

Generating Synthetic Resume Data with Large Language Models for Enhanced Job Description Classification †

Abstract
:
1. Introduction
2. Previous Work
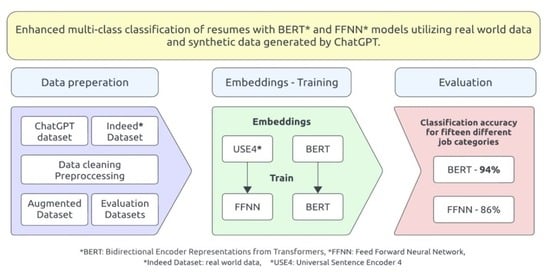
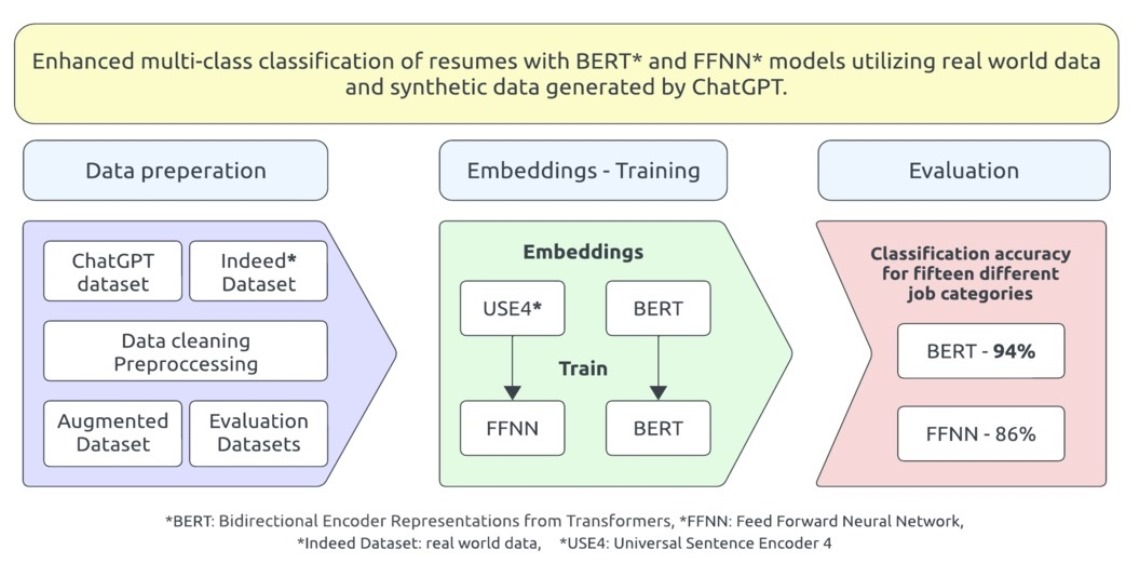
3. Methodology
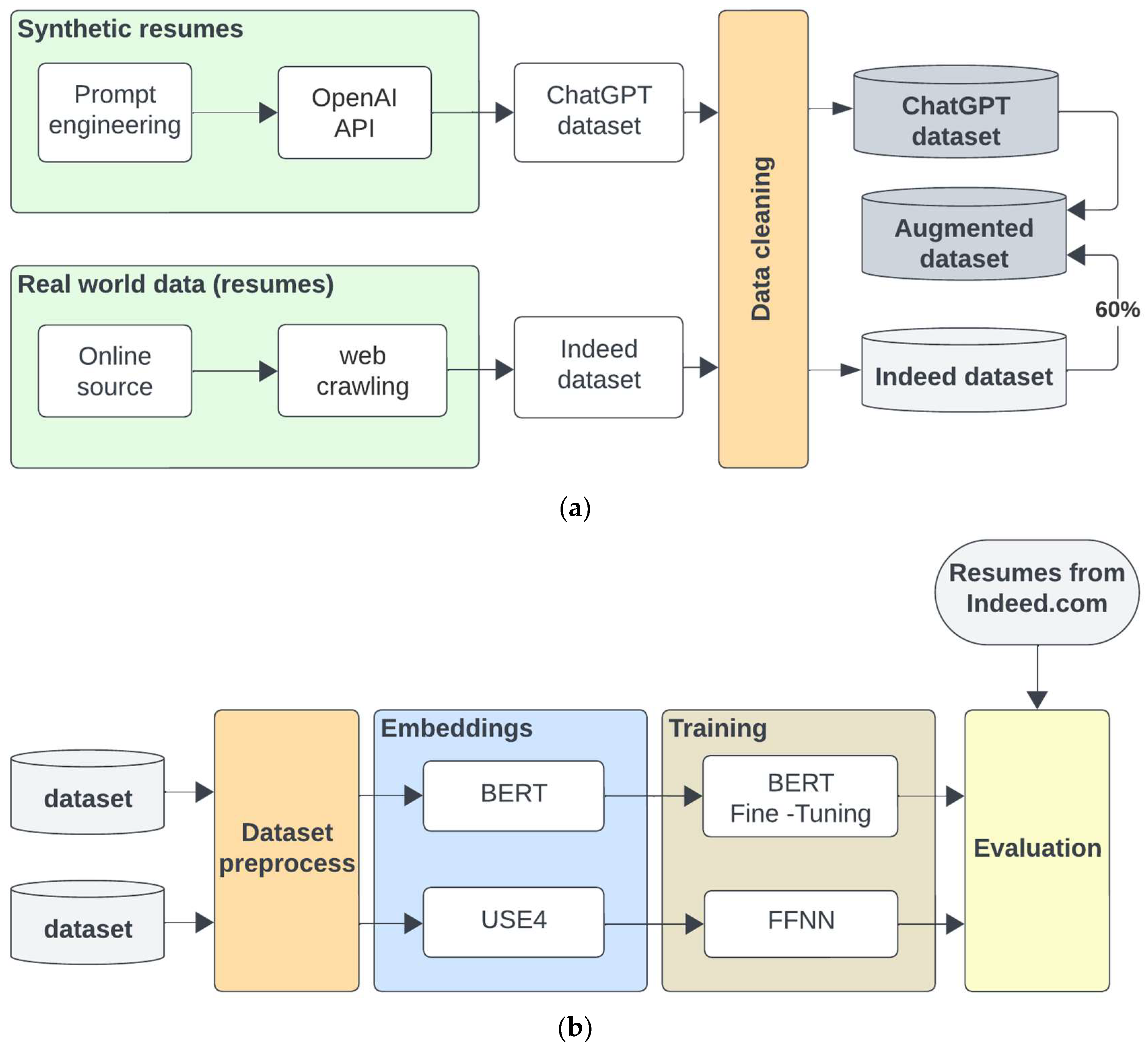
3.1. Overview
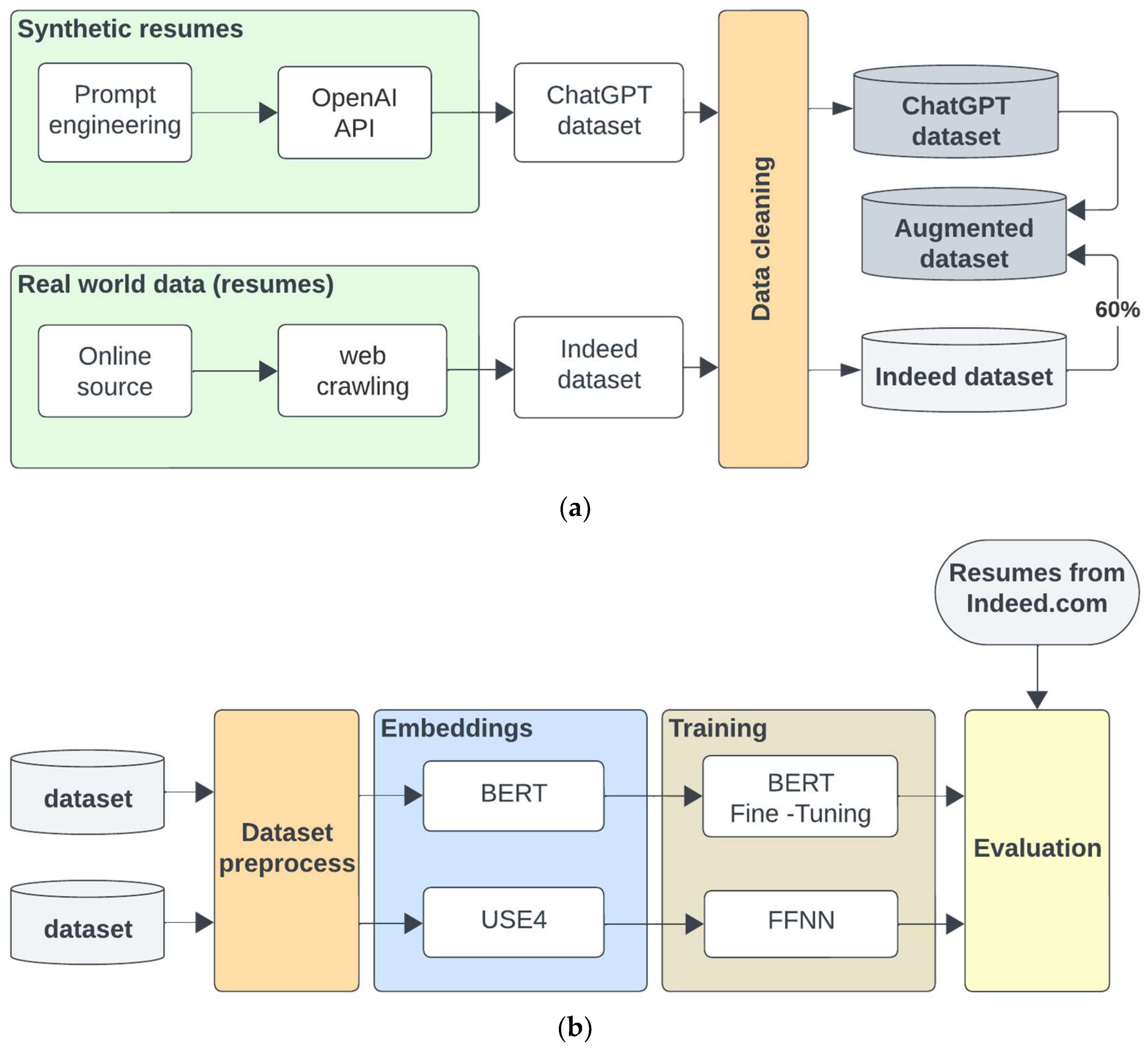
3.2. Data Collection from Online Sources and Processing
- ○
- Correcting typographical errors.
- ○
- Removing duplicate records.
- ○
- Stripping special characters like &NBSP (HTML element), \r and _.
- ○
- Managing empty lines within a text block.
- ○
- Using regular expressions to identify and exclude URLs embedded in job descriptions.
- ○
- Deleting site-specific prefix keywords.
3.3. Utilization of ChatGPT for Resume Generation
3.4. Model Architectures and Training
3.4.1. FFNN Model
3.4.2. BERT Model
3.5. Training Datasets and Experimental Setup
- One synthetic dataset from ChatGPT (ChatGPT, Section 3.3).
- One dataset (Indeed, Section 3.2) with real-world data from Indeed.com.
- A training dataset (Indeed_60) derived from the Indeed dataset (approximately 60%).
- An evaluation dataset (Indeed_40) derived from the Indeed dataset (approximately 40%). The selection of instances for both Indeed_60 and Indeed_40 was performed randomly, ensuring against a biased distribution or the exclusion of difficult-to-learn or classify instances.
- An augmented dataset (Indeed augmented) was constructed by combining the “Indeed_60” dataset, which contained 919 resumes, with an additional 1331 resumes generated with ChatGPT. This resulted in a total of 2250 resumes in the augmented dataset. A primary objective behind this augmentation was to ensure a balanced representation across resume categories within the dataset.
