
Mapping of Dominant Tree Species in Yunnan Province Based on Sentinel-2 Time-Series Data and Assessment of the Influence of Understory Background on Mapping Accuracy


Abstract
1. Introduction
- To assess the effectiveness of Sentinel-2 time-series data for mapping dominant tree species in Yunnan Province.
- To quantify the negative correlation between canopy cover and classification uncertainty.
2. Study Area and Data
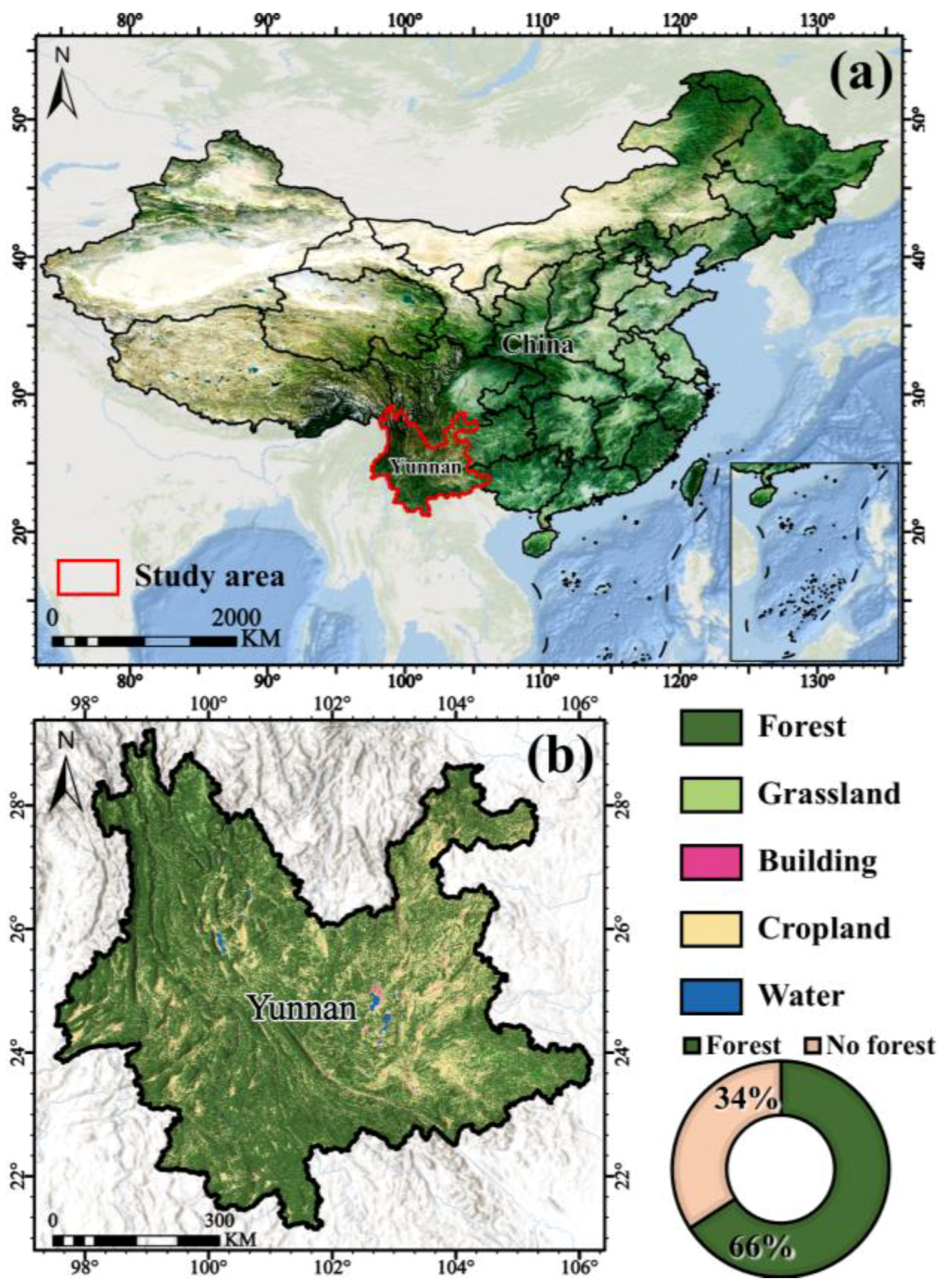
2.1. Study Area
2.2. Data
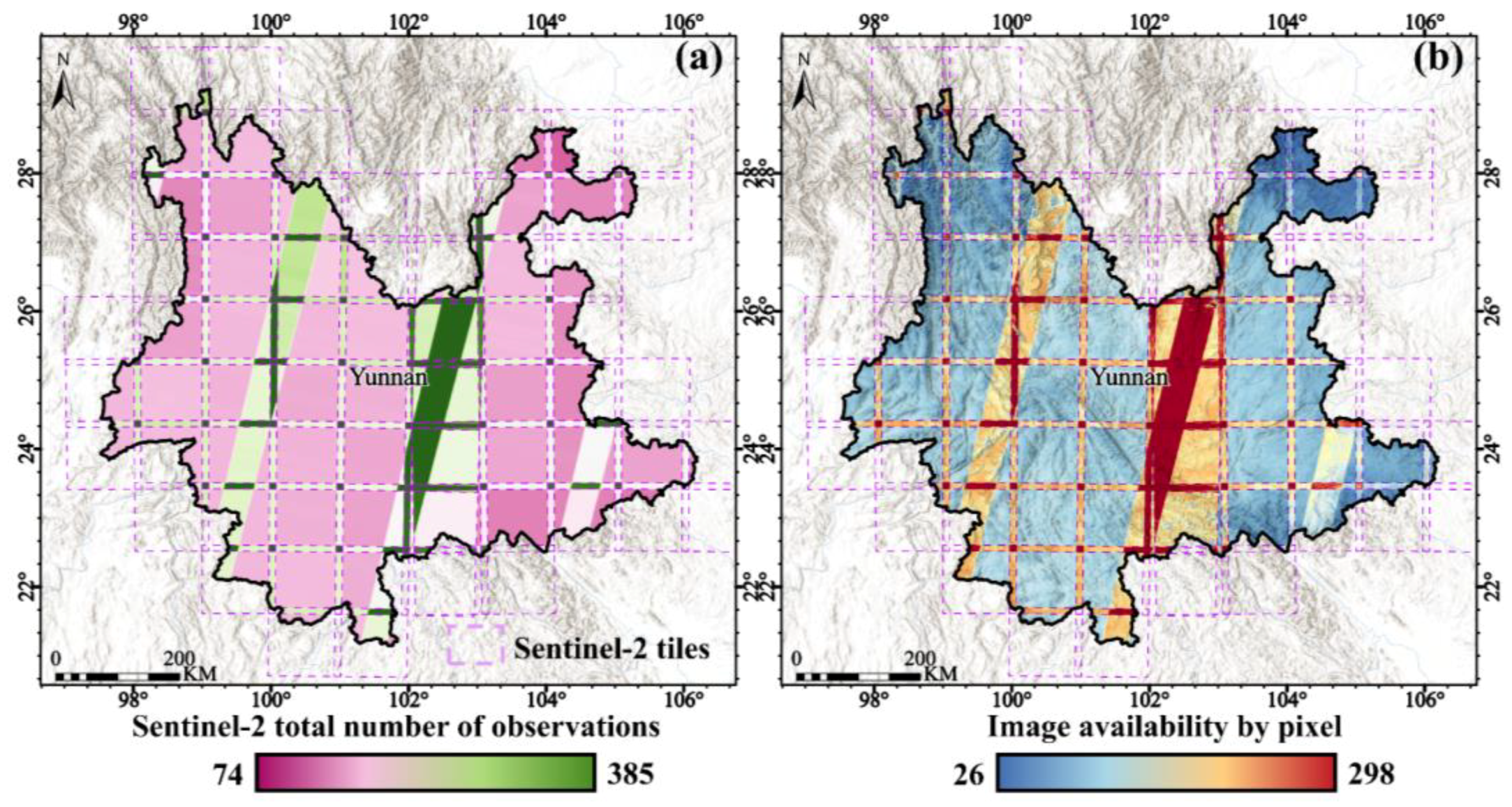
2.2.1. Sentinel-2 Time-Series Data
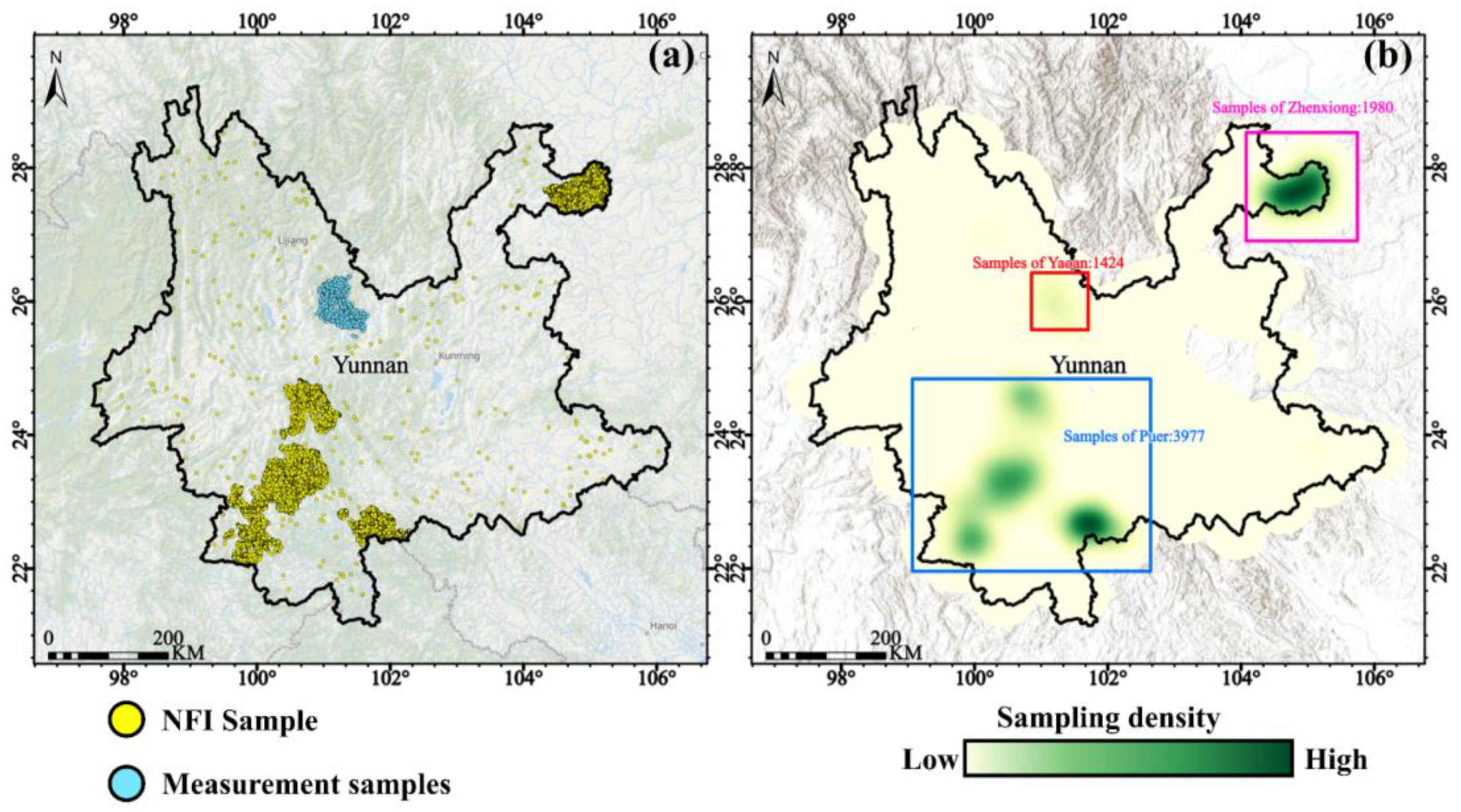
2.2.2. Tree Species Reference Data
2.2.3. Auxiliary Data
3. Methods
3.1. Constructing the Classification Model for Tree Species
3.2. Calculation of Classification Uncertainty
