Digital Labour in the Platform Economy: The Case of Facebook


Abstract
1. Introduction
“There are five broad ways in which using big data can create value. First, big data can unlock significant value by making information transparent and usable at much higher frequency. Second, as organizations create and store more transactional data in digital form, they can collect more accurate and detailed performance information on everything from product inventories to sick days, and therefore expose variability and boost performance. Leading companies are using data collection and analysis to conduct controlled experiments to make better management decisions; others are using data for basic low-frequency forecasting to high-frequency now casting to adjust their business levers just in time. Third, big data allows ever-narrower segmentation of customers and therefore much more precisely tailored products or services. Fourth, sophisticated analytics can substantially improve decision-making. Finally, big data can be used to improve the development of the next generation of products and services.”[4]
2. The Case of Facebook
2.1. Facebook: The Creation of a Giant
- The first includes all those purchases aimed to improving features of the Facebook website: among these we find FriendFeed (a real-time feed aggregator whose “Like” button and “News Feed” functions have become Facebook’s hallmarks since 2009), Octazen Solutions (whose contact importer service was incorporated into “Facebook’s Friend Finder” in 2010), and DivvyShot (whose photo-sharing technologies were integrated into “Facebook Photos” in the same year).
- The second subset encompasses acquisitions needed to enter the smartphone industry: SnapTu (a mobile application platform) and Beluga (an instant group messaging app and web service also) represent the foundations of Facebook Mobile and Facebook Messenger (a messaging app both for mobile and desktop computers, separated from Facebook’s platform). In this field, we also find the most expensive company investments: in 2012 Instagram (a photo-sharing social network still working under its own brand although some of its features have been integrated into Facebook) was bought for $1 billion, while the acquisition of WhatsApp (a free mobile messaging app) was valued at $19 billion.
- The third segment concerns the implementation of Facebook’s advertising revenue model. In 2013 the company absorbed and re-designed the ad-serving and ad-campaign performance measurement platform Atlas Solutions, previously owned by Microsoft. This acquisition permitted to match Atlas’ own tracking techniques with Facebook’s huge repository of anonymized first-party data, insights from offline purchase data providers and people-based advertising (Facebook has partnered with third party data vendors, that is, the data brokers Axciom, Epilson, Experian, Datalogix, Oracle, and Quantium to reach people on the basis of what they buy and do offline [18]). Instead of the outdated cookies-based model, which has become unreliable since the advent of mobile and the consequent change in users’ purchasing behaviour, which shifted to cross-device habits, this investment appeared to some observers [19] as an attempt to build an ad network outside of Facebook, challenging Google’s domain in online display advertising. The decision, announced in 2016, to move Atlas from Facebook’s ad tech group to its measurement division due to bad quality and fraud issues [20], resulted in the synchronous closure of both Facebook Exchange [21] (a desktop ad-exchange service allowing third party companies to buy advertising spots on the social network) and LiveRail [22] (a video ad-exchange acquired in 2014 for half a billion dollars). This decision mirrored Facebook’s intentions to build a closed and centrally controlled “off Facebook” digital advertising ecosystem, a “walled garden” that keeps data sheltered from other parties’ access, called the Facebook Audience Network [23]. The latter, working in synergy with Facebook Ads Manager, represents company essential revenue source of the company.
- The fourth and final segment concerns diversification, namely acquisitions in sectors other than social advertising. Nonetheless, these purchases can be considered still strongly related to its core business. In 2014, Facebook acquired the virtual reality tech company Oculus VR, the fitness/health tracking app company ProtoGeo, and the UK solar-powered drone maker Ascenta. This latter talent acquisition—combined with a team composed of members of the NASA Jet Propulsion Laboratory, NASA Ames Research Centre, and the National Optical Astronomy Observatory—has been functional to the development of a larger project in the framework of a specifically created Research and Development group called Connectivity Lab: Internet.org [24], in partnership with some telecom industry giants. The project is a mobile application with the goal of bringing affordable internet access to that still-prevalent portion of the world that has not yet experienced the ‘benefits of connectivity,’ of using vehicles such as, precisely, high altitude solar powered unmanned aircrafts (that is, drones), lasers and satellites. The platform was rechristened with the less pretentious name of “Free Basics” in September 2015, after digital rights groups from 31 countries signed an open letter [25] to Zuckerberg, saying that Internet.org, by providing access to a tiny and selected set of websites and services rather than to the full Internet, ‘violates the principles of net neutrality, threatening freedom of expression, equality of opportunity, security, privacy and innovation’.
