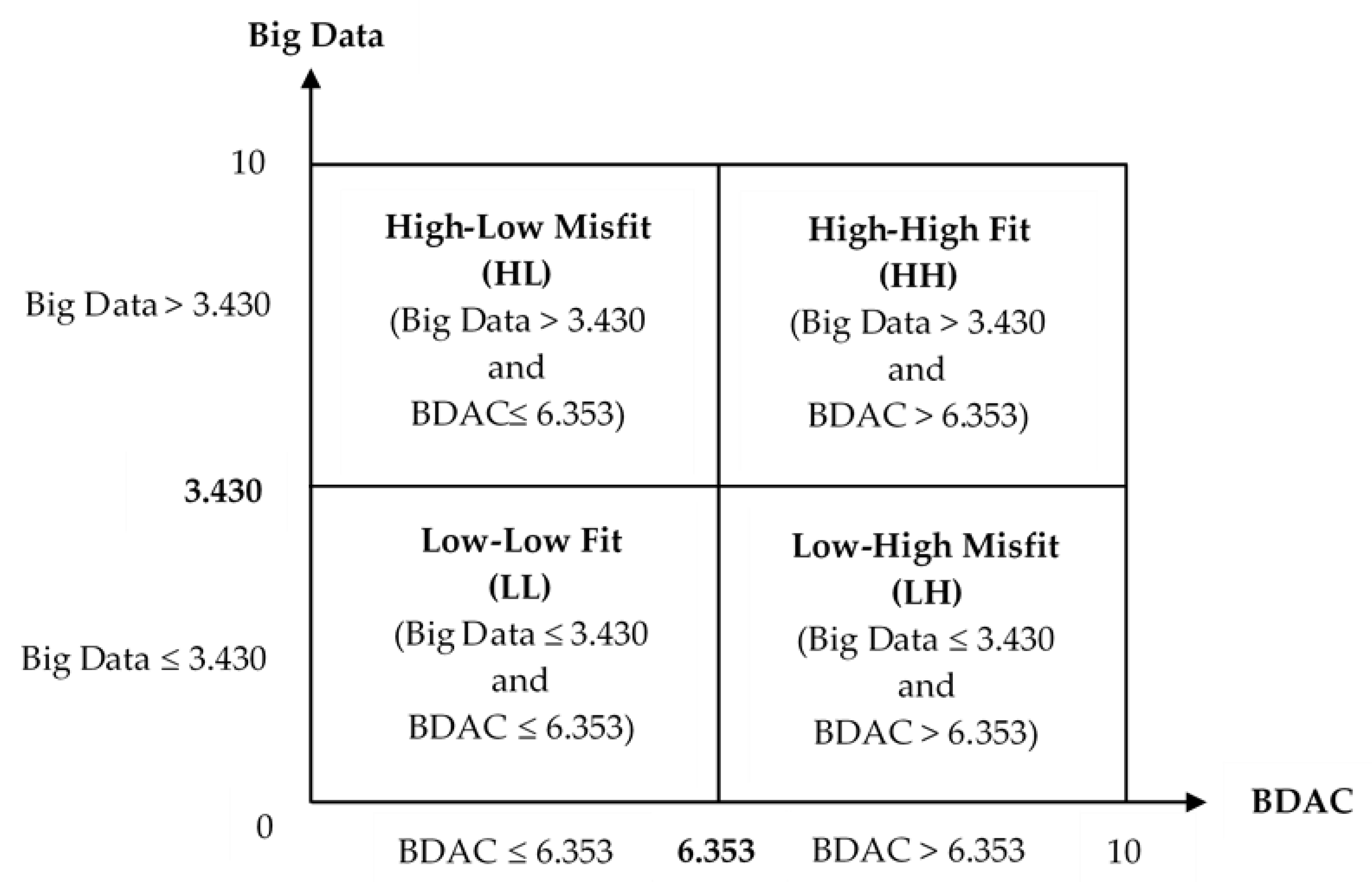
| Mean | 4.298 | 3.430 | 6.353 |
| S.D. | 2.184 | 2.507 | 2.167 |
| Measure Items | Innovativeness | Big Data | BDAC | |
|---|---|---|---|---|
| Innovativeness | INNO 1 | 0.854 | 0.249 | 0.117 |
| INNO 3 | 0.850 | 0.123 | 0.002 | |
| INNO 2 | 0.778 | 0.116 | 0.222 | |
| INNO 4 | 0.700 | 0.335 | 0.105 | |
| INNO 5 | 0.679 | 0.397 | 0.199 | |
| Big Data | Big Data 1 | 0.214 | 0.884 | 0.168 |
| Big Data 2 | 0.273 | 0.842 | 0.205 | |
| Big Data 4 | 0.280 | 0.831 | 0.197 | |
| Big Data 3 | 0.243 | 0.744 | 0.225 | |
| BDAC | BDAC 1 | 0.058 | 0.240 | 0.817 |
| BDAC 2 | 0.096 | 0.002 | 0.743 | |
| BDAC 4 | 0.302 | 0.242 | 0.703 | |
| BDAC 5 | 0.062 | 0.413 | 0.641 |
| Dependent Variable: Sustainable Innovativeness | |||
|---|---|---|---|
| Parameter Estimate (β) | Standard Error (S.E.) | Standardized Estimate (b) | |
| High-Low Misfit | 5.144 *** | 0.426 | 0.264 |
| High-High Fit | 6.091 *** | 0.195 | 0.684 |
| Low-Low Fit | 3.215 *** | 0.177 | 0.399 |
| Low-High Misfit | 3.642 *** | 0.196 | 0.406 |
| Model F-value | 449.170 *** | ||
| R-square | 0.861 | ||
| Adjusted R-square | 0.859 | ||
| Hypothesis | Pair Comparison | The United States (N = 477) | China (N = 632) | Singapore (N = 294) |
|---|---|---|---|---|
| H1 (fits > misfits) | High-High Fit > Low-High Misfit | 39.680 *** | 98.070 *** | 78.300 *** |
| High-High Fit > High-Low Misfit | 11.860 *** | 17.760 *** | 4.070 ** | |
| Low-Low Fit > Low-High Misfit | 21.640 *** | 6.180 *** | 2.620 * (<) | |
| Low-Low Fit > High-Low Misfit | 59.020 *** (<) | 35.350 *** | 17.480 *** | |
| H2 (HH > LL) | High-High Fit > Low-Low Fit | 197.290 *** | 212.910 *** | 119.450 *** |
| H3 (LH > HL) | Low-High Misfit > High-Low Misfit | 6.220 *** (<) | 12.860 *** | 10.240 *** |
| Dependent Variable: Sustainable Innovativeness | |||
|---|---|---|---|
| Rank | The United States (Standardized Estimate b) | China (Standardized Estimate b) | Singapore (Standardized Estimate b) |
| 1 | High-High Fit (0.701) | High-High Fit (0.688) | High-High Fit (0.684) |
| 2 | High-Low Misfit (0.400) | Low-Low Fit (0.427) | Low-High Misfit (0.406) |
| 3 | Low-Low Fit (0.384) | Low-High Misfit (0.360) | Low-Low Fit (0.399) |
| 4 | Low-High Misfit (0.340) | High-Low Misfit (0.329) | High-Low Misfit (0.264) |
| Dependent Variable: Sustainable Innovativeness | |||
