
Land Cover Mapping Using Sentinel-1 Time-Series Data and Machine-Learning Classifiers in Agricultural Sub-Saharan Landscape



Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Sentinel-1 Data
2.3. Processing
2.4. PCA
2.5. RF, K-D Tree KNN, and MLL Classifiers
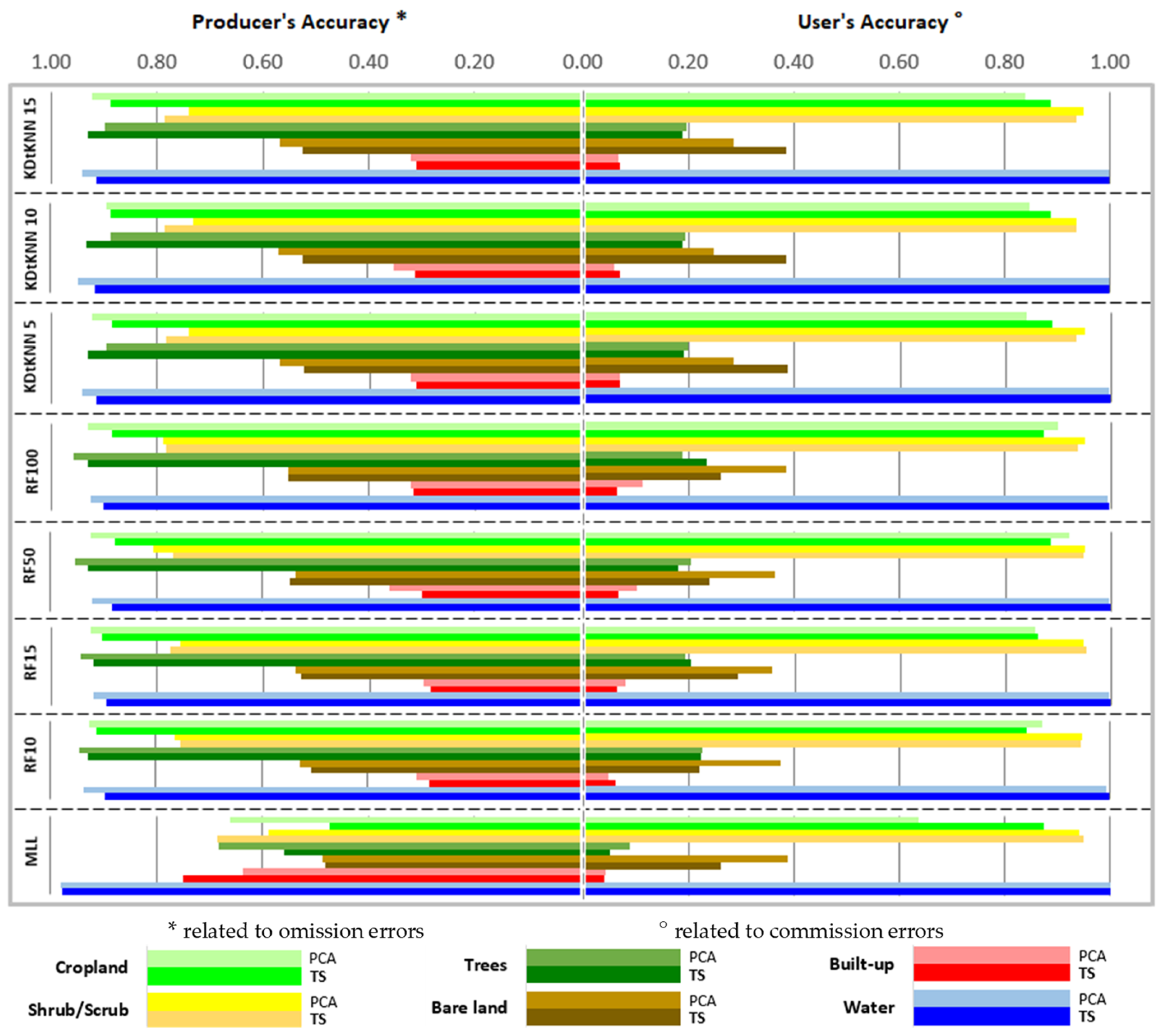
3. Results and Discussions
3.1. PCA
3.2. Assessment of Different Classification Methods and Input Parameters
3.3. Land Cover Mapping
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAO. The Future of Food and Agriculture: Trends and Challenges; Food and Agriculture Organization of the United Nations: Rome, Italy, 2017; p. 163. [Google Scholar]
- Thenkabail, P.S. Global Croplands and their Importance for Water and Food Security in the Twenty-first Century: Towards an Ever Green Revolution That Combines a Second Green Revolution with a Blue Revolution. Remote Sens. 2010, 2, 2305–2312. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; Bayas, J.C.L.; Waldner, F.; Jacques, D.; Becker-Reshef, I.; Whitcraft, A.; Baruth, B.; Bonifacio, R.; Crutchfield, J.; et al. A comparison of global agricultural monitoring systems and current gaps. Agric. Syst. 2019, 168, 258–272. [Google Scholar] [CrossRef]
- Saah, D.; Tenneson, K.; Poortinga, A.; Nguyen, Q.; Chishtie, F.; Aung, K.S.; Markert, K.N.; Clinton, N.; Anderson, E.R.; Cutter, P.; et al. Primitives as building blocks for constructing land cover maps. Int. J. Appl. Earth Obs. Geoinf. 2020, 85, 101979. [Google Scholar] [CrossRef]
- Ngo, K.D.; Lechner, A.M.; Vu, T.T. Land cover mapping of the Mekong Delta to support natural resource management with multi-temporal Sentinel-1A synthetic aperture radar imagery. Remote Sens. Appl. Soc. Environ. 2020, 17, 100272. [Google Scholar] [CrossRef]
- Nijhawan, R.; Joshi, D.; Narang, N.; Mittal, A.; Mittal, A. A Futuristic Deep Learning Framework Approach for Land Use-Land Cover Classification Using Remote Sensing Imagery. In Advanced Computing and Communication Technologies; Springer: Singapore, 2019; pp. 87–96. [Google Scholar]
- Zhang, C.; Li, X. Land Use and Land cover Mapping in the Era of Big Data. Land 2022, 11, 1692. [Google Scholar] [CrossRef]
- Ohki, M.; Shimada, M. Large-Area Land Use and Land Cover Classification with Quad, Compact, and Dual Polarization SAR Data by PALSAR-2. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5550–5557. [Google Scholar] [CrossRef]
- Dingle Robertson, L.; Davidson, A.M.; McNairn, H.; Hosseini, M.; Mitchell, S.; de Abelleyra, D.; Verón, S.; le Maire, G.; Plannells, M.; Valero, S.; et al. C-band synthetic aperture radar (SAR) imagery for the classification of diverse cropping systems. Int. J. Remote Sens. 2020, 41, 9628–9649. [Google Scholar] [CrossRef]
