
BI-TST_YOLOv5: Ground Defect Recognition Algorithm Based on Improved YOLOv5 Model


Abstract
1. Introduction
2. Materials and Methods
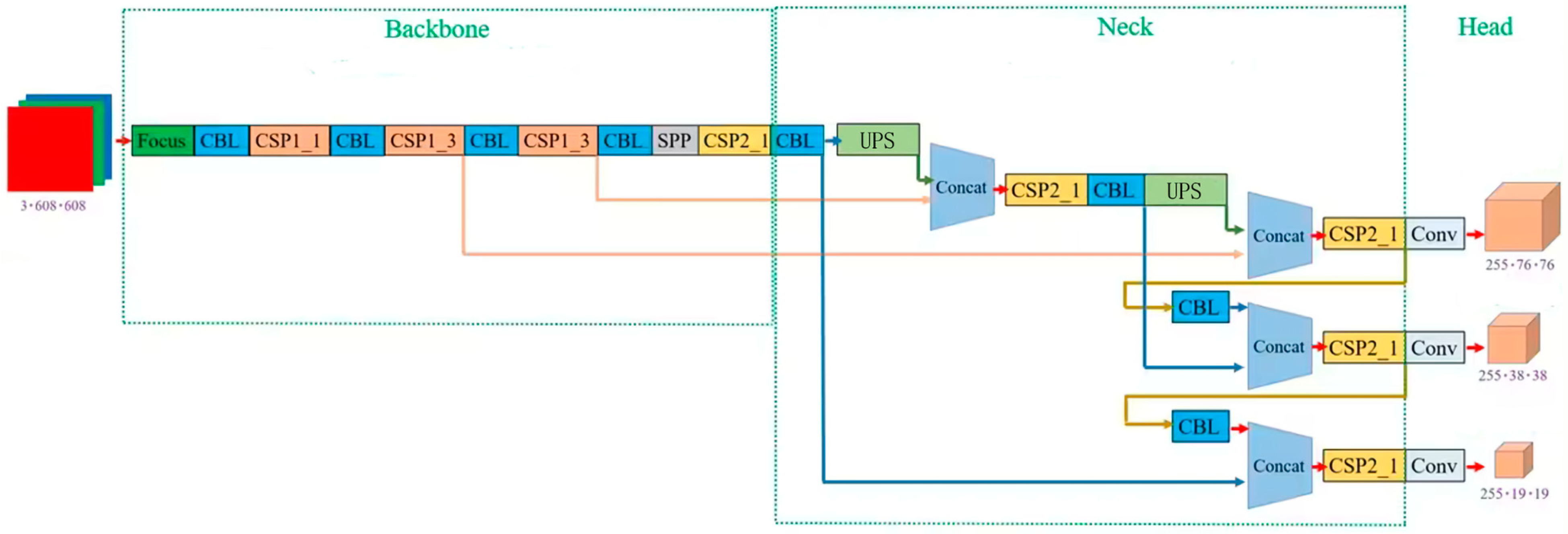
Introduction to the YOLOv5 Algorithm
3. Implemented YOLOv5 Algorithm
