
ForestFireDetector: Expanding Channel Depth for Fine-Grained Feature Learning in Forest Fire Smoke Detection


Abstract
:1. Introduction
- We propose an improved model that expands the channel depth to reduce fine-grain loss and retains more feature information, thus enhancing the detection accuracy and providing a new idea and method for forest fire detection.
- This model makes the network more focused on the identification of small targets, improves the detection ability of small smoke and makes it more suitable for early-stage forest fires.
- The parameters of the model have been further reduced to 2.7M compared to the 3M of YOLOv8. It strikes a balance between computational efficiency and performance enhancement, making it possible for deployment.
2. Materials and Methods
2.1. Dataset
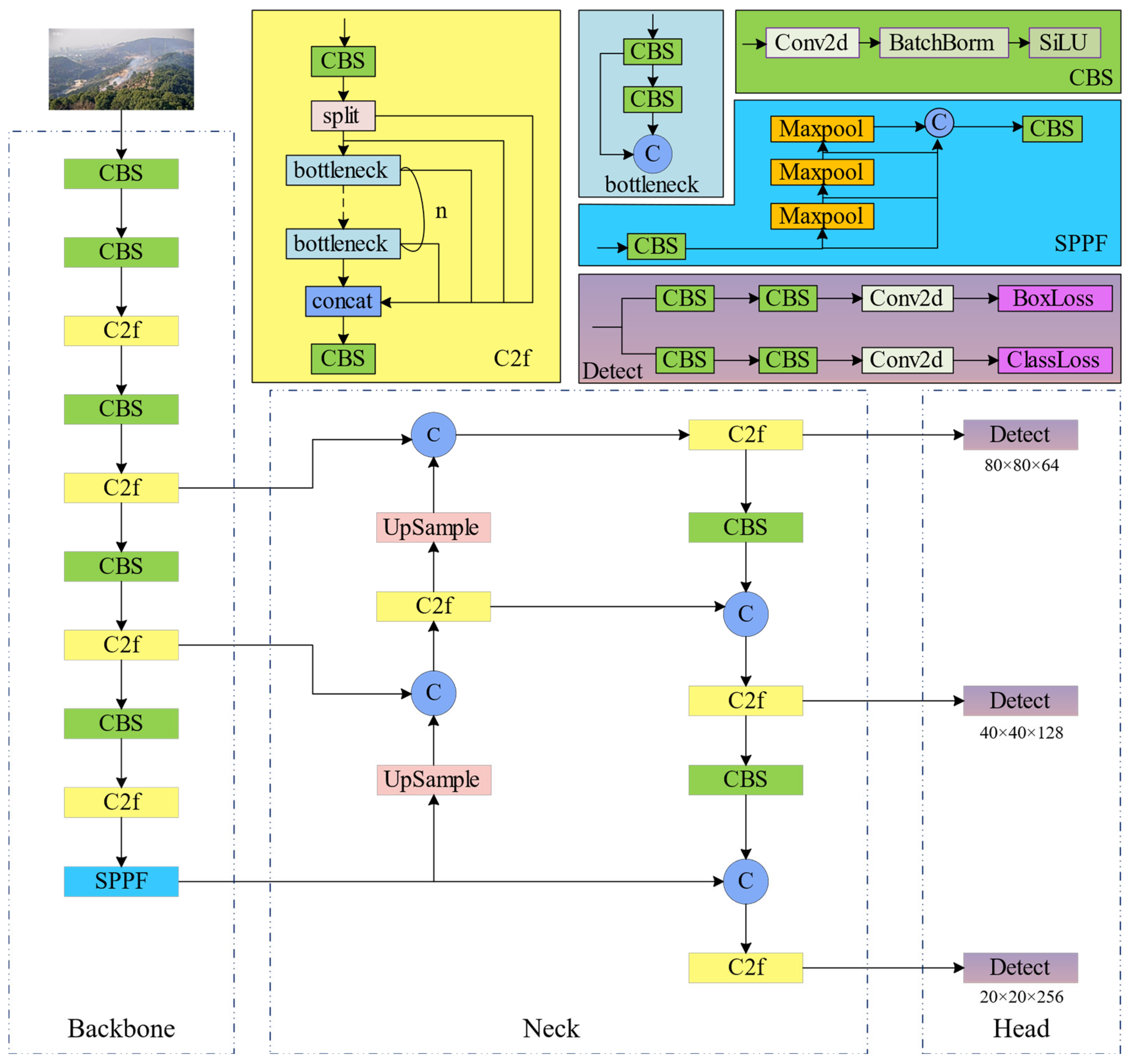
2.2. Model Structure of YOLOv8
