

A Hybrid Text Generation-Based Query Expansion Method for Open-Domain Question Answering
Abstract
:1. Introduction
2. Materials and Methods
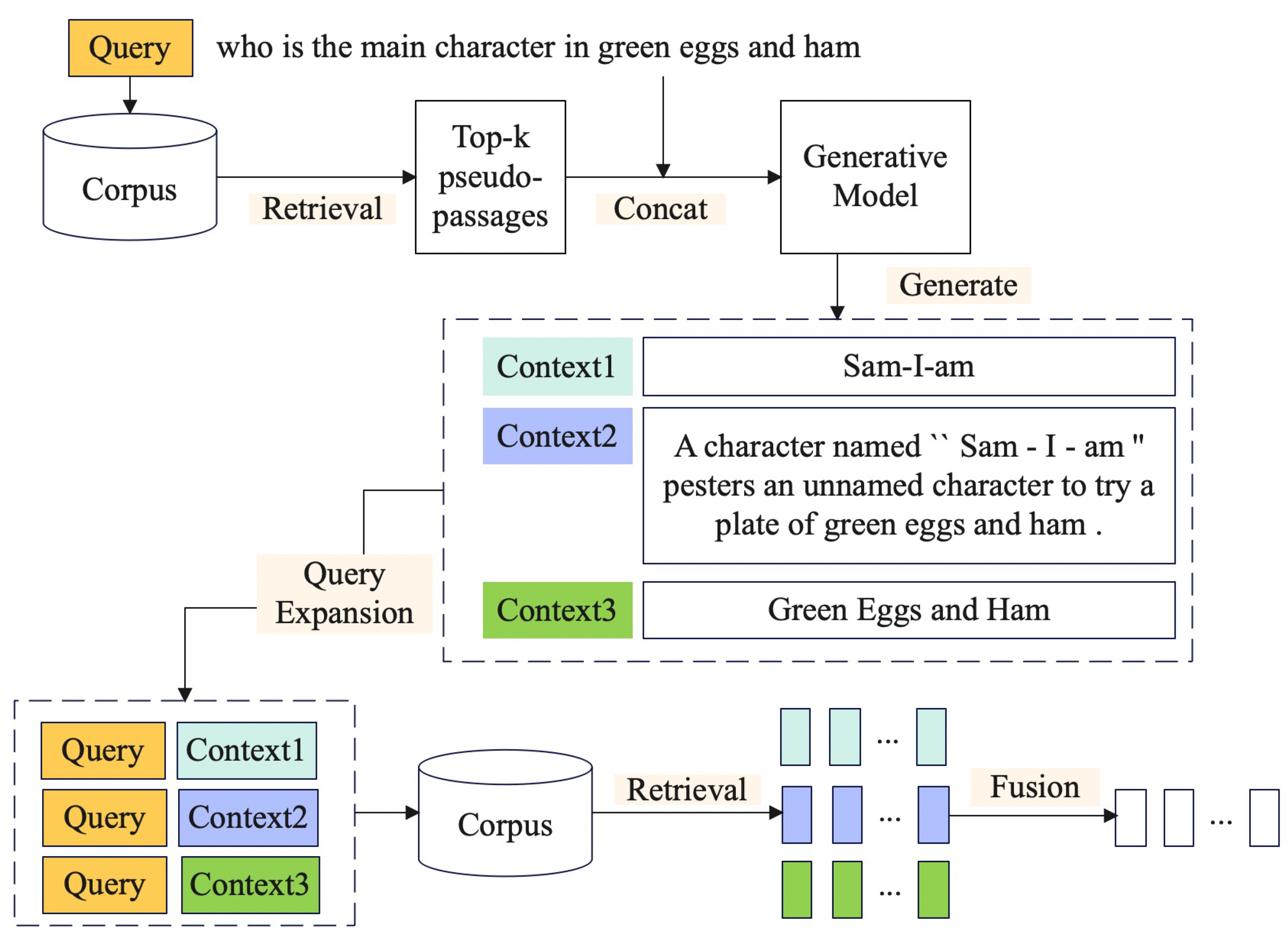
2.1. HTGQE Framework and Task Definition
2.2. Datasets
- (1)
- Passage Candidate Pool: This study adopts the same version of Wikipedia used in other OpenQA research to construct a candidate pool [1,11], specifically using the English Wikipedia from 20 December 2018, as the source passages for answering questions. By applying the preprocessing code released in DrQA [1], the data is cleaned and each article is divided into multiple unrelated 100-word text blocks, which serve as basic search units. In the end, 21,015,324 passages are obtained. Pyserini [12] has pre-built sparse and dense indexed for these passages, and achieved offline encoding for these passages. The offline indices are used directly in this study for inference, significantly improving efficiency.
