
An Efficient Forest Fire Detection Algorithm Using Improved YOLOv5


Abstract
:1. Introduction
2. Methods
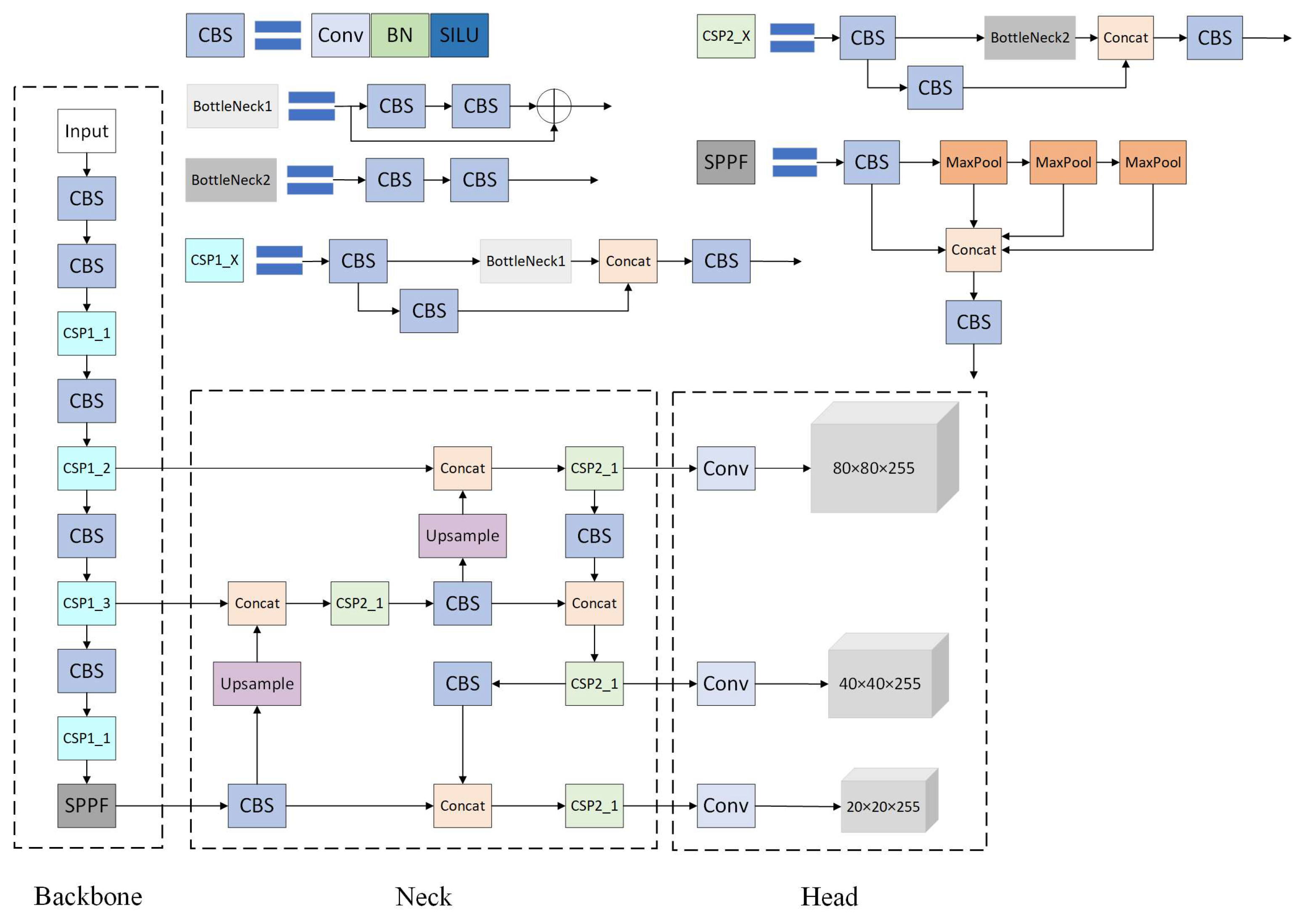
2.1. YOLOv5m Algorithm
- Backbone: In the YOLOv5m model, CSPDarknet53 serves as the backbone network. CSPDarknet53 is rooted in the Darknet53 network architecture and incorporates Cross Stage Partial (CSP) [43] connections. These connections enhance the network’s ability for extracting image features and computational efficiency;
- Neck: This section employs a combined architecture that consists of the Feature Pyramid Network (FPN) [44] and the Path Aggregation Network (PAN) [45]. FPN propagates semantic information top-down, while PAN conveys localization information top-down. Then, utilizing both up-sampling and down-sampling operations, it effectively integrates feature maps from various levels to produce a multi-scale feature pyramid. This pyramid enhances the algorithm’s capacity to capture information at various scales;
- Head: This component consists of four parts: Anchors, Convolutional Layers, Prediction Layers, and Non-Maximum Suppression. The anchors are a predefined set of bounding boxes used to generate candidate boxes on the feature map. The convolutional layers in the detection head are responsible for processing the feature maps and extracting features. Each prediction layer is responsible for predicting a set of bounding boxes and their corresponding class probabilities. In the output bounding boxes, the non-maximum suppression algorithm is employed to suppress overlapping boxes, retaining only the most representative ones. The primary function of the head is to extract features and make predictions for object detection. It extracts high-level features from the input image and utilizes them to predict the position and category of objects in the image.
