


Exploring Homomorphic Encryption and Differential Privacy Techniques towards Secure Federated Learning Paradigm



Abstract
:1. Introduction
1.1. Background
1.2. Motivation
1.3. Contribution
- We scrutinize the array of research addressing privacy-related attacks in federated learning (FL), demonstrating the practicality and real-world relevance of these threats, highlighting their potential implications in distributed learning environments. Our primary focus lies on privacy attacks, where we delve into various techniques that adversaries can employ to compromise the privacy and security of FL systems.
- We delve into the role of differential privacy (DP) in FL, detailing its deployment across various settings: central differential privacy (CDP), local differential privacy (LDP), and the shuffle model. By providing a comprehensive analysis of these DP deployment settings, we offer insights into the strengths, limitations, and practical implications of each approach.
- We investigate the application of homomorphic encryption (HE) as a powerful tool to enhance privacy within FL. Our primary focus is on countering privacy attacks and safeguarding sensitive data during the collaborative learning process. Through our investigation, we provide valuable insights into the capabilities and limitations of homomorphic encryption in FL.
- We examine the body of research that explores the fusion of homomorphic encryption (HE) and differential privacy (DP) in the context of federated learning (FL). Our primary objective is to shed light on the motivations behind such integrations and understand the potential benefits they offer in enhancing privacy and security in distributed learning environments.
2. Preliminaries
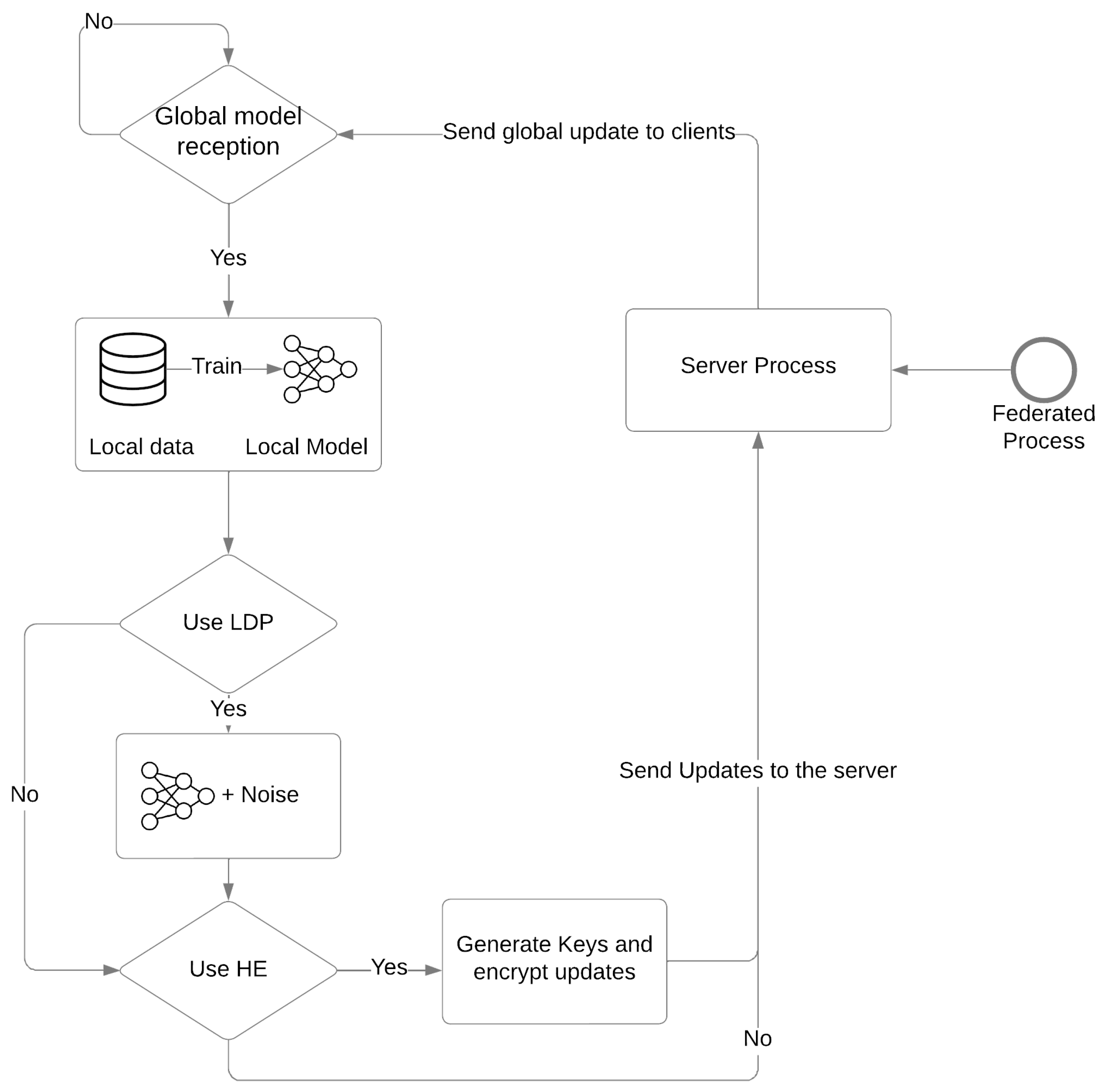
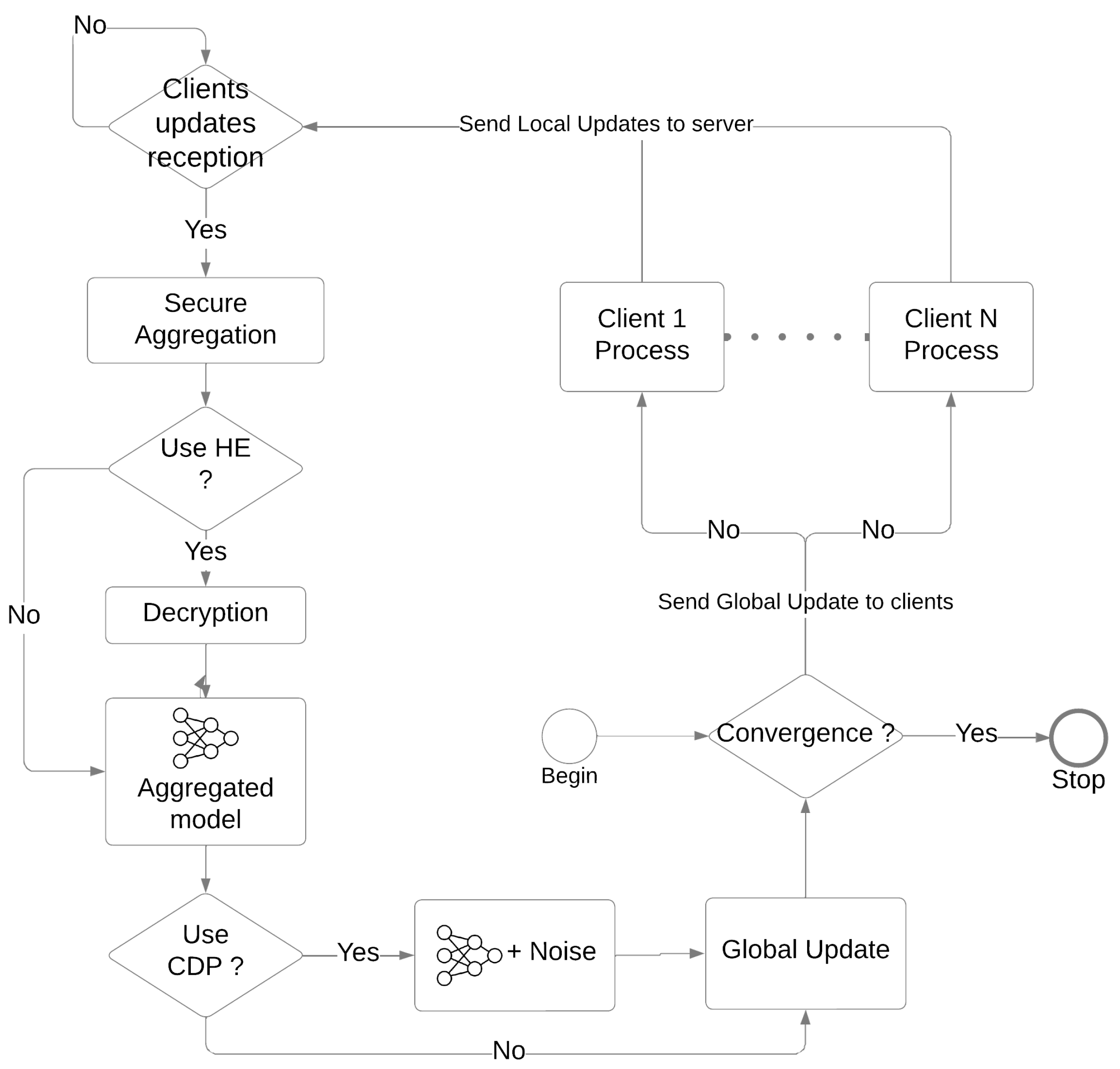
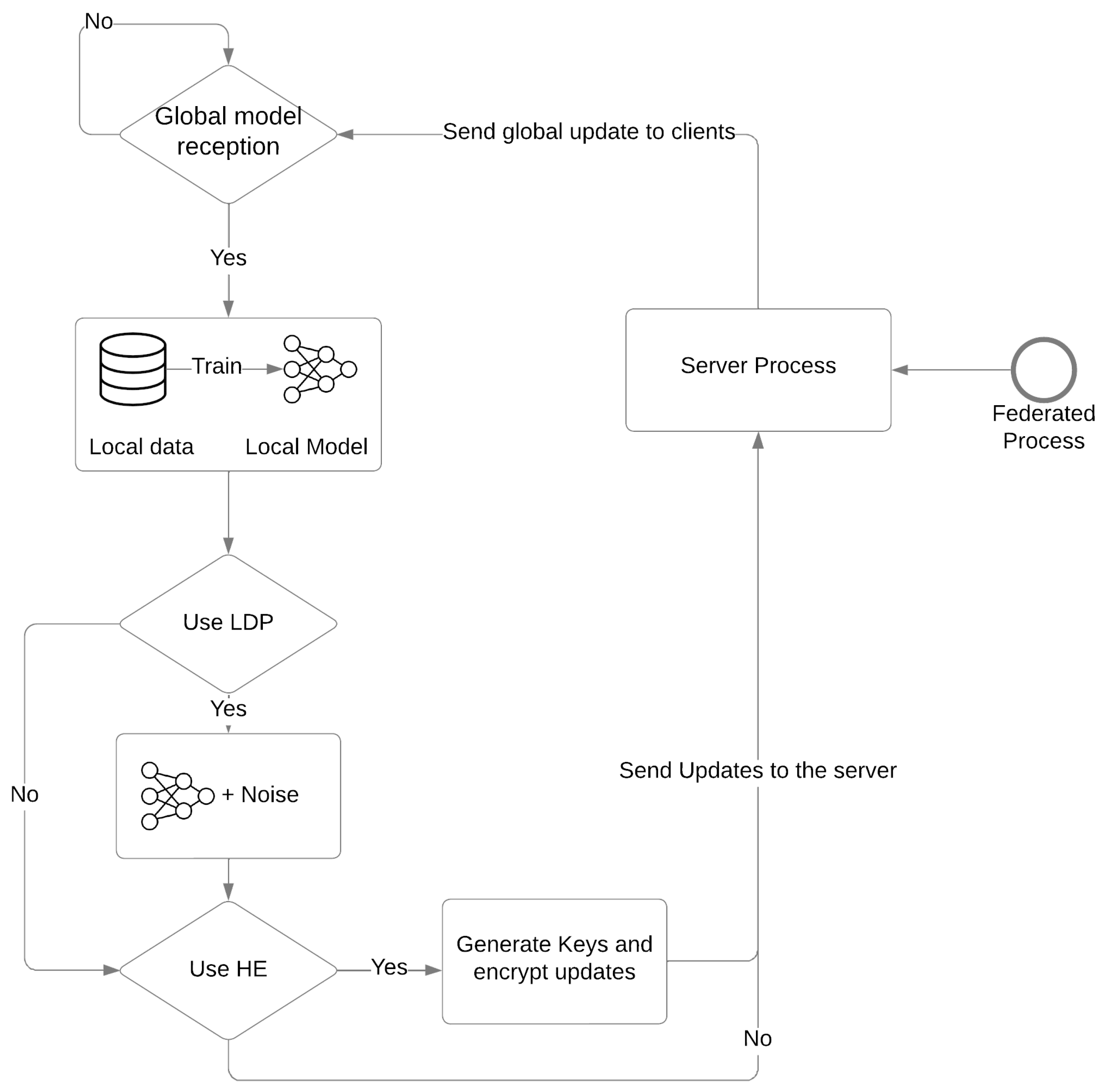
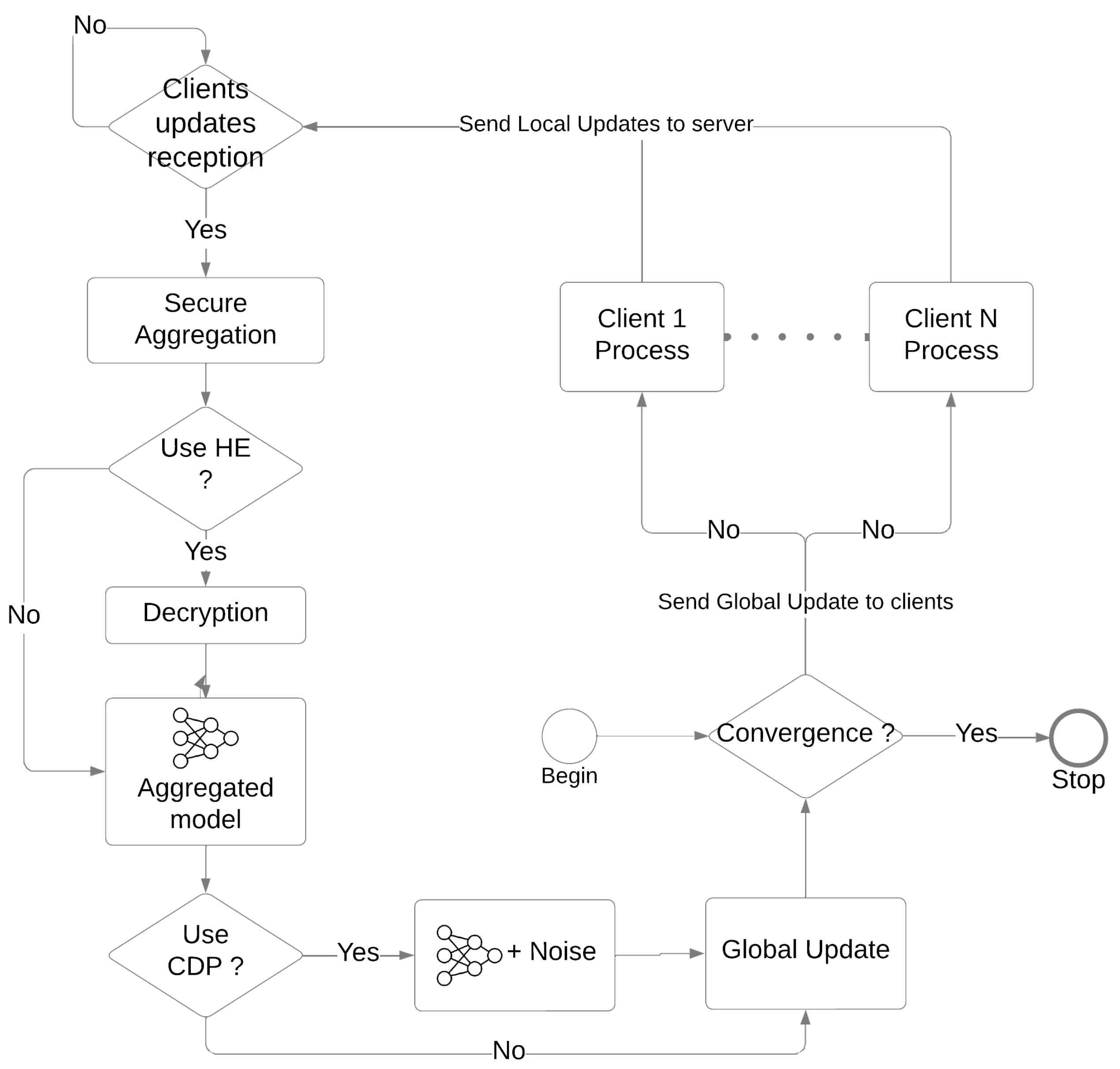
2.1. Federated Learning
2.2. Differential Privacy
- Composition: offers a way to bound privacy cost of answering multiple queries on the same data.
- Post-processing: ensures that the privacy guarantees of a differential privacy mechanism remain unchanged even if the output is further processed or analyzed.
- Group privacy: this definition can be extended to group privacy by considering two datasets differing on at most k records instead of 1 record.
