

Latency-Aware Semi-Synchronous Client Selection and Model Aggregation for Wireless Federated Learning


Abstract
:1. Introduction
- A new semi-synchronous FL algorithm, i.e., LESSON, is introduced. LESSON introduces a latency-aware client clustering technique that groups clients into different tiers based on their computing and uploading latency. LESSON allows all the clients in the system to participate in the training process but at different frequencies, depending on the clients’ associated tiers. LESSON is expected to mitigate the straggler problem in synchronous FL and model overfitting in asynchronous FL, thus expediting model convergence.
- LESSON also features a specialized model aggregation method tailored to client clustering. This method sets the weight and timing for local model aggregation for each client tier.
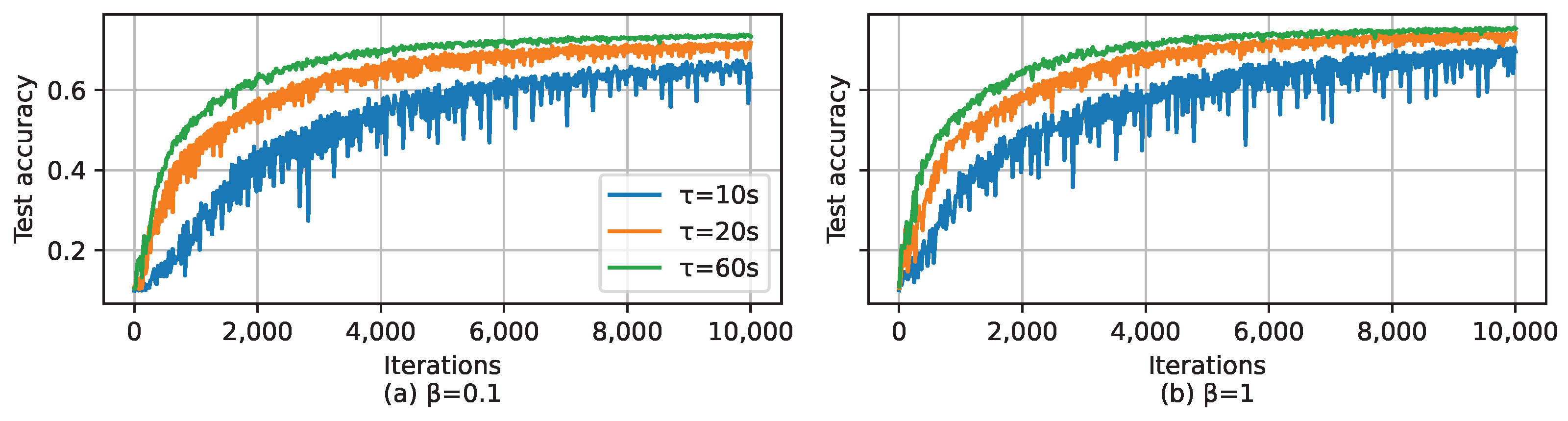
- The proposed LESSON algorithm also integrates the dynamic model aggregation and step size adjustment according to client clustering and offers flexibility in balancing model accuracy and convergence speed by adjusting the deadline .
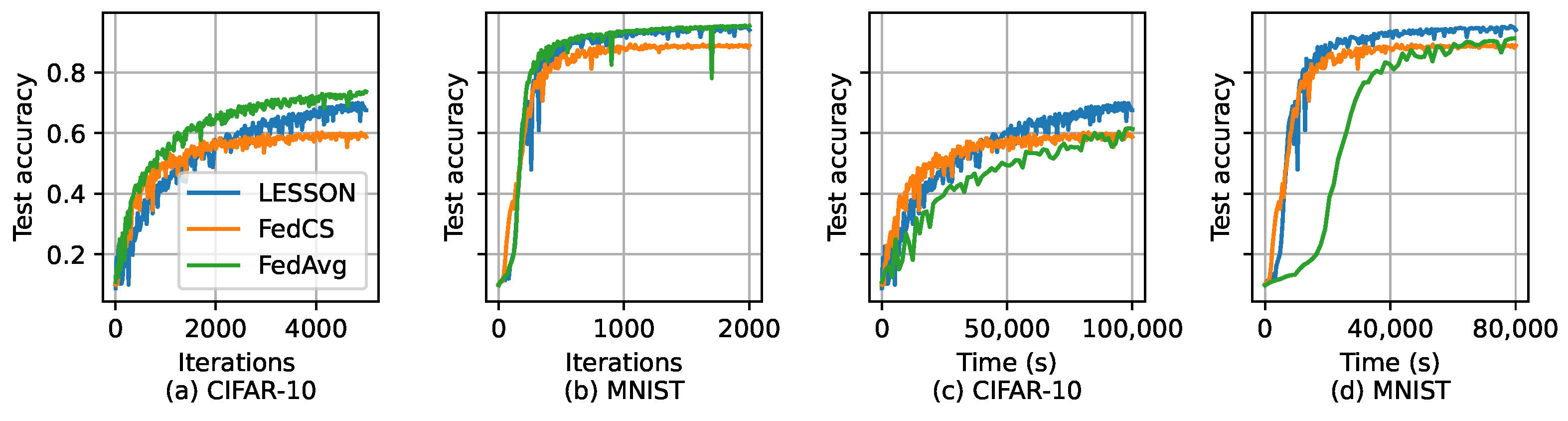
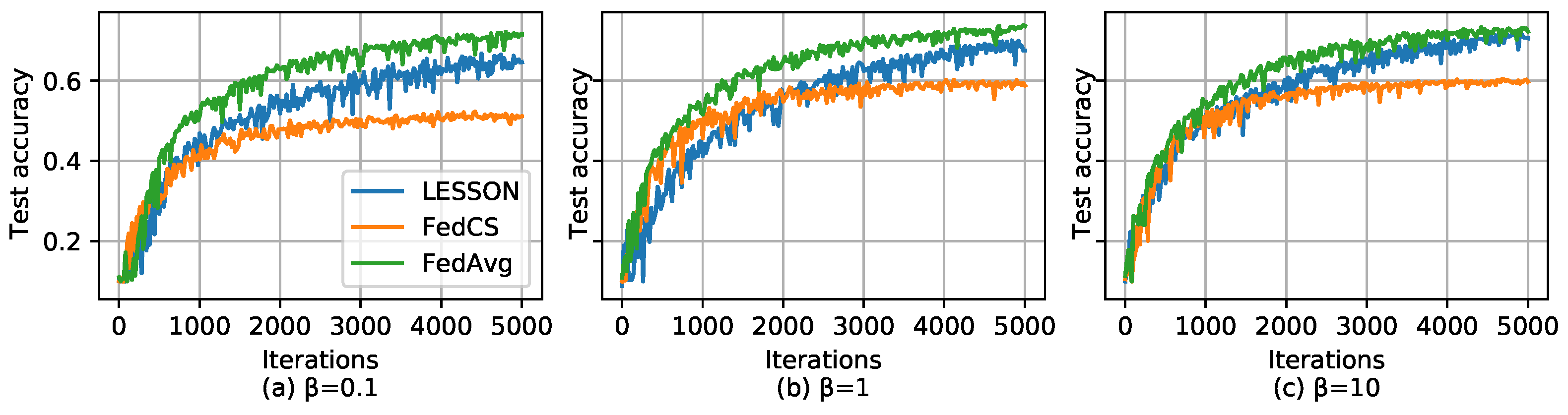
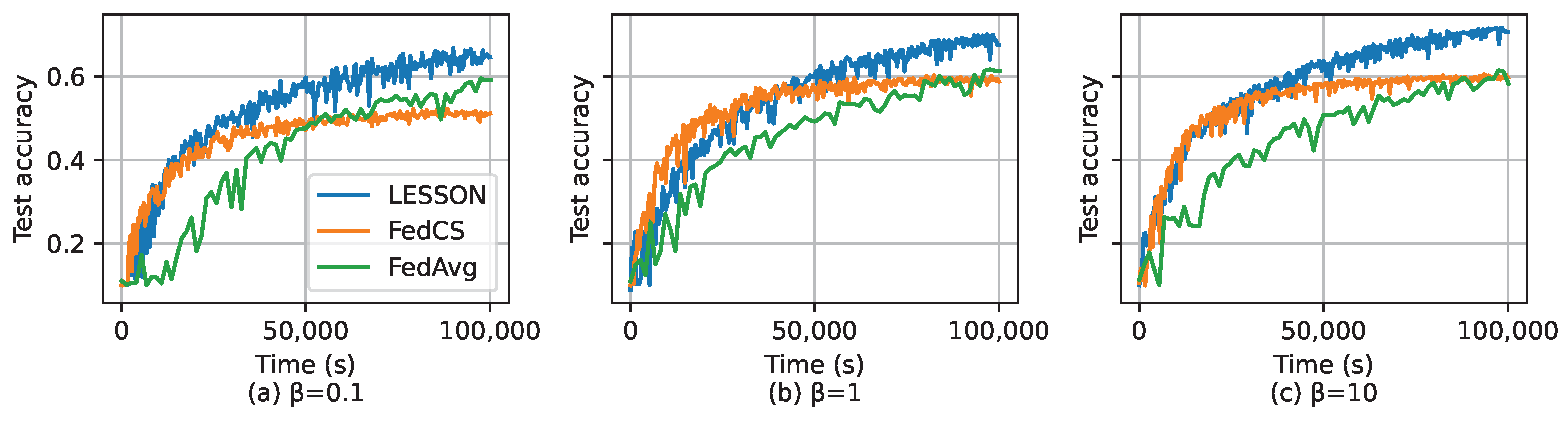
- Extensive experimental evaluations show that LESSON outperforms FedAvg and FedCS in terms of faster convergence and higher model accuracy.
2. Related Work
