2.1. RRT* Algorithm
The core of the RRT algorithm is to perform random sampling within the global feasible range, find the nearest node in the search tree as the next reference node under the premise of collision, and continue to grow at a given growth step until the maximum growth limit is reached or a feasible path is realized. But in fact, since the RRT algorithm constantly diverges sampling on the tree of the same backbone, it can only ensure that the searched path is a “feasible solution” and not necessarily an “optimal solution”. Moreover, due to random sampling, the resulting path may have many vertices, which is not conducive to the actual state of vehicle driving; in complex environments, search efficiency may be reduced due to obstacle limitations or narrow search channels.
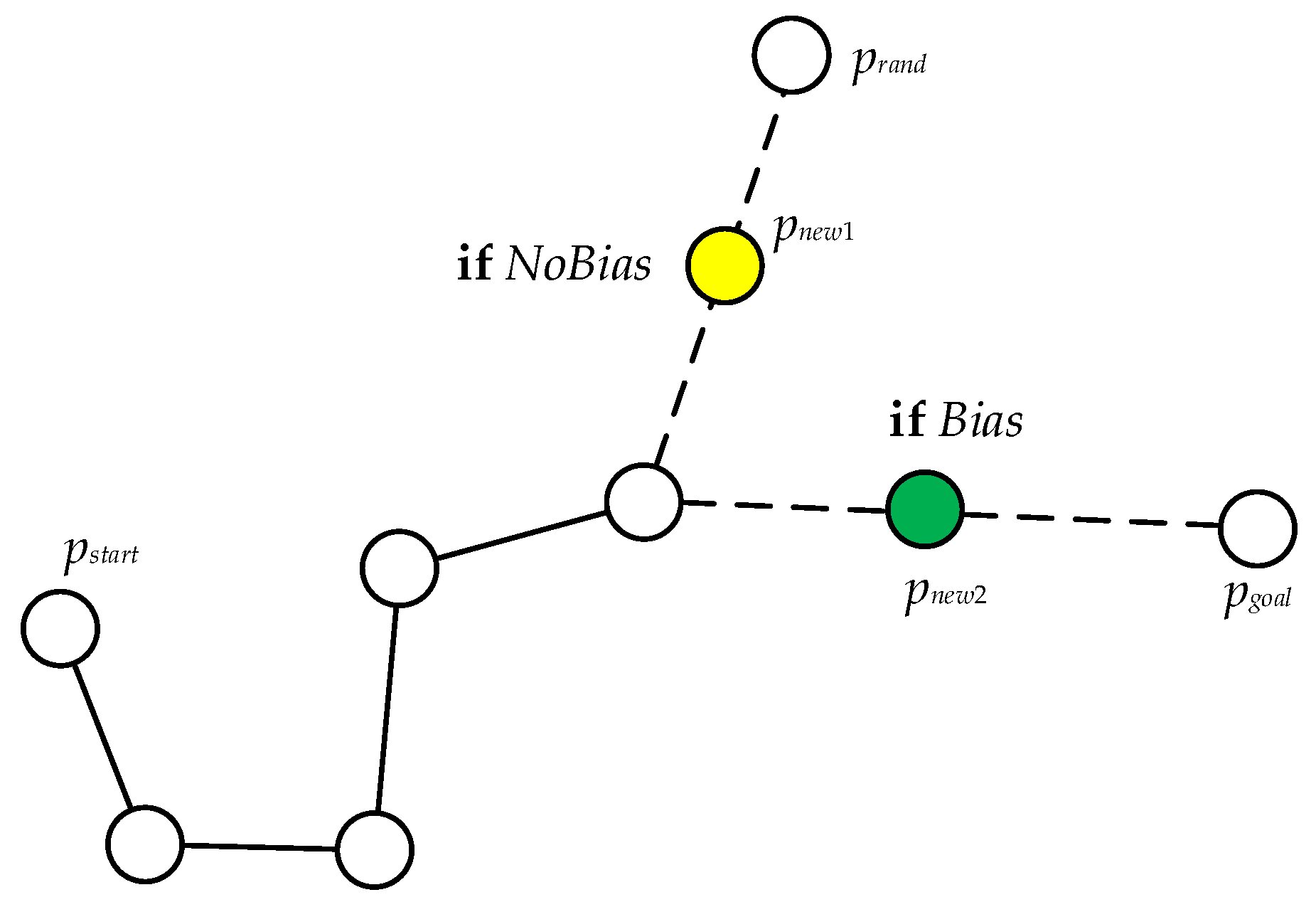
In the ordinary RRT algorithm, the initial position is the starting node
of the entire random tree, and then a random point is generated in the environment, which is named random point
. The closest node
is found within a certain range, and the two nodes are connected and collision detection is performed. If the connection line does not collide with an obstacle, a distance of step
will be grown from the closest node
to the random node
in the direction of the connection line. If the growing node does not collide with the obstacle, the node at that location is the newly generated node
, which is added to the extension tree, but if a collision is found during detection, delete this node. The above process continues to repeat in the algorithm until the target node
is added to the extension tree or the iteration reaches the maximum number of times; the algorithm stops. At this time, you can trace back to the entire expansion tree from the connection line from the starting node
o the target node
and each node to obtain a global path. The way of generating new nodes in the random tree is shown in
