Extracting Knowledge from Big Data for Sustainability: A Comparison of Machine Learning Techniques



Abstract
:1. Introduction
2. Background
3. Materials and Methods
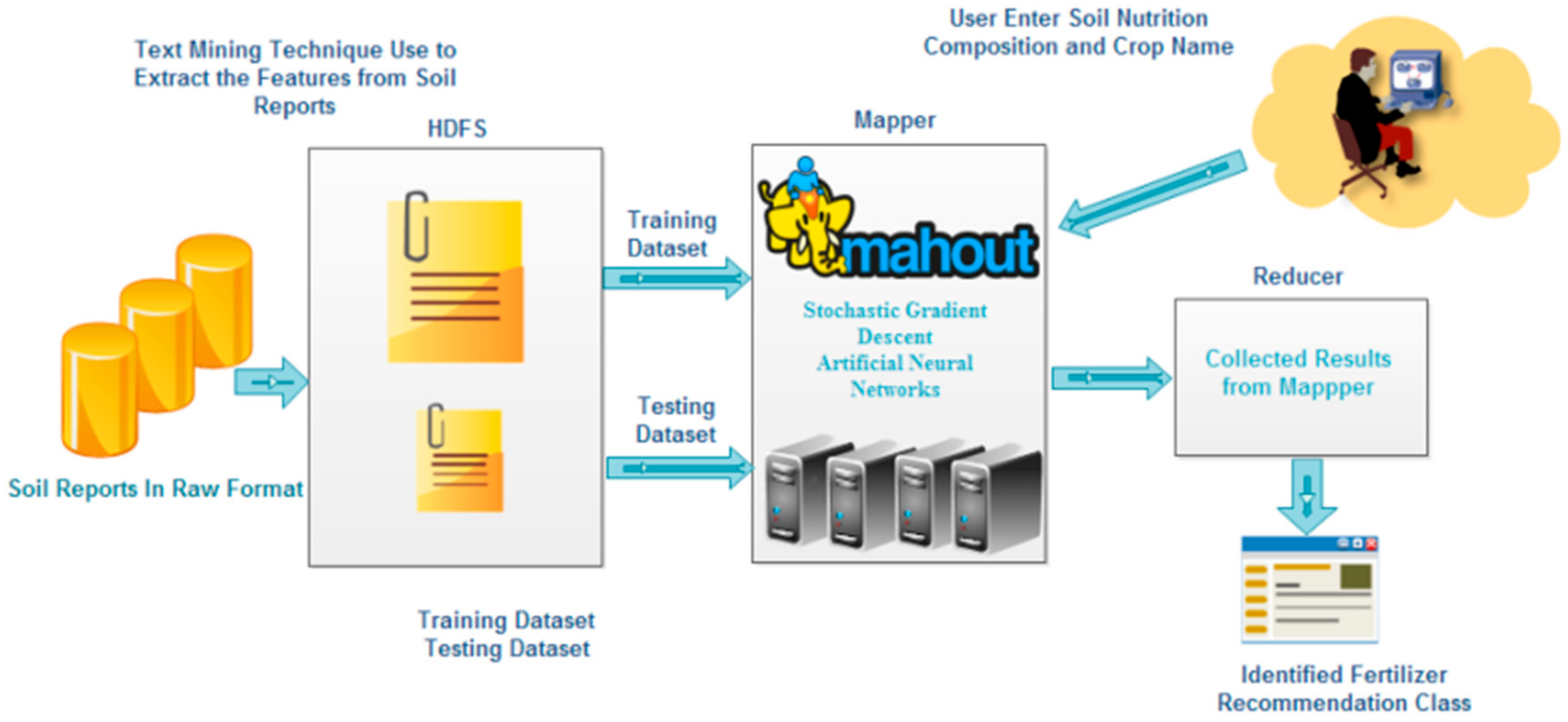
3.1. Problem Statement
3.2. Dataset
3.3. Fertilizer Recommendation Class
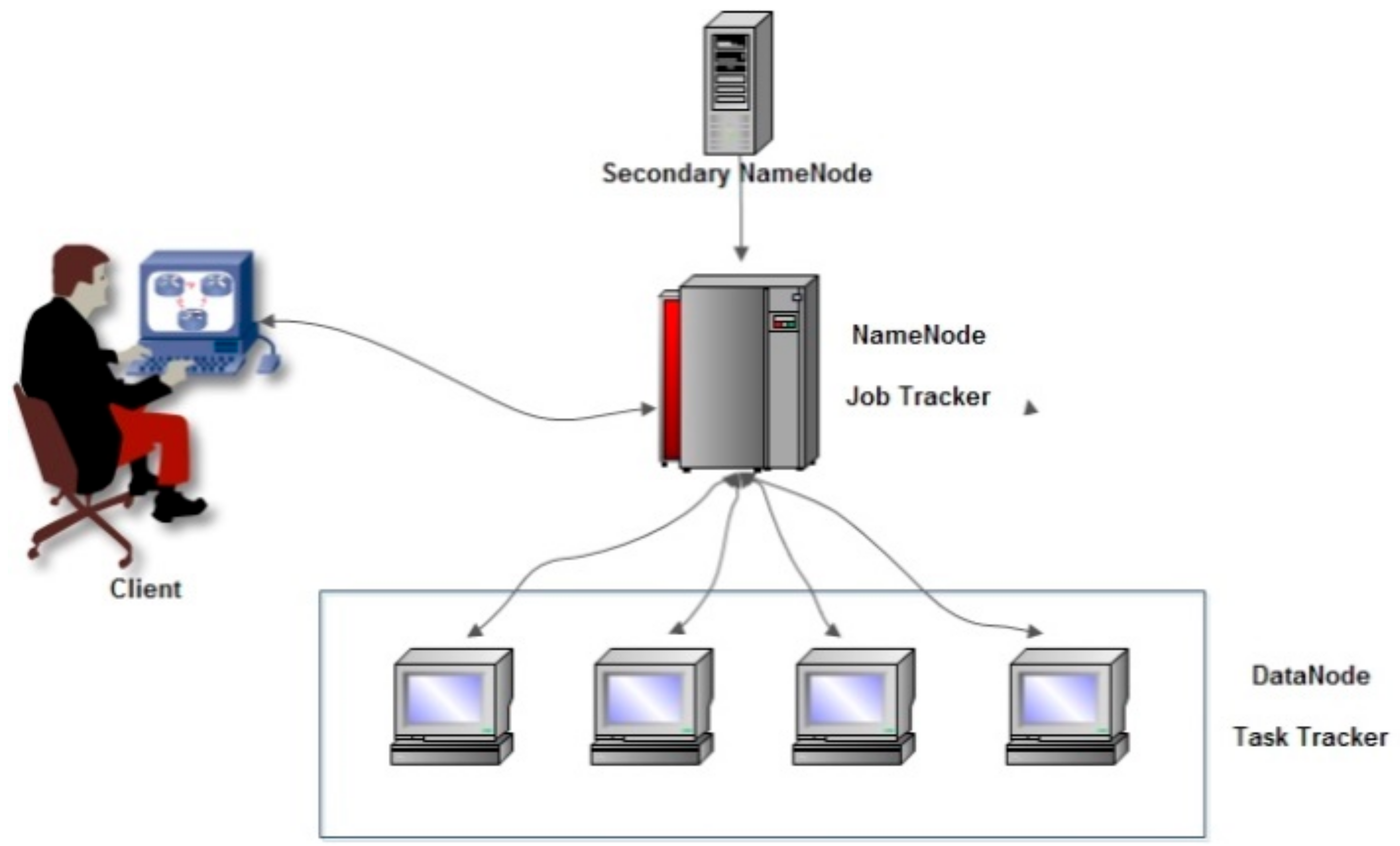
3.4. Hadoop
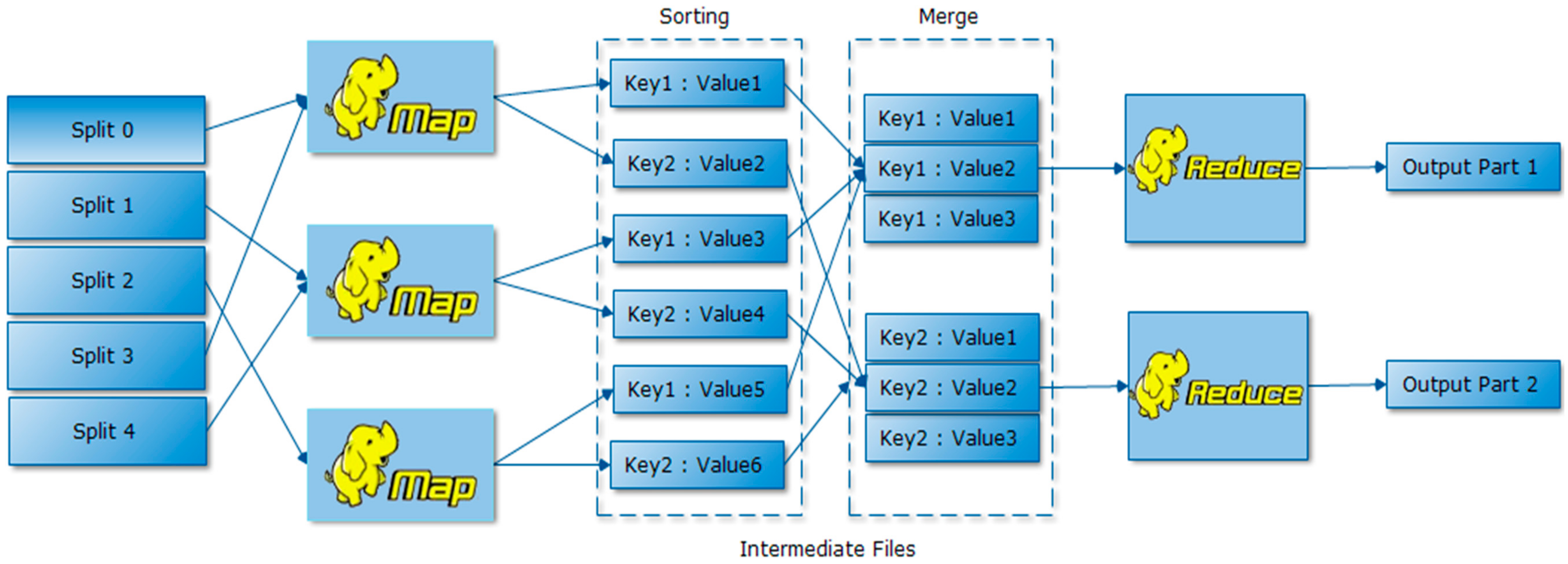
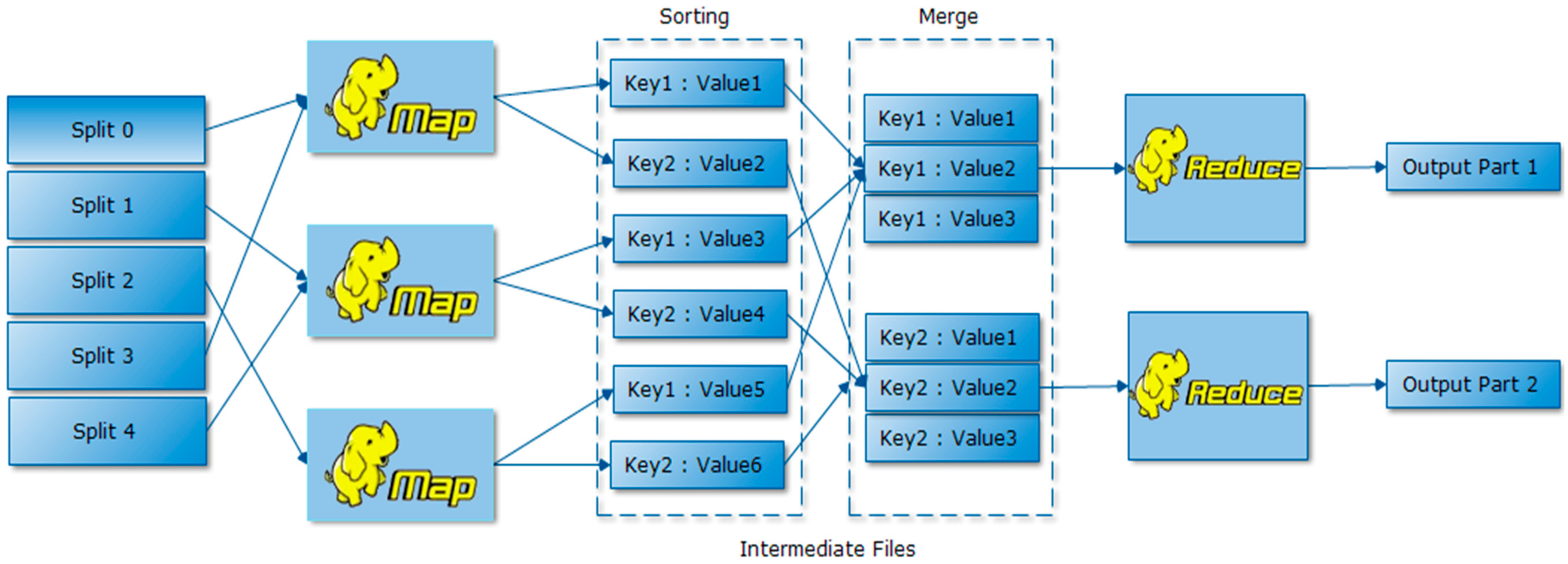
3.5. MapReduce