2.3. Homomorphic Encryption
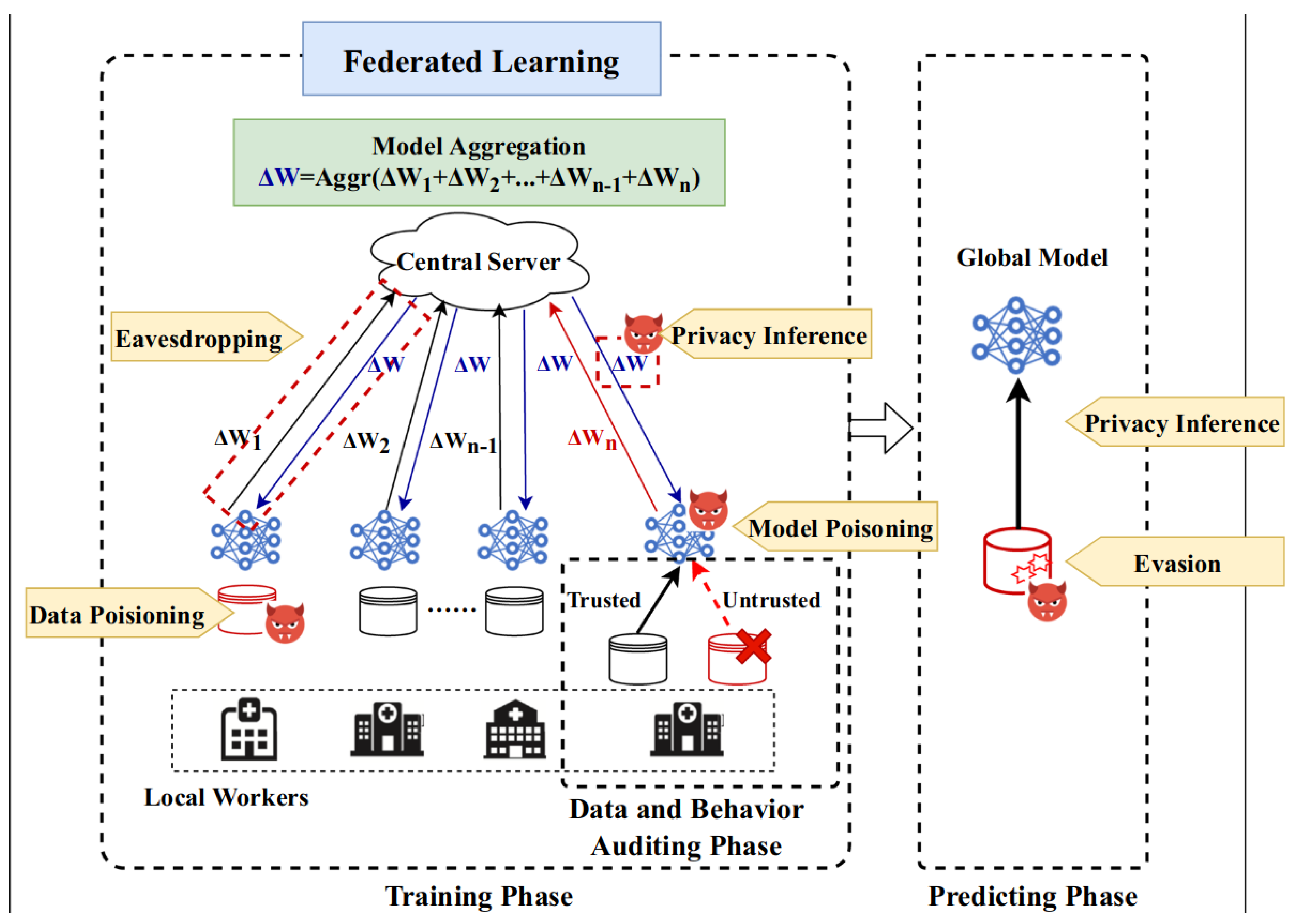
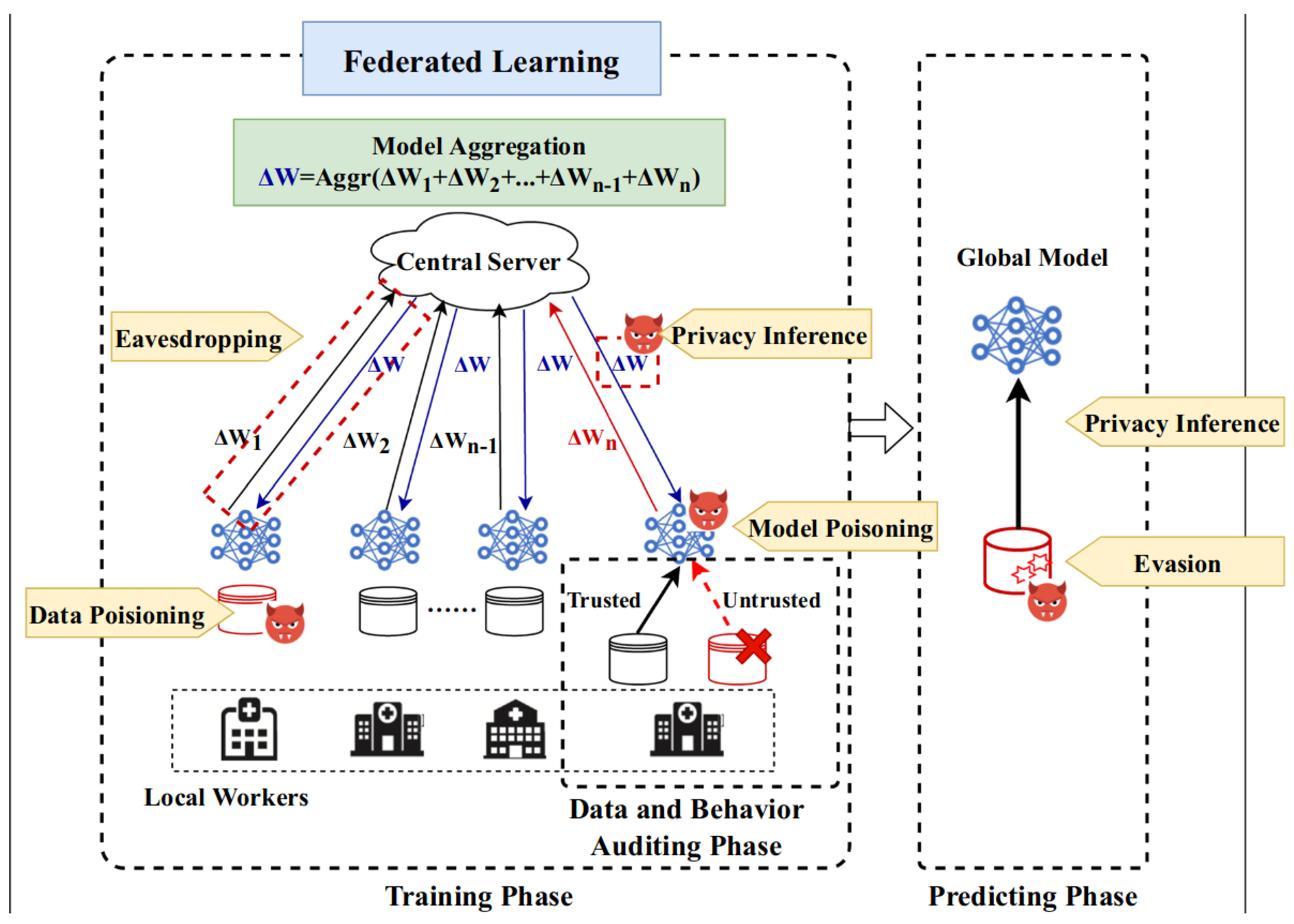
3. Privacy Attacks in FL
3.1. Membership Inference
3.2. Class Representatives Inference
3.3. Properties Inference
3.4. Training Samples and Labels Inference

{kind=link}
{kind=link}
{kind=link}
| Ref | Year | Assumption | Goal | Exploit | |
|---|---|---|---|---|---|
| Adversary | Active/Passive | ||||
| [41] | 2017 | Client | Active | Class representative inference | Influencing the learning process. |
| [39] | 2018 | Server | Active | Class representative inference | Influencing the learning process. |
| [37] | 2019 | Client | Active/Passive | Membership inference | Vulnerabilities of the SGD algorithm. |
| [38] | 2022 | Client/Server | Passive | Membership inference | Prediction confidence series. |
| [43] | 2018 | Client | Passive | Properties inference | Global model updates. |
| [44] | 2018 | Client | Passive | Global Properties inference | Shared gradients. |
| [4] | 2019 | Server | Passive | Training data inference | Shared gradients. |
| [5] | 2020 | Server | Passive | Training data inference | Shared gradients and their signs. |
| [6] | 2020 | Server | Passive | Training data inference | Shared Gradients and Cosine similarity. |
| [46] | 2021 | Server | Passive | batch data recovery | Gradient inversion. |
| [9] | 2021 | Server | Passive | Large batch data recovery | Shared aggregated gradients. |
| [7] | 2022 | Server | Passive | Training image recovery | Shared gradients. |
4. Federated Learning with Differential Privacy
4.1. Role of DP in FL
- Protecting individual participant’s data: DP achieves this by adding noise to the shared updates, thereby hiding the contributions of each individual in the FL process.
- Protecting data against membership inference and reconstructions attacks: DP is known to be robust to this type of attacks.
- Encouraging the user to participate in the learning process: DP provides strong privacy guarantees to the user by offering plausible deniability for them.
- Facilitating compliance with regulations: DP offers a way for companies to comply with the requirements of various data protection regulations, such as the General Data Protection Regulation (GDPR).
4.2. Related Works
| Ref | Year | DP Type | Key Idea | Trade-offs and Shortcomings |
|---|---|---|---|---|
| [47] | 2017 | CDP | Adding Gaussian noise by the server before global aggregation. | Increased computation cost and poor performance in non-IID setting |
| [49] | 2017 | CDP | Same as [47], but using subsampling of clients and clipping before sending updates. | The number of clients has a major impact on the accuracy of the model. |
| [50] | 2019 | CDP | Adding noise to the objective function instead of the updates. | Poor performance for healthcare applications |
| [51] | 2020 | CDP | Training a personalized model for each client using local data and the shared updates from other clients (Protected using DP). | Increased computation and communication cost |
| [52] | 2019 | LDP | Protecting local update from server using DP in the client side and protect global updates from clients using DP in the server side. | Increased computation cost |
| [61] | 2020 | LDP | Reducing noise injection by selecting the top k important dimension, then applying LDP. | Increased computation cost |
| [54] | 2021 | LDP | Adding adaptive noise to the model parameters using a deep neural network. | Increased computation cost |
| [55] | 2021 | LDP | Same as [54], but using adaptive range setting for weights and adding a shuffling step to amplify privacy | Increased computation cost |
| [56] | 2022 | LDP | Using the randomized response mechanism instead of the Gaussian and Laplacian mechanism. | Increased computation cost |
| [57] | 2023 | LDP | Using personalized privacy budget according to clients’ requirements | The privacy budget is the same for all attributes. |
| [60] | 2021 | Shuffle | Amplifying privacy by self-sampling and shuffling. Real participants are unknown to the server. | Increased system complexity. |
4.3. Discussion and Learned Lessons
5. Federated Learning with Homomorphic Encryption
5.1. Role of HE in FL
5.2. Related Works
| Ref | Year | Scheme | Key Idea | Trade-offs and Shortcomings |
|---|---|---|---|---|
| [63] | 2020 | Additive | Propose a batch additive scheme to reduce communication and computation overhead. | Batchcrypt is not applicable in Vertical FL. |
| [64] | 2021 | Additive | Hide shared gradients from from the server to protect against membership inference attack. | Scalability issue, computational and communication overhead |
| [66] | 2021 | Additive | Reduce the number of gradients to be encrypted by filtering insignificant gradients. | Scalability issues, computational and communication overhead |
