A Hybrid Online Forecasting Model for Ultrashort-Term Photovoltaic Power Generation


Abstract
1. Introduction
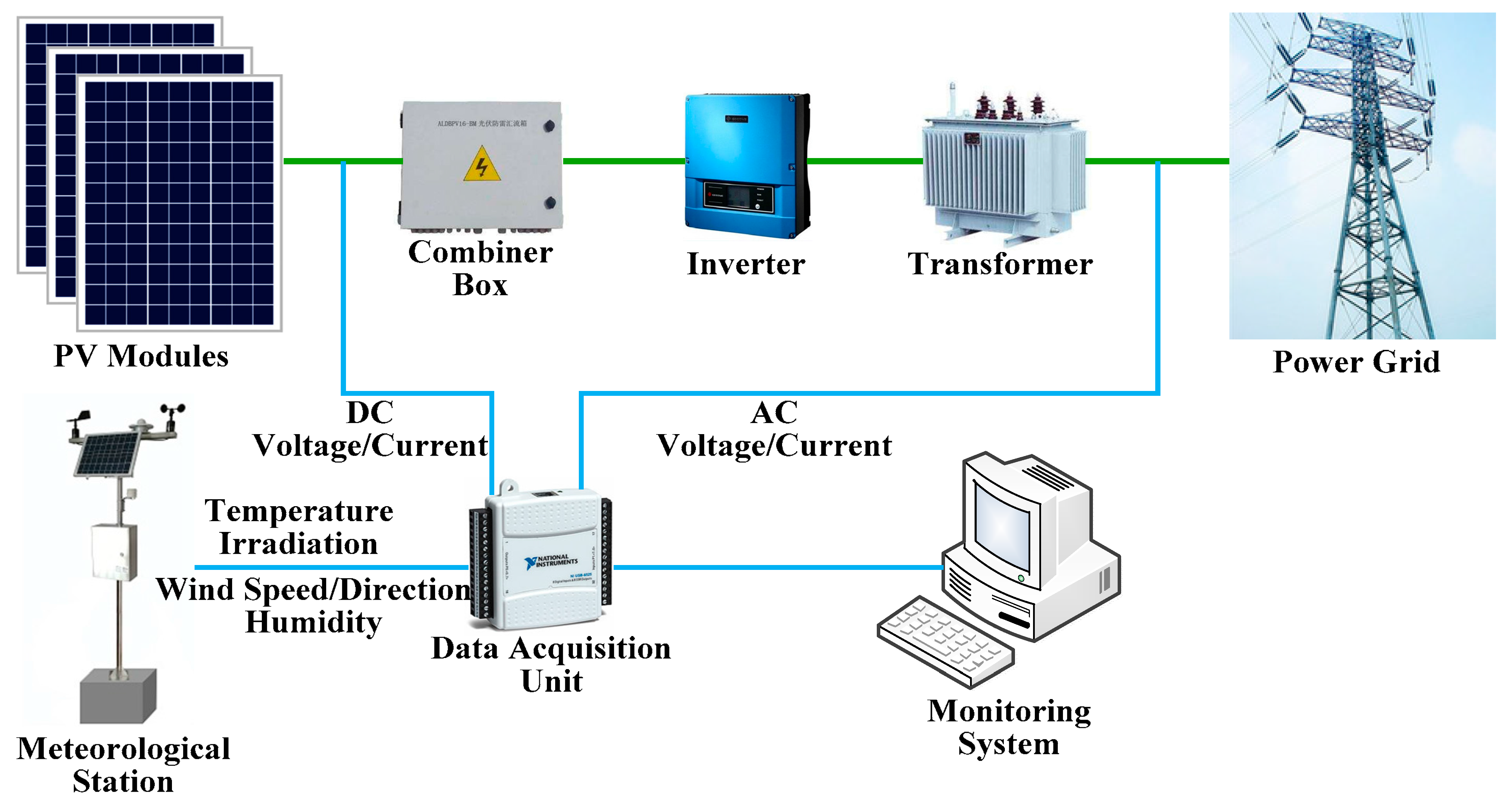
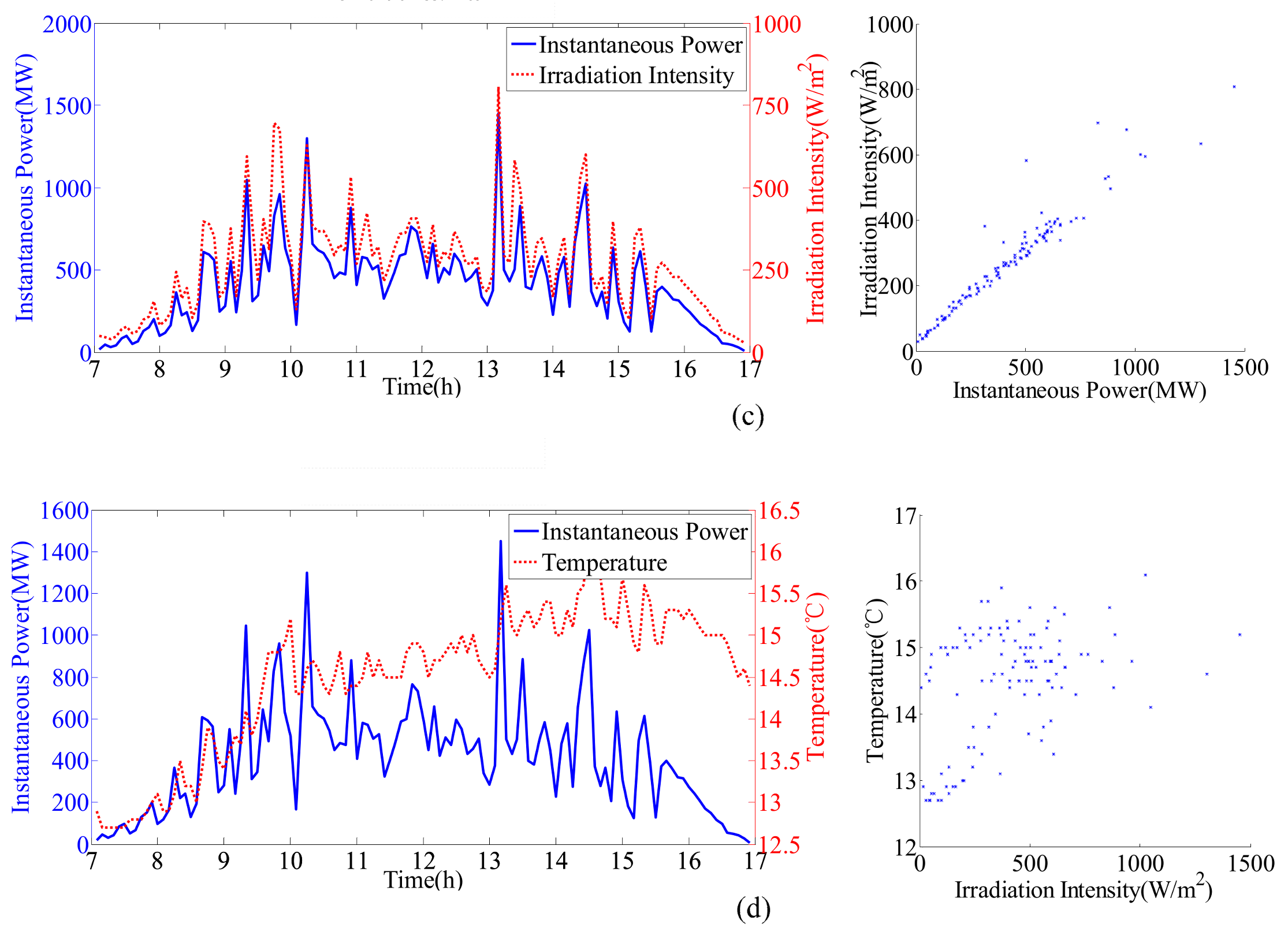
2. Correlation Analysis of PV Generation Factors
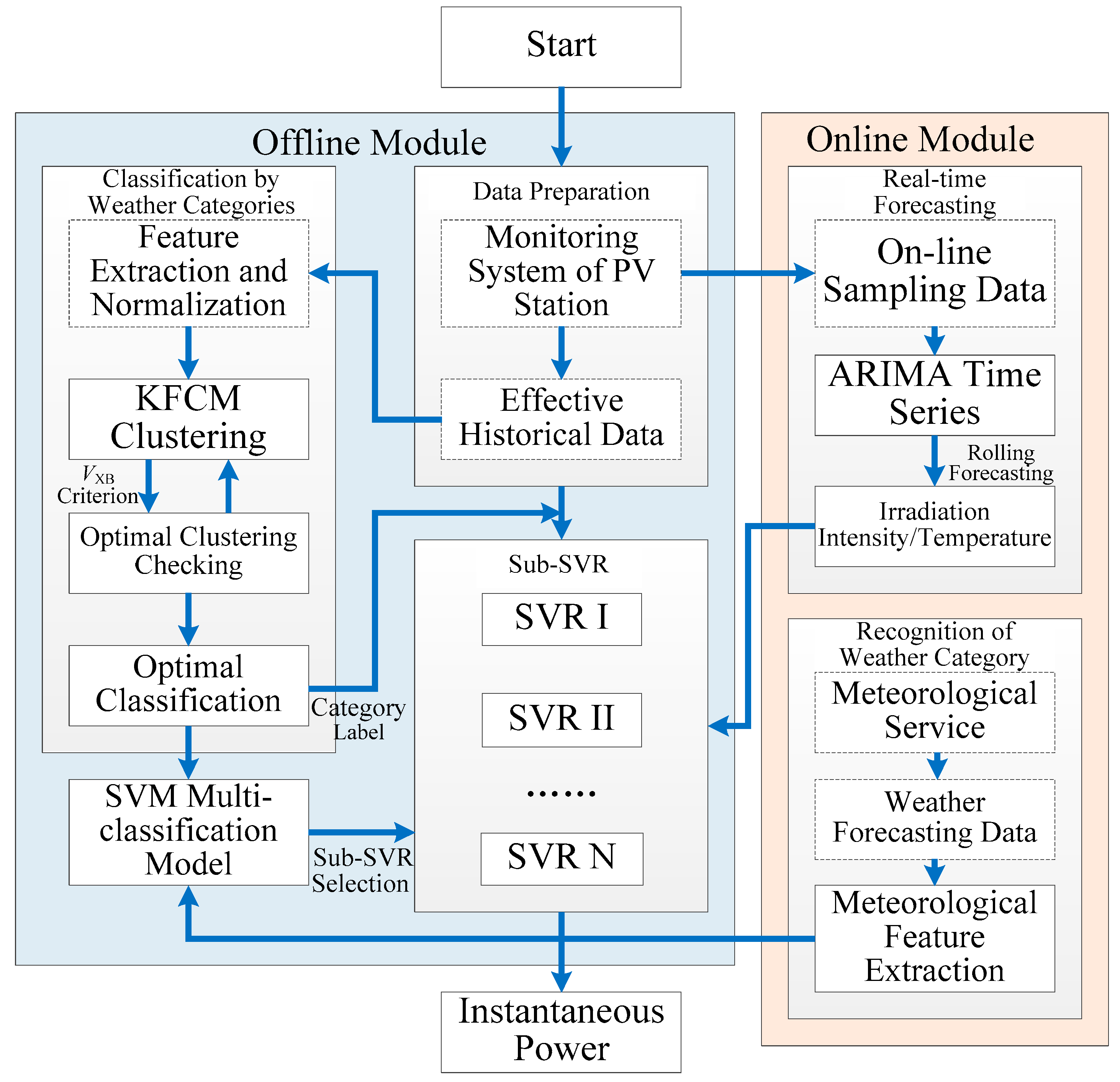