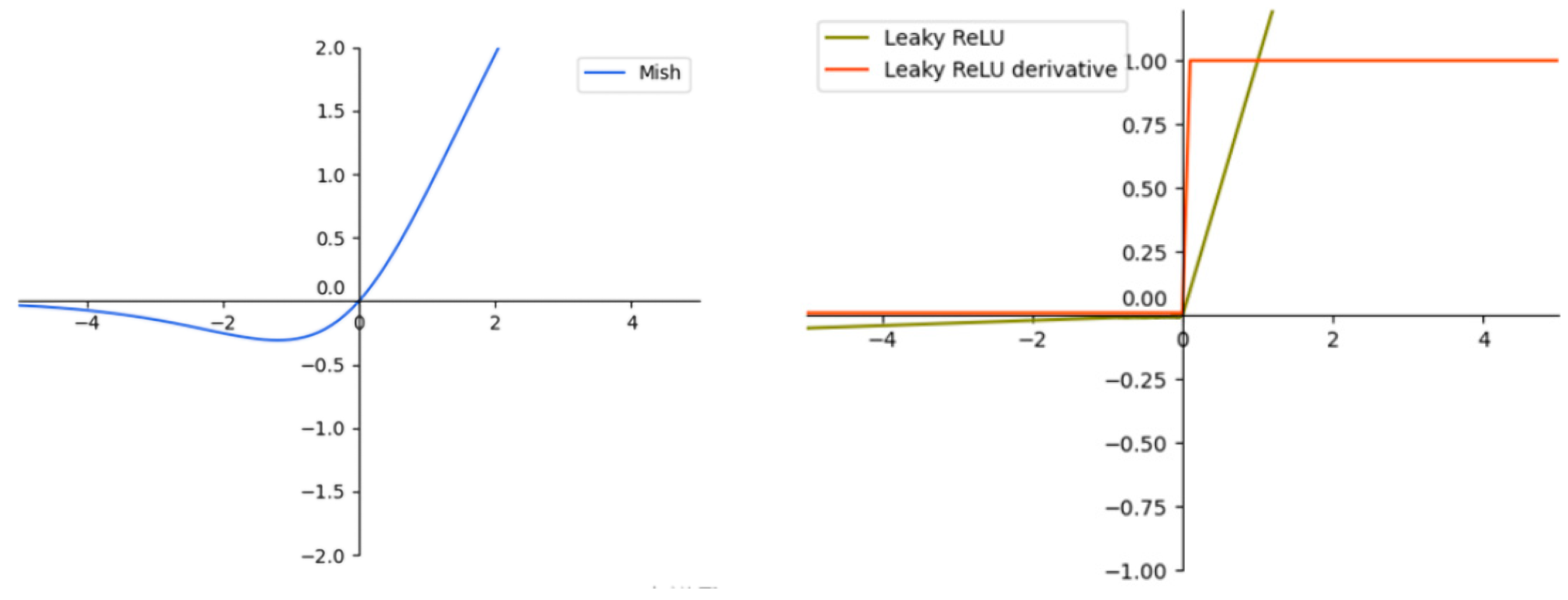
3.1. Adjust Model Activation Function
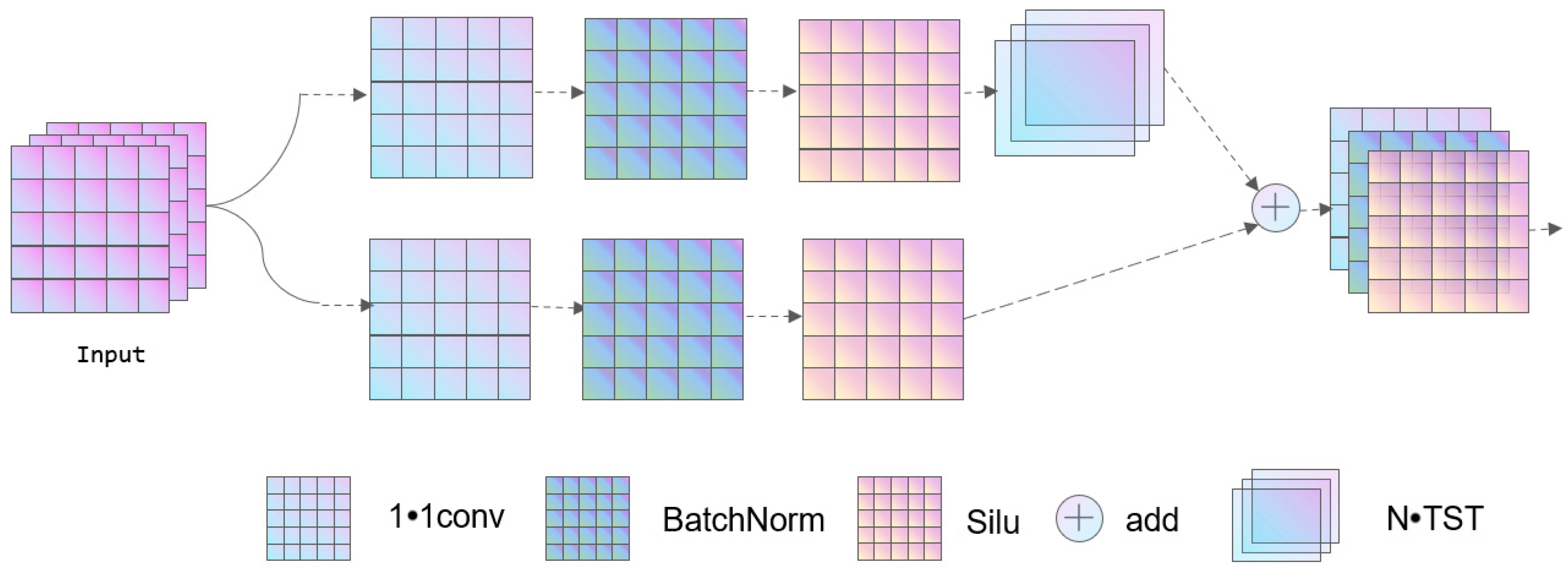
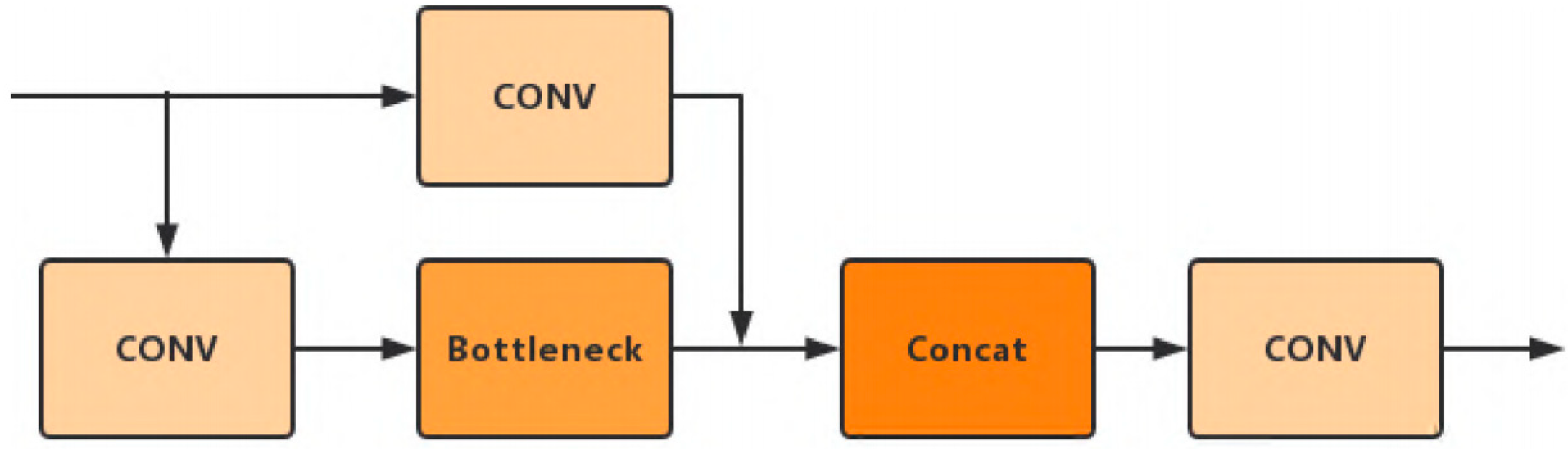
3.2. C3-TST Block
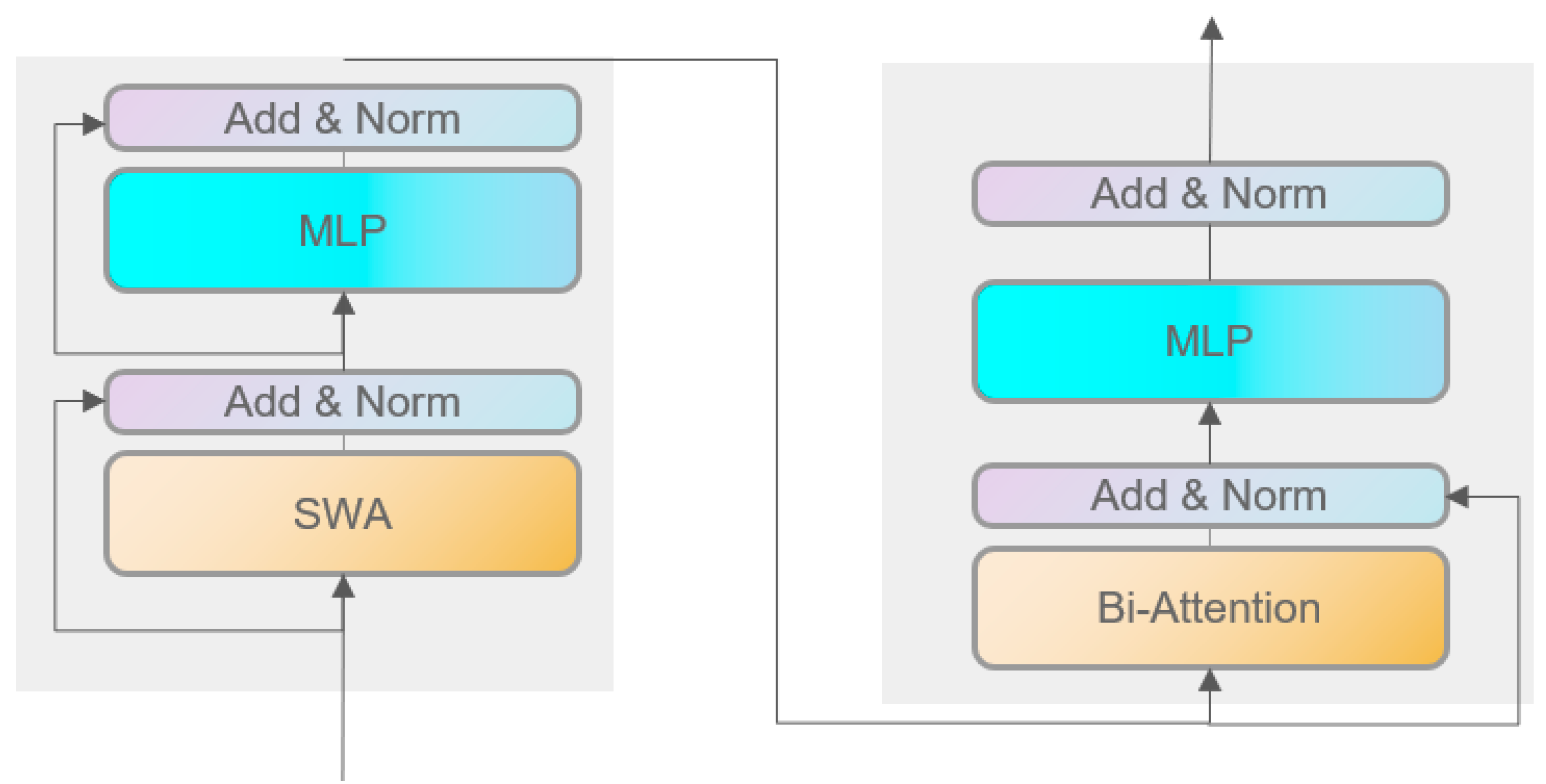
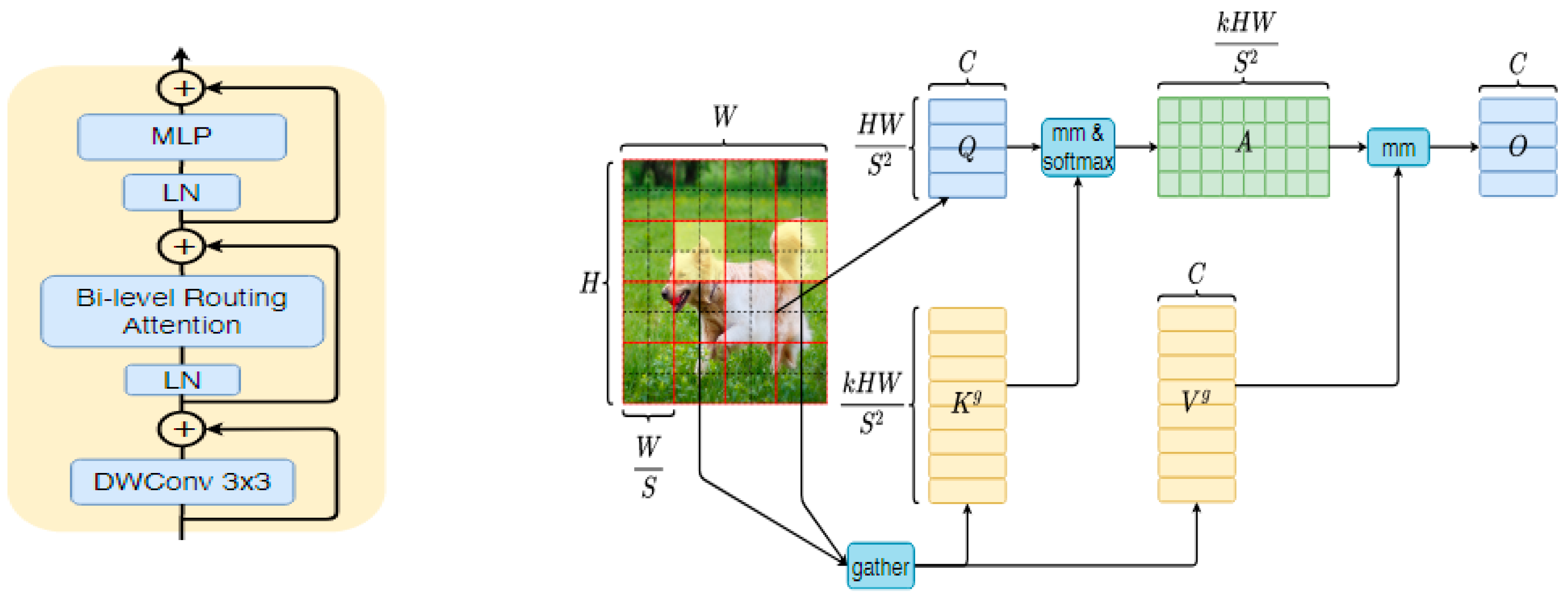
