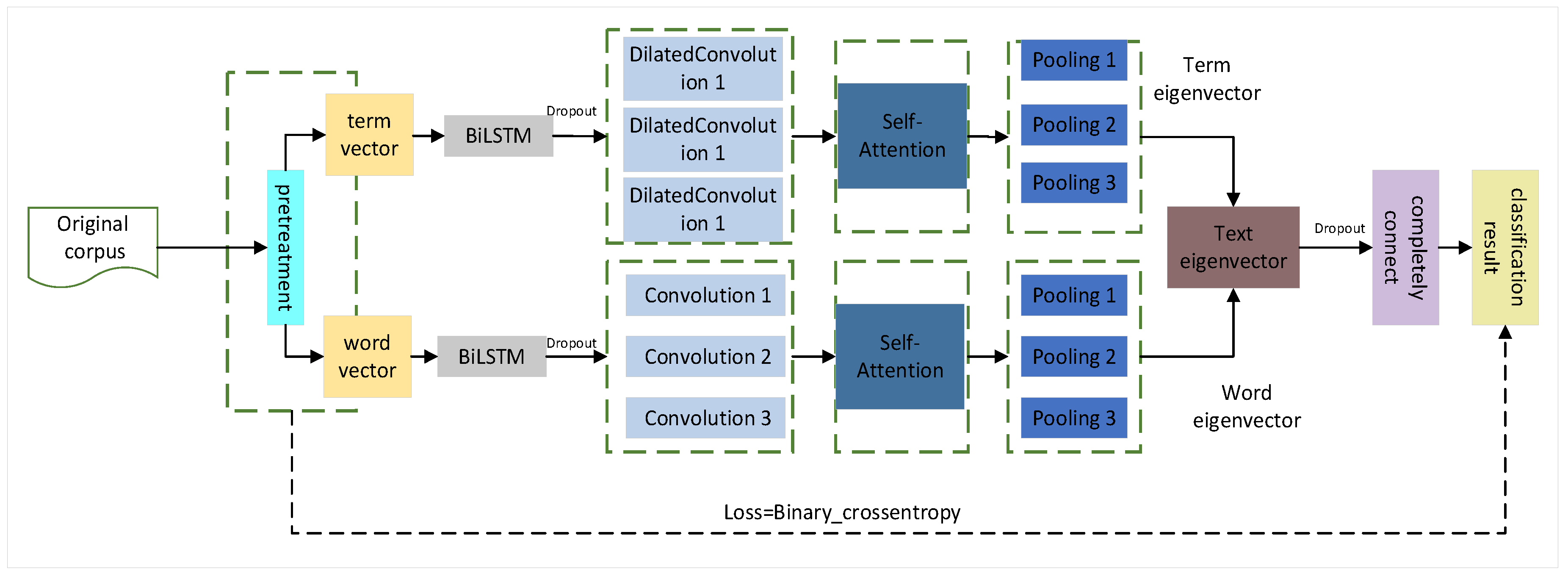
4.1. Comparison and Analysis with Other Methods
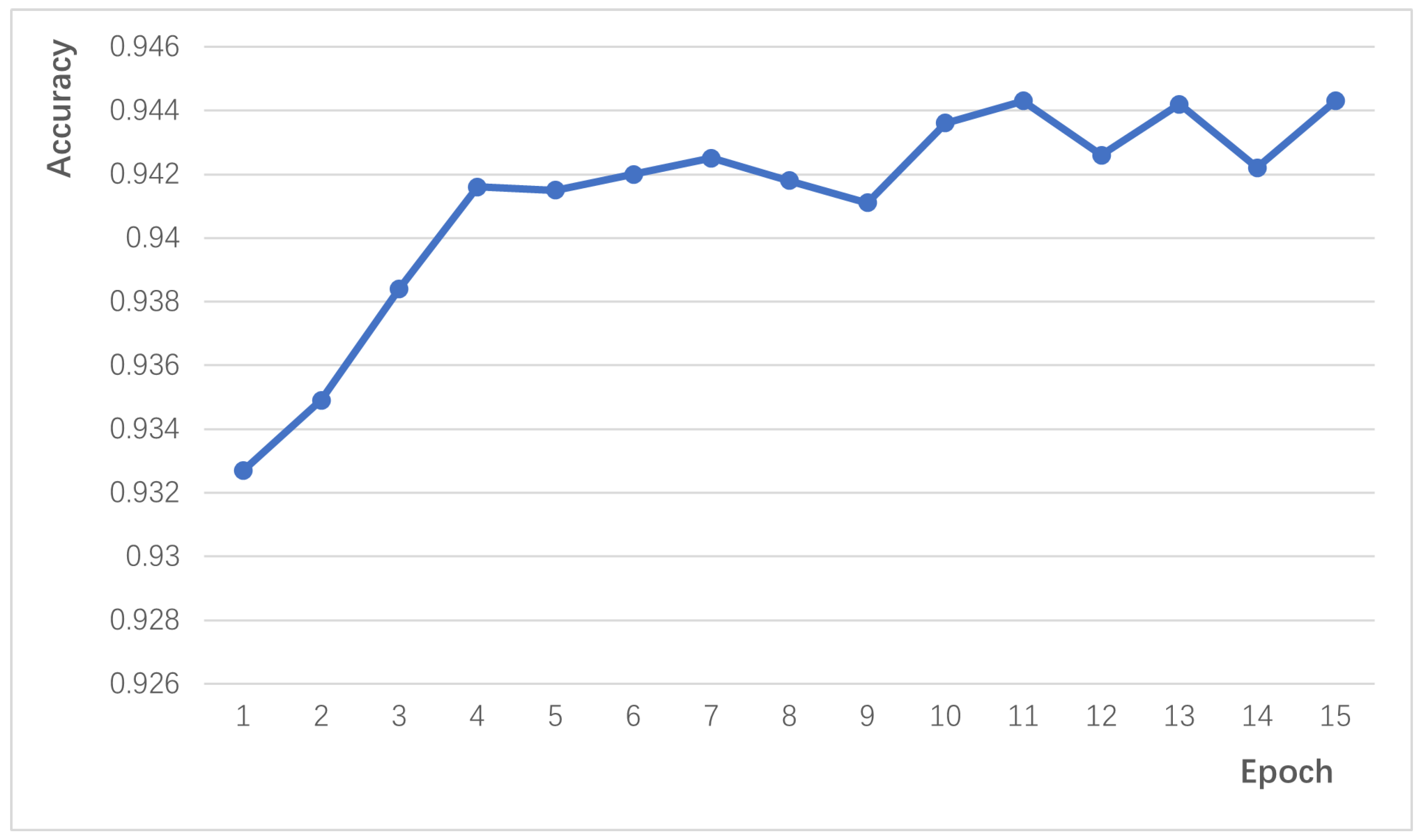
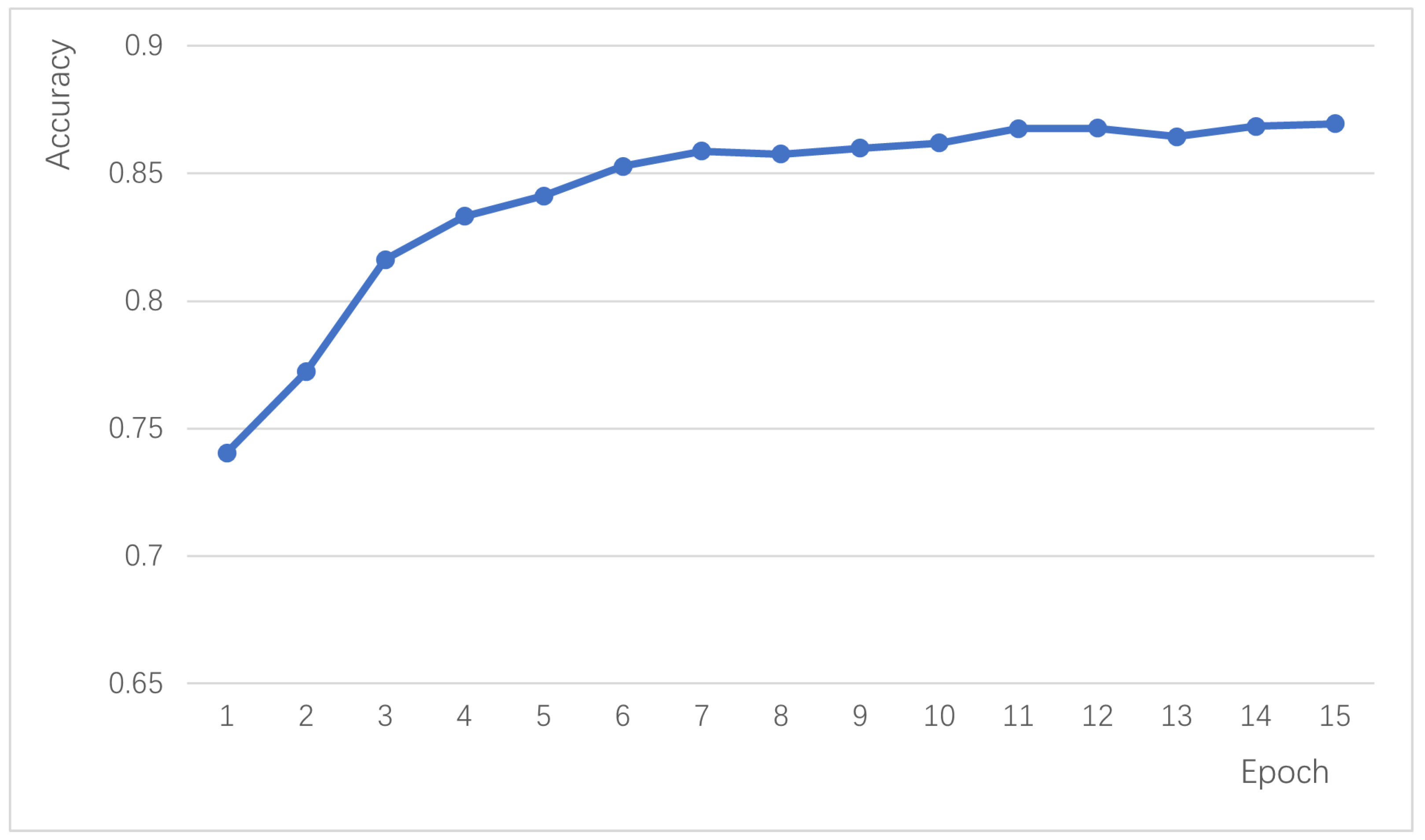
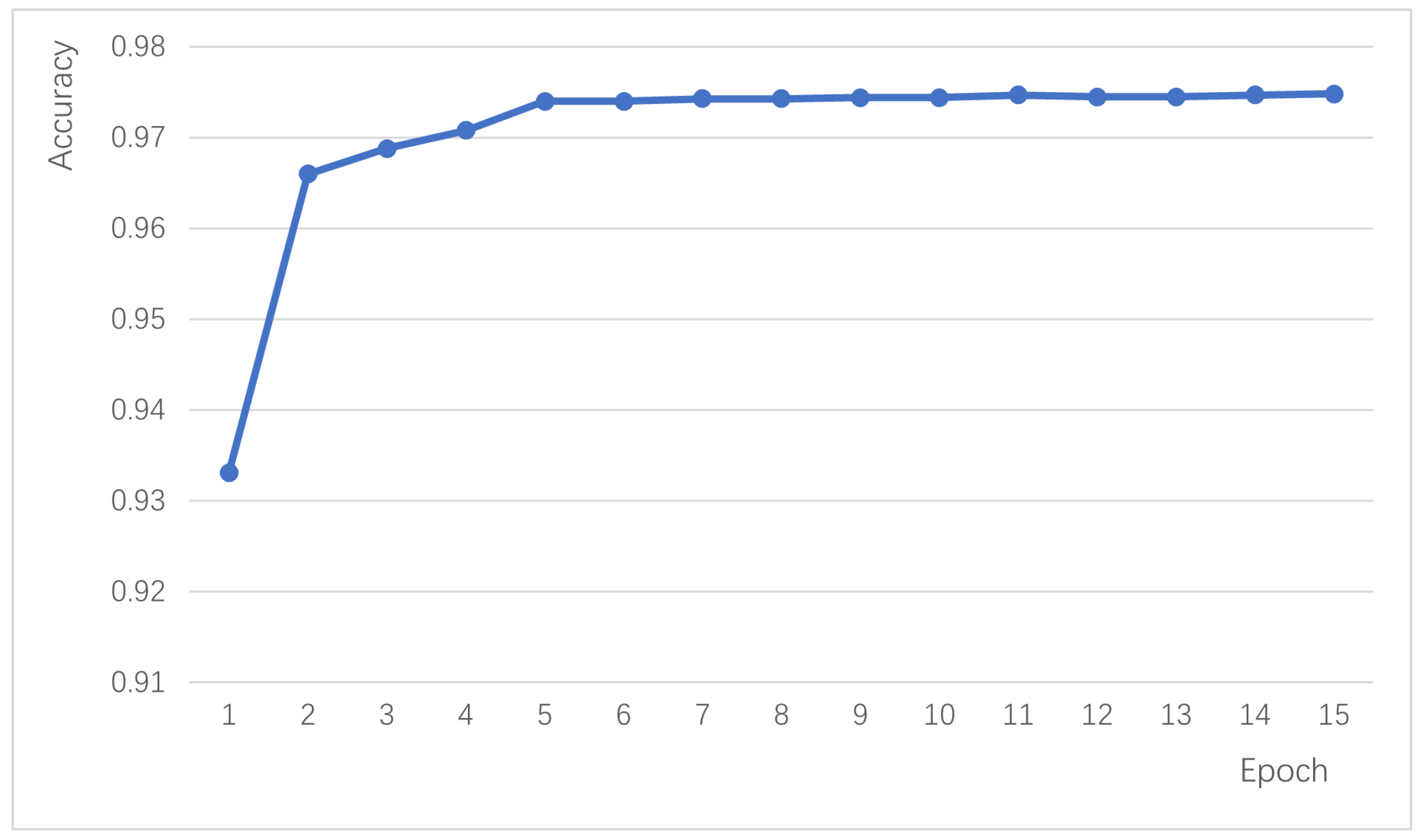
The proposed Sac-BiLSTM algorithm in this study achieves efficient text sentiment analysis, with the model rapidly converging within the first five iterations and maintaining a classification accuracy above 0.94. To validate the effectiveness and superiority of the proposed algorithm, it is compared with other mainstream text classification algorithms, including Static-CNN, Non-Static-CNN, S-Non-CNN (Multi-channel Convolutional Neural Network), CNN-character (Character-level Convolutional Neural Network), DCCNN (Dual-channel Convolutional Neural Network), BiLSTM-CNN Concatenation, and BiLSTM-CNN Parallel.
In this section, we provide a brief introduction to different comparative models, all of which use the Word2Vec model as their pre-trained model.