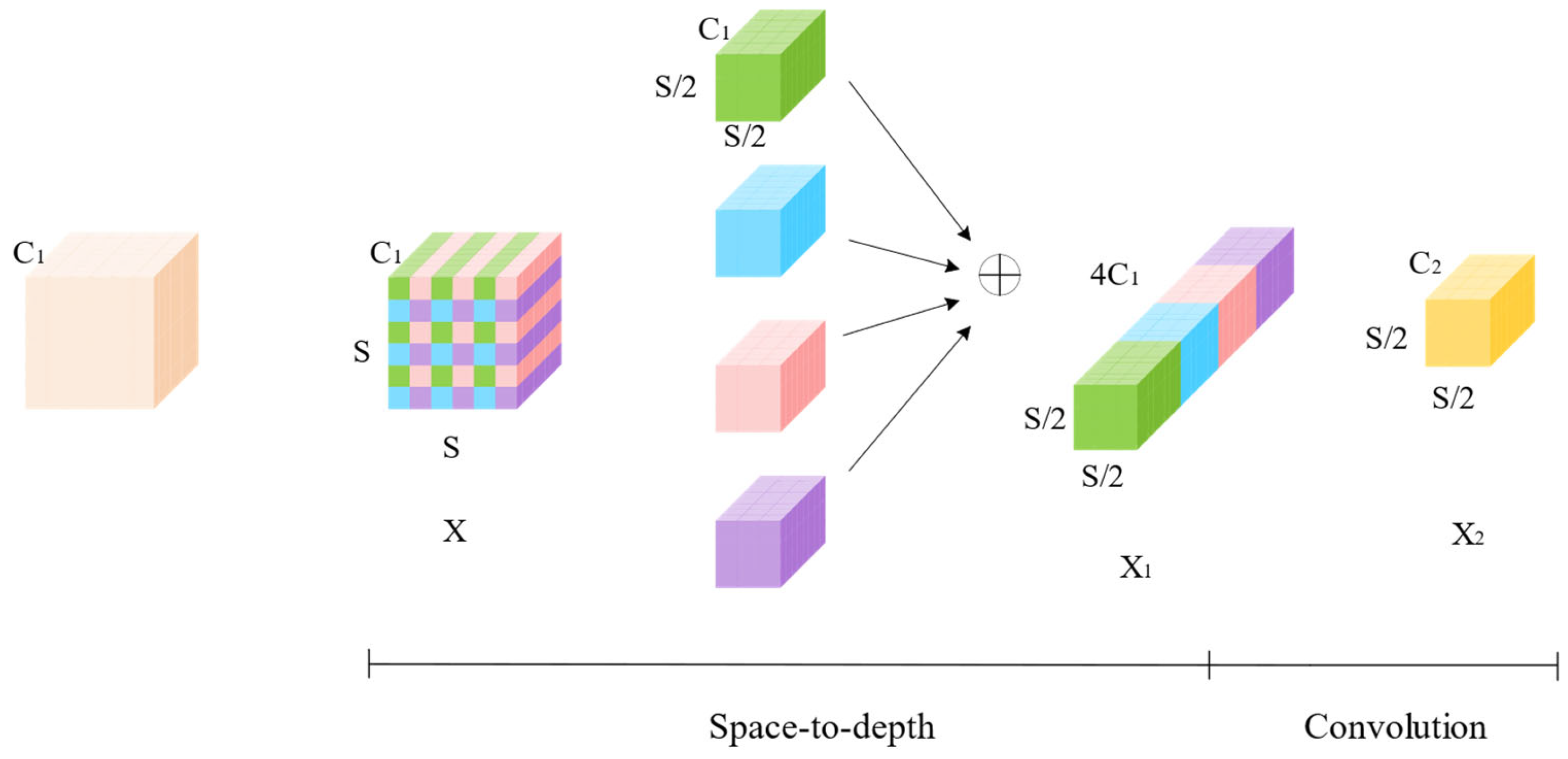
2.3. Space-to-Depth Convolution
2.4. GSConv
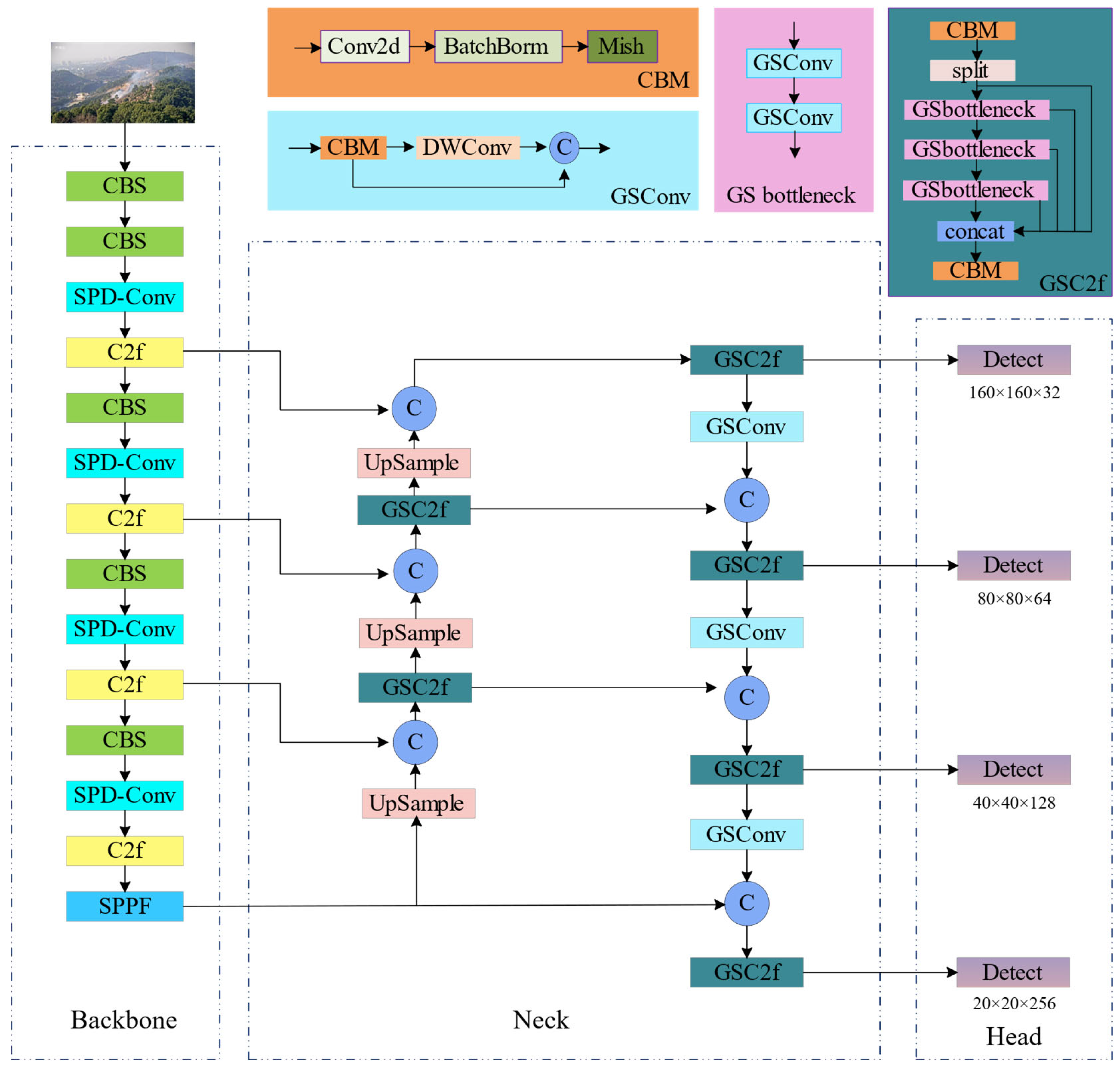
2.5. ForestFireDetector
3. Results
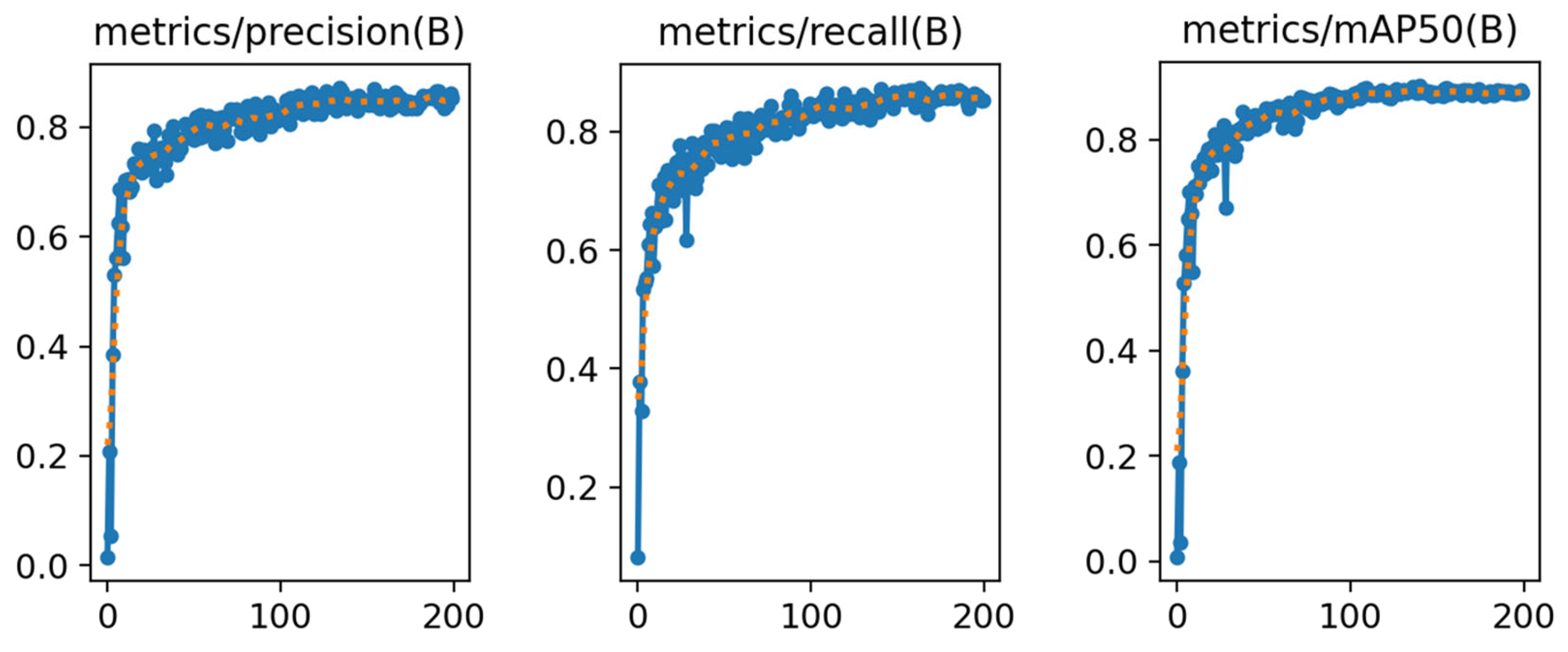
3.1. Training
3.2. Model Evaluation
3.3. Detection Performance and Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, S.; Chen, J.; Jiang, C.; Yao, R.T.; Xue, J.; Bai, Y.; Wang, S. Trends in research on forest ecosystem services in the most recent 20 years: A bibliometric analysis. Forests 2022, 13, 1087. [Google Scholar] [CrossRef]
- Wang, L.R.; Huang, T.L.; Li, Y. Classification and research status of forest natural disasters. For. Sci. Technol. Commun. 2022, 8, 8–13. [Google Scholar]
- Wang, M.Y.; Xu, Y.; Zhao, M.W. Analysis of the spatial and temporal distribution pattern and causes of forest fires in China in the past 10 years. Agric. Sci. Technol. Commun. 2021, 10, 201–204. [Google Scholar]