3.3. Modeling Canopy Cover Inversion
3.4. Assessing the Relationship Between Canopy Cover and Classification Uncertainty
4. Results
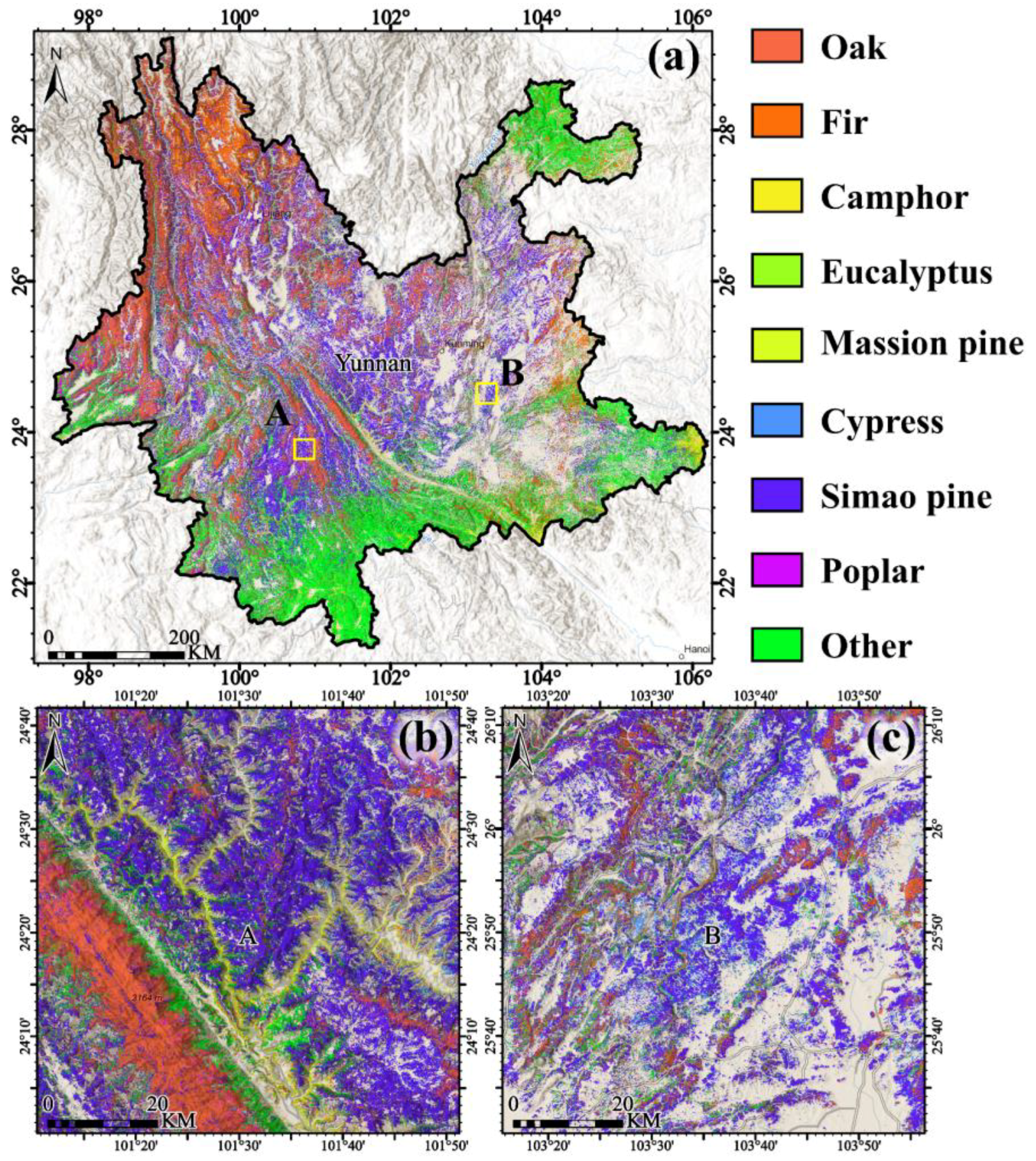
4.1. Projected Map of Dominant Tree Species
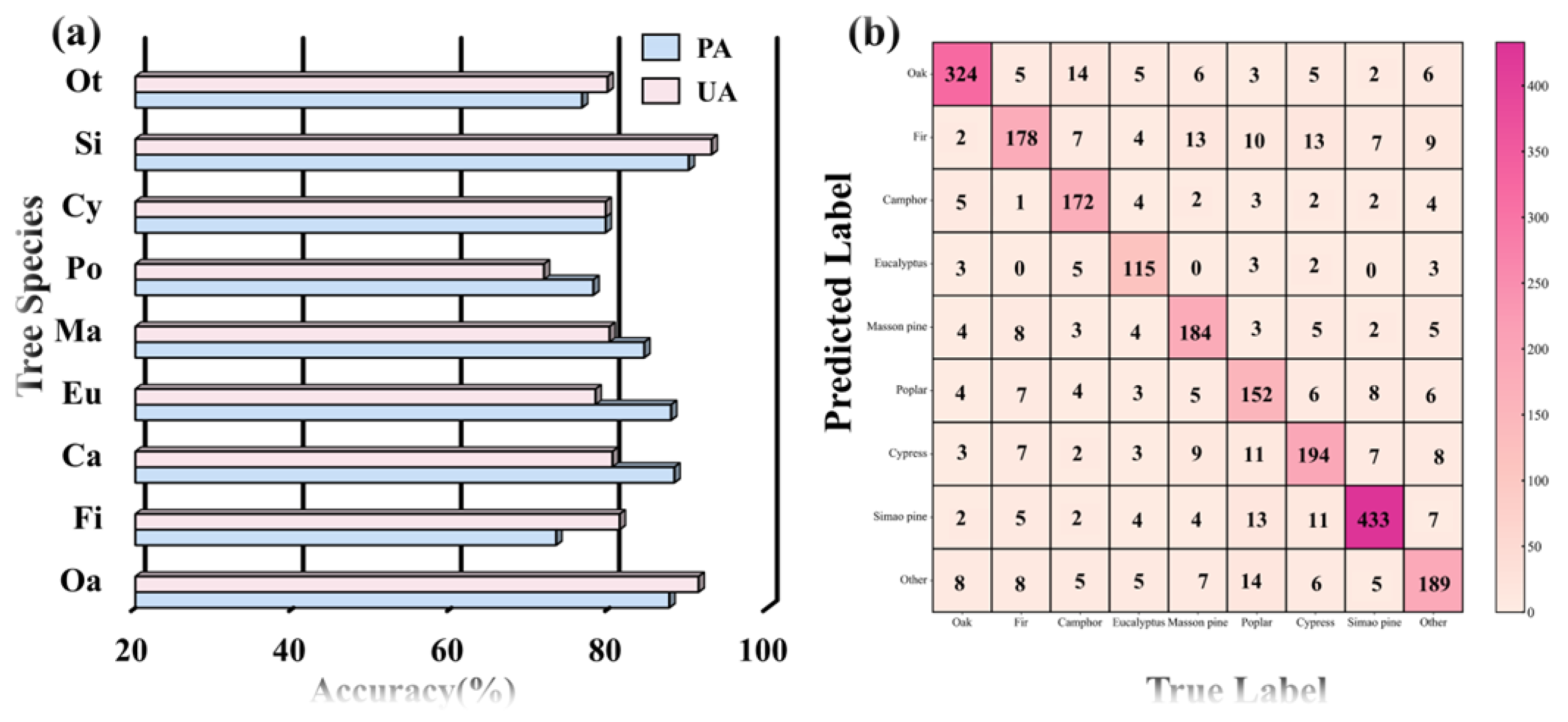
4.2. Classification Model Mapping Accuracy
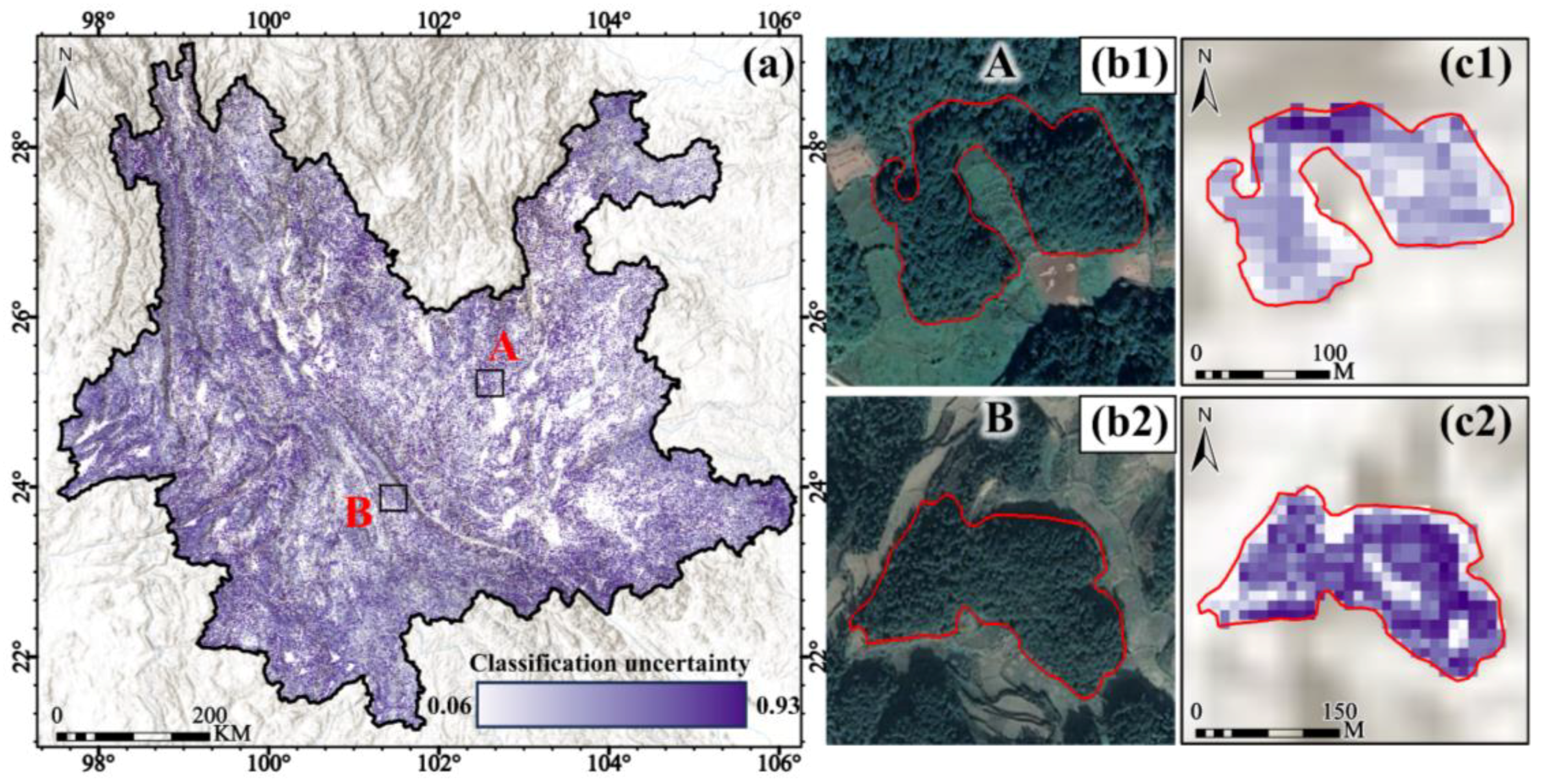
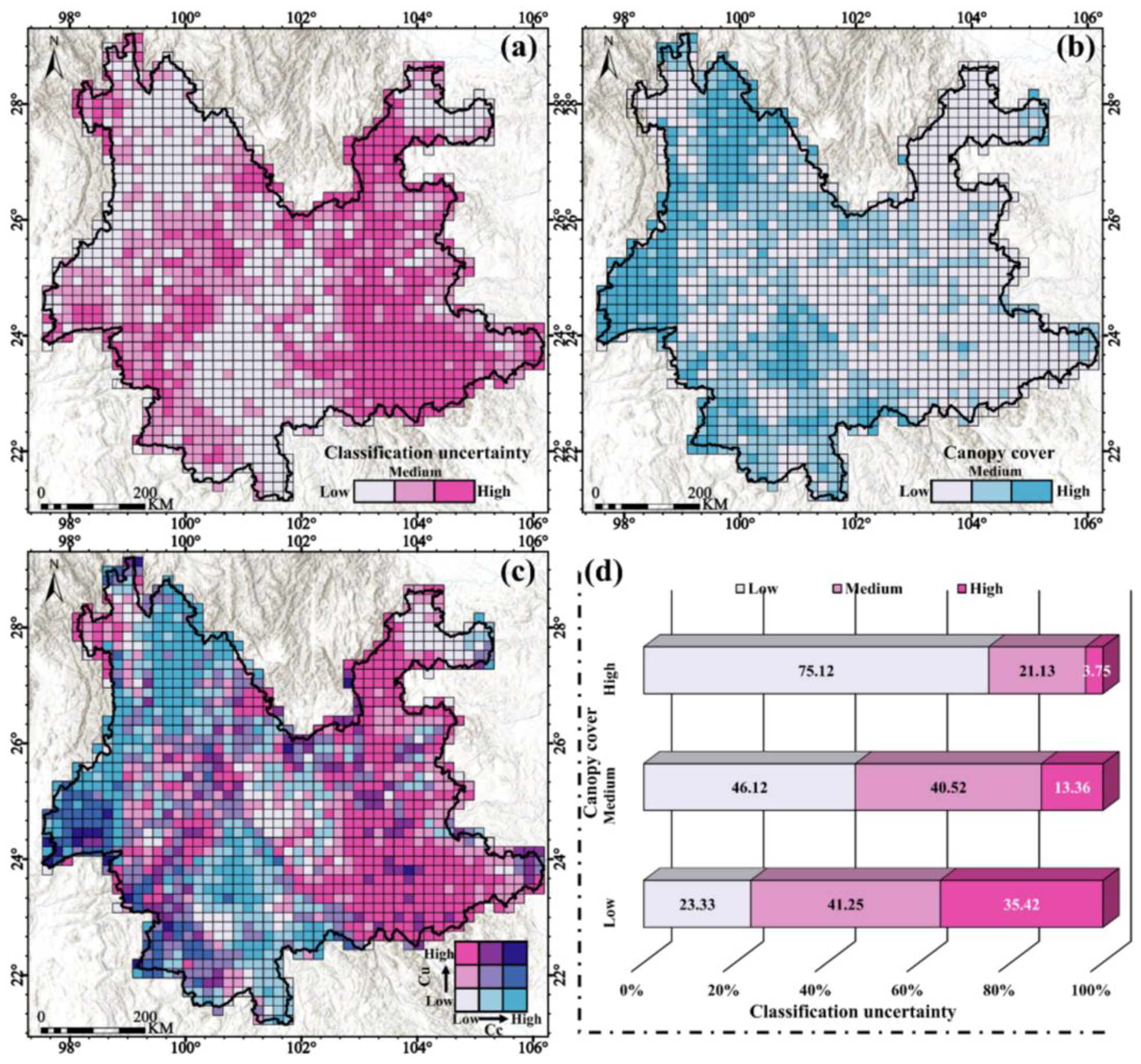