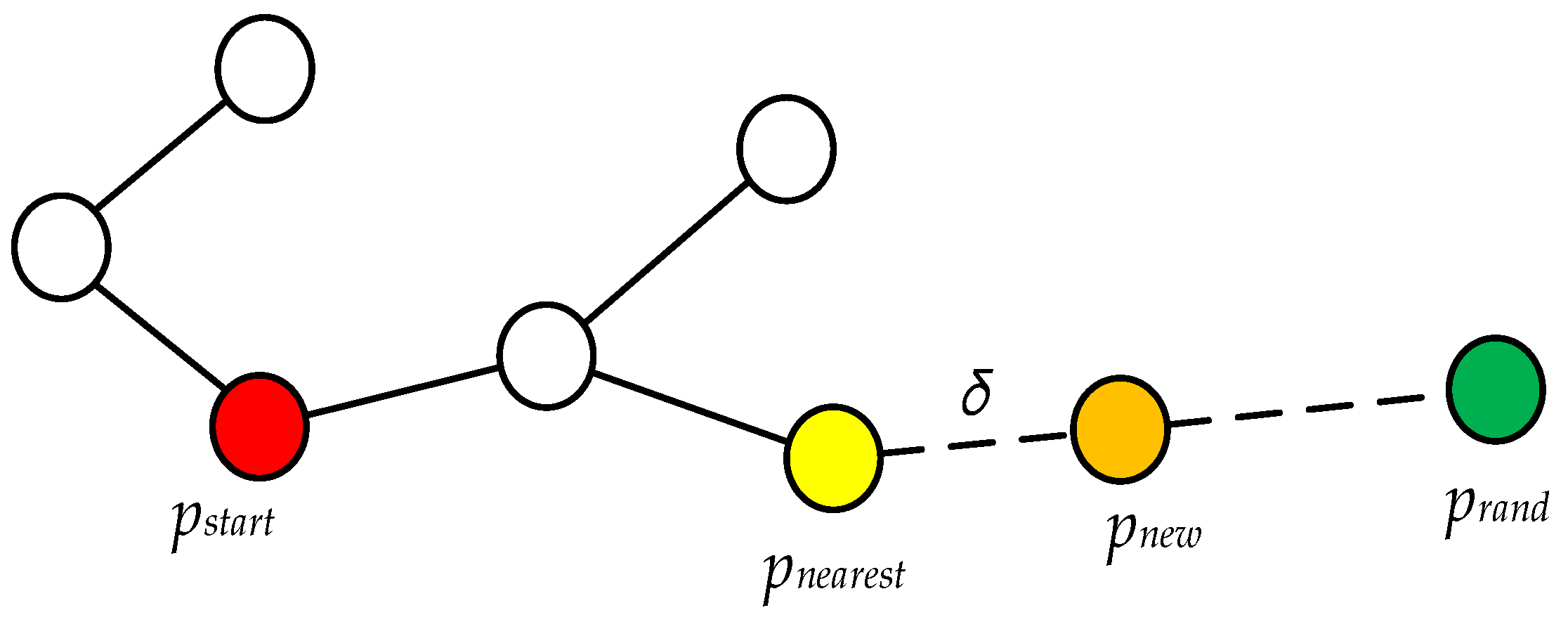
Figure 1, where the red point is the starting node
, the green node is the generated random point
, and the orange node
is a new node obtained by growing a step toward the random point at the nearest node
from
[
9].
Based on the above RRT algorithm, the RRT* algorithm introduces parent node reselect and node reconnection strategies [
10]. Among them, parent node reselection refers to searching for a node with a smaller cost than its parent node in the circle where the new node
is the center of the circle and using this node as a new parent node
instead of the original parent node
of the new node. The parent node reselect strategy as shown in
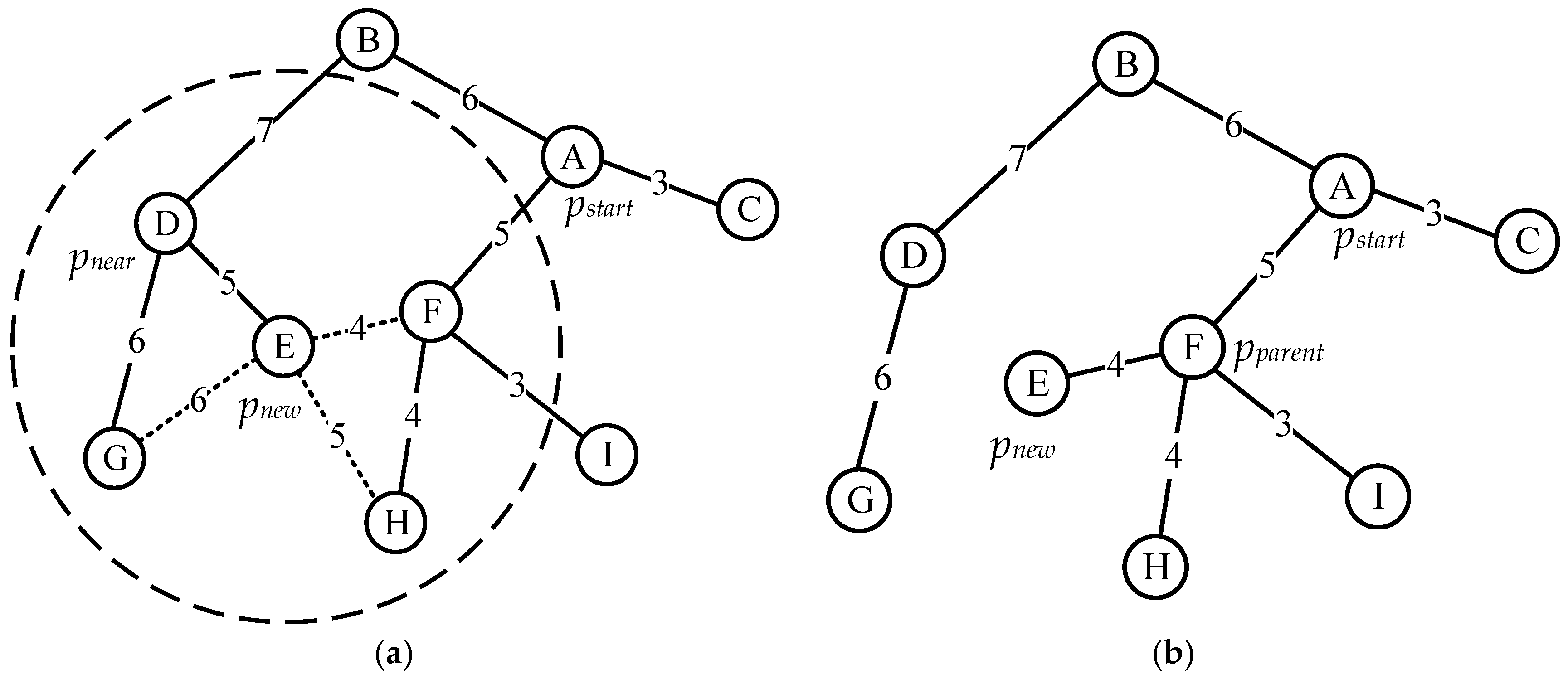
Figure 2.
In
Table 1, the node is a new node. In addition to its own parent node
, there are three possible parent nodes. The total cost of these three nodes is compared with the total cost of the path of the parent node. The parent node on the path with the smallest cost is taken. Here, the total cost of the
and
nodes is less than the total cost of the original parent node, but obviously the total cost of the node is smaller, so the
node becomes the new parent node
of the
node. This process significantly reduces the total path length of the random tree. The pseudocode for this strategy is shown in Algorithm 1.
| Algorithm 1. Parent Node Reselect Strategy |
| 1: | |
| 2: | |
| 3: | for each do |
| 4: | |
| 5: | if then |
| 6: | if |
| 7: | |
| 8: | |
| 9: | end if |
| 10: | end if |
| 11: | end for |
| 12: | return |
The node reconnection strategy refers to finding all nearby nodes within a certain range of the new node
after reselecting the parent node and using the new node
as the parent node to calculate the generation value of its arrival at other nearby nodes. If the cost is less than the price of the nearby node reaching its original parent node, then