- (2)
- Benchmark Datasets: We conduct experiments on the open-domain versions of two widely used QA benchmarks: Natural Questions (NQ) [13] and TriviaQA (Trivia) [14], corresponding to DPR [11]. The questions in NQ were mined from real Google search queries and the answers were spans in Wikipedia articles identified by annotators. Trivia contains a set of trivia questions with answers that were originally scraped from the Web. Each question in both datasets corresponds to a list of answers, and as long as the reader’s top-ranked predicted answer appears in the answer list, the current question is considered to be answered correctly. The final statistical information of the datasets used in the experiments is shown in Table 1. represents the amount of data in each part of the original dataset. We adjusted the dataset according to GAR [10], removing entries that did not qualify, such as queries without corresponding context or title. Finally, we obtain , and , which are used to train three types of query expansion generators.
2.3. Evaluation Metrics
2.4. Model Structure and Initialization
2.5. Hyperparameter Settings
- (1)
- Evidence Mixing Parameters and . Following the GAR* implementation in the PyGaggle library [15], for sparse retrieval, we set the parameters (i.e., the relevance score obtained from the reader) and (i.e., the retrieval score obtained from the retriever) to 0.46 and 0.308 on the NQ dataset, and 0.78 and 0.093 on the Trivia dataset, respectively. For mixed retrieval results, we set and to 0.32 and 0.1952 on the NQ dataset, and 0.76 and 0.152 on the Trivia dataset, respectively.
- (2)
- In the paper, BART-large is employed as the query expansion generator, with the generative model training conducted on two Tesla V100 GPUs. For both the NQ and Trivia, the learning rate can be uniformly set at ; however, when training the , it is advisable to increase the learning rate, such as by adjusting it to . While training the , and , the batch sizes are set at 64, 16, and 8, respectively; for the Trivia dataset, they are 16, 8 and 8. Furthermore, due to the incorporation of PRF, the maximum input length is set to 768 tokens, with the maximum generation lengths being 16 (), 64 (), and 32 () tokens, respectively. However, if the experimental conditions are changed, the above parameters also need to be adjusted appropriately.
- (3)
- When we select top-k pseudo-relevant passages as references for generative models, we set k = 3 in our experiments. If k is too large, the input for the query expansion generation model will become too long, affecting the training and inference speed of the generation model. If k is too small, the reference material provided to the generation model will be insufficient, making it difficult to produce correct answers. Of course, other values of k are also worth trying.
