All the experiments were executed sequentially and we collected all the data for this section from the annotated output of ProbSKnife.
7.1. Experimental Results
We started by taking the execution time of the probabilistic model creation as
K varies. The execution times include the queries to the
labellingK predicate and for every labelling, the probability of being in a specific labelling (random variable
) and the probability of reaching a labelling from the starting one (random variable
) are computed.
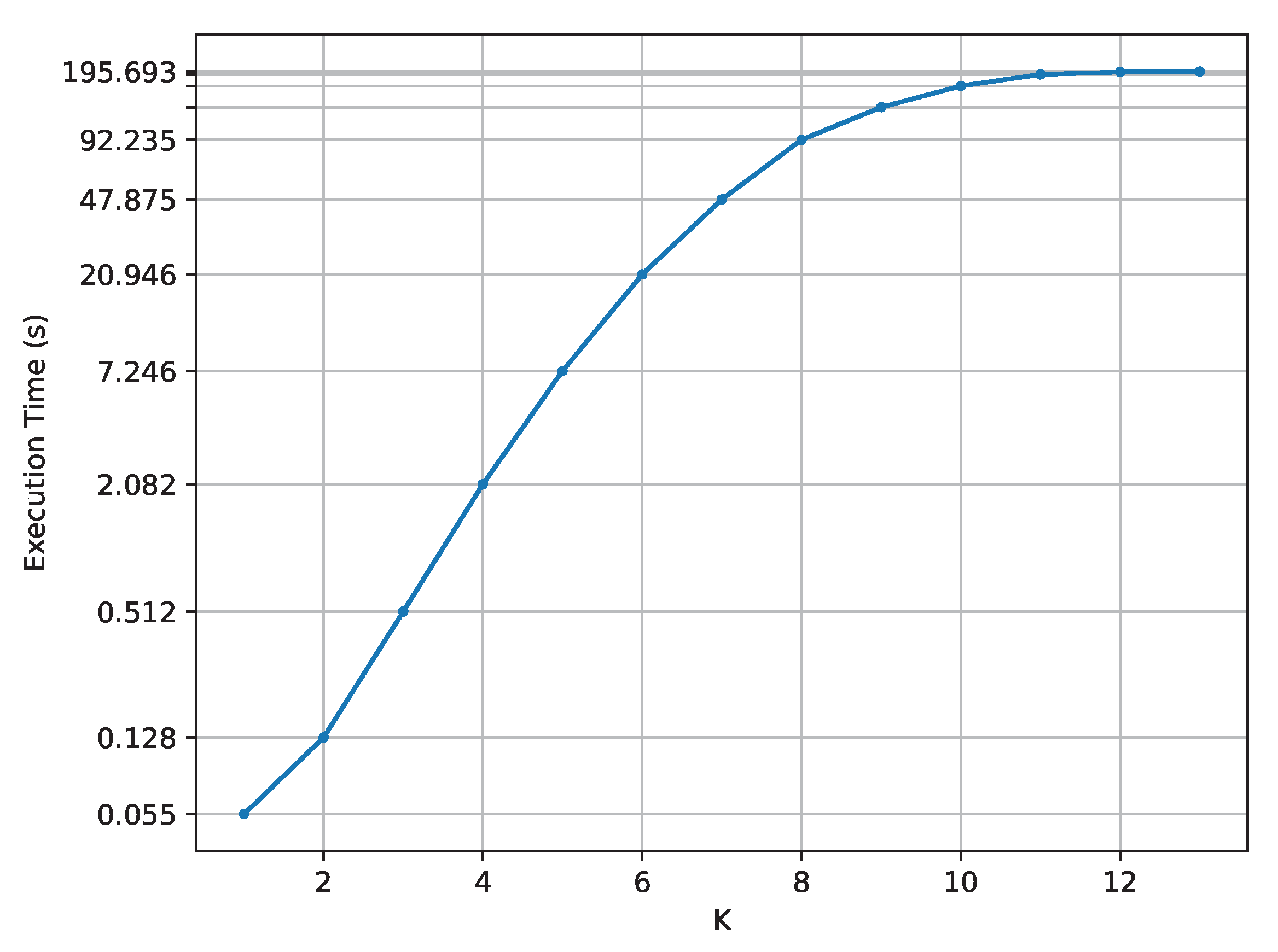
Figure 6 shows the average execution time in seconds on a logarithmic scale (
y-axis) at varying values of
K of each probabilistic model (
x-axis).
Increasing K, the execution time grows exponentially, from 55 milliseconds of K equal to 1 to over 3 min of K greater than 11. As aforementioned, for K equal to 11, 12 and 13 the labellings are the same and the difference in execution time is reduced drastically for those values of K.