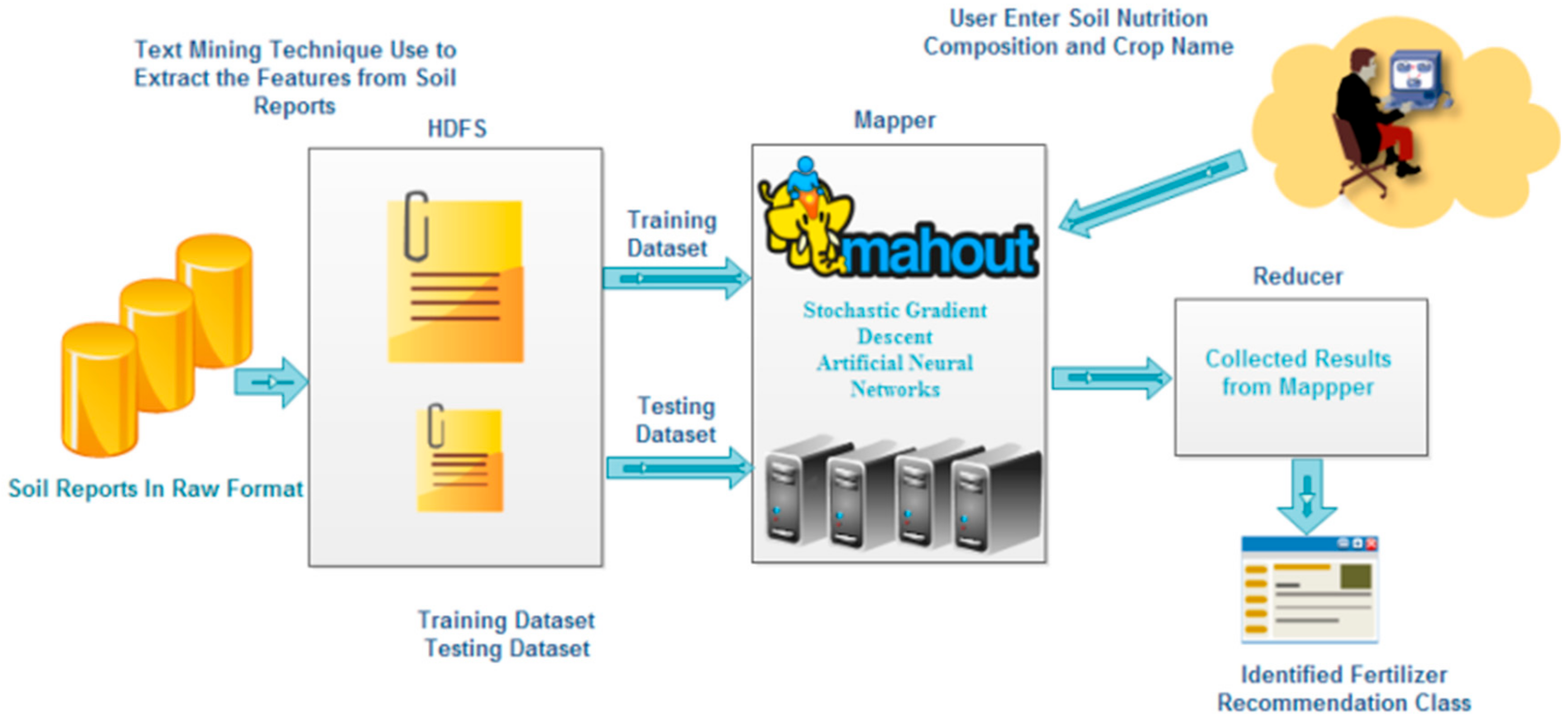
3.6. Mahout
3.7. Stochastic Gradient Descent
3.8. Artificial Neural Network
3.9. Random Forest
3.10. K-Nearest Neighbor Algorithm
3.11. Regression Tree Models
3.12. Support Vector Machine (SVM)
3.13. Performance Evaluation
4. Proposed Model and Results
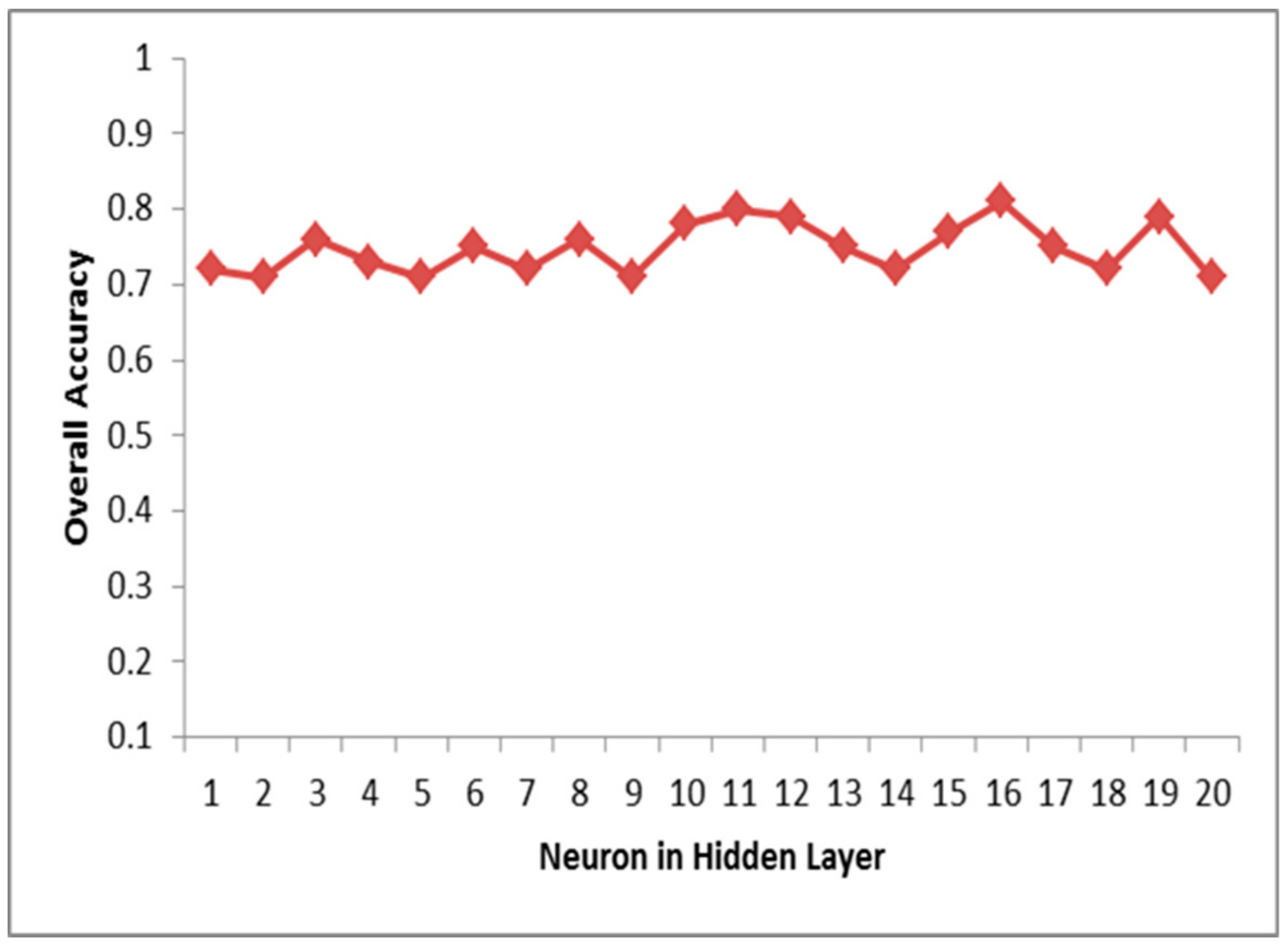
4.1. Experimental Setup
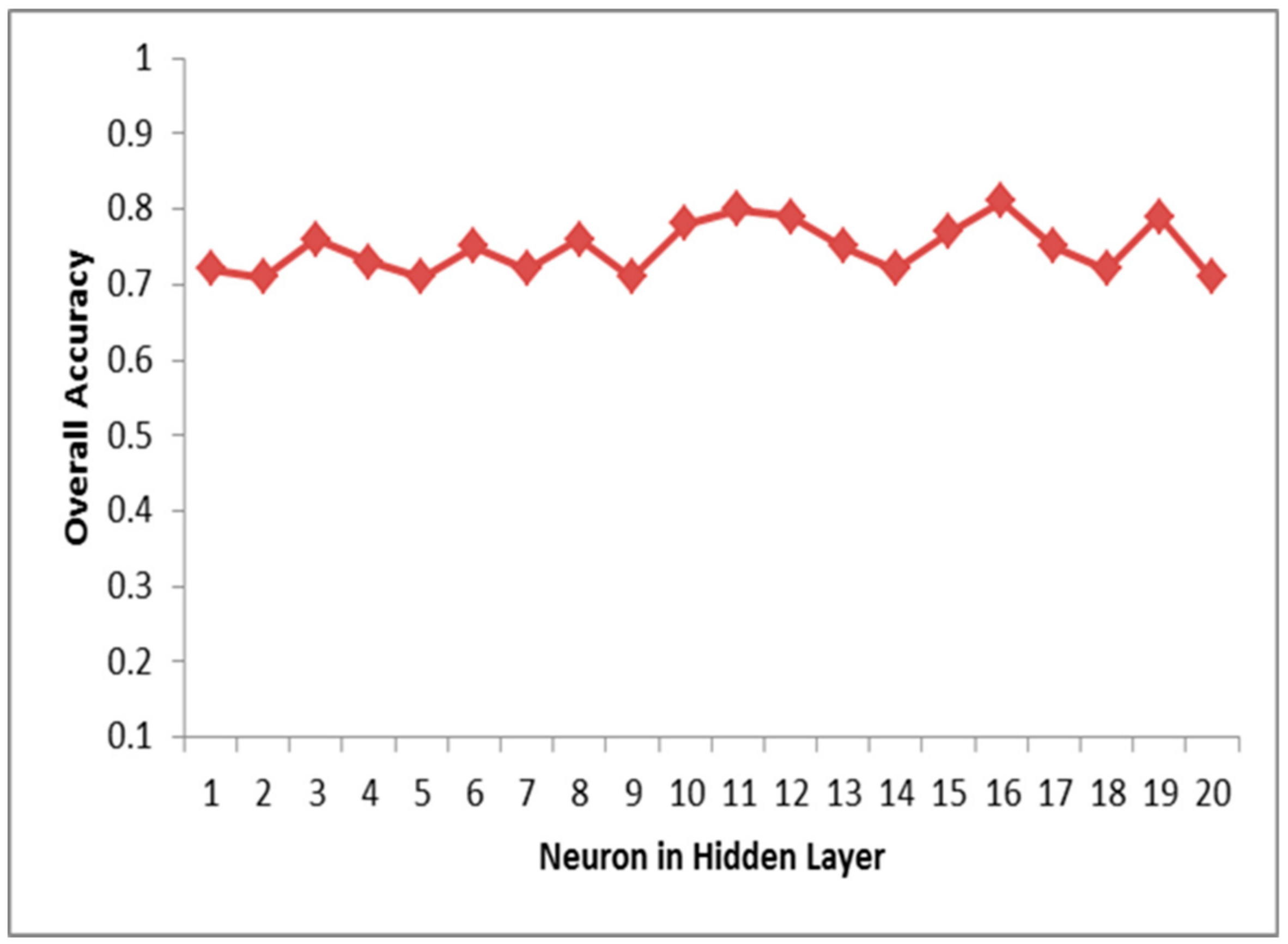
4.2. Model Performance and Results
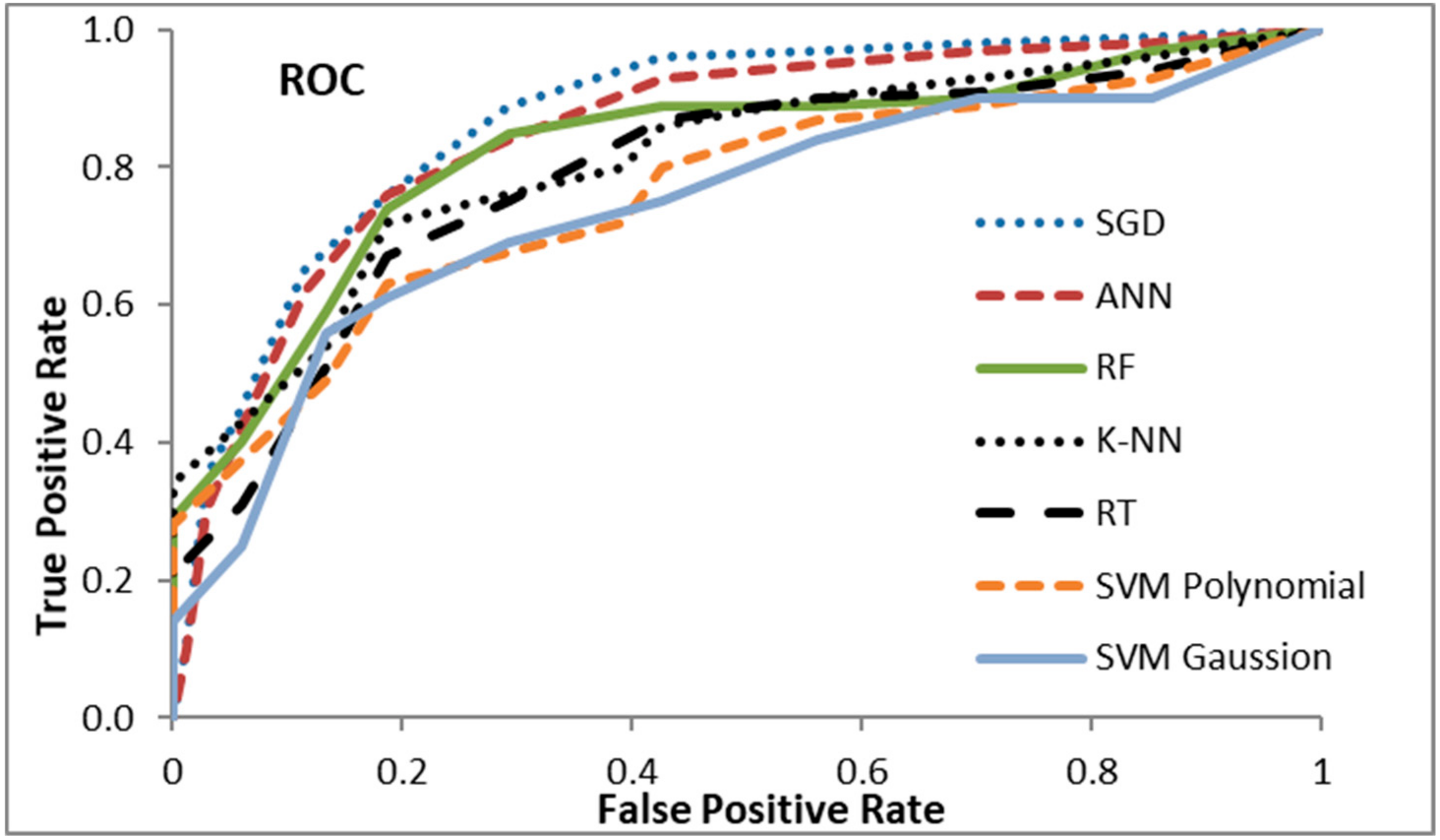
