Modeling and Management Big Data in Databases—A Systematic Literature Review



Abstract
1. Introduction

1.1. Big Data Concepts
1.1.1. A Brief History of Big Data
1.1.2. Big Data Characterization
1.1.3. Volume and Velocity
1.1.4. Variety
Structured Data
Semi-Structured Data
Unstructured Data
1.2. NoSQL
Data Models
- Column-oriented
- Document-oriented
- Graph
- Key-value
Column-Oriented
Document-Oriented
Graph
Key-value
1.3. Data Abstraction Levels
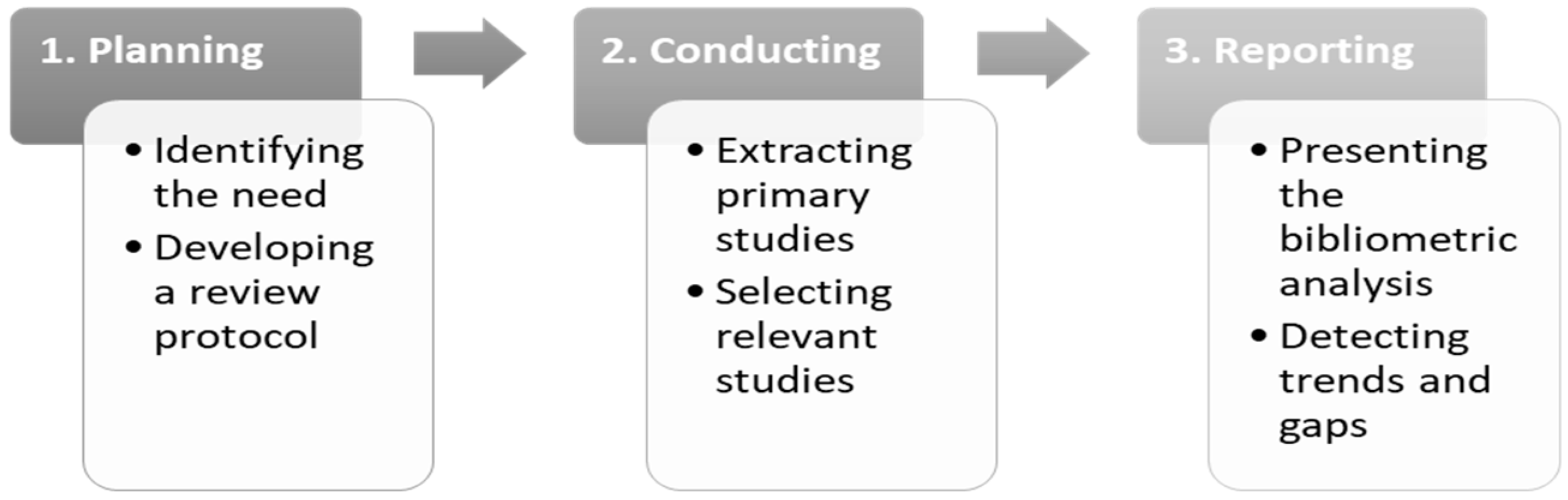
2. Method
2.1. Planning the SLR Study
2.1.1. Identification of need for a SLR study
2.1.2. Development of a Review Protocol
Objectives and Justification
Research Questions
- For source: The dataset sources and data types;
- For modeling: The data abstraction levels, the data model proposed at conceptual, logical and physical levels, the techniques used for transformations between abstraction levels, the applied modeling language, the modeling methodology and the proposed tools for automatic model transformation;
- For database: The database type and the evaluation and performance comparison between models.
Strategy
- IEEE Xplore
- ScienceDirect
- Scopus
- Web of Science (WoS)
- IEEE Xplore—(((“Document Title”:”big data” and “data model”) OR “Abstract”:”big data” and “data model”) OR “Index Terms”:”big data” and “data model”)
- ScienceDirect—Title, abstract, keywords: “big data” and “data model”
- Scopus—TITLE-ABS-KEY (“big data” AND “data model”)
- WoS—TS = (“big data” AND “data model”). TS regards to Topic fields that include titles, abstracts and keywords.
2.2. Conducting the SLR Study
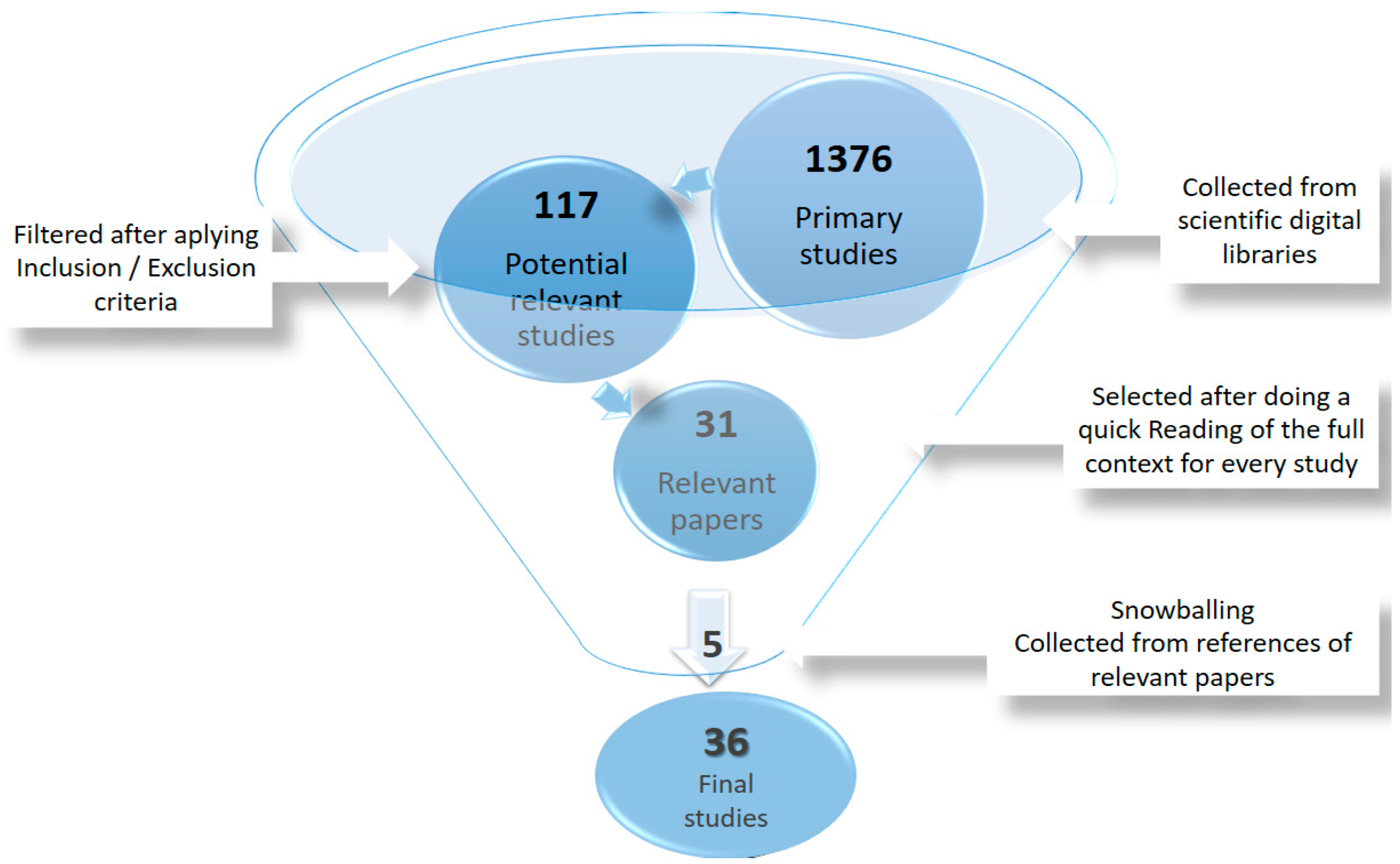
2.2.1. Inclusion Stage
2.2.2. Selection Stage
2.3. Reporting the SLR Study
3. Results
3.1. Bibliometric Analysis
- The average annual growth rate of published articles follows Equation (1)
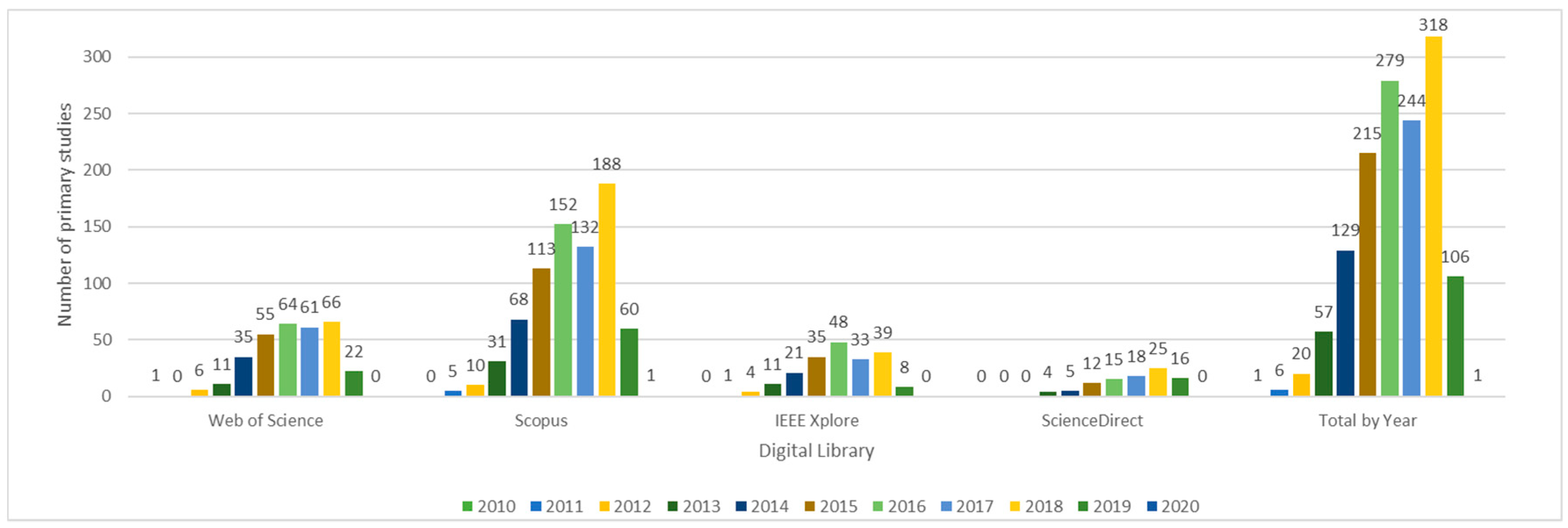
- Prior to 2010, no relevant studies about Big Data modeling are published
- Since 2015, the number of studies has increased significantly and, in 2018, there were 318 published articles. In 2019, there were already 106 publications before August
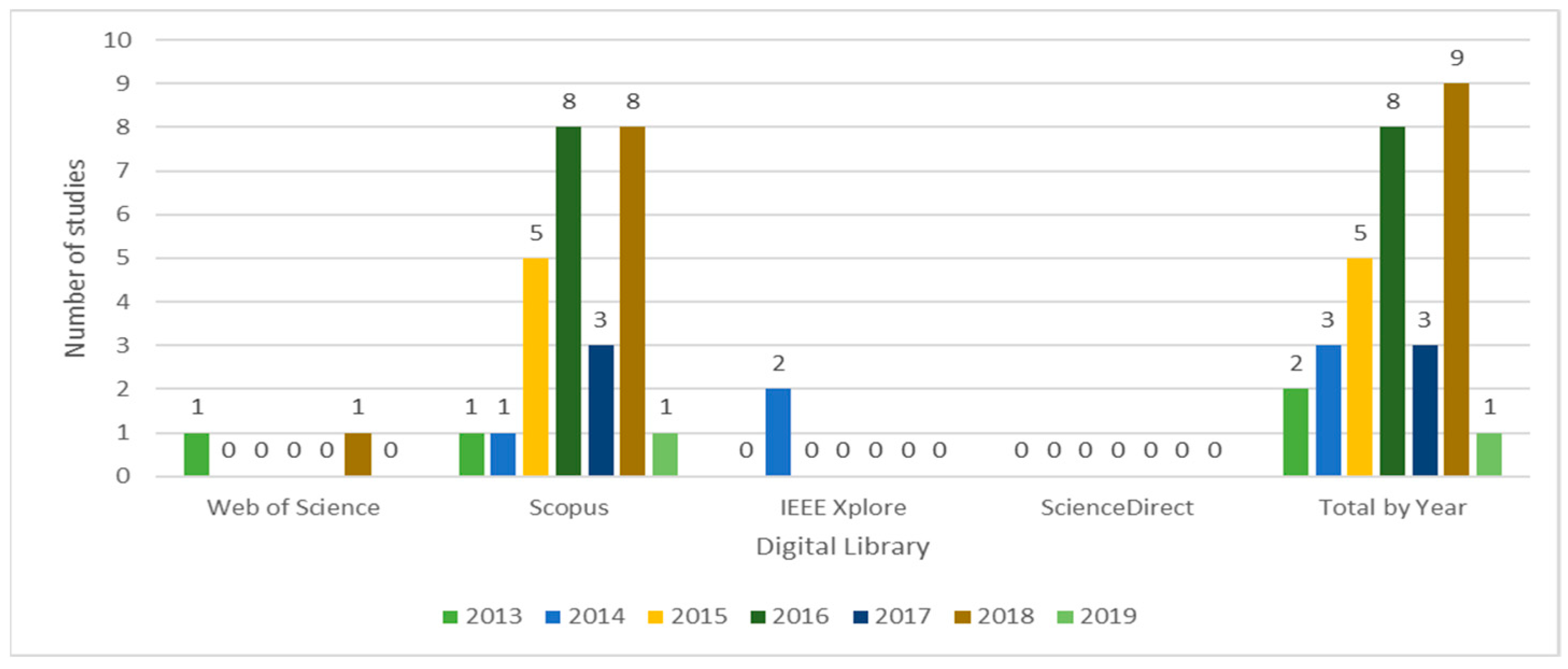
- Scopus ranked the highest of all considered sources, with 760 collected works, followed by WoS with 321 works, IEEE Xplore with 200 and ScienceDirect with 95
- Prior to 2013, no relevant studies were found;
- The year in which we found the most quantity of studies about Big Data modeling is 2018. However, it is important to highlight that 2019 is ongoing and could ultimately have more studies than 2018;
- With 27 papers, Scopus is the source holding the highest number of relevant studies, followed by WoS and IEEE Xplore with two papers each. ScienceDirect does not report any relevant paper about the topic.