Concerning the total execution time, we collected the data from each experiment and grouped them by
. The execution times were obtained by timing the
ProbSKnife script after the creation of the probabilistic model.
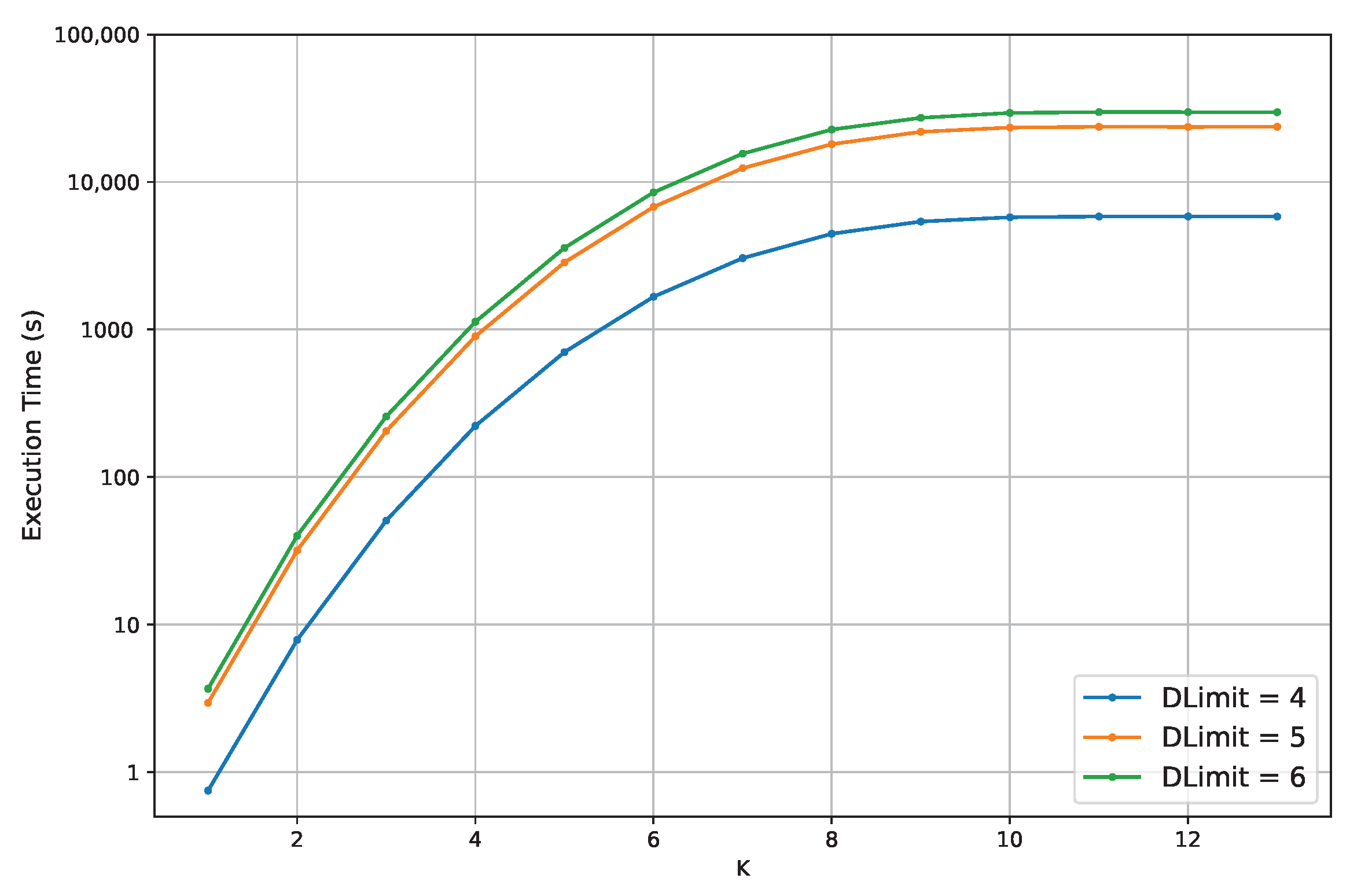
Figure 7 shows the average execution time in seconds on a logarithmic scale (
y-axis) at a range of values of
K of each probabilistic model (
x-axis). The three lines represent the experiments as
varies from four to six. In this plot, the execution time grows exponentially as
K varies until
K is equal to 11, being on the order of a few seconds for
K equal to one and reaching over 8 h (about 28,000 s) for
K equal to 13. The three highest values of
K have a negligible difference in time, on the order of a few seconds. Concerning the
lines, the execution time for
equal to four is always the lowest, for
equal to five is always the intermediate one and for
equal to six is always the greatest.
