


Task-Aware Meta Learning-Based Siamese Neural Network for Classifying Control Flow Obfuscated Malware
 , , ,
, , , 

Abstract
1. Introduction
- Our task-aware meta-learner network combines entropy attributes with image-based features for malware detection and classification. By utilizing the VGG-16 network as part of the meta-learning process, the weight generator assigns the weights of the combined features, which avoids the potential issue of introducing bias when the training sample size is limited;
- For the hybrid loss to compute the intra-class variance, the center loss is added alongside the constructive loss, to enable positive pairs and negative pairs to form more distinct clusters across the pairs of images processed by two CNNs;
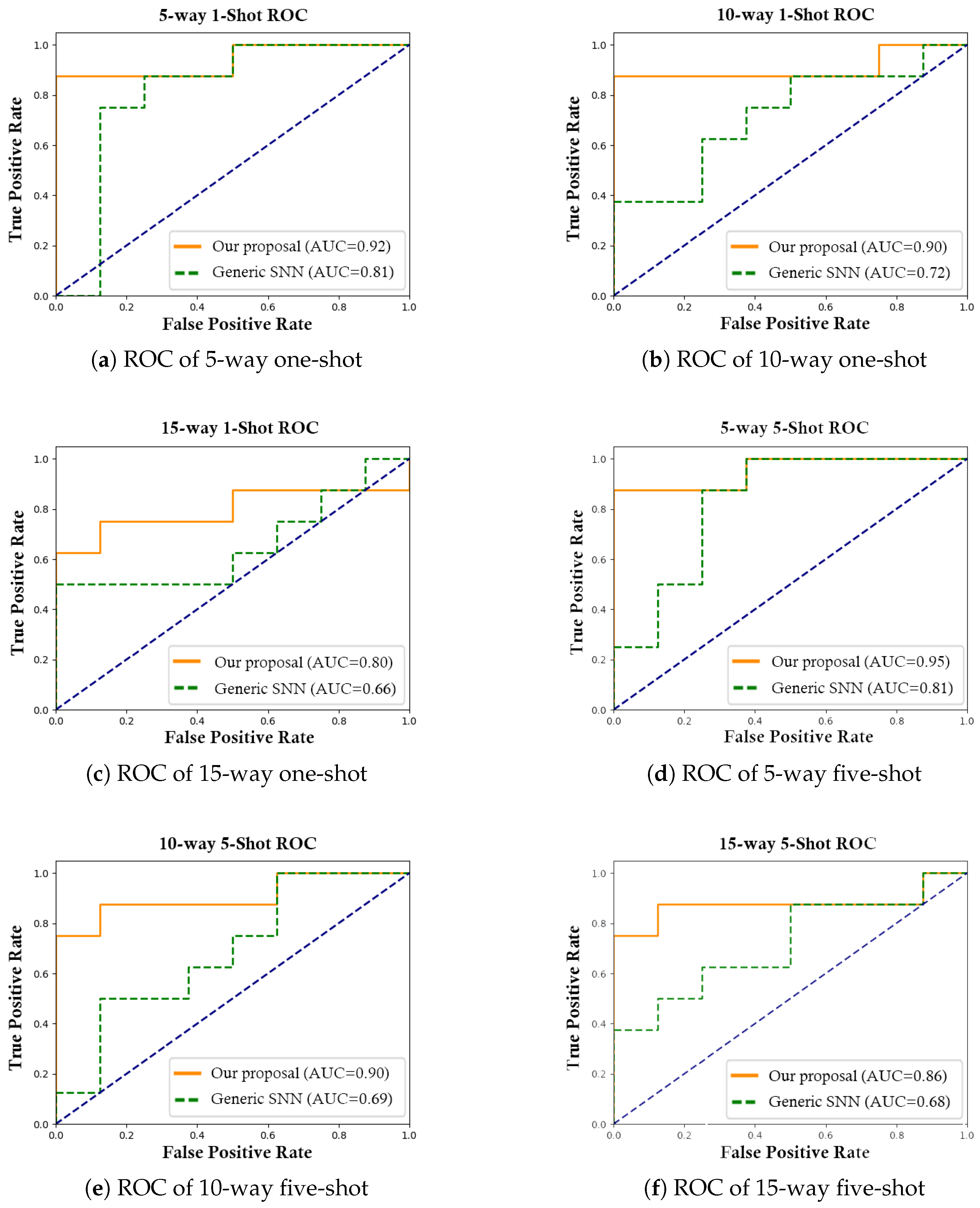
- The results of our extensive experiments show that our proposed model is highly effective in recognizing the presence of a unique malware signature, despite the presence of obfuscation techniques, and that its accuracy exceeds the performance of similar methods.
2. Related Work
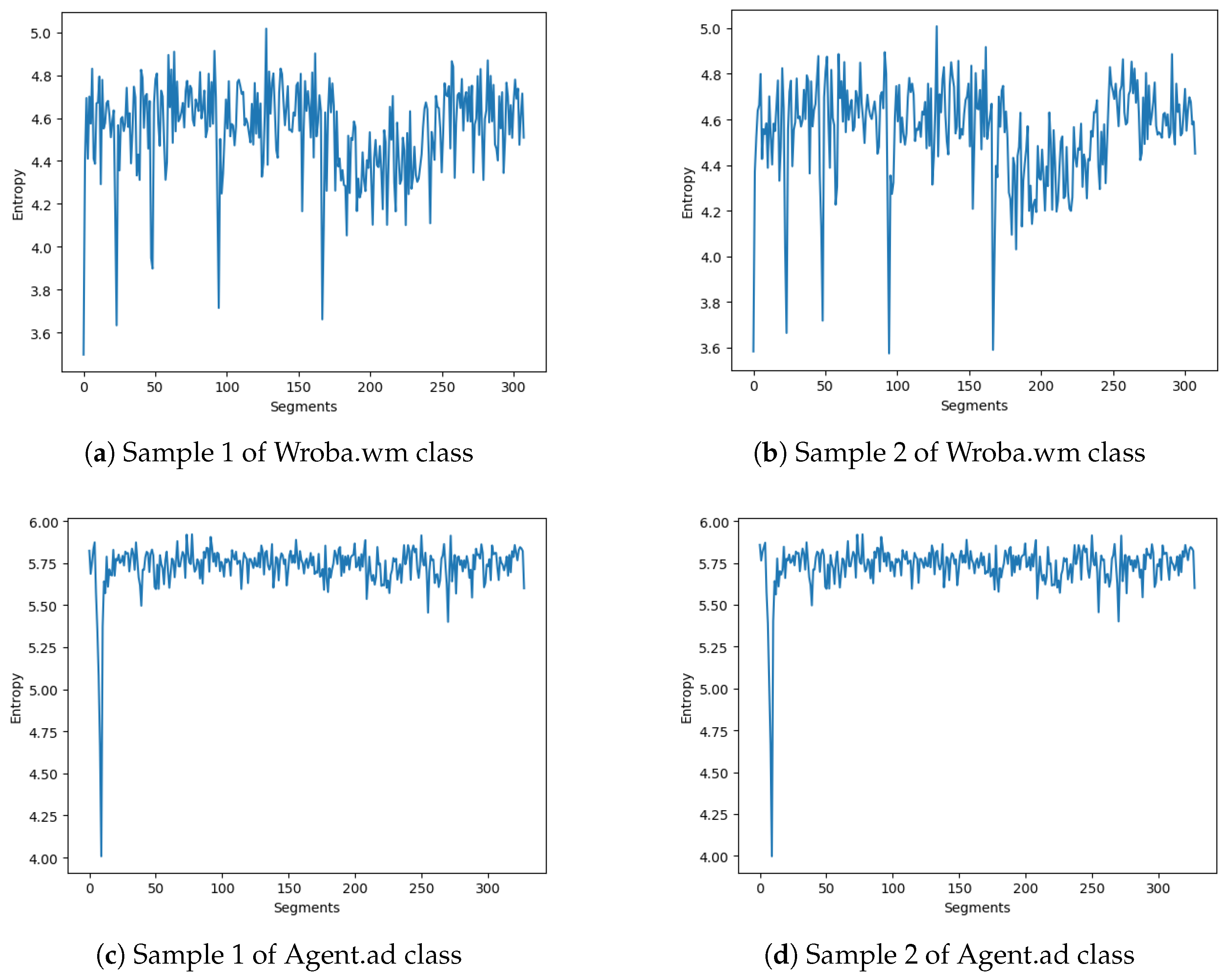
2.1. Entropy Feature in Feature Selection
2.2. Meta-Learning in Cyber Threat Intelligence
2.3. Few-Shot Learning for Malware Detection
2.4. Feature Embedding for Malware Detection
3. Preliminary
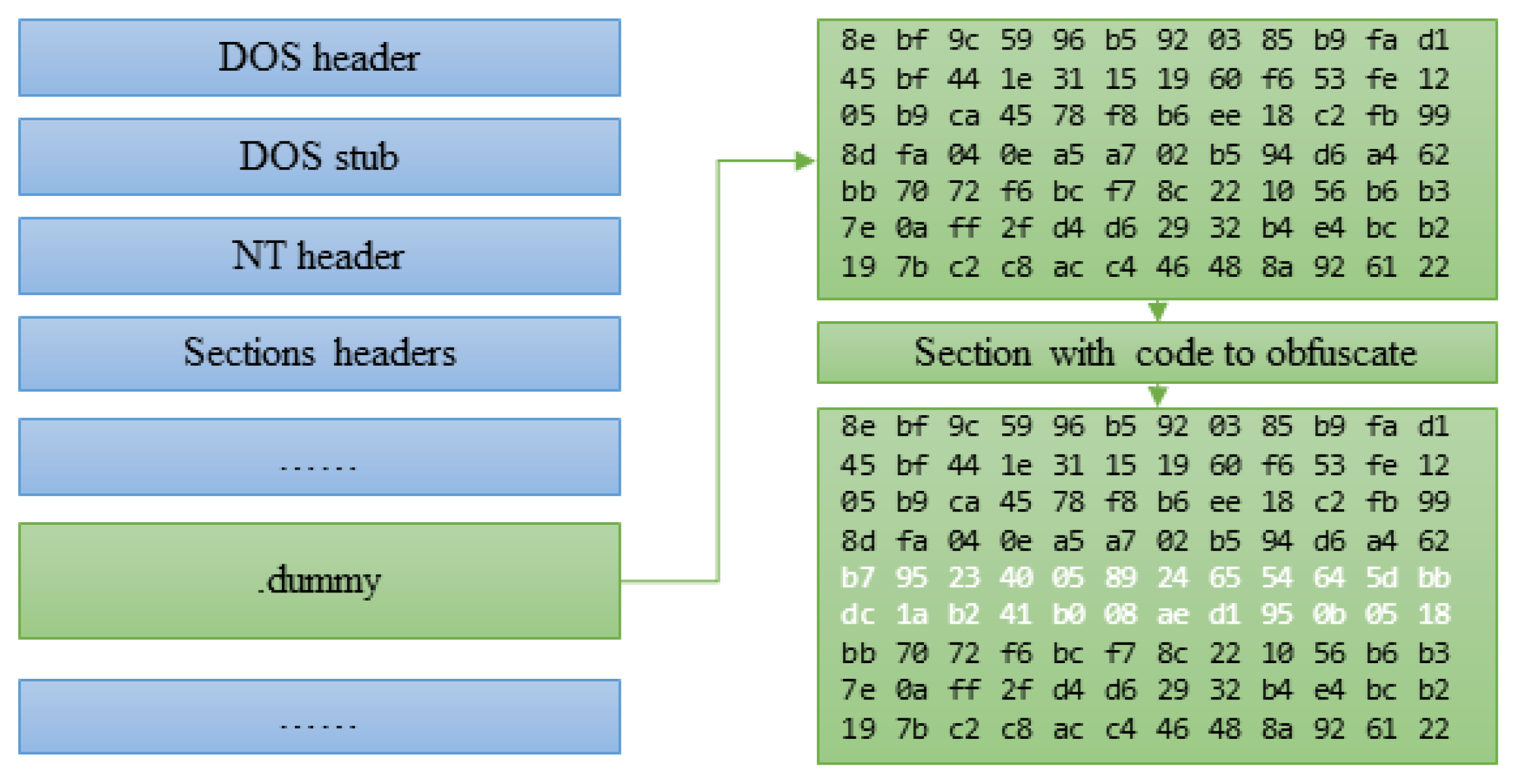
3.1. Control Flow Obfuscation
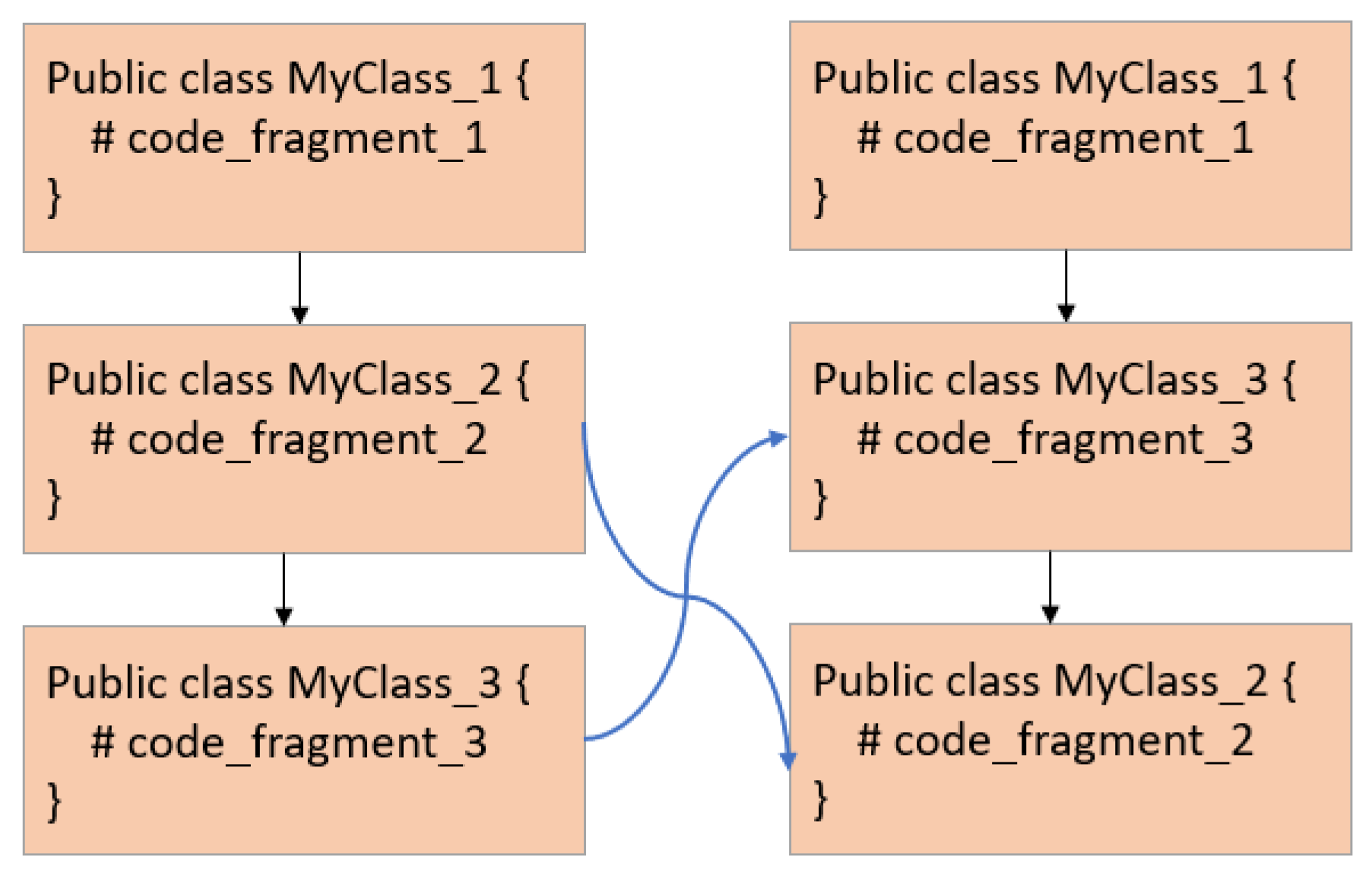
3.1.1. Function Logic Shuffling
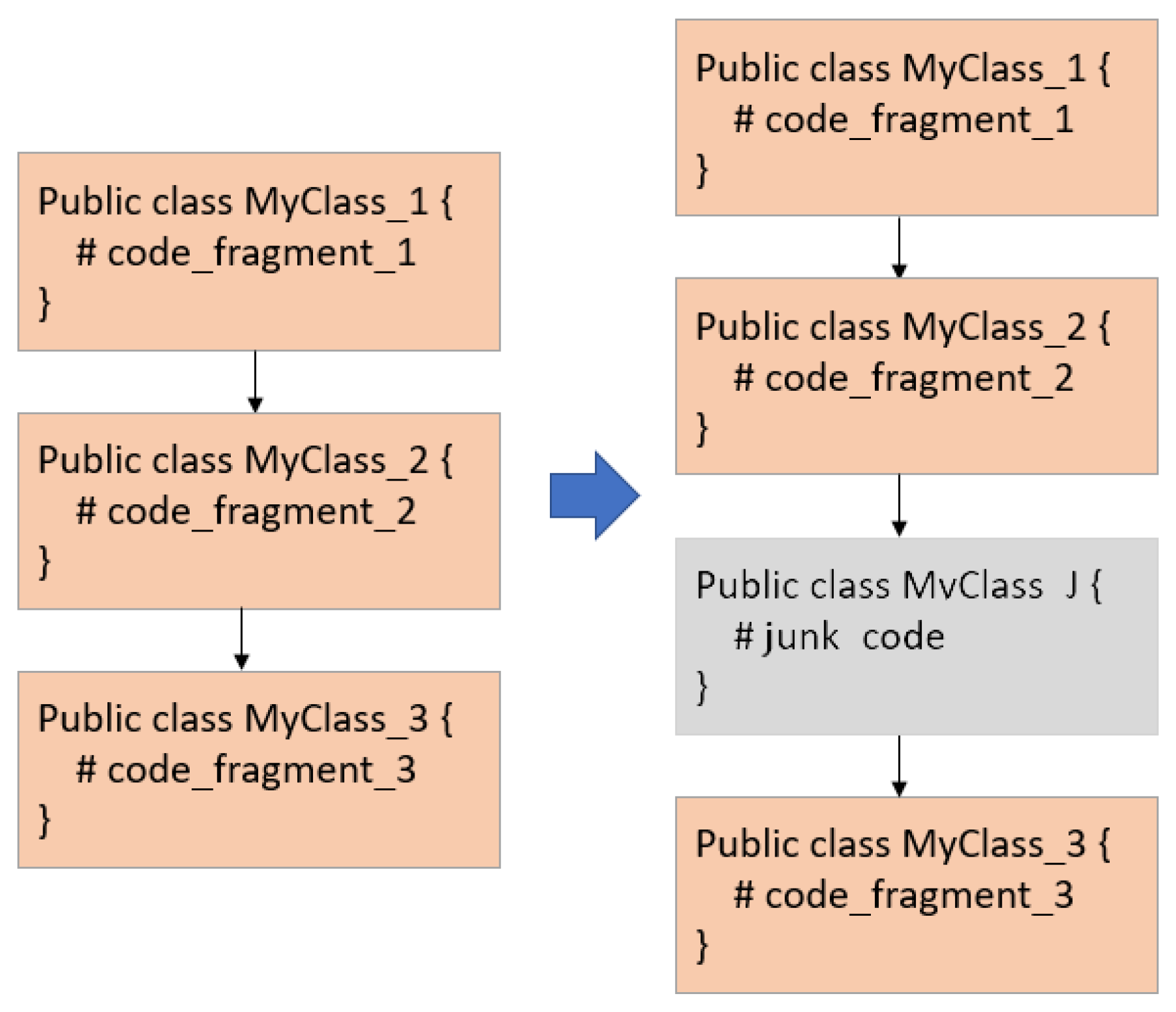
3.1.2. Junk Code Insertion
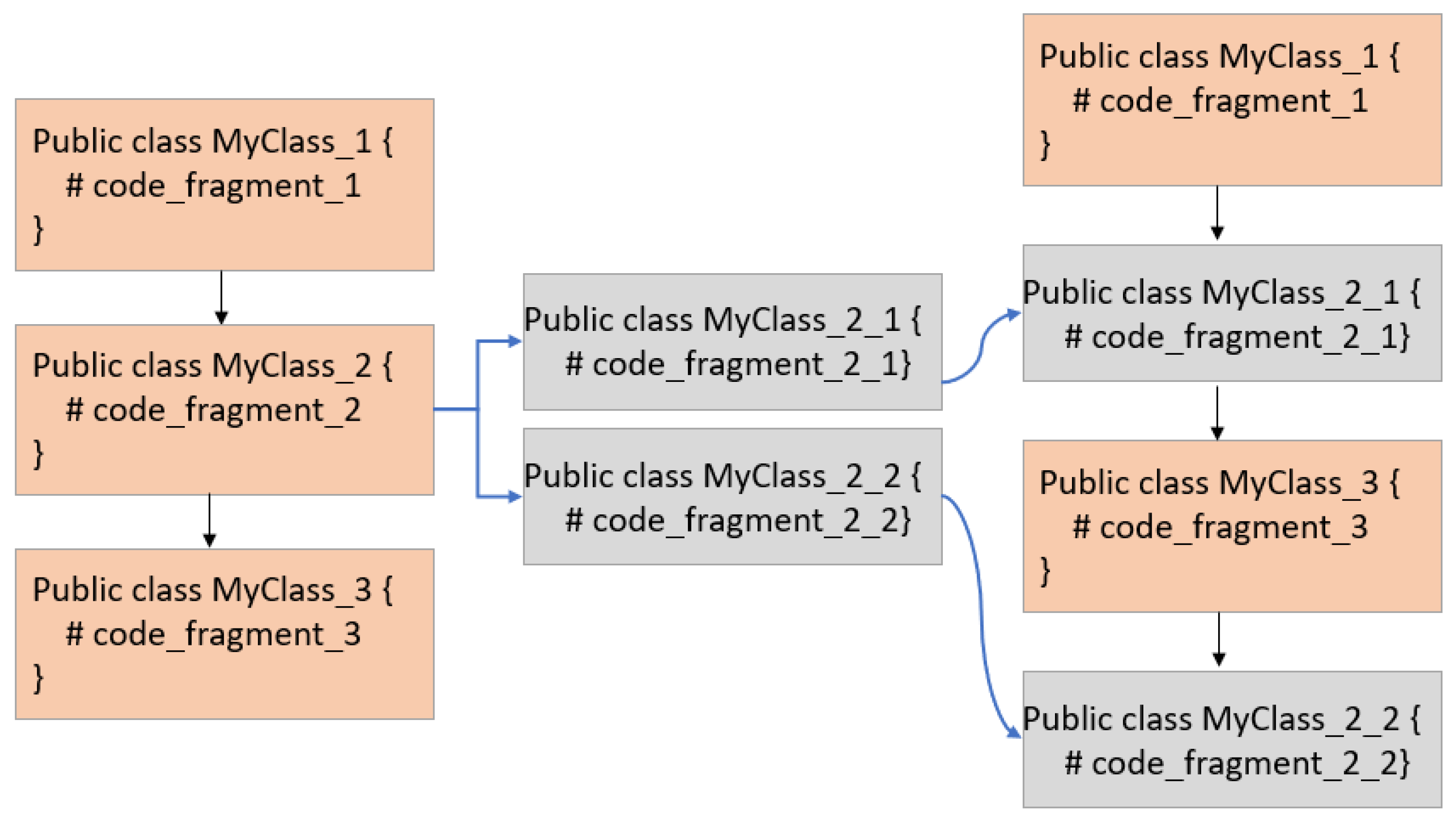
3.1.3. Function Splitting
3.2. Generic Approach and Issues
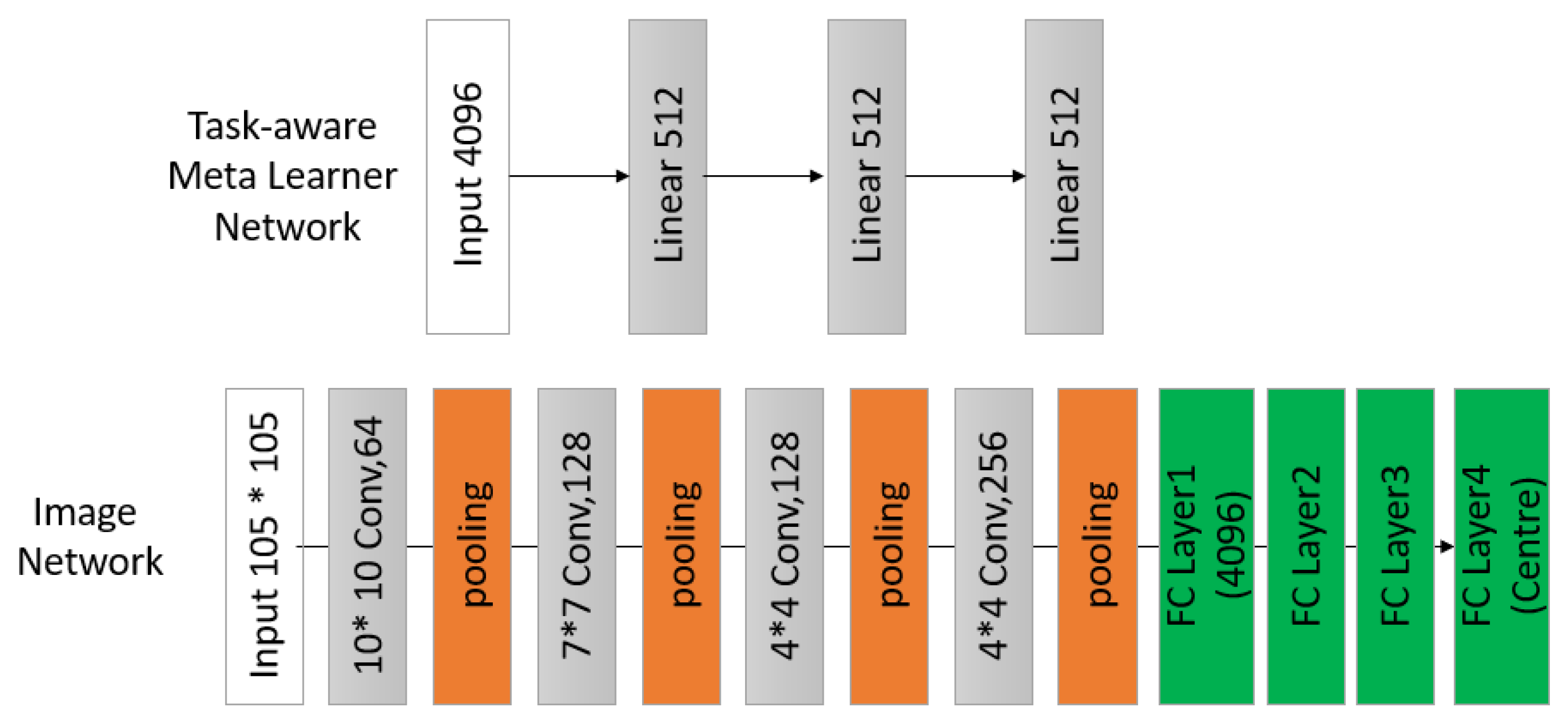