4.3. Results of Classification Uncertainty
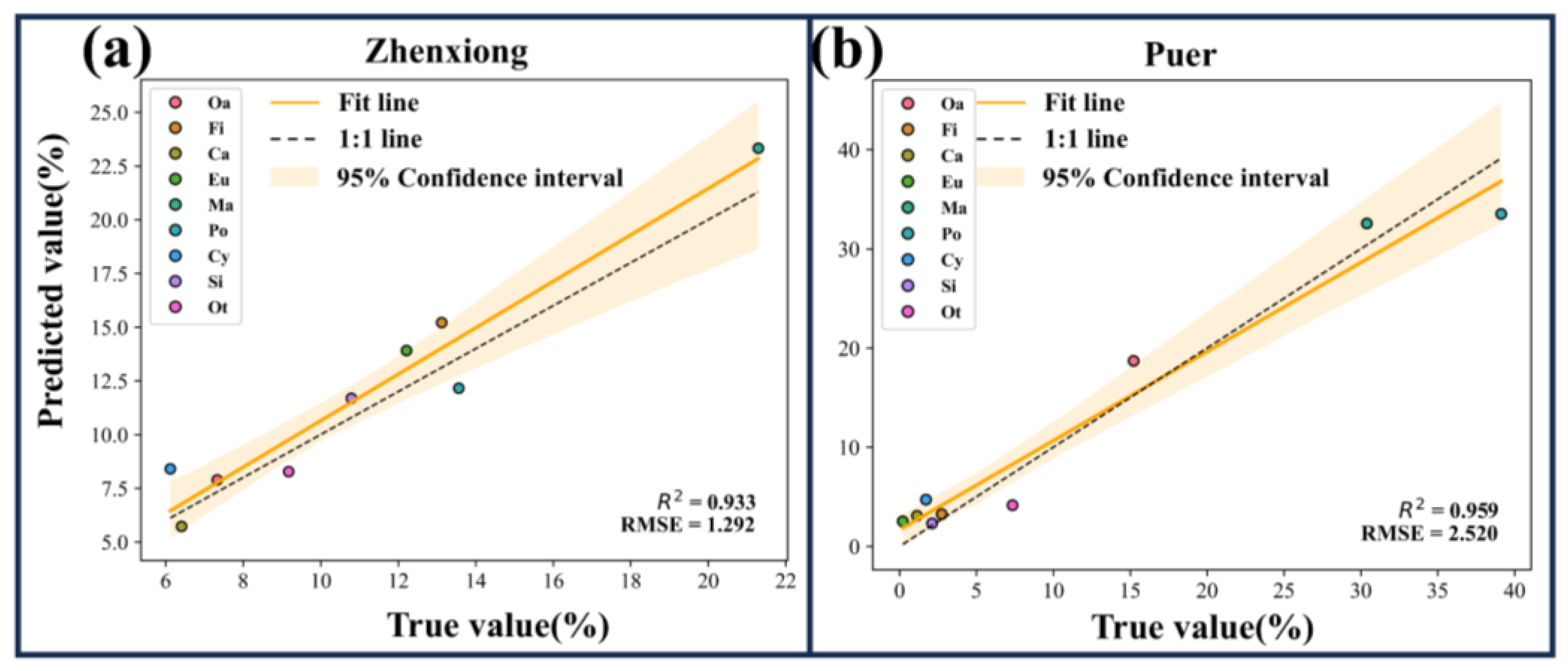
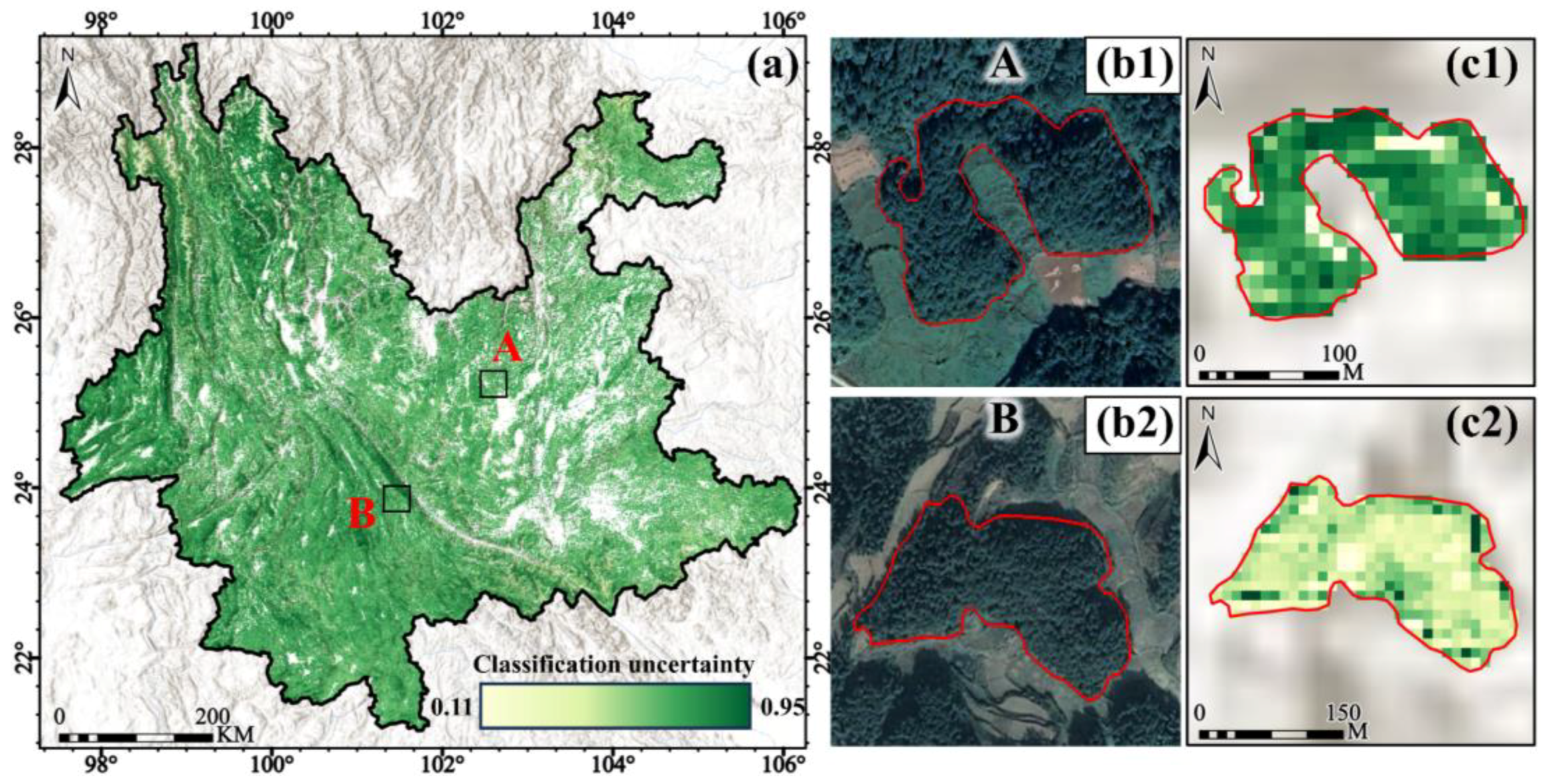
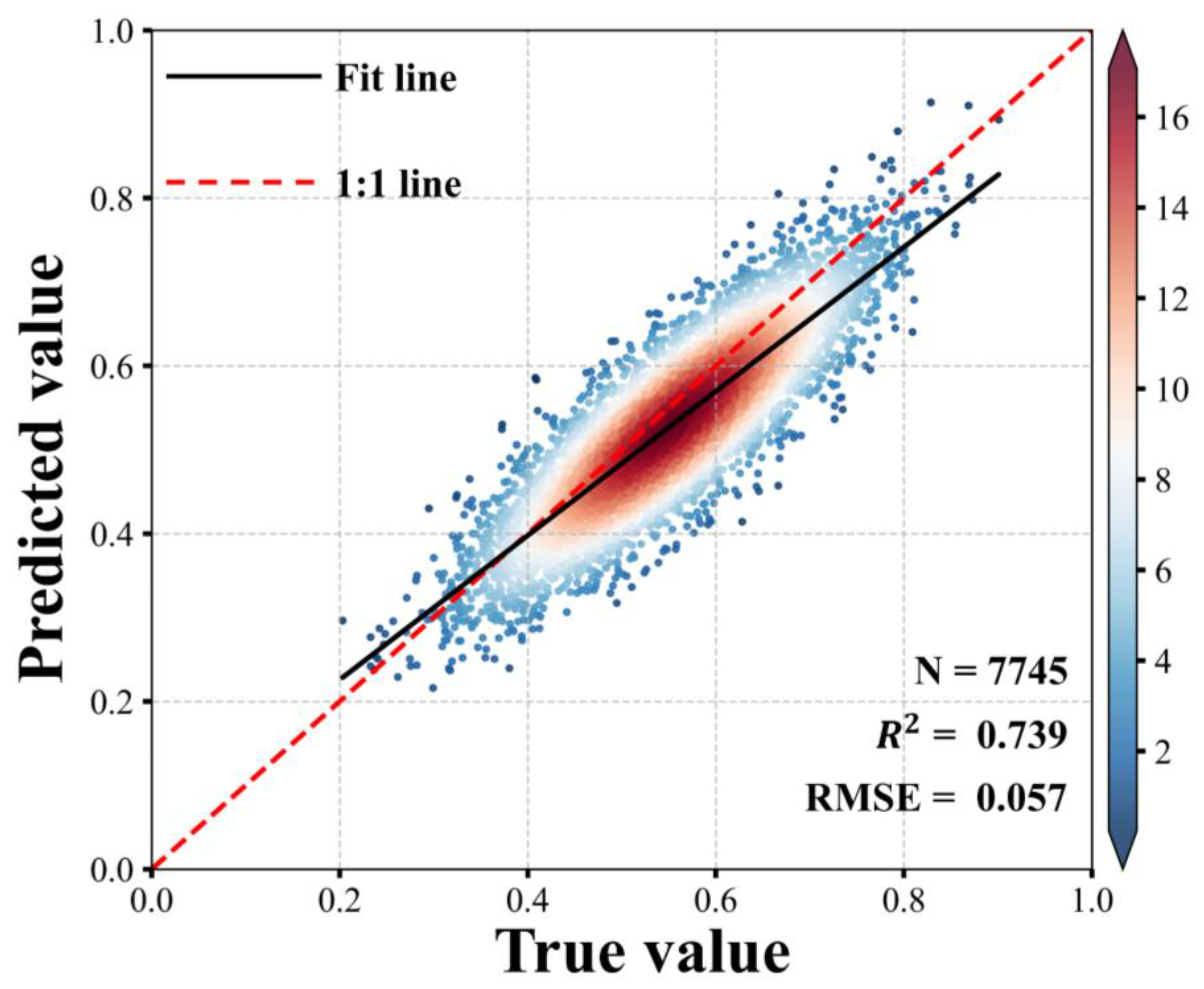
4.4. Canopy Cover Inversion Results and Inversion Accuracy
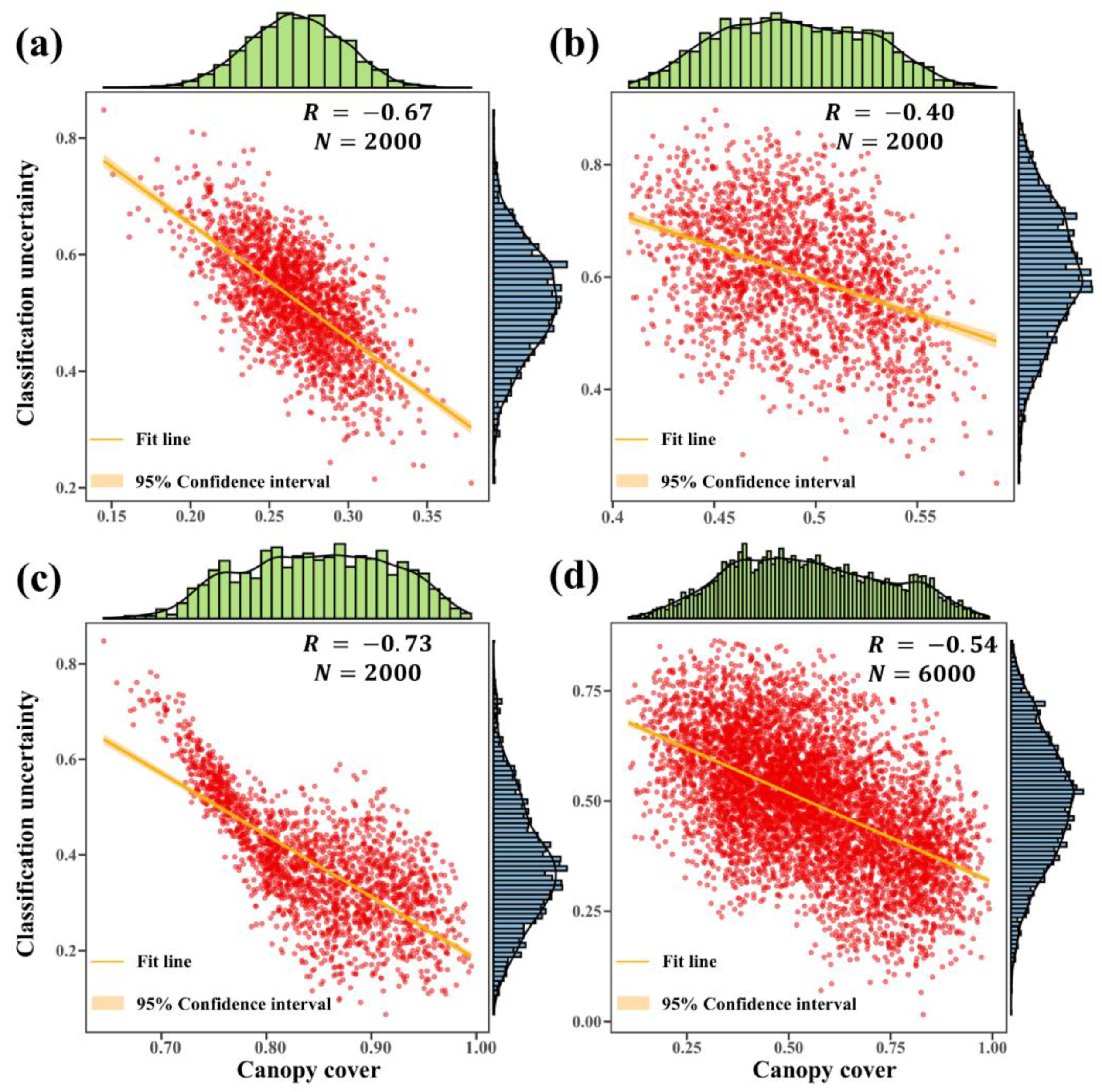
4.5. Relationship Between Canopy Cover and Classification Uncertainty
5. Discussion
5.1. Limitations of Reference Data
5.2. Uncertainty Due to Background Spectral Mixing Effects in the Forest Understory
6. Conclusions
- Applicability of time-series Sentinel-2 for tree species mapping: The integration of time-series Sentinel-2 data, vegetation index characteristics, and environmental variables enabled the accurate mapping of eight dominant tree species in Yunnan Province. The mapping achieved an overall accuracy of 83.52%, with a Kappa coefficient of 0.8115. The predicted tree species maps exhibited a strong agreement with National Forest Inventory (NFI) data, achieving an R2 value exceeding 0.93 and root mean square errors (RMSEs) below 2.6. These results validate the classification performance of the proposed framework and the reliability of the generated tree species maps.
