In this section we first present the work on which we based our solution and experiments and then we describe the solution that we propose for an automatic search for new convolutional neural network architectures.
2.1. Related Work
As computer science progresses, more and more domains take advantage of the power of computing. Applications of computer science can be found in communication [
12,
13], finance [
14], education [
15], healthcare [
16,
17], management [
18] and many more. As the quantity and variety of data increases, there is a need for more artificial intelligence algorithms to process this data. Machine learning algorithms need to be tailored specifically to each task and it is difficult to handcraft algorithms for each problem. Automatic methods of creating algorithms for solving each task are a possible solution.
While earlier CNN architectures consisted of convolutional and pooling layers simply stacked on top of each other [
19,
20], newer architectures included reusable modules, or CNN cells, which are more complex structures, yet still small, that can be the building blocks of a full CNN architecture [
21,
22,
23,
24].
As CNNs were used more and more in various domains, it became clear that handcrafting an architecture which obtains the best results on every task is very challenging. Different architectures obtain results for different problems and obtaining the best performance on a task using a certain CNN does not necessarily imply obtaining the best performance on another given task. A possible solution is to handcraft an architecture for every problem, but this is very demanding. Researchers must try various configurations, study the results, and decide what modifications must be made. This is very time-consuming and requires many people working for solving the many computer vision tasks.
Another solution is to automate the architecture search process. NAS algorithms aim to automatically find an efficient architecture for solving a given task. As described by Elsken et al. [
25] a NAS algorithm has three main components: search space, search strategy, and performance estimation strategy. The search space is the set of all possible architectures that the method considers. This space is usually defined by the representation of the solutions and the constrictions imposed on them.
As this space is very large for most NAS algorithms, a method for “traversing” this space in an efficient way is necessary. This is the search strategy. For example, using random search is not appropriate as it would not take advantage of the previously explored and evaluated architectures. All potential architectures would have an equal proposal probability-yielding thus a low improvement chance for the overall solution. Other, more sophisticated, strategies use the experience gained during the analysis of the subspace that was done such that the direction of the search is selected in a way that the chance of improving the solution is greater. There were proposed NAS algorithms which use for the search strategy evolutionary algorithms [
25], reinforcement learning [
26,
27,
28,
29,
30] or fully-differentiable methods [
31,
32].
Each search strategy has its own challenges. Evolutionary algorithms require large populations of individuals, which in the case of NAS algorithms would represent the architecture descriptions. A particularly challenging task is to create crossover operators that would take two architectures and create a single architecture from them while preserving the useful structural elements of each “parent” architecture. Fully-differentiable methods require training super-networks, which are very large, use many learnable parameters, make many computations and hence require high computational resources to train.
Finding an efficient architecture for a task may imply evaluating a very large number of designs, this may cause NAS algorithms to be highly demanding in computing resources. If every evaluated architecture would be completely trained, the NAS algorithm may take impractical periods of time to run or need a very large number of computing units. To diminish this problem, NAS performance estimation strategies are employed. These strategies are given a design and estimate how well this design will be able to solve the task without completely training it.
Reinforcement learning is a method of training machine learning algorithms based on how well they are able to accomplish what is required of them. In supervised training scenarios, for each input, the expected output is known and the machine learning algorithm is taught to make these associations and penalized when it fails to do so. Unfortunately, not all problems have a known correct answer. Reinforcement learning scenarios can be applied in such cases, provided there is a measure of the quality of the given answer. The model is given the input, produces the output and this output is then processed by a reward function which is greater if the answer has a good quality or lower if the answer is not appropriate.
The NAS algorithm proposes an architecture and the reward is the performance of the architecture on the given task. As previously mentioned, the exact performance can be difficult to always calculate given a long time required and a large number of architectures to evaluate. Because of this reason, the performance estimation is used as a reward function.
