1. Introduction
In comparison to fifth-generation (5G) wireless communication networks, 6G networks are expected to have much higher spectral, energy, and cost efficiency, with higher data rates (in Tbps), latency reduced by a factor of ten, connection density increased by a factor of a hundred, and increased intelligence for full automation. Innovations such as index modulation (IM), reconfigurable intelligent surfaces (RISs), non-orthogonal multiple access (NOMA), and artificial intelligence (AI) will all be introduced into 6G networks to fulfill these overall objectives [
1,
2,
3,
4,
5,
6]. Massive MIMO designs can increase the spectral efficiency (SE) of 6G systems because of the higher frequencies and dense networks. In 6G, technologies like SM, RIS, NOMA, orbital angular momentum, and rate splitting multiple access have the potential to increase SE [
7].
The energy efficiency (EE) of wireless networks may be enhanced by using four major approaches: (1) Resource allocation. Rather than maximizing throughput, the EE of the network is optimized by efficiently distributing resources [
8]. (2) Instead of simply increasing the coverage area, the second option employs infrastructure nodes to increase the network’s EE. (3) Use renewable energy sources to power communication systems. (4) Design energy-efficient hardware solutions. In a network, IM and its derivatives can also be utilized to shoot up EE [
9,
10].
Massive MIMO is an essential technique for achieving the SE requirements of 5G. When adopting a multi-antenna system, two issues arise: inter-antenna synchronization (IAS) and inter-channel interference (ICI) [
11]. With more radio frequency (RF) links, the hardware complexity of the system grows, lowering EE [
12]. To overcome this problem, the concept of SM has been presented [
9,
10]. Because one antenna is functional at a time, the RF chain is simpler to handle in SM [
9,
10,
11].
SM’s SE is given by
where the number of transmit antennas and modulation order are denoted by
and
M, respectively. The SE of SM is proportional to
. As a result, in order to enhance SE, a higher proportion of transmit antennas is required. SM cannot satisfy SE demands since only one antenna is simultaneously active [
11]. High-rate SM variants are needed for future-generation networks to meet SE requirements [
13]. The high-rate SM variants may transmit the same or distinct symbols at the same time across multiple antennas, depending on their operating principle. FGSM is a cutting-edge SM variant in which the transmitter uses just one or several, or all of its antennas for transmission [
13]. As a result, the possible SE grows linearly with
. Gudla V.V. et al. briefly discussed the system architecture and functioning theory of FGSM [
13].
Transmit diversity gain could not be achieved in SM since only one antenna is fully functional at once [
14,
15,
16,
17]. The integration of TAS practices into SM improves its transmit diversity. The receiver decides on transmitter antenna subsets driven by the channel quality information (CQI). In ML, machines are taught new skills so that they may execute tasks on their own using data. In terms of planning and optimizing future-generation networks, ML plays a critical role. ML may be used to solve a wide range of technical difficulties in future-generation systems, including massive MIMO, NOMA, device-to-device (D2D) networks, etc. [
2,
3]. The present research performs TAS on FGSM using ML algorithms, and the effectiveness of these algorithms is evaluated using classification accuracy and ABER.
Related Work
The future-generation network demands improvements in EE and SE [
1]. The SE of SM is proportional to
, which lowers the performance of SM in terms of SE [
9,
10]. To overcome this, high-rate versions of SM are developed [
13]. FGSM is a high-rate variation of SM, where transmit antennas and SE are linearly related and could meet the expanding demands of 6G [
13].
Lower-powered integrated circuits, antenna diversity, or a mix of the two, may be adopted to boost EE [
18]. The traditional SM technique does not provide transmit diversity gain. TAS practices have been incorporated to boost the SM system’s transmit diversity gain [
14]. TAS approaches are applied to overcome the cost and complexity challenges in massive MIMO systems [
12]. Different massive MIMO configurations have shown that antenna selection can improve performance and lower RF costs [
19]. For optimal channel utilization, a novel SM technique is developed by fusing transmit mode switching and adaptive modulation techniques [
20]. The free distance (FD) strategy is computationally more expensive due to the requirement of simultaneously searching for antenna pairs and constellation orders that maximize the least FD. Although FD-TAS provides the best EE performance, its implementation is more challenging. The FD-TAS system has gained popularity and is used as a benchmark in many TAS-related articles [
3,
13,
14,
15,
16,
17,
21].
A capacity-optimized antenna selection (COAS) technique is addressed in conjunction with FD-TAS, where the antenna subset with the most prominent channel capacity is chosen [
13,
14,
15,
17]. The correlation angle of two antennas is used to evaluate the TAS [
13,
16]. In this study, the antenna subset with the least correlation is prioritized. The capacity and correlation angle-based technique is proposed to enhance ABER performance [
13] while increasing computing complexity. A partitioning strategy that relies on the capacity and correlation angle further reduces the system’s complexity [
13]. Sub-optimal techniques are less efficient than FD-TAS when it comes to TAS in SM and its variants [
13,
14,
15,
16,
17].
To save the computations offered by FD-TAS, nowadays data-driven approaches are utilized. TAS is a classification problem that can be solved using supervised ML algorithms. A pattern recognition-based approach is proposed for traditional MIMO [
22]. This work is tested for 5000 samples with KNN and SVM algorithms. This work can be extended further to various supervised learning algorithms and larger datasets to boost the overall system performance. Two unique features of the channel space are the element norm of
and element norm of
, which are used to analyze the performance of these algorithms. The absolute of elements of
is used to analyze NB- and SVM-based TAS algorithms in conventional MIMO architecture [
23]. The purpose of this research is to demonstrate how ML can be utilized to enhance the security of MIMO architecture. In the future, other ML algorithms could be employed to carry out this research. In this example, the algorithms are only trained on 10,000 samples; nevertheless, this number can be increased to improve overall efficiency.
To solve power assignment problems in adaptive SM-MIMO, supervised ML algorithms and deep neural networks (DNNs) are proposed and implemented [
24]. The ABER performance in this work can be enhanced by extending the training data beyond 2000 feature label pairs. Other features, such as the angle of elements of
, real and imaginary parts of elements of
, etc., can be used as attributes to obtain better results. TAS as a classification problem is addressed using DNN and SVM for SM [
25]. To construct the models, the channel gain and correlation properties of the column space of
are retrieved. In this work, the comparison with other ML-based algorithms is not conducted with DNN and SVM. Altın, G. and Arslan, İ.A. selected both the transmit and receive antennas for SM using deep learning (DL) architectures [
26]. We used DL-based algorithms to execute TAS for FGSM in [
3] to meet the SE requirements and improve classification accuracy. The following is a list of research gaps identified:
Most of these data-driven approaches are proposed and implemented for conventional MIMO and basic SM architectures.
These data-driven strategies are neither proposed nor implemented for high-rate variants of SM.
The TAS dataset is not available for FGSM in any of the repositories.
Listed below are the key contributions of this work:
Through the repeated application of the FD-TAS algorithm, 4 different datasets (with a total of 10,000 entries) are produced. The dataset contains channel information for a variety of MIMO setups and antenna counts, as well as essential performance measures, like FD.
For FGSM, four distinct supervised ML classification methods are used and tested for TAS: SVM, NB, KNN, and DT. The dataset size, the value of k, which is used in k-fold cross-validation, and parameters, such as the kernel type and hyperparameter K, are optimized to obtain the best results.
The ABER and computational complexity of ML-based TAS approaches are contrasted to those of FGSM-NTAS and FD-TAS.
An analysis of the proposed work is carried out in terms of SNR gain and classification accuracy.
The following is how the manuscript is structured: The principle of operation of FGSM is discussed elaborately in
Section 2. The various ML algorithms used for TAS in the FGSM system are covered in
Section 3. The proposed ML-based TAS practices and the conventional FD-TAS practice are subjected to a computational complexity study in
Section 4. The ABER performance of ML-based algorithms is contrasted to the FD-TAS scheme in
Section 5.
Section 6 concludes the work by laying out future research directions.
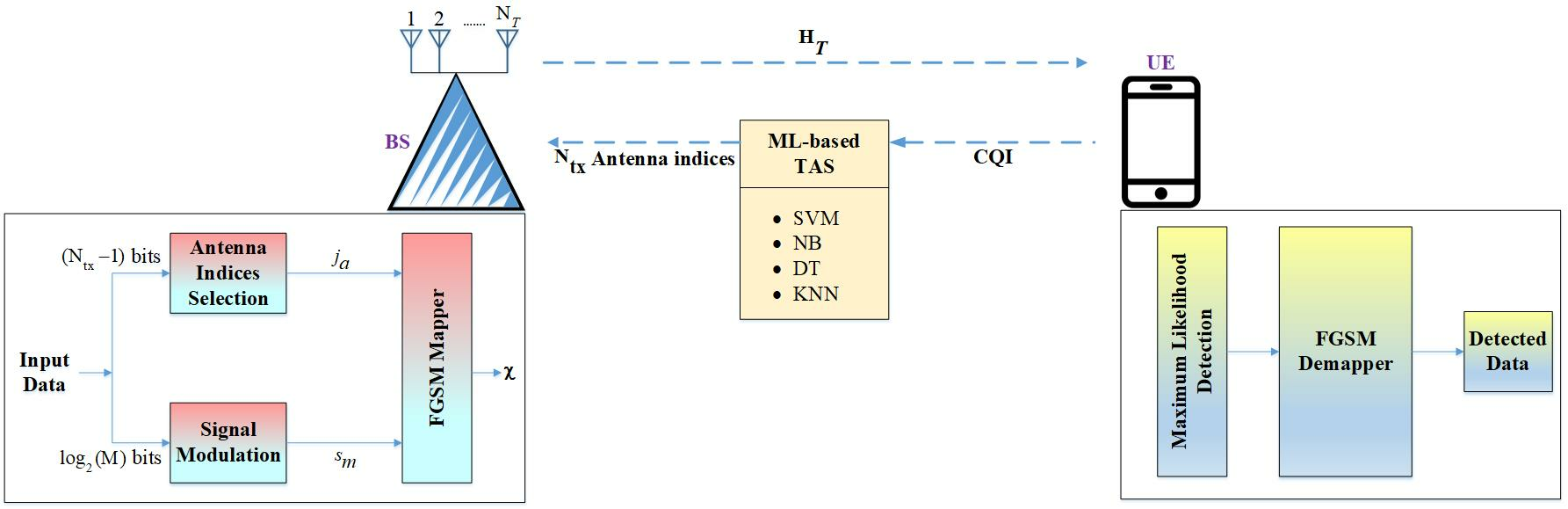
2. System Model of FGSM Transceiver
FGSM is a high-rate version of SM that allows one, many, or all antennas to transmit the same symbol at the same instant. The SE is directly proportional to
as compared to SM, which improves the SE. This variation does not require that the number of transmit antennas be a power of two. The SE of FGSM is calculated as follows:
Consider the input bits [0 0 1 1] to comprehend FGSM mapping. An example with an SE of 4 bpcu (
M = 4 and
= 3) is used to demonstrate FGSM mapping. As indicated in
Table 1, the symbol
is identified using the first
bits, i.e., [0 0]. It will be transmitted by the antenna pair (1, 2), which is selected using the next
bits, i.e., [1 1], as illustrated in
Table 2. For the given block of bits, the transmit vector generated is given by
. Consider an alternative set of bits [0 1 0 1], where the symbol
is chosen by using the first
bits [0 1], as shown in
Table 1. It will be transmitted by antenna 2, which is selected using the next
bits, i.e., [0 1], as illustrated in
Table 2. For this set of bits, the vector to be transmitted is
.