- Prudente, V.H.R.; Sanches, I.D.; Adami, M.; Skakun, S.; Oldoni, L.V.; Xaud, H.A.M.; Xaud, M.R.; Zhang, Y. SAR Data for Land Use Land Cover Classification in a Tropical Region with Frequent Cloud Cover. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 4100–4103. [Google Scholar]
- Denize, J.; Hubert-Moy, L.; Betbeder, J.; Corgne, S.; Baudry, J.; Pottier, E. Evaluation of Using Sentinel-1 and -2 Time-Series to Identify Winter Land Use in Agricultural Landscapes. Remote Sens. 2019, 11, 37. [Google Scholar] [CrossRef]
- Pham, L.H.; Pham, L.T.H.; Dang, T.D.; Tran, D.D.; Dinh, T.Q. Application of Sentinel-1 data in mapping land-use and land cover in a complex seasonal landscape: A case study in coastal area of Vietnamese Mekong Delta. Geocarto Int. 2021, 37, 3743–3760. [Google Scholar] [CrossRef]
- Fonteh, M.L.; Theophile, F.; Cornelius, M.L.; Main, R.; Ramoelo, A.; Cho, M.A. Assessing the Utility of Sentinel-1 C Band Synthetic Aperture Radar Imagery for Land Use Land Cover Classification in a Tropical Coastal Systems When Compared with Landsat 8. J. Geogr. Inf. Syst. 2016, 8, 495–505. [Google Scholar] [CrossRef]
- Kpienbaareh, D.; Sun, X.; Wang, J.; Luginaah, I.; Bezner Kerr, R.; Lupafya, E.; Dakishoni, L. Crop Type and Land Cover Mapping in Northern Malawi Using the Integration of Sentinel-1, Sentinel-2, and PlanetScope Satellite Data. Remote Sens. 2021, 13, 700. [Google Scholar] [CrossRef]
- Carrasco, L.; O’Neil, A.W.; Morton, R.D.; Rowland, C.S. Evaluating Combinations of Temporally Aggregated Sentinel-1, Sentinel-2 and Landsat 8 for Land Cover Mapping with Google Earth Engine. Remote Sens. 2019, 11, 288. [Google Scholar] [CrossRef]
- Hu, B.; Xu, Y.; Huang, X.; Cheng, Q.; Ding, Q.; Bai, L.; Li, Y. Improving Urban Land Cover Classification with Combined Use of Sentinel-2 and Sentinel-1 Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 533. [Google Scholar] [CrossRef]
- Steinhausen, M.J.; Wagner, P.D.; Narasimhan, B.; Waske, B. Combining Sentinel-1 and Sentinel-2 data for improved land use and land cover mapping of monsoon regions. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 595–604. [Google Scholar] [CrossRef]
- Lopes, M.; Frison, P.-L.; Crowson, M.; Warren-Thomas, E.; Hariyadi, B.; Kartika, W.D.; Agus, F.; Hamer, K.C.; Stringer, L.; Hill, J.K.; et al. Improving the accuracy of land cover classification in cloud persistent areas using optical and radar satellite image time series. Methods Ecol. Evol. 2020, 11, 532–541. [Google Scholar] [CrossRef]