4.3. Comparison with Existing Methods
5. Conclusions and Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Emerson, R.; Arnold, W. The photochemical reaction in photosynthesis. J. Gen. Physiol. 1932, 16, 191–205. [Google Scholar] [CrossRef] [PubMed]
- Evans, L.T. Environmental Control of Plant Growth; Academic Press: New York, NY, USA, 1963. [Google Scholar]
- Acker, O.; Blockus, A.; Pötscher, F. Benefiting from Big Data: A New Approach for the Telecom Industry; Strategy, Analysis Report; PWC: London, UK, 2013. [Google Scholar]
- Andreu-Perez, J.; Poon, C.; Merrifield, R.D.; Wong, S.T.; Yang, G.Z. Big data for health. IEEE J. Biomed. Health Inf. 2015, 19, 1193–1208. [Google Scholar] [CrossRef] [PubMed]
- Lytras, M.D.; Visvizi, A. Big Data and Their Social Impact: Preliminary Study. Sustainability 2019, 11, 5067. [Google Scholar] [CrossRef]
- Osden, J. Towards a Big Data Framework for the Prevention and Control of HIV/AIDS, TB and Silicosis in the Mining Industry. International Conference on Health and Social Care Information Systems and Technologies, Portugal. Procedia Technol. 2014, 16, 1533–1541. [Google Scholar]
- Bernard, M. Amazon Big Data. Available online: http://www.smartdatacollective.com/bernardmarr/182796/amazon-using-big-data-analytics-read-your-mind (accessed on 6 February 2014).
