1. Introduction
One aspect of industry 4.0 aims towards the interconnecting of devices and sensors (cf. Industrial Internet of Things, IIoT) to, e.g., increase efficiency by enhancing business models and identifying bottlenecks [
1]. Therefore, data are a key factor. Using data-driven applications enables companies to optimize internal and external processes to decrease resource consumption or to gain competitive advantage [
2]. However, to exploit the full potential, analyst require a high data quality which has to be ensured during acquisition and storing process-related information [
2,
3]. Simultaneously, information and communication technologies (ICT) lead to steadily increasing energy usage (between 1% and 3.2% of global consumption in 2020) and are prognosticated to represent up to 23% by 2030 [
4]. In order to reduce climate-damaging emissions and become climate-neutral, the IT landscape is therefore an important factor to consider.
In our work, we aim to combine the aspects of data quality in combination with green computing approaches to archive improvements in data pipelines for IoT environments. Since our work is in cooperation with Robert Bosch Elektronik GmbH, we mainly focus on smart manufacturing scenarios, but our results can be adapted to other areas like smart healthcare as well.
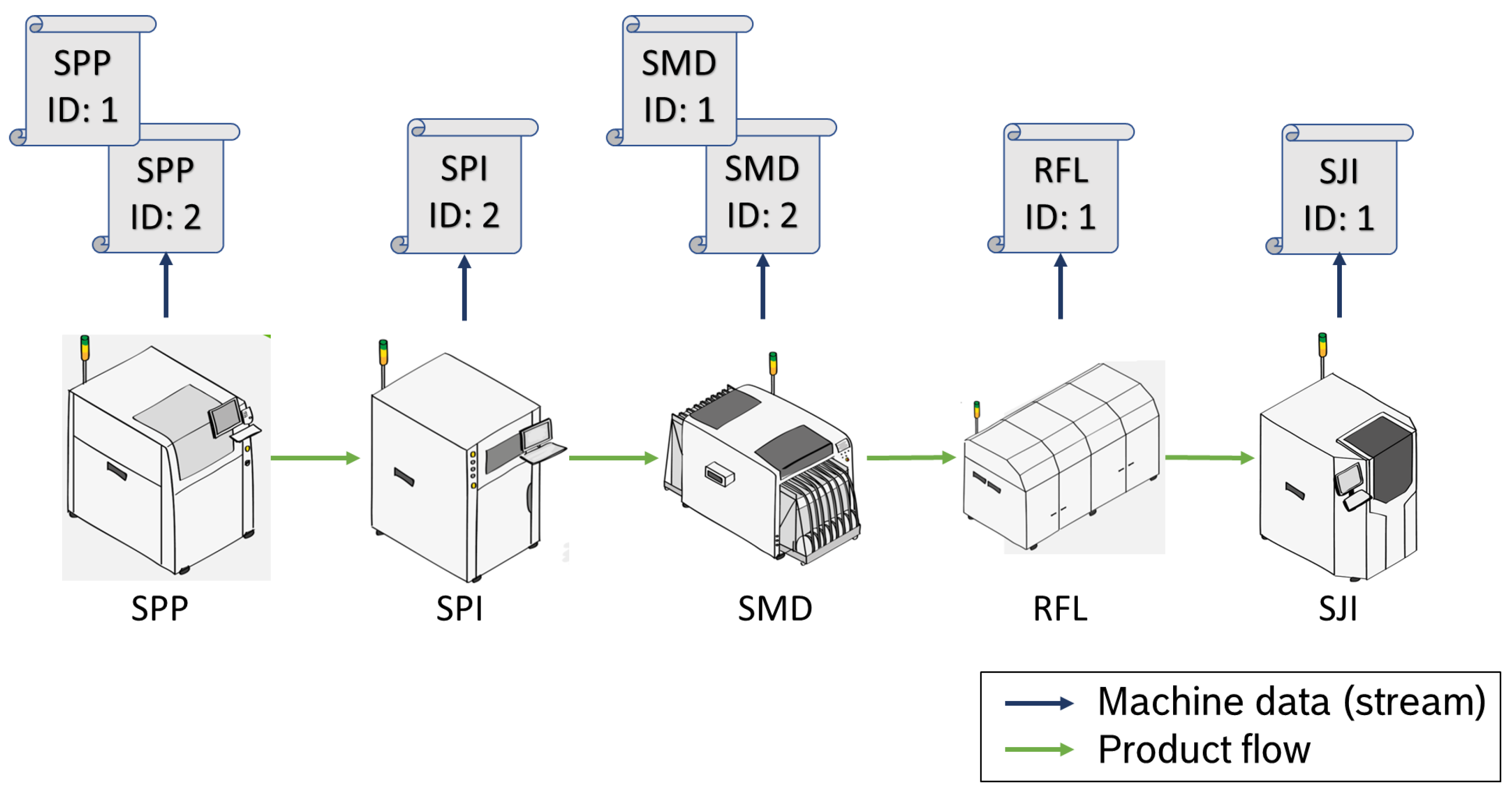
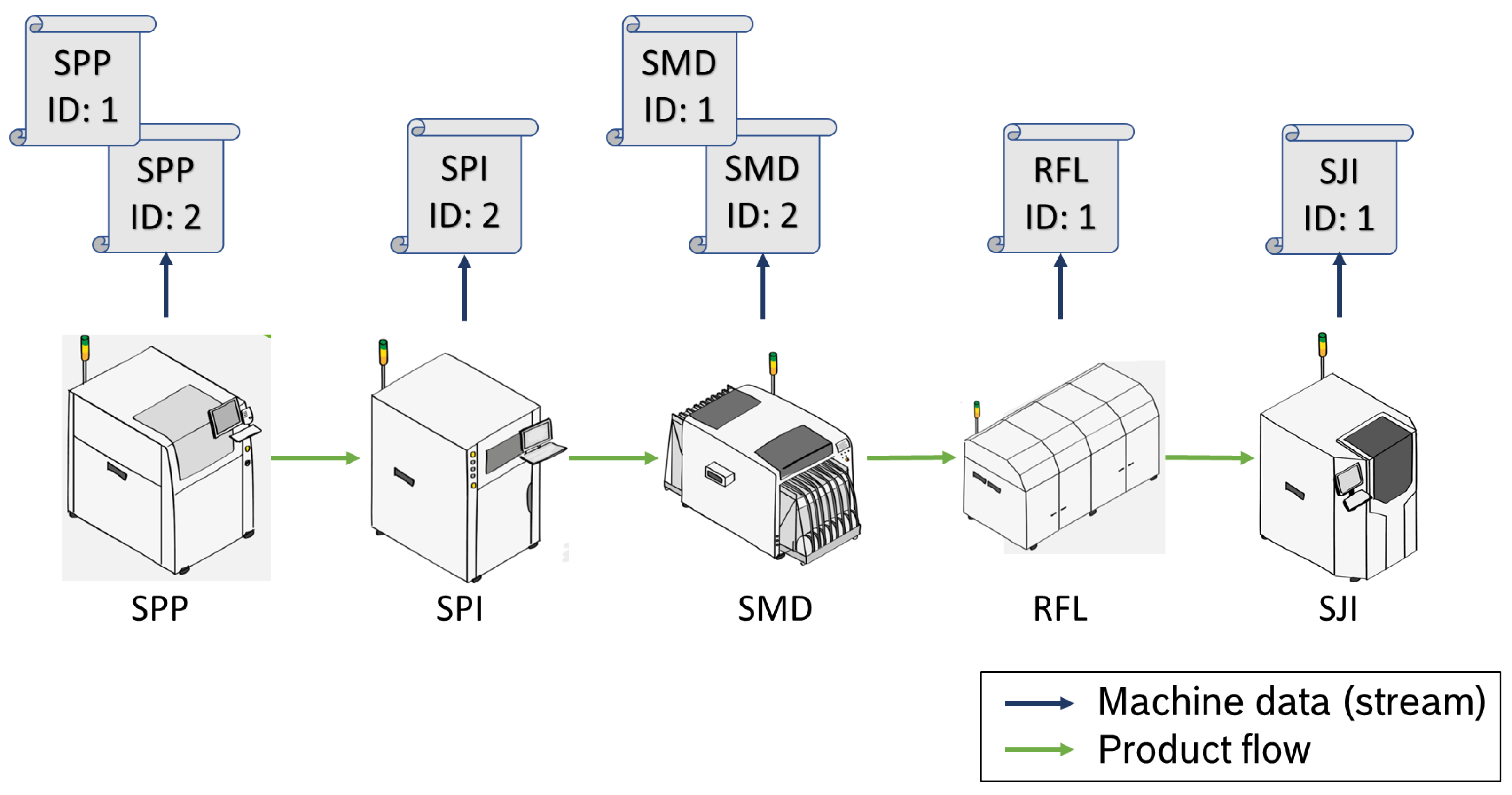
Figure 1 shows an example of a smart surface-mount technology (SMT) line. Such lines are used at Bosch among others to manufacture printed circuit boards (PCBs) for control units (e.g., for vehicles and e-bikes). SMT basically includes five processes: (1) solder paste printing (SPP) for printing solder paste on the circuit board, (2) solder paste inspection (SPI) to inspect the paste, (3) surface-mounted device (SMD) for placing components on the board, (4) reflow soldering (RFL), which is the actual soldering process, and (5) solder joint inspection (SJI) to inspect and test the final product. From a data point of view, SPI, SMD, and SJI provide the most important information; thus, the highest effort has to be on these processes.
During manufacturing, we noticed that in some cases, data and final product did not match. On a closer inspection, we observed that these mismatches are due to erroneous data, which are the result of a heterogeneous production landscape with various machines and software versions. We called these mismatches inconsistencies. Inconsistencies usually refer to a data set, which corresponds to all messages and information related to one manufactured product. To handle erroneous data, we categorized our inconsistencies into four main classes (cf. [
5,
6]):
- 1.
Missing message. A missing message leads to incomplete data and thus, an information gap.
- 2.
Multiple message. Multiple messages from one process may indicate problems with a machine.
- 3.
Incorrect content. This category refers to the content of a single message.
- 4.
With contradictions. By comparing the data of a data set, the matching has to be conflict-free.
The classification resulted from the study of our internal data. Categories 1 and 2 refer to entire messages that are either missing or duplicated (cf. Zhang et al. [
7]). Since we validate complex JSON files, the content is of major interest in our use case. Our examinations have shown that inconsistencies either concern the content of a single message (incorrect content) or constitute a mismatch between the information content of two or more messages (with contradictions). Although the categories (especially 3 and 4) evolved from a smart manufacturing use case, the manifestations of inconsistencies are similar in related IIoT and IoT domains. In smart healthcare, we can, for example, track the completeness of health records and identify discrepancies between two related parameters.
In order to ensure a high quality, in the past we presented a concept for a consistency checker (CC) [
5]. Our CC enables the detection of known anomalies on a continuous data stream, making use of a domain ontology. According to [
8], working on streams allows for fast feedback. In our scenario at Bosch, this domain ontology contains process flows and machine specifications. The CC utilizes this knowledge to map incoming data using SPARQL Protocol And RDF Query Language (SPARQL) (
https://www.w3.org/TR/sparql11-query/, accessed on 14 September 2023) queries. These queries contain characteristics of relevant inconsistencies. We further adapted our CC to be more resource-efficient and energy-saving (GreenCC) [
6]. The GreenCC consists of two units: (1) LightCC to predict the likelihood of inconsistencies and (2) FullCC to perform an accurate check using semantics. Experimental results showed that we can significantly reduce the energy consumption of data validation by adapting our architecture and optimizing the implementation. The GreenCC is currently running in an adapted version on real data. With the help of the CC, we were able to show that the inconsistencies affect between about 1% and 10% of the data, depending on the plant (larger plants are more likely to be affected). The small amount argues for an approach that is as efficient as possible to keep overhead to a minimum during monitoring. Although our previous CCs run stably on real data, we still encounter the following problems:
We are able to detect known inconsistencies. If, for example, the characteristics of an inconsistency or the production environment change, these changes have to be entered manually. Similarly, new inconsistencies must be modeled accordingly in a machine-readable format. Nevertheless, the currently running version has its justification for existence, since newly modeled inconsistencies can be transferred to other plants and checked. Furthermore, the knowledge about possible causes can be transferred. Due to the heterogeneous landscape, it is not economical to prophylactically adjust all machines and process flows without knowing the problems.