3. Experimental Results and Analysis
3.1. Passage Retrieval with HTGQE
3.2. Passage Reading with HTGQE
3.3. Fusion Strategies for Retrieval Results
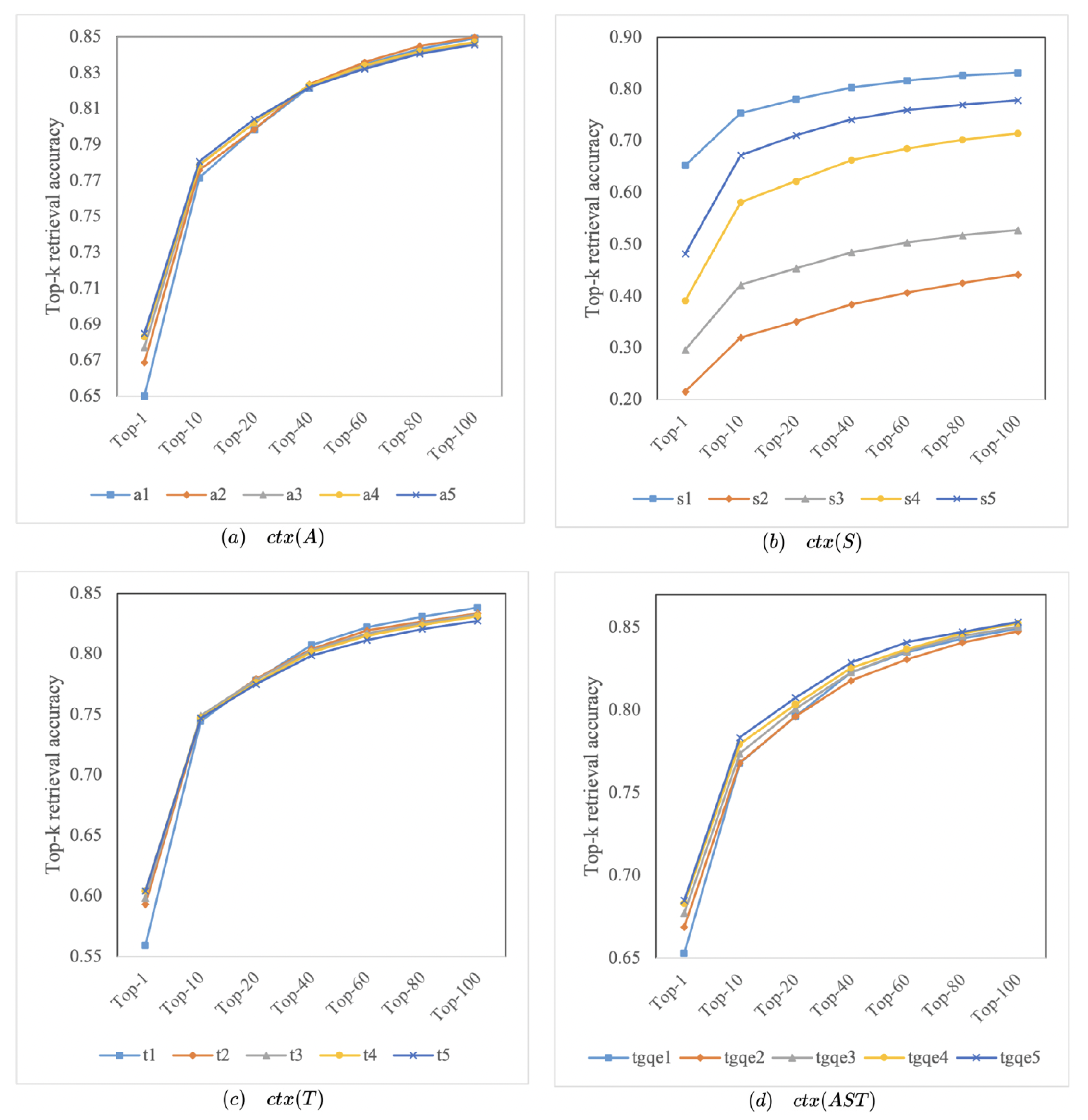
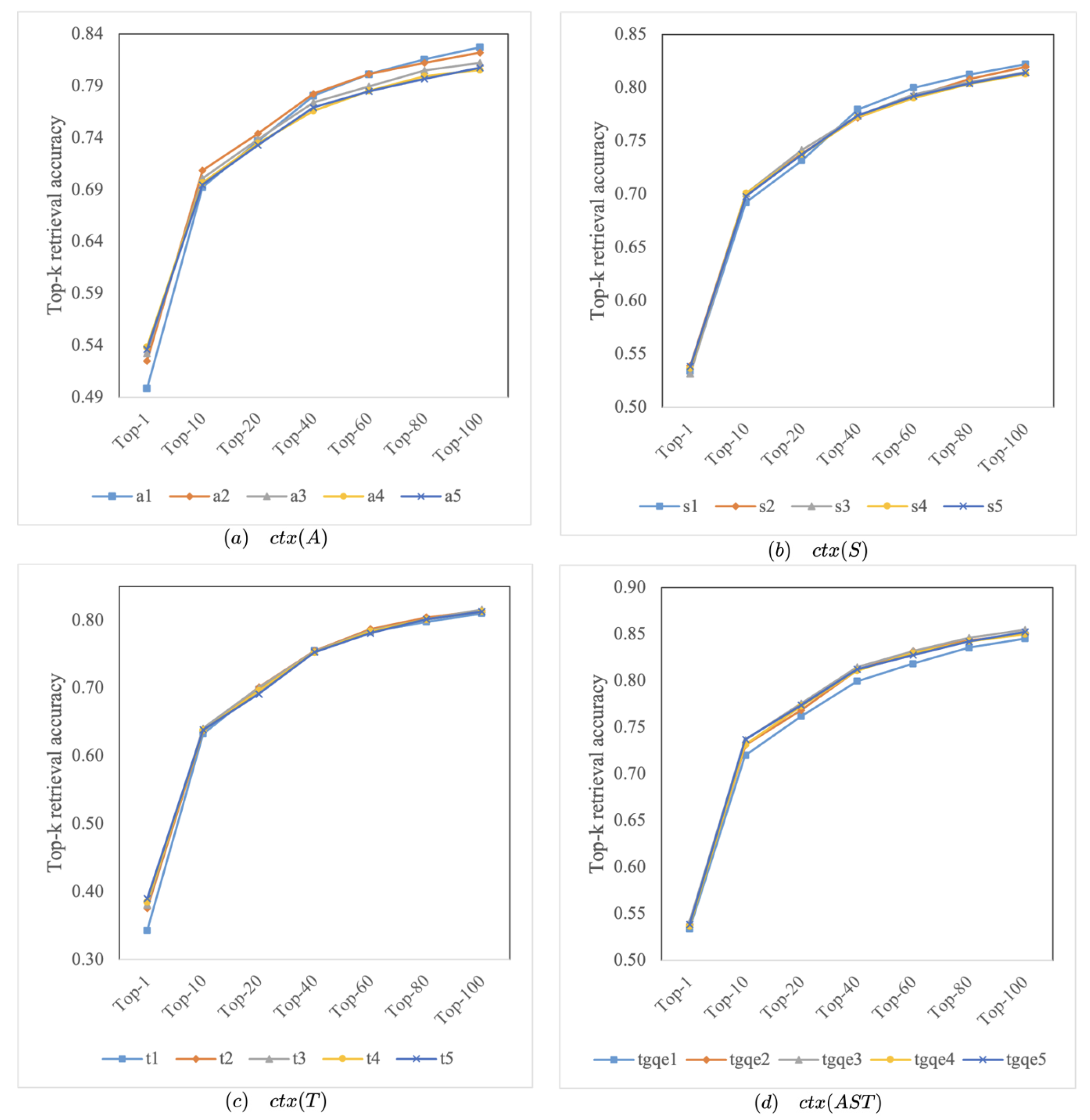
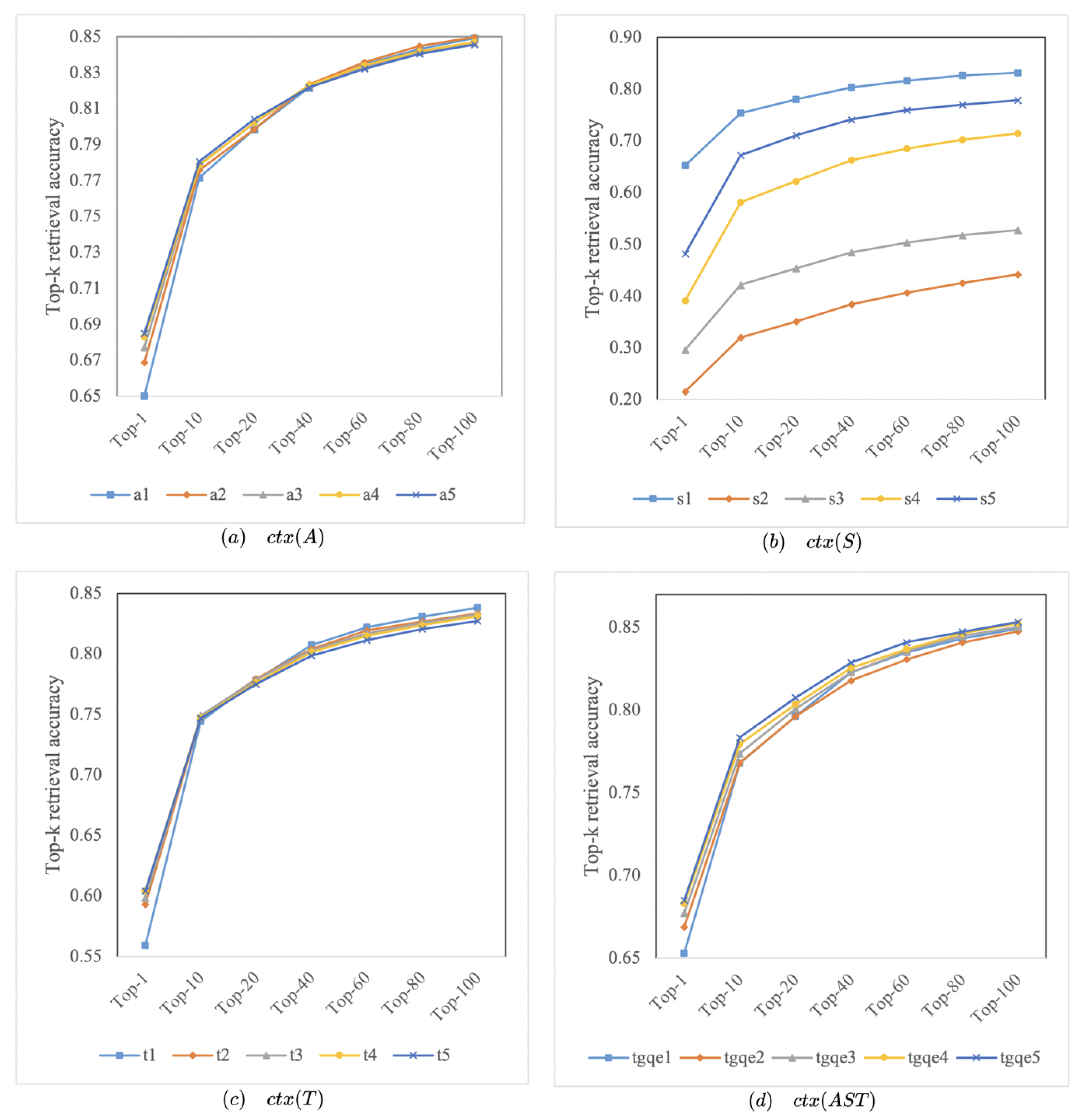
3.4. Exploring the Optimal Number of Expansion Terms
3.5. Case Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| OpenQA | Open-Domain Question Answering |
| PRF | Pseudo-Relevance Feedback |
| HTGQE | Hybrid Text Generation-based Query Expansion |
| QE | Query Expansion |
| NQ | Natural Questions |
| Trivia | TriviaQA |
References
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading wikipedia to answer open-domain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1870–1879. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Lewis, P.S.H.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Yu, H.; Dai, Z.; Callan, J. PGT: Pseudo Relevance Feedback Using a Graph-Based Transformer. In Advances in Information Retrieval, Proceedings of the 43rd European Conference on IR Research, ECIR 2021, Virtual Event, 28 March–1 April 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12657, pp. 440–447. [Google Scholar]