3. System Models
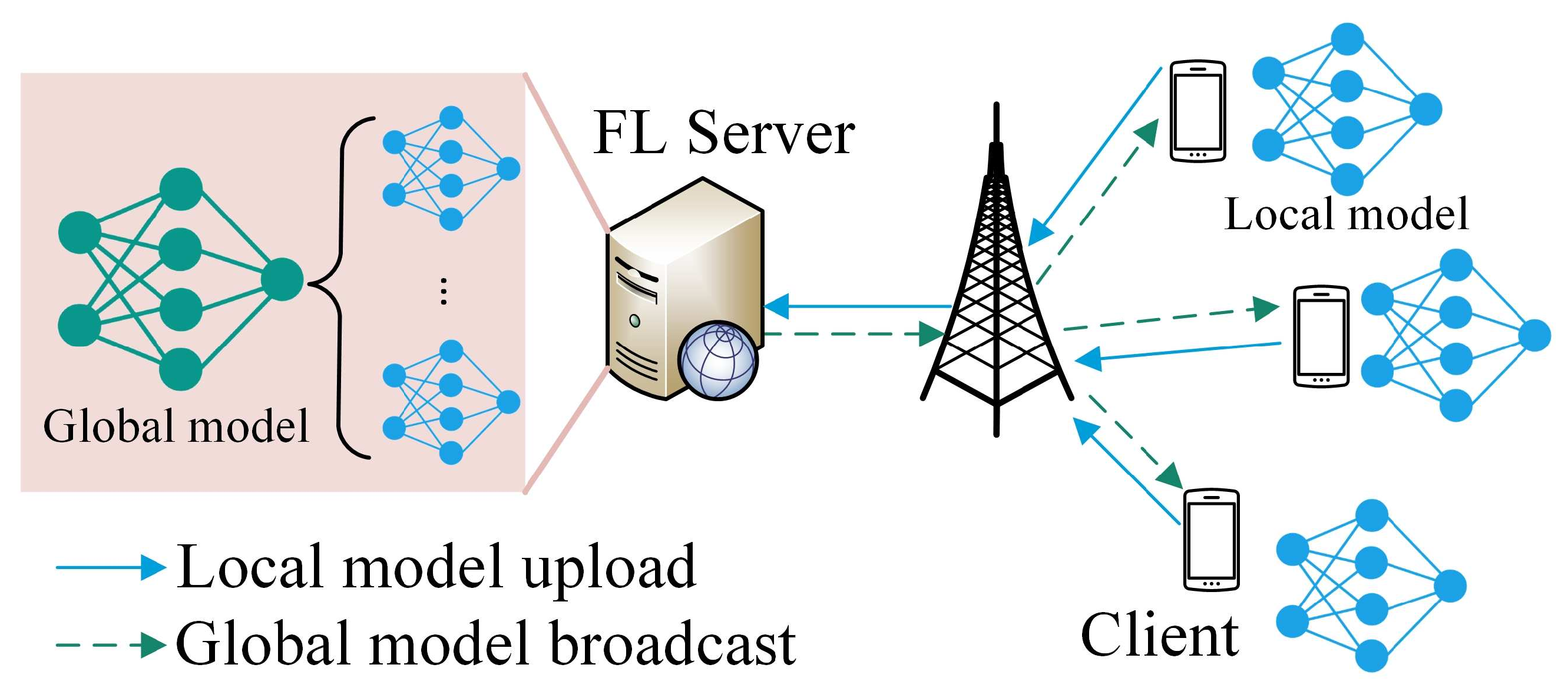
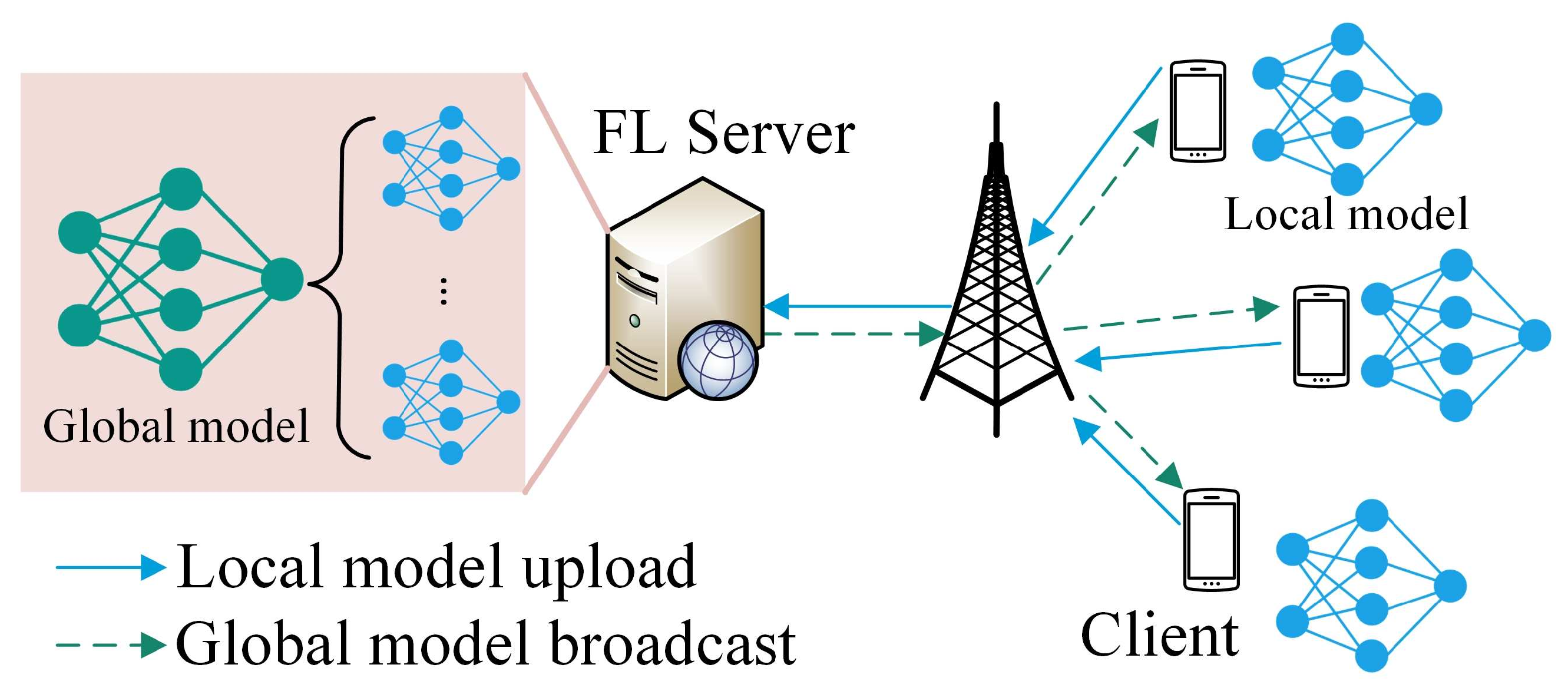
3.1. Federated Learning Preliminary
- Server broadcast: In the k-th global iteration, the FL server broadcasts the global model generated in the previous global iteration, denoted as , to all the selected clients.
- Client local training: Each client i trains its local model over its local data set , i.e., , where is the learning rate.
- Client model uploading: After deriving the local model , client i uploads its local model to the FL server.
- Server model aggregation: The FL server aggregates the local models from the clients and updates the global model based on, for example, FedAvg [5], i.e., .