2.2. Facebook’s Business Model
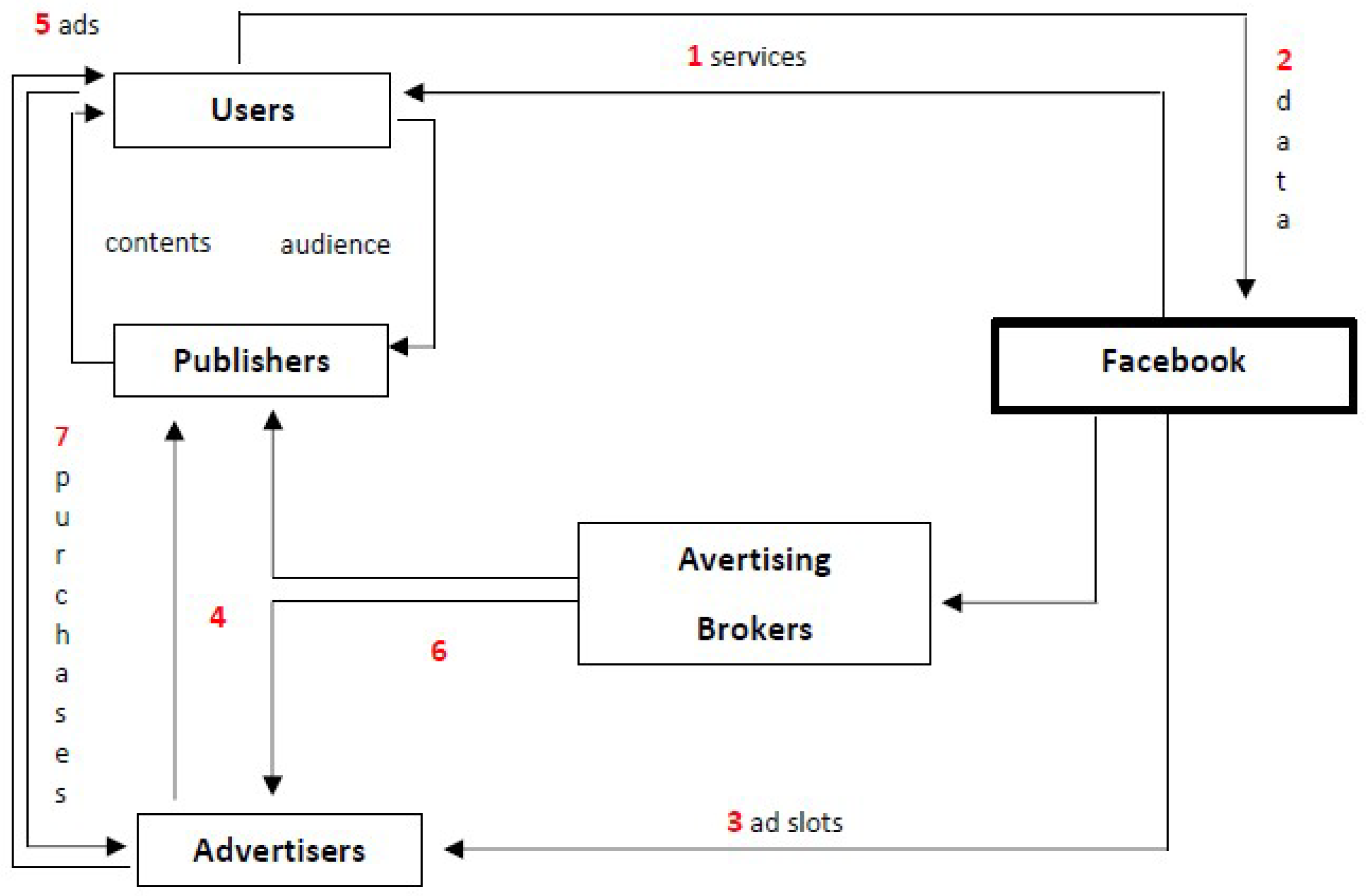
- Facebook’s platform offers a costless vast array of technology features to its subscribed users.
