1. Introduction
Big Data (BD) has gained wide attention since the first introduction of the definitional statement in which they were described as “high-volume, high-velocity and high-variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making” [
1]. This seminal definition gave BD its signature “V”, originally the three Vs of Volume, to indicate the vast amount of data in play, Velocity, to indicate the rate of data generation and possible successive processing and Variety, to indicate the many data types and sources. Further “Vs” have been since be added: Veracity, to spell out the need for carefully scrutinizing the reliability of data, and Value, which can be seen as the ultimate goal when BD are used in social science [
2,
3,
4]. Value is understood as the capability of BD to generate insights that can benefit decision-makers, organizations, policy-makers and other end users [
2,
3,
4].
To date, an enormous number of studies have been carried out on BD [
2,
5], but their interest for social science is more recent [
4]. The available studies offer, on the one hand, experimentations in the use of BD [
6], social media, in particular, to generate Value, without involving decision-makers [
7]. On the other hand, several previous works of research have pointed out that BD has the potential to generate Value for business and also to tackle societal challenges [
8,
9,
10]. Further to this, an issue that has been overlooked in previous studies is that this generation of Value is linked to the way BD is used by people working inside organizations and governments. When decisions continue to be made by “humans”, the value and use of the information is dependent on the characteristics and knowledge of the decision-maker [
11]. This problem is not new or specifically pertinent to BD (see, for example, [
12]), hence it is surprising that it has been neglected so far.
The path towards generating knowledge for decision-makers and then Value is clearly more complex in the BD arena. Many scientists from different disciplines are involved in elaborating BD in order to acquire, analyze, model and visualize data. These scientists often make arbitrary decisions [
4], for example about what material to select from the entire world of social media [
6] or how to model the information [
13]. Without the involvement of decision-makers—who, it must be remembered, are the final users of the data—there is the high risk of creating a mismatch between the needs of the users and the information provided by the data scientists. What happens is that “obscure” areas in BD processing are created and, as a consequence, two contradictory situations can arise. In the first case, “slave” decision-makers blindly follow the indications proposed by algorithms without mastering the numbers, while in the second case, “reluctant” decision-makers [
14] ignore the information extrapolated from BD entirely. Both situations are problematic and can result in sub-optimal decisions being made.
In this paper, the author argues that a new BD cycle is urgently needed to achieve social impact and, at its centre, is the true missing variable for pursuing Value: the decision-maker. When “humans” retain a role in the decision-making process, the value of information is, accordingly, no longer objective but is influenced by the end users’ own knowledge and mental outlook. More specifically the research question addressed in this paper is how decision-makers can be put at the centre of the BD cycle and become the point of reference for knowledge generation? To pursue this goal, two processes that are usually carried out implicitly by data scientists—filtering and framing—become clear-cut and explicit. The new approach was tested out in two cases of wider social interest: City and Art. In the City case, the key actor (CityEx) wanted to have new insight from BD, to stimulate the public debate during the mayor election campaign. In the Art case, a cultural foundation wanted to explore its network and its role in the local scene. Both cases are located in the same major city in northern Italy.
To describe these arguments, the paper is articulated as follows: the next section sets out the methodology; section three outlines the results. The discussion is lastly presented and conclusions are drawn.
4. Discussion
As explained initially, this paper is concerned with examining how decision-makers play an important role in establishing what information is to be extrapolated from large quantities of BD and how it is to be used, and to analyze the way in which the BD cycle is affected. The previous section, dealt with how the decision-maker centric approach was applied. The study started from the hypothesis that there are two processes, framing and filtering. These are carried out by scientists translating data into knowledge. However, these processes are also traditionally carried out by decision-makers using information to take action, and they are at the basis of their understanding, trust in data and, more importantly, awareness about their use, which is an essential step for creating Value [
30]. The cases presented here are experimental and test an interactive approach involving decision-makers, where the filtering and framing procedures were made transparent, and the final aim was to highlight the key elements in the decision-maker-centric approach.