4. Results
4.1. Previous Work Results
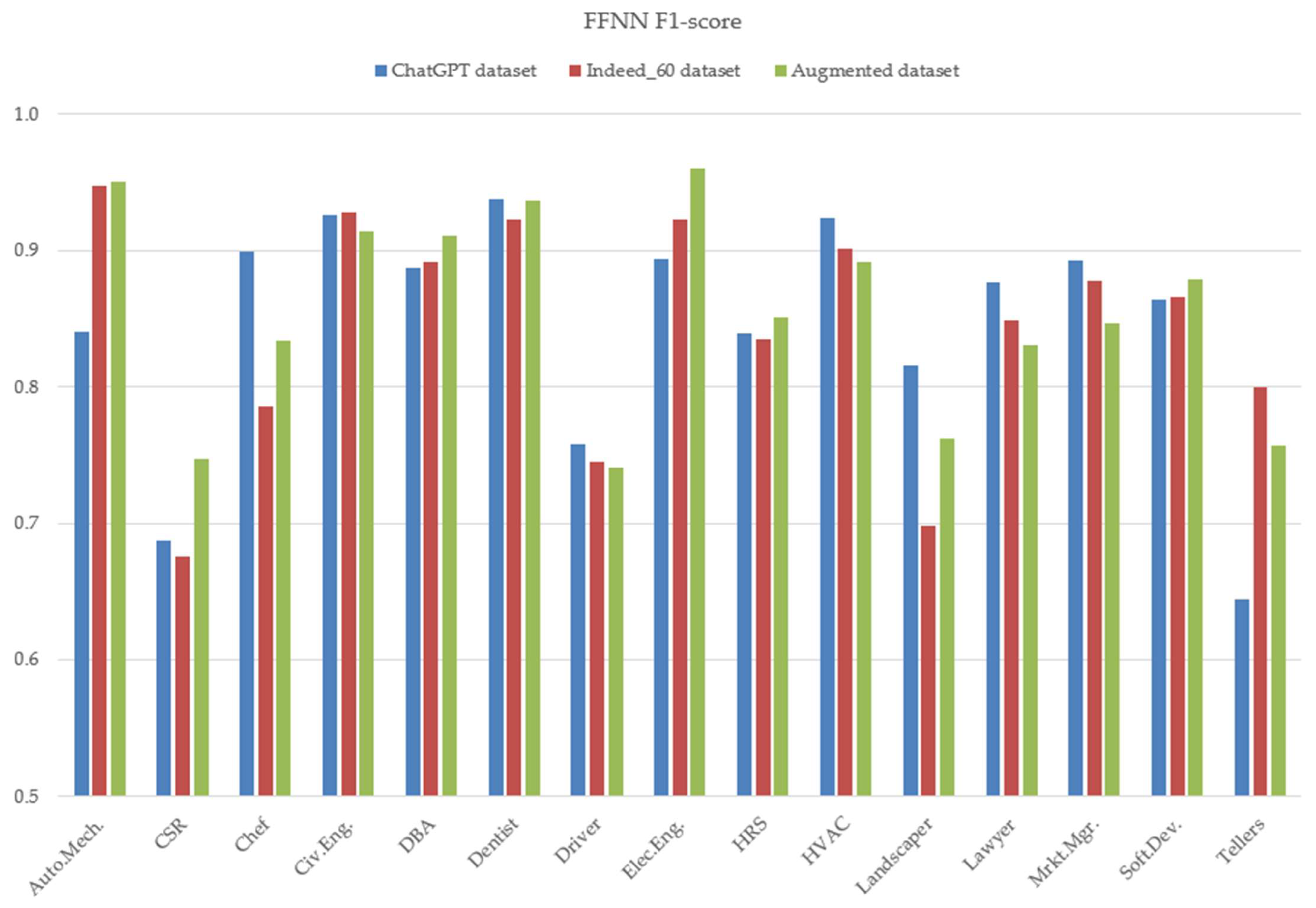
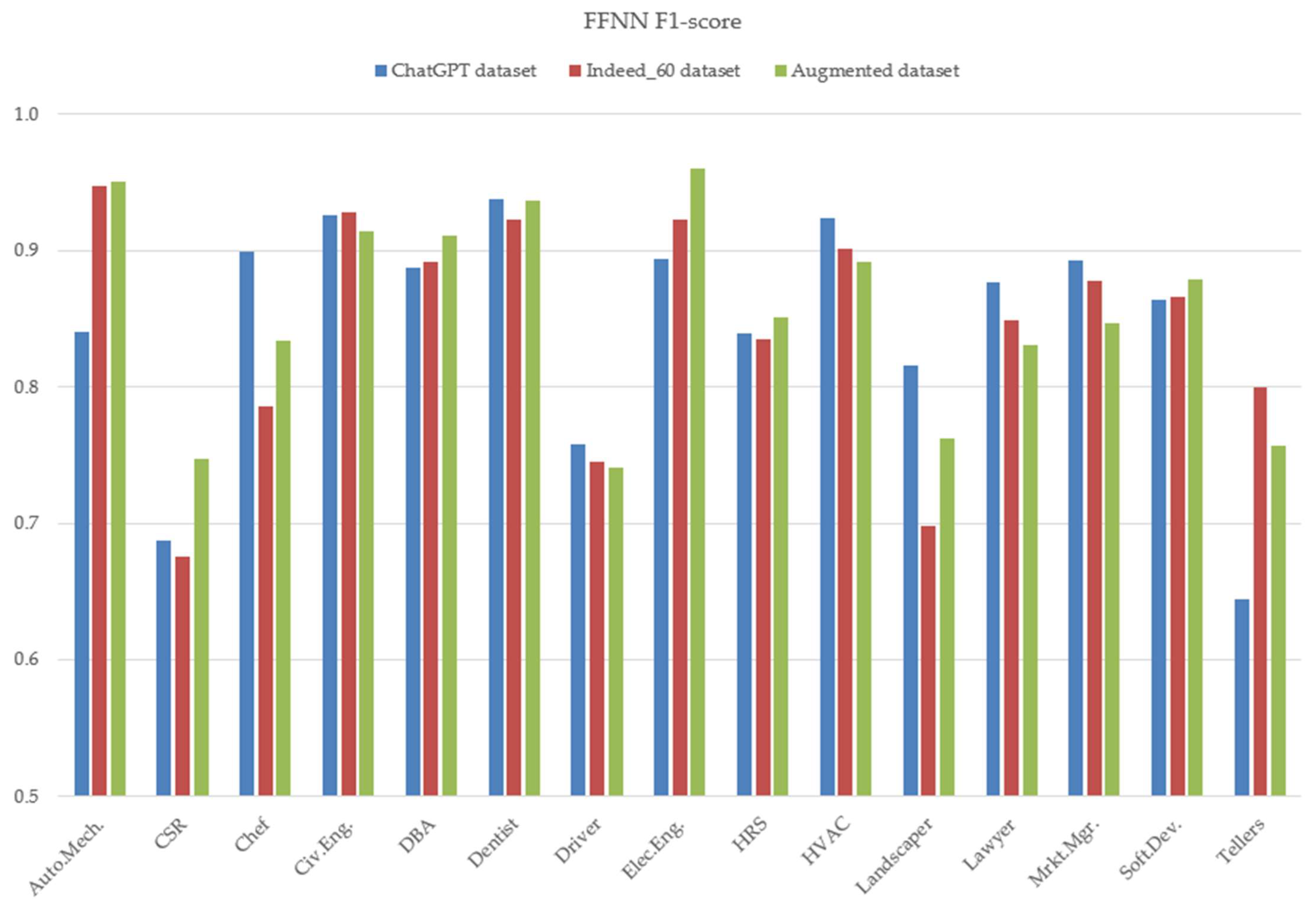
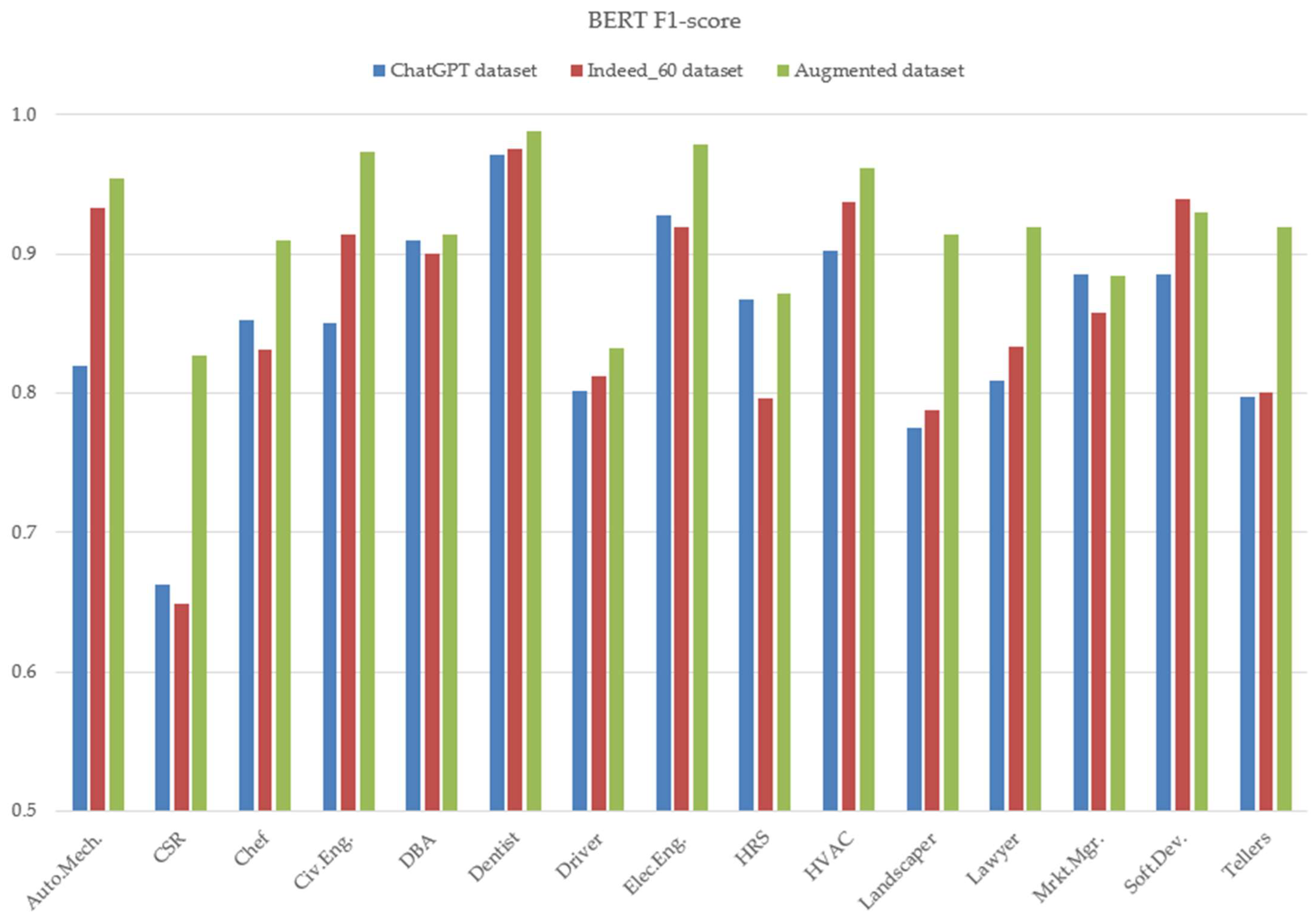
4.2. Main Use Case and per Class Results
- Training with the Indeed_60 and evaluating with the Indeed_40 dataset (experiments three and four).
- Training with the Indeed augmented and evaluating with the Indeed_40 datasets (experiments five and six).
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ye, J.; Chen, X.; Xu, N.; Zu, C.; Shao, Z.; Liu, S.; Cui, Y.; Zhou, Z.; Gong, C.; Shen, Y.; et al. A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models. arXiv 2023, arXiv:2303.10420. [Google Scholar] [CrossRef]
- Kuchnik, M.; Smith, V.; Amvrosiadis, G. Validating Large Language Models with ReLM. ArXiv [Cs.LG]. arXiv 2022, arXiv:2211.15458. [Google Scholar] [CrossRef]
- OpenAI API. Available online: https://bit.ly/3UOELSX (accessed on 29 September 2023).
- White, J.; Fu, Q.; Hays, S.; Sandborn, M.; Olea, C.; Gilbert, H.; Elnashar, A.; Spencer-Smith, J.; Schmidt, D. A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. arXiv 2023, arXiv:2302.11382. [Google Scholar] [CrossRef]
- Strobelt, H.; Webson, A.; Sanh, V.; Hoover, B.; Beyer, J.; Pfister, H.; Rush, A.M. Interactive and Visual Prompt Engineering for Ad-hoc Task Adaptation with Large Language Models. IEEE Trans. Vis. Comput. Graph. 2023, 29, 1146–1156. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, G.; Xu, Z.; Li, Y.; Zheng, Y.; Zhang, Y.; Zhao, L.; Zhang, T.; Liu, Y. Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study. arXiv 2023, arXiv:2305.13860. [Google Scholar] [CrossRef]