4. Task-Aware Meta Learning-Based Siamese Neural Network
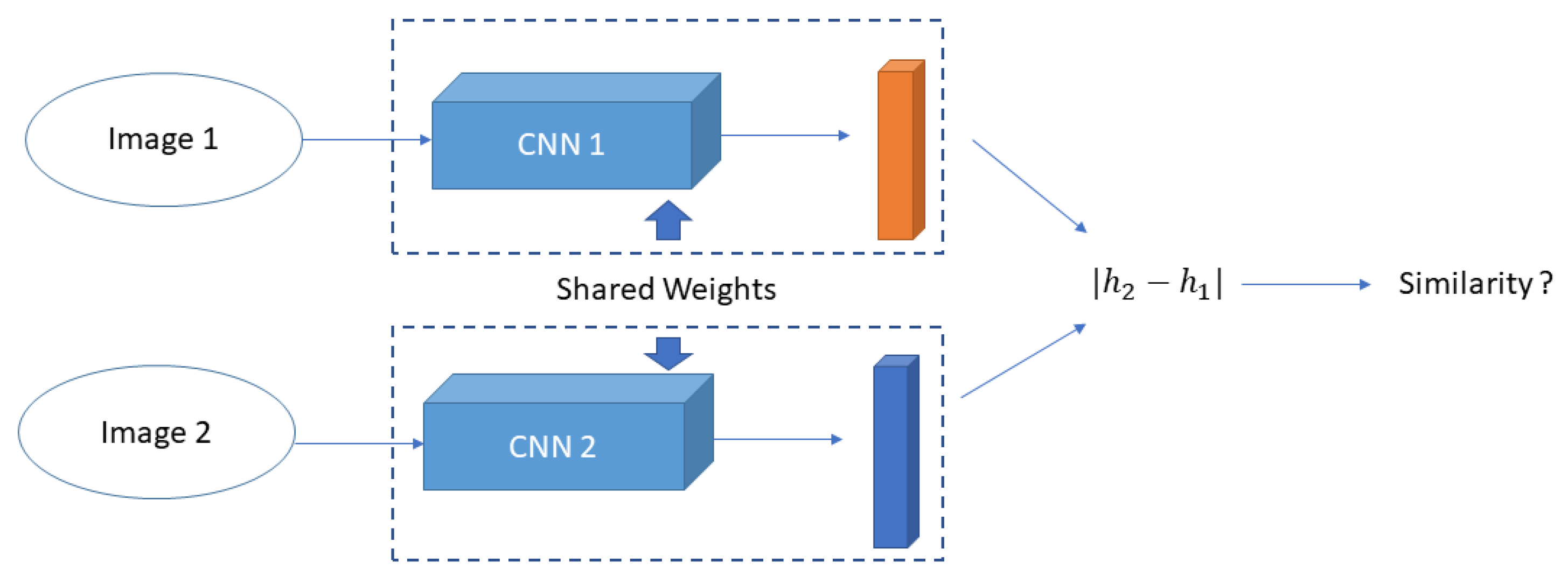
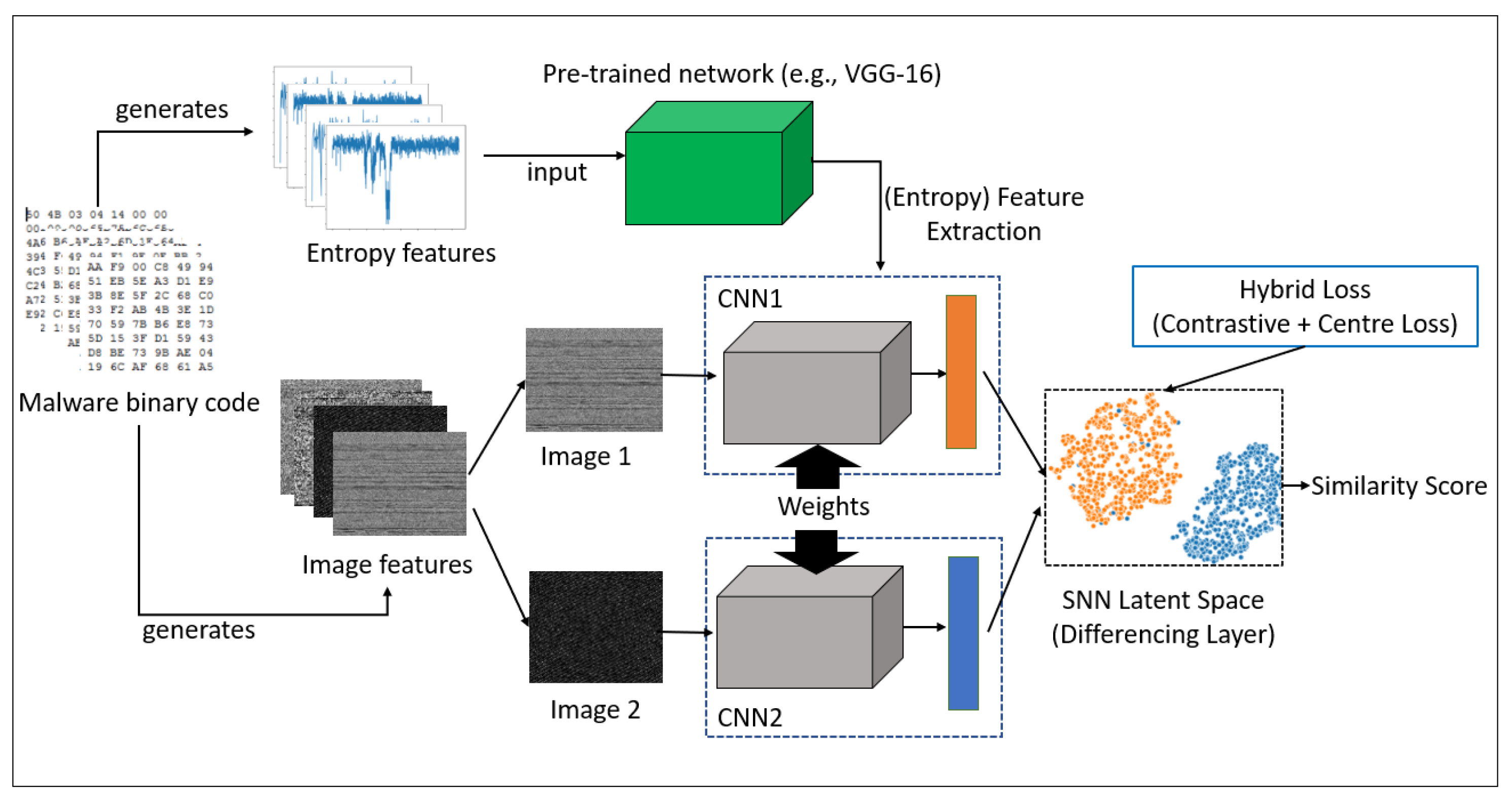
4.1. Our Model
| Algorithm 1: Pseudo-code of our proposed algorithm. |
 |
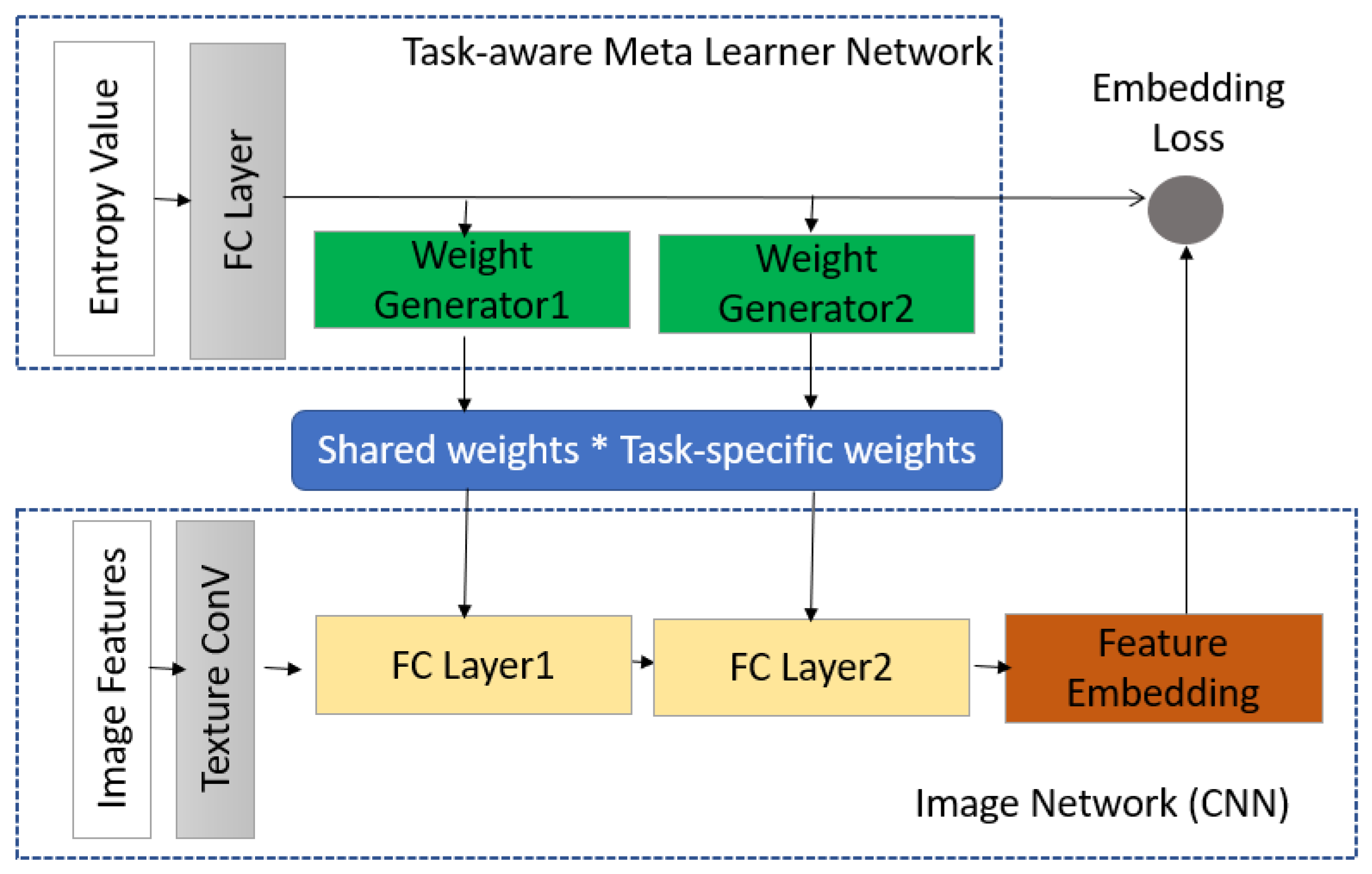
4.2. Task-Aware Meta-Learner
| Algorithm 2: Pseudo-code of entropy graph |
 |
4.3. Weight Generator via Factorization
4.4. Loss Function
4.4.1. Embedding Loss for Meta-Learner
4.4.2. Hybrid Loss for Our SNN
5. Experiments
5.1. Andro-Dumpsys Dataset
5.1.1. Image Feature
5.1.2. Entropy Feature
5.2. Model Configurations
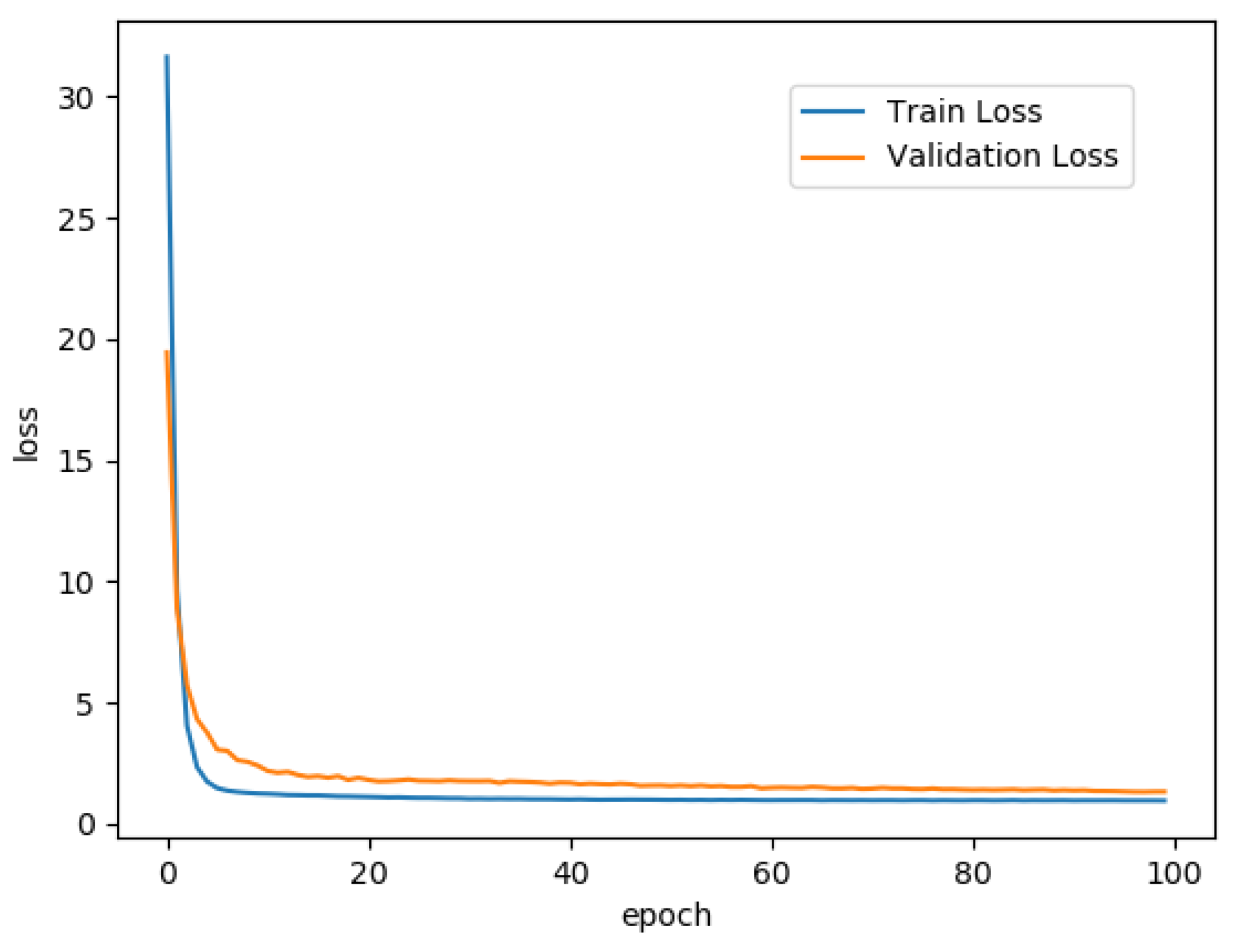
5.3. Results
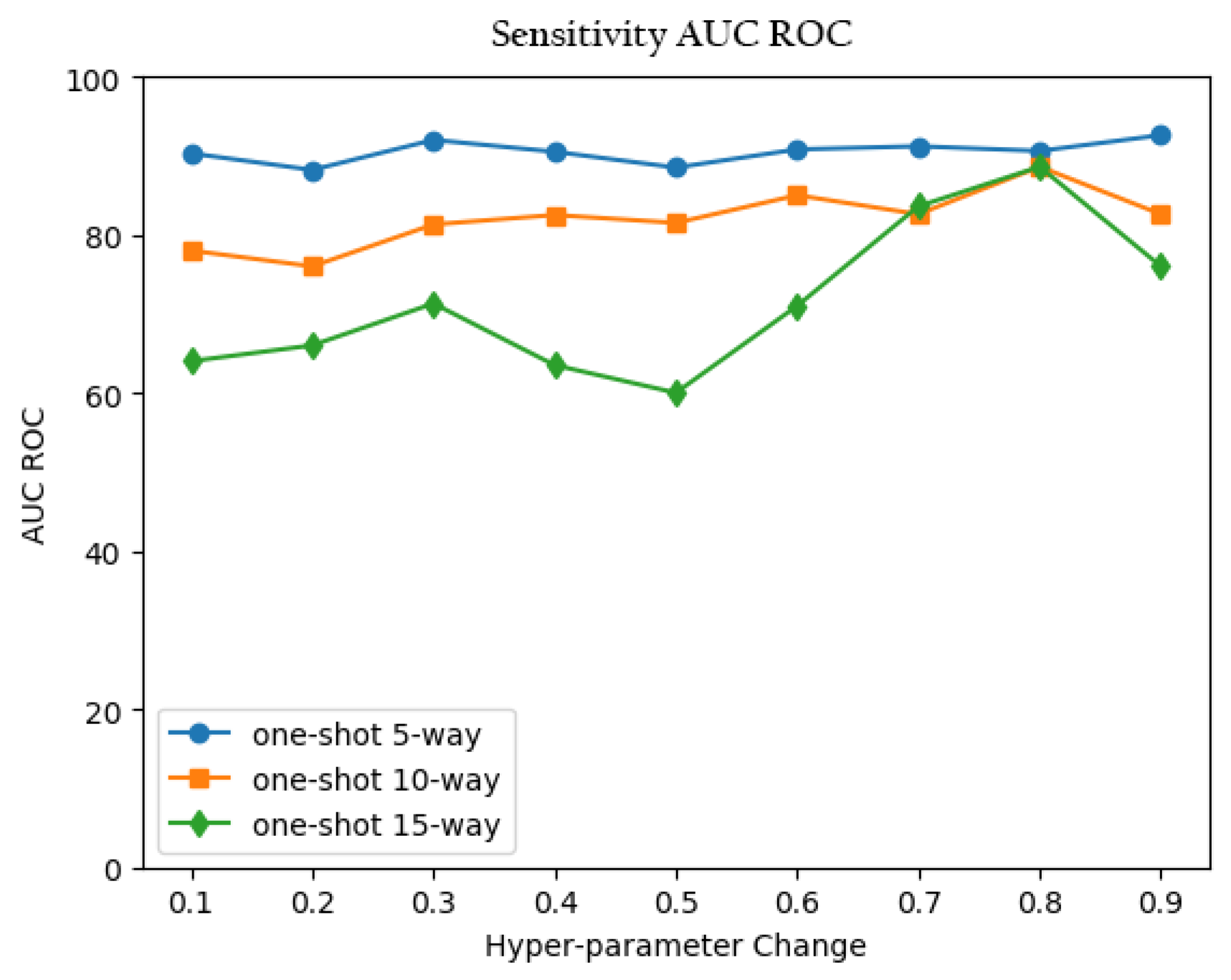
5.3.1. N-Way Matching Accuracy
5.3.2. Benchmark against Similar Methods
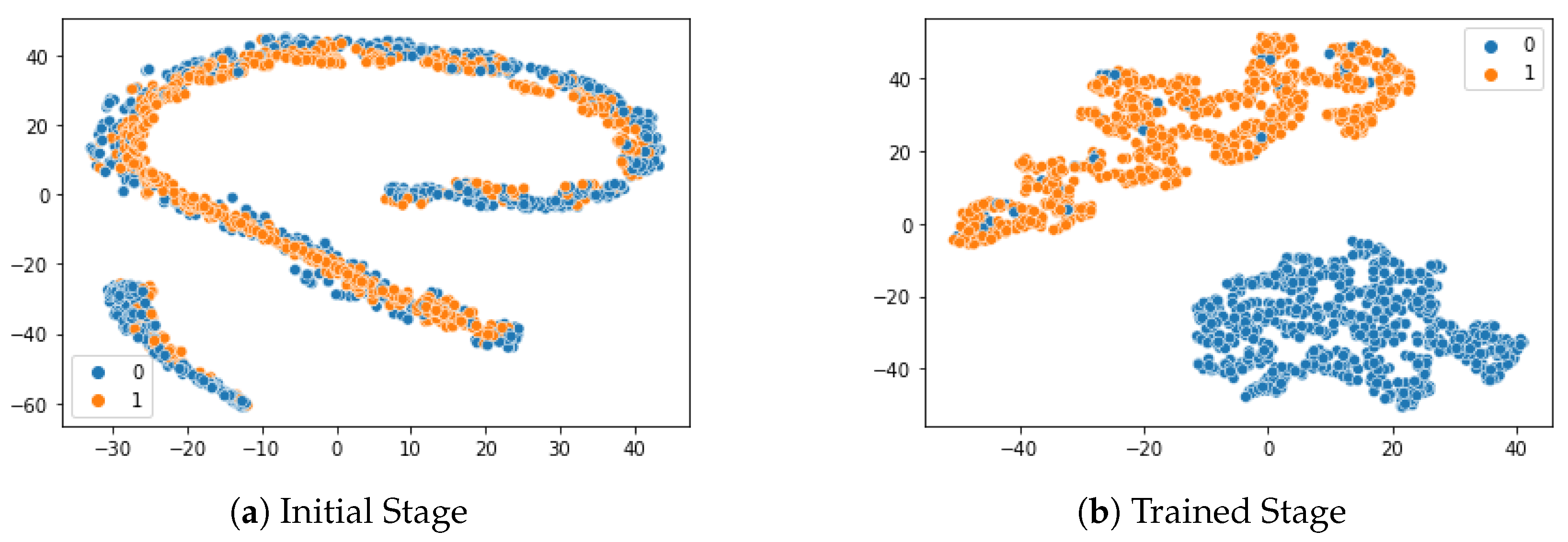
5.3.3. Distance Measure Effectiveness
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, S.; Li, M.; Diao, W.; Liu, X.; Liu, J.; Li, Z.; Xu, F.; Chen, K.; Wang, X.; Zhang, K. Understanding android obfuscation techniques: A large-scale investigation in the wild. In Proceedings of the International Conference on Security and Privacy in Communication Systems, Singapore, 8–10 August 2018; Springer: Cham, Switzerland, 2018; pp. 172–192. [Google Scholar]
- Chua, M.; Balachandran, V. Effectiveness of android obfuscation on evading anti-malware. In Proceedings of the Eighth ACM Conference on Data and Application Security and Privacy, Tempe, AZ, USA, 19–21 March 2018; pp. 143–145. [Google Scholar]