| [67] | 2022 | Additive | Use a doubly homomorphic secure aggregation by using homomorphic encryption and masking technique. | Computational and communication overhead |
| [68] | 2022 | Additive | Additionally to previous work, protect the dataset size by adding interactions between clients using homomorphic encryption. | Computational and communication overhead |
| [69] | 2023 | Additive | Encrypting only a part of the model instead of the whole model. They showed that encrypting just 10% of the model parameter using a robust selection mechanism is efficient to counter DLG attack. | Need for theoretical analysis of the trade-offs among privacy guarantee, system overheads and model performance. |
5.3. Discussion and Learned Lessons
6. Combining DP and HE in Federated Learning
6.1. Related Works
| Ref | Year | Key Idea | Trade-offs and Shortcomings |
|---|---|---|---|
| [70] | 2019 | Add less noise by amplifying privacy by homomorphic encryption | Trade-off between privacy, communication, and computation. |
| [71] | 2020 | Amplify privacy with the shuffle model and protect data against collision attacks using Encrypted oblivious shuffle. | Increased system complexity. |
| [73] | 2021 | Split the updates into two shares and send them to two non-colluding servers that add CDP and use additive secret sharing to mitigate poisoning attacks and conduct secure aggregation. | Increased system complexity. |
| [74] | 2022 | Protect updates from the server using homomorphic encryption and protect global updates from clients using DP | Computational overhead. |
6.2. Discussion and Learned Lessons
7. Discussion
Ongoing Research
8. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AHE | Additive Homomorphic Encryption |
| CDP | Centralized Differential Privacy |
| CNN | Convolutional Neural Network |
| DLG | Deep Leakage from Gradients |
| DNN | Deep Neural Network |
| DP | Differential Privacy |
| FC | Fully Connected |
| FCN | Fully Connected Network |
| FCNN | Fully connected neural network |
| FHE | Fully Homomorphic Encryption |
| FL | Federated Learning |
| GAN | Generative Adversial Network |
| GDPR | General Data Protection Regulation |
| GRNN | Generative Regression Neural Network |
| HE | Homomorphic Encryption |
| HFL | Horizontal Federated Learning |
| LDP | Local Differential Privacy |
| MIA | Membership Inference Attack |
| ML | Machine Learning |
| PCS | Prediction Confidence series |
| PHE | Partially Homomorphic Encryption |
| SGD | Stochastic Gradient Descent |
| SWHE | Somewhat Homomorphic Encryption |
| VFL | Vertical Federated Learning |
References
- Gartner. Gartner Identifies Top Five Trends in Privacy Through 2024. Available online: https://www.gartner.com/en/newsroom/press-releases/2022-05-31-gartner-identifies-top-five-trends-in-privacy-through-2024 (accessed on 1 June 2023).
- European Commission. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance). Off. J. Eur. Union 2016, 4, 1–88. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Zhu, L.; Liu, Z.; Han, S. Deep Leakage from Gradients. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Zhao, B.; Mopuri, K.R.; Bilen, H. idlg: Improved deep leakage from gradients. arXiv 2020, arXiv:2001.02610. [Google Scholar]
- Geiping, J.; Bauermeister, H.; Dröge, H.; Moeller, M. Inverting Gradients—How easy is it to break privacy in federated learning? In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 16937–16947. [Google Scholar]
- Ren, H.; Deng, J.; Xie, X. GRNN: Generative Regression Neural Network—A Data Leakage Attack for Federated Learning. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–24. [Google Scholar] [CrossRef]
- Wei, W.; Liu, L.; Loper, M.; Chow, K.H.; Gursoy, M.E.; Truex, S.; Wu, Y. A Framework for Evaluating Client Privacy Leakages in Federated Learning. In Proceedings of the Computer Security—ESORICS 2020; Chen, L., Li, N., Liang, K., Schneider, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 545–566. [Google Scholar]
- Jin, X.; Chen, P.Y.; Hsu, C.Y.; Yu, C.M.; Chen, T. CAFE: Catastrophic Data Leakage in Vertical Federated Learning. In Proceedings of the Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 994–1006. [Google Scholar]
- Zhang, J.; Zhang, J.; Chen, J.; Yu, S. GAN Enhanced Membership Inference: A Passive Local Attack in Federated Learning. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mao, Y.; Zhu, X.; Zheng, W.; Yuan, D.; Ma, J. A Novel User Membership Leakage Attack in Collaborative Deep Learning. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP), Shaanxi, China, 23–25 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, J.; Zhao, Y.; Han, H.; Zhu, K.; Chen, B. Beyond Model-Level Membership Privacy Leakage: An Adversarial Approach in Federated Learning. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Wang, L.; Xu, S.; Wang, X.; Zhu, Q. Eavesdrop the composition proportion of training labels in federated learning. arXiv 2019, arXiv:1910.06044. [Google Scholar]