3.2. Latency Models of a Client
3.2.1. Computing Latency
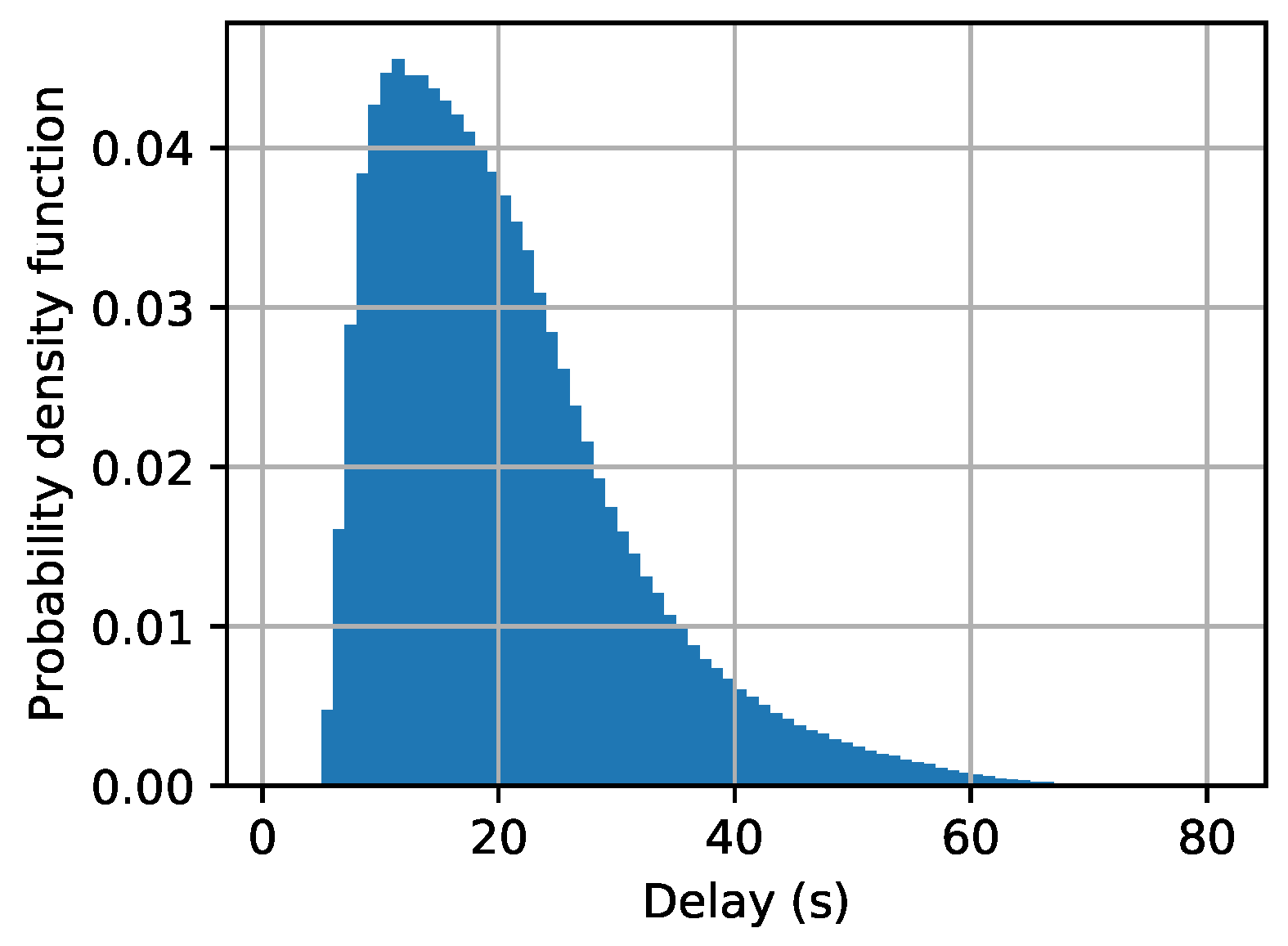
3.2.2. Uploading Latency
4. Latency-awarE Semi-Synchronous Client Selection and mOdel Aggregation for Federated learNing (LESSON)
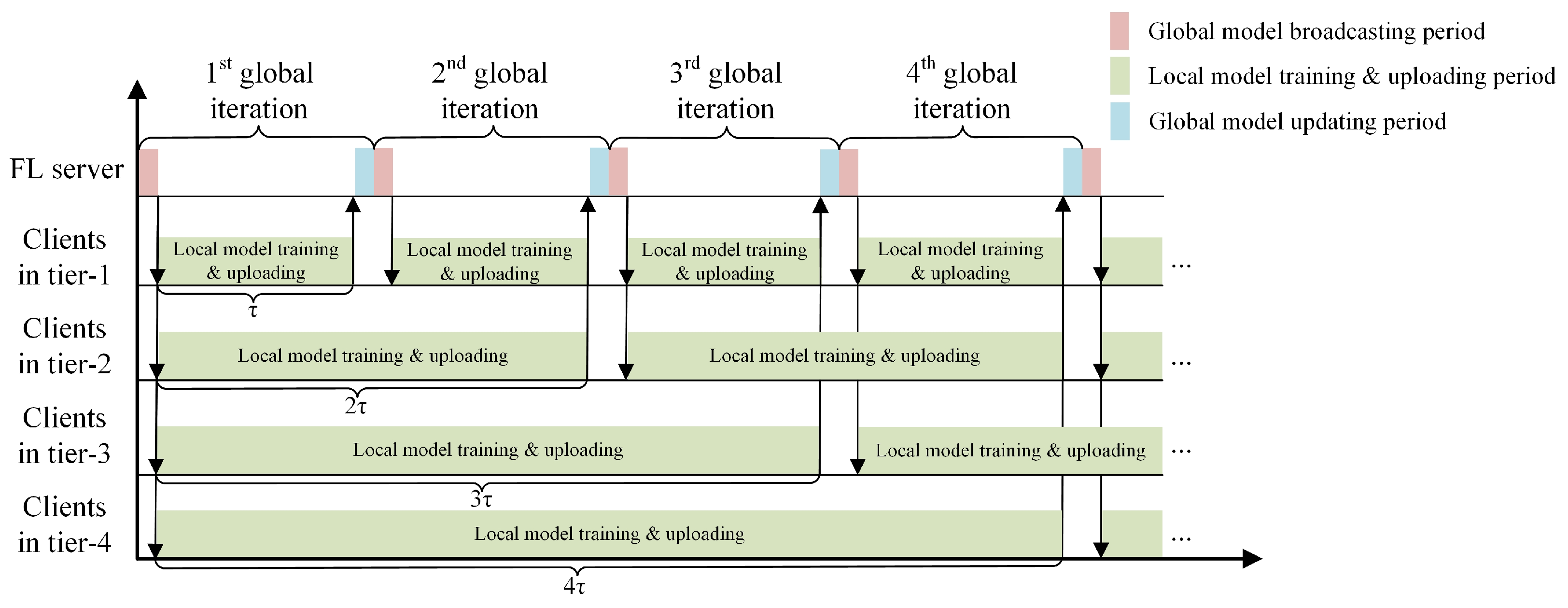
4.1. Latency-Aware Client Clustering
4.2. Semi-Synchronized Model Aggregation
4.3. Summary of LESSON
| Algorithm 1: LESSON algorithm |
 |
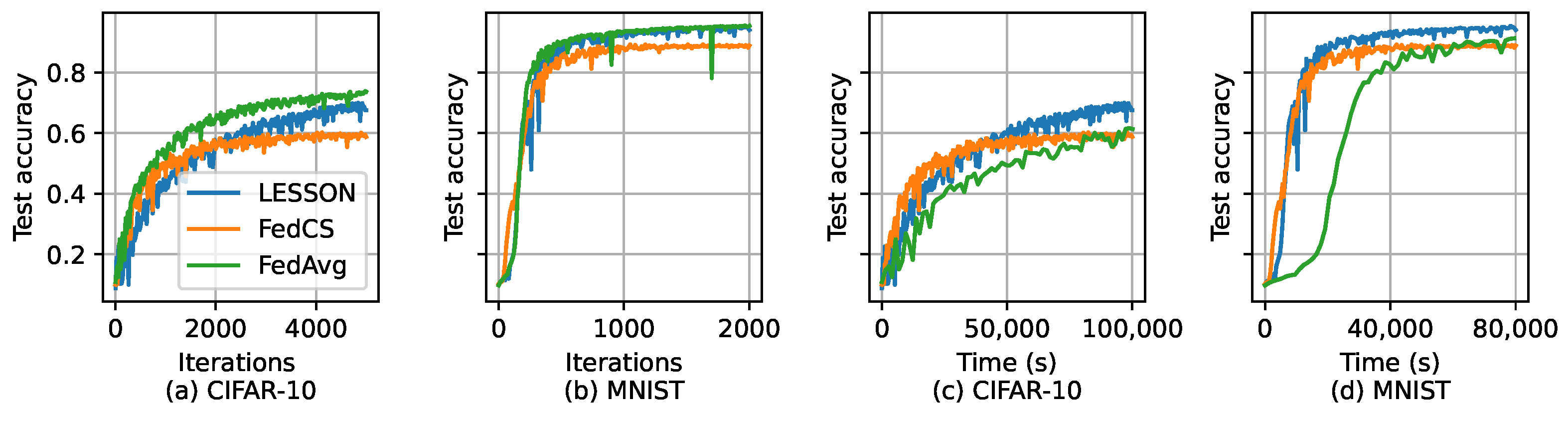
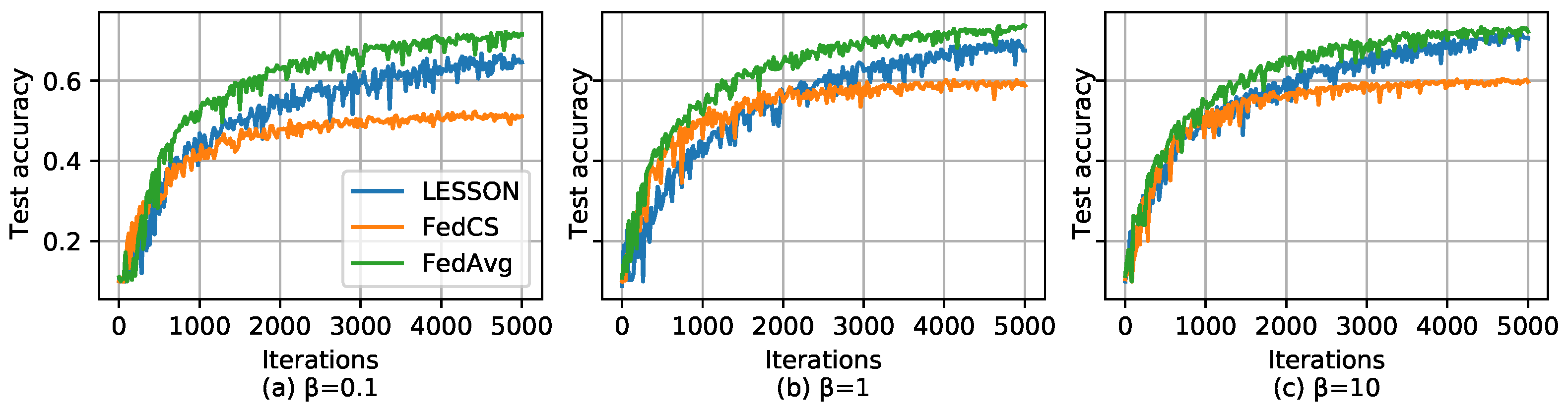
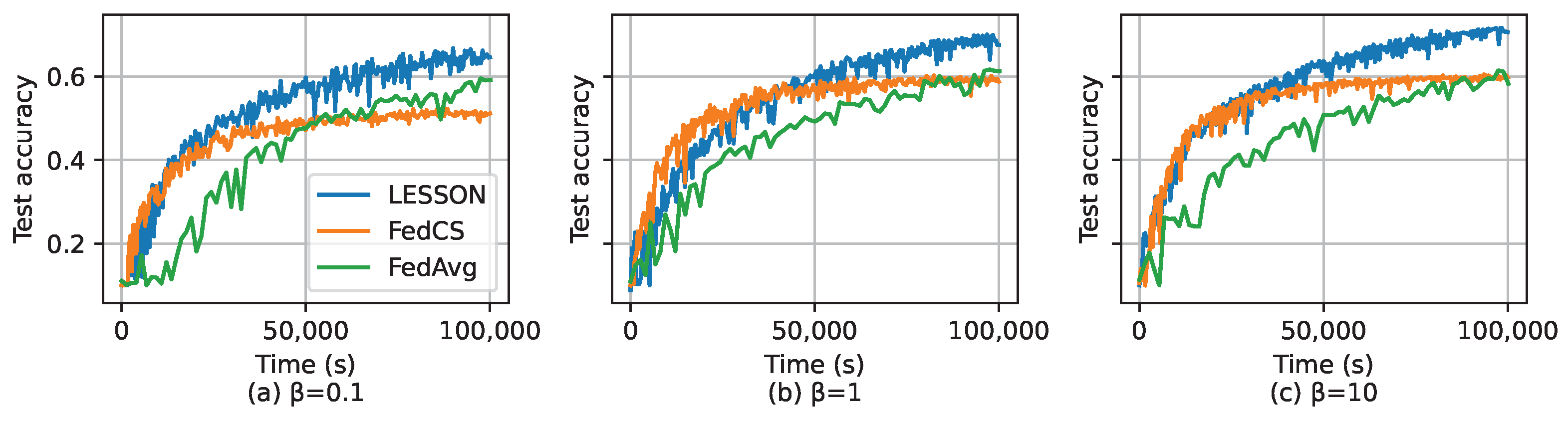
5. Simulation
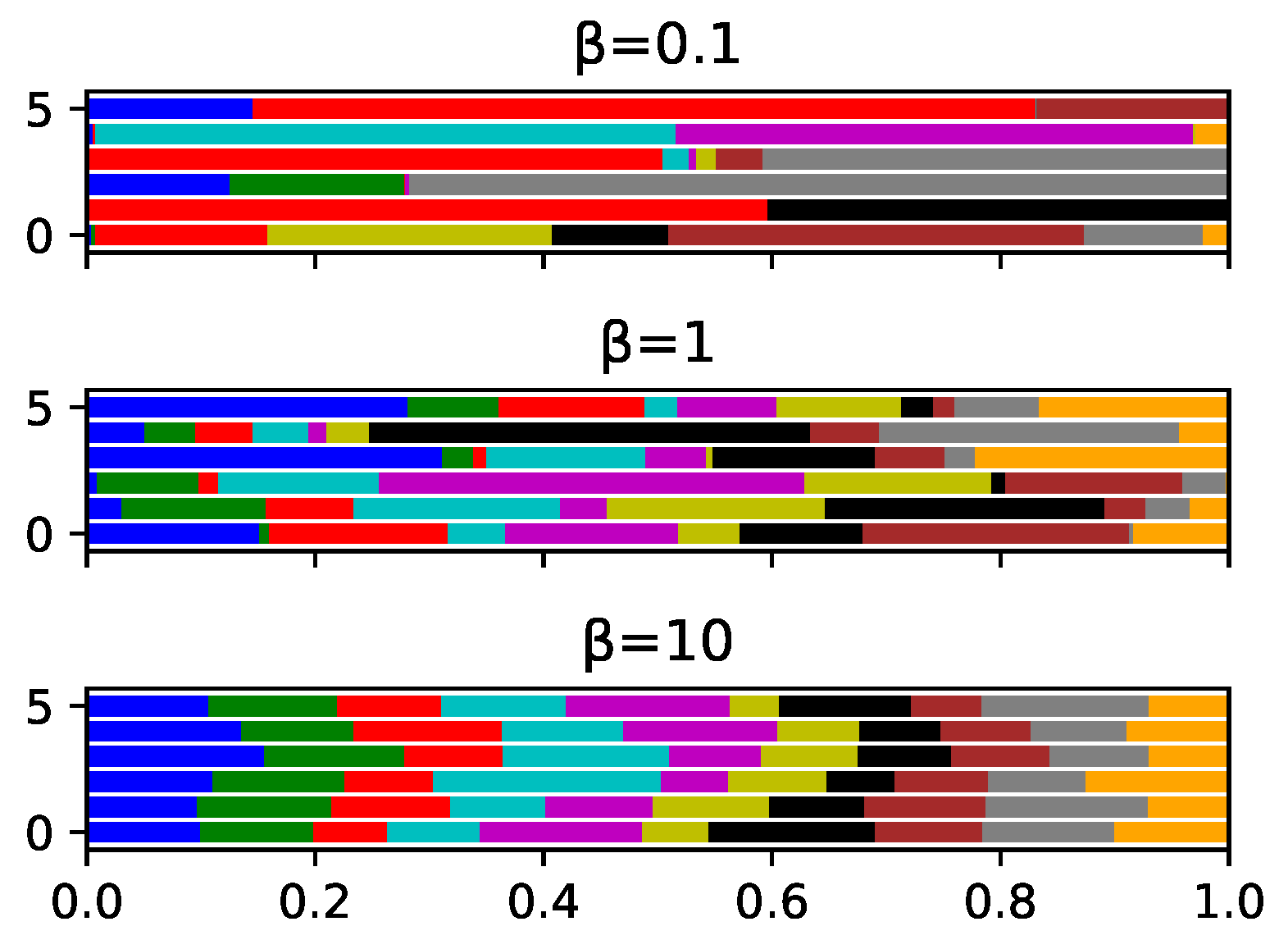
5.1. Simulation Setup
5.1.1. Configuration of Clients
5.1.2. Machine-Learning Model and Training Datasets
- CIFAR-10 [36] is an image classification dataset containing 10 labels/classes of images, each of which has 6000 images. Among the 60,000 images, 50,000 are used for model training and 10,000 for model testing.
- MNIST [37] is a handwritten digit dataset that includes many pixel grayscale images of handwritten single digits between 0 and 9. The whole dataset has a training set of 60,000 examples and a test set of 10,000 examples.
5.1.3. Baseline Comparison Methods
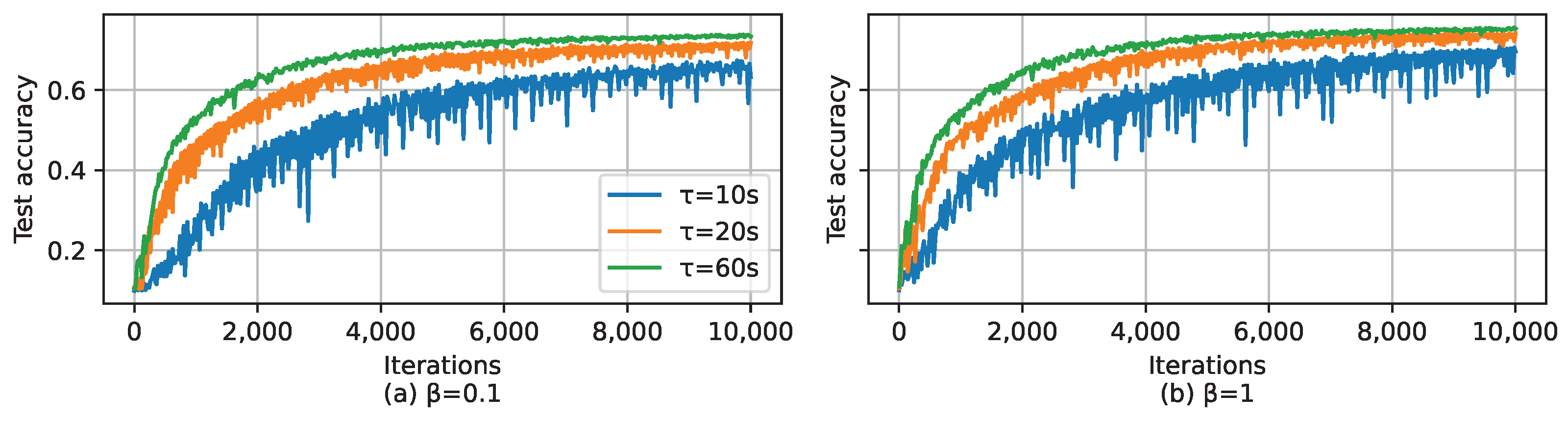
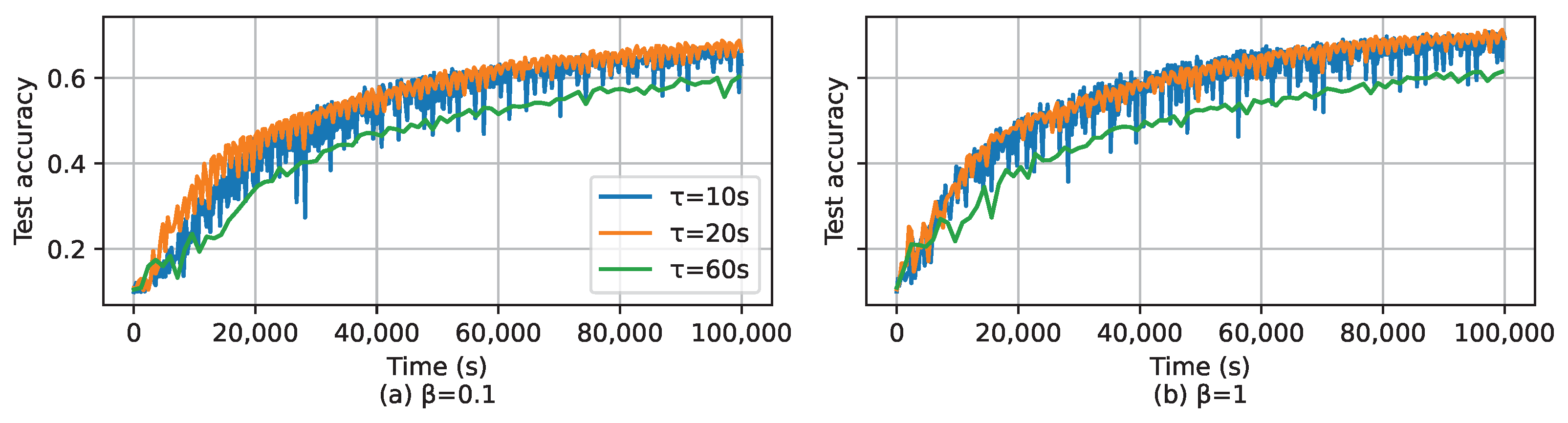