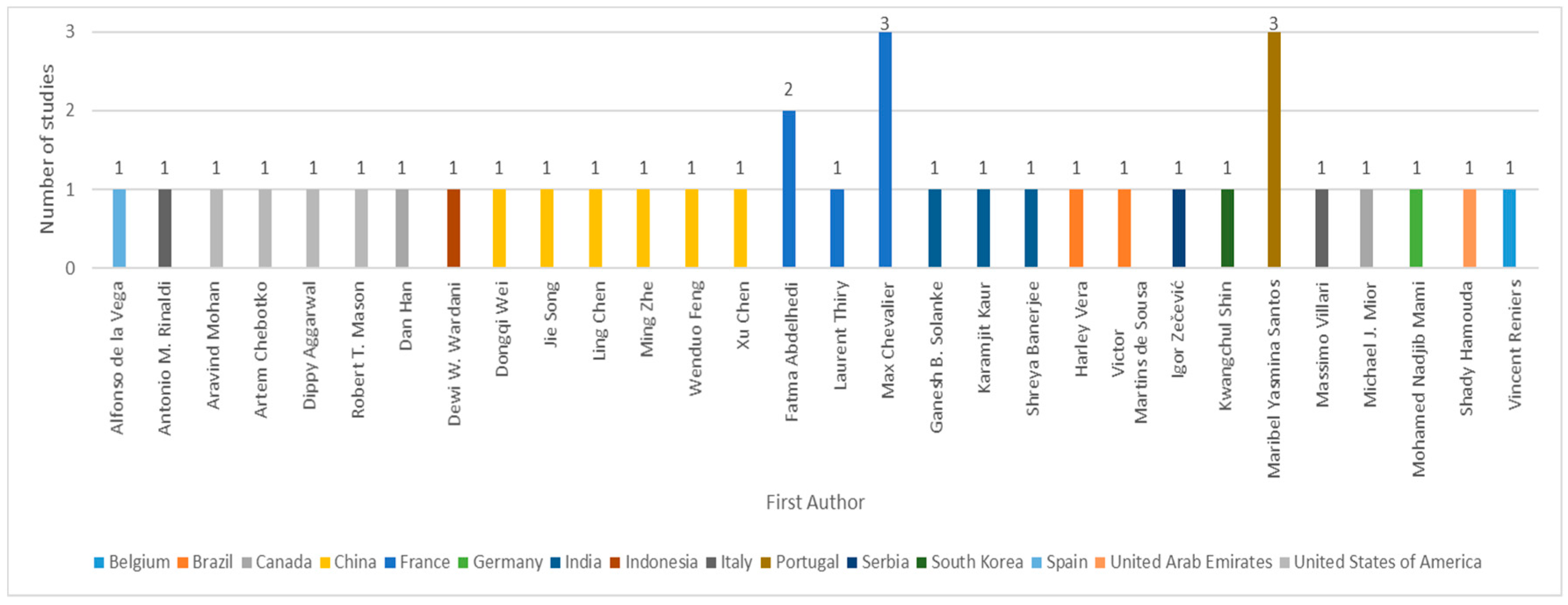
3.1.1. Authors
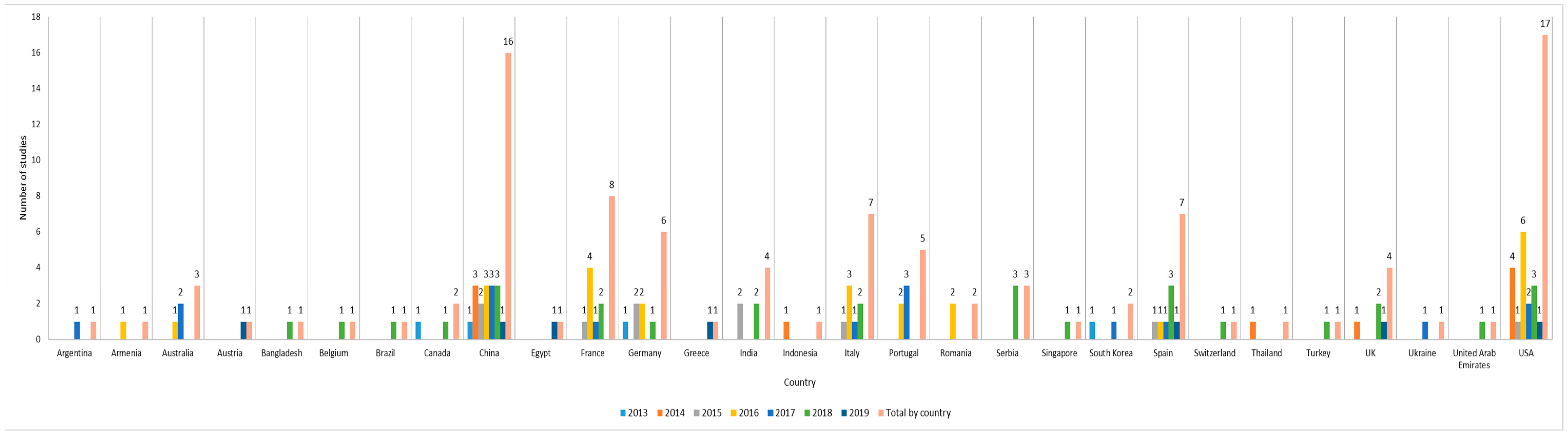
3.1.2. Countries and Years
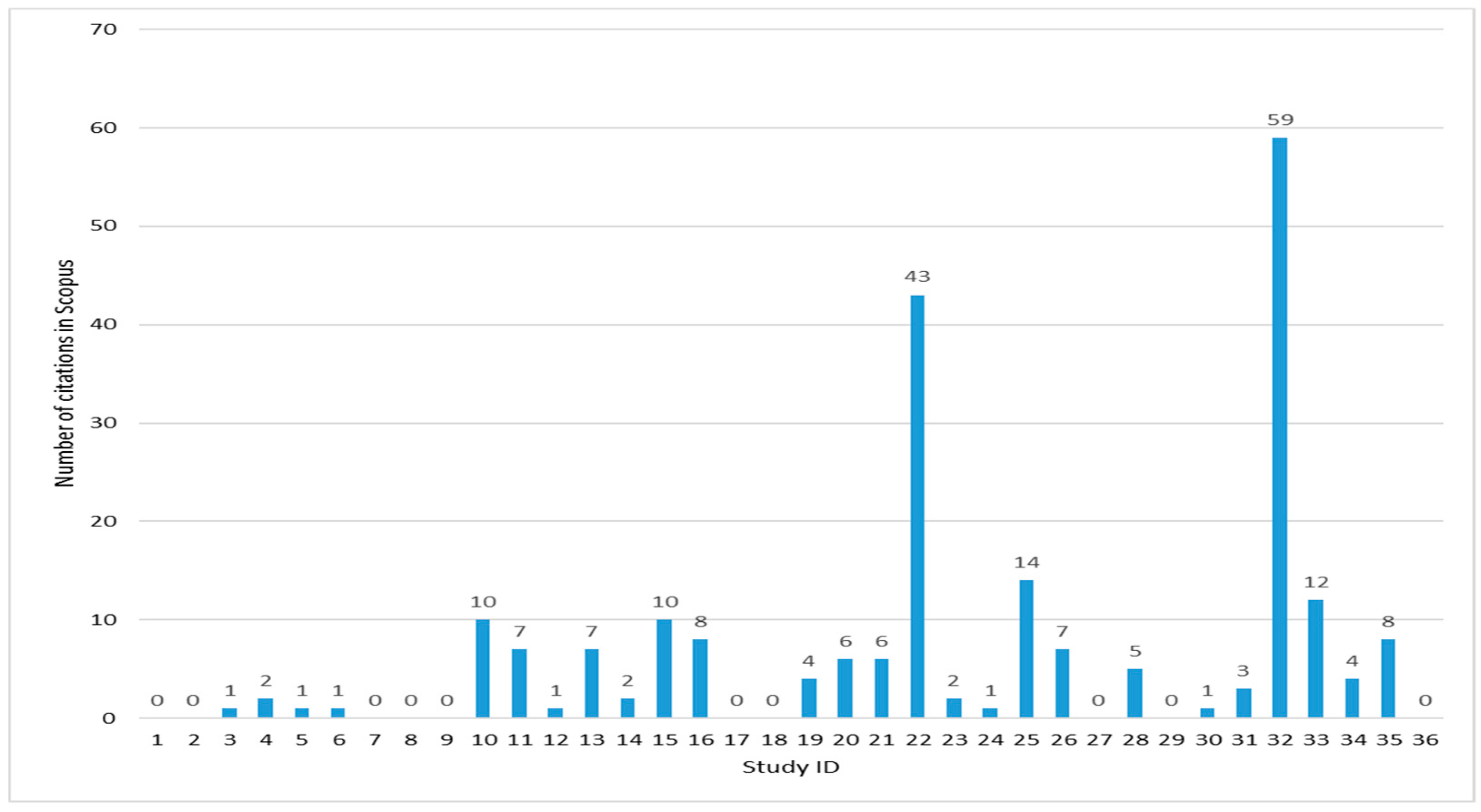
3.1.3. Citations
3.1.4. Journals
3.1.5. Conferences
3.2. Systematic Literature Review
- Source
- Modeling
- Database
3.2.1. Source
Data Set Sources
Data Types
3.2.2. Modeling
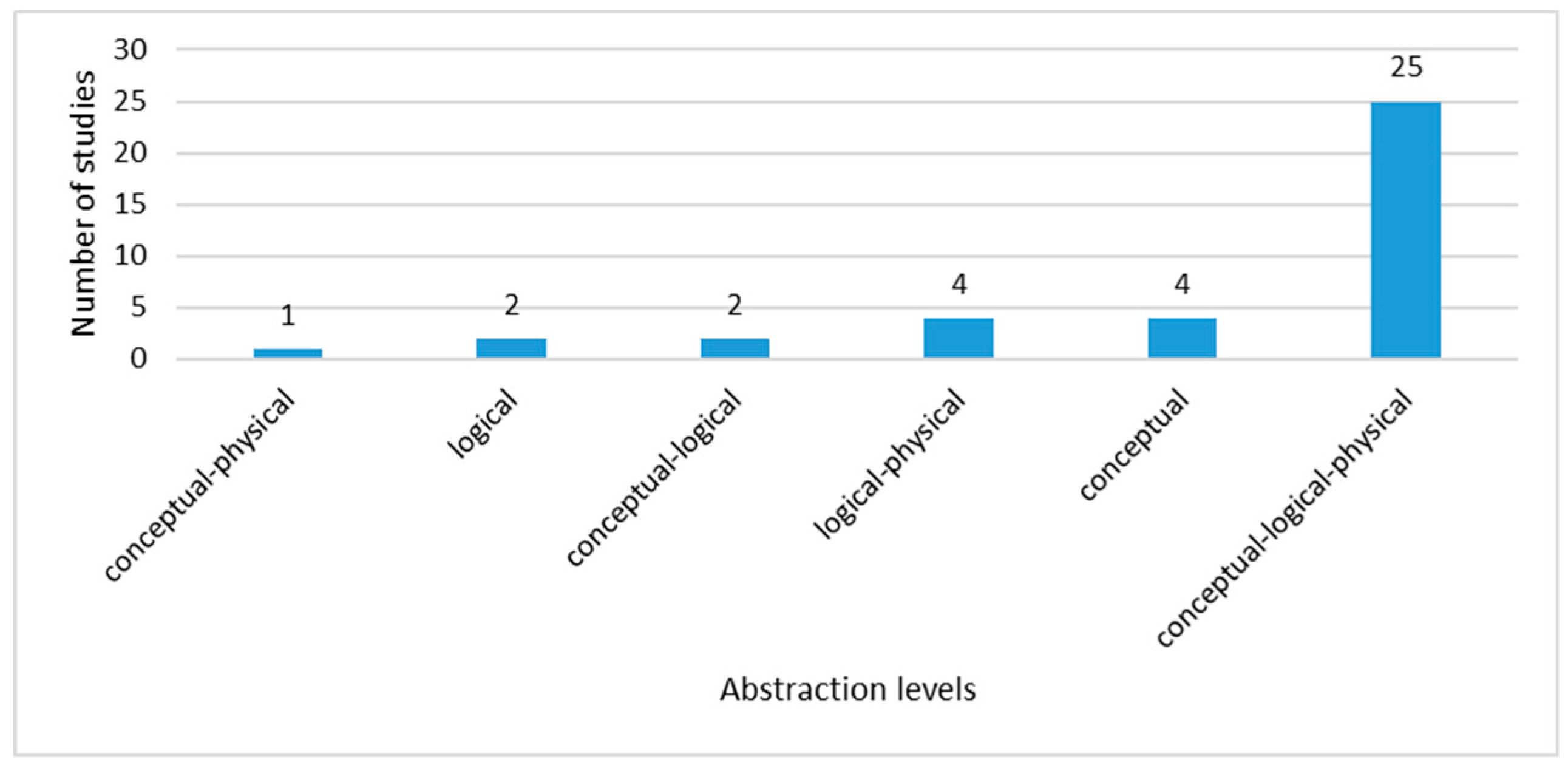
Data Abstraction Levels
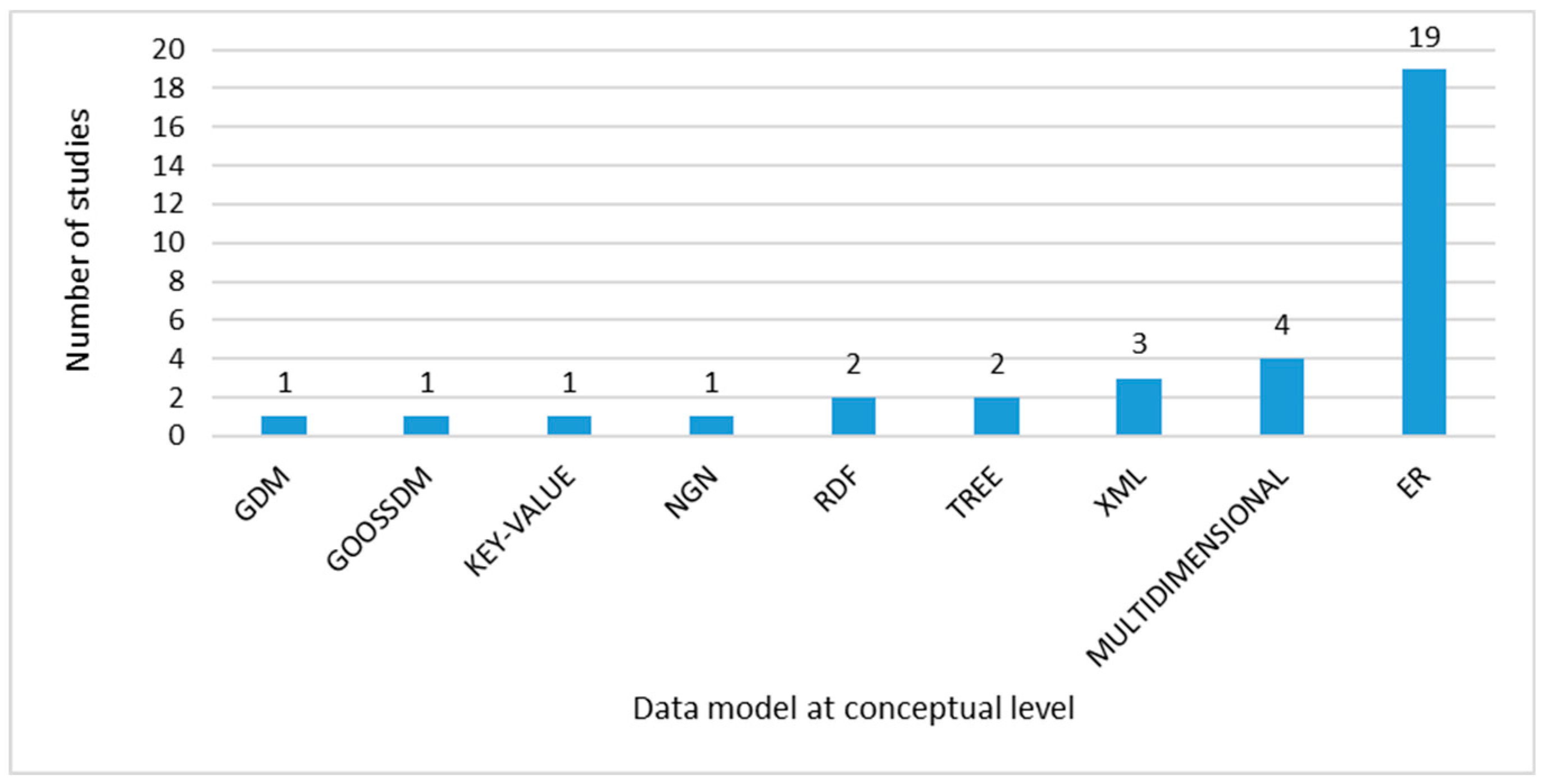
Data Model at Conceptual Level
Data Model at Logical Level
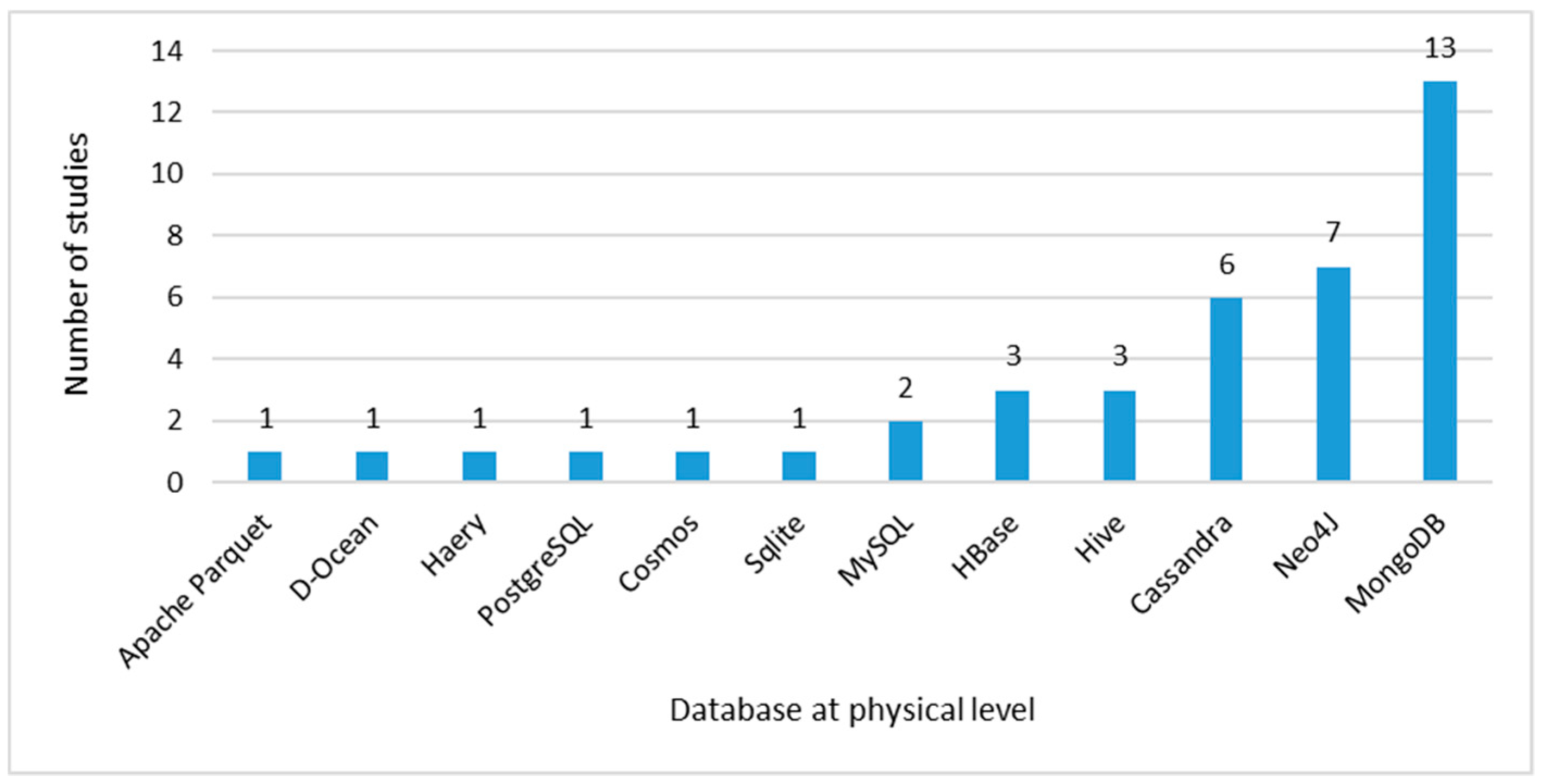
Data Model at Physical Level
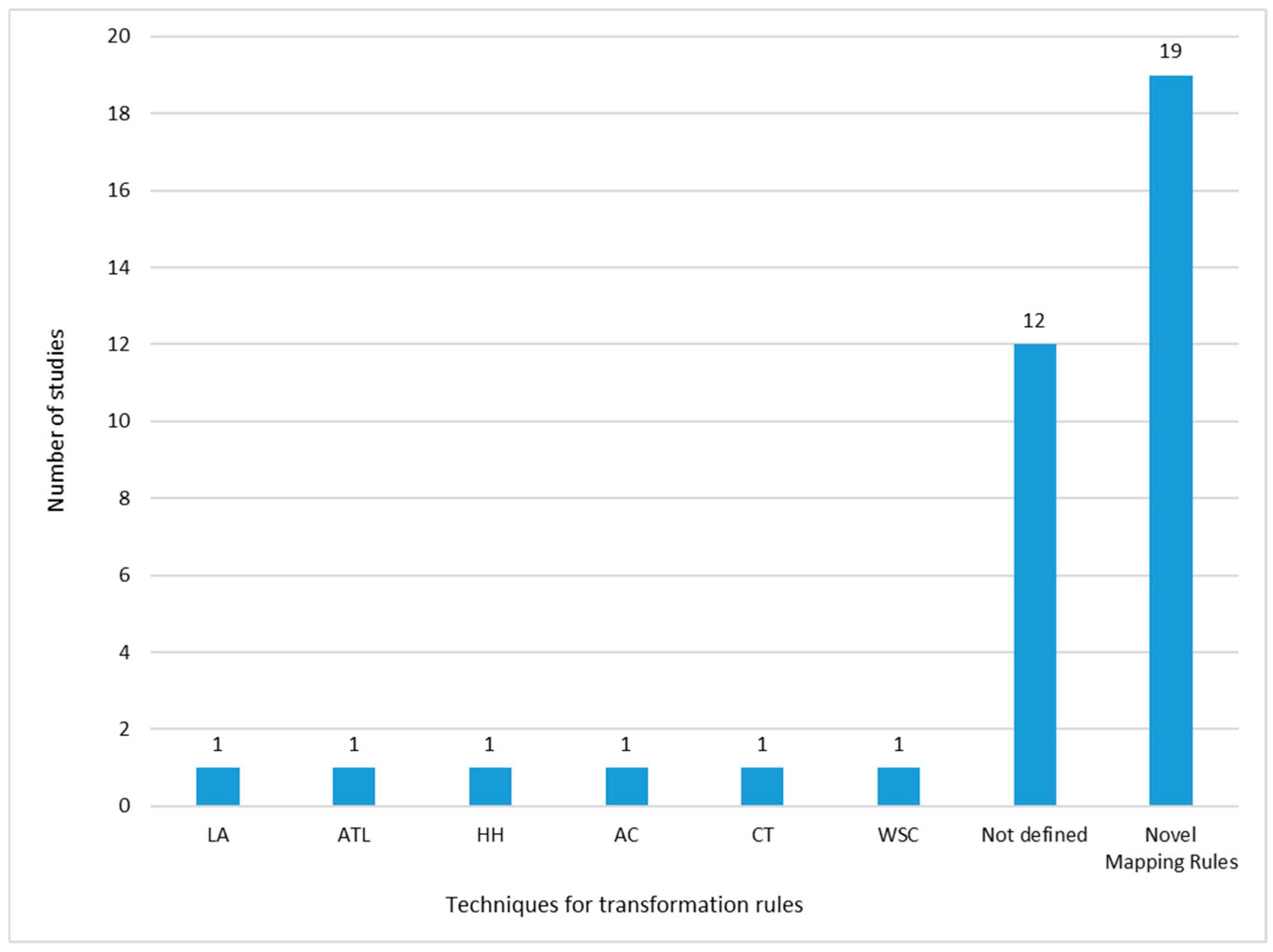
Transformation between Abstraction Levels
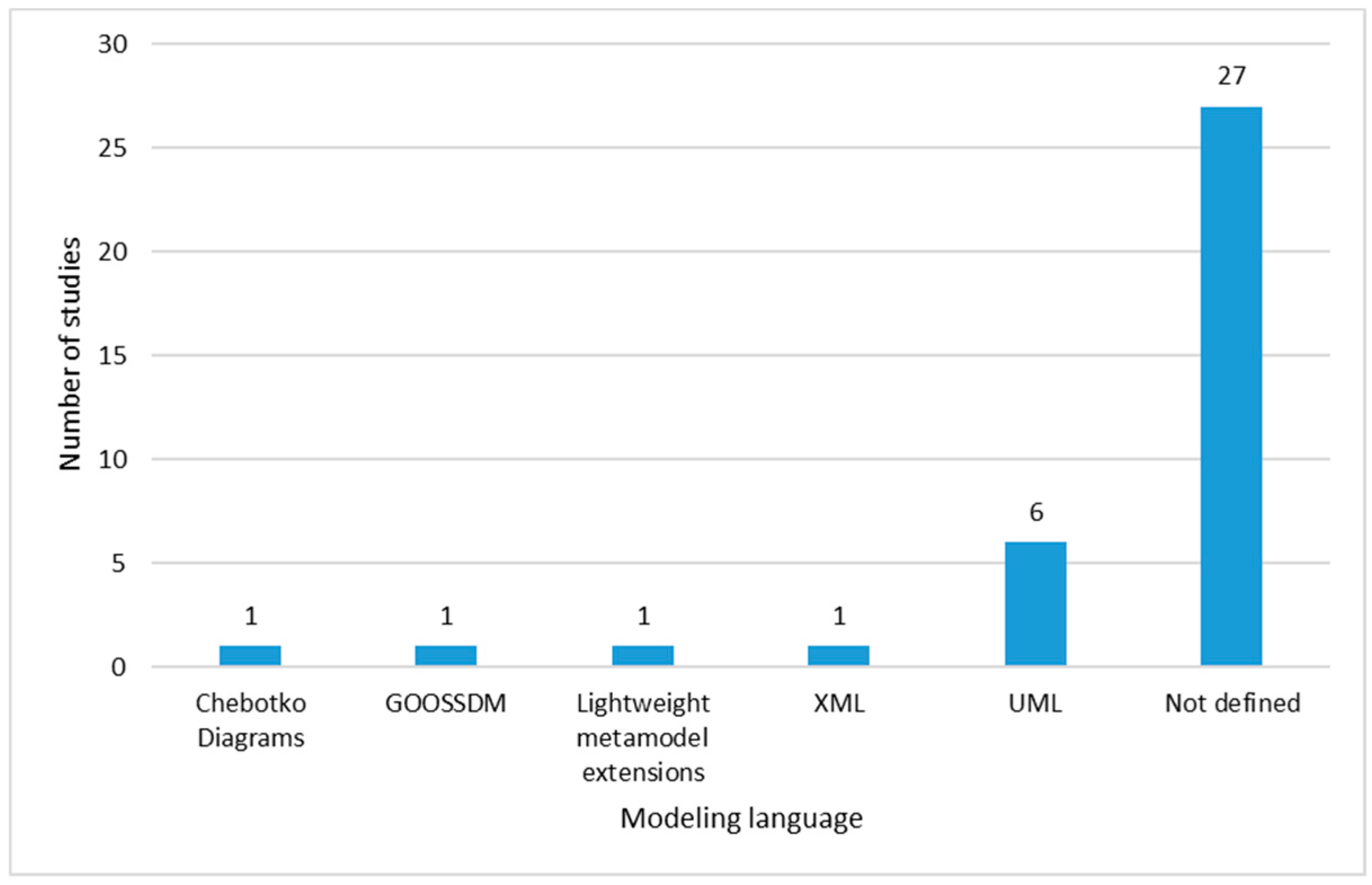
Modeling Language
Modeling Methodology
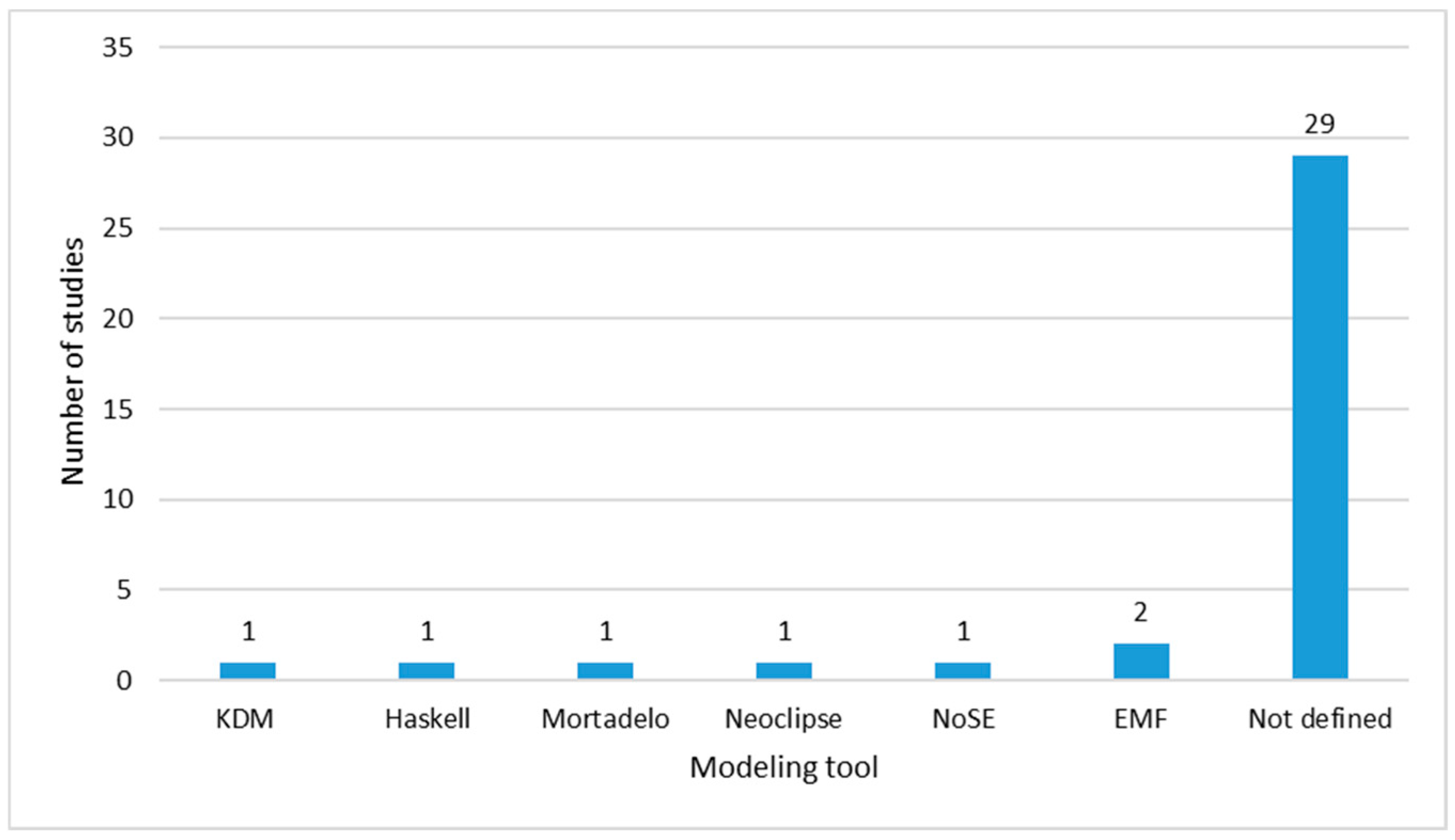
Modeling Tool
3.2.3. Database