The multipath channel
and AWGN
influence the transmit vector
. At the receiver end, the signal vector
is stated as follows:
Consider the MIMO configuration
with
. For the single antenna operational configuration explained earlier, the received signal vector could be expressed as follows:
For single antenna operational case, the generalized form of the received signal is
For the double antenna operational configuration explained earlier, the received signal vector could be indicated as follows:
For the double antenna operational case, the generalized form of the received signal is given by
For the
number of functional antennas, the generalized form of the received signal is represented as follows:
When a receiver possesses perfect CQI, the maximum likelihood detection for the FGSM system with
functional antennas is given by
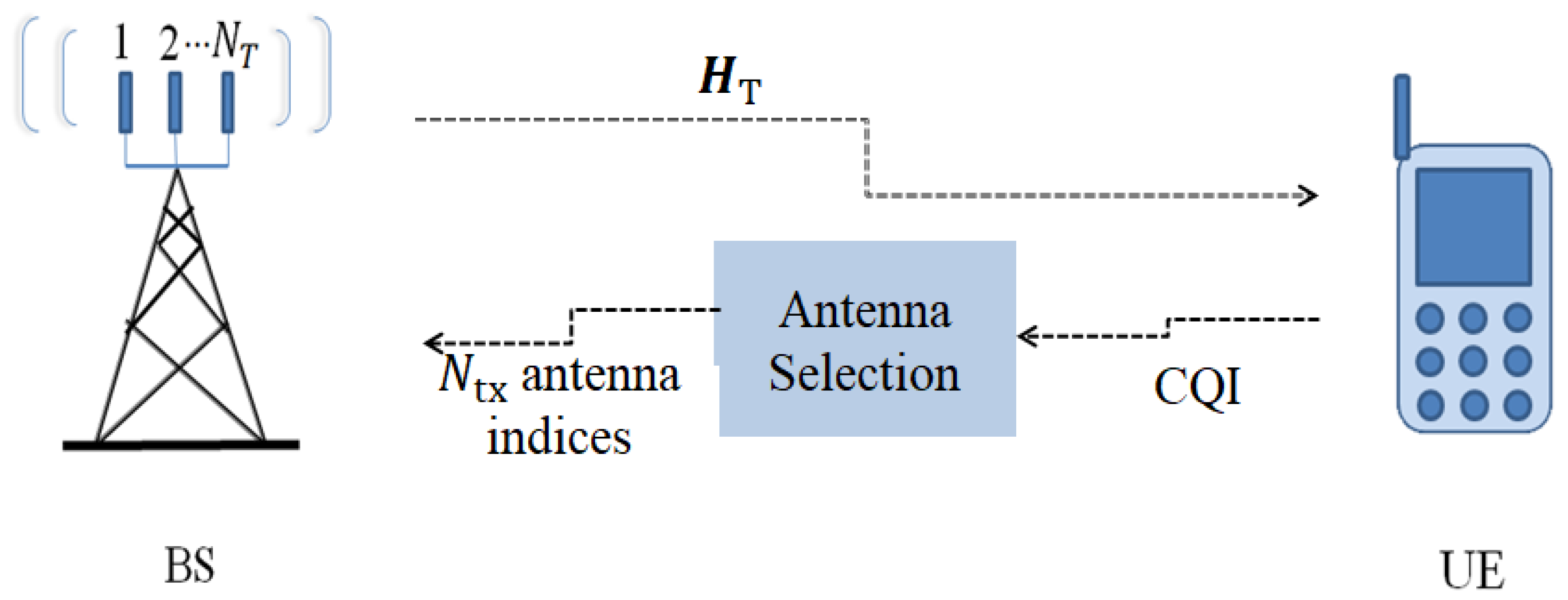
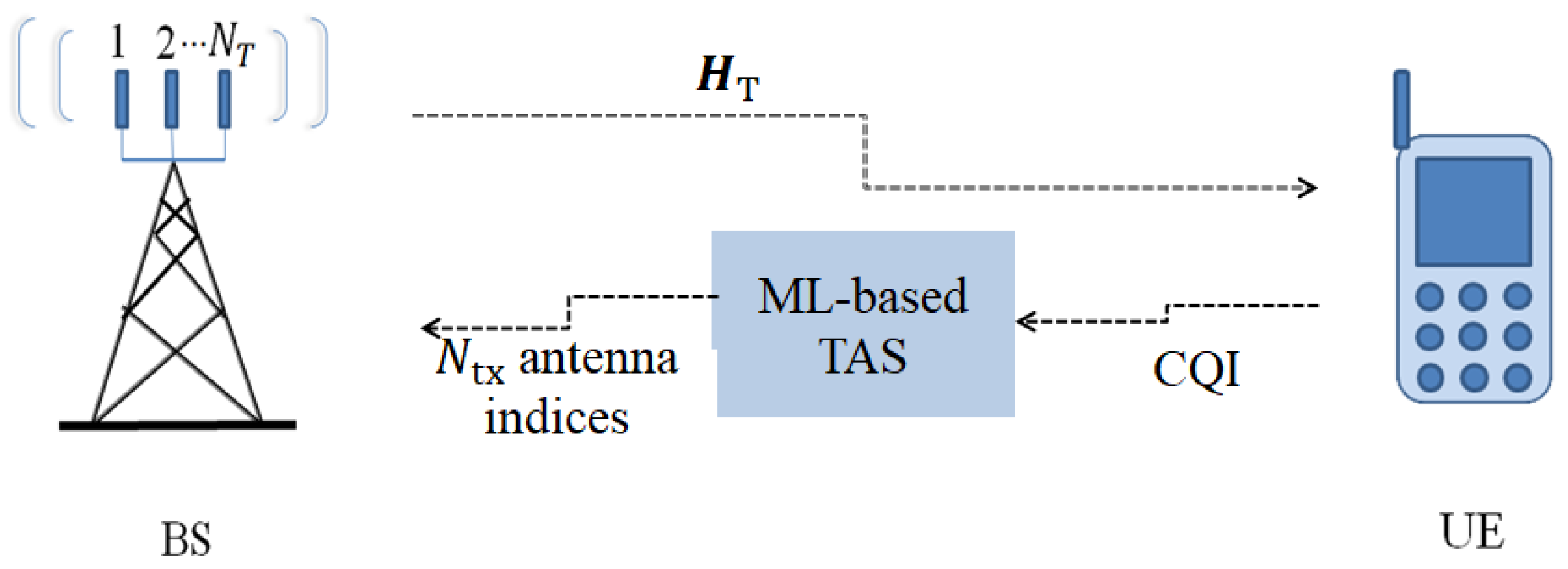
3. Antenna Selection Schemes for FGSM
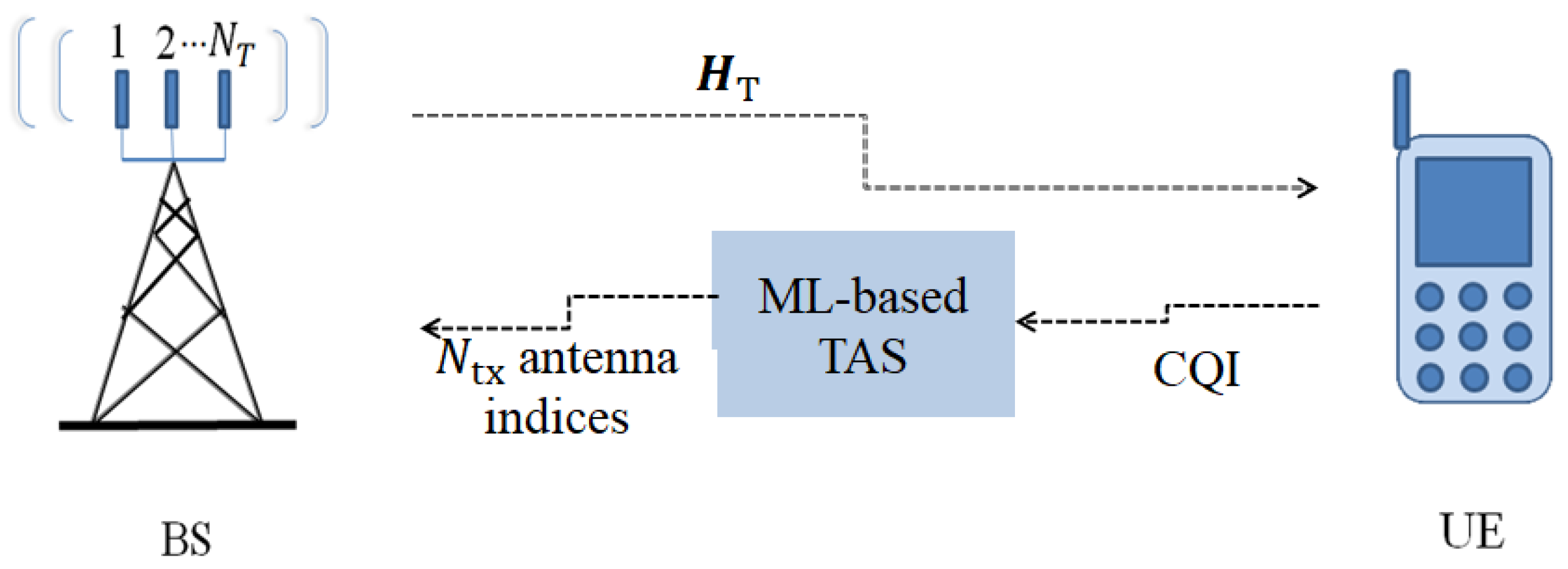
TAS for FGSM is schematically depicted in
Figure 1. TAS drives up the transmit diversity in traditional MIMO and SM, as described in the literature review section. Let
=
∼
be the channel matrix for a MIMO. Here,
are the column vectors of
. The TAS scheme is employed to select a subset from the candidate set
S=
.
antennas are picked from
antennas when the CQI is perfectly known to the user equipment (UE). There are
possible antenna subsets, each with
antennas, as given below:
where
represents the
lth possible transmit antenna subset. A low-rate feedback channel communicates the chosen subset antenna index to the base station (BS). The CQI feedback latency is assumed to be insignificant in this case. If
is selected, then the signal received is expressed as follows:
where
is the channel matrix corresponding to the selected set
. An example of the TAS candidate set mapping is illustrated in
Table 3 for
.