5.2. Simulation Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, X.; Ansari, N. EdgeIoT: Mobile Edge Computing for the Internet of Things. IEEE Commun. Mag. 2016, 54, 22–29. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Jiang, L.; Xie, S.; Zhang, Y. Intelligent Edge Computing for IoT-Based Energy Management in Smart Cities. IEEE Netw. 2019, 33, 111–117. [Google Scholar] [CrossRef]
- Dhanvijay, M.M.; Patil, S.C. Internet of Things: A survey of enabling technologies in healthcare and its applications. Comput. Netw. 2019, 153, 113–131. [Google Scholar] [CrossRef]
- Goddard, M. The EU General Data Protection Regulation (GDPR): European regulation that has a global impact. Int. J. Mark. Res. 2017, 59, 703–705. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 20–22 April 2017; PMLR: Cambridge, MA, USA, 2017; pp. 1273–1282. [Google Scholar]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- Imteaj, A.; Amini, M.H. Fedar: Activity and resource-aware federated learning model for distributed mobile robots. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 1153–1160. [Google Scholar]
- Wu, W.; He, L.; Lin, W.; Mao, R.; Maple, C.; Jarvis, S. SAFA: A semi-asynchronous protocol for fast federated learning with low overhead. IEEE Trans. Comput. 2020, 70, 655–668. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Tziotis, I.; Hassani, H.; Mokhtari, A.; Pedarsani, R. Straggler-resilient federated learning: Leveraging the interplay between statistical accuracy and system heterogeneity. arXiv 2020, arXiv:2012.14453. [Google Scholar] [CrossRef]