3.3. Bi-Level-Routing Attention Head
- They use manual static mode (unable to adapt);
- They share the sample set of key-value pairs in all queries (it is impossible for them not to interfere with each other).
4. Results
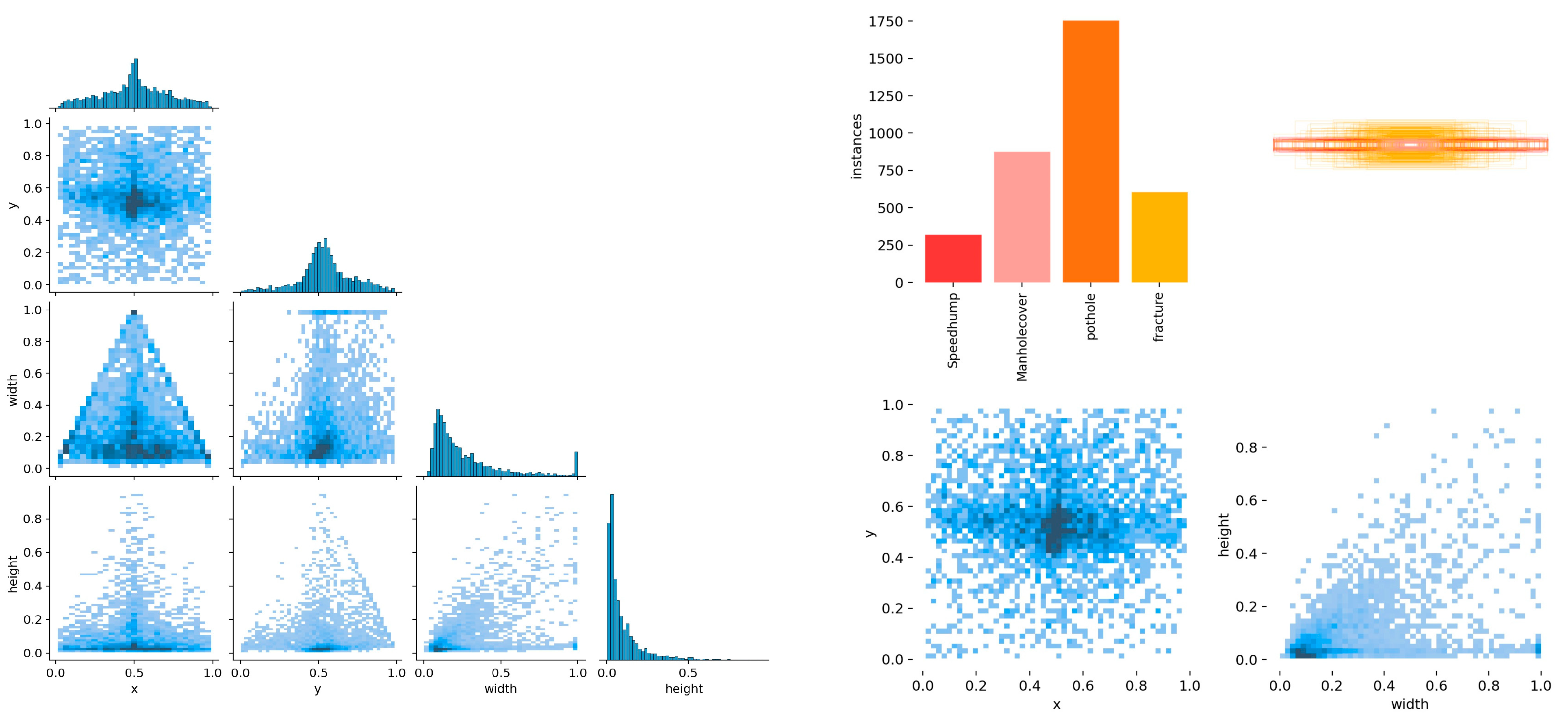
4.1. Dataset Preparation
- For the acquisition of the dataset, we used real-time driving videos of the road in a certain region of China, used FFmpeg v6.1.1 software to cut the video screen into pictures, and selected the effective part of the total 1.45 g data for use.