1. WordCNN-static: This model uses pre-trained word embeddings as the embedding layer. Multiple one-dimensional convolutions with different sizes are applied to the output of the embedding layer, followed by batch normalization, activation, and pooling. The outputs of the pooling layers are concatenated, flattened, and passed through a Dropout layer and a fully connected layer for classification.
2. CNN-character: This model uses pre-trained character embeddings as the embedding layer. Different-sized convolutional kernels are applied to the input, followed by Max pooling to reduce the dimensionality of each convolutional kernel’s output, resulting in a set of feature vectors. The pooling results of all convolutional kernels are then concatenated and further processed by a fully connected layer for feature extraction and classification.
3. S-Non-CNN: This model defines two different word embedding layers that load pre-trained word embeddings. Next, different-sized convolutional kernels are applied to each channel independently, followed by non-linear transformations. The outputs of each convolutional kernel are then reduced in dimensionality through Max pooling, resulting in two sets of feature vectors. These feature vectors are flattened and concatenated to form a global feature vector. The global feature vector is further processed by a fully connected layer for feature extraction and classification.
4. DCCNN: This model defines two different word embedding layers that load different pre-trained word and character embeddings. Different-sized convolutional kernels are applied to the input, followed by non-linear transformations and dimensionality reduction, resulting in two sets of feature vectors. These feature vectors are flattened and concatenated to form a global feature vector. The global feature vector is further processed by a fully connected layer for feature extraction and classification.
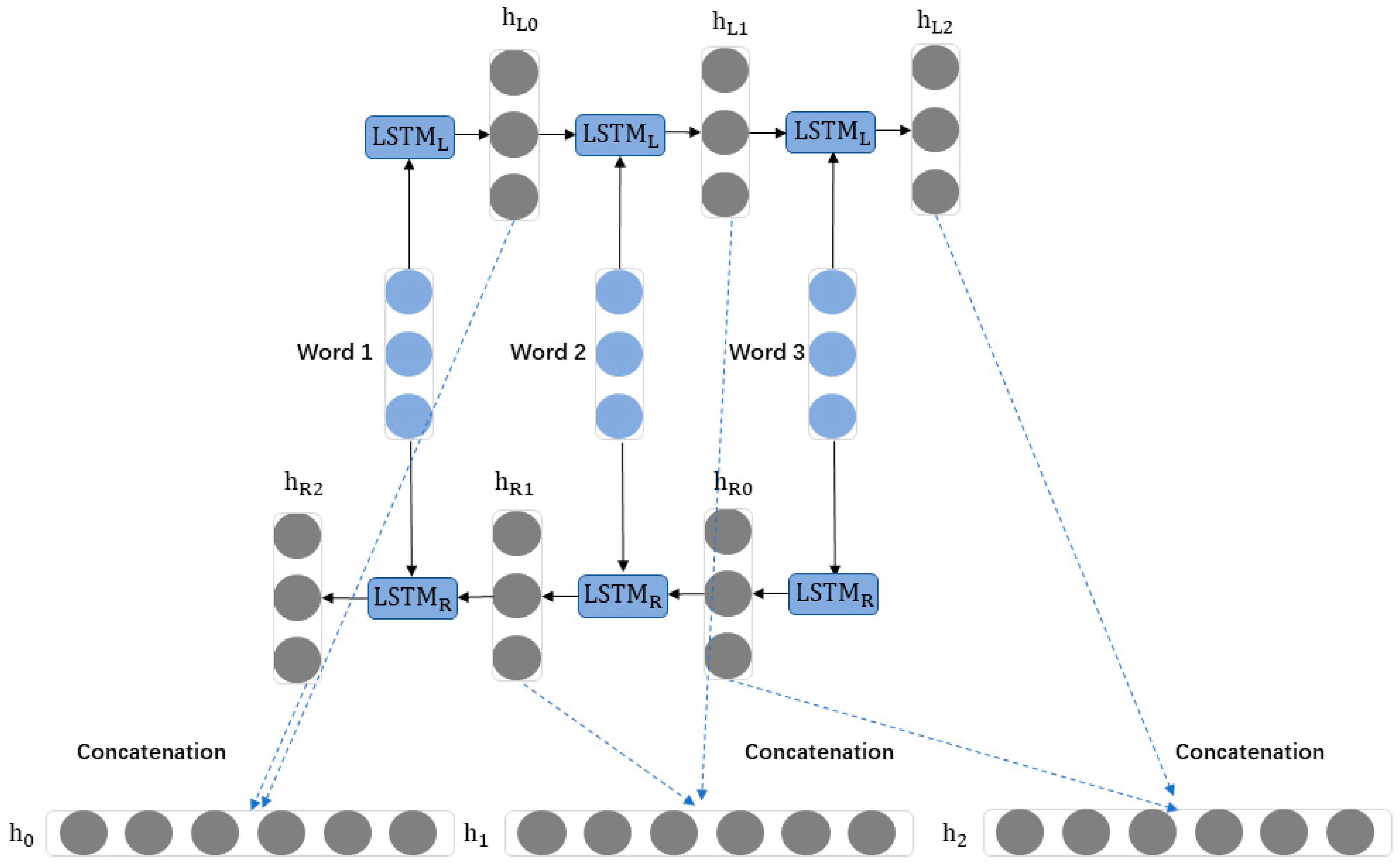
5. BiLSTM-CNN Concatenation: This model loads pre-trained word embeddings and applies a BiLSTM layer for sequence modeling. Then, different-sized convolutional kernels are applied to the output of the BiLSTM layer, followed by non-linear transformations and dimensionality reduction, resulting in a set of feature vectors. These feature vectors are flattened and further processed by a fully connected layer for feature extraction and classification.