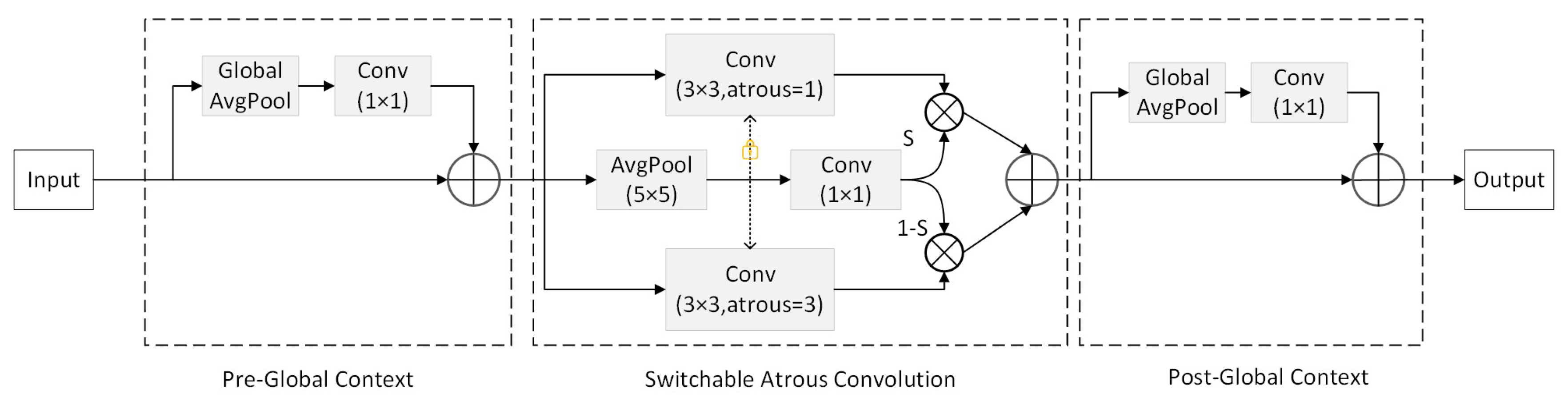
2.2. Switchable Atrous Convolution
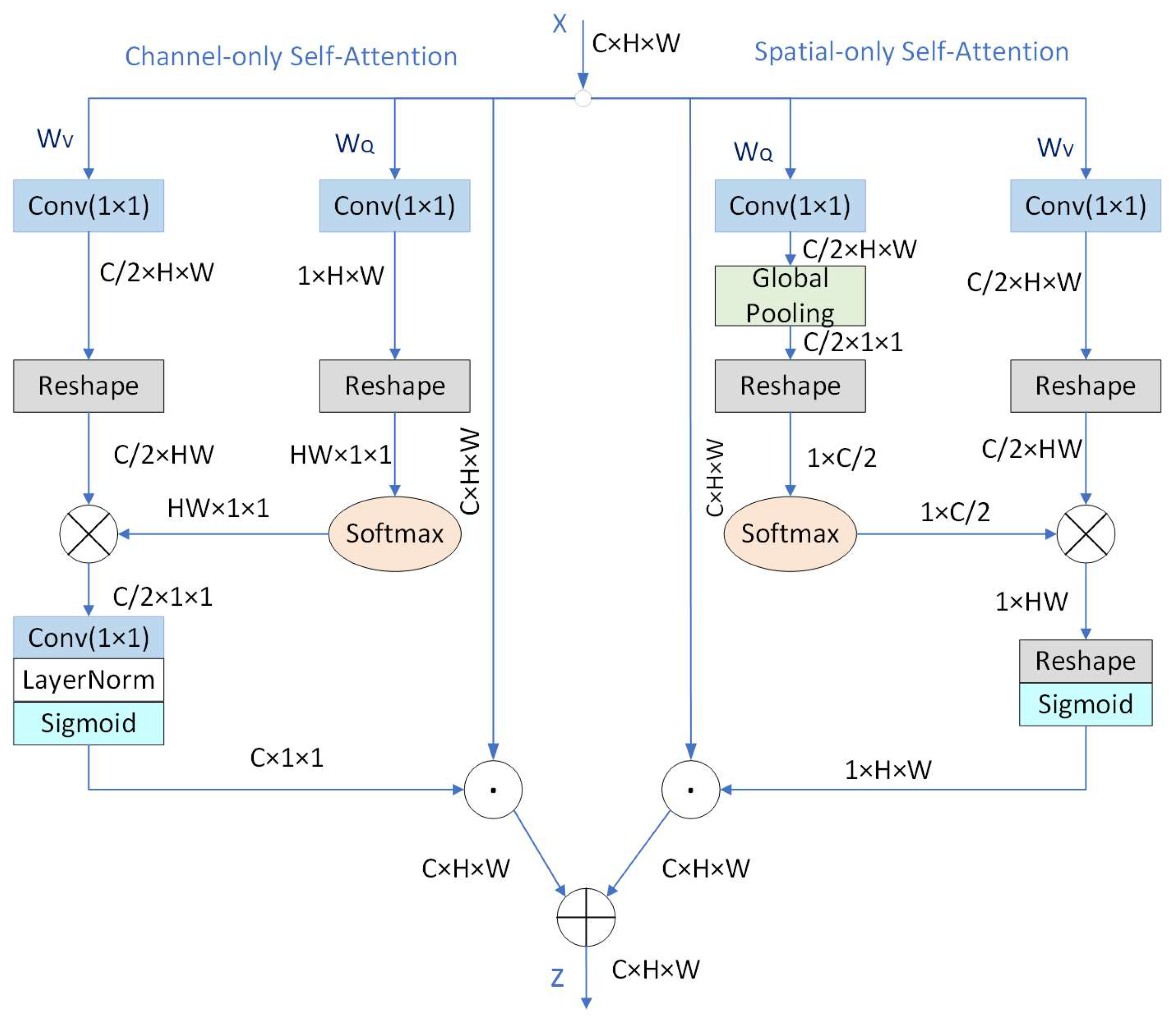
2.3. Polarized Self-Attention
2.4. Soft-NMS
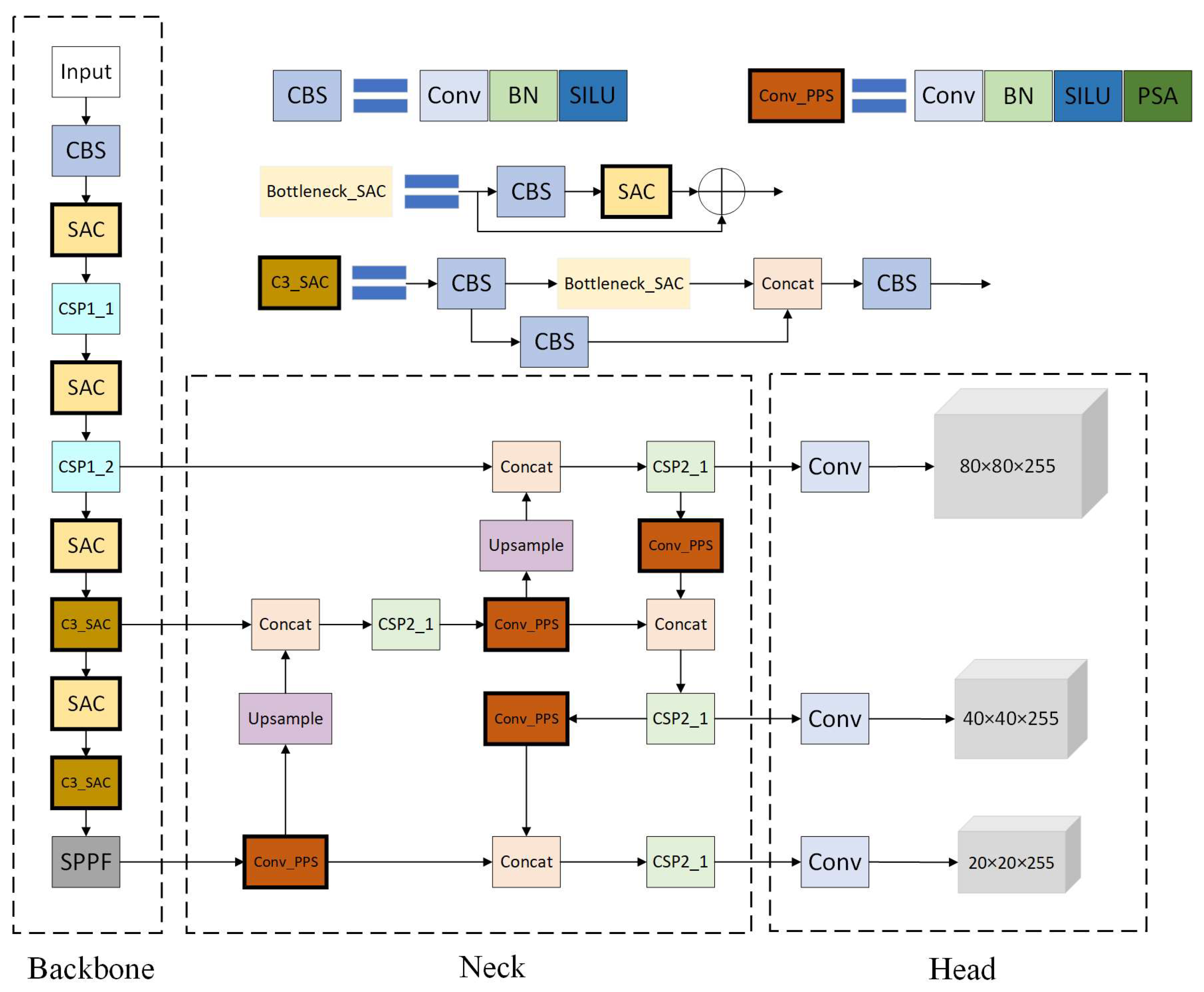
2.5. The Proposed Algorithm for Smoke and Fire Detection
3. Experiment
3.1. Datasets
3.2. Experiment Setup
3.3. Model Evaluation Metrics
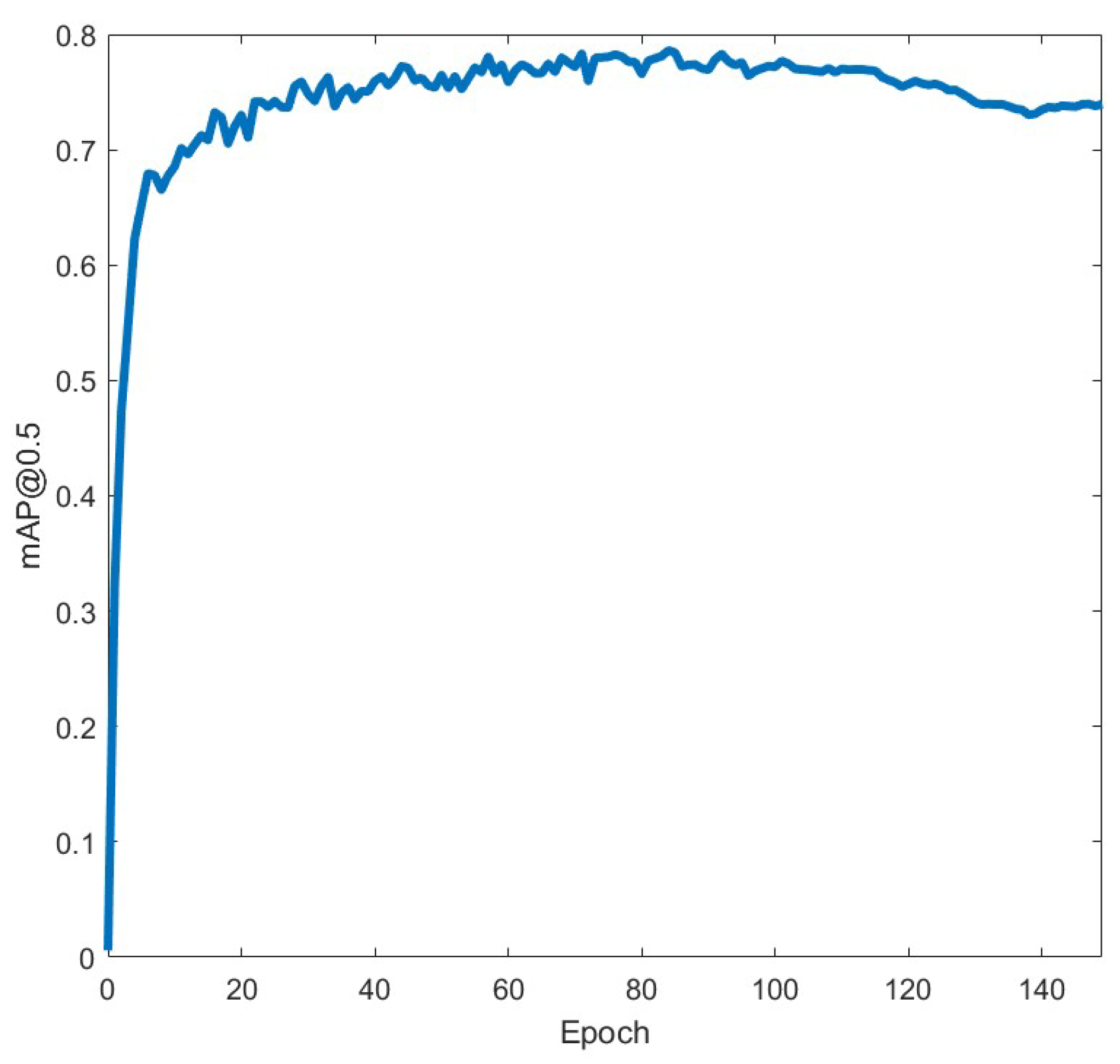
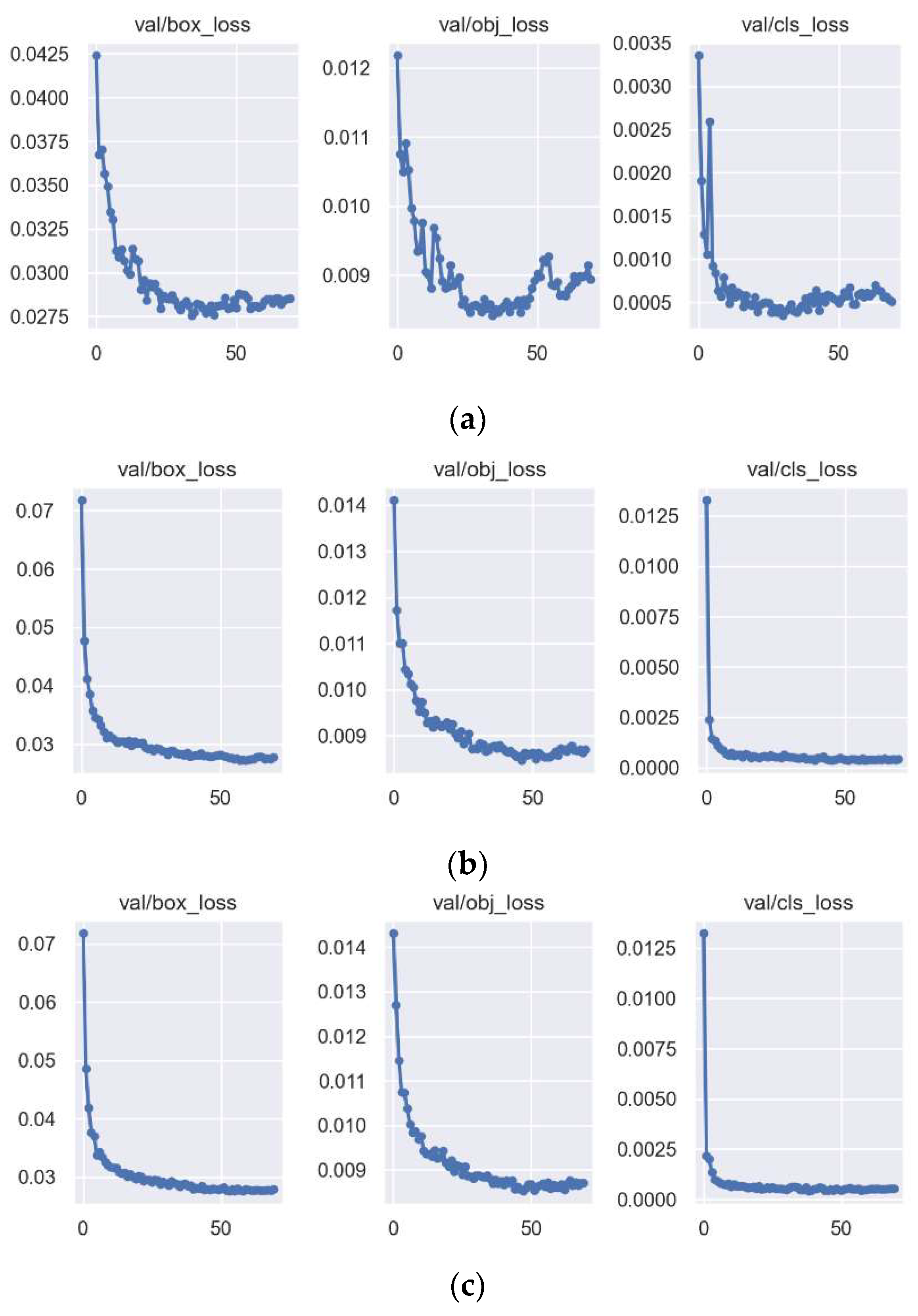
4. Results
4.1. YOLO Series Algorithms Comparison
4.2. Analysis of Ablation Experiments
4.3. Comparison of Different Detection Algorithms
5. Discussion
- (1)
- Based on various drone images, we reconstructed a fire dataset that encompasses multiple scenarios and includes images of flames and smoke in different patterns.
- (2)
- By combining SAC, PSA, and Soft-NMS with YOLOv5, we designed and verified a more suitable fire detection algorithm: SPS-YOLOv5.
- (3)
- We compared SPS-YOLOv5 with several classical detection algorithms, and its good detection performance addresses the problem of complex targets detection and highlights the superiority of SPS-YOLOv5.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guha-Sapir, D.; Hoyois, P.; Below, R. Annual Disaster Statistical Review 2015: The Numbers and Trends; Louvain-la-Neuve, Belgium, 2016; pp. 27–28. Available online: http://www.cred.be/sites/default/files/ADSR_2015.pdf (accessed on 31 October 2016).