Database Type
Evaluation and Performance Comparison
3.3. Discussion
3.3.1. Trends
Source
Modeling
- Most studies present their proposals at the conceptual, logical and physical abstraction levels;
- ER model is the most used in the approaches at the conceptual abstraction level, followed by the multidimensional model and, thirdly, XML;
- At the logical abstraction level, the most researched model is document-oriented, followed by column-oriented and graph-oriented;
- At the physical abstraction level, implementations focus more on the MongoDB DBMS, followed by Neo4j and Cassandra. Thus, the following de facto standards have emerged, MongoDB for the document-oriented data model, Cassandra for column-oriented and Neo4j for graph data model. These data are supported by statistical information from DB-Engines Ranking - Trend Popularity of the Solid IT company as of December 2019 [64];
- The most proposed modeling methodology is data-driven;
- There is not a clear tendency towards a data modeling approach but there are proposals with UML and XML;
- No data modeling tool is defined as a trend but some studies used EMF;
- Regarding the different fields of application, ER is commonly used at the conceptual abstraction level in the different case studies. At the logical level, approaches for the migration from relational to document-oriented, graph and column-oriented models are proposed. Specifically, for spatio-temporal and transmission data, solutions for the graph model are proposed. And, for XML and JSON formats from web servers, solutions for all NoSQL data models are suggested.