- Singh, I.; Singh, S. Framework for targeting high value customers and potential churn customers in telecom using Big Data Analytics. Int. J. Educ. Manag. Engin. [CrossRef]
- Long, P.; Siemens, G. Analytics In Learning And Education. Educ. Rev. 2011, 46, 30. [Google Scholar]
- Wilcke, W.; Yasin, S.; Schmitt, A.; Valarezo, C.; Zech, W. Soils along the altitudinal transect and in catchments. In Gradients in a Tropical Mountain Ecosystem of Ecuador; Springer: Berlin/Heidelberg, Germany, 2008; pp. 75–85. [Google Scholar]
- Zhen, L.; Zoebisch, M. Resource Use and Agricultural Sustainability: Risks and Consequences of Intensive Cropping in China; Kassel University Press GmbH: Kassel, Germany, 2006; Volume 86. [Google Scholar]
- Babu, T.G.; Babu, A. IoT (Internet of Things) & Big Data Solutions to Boost Yield and Reduce Waste in Farming. In Proceedings of the 2018 IADS International Conference on Computing, Communications & Data Engineering (CCODE), Tirupati, India, 7–8 February 2018. [Google Scholar]
- Bodake, K.; Ghate, R.; Doshi, H.; Jadhav, P.; Tarle, B. Soil based Fertilizer Recommendation System using Internet of Things. MVP J. Eng. Sci. 2018, 1, 13–19. [Google Scholar]
- Shastry, K.A.; Sanjay, H.A. Cloud-Based Agricultural Framework for Soil Classification and Crop Yield Prediction as a Service. In Emerging Research in Computing, Information, Communication and Applications; Springer: Singapore, 2019; pp. 685–696. [Google Scholar]
- Wu, W.; Li, A.D.; He, X.H.; Ma, R.; Liu, H.B.; Lv, J.K. A comparison of support vector machines, artificial neural network and classification tree for identifying soil texture classes in southwest China. Comput. Electron. Agric. 2018, 144, 86–93. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Nabiollahi, K.; Kerry, R. Digital mapping of soil organic carbon at multiple depths using different data mining techniques in Baneh region, Iran. Geoderma 2016, 266, 98–110. [Google Scholar] [CrossRef]
- Cattaneo, G.; Giancarlo, R.; Piotto, S.; Petrillo, U.F.; Roscigno, G.; Di Biasi, L. MapReduce in Computational Biology—A Synopsis. In Italian Workshop on Artificial Life and Evolutionary Computation; Springer: Cham, Switzerland, 2016; pp. 53–64. [Google Scholar]
- Kovačević, M.; Bajat, B.; Gajić, B. Soil type classification and estimation of soil properties using support vectormachines. Geoderma 2010, 154, 340–347. [Google Scholar] [CrossRef]
- Guevara-Hernandez, F.; Gil, J.G. A machine vision system for classification of wheat and barley grain kernels. Span. J. Agric. Res. 2011, 3, 672–680. [Google Scholar] [CrossRef]
- Ronge, R.; Sardeshmukh, M. Indian wheat seed classification based on texture analysis using ann. In Proceedings of the 2014 International Conference on Advances in Computing. Communications and Informatics, New Delhi, India, 24–27 September 2014; pp. 937–942. [Google Scholar]
- Gülmezoğlu, M.B.; Gülmezoğlu, N. Classification of bread wheat varieties and their yield characters with the common vector approach. In Proceedings of the International Conference on Chemical, Environmental and Biological Sciences, Dubai, United Arab Emirates, 18–19 March 2015; pp. 120–123. [Google Scholar]
- Pazoki, A.; Pazoki, Z. Classification system for rain fed wheat grain cultivars using artificial neural network. Afr. J. Biotechnol. 2011, 10, 8031–8038. [Google Scholar]
- Romero, J.R.; Roncallo, P.F.; Akkiraju, P.C.; Ponzoni, I.; Echenique, V.C.; Carballido, J.A. Using classification algorithms for predicting durum wheat yield in the province of Buenos Aires. Comput. Electron. Agric. 2013, 96, 173–179. [Google Scholar] [CrossRef]
- Brungard, C.W.; Boettinger, J.L.; Duniway, M.C.; Wills, S.A.; Edwards, T.C., Jr. Machine learning for predicting soil classes in three semi-arid landscapes. Geoderma 2015, 239, 68–83. [Google Scholar] [CrossRef]
