

Contrastive Refinement for Dense Retrieval Inference in the Open-Domain Question Answering Task
Abstract
1. Introduction
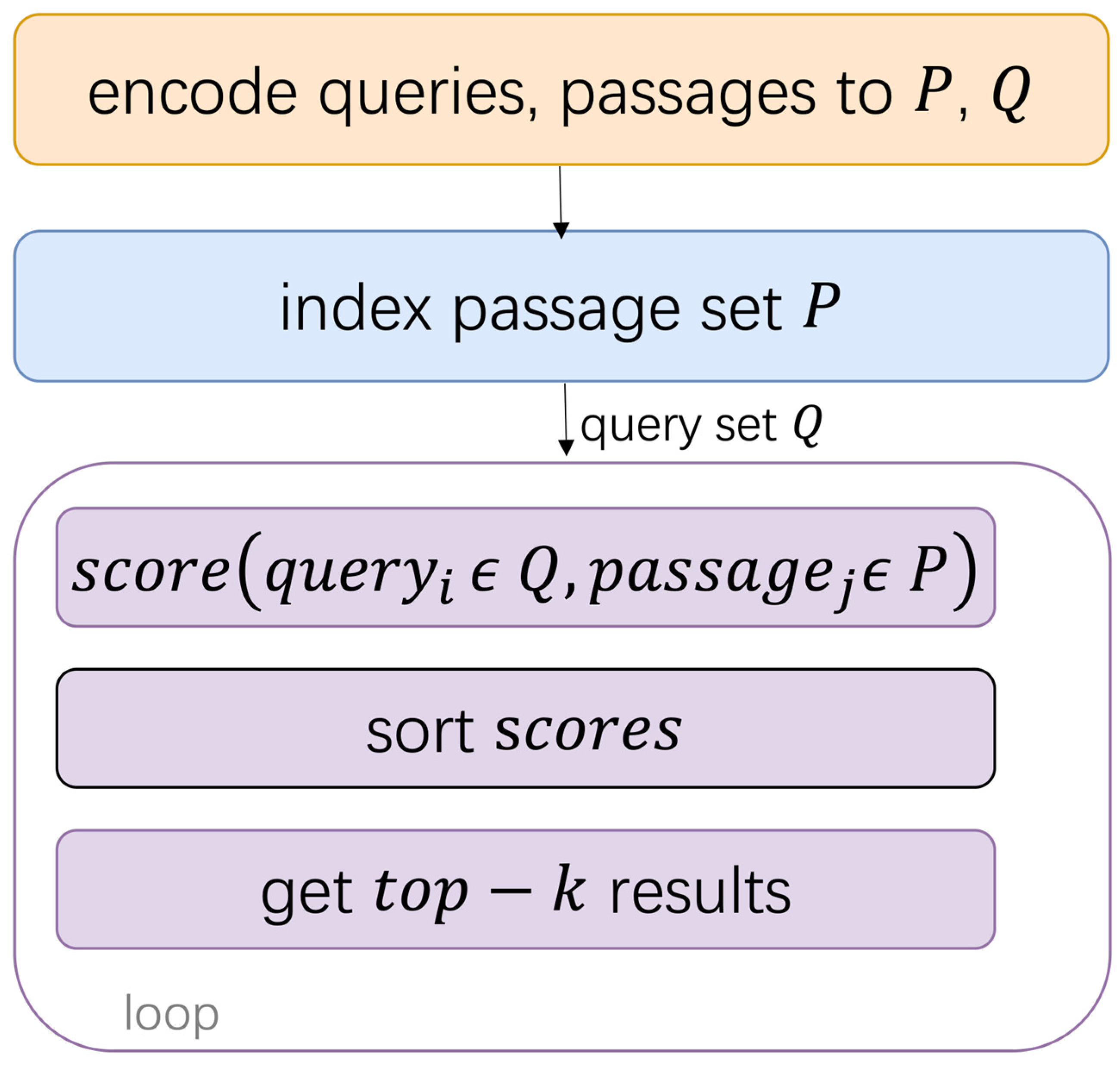
2. Materials and Methods
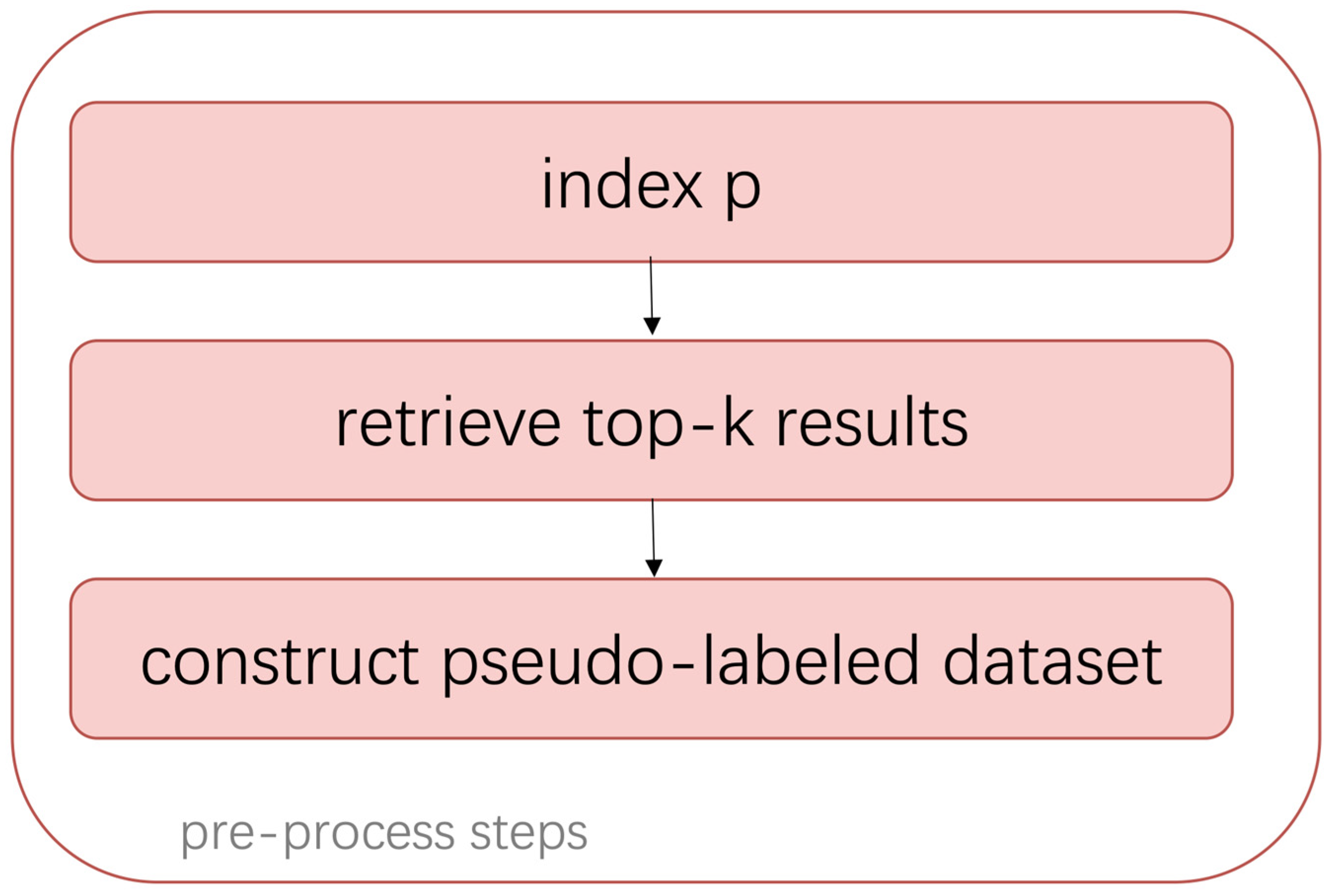
2.1. Constructing Pseudo-Labels