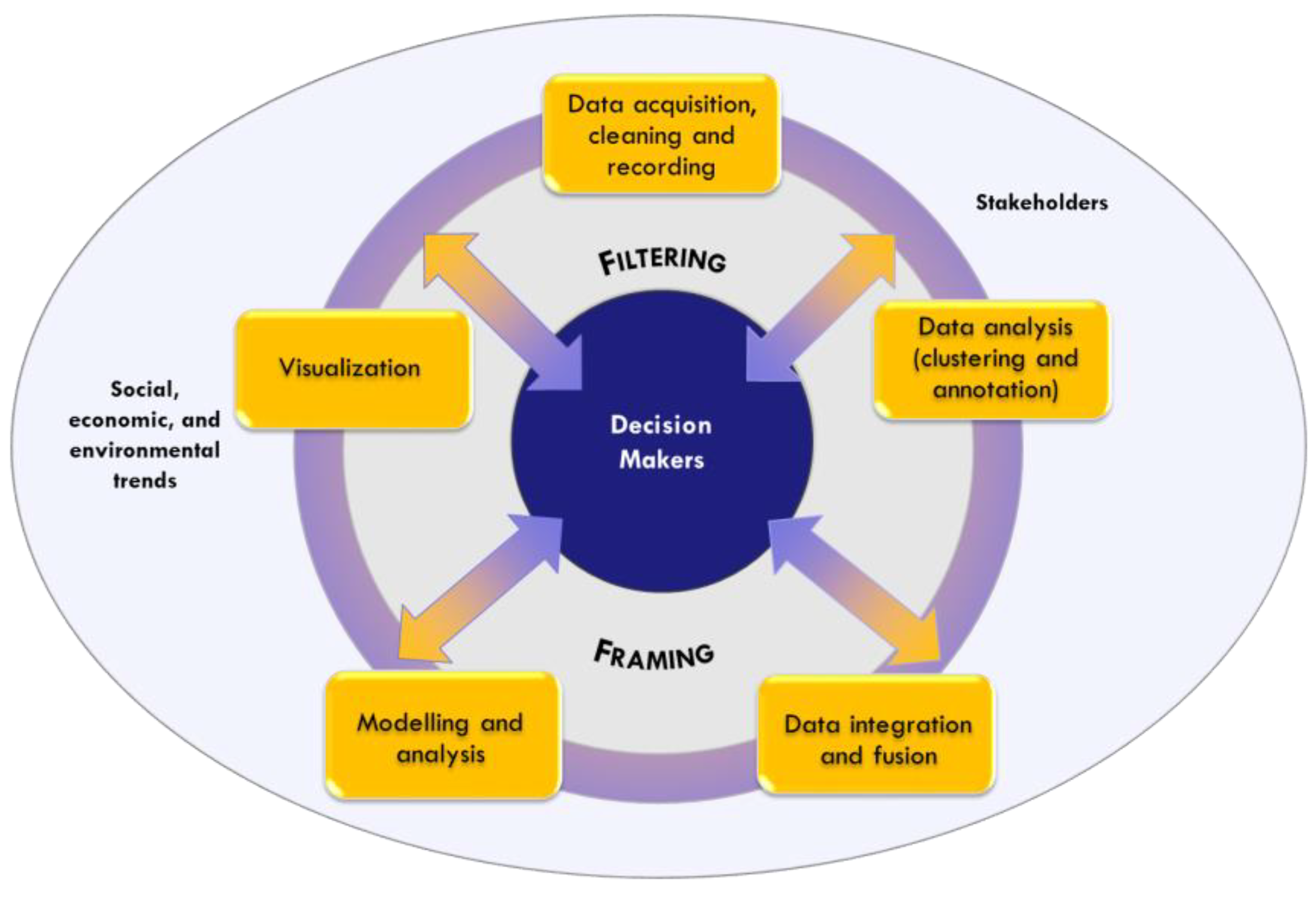
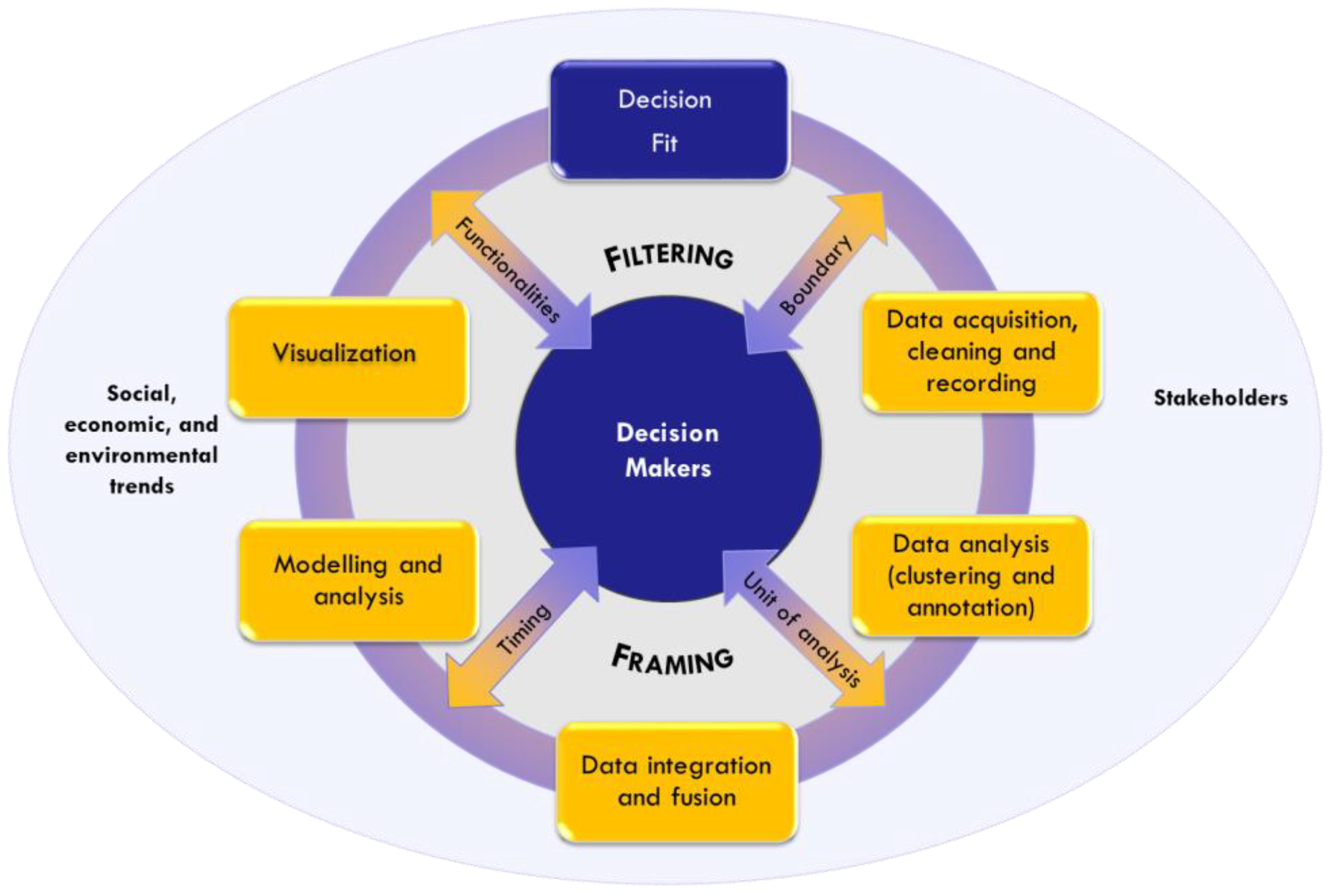
This application lead to the revision of the initial scheme. More specifically: (1) four spokes were introduced to the graphic scheme, as they were seen as pivotal to the filtering and framing proceedings, and, as a consequence, also to the interaction between decision-makers and scientists; these spokes were the boundary, unit of analysis, timing, and functionalities; (2) a new phase was inserted, described as the “Decision Fit” (
Figure 8).