- Bacci, A.; Bartoli, A.; Martinelli, F.; Medvet, E.; Mercaldo, F. Detection of obfuscation techniques in Android applications. In Proceedings of the 13th International Conference on Availability, Reliability and Security, Hamburg, Germany, 27–30 August 2018; pp. 1–9. [Google Scholar]
- Song, L.; Tang, Z.; Li, Z.; Gong, X.; Chen, X.; Fang, D.; Wang, Z. Appis: Protect android apps against runtime repackaging attacks. In Proceedings of the 2017 IEEE 23rd International Conference on Parallel and Distributed Systems (ICPADS), Shenzhen, China, 15–17 December 2017; pp. 25–32. [Google Scholar]
- Lee, Y.; Woo, S.; Lee, J.; Song, Y.; Moon, H.; Lee, D.H. Enhanced Android app-repackaging attack on in-vehicle network. Wirel. Commun. Mob. Comput. 2019, 2019, 5650245. [Google Scholar] [CrossRef]
- Zheng, X.; Pan, L.; Yilmaz, E. Security analysis of modern mission critical android mobile applications. In Proceedings of the ACSW 2017: Australasian Computer Science Week 2017, Geelong, Australia, 30 January–3 February 2017; pp. 1–9. [Google Scholar]
- Zhu, H.J.; You, Z.H.; Zhu, Z.X.; Shi, W.L.; Chen, X.; Cheng, L. DroidDet: Effective and robust detection of android malware using static analysis along with rotation forest model. Neurocomputing 2018, 272, 638–646. [Google Scholar] [CrossRef]
- Sun, B.; Li, Q.; Guo, Y.; Wen, Q.; Lin, X.; Liu, W. Malware family classification method based on static feature extraction. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 507–513. [Google Scholar]
- Hu, X.; Griffin, K.E.; Bhatkar, S.B. Encoding Machine Code Instructions for Static Feature Based Malware Clustering. U.S. Patent 8,826,439, 2 September 2014. [Google Scholar]
- Vasan, D.; Alazab, M.; Wassan, S.; Safaei, B.; Zheng, Q. Image-based malware classification using ensemble of CNN architectures (IMCEC). Comput. Secur. 2020, 92, 101748. [Google Scholar] [CrossRef]