will become the new parent node of this node. The node reconnection strategy as shown in
Figure 3.
It can be seen in
Table 2 that the
node is the parent node, and its adjacent nodes are
,
, and
, respectively. The total cost of calculating the original path of these three nodes is compared with the total cost of the path of node
as the parent node. The total cost of the
node is less than the total cost of the original parent node. Therefore, the
node becomes the new parent node of the
node, and this process also reduces the total path length of the random tree. The pseudocode of the node reconnection strategy is shown in Algorithm 2.
| Algorithm 2. Node Reconnection Strategy |
| 1: | |
| 2: | for each do |
| 3: | if and |
| | then |
| 4: | |
| 5: | |
| 6: | end if |
| 7: | |
| 8: | return
|
Overall, the RRT* algorithm reduces the overall length of the path by introducing two strategies and optimizes the path quality.
2.2. Bi-RRT* Algorithm
The Bi-RRT* algorithm (Bi-directional RRT*) is improved on the basis of the RRT* algorithm [
11]. Compared with the RRT* algorithm, the Bi-RRT* algorithm uses the initial position and target position in the global area as the starting points of two random trees, namely
and
. Then, starting with two starting points, the RRT* process is performed separately, and two expansion trees,
and
, are gradually generated. During the operation, the parent node reselect strategy and node reconnection strategy of the RRT* algorithm are also performed, and the path is expanded and optimized at the same time. The condition for the operation to terminate is to reach the maximum number of iterations
or make the distance between nodes
in
and node
in
not greater than the node growth step
set in the Bi-RRT* algorithm. At this time, the two nodes,
and
, will be connected; that is, the two expansion trees are merged into an expansion tree, and a global path from
to
is traced back. Its pseudocode is shown in Algorithm 3.