3.1. FD-TAS Based FGSM System
The purpose of FD-TAS is to find antenna pairs that optimize the least FD between the received constellations [
3,
13,
14,
15,
16,
17,
21]. FD-TAS results in
of size
from
of size
. FD-TAS involves the following major steps:
Step 1: Compute the number of possible subsets = .
Step 2: Determine all feasible transmit vectors for every antenna subset.
Step 3: Determine the minimum FD for every antenna subset using
here,
is the set of all feasible transmit vectors.
Step 4: Find an antenna subset that has the maximum FD.
here,
=
Based on the antenna subset index obtained in step 4, the antenna indices and the associated channel matrix of size are computed.
3.2. TAS Based on ML for FGSM
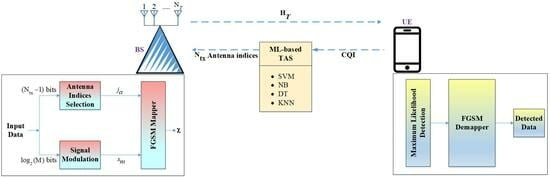
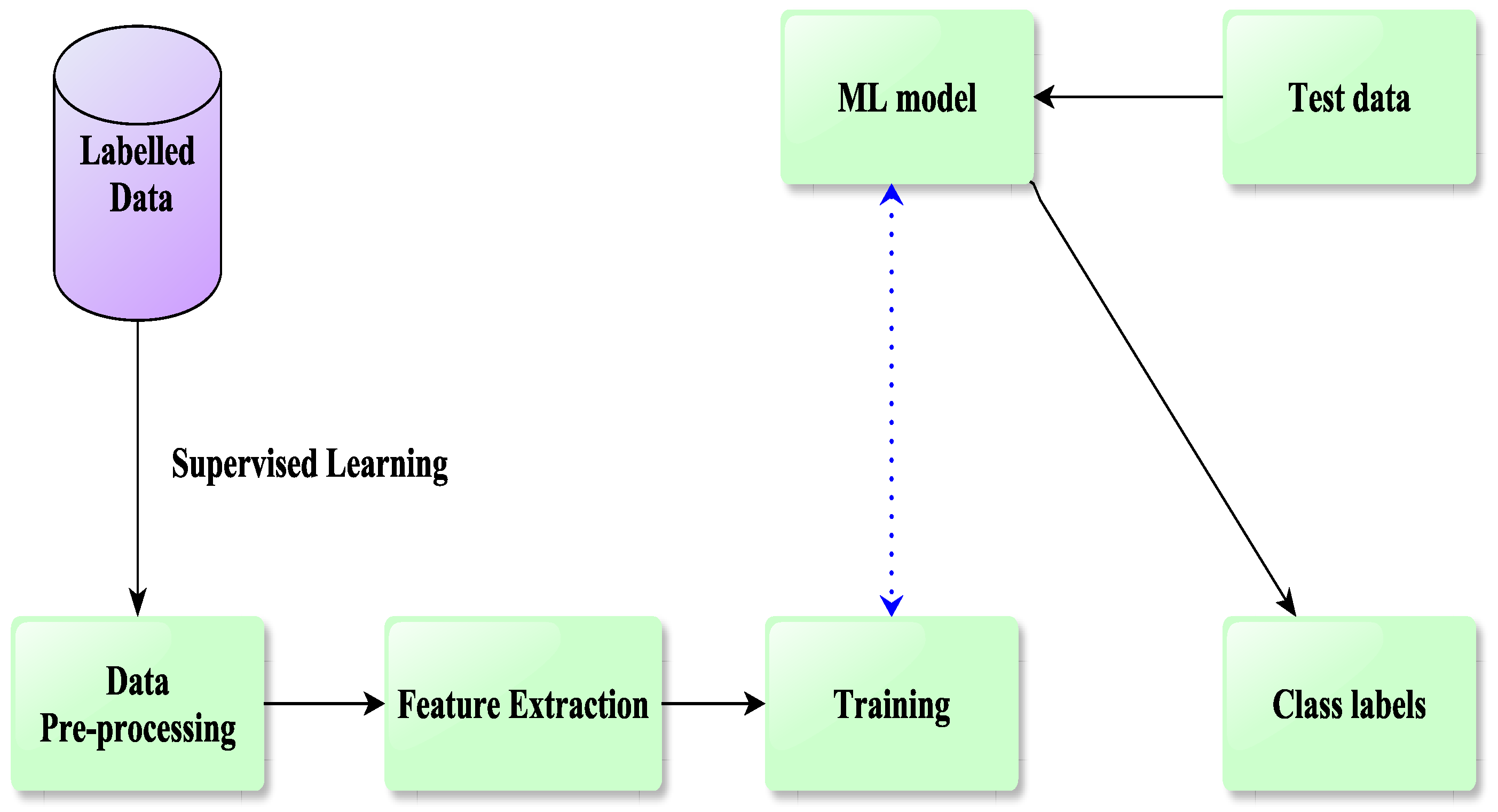
In this work, TAS in FGSM is carried out with the use of ML-based methods. An ML-based classification architecture is depicted in
Figure 2. At first, source data are normalized using the mean normalization technique. Pre-processed data are then used to extract features. Several ML methods are then used to train the model using the chosen features and class labels. A trained model can be used to predict the class labels for new data using data that have not previously been fed into the system. The process for the execution of ML-based TAS for FGSM is shown in
Figure 3. If CQI is present at the UE, the class labels obtained by the ML algorithms are utilized to choose
antennas from
. Algorithm 1 shows the processes that must be followed for ML-based TAS. This section also includes details on the dataset development process and the supervised algorithms that are employed.
| Algorithm 1 Primary steps involved in ML-based TAS |
1. Establish a mapping between the antenna subsets and class labels. 2. Pre-process the input data using the mean normalization technique. 3. Identify the key performance indicators (KPI) for each input sample. Find out the class label c on the basis of the KPI. 4. Employ the normalized feature matrix and the class label c to create a learning system utilizing SVM, NB, KNN, and DT algorithms. 5. The learning system converts the test channel to a normalized feature vector and determines the class label c. 6. Compare the class label acquired in Step 5 with the map created in Step 1 to identify the antenna subset.
|
3.3. Generation of a Dataset
Elements of channel matrices are used to generate the training dataset. A multiclass classification technique is then used to divide the channel matrix into numerous corresponding classes, each of which represents the optimal antenna subset. ML methods are used to build the model. The developed models can also be used to predict the class labels of test data.
Four major steps are involved in the collection of the dataset: (1) Generation of training data. (2) Extraction of feature vectors. (3) Evaluation of KPI. (4) Use of the KPI information to obtain the class labels.
- 1.
Generation of training data.
To form the training data, the
N number of channel matrices of size
are randomly generated.
- 2.
Extraction of feature vectors
The training performance is generally influenced by the feature vectors. In this work, four different features, i.e., , , channel gain , and channel gain of every element of the correlation matrix , are considered to train the models. From each sample , a feature of size is extracted. The process of extracting these four features is as follows:
- (a)
: The absolute value of each element of the channel matrix is considered as a dominating feature, which is used throughout this work. The extraction of the feature vector, in this case, is given as follows:
where
is a
th complex element of
, whose absolute value is calculated as follows:
- (b)
: This is the second feature that is extracted to build the model from the elements of
. The feature vector is constructed as follows:
where
- (c)
Channel gain
: The channel gain of an individual element of the matrix is considered to be another feature to train the models whose feature vector is given by:
- (d)
Squared element norm of
: In addition, the similarity between two distinct column vectors is a major feature. Similar column vectors introduce detection ambiguity while estimating the transmit antenna index. The feature vector extraction is conducted as follows:
To avoid bias, features are normalized using
- 3.
Evaluation of KPI.
Input data samples are labeled using KPI. FD is considered as the KPI in this work, which is calculated using (
14).
- 4.
Class labeling.
Associate each feature with a label. A transmit antenna subset S= is mapped to each feature vector. The feature vector corresponding to each channel matrix is mapped to label . Hence, the class label vector =.
3.4. ML Methods
This section examines four different supervised ML methods utilized for TAS.
3.4.1. SVM
An SVM model consists of a hyperplane containing representations of distinct classes in multidimensional space [
22]. SVM will iteratively create the hyperplane in order to reduce errors. SVM divides datasets into classes in order to determine the best marginal hyperplane. TAS is a multiclass classification problem. The one-versus-one and one-versus-all (OVA) approaches are two common ways of creating multiclass SVM classifiers. This work looks at how OVA can be used to overcome the drawback of complexity in FD-TAS. It creates
r binary SVMs for an
R-class problem. Specifically, for TAS-assisted FGSM,
R SVM models are generated as follows:
- •
To address this two-class classification problem for the attribute label combinations , where n=1,, r , an R order SVM is constructed. In this case, represents the nth row of the normalized attribute matrix . Samples belonging to the rth class are characterized by positive labels, while those belonging to the other classes are characterized by negative labels.
- •
The following approach is used for solving the optimization problem for the two-class SVM:
here,
and
are linear parameters,
and
are the regularization and penalty parameters, respectively, for
rth SVM. By applying kernel function
to an attribute vector in (
23), the SVM maps them into a higher-dimensional space.
In this work, the radial basis function (RBF) kernel is utilized to fit the model, which is specified by [
22]
By calculating parameters
and
for all valid
, the prediction functions obtained can be given as follows:
For a new observation
, we utilize (
17) to retrieve its feature vector as
, and (
26) to obtain its label.
3.4.2. NB
An NB classifier is a supervised ML technique that uses the Bayesian theorem to solve classification problems [
21,
27]. Consider the
N features
and
feasible classes in a classification task. One of the
classes must be assigned to the new instance
.