- Zhang, N.; Shen, S.L.; Zhou, A.N.; Chen, J. A brief report on the March 21, 2019 explosions at a chemical factory in Xiangshui, China. Process Saf. 2019, 38, e12060. [Google Scholar] [CrossRef]
- Zhao, B. Facts and lessons related to the explosion accident in Tianjin Port. China Nat. Hazards 2016, 84, 707–713. [Google Scholar] [CrossRef]
- Wu, L.; Chen, L.; Hao, X. Multi-Sensor Data Fusion Algorithm for Indoor Fire Early Warning Based on BP Neural Network. Information 2021, 12, 59. [Google Scholar] [CrossRef]
- Hu, K.; Li, Y.; Xia, M.; Wu, J.; Lu, M.; Zhang, S.; Weng, L. Federated learning: A distributed shared machine learning method. Complexity 2021, 2021, 8261663. [Google Scholar] [CrossRef]
- Solórzano, A.; Eichmann, J.; Fernández, L.; Ziems, B.; Jiménez-Soto, J.M.; Marco, S.; Fonollosa, J. Early fire detection based on gas sensor arrays: Multivariate calibration and validation. Sens. Actuators B Chem. 2022, 352, 130961. [Google Scholar] [CrossRef]
- Sun, B.; Xu, Z.D. A multi-neural network fusion algorithm for fire warning in tunnels. Appl. Soft Comput. 2022, 131, 109799. [Google Scholar] [CrossRef]
- Pang, Y.; Li, Y.; Feng, Z.; Feng, Z.; Zhao, Z.; Chen, S.; Zhang, H. Forest fire occurrence prediction in China based on machine learning methods. Remote Sens. 2022, 14, 5546. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kalantar, B.; Ueda, N.; Idrees, M.O.; Janizadeh, S.; Ahmadi, K.; Shabani, F. Forest fire susceptibility prediction based on machine learning models with resampling algorithms on remote sensing data. Remote Sens. 2020, 12, 3682. [Google Scholar] [CrossRef]
- Hu, K.; Wu, J.; Li, Y.; Lu, M.; Weng, L.; Xia, M. Fedgcn: Federated learning-based graph convolutional networks for non-euclidean spatial data. Mathematics 2022, 10, 1000. [Google Scholar] [CrossRef]
- Hu, K.; Weng, C.; Shen, C.; Wang, T.; Weng, L.; Xia, M. A multi-stage underwater image aesthetic enhancement algorithm based on a generative adversarial network. Eng. Appl. Artif. Intell. 2023, 123, 106196. [Google Scholar] [CrossRef]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Zhao, E.; Liu, Y.; Zhang, J.; Tian, Y. Forest fire smoke recognition based on anchor box adaptive generation method. Electronics 2021, 10, 566. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Nguyen, A.Q.; Nguyen, H.T.; Tran, V.C.; Pham, H.X.; Pestana, J. A Visual Real-time Fire Detection using Single Shot MultiBox Detector for UAV-based Fire Surveillance. In Proceedings of the 2020 IEEE Eighth International Conference on Communications and Electronics (ICCE), Phu Quoc, Vietnam, 13–15 January 2021; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2021; pp. 338–343. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. Part I 14. pp. 21–37. [Google Scholar]