- Gao, A. Prompt Engineering for Large Language Models. Soc. Sci. Res. Netw. 2023, in press. [Google Scholar] [CrossRef]
- Liu, V.; Chilton, L.B. Design Guidelines for Prompt Engineering Text-to-Image Generative Models. In Proceedings of the CHI ‘22: Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–23. [Google Scholar] [CrossRef]
- Sabit, E. Prompt Engineering for ChatGPT: A Quick Guide to Techniques, Tips, And Best Practices. TechRxiv 2023. [Google Scholar] [CrossRef]
- Josifoski, M.; Sakota, M.; Peyrard, M.; West, R. Exploiting Asymmetry for Synthetic Training Data Generation: SynthIE and the Case of Information Extraction. arXiv 2023, arXiv:2303.04132. [Google Scholar] [CrossRef]
- Xu, B.; Wang, Q.; Lyu, Y.; Dai, D.; Zhang, Y.; Mao, Z. S2ynRE: Two-stage Self-training with Synthetic data for Low-resource Relation Extraction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 8186–8207. [Google Scholar] [CrossRef]
- Whitehouse, C.; Choudhury, M.; Aji, A.F. LLM-powered Data Augmentation for Enhanced Crosslingual Performance. arXiv 2023, arXiv:2305.14288. [Google Scholar] [CrossRef]
- Jeronymo, V.; Bonifacio, L.; Abonizio, H.; Fadaee, M.; Lotufo, R.; Zavrel, J.; Nogueira, R. InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval. arXiv 2023, arXiv:2301.01820. [Google Scholar] [CrossRef]