There are already multiple NAS approaches based on reinforcement learning. Baker et al. [
26] proposed a NAS algorithm that searches for full CNN architectures. The representation of a possible architecture is a sequence of layers, each one falling in one of these categories: convolutional, pooling, fully-connected, global average pooling or softmax. For the search space, they modeled the problem as a Markov chain. The initial state represents an empty architecture and the transition to each following state implies the addition of a new layer to the CNN. A type of reinforcement learning, Q-Learning, was used to guide the search. Each discovered CNN was trained on three image processing datasets. One of these is the CIFAR-10 dataset [
33], a popular option for testing NAS algorithms because its complexity is not that large. The accuracy on the validation sets is taken as performance estimation.
Zoph et al. [
27] propose another NAS algorithm in which full CNN architectures are searched for. The networks are again a sequence of layers, but these layers may also have skip-connections [
34]. If the dimensions of the two layers concatenated by the skip-connection do not coincide, the smaller one is padded. The convolutional layers have a set of characteristics: filter height, filter weight, stride height, stride width, and a number of filters. A “controller RNN” is used for proposing CNN architectures. At each generation step, this controller describes the next layer with all of its characteristics. For the skip-layers, a feed-forward layer takes as input the hidden state of the controller at the current step and at each previous step, deciding if a connection is made.
For training the controller, Zoph et al. [
27] use reinforcement learning, more exactly, policy gradient. At each training step, multiple CNN architectures are proposed and trained on CIFAR-10 for a fixed number of steps. The best performing one is retrained until it converges and its final accuracy on the validation set is taken as the reward. This NAS solution is highly resource-demanding, as 800 networks are trained in parallel on 800 GPUs at any time of a run of this algorithm.
Zoph et al. [
28] built on the solution from [
27]. In this new iteration of the NAS algorithm, the search space does not contain full CNN architectures, but CNN cells. The algorithm searches for a smaller structure that is then used to create a full CNN architecture by stacking multiple such structures. Each cell is composed of 5 “blocks”. Each block takes as input the outputs of two previous blocks, applies an operation on them and then combines them. The possible operations are various convolutional or pooling operations. The combination is done either by element-wise addition or concatenation. As the input blocks, the input of the cell may also be taken.
For describing the cells, a controller RNN is used in [
28]. Pairs of two cells are generated at each step: one “Normal Cell” and one “Reduction Cell”, the difference being that the first preserves the width and height of the input, while the second reduces it. Based in these pairs, full CNN architectures are built by stacking multiple cells of each type. The controller RNN generates multiple pairs for which the full CNNs are trained on CIFAR-10 and evaluated and the best result is used as reward for reinforcement learning.
Another interesting approach is taken in [
35], where an exhaustive search is attempted. The method only trains a few CNN cells and predicts the performance of the others based on the evaluated ones. In this NAS algorithm, cells of increasing size are discovered, as the search progresses.