- Izacard, G.; Grave, E. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Online, 19–23 April 2021; pp. 874–880. [Google Scholar]
- Liu, J.; Liu, A.; Lu, X.; Welleck, S.; West, P.; Bras, R.L.; Choi, Y.; Hajishirzi, H. Generated knowledge prompting for commonsense reasoning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 3154–3169. [Google Scholar]
- Yu, W.; Zhu, C.; Li, Z.; Hu, Z.; Wang, Q.; Ji, H.; Jiang, M. A survey of knowledge-enhanced text generation. ACM Comput. Surv. 2022, 54, 1–38. [Google Scholar] [CrossRef]
- Li, H.; Su, Y.; Cai, D.; Wang, Y.; Liu, L. A Survey on Retrieval-Augmented Text Generation. arXiv 2022, arXiv:2202.01110. [Google Scholar]
- Mao, Y.; He, P.; Liu, X.; Shen, Y.; Gao, J.; Han, J.; Chen, W. Generation-augmented retrieval for open-domain question answering. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, Virtual Event, 1–6 August 2021; pp. 4089–4100. [Google Scholar]
- Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.T. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; pp. 6769–6781. [Google Scholar]
- Lin, J.; Ma, X.; Lin, S.C.; Yang, J.H.; Pradeep, R.; Nogueira, R. Pyserini: A Python toolkit for reproducible information retrieval research with sparse and dense representations. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 2356–2362. [Google Scholar]
- Seo, M.J.; Lee, J.; Kwiatkowski, T.; Parikh, A.; Farhadi, A.; Hajishirzi, H. Real-time open-domain question answering with dense-sparse phrase index. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; pp. 4430–4441.
- Joshi, M.; Choi, E.; Weld, D.S.; Zettlemoyer, L. Triviaqa: A large scaled istantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1601–1611. [Google Scholar]
- Nogueira, R.; Jiang, Z.; Lin, J. Document ranking with a pretrained sequence-to-sequence model. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; pp. 708–718. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 202; pp. 7871–7880.
- Min, S.; Chen, D.; Hajishirzi, H.; Zettlemoyer, L. A discrete hard EM approach for weakly supervised question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 2851–2864. [Google Scholar]
- Asai, A.; Hashimoto, K.; Hajishirzi, H.; Socher, R.; Xiong, C. Learning to retrieve reasoning paths over wikipedia graph for question answering. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Lee, K.; Chang, M.; Toutanova, K. Latent retrieval for weakly supervised open domain question answering. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; pp. 6086–6096. [Google Scholar]
- Min, S.; Chen, D.; Zettlemoyer, L.; Hajishirzi, H. Knowledge guided text retrieval and reading for open domain question answering. arXiv 2019, arXiv:1911.03868. [Google Scholar]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M.W. REALM: Retrieval-Augmented Language Model Pre. Training. 2020. Available online: https://www.semanticscholar.org/paper/REALM%3A-Retrieval-Augmented-Language-Model-Guu-Lee/832fff14d2ed50eb7969c4c4b976c35776548f56 (accessed on 1 May 2023).