To analyse the partitioning costs we divided the collected data by
to show the future cost as
K varies. For each
Figure 8,
Figure 9 and
Figure 10 show the future cost in work hours (
y-axis) at varying values of
K of each probabilistic model (
x-axis). The number of domains of each partitioning is annotated in the legend as
. In the future cost calculation, the results with
K equal to 11, 12 and 13 have the exact same values. As aforementioned, this happens due to the data with a probability of 1 of maintaining the same label. We generated three plots with the future cost of a partitioning having the same colour in all the figures; for instance, the minimal partitioning
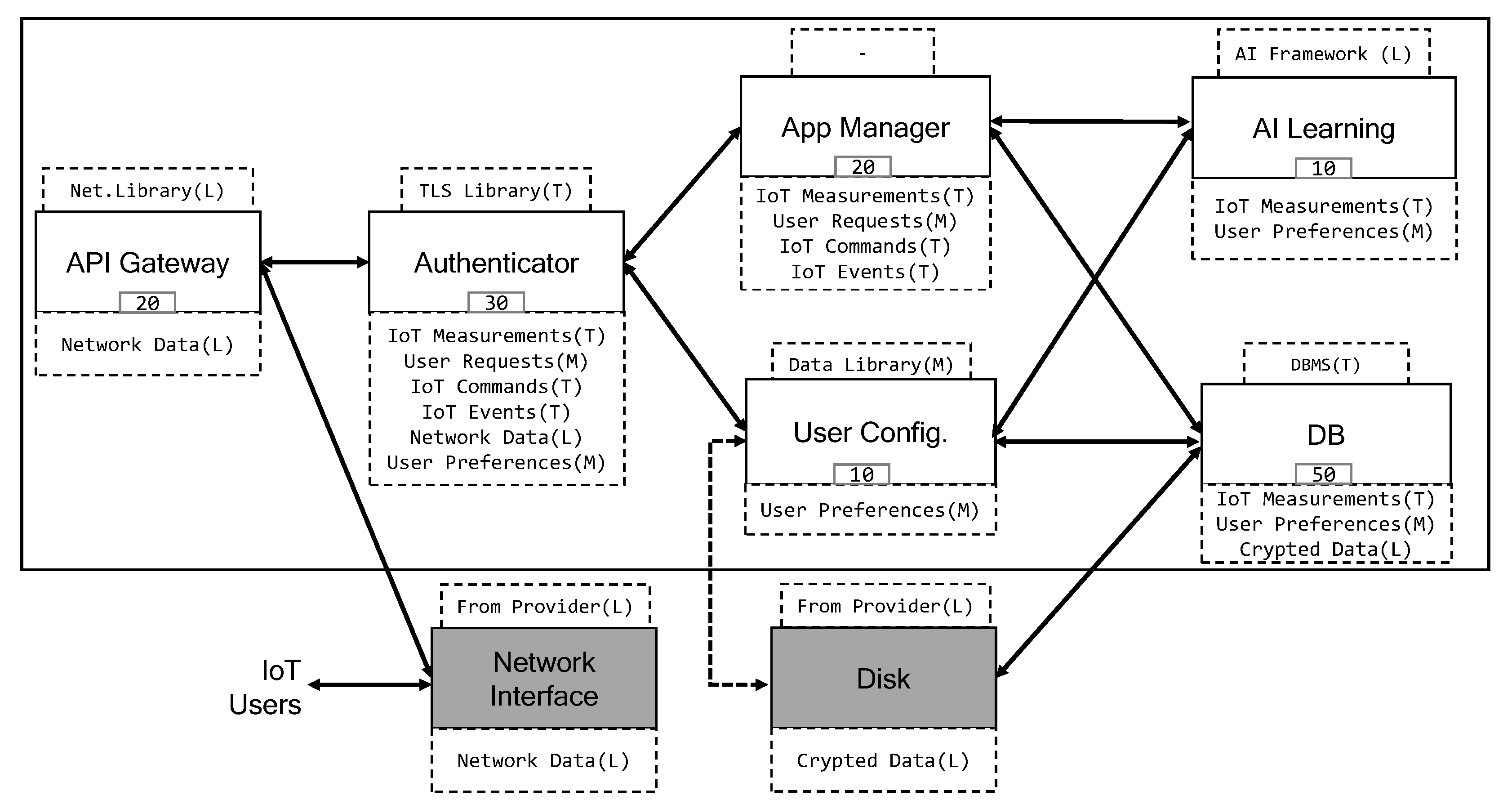
[[appManager,authenticator,db],[apiGateway], [aiLearning],[userConfig]] is always represented with a blue line.