- Zheng, S.; Gao, P.; Wang, W.; Zou, X. A Highly Accurate Forest Fire Prediction Model Based on an Improved Dynamic Convolutional Neural Network. Appl. Sci. 2022, 12, 6721. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Wang, Q.; Zhong, Z. DyNet: Dynamic Convolution for Accelerating Convolutional Neural Networks. arXiv 2020, arXiv:2004.10694. [Google Scholar]
- Li, Y.; Zhang, W.; Liu, Y.; Jing, R.; Liu, C. An efficient fire and smoke detection algorithm based on an end-to-end structured network. Eng. Appl. Artif. Intell. 2022, 116, 105492. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. Comput. Vis. ECCV 2020, 2020, 213–229. [Google Scholar]
- Qin, Y.Y.; Cao, J.T.; Ji, X.F. Fire Detection Method Based on Depthwise Separable Convolution and YOLOv3. Int. J. Autom. Comput. 2021, 18, 300–310. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, Y.; Hua, C.; Ding, W.; Wu, R. Real-time detection of flame and smoke using an improved YOLOv4 network. Signal Image Video Process. 2022, 16, 1109–1116. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Bahhar, C.; Ksibi, A.; Ayadi, M.; Jamjoom, M.M.; Ullah, Z.; Soufiene, B.O.; Sakli, H. Wildfire and Smoke Detection Using Staged YOLO Model and Ensemble CNN. Electronics 2023, 12, 228. [Google Scholar] [CrossRef]