- Users provide Facebook (who takes note of every single bit) with information of all kinds, from more standard to less intuitive types of data [35].
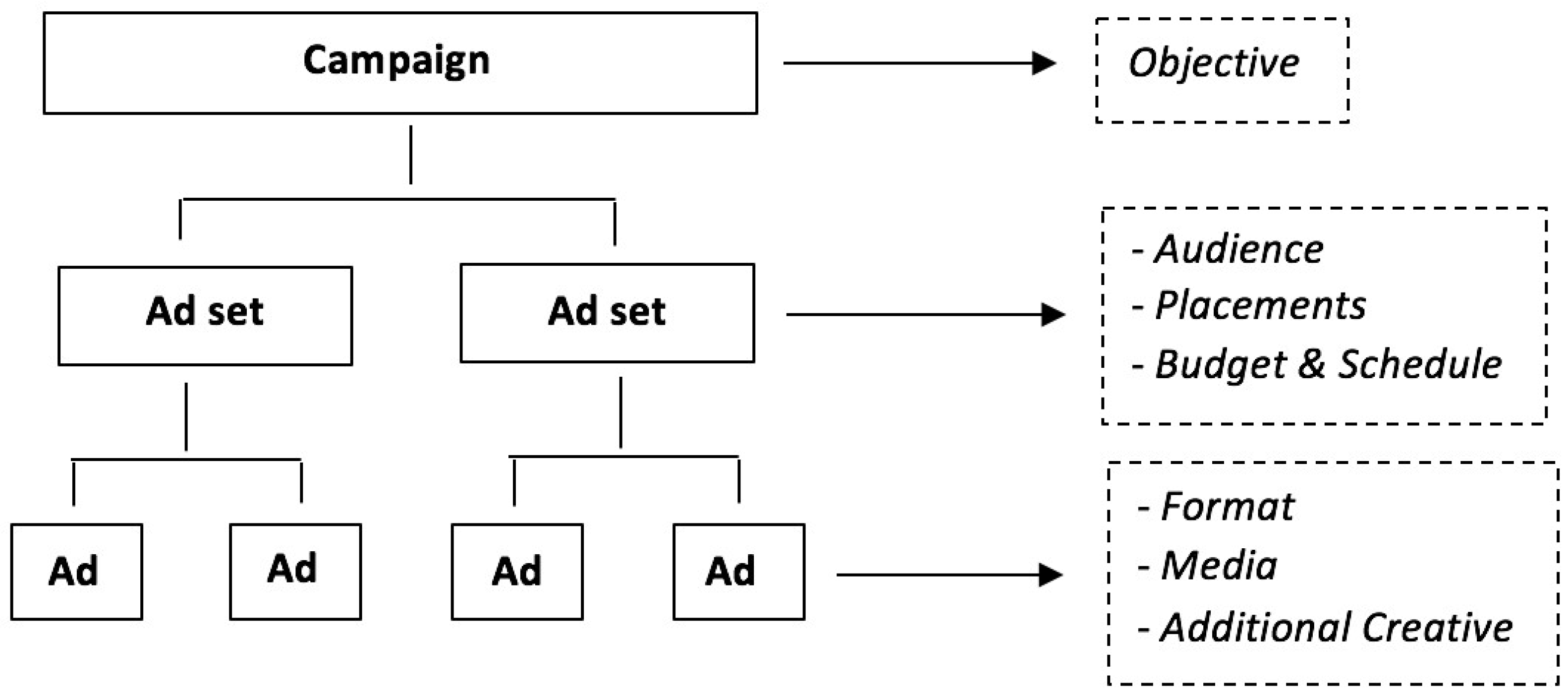
- Through Facebook Ads Manager, advertisers purchase advertising slots from Facebook, based on a real-time auction mechanism.