- We used Labellmg v1.8.1 software to complete the labeling task and carried out preliminary data cleaning.
4.2. Evaluation Index
- Calculation of Precision and Recall: For each class, the model computes precision and recall at varying confidence thresholds. Precision signifies the proportion of correctly identified positive samples out of all predicted positives, while recall denotes the fraction of true positives detected by the model.
- Precision–Recall Curve: precision–recall curves are constructed based on the computed precision and recall values across different confidence thresholds.
- AP Computation (Average Precision): The area under the precision–recall curve is calculated for each class, representing the average precision (AP) value for that class.
- mAP Calculation: mAP is obtained by averaging the AP values across all classes, offering an overall assessment of the model’s performance across the entire dataset.
- mAP serves as a holistic performance metric, providing a unified evaluation of detection outcomes for diverse object classes, thereby offering a comprehensive assessment. In the context of training and optimizing object detection models, achieving a high mAP typically indicates superior performance in detecting objects across multiple categories.
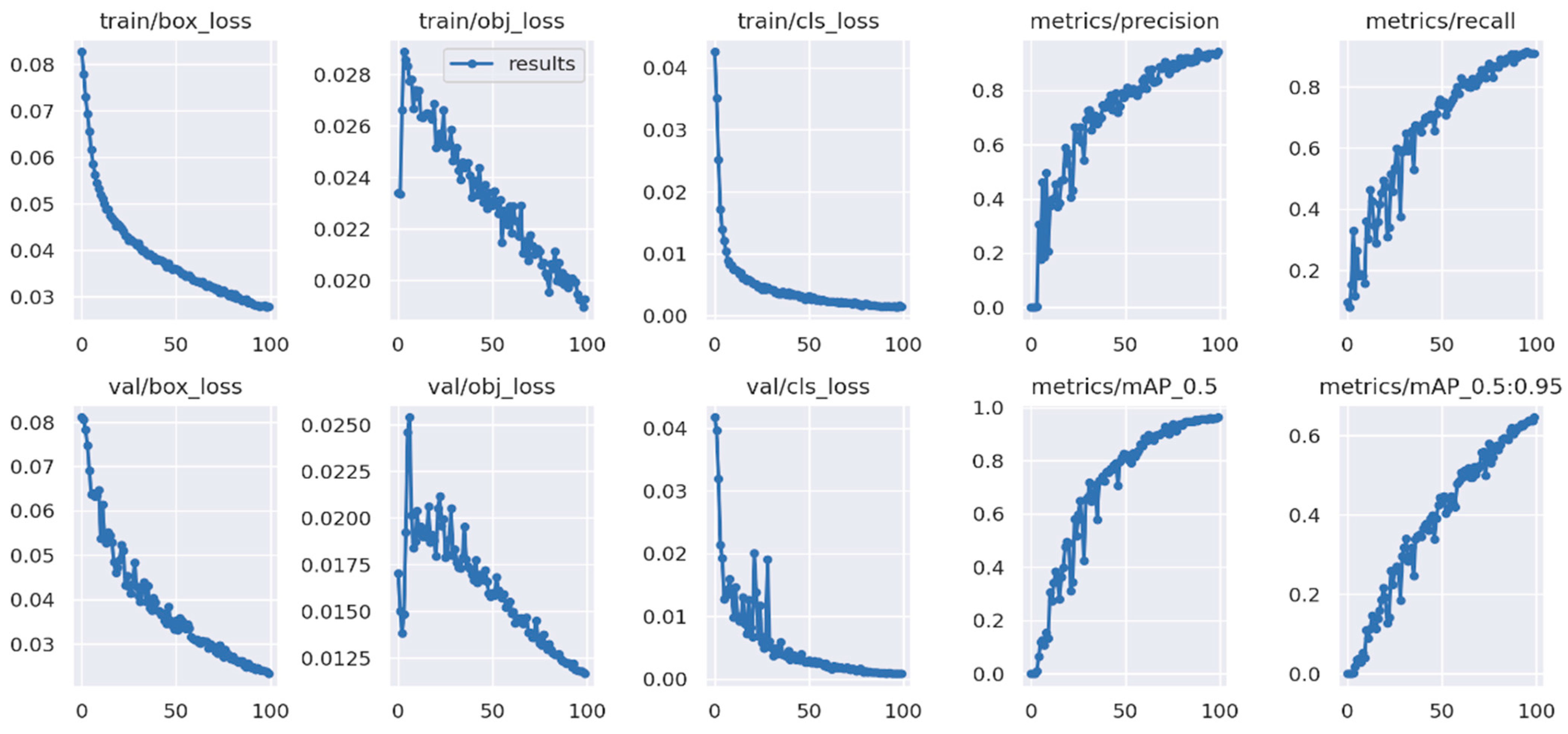
4.3. Ablation Study
- Feature ablation:
- b.