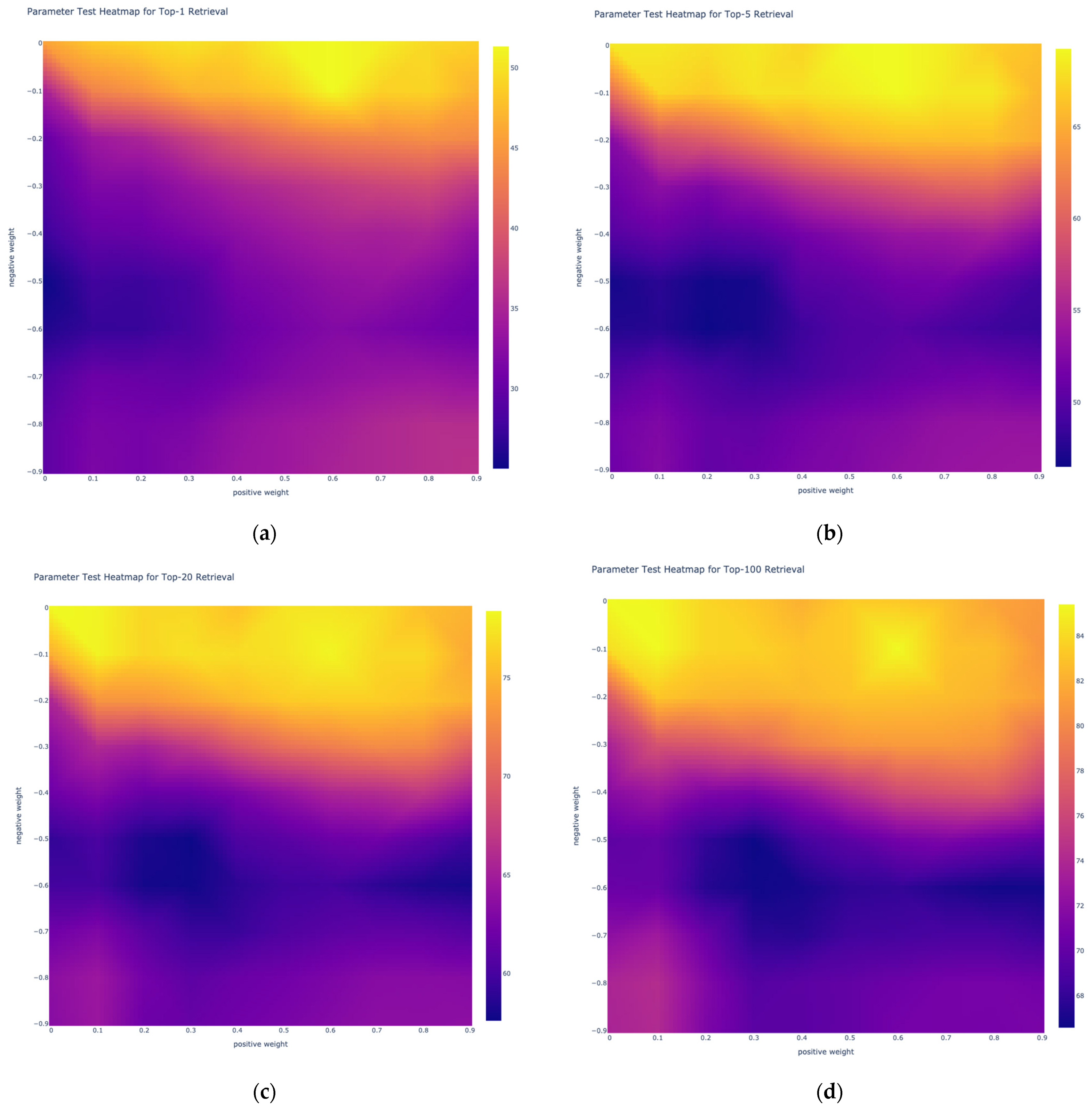
2.2. A Simple Linear Weight Calculation Method
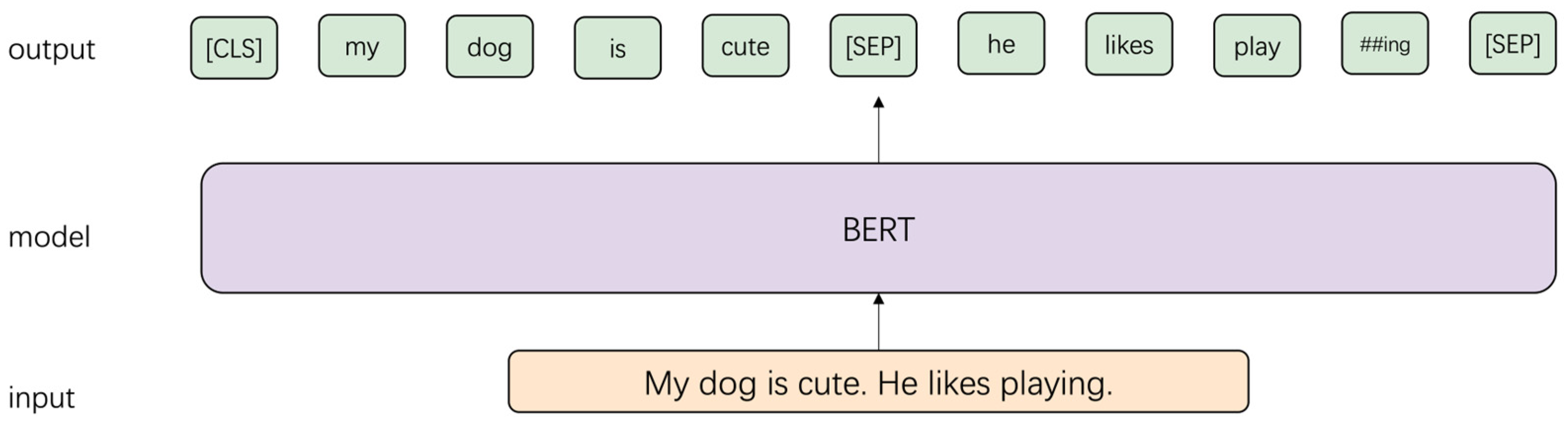
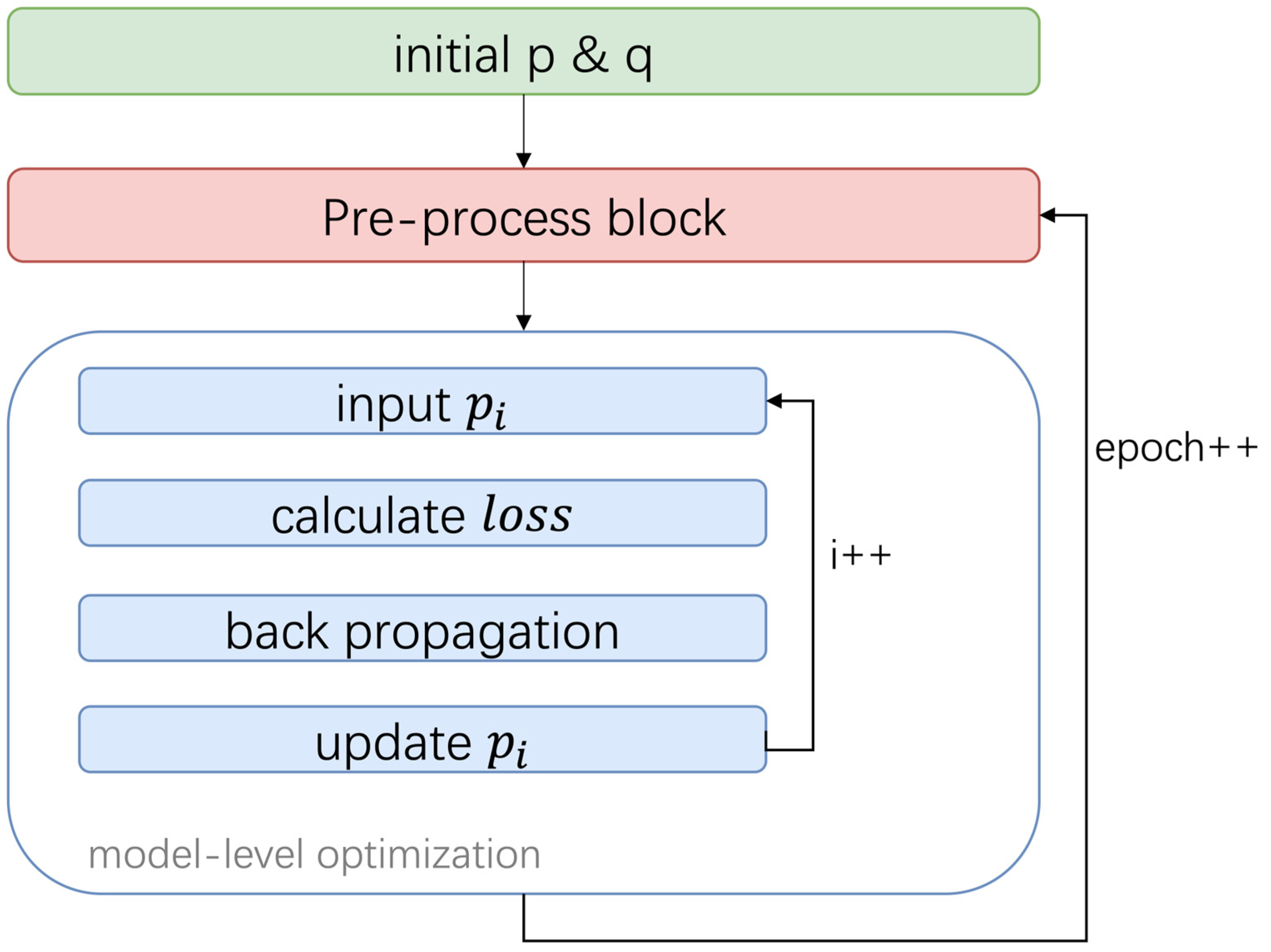