The first element is the boundary, indicating the abstract outer limit of information and decisional space. When approaching BD, despite the scope of their questions being different, both managers set no limits to the type of data to be collected to analyze their initial questions, which, to remind ourselves, were: “in what way is Milan international?”, for CityEx; and “who are the followers of Art on social media and are there particular patterns in their digital traces?”, for ArtEx. Since the data acquisition phase, the interactive approach led to reshaping the decision-makers’ boundaries through filtering and framing. The link between filtering and boundary was more visible in City, within the key word search on social media. The data acquisition process gave rise to a two-fold perspective: global, looking at “Milan” and its reputation; and local, collecting data geo-referenced within the city itself. This first set of information, interesting though it was for its insights into Milan’s reputation, was considered beyond the scope of CityEx’s action boundary and so abandoned. The interaction led the author to focus instead on detailed information at district level, which had initially been overlooked.
The case of Art is interesting, as it shows how a boundary is shaped by framing. Due to the basic need of having a numerical benchmark for data on social media followers, ArtEx and the research group started by positioning the theatre among its international competition. This framing process affected the way in which data was acquired as well as the filtering process, and it also changed the type of the search being carried out, from a proprietary network to a “key word” search on social media.
The boundary is also reflected in the ethical sphere. Public data collected from APIs are subject to rules that are interpreted differently by researchers and scientists, often propounding a tradeoff between the completeness of data and ethical behaviour [
31]. The problem was highlighted by CityEx and there was the general consensus about respecting rules and privacy, even if this meant reducing the volume and granularity of the data collected. This is an issue often overlooked in practice and in academic studies, but one that needs serious consideration in the decision-maker-centric approach.
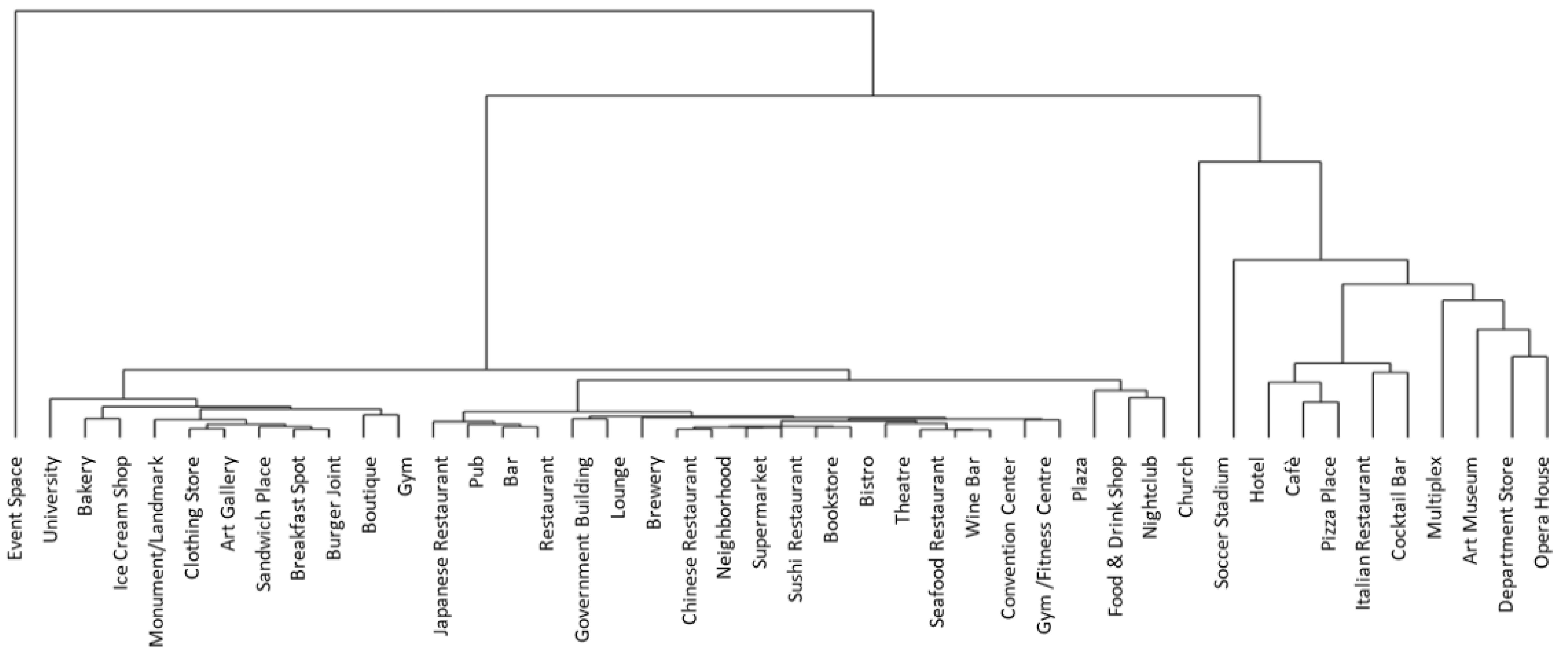
The second element is the unit of analysis for decisions (and action). With traditional data, decision-makers use reference schemes where the unit of analysis is the organization or its nested sub-units (processes, organizational units, people). With BD, the starting point is a given problem and the unit of analysis is often undefined and different from common references. Filtering and framing were seen to be powerful processes where both sides (scientists and decision-makers) needed to clarify what the unit to be “controlled” actually was. This issue emerged more clearly during the process of clustering data, when trying to build the relevant categories to be operated on and managed. In the case of City, the focus on the local dimension of internationalization led to filtering the districts within the city of Milan, which became the main unit of analysis. Data then needed to be re-framed in relation to this main unit, through guided clustering. At the practical level, data were easily anchored to districts, but social media