- Yu, S.; Sun, C.; Wang, X.; Li, B. Forest fire detection algorithm based on Improved YOLOv5. J. Phys. Conf. Ser. 2022, 2384, 012046. [Google Scholar] [CrossRef]
- Dou, Z.; Zhou, H.; Liu, Z.; Hu, Y.; Wang, P.; Zhang, J.; Wang, Q.; Chen, L.; Diao, X.; Li, J. An Improved YOLOv5s Fire Detection Model. Fire Technol. 2023. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Du, H.; Zhu, W.; Peng, K.; Li, W. Improved High Speed Flame Detection Method Based on YOLOv7. Open J. Appl. Sci. 2022, 12, 2004–2018. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Chen, G.; Cheng, R.; Lin, X.; Jiao, W.; Bai, D.; Lin, H. LMDFS: A Lightweight Model for Detecting Forest Fire Smoke in UAV Images Based on YOLOv7. Remote Sens. 2023, 15, 3790. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized Self-Attention: Towards High-quality Pixel-wise Regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 3, pp. 850–855. [Google Scholar]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A New Backbone that Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; Springer: Cham, Switzerland; pp. 390–391. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmen-tation with deep convolutional nets and fully connected crfs. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Agbeshie, A.A.; Abugre, S.; Atta-Darkwa, T.; Awuah, R. A review of the effects of forest fire on soil properties. J. For. Res. 2022, 33, 1419–1441. [Google Scholar] [CrossRef]