| Algorithm 3. Bi-RRT* algorithm |
| 1: | Initialize trees , |
| 2: | for to do |
| 3: | |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | if then |
| 9: | |
| 10: | end if |
| 11: | end for |
| 12: | return
|
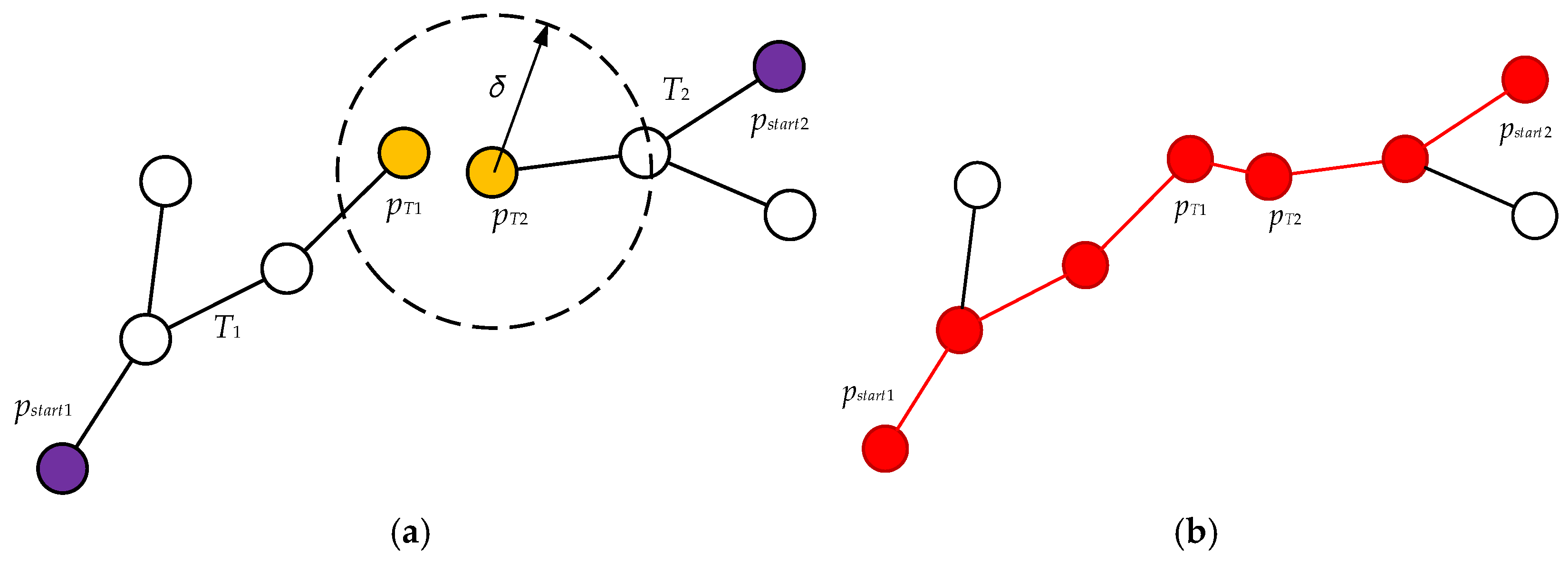
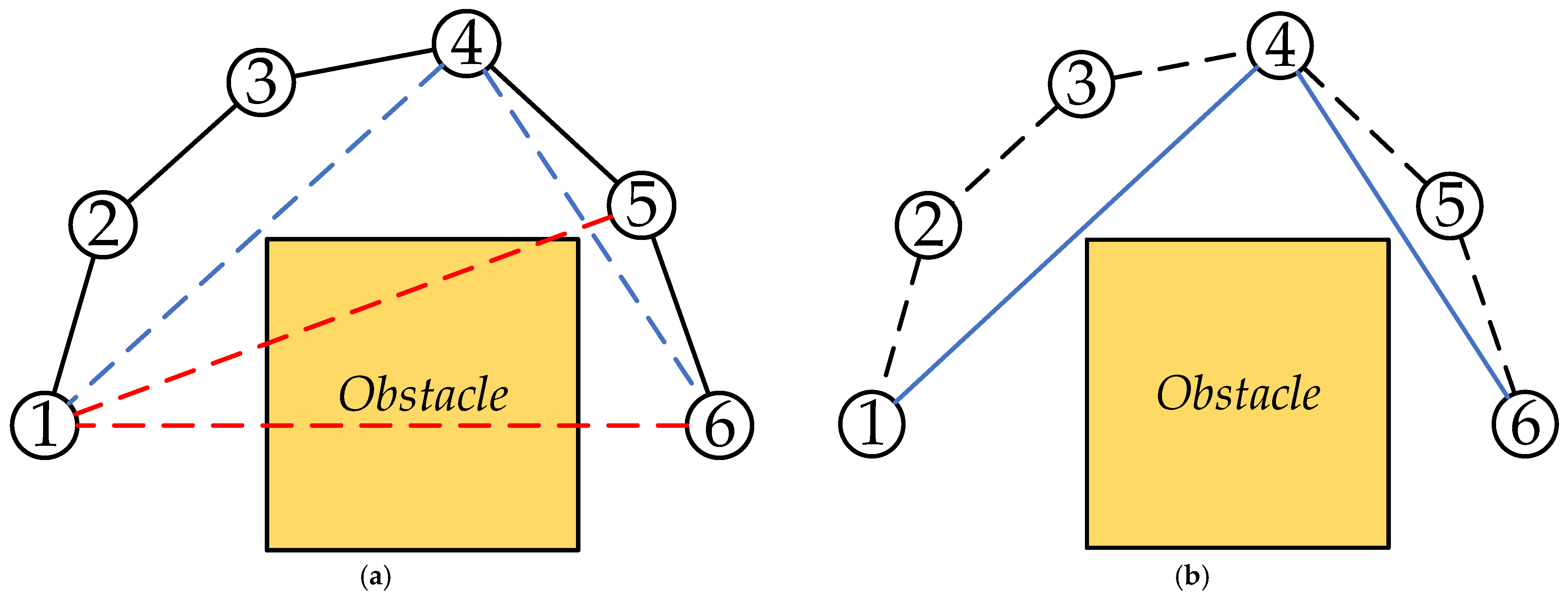