3. Hybrid Forecasting Model
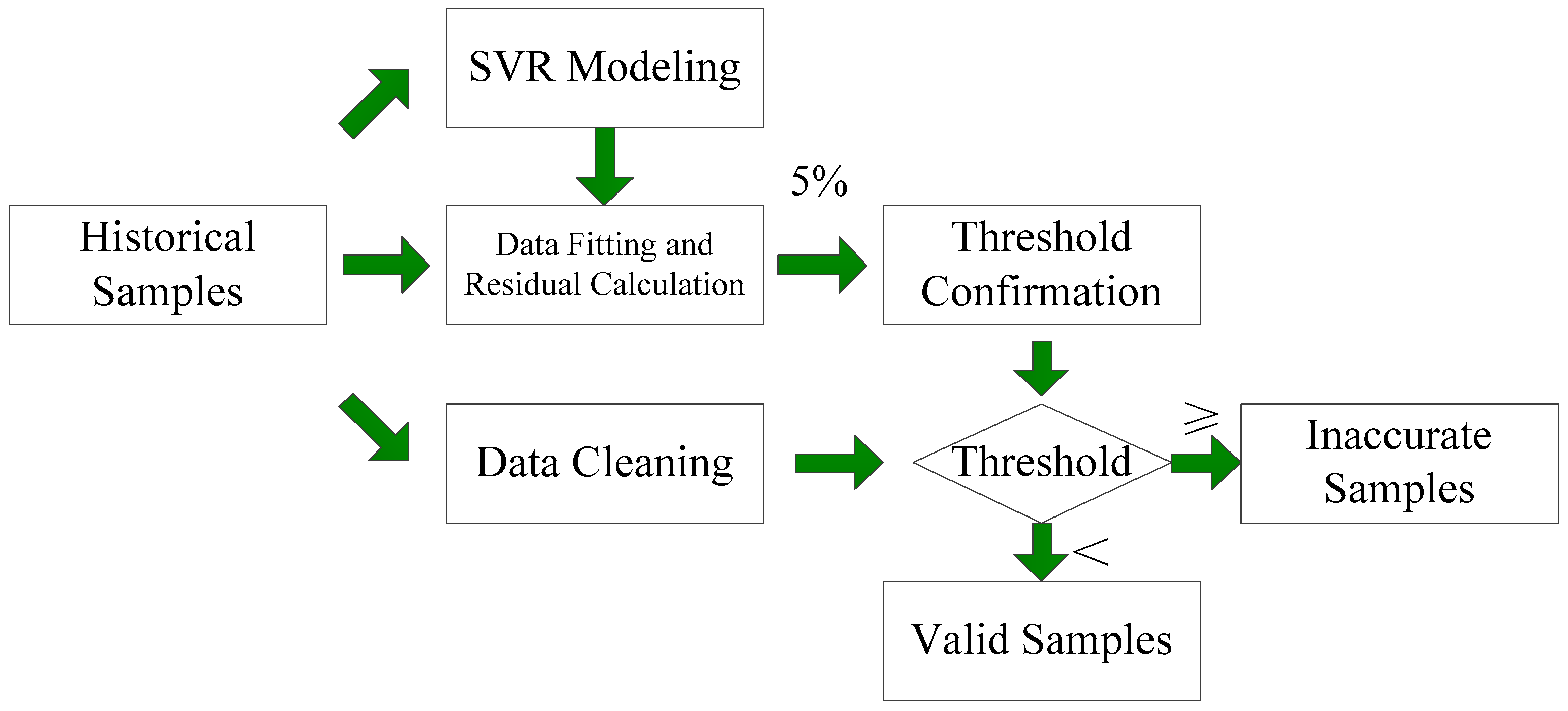
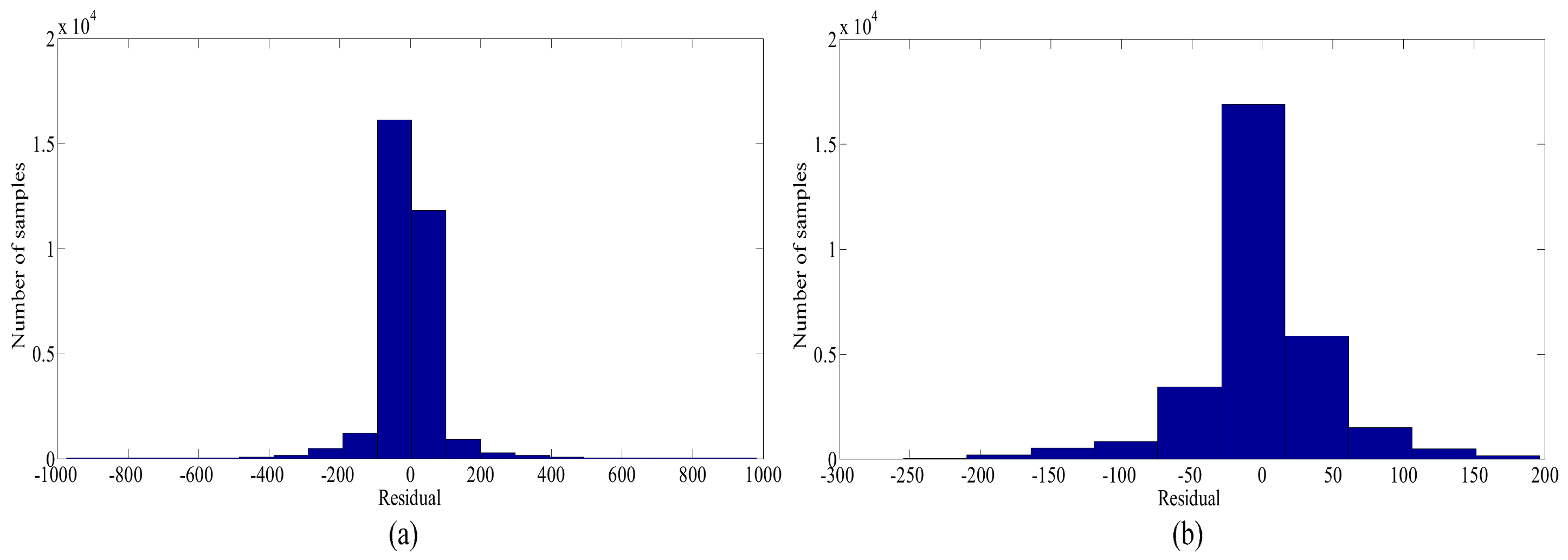
3.1. Data Verification and Cleaning
3.2. Hybrid Forecasting Model
- the classification of historical samples according to meteorological characteristics;
- the establishment of regression submodels (sub-SVRs);
- the effective identification of weather types and selection of sub-SVRs.
- the forecasting of irradiation intensities and temperatures in rolling mode;
- the real-time forecasting of instantaneous power generation for a PV station.
- Step 1.