6. BiLSTM-CNN Parallel: This model uses two input channels. The model applies a BiLSTM layer for sequence modeling on inputA, resulting in a sequence output (outputA). Simultaneously, different-sized convolutional kernels (three, five, and seven) are applied to inputB, followed by non-linear transformations and dimensionality reduction, resulting in a set of feature vectors (outputB). These feature vectors are flattened and merged with outputA, resulting in a comprehensive feature vector. The comprehensive feature vector is further processed by a fully connected layer for feature extraction and classification.
The text classification results of this algorithm compared to the other six algorithms on various test datasets are shown in
Table 6,
Table 7 and
Table 8.
By comparing the results of various methods in
Table 6,
Table 7 and
Table 8, it can be observed that the proposed Sac-BiLSTM algorithm outperforms the other six methods in all performance metrics.
Analyzing the results of the comparative experiments, we can understand the impact of different feature fusion and algorithm combinations on model performance in sentiment analysis tasks. From the results in
Table 6,
Table 7 and
Table 8, the following can be concluded.
(1) Compared to Static-CNN, the Character-level Convolutional Neural Network (CNN-character) utilizes pre-trained character embeddings as input, validating that using character embeddings as the original features is superior to using word embeddings.
(2) The multi-channel algorithm can improve the accuracy of the model to some extent. The S-Non-CNN multi-channel algorithm trains with both static and non-static word embeddings in two separate channels, resulting in higher Accuracy, Recall, and F1 score values compared to single-channel algorithms.
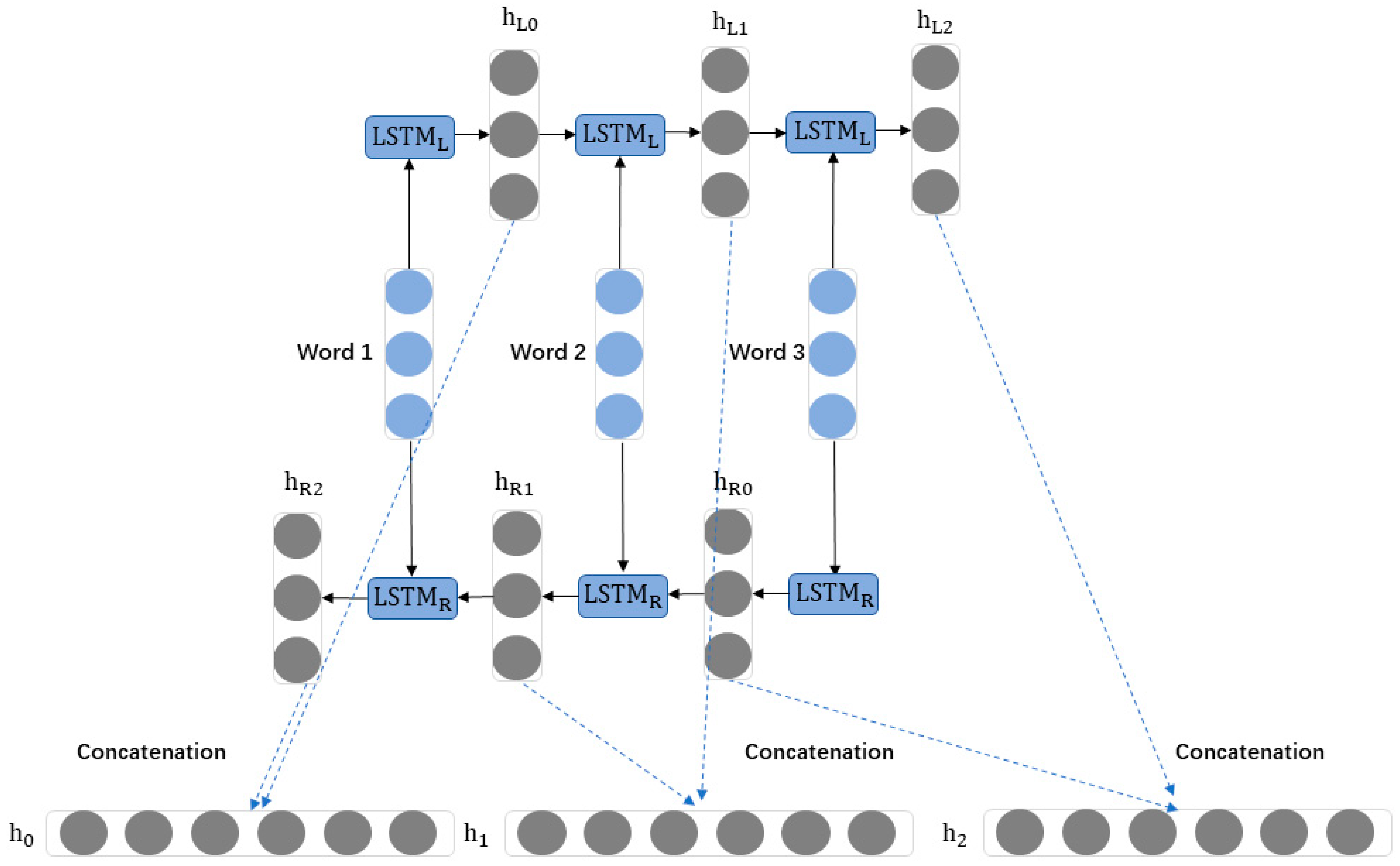
(3) BiLSTM can improve the accuracy of the model. Adding a BiLSTM layer in the network architecture allows each time step’s feature vector more information. Experimental results show that adding BiLSTM to the convolutional neural network can achieve higher accuracy. Comparing the effects of BiLSTM-CNN concatenation and BiLSTM-CNN parallelization in sentiment classification, it is found that adding BiLSTM in series with CNN performs better than adding them in parallel. Additionally, the dual-channel algorithm using character/word embeddings can better utilize the ability of BiLSTM to extract global feature vectors, resulting in better performance compared to that of algorithms that combine BiLSTM and CNN in series or in parallel.
