1. Introduction
Knowledge graphs (KGs), which stores a human’s knowledge and facts of the real world, are widely used in various applications [
1,
2,
3]. However, knowledge graphs are often uncompleted, which limits its application in real world. As the incompleteness of facts may obstruct the reasoning procedure, it is necessary to complete knowledge graphs by predicting the missing facts. Several methods have been proposed for completing knowledge graphs, such as TransE [
4], DistMult [
5], ConvE [
6]. The other issue that cannot be ignored is that facts often change over time. In order to depict the changing trend of facts over time, the relevant information can be organized into a series of knowledge graphs and each of them corresponds to a group of facts at different time stamps [
1,
3,
7,
8]. This series of knowledge graphs organized in chronological order is called temporal knowledge graphs (TKGs). There is concern regarding whether we can predict unseen facts through historical information. Therefore, learning the evolution of facts over time and then predicting unseen entities on TKGs has attracted the attention of researchers and has become a hot topic recently.
Prediction of facts over TKGs is classified into two categories: interpolation and extrapolation [
9]. Interpolation, known as the completion problem, is mainly used for completing missing information during a given time interval [
10,
11,
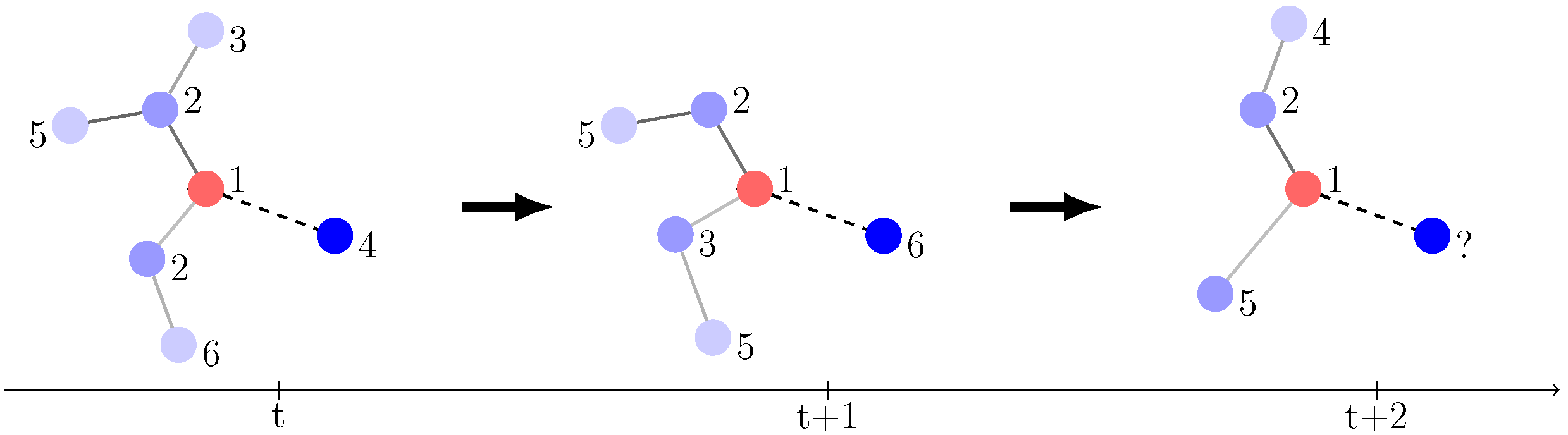
12]. A sample of the interpolation problem is to infer the president of America in 2016 when this fact is not seen between 1990 and 2020. Extrapolation, which is also known as entity prediction tasks, involves making a forecast of unknown facts at a future time. Extrapolation is a more difficult challenge than interpolation. An example of extrapolation is predicting who will win the next US presidential election. We prepare a example of entity prediction in
Figure 1. Extrapolation research is not only of practical significance, but also theoretical value, because studying the evolution of facts can help us understand the informative relationship hidden behind the structural knowledge graphs. There have been many efforts focused on this problem but it is far from being solved.
The entity prediction tasks on knowledge graphs can be separated into two parts—static prediction methods and dynamic prediction models.