- Li, Q.; Qiu, C.; Ma, L.; Schmitt, M.; Zhu, X.X. Mapping the Land Cover of Africa at 10 m Resolution from Multi-Source Remote Sensing Data with Google Earth Engine. Remote Sens. 2020, 12, 602. [Google Scholar] [CrossRef]
- USAID. Climate Change Adaptation in Senegal; InTech: Singapore, 2012; ISBN 978-953-51-0747-7. [Google Scholar]
- ANSD. Agence Nationale de la Statistique et de la Démographie; ANSD: Singapore, 2016. [Google Scholar]
- Dobrinić, D.; Gašparović, M.; Medak, D. Sentinel-1 and 2 Time-Series for Vegetation Mapping Using Random Forest Classification: A Case Study of Northern Croatia. Remote Sens. 2021, 13, 2321. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10 m 2020 v100. 2021. Available online: https://doi.org/10.5281/zenodo.5571936 (accessed on 28 July 2022).
- Pereira, L.O.; Freitas, C.C.; Sant´Anna, S.J.S.; Reis, M.S. Evaluation of Optical and Radar Images Integration Methods for LULC Classification in Amazon Region. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3062–3074. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Meng, Q.; Cieszewski, C.J.; Madden, M.; Borders, B.E. K Nearest Neighbor Method for Forest Inventory Using Remote Sensing Data. GIScience Remote Sens. 2007, 44, 149–165. [Google Scholar] [CrossRef]
- Cao, X.; Wei, C.; Han, J.; Jiao, L. Hyperspectral Band Selection Using Improved Classification Map. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2147–2151. [Google Scholar] [CrossRef]
- Paul, S.; Kumar, D.N. Evaluation of Feature Selection and Feature Extraction Techniques on Multi-Temporal Landsat-8 Images for Crop Classification. Remote Sens. Earth Syst. Sci. 2019, 2, 197–207. [Google Scholar] [CrossRef]
- Schulz, D.; Yin, H.; Tischbein, B.; Verleysdonk, S.; Adamou, R.; Kumar, N. Land use mapping using Sentinel-1 and Sentinel-2 time series in a heterogeneous landscape in Niger, Sahel. ISPRS J. Photogramm. Remote Sens. 2021, 178, 97–111. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef]
- Feng, Q.; Liu, J.; Gong, J. UAV Remote Sensing for Urban Vegetation Mapping Using Random Forest and Texture Analysis. Remote Sens. 2015, 7, 1074. [Google Scholar] [CrossRef]
- Qian, Y.; Zhou, W.; Yan, J.; Li, W.; Han, L. Comparing Machine Learning Classifiers for Object-Based Land Cover Classification Using Very High Resolution Imagery. Remote Sens. 2015, 7, 153. [Google Scholar] [CrossRef]
- Dong, S.; Gao, B.; Pan, Y.; Li, R.; Chen, Z. Assessing the suitability of FROM-GLC10 data for understanding agricultural ecosystems in China: Beijing as a case study. Remote Sens. Lett. 2020, 11, 11–18. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Month | Day (Scene 1,4/Scene 2,3) | Polarization | Orbit | Mean Incidence Angle |
|---|---|---|---|---|