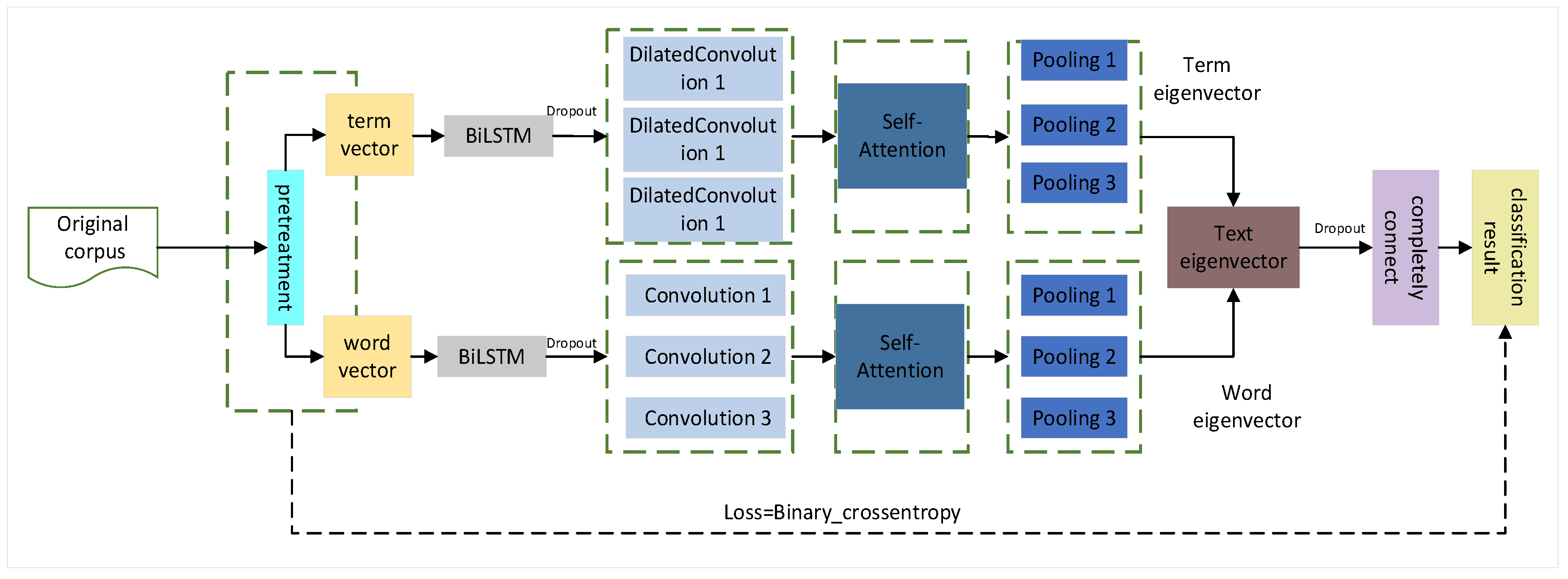
The proposed Sac-BiLSTM introduces a novel dual-channel architecture, where features are separately extracted from character and word vectors and then fused before classification, allowing the model the learning of semantic features of different sizes. Furthermore, the proposed method incorporates Self-Attention units into the dual-channel network structure, making it easier for the network to capture long-distance dependent features in sentences. The experimental results on the online_shopping_10_cats dataset demonstrate that the Sac-BiLSTM achieves an Accuracy of 0.9463, Recall of 0.9409, Precision of 0.9469, and F1-score of 0.9404, which are the highest among all the algorithms.In the food delivery dataset, the Accuracy is 0.8776, Precision is 0.86363, Recall is 0.8980, and the F1-score is 0.8804. In the Weibo comment dataset, the Accuracy is 0.9775, Precision is 0.9940, Recall is 0.9592, and the F1-score is 0.9763. These metrics indicate that the Sac-BiLSTM model performs the best among all the models. The experimental results show that the performance of the model is influenced by the size of the data, with better results observed with larger datasets. Moreover, the model demonstrates good robustness. In the imbalanced classification task for water heater reviews, the Sac-BiLSTM model achieves an Accuracy of 94.9874, matching the results of the test set. Additionally, in the imbalanced food delivery comment dataset, the Sac-BiLSTM model still outperforms other models.