2.2. Proposed Solution
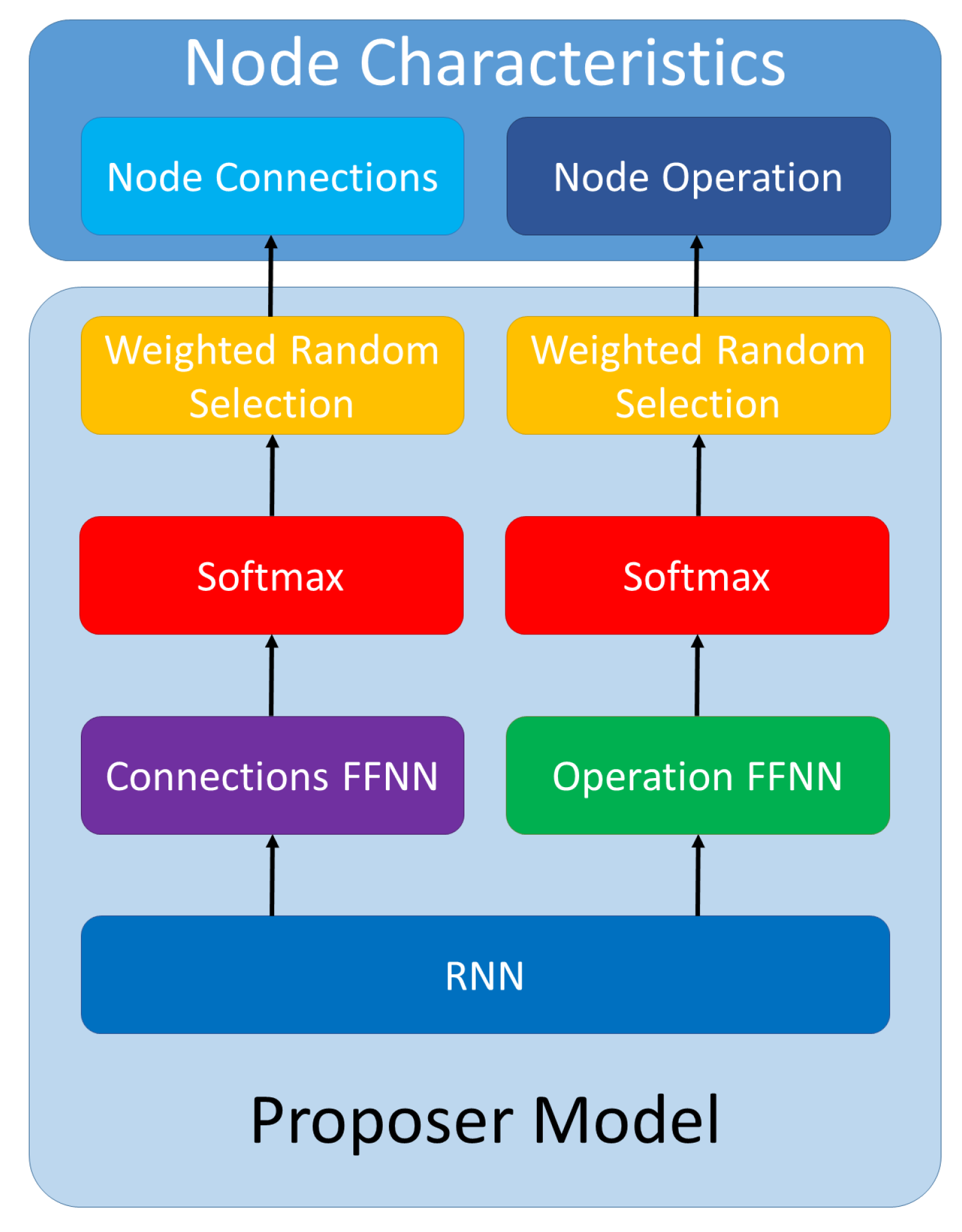
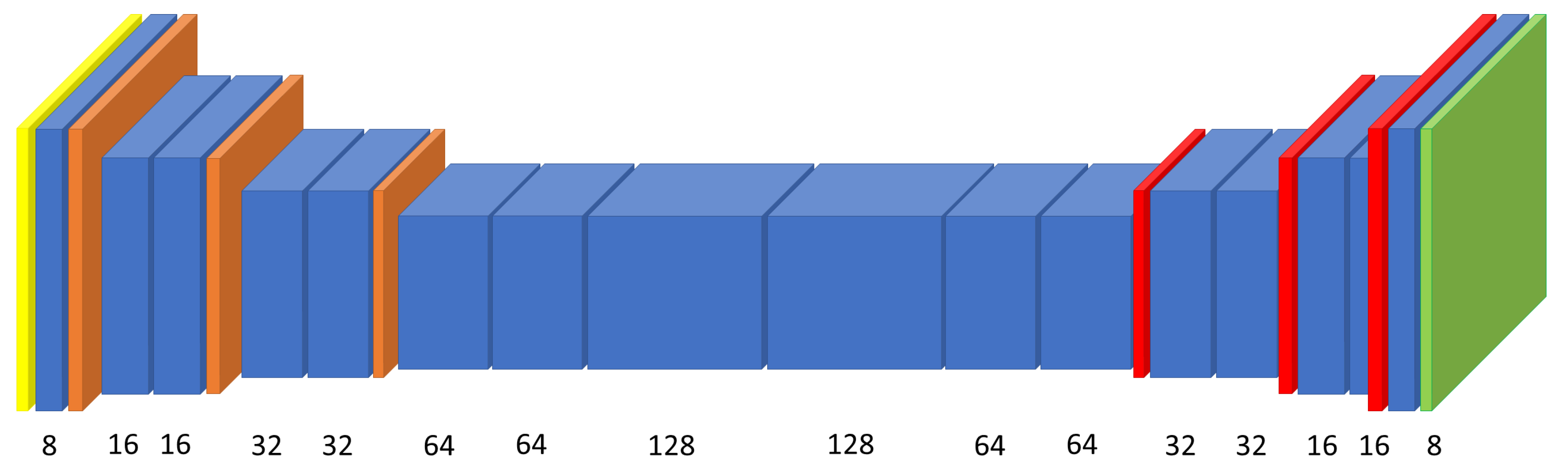
In this subsection, we describe the method that we propose for developing new convolutional neural network architectures. The proposed solution is to automatically generate CNN architectures by inferring task specific CNN sub-part cell architectures (Figure 11) and integrating them into a larger CNN template (as presented in Figures 9 and 10). For generating the cells, we use a proposer model based on a RNN, which we train using reinforcement learning.
A cell is a small CNN sub-part composed of nodes. Each node is a computational unit that aggregates data and applies an operation. A cell can be instantiated multiple times when building the full CNN architecture and each such instance may/will have a different number of filters. We chose the cell sub-part generation approach as opposed to proposing entire full sized CNNs as the search space that needs to be explored differs by orders of magnitude. We start from the assumption that generating a task-efficient cell and assembling its instances in a larger architecture would transfer the cell
good properties to the fully assembled CNN. This approach allows the proposer model to focus on smaller, yet more complex individual sub-part structures that can be reused in the full CNN architecture. While proposing the entire network architecture gives the algorithm the freedom to describe the full CNN, the large search space is difficult to explore and the proposer model is less likely to find an efficient solution. At the same time, approaches that search for the full architecture are very resource-demanding and allow only very simple structures in the network, like sequences of convolutional and pooling layers and sometimes skip-connections [
26,
27].
We propose CNN cells and integrate them into larger architectures. Once a cell is generated by the RNN, we compose a CNN by using multiple head-to-tail instances of this cell, with various numbers of filters, according to a template we describe for the particular problem we need to solve. In this way, the solutions that we propose are configurable and reusable. Depending on the complexity of the task, deeper or shallower CNN architectures can be created by integrating varying number of instances of the discovered cell, much like in a LEGO game.
Our representation of the cell is a directed acyclic graph (DAG). The cell consists of an input node, an output node, and intermediary nodes. The input node represents the input that is given to the cell. As multiple instances of the cell are used in the full CNN architecture, the input can be received from different sources. For example, if the cell is right at the beginning of the CNN, then the input node will be the input image. If we have two consecutive cells in the network, the input node of the second cell will receive the data from the output node of the first cell.
Excepting the input node, each of the other nodes of the cell may receive the input from any number of the other nodes. To ensure that no cycles exist, we impose an ordering of the nodes, in which the first node is the input node and the last node is the output node, and we allow nodes to receive the input only from the nodes that are placed before in the ordering. The inputs from the nodes are concatenated on the depth dimension and an operation is applied for computing the output of the node.