- Luo, J.S.; Lo, D.C.T. Binary malware image classification using machine learning with local binary pattern. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4664–4667. [Google Scholar]
- Su, J.; Vasconcellos, D.V.; Prasad, S.; Sgandurra, D.; Feng, Y.; Sakurai, K. Lightweight classification of IoT malware based on image recognition. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 2, pp. 664–669. [Google Scholar]
- Makandar, A.; Patrot, A. Trojan malware image pattern classification. In Proceedings of the International Conference on Cognition and Recognition, London, UK, 27–30 June 2016; Springer: Singapore, 2018; pp. 253–262. [Google Scholar]
- Hsiao, S.C.; Kao, D.Y.; Liu, Z.Y.; Tso, R. Malware image classification using one-shot learning with Siamese networks. Procedia Comput. Sci. 2019, 159, 1863–1871. [Google Scholar] [CrossRef]
- Singh, A.; Dutta, D.; Saha, A. Migan: Malware image synthesis using gans. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 10033–10034. [Google Scholar]
- Raff, E.; Zak, R.; Cox, R.; Sylvester, J.; Yacci, P.; Ward, R.; Tracy, A.; McLean, M.; Nicholas, C. An investigation of byte n-gram features for malware classification. J. Comput. Virol. Hacking Tech. 2018, 14, 1–20. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J. A hierarchical convolutional neural network for malware classification. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Shen, J.; Cao, X.; Li, Y.; Xu, D. Feature adaptation and augmentation for cross-scene hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2018, 15, 622–626. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J.; Vicens, R. Classification of malware by using structural entropy on convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Akarsh, S.; Poornachandran, P.; Menon, V.K.; Soman, K. A Detailed Investigation and Analysis of Deep Learning Architectures and Visualization Techniques for Malware Family Identification. In Cybersecurity and Secure Information Systems; Springer: Cham, Switzerland, 2019; pp. 241–286. [Google Scholar]
- Ni, S.; Qian, Q.; Zhang, R. Malware identification using visualization images and deep learning. Comput. Secur. 2018, 77, 871–885. [Google Scholar] [CrossRef]
- Naeem, H.; Ullah, F.; Naeem, M.R.; Khalid, S.; Vasan, D.; Jabbar, S.; Saeed, S. Malware detection in industrial internet of things based on hybrid image visualization and deep learning model. Ad Hoc Netw. 2020, 105, 102154. [Google Scholar] [CrossRef]
- Kalash, M.; Rochan, M.; Mohammed, N.; Bruce, N.D.; Wang, Y.; Iqbal, F. Malware classification with deep convolutional neural networks. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar]
- Milosevic, N.; Dehghantanha, A.; Choo, K.K.R. Machine learning aided Android malware classification. Comput. Electr. Eng. 2017, 61, 266–274. [Google Scholar] [CrossRef]
- Yuan, B.; Wang, J.; Liu, D.; Guo, W.; Wu, P.; Bao, X. Byte-level malware classification based on markov images and deep learning. Comput. Secur. 2020, 92, 101740. [Google Scholar] [CrossRef]
- Cao, J.; Su, Z.; Yu, L.; Chang, D.; Li, X.; Ma, Z. Softmax cross entropy loss with unbiased decision boundary for image classification. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December; pp. 2028–2032.