-conditional probabilities
,
l=1,
are computed by the NB approach. The calculation of joint probability becomes simpler if all features are independent. According to Bayes’ theorem, conditional probability is calculated as follows:
In (
28), prior probability of the
lth class is given by
. Here,
indicates the likelihood probability and
represents evidence probability. The probability of evidence is the same for all classes. As a result, this term can be discarded. Using this method, the class with the greatest probability is selected.
Equation (
29) can also be written as follows:
Here, is the qth feature of the new observation .
3.4.3. DT
Tree-structured classifiers can classify a dataset using internal nodes as attributes, branches as decision rules, and leaves as the inference [
21,
28]. Two nodes exist in a decision tree—the leaf node and the decision node. Decision nodes make decisions and have multiple branches, whereas leaf nodes generate the output of that decision process and do not contain any additional branches. In a decision tree, an initial question is asked, and based on the answer (yes/no), subtrees are constructed. The attribute value with the highest information gain will be chosen for further branching. The probability
of a sample being owned by a specific class
l is computed using
here,
is the number of occurrences in
. freq
represents the number of samples owned by a particular class
l. An entropy of
is given as
The dataset
is split into
X partitions depending on the domain values of a non-class attribute
. The entropy associated with this is determined using
For attribute
, information gain is computed using
The information gain is computed for every feature–value combination. When splitting the root node, the feature–value combination that yields the highest information gain is chosen. The process is repeated at all decision nodes. Repeat this process until the maximum depth has been reached. Since the gain will not rise beyond a certain depth, the depth of the DT is regarded as a hyperparameter in the learning process.
3.4.4. KNN
This algorithm is lazy; it does not immediately begin learning from the data [
22]. Instead, it saves it and performs the action when it is time to classify. For a new instance
, its feature vector
is acquired. When this feature vector is normalized, we obtain
. The KNN classifier finds the
K-closest data points amidst
N data points. The KNN classifier performs the following main steps:
Step 1: Determine K through k-fold cross-validation for which the model has low variance and reasonably good accuracy.
Step 2: Calculate the FD of a new observation
for each data point in the dataset.
Step 3: Find out the K-nearest neighbors.
Step 4: For each K-nearest neighbor, count the data samples.
Step 5: Allocate the test data sample to the class label, which obtains the maximum number of votes .
Despite its apparent simplicity, the cost of computing the FD between data samples and the time complexity increases with the dataset size. One of the disadvantages of KNN is that it works well for small datasets but becomes more difficult and time-expensive with larger datasets. Identifying the value of K is always necessary, although it might be difficult at times.
4. Complexity Analysis
Table 4 shows the complexity analysis for traditional FD-TAS and distinct supervised TAS systems.
requires
computations.
needs
computations. These computations are carried out only for one value of FD. This process is repeated
times for all possible antenna subsets. It is observed that the number of computations required for TAS using the traditional method is tedious. For ML techniques, it depends on the attribute vector length
. The number of computations required is much less compared to the traditional FD-TAS for a higher-order configuration, i.e., for a larger number of
,
, and
. KNN is the least computationally efficient of all ML approaches because it stores the training data. This analysis is conducted for
B =
bits. By decreasing the length of the attribute vector, we can reduce the complexity of ML-based TAS practices. Traditional FD-TAS becomes increasingly complex as these components rise, necessitating the use of ML techniques for TAS to simplify the system.
5. Discussion on the Simulation Results
This section presents an ABER analysis of the classic FD-TAS method, four distinct ML-based TAS methods, and the FGSM-NTAS scheme.
Table 5 lists the parameters used in this investigation. In MATLAB 2022b, all ML models are trained using the Statistics and ML toolbox. All the simulation results are generated for distinct values of
,
,
, and
M. FD-TAS and ML-based TAS are labeled as
in the figures, while FGSM-NTAS is labeled as
.
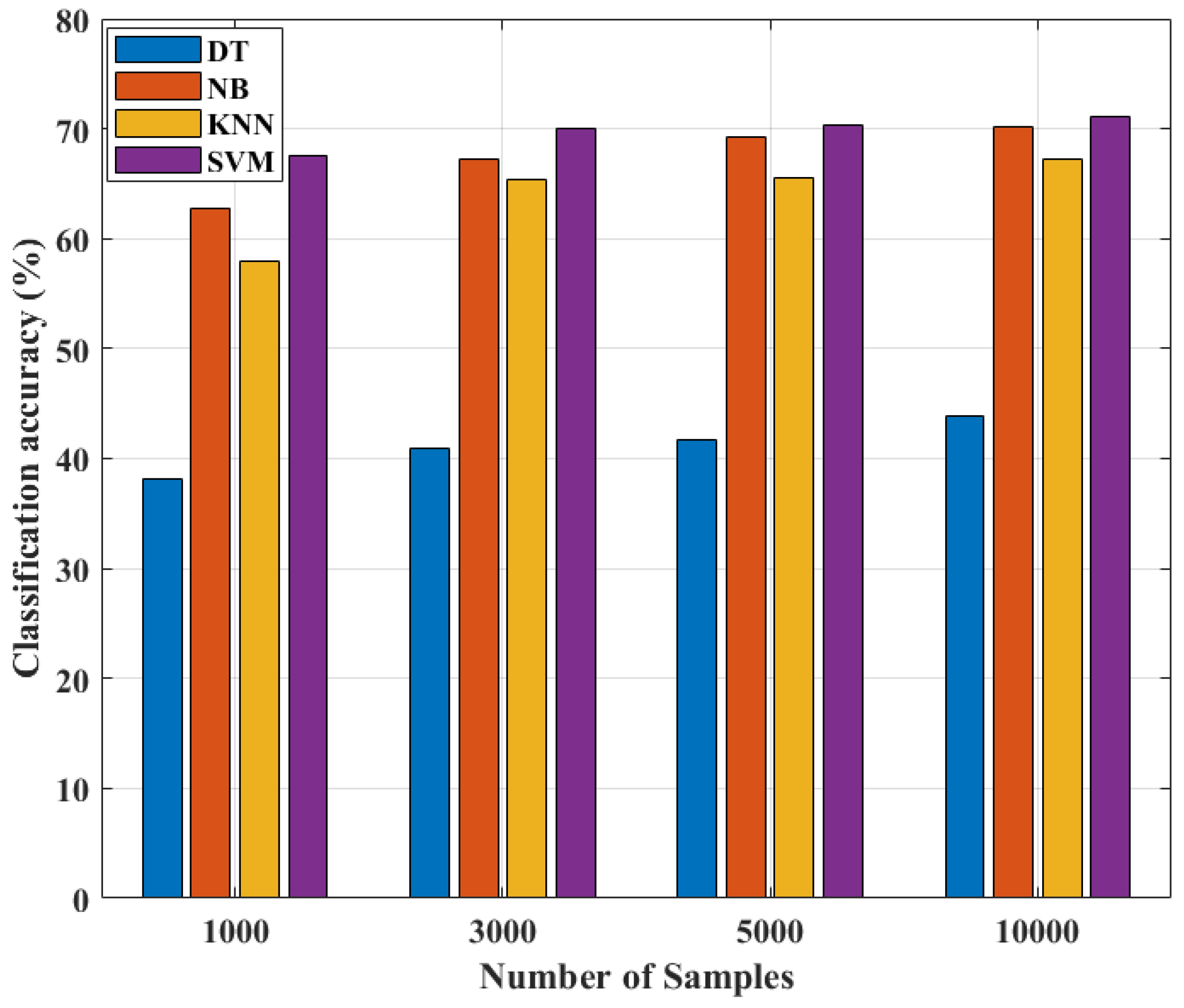
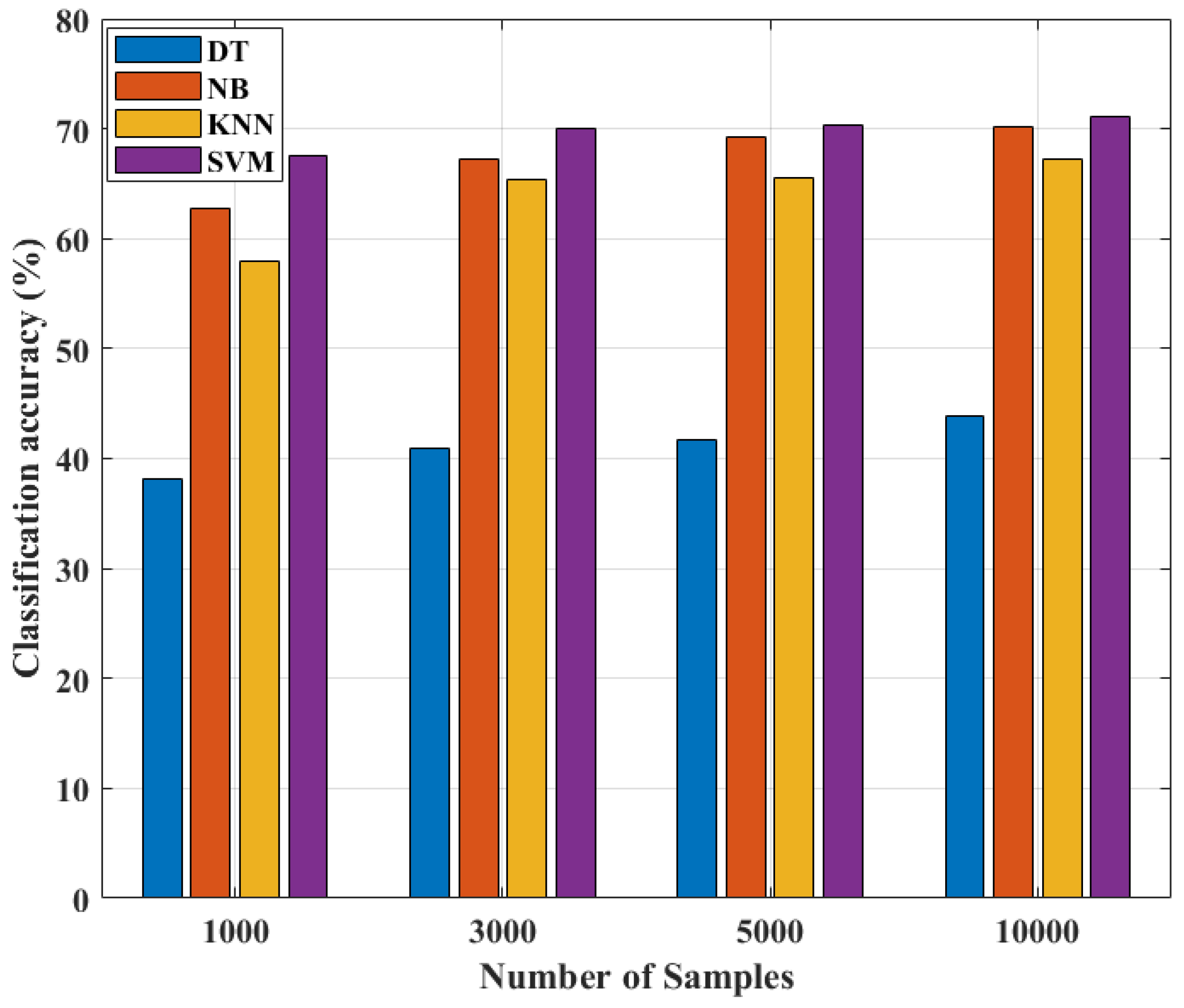
From
Figure 4, it is observed that with an increased dataset size, ML models show an improvement in classification accuracy. Since the accuracy of classification does not improve any further after 10,000 samples, all models are trained for the same number of samples.