Inconsistencies in categories 1 and 2 can already be checked via an efficient procedure. For the other categories, it is so far only possible to identify periods in which they are more likely. A corresponding check must be carried out via transforming all gathered data from JSON into Resource Description Framework (RDF) (
https://www.w3.org/RDF/, accessed on 14 September 2023).
A final result is only available after the product has been manufactured. Depending on the production, this means that important time passes during which any errors cannot yet be corrected. Thus, in the worst case, many inconsistencies of the same kind are present.
The longer the validation steps are, the longer large amounts of data are retained. This leads to increased memory and corresponding energy consumption of a CC.
We can transform these problems to four open challenges:
- (C1)
Detect inconsistencies of any kind and expression;
- (C2)
Increase efficiency of the checking process;
- (C3)
Shorten validation process;
- (C4)
Reduce the memory consumption during validation.
Challenge (C1) refers to quality aspects. To address this challenge, we propose an efficient matching using a message template in combination with an automaton structure. The machine specifies how the overall process to be checked is structured. The template is used to map the flow and steps of the sub-processes and thus to check complex inconsistencies. Deviations from the template are treated as anomalous.
Challenges (C2) to (C4) refer to sustainability aspects and complement each other. On the one hand, the explained template has the potential to check inconsistencies of Category 3 and 4 more efficiently (C2). On the other hand, our aforementioned automaton structure shortens the validation in case of detected inconsistencies (C3). Depending on the state, the automaton shows whether consistency is present or can still be achieved. Inconsistencies become directly visible in this way. We also take advantage of the fact that many production lines operate in a linear fashion. This means that the products pass through the machines one after the other and no overtaking is possible. If the data overtake each other, we can conclude that there is an error in the message transmission. Thus, we do not only consider the current data set as before, but include surrounding information and link further knowledge with it. In particular, the detection of overtaking data sets and drawing conclusions from an overtake in complex IoT environments are not addressed in existing studies. We want to achieve further sustainability benefits through clever internal handling of large amounts of data. In many IIoT scenarios, immense amounts of data of several gigabytes (GB) occur during, e.g., manufacturing. If these data volumes have to be held internally due to a long validation process, the storage requirements of a CC increase enormously. At this point, we also want to implement two optimizations: (1) perform validations as early as possible and release data that are no longer needed, and (2) store data smartly while they are in the checker. In this way, we address challenge (C4). Our present work includes an automaton that processes incoming messages, detects overtakes in the data stream, and handles time constraints. In this way, the automaton concept is useful for any IoT application where data quality is of high importance and at the same time limited computing resources are available or required in terms of energy consumption.
To present and explain our automaton, the remainder of this paper is as follows:
Section 2 provides an overview of relevant work in the fields of data validation. We subdivide this into pure methods and efforts to use resource-saving technologies. Subsequently, we present our automaton concept in
Section 3. In the course of this, we introduce an example automaton on which we visualize properties and algorithms.
Section 4 shows possible applications based on two use cases. Afterwards, we evaluate our automaton with respect to the three identified challenges. We compare our new automaton with previous implementations in several experiments. The evaluation is followed by a discussion section. Finally, we conclude in
Section 7.
2. Related Work
The literature provides a large body of work on the topic of data quality and validation. We first have a look at quality issues to work out how the use of the term relates to our view. Afterwards, we address the detection of inconsistent data in (I)IoT scenarios. We present semantic methods, complex event processing (CEP) systems, automatons, and machine learning methods. Furthermore, we investigate to what extent green computing has already found acceptance in the community. Additionally, our literature study includes related work with a focus on energy efficiency.
The work of Gao et al. [
9] presents an overview of data quality and validation in big data environments. The authors point out that insufficient quality can lead to high costs for companies. In the literature, data quality often refers to aspects such as completeness, correctness, timeliness, accuracy, and availability (cf. [
7,
10,
11,
12]). The criteria
completeness and
correctness are similar to those in our work. Thus, we also try to detect incomplete data sets and aim to keep correct information in the data. With our categories 3 and 4, we also specifically address the fact that content correctness of data may depend on a single message or a set of messages. The arrival of the messages plays a minor role, especially in our manufacturing scenario, since we handle long delays via timers or detection of overtakes. Accuracy of the data is not a criterion, as we do not aim to create a trust score with our automaton but to detect and subsequently report inconsistencies. Karkouch et al. [
10] also address
contextual anomalies, which can only be detected with the addition of the context. However, the focus of the work is on individual values and not on detection in complex documents.
The work of Haav et al. [
13] refers to data validation in the timber industry. The authors use SHACL shapes to define constraints. The work describes their real example case in detail and gives descriptive examples. Nevertheless, the authors do not provide a concrete implementation of their approach. Furthermore, the proposal is not intended to process big data streams. Cortés et al. [
14] introduce a practical data stream scenario from the medical sector. The authors explain data validation techniques to address IoT problems in healthcare, but mainly evaluate data throughput to identify challenges in the big data area. Concrete implementations and experiments are missing. In [
3,
15,
16], further approaches are presented. In contrast to our work, the presented methods do either use fixed knowledge bases, work on static data instead of streams, or are not intended to be applied in real-world IoT environments. Furthermore, none of these validation approaches focus on green computing solutions.
The work of Maier et al. [
17] and Hranislav et al. [
18] present automatons for data validation. The authors refer to production plants and introduce time constraints. However, the authors do not mention detections of overtakes. This detection helps us to reduce the energy and resource consumption of the automaton.
In [
19], the authors provide an overview of further anomaly detection approaches to detect outliers in time series. In general, the problem is very similar to our data validation. Time series, however, usually contain much simpler data sets. In our work, we present an approach that tests complex content issues.
Another possible solution to our data validation problems is complex event processing (CEP) systems. In preparation for this work, a literature search of existing CEP approaches has been performed. The literature search revealed that with Siddhi [
20], Wihidum [
21], and ETALIS [
22], a large selection of CEPs exists. These systems allow the definition of simple constraints to detect patterns on a data stream. To do this, each of our consistency checks would have to be transformed into a pattern. For categories 1 and 2, this is possible. For inconsistencies of categories 3 and 4, however, the content is important. Since the content varies depending on the product, no uniform pattern is possible. Furthermore, the considered CEP systems do not offer different operating modes. We hope for an advantage in terms of energy consumption especially with the light mode.
Regarding energy efficiency, Ahmed et al. [
23] present a blockchain-based approach with a focus on aggregation and protecting the IoT network. The system is used to validate edge servers in a hierarchical scenario. Our system is also suitable to run as a distributed application in large IoT scenarios. However, with our current application scenarios, we directly validate incoming data streams before data are stored. Furthermore, since we operate in protected environments and not in public networks, security and privacy play a subordinate role during validation. The work of Batmunkh et al. [
24] provides an overview of carbon emissions emitted by social media platforms. The authors describe the effects of using these platforms, for example, by streaming videos and movies. The main energy consumption is due to the platform architectures consisting of large data centers. In our approach, we also consider carbon emissions due to the energy consumption of our system. However, our consistency checker does not consist of a large backend. We connect to an existing data pipeline to increase the usability of the collected data.
Other possibilities to increase the efficiency of IoT application are data prioritization techniques. According to Zahedina et al., data prioritization approaches focus on accessing correct data as quickly as possible. Therefore, IoT data are prioritized based on properties such as timeliness and significance to only use the most valuable data [
25,
26]. As a result, the approach of Zahedina et al. [
25], for example, removes low-priority data from the cache. Sultana et al. [
27] present an approach to implement patient monitoring in smart healthcare efficiently. Therefore, the authors classify patient data into critical and non-critical data packets to determine the urgency of the data. In general, we also aim to only store valuable data in our databases. In our scenarios, however, the focus is not on the real-time use of data, but on monitoring processes and workflows. To achieve this, our automaton identifies deviations from the expected information. The detection and categorization of inconsistencies enable us to determine causes of errors to prevent them from recurring. How to deal with the detected anomalies is decided at a later stage (cf. [
6]).
3. Concept of an Automaton for Data Validation
This section describes our concept to build automatons to handle stream data validation tasks in (I)IoT environments. The formal representation of our automaton is a tuple where:
Q is a finite set, called the states of our automaton. In our case, an element of Q is a tuple where q is the actual name of the state and E is a list of all current elements that are in the state. Each element of E is in turn a triple , where represents a unique identifier, is the position of arrival, and t is a process-specific timer.
is the alphabet. A word of the alphabet consists of messages (m), timer expirations (), overtaking (o), and category 3 and 4 checks ( and ).
is a function (transition function).
represents a finite set (), called the initial states.
F is a finite set with , which holds the accepting states.
We call our concept
AutomatonCC. In the following, we give deeper insights into each element of the automaton and explain our concept step by step, building up an example automation. Therefore, we use the process described in
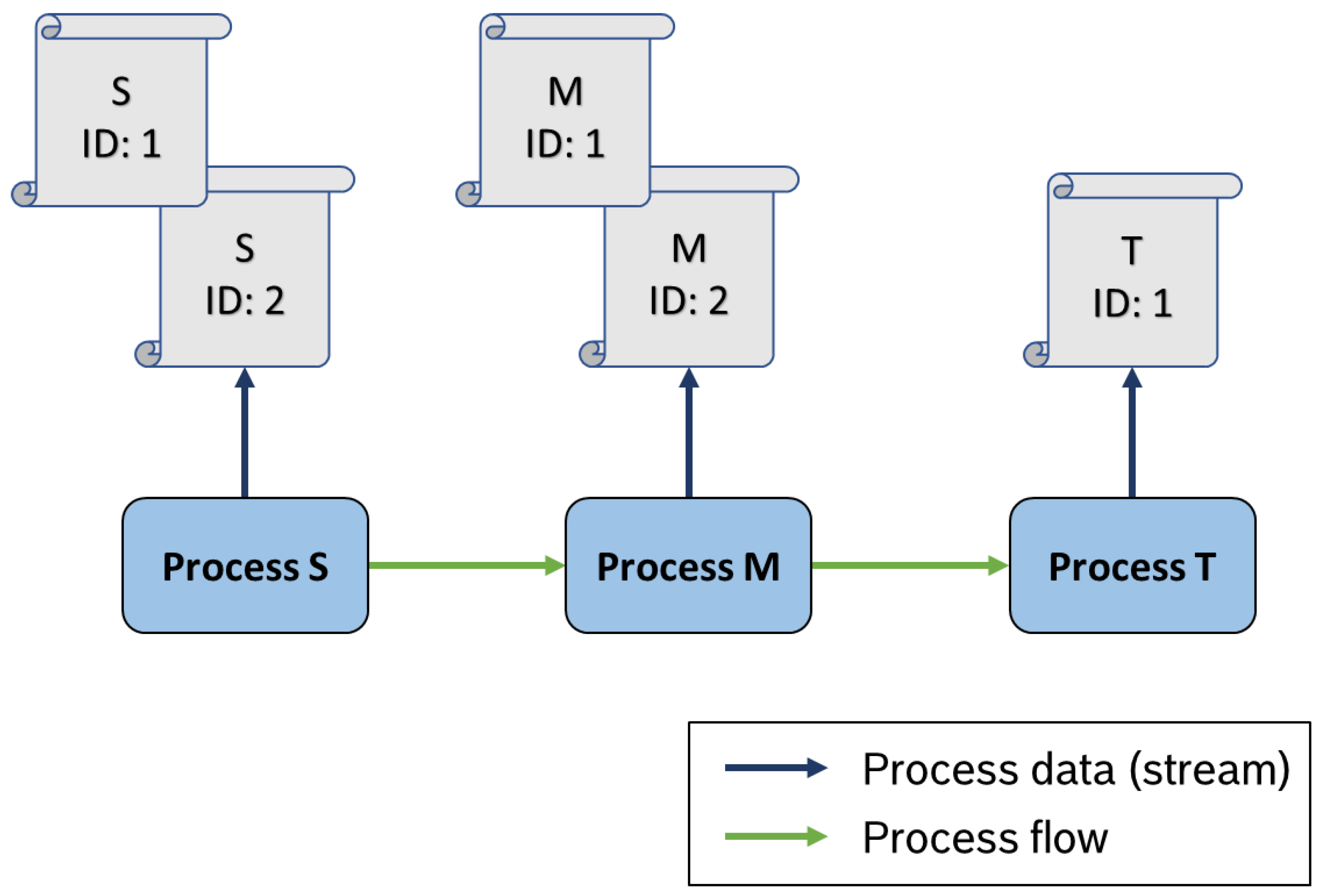
Figure 2. Our process consists of the three steps S, M, and T, which are aligned linearly.