- Veselovsky, V.; Ribeiro, M.H.; Arora, A.; Josifoski, M.; Anderson, A.; West, R. Generating Faithful Synthetic Data with Large Language Models: A Case Study in Computational Social Science. arXiv 2023, arXiv:2305.15041. [Google Scholar] [CrossRef]
- Abonizio, H.; Bonifacio, L.; Jeronymo, V.; Lotufo, R.; Zavrel, J.; Nogueira, R. InPars Toolkit: A Unified and Reproducible Synthetic Data Generation Pipeline for Neural Information Retrieval. arXiv 2023, arXiv:2307.04601. [Google Scholar] [CrossRef]
- Bayer, M.; Kaufhold, M.A.; Reuter, C. A Survey on Data Augmentation for Text Classification. ACM Comput. Surv. 2022, 55, 7. [Google Scholar] [CrossRef]
- Shi, Z.; Lipani, A. Rethink the Effectiveness of Text Data Augmentation: An Empirical Analysis. arXiv 2023, arXiv:2306.07664. [Google Scholar] [CrossRef]
- Kumar, V.; Choudhary, A.; Cho, E. Data Augmentation using Pre-trained Transformer Models. arXiv 2021, arXiv:2003.02245. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Miao, Z.; Tan, W.C. Data augmentation for ML-driven data preparation and integration. ACM Proc. VLDB Endow. 2021, 14, 3182–3185. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Under-standing. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Malinowski, J.; Keim, T.; Wendt, O.; Weitzel, T. Matching people and jobs: A bilateral recommendation approach. In Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS’06), Kauai, HI, USA, 4–7 January 2006; p. 137c. [Google Scholar] [CrossRef]
- Yi, X.; Allan, J.; Croft, W.B. Matching resumes and jobs based on relevance models. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007. [Google Scholar] [CrossRef]
