Predicting the Water-Conducting Fracture Zone (WCFZ) Height Using an MPGA-SVR Approach

Abstract
1. Introduction
2. Methods
2.1. Support Vector Regression (SVR)
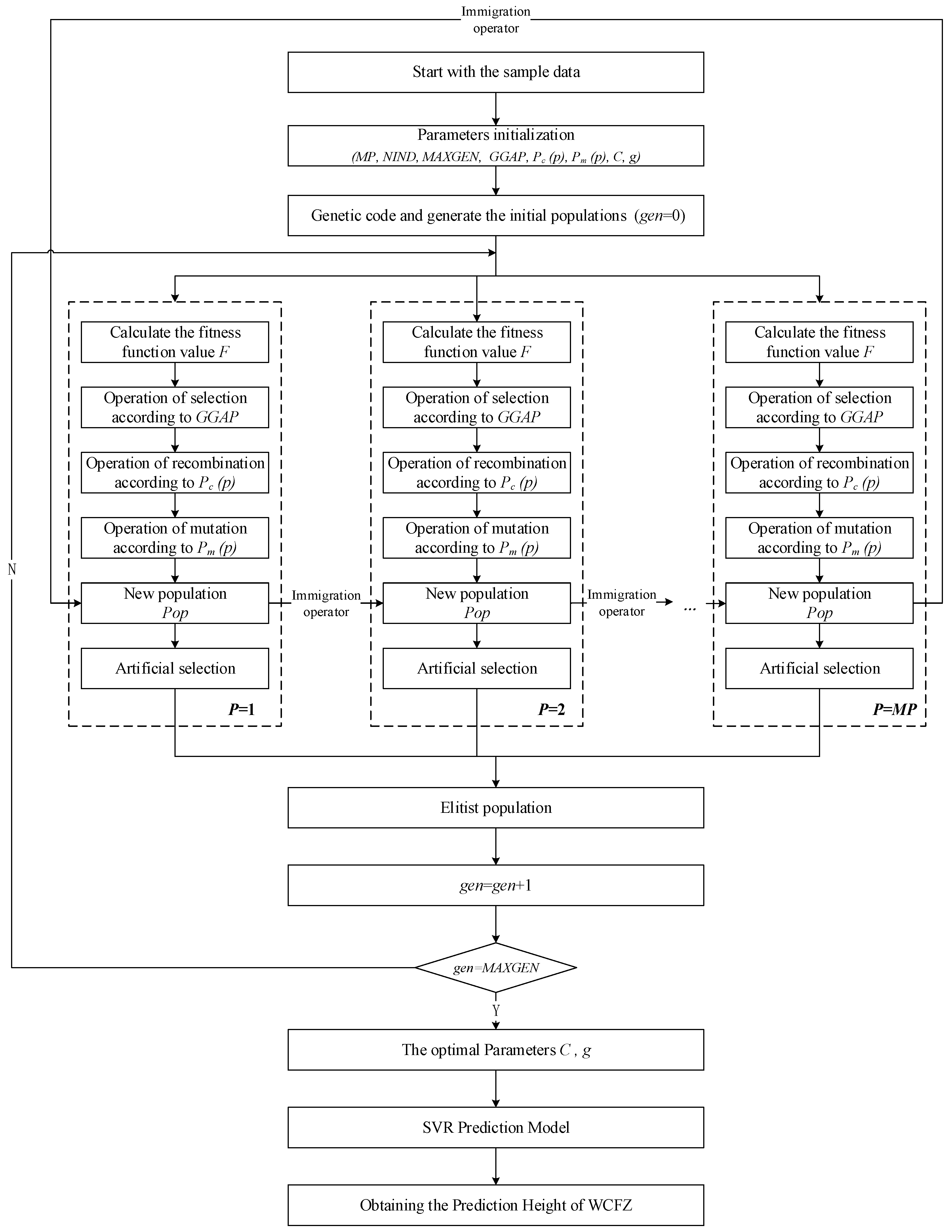
2.2. The Multi-Population Genetic Algorithm (MPGA)
2.3. MPGA-SVR Model
3. Study Area and Data Set
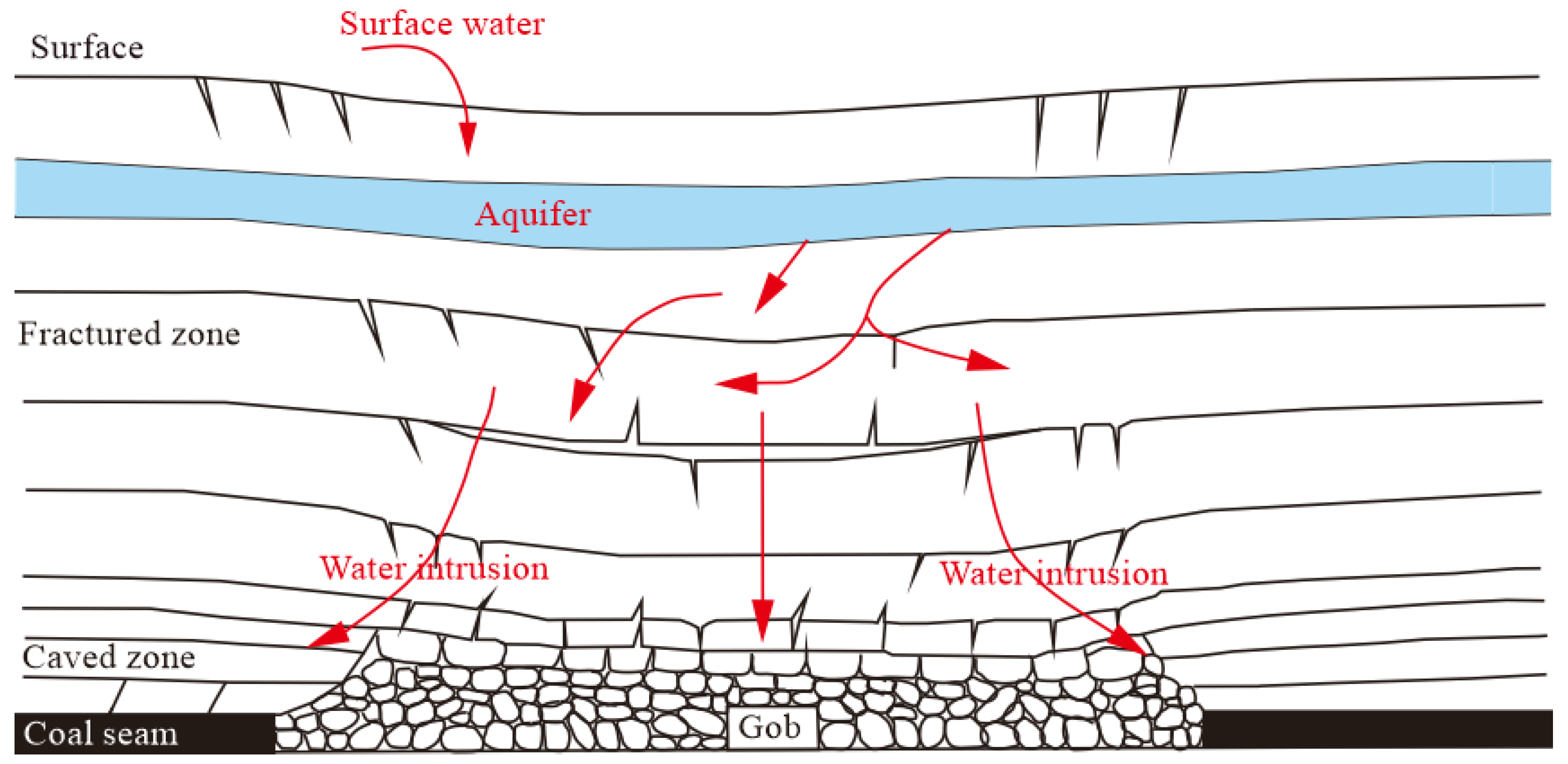
3.1. Engineering background
3.2. Model Sample Data
4. Result and Discussion
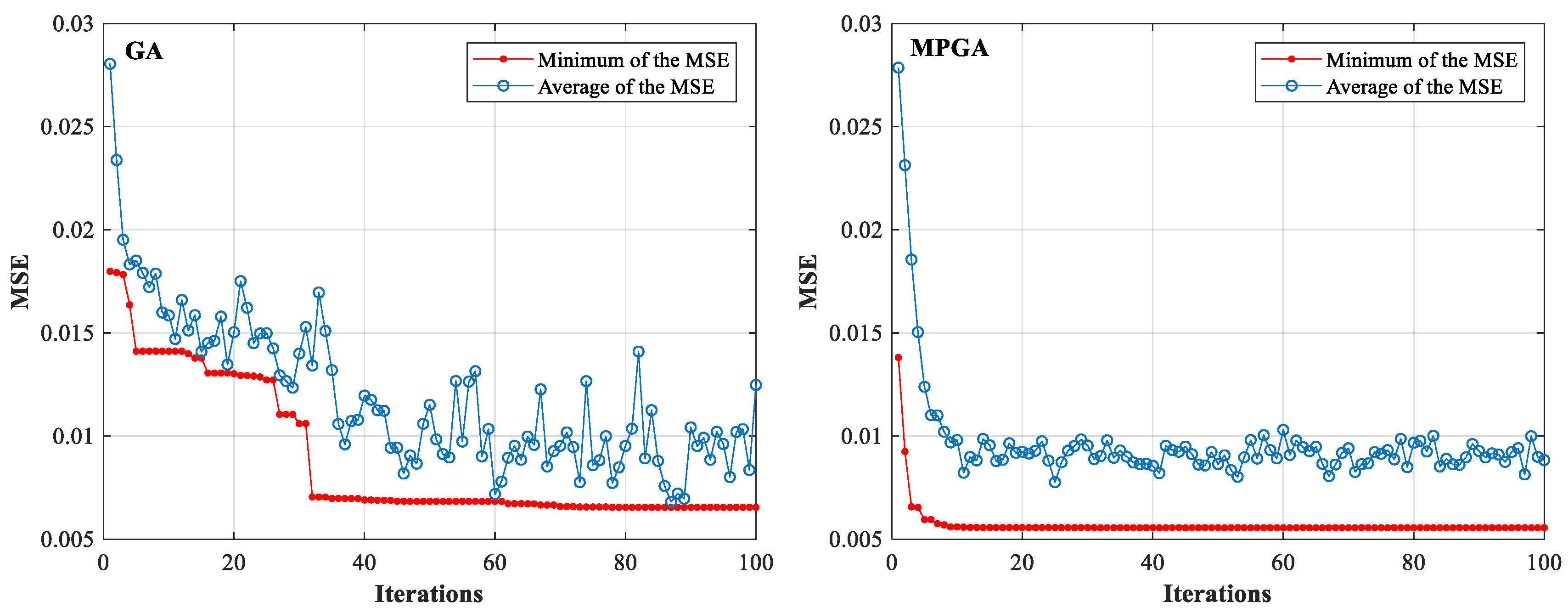
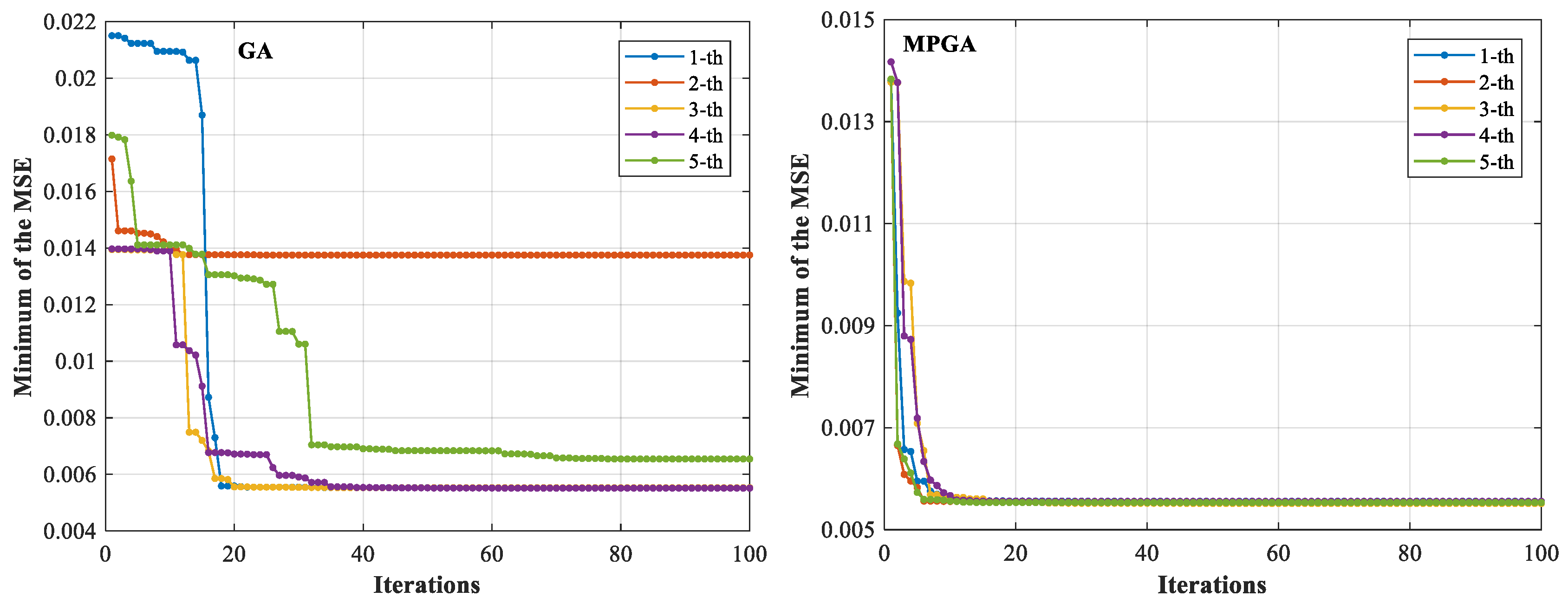
4.1. The Parametric Optimization Process of the SVR Model
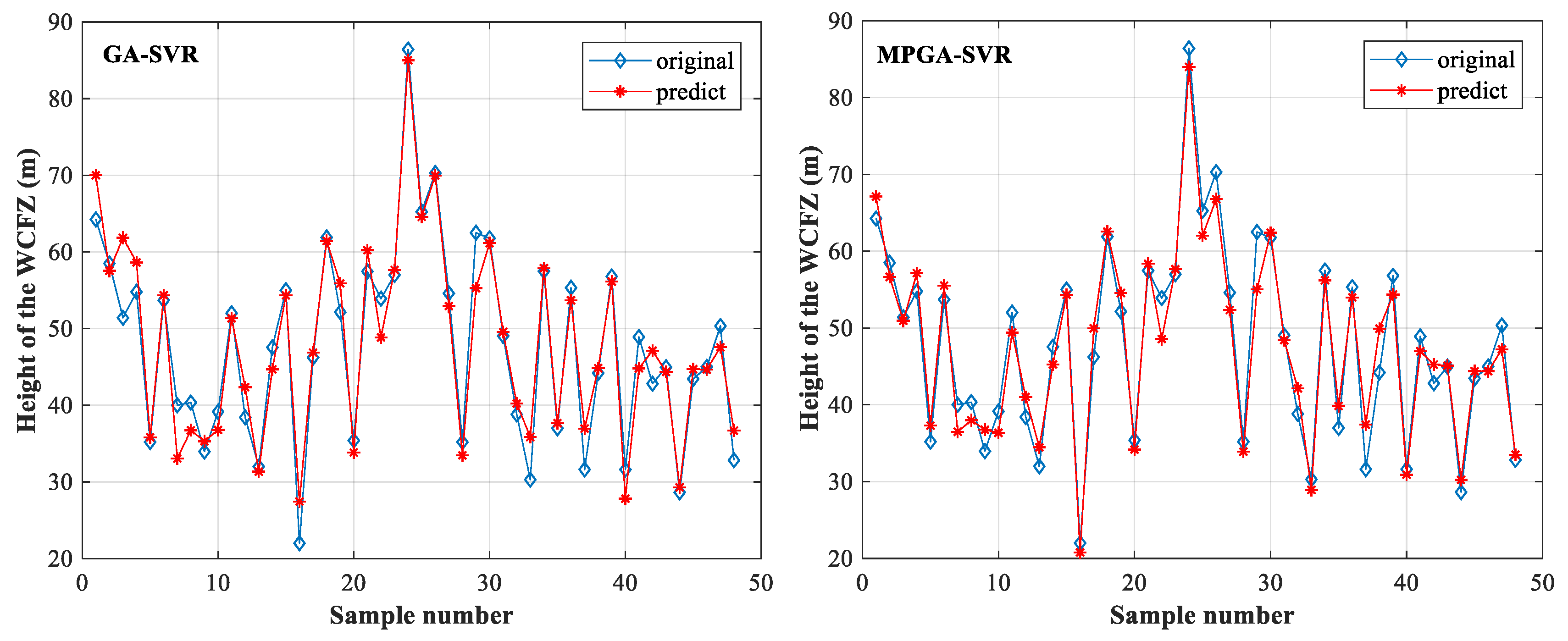
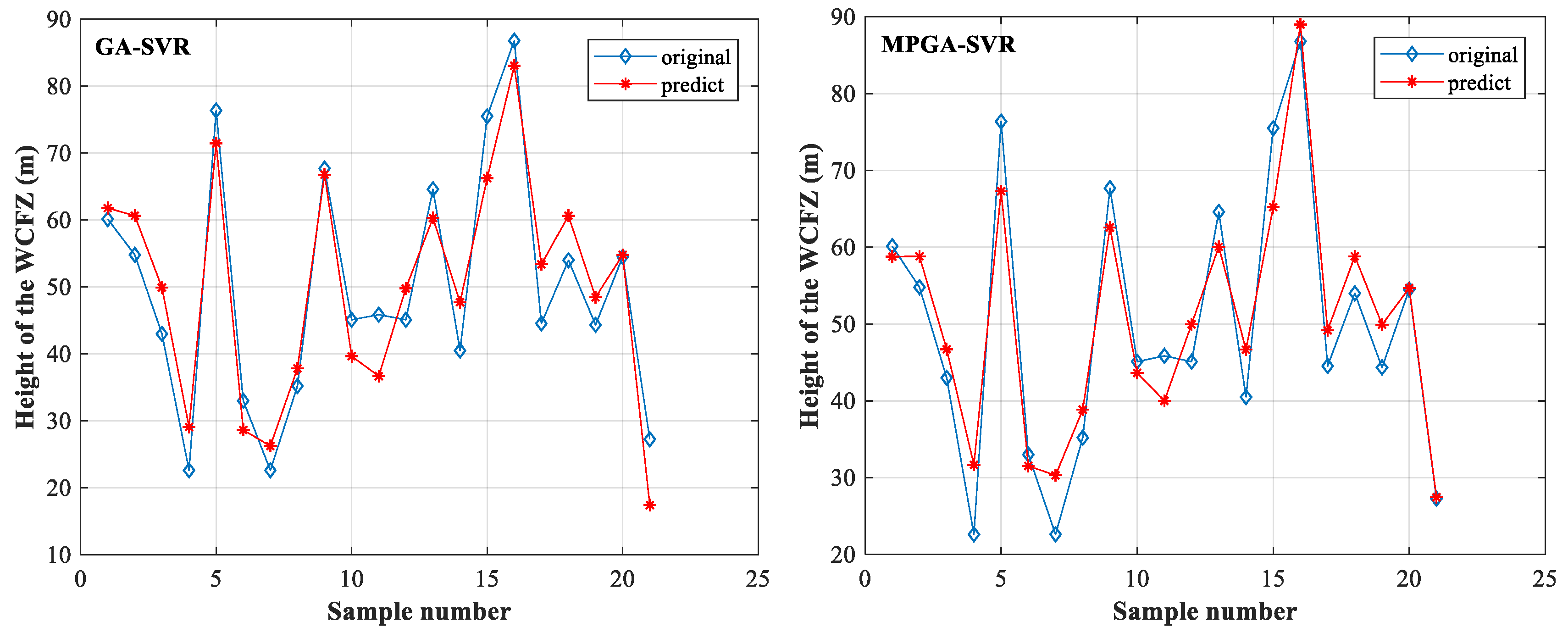
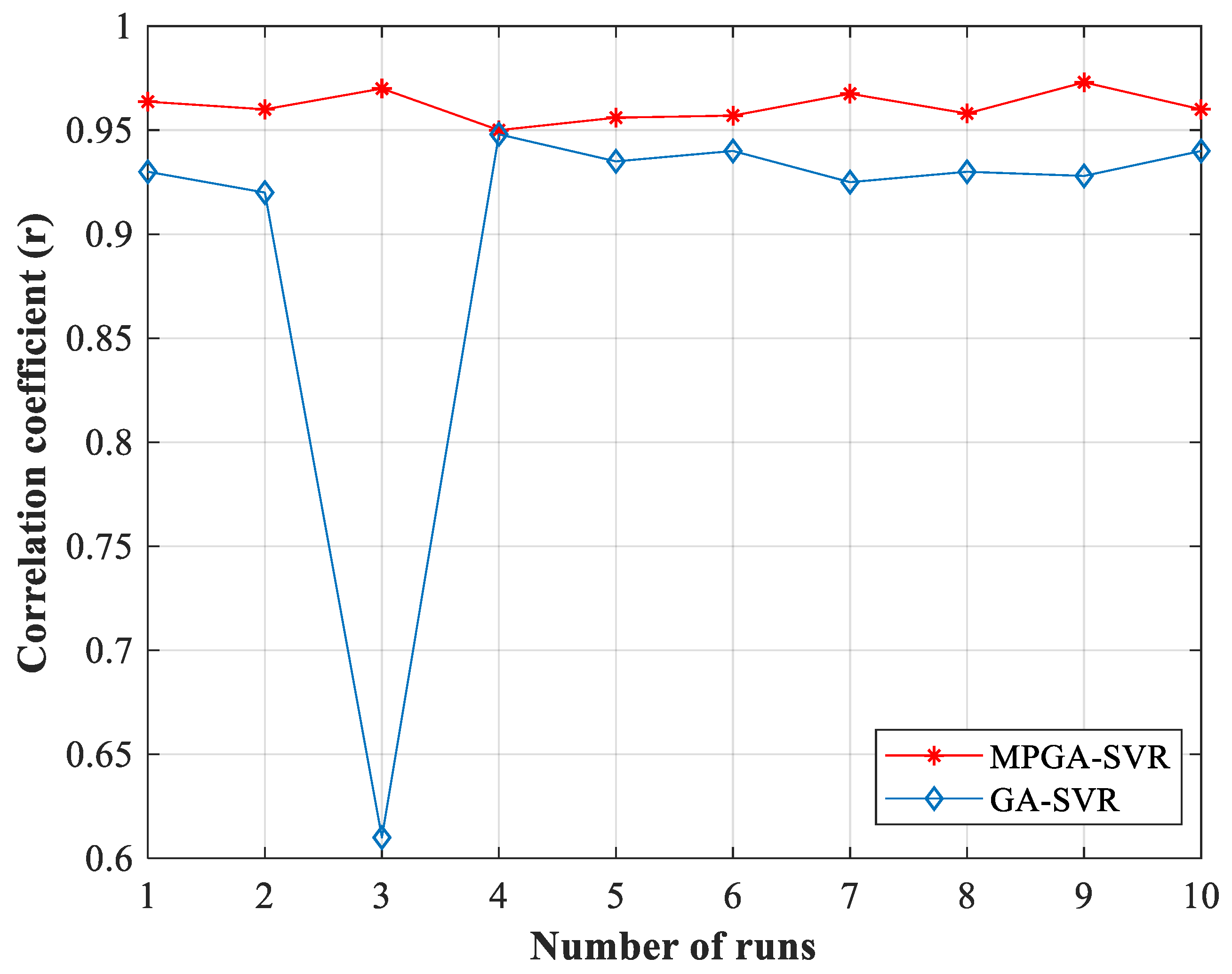
4.2. The Test of the MPGA-SVR Model
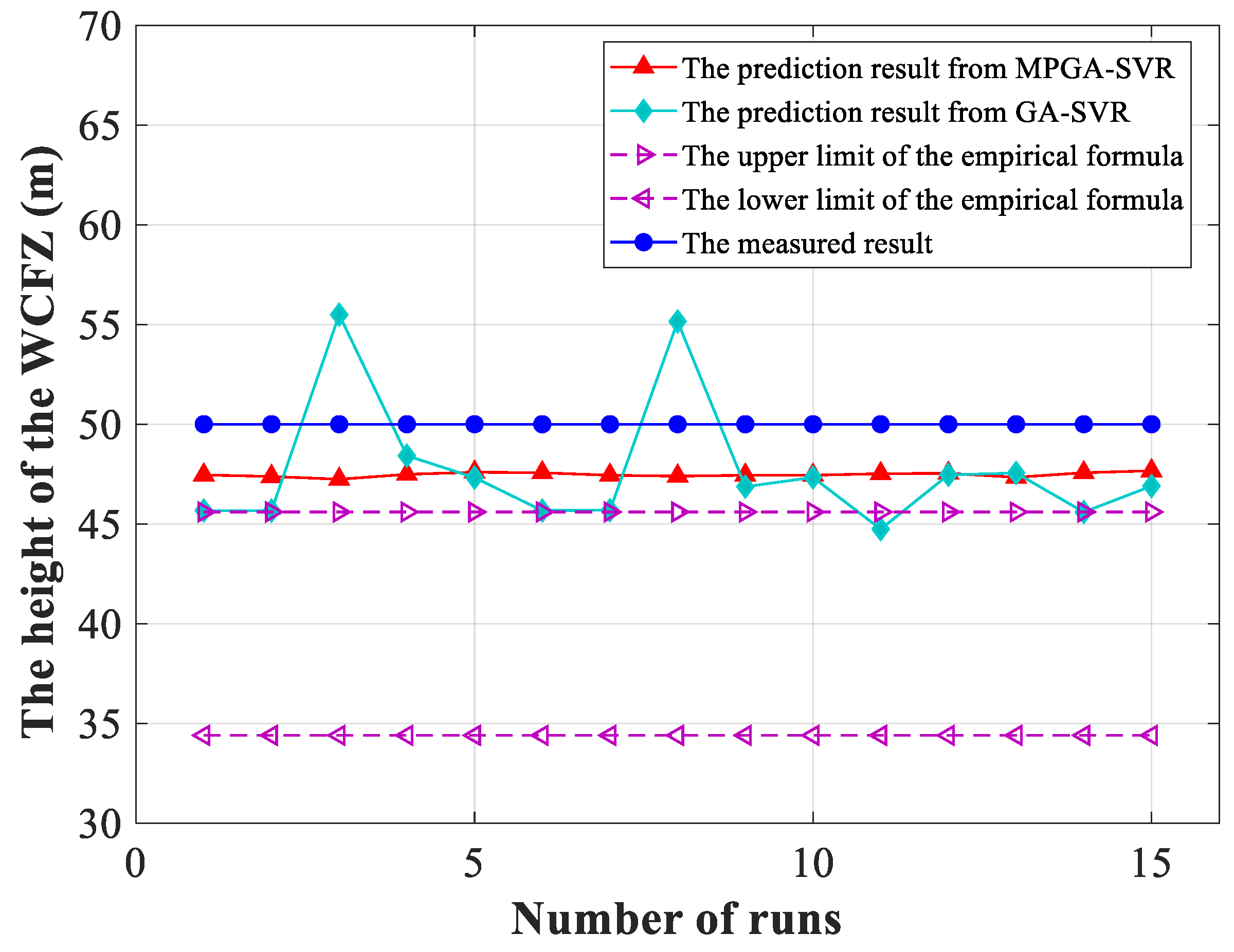
4.3. Application of the MPGA-SVR Model