- Huang, S.; Tran, D.N.; Tran, T.D. Sparse signal recovery based on nonconvex entropy minimization. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3867–3871. [Google Scholar]
- Finlayson, G.D.; Drew, M.S.; Lu, C. Entropy minimization for shadow removal. Int. J. Comput. Vis. 2009, 85, 35–57. [Google Scholar] [CrossRef]
- Kolouri, S.; Rostami, M.; Owechko, Y.; Kim, K. Joint dictionaries for zero-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Allahverdyan, A.E.; Galstyan, A.; Abbas, A.E.; Struzik, Z.R. Adaptive decision making via entropy minimization. Int. J. Approx. Reason. 2018, 103, 270–287. [Google Scholar] [CrossRef]
- Yang, A.; Lu, C.; Li, J.; Huang, X.; Ji, T.; Li, X.; Sheng, Y. Application of meta-learning in cyberspace security: A survey. Digit. Commun. Netw. 2023, 9, 67–78. [Google Scholar] [CrossRef]
- Zoppi, T.; Gharib, M.; Atif, M.; Bondavalli, A. Meta-learning to improve unsupervised intrusion detection in cyber-physical systems. ACM Trans. Cyber-Phys. Syst. (TCPS) 2021, 5, 1–27. [Google Scholar] [CrossRef]
- Zoppi, T.; Ceccarelli, A.; Puccetti, T.; Bondavalli, A. Which Algorithm can Detect Unknown Attacks? Comparison of Supervised, Unsupervised and Meta-Learning Algorithms for Intrusion Detection. Comput. Secur. 2023, 127, 103107. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Shimizu, S.; Ma, J.; Jin, Q. Siamese neural network based few-shot learning for anomaly detection in industrial cyber-physical systems. IEEE Trans. Ind. Inform. 2020, 17, 5790–5798. [Google Scholar] [CrossRef]