data, in particular, needed to be structured into sub-units of analysis that were meaningful in terms of analyzing one district on its own and making comparisons with other districts. In the case of Art, the main unit of analysis was the international network, which was compared over time and against other theatres of reference. After this filtering process, in this case, other variables also had to be re-framed and related to the network. Content clustering and analysis became relevant to trace the content and/or actors that activate the network; the network users were clustered in order to monitor and reshape the communication strategy, revealing “hubs” and “authorities”. In both cases, the interaction on the unit of analysis uncovered a hybrid approach where qualitative choices (driven by decision-makers) are mixed with quantitative–statistical indications in the common objective of fitting data to the decision needs.
The third element is timing, indicating the appropriate temporal resolution of data in relation to the decision-makers’ needs. The decision-maker centric approach implies understanding not only which data are more suited to the process, but also when and how frequently they are needed. A first choice that entered the interactive approach was the reference period of the algorithm. Starting from the decision-makers’ initial desire to have data in real time, the analysts proposed techniques to frame the various frequencies of the data (ranging from yearly to real time). In practice, different algorithms were proposed to divide greater periods into sub-intervals, based on historical paths and trends. From discussions with the decision-makers, it became clear that this division of original data was considered to be “fake”, even when refined division methods were proposed. The failure of this statistical approach of dividing time into periods meant that data was aggregated into longer periods, and one point that emerged was that the high frequency of some data was just an over-ambitious yearning thrown up by the potential of actual real time data. The two cases show how this approach can present a wide range of possibilities. Some data about events were retained with real time frequency: leading venues from Foursquare, for CityEx; and audience monitoring for operas, for ArtEx. Other data were aggregated on a quarterly base: language diversity among districts based on Twitter, for CityEx; and monthly reports on reputation, for ArtEx, where various sets of data are evaluated against the chosen benchmark theatre.
The final element of interaction consists of the functionalities needed by the decision-makers. This last element, although present throughout the BD cycle, finds its full expression in the visualization choices. In the case of CityEx, external communications were considered as crucial to promote awareness of the city’s dynamics, leading to an intriguing and innovative interface being developed. Careful attention was placed on the type of interaction that users could come up with at every layer, in full coherence with the decisions taken on the first three spokes. In the case of Art, interactions regarding functionalities brought up another important factor of the need to integrate new reporting procedures within the existing system and, crucially, with the mindset and time-frame that the managers were used to working with.