3.1. States
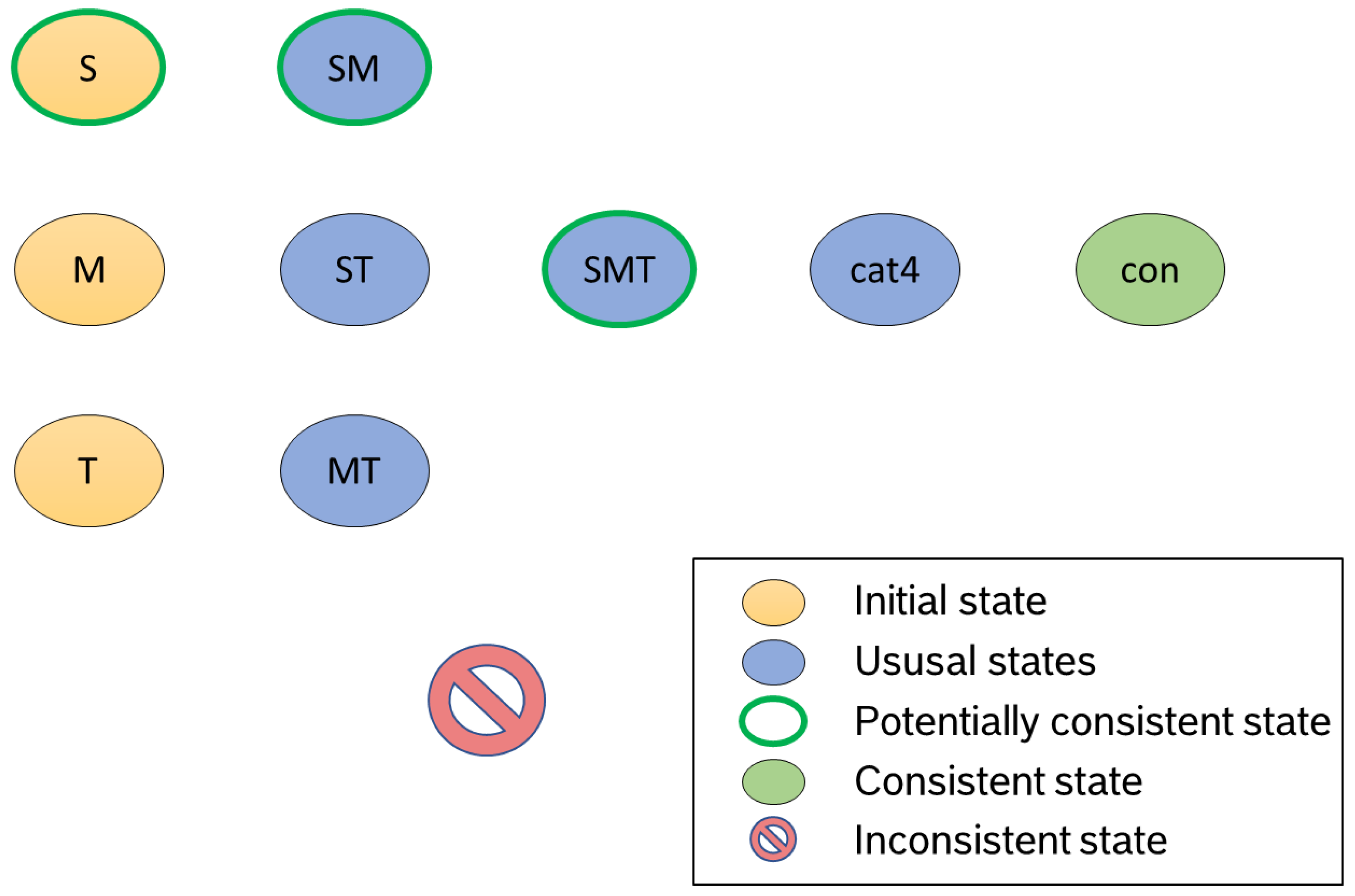
The first parameter we consider are the states Q. To create an automaton from the example process above, we determine the power set of the process steps: , , , , , , , .
We use the elements of this set as states of our automaton. We ignore the empty set (see
Figure 3). Sets containing only one element form the start states in each case. We characterize states that follow the process run as potentially consistent (
). Potentially consistent means that it is ensured that the existing messages have arrived in the correct order, but it remains to be checked whether there are inconsistencies within the messages (category 3 and 4). Furthermore, we add an inconsistent, a
cat4 state, in which a data set waits until it has been checked for category 4 inconsistencies, and a consistent state to our automaton. This gives us a total of ten states for our example process.
As mentioned, we define a state as a tuple . With q, we denote the unique name of a state. E is a list consisting of all products, waiting in the corresponding state. An element of E is a triple . The parameters of this triple are a unique product identifier () to be able to track each product and group related data, a rank (), to detect overtakings, and a process-specific timer (t), to be able to terminate in the case of a missing message. Depending on the current manufacturing conditions, these timers can be extended or shortened.
3.2. Transitions
The second parameter is the transitions. In our automaton, state transitions are triggered by one of the following four types:
- 1.
Incoming message. For each incoming message, an identifier switches its state.
- 2.
Expiring timer. In case of an expiring timer, we terminate the run for the affected identifier.
- 3.
Overtaking of a subsequent identifier. In case of an overtake, we terminate the run for all elements with a smaller rank than the actual identifier.
- 4.
Content violation (Category 3 & 4). Content violations indicate an inconsistency in the considered data set.
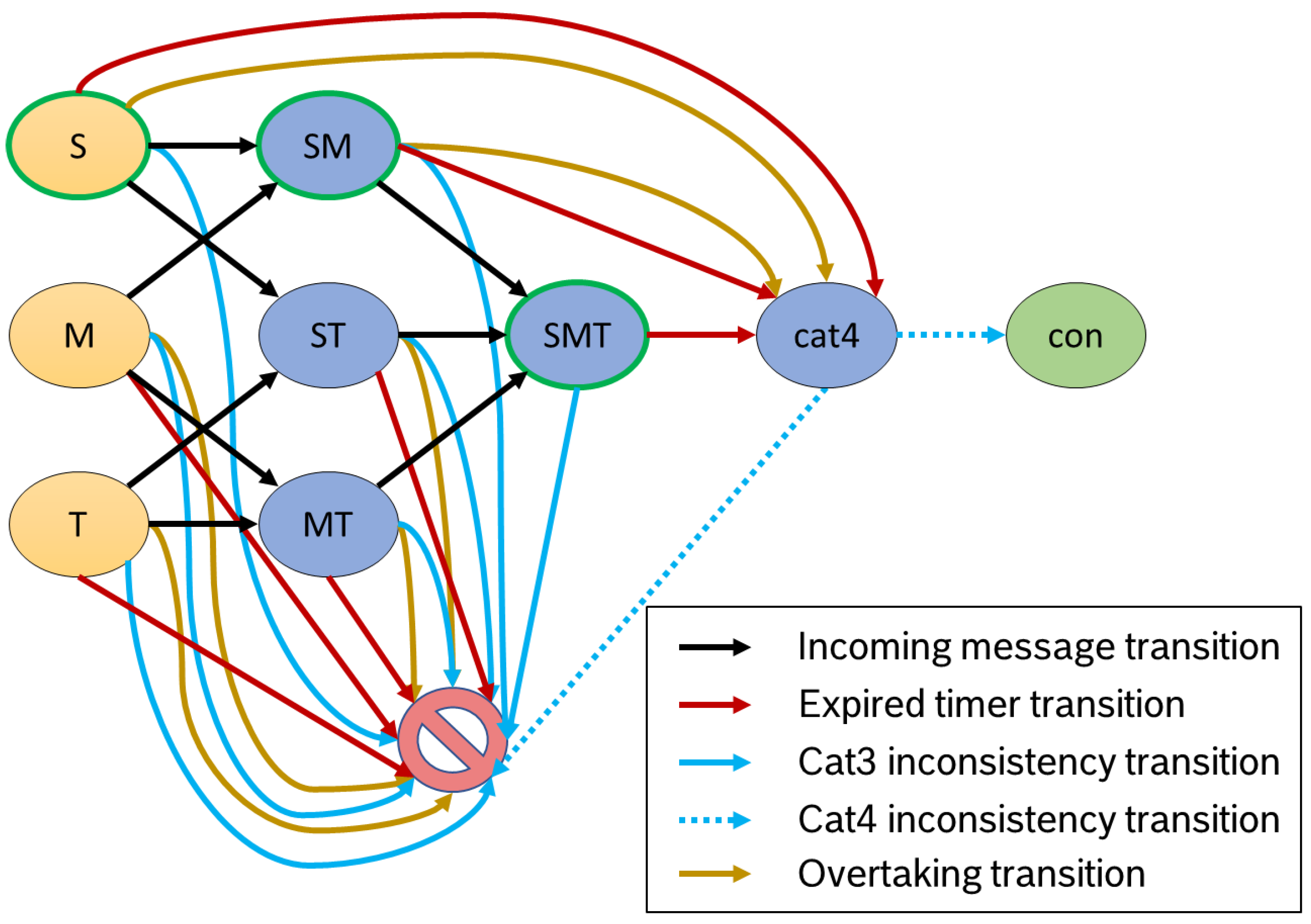
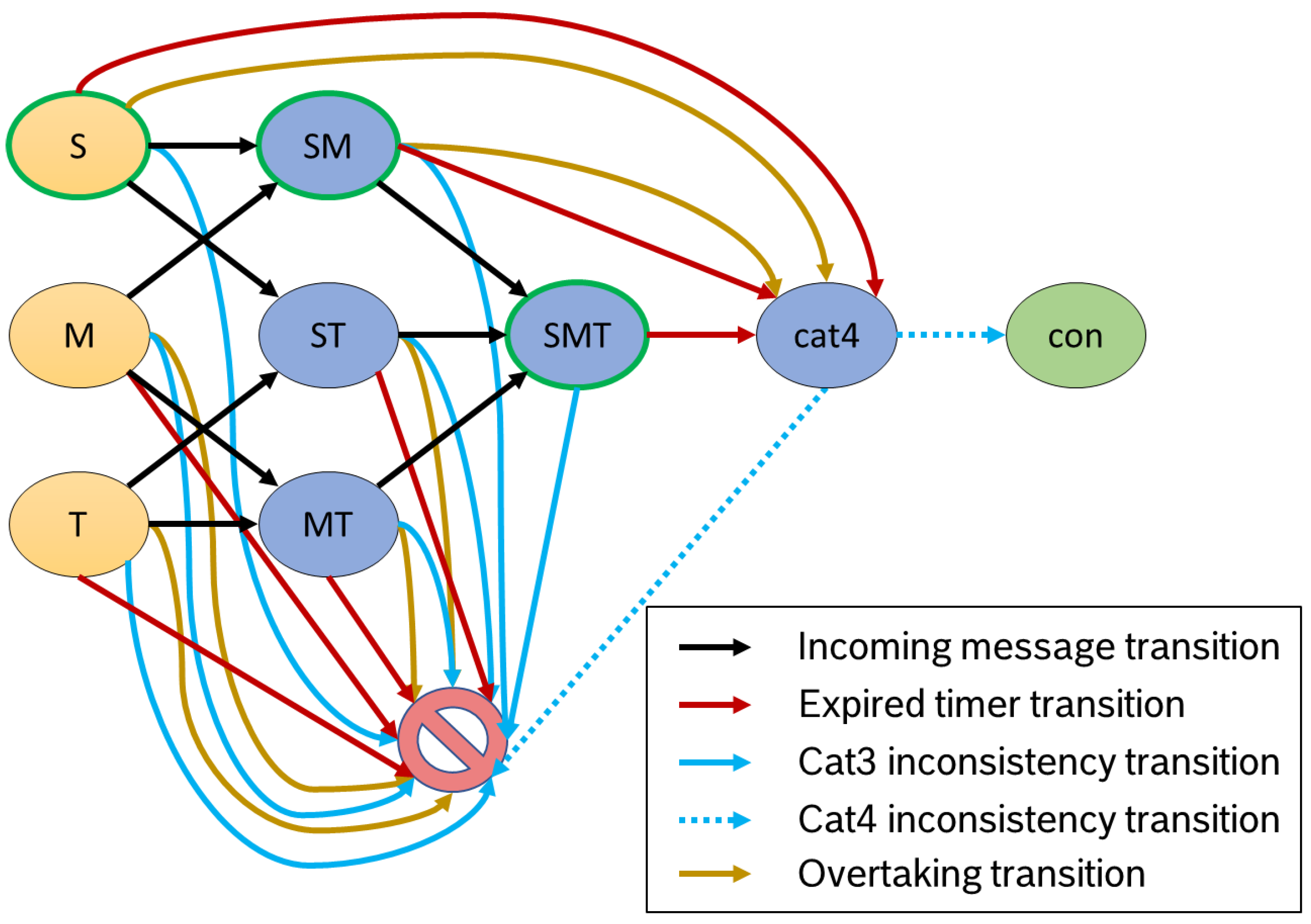
Figure 4 provides an overview of all automaton transitions of our example process from
Figure 2. As we develop a finite
automaton, we have a transition function, mapping each possible input to exactly one output. Our function
takes as input the current state
and the trigger
and maps to a new state from
Q (
) Since our alphabet
consists of four different types of triggers, our
is of the form of
m, for an incoming message,
, for an expired timer,
o, for a detected overtake of a subsequent product, or
/
, which denotes a content violation in our gathered data.