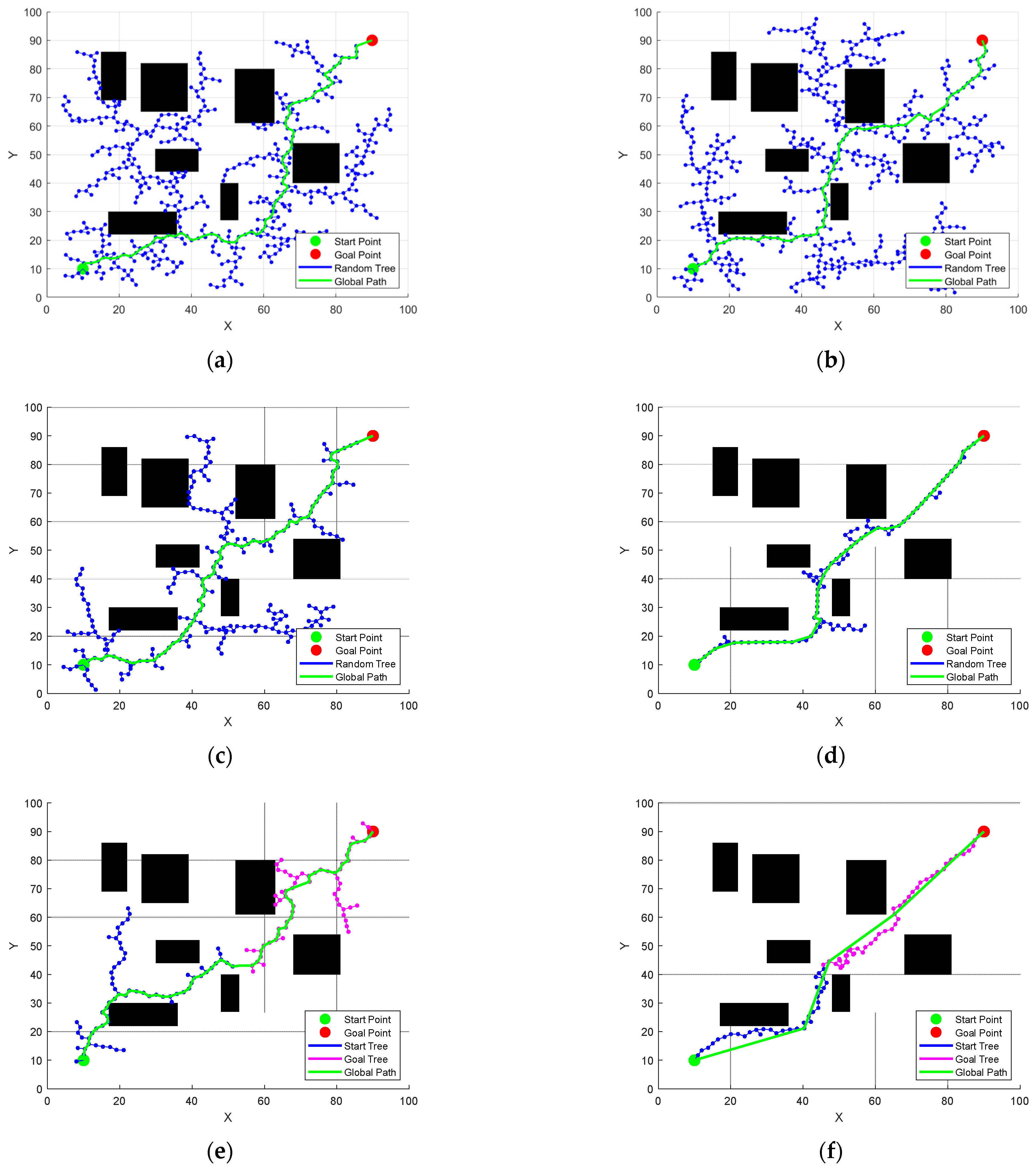
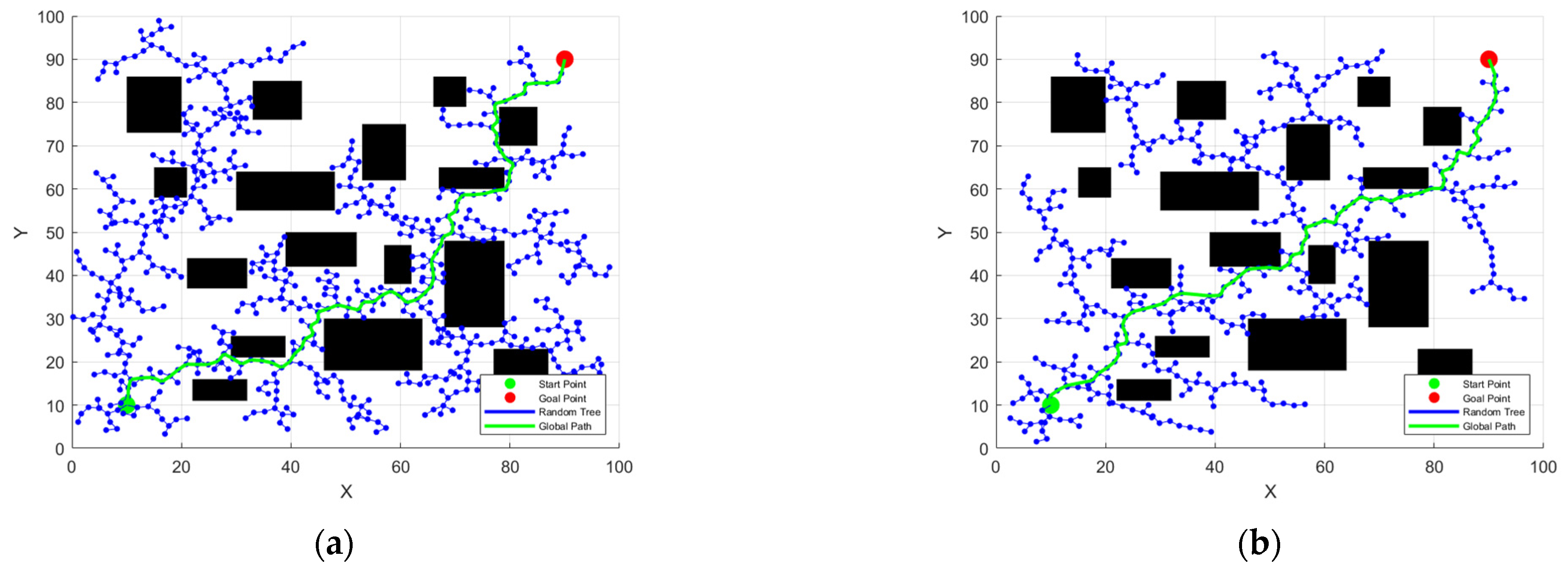
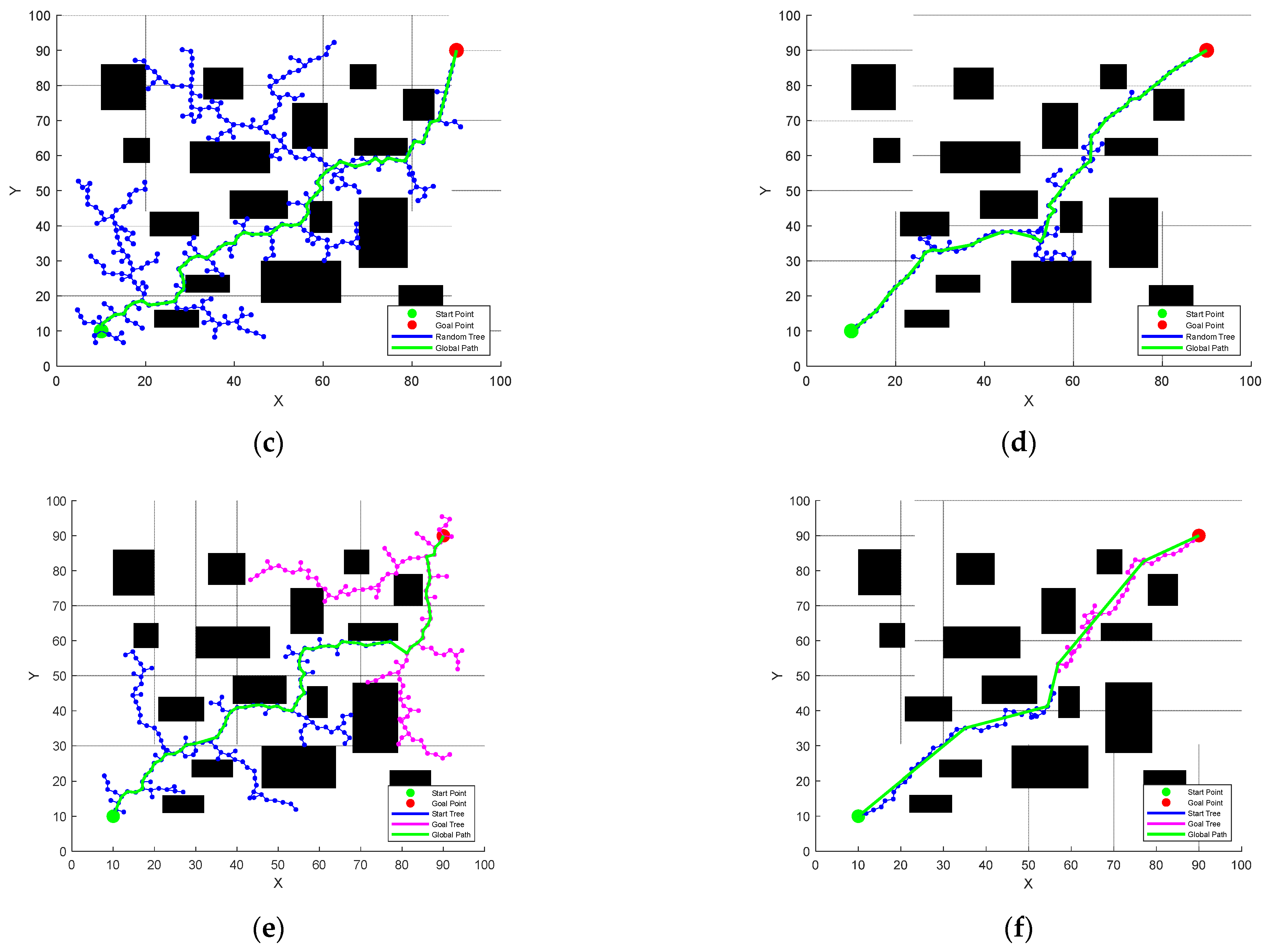
For
Figure 4, the left is the random tree
grown from the starting point
, and the right is the random tree
grown from the global end point
, and
and
are points in the two random trees respectively. At this time, the point among these two points is the center and the growth step
is the radius as a circular determination range. It can be seen that
is already within the selection range of
, so the two points are connected and a complete global path is traced back. The red line in the
Figure 4b is the global path.