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chang, S.; Zhuo, J.; Meng, S.; Qin, S.; Yao, Q. Clean coal technologies in China: Current status and future perspectives. Engineering 2016, 2, 447–459. [Google Scholar] [CrossRef]
- Liu, S.L.; Li, W.P.; Wang, Q.Q. Height of the Water-Flowing Fractured Zone of the Jurassic Coal Seam in Northwestern China. Mine Water Environ. 2018, 37, 312–321. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Q.M.; Li, W.P.; Li, T.; He, J.H. Height of water-conducting fractured zone in coal mining in the soil-rock composite structure overburdens. Environ. Earth Sci. 2019, 78. [Google Scholar] [CrossRef]
- Feng, X.; Zhang, N.; Chen, X.; Gong, L.; Lv, C.; Guo, Y. Exploitation contradictions concerning multi-energy resources among coal, gas, oil, and uranium: A case study in the Ordos Basin (Western North China Craton and Southern Side of Yinshan Mountains). Energies 2016, 9, 119. [Google Scholar] [CrossRef]
- Wu, Q.; Liu, Y.; Zhou, W.; Wu, X.; Liu, S.; Sun, W.; Zeng, Y. Assessment of water inrush vulnerability from overlying aquifer using GIS-AHP-based ’three maps-two predictions’ method: A case study in Hulusu coal mine, China. Q. J. Eng. Geol. Hydrogeol. 2015, 48, 234–243. [Google Scholar] [CrossRef]
- Adhikary, D.P.; Guo, H. Measurement of longwall mining induced strata permeability. Geotech. Geol. Eng. 2014, 32, 617–626. [Google Scholar] [CrossRef]
- Han, Y.; Cheng, J.; Huang, Q.; Zou, D.H.; Zhou, J.; Huang, S.; Long, Y. Prediction of the height of overburden fractured zone in deep coal mining: Case study. Arch. Min. Sci. 2018, 63, 617–631. [Google Scholar] [CrossRef]
- Zhang, Y.; Cao, S.; Gao, R.; Guo, S.; Lan, L. Prediction of the Heights of the Water-Conducting Fracture Zone in the Overlying Strata of Shortwall Block Mining Beneath Aquifers in Western China. Sustainability 2018, 10, 1636. [Google Scholar] [CrossRef]