3.2.1. Incoming Message
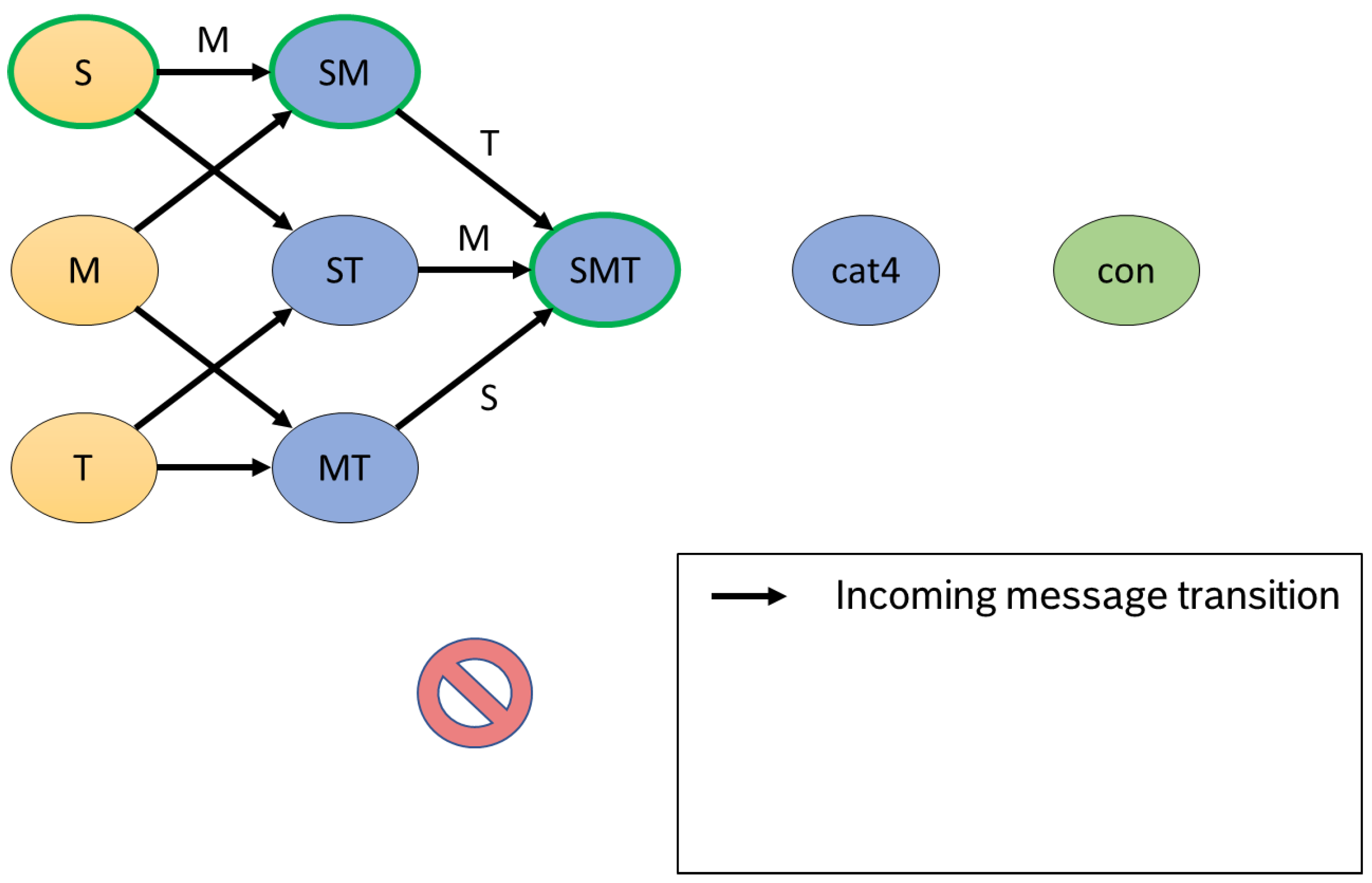
An incoming message can be assigned to a product. It thus leads to a data record being extended. For each message, we therefore check whether it contains new information or already exists. New information leads to a new state. If a piece of information is already present, we classify this as a multiple message inconsistency. The dataset under consideration is thus inconsistent and is moved to the inconsistent state. Further messages with the identifier of an inconsistent record do not change the state. Usually, all redundant messages lead to inconsistency.
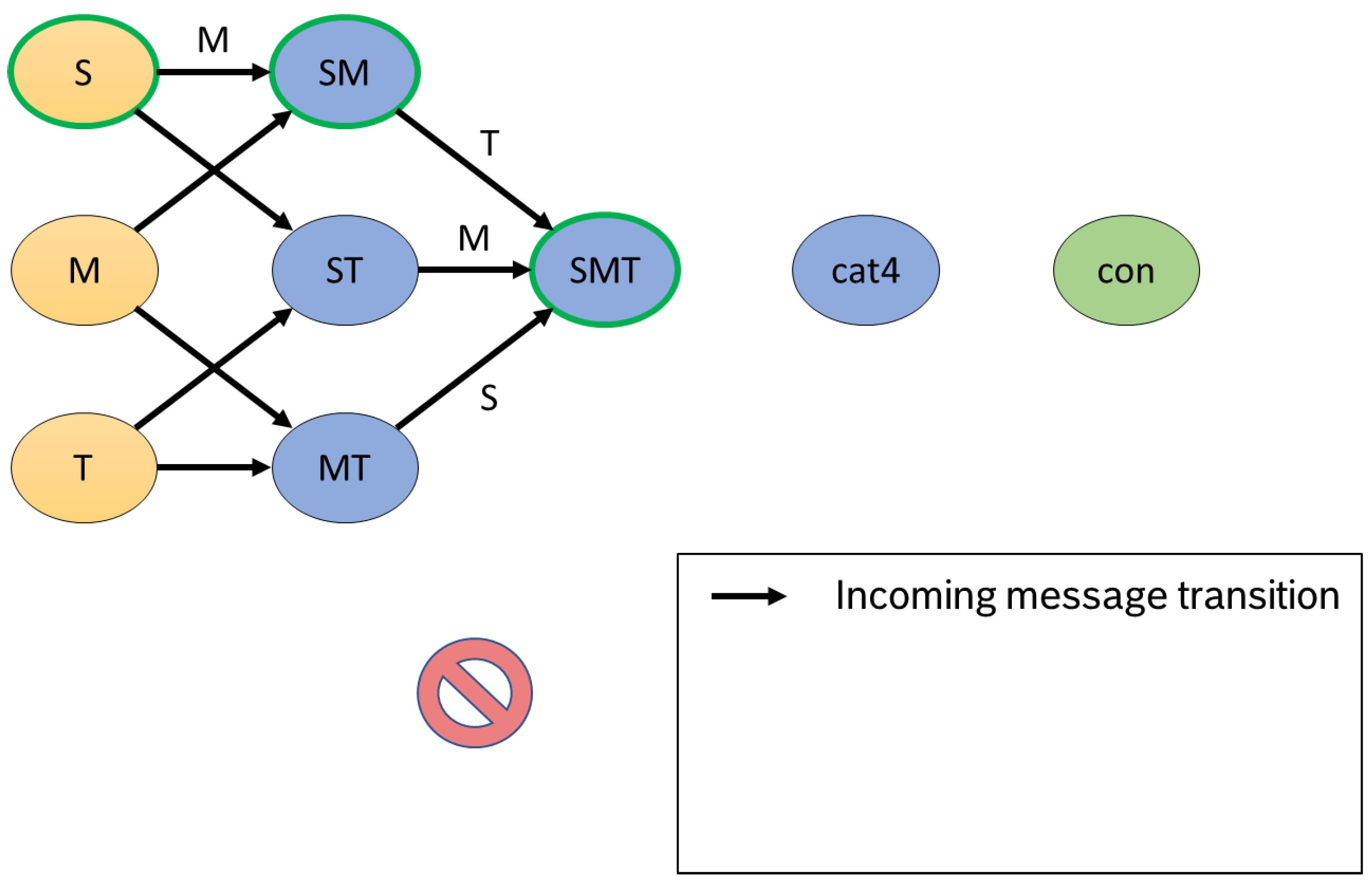
Figure 5 shows the transition as an example for our S-M-T process. The regular pass in our example is the sequence
. Since it is possible that messages are delayed, we can not build up a linear automaton but have various paths. For overview purposes, the state transitions to the
inconsistent state have been omitted from the figure.