The second proposed revision of the new BD cycle is to bring in the new phase of decision fit, where scientists and decision-makers assess the benefit and costs of BD in the context of use. This assessment emerged naturally as a need when the data started to be used. Decision fit is carried out on a mix of technical and business parameters such as completeness, precision and cost. Completeness is the value added when capturing the critical success factors within the boundaries of the decision. In both the cases, the data added new knowledge to traditional data. For example, the variety of language among the districts, for CityEx; and the drivers of international expansion, for ArtEx. Precision is instead determined by the relevance and correlation of specific data for the decision-makers’ goals. For instance, the cross-over effect of City’s events on various sectors (hotels, entertainment, etc.); and monitoring and using “hubs” and “authorities” as promotional vehicles in Art’s network. Lastly, the term cost refers to the cost needed to process data on a routine basis.
During the concluding phase of the test, the work on the two cases confirmed the benefits of the approach, but it is also important to highlight the limitations of this study. A first such limitation is linked to the decision-making sphere. In both cases, the experiment was carried out in arenas where the decision-maker had the power to use the data with only marginal involvement of other actors. In complex decisions, it is often the case that many actors are closely involved and rational choices are mixed up by political inputs, even down to the choice of the data to be used. These contexts are typically public–private domains, such as transport and health care, where BD can heighten awareness of the impact that various policies can have. The new cycle should be tested from a shared viewpoint to observe both the interaction between scientists and decision-makers and, especially, between the decision-makers themselves.
A second limitation is linked to the actual type of decision-makers included in the tests. The two experts were chosen on purpose for their mid-way outlook towards BD: they were open to BD but remained wary. Referring to the two opposing attitudes towards BD, blind faith and reluctance, they were in a half-way house situation and ready to challenge themselves and the team. Further studies are needed to test the approach derived at when decision-makers lean more towards one side of the argument or the other, but it also opens a new question: “what manner of training do decision-makers and scientists need?”. In order to interact along the spokes of the scheme, at least initially, both parties must be able to share their language and toolkit to a certain degree.
5. Conclusions
This paper has addressed an issue that had only been studied marginally in BD research: the need and manner to involve decision-makers in the data processing to avoid any misalignment between information provided by data scientists and the decision-makers’ needs. This is particularly relevant in the field of social science, where BD are seen as a panacea to provide Value when addressing business and social challenges. To tackle this problem, a new BD cycle centred around the decision-maker has been proposed and applied using action research methodology in two cases.
The findings enhance previous studies in BD for social sciences at two levels. The first results show that the interaction between scientists and decision-makers when preparing BD is a reciprocal process of knowledge, which, in turn, meant that it was possible to avoid two opposing and risky behaviours: blind faith, where decision-makers overestimate the benefits of BD; and reluctance, where decision-makers treat all data they do not fully understand with suspicion. In pursuing the path of further knowledge, two operations embedded in the information processing system must be made transparent: filtering and framing. Second, the study provides evidence of the value of a quali-quantitative approach to BD for social science; the final cycle provided the dimensions of interaction, in the form of boundary, unit of analysis, timing and functionalities, which confer rigor to the whole process. These dimensions are the grey area between scientists and decision-makers. When explicitly addressed during the information preparation stage, they enable the transfer of skills necessary to make technical choices and in the business context. While the study was conducted with the involvement of only two experts, which could be seen as a major limitation, in both cases, the experts were highly engaged and positive about BD and they had sufficient backing from their organization to carry out the study and interact with the team.
To conclude, this study places the missing variable of decision-making at the centre of the process, reinforcing previous studies on information processing in the BD age and opening the way for future research in social sciences. A first area of development is to apply the cycle to more complex contexts where the decision-making power is distributed among many actors who could be reluctant to work with BD. Further areas for future research include monitoring decision-makers over a longer period of time, examining how information that originated from BD is used and, lastly, studying the impact of BD, and the knowledge that it brings about, on organizations and societal challenges.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