2.3. Text Representation Optimization Model AOpt
2.3.1. AOpt-Query LOSS
2.3.2. AOpt-Passage Loss
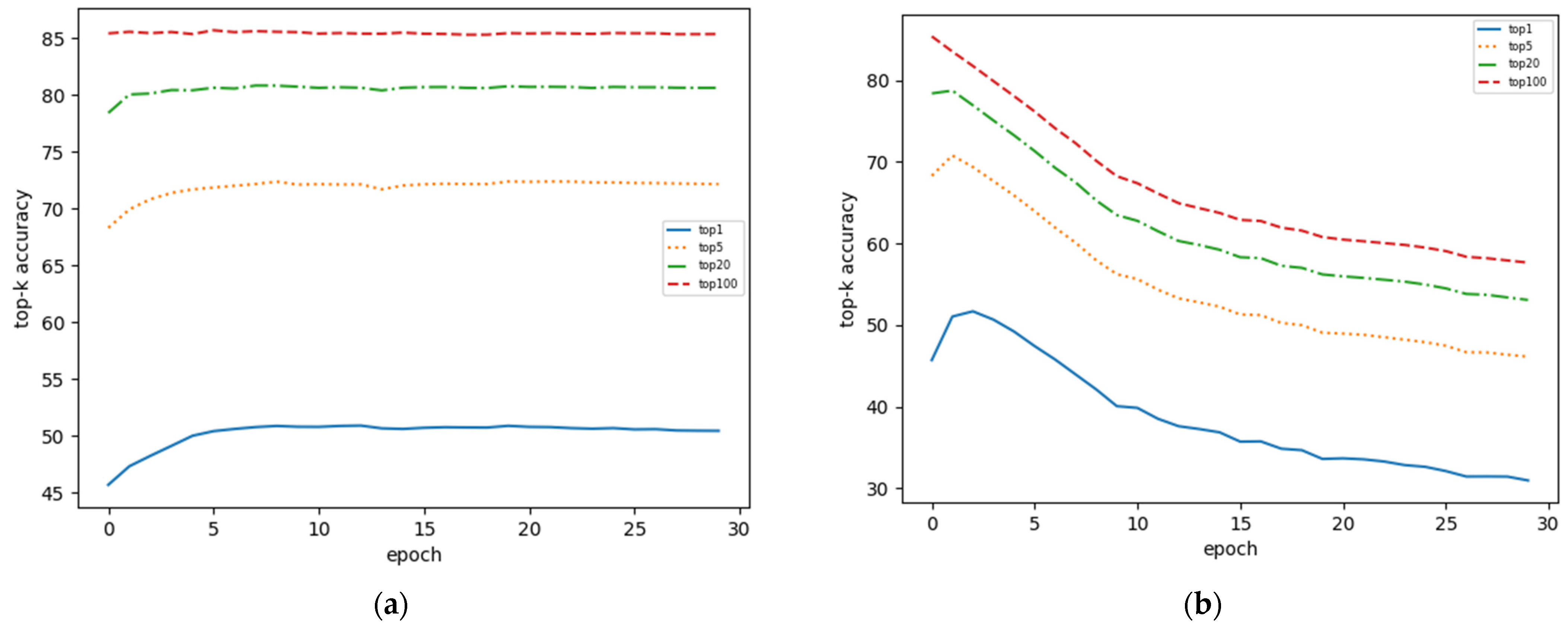
2.3.3. Dense Representations Update
3. Results
3.1. Experimental Preparations
3.1.1. Dataset
- Wikipedia Dataset
- 2.