- Xu, Z.; Yang, Z.; Xiong, J.; Yang, J.; Chen, X. Elfish: Resource-aware federated learning on heterogeneous edge devices. Ratio 2019, 2, r2. [Google Scholar]
- Albelaihi, R.; Sun, X.; Craft, W.D.; Yu, L.; Wang, C. Adaptive Participant Selection in Heterogeneous Federated Learning. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Tang, T.; Ali, R.E.; Hashemi, H.; Gangwani, T.; Avestimehr, S.; Annavaram, M. Adaptive Verifiable Coded Computing: Towards Fast, Secure and Private Distributed Machine Learning. In Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Lyon, France, 30 May–3 June 2022; pp. 628–638. [Google Scholar] [CrossRef]
- Wang, J.; Joshi, G. Cooperative SGD: A unified framework for the design and analysis of communication-efficient SGD algorithms. arXiv 2018, arXiv:1808.07576. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Lin, K.Y. A survey on federated learning. In Proceedings of the 2020 IEEE 16th International Conference on Control & Automation (ICCA), Singapore, 9–11 October 2020; pp. 791–796. [Google Scholar]
- Xu, C.; Qu, Y.; Xiang, Y.; Gao, L. Asynchronous federated learning on heterogeneous devices: A survey. arXiv 2021, arXiv:2109.04269. [Google Scholar] [CrossRef]