- Zhang, W.; Tople, S.; Ohrimenko, O. Leakage of Dataset Properties in Multi-Party Machine Learning. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Vancouver, BC, Canada, 11–13 August 2021; pp. 2687–2704. [Google Scholar]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. IEEE Trans. Knowl. Data Eng. 2023, 35, 3347–3366. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. arXiv 2021, arXiv:1912.04977. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Yang, Q. Threats to Federated Learning: A Survey. arXiv 2020, arXiv:2003.02133. [Google Scholar]
- Rodríguez-Barroso, N.; Jiménez-López, D.; Luzón, M.V.; Herrera, F.; Martínez-Cámara, E. Survey on federated learning threats: Concepts, taxonomy on attacks and defences, experimental study and challenges. Inf. Fusion 2023, 90, 148–173. [Google Scholar] [CrossRef]
- Zhang, K.; Song, X.; Zhang, C.; Yu, S. Challenges and future directions of secure federated learning: A survey. Front. Comput. Sci. 2021, 16, 165817. [Google Scholar] [CrossRef]
- Li, Z.; Sharma, V.; Mohanty, S.P. Preserving Data Privacy via Federated Learning: Challenges and Solutions. IEEE Consum. Electron. Mag. 2020, 9, 8–16. [Google Scholar] [CrossRef]
- Yin, X.; Zhu, Y.; Hu, J. A Comprehensive Survey of Privacy-Preserving Federated Learning: A Taxonomy, Review, and Future Directions. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Kaissis, G.A.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, privacy-preserving and federated machine learning in medical imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Gu, X.; Sabrina, F.; Fan, Z.; Sohail, S. A Review of Privacy Enhancement Methods for Federated Learning in Healthcare Systems. Int. J. Environ. Res. Public Health 2023, 20, 6539. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Niknam, S.; Dhillon, H.S.; Reed, J.H. Federated Learning for Wireless Communications: Motivation, Opportunities and Challenges. arXiv 2020, arXiv:1908.06847. [Google Scholar] [CrossRef]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our Data, Ourselves: Privacy Via Distributed Noise Generation. In Proceedings of the Advances in Cryptology—EUROCRYPT 2006; Vaudenay, S., Ed.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 486–503. [Google Scholar]
- Albrecht, M.; Chase, M.; Chen, H.; Ding, J.; Goldwasser, S.; Gorbunov, S.; Halevi, S.; Hoffstein, J.; Laine, K.; Lauter, K.; et al. Homomorphic Encryption Security Standard; Technical Report; HomomorphicEncryption.org: Toronto, ON, Canada, 2018. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the Advances in Cryptology—EUROCRYPT’99: International Conference on the Theory and Application of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Gentry, C. Fully Homomorphic Encryption Using Ideal Lattices. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; Association for Computing Machinery: New York, NY, USA; pp. 169–178. [CrossRef]
- Liu, P.; Xu, X.; Wang, W. Threats, attacks and defenses to federated learning: Issues, taxonomy and perspectives. Cybersecurity 2022, 5, 4. [Google Scholar] [CrossRef]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks against Machine Learning Models. arXiv 2017, arXiv:1610.05820. [Google Scholar]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. In Proceedings of the 2019 Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar] [CrossRef]
- Pustozerova, A.; Mayer, R. Information Leaks in Federated Learning. In Proceedings of the 2020 Workshop on Decentralized IoT Systems and Security, San Diego, CA, USA, 23 February 2020. [Google Scholar] [CrossRef]
- Hu, H.; Salcic, Z.; Sun, L.; Dobbie, G.; Zhang, X. Source Inference Attacks in Federated Learning. arXiv 2021, arXiv:2109.05659. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), Francisco, CA, USA, 20–22 May 2019; pp. 739–753. [Google Scholar] [CrossRef]
- Gu, Y.; Bai, Y.; Xu, S. CS-MIA: Membership inference attack based on prediction confidence series in federated learning. J. Inf. Secur. Appl. 2022, 67, 103201. [Google Scholar] [CrossRef]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond Inferring Class Representatives: User-Level Privacy Leakage From Federated Learning. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2512–2520. [Google Scholar] [CrossRef]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar] [CrossRef]