- Wei, J.; Wu, F.; Yin, H.; Guo, J.; Xie, D.; Xiao, L. Formation and height of the interconnected fractures zone after extraction of thick coal seams with weak overburden in western China. Mine Water Environ. 2017, 36, 59–66. [Google Scholar] [CrossRef]
- Zhang, D.; Li, W.; Lai, X.; Fan, G.; Liu, W. Development on basic theory of water protection during coal mining in northwest of China. J. China Coal Soc. 2017, 42, 36–43. [Google Scholar]
- Lawson, H.E.; Tesarik, D.; Larson, M.K.; Abraham, H. Effects of overburden characteristics on dynamic failure in underground coal mining. Int. J. Min. Sci. Technol. 2017, 27, 121–129. [Google Scholar] [CrossRef]
- Liu, X.; Tan, Y.; Ning, J.; Tian, C.; Wang, J. The height of water-conducting fractured zones in longwall mining of shallow coal seams. Geotech. Geol Eng. 2015, 33, 693–700. [Google Scholar] [CrossRef]
- Zhang, Y.; Tu, S.; Bai, Q.; Li, J. Overburden fracture evolution laws and water-controlling technologies in mining very thick coal seam under water-rich roof. Int. J. Min. Sci. Technol. 2013, 23, 693–700. [Google Scholar] [CrossRef]
- Pillar Design and Mining Regulations Under Buildings, Water, Rails and Major Roadways; China Coal Industry Publishing House: Beijing China, 2000.
- Yang, G.; Chen, C.; Gao, S.; Feng, B. Study on the height of water flowing fractured zone based on analytic hierarchy process and fuzzy clustering analysis method. J. Min. Saf. Eng. 2015, 32, 206–212. [Google Scholar]
- Zhao, D.; Wu, Q. An approach to predict the height of fractured water-conducting zone of coal roof strata using random forest regression. Sci. Rep. 2018, 8, 1–12. [Google Scholar] [CrossRef]
- Chai, H.; Zhang, J.; Yang, C. Prediction of water-flowing height in fractured zone of overburden strata based on GA-SVR. J. Min. Saf. Eng. 2018, 35, 359–365. [Google Scholar]
- Ma, Y.; Wu, Q.; Zhang, Z.; Hong, Y.; Guo, L.; Tian, H.; Zhang, L. Research on prediction of water conducted fissure height in roof of coal mining seam. Coal Sci. Technol. 2008, 5, 59–62. [Google Scholar]
- Wu, Q.; Shen, J.J.; Liu, W.T.; Wang, Y. A RBFNN-based method for the prediction of the developed height of a water-conductive fractured zone for fully mechanized mining with sublevel caving. Arab. J. Geosci. 2017, 10, 9. [Google Scholar] [CrossRef]
- Qi, Y.; Zhao, X.; Luo, B.; Luo, M. GA-SVR Prediction of Failure Depth of Coal Seam Floor Based on Small Sample Data. Proceedings of the Fifth National Conference on Computer Mathematics, Hong Kong, China, 2013. Available online: http://www.ipcbee.com/vol52/017-ICGES2013-G30006.pdf (accessed on 28 February 2020).