The plot with
equal to four (
Figure 8) represents the future cost of only the minimal partitioning. We proved in
Section 5 that the solution with the minimum number of domains is unique. The future cost of such a partitioning grows linearly with
K, starting from
with
K equal to one and arriving at a future cost of
with
K equal to 11, 12 and 13.
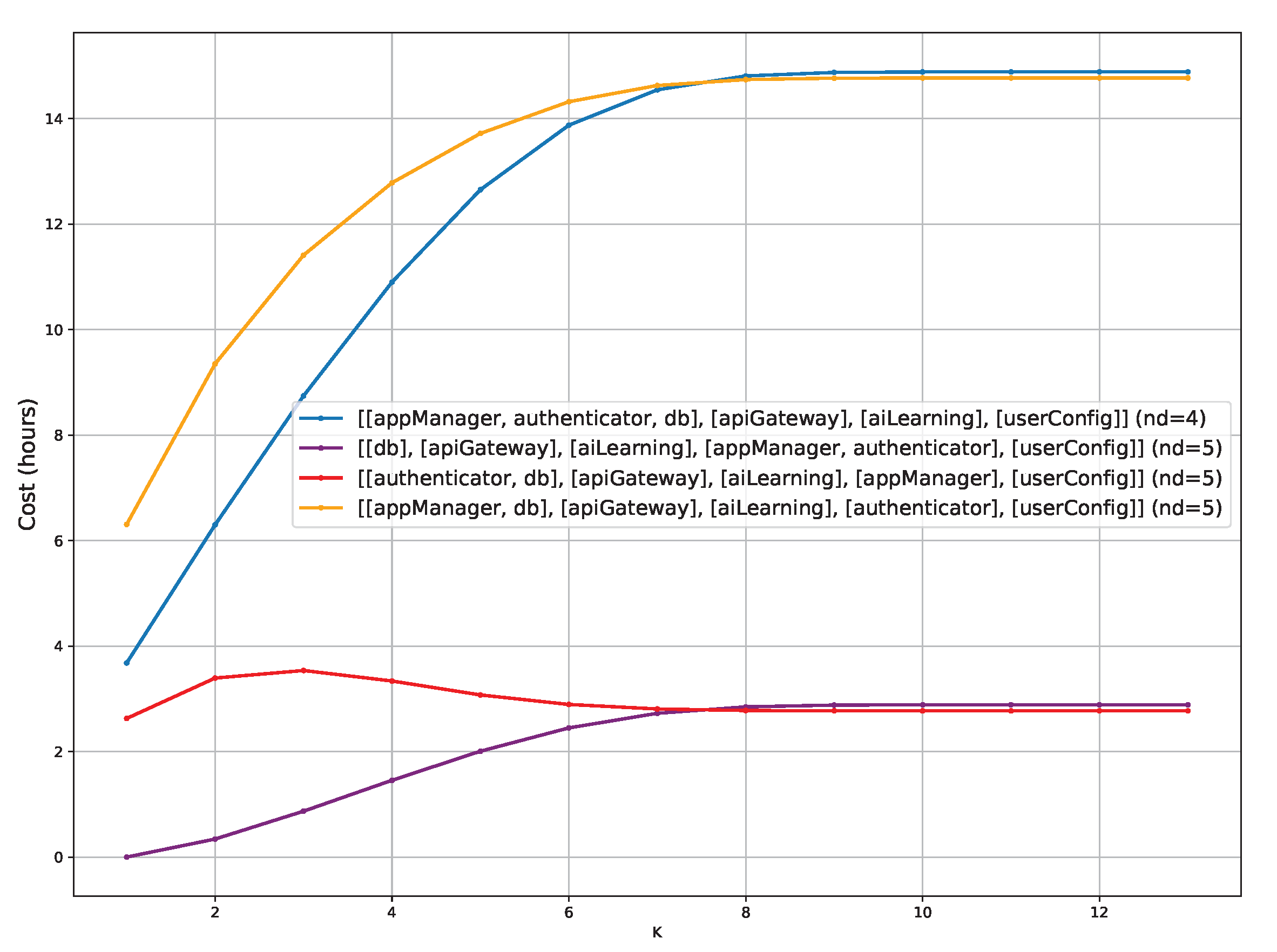
The plot with
equal to five (
Figure 9) represents the future cost of four different partitionings, the minimal one with four domains and the other with five domains. Two partitionings (the blue and the orange one) have a future cost that grows linearly until
K is equal to seven, then it remains stable around 15 h. The blue lines stay under the orange one until that
K, and then they switch, with the blue one being the more costly for the highest values of
K. The other two partitionings have the same behaviour from
K equal to seven onward, but the stabilisation value is around 3 h. With low values of
K, the red partitioning starts at
h, grows slightly until
K is equal to three, reaching a future cost of
h, and decreases until
K is equal to five, becoming stable at
h of future cost. The purple partitioning starts from zero cost, grows slightly until overcoming the red partitioning at
K equal to seven and stabilises around a future cost of
h. In comparison with the previous plot, the blue partitioning has the same behaviour as before but the values of future cost are always 2 or 3 h less.