- Hitaj, B.; Ateniese, G.; Perez-Cruz, F. Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; CCS ’17. pp. 603–618. [Google Scholar] [CrossRef]
- Ateniese, G.; Mancini, L.V.; Spognardi, A.; Villani, A.; Vitali, D.; Felici, G. Hacking Smart Machines with Smarter Ones: How to Extract Meaningful Data from Machine Learning Classifiers. Int. J. Secur. Netw. 2015, 10, 137–150. [Google Scholar] [CrossRef]
- Melis, L.; Song, C.; Cristofaro, E.D.; Shmatikov, V. Exploiting Unintended Feature Leakage in Collaborative Learning. arXiv 2018, arXiv:cs.CR/1805.04049. [Google Scholar]
- Ganju, K.; Wang, Q.; Yang, W.; Gunter, C.A.; Borisov, N. Property Inference Attacks on Fully Connected Neural Networks Using Permutation Invariant Representations. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 15–19 October 2018; Association for Computing Machinery: New York, NY, USA; pp. 619–633. [CrossRef]
- Zhou, J.; Chen, Y.; Shen, C.; Zhang, Y. Property Inference Attacks Against GANs. arXiv 2021, arXiv:2111.07608. [Google Scholar]
- Yin, H.; Mallya, A.; Vahdat, A.; Alvarez, J.M.; Kautz, J.; Molchanov, P. See through Gradients: Image Batch Recovery via GradInversion. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 16332–16341. [Google Scholar] [CrossRef]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning Differentially Private Language Models Without Losing Accuracy. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially Private Federated Learning: A Client Level Perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar]
- Choudhury, O.; Gkoulalas-Divanis, A.; Salonidis, T.; Sylla, I.; Park, Y.; Hsu, G.; Das, A. Differential Privacy-enabled Federated Learning for Sensitive Health Data. arXiv 2019, arXiv:1910.02578. [Google Scholar]
- Hu, R.; Guo, Y.; Li, H.; Pei, Q.; Gong, Y. Personalized Federated Learning With Differential Privacy. IEEE Internet Things J. 2020, 7, 9530–9539. [Google Scholar] [CrossRef]
- Bhowmick, A.; Duchi, J.; Freudiger, J.; Kapoor, G.; Rogers, R. Protection Against Reconstruction and Its Applications in Private Federated Learning. arXiv 2019, arXiv:1812.00984. [Google Scholar]
- Liu, R.; Cao, Y.; Yoshikawa, M.; Chen, H. FedSel: Federated SGD under Local Differential Privacy with Top-k Dimension Selection. arXiv 2020, arXiv:2003.10637. [Google Scholar]
- Ni, L.; Huang, P.; Wei, Y.; Shu, M.; Zhang, J. Federated Learning Model with Adaptive Differential Privacy Protection in Medical IoT. Wirel. Commun. Mob. Comput. 2021, 2021, 8967819. [Google Scholar] [CrossRef]
- Sun, L.; Qian, J.; Chen, X. LDP-FL: Practical Private Aggregation in Federated Learning with Local Differential Privacy. arXiv 2021, arXiv:2007.15789. [Google Scholar]
- Chamikara, M.A.P.; Liu, D.; Camtepe, S.; Nepal, S.; Grobler, M.; Bertok, P.; Khalil, I. Local Differential Privacy for Federated Learning. arXiv 2022, arXiv:2202.06053. [Google Scholar]
- Shen, X.; Jiang, H.; Chen, Y.; Wang, B.; Gao, L. PLDP-FL: Federated Learning with Personalized Local Differential Privacy. Entropy 2023, 25, 485. [Google Scholar] [CrossRef] [PubMed]
- Girgis, A.; Data, D.; Diggavi, S. Renyi Differential Privacy of The Subsampled Shuffle Model In Distributed Learning. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 29181–29192. [Google Scholar]
- Girgis, A.M.; Data, D.; Diggavi, S. Differentially Private Federated Learning with Shuffling and Client Self-Sampling. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 338–343. [Google Scholar] [CrossRef]
- Girgis, A.; Data, D.; Diggavi, S.; Kairouz, P.; Suresh, A.T. Shuffled Model of Differential Privacy in Federated Learning. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 13–15 April 2021; pp. 2521–2529. [Google Scholar]
- Li, Y.; Chang, T.H.; Chi, C.Y. Secure Federated Averaging Algorithm with Differential Privacy. In Proceedings of the 2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP), Espoo, Finland, 21–24 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Yaldiz, D.N.; Zhang, T.; Avestimehr, S. Secure Federated Learning against Model Poisoning Attacks via Client Filtering. arXiv 2023, arXiv:2304.00160. [Google Scholar]
- Zhang, C.; Li, S.; Xia, J.; Wang, W.; Yan, F.; Liu, Y. BatchCrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning. In Proceedings of the 2020 USENIX Conference on Usenix Annual Technical Conference, Boston, MA, USA, 15–17 July 2020. USENIX ATC’20. [Google Scholar]
- Fang, H.; Qian, Q. Privacy Preserving Machine Learning with Homomorphic Encryption and Federated Learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Jost, C.; Lam, H.; Maximov, A.; Smeets, B.J.M. Encryption Performance Improvements of the Paillier Cryptosystem. IACR Cryptol. ePrint Arch. 2015, 864. Available online: https://eprint.iacr.org/2015/864 (accessed on 2 June 2023).