|---|---|---|---|
| Independent Variables | Parameter Estimate (β) | Standard Error (S.E.) | Standardized Estimate (b) |
| High-Low Misfit | 6.118 *** | 0.211 | 0.368 |
| High-High Fit | 6.963 *** | 0.137 | 0.718 |
| Low-Low Fit | 4.179 *** | 0.150 | 0.429 |
| Low-High Misfit | 5.380 *** | 0.218 | 0.423 |
| China × High-Low Misfit | −0.458 | 0.304 | −0.018 |
| China × High-High Fit | −0.215 | 0.185 | −0.015 |
| China × Low-Low Fit | −0.049 | 0.194 | −0.003 |
| China × Low-High Misfit | −0.727 *** | 0.273 | −0.038 |
| Singapore × High-Low Misfit | −0.974 ** | 0.481 | −0.019 |
| Singapore × High-High Fit | −0.873 *** | 0.241 | −0.038 |
| Singapore × Low-Low Fit | −0.963 *** | 0.234 | −0.046 |
| Singapore × Low-High Misfit | −1.738 *** | 0.295 | −0.075 |
| Model F-value | 1006.620 *** | ||
| R-square | 0.897 | ||
| Adjusted R-square | 0.896 | ||
| China | Singapore | Does the Effect Differ? (F-Statistics and Significant Level) |
|---|---|---|
| The Effect of High-Low Misfit | The Effect of High-Low Misfit | 1.130 |
| The Effect of High-High Fit | The Effect of High-High Fit | 7.900 *** |
| The Effect of Low-Low Fit | The Effect of Low-Low Fit | 17.700 *** |
| The Effect of Low-High Misfit | The Effect of Low-High Misfit | 15.300 *** |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, M.; Zhang, H.; Heng, J. Creating Sustainable Innovativeness through Big Data and Big Data Analytics Capability: From the Perspective of the Information Processing Theory. Sustainability 2020, 12, 1984. https://doi.org/10.3390/su12051984
Song M, Zhang H, Heng J. Creating Sustainable Innovativeness through Big Data and Big Data Analytics Capability: From the Perspective of the Information Processing Theory. Sustainability. 2020; 12(5):1984. https://doi.org/10.3390/su12051984
Chicago/Turabian StyleSong, Michael, Haili Zhang, and Jinjin Heng. 2020. "Creating Sustainable Innovativeness through Big Data and Big Data Analytics Capability: From the Perspective of the Information Processing Theory" Sustainability 12, no. 5: 1984. https://doi.org/10.3390/su12051984
APA StyleSong, M., Zhang, H., & Heng, J. (2020). Creating Sustainable Innovativeness through Big Data and Big Data Analytics Capability: From the Perspective of the Information Processing Theory. Sustainability, 12(5), 1984. https://doi.org/10.3390/su12051984