- QA Dataset
- NQ
- TriviaQA
3.1.2. Evaluation Metrics
- Top-k Accuracy
- Exact Match
3.1.3. Experimental Details
- Device
- 2.
- Main Libraries
- We used the PyTorch deep learning framework for our experiments.
- Similar to DPR [1], we used the HNSW index from the FAISS-cpu library for retrieval experiments, with 512 neighbors stored for each node.
- 3.
- Retriever and Reader
3.1.4. Hyperparameters
- Weight-Based Calculation
- AOpt Model
3.2. Experimental Results
3.2.1. Linear Weight Calculation Result
3.2.2. Retriever Performance
3.2.3. Reader Performance
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, QC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1870–1879. [Google Scholar]
- Robertson, S.; Zaragoza, H. The Probabilistic Relevance Framework: BM25 and Beyond. Found. Trends® Inf. Retr. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Karpukhin, V.; Oğuz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W. Dense Passage Retrieval for Open-Domain Question Answering. arXiv 2020, arXiv:2004.04906. [Google Scholar]
- Zhu, W.; Liu, S.; Liu, C. Learning multimodal word representation with graph convolutional networks. Inf. Process. Manag. 2021, 58, 102709. [Google Scholar] [CrossRef]
- Zhu, W.; Jin, X.; Liu, S.; Lu, Z.; Zhang, W.; Yan, K.; Wei, B. Enhanced double-carrier word embedding via phonetics and writing. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2020, 19, 1–18. [Google Scholar] [CrossRef]
- Xiong, L.; Xiong, C.; Li, Y.; Tang, K.-F.; Liu, J.; Bennett, P.; Ahmed, J.; Overwijk, A. Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. arXiv 2020, arXiv:2007.00808. [Google Scholar]
- Ren, R.; Lv, S.; Qu, Y.; Liu, J.; Zhao, W.X.; She, Q.; Wu, H.; Wang, H.; Wen, J.-R. PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 2173–2183. [Google Scholar]
- Sung, M.; Park, J.; Kang, J.; Chen, D.; Lee, J. Optimizing Test-Time Query Representations for Dense Retrieval. arXiv 2022, arXiv:2205.12680. [Google Scholar]
- Lee, K.; Chang, M.-W.; Toutanova, K. Latent Retrieval for Weakly Supervised Open Domain Question Answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 6086–6096. [Google Scholar]
- Lee, J.; Sung, M.; Kang, J.; Chen, D. Learning Dense Representations of Phrases at Scale. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 5–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 6634–6647. [Google Scholar]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M.-W. REALM: Retrieval-Augmented Language Model Pre-Training. arXiv 2020, arXiv:2002.08909. [Google Scholar]
- Liu, C.; Zhu, W.; Zhang, X.; Zhai, Q. Sentence part-enhanced BERT with respect to downstream tasks. Complex Intell. Syst. 2023, 9, 463–474. [Google Scholar] [CrossRef]
- Sciavolino, C.; Zhong, Z.; Lee, J.; Chen, D. Simple Entity-Centric Questions Challenge Dense Retrievers. arXiv 2022, arXiv:2109.08535. [Google Scholar]
- Lee, D.-H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the ICML 2013 Workshop on Challenges in Representation Learning (WREPL), Atlanta, GA, USA, 17–19 June 2013. [Google Scholar]