- Model evaluation:
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OS | CPU | GPU | Memory |
|---|---|---|---|
| WINDOWS 11 | I7 13,700 KF 3.4 GHZ | RTX3060TI-8G | DDR5 32 G 5600 MHZ |


References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, VA, USA, 17–21 June 2016. [Google Scholar]
- Demasi, F.; Loprencipe, G.; Moretti, L. Road safety analysis of urban roads: Case study of an Italian municipality. Safety 2018, 4, 58. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Robust real-time face detection. In Proceedings of the Procedures Eight IEEE International Conference on Computer Vision ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; p. 747. [Google Scholar] [CrossRef]
- Smirnov, E.A.; Timoshenko, D.M.; Andrianov, S.N. Comparison of Regularization Methods for Imagenet Classification with Deep Revolutionary Neural Networks. AASRI Procedia 2014, 6, 89–94. [Google Scholar] [CrossRef]
- Girshock, r. Fast R-CNN. In Proceedings of the Procedures of IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Fast R-CNN: Towards real time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollar, P.; Girsick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in DCEP revolutionary networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Procedures of European Conference on Computer Vision, Berlin, Germany, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and effective object detection. In Proceedings of the Procedures of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Chaurasia, A.; Xie, T.; Liu, C.; Abhiram; Laughing; tkianai; yxNONG; et al. ultralyt-ics/YOLOv5: v5.0—YOLOv5-p6 1280 Models, AWS, su-visit.ly and Youtube Integrations. Zenodo. 2021; Available online: https://www.semanticscholar.org/paper/ultralytics-yolov5%3A-v5.0-YOLOv5-P6-1280-models%2C-and-Jocher-Stoken/fd550b29c0efee17be5eb1447fddc3c8ce66e838 (accessed on 23 November 2023).
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y. YOLO4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.027672018. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Li, P.; Shan, S.; Zeng, P.; Wei, H. Improved YOLOv5 algorithm for surface defect detection of solar cell. In Proceedings of the 35th China Control and Decision Making Conference, Yichang, China, 20–22 May 2023; pp. 379–383. [Google Scholar]
- Zhang, L.; Satta, R.; Merialdo, B. Road damage detection and classification in smartphone images. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Guo, X.; Hu, B.; Hu, L.; Yang, Z.; Huang, L.; Li, P. Pavement Crack Detection Method Based on Deep Learning Models. Wirel. Commun. Mob. Comput. 2021, 2021, 13. [Google Scholar] [CrossRef]