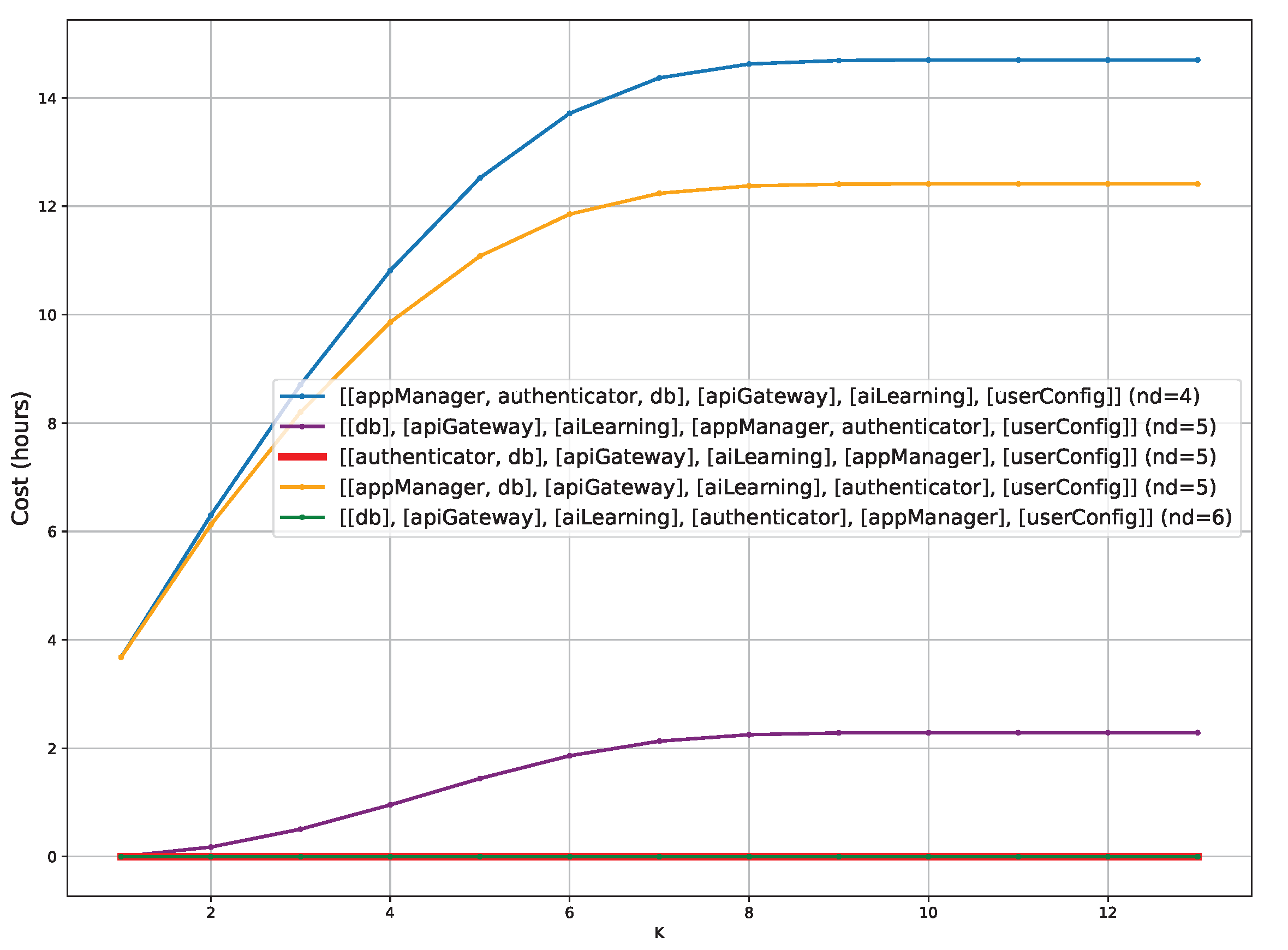
The plot with
equal to six (
Figure 10) represents the future cost of five different partitionings, the previous four and the greatest partitioning with all the software components isolated in different domains. To draw this plot the red partitioning has a line slightly bigger than before to avoid hiding the green partitioning because both have a future cost equal to 0 for all the
K values. The purple line has the same behaviour as before, but with a future cost value always slightly (
to
h) less. Differently from before, the orange line is always under the blue line, having the same kind of growth in the cost as
K grows but with smaller values, from the minus 1 h with
K equal to one until minus 2 with
K equal to eight, where it stabilises in both plots.