- Understory background and classification uncertainty: Binary contour plots revealed that areas with high classification uncertainty decreased as canopy cover increased, while areas with low classification uncertainty expanded with lower canopy cover. The model demonstrated superior classification performance and greater confidence in regions with dense canopy cover. Pearson’s correlation analysis further confirmed a significant negative correlation between canopy cover and classification uncertainty, with an overall correlation coefficient of −0.54. In areas with low canopy cover, the correlation was 0.67. The correlation was −0.40 in the region of medium canopy cover. The correlation was −0.73 in the region of high canopy cover.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schelhaas, M.; Teeuwen, S.; Oldenburger, J.; Beerkens, G.; Velema, G.; Kremers, J.; Lerink, B.; Paulo, M.; Schoonderwoerd, H.; Daamen, W. Zevende Nederlandse Bosinventarisatie: Methoden en Resultaten; Wettelijke Onderzoekstaken Natuur & Milieu: Wageningen, The Netherlands, 2022; pp. 2352–2739. [Google Scholar]
- Wang, R.; Gamon, J.A. Remote sensing of terrestrial plant biodiversity. Remote Sens. Environ. 2019, 231, 111218. [Google Scholar] [CrossRef]
- Xiao, J.; Chevallier, F.; Gomez, C.; Guanter, L.; Hicke, J.A.; Huete, A.R.; Ichii, K.; Ni, W.; Pang, Y.; Rahman, A.F. Remote sensing of the terrestrial carbon cycle: A review of advances over 50 years. Remote Sens. Environ. 2019, 233, 111383. [Google Scholar] [CrossRef]
- Young, B.; Yarie, J.; Verbyla, D.; Huettmann, F.; Herrick, K.; Chapin, F.S. Modeling and mapping forest diversity in the boreal forest of interior Alaska. Landsc. Ecol. 2017, 32, 397–413. [Google Scholar] [CrossRef]
- Gillis, M.D.; Leckie, D.G. Forest Inventory Mapping Procedures Across Canada; Information Report No. PI-X-114; Petawawa National Forestry Institute: Chalk River, ON, Canada, 1993. [Google Scholar]
- Tomppo, E.; Gschwantner, T.; Lawrence, M.; McRoberts, R.E.; Gabler, K.; Schadauer, K.; Vidal, C.; Lanz, A.; Ståhl, G.; Cienciala, E. Pathways for Common Reporting. In National Forest Inventories; European Science Foundation: Strasbourg, France, 2010; Volume 1, pp. 541–553. [Google Scholar]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Matasci, G.; Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W.; Bolton, D.K.; Tompalski, P.; Bater, C.W. Three decades of forest structural dynamics over Canada’s forested ecosystems using Landsat time-series and lidar plots. Remote Sens. Environ. 2018, 216, 697–714. [Google Scholar] [CrossRef]
- Ørka, H.O.; Jutras-Perreault, M.-C.; Næsset, E.; Gobakken, T. A framework for a forest ecological base map–An example from Norway. Ecol. Indic. 2022, 136, 108636. [Google Scholar] [CrossRef]
- Hemmerling, J.; Pflugmacher, D.; Hostert, P. Mapping temperate forest tree species using dense Sentinel-2 time series. Remote Sens. Environ. 2021, 267, 112743. [Google Scholar] [CrossRef]
- Francini, S.; Schelhaas, M.-J.; Vangi, E.; Lerink, B.; Nabuurs, G.-J.; McRoberts, R.E.; Chirici, G. Forest species mapping and area proportion estimation combining Sentinel-2 harmonic predictors and national forest inventory data. Int. J. Appl. Earth Obs. Geoinf. 2024, 131, 103935. [Google Scholar] [CrossRef]
- Nasiri, V.; Beloiu, M.; Asghar Darvishsefat, A.; Griess, V.C.; Maftei, C.; Waser, L.T. Mapping tree species composition in a Caspian temperate mixed forest based on spectral-temporal metrics and machine learning. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103154. [Google Scholar] [CrossRef]
- Waser, L.T.; Küchler, M.; Jütte, K.; Stampfer, T. Evaluating the Potential of WorldView-2 Data to Classify Tree Species and Different Levels of Ash Mortality. Remote Sens. 2014, 6, 4515–4545. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Shang, C.; Coops, N.C.; Wulder, M.A.; White, J.C.; Hermosilla, T. Update and spatial extension of strategic forest inventories using time series remote sensing and modeling. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101956. [Google Scholar] [CrossRef]
- Hermosilla, T.; Bastyr, A.; Coops, N.C.; White, J.C.; Wulder, M.A. Mapping the presence and distribution of tree species in Canada’s forested ecosystems. Remote Sens. Environ. 2022, 282, 113276. [Google Scholar] [CrossRef]
- Hościło, A.; Lewandowska, A. Mapping forest type and tree species on a regional scale using multi-temporal Sentinel-2 data. Remote Sens. 2019, 11, 929. [Google Scholar] [CrossRef]
- Pasquarella, V.J.; Holden, C.E.; Woodcock, C.E. Improved mapping of forest type using spectral-temporal Landsat features. Remote Sens. Environ. 2018, 210, 193–207. [Google Scholar] [CrossRef]
- Wan, L.; Ryu, Y.; Dechant, B.; Hwang, Y.; Feng, H.; Kang, Y.; Jeong, S.; Lee, J.; Choi, C.; Bae, J. Correcting confounding canopy structure, biochemistry and soil background effects improves leaf area index estimates across diverse ecosystems from Sentinel-2 imagery. Remote Sens. Environ. 2024, 309, 114224. [Google Scholar] [CrossRef]
- Mandl, L.; Viana-Soto, A.; Seidl, R.; Stritih, A.; Senf, C. Unmixing-based forest recovery indicators for predicting long-term recovery success. Remote Sens. Environ. 2024, 308, 114194. [Google Scholar] [CrossRef]
- Farwell, L.S.; Gudex-Cross, D.; Anise, I.E.; Bosch, M.J.; Olah, A.M.; Radeloff, V.C.; Razenkova, E.; Rogova, N.; Silveira, E.M.; Smith, M.M. Satellite image texture captures vegetation heterogeneity and explains patterns of bird richness. Remote Sens. Environ. 2021, 253, 112175. [Google Scholar] [CrossRef]