- Lam, C. Hadoop in Action; Manning Publications: Greenwich, CT, USA, 2010; pp. 3–5. [Google Scholar]
- White, T. Hadoop: The Definitive Guide; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Sun, J.; Jin, Q. Scalable rdf store based on hbase and mapreduce. Proceedings of the IEEE 3rd International Conference on Advanced Computer Theory and Engineering (ICACTE), Chengdu, China, 20–22 August 2010. [Google Scholar]
- Thusoo, A.; Sarma, J.S.; Jain, N.; Shao, Z.; Chakka, P.; Anthony, S.; Murthy, R. Hive: A warehousing solution over a map-reduce framework. Proc. VLDB Endow. 2009, 2, 1626–1629. [Google Scholar] [CrossRef]
- Owen, S.; Anil, R.; Dunning, T.; Friedman, E. Mahout in Action; Manning Publications Co.: New York, NY, USA, 2011. [Google Scholar]
- Gates, A.; Dai, D. Programming Pig: Dataflow Scripting with Hadoop; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Gardner, W.A. Learning characteristics of stochastic-gradient-descent algorithms: A general study, analysis, and critique. Signal Process. 1984, 6, 113–133. [Google Scholar] [CrossRef]
- Yegnanarayana, B. Artificial Neural Networks; Prentice-Hall: New Delhi, India, 1999. [Google Scholar]
- Rabiner, L.R.; Juang, B.H. An introduction to hidden Markov models. IEEE Assp Magazine 1986, 3, 4–16. [Google Scholar]
- Shvachko, K.; Hairong, K.; Radia, S.; Chansler, R. The Hadoop Distributed File System. In Proceedings of the IEEE 26th Symposium On Mass Storage Systems and Technologies, Incline Village, NV, USA, 7 October 2010; pp. 1–10. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lieb, M.; Glaser, B.; Huwe, B. Uncertainty in the spatial prediction of soil texture: Comparison of regression tree and random forest models. Geoderma 2012, 170, 70–79. [Google Scholar]
- Nemes, A.; Rawls, W.J.; Pachepsky, Y.A. Use of the nonparametric nearest neighbor approach to estimate soil hydraulic properties. Soil Sci. Soc. Am. J. 2006, 70, 327–336. [Google Scholar] [CrossRef]
- Martin, M.P.; Wattenbach, M.; Smith, P.; Meersmans, J.; Jolivet, C.; Boulonne, L.; Arrouays, D. Spatial distribution of soil organic carbon stocks in France. Biogeosciences 2010, 8, 1053–1065. [Google Scholar] [CrossRef]
- Skurichina, M.; Duin, R.P. Bagging, boosting and the random subspace method for linear classifiers. Pattern Anal. Appl. 2002, 5, 121–135. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Were, K.; Bui, D.T.; Dick, Ø.B.; Singh, B.R. A comparative assessment of support vector regression, artificial neural networks, and random forests for predicting and mapping soil organic carbon stocks across an Afromontane landscape. Ecol. Indic. 2015, 52, 394–403. [Google Scholar] [CrossRef]
- Mansuy, N.; Thiffault, E.; Pare, D.; Bernier, P.; Guindon, L.; Villemaire, P.; Poirier, V.; Beaudoin, A. Digital mapping of soil properties in Canadian managed forests at 250 m of resolution using the k-nearest neighbor method. Geoderma 2014, 235, 59–73. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fertilizer Name | Soil Nutrition Composition |
|---|---|
| Urea | Nitrogen 46% |
| Diammonium Phosphate (D.A.P) | Nitrogen 18%, Diammonium Phosphate 46% |
| Muriate of Potash (M.O.P) | Muriate of potash K60% |
| Sulfur Bentonite | Bentonite Sulfur S90% |
| Zink Sulfate | Zink Sulfate 33% |
| Granubor Natur | Di-Sodium Tetra Borate Penta hydrate B14.6% |
| Target Value | Fertilizers During Seeding | Urea After Seeding | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Urea | D.A.P | M.O.P | Sulfur Bentonite | Zink Sulfate | Granubor | After First Irrigation | After Second Irrigation | ||
| Wheat | Sol. I | 7 | 56 | 33 | 11.1 | 0.0 | 2.7 | 29 | 29 |
| Sol. II | 28 | 43 | 33 | 11.1 | 0.0 | 2.7 | 45 | 45 | |
| Sol. III | 2 | 69 | 33 | 0.0 | 0.0 | 2.7 | 29 | 29 | |
| Sol. IV | 12 | 43 | 33 | 0.0 | 0.0 | 2.1 | 29 | 29 | |
| Sol. V | 19 | 43 | 27 | 0.0 | 0.0 | 0.0 | 36 | 36 | |
| Paddy | Sol. VI | 10 | 22 | 33 | 0.0 | 3.6 | 2.1 | 19 | 19 |