- Singh, J.; Shekhar, S. Road Damage Detection and Classification in Smartphone Captured Images Using Mask R-CNN. arxiv 2018, arXiv:1811.04535. [Google Scholar]
- Verma, A.; Jain, A. Road damage detection and classification using convolutional neural networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2018. [Google Scholar]
- Zhou, S.; Yuan, Y.; Guo, C.; Li, J.; Lei, Z. A road crack detection method based on deep learning. IEEE Access 2019, 7, 31560–31569. [Google Scholar]
- Bochkovskiy, A.; Chien, Y.W.; Hong, Y.; Liao, M. YOLOv5: End to end real time object detection with YOLO. arXiv 2021, arXiv:2103.06317. [Google Scholar]
- Sadeghi, F.; Balog, M.; Popovic, M.; Gross, M. Gated activation functions. In Proceedings of the Advances in Neural Information Processing Systems (NEurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surmounting human level performance on Imagenet classification. In Proceedings of the Procedures of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chille, 7–13 December 2015. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D. Training data effective image transformers & disintegration through attention. arXiv 2020, arXiv:2012.12877. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014; Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; Volume 8689. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swing transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Arya, D.; Maeda, H.; Kumar Ghosh, S.; Toshniwal, D.; Omata, H.; Kashiyama, T.; Sekimoto, Y. Crowdsensing-Based Road Damage Detection Challenge (CRDDC’2022). In Proceedings of the 2022 IEEE International Conference on Big Data (IEEE Big Data), Osaka, Japan, 17–20 December 2022; pp. 6378–6386. Available online: https://github.com/sekilab/RoadDamageDetector/ (accessed on 23 November 2023).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arxiv 2015, arXiv:1502.03167. [Google Scholar]
- Yang, W.; Wu, H.; Tang, C.; Lv, J. YOLOv5: Improved YOLOv5 based on swing transformer and coordinated attention for surface defect detection. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, QLD, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, I.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Prahar, M.B.; Malhan, R.; Rajendran, P.; Shah, B.; Thakar, S.; Yoon, Y.J.; Gupta, S.K. Image-based surface defect detection using deep learning: A review. J. Comput. Inf. Sci. Eng. 2021, 21, 040801. [Google Scholar]