Since the growth of the random tree grows opposite to the starting point and the target point, and the parent node reselecting and node reconnection strategies in the original RRT* algorithm are retained, the Bi-RRT* algorithm improves the search efficiency and makes the path better.
2.3. APF Algorithm
APF algorithm (Artificial Potential Field algorithm), which implements path planning by simulating a virtual potential field environment in the map. When planning the vehicle’s path, use the current position of the vehicle as the starting point of the global path and the target position as the target point, and apply a potential field on the target point and the obstacles in the map so that the target point has a gravitational effect on the vehicle and the obstacles have a repulsive effect on the vehicle. Under the combined force, guide the vehicle to plan and avoid obstacles [
12].
In the potential field, assuming the gravitational potential field is
, the gravitational force on the vehicle is
, the gain coefficient of the gravitational potential field is
, the current position of the vehicle is
, the target point is
, and the Euclidean distance between the two is
, then the gravitational potential field function is shown in the following equation.
The gravitational function of the target point to the vehicle is as follows.
As can be seen from the above two equations, the gravity of the target point to the vehicle is proportional to the distance between the vehicle and the target point.
For a repulsive force field, a repulsive force field influence range is often set. When the vehicle is currently located within the range of the repulsive force field of the obstacle, the vehicle will be subject to the repulsive force exerted by the obstacle. If it leaves this range, the repulsive force field of the obstacle will not affect the vehicle. It is also assumed that the repulsive potential field is