- Sun, G.; Qian, Q. Deep learning and visualization for identifying malware families. IEEE Trans. Dependable Secur. Comput. 2018, 18, 283–295. [Google Scholar] [CrossRef]
- Moustakidis, S.; Karlsson, P. A novel feature extraction methodology using Siamese convolutional neural networks for intrusion detection. Cybersecurity 2020, 3, 1–13. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, P.; Wang, J. ConvProtoNet: Deep Prototype Induction towards Better Class Representation for Few-Shot Malware Classification. Appl. Sci. 2020, 10, 2847. [Google Scholar] [CrossRef]
- Zhang, B.; Xiao, W.; Xiao, X.; Sangaiah, A.K.; Zhang, W.; Zhang, J. Ransomware classification using patch-based CNN and self-attention network on embedded N-grams of opcodes. Future Gener. Comput. Syst. 2020, 110, 708–720. [Google Scholar] [CrossRef]
- Ng, C.K.; Jiang, F.; Zhang, L.Y.; Zhou, W. Static malware clustering using enhanced deep embedding method. Concurr. Comput. Pract. Exp. 2019, 31, e5234. [Google Scholar] [CrossRef]
- Hashemi, H.; Azmoodeh, A.; Hamzeh, A.; Hashemi, S. Graph embedding as a new approach for unknown malware detection. J. Comput. Virol. Hacking Tech. 2017, 13, 153–166. [Google Scholar] [CrossRef]
- Pektaş, A.; Acarman, T. Deep learning for effective Android malware detection using API call graph embeddings. Soft Comput. 2020, 24, 1027–1043. [Google Scholar] [CrossRef]
- Chen, L.; Sahita, R.; Parikh, J.; Marino, M. STAMINA: Scalable Deep Learning Approach for Malware Classification. Intel Labs Whitepaper. 2020. Available online: https://www.intel.com/content/www/us/en/artificial-intelligence/documents/stamina-deep-learningfor-malware-protection-whitepaper.html (accessed on 20 June 2021).