- Tian, C.; Leng, B.; Hou, X.; Huang, Y.; Zhao, W.; Jin, D.; Xiong, L.; Zhao, J. Robust Identification of Road Surface Condition Based on Ego-Vehicle Trajectory Reckoning. Automot. Innov. 2022, 5, 376–387. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R. Biformer: Vision transformer with bi level routing attention. arXiv 2023, arXiv:2303.08810. [Google Scholar]
- Deng, H.; Zhao, Y.; Wang, Q.; Nguyen, A.-T. Deep Reinforcement Learning Based Decision-Making strategy of Autonomous Vehicle in Highway Uncertain Driving Environments. Automot. Innov. 2023, 6, 438–452. [Google Scholar] [CrossRef]
- Lucente, G.; Dariani, R.; Schindler, J.; Ortgiese, M. A Bayesian Approach with Prior Mixed strategy Nash Equilibrium for Vehicle Intention Prediction. Automot. Innov. 2023, 6, 425–437. [Google Scholar] [CrossRef]
- Nguyen, S.D.; Tran, T.S.; Tran, V.P.; Lee, H.J.; Piran, M.J.; Le, V.P. Deep learning-based crack detection: A survey. Int. J. Pavement Res. Technol. 2023, 16, 943–967. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]

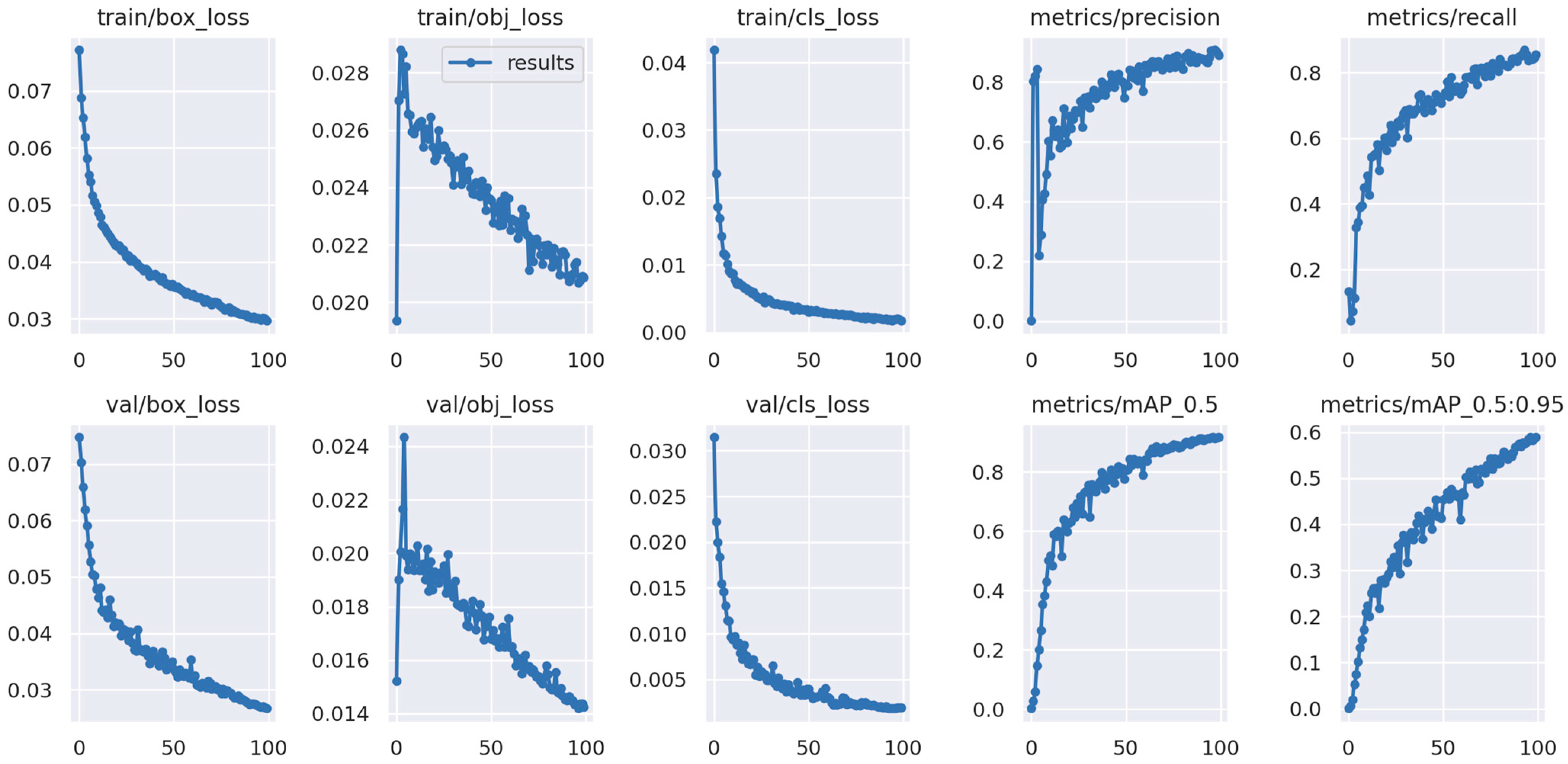
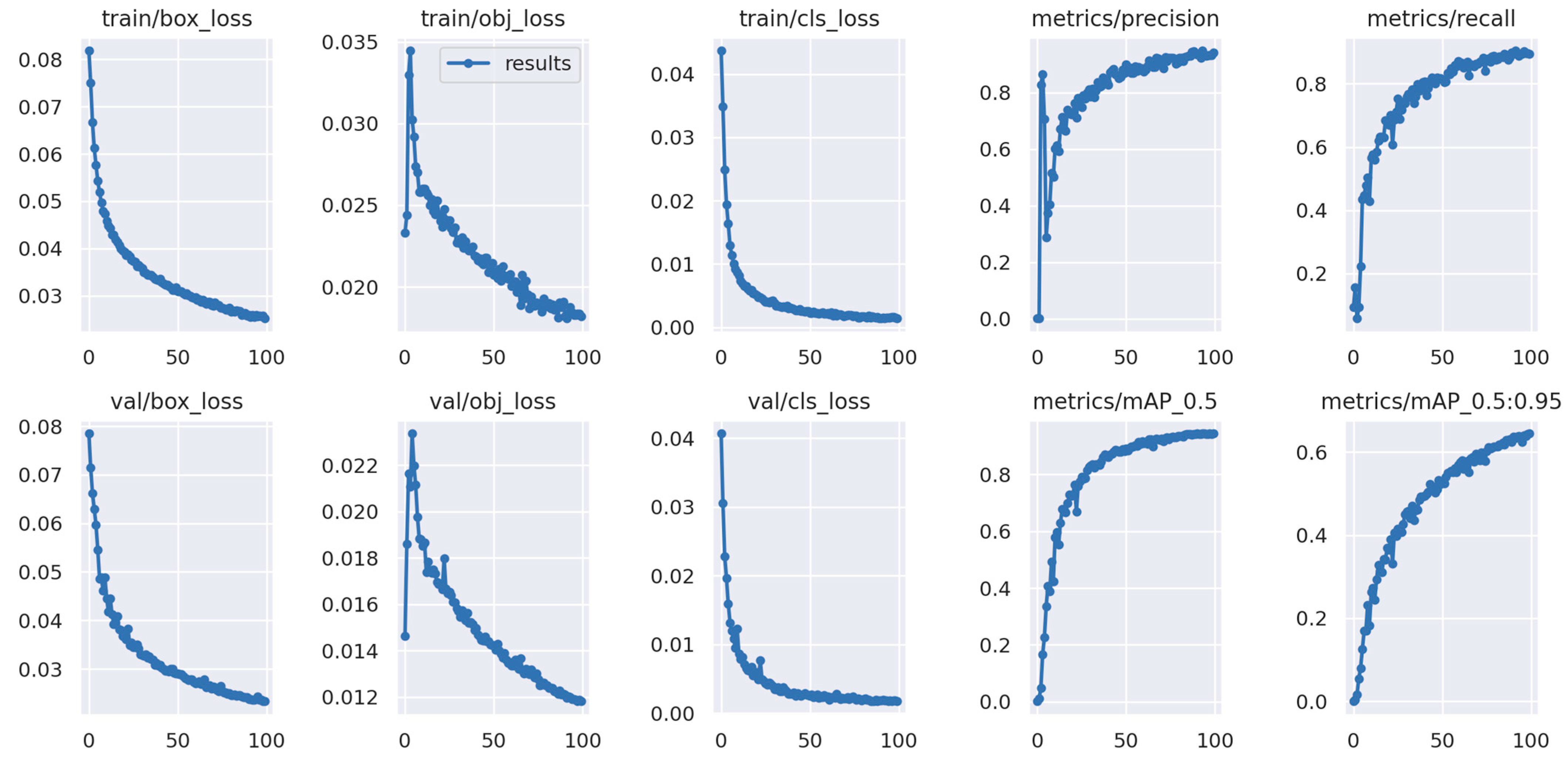
| P/% | R/% | Map-50/% | F1/% | |
|---|---|---|---|---|
| YOLOv5n | 90.0 | 90.3 | 91.7 | 38.1 |
| YOLOv5s | 90.2 | 90.9 | 94.4 | 44.2 |
| YOLOv5 + Leaky ReLU | 93.7 | 94.2 | 95.5 | 43.5 |
| YOLOv5 + Leaky ReLU + C3-TST | 91.2 | 95.3 | 95.4 | 39.6 |
| YOLOv5 + Leaky ReLU + C3-TST + bi-head | 89.8 | 96.3 | 96.4 | 46.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, J.; Yang, X.; Zhang, T.; Bi, S. BI-TST_YOLOv5: Ground Defect Recognition Algorithm Based on Improved YOLOv5 Model. World Electr. Veh. J. 2024, 15, 102. https://doi.org/10.3390/wevj15030102
Qin J, Yang X, Zhang T, Bi S. BI-TST_YOLOv5: Ground Defect Recognition Algorithm Based on Improved YOLOv5 Model. World Electric Vehicle Journal. 2024; 15(3):102. https://doi.org/10.3390/wevj15030102
Chicago/Turabian StyleQin, Jiahao, Xiaofeng Yang, Tianyi Zhang, and Shuilan Bi. 2024. "BI-TST_YOLOv5: Ground Defect Recognition Algorithm Based on Improved YOLOv5 Model" World Electric Vehicle Journal 15, no. 3: 102. https://doi.org/10.3390/wevj15030102
APA StyleQin, J., Yang, X., Zhang, T., & Bi, S. (2024). BI-TST_YOLOv5: Ground Defect Recognition Algorithm Based on Improved YOLOv5 Model. World Electric Vehicle Journal, 15(3), 102. https://doi.org/10.3390/wevj15030102