- Meteorological feature selection: The feature vectors of the KFCM model are calculated. is the maximum irradiance, and is the maximum temperature. , , and are the maximum fluctuation, mean fluctuation, standard deviation of fluctuate on and maximum third derivative, respectively. They are standardized by the Z-score method.
- Step 2.
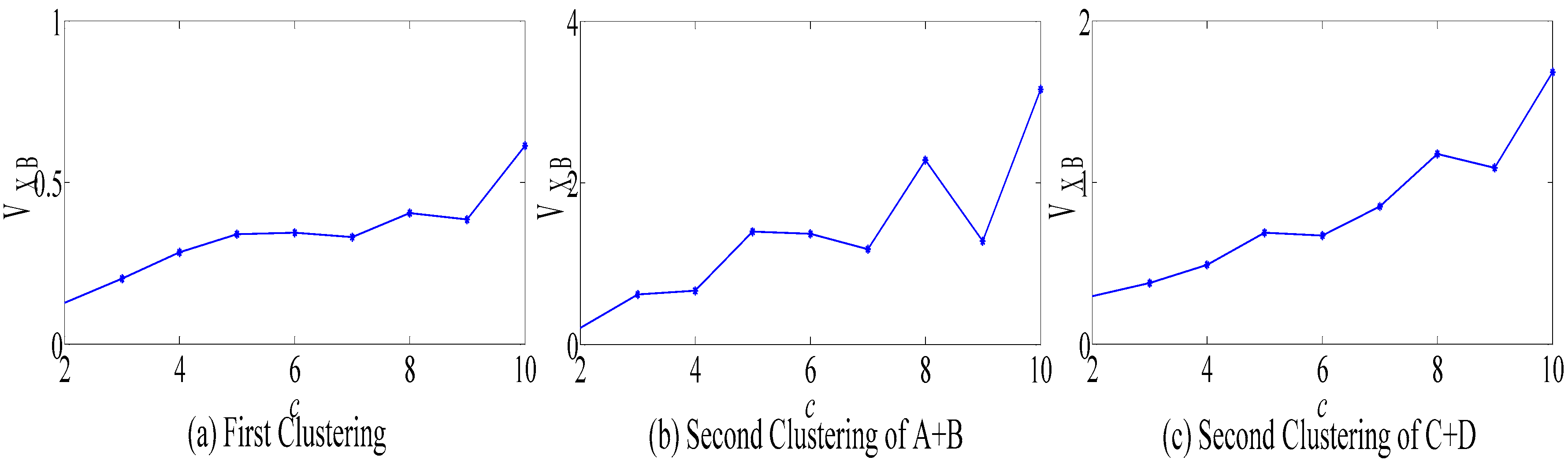
- Clustering and optimization: An unsupervised clustering model is established using KFCM. In addition, the VXB indicator is selected to determine the optimal clustering number. Both historical samples and meteorological features are denoted by category labels.
- Step 3.
- Establishment of the sub-SVR model: the historical samples in one category are used to construct the SVR submodel. Additionally, several submodels are established.
- Step 4.
- Multiclassification modeling: An SVM recognition model is established using meteorological features. To obtain the category attributes on target days, the features calculated from the NWP service are input into the SVM model. Corresponding submodels are selected according to the category label of the target day.
- Step 5.
- Time series modeling: The ARIMA time series model is established using some data, including and , collected by the online PV monitoring system on the target day. Then, new predicted values of the time series can be obtained via rolling forecasting.
- Step 6.
- Instantaneous power forecasting: The predicted values are input into the corresponding sub-SVR models and yield the final instantaneous power .
3.3. Feature Selection for Weather Identification
- maximum irradiance ,
- maximum temperature ,
- the maximum fluctuation .
- the fluctuation mean value , which is the average of ,
- the fluctuation standard deviation of , and
- the maximum third derivative of . The third derivative is more sensitive to rapid weather changes than are the other derivatives [31].
3.4. KFCM Clustering and Optimization
- Step 1.
- Data preparation: the samples in the first clustering include .
- Step 2.
- The initial clustering number is C = 2.
- Step 3.
- KFCM is executed as follows:
- Step a.
- Initialization of KFCM clustering centers ,
- Step b.
- Membership degrees are calculated by the following equation:where xk is the sample, and K is the Gaussian kernel function:is the kernel parameter.
- Step c.
- New clustering centers are updated as follows:
- Step d.
- KFCM terminal conditions: When the minimum variation in clustering centers or the cycle number threshold is met, the cycle is stopped. Otherwise, the cycle continues from Steps a to d.
- Step 4.
- The clustering validity coefficient is calculated using Formula (3).
- Step 5.
- C = C + 1; if , proceed to step 3. Otherwise, proceed to step 6.
- Step 6.
- The optimum clustering number Copt is determined by the minimum VXB(C).
- Step 7.
- A second clustering process will be executed to classify the results of the first clustering using and based on steps 1–6.
3.5. SVM Recognition and the Sub-SVR Model
3.6. ARIMA Model
- Step 1.
- Differential processing: The stationary time series data [XAt] are obtained from the original time series [Xt] based on a difference method. In this paper, two ARIMAs are established based on the irradiance intensity sequence [Xt-IR] and the temperature sequence [Xt-T].
- Step 2.
- Model identification and p and q confirmation: An autocorrelation function (ACF) and a partial correlation function (PACF) are calculated for [XAt]. Then, the model type (AR, MA, or ARMA) will be determined according to the ACF and PACF. In general, the ARIMA model can be expressed as follows:where is the autoregressive coefficient, is the moving average coefficient, and is a white noise series, which represents independent error. The Akaike information criterion (AIC) is commonly used to confirm p and q.
- Step 3.
- Parameter estimation: After parameter estimation, ARIMA(p, q, d) is established.
- Step 4.
- Data forecasting: Single-step forecasting is performed to obtain predictions of the irradiance intensity and temperature using the ARIMA model.