Database
3.3.2. Gaps
Source
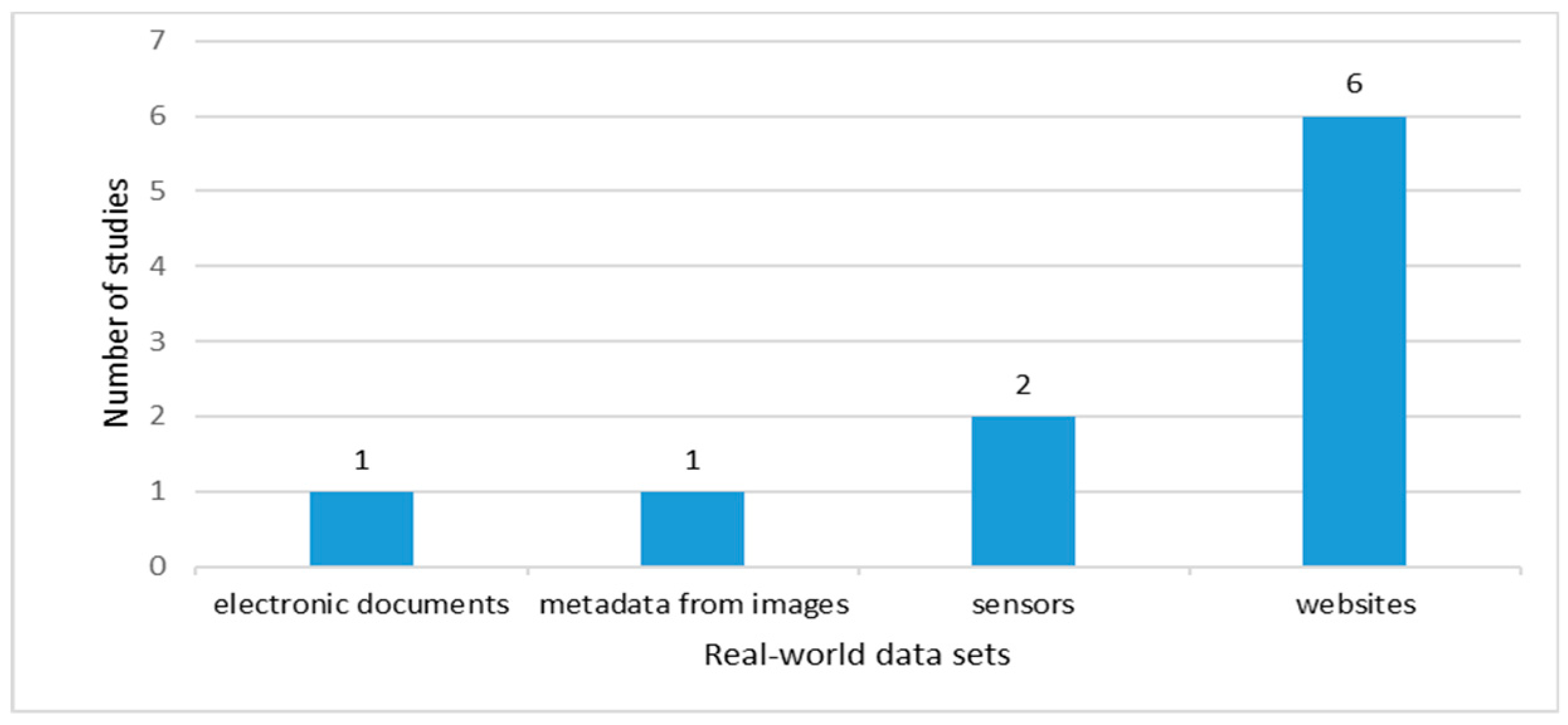
- One of the main objectives of Big Data is to use the data to generate value; this value will depend on the needs of the business. For this reason, it is considered very important that studies are validated with real use cases, since only with the use of real datasets can whether value is being generated be verified. As result of our SLR, only ten studies, corresponding to 27.78%, use real datasets; 16.67% of these works present their case studies with data from websites, 5.56% use data from sensors and 2.78% involve electronic documents’ data and images’ metadata;
- Additionally, other Big Data main features must be guaranteed, such as volume, velocity and veracity. According to the results of Table 6, not all of these features are justified in the approaches;
- To comply with the variety, studies should consider that data can come in any format: structured, semi-structured or unstructured. Therefore, the proposed approaches should address any of these types. Only 2.78% have proposed a solution for all three types of data. The remaining 47.22% of the studies only present approaches for unstructured data, 30.56% only for structured data, 13.89% for semi-structured data, 2.78% combine structured and semi-structured data and 2.78% do not specify any type.
Modeling
- There is no standardization regarding the definition of mapping rules for the transformation between models at the conceptual, logical and physical data abstraction levels. Thus, the 36 studies propose different approaches for the transformation, making it difficult for users to choose the most appropriate one;
- No NoSQL system has emerged as a standard or as a de facto standard yet;
- There is no clearly defined use of some standardized language or method for modeling data at the logical and physical levels. According to the results of our SLR, only at the conceptual level can ER be considered as a trend, maybe because the conceptual level is technologic-agnostic;
- As mentioned in the Modeling Language subsection, for NoSQL databases the new paradigm for the modeling process is query-driven. However, only five studies are focused on this methodology.
- For Big Data analysis, the implementation of efficient systems is required. In the data-driven methodology, the models are designed before assessing what queries will be performed. The limitation of this solution is that all data will be stored, when only a limited fraction are needed to answer the required queries. On the contrary, in query-driven methodologies, a set of queries must be expressed, evaluated and integrated before modeling, so that planning can focus on the answers to the necessary queries. For solutions where real-time data are used, data-driven models have the risk of being impractical because of the diverse nature of data streams [65].
- A research [66] demonstrates that the treatment of data, in terms of time–cost, with the use of query-driven requires less processing time than data-driven. This, in turn, leads to smaller amounts of consumed energy and, therefore, longer life of equipment.
- According to another study [67], the use of a query-driven methodology allowed users to make queries in a natural user language that focuses on relevant regions of interest;
Database
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Concept Matrix
| ID | Authors | Title | Data Set | Model | Modeling | Database Type | Evaluation and Performance Comparison | ||||||||
| Source | Structured | Semi-Structured | Unstructured | Conceptual | Logical | Physical | Transformation between Abstraction Levels | Modeling Language | Modeling Tool | Modeling Methodology | |||||
| 1 | Jie SONG, Hongyan HE, Richard THOMAS, Yubin BAO, Ge YU | Haery: a Hadoop based Query System on Accumulative and High-dimensional Data Model for Big Data | sample data | - | - | text file | key-value | key-cube | Haery | Query Algorithm Linearization Algorithm | Not defined | NA | model-driven query-driven | Homogeneous | queries |
| 2 | Laurent Thiry, Heng Zhao and Michel Hassenforder | Categories for (Big) Data models and optimization | sample data | - | csv | - | Entity–Relationship (ER) | ER document graph | Sqlite Mongo MySql Neo4J | Category Theory (CT) | Not defined | Haskell script | model-driven | Hybrid | queries |
| 3 | Victor Martins de Sousa, Luis Mariano del Val Cura | Logical Design of Graph Databases from an Entity Relationship Conceptual Model | sample data | - | - | website | Extended Binary ER (EB-ER) | graph | Neo4j | Mapping Algorithm Cardinality Constraints Algorithm Vertex Constraints Algorithm | Not defined | NA | model-driven | Homogeneous | NA |
| 4 | Igor Zečević, Petar Bjeljac, Branko Perišić, Stevan Stankovski, Danijel Venus & Gordana Ostojić | Model-driven development of hybrid databases using lightweight metamodel extensions | real data | management data | JSON files | websites | ER | ER document key-value graph | MySQL MongoDB Cosmos | Mapping rules | lightweight metamodel extensions | NA | model-driven | Hybrid | NA |
| 5 | Antonio M. Rinaldi, Cristiano Russo | A Semantic-based Model to represent Multimedia Big Data | real data | - | - | metadata from images | - | graph | Neo4j | NA | Not defined | NA | model-driven query-driven | Homogeneous | NA |
| 6 | Shady Hamoud, Zurinahni Zainol | Document-Oriented Data Schema for Relational Database Migration to NoSQL | sample data | relational database data | - | - | ER | document | MongoDB | Mapping rules Normalization & Denormalization process | Not defined | NA | model-driven | Homogeneous | NA |
| 7 | Dippy Aggarwal, Karen C. Davis | Employing Graph Databasesas a Standardization Model for Addressing Heterogeneity and Integration | sample data | relational database data RDF | csv | - | ER Resource Description Framework (RDF) | graph | Neo4j | Mapping rules | Not defined | NA | model-driven | Homogeneous | NA |
| 8 | Alfonso de la Vega, Diego García-Saiz, Carlos Blanco, Marta Zorrilla, and Pablo Sánchez | Mortadelo: A Model-Driven Framework for NoSQL Database Design | sample data | relational database | - | - | Generic Data Model (GDM) | column document | Cassandra MongoDB | Mapping rules | Unified Modeling Language (UML) | Mortadelo | model-driven | Hybrid | NA |
| 9 | Xu Chena, Li Yanb, Weijun Lia, Fu Zhangc | Fuzzy Spatio-temporal Data Modeling Based on XML Schema | real data | - | - | sensors | XML | - | - | NA | Tree | NA | model-driven | NA | NA |
| 10 | Maribel Yasmina Santos, Bruno Martinho & Carlos Costa | Modeling and implementing big data warehouses for decision support | real data | multidimensional | - | websites | ER | ER | Hive | Mapping rules | Not defined | NA | model-driven | Homogeneous | NA |
| 11 | Kwangchul Shin, Chulhyun Hwang, Hoekyung Jung | NoSQL Database Design Using UML Conceptual Data Model Based on Peter Chen’s Framework | sample data | - | csv | - | ER | ER | - | Mapping rules | UML | NA | model-driven | NA | NA |
| 12 | Fatma Abdelhedi, Amal Ait Brahim, Faten Atigui, Gilles Zurfluh | Logical Unified Modeling For NoSQL DataBases | NA | a class diagram from a relational database | - | - | ER | GLM | Cassandra MongoDB Neo4J | Mapping rules | UML at conceptual | EMF | model-driven | Hybrid | NA |
| 13 | Victor Martins de Sousa, Luis Mariano del Val Cura | A NoSQL Data Model For Scalable Big Data Workflow Execution | real data | - | - | sensors | NA | NCDM | NA | NA | NA | NA | NA | NA | NA |
| 14 | Massimo Villari, Antonio Celesti, Maurizio Giacobbe and Maria Fazio | Enriched E-R Model to Design Hybrid Database for Big Data Solutions | NA | - | - | e-health medical records | EE-R | - | - | NA | NA | NA | model-driven | NA | NA |
| 15 | Maribel Yasmina Santos, Carlos Costa | Data Warehousing in Big Data From Multidimensional to Tabular Data Models | sample data | multidimensional | - | - | multidimensional | constellation | Hive | Mapping rules | NA | NA | model-driven | Homogeneous | NA |
| 16 | Maribel Yasmina Santos, Carlos Costa | Data Models in NoSQL Databases for Big Data Contexts | sample data | relational database data | - | - | ER | column ER | Hbase Hive | Mapping rules | NA | NA | model-driven | Hybrid | NA |