- Al-Anazi, A.F.; Gates, I.D. Support vector regression to predict porosity and permeability: Effect of sample size. Comput. Geosci. 2012, 39, 64–76. [Google Scholar] [CrossRef]
- Dhiman, H.S.; Deb, D.; Guerrero, J.M. Hybrid machine intelligent SVR variants for wind forecasting and ramp events. Renew. Sustain. Energy Rev. 2019, 108, 369–379. [Google Scholar] [CrossRef]
- Jiang, X.; Lu, W.X.; Hou, Z.Y.; Zhao, H.Q.; Na, J. Ensemble of surrogates-based optimization for identifying an optimal surfactant-enhanced aquifer remediation strategy at heterogeneous DNAPL-contaminated sites. Comput. Geosci. 2015, 84, 37–45. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Y.; Deng, X. Analysis the height of water conducted zone of coal seam roof based on GA-SVR. J. China Coal Soc. 2009, 34, 1610–1615. [Google Scholar]
- Roushangar, K.; Koosheh, A. Evaluation of GA-SVR method for modeling bed load transport in gravel-bed rivers. J. Hydrol. 2015, 527, 1142–1152. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Ssystems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Yeh, C.W.; Jang, S.S. The development of information guided evolution algorithm for global optimization. J. Glob. Optim. 2006, 36, 517–535. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 2nd ed.; Statistics for Engineering and Information Science; Springer: New York, NY, USA, 2000. [Google Scholar]
- Hou, Z.Y.; Lu, W.X. Comparative study of surrogate models for groundwater contamination source identification at DNAPL-contaminated sites. Hydrogeol. J. 2018, 26, 923–932. [Google Scholar] [CrossRef]
- Jayasumana, S.; Hartley, R.I.; Salzmann, M.; Li, H.; Harandi, M.T. Kernel Methods on riemannian manifolds with gaussian RBF kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2464–2477. [Google Scholar] [CrossRef]
- Du, H.; Chen, W.; Zhu, Q.; Liu, S.; Zhou, J. Identification of weak peaks in X-ray fluorescence spectrum analysis based on the hybrid algorithm combining genetic and Levenberg Marquardt algorithm. Appl. Radiat. Isot. 2018, 141, 149–155. [Google Scholar] [CrossRef]
- Joo, A.; Ekart, A.; Neirotti, J.P. Genetic Algorithms for Discovery of Matrix Multiplication Methods. IEEE Trans. Evol. Comput. 2012, 16, 749–751. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.X.; Chan, F.T.S.; Chung, S.H. A genetic algorithm for optimizing space utilization in aircraft hangar shop. Int. Trans. Oper. Res. 2019, 26, 1655–1675. [Google Scholar] [CrossRef]
- Mera, N.S.; Elliott, L.; Ingham, D.B. A multi-population genetic algorithm approach for solving ill-posed problems. Comput. Mech. 2004, 33, 254–262. [Google Scholar] [CrossRef]
- Jiao, Y.L.; Xing, X.C.; Zhang, P.; Xu, L.C.; Liu, X.R. Multi-objective storage location allocation optimization and simulation analysis of automated warehouse based on multi-population genetic algorithm. Concurr. Eng. Res. Appl. 2018, 26, 367–377. [Google Scholar] [CrossRef]
- Li, Z.; Xu, Y.; Li, L.; Zhai, C. Forecast of the height of water flowing fractured zone based on BP neural networks. J. Min. Saf. Eng. 2015, 123, 39–44. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | H/m | c | d/m | L/m | Hf/m | No. | H/m | c | d/m | L/m | Hf/m |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 412.40 | 0.09 | 2.20 | 157.00 | 35.40 | 36 | 476.40 | 0.63 | 3.65 | 132.00 | 57.49 |
| 2 | 489.00 | 0.47 | 4.50 | 160.00 | 54.79 | 37 | 515.70 | 0.35 | 4.50 | 147.00 | 55.00 |
| 3 | 86.10 | 0.50 | 4.60 | 170.00 | 53.90 | 38 | 450.00 | 0.72 | 8.00 | 170.00 | 86.80 |
| 4 | 472.50 | 0.53 | 4.50 | 132.00 | 57.45 | 39 | 283.90 | 0.63 | 5.70 | 177.90 | 51.40 |
| 5 | 336.40 | 0.12 | 2.00 | 76.00 | 27.25 | 40 | 499.90 | 0.47 | 4.80 | 150.00 | 54.79 |
| 6 | 89.00 | 0.95 | 2.03 | 69.00 | 45.86 | 41 | 49.00 | 0.52 | 4.00 | 135.00 | 45.00 |
| 7 | 424.42 | 0.26 | 3.40 | 120.00 | 45.10 | 42 | 420.06 | 0.14 | 3.00 | 145.00 | 30.29 |