| January | 04-01-2020/11-01-2020 | VH | Ascending | 38.415 |
| February | 04-02-2020/09-02-2020 | VH | Ascending | 38.415 |
| March | 11-03-2020/16-03-2020 | VH | Ascending | 38.430 |
| April | 04-04-2020/09-04-2020 | VH | Ascending | 38.420 |
| May | 03-05-2020/10-05-2020 | VH | Ascending | 38.435 |
| June | 15-06-2020/20-06-2020 | VH | Ascending | 38.434 |
| July | 21-07-2020/26-07-2020 | VH | Ascending | 38.421 |
| August | 14-08-2020/19-08-2020 | VH | Ascending | 38.418 |
| September | 19-09-2020/24-09-2020 | VH | Ascending | 38.434 |
| October | 13-10-2020/18-10-2020 | VH | Ascending | 38.434 |
| November | 23-11-2020/28-11-2020 | VH | Ascending | 38.416 |
| December | 24-12-2020/29-12-2020 | VH | Ascending | 38.417 |
| Reference Data | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Classes | Cropland | Shrub/ Scrub | Trees | Bare Land | Built-up | Water | Row Total | U Accuracy | Errors of Commission |
| Cropland | 96,299 | 7731 | 5 | 512 | 2 | 0 | 104,549 | 0.92 | 7.89 |
| Shrub/Scrub | 6891 | 166,531 | 62 | 1757 | 208 | 0 | 175,449 | 0.95 | 5.08 |
| Trees | 588 | 22,072 | 6120 | 19 | 1148 | 0 | 29,947 | 0.20 | 79.56 |
| Bare land | 383 | 3634 | 0 | 2713 | 0 | 715 | 7445 | 0.36 | 63.56 |
| Built-up | 6 | 6390 | 227 | 20 | 764 | 0 | 7407 | 0.10 | 89.69 |
| Water | 0 | 19 | 0 | 18 | 0 | 8583 | 8620 | 1.00 | 0.43 |
| Column Total | 104,167 | 206,377 | 6414 | 5039 | 2122 | 9298 | 333,417 | ||
| P Accuracy | 0.92 | 0.81 | 0.95 | 0.54 | 0.36 | 0.92 | Overall Accuracy | 0.84 | |
| Errors of Omission | 7.55 | 19.31 | 4.58 | 46.16 | 64.00 | 7.69 | Kappa Coefficient | 0.73 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dahhani, S.; Raji, M.; Hakdaoui, M.; Lhissou, R. Land Cover Mapping Using Sentinel-1 Time-Series Data and Machine-Learning Classifiers in Agricultural Sub-Saharan Landscape. Remote Sens. 2023, 15, 65. https://doi.org/10.3390/rs15010065
Dahhani S, Raji M, Hakdaoui M, Lhissou R. Land Cover Mapping Using Sentinel-1 Time-Series Data and Machine-Learning Classifiers in Agricultural Sub-Saharan Landscape. Remote Sensing. 2023; 15(1):65. https://doi.org/10.3390/rs15010065
Chicago/Turabian StyleDahhani, Sara, Mohamed Raji, Mustapha Hakdaoui, and Rachid Lhissou. 2023. "Land Cover Mapping Using Sentinel-1 Time-Series Data and Machine-Learning Classifiers in Agricultural Sub-Saharan Landscape" Remote Sensing 15, no. 1: 65. https://doi.org/10.3390/rs15010065
APA StyleDahhani, S., Raji, M., Hakdaoui, M., & Lhissou, R. (2023). Land Cover Mapping Using Sentinel-1 Time-Series Data and Machine-Learning Classifiers in Agricultural Sub-Saharan Landscape. Remote Sensing, 15(1), 65. https://doi.org/10.3390/rs15010065