The operations that we consider are the following:
3 × 3 convolution
1 × 1 convolution
1 × 3 convolution followed by 3 × 1 convolution
1 × 7 convolution followed by 7 × 1 convolution
3 × 3 depthwise-separable convolution
5 × 5 depthwise-separable convolution
7 × 7 depthwise-separable convolution
3 × 3 dilated convolution
For all convolutional layers, the activation function is rectified linear unit (ReLU). We chose these operations as they were proved to be useful for both handcrafted architectures [
20,
22,
24] and architectures found with automatic methods [
28,
35]. Classical convolutional layers learn filters that have access to a region of the input, which is a compact slice, having a certain height and width and the depth equal to the depth of the input. This is the type of operations represented by the 3 × 3 and 1 × 1 convolutions. The pairs of 1 × 3, 3 × 1 and 1 × 7, 7 × 1 convolutions preserve the receptive field of the 3 × 3 and 7 × 7 convolutions respectively while using a lower number of learnable parameters.
A depthwise-separable convolution [
36] is another variation which preserves the receptive field while lowering the number of parameters. In this case, if we consider an
A ×
B convolution, the first step is to apply filters of size
A ×
B × 1, meaning that each filter will have access only to one slice in the depth of the input. The second step is to apply a classical convolution of size 1 × 1, which has access to the entire depth of the input.
A dilated convolution [
37,
38] will skip some inputs. In our case for a 3 × 3 dilated convolution, for each value in the output, 3 × 3 values of each depth slice of the input are considered, but these values are not consecutive. They are taken from a 5 × 5 input where only the first and then every second value is considered. This process goes on both axes, having only 3 × 3 values taken by the computation.
The number of filters of our cell is configurable to allow different instances of the cell to have different numbers of filters. Cells closer to the input of the full CNN architecture should have fewer filters, while cells placed in the middle of the architecture should have a higher number of filters. Each node in a given cell is an independent computational unit, but in our approach, they have the same number of filters for all nodes in a cell to make the cell homogeneous.
While there are other works that represent a cell similarly to our definition, most fix a number of nodes from which the input is taken. For example, in [
28,
29] each node takes inputs from exactly two preceding nodes. We consider that allowing the proposing algorithm to select more inputs for each node gives it greater flexibility. By fixing the number of the inputs, to represent the same cell would require a larger number of nodes and including the identity operation. Our approach allows greater flexibility by having a variable number of inputs and also allows skip-connections similar to residual networks [
34] inside the cells.
For proposing the networks we use a recurrent neural network (RNN). For each CNN cell, the proposer network will generate the characteristics of each component node: the nodes from which it takes input and the operation that it applies. The proposer RNN generates each node directly in the order used for assuring the DAG property, so the last generated node is the output node. From our perspective, a cell (as a DAG) is a sequential entity and hence we model it by using a RNN [
39]. As there is no information to be generated for the input node, the cell description starts with the first intermediary node.
The proposer RNN has two layers of 32 Gated Recurrent Units (GRUs) [
40]. The output of the last recurrent layer is processed by two feed-forward neural networks (FFNNs): one for the input nodes and one for the operation. The FFNNs each consist of two layers of 32 units with ReLU activation and one additional final layer for making the prediction. The final layer of the FFNN has two units for each node. They are used to decide whether the node is taken as input or not. The corresponding node operation is decided in the final layer of the FFNN using one unit for each potential operation.
When deciding each characteristic (operations and connections) of the node, the outputs are passed through a softmax operation and the results are used as probabilities for weighted random selection. We do this selection for encouraging the proposer to explore more of the search space. As the random selection is weighted using the softmax probabilities, characteristics which the RNN considers more appropriate have a higher chance of being selected, while other options have a smaller chance of being selected.
A graphical representation of the proposer network generating the characteristics of a node can be seen in
Figure 1.
When describing a CNN cell, the number of nodes is known from the start. As we do not want to limit our method to a predefined number of nodes, we increment the number of nodes during the training of the RNN such that it will propose cells with different dimensions.