- Damaskinos, G.; Guerraoui, R.; Kermarrec, A.M.; Nitu, V.; Patra, R.; Taiani, F. FLeet: Online Federated Learning via Staleness Awareness and Performance Prediction. In Proceedings of the 21st International Middleware Conference, Delft, The Netherlands, 7–11 December 2020; Association for Computing Machinery: New York, NY, USA, 2020. Middleware ’20. pp. 163–177. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge. In Proceedings of the 2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Abdulrahman, S.; Tout, H.; Mourad, A.; Talhi, C. FedMCCS: Multicriteria Client Selection Model for Optimal IoT Federated Learning. IEEE Internet Things J. 2021, 8, 4723–4735. [Google Scholar] [CrossRef]
- Yu, L.; Albelaihi, R.; Sun, X.; Ansari, N.; Devetsikiotis, M. Jointly Optimizing Client Selection and Resource Management in Wireless Federated Learning for Internet of Things. IEEE Internet Things J. 2022, 9, 4385–4395. [Google Scholar] [CrossRef]
- Shi, W.; Zhou, S.; Niu, Z. Device Scheduling with Fast Convergence for Wireless Federated Learning. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Networks. In Proceedings of the Machine Learning and Systems. Dhillon, I., Papailiopoulos, D., Sze, V., Eds.; 2020, Volume 2, pp. 429–450. Available online: https://proceedings.mlsys.org/paper_files/paper/2020/hash/1f5fe83998a09396ebe6477d9475ba0c-Abstract.html (accessed on 29 September 2023).