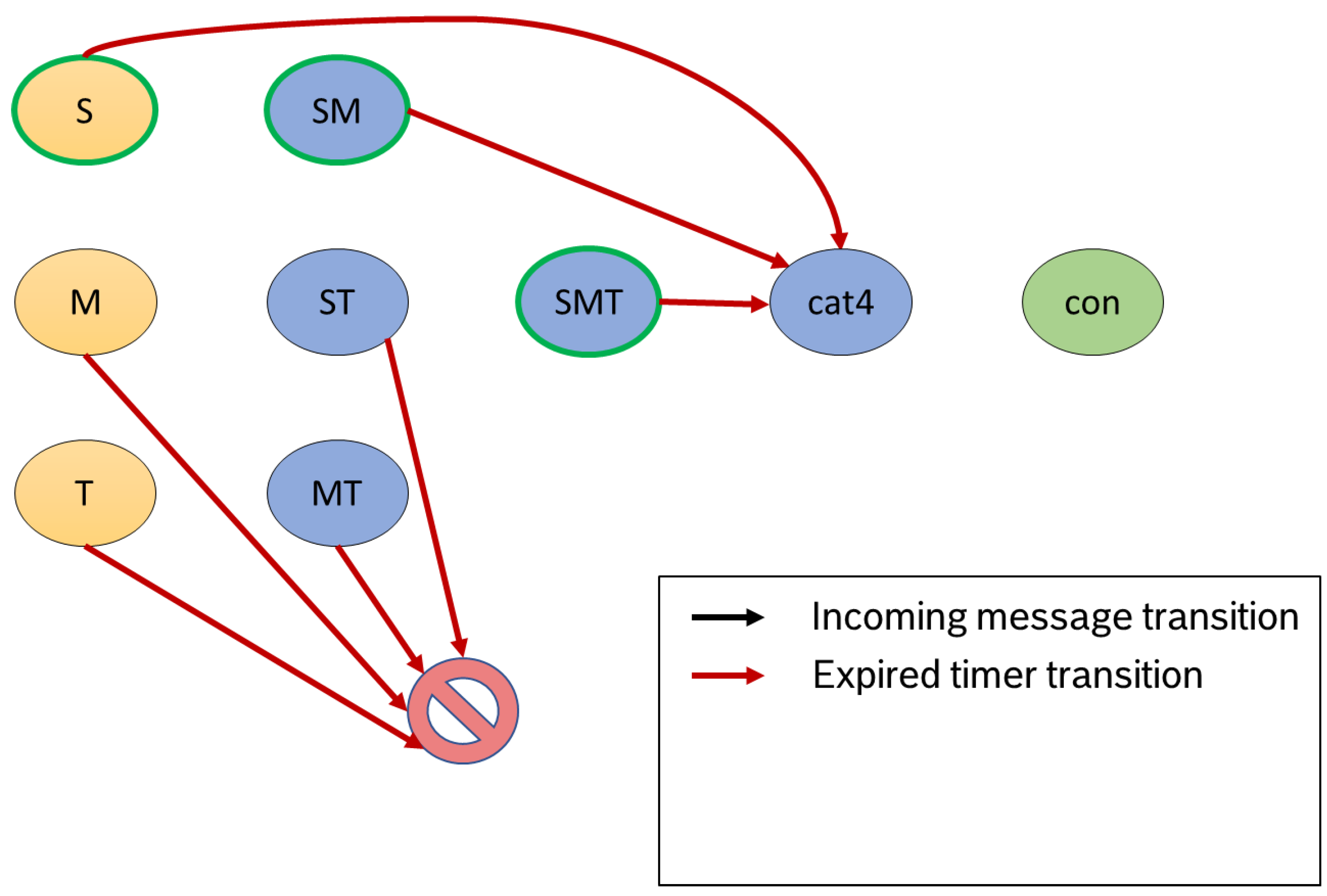
3.2.2. Expired Timer
If a timer expires, we terminate the run through the automaton for the affected identifier. A timer expiration indicates that we did not receive any information belonging to this data set for a longer period. To save resources and to prevent running out of memory, we stop tracking this product. If our product is in a
potentially consistent state at this time, we transfer the identifier to the
cat4 state. Otherwise, the records will end up in the
inconsistent state because not all expected information has arrived in the time limit (see example in
Figure 6). Timers should be set accordingly, depending on the domain. Furthermore, we decided to automatically adjust the timers to the process flow at regular intervals, for example, to take into account traffic jams in a manufacturing line. Since in our manufacturing use case we sometimes receive operator messages regarding the final inspection, we also have a timer in the last process state (
in the example).
3.2.3. Detected Cat and Cat Inconsistency
As in our previous validation approaches, we have to check for content violations in our data [
5,
6]. By validating categories 3 and 4, our automaton has a larger range of functions than our LightCC (cf. [
6]), which only tests for the first two categories. In addition, we do not use semantic SPARQL queries for the validation step as before, but match the received data with a template. Expert knowledge is still involved via the template as well as through the actual transitions and states. In the automaton, this on the one hand eliminates the transformation step from JSON to RDF, which we expect to result in more efficient resource usage. On the other hand, unknown discrepancies can be detected as well. This possibility did not exist in the previous GreenCC (cf. [
6]). Overall, the automaton thus offers an extended range of functions.
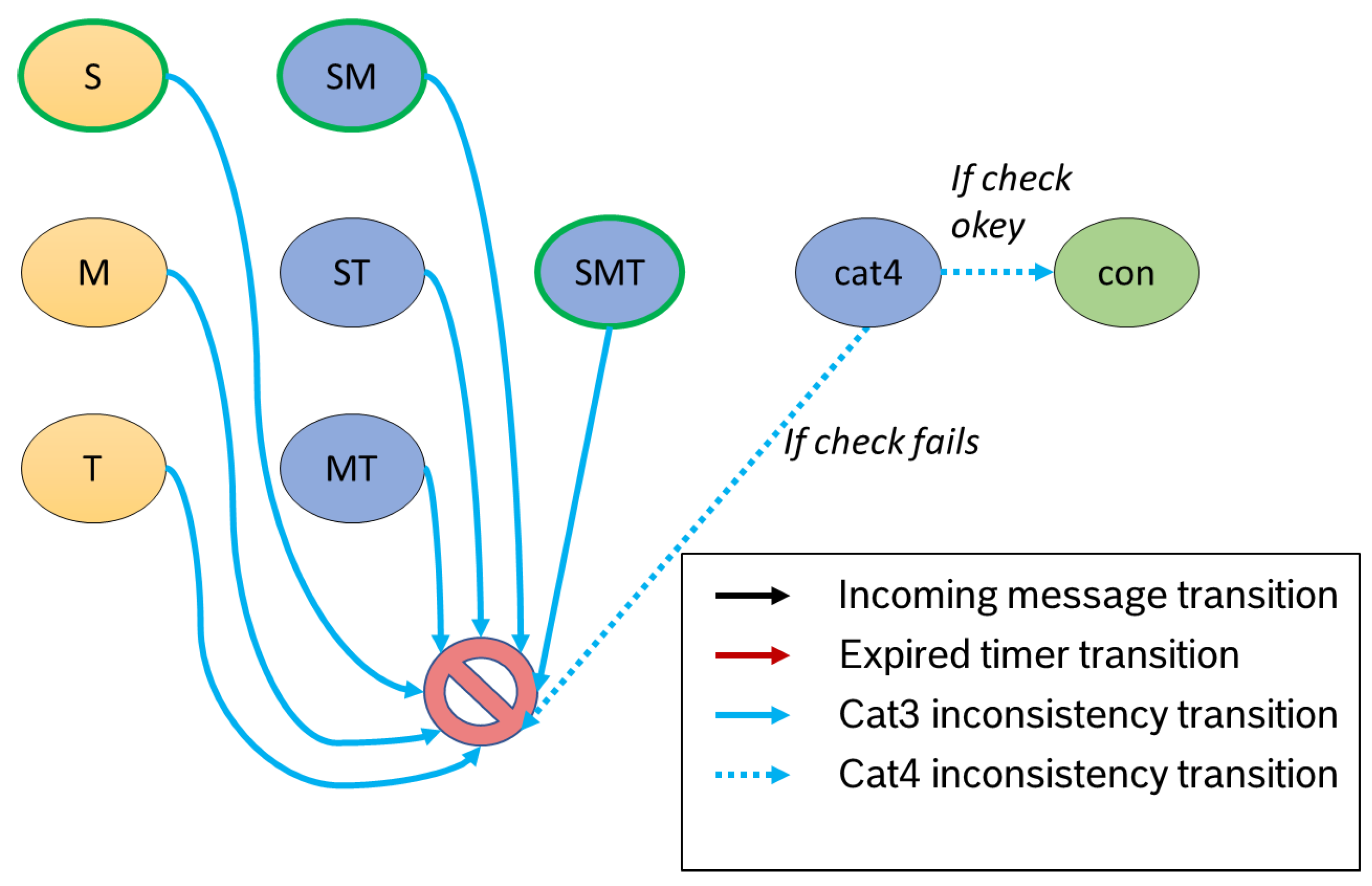
In our machine, we follow the approach of detecting inconsistencies as soon as possible. As a result, we check as soon as something is testable. Category 3 Inconsistencies refer to the content of a single message. The validation takes place after each incoming piece of machine information (see
Figure 7). Violations result in the
inconsistent state. If the test is successful, the data set remains in the current state. In the
cat4 state, validation for category 4 inconsistencies takes place. This step is only possible when all expected data are available, as discrepancies between messages are validated.