- Brown, T.B.; Mann, B.; Ryder, N. Language models are few-shot learners. In Proceedings of the Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Min, S.; Michael, J.; Hajishirzi, H.; Zettlemoyer, L. Ambigqa: Answering ambiguous open-domain questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; pp. 5783–5797. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Val | Test | |
|---|---|---|---|---|
| NQ | 79,168 | 8757 | 3610 | |
| 79,168 | 8757 | 3610 | ||
| 79,168 | 8757 | 3610 | ||
| 67,969 | 7514 | 3610 | ||
| Trivia | 78,785 | 8837 | 11,313 | |
| 78,785 | 8837 | 11,313 | ||
| 65,375 | 7388 | 11,313 | ||
| 69,595 | 7848 | 11,313 |
| Dataset | NQ | Trivia | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | Top-5 | Top-20 | Top-100 | Top-500 | Top-1000 | Top-5 | Top-20 | Top-100 | Top-500 | Top-1000 | |
| Sparse | BM25 (ours) | 43.8 | 62.9 | 78.3 | 85.6 | 88.0 | 66.3 | 76.4 | 83.2 | 87.3 | 88.5 |
| BM25+RM3 [10] | 44.6 | 64.2 | 79.6 | 86.8 | 88.9 | 67.0 | 77.1 | 83.8 | 87.7 | 88.9 | |
| GAR () | 53.2 | 67.1 | 79.4 | 86.7 | 89.2 | 66.5 | 76.0 | 83.7 | 88.0 | 89.2 | |
| HTGQE () | 64.2 | 73.7 | 82.7 | 87.8 | 89.5 | 74.2 | 79.8 | 85.0 | 88.5 | 89.5 | |
| GAR () | 52.7 | 66.6 | 79.5 | 86.5 | 89.0 | 62.3 | 72.6 | 81.0 | 86.7 | 88.0 | |
| HTGQE () | 64.4 | 73.2 | 82.2 | 88.1 | 89.6 | 72.6 | 78.0 | 83.2 | 87.1 | 88.4 | |
| GAR () | 50.8 | 67.2 | 79.8 | 87.0 | 88.8 | 65.1 | 75.3 | 82.6 | 87.0 | 88.3 | |
| HTGQE () | 55.7 | 69.8 | 81.0 | 87.4 | 89.2 | 70.2 | 77.8 | 83.8 | 87.7 | 88.8 | |
| GAR (ours) | 58.5 | 72.6 | 83.8 | 89.2 | 90.9 | 68.7 | 77.7 | 84.2 | 88.2 | 89.3 | |
| HTGQE | 67.3 | 76.2 | 84.5 | 89.8 | 91.3 | 74.2 | 79.6 | 84.9 | 88.6 | 89.6 | |
| Hybrid | BM25+DPR [12] | 60.3 | 76.1 | 86.0 | 90.1 | 91.7 | 72.1 | 80.9 | 86.3 | 89.0 | 89.8 |
| GAR+DPR (ours) | 66.2 | 79.1 | 87.3 | 91.3 | 92.4 | 73.2 | 81.5 | 86.6 | 89.2 | 90.0 | |
| HTGQE+DPR | 69.7 | 80.6 | 87.4 | 91.5 | 92.5 | 75.2 | 81.8 | 86.7 | 89.5 | 90.2 |
| Methods | NQ | Trivia | |
|---|---|---|---|
| Extractive | Hard EM [17] | 28.1 | 50.9 |
| Path Retriever [18] | 32.6 | - | |
| ORQA [19] | 33.3 | 45.0 | |
| Graph Retriever [20] | 34.5 | 56.0 | |
| REALM [21] | 40.4 | - | |
| DPR [11] | 41.5 | 57.9 | |
| 2-4 Generative | GPT3 [22] | 29.9 | - |
| T5 [3] | 36.6 | 60.5 | |
| SpanSeqGen [23] | 42.2 | - | |
| RAG [4] | 44.5 | 56.1 | |
| FiD [6] | 51.4 | 67.6 | |
| 2-4 Sparse | BM25 (E,ours) | 27.2 | 35.4 |
| GAR (E) | 30.4 | 44.4 | |
| HTGQE (E) | 35.0 | 50.7 | |
| BM25 (G,ours) | 28.8 | 47.1 | |
| GAR (G) | 24.0 | 39.7 | |
| HTGQE (G) | 38.3 | 56.8 | |
| NQ | Trivia | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-1 | Top-5 | Top-20 | Top-100 | Top-500 | Top-1000 | Top-1 | Top-5 | Top-20 | Top-100 | Top-500 | Top-1000 | |