- Wu, D.; Ullah, R.; Harvey, P.; Kilpatrick, P.; Spence, I.; Varghese, B. Fedadapt: Adaptive offloading for iot devices in federated learning. arXiv 2021, arXiv:2107.04271. [Google Scholar] [CrossRef]
- Chen, Y.; Ning, Y.; Slawski, M.; Rangwala, H. Asynchronous online federated learning for edge devices with non-iid data. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 15–24. [Google Scholar]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Differentially private asynchronous federated learning for mobile edge computing in urban informatics. IEEE Trans. Ind. Inform. 2019, 16, 2134–2143. [Google Scholar] [CrossRef]
- Gu, B.; Xu, A.; Huo, Z.; Deng, C.; Huang, H. Privacy-preserving asynchronous federated learning algorithms for multi-party vertically collaborative learning. arXiv 2020, arXiv:2008.06233. [Google Scholar]
- Lian, X.; Zhang, W.; Zhang, C.; Liu, J. Asynchronous decentralized parallel stochastic gradient descent. In Proceedings of the International Conference on Machine Learning, Macau, China, 26–28 February 2018; PMLR: Cambridge, MA, USA, 2018; pp. 3043–3052. [Google Scholar]
- Chai, Z.; Chen, Y.; Zhao, L.; Cheng, Y.; Rangwala, H. Fedat: A communication-efficient federated learning method with asynchronous tiers under non-iid data. arXiv 2020, arXiv:2010.05958. [Google Scholar]
- Feyzmahdavian, H.R.; Aytekin, A.; Johansson, M. A delayed proximal gradient method with linear convergence rate. In Proceedings of the 2014 IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Reims, France, 21–24 September 2014; pp. 1–6. [Google Scholar]
- Jiang, J.; Cui, B.; Zhang, C.; Yu, L. Heterogeneity-Aware Distributed Parameter Servers. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; Association for Computing Machinery: New York, NY, USA, 2017. SIGMOD ’17. pp. 463–478. [Google Scholar] [CrossRef]
- Zhang, W.; Gupta, S.; Lian, X.; Liu, J. Staleness-Aware Async-SGD for Distributed Deep Learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; AAAI Press: Washington, DC, USA, 2016. IJCAI’16. pp. 2350–2356. Available online: https://arxiv.org/abs/1511.05950 (accessed on 29 September 2023).
- Stripelis, D.; Ambite, J.L. Semi-synchronous federated learning. arXiv 2021, arXiv:2102.02849. [Google Scholar]
- Hao, J.; Zhao, Y.; Zhang, J. Time efficient federated learning with semi-asynchronous communication. In Proceedings of the 2020 IEEE 26th International Conference on Parallel and Distributed Systems (ICPADS), Hong Kong, China, 2–4 December 2020; pp. 156–163. [Google Scholar]
- Yang, Z.; Chen, M.; Saad, W.; Hong, C.S.; Shikh-Bahaei, M.; Poor, H.V.; Cui, S. Delay Minimization for Federated Learning Over Wireless Communication Networks. arXiv 2020, arXiv:2007.03462. [Google Scholar]
- ETSI. Radio Frequency (RF) Requirements for LTE Pico Node B (3GPP TR 36.931 Version 9.0.0 Release 9). 2011, Number ETSI TR 136 931 V9.0.0. LTE; Evolved Universal Terrestrial Radio Access (E-UTRA). Available online: https://www.etsi.org/deliver/etsi_tr/136900_136999/136931/09.00.00_60/tr_136931v090000p.pdf (accessed on 29 September 2023).
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 29 September 2023).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Li, Q.; Diao, Y.; Chen, Q.; He, B. Federated learning on non-iid data silos: An experimental study. arXiv 2021, arXiv:2102.02079. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Pierre, J.E.; Sun, X.; Fierro, R. Multi-Agent Partial Observable Safe Reinforcement Learning for Counter Uncrewed Aerial Systems. IEEE Access 2023, 11, 78192–78206. [Google Scholar] [CrossRef]
- Salimi, M.; Pasquier, P. Deep Reinforcement Learning for Flocking Control of UAVs in Complex Environments. In Proceedings of the 2021 6th International Conference on Robotics and Automation Engineering (ICRAE), Guangzhou, China, 19–22 November 2021; pp. 344–352. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Noise and inter-cell interference () | dBm |
| Bandwidth B | 30 kHz |
| Transmission power | 0.1 watt |
| Size of the local model (s) | 100 kbit |
| Number of local iterations | |
| Number of local samples | 1000 |
| CPU cycles required for training one data sample | |
| CPU frequency | GHz |
| Number of local epochs | 1 |
| Number of local batch size | 20 |
| Non-IID Dirichlet distribution parameter | |
| Client Learning Rate |
| Algorithms | Average Latency of a Global Iteration |
|---|---|
| FedAvg | 68 s |
| FedCS | 20 s |
| LESSON | 20 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Sun, X.; Albelaihi, R.; Yi, C. Latency-Aware Semi-Synchronous Client Selection and Model Aggregation for Wireless Federated Learning. Future Internet 2023, 15, 352. https://doi.org/10.3390/fi15110352
Yu L, Sun X, Albelaihi R, Yi C. Latency-Aware Semi-Synchronous Client Selection and Model Aggregation for Wireless Federated Learning. Future Internet. 2023; 15(11):352. https://doi.org/10.3390/fi15110352
Chicago/Turabian StyleYu, Liangkun, Xiang Sun, Rana Albelaihi, and Chen Yi. 2023. "Latency-Aware Semi-Synchronous Client Selection and Model Aggregation for Wireless Federated Learning" Future Internet 15, no. 11: 352. https://doi.org/10.3390/fi15110352
APA StyleYu, L., Sun, X., Albelaihi, R., & Yi, C. (2023). Latency-Aware Semi-Synchronous Client Selection and Model Aggregation for Wireless Federated Learning. Future Internet, 15(11), 352. https://doi.org/10.3390/fi15110352