According to the optimization targets, static prediction methods can be further classified into three types: distance-based methods, semantic similarity-based methods and deep learning methods. Among the distance-based methods, TransE [
4] is a classical approach to interpret relations on KGs. TransE regards the representation of entities and relations as transitional vectors, the goal is to minimize the distance of representation in the triple
, i.e.,
. Based on the idea, TransD [
13], TransR [
14] and TransH [
14] were proposed with different weight matrices to transfer entities’ vectors before scoring the distance loss. The semantic similarity-based methods, e.g., DistMult [
5], use a bi-linear function to calculate the plausibility in the triple. Some studies on knowledge graph completion follow this idea, such as HolE [
15] and Ripplenet [
3]. The scoring function is generally formed as
where
is a parameter matrix to represent the relation types. A popular genre of deep learning methods for entity prediction in KGs is GCN-based approaches, such as GAT [
16], SAGE [
17]. A GCN-based block consists of multiple layers of neural network blocks to generate hidden representations of entities which include rich semantic information of context. A common GCN block is formed as
Here,
represent the hidden representations of entity
s and its related entity
j in the
l-th layer.
denotes the set of neighbors of entity
s.
is a specific neural network function for propagating messages. For instance, Kifp et al. [
18] propose a linear parameter matrix to transform representations of entities and their neighbors. GAT [
16] uses a local attention weight to distinguish the importance of the target entity’s neighbors. SAGE [
17] concatenates the embedding of a target entity and its neighbors as a type of feature vector which is able to reserve more original features of the target. Different from models mentioned above for graphs where there is only one type of relations, RGCN [
19] is a notable approach which introduces a relational specific transformation function to deal with multiple relation types.
As static methods ignore the influence of time, they cannot model the evolutionary trend of facts on knowledge graphs. In order to predict future facts based on histories, dynamic prediction models try to train time-varying representation of facts to reflect the evolution over time. Several works modified static methods to adapt to the temporal change of data. One aspect of efforts adds extra weights or features to entities’ representations, such as Time-Aware [
12], TA-TransE [
11], DE-TransE [
20]. The comparative experiments show that dynamic methods which learn the evolution of facts perform better. Time-aware [
12] is an early work to predict the changes of relations on TKGs. It uses an asymmetric matrix to translate the relation matrix of TransE and add integer programming as constraints to capture temporal features. TTransE [
21] uses a series of weights to represent the relations on different time. TA-TransE [
11] directly defines the representation of time as a series of vectors. DE-TransE [
20] creates a diachronic method to represent evolution of entities. Know-Evolve [
10] and its follow-up Dyrep [
22] use RNN-based models to create dynamic representation of entities. The other aspect of efforts uses sequence-encoder modeling methods to create extra hidden vectors standing for chronological features of facts [
9]. GCRN [
23] is the first sequence modeling method on TKGs. RE-NET [
1] follows GCRN’s structure but adds a global vector to represent global states of whole facts at each time. Evolve-GCN [
24] merges GCN block into a GRU [
25] unit to update GCN’s weights which allows the GCN block adapts to relations at a different time. REGCN [
26] designs a static properties algorithm to reflect the evolutionary trend of TKGs.
However, most of the previous dynamic prediction methods pay attention to extracting semantic features on entities and their neighbors, but fail to consider the interactions between entities and pairwise relations. Therefore, in this research, we try to make up for the deficiencies of previous methods through learning semantic interactions between entities and relations, and then combining them into the prediction model. We believe that these semantic interactions contain informative clues about context dependencies. Capturing these factors for inferring on TKGs holds promise for making the results more reasonable.
Therefore, we propose a GCN-based model, Enhanced Relation Graph Convolution Network (ERGCN) (code is available at
https://github.com/Uynixu/ERGCN (accessed on 22 November 2022)), to accomplish the entity prediction task. The model especially focuses on learning the full semantic information of facts between relations and entities. We try to evaluate the performance of the model, and try to prove the necessity of adding the full semantic interaction between relations and entities into the model. We will compare the proposed models in this paper with previous models on relevant data through several experiments designed for the task and then reach a conclusion. Overall, the contributions in this paper can be summarized as below:
1. We test a new GCN-based method, named ERGCN, which takes context dependencies between pairwise entities and relations into account during training, and achieves better performance than previous methods;
2. We design a new approach to predict unseen facts on TKGs and compare it with different models to demonstrate the necessity of using the full semantic information of facts in relevant reasoning tasks.
2. Methodology
2.1. Problem Definition
We firstly give the following definitions used in this paper.
Definition 1 (Temporal knowledge graphs). A temporal knowledge graph (TKG) is represented as a set of chronological knowledge graphs with discrete time stamps, , where each graph at time t is . Here, V is the set of entities, R is the set of relation types, and is the set of edges. Each edge represents a fact which includes two entities linked by a relation type. Therefore, , where the triple stands for an event or fact that the subject entity s has the relationship r with object entity o at time t.