- Feng, X.; Du, H. FLZip: An Efficient and Privacy-Preserving Framework for Cross-Silo Federated Learning. In Proceedings of the 2021 IEEE International Conferences on Internet of Things (iThings) and IEEE Green Computing & Communications (GreenCom) and IEEE Cyber, Physical & Social Computing (CPSCom) and IEEE Smart Data (SmartData) and IEEE Congress on Cybermatics (Cybermatics), Melbourne, Australia, 6–8 December 2021; pp. 209–216. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, S.; Ye, J.; Fan, J.; Li, H.; Li, X. DHSA: Efficient doubly homomorphic secure aggregation for cross-silo federated learning. J. Supercomput. 2023, 79, 2819–2849. [Google Scholar] [CrossRef]
- Shin, Y.A.; Noh, G.; Jeong, I.R.; Chun, J.Y. Securing a Local Training Dataset Size in Federated Learning. IEEE Access 2022, 10, 104135–104143. [Google Scholar] [CrossRef]
- Jin, W.; Yao, Y.; Han, S.; Joe-Wong, C.; Ravi, S.; Avestimehr, S.; He, C. FedML-HE: An Efficient Homomorphic-Encryption-Based Privacy-Preserving Federated Learning System. arXiv 2023, arXiv:2303.10837. [Google Scholar]
- Xu, R.; Baracaldo, N.; Zhou, Y.; Anwar, A.; Ludwig, H. HybridAlpha: An Efficient Approach for Privacy-Preserving Federated Learning. In Proceedings of the Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security. arXiv 2019, arXiv:1912.05897. [Google Scholar]
- Wang, T.; Ding, B.; Xu, M.; Huang, Z.; Hong, C.; Zhou, J.; Li, N.; Jha, S. Improving Utility and Security of the Shuffler-Based Differential Privacy. Proc. VLDB Endow. 2020, 13, 3545–3558. [Google Scholar] [CrossRef]
- Bittau, A.; Erlingsson, U.; Maniatis, P.; Mironov, I.; Raghunathan, A.; Lie, D.; Rudominer, M.; Kode, U.; Tinnes, J.; Seefeld, B. Prochlo: Strong Privacy for Analytics in the Crowd. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; SOSP ’17. pp. 441–459. [Google Scholar] [CrossRef]
- Gu, X.; Li, M.; Xiong, L. PRECAD: Privacy-Preserving and Robust Federated Learning via Crypto-Aided Differential Privacy. arXiv 2021, arXiv:2110.11578. [Google Scholar]
- Sébert, A.G.; Sirdey, R.; Stan, O.; Gouy-Pailler, C. Protecting Data from all Parties: Combining FHE and DP in Federated Learning. arXiv 2022, arXiv:2205.04330. [Google Scholar]
- Roy Chowdhury, A.; Wang, C.; He, X.; Machanavajjhala, A.; Jha, S. Crypt ϵ: Crypto-Assisted Differential Privacy on Untrusted Servers. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 603–619. [Google Scholar] [CrossRef]
- Liu, T.; Wang, Z.; He, H.; Shi, W.; Lin, L.; An, R.; Li, C. Efficient and Secure Federated Learning for Financial Applications. Appl. Sci. 2023, 13, 5877. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aziz, R.; Banerjee, S.; Bouzefrane, S.; Le Vinh, T. Exploring Homomorphic Encryption and Differential Privacy Techniques towards Secure Federated Learning Paradigm. Future Internet 2023, 15, 310. https://doi.org/10.3390/fi15090310
Aziz R, Banerjee S, Bouzefrane S, Le Vinh T. Exploring Homomorphic Encryption and Differential Privacy Techniques towards Secure Federated Learning Paradigm. Future Internet. 2023; 15(9):310. https://doi.org/10.3390/fi15090310
Chicago/Turabian StyleAziz, Rezak, Soumya Banerjee, Samia Bouzefrane, and Thinh Le Vinh. 2023. "Exploring Homomorphic Encryption and Differential Privacy Techniques towards Secure Federated Learning Paradigm" Future Internet 15, no. 9: 310. https://doi.org/10.3390/fi15090310
APA StyleAziz, R., Banerjee, S., Bouzefrane, S., & Le Vinh, T. (2023). Exploring Homomorphic Encryption and Differential Privacy Techniques towards Secure Federated Learning Paradigm. Future Internet, 15(9), 310. https://doi.org/10.3390/fi15090310