| Sol. VII | 1 | 35 | 33 | 0.0 | 3.6 | 2.7 | 14 | 14 | |
| Sol. VIII | 9 | 26 | 33 | 5.8 | 3.6 | 2.1 | 19 | 19 | |
| Sol. IX | 4 | 26 | 33 | 5.8 | 3.6 | 0.0 | 14 | 14 | |
| Sol. X | 5 | 35 | 27 | 0.0 | 3.6 | 2.1 | 19 | 19 | |
| Core | HDD | RAM (GB) | Core Speed (GHz) | Hadoop | Ubuntu |
|---|---|---|---|---|---|
| 8 | 1 | 16 | 2.40 | 2.7 | 16.04 |
| 4 | 1 | 6 | 2.0 | 2.7 | 16.04 |
| 4 | 1 | 4 | 2.0 | 2.7 | 16.04 |
| 4 | 1 | 4 | 2.0 | 2.7 | 16.04 |
| Solution | (a) | (b) | (c) | (d) | (e) | (f) | (g) | (h) | (i) | (h) | Overall Accuracy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SGD | (a) | 1462 | 17 | 9 | 13 | 27 | 39 | 4 | 3 | 23 | 4 | 88.15 |
| (b) | 24 | 1103 | 6 | 22 | 2 | 10 | 14 | 18 | 3 | 8 | ||
| (c) | 20 | 8 | 731 | 8 | 4 | 16 | 33 | 17 | 7 | 11 | ||
| (d) | 7 | 9 | 11 | 586 | 11 | 8 | 7 | 15 | 0 | 1 | ||
| (e) | 15 | 28 | 27 | 16 | 1143 | 32 | 9 | 20 | 9 | 37 | ||
| (f) | 5 | 19 | 12 | 9 | 0 | 898 | 4 | 24 | 16 | 43 | ||
| (g) | 23 | 4 | 41 | 18 | 16 | 21 | 1345 | 22 | 13 | 49 | ||
| (h) | 9 | 11 | 6 | 14 | 1 | 2 | 0 | 643 | 19 | 12 | ||
| (i) | 16 | 3 | 20 | 8 | 16 | 1 | 33 | 9 | 1012 | 18 | ||
| (j) | 6 | 11 | 22 | 2 | 0 | 18 | 13 | 17 | 2 | 548 | ||
| ANN | (a) | 1321 | 35 | 27 | 23 | 21 | 66 | 19 | 28 | 29 | 32 | 81.42 |
| (b) | 53 | 972 | 2 | 21 | 68 | 36 | 6 | 10 | 37 | 7 | ||
| (c) | 26 | 0 | 753 | 16 | 3 | 22 | 4 | 7 | 1 | 29 | ||
| (d) | 11 | 15 | 28 | 496 | 22 | 2 | 20 | 42 | 11 | 8 | ||
| (e) | 7 | 18 | 27 | 47 | 1097 | 51 | 17 | 18 | 25 | 31 | ||
| (f) | 31 | 49 | 20 | 29 | 3 | 779 | 14 | 38 | 11 | 56 | ||
| (g) | 29 | 34 | 38 | 11 | 41 | 35 | 1261 | 7 | 53 | 42 | ||
| (h) | 14 | 35 | 14 | 21 | 7 | 8 | 2 | 585 | 26 | 15 | ||
| (i) | 18 | 37 | 23 | 59 | 62 | 46 | 80 | 45 | 928 | 30 | ||
| (j) | 5 | 11 | 17 | 60 | 4 | 3 | 14 | 1 | 3 | 543 | ||
| Solution | SGD | ANN |
|---|---|---|
| (a) | 0.93 | 0.81 |
| (b) | 0.91 | 0.80 |
| (c) | 0.83 | 0.82 |
| (d) | 0.87 | 0.80 |
| (e) | 0.88 | 0.79 |
| (f) | 0.89 | 0.75 |
| (g) | 0.84 | 0.87 |
| (h) | 0.90 | 0.80 |
| (i) | 0.88 | 0.84 |
| (j) | 0.89 | 0.88 |
| Average | 0.882 | 0.816 |
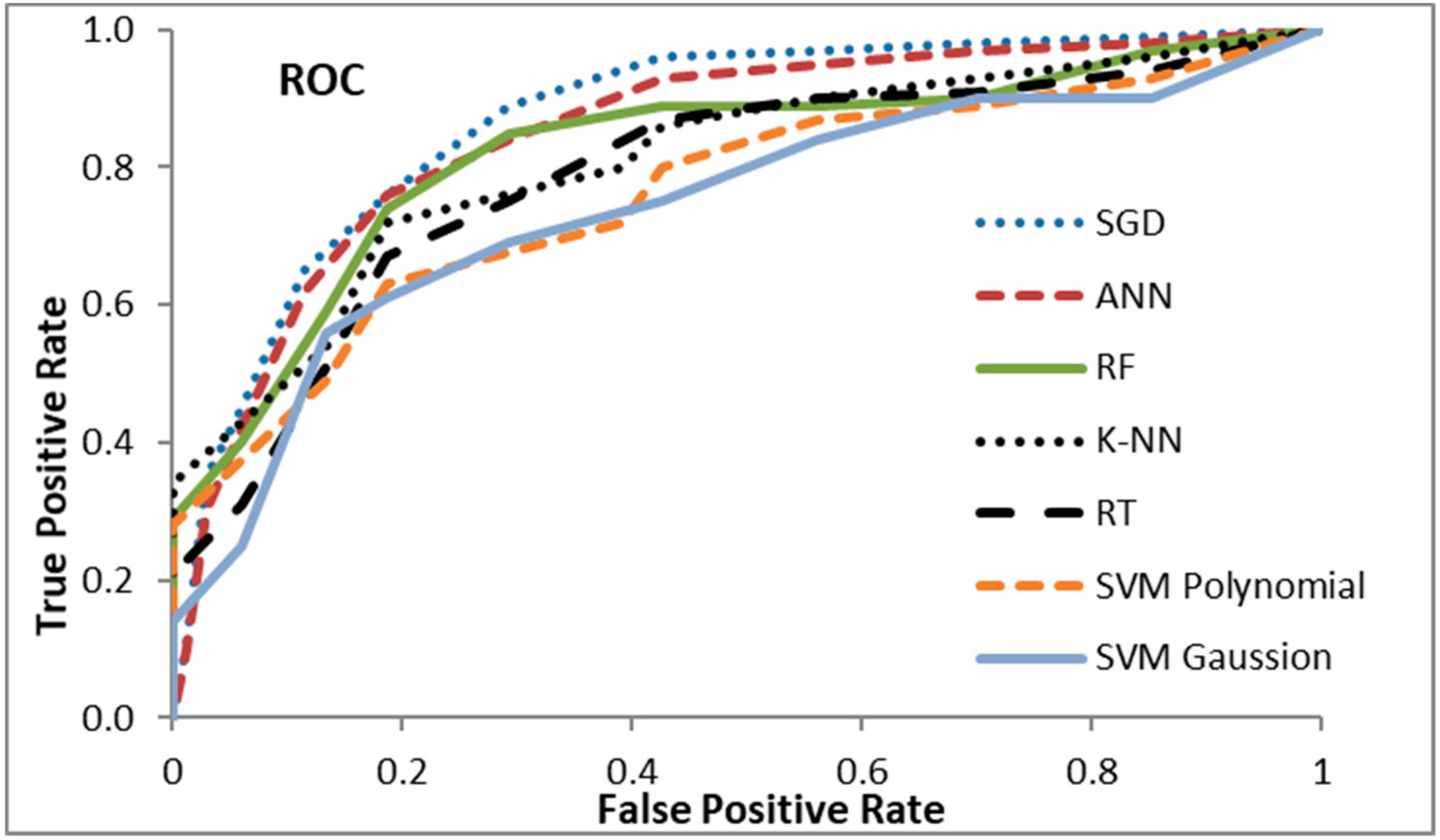
| Methods | Average AUC | Overall Accuracy |
|---|---|---|
| SGD [11] | 0.882 | 0.881 |
| ANN [32] | 0.816 | 0.814 |
| RF (Random Forest) [44] | 0.790 | 0.786 |
| K-NN [45] | 0.783 | 0.761 |
| RT (Regression Tree) [38] | 0.756 | 0.749 |
| SVM using Polynomial functions [15] | 0.743 | 0.737 |
| SVM using Gaussian radius basis functions [15] | 0.728 | 0.720 |
| Methods | |||
|---|---|---|---|
| SGD [11] | 0.41 | 0.45 | 0.74 |
| ANN [32] | 0.49 | 0.58 | 0.71 |
| RF(Random Forest) [44] | 0.53 | 0.65 | 0.69 |
| K-NN [45] | 0.57 | 0.60 | 0.64 |
| RT(Regression Tree) [38] | 0.66 | 0.73 | 0.62 |
| SVM using Polynomial functions [15] | 0.73 | 0.82 | 0.60 |
| SVM using Gaussian radius basis functions [15] | 0.75 | 0.86 | 0.59 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garg, R.; Aggarwal, H.; Centobelli, P.; Cerchione, R. Extracting Knowledge from Big Data for Sustainability: A Comparison of Machine Learning Techniques. Sustainability 2019, 11, 6669. https://doi.org/10.3390/su11236669
Garg R, Aggarwal H, Centobelli P, Cerchione R. Extracting Knowledge from Big Data for Sustainability: A Comparison of Machine Learning Techniques. Sustainability. 2019; 11(23):6669. https://doi.org/10.3390/su11236669
Chicago/Turabian StyleGarg, Raghu, Himanshu Aggarwal, Piera Centobelli, and Roberto Cerchione. 2019. "Extracting Knowledge from Big Data for Sustainability: A Comparison of Machine Learning Techniques" Sustainability 11, no. 23: 6669. https://doi.org/10.3390/su11236669
APA StyleGarg, R., Aggarwal, H., Centobelli, P., & Cerchione, R. (2019). Extracting Knowledge from Big Data for Sustainability: A Comparison of Machine Learning Techniques. Sustainability, 11(23), 6669. https://doi.org/10.3390/su11236669