Definition 2 (Entity prediction task)
. Given the query , the entity prediction task is to model the conditional probability distributions of all object entities under the subjects s when relation r is given and historical graphs in a fixed length of observation windows m, , are also given. The conditional probability distribution is represented as function in Formula (1). Meanwhile, we add a sub-query to constrain the reasoning process. The sub-query is to model the conditional probability distribution of all relation types when s and historical graphs are given. This probability distribution is represented as function in Formula (2). Therefore, our task is to find appropriate trainable functions to fit the conditional probability distribution of entities on TKGs. The formulations are shown as: Definition 3 (Neighbor set of an entity). Given a snapshot of the TKG at time t, the entity s with its neighbor entities and linked relations types make a sub-graph . In this sub-graph, all nodes from the neighbor entity set of s, which is denoted as . Its linked relations constitute the neighbor relation set of s, denoted as .
2.2. Framework of the Model
Following the study of RENET [
1], the key idea of our approach is to learn the local context dependencies near the central facts by our ERGCN block as well as to learn the global semantic structure of the whole graph on TKGs. The reasoning logic is based on the following assumptions: (1) Reasoning future facts can be regarded as a sequential inference processing via past relevant histories at different timestamps. (2) Temporal adjacent of facts may contain necessary informative patterns which imply the evolutionary trend of facts.
To approach the problem, our model is divided into two parts, the local learning unit and the global unit. The local learning unit is made for aggregating features in the neighborhood to extract the local dependency around the specific entity which stands for the local temporal features. As the same time, the goal of the global unit is to generate a single vector to represent the informative structure of the current graph as a whole, referred to as the global representation.
Both the local learning unit and the global unit follow the encoder–decoder structure. Here, the encoder part consist of certain layers of the GCN block and one layer of the GRU block. The GCN block integrates the dependencies of edges in a knowledge graph at each timestamp, and then the informative sequential features learned in GCN and their pairwise time presentations are merged into single vectors to represent the evolution of facts at different timestamp via the GRU block. Based on these various vectors and the static representation of entities and relations, temporal reasoning results at the next timestamps can be evaluated by the decoder function. The structure of our model that reflects the above idea is illustrated in
Figure 2.
2.3. Local Learning Unit
To represent the semantic features of entities and relations, we use internal initialized embedding vectors, and , to stand for entities and relations, respectively. Here, n, r stand for the number of entities and relation types, respectively, and d is the dimension size of each embedding.
Since static embedding vectors are not able to reflect the evolution characteristics of facts over time, two types of representations, the local temporal feature and the global vector, are proposed to reflect the evolution of facts. The local temporal feature summarizes the local information around a central entity until timestamp t, reflecting the change of relationships between these linked facts in the past. The global vector focuses on leaning the trend of background information of entire facts on the current knowledge graph. The two types of dynamic representation capture different aspect of informative knowledge from TKGs, which allows us to verify the reasoning process in different ways.
To capture the local structural information around the fact, GCN blocks are proposed to aggregate neighbor information and transform them into a single representation standing for the main feature of the central entity. The problem is that previous GCN blocks used in knowledge graphs ignore the semantics of relations, and some recent models only regard relation types as a part of entities. However, classical knowledge graph embedding studies show that semantic features from entities and relations have different effects on the performance in the model. To illustrate this divergence, we introduce a new GCN algorithm, which uses the full semantic information of facts to create representations of facts, named ERGCN. The aggregator is formally defined as follows:
Here, stands for the neighborhood message of entity s at the l-th layer. and are trainable parameters for self-loop and aggregating features at the l-th layer. represent the embedding of entities and relations. n is the number of neighbor of entity s.
Therefore, the local historical representation of entity
s at time
t can be illustrated as a sequence of the neighborhood message in an observed length
m:
Then, we update the state of the local temporal feature for query and its sub-query via a GRU block:
We use the final hidden state vector to represent the local temporal feature of entity s at time t. is the sequential temporal features trained in the global unit and it will be discussed in the next part. The symbol: represents the concatenation operation.