- Ads are displayed on publishers’/developers’ websites/apps who, being registered to FAN (net) through FAN (tool), are paid for hosting Facebook-powered ads.
- Ads are displayed also on Facebook platform itself (Facebook news feed for desktop and/or mobile, Facebook right-hand column, Instagram, and Messenger).
- Advertising spaces can be purchased/offered either directly through Facebook Ads Manager/FAN (tool) or indirectly through an advertising agency.
- Advertiser/publisher/developer expenses/revenues do not depend on the actual purchase of the advertised product or service, but on the number of user clicks on the ads, namely on the mere “attention” that they generate (by chance, mistake or real interest) for ads.
3. The Transformation Process and the Sources of Valorisation in the Platform Economy
- Advertising platforms like Google and Facebook, extracting information from their users to resell their profiles in the form of advertising spaces.
- Cloud platforms such as Amazon Web Services, which create hardware and software for digital-dependent markets and lease them to businesses of all kinds, creating monopolies on knowledge.
- Industrial platforms like General Electric or Siemens, building hardware and software at lower production costs, manufacturing and transforming goods into services (Industry 4.0).
- Product platforms like Spotify, which generates profits by relying on other platforms that transform a commodity like music in a service, and earn through share of subscription paid to subscribers to the aforementioned service.
- Work platforms such as Uber, Airbnb, Deliveroo or Foodora, which organize the workforce through an algorithm and connect customers and businesses by drawing profit through the reduction of labour costs.
- Logistic platforms like Amazon, that govern trade and the displacement of goods.
“Despite the confusion of the input, the Google system works better. Its translations are more accurate than those offered by other systems. And it is much, much richer. In mid-2012, its dataset covered over 60 languages. He was even able to accept voice input in 14 languages to make translations more fluid. And since it treats the language simply as a chaotic mass of data to which the calculation of probabilities can be applied, it can even translate between two languages like Hindi and Catalan”.[44] (p. 132)
“The set of business processes to collect data and analyse strategic information, the technology used to implement these processes and the information obtained as a result of these processes”.[46] (p. 54)
- company data collection;
- their cleaning, validation and integration;
- the subsequent data processing, aggregation and analysis; and
- the fundamental use of this amount of information in strategic and enhancement processes.
- The first is related to the large amount of data, because the more we have, the more we can learn. The spread of machine learning is closely linked to the appearance of big data.
- The second aspect shows instead how a mountain of available data can reduce the complexity that characterizes these processes. With machine learning, the process undergoes a strong acceleration. “The Industrial Revolution has automated manual labour, and the Information Revolution has done the same with the intellectual. Machine learning, on the other hand, automates automation itself: if it were not there, programmers would become bottlenecks that curb progress” [3] (p. 14).
“Amazon cannot adequately encode the tastes of all its customers in a program, and Facebook is not able to write a program that chooses the best updates to show to each of its users. Walmart, the distribution giant, sells millions of products and must make billions of decisions a day: if its programmers tried to write a dedicated program, they would never finish. The solution adopted by such companies, instead, is to unleash the learning algorithms on the mountains of data that have accumulated and let them guess what customers want”.[3] (p. 17)
4. Digital Labour or Digital Work?
- Digital labour has been used to describe the labour-force of independent contractors who work on their own account and at their own risk for low wages and without social security, as in the case of many platform-based business models like Uber, Foodora or other work and logistic platforms.
- Digital labour means also the human activity used by other platform-based business models like Facebook or Google that rely on a new composition of capital capable of capturing personal information and transforming it into big data.