Figure 2 contains an example of the visual representation of the proposal of a CNN cell which consists of the input node and three other nodes. For each node, the RNN model generates the characteristics. The characteristics of each node are then fed back as input to the proposer network so that the next node can be generated in a recurrent manner. With red arrows, we represent the recurrent connections, as the state of the RNN is updated and used at each step. The connections of each node are to the ones with a strictly lower identifier, as the index in the node ordering that assures the DAG property. The input node has 0 as identifier. Each operation has an operation identifier.
For training our proposer network, we use reinforcement learning (RL). At each training step, the RNN will propose a cell. For each cell, we build a full CNN by integrating multiple instances of the cell in a predefined
evaluation architecture template and partially train it on a task. The templates that we used for our specific task are described in
Section 3.2. The network is then evaluated on this task and the metric is used as the performance score of the cell.
As we do not have a priori (ground truth) training data, we train the proposer RNN in a synthetic auto-feedback loop. We generate cells, we estimate their performance and we use the RL rewards as feedback. The feedback is implemented as a gradient scaling process. The generated cells become thus training data and the rewards become a form of learning rate. As we want to direct the proposer towards efficient designs, we scale the gradients with the rewards computed as in Equation (
1) such that the network is encouraged to make decisions similar to the ones that led to high-performance architectures. We compute the loss between the softmax probabilities generated by the proposer and the representation of the cell. As the loss function, we use cross-entropy. As an example, if the proposer would give the score 0.85 in favor of establishing a connection between two particular nodes and 0.15 against it and the final decision was to create the connection, the values used for computing the loss would be (0.15, 0.85) as the prediction and (0, 1) as the ground truth.
Because training a deep network on a large dataset requires many computational resources, we employ a performance estimation strategy. Firstly, the CNN constructed at this phase is small, so that a forward pass takes very little time and each training step is completed quickly. Secondly, in this evaluation phase we do not use the full dataset which contains large-size images of the task at hand, but derive a dataset of smaller-size images that are faster to process. The CNN is trained for a fixed number of epochs and then it is evaluated.
At this stage, we are not interested in an absolute performance metric of the architectures, but in the performance of the architectures relative to one another. A hint on this decisions would be the fact that the template evaluation networks built from the generated cells have closely similar sizes and structure and training them for the same number of epochs would give an indication on their relative performance and guiding thus the proposer towards architectures of increasing quality. Using this approach allows us to estimate the performance of a cell much faster than a complete evaluation of its performance-which might not even be necessary at this step.
We compute the reward as in Equation (
1) where
s is the performance score of the cell.
In the beginning, the improvements might be larger as the proposer discovers what is generally useful for the task. We assume that the metric is directly proportional to the performance. As the training progresses, the performance metric increases slower. This is because increasingly finer improvements must be made to the cell architectures as better and better designs are generated. As a result, we have a system where the reward increases exponentially with the performance.
During the training of the proposer model, we start with cells consisting of a certain number of nodes. We train the RNN for a number of steps using this size, and then we increase by one the number of nodes. We repeat this process until we reach a superior limit that we establish for the size. By starting with a smaller size, the proposer has a smaller search space and can more easily find an efficient design. Gradually increasing the sizes of the cells increases the search space, giving the proposer the possibility to explore new options. This way the proposer starts with a smaller space to explore and with limited space jumps. While it trains itself in auto-feedback, the exploring space is dilated by increasing the number of nodes and the proposer is encouraged to use its past accumulated knowledge to explore it.
The cell size increase is implemented by extending the last layer of the Connections FFNN with two additional neurons that are used to decide if a connection exists from the last intermediary node to the nodes after it in the ordering. One neuron votes for keeping a connection, while the other votes for discarding the connection. The higher score imposes the final decision, allowing thus the architecture to evolve. While training the RNN for the current size, a connection from the last intermediary node can only be made to the output node so that no cycles are formed. As the cell-size is increased, connections to multiple nodes could be made. For example, when extending the cell size from 3 to 4, node 3 can only have connections towards node 4. Extending the size further to 5, 6, ..., would allow potential connections from node 3 to all these added nodes.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}