Finally, we present the results for the probability of having a non-safely partitionable application as
K varies. As before, we grouped the data by different
.
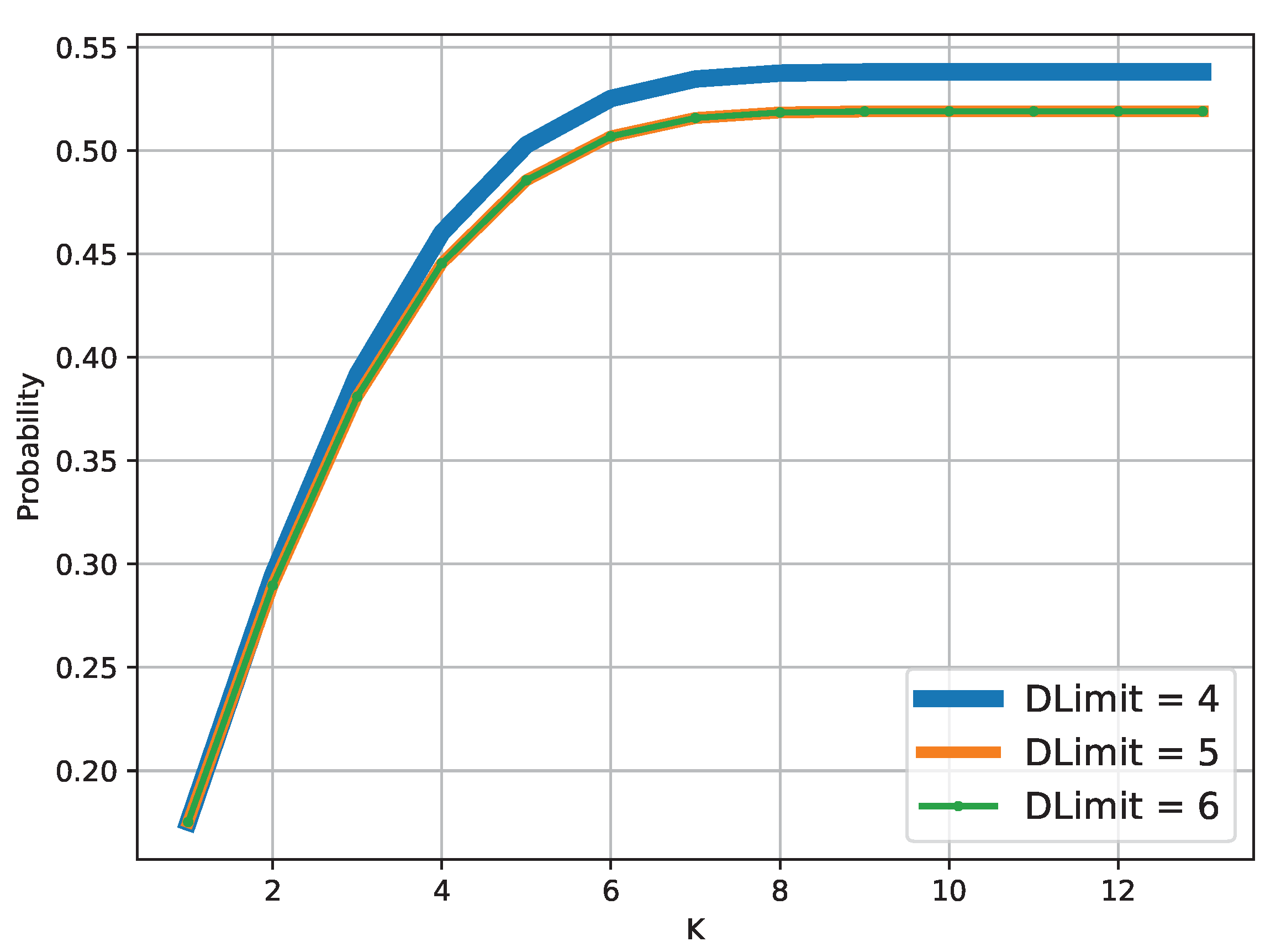
Figure 11 shows the probability of reaching a non-partitionable application (
y-axis) at varying values of
K of each probabilistic model (
x-axis). We drew a line for every value of
with a different size to have a better distinction between the three lines when the probability is similar. Indeed, for
equal to five and six the probability of having a non-safely partitionable application is the same for every
K. All three lines start from a probability of
with
K equal to one and they grow to stabilise with
K equal to seven, the blue line at probability
and the other two at probability
. Then, the probability grows with tiny values until
K is equal to 11, reaching, respectively,
and
. As before, when
K is equal to 11, 12 and 13 all the lines have the same values.