“The basic argument in this debate is that the dominant capital accumulation model of contemporary corporate Internet platforms is based on the exploitation of users’ unpaid labour, who engage in the creation of content and the use of blogs, social networking sites, wikis, microblogs, content sharing sites for fun and in these activities create value that is at the heart of profit generation”.[9] (p. 237)
“Our online identity, so eagerly performed, has a curious afterlife in faraway data centers where subjectivities and data are turned into monetary value. Without being recognized as labour, our location, expressions, and time spent on the network can be turned into economic value. The tracking and monetization of users is frequently justified with the significant operating costs of platform operators. It is unclear, however, what exactly is recorded, how its value is measured, to whom it is sold, and for what purpose.”.[10] (p. 69)
“The process, described as the ‘becoming-rent of profit’ (Marazzi, 2010 [66]; Vercellone, 2010 [67]) here becomes apparent: Facebook does not reap a profit merely from organizing the paid labour of its relatively few employees (as labour process theory would suggest), but extracts a rent from the commons produced by the free labour of its users”.[68] (p. 2)
5. Preliminary Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- All about the Human Genome Project (HGP). Available online: https://www.genome.gov/10001772/all-about-the--human-genome-project-hgp/ (accessed on 1 March 2018).
- Boyer, R. The Future of Economic Growth; Eward Elgar: Cheltenham, UK, 2004; p. 136. [Google Scholar]
- Domingos, P. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World; Basic Books: New York, NY, USA, 2015. [Google Scholar]
- McKynsey Global Institute, Big Data: The Next Frontier for Innovation, Competition and Productivity. May 2011. Available online: https://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/big-data-the-next-frontier-for-innovation (accessed on 16 May 2018).
- Kenney, M.; Zysman, J. The Rise of the Platform Economy. Issues Sci. Technol. 2016, 32, 61. Available online: http://issues.org/32-3/the-rise-of-the-platform-economy/ (accessed on 16 May 2018).
- Fumagalli, A. Per una teoria del valore-rete: Big data e processi di sussunzione. In Datacrazia. Società, Cultura e Conflitti al Tempo dei Big Data; Gambetta, D., Ed.; D Editore: Roma, Italy, 2018. [Google Scholar]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Srnicek, N. Platform Capitalism; Polity Press: Cambridge, UK, 2017. [Google Scholar]
- Fuchs, C.; Sevignani, S. What is Digital Labour? What is Digital Work? What’s their Difference? And why do these Questions Matter for Understanding Social Media? tripleC 2013, 11, 237–293. [Google Scholar] [CrossRef]
- Scholz, T. Uberworked and Underpaid. How Workers are Disrupting the Digital Economy; Polity Press: Cambridge, UK, 2017. [Google Scholar]
- Statista. Available online: https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwide/ (accessed on 1 March 2018).
- Facebook Annual Report (2016). Available online: http://www.annualreports.com/Company/facebook (accessed on 1 March 2018).
- Statcounter, GlobalStats. Available online: http://gs.statcounter.com/platform-market-share/desktop-mobile-tablet/worldwide (accessed on 1 March 2018).
- Boyd, D.; Ellison, N.B. Social network sites: Definition, history, and scholarship. J. Comput. Med. Commun. 2008, 13, 210–230. [Google Scholar] [CrossRef]
- Gebika, A.; Heinemann, A. Social Media & Competition Law. World Compet. 2014, 37, 149–172. [Google Scholar]
- Phillips, S. A Brief History of Facebook. The Guardian, 25 July 2017. Available online: https://www.theguardian.com/technology/2007/jul/25/media.newmedia (accessed on 1 March 2018).
- Techwyse. Available online: https://www.techwyse.com/blog/infographics/65-facebook-acquisitions-the-complete-list-infographic/ (accessed on 1 March 2018).
- Facebook Partner Categories. Available online: https://www.facebook.com/business/a/facebook-partner-categories (accessed on 1 March 2018).