4. Modeling and Evaluation
4.1. Data Verification and Cleaning Based on SVR
4.2. Weather Identification and Regression Submodel Establishment
4.3. ARIMA Time Series Forecasting and Sub-SVRs
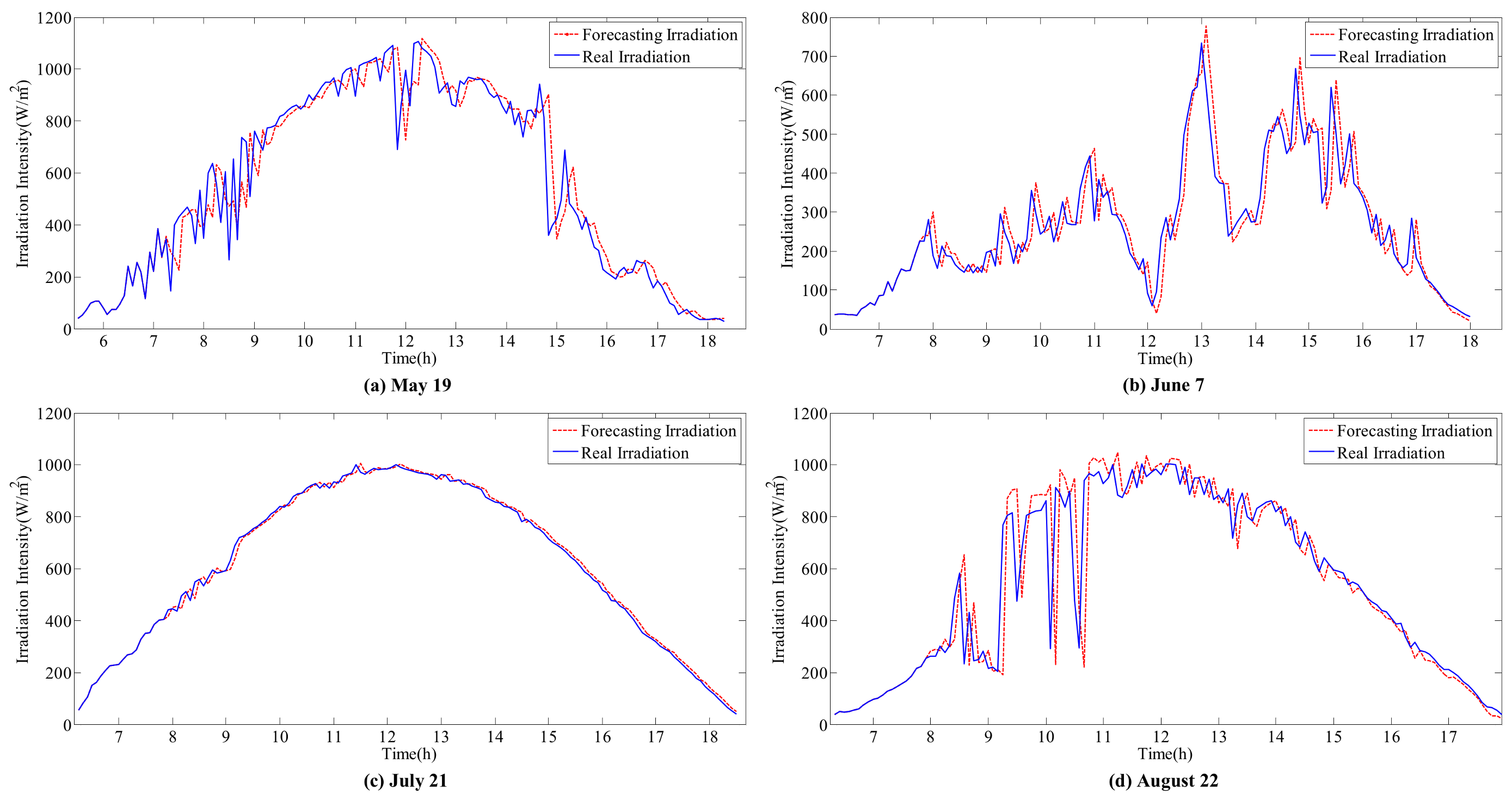
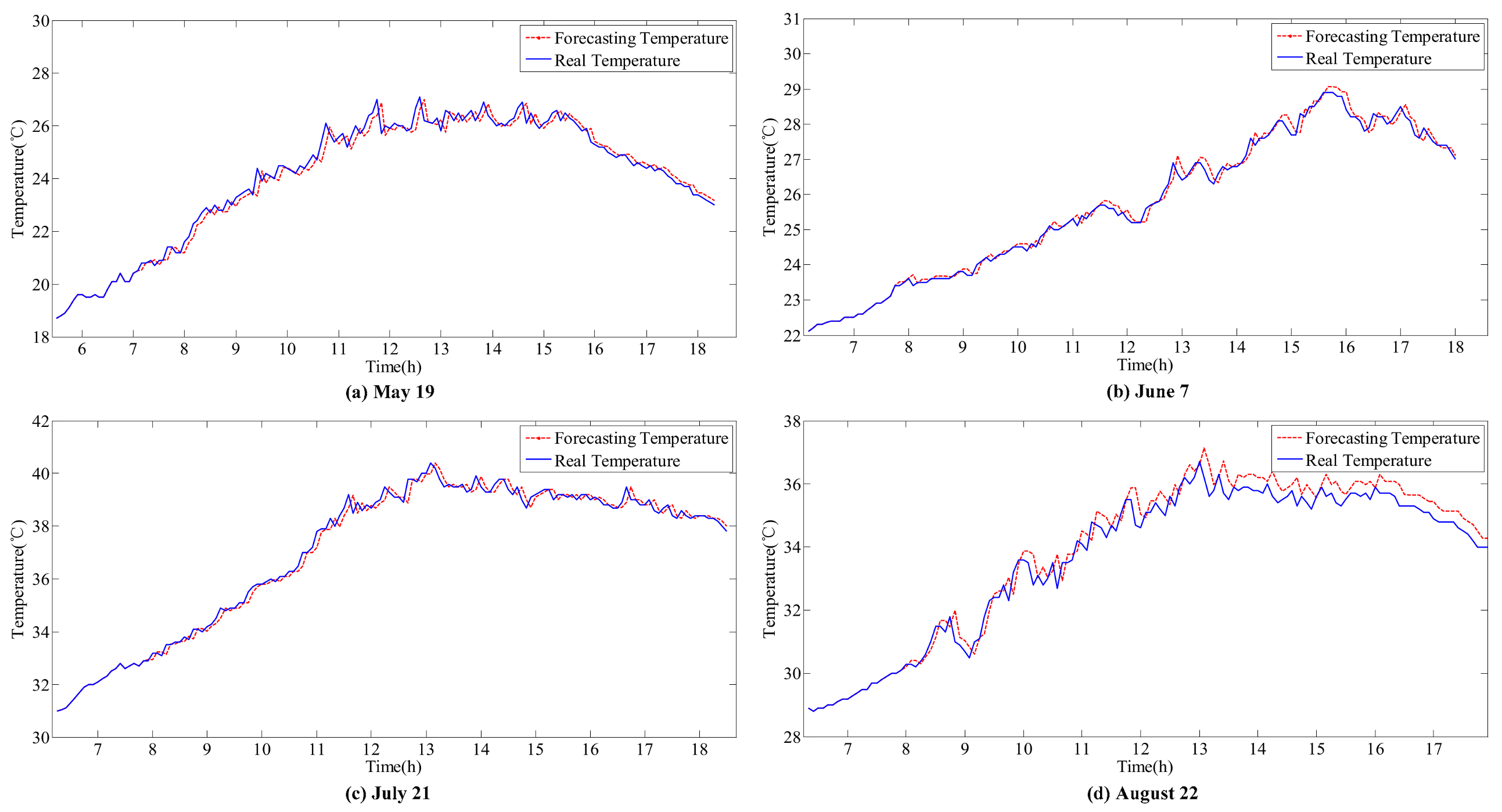
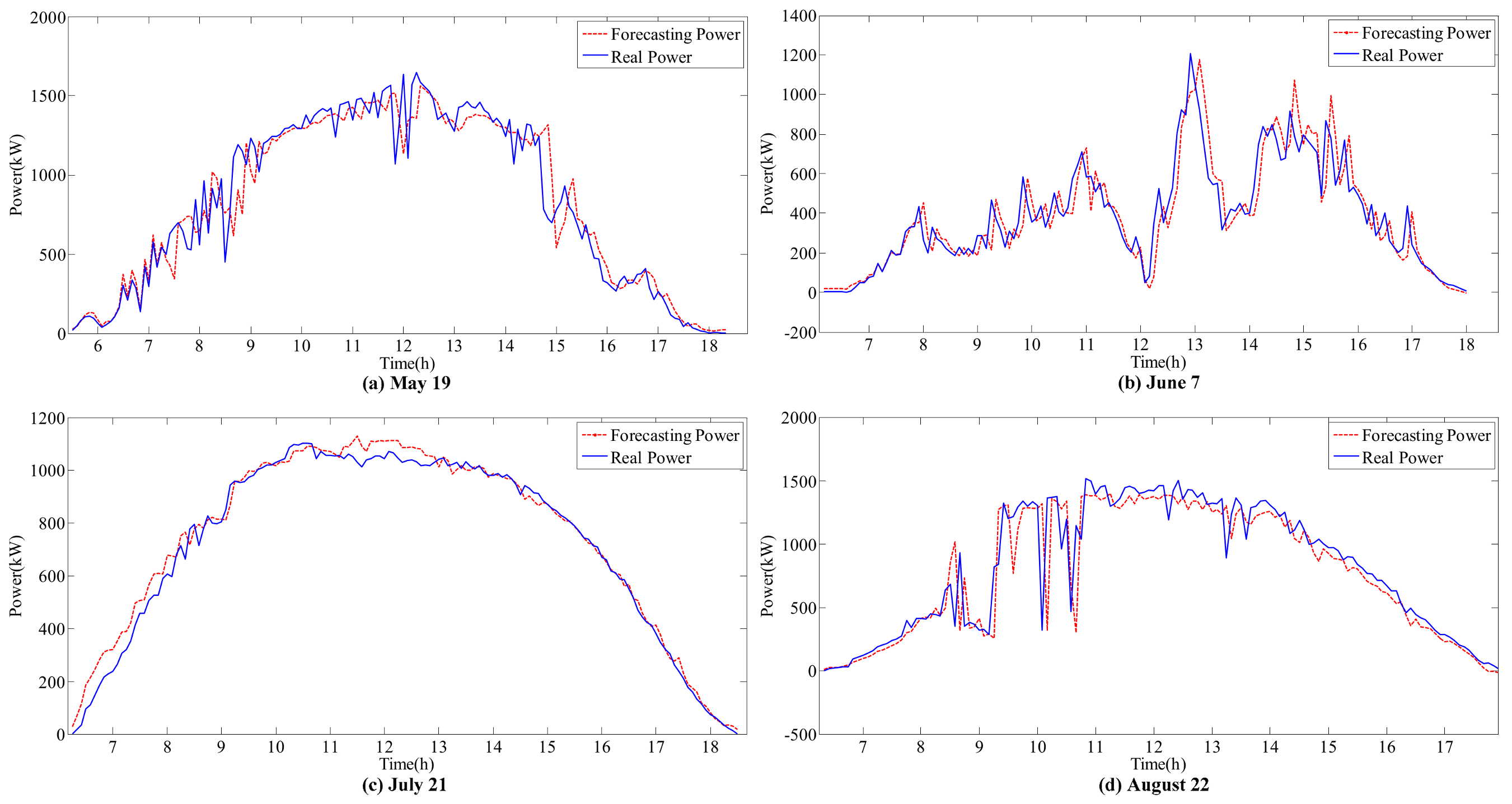
- The accurate forecasting results of IR and T can be used as inputs in the sub-SVR to improve the forecasting performance of P. As a result, the forecasted and actual curves are similar.
- IR and T are relatively stable on the sunny day (21 July), and the variation trends are clear. Reasonable forecasting results can be obtained with the ARIMA models. The curves of forecasted IR and T are coincident with the actual monitoring curves on the sunny day. However, in other weather conditions, errors can be observed in the forecasting results for various reasons.
- The effect of variations in T on P is considered in this hybrid model. For instance, on 21 July, the peak value of IR occurs at approximately 12 p.m. However, the peak value of P appears between 10 p.m. and 11 p.m. On one hand, IR is stable and does not considerably affect the fluctuation in P. On the other hand, the increase in temperature during this period decreases P. This result is reflected by the forecasting curve in Figure 8, Figure 9 and Figure 10c.