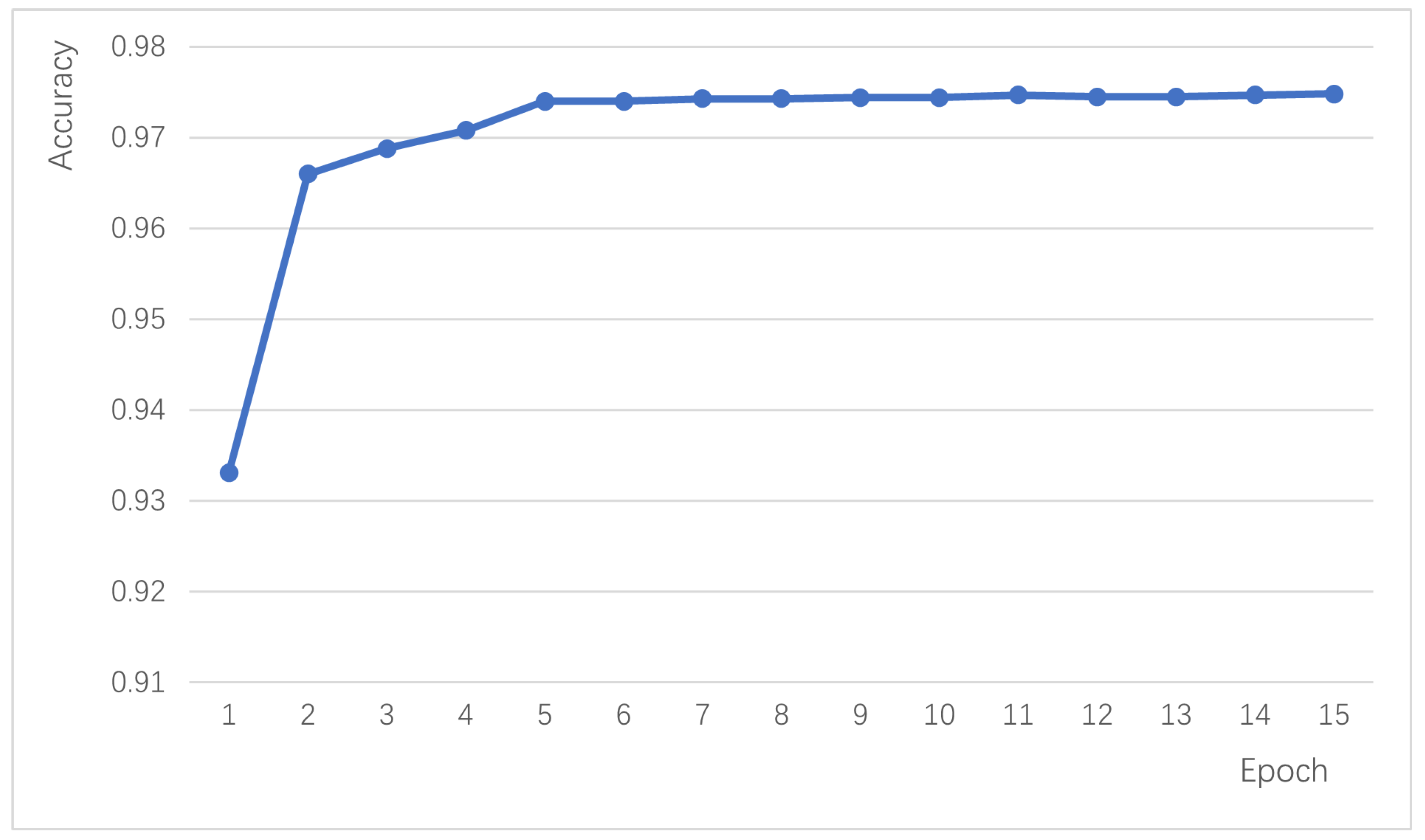
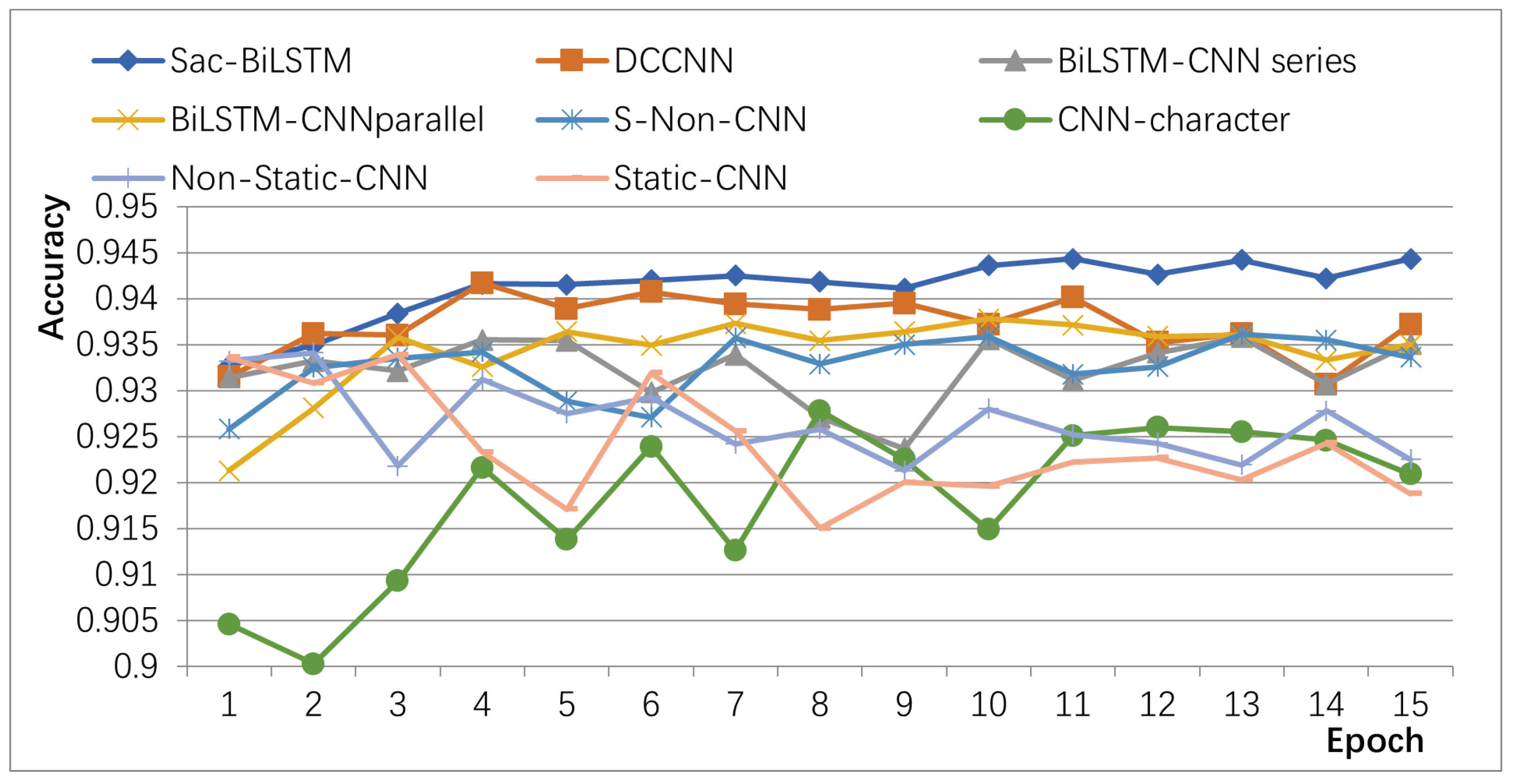
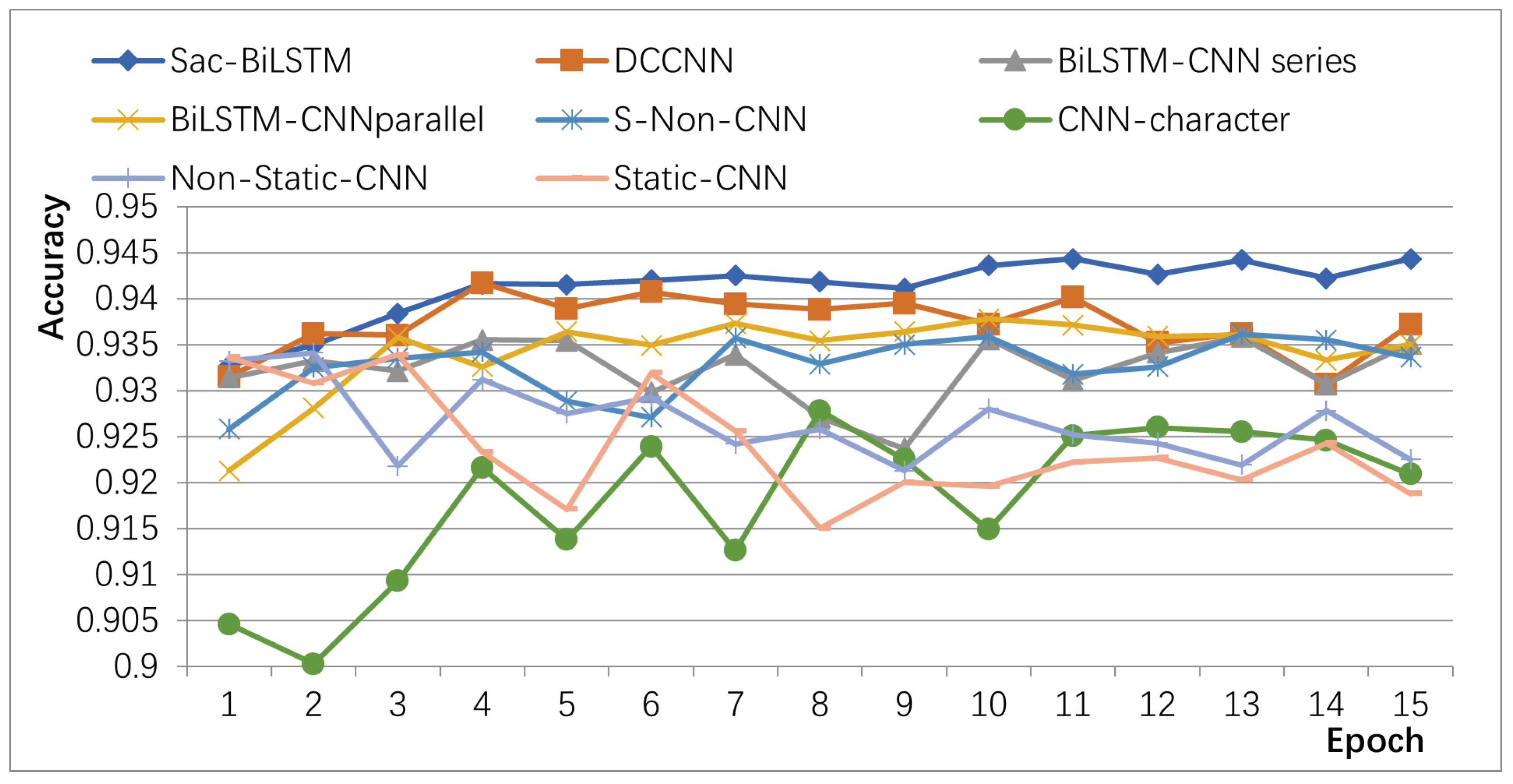
The accuracy variations of different algorithms on the validation set of the product review dataset at different iteration numbers are shown in
Figure 8. From
Figure 8, it can be observed that the static single-channel Static-CNN algorithm has the lowest accuracy and significant fluctuations. Other methods that optimize using non-static and multi-channel approaches show improved accuracy and stability. The proposed Sac-BiLSTM algorithm achieves significantly higher accuracy than other algorithms, with smaller fluctuations. It rapidly converges within the first five iterations and reaches a stable accuracy level after the tenth iteration.