- Marshall, J. Facebook Extends Reach with New Advertising Platform. The Wall Street Journal, 22 September 2014. Available online: https://www.wsj.com/articles/facebook-extends-reach-withad-platform-1411428726/ (accessed on 1 March 2018).
- Atlassolutions. Available online: https://atlassolutions.com/2016/03/07/value-with-atlas/ (accessed on 1 March 2018).
- Meola, A. Facebook Is Shutting down Facebook Exchange. Business Insider, 26 May 2016. Available online: http://www.businessinsider.com/facebook-is-shutting-down-acebookexchange-2016-5?IR=T (accessed on 1 March 2018).
- Shields, M. Facebook Plans to Shut Down Video Ad Exchange Product LiveRail. The Wall Street Journal, 26 May 2016. Available online: https://www.wsj.com/articles/facebook-plans-to-shut-downvideo-ad-exchange-product-liverail-1464303877 (accessed on 1 March 2018).
- Peterson, T. How Facebook Turned an End-to-End Ad Tech Strategy on Its Head. Marketing Land, 17 June 2016. Available online: https://marketingland.com/facebook-turned-end-end-ad-tech-strategy-head-181395 (accessed on 1 March 2018).
- Infointernet. Available online: https://info.internet.org/en/ (accessed on 1 March 2018).
- Open Letter to Mark Zuckerberg Regarding Internet.org, Net Neutrality, Privacy, and Security. 2015. Available online: https://www.facebook.com/notes/access-now/open-letter-to-mark-zuckerberg-regarding-internetorg-net-neutrality-privacy-and-/935857379791271/ (accessed on 1 March 2018).
- Emarketer. Available online: https://www.emarketer.com/Article/Social-Media-Marketers-Facebook-Produces-Best-ROI/1013918 (accessed on 1 March 2018).
- Fortune. Available online: http://fortune.com/company/pgpef/ (accessed on 1 March 2018).
- Zenithmedia. Available online: https://www.zenithmedia.com/google-facebook-now-control-20-global-adspend/ (accessed on 1 March 2018).
- Business Facebook. Available online: https://business.facebook.com/ (accessed on 1 March 2018).
- Facebook for Developers. Available online: https://developers.facebook.com/?locale=en_UK (accessed on 1 March 2018).
- Chaykowski, K. Facebook Extends Its Ad Network To Mobile Websites. Forbes, 20 January 2016. Available online: https://www.forbes.com/sites/kathleenchaykowski/2016/01/26/facebook-extends-its-ad-network-to-the-mobile-web/#1fe829b7132e (accessed on 1 March 2018).
- Slefo, G. Facebook to Serve Ads to Non-Users through Its Audience Network. Advertising Age, 27 May 2016. Available online: http://adage.com/article/digital/facebook-serve-ads-users-audience-network/304195/ (accessed on 1 March 2018).
- Facebook Business. Available online: https://en-gb.facebook.com/business (accessed on 1 March 2018).
- Audience Network by Facebook. Available online: https://www.facebook.com/audiencenetwork (accessed on 1 March 2018).
- Dewey, C. 98 Personal Data Points that Facebook Uses to Target Ads to You. The Washington Post, 19 August 2016. Available online: https://www.washingtonpost.com/news/theintersect/wp/2016/08/19/98-personal-data-points-that-facebook-uses-to-target-ads-toyou/?utm_term=.038a29370111 (accessed on 1 March 2018).