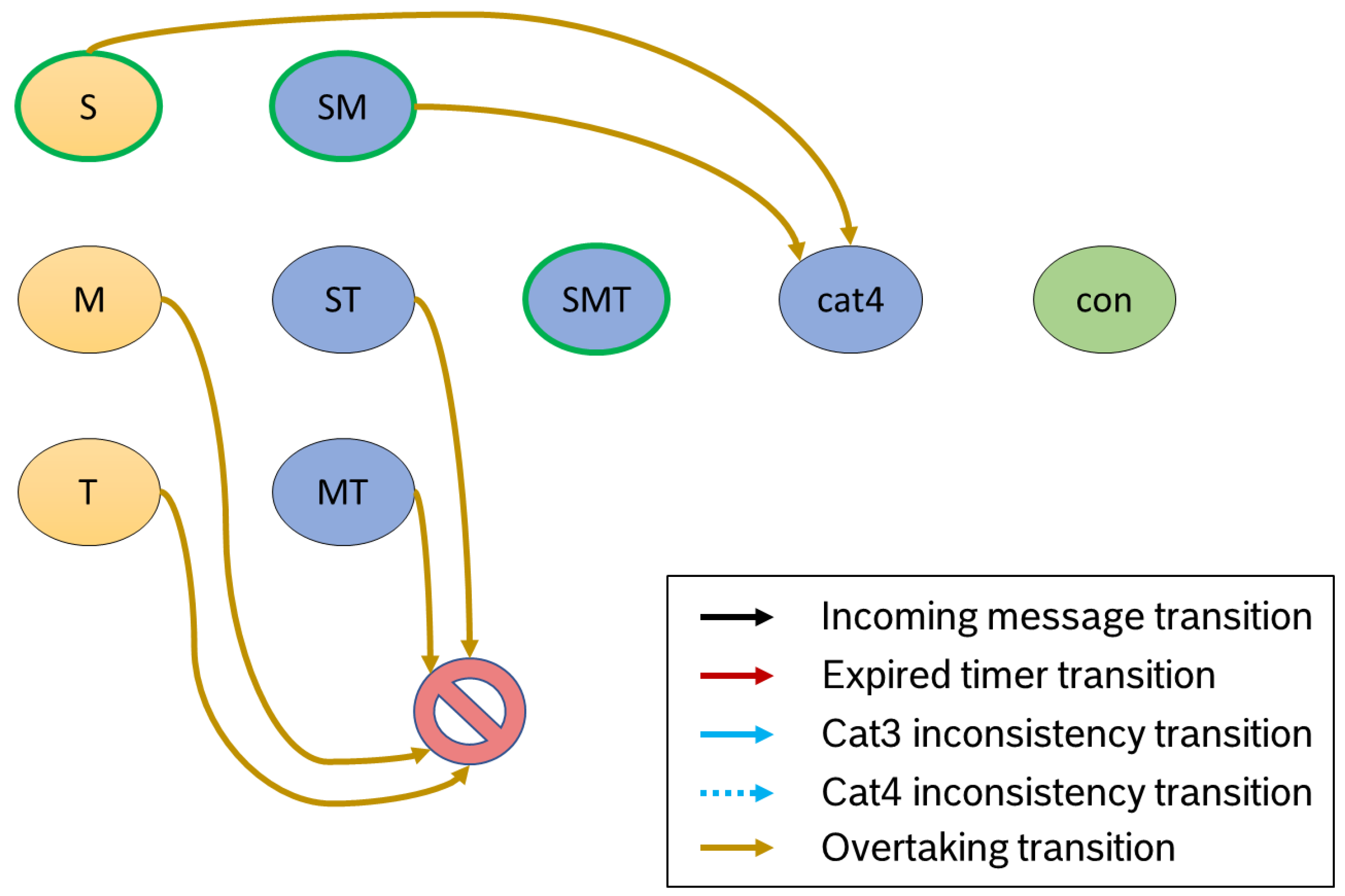
3.2.4. Detected Overtake
In our special case of a manufacturing scenario, it is often the case that the individual machines are arranged linearly. This means that it is not possible to overtake another product. If overtaken identifiers are in a normal state, an overtake leads to inconsistency (see
Figure 8). In this case, we assume that messages have been lost and thus incomplete information is available (
missing message inconsistency). In contrast, an overtake in a
potentially consistent state does not automatically lead to inconsistency. In this scenario, the first assumption is that the overtaken identifiers were taken out of the manufacturing line prematurely. For this reason, the state transitions in
Figure 8 of
S and
each lead to
cat4. As described previously, category 4 is validated in this state. In the last regular state (in our example
), an overtake is no longer possible. As described in
Section 3.2.2, in this state we wait only for the timer end.
3.3. Algorithms
To implement our automaton, we split up the functionality in three main algorithms running in parallel. These are: (1) handleMessage(m), (2) expiringTimer(t), and (3) validateContent(m). In the following, we will go into more detail about these three algorithms and describe how they work in general.
3.3.1. Handle Incoming Messages and Detect Overtakings
The most important task is to handle incoming data from the IoT environment. Algorithm 1 provides an overview of the steps to perform. For incoming information, we first have to identify the data set it belongs to. If a corresponding data set does not yet exist and the identifier is thus unknown, we proceed as follows: Depending on the message type, we enter the associated initial state. The new identifier is then assigned with a rank and a process-specific timer is started.
| Algorithm 1 Process incoming messages and detect overtakings |
- Require:
|
- 1:
procedure(m)
| ▹ For each incoming message |
- 2:
|
- 3:
if then
| ▹ Start of a new manufacturing process |
- 4:
| ▹ Enter initial state |
- 5:
|
- 6:
| ▹ Process-specific timer per product |
- 7:
| ▹ Compute rank considering time of arrival |
- 8:
else
|
- 9:
|
- 10:
|
- 11:
|
- 12:
if then
| ▹ Overtake detected |
- 13:
⊓
|
- 14:
⊓
|
- 15:
end if - 16:
|
- 17:
|
- 18:
if then
| ▹ Reached final consistent state |
- 19:
| ▹ M contains all messages related to the current id |
- 20:
else if then
|
- 21:
| ▹ Start timer considering next process |
- 22:
| ▹ Compute new rank |
- 23:
else
|
- 24:
| ▹ When entering invalid state, report inconsistency |
- 25:
end if
|
- 26:
end if
|
- 27:
end procedure
|
Otherwise, we clear the active timer to prevent an expiring timer from triggering unwanted actions. Afterwards, we check the rank of our identified set. If , we detect an overtake, because the state contains older data sets. An overtake is not problematic for the current data set, but is for older ones. If the overtake happens in a potentially consistent state, we can transfer all older elements into the cat4 state. This is possible because we assume that the identifier has been removed from the IoT scenario. An overtake in a usual state means that older data sets are not currently consistent. We conclude that information was lost. The affected data sets are classified as inconsistent according to the missing message criterion.
Thereafter, we can switch the state and proceed. First, the algorithm checks in what type of state the identifier is. In the
cat4 state, the entire data set is checked for category 4 inconsistencies. In a valid state, a new process-dependent timer is started and the new rank of the identifier is determined. As we already mentioned in
Section 3.1, each process has its own time restrictions. The rank is derived from the timestamp of a message. The recalculation of the rank is necessary in order to further identify overtaking items.
If we are in an inconsistent state, there is no longer the possibility to receive an anomalous-free data set. As a result, we can report an identified inconsistency directly.
3.3.2. Handle Expiring Timer
Algorithm 2 lists the steps for the
expiringTimer(t) procedure. In case of an expired timer, we check if the affected identifier currently is a
potentially consistent state. If so, we assume that we received all expected messages and transfer the identifer to the last check (
cat4). Otherwise, we report a
missing message inconsistency.
| Algorithm 2 Handle expiring timer |
- Require:
- 1:
procedure (t) - 2:
- 3:
- 4:
if q then - 5:
▹ Check for Category 4 - 6:
else - 7:
- 8:
end if - 9:
end procedure
|
3.3.3. Inconsistencies of Category 3
Our last algorithm shows how to treat inconsistencies of category 3 (Algorithm 3). As already mentioned, we validate each incoming machine message directly to report discrepancies as early as possible. In contrast to earlier approaches, we check for these inconsistencies by matching a message with a consistent template. If the match is above a defined threshold, the message is consistent. Otherwise, an error will be reported.
| Algorithm 3 Handle complex Inconsistencies |
- 1:
procedure (m) - 2:
- 3:
- 4:
- 5:
if then - 6:
- 7:
end if - 8:
end procedure
|
3.4. Example Runs
To visualize our algorithms, we use three example data sets and present the runs through our automaton in
Figure 9,
Figure 10 and
Figure 11. The graphics each represent a time-dependent snapshot of the automaton.
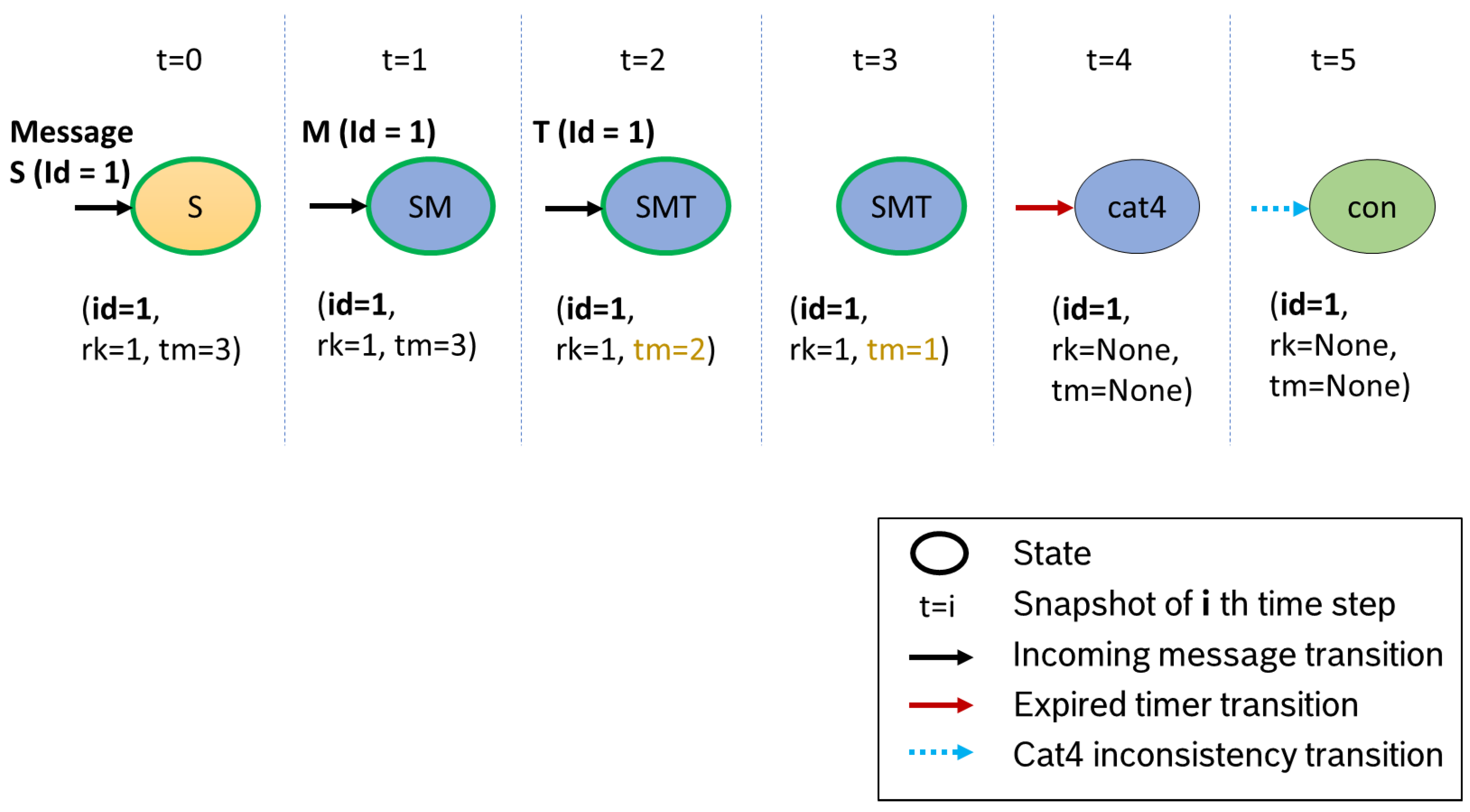
Figure 9 shows the automaton in case of clean data. As one can see in the Figure, our automaton runs step by step through the
potentially consistent states, starting with state
S (timestep
). In each step, a check for category 3 inconsistencies is performed. After the last message has arrived, the data set remains in state
SMT until the last timer expires (timesteps
and
). The automaton switches into state
cat4, where the whole data set is checked for category 4. As the data set is consistent, the automaton switches into the final state
con. For the last two states, we do neither need to start a new timer nor calculate the new rank.