- Zeug, G.; Immitzer, M.; Neuwirth, M.; Atzberger, C. Machbarkeitsstudie zur Nutzung von Satellitenfernerkundungsdaten (Copernicus) für Zwecke der Ableitung Ökologischer Belastungsgrenzen und der Verifizierung von Indikatoren der Deutschen Anpassungsstrategie an den Klimawandel: Feasibility Study on the Use of Earth Observation Data for the Purpose of Determining Ecological Exposure Limits and for the Verification of Indicators of the German Adaptation Strategy to Climate Change; Terranea UG: Geltendorf, Germany, 2018. [Google Scholar]
- Sudmanns, M.; Tiede, D.; Augustin, H.; Lang, S. Assessing global Sentinel-2 coverage dynamics and data availability for operational Earth observation (EO) applications using the EO-Compass. Int. J. Digit. Earth 2020, 13, 768–784. [Google Scholar] [CrossRef] [PubMed]
- Kollert, A.; Bremer, M.; Löw, M.; Rutzinger, M. Exploring the potential of land surface phenology and seasonal cloud free composites of one year of Sentinel-2 imagery for tree species mapping in a mountainous region. Int. J. Appl. Earth Obs. Geoinf. 2021, 94, 102208. [Google Scholar] [CrossRef]
- Blickensdörfer, L.; Oehmichen, K.; Pflugmacher, D.; Kleinschmit, B.; Hostert, P. National tree species mapping using Sentinel-1/2 time series and German National Forest Inventory data. Remote Sens. Environ. 2024, 304, 114069. [Google Scholar] [CrossRef]
- Dong, T.; Liu, J.; Liu, J.; He, L.; Wang, R.; Qian, B.; McNairn, H.; Powers, J.; Shi, Y.; Chen, J.M. Assessing the consistency of crop leaf area index derived from seasonal Sentinel-2 and Landsat 8 imagery over Manitoba, Canada. Agric. For. Meteorol. 2023, 332, 109357. [Google Scholar] [CrossRef]
- Grabska, E.; Frantz, D.; Ostapowicz, K. Evaluation of machine learning algorithms for forest stand species mapping using Sentinel-2 imagery and environmental data in the Polish Carpathians. Remote Sens. Environ. 2020, 251, 112103. [Google Scholar] [CrossRef]
- Wang, J.; Lopez-Lozano, R.; Weiss, M.; Buis, S.; Li, W.; Liu, S.; Baret, F.; Zhang, J. Crop specific inversion of PROSAIL to retrieve green area index (GAI) from several decametric satellites using a Bayesian framework. Remote Sens. Environ. 2022, 278, 113085. [Google Scholar] [CrossRef]
- Broge, N.; Mortensen, J. Deriving green crop area index and canopy chlorophyll density of winter wheat from spectral reflectance data. Remote Sens. Environ. 2002, 81, 45–57. [Google Scholar] [CrossRef]
- Bolyn, C.; Michez, A.; Gaucher, P.; Lejeune, P.; Bonnet, S. Forest mapping and species composition using supervised per pixel classification of Sentinel-2 imagery. Biotechnol. Agron. Soc. Environ. 2018, 22, 16. [Google Scholar] [CrossRef]
- Jordan, C.F. Derivation of Leaf-Area Index from Quality of Light on the Forest Floor. Ecology 1969, 50, 663–666. [Google Scholar] [CrossRef]
- Badgley, G.; Field, C.B.; Berry, J.A. Canopy near-infrared reflectance and terrestrial photosynthesis. Sci. Adv. 2017, 3, e1602244. [Google Scholar] [CrossRef]
- Martimort, P.; Fernandez, V.; Kirschner, V.; Isola, C.; Meygret, A. Sentinel-2 MultiSpectral imager (MSI) and calibration/validation. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 6999–7002. [Google Scholar]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel-2 and deep learning. In Proceedings of the IGARSS 2021–2021 IEEE International Geoscience and Remote Sensing Symposium. IEEE, Brussels, Belgium, 11–16 July 2021. [Google Scholar]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Wulder, M.A.; Hermosilla, T.; White, J.C.; Coops, N.C. Biomass status and dynamics over Canada’s forests: Disentangling disturbed area from associated aboveground biomass consequences. Environ. Res. Lett. 2020, 15, 094093. [Google Scholar] [CrossRef]
- Li, L.; Mu, X.; Qi, J.; Pisek, J.; Roosjen, P.; Yan, G.; Huang, H.; Liu, S.; Baret, F. Characterizing reflectance anisotropy of background soil in open-canopy plantations using UAV-based multiangular images. ISPRS J. Photogramm. Remote Sens. 2021, 177, 263–278. [Google Scholar] [CrossRef]
- Weiss, M.; Baret, F.; Jay, S. S2ToolBox Level 2 products: LAI, FAPAR, FCOVER. Available online: https://step.esa.int/docs/extra/ATBD_S2ToolBox_L2B_V1.1.pdf (accessed on 1 January 2025).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spectral Indices | Formula |
|---|---|
| NDVI [29] | (B8 − B4)/(B8 + B4) |
| SAVI [30] | (1 + 0.2) × float (B8 − B4)/(B8 + B4 + 0.2) |
| RVI [31] | B4/B8 |
| NIRV [32] | ((B8 − B4)/(B8 + B4)) × B8 |
| REIP [33] | 705 + 35 × ((B4 + B7)/2 – (B5/B6) − B5) |
| EVI [34] | 2.5 × (B8 – B4)/(B8 + 6 × B4 − 7.5 × B2 + 1) |
| Tree Species Name | Tree Species Code | Number | |
|---|---|---|---|
| Dominant tree species | Oak | Oa | 1233 |
| Fir | Fi | 811 | |
| Camphor | Ca | 649 | |
| Eucalyptus | Eu | 436 | |
| Masson Pine | Ma | 648 | |
| Cypress | Cy | 814 | |
| Simao Pine | Si | 1604 | |
| Poplar | Po | 726 | |
| Other species | Maple, willow, etc. | Ot | 824 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Zhu, J.; Yang, B.; Liu, H. Mapping of Dominant Tree Species in Yunnan Province Based on Sentinel-2 Time-Series Data and Assessment of the Influence of Understory Background on Mapping Accuracy. Forests 2025, 16, 272. https://doi.org/10.3390/f16020272
Sun Y, Zhu J, Yang B, Liu H. Mapping of Dominant Tree Species in Yunnan Province Based on Sentinel-2 Time-Series Data and Assessment of the Influence of Understory Background on Mapping Accuracy. Forests. 2025; 16(2):272. https://doi.org/10.3390/f16020272
Chicago/Turabian StyleSun, Yihao, Jingyuan Zhu, Ben Yang, and Haodong Liu. 2025. "Mapping of Dominant Tree Species in Yunnan Province Based on Sentinel-2 Time-Series Data and Assessment of the Influence of Understory Background on Mapping Accuracy" Forests 16, no. 2: 272. https://doi.org/10.3390/f16020272
APA StyleSun, Y., Zhu, J., Yang, B., & Liu, H. (2025). Mapping of Dominant Tree Species in Yunnan Province Based on Sentinel-2 Time-Series Data and Assessment of the Influence of Understory Background on Mapping Accuracy. Forests, 16(2), 272. https://doi.org/10.3390/f16020272