2.4. Global Unit
Distribution of entities on certain knowledge graphs represents specific temporal information to imply the evolutionary trend of facts. Therefore, we try to represent these global evolutionary trends by modeling the entity distribution over time. We assume that the entity distributions depend on historical graph features at the last
m steps. Therefore, the entity distribution is modeled by function
in Formula (6), where the current graph embedding vector
is inputs:
To learn the graph embedding, we propose the global unit to capture the global structural state of the entire current graph and record the evolutionary trend of the state. To capture the global structural state at each TKG, we use our ERGCN block to learn the semantic vectors of all entities
and then propose an element-wise max-pooling operation
to represent the current global state:
Then, we use the graph historical sequence in the last timestamps
m to represent the evolutionary trend:
To reflect the evolutionary trend from
, we use the hidden state trained from a GRU block:
summarizes the evolutionary trend of the whole graph with a global view. Obviously, a neighbor message aggregated from ERGCN only provides a local view around the facts. Therefore, many context dependencies and semantic interactions between distant facts lose if we only focus on the local views. To compensate for this drawback, we use the graph embedding as a complement of the local views to represent a global view of whole facts. Then, we define the historical sequences of global embedding
as the global temporal features in an observed windows with length
m:
2.5. Decoding Process
To answer the query and sub-query, the conditional distributions of predicted objects
and relations
are modeled by two linear functions. The formulas are presented as Formula (11) and (12)
As the entities prediction task is considered as a multi-classification task, cross-entropy loss is selected as the loss function. For simplicity of expression, we omit the notations of prediction in Formula (13). The loss function is as follows:
Here, is a hyper-parameter to balance the importance between two parts. In entity prediction tasks, we aim to predict objects depending on relevant subjects and their linked relations.
We summarize the whole training process as shown in Algorithm 1. Our training approach is divided into two steps. In the first step, during the preset maximum number of iterations
, we generate the graph embedding from the global unit and save the optimal results for the next step. It is noticed that we choose 2-norm as the loss function in the global model to fit the temporal distribution of all subject entities
. In the second step, we use the local learning unit to estimate the conditional probability distribution of object entities
and answer the queries. It is worth noting that, at the preset maximum iteration number
, we regard the model with the best
ratio as the best situation of our model.
| Algorithm 1: Learning algorithm of ERGCN |
![Futureinternet 14 00376 i001]() |
3. Results
3.1. Datasets
To evaluate the performance of ERGCN, we selected six representative datasets widely used in previous works for the entity prediction task on TKGs. They are YAGO [
27], WIKI [
21], ICEWS14 [
11], ICEWS15 [
11], ICEWS18 [
28] and GDELT [
29]. YAGO and WIKI include temporal facts extracted from open-source datasets. The series of ICEWS are event-based datasets from the Integrated Crisis Early Warning System. GDELT is from the Global Database of Events, Language and Tone. The statistical details of all datasets are shown in
Table 1.
3.2. Evaluation Metrics
In the experiments, MRR and Hits@1, 3, 10 are selected as the metrics for entity prediction. Because the Hit@1 in YAGO and WIKI are not reported in previous works [
1,
26], we only record Hit@3, 10. It is worth noting that some previous works use different filter settings to evaluate the performance of their works. Hence, in order to make the results comparable, we only report the original results (named
) of each model.
3.3. Benchmarks
Our ERGCN model is compared to two types of models: static KG models and dynamic TKG reasoning models. Here, Distmult [
5], ConvE [
6], RGCN [
19], HyTE [
30] are selected as static models. On the other hand, TTransE [
21], TA-Distmult [
11], R-GCRN [
23], RENET [
1], REGCN [
26] are selected as dynamic methods released in recent years.
3.4. Implementation Settings
The embedding dimension d is 200 in both the local learning unit and the global unit. The number of ERGCN layers in the local learning unit is 1, but that in the global unit is 2. The dropout rate is 0.2 in both units. We test the length of history m from 1 to 10 and find that the optimal length is 5 in all datasets. The experiments include one-step inference in the validation and test. All experiments only report the results of reasoning the objects in test set with the raw metric. We obtain the results in five runs on each datasets and report the average of the results.