Table 6 compares the classification accuracies of several ML algorithms with different sample counts. SVM has the highest accuracy in classification (71.1%), NB has the second greatest accuracy (70.2%), followed by KNN (67.2%), and DT has the lowest classification accuracy (43.8%).
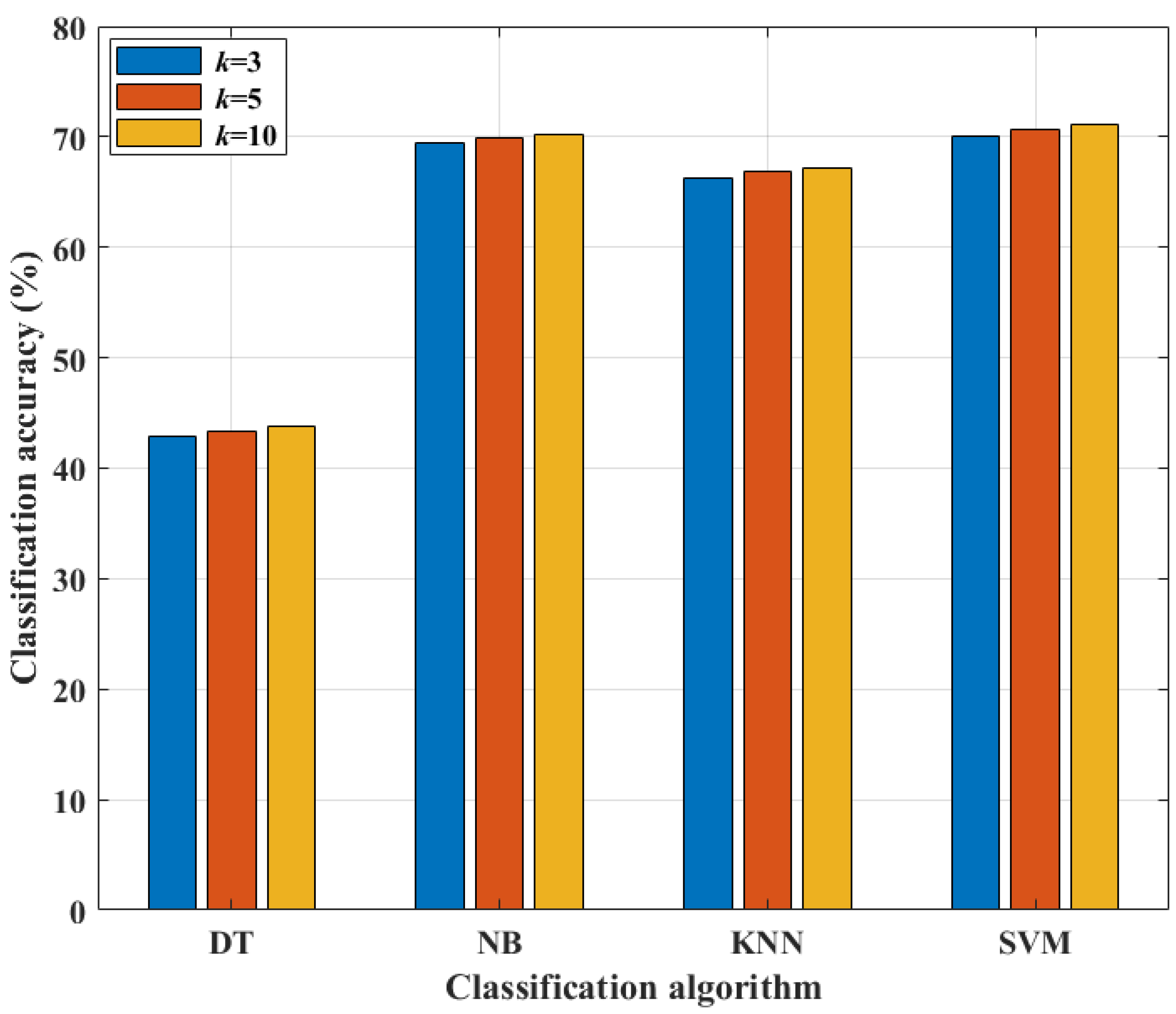
Cross-validation is an approach that allows the model to learn from many train–test splits. This provides a better idea of how well the trained model will perform on data that have not been seen before. In contrast, hold-out is based on a single train–test split. As a result, the hold-out method’s score is influenced by the way the data are divided into train and test sets.
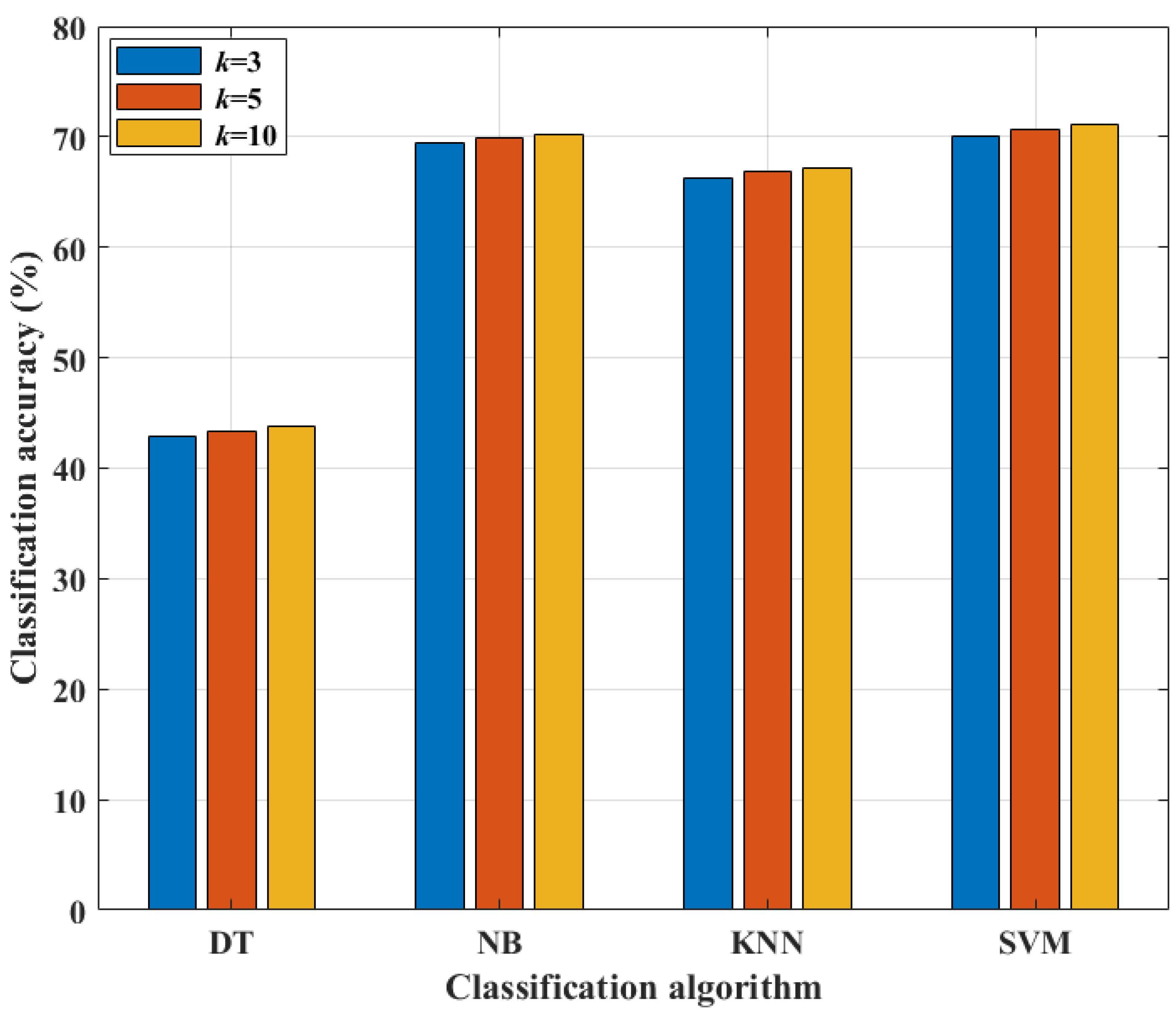
Figure 5 and
Table 7 show how altering the value of
k-folds during cross-validation improves classification accuracy. The highest classification accuracy is observed for
k = 10. As a result, the value of
k is set to 10.
After performing normalization, these models are trained for four distinct features, as discussed earlier in
Section 3.3. The complexities of all features based on their attribute vector lengths are listed in
Table 8. The worst-performing attribute is
. Attribute 4 performs well only for DT, but its complexity increases with a higher-order configuration, so it is discarded. Combining features lengthens the feature vector and increases model complexity; hence, feature combination is avoided in this study. The absolute feature outperforms the other features in SVM, NB, and KNN, and its complexity is low; thus, only the absolute feature is utilized for this work.