| 17 | Ganesh B. Solanke, K. Rajeswari | Migration of Relational Database to MongoDB and Data Analytics using Naïve Bayes Classifier based on Mapreduce Approach | sample data | relational database data | - | - | ER | document | MongoDB | Mapping rules | NA | SQL scripts | model-driven | Homogeneous | queries |
| 18 | Vincent Reniers, Dimitri Van Landuyt, Ansar Rafique, Wouter Joosen | Schema Design Support for Semi-Structured Data: Finding the Sweet Spot between NF and De-NF | real data | - | - | websites | ER | document | - | Mapping rules | NA | NA | model-driven workload-driven | Homogeneous | NA |
| 19 | Fatma Abdelhedi, Amal Ait Brahim, Faten Atigui and Gilles Zurfluh | Big Data and Knowledge Management: How to Implement Conceptual Models in NoSQL Systems? | sample data | - | - | sensors | ER | column | Hbase Cassandra | Mapping rules | UML XML | EMF | model-driven | Hybrid | NA |
| 20 | Max Chevalier, Mohammed El Malki, Arlind Kopliku, Olivier Teste and Ronan Tournier | Document-oriented Models for Data Warehouses | sample data | - | JSON files | - | multidimensional | document | MongoDB | Mappings rules | NA | NA | model-driven | Homogeneous | data load |
| 21 | Shreya Banerjee, Renuka Shaw, Anirban Sarkar, Narayan C Debnath | Towards Logical Level Design of Big Data | sample data | relational database data | - | - | GOOSSDM | document | MongoDB | Mapping rules | GOOSSDM | NA | model-driven | Homogeneous | NA |
| 22 | Artem Chebotko, Andrey Kashlev, Shiyong Lu | A Big Data Modeling Methodology for Apache Cassandra | sample data | - | - | website | ER | column | Cassandra | Mapping rules Application workflow Mapping patterns | Chebotko Diagrams at logical level | KDM | query-driven | Homogeneous | NA |
| 23 | Wenduo Feng∗, Ping Gu, Chao Zhang, Kai Zhou | Transforming UML Class Diagram into Cassandra Data Model with Annotations | sample data | - | JSON files | - | ER | column | Cassandra | ATL Transformation Language (ATL) Mapping rules | UML at conceptual | NA | model-driven | Homogeneous | NA |
| 24 | Ling Chen, Jian Shao, Zhou Yu, Jianling Sun, Fei Wu, Yueting Zhuang | RAISE: A Whole Process Modeling Method for Unstructured Data Management | NA | - | - | website | XML | - | D-Ocean | NA | NA | NA | model-driven | Homogeneous | NA |
| 25 | M. Chevalier, M. El Malki, A. Kopliku, O. Teste and R. Tournier | Implementation of Multidimensional Databases with Document-Oriented NoSQL | sample data | - | JSON files | - | multidimensional | document | MongoDB | Mapping rules | NA | NA | model-driven | Homogeneous | transformation |
| 26 | Dewi W. Wardani, Josef Küng | Semantic Mapping Relational to Graph Model | sample data | relational database data | - | - | ER | graph RDF linked data | Neo4j | Mapping rules | NA | NA | model-driven | Homogeneous | queries |
| 27 | Ming Zhe, Kang Ruihua | A Data Modeling Approach for Electronic Document based on Metamodel | real data | - | JSON files | electronic documents | Tree | - | - | NA | NA | NA | model-driven | NA | NA |
| 28 | Mohamed Nadjib Mami, Simon Scerri, S¨oren Auer and Maria-Esther Vidal | Towards Semantification of Big Data Technology | sample data | - | - | website | RDF RDF-XML | column | Apache Parquet | NA | NA | NA | NA | NA | NA |
| 29 | Dan Han, Eleni Stroulia | HGrid: A Data Model for Large Geospatial Data Sets in Hbase | sample data | - | - | sensors | - | Hgrid | Hbase | NA | NA | NA | model-driven | Homogeneous | queries |
| 30 | Zhiyun Zheng, Zhimeng Du, Lun Li, Yike Guo | Big Data-Oriented Open Scalable Relational Data Model | real data | - | - | websites | - | OSRDM | - | NA | NA | NA | model-driven | NA | queries |
| 31 | Dongqi Wei, Chaoling Li, Wumuti Naheman, Jianxin Wei, Junlu Yang | Organizing and Storing Method for Large-scale Unstructured Data Set with Complex Content | NA | - | - | geosciences data | Tree | - | - | NA | NA | NA | model-driven | NA | NA |
| 32 | Karamjit Kaur, Rinkle Rani | Modeling and Querying Data in NoSQL Databases | real data | - | - | websites | ER | document grapgh | MongoDB Neo4J | NA | UML at conceptual and document | Neoclipse | model-driven | Hybrid | NA |
| 33 | Michael J. Mior, Kenneth Salem, Ashraf Aboulnaga and Rui Liu | NoSE: Schema Design for NoSQL Applications | real data | - | - | websites | ER | column | Cassandra | Workload Space Constraint | NA | NoSE | query-driven | Homogeneous | queries |
| 34 | Max Chevalier, Mohammed El Malki, Arlind Kopliku, Olivier Teste, Ronan Tournier | Document-Oriented Data Warehouses: Models and Extended Cuboids | sample data | relational database | - | - | multidimensional | document | MongoDB PostgrSQL | Mapping rules | NA | NA | model-driven | Hybrid | queries |
| 35 | Harley Vera, Wagner Boaventura, Maristela Holanda, Valeria Guimarães, Fernanda Hondo | Data Modeling for NoSQL Document-Oriented Databases | sample data | - | - | sensors | NGN | document | MongoDB | NA | NA | NA | model-driven | Homogeneous | NA |
| 36 | Robert T. Mason | NoSQL Databases and Data Modeling Techniques for a Document-oriented NoSQL Database | sample data | - | - | - | ER | document | MongoDB | Hoberman heuristic | NA | NA | model-driven | Homogeneous | NA |
References
- Kitchenham, B. Procedures for Performing Systematic Reviews; Keele University: Keele, UK, 2004; Volume 33, pp. 1–26. [Google Scholar]
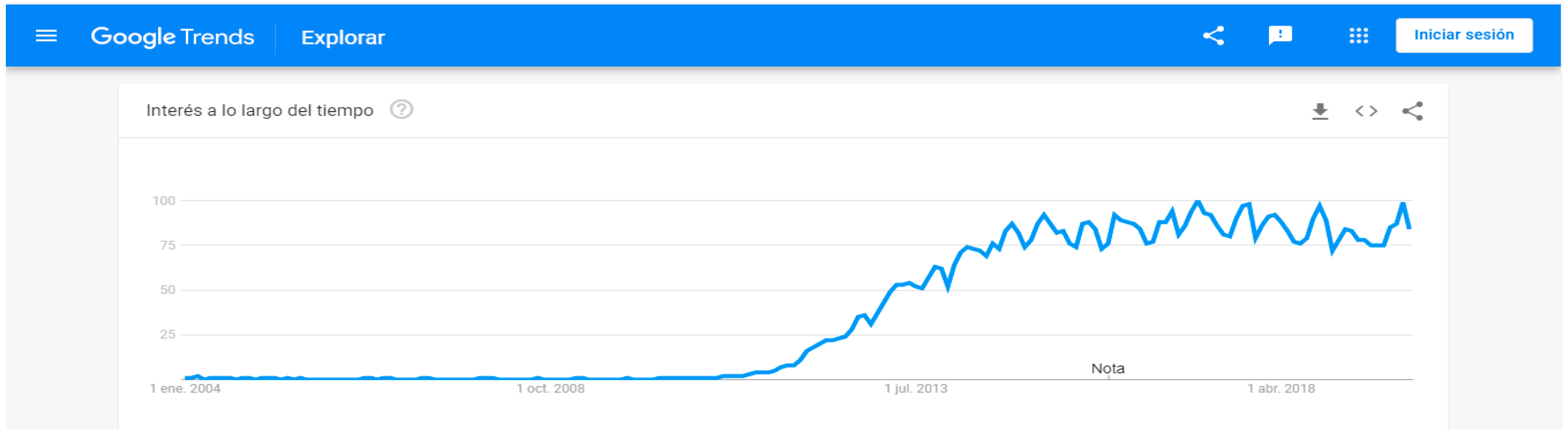
- Google. Google Trends. Available online: https://trends.google.es/trends/explore?date=all&q=%22big%20data%22 (accessed on 23 August 2019).
- Rider, F. The Scholar and the Future of the Research Library: A Problem and Its Solution; Hadham Press: New York, NY, USA, 1944; pp. 98–100. [Google Scholar]
- Cox, M.; Ellsworth, D. Application-controlled demand paging for out-of-core visualization. In Proceedings of the 8th IEEE Conference on Visualization, Phoenix, AZ, USA, 24 October 1997; pp. 235–244. [Google Scholar]
- Ribeiro, A.; Rodrigues da Silva, A. Data Modeling and Data Analytics: A Survey from a Big Data Perspective. J. Softw. Eng. Appl. 2015, 8, 617–634. [Google Scholar] [CrossRef]
- Shafer, T. The 42 V’s of Big Data and Data Science. Available online: https://www.elderresearch.com/blog/42-v-of-big-data (accessed on 23 August 2019).
- Manogaran, G.; Thota, C.; Lopez, D.; Vijayakumar, V.; Abbas, K.M.; Sundarsekar, R. Big Data Knowledge System in Healthcare. In Internet of Things and Big Data Technologies for Next Generation Healthcare; Springer International Publishing: Cham, Switzerland, 2017; Volume 23, pp. 133–157. [Google Scholar]
- Persico, V.; Pescapé, A.; Picariello, A.; Sperlí, G. Benchmarking big data architectures for social networks data processing using public cloud platforms. Future Gener. Comput. Syst. 2018, 89, 98–109. [Google Scholar] [CrossRef]
- Costa, C.; Santos, Y. Big Data: State-of-the-art Concepts, Techniques, Technologies, Modeling Approaches and Research Challenges. Int. J. Comput. Sci. 2017, 44, 1–17. [Google Scholar]
- Davoudian, A.; Chen, L.; Liu, M. A Survey on NoSQL Stores. ACM Comput. Surv. 2018, 51, 1–43. [Google Scholar] [CrossRef]
- CISCO. Big Data: Not Just Big, but Different—Part 2. Available online: https://www.cisco.com/c/dam/en_us/about/ciscoitatwork/enterprise-networks/docs/i-bd-04212014-not-just-big-different.pdf (accessed on 10 September 2019).
- O’Sullivan, P.; Thompson, G.; Clifford, A. Applying data models to big data architectures. IBM J. Res. Dev. 2014, 58, 18:1–18:11. [Google Scholar] [CrossRef]
- CISCO VNI. Cisco Visual Networking Index: Forecast and Trends, 2017–2022 White Paper. Available online: https://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/white-paper-c11-741490.htm (accessed on 10 September 2019).
- Karamjit, K.; Rinkle, R. Modeling and querying data in NoSQL databases. In Proceedings of the 1st IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 1–7. [Google Scholar]
- Wu, D.; Sakr, S.; Zhu, L. Big Data Storage and Data Models. In Handbook of Big Data Technologies; Springer International Publishing: Cham, Switzerland, 2017; pp. 3–29. [Google Scholar] [CrossRef]
- Chebotko, A.; Kashlev, A.; Lu, S. A Big Data Modeling Methodology for Apache Cassandra. In Proceedings of the 4th IEEE International Congress on Big Data, New York, NY, USA, 27 June–2 July 2015; pp. 238–245. [Google Scholar]
- Edlich, S. List of NoSQL Database Management Systems. Available online: http://nosql-database.org/ (accessed on 15 September 2019).