| 8 | 590.00 | 0.51 | 9.00 | 220.00 | 76.37 | 43 | 516.00 | 0.74 | 2.95 | 206.10 | 54.50 |
| 9 | 290.00 | 1.00 | 2.60 | 168.00 | 46.22 | 44 | 264.50 | 0.26 | 2.80 | 148.50 | 40.35 |
| 10 | 290.00 | 0.18 | 2.60 | 168.00 | 39.14 | 45 | 367.00 | 0.41 | 7.52 | 190.00 | 61.77 |
| 11 | 420.50 | 0.52 | 3.00 | 209.00 | 52.01 | 46 | 434.40 | 0.46 | 3.40 | 136.00 | 45.10 |
| 12 | 357.00 | 0.38 | 7.53 | 170.00 | 61.90 | 47 | 445.40 | 0.07 | 4.00 | 195.00 | 38.81 |
| 13 | 649.10 | 0.23 | 3.00 | 186.00 | 42.99 | 48 | 304.00 | 0.12 | 3.10 | 150.00 | 40.00 |
| 14 | 475.20 | 0.28 | 3.90 | 209.00 | 49.05 | 49 | 362.80 | 0.33 | 2.00 | 138.00 | 31.62 |
| 15 | 568.60 | 0.65 | 3.65 | 132.00 | 60.14 | 50 | 270.00 | 0.65 | 3.80 | 168.00 | 54.60 |
| 16 | 557.25 | 0.45 | 5.80 | 186.00 | 65.25 | 51 | 331.00 | 0.55 | 7.40 | 160.00 | 64.25 |
| 17 | 320.00 | 0.81 | 5.00 | 122.00 | 67.70 | 52 | 499.92 | 0.47 | 4.80 | 150.00 | 54.00 |
| 18 | 412.55 | 0.08 | 2.20 | 157.00 | 35.20 | 53 | 351.30 | 0.53 | 2.00 | 105.00 | 36.99 |
| 19 | 312.00 | 0.24 | 5.30 | 145.70 | 44.20 | 54 | 419.03 | 0.16 | 3.00 | 145.00 | 32.83 |
| 20 | 679.00 | 0.46 | 2.10 | 180.00 | 44.54 | 55 | 357.70 | 0.33 | 2.00 | 128.00 | 33.96 |
| 21 | 367.00 | 0.47 | 7.50 | 173.50 | 75.50 | 56 | 550.00 | 0.81 | 2.40 | 180.00 | 55.32 |
| 22 | 403.20 | 0.10 | 1.80 | 120.00 | 22.61 | 57 | 265.00 | 0.56 | 2.70 | 192.00 | 42.81 |
| 23 | 125.00 | 0.06 | 3.00 | 150.00 | 22.00 | 58 | 320.80 | 0.16 | 2.00 | 128.00 | 33.01 |
| 24 | 665.00 | 0.19 | 7.50 | 222.00 | 53.70 | 59 | 316.80 | 0.14 | 2.00 | 128.00 | 31.61 |
| 25 | 433.00 | 0.52 | 7.00 | 168.00 | 70.30 | 60 | 420.00 | 0.71 | 3.70 | 70.00 | 56.80 |
| 26 | 434.10 | 0.35 | 3.00 | 145.00 | 47.55 | 61 | 478.30 | 0.54 | 3.85 | 209.00 | 52.15 |
| 27 | 290.00 | 0.37 | 2.60 | 168.00 | 38.41 | 62 | 568.40 | 0.85 | 2.94 | 180.40 | 57.00 |
| 28 | 485.00 | 0.36 | 4.80 | 175.00 | 62.50 | 63 | 295.00 | 0.64 | 2.60 | 185.00 | 40.50 |
| 29 | 265.00 | 0.60 | 2.60 | 147.00 | 43.43 | 64 | 453.60 | 0.16 | 4.00 | 195.00 | 44.96 |
| 30 | 269.00 | 0.68 | 2.80 | 156.00 | 50.34 | 65 | 412.50 | 0.24 | 2.20 | 136.00 | 35.20 |
| 31 | 387.50 | 0.55 | 4.50 | 175.00 | 58.50 | 66 | 320.00 | 0.60 | 1.23 | 90.00 | 31.98 |
| 32 | 441.97 | 0.36 | 3.40 | 120.00 | 48.90 | 67 | 411.70 | 0.30 | 2.20 | 136.00 | 35.21 |
| 33 | 437.17 | 0.05 | 3.40 | 120.00 | 28.63 | 68 | 264.50 | 0.93 | 2.80 | 156.00 | 44.34 |
| 34 | 463.00 | 0.62 | 7.60 | 116.00 | 86.40 | 69 | 475.00 | 0.37 | 6.10 | 170.00 | 64.60 |
| 35 | 403.10 | 0.08 | 2.00 | 136.00 | 22.61 |
| Model | Parameter | Optimal Value |
|---|---|---|
| GA | C | 19.30 |
| g | 0.10 | |
| MPGA | C | 2.58 |
| g | 0.36 |
| Sample data | Prediction Model | MSE (m2) | Correlation Coefficient (r) |
|---|---|---|---|
| Training sample | GA-SVR | 11.13 | 0.96 |
| MPGA-SVR | 7.29 | 0.97 | |
| Test sample | GA-SVR | 34.91 | 0.93 |
| MPGA-SVR | 28.70 | 0.96 |
| Lithology | Computing Formula |
|---|---|
| Hard | |
| Medium hard | |
| Weak | |
| Extremely weak |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, C.; Yang, Z.; Li, S.; Lou, J. Predicting the Water-Conducting Fracture Zone (WCFZ) Height Using an MPGA-SVR Approach. Sustainability 2020, 12, 1809. https://doi.org/10.3390/su12051809
Guo C, Yang Z, Li S, Lou J. Predicting the Water-Conducting Fracture Zone (WCFZ) Height Using an MPGA-SVR Approach. Sustainability. 2020; 12(5):1809. https://doi.org/10.3390/su12051809
Chicago/Turabian StyleGuo, Changfang, Zhen Yang, Shen Li, and Jinfu Lou. 2020. "Predicting the Water-Conducting Fracture Zone (WCFZ) Height Using an MPGA-SVR Approach" Sustainability 12, no. 5: 1809. https://doi.org/10.3390/su12051809
APA StyleGuo, C., Yang, Z., Li, S., & Lou, J. (2020). Predicting the Water-Conducting Fracture Zone (WCFZ) Height Using an MPGA-SVR Approach. Sustainability, 12(5), 1809. https://doi.org/10.3390/su12051809