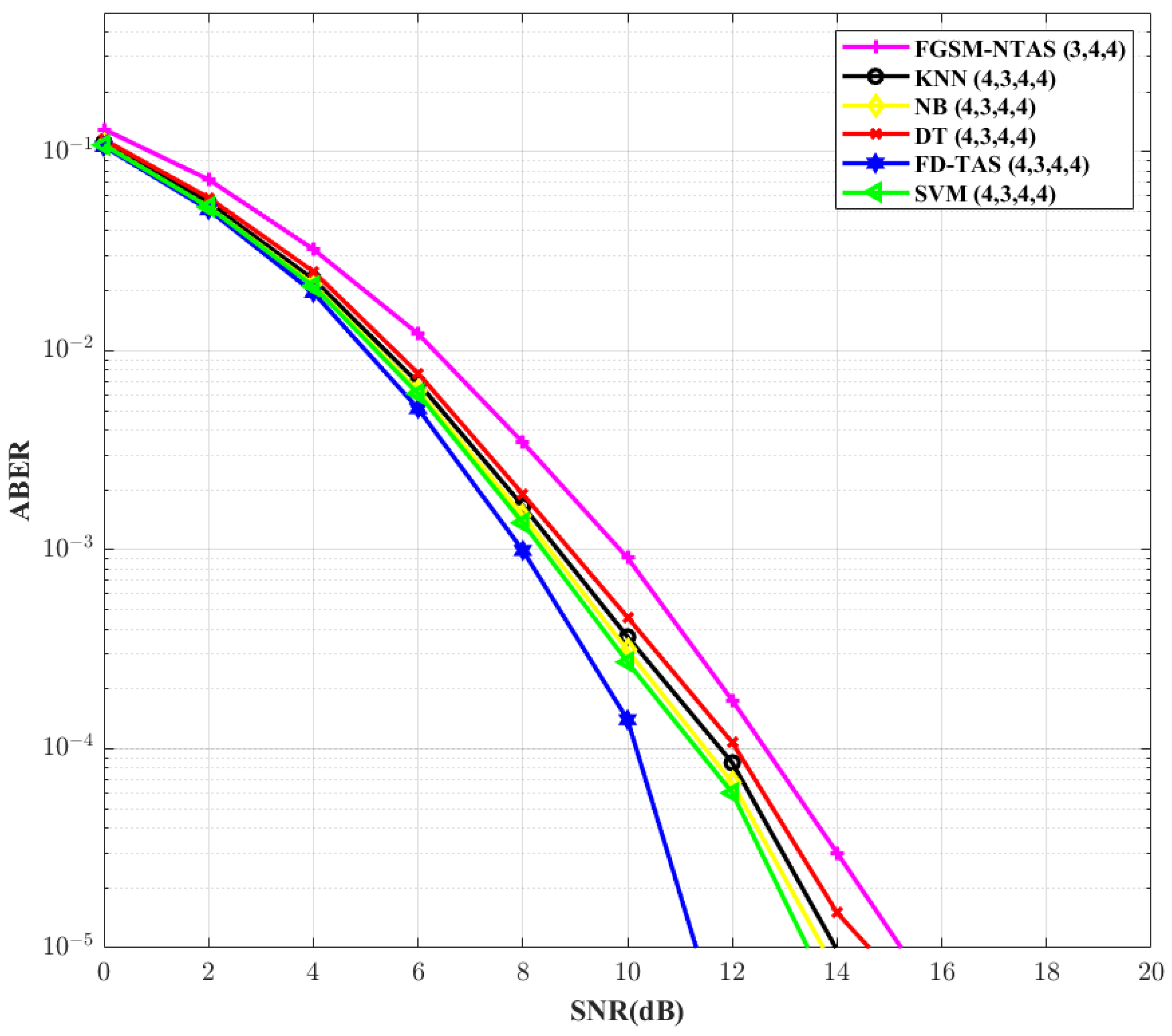
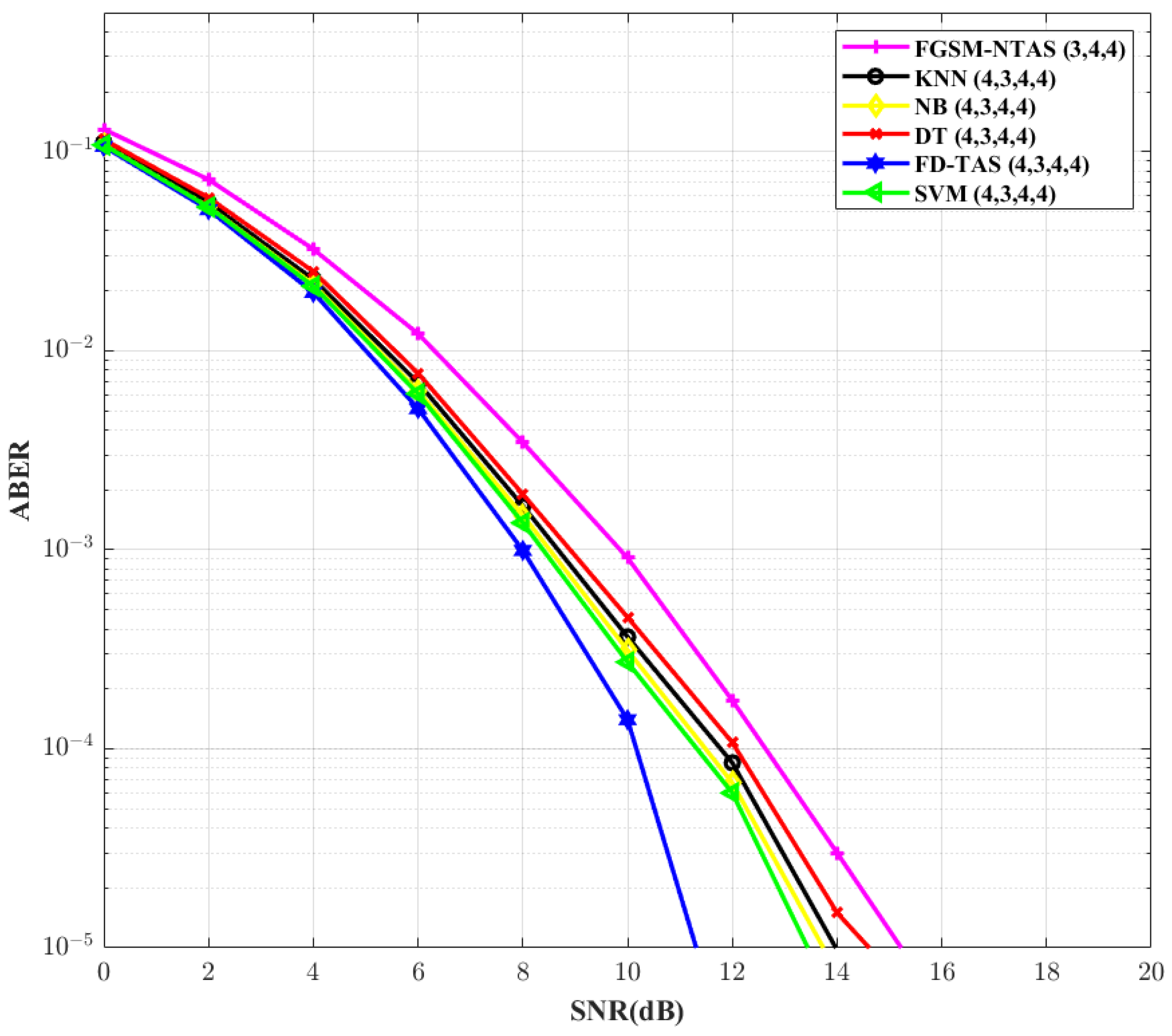
After conventional FD-TAS, the SVM-based TAS scheme outshines other ML-based systems, as shown in
Figure 6. In comparison to the FGSM-NTAS method, the SVM-based TAS scheme cut downs the SNR need by ∼2 dB. This analysis is conducted for
= 4,
= 3,
= 4, and
M = 4. The ABER performance of the system is re-examined in
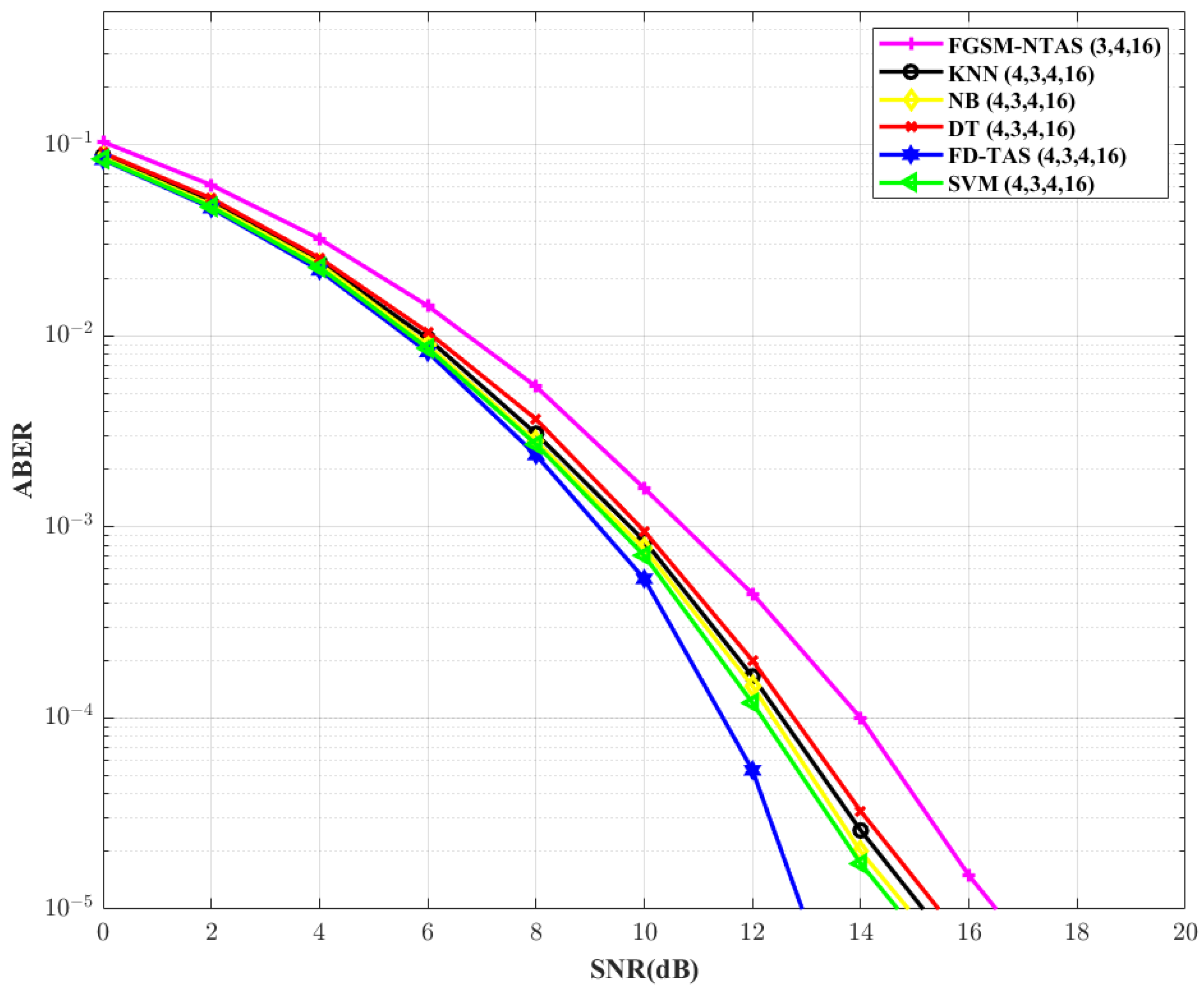
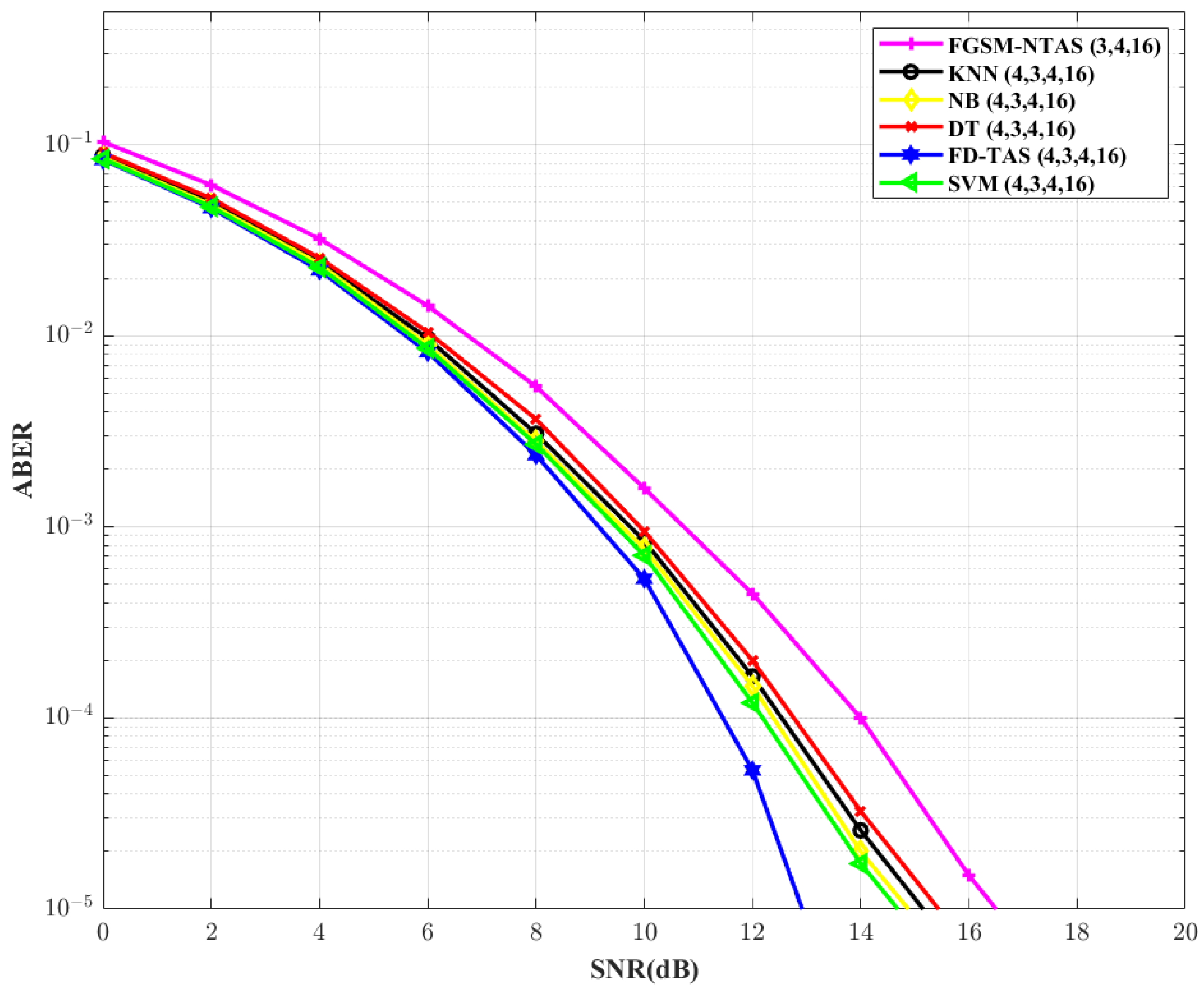
Figure 7 by increasing the constellation order to 16. For larger values of