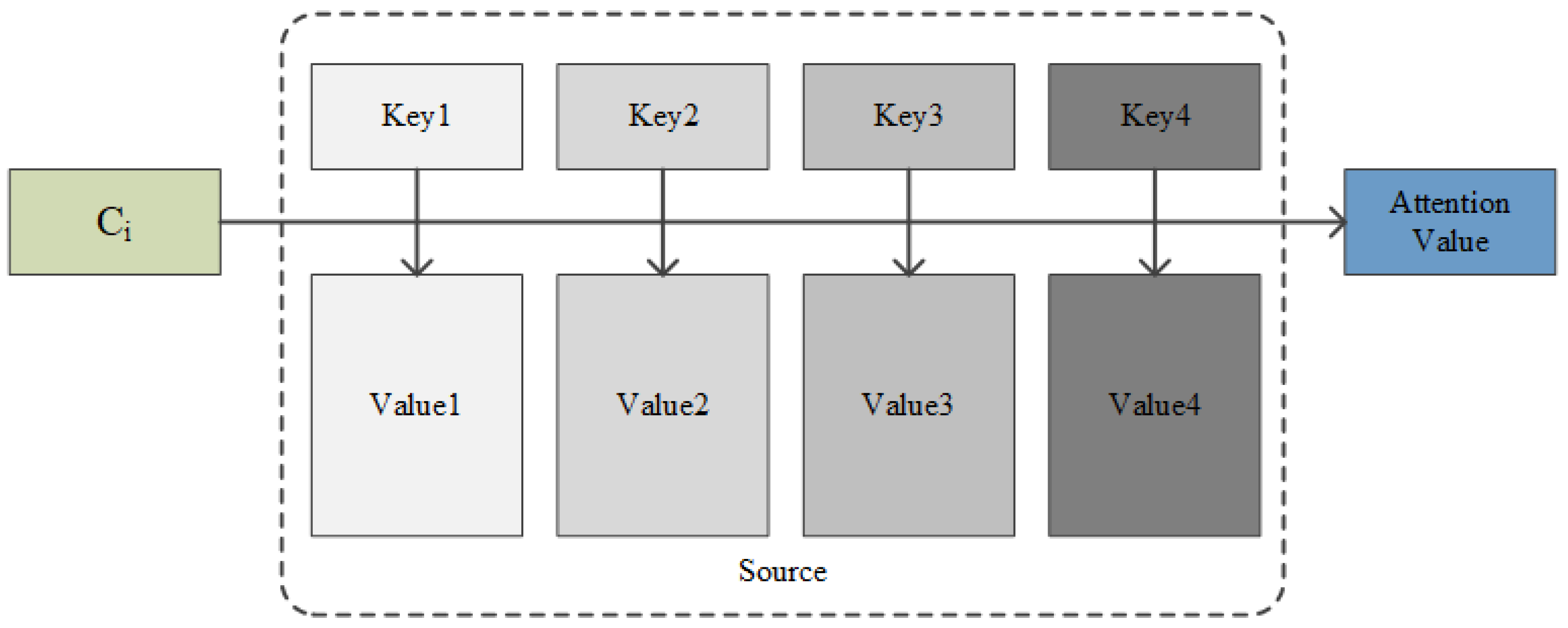
Furthermore, the proposed algorithm introduces a novel dual-channel structure that fully utilizes the feature extraction capabilities of CNN combined with dilated convolutions. This allows the algorithm stabilization at a high level within a small number of iterations. Additionally, the Sac-BiLSTM incorporates Self-Attention units in the BiLSTM module, enabling the model to weight the importance of different words and better capture key information for sentiment expression. Compared to a regular BiLSTM, this further improves accuracy. Additionally, the accuracy of Sac-BiLSTM is higher than that of BiLSTM-CNN (series and parallel) in different categories. In the tablet and fruit categories, the accuracy of Sac-BiLSTM reaches 88.5293 and 87.3329, respectively. On the other hand, the accuracy of the BiLSTM-CNN (series) is 84.6752 and 83.9825, and the accuracy of the BiLSTM-CNN (parallel) is 85.6842 and 86.5796.
4.2. Feature Analysis of the Proposed Dual-Channel Structure
In this paper, a novel dual-channel structure, BiLSTM-Dilated Convolution combined with CNN, is designed for text sentiment analysis. It was found that when the BiLSTM module is connected to CNN through a single channel, it fails to understand deep semantic correlations and faces difficulties in simultaneously capturing local and global information. Consequently, the accuracy decreases compared to using only CNN, as shown in
Table 6, where both the serial and parallel BiLSTM-CNN methods have lower accuracy than DCCNN.
The DCCNN model, in the aspect of text sentiment analysis, computes faster than current mainstream text sentiment classification methods and can achieve high accuracy in a very short number of iterations. This ability to quickly capture features makes it more effective in extracting and modeling local features. However, for global models, it may overlook longer dependency relationships. On the other hand, algorithms like BiLSTM-CNN serial and BiLSTM-CNN parallel can learn deeper contextual information in text sentiment analysis, enabling simultaneous modeling of local features and global context information, resulting in higher precision values. However, these methods struggle with feature fusion and suffer from reduced accuracy due to repeated features.
The proposed dual-channel approach effectively addresses these issues. In this study, a new dual-channel connection method is designed to connect the BiLSTM module separately with CNN and Dilated Convolution. This involves setting up channels for word vectors and character vectors, combining word embedding channels with dilated convolutions, and character embedding channels with convolutions. The word embedding channel captures word-level global information and semantic associations using dilated convolutions, capturing a broader range of contextual information. Simultaneously, the character embedding channel utilizes convolutions to capture local information and semantic correlations between adjacent characters, learning features from different window sizes. The combination of features from both channels provides a richer representation, effectively addressing the problem of understanding deep semantic correlations.
Experimental verification shows that when the convolutional kernel sizes are set to three, five, and seven with a quantity of 128, the Sac-BiLSTM algorithm achieves the best performance.
In conclusion, the proposed Sac-BiLSTM algorithm accurately extracts features from Chinese product review corpus for sentiment analysis. This algorithm utilizes fine-grained character vectors to assist in extracting semantic information from word vectors, constructs a non-static dual-channel, and combines long short-term memory models with convolutional neural networks and dilated convolutions to avoid semantic extraction biases. It effectively extracts feature information from text, thereby improving the accuracy of sentiment analysis. Additionally, the Sac-BiLSTM algorithm proposed in this paper incorporates the Self-Attention mechanism to better capture key information in the text, enhancing the model’s understanding of text relationships and contextual information, further improving the accuracy of sentiment analysis. Experimental results demonstrate the higher precision of the proposed Sac-BiLSTM algorithm.
4.3. Shortcomings and Prospects
Currently, there are still directions for improvement in algorithms to further enhance their performance and application scope.
Firstly, the interpretability of the algorithm can be improved. Although the Sac-BiLSTM algorithm performs well in terms of accuracy, its internal decision-making process is not easily understood. Further research can explore methods such as visualization to make the algorithm’s decision-making process more transparent and interpretable to users, thereby enhancing trust in the algorithm.
In addition, efficiency and real-time performance are also important aspects to consider. Despite achieving good accuracy, the Sac-BiLSTM algorithm has a high computational complexity and requires longer processing time. To meet the demands of real-time applications, further optimization of the algorithm’s structure and parameters can improve its running efficiency.
Lastly, the impact of data quality and scale on the algorithm should also be emphasized. The performance of the algorithm largely depends on the quality and scale of the training data. Future research can focus on constructing larger-scale, high-quality sentiment-annotated datasets to further enhance the algorithm’s performance and generalization ability.
In summary, looking ahead, the Sac-BiLSTM algorithm has broad application prospects in the field of text sentiment analysis. By improving the algorithm’s interpretability, generalization ability, efficiency, and real-time performance, as well as focusing on data quality and scale, the algorithm’s performance and applicability can be further enhanced, promoting its application in areas such as business analytics and user experience improvement.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}