- Chew, Y.J.; Ooi, S.Y.; Pang, Y.H.; Wong, K.S. A Review of forest fire combating efforts, challenges and future directions in Peninsular Malaysia, Sabah, and Sarawak. Forests 2022, 13, 1405. [Google Scholar] [CrossRef]
- Alkhatib, R.; Sahwan, W.; Alkhatieb, A.; Schütt, B. A Brief Review of Machine Learning Algorithms in Forest Fires Science. Appl. Sci. 2023, 13, 8275. [Google Scholar] [CrossRef]
- Sathishkumar, V.E.; Cho, J.; Subramanian, M.; Naren, O.S. Forest fire and smoke detection using deep learning-based learning without forgetting. Fire Ecol. 2023, 19, 9. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Type |
|---|---|
| CPU | Intel(R) Core(TM) i7-12700H 2.70 GHz |
| GPU | NVIDIA GeForce GTX 1080 Ti 11G |
| Programming language | Python 3.9 |
| Operating system | Windows 11 |
| Deep learning framework | PyTorch 1.13.1 |
| Number | Method | mAP50 (%) | R (%) | FPS | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| 1 | YOLOv3 | 77.4 | 58.8 | 56 | 61.5 | 65.6 |
| 2 | YOLOv4 | 65.3 | 38.2 | 45 | 63.9 | 60.0 |
| 3 | YOLOv5 | 77.8 | 71.2 | 65 | 20.1 | 47.9 |
| 4 | YOLOv7 | 77.3 | 72.8 | 68 | 36.5 | 103.2 |
| 5 | YOLOv8 | 77.6 | 74.0 | 45 | 25.8 | 78.7 |
| Model | mAP50 (%) | mAP75 (%) | R (%) | FLOPs (G) | FPS |
|---|---|---|---|---|---|
| YOLOv5 | 77.8 | 54.0 | 71.2 | 47.9 | 65 |
| YOLOv5 + SAC | 78.5 | 53.1 | 73.7 | 30.9 | 47 |