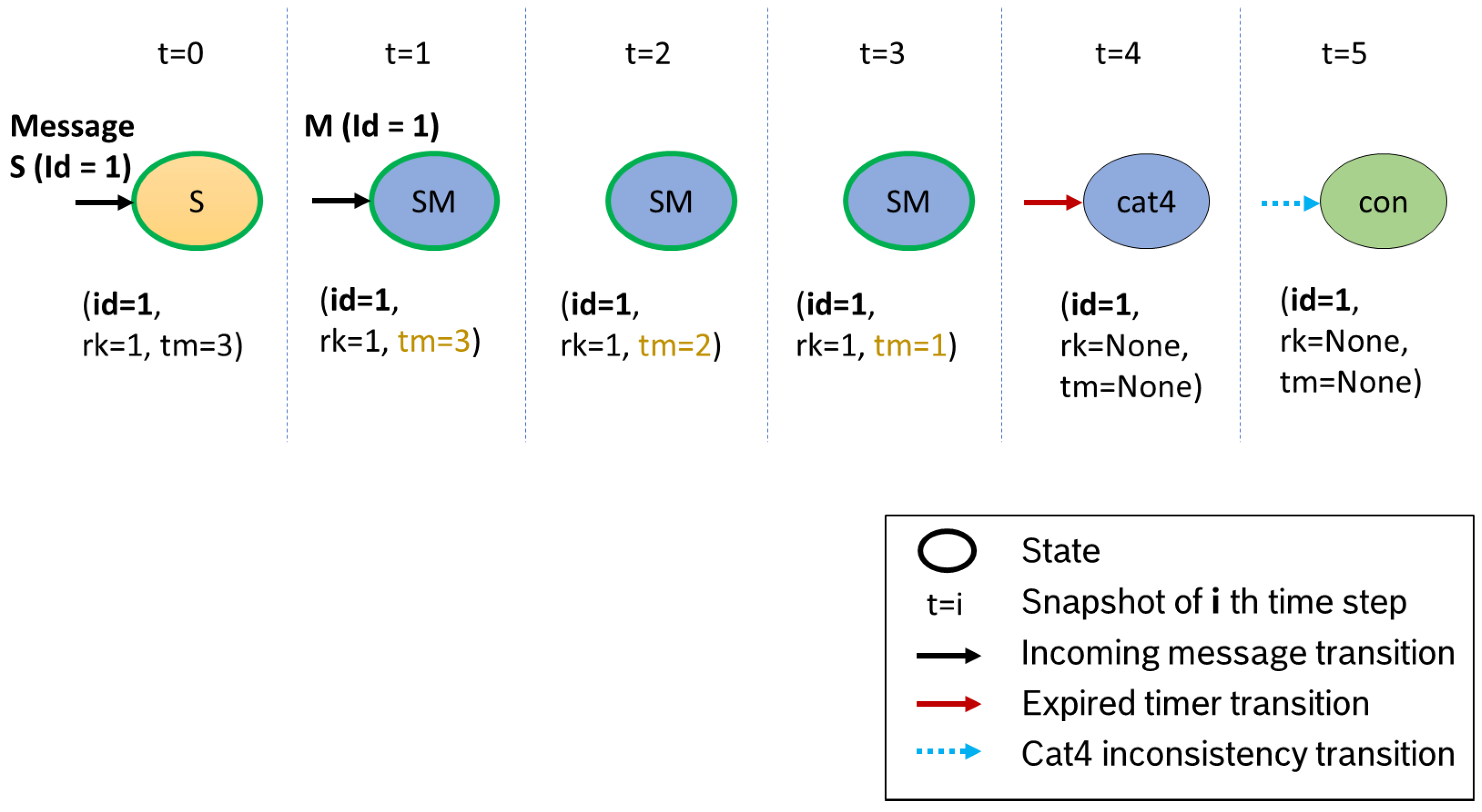
Figure 10 illustrates the run of a data set with a potentially missing message. Again, we start in state
S, then change into
SM. At this point, no more messages arrive. When the timer expires (time step
), we switch into state
cat4. Since
SM is a
potentially consistent state and we did not yet recognize any inconsistent content, we assume that the process has been stopped after step M. Our data are thus consistent and can be processed further.
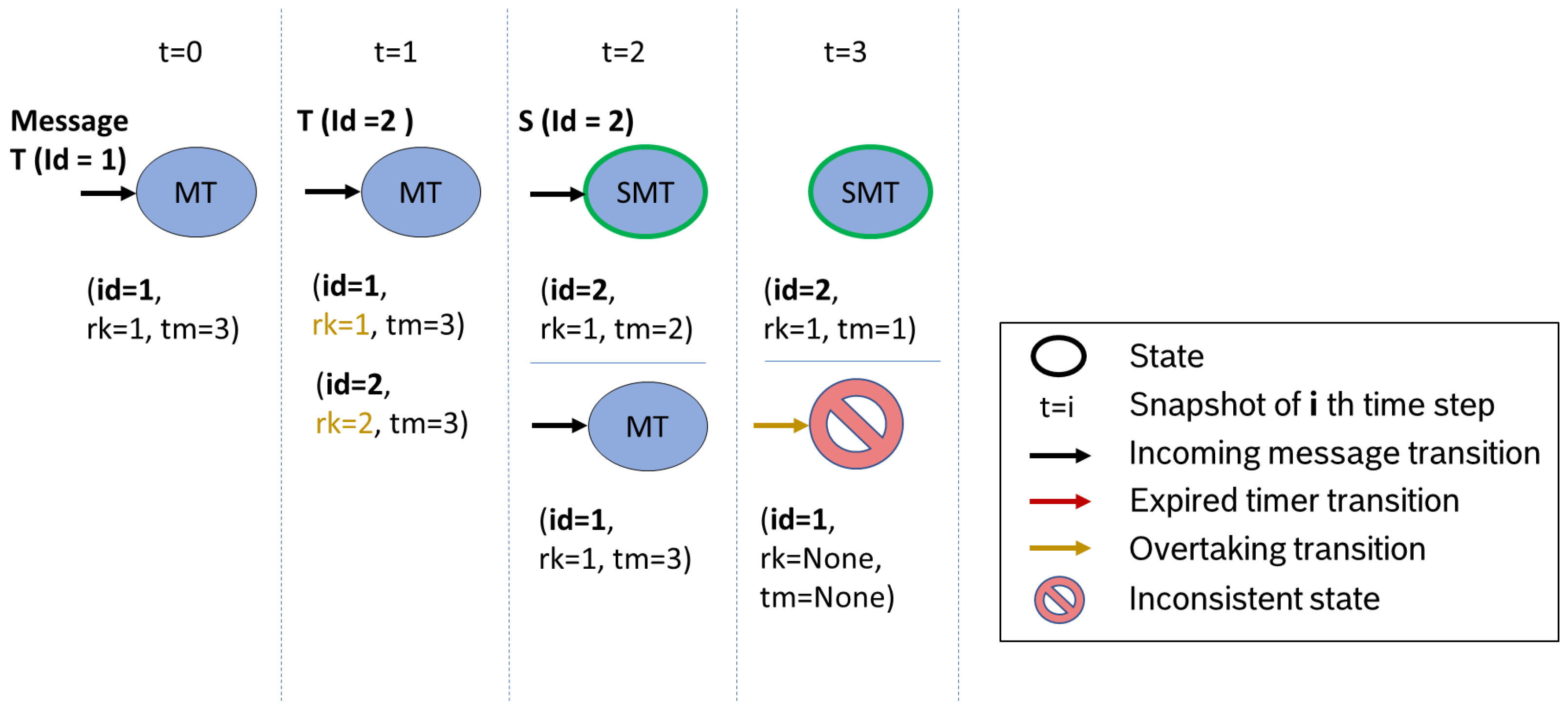
Figure 11 exemplifies a detected overtake in
. The data set with
has rank
in state
MT. Data with
enter state
MT and receive the rank
. In
, data with
switch into state
SMT. At this point, our automaton detects an overtake due to the higher rank of
. According to our algorithm, each data set with smaller rank has to leave the current state. Since the overtake takes place in a normal state, the overtaken data set (
) is moved into the trash state.
6. Discussion
This section discusses the advantages and disadvantages of the automaton in comparison with our previous semantic approaches. To this end, we first discuss the general structure and the extensibility of the methods. Afterwards, we will explicitly consider the checking for content inconsistencies (complex inconsistencies).
6.1. Automaton vs. Semantic Approach
The major difference between our
AutomatonCC and our
GreenCC is the response to incoming messages. As explained in the previous sections, in
AutomatonCC we use an automaton structure for information management and processing, in which a state can change based on incoming information. From our point of view, this has the advantage that we know at any point in time whether all previously expected information is available or not. The check for inconsistencies of categories 1 and 2 therefore happens in the automaton almost without explicit checks (exception: SMD; see
Section 4.1). In
GreenCC, we had to perform a SPARQL test after timer expiration for this information.
However, the automaton structure shifts many tasks from the SPARQL queries to the automaton. This increases the complexity of the overall system. The program is developed modularly; the higher complexity has the consequence that fundamental changes bring more expenditure. In comparison, the GreenCC has a module for handling the data stream. This module does nothing but categorize incoming messages and store them until validation. Changes to the checking process take place in the SPARQL script.
Depending on the scope of the constraint to be checked, changes in SPARQL also become messy and difficult. For this, we consider the following section.
6.2. Checking Complex Inconsistencies via Template
In previous work, we performed the checks via SPARQL queries. For this purpose, the manufacturing environment had to be modeled with ontologies in advance. For the validation step, incoming process and machine data were converted from JSON to RDF format using these ontologies. RDF creates a graph structure that can be traversed via SPARQL queries. Validation via ontologies and SPARQL has the advantage that changes can be incorporated in a simple way. In addition, the modeling languages are easy to understand. These are two properties that argue for its use in a heterogeneous, continuously changing environment. A serious disadvantage of semantic modeling in our scenario is that every discrepancy to be checked must be modeled and thus known. This makes it impossible to cover unknown errors. In addition, many models (including queries and ontology) have to be adapted even for small changes.
Therefore, we have decided to no longer perform checks of Categories 3 and 4 semantically, but by means of template matching. We receive the templates directly when changes are made. The line structure and the general process flow are relatively fixed. Thus, we can still refer to the respective process ontology when creating an automaton.
Template matching also offers further scope for optimization. Currently, we use an accurate method to detect inconsistencies with very high probability. As the authors have indicated in [
6], relevant savings are recognizable in energy consumption when small measurement errors are taken into account. The consideration and evaluation of approximate approaches will be part of future work.
In summary, both concepts have their advantages and disadvantages. If changes in the checking process of complex inconsistencies are necessary, the adaptation of the template is easier than revising ontology and SPARQL queries. If the process changes, complex changes in the automaton are necessary. The GreenCC, on the other hand, remains unaffected. The stream handling controls the message grouping; at the end, a check is performed.