- Morini, C. Social Reproduction as a Paradigm of the Common. Reproduction Antagonism, Production Crisis. In Post-Crisis Perspectives; Augustin, O., Ydesen, C., Eds.; Peter Lang: Frankfurt, Germany; New York, NY, USA, 2013; pp. 83–98. [Google Scholar]
- Fumagalli, A.; Morini, C. Life put to work: Towards a life theory of value. Ephemer. Theory Polit. Organ. 2010, 10, 234–252. [Google Scholar]
- Codeluppi, V. Il Biocapitalismo. Verso lo Sfruttamento Integrale di Corpi, Cervelli ed Emozioni; Bollati Boringhieri: Torino, Italy, 2008. [Google Scholar]
- Pasquinelli, M. Italian Operaismo and the Information Machine. Theory Cult. Soc. 2015, 32, 49–68. [Google Scholar] [CrossRef]
- Smith, A. Gig Work, Online Selling and Home Sharing. Pew Research Center, 17 November 2016. Available online: http://www.pewinternet.org/2016/11/17/gig-work-online-selling-and-home-sharing/ (accessed on 1 March 2018).
- Vecchi, B. Il Capitalismo delle Piattaforme; Manifestolibri: Roma, Italy, 2017. [Google Scholar]
- Tarleton, G. The Platform Metaphor, Revisited. Alexander Von Humboldt Institut für Internet und Gesellschaft, 24 August 2017. Available online: http://culturedigitally.org/2017/08/platform-metaphor/ (accessed on 1 March 2018).
- Mosco, V. To the Cloud: Big Data in a Turbulent World; Paradigm Publishers: Boulder, CO, USA, 2014. [Google Scholar]
- Mayer Schoenberger, V.; Cukier, K. Big Data: A Revolution that Will Transform How We Live, Work, and Think; Eamon Dolan Book: Boston, NY, USA, 2013. [Google Scholar]
- Carr, N. The Big Switch: Rewiring the World, from Edison to Google; W.W. Norton & Company: New York, NY, USA, 2008. [Google Scholar]
- Davemport, T.H. Big Data at Work: Dispelling the Myths, Uncovering the Opportunities; Harward Business Review Press: Boston, NY, USA, 2014. [Google Scholar]
- Booth, A. Marx’s Capital: Chapter 15—The Machine. Available online: https://www.socialist.net/marx-s-capital-chapters-15-the-machine.htm (accessed on 20 April 2018).
- Beyerungen, A.; Murtola, A.M.; Schwartz, G. The communism of capital. Ephemer. Theory Polit. Organ. 2013, 13, 483–495. [Google Scholar]
- Marazzi, C. Il Comunismo del Capitale. Biocapitalismo, Finanziarizzazione Dell’Economia e Appropriazioni del Comune; Ombre Corte: Verona, Italy, 2010. [Google Scholar]
- Virno, P. A Grammar of the Multitude: For an Analysis of Contemporary Forms of Life; Semiotext(e): New York, NY, USA, 2004. [Google Scholar]
- Burston, J.; Dyer-Witheford, N.; Hearn, A. Digital Labour: Workers, Authors, Citizens. Ephemer. Theory Polit. Organ. 2010, 10, 214–221. [Google Scholar]
- Scholz, T. (Ed.) Digital Labour. The Internet as Playground and Factory; Routledge: New York, NY, USA, 2012. [Google Scholar]
- Huws, U. Labor in the Global Digital Economy: The Cybertariat Comes of Age; Monthly Review Press: New York, NY, USA, 2104. [Google Scholar]
- Huws, U. New forms of platform employment. In The Digital Economy and the Single Market; Wobbe, W., Bova, E., Dragomirescu-Gaina, C., Eds.; Foundation for European Progressive Studies: Brussels, Belgium, 2014; pp. 65–82. [Google Scholar]
- Cardon, D.; Casilli, A. Qu’est-ce que le Digital Labor? INAGLOBAL, 7 September 2015. Available online: https://www.inaglobal.fr/numerique/article/quest-ce-que-le-digital-labor-8475#sommaire (accessed on 1 March 2018).