- Santos, M.Y.; Martinho, B.; Costa, C. Modelling and implementing big data warehouses for decision support. J. Manag. Anal. 2017, 4, 111–129. [Google Scholar] [CrossRef]
- Centre for Reviews and Dissemination; (University of York: Centre for Reviews and Dissemination, York, UK). Undertaking systematic reviews of research on effectiveness: CRD’s guidance for carrying out or commissioning reviews. Personal communication, 2001. [Google Scholar]
- Martins de Sousa, V.; del Val Cura, L.M. Modelagem Lógica para Bancos de Dados NoSQL: Uma revisão sistemática. Anais WCF 2016, 3, 32–39. [Google Scholar]
- Brewer, E.A. Towards robust distributed systems. In Proceedings of the ACM Symposium on Principles of Distributed Computing, Portland, Oregon, 16–19 July 2000; Volume 7. [Google Scholar]
- Pouyanfar, S.; Yang, Y.; Chen, S.; Shyu, M.L.; Iyengar, S. Multimedia big data analytics: A survey. ACM Comput. Surv. 2018, 51, 10. [Google Scholar] [CrossRef]
- Bruno, R.; Ferreira, P. A Study on Garbage Collection Algorithms for Big Data Environments. ACM Comput. Surv. 2018, 51, 20. [Google Scholar] [CrossRef]
- Gusenbauer, M.; Haddaway, N. Which Academic Search Systems are Suitable for Systematic Reviews or Meta-Analyses? Evaluating Retrieval Qualities of Google Scholar, PubMed and 26 other Resources. Res. Synth. Methods 2019. [Google Scholar] [CrossRef] [PubMed]
- Song, J.; He, H.; Thomas, R.; Bao, Y.; Yu, G. Haery: A Hadoop based Query System on Accumulative and High-dimensional Data Model for Big Data. IEEE Trans. Knowl. Data Eng. 2019. [Google Scholar] [CrossRef]
- Thiry, L.; Zhao, H.; Hassenforder, M. Categories for (Big) Data models and optimization. J. Big Data 2018, 5, 1–20. [Google Scholar] [CrossRef]
- Martins de Sousa, V.; del Val Cura, L.M. Logical Design of Graph Databases from an Entity-Relationship Conceptual Model. In Proceedings of the 20th International Conference on Information Integration and Web-Based Applications and Services, Yogyakarta, Indonesia, 19–21 November 2018; pp. 183–189. [Google Scholar]
- Zečević, I.; Bjeljac, P.; Perišić, B.; Stankovski, S.; Venus, D.; Ostojić, G. Model driven development of hybrid databases using lightweight metamodel extensions. Enterp. Inf. Syst. 2018, 12, 1221–1238. [Google Scholar] [CrossRef]
- Rinaldi, A.; Russo, C. A Semantic-based Model to represent Multimedia Big Data. In Proceedings of the 10th International Conference on Management of Digital EcoSystems, Tokyo, Japan, 25–28 September 2018; pp. 31–38. [Google Scholar]
- Hamouda, S.; Zainol, Z. Document-Oriented Data Schema for Relational Database Migration to NoSQL. In Proceedings of the 2017 International Conference on Big Data Innovations and Applications, Prague, Czech Republic, 21–23 August 2018; pp. 43–50. [Google Scholar]
- Aggarwal, D.; Davis, K. Employing Graph Databases as a Standardization Model for Addressing Heterogeneity and Integration. Adv. Intell. Syst. Comput. 2018, 561, 109–138. [Google Scholar] [CrossRef]
- De la Vega, A.; García-Saiz, D.; Blanco, C.; Zorrilla, M.; Sánchez, P. Mortadelo: A Model-Driven Framework for NoSQL Database Design. In Proceedings of the 8th International Conference on Model and Data Engineering, Marrakesh, Morocco, 24–26 October 2018; pp. 41–57. [Google Scholar]
- Chen, X.; Yan, L.; Li, W.; Zhang, F. Fuzzy spatio-temporal data modeling based on XML schema. Filomat 2018, 32, 1663–1677. [Google Scholar] [CrossRef]
- Shin, K.; Hwang, C.; Jung, H. NoSQL Database Design Using UML Conceptual Data Model Based on Peter Chen’s Framework. Int. J. Appl. Eng. Res. 2017, 12, 632–636. [Google Scholar]
- Abdelhedi, F.; Brahim, A.A.; Atigui, F. Logical unified modeling for NoSQL databases. In Proceedings of the 19th International Conference on Enterprise Information Systems, Porto, Portugal, 26–29 April 2017; pp. 249–256. [Google Scholar]
- Mohan, A.; Ebrahimi, M.; Lu, S.; Kotov, A. A NoSQL Data Model for Scalable Big Data Workflow Execution. In Proceedings of the 2016 IEEE International Congress on Big Data, San Francisco, CA, USA, 27 June–2 July 2016; pp. 52–59. [Google Scholar]
- Villari, M.; Celesti, A.; Giacobbe, M.; Fazio, M. Enriched E-R Model to Design Hybrid Database for Big Data Solutions. In Proceedings of the 2016 IEEE Symposium on Computers and Communication, Messina, Italy, 27–30 June 2016; pp. 163–166. [Google Scholar]
- Santos, M.Y.; Costa, C. Data Warehousing in Big Data: From Multidimensional to Tabular Data Models. In Proceedings of the 9th International C* Conference on Computer Science and Software Engineering, Porto, Portugal, 20–22 July 2016; Volume 20, pp. 51–60. [Google Scholar]
- Santos, M.Y.; Costa, C. Data Models in NoSQL Databases for Big Data Contexts. In Proceedings of the International Conference on Data Mining and Big Data, Bali, Indonesia, 25–30 June 2016; Volume 9714, pp. 475–485. [Google Scholar]
- Solanke, G.B.; Rajeswari, K. Migration of Relational Database to MongoDB and Data Analytics using Naïve Bayes Classifier based on Mapreduce Approach. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation, Maharashtra, India, 17–18 July 2017; pp. 1–6. [Google Scholar]
- Reniers, V.; Van Landuyt, D.; Rafique, A.; Joosen, W. Schema Design Support for Semi-Structured Data: Finding the Sweet Spot between NF and De-NF. In Proceedings of the 2017 IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017; pp. 2921–2930. [Google Scholar]
- Abdelhedi, F.; Ait Brahim, A.; Atigui, F.; Zurfluh, G. Big Data and Knowledge Management: How to Implement Conceptual Models in NoSQL Systems. In Proceedings of the 8th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2016), Porto, Portugal, 9–11 November 2016; pp. 235–240. [Google Scholar]
- Chevalier, M.; El Malki, M.; Kopliku, A.; Teste, O.; Tournier, R. Document-Oriented Models for Data Warehouses: NoSQL Document-Oriented for Data Warehouses. In Proceedings of the 18th International Conference on Enterprise Information Systems (ICEIS 2016), Rome, Italy, 25–28 April 2016; pp. 142–149. [Google Scholar] [CrossRef]
- Banerjee, S.; Shaw, R.; Sarkar, A.; Debnath, N.C. Towards Logical Level Design of Big Data. In Proceedings of the 13th IEEE International Conference on Industrial Informatics, Cambridge, UK, 22–24 July 2015; pp. 1665–1671. [Google Scholar]
- Feng, W.; Gu, P.; Zhang, C.; Zhou, K. Transforming UML Class Diagram into Cassandra Data Model with Annotations. In Proceedings of the IEEE International Conference on Smart City/SocialCom/SustainCom, Chengdu, China, 19–21 December 2015; pp. 798–805. [Google Scholar]
- Chen, L.; Shao, J.; Yu, Z.; Sun, J.; Wu, F.; Zhuang, Y. RAISE: A Whole Process Modeling Method for Unstructured Data Management. In Proceedings of the 2015 IEEE International Conference on Multimedia Big Data, Beijing, China, 20–22 April 2015; pp. 9–12. [Google Scholar]
- Chevalier, M.; Malki, M.; Kopliku, A.; Teste, O.; Tournier, R. Implementation of Multidimensional Databases with Document-Oriented NoSQL. Lect. Notes Comput. Sci. 2015, 9263, 379–390. [Google Scholar] [CrossRef]
- Wardani, D.; Küng, J. Semantic Mapping Relational to Graph Model. In Proceedings of the 2014 International Conference on Computer, Control, Informatics and Its Applications, Bandung, Indonesia, 21–23 October 2014; pp. 160–165. [Google Scholar]
- Zhe, M.; Ruihua, K. A Data Modeling Approach for Electronic Document Based on Metamodel. In Proceedings of the 2013 International Conference on Computer Sciences and Applications, Wuhan, China, 14–15 December 2013; pp. 829–832. [Google Scholar]
- Mami, M.N.; Scerri, S.; Auer, S.; Vidal, M.E. Towards Semantification of Big Data Technology. In Proceedings of the 18th International Conference on Big Data Analytics and Knowledge Discovery, Porto, Portugal, 6–8 September 2016; pp. 376–390. [Google Scholar]
- Han, D.; Stroulia, E. HGrid: A Data Model for Large Geospatial Data Sets in HBase. In Proceedings of the 6th International Conference on Cloud Computing, Shanghai, China, 9–11 November 2013; pp. 910–917. [Google Scholar]
- Zheng, Z.; Du, L.; Guo, Y. BigData oriented open scalable relational data model. In Proceedings of the 3rd IEEE International Congress on Big Data, Washington, DC, USA, 27–30 October 2014; pp. 398–405. [Google Scholar]
- Wei, D.; Li, C.; Naheman, W.; Wei, J.; Yang, J. Organizing and Storing Method for Large-scale Unstructured Data Set with Complex Content. In Proceedings of the 5th International Conference on Computing for Geospatial Research and Application, Washington, DC, USA, 4–6 August 2014; pp. 70–76. [Google Scholar]
- Mior, M.; Salem, K.; Aboulnaga, A.; Liu, R. NoSE: Schema design for NoSQL applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2275–2289. [Google Scholar] [CrossRef]
- Chavalier, M.; El Malki, M.; Kopliku, A.; Teste, O.; Tournier, R. Document-Oriented Data Warehouses: Models and Extended Cuboids. In Proceedings of the 10th IEEE International Conference on Research Challenges in Information Science, Grenoble, France, 1–3 June 2016; pp. 1–11. [Google Scholar]
- Vera, H.; Boaventura, W.; Holanda, M.; Guimaraes, V.; Hondo, F. Data modeling for NoSQL document-oriented databases. In Proceedings of the CEUR Workshop, Turin, Italy, 28–29 September 2015; pp. 129–135. [Google Scholar]
- Mason, R.T. NoSQL Databases and Data Modeling Techniques for a Document-oriented NoSQL Database. In Proceedings of the Informing Science & IT Education Conference, Tampa, FL, USA, 2–5 July 2015; pp. 259–268. [Google Scholar]
- Webster, J.; Watson, R. Analyzing the Past to Prepare for the Future: Writing a Literature Review. Manag. Inf. Syst. 2002, 26, 13–23. [Google Scholar]
- ACENS. Bases de Datos NoSQL. Qué son y Tipos que nos Podemos Encontrar. Available online: https://www.acens.com/wp-content/images/2014/02/bbdd-nosql-wp-acens.pdf (accessed on 20 September 2019).
- IBM and IBM Knowledge Center. Data Driven Modeling. Available online: https://www.ibm.com/support/knowledgecenter/en/SSGTJF/com.ibm.help.omcloud.omniconfig.doc/productconcepts/c_OC_DDMIntro.html (accessed on 20 September 2019).
- Abelló, A. Big Data Design. In Proceedings of the 18th International Workshop on Data Warehousing and OLAP, Melbourne, Australia, 23 October 2015; pp. 35–38. [Google Scholar]
- Schaarschmidt, M.; Gessert, F.; Ritter, N. Towards automated polyglot persistence. In Proceedings of the Datenbanksysteme für Business, Technologie und Web, Stuttgart, Germany, 6–7 March 2015. [Google Scholar]
- Sevilla Ruiz, D.; Morales, S.F.; Garcia Molina, J. Inferring Versioned Schemas from NoSQL Databases and Its Applications. Lect. Notes Comput. Sci. 2015, 9381, 467–480. [Google Scholar] [CrossRef]
- Solid, I.T. DB-Engines Ranking—Trend Popularity. Available online: https://db-engines.com/en/ranking_trend (accessed on 1 January 2020).