- In the ARIMA models, T is more stable than IR under all weather conditions, with higher forecasting accuracy. However, the correlation between IR and P is higher than the correlation between T and P. Thus, the influence of IR on P is larger than that of T. Meanwhile, volatility will considerably affect the time series fitting ability of ARIMA. Therefore, the forecasting accuracy of the hybrid model depends on the processing of IR volatility.
5. Conclusions
- The hybrid forecasting model is established based on actual monitoring data from a PV power station. These data reflect the actual meteorological and working conditions of the PV station in real time. Rolling forecasting is adopted to correct the ARIMA model using real-time data. Meanwhile, the hybrid model exhibits good agreement with the online monitoring system and displays high accuracy.
- The data fitting accuracy was improved by excluding abnormal data through data preprocessing, including data cleaning and correction processes. Correlation analysis was used to determine the inputs of the forecasting model and improve the calculation efficiency by simplifying the model.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Liu, J.P.; Long, Y.; Song, X.H. A Study on the Conduction Mechanism and Evaluation of the Comprehensive Efficiency of Photovoltaic Power Generation in China. Energies 2017, 10, 723. [Google Scholar] [CrossRef]
- National Energy Administration. Photovoltaic Power Generation Statistics in 2015. Available online: http://www.nea.gov.cn/2016-02/05/c_135076636.htm (accessed on 2 June 2016).
- Juamperez, M.; Yang, G.Y.; Kjaer, S.B. Voltage regulation in LV grids by coordinated volt-var control strategies. J. Mod. Power Syst. Clean Energy 2014, 2, 319–328. [Google Scholar] [CrossRef]
- Yang, G.Y.; Marra, F.; Juamperez, M.; Kjaer, S.B.; Hashemi, S.; Ostergaard, J.; Ipsen, H.H.; Frederiksen, K.H.B. Voltage rise mitigation for solar PV integration at LV grids: Studies from PVNET. dk. J. Mod. Power Syst. Clean Energy 2015, 3, 411–421. [Google Scholar] [CrossRef]
- Pinto, R.; Mariano, S.; Calado, M.; Souza, J.D. Impact of Rural Grid-Connected Photovoltaic Generation Systems on Power Quality. Energies 2017, 9, 723. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, B.L.; Mao, J.L.; Liu, Y. Machine Learning-Based Adaptive Very-Short-Term Forecast Model for Photovoltaic Power. Power Syst. Technol. 2015, 39, 307–311. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Congedo, P.M.; Malvoni, M. Photovoltaic power forecasting using statistical methods: Impact of weather data. IET Sci. Meas. Technol. 2014, 8, 90–97. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Lughi, V. Short-term forecasting of power production in a large-scale photovoltaic plant. Sol. Energy 2014, 105, 401–413. [Google Scholar] [CrossRef]
- Ehsan, R.M.; Simon, S.P.; Venkateswaran, P.R. Day-ahead forecasting of solar photovoltaic output power using multilayer perceptron. Neural Comput. Appl. 2017, 28, 3981–3992. [Google Scholar] [CrossRef]
- Shi, J.; Lee, W.J.; Liu, Y.Q.; Yang, Y.P.; Wang, P. Forecasting Power Output of Photovoltaic Systems Based on Weather Classification and Support Vector Machines. IEEE Trans. Ind. Appl. 2012, 48, 1064–1069. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Congedo, P.M.; Malvoni, M.; Laforgia, D. Error analysis of hybrid photovoltaic power forecasting models: A case study of mediterranean climate. Energy Convers. Manag. 2015, 100, 117–130. [Google Scholar] [CrossRef]
- Li, Y.T.; He, Y.; Su, Y.; Shu, L.J. Forecasting the daily power output of a grid-connected photovoltaic system based on multivariate adaptive regression splines. Appl. Energy 2016, 180, 392–401. [Google Scholar] [CrossRef]
- Marquez, R.; Coimbra, C.F.M. Intra-hour DNI forecasting based on cloud tracking image analysis. Sol. Energy 2013, 91, 327–336. [Google Scholar] [CrossRef]
- Yang, H.D.; Kurtz, B.; Nguyen, D.; Urquhart, B.; Chow, C.W.; Ghonima, M.; Kleissl, J. Solar irradiance forecasting using a ground-based sky imager developed at UC San Diego. Sol. Energy 2014, 103, 502–524. [Google Scholar] [CrossRef]
- Escrig, H.; Batlles, F.J.; Alonso, J.; Baena, F.M.; Bosch, J.L.; Salbidegoitia, I.B.; Burgaleta, J.I. Cloud detection, classification and motion estimation using geostationary satellite imagery for cloud cover forecast. Energy 2013, 55, 853–859. [Google Scholar] [CrossRef]
- Voyant, C.; Muselli, M.; Paoli, C.; Nivet, M.L. Numerical weather prediction (NWP) and hybrid ARMA/ANN model to predict global radiation. Energy 2012, 39, 341–355. [Google Scholar] [CrossRef]
- Bouzerdoum, M.; Mellit, A.; Pavan, A.M. A hybrid model (SARIMA-SVM) for short-term power forecasting of a small-scale grid-connected photovoltaic plant. Sol. Energy 2013, 98, 226–235. [Google Scholar] [CrossRef]
- Chen, S.X.; Gooi, H.B.; Wang, M.Q. Solar radiation forecast based on fuzzy logic and neural networks. Renew. Energy 2013, 60, 195–201. [Google Scholar] [CrossRef]
- Li, J.M.; Ward, J.K.; Tong, J.N.; Collins, L.; Platt, G. Machine learning for solar irradiance forecasting of photovoltaic system. Renew. Energy 2016, 90, 542–553. [Google Scholar] [CrossRef]