- Arvidsson, A.; Colleoni, E. Value in Informational Capitalism on the Internet. Inf. Soc. 2012, 28, 135–150. [Google Scholar] [CrossRef]
- Fumagalli, A. Bioeconomia e Capitalismo Cognitivo. Verso un Nuovo Paradigma di Accumulazione; Carocci: Roma, Italy, 2007. [Google Scholar]
- Fumagalli, A. Twenty Theses on Contemporary Capitalism (Cognitive Biocapitalism). Angelaki 2011, 6, 7–17. [Google Scholar] [CrossRef]
- Fumagalli, A.; Lucarelli, S. Valorization and financialization in cognitive biocapitalism. Investig. Manag. Financ. Innov. 2011, 8, 88–103. [Google Scholar]
- Moulier-Boutang, Y. Le Capitalisme Cognitif: La Nouvelle Grande Transformation; Editions Amsterdam: Paris, France, 2008; (English Translation. Cognitive Capitalism; Translated by Emery, E.; Polity Press: New York, NY, USA, 2011). [Google Scholar]
- Vercellone, C. (Ed.) Capitalismo cognitivo. Conoscenza e finanza nell’epoca postfordista; Manifestolibri: Roma, Italia, 2006. [Google Scholar]
- Terranova, T. Network Culture: Politics for the Information Age; Pluto Press: London, UK, 2004. [Google Scholar]
- Marx, K. Capital; Penguin Book: London, UK, 2004; Volume 1. [Google Scholar]
- Ciccarelli, R. Forza Lavoro; DeriveApprodi: Roma, Italy, 2018. [Google Scholar]
- Vercellone, C. From Formal Subsumption to General Intellect: Elements for a Marxist Reading of the Thesis of Cognitive Capitalism. Hist. Mater. 2007, 15, 13–36. [Google Scholar] [CrossRef]
- Marazzi, C. The Violence of Capital; Semiotext(e): New York, NY, USA, 2010. [Google Scholar]
- Vercellone, C. The Crisis of the Law of Value and the Becoming-Rent of Profit. In Crisis in the Global Economy: Financial Markets, Social Struggles and New Political Scenarios; Fumagalli, A., Mezzadra, S., Eds.; Semiotext(e): New York, NY, USA, 2010; pp. 85–118. [Google Scholar]
- Böhm, S.; Land, C.; Beverungen, A. The Value of Marx: Free Labour, Rent and ‘Primitive’ Accumulation in Facebook. Working Paper Series; University of Essex, May 2012. Available online: https://www.researchgate.net/publication/239735772 (accessed on 17 May 2018).
- Vercellone, C.; Monnier, J.-M.; Lucarelli, S.; Griziotti, G. Theoretical Framework on Future Knwoledge-Based Economy. D3.1 of D-Cent European Project. 2014. Available online: https://dcentproject.eu/wp-content/uploads/2014/04/D3.1-final_new.pdf (accessed on 1 March 2018).
- Sampson, T. Various joyful encounters with the dystopias of affective capitalism. Ephemer. Theory Polit. Organ. 2016, 16, 51–74. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Type of Data | Source of Data | Sector | Function |
|---|---|---|---|
| Big volume | Online | Financial Services | Marketing |
| Unstructured | Video | Health | Logistics |
| Continuous flows | Sensors | Manufacturing | Human Resources |
| Multiple Formats | Genomics | Tourism/Transport | Finance |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fumagalli, A.; Lucarelli, S.; Musolino, E.; Rocchi, G. Digital Labour in the Platform Economy: The Case of Facebook. Sustainability 2018, 10, 1757. https://doi.org/10.3390/su10061757
Fumagalli A, Lucarelli S, Musolino E, Rocchi G. Digital Labour in the Platform Economy: The Case of Facebook. Sustainability. 2018; 10(6):1757. https://doi.org/10.3390/su10061757
Chicago/Turabian StyleFumagalli, Andrea, Stefano Lucarelli, Elena Musolino, and Giulia Rocchi. 2018. "Digital Labour in the Platform Economy: The Case of Facebook" Sustainability 10, no. 6: 1757. https://doi.org/10.3390/su10061757
APA StyleFumagalli, A., Lucarelli, S., Musolino, E., & Rocchi, G. (2018). Digital Labour in the Platform Economy: The Case of Facebook. Sustainability, 10(6), 1757. https://doi.org/10.3390/su10061757