7.2. Discussion of the Results
We discuss now the question
Q1: How much does K impact the creation time of the probabilistic model?
We have to consider that the number of labellings with at most
K different labels from the starting labelling grows exponentially as
K grows, as discussed in
Section 6.1. This behaviour is confirmed by the data shown in
Figure 6: the time needed to calculate the probability of each labelling grows exponentially as
K grows. With a probabilistic model that is not parameterised with
K it could be difficult for
ProbSKnife to determine the probabilistic model in a reasonable amount of time. An application with a large number of data types and characteristics has difficulties calculating all the possible labellings, making it hard to calculate the future cost of the initial partitionings. As aforementioned, choosing a low value of
K in advance is reasonable given that, in general, the number of labels that change simultaneously is low. We can conclude that having
K as a parameter in our methodology can reduce drastically the complexity of the search space for all possible labellings, thus reducing the execution time to create the probabilistic model.
To summarise, the average execution time to create the probabilistic model is exponential with K for the number of labels that can change (11 in our motivating example), with a minimum of seconds with K equal to one and about 195 seconds with K equal to 13.
To answer the question
Q2: How much do K and impact the execution time of ProbSKnife?
We should add a consideration to the previous one. The maximum number of domains admitted
reduces the number of ways to partition an application and, thus, the number of safe partitionings that satisfy a labelling. Indeed, only one partitioning with
equal to four satisfies the starting labelling (
Figure 8). There are four partitionings when
is equal to five (
Figure 9) and there are five partitioning when
is equal to six (
Figure 10). The number of initial partitionings is the reason behind the difference in the execution times of
ProbSKnife, as for different values of
there are different numbers of future costs to calculate. The behaviour of the three lines is the same and they have about the same distance for every point of the plot. This distance is given by the number of partitionings. In particular, the orange line (
equal to five) and the green line (
equal to six) show the time to calculate the future cost of one partitioning, given that they have only one partitioning of difference.
Concerning the behaviour of the execution time, we reach the same conclusion as for the previous question: the value of
K increases exponentially the space of possible labellings and
ProbSKnife looks for the partitioning with the minimum cost for every labelling, thus increasing the execution time. To summarise, we conclude that increasing
K increases the execution time exponentially and increasing
increases the execution time by the number of partitionings that satisfy the starting labelling. This number depends on the application; in the worst-case scenario it is also exponential, as discussed in
Section 6.1. Thus, choosing a low value for
exponentially reduces the execution time of
ProbSKnife and also decreases the impact on the performance of the separation kernel technology.
To summarise: the average execution time to calculate the initial partitionings and their future costs is exponential with K for the number of labels that can change (11 in our motivating example) and linear with the number of initial partitionings (in the worst case, exponential with ). Our results have a minimum of seconds with K and D equal to one and about 28,000 s with K and D at their maximum values, respectively, 13 and six.
From the point of view of execution time, the best choice seems to be the lowest possible values for K and , but we have also to consider their impact on the partitioning costs. In this regard, we now answer the question
Q3: How much do K and impact the safe partitioning costs?
Having a low value of
reduces the choice for the starting partitioning.
Figure 8 shows that having
equal to four has only one partitioning satisfying the starting labelling, the minimal partitioning. Its future cost grows with
K because the number of labellings to be satisfied that need a different minimal partitioning grows.
The situation is more interesting with
equal to five, as depicted in
Figure 9, where the choice is among four partitionings. The minimal partitioning cost is less than before because when a labelling is not satisfied, the software can also be migrated to partitionings with five domains, with a lower cost than partitioning with four domains. Obviously, the orange partitioning will always be a bad choice, as it is the most costly, with five domains. The choice of the starting partitioning depends on the selected
K; the application operator should decide whether to minimise the number of domains—having a higher future cost—or have one more domain with a lower future cost. For example, with
K equal to one, the choice is between the purple partitioning (five domains and 0 future cost) and the blue one (four domains and
future cost).