| 53.4 | 67.0 | 75.3 | 84.2 | 89.5 | 90.8 | 65.3 | 74.3 | 79.8 | 84.9 | 88.6 | 89.5 | |
| 34.3 | 64.2 | 75.1 | 83.7 | 89.2 | 90.2 | 65.1 | 74.0 | 79.6 | 84.8 | 88.5 | 89.5 | |
| 34.3 | 65.5 | 75.9 | 84.5 | 89.6 | 91.1 | 65.3 | 73.4 | 79.2 | 84.5 | 88.2 | 89.2 | |
| 53.4 | 67.3 | 76.2 | 84.5 | 89.8 | 91.3 | 65.3 | 74.2 | 79.6 | 84.9 | 88.6 | 89.6 | |
| case1 | query: who started the trojan war in the iliad? |
| : Paris {[Paris of Troy]} | |
| : the Trojan War was started by the Achaeans (Greeks). {In Greek mythology, the Trojan War was waged against the city of Troy by the Achaeans (Greeks) after Paris of Troy took Helen from her husband Menelaus.} | |
| : Trojan War {Helen of Troy (film)} | |
| case2 | query: what is the european recovery program of 1947 better known as? |
| : European Recovery Plan {[The Marshall Plan]} | |
| : The Marshall Plan, officially the European Recovery Program. ( born November 26, 1962 ) is an American country music singer. {The Marshall Plan was an American initiative to aid Western Europe, in which the United States gave over $13 billion in economic support to help rebuild Western European economies after the end of World War II.} | |
| : as Marshall Plan [SEP] Committee for the Marshall Plan [SEP] I Do (Reba McEntire album) {Committee of European Economic Co-operation [SEP] Federal Ministry of Matters of the Marshall Plan.} | |
| case3 | query: who is the original singer of and i am telling you? |
| : Amber Riley {[Jennifer Holliday]} | |
| : Jennifer Holliday for its re-release in 1982 for which it became a number - one R&B hit for Holliday. {Jennifer Holliday originated the role on Broadway in 1981 and won a Tony Award for her performance as well as the Grammy for Best R&B Performance.} | |
| : And I Am Telling You I’m Not Going {I Am Changing [SEP] Jennifer Hudson [SEP] Jennifer Holliday [SEP] Dreamgirls} |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, W.; Zhang, X.; Zhai, Q.; Liu, C. A Hybrid Text Generation-Based Query Expansion Method for Open-Domain Question Answering. Future Internet 2023, 15, 180. https://doi.org/10.3390/fi15050180
Zhu W, Zhang X, Zhai Q, Liu C. A Hybrid Text Generation-Based Query Expansion Method for Open-Domain Question Answering. Future Internet. 2023; 15(5):180. https://doi.org/10.3390/fi15050180
Chicago/Turabian StyleZhu, Wenhao, Xiaoyu Zhang, Qiuhong Zhai, and Chenyun Liu. 2023. "A Hybrid Text Generation-Based Query Expansion Method for Open-Domain Question Answering" Future Internet 15, no. 5: 180. https://doi.org/10.3390/fi15050180
APA StyleZhu, W., Zhang, X., Zhai, Q., & Liu, C. (2023). A Hybrid Text Generation-Based Query Expansion Method for Open-Domain Question Answering. Future Internet, 15(5), 180. https://doi.org/10.3390/fi15050180