3.5. Result Analysis
The experimental results are illustrated in
Table 2 and
Table 3. ERGCN outperforms the benchmarks on WIKI and ICEWS. Especially, the performances on WIKI rise significantly. The experimental results show that it is helpful to make full use of semantic information in entity prediction tasks. Obviously, ERGCN works better than static models because ERGCN captures the evolutionary pattern of facts. Thus, it can achieve higher performance when testing on unseen temporal knowledge graphs. Compared with recent dynamic models, such as REGCN and RENET, our ERGCN overtakes the others in most tasks. Although ERGCN does not have the best performance on YAGO and GDELT, its performance is very close to the best results. Therefore, ERGCN’s overall performance is better. The results verify the importance of differential treatment for various relation types, which contains much useful semantic information about the temporal dependencies of facts. As mentioned above, we only use a one-layer ERGCN block in the tasks. The reason is that the performance on the high-accuracy metrics, such as Hit@1 and Hit@3, drops significantly when the layers are more than one. This phenomenon may indicate that ERGCN focuses on 1-hop neighborhoods, while long-distance relationships may interfere with the entity reasoning process. However, ERGCN still outperforms the other dynamic models and these results suggest that information in the 1-hop neighborhood is underutilized in previous approaches, and that ERGCN can extract these information more effectively.
ERGCN is similar to RENET, but we pay more attention to applying full semantic information of facts. By capturing more precise temporal representation of sequential knowledge, ERGCN overtakes RENET in the majority of the datasets and our results are close to those of RENET on GDELT. Different from REGCN, which includes a new recurrent block to learn sequential histories of entities, the structure of ERGCN is simple, but the performance is good.
Compared with the previous best results on WIKI, ERGCN has improved 11.44% in MRR metric, 11.35% in Hit@3 metric and 8.40% in Hit@10 metric, respectively. In this dataset, temporal facts are widely collected from the open-source dataset, Wikipedia. The informative interactions between different entities are discrete, temporal dependencies around facts are often limited in small areas, and then 1-hop neighborhoods contain the most important structural information of dependencies. Different from concentrating attention on neighbors’ entities, ERGCN concerns the interaction between entities and their linked relation types, which provides more relevant structural dependencies between facts.
The results on ICEWS show that, compared with other methods, using more semantic information of facts provides more accurate temporal characteristics for the reasoning process. In terms of the MRR metric, the performance of ERGCN is 0.17/5.38/0.78% higher than the previous best on ICEWS14/ICEWS15/ICEWS18, respectively. Moreover, ERGCN improves Hit@1,3,10 in each dataset as well. The ICEWS series dataset is event-based and facts here often change frequently. Therefore, learning the relation type becomes a key point, which is able to provide basic information indicating the trend of the facts. Different from previous studies, ERGCN focuses on learning the interaction between entities and relation types, which reserves various temporal dependencies. If these complex structural dependencies are ignored, there will be a lot of loss in modeling sequential patterns. The results demonstrate that ERGCN is more capable of learning the complex temporal structures in TKG.
ERGCN’s performances on YAGO and GDELT are a little worse than the previous best. YAGO consists of lots of temporal facts with repetitive patterns. ERGCN does not handle this problem well, but this phenomenon does not appear in other datasets. GDELT includes massive concepts and definitions that follow specific rules. This situation makes entity reasoning difficult. The results of all models are similarly poor in GDELT.
It is noticed that the results of all methods on ICEWS18 and GDELT are still at a low level. For example, the is under 20% and 30% in GDELT and ICEWS18, respectively. This phenomenon shows that capturing the evolutionary trends of facts on TKGs is still a hard challenge and we need further studies to identify the complex dependent relationships between facts at different time.
3.6. Ablation Study
In this part, we discuss the effect of each part in ERGCN. To test the contribution of each part in ERGCN, we conduct the ablation studies in WIKI and ICEWS18. To test the importance of graph embedding, we remove the global unit in our approach, named as
. To illustrate the essential context semantic information, we remove the learnable weight
in ERGCN, named
. To demonstrate the necessity of the semantic interaction, we remove the sub-query when training, named
. The further discussion of the contributions of each part in ERGCN is reported in
Table 4 and
Table 5.
To illustrate how the global embedding affects the results, we conduct experiments without the global model. The results are denoted as . It can be seen that removing the global embedding results in a significant decline in the performance on WIKI and ICEWS18. When we remove the global embedding, ERGCN will lose lots of temporal dependencies around the whole graphs and the model will only focus on learning the neighbor structural information.
After removing the independent weight on relation types from the model, the model becomes . Therefore, our ERGCN becomes similar to the other studies where entities and relations share the same transform weights in training process. Since the correlations between various entities and relations are usually different, after removing the weight on relation types from the model, we will lose specific features between certain combinations of facts. The results prove our prediction as the results decrease by about 1–2% in WIKI and ICEWS18.
The results are labeled as ERGCN wtc, where the relation constraint between entities and relations are removed. The relation constraint can be seen as interactions between entities and their linked relations, which helps the model obtains the combination features of facts.





{kind=link}
{kind=link}