The last scenario, with
set to six, is depicted in
Figure 10. There is one partitioning more than before, the green one, that is the partitioning where all the software components are isolated in different domains. This partitioning is always safe and always has zero future cost because there is no labelling that forces migration of the software components, but it has the highest number of domains.
For applications with a high number of software components, it is not affordable to isolate all the components and also, in this example, it is not the best choice. The red partitioning has one domain less and the same zero future cost. This happens because changing the partitioning from the red one to the green one has zero cost, so labellings that are not satisfied by the red partitioning are enough to migrate the software to the green one, increasing the number of domains but without paying an additional cost in working on the software communication.
The idea behind the choice of the starting partitioning is the same as before: once K is picked, the application operator should decide how many domains to use at the start, knowing that the migration could require up to six domains to have the minimal cost.
In conclusion, having a low value of K brings lower future costs because the probability of reaching an unsatisfiable labelling is less. Instead, having a low value of brings higher future costs because there is less choice for the starting partitioning and for the migration.
In summary, fixing equal to four, the future cost of the minimal partitioning is work hours, the lowest value, when K is equal to one. As K grows over seven the future cost is stabilised at about work hours. Fixing equal to five, the future cost of the minimal partitioning is work hours, the lowest value, when K is equal to one. As K grows over seven the future cost is stabilised at about work hours. For partitioning with five domains, the behaviour depends on the application architecture and we record as the minimum future cost 0 work hours with K equal to one and with K equal to 13. Finally, fixing equal to six, the future cost of the minimal partitioning is work hours, the lowest value, when K is equal to one. As K grows over seven the future cost is stabilised at about work hours. For partitioning with five domains, the behaviour depends on the application architecture as before and we record a minimum future cost of 0 work hours for every K. The partitioning with full isolation, having six domains, always has zero future cost.
Finally, we have to answer the question
Q4: How much do K and impact the probability of not having a safe partitioning?
A labelling does not have a safe partitioning when the application is non-safely partitionable or
is less than the possible configuration of software component labels. We recall that an application is non-safely partitionable when it has untrusted hardware or when there is an untrusted path toward the hardware. When
K grows the number of labellings grows exponentially; thus, the probability of having a non-safely partitionable application also grows. This is shown in
Figure 11; the three lines grow with
K. The growth is bigger at the start, then decreases around
K equal to seven. This happens because it is enough to have a few
bad labels to have a non-safely partitionable application that can be mitigated with several others. For instance, to make a hardware component untrusted it is enough to have one
low characteristic and to make it trusted again all the data need to be
low as well.
The lower bound of domains to satisfy all the possible labellings is six. In general, the probability of finding non-satisfiable labellings grows until reaches the lower bound. For this reason, the figure shows that having the lowest value of (four) increases the probability of finding non-satisfiable labellings. With equal to five this does not happen because the labellings that are satisfiable only by six domains make the application non-safely partitionable. Thus, the orange and green lines are overlapping.
To summarise, having a low value of K brings a lower probability of not finding a safe partitioning. When the starting labelling makes the application safely partitionable, having few changes does not increase drastically the probability of making it safely partitionable. Instead, having a low value of brings a higher probability of not finding a partitioning that satisfies a labelling until the lower bound on the number of domains is reached.
To summarise, the probability of not having an application safely partitionable is the lowest with K equal to one for every , being about . With K equal to 13 the probability reaches the maximum of with equal to four and both with equal to five and six.
As a final remark, our methodology has the benefit of (i) determining secure deployments of multi-component applications and (ii) proposing different solutions to allow the application operator to choose the trade-off between SK impact and future deployment changes. The main drawback of our methodology resides in the high execution time to handle instances in which applications have several components and a high number of data types and characteristics. To overcome this drawback we give the opportunity to select the K and parameters to reduce the execution time. According to our experiments:
Low values of K are suitable to handle problem instances that are likely to incur in a few label changes (e.g., 1–3). In such cases, selecting a low value of K can drastically reduce the execution times, contain future costs and reduce the probability that an application will not be safely partitionable in the future.
The decision on setting the value of is less immediate. Low values are suitable to reduce ProbSKnife’s execution time. Instead, high values reduce the future costs and the probability of incurring in a non-safely partitionable application. Assuming that the application deployment is not a latency-sensitive operation, it is advisable to run different instances of ProbSKnife with different values in order to find the best solution that fits the specific needs of each specific situation.


 ,
, 



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}