- Tallapragada, V.V.S.; Raj, V.S.; Deepak, U.; Sai, P.D.; Mallikarjuna, T. Improved Resume Parsing based on Contextual Meaning Extraction using BERT. In Proceedings of the 2023 7th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 17–19 May 2023; pp. 1702–1708. [Google Scholar] [CrossRef]
- Jiechieu, K.F.; Tsopze, N. Skills prediction based on multi-label resume classification using CNN with model predictions explanation. Neural Comput. Appl. 2020, 33, 5069–5087. [Google Scholar] [CrossRef]
- Li, X.; Shu, H.; Zhai, Y.; Lin, Z. A Method for Resume Information Extraction Using BERT-BiLSTM-CRF. In Proceedings of the 2021 IEEE 21st International Conference on Communication Technology (ICCT), Tianjin, China, 13–16 October 2021; pp. 1437–1442. [Google Scholar] [CrossRef]
- Vukadin, D.; Kurdija, A.S.; Delač, G.; Šilić, M. Information Extraction from Free-Form CV Documents in Multiple Languages. IEEE Access 2021, 9, 84559–84575. [Google Scholar] [CrossRef]
- O*NET Code Connector. Available online: https://www.onetcodeconnector.org/ (accessed on 29 September 2023).
- “Welcome to the O*Net Web Services Site!” O*NET Web Services. Available online: https://services.onetcenter.org/ (accessed on 29 September 2023).
- Anand, Y.; Nussbaum, Z.; Duderstadt, B.; Schmidt, B.; Mulyar, A. GPT4All: Training an Assistant-Style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo. 2023. Available online: https://github.com/nomic-ai/gpt4all (accessed on 29 September 2023).