, the repulsive force on the vehicle is
, the repulsive potential field gain coefficient is
, the current vehicle position is
, the obstacle position is
the Euclidean distance between the two is
, and the impact range of the obstacle is
, then the repulsive potential field function equation is as follows.
The repulsive force function of an obstacle to a vehicle is shown below.
When a vehicle is driving, it will be affected by the joint influence of the gravitational potential field and the repulsive potential field. It is not only affected by the gravitational effect of the target point on it, but also the impact range includes the repulsive force effect of the obstacle where the vehicle is currently located. The combined potential field and combined force effect of the vehicle are shown in the following two formulas.
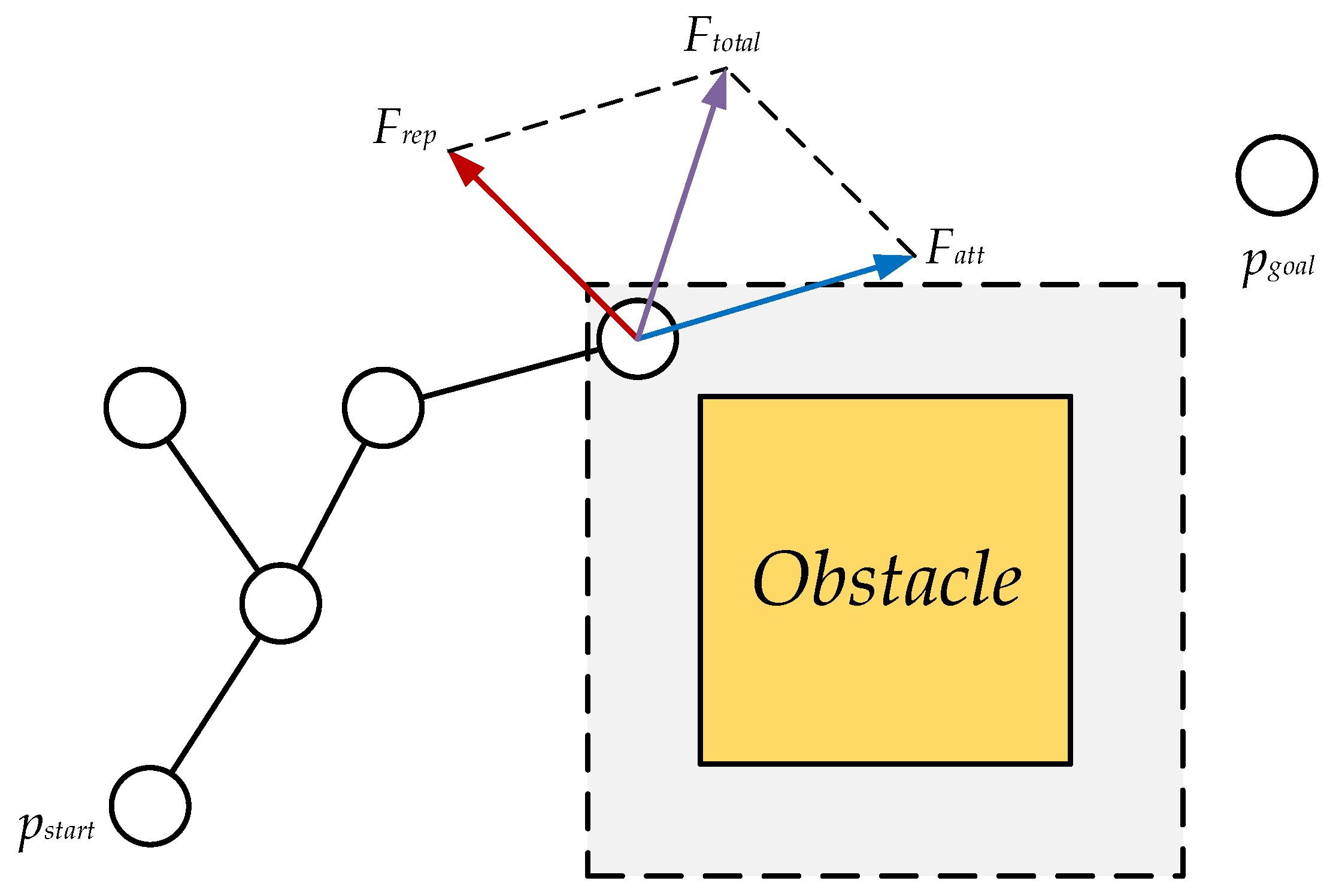
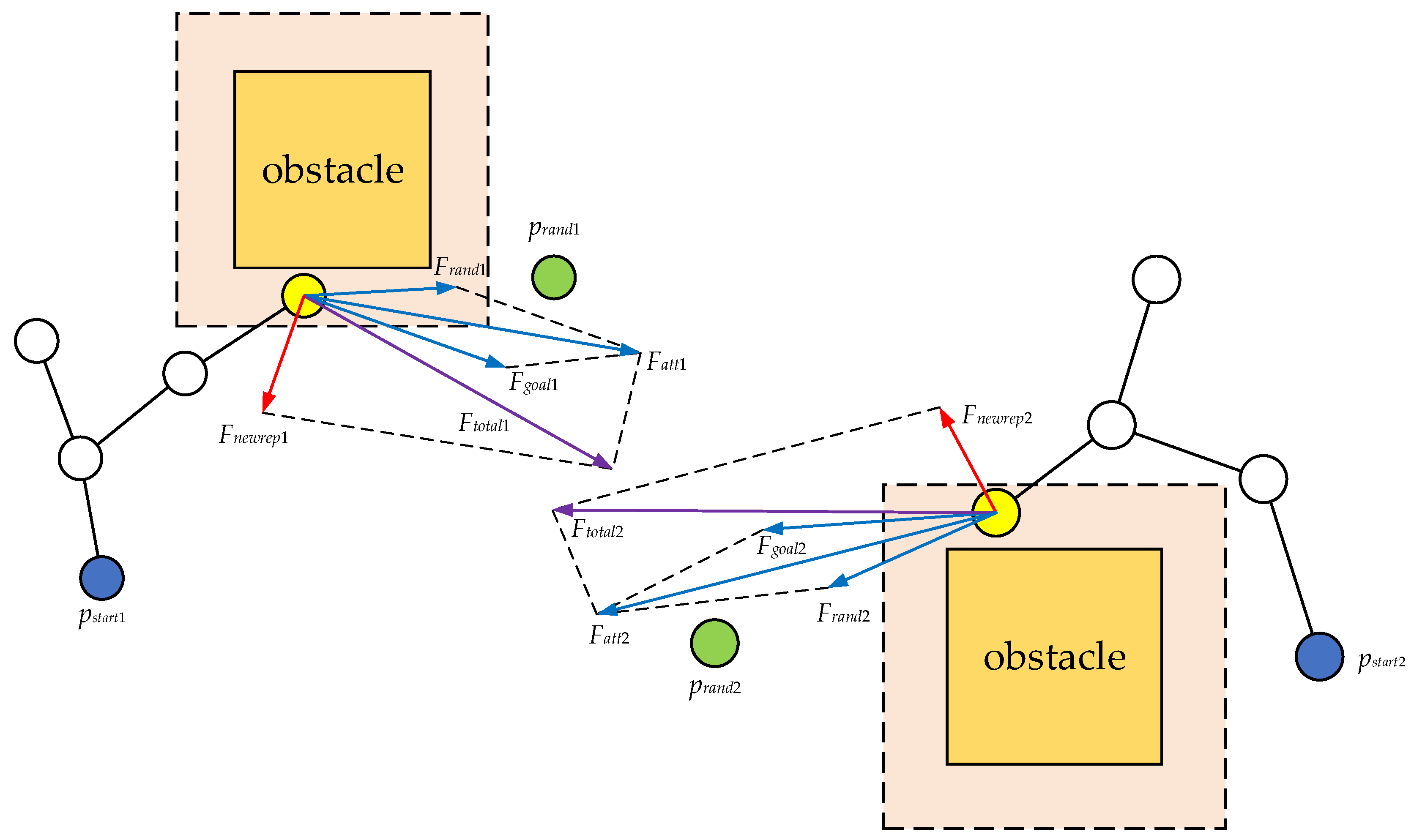
In the formula,
represents the number of obstacles that produce repulsive force on the vehicle at the current position. The algorithm diagram is shownin
Figure 5. The gray part in the figure is the influence range of the obstacle. At this time, the node is within the influence range, so it is affected by the repulsion force of this obstacle. The direction of the red arrow is the direction of the repulsion force of the obstacle on the node. At this time,
also has a gravitational effect on this node, and the gravitational direction is shown by the blue arrow. The combined force of repulsion and gravity is in the direction of the purple arrow
, and the vehicle will move in this direction.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}