| YOLOv5 + SAC + Soft-NMS | 78.8 | 58.9 | 73.7 | 30.9 | 45 |
| SPS-YOLOv5 | 79.8 | 58.3 | 74.3 | 31.7 | 43 |
| Number | Method | mAP50 (%) | R (%) | FPS | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| 1 | SSD | 71.8 | 62.7 | 78 | 23.7 | 60.9 |
| 2 | Faster R-CNN | 75.8 | 84.9 | 11 | 40.3 | 269.7 |
| 3 | EfficientDet | 78.0 | 63.3 | 22 | 3.8 | 4.7 |
| 4 | YOLOv3-EfficientNet | 74.0 | 53.3 | 58 | 7.0 | 3.8 |
| 5 | CenterNet | 75.3 | 40.7 | 59 | 32.7 | 70.2 |
| 6 | SPS-YOLOv5 | 79.8 | 74.3 | 43 | 31.8 | 31.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, P.; Lu, J.; Wang, Q.; Zhang, Y.; Kuang, L.; Kan, X. An Efficient Forest Fire Detection Algorithm Using Improved YOLOv5. Forests 2023, 14, 2440. https://doi.org/10.3390/f14122440
Shi P, Lu J, Wang Q, Zhang Y, Kuang L, Kan X. An Efficient Forest Fire Detection Algorithm Using Improved YOLOv5. Forests. 2023; 14(12):2440. https://doi.org/10.3390/f14122440
Chicago/Turabian StyleShi, Pei, Jun Lu, Quan Wang, Yonghong Zhang, Liang Kuang, and Xi Kan. 2023. "An Efficient Forest Fire Detection Algorithm Using Improved YOLOv5" Forests 14, no. 12: 2440. https://doi.org/10.3390/f14122440
APA StyleShi, P., Lu, J., Wang, Q., Zhang, Y., Kuang, L., & Kan, X. (2023). An Efficient Forest Fire Detection Algorithm Using Improved YOLOv5. Forests, 14(12), 2440. https://doi.org/10.3390/f14122440