- Dell’Aglio, D.; Balduini, M.; Della Valle, E. Applying semantic interoperability principles to data stream management. In Data Management in Pervasive Systems; Springer: Cham, Switzerland, 2015; pp. 135–166. [Google Scholar] [CrossRef]
- Haghighi, M. Market-based resource allocation for energy-efficient execution of multiple concurrent applications in wireless sensor networks. In Mobile, Ubiquitous, and Intelligent Computing; Springer: Berlin, Germany, 2014; pp. 173–178. [Google Scholar] [CrossRef]
- Bajcsy, R.; Joshi, A.; Krotkov, E.; Zwarico, A. Landscan: A natural language and computer vision system for analyzing aerial images. In Proceedings of the 9th International Joint Conference on Artificial Intelligence, Los Angeles, CA, USA, 18–23 August 1985; Volume 2, pp. 919–921. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Brief Description |
|---|---|
| Volume | Large data sets |
| Velocity | High data generation rate |
| Variety | Different type of data formats |
| Variability | Consistent data |
| Viscosity | Data velocity variations |
| Virality | Data transmission rate |
| Veracity | Accuracy of data |
| Validity | Assessment of data |
| Visualization | Data symbolization |
| Value | Useful data to retrieve info |
| Characteristic/Data Model | Column-Oriented | Document-Oriented | Graph-Oriented | Key-Value |
|---|---|---|---|---|
| Concept | A model that allows representing data in columns | A model that allows representing data via structured text | A model that allows representing data and their connections | A model that allows representing the data in a simple format (key and values) |
| Structure | Data are stored in tables | Nesting of key-value pairs | Set of data objects (nodes) | Tuple of two strings (key and value) |
| Each document identified by a unique identifier | Set of links between the objects (edges) | A key represents any entity’s attribute | ||
| Values in a column are stored consecutively | Any value can be a structured document | Values can be of any data type | ||
| Key and value are separated by a colon “:” | ||||
| Key-value pairs are separated by commas “,” | ||||
| Data enclosed in curly braces denotes documents | ||||
| Data enclosed in square brackets denotes array collection | ||||
| Techniques | With compression: Lightweight encoding Bit-vector encoding Dictionary encoding Frame of reference encoding Differential encoding | Denormalized flat model | Simple direct graph Undirected multigraph Directed multigraph | NA |
| Denormalized model with more structure (metadata) | Weighted graph | |||
| With join algorithm | Shattered, equivalent to normalization (https://pdfs.semanticscholar.org/ea15/945ce9ec0c12b92794b8ace69ce44ebe40cc.pdf) | Hypergraph | ||
| With late materialization | Nested graph | |||
| Tuple at a time | ||||
| Applications | Consumer data Inventory data | JSON documents XML documents | Social networks Supply-chain Medical records IT operations Transports | User profiles and their attributes |
| Advantages | High performance in loading and querying operations Efficient data compression and partitioning (both horizontally and vertically) Scalability Support for massive parallel processing Well-suited for Online Analytical Processing and OnLine Transaction Processing workloads | Support for multiple document types Support for atomicity, consistency, isolation and durability transactions Scalability Suitable for complex data, nested documents and arrays | Easy modeling Fast and simple querying Scalability | Easy design and implementation Fault tolerance Redundancy Scalability High speed |
| Disadvantages | Difficult to use wide-columns Delays in querying specific data | Information duplication across multiple documents Inconsistencies in complex designs | Lack of a standard declarative language Support to limited concurrency and parallelism | Very basic query language Some queries can only depend on the primary key |
| Reference | First Author’s Name | First Author’s Affiliation | Country | Journal/Conference ID | Digital Library | Publication Year | Citations in Scopus | Knowledge Application | Funding |
|---|---|---|---|---|---|---|---|---|---|
| [25] | Jie Song | Software College, Northeastern | China | J1 | Scopus | 2019 | 0 | Academy | Yes |
| [26] | Laurent Thiry | University of Haute Alsace | France | J2 | Scopus | 2018 | 0 | Academy | NA |
| [27] | Victor Martins de Sousa | UNIFACCAMP | Brazil | C1 | Scopus | 2018 | 1 | Academy | Yes |
| [28] | Igor Zečević | University of Novi Sad | Serbia | J3 | Scopus | 2018 | 2 | Academy | Yes |
| [29] | Antonio M. Rinaldi | University of Naples Federico II | Italy | C2 | Scopus | 2018 | 1 | Academy | NA |
| [30] | Shady Hamouda | Emirates College of Technology | United Arab Emirates | C3 | Scopus | 2018 | 1 | Academy | NA |
| [31] | Dippy Aggarwal | University of Cincinnati | United States of America | J4 | Scopus | 2018 | 0 | Academy | NA |
| [32] | Alfonso de la Vega | University of Cantabria | Spain | C4 | Scopus | 2018 | 0 | Academy | Yes |
| [33] | Xu Chen | North Minzu University | China | J5 | Scopus | 2018 | 0 | Academy | NA |
| [18] | Maribel Yasmina Santos | University of Minho | Portugal | J6 | Scopus | 2017 | 10 | Academy | Yes |
| [34] | KwangchuShin | Kook Min University | South Korea | J7 | Scopus | 2017 | 7 | Academy | Yes |
| [35] | Fatma Abdelhedi | Toulouse Capitole University | France | C5 | Scopus | 2017 | 1 | Academy | NA |
| [36] | Aravind Mohan | Wayne State University | United States of America | C6 | Scopus | 2016 | 7 | Academy | Yes |
| [37] | Massimo Villari | University of Messina | Italy | C7 | Scopus | 2016 | 2 | Academy | NA |
| [38] | Maribel Yasmina Santos | University of Minho | Portugal | C8 | Scopus | 2016 | 10 | Academy | Yes |
| [39] | Maribel Yasmina Santos | University of Minho | Portugal | J8 | Scopus | 2016 | 8 | Academy | Yes |
| [40] | Ganesh B. Solanke | PCCoE, Nigdi | India | C9 | Scopus | 2018 | 0 | Academy | NA |
| [41] | Vincent Reniers | KU Leuven | Belgium | C10 | Scopus | 2018 | 0 | Academy | Yes |
| [42] | Fatma Abdelhedi | Toulouse Capitole University | France | C11 | Scopus | 2016 | 4 | Academy | NA |
| [43] | Max Chevalier | University of Toulouse | France | C12 | Scopus | 2016 | 6 | Academy | ANRT |
| [44] | Shreya Banerjee | National Institute of Technology | India | C13 | Scopus | 2015 | 6 | Academy | NA |
| [16] | Artem Chebotko | DataStax Inc. | United States of America | C14 | Scopus | 2015 | 43 | Industry | Yes |
| [45] | Wenduo Feng | Guangxi University | China | C15 | Scopus | 2015 | 2 | Academy | Yes |
| [46] | Ling Chen | Zhejiang University | China | C16 | Scopus | 2015 | 1 | Academy | Yes |
| [47] | Max Chevalier | University of Toulouse | France | C17 | Scopus | 2015 | 14 | Academy | NA |
| [48] | Dewi W. Wardani | Sebelas Maret University | Indonesia | C18 | Scopus | 2014 | 7 | Academy | NA |
| [49] | Ming Zhe | Hubei University of Technology | China | C19 | Scopus | 2013 | 0 | Academy | NA |
| [50] | Mohamed Nadjib Mami | University of Bonn | Germany | C20 | Scopus | 2016 | 5 | Academy | Yes |
| [51] | Dan Han | University of Alberta | Canada | C21 | WoS | 2013 | 0 | Academy | Yes |
| [52] | Zhiyun Zheng | Zhengzhou University | China | C22 | IEEE | 2014 | 1 | Academy | Yes |
| [53] | Dongqi Wei | University of Geosciences | China | C23 | IEEE | 2014 | 3 | Academy | NA |
| [14] | Karamjit Kaur | Thapar University | India | C24 | IEEE | 2013 | 59 | Academy | NA |
| [54] | Michael J. Mior | University of Waterloo | Canada | J1 | IEEE | 2017 | 12 | Academy | Yes |
| [55] | Max Chevalier | University of Toulouse | France | C25 | Scopus | 2016 | 4 | Academy | Yes |
| [56] | Harley Vera | University of Brasília | Brazil | C26 | Scopus | 2015 | 8 | Academy | NA |
| [57] | Robert T. Mason | Regis University | United States of America | C27 | NA | 2015 | 0 | Academy | NA |
| Journal ID | Journal Name | Country | JCR IF | SJR | Study ID |
|---|---|---|---|---|---|
| J1 | IEEE Transaction on Knowledge and Data Engineering | United States of America | 3.86 | 1.1 | 1, 33 |
| J2 | Journal of Big Data | United Kingdom | NA | 1.1 | 2 |
| J3 | Enterprise Information Systems | United Kingdom | 2.12 | 0.7 | 4 |
| J4 | Advances in Intelligent Systems and Computing | Germany | NA | 0.2 | 7 |
| J5 | Filomat | Serbia | 0.79 | 0.4 | 9 |
| J6 | Journal of Management Analytics | United Kingdom | NA | NA | 10 |
| J7 | International Journal of Applied Engineering Research | India | NA | 0.1 | 11 |
| J8 | Lecture Notes in Computer Science | Germany | 0.4 | 0.3 | 16 |
| Conference ID | Conference Name | CORE 2018 Ranking | Study ID |
|---|---|---|---|
| C1 | 20th International Conference on Information Integration and Web-Based Applications and Services | C | 3 |
| C2 | 10th International Conference on Management of Digital EcoSystems | Not ranked | 5 |
| C3 | 2017 International Conference on Big Data Innovations and Applications | Not ranked | 6 |
| C4 | 8th International Conference on Model and Data Engineering | Not ranked | 8 |
| C5 | 19th International Conference on Enterprise Information Systems | C | 12 |
| C6 | 5th IEEE International Congress on Big Data | Not ranked | 13 |
| C7 | 2016 IEEE Symposium on Computers and Communication | B | 14 |
| C8 | 9th International C* Conference on Computer Science and Software Engineering | Not ranked | 15 |
| C9 | 2017 International Conference on Computing, Communication, Control and Automation | Not ranked | 17 |
| C10 | 2017 IEEE International Conference on Big Data | Not ranked | 18 |
| C11 | 8th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management | C | 19 |
| C12 | 18th International Conference on Enterprise Information Systems | C | 20 |
| C13 | 2015 IEEE International Conference on Industrial Informatics | Not ranked | 21 |
| C14 | 4th IEEE International Congress on Big Data | Not ranked | 22 |
| C15 | 2015 IEEE International Conference on Smart City/SocialCom/SustainCom together with DataCom | Not ranked | 23 |
| C16 | 2015 IEEE International Conference on Multimedia Big Data | Not ranked | 24 |
| C17 | 17th International Conference on Big Data Analytics and Knowledge Discovery | Not ranked | 25 |
| C18 | 2014 International Conference on Computer, Control, Informatics and Its Applications | Not ranked | 26 |
| C19 | 2013 International Conference on Computer Sciences and Applications | Not ranked | 27 |
| C20 | 18th International Conference on Big Data Analytics and Knowledge Discovery | Not ranked | 28 |
| C21 | 2013 IEEE Sixth International Conference on Cloud Computing | B | 29 |
| C22 | 3rd IEEE International Congress on Big Data | Not ranked | 30 |
| C23 | 2014 Fifth International Conference on Computing for Geospatial Research and Application | Not ranked | 31 |
| C24 | 2013 IEEE International Conference on Big Data | Not ranked | 32 |
| C25 | IEEE Tenth International Conference on Research Challenges in Information Science | B | 34 |
| C26 | 2nd Annual International Symposium on Information Management and Big Data | B | 35 |
| C27 | Informing Science & IT Education Conference | C | 36 |
| Real-World Data Sets | Study ID | Domain | Volume | Velocity | Veracity | Value |
|---|---|---|---|---|---|---|
| Electronic documents | 27 | e-government electronic documents | A large number of e-government electronic documents | Not available | Documents are laws and regulations | Managing housing transfer process |
| Images metadata | 5 | Images from a web server | Network with 8000 relationships and 5990 nodes | Not available | Knowledge base of famous painters | Obtaining images related to the famous painters |
| Sensors | 9 | Fuzzy spatio-temporal data | Not available | Not available | Data from the real movement of the tropical cyclones Saomei and Bopha under the influence of subtropical high | Analyzing meteorological phenomena |
| 13 | Vehicles into OpenXC | 14 exabytes per year | Up to 5GB/hour | Data from devices that are installed in the vehicles | Providing insights on the risk level based on the drivers driving behavior | |
| Websites | 4 | Web-based agriculture application | Not available | Not available | Data from a Precision Agriculture Based Information Service (PAIS) application | Providing an online service to the farmers, with 24/7 access to the images of the crops |
| 10 | Commercial flights in the USA | More than 123 million records | Not available | Domestic flights in the USA obtained from RITA-BTS | Presenting the behavior of the companies regarding to the accomplished and cancelled flights | |
| 18 | Review site Epinions | Not available | Not available | Data from online consumers | Identifying the user preferences | |
| 30 | Microblog SINA | 1.75 GB | Not available | Data from 1500 user profiles and their microblogs | Not available | |
| 32 | Slashdot | Not available | Not available | User posts | Finding useful information about the user posts | |
| 33 | EasyAntiCheat | Large volumes from real-time data of players behavior | Not available | Partial workload extracted from multiplayer games | Determine patterns for cheating detection |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martinez-Mosquera, D.; Navarrete, R.; Lujan-Mora, S. Modeling and Management Big Data in Databases—A Systematic Literature Review. Sustainability 2020, 12, 634. https://doi.org/10.3390/su12020634
Martinez-Mosquera D, Navarrete R, Lujan-Mora S. Modeling and Management Big Data in Databases—A Systematic Literature Review. Sustainability. 2020; 12(2):634. https://doi.org/10.3390/su12020634
Chicago/Turabian StyleMartinez-Mosquera, Diana, Rosa Navarrete, and Sergio Lujan-Mora. 2020. "Modeling and Management Big Data in Databases—A Systematic Literature Review" Sustainability 12, no. 2: 634. https://doi.org/10.3390/su12020634
APA StyleMartinez-Mosquera, D., Navarrete, R., & Lujan-Mora, S. (2020). Modeling and Management Big Data in Databases—A Systematic Literature Review. Sustainability, 12(2), 634. https://doi.org/10.3390/su12020634