- Li, X.; Qiu, K.; Qian, C.; Zhao, G. An Adversarial Machine Learning Method Based on OpCode N-grams Feature in Malware Detection. In Proceedings of the 2020 IEEE Fifth International Conference on Data Science in Cyberspace (DSC), Hong Kong, China, 27–29 July 2020; pp. 380–387. [Google Scholar]
- Zhu, J.; Jang-Jaccard, J.; Liu, T.; Zhou, J. Joint Spectral Clustering based on Optimal Graph and Feature Selection. Neural Process. Lett. 2021, 53, 257–273. [Google Scholar] [CrossRef]
- Tran, T.K.; Sato, H.; Kubo, M. Image-Based Unknown Malware Classification with Few-Shot Learning Models. In Proceedings of the 2019 Seventh International Symposium on Computing and Networking Workshops (CANDARW), Nagasaki, Japan, 26–29 November 2019; pp. 401–407. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Gidaris, S.; Komodakis, N. Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4367–4375. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 499–515. [Google Scholar]
- Jang, J.-w.; Kang, H.; Woo, J.; Mohaisen, A.; Kim, H.K. Andro-Dumpsys: Anti-malware system based on the similarity of malware creator and malware centric information. Comput. Secur. 2016, 58, 125–138. [Google Scholar] [CrossRef]
- Zhu, J.; Jang-Jaccard, J.; Watters, P.A. Multi-Loss Siamese Neural Network with Batch Normalization Layer for Malware Detection. IEEE Access 2020, 8, 171542–171550. [Google Scholar] [CrossRef]
- Malvar, H.S.; He, L.W.; Cutler, R. High-quality linear interpolation for demosaicing of bayer-patterned color images. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 3, pp. iii–485. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. arXiv 2016, arXiv:1606.04080. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Wei, Y.; Jang-Jaccard, J.; Sabrina, F.; Singh, A.; Xu, W.; Camtepe, S. Ae-mlp: A hybrid deep learning approach for ddos detection and classification. IEEE Access 2021, 9, 146810–146821. [Google Scholar] [CrossRef]
- Zhu, J.; Jang-Jaccard, J.; Singh, A.; Watters, P.A.; Camtepe, S. Task-aware meta learning-based siamese neural network for classifying obfuscated malware. arXiv 2021, arXiv:2110.13409. [Google Scholar]
- Zhu, J.; Jang-Jaccard, J.; Singh, A.; Welch, I.; AI-Sahaf, H.; Camtepe, S. A Few-Shot Meta-Learning based Siamese Neural Network using Entropy Features for Ransomware Classification. arXiv 2021, arXiv:2112.00668. [Google Scholar] [CrossRef]
- McIntosh, T.R.; Jang-Jaccard, J.; Watters, P.A. Large scale behavioral analysis of ransomware attacks. In Proceedings of the International Conference on Neural Information Processing, Siem Reap, Cambodia, 13–16 December 2018; Springer: Cham, Switzerland, 2018; pp. 217–229. [Google Scholar]
- McIntosh, T.; Jang-Jaccard, J.; Watters, P.; Susnjak, T. The inadequacy of entropy-based ransomware detection. In Proceedings of the International Conference on Neural Information Processing, Sydney, Australia, 12–15 December 2019; Springer: Cham, Switzerland, 2019; pp. 181–189. [Google Scholar]
- Feng, S.; Liu, Q.; Patel, A.; Bazai, S.U.; Jin, C.K.; Kim, J.S.; Sarrafzadeh, M.; Azzollini, D.; Yeoh, J.; Kim, E.; et al. Automated pneumothorax triaging in chest X-rays in the New Zealand population using deep-learning algorithms. J. Med. Imaging Radiat. Oncol. 2022, 6, 1035–1043. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| The log probability calculated by the | |
| The log probability calculated by the | |
| The malware image feature of ith samples | |
| The class t of ith samples | |
| The feature layers’ parameters | |
| I-th feature layer in ’s weights | |
| The shared parameters for all malware families | |
| The task-specific parameters for each malware family | |
| The center point of each class | |
| The embedding loss | |
| The binary cross entropy loss with center loss | |
| The distance feature of a pair of images | |
| The label of pairs of images. | |
| The convolutional filter with parameters w | |
| The hyper-parameter |
| No. | Family | Number of Variants | Number of Samples |
|---|---|---|---|
| (+3 Synthetic) | (+6 Synthetic) | ||
| 1 | Agent | 39 (42) | 150 (156) |
| 2 | Blocal | 1 (4) | 1 (7) |
| 3 | Climap | 1 (4) | 5 (11) |
| 4 | Fakeguard | 1 (4) | 10 (16) |
| 5 | Fech | 1 (4) | 3 (9) |
| 6 | Gepew | 4 (7) | 112 (118) |
| 7 | Gidix | 6 (9) | 108 (114) |
| 8 | Helir | 1 (4) | 15 (21) |
| 9 | Newbak | 1 (4) | 1 (7) |
| 10 | Recal | 2 (5) | 25 (31) |
| 11 | SmForw | 23 (26) | 166 (172) |
| 12 | Tebak | 10 (13) | 93 (99) |
| 13 | Wroba | 23 (26) | 108 (114) |
| Parameters | Values | Description |
|---|---|---|
| rescale | 1./255 | Resizing an image by a given scaling factor. |
| zca_epsilon | Epsilon for ZCA whitening. | |
| fill_mode | wrap | Points outside the boundaries of the input are filled according to the given mode. |
| rotation_range | 0.1 | Setting degree of range for random rotations. |
| height_shift_range | 0.5 | Setting range for random vertical shifts. |
| horizontal_flip | True | Randomly flips inputs horizontally. |
| 1-shot | ||||
| Ref | Method | 5-way | 10-way | 15-way |
| [53] | Matching network | 85 ± 2.2% | 84 ± 2.4% | 76 ± 2.6% |
| [54] | Prototypical network | 86 ± 1.7% | 82 ± 1.7% | 81 ± 1.9% |
| [52] | Siamese network | 82 ± 2.5% | 69 ± 2.3% | 64 ± 2.6% |
| Task-aware SNN | 88 ± 2.2% | 86 ± 2.2% | 82 ± 2.4% | |
| 5-shot | ||||
| Ref | Method | 5-way | 10-way | 15-way |
| [53] | Matching network | 89 ± 2.1% | 86 ± 2.1% | 78 ± 2.3% |
| [54] | Prototypical network | 89 ± 1.2% | 85 ± 1.4% | 82 ± 1.5% |
| [52] | Siamese network | 85 ± 2.0% | 72 ± 2.2% | 69 ± 2.7% |
| Task-aware SNN | 91 ± 1.8% | 88 ± 2.1% | 83 ± 2.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Jang-Jaccard, J.; Singh, A.; Watters, P.A.; Camtepe, S. Task-Aware Meta Learning-Based Siamese Neural Network for Classifying Control Flow Obfuscated Malware. Future Internet 2023, 15, 214. https://doi.org/10.3390/fi15060214
Zhu J, Jang-Jaccard J, Singh A, Watters PA, Camtepe S. Task-Aware Meta Learning-Based Siamese Neural Network for Classifying Control Flow Obfuscated Malware. Future Internet. 2023; 15(6):214. https://doi.org/10.3390/fi15060214
Chicago/Turabian StyleZhu, Jinting, Julian Jang-Jaccard, Amardeep Singh, Paul A. Watters, and Seyit Camtepe. 2023. "Task-Aware Meta Learning-Based Siamese Neural Network for Classifying Control Flow Obfuscated Malware" Future Internet 15, no. 6: 214. https://doi.org/10.3390/fi15060214
APA StyleZhu, J., Jang-Jaccard, J., Singh, A., Watters, P. A., & Camtepe, S. (2023). Task-Aware Meta Learning-Based Siamese Neural Network for Classifying Control Flow Obfuscated Malware. Future Internet, 15(6), 214. https://doi.org/10.3390/fi15060214