M, the SNR requirement for all ML-based methods increases. For FGSM-NTAS and conventional FD-TAS SNR gain requirements increase by ∼1.3 dB and ∼1.61 dB, respectively. SVM outperforms the FGSM-NTAS system in this circumstance as well, with a gain improvement of ∼2 dB.
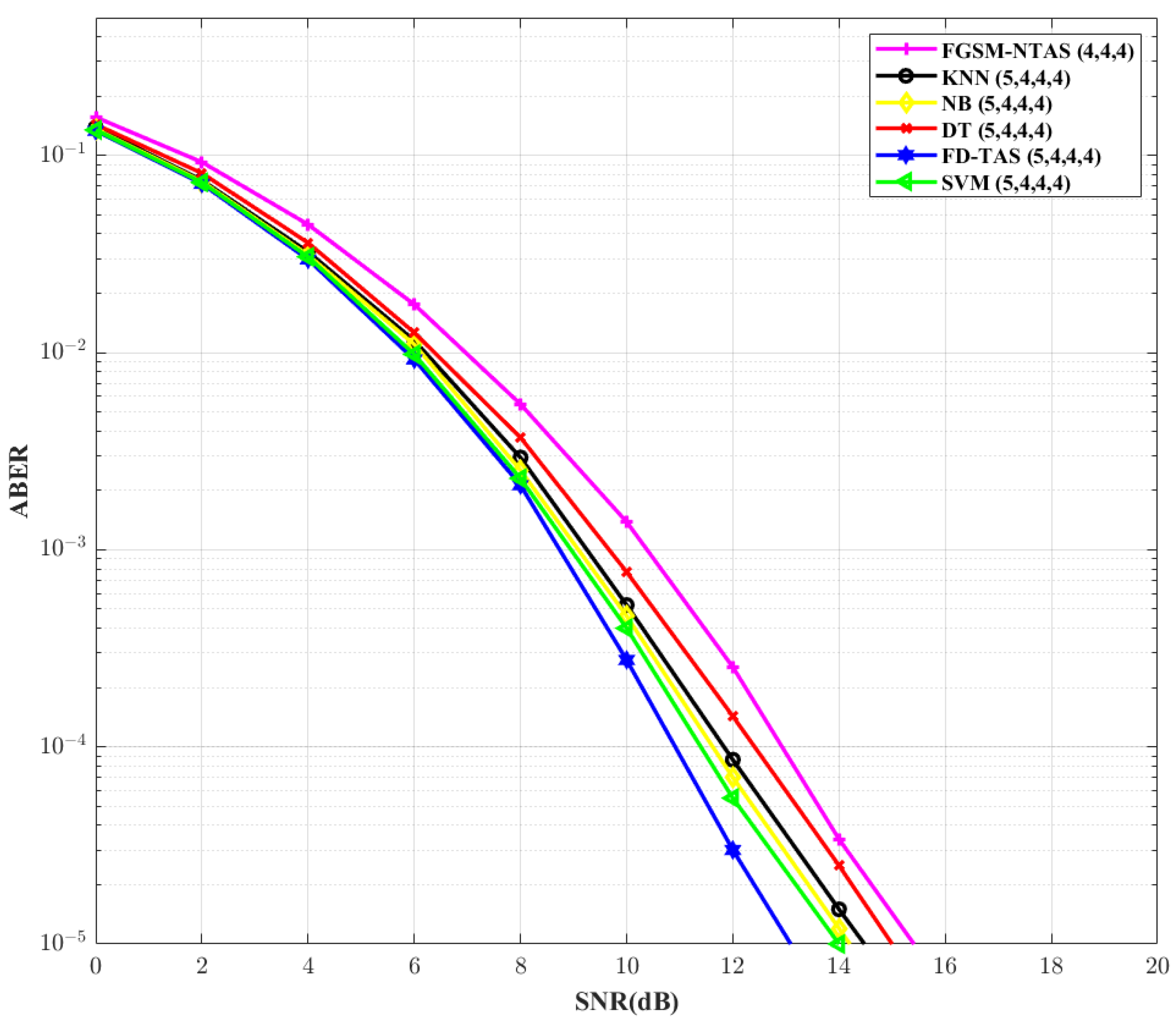
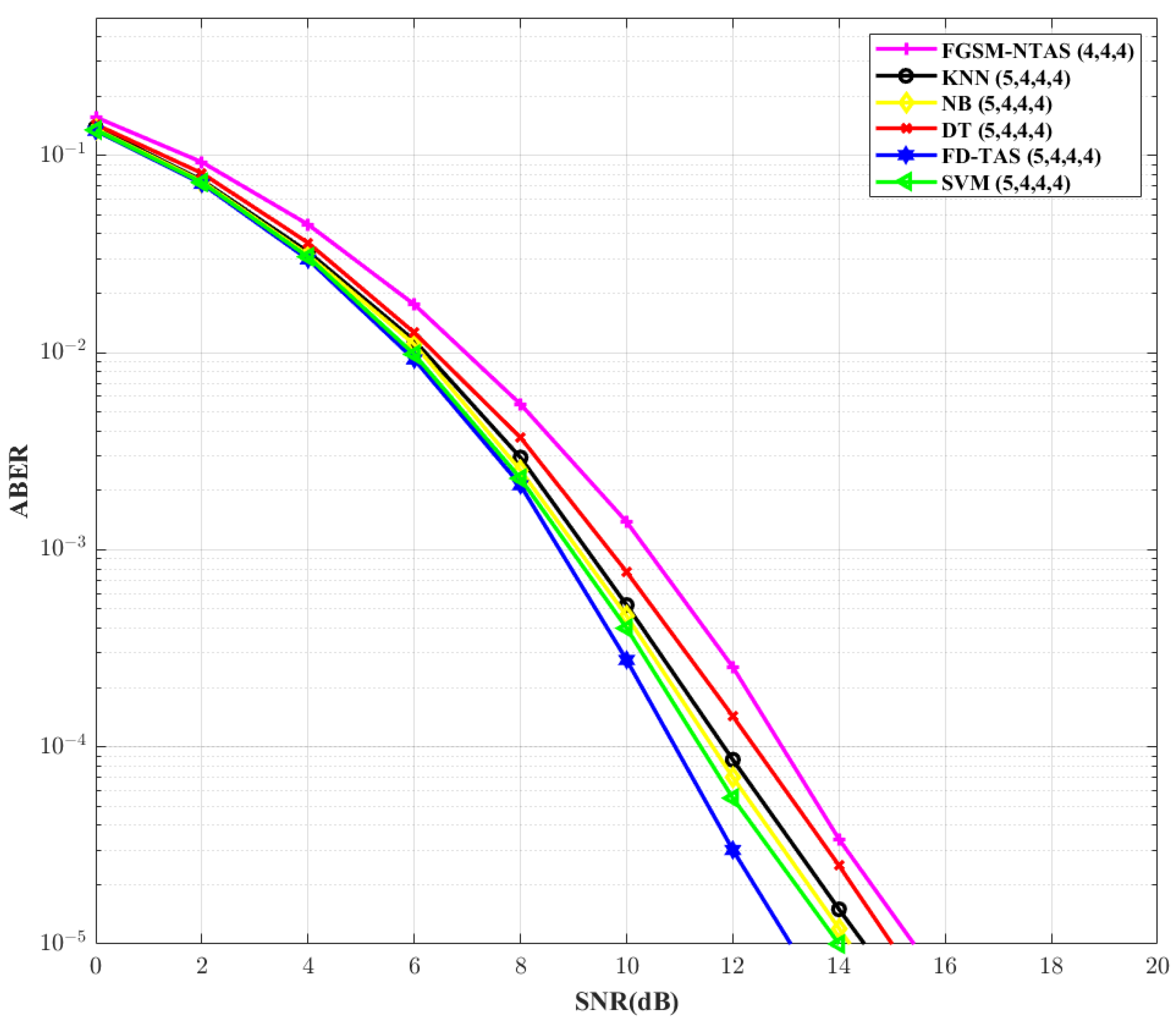
Figure 8 analyzes the ABERs of different TAS schemes for
= 5,
= 4,
= 4, and
M = 4 configuration. It is found that SVM-based TAS outperforms FGSM-NTAS by ∼1.42 dB in terms of SNR gain. By increasing