7. Summary and Conclusions
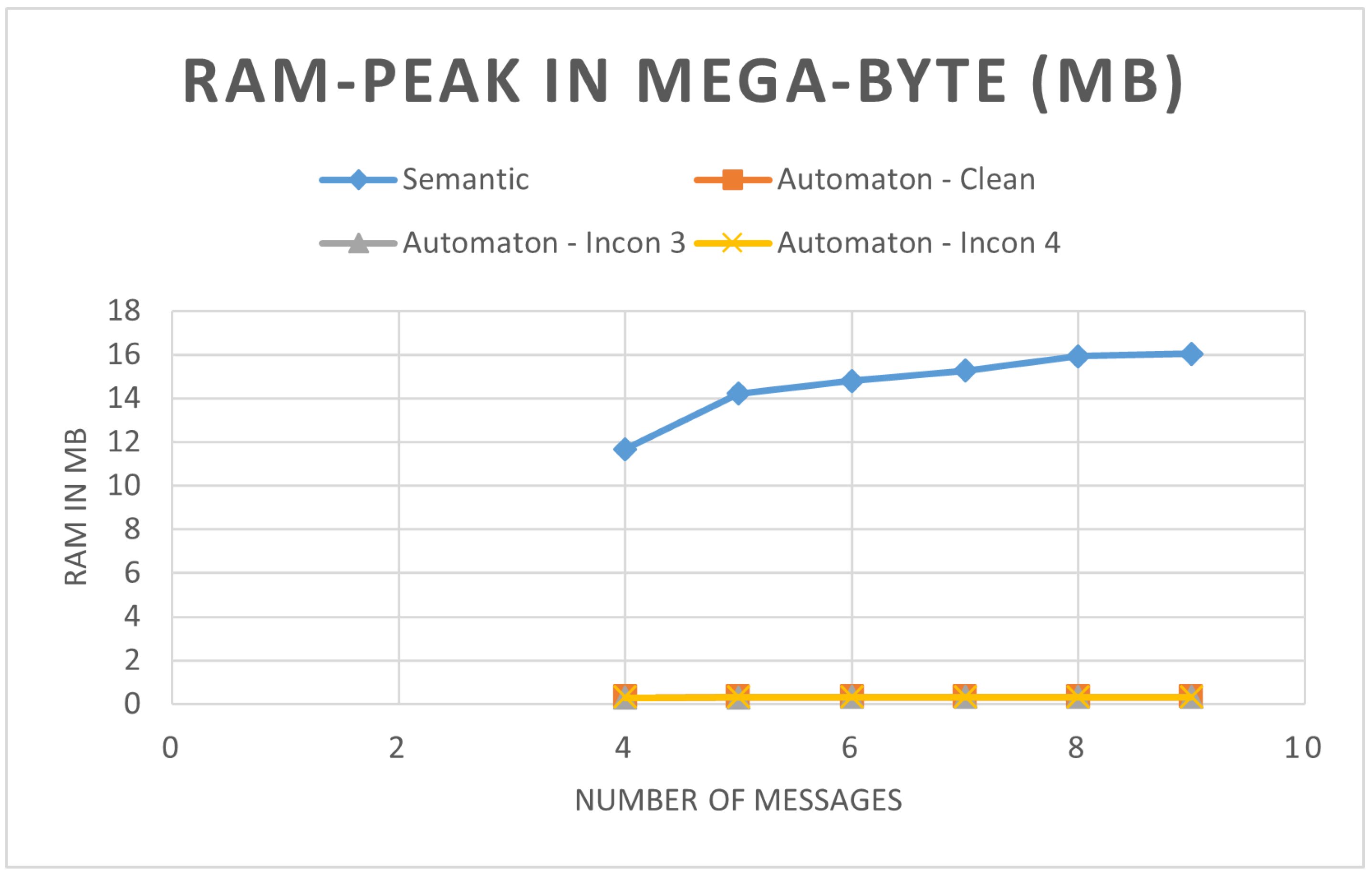
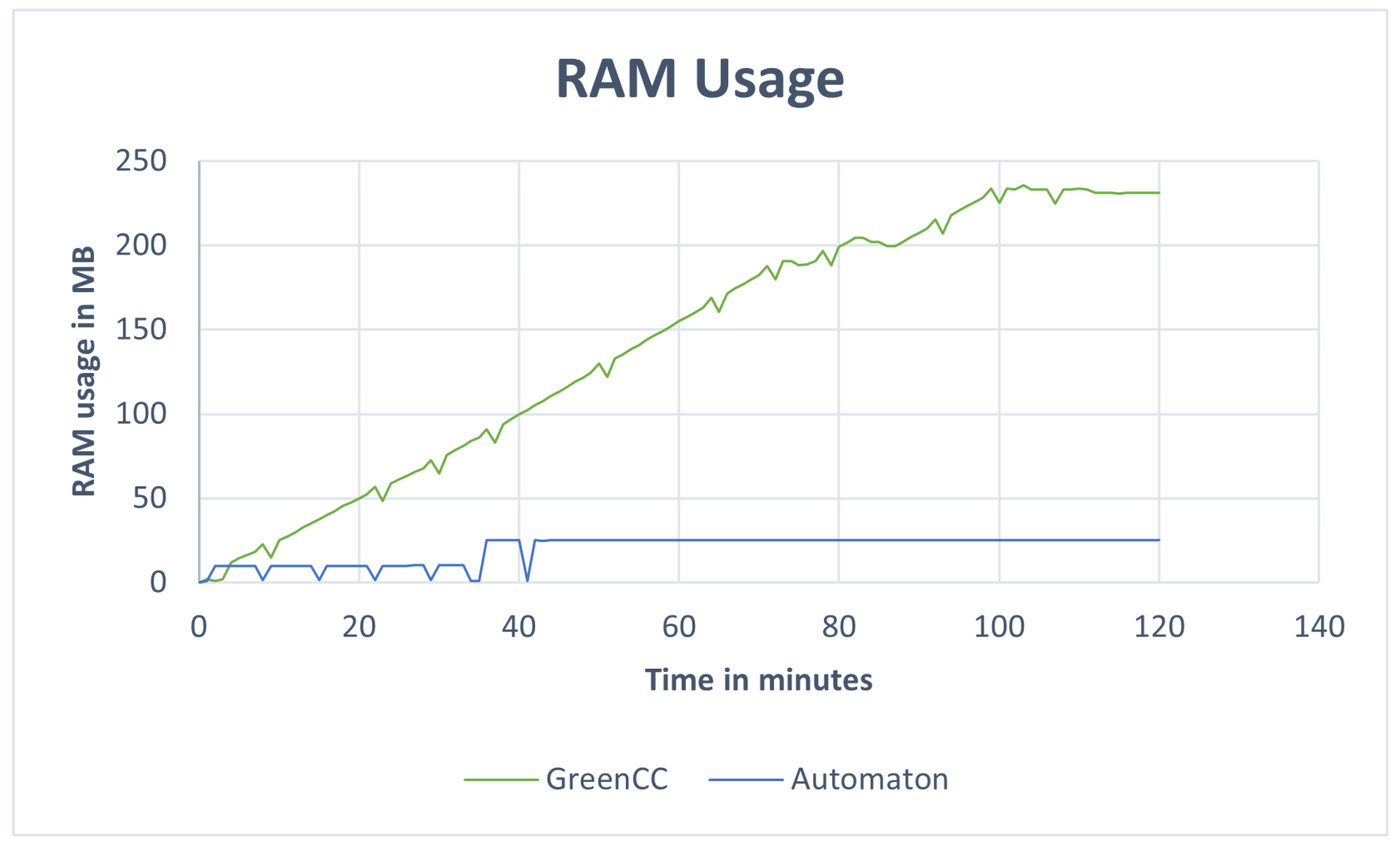
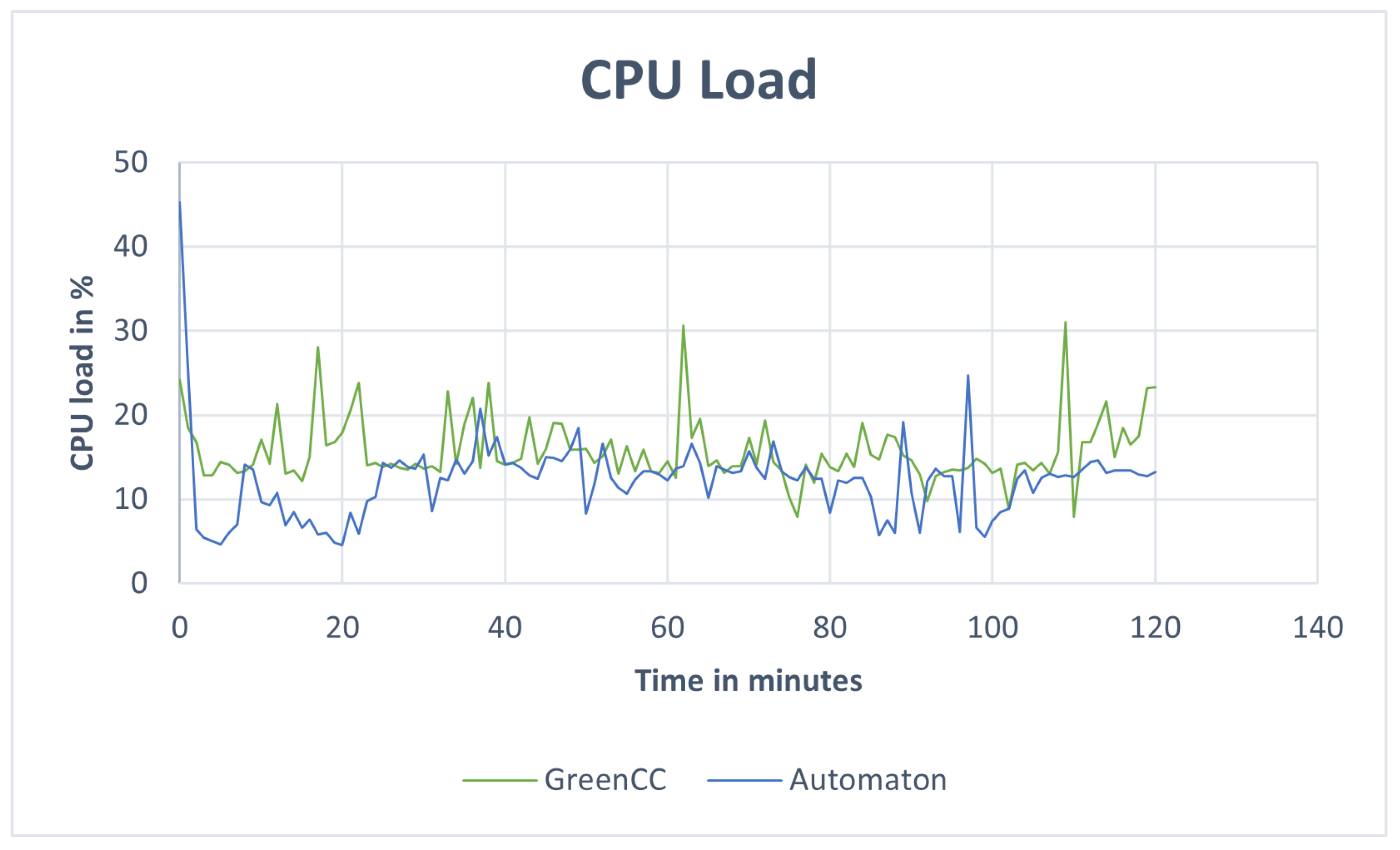
Our paper presented an automaton for data validation tasks in (I)IoT scenarios. At the beginning, we presented the problem of invalid data, especially in smart manufacturing environments, and first prototypes to cope with the task. Subsequently, we discussed the novel AutomatonCC concept, in which we particularly dealt with aspects of increasing efficiency. By direct validation of incoming messages as well as detection of overtakes, the automaton terminates the validation earlier in many cases and stores less data during the validation than previous methods. This is also reflected in the evaluation results, in which we have demonstrated the lower energy consumption due to reduced memory usage. Since our automaton concept is adaptable to related domains, it can be applied in each (I)IoT scenario where quality of data is of importance.
In future work, we want to further consider two limitations of our automaton: (1) Currently, an automaton has to be adapted manually to an (I)IoT scenario. Especially with many devices that are mapped to states, this process is time-consuming and error-prone. (2) With an increasing number of devices, the number of states increases nearly exponentially. An open question remains, up to which environment size our approach scales. For (1), we propose to automatically create automata based on an ontology of the environment to be validated. To address the second limitation, we propose to divide big IoT scenario into sub-scenarios. An automaton can be created for each sub-scenario. The resulting automata can exchange information at a higher level.
Further, we aim to incorporate data cleaning techniques into our automaton. Therewith, we want to consider in particular at what point cleaning should take place (e.g., directly after false validation or at the very end). Afterwards, we want to perform more tests with our automaton prototype on real manufacturing data to continuously increase the overall stability and performance of the consistency checker.
Our list also includes looking at machine learning techniques for validating data. These methods usually fall under the term Anomaly Detection. In analyses, we would like to find out whether machine learning can help us to efficiently detect outliers.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}