- Yang, D.Z.; Kleissl, J.; Gueymard, C.A.; Pedro, H.T.C.; Coimbra, C.F.M. History and trends in solar irradiance and PV power forecasting: A preliminary assessment and review using text mining. Sol. Energy 2018. [Google Scholar] [CrossRef]
- Antonanzas, J.; Osorio, N.; Escobar, R.; Urraca, R.; Martinez-de-Pison, F.J.; Antonanzas-Torres, F. Review of photovoltaic power forecasting. Sol. Energy 2016, 136, 78–111. [Google Scholar] [CrossRef]
- Raza, M.Q.; Nadarajah, M.; Ekanayake, C. On recent advances in PV output power forecast. Sol. Energy 2016, 136, 125–144. [Google Scholar] [CrossRef]
- Inman, R.H.; Pedro, H.T.C.; Coimbra, C.F.M. Solar forecasting methods for renewable energy integration. Prog. Energy Combust. Sci. 2013, 39, 535–576. [Google Scholar] [CrossRef]
- Eseye, A.T.; Zhang, J.H.; Zheng, D.H. Short-term photovoltaic solar power forecasting using a hybrid Wavelet-PSO-SVM model based on SCADA and Meteorological information. Renew. Energy 2018, 118, 357–367. [Google Scholar] [CrossRef]
- Bae, K.Y.; Jang, H.S.; Sung, D.K. Hourly Solar Irradiance Prediction Based on Support Vector Machine and Its Error Analysis. IEEE Trans. Power Syst. 2017, 32, 935–945. [Google Scholar] [CrossRef]
- Lai, C.S.; Jia, Y.W.; McCulloch, M.D.; Xu, Z. Daily Clearness Index Profiles Cluster Analysis for Photovoltaic System. IEEE Trans. Ind. Inform. 2017, 13, 2322–2332. [Google Scholar] [CrossRef]
- Yang, H.T.; Huang, C.M.; Huang, Y.C.; Pai, Y.S. A Weather-Based Hybrid Method for 1-Day Ahead Hourly Forecasting of PV Power Output. IEEE Trans. Sustain. Energy 2014, 5, 917–926. [Google Scholar] [CrossRef]
- Wang, J.D.; Ran, R.; Song, Z.L.; Sun, J.W. Short-Term Photovoltaic Power Generation Forecasting Based on Environmental Factors and GA-SVM. J. Electr. Eng. Technol. 2017, 12, 64–71. [Google Scholar] [CrossRef]
- Wang, F.; Zhen, Z.; Mi, Z.Q.; Sun, H.B.; Su, S.; Yang, G. Solar irradiance feature extraction and support vector machines based weather status pattern recognition model for short-term photovoltaic power forecasting. Energy Build. 2015, 86, 427–438. [Google Scholar] [CrossRef]
- Dong, Z.B.; Yang, D.Z.; Reindl, T.; Walsh, W.M. A novel hybrid approach based on self-organizing maps, support vector regression and particle swarm optimization to forecast solar irradiance. Energy 2015, 82, 570–577. [Google Scholar] [CrossRef]
- Wang, F.; Mi, Z.Q.; Zhen, Z.; Yang, G.; Zhou, H.M. A Classified Forecasting Approach of Power Generation for Photovoltaic Plants Based on Weather Condition Pattern Recognition. Proc. CSEE 2013, 33, 75–82. [Google Scholar] [CrossRef]
- Li, H.P.; Zhang, S.Q.; Ding, X.H.; Zhang, C.; Dale, P. Performance evaluation of cluster validity indices (CVIs) on multi/hyperspectral remote sensing datasets. Remote Sens. 2016, 8, 295. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Meteorological Factor | Correlation |
|---|---|
| Irradiation intensity | 0.885 |
| Temperature | 0.316 |
| Wind speed | 0.025 |
| Direction (sin) | −0.028 |
| Direction (cos) | −0.128 |
| Before Cleaning | After Cleaning | |
|---|---|---|
| 19.38% | 18.56% | |
| 83.73 | 45.63 |
| Days Number in Clusters | ||||
|---|---|---|---|---|
| First clustering | 118 (A + B) | 143 (C + D) | ||
| Second clustering | 45 (A) | 79 (B) | 39 (C) | 104 (D) |
| Actual Category | Test Category | Total | |||
|---|---|---|---|---|---|
| A | B | C | D | ||
| A | 10 | 0 | 0 | 0 | 10 |
| B | 3 | 22 | 1 | 0 | 26 |
| C | 0 | 0 | 11 | 0 | 11 |
| D | 0 | 0 | 0 | 31 | 31 |
| Total | 13 | 22 | 12 | 31 | 78 |
| Model | Data | Object | ||
|---|---|---|---|---|
| ARIMA | 19 May | IR | 17.24% | 105.20 |
| T | 1.11% | 0.3373 | ||
| 7 June | IR | 18.93% | 73.70 | |
| T | 0.56% | 0.1967 | ||
| 21 July | IR | 2.35% | 17.13 | |
| T | 0.52% | 0.2629 | ||
| 22 August | IR | 16.02% | 152.54 | |
| T | 1.14% | 0.4634 |
| Model | Accuracy | |||
| 19 May | 7 June | |||
| Sub-SVR | 17.12% | 142.71 | 20.76% | 112.77 |
| G-SVR | 18.33% | 143.51 | 22.21% | 112.29 |
| S-BPNN | 17.48% | 146.38 | 24.48% | 117.90 |
| G-BPNN | 19.09% | 144.59 | 29.13% | 114.54 |
| Model | 21 July | 22 August | ||
| Sub-SVR | 4.47% | 43.34 | 17.00% | 201.09 |
| G-SVR | 7.58% | 56.71 | 17.53% | 207.78 |
| S-BPNN | 4.51% | 42.40 | 20.52% | 222.25 |
| G-BPNN | 7.45% | 55.62 | 24.58% | 218.42 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mei, F.; Pan, Y.; Zhu, K.; Zheng, J. A Hybrid Online Forecasting Model for Ultrashort-Term Photovoltaic Power Generation. Sustainability 2018, 10, 820. https://doi.org/10.3390/su10030820
Mei F, Pan Y, Zhu K, Zheng J. A Hybrid Online Forecasting Model for Ultrashort-Term Photovoltaic Power Generation. Sustainability. 2018; 10(3):820. https://doi.org/10.3390/su10030820
Chicago/Turabian StyleMei, Fei, Yi Pan, Kedong Zhu, and Jianyong Zheng. 2018. "A Hybrid Online Forecasting Model for Ultrashort-Term Photovoltaic Power Generation" Sustainability 10, no. 3: 820. https://doi.org/10.3390/su10030820
APA StyleMei, F., Pan, Y., Zhu, K., & Zheng, J. (2018). A Hybrid Online Forecasting Model for Ultrashort-Term Photovoltaic Power Generation. Sustainability, 10(3), 820. https://doi.org/10.3390/su10030820