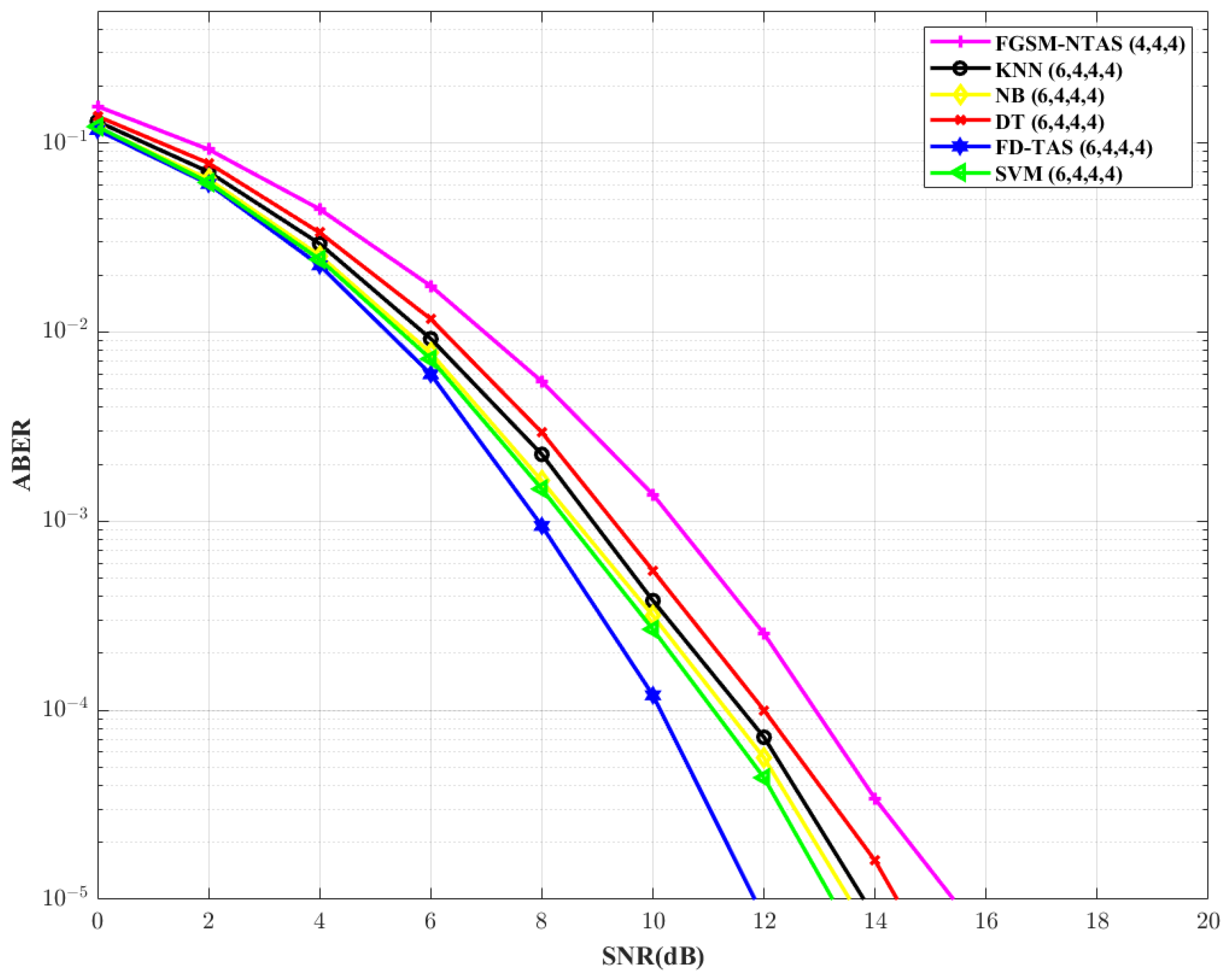
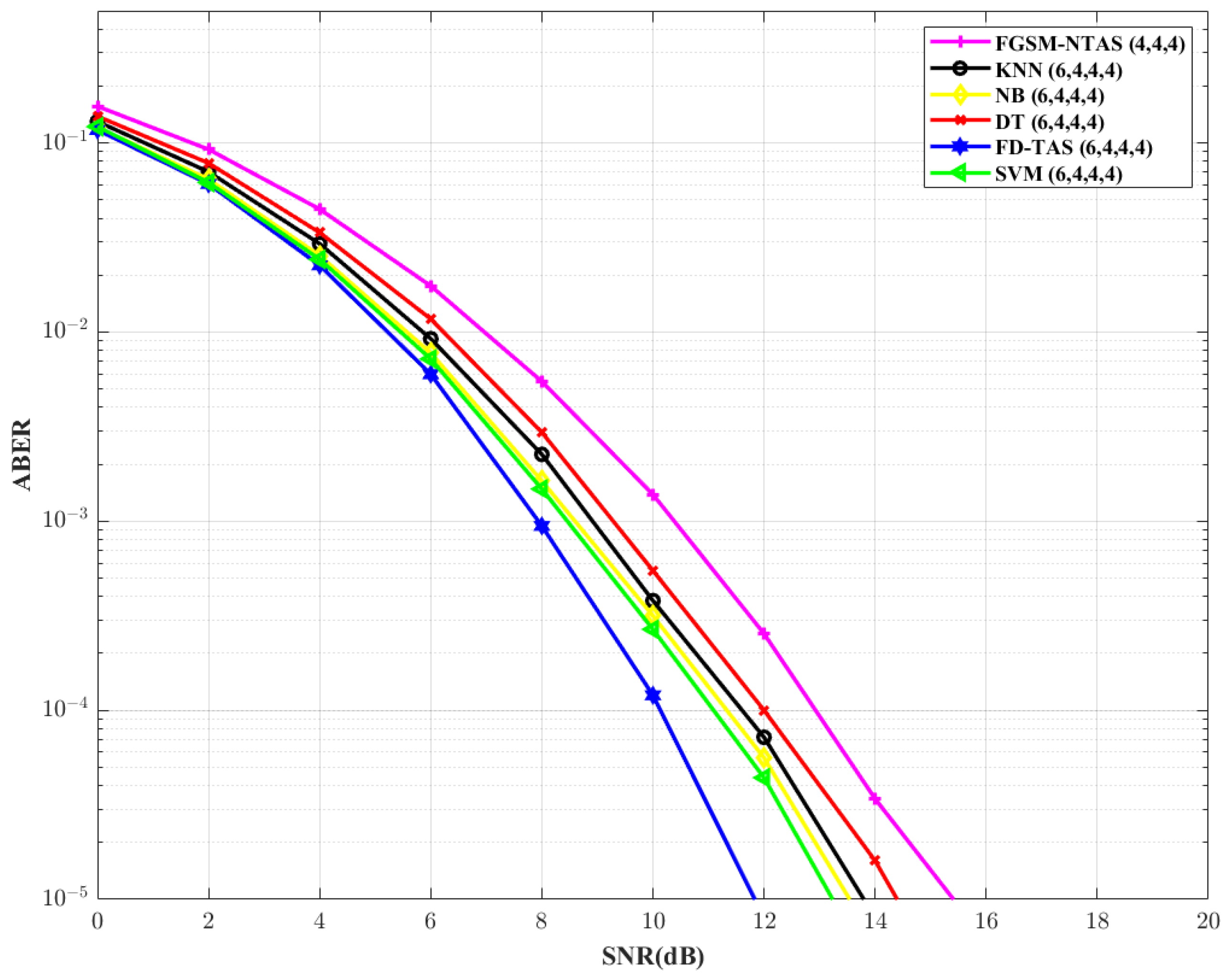
to 6, the analysis is repeated in
Figure 9. For traditional FD-TAS, the required SNR drops by ∼1.28 dB. For SVM, NB, KNN, and DT-based TAS systems, respectively, there is a reduction of ∼0.78 dB, ∼0.66 dB, ∼0.68 dB, and ∼0.59 dB in the SNR requirements. In comparison to the FGSM-NTAS system, the SVM-based TAS technique gains ∼2.2 dB.
Table 9 lists the SNR gain achieved by the proposed ML-based TAS practices over traditional FGSM-NTAS.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}