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Hugging Face Libraries. Available online: https://huggingface.co/docs/hub/models-libraries (accessed on 29 September 2023).
- Skondras, P.; Psaroudakis, G.; Zervas, P.; Tzimas, G. Efficient Resume Classification through Rapid Dataset Creation Using ChatGPT. In Proceedings of the Fourteenth International Conference on Information, Intelligence, Systems and Applications (IISA 2023), Volos, Greece, 10–12 July 2023. [Google Scholar]
- Decorte, J.-J.; Van Hautte, J.; Demeester, T.; Develder, C. JobBERT: Understanding Job Titles through Skills. arXiv 2021, arXiv:2109.09605. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Job Category/Class | Occupation Abbr. | O*NET Alt. Titles | Indeed Dataset | ChatGPT Dataset | Indeed Augmented | Indeed_60 | Indeed_40 |
|---|---|---|---|---|---|---|---|
| Heating, Air Conditioning and Refrigeration Mechanics and Installers | HVAC | 9 | 99 | 296 | 150 | 59 | 40 |
| Human Resources Specialists | HRS | 10 | 139 | 342 | 150 | 83 | 56 |
| Driver/Sales Workers | Driver | 10 | 133 | 284 | 150 | 80 | 53 |
| Landscaping and Groundskeeping Workers | Landscaper | 10 | 86 | 424 | 150 | 52 | 34 |
| Marketing Managers | Mrkt.Mgr | 10 | 101 | 373 | 150 | 60 | 41 |
| Tellers | Tellers | 10 | 85 | 302 | 150 | 51 | 34 |
| Automotive Service Technicians and Mechanics | Auto.Mech. | 10 | 53 | 296 | 150 | 32 | 21 |
| Dentists, General | Dentist | 7 | 101 | 324 | 150 | 60 | 41 |
| Customer Service Representatives | CSR | 10 | 95 | 278 | 150 | 57 | 38 |
| Chefs and Head Cooks | Chef | 10 | 87 | 308 | 150 | 52 | 35 |
| Electrical Engineers | Elec.Eng. | 10 | 175 | 272 | 150 | 105 | 70 |
| Software Developer | Soft.Dev. | 16 | 86 | 326 | 150 | 52 | 34 |
| Civil Engineers | Civ.Eng. | 5 | 96 | 362 | 150 | 58 | 38 |
| Database Administrators | DBA | 5 | 101 | 278 | 150 | 60 | 41 |
| Lawyers | Lawyer | 8 | 95 | 326 | 150 | 57 | 38 |
| Total | 15 | 1533 | 4791 | 2250 | 919 | 614 |
| Exp. | Model | Training Dataset | Evaluation Dataset | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|
| 1 | FFNN | ChatGPT | Indeed | 0.85 | 0.85 | 0.85 | 0.85 |
| 2 | BERT | ChatGPT | Indeed | 0.85 | 0.85 | 0.85 | 0.85 |
| 3 | FNN | Indeed_60 | Indeed_40 | 0.84 | 0.86 | 0.84 | 0.84 |
| 4 | BERT | Indeed_60 | Indeed_40 | 0.85 | 0.88 | 0.86 | 0.86 |
| 5 | FNN | Indeed augmented | Indeed_40 | 0.85 | 0.86 | 0.85 | 0.85 |
| 6 | BERT | Indeed augmented | Indeed_40 | 0.92 | 0.92 | 0.92 | 0.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Skondras, P.; Zervas, P.; Tzimas, G. Generating Synthetic Resume Data with Large Language Models for Enhanced Job Description Classification. Future Internet 2023, 15, 363. https://doi.org/10.3390/fi15110363
Skondras P, Zervas P, Tzimas G. Generating Synthetic Resume Data with Large Language Models for Enhanced Job Description Classification. Future Internet. 2023; 15(11):363. https://doi.org/10.3390/fi15110363
Chicago/Turabian StyleSkondras, Panagiotis, Panagiotis Zervas, and Giannis Tzimas. 2023. "Generating Synthetic Resume Data with Large Language Models for Enhanced Job Description Classification" Future Internet 15, no. 11: 363. https://doi.org/10.3390/fi15110363
APA StyleSkondras, P., Zervas, P., & Tzimas, G. (2023). Generating Synthetic Resume Data with Large Language Models for Enhanced Job Description Classification. Future Internet, 15(11), 363. https://doi.org/10.3390/fi15110363