- Kwiatkowski, T.; Palomaki, J.; Redfield, O.; Collins, M.; Parikh, A.; Alberti, C.; Epstein, D.; Polosukhin, I.; Devlin, J.; Lee, K.; et al. Natural Questions: A Benchmark for Question Answering Research. Trans. Assoc. Comput. Linguist. 2019, 7, 453–466. [Google Scholar] [CrossRef]
- Ma, X.; Sun, K.; Pradeep, R.; Lin, J. A replication study of dense passage retriever. arXiv Prepr. 2021, arXiv:2104.05740. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | DPR-Single 1 | DPR-Multi 2 | BM25 |
|---|---|---|---|
| NQ | 80.1 | 79.4 | 64.4 |
| EQ | 49.7 | 56.7 | 72.0 |
| Id: wiki: 14572616 |
|
| Title: The Big Bang Theory (season 3) |
| Positive Section: when do amy and bernadette come into the big bang theory {third season} when does amy come in big bang theory {The third season} |
| Negative Section: what is the cast of big bang theory paid {$1 million} when is the new episode of big bang theory airing {25 September 2017} where is the big bang theory show based {Pasadena, California} |
| NQ | TriviaQA | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Top1 | Top5 | Top20 | Top100 | Top1 | Top5 | Top20 | Top100 |
| BM25 | - | - | 59.1 | 73.7 | - | - | 66.9 | 76.7 |
| DPR(single 1) | - | - | 78.4 | 85.4 | - | - | 79.4 | 85.0 |
| DPR(multi 2) | - | - | 79.4 | 86.0 | - | - | 78.8 | 84.7 |
| Hybrid 3(single) | - | - | 76.6 | 83.8 | - | - | 79.8 | 84.5 |
| Hybrid(multi) | - | - | 78.0 | 83.9 | - | - | 79.9 | 84.4 |
| GAR | - | 60.9 | 74.4 | 85.3 | - | 73.1 | 80.4 | 85.7 |
| ANCE(single) | - | - | 81.9 | 87.5 | - | - | 80.3 | 85.3 |
| ANCE(multi) | - | - | 82.1 | 87.9 | - | - | 80.3 | 85.2 |
| PAIR | - | 74.9 | 83.5 | 89.1 | - | - | - | - |
| DPR * | 45.7 | 68.3 | - | - | 47.2 | 72.7 | - | - |
| Weighted-based ) | 51.6 | 69.6 | 78.2 | 84.3 | - | - | - | - |
| DPR + AOpt(query) | 52.9 | 75.1 | 82.1 | 86.2 | 55.4 | 80.3 | 83.3 | 86.0 |
| DPR + AOpt(passage) | 51.3 | 72.1 | 80.4 | 85.9 | 53.0 | 77.3 | 81.1 | 85.6 |
| DPR + AOpt(hybrid) 4 | 57.1 | 74.5 | 81.2 | 85.4 | 59.3 | 79.9 | 82.3 | 84.9 |
| Model | NQ | TriviaQA |
|---|---|---|
| BM25 | 32.6 | 52.4 |
| DPR | 41.5 | 56.8 |
| Hybrid | 39.0 | 57.9 |
| GAR | 45.3 | 62.7 |
| ANCE | 46.0 | 57.5 |
| DPR + AOpt(query) | 43.9 | 58.9 |
| DPR + AOpt(passage) | 43.3 | 58.5 |
| DPR + AOpt(hybrid) | 47.2 | 61.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, Q.; Zhu, W.; Zhang, X.; Liu, C. Contrastive Refinement for Dense Retrieval Inference in the Open-Domain Question Answering Task. Future Internet 2023, 15, 137. https://doi.org/10.3390/fi15040137
Zhai Q, Zhu W, Zhang X, Liu C. Contrastive Refinement for Dense Retrieval Inference in the Open-Domain Question Answering Task. Future Internet. 2023; 15(4):137. https://doi.org/10.3390/fi15040137
Chicago/Turabian StyleZhai, Qiuhong, Wenhao Zhu, Xiaoyu Zhang, and Chenyun Liu. 2023. "Contrastive Refinement for Dense Retrieval Inference in the Open-Domain Question Answering Task" Future Internet 15, no. 4: 137. https://doi.org/10.3390/fi15040137
APA StyleZhai, Q., Zhu, W., Zhang, X., & Liu, C. (2023). Contrastive Refinement for Dense Retrieval Inference in the Open-Domain Question Answering Task. Future Internet, 15(4), 137. https://doi.org/10.3390/fi15040137