- Statistical Data-Emergency Management Department of People’s Republic of China (PRC). The Emergency Management Department Released the National Natural Disasters in the First Half of 2023. Available online: https://www.mem.gov.cn/gk/tjsj/ (accessed on 31 August 2023).
- Krüll, W.; Tobera, R.; Willms, I.; Essen, H.; von Wahl, N. Early Forest Fire Detection and Verification Using Optical Smoke, Gas and Microwave Sensors. Procedia Eng. 2012, 45, 584–594. [Google Scholar] [CrossRef]
- Von Wahl, N.; Heinen, S.; Essen, H.; Kruell, W.; Tobera, R.; Willms, I. An Integrated Approach for Early Forest Fire Detection and Verification Using Optical Smoke, Gas and Microwave Sensors. WIT Trans. Ecol. Environ. 2010, 137, 97–106. [Google Scholar]
- Yang, N.; Wang, Z.; Wang, S. Computer Image Recognition Technology and Application Analysis. In Proceedings of the IOP Conference Series Earth and Environmental Science; IOP Publishing: Bristol, UK, 2021; Volume 769, p. 032065. [Google Scholar]
- Li, M.N.; Zhang, Y.M.; Mu, L.X.; Xin, J.; Yu, Z.Q.; Liu, H.; Xie, G. Early forest fire detection based on deep learning. In Proceedings of the 2021 3rd International Conference on Industrial Artificial Intelligence, Shenyang, China, 8–11 November 2021; pp. 1–5. [Google Scholar]
- Ya’acob, N.; Najib, M.S.M.; Tajudin, N.; Yusof, A.L.; Kassim, M. Image Processing Based Forest Fire Detection Using Infrared Camera. J. Phys. Conf. Ser. 2021, 1768, 012014. [Google Scholar] [CrossRef]
- Miao, Z.W.; Lu, Z.N.; Wang, J.L.; Wang, Y. Research on fire detection based on vision. For. Eng. 2022, 38, 86–92. [Google Scholar]
- Ding, X.; Gao, J. A New Intelligent Fire Color Space Approach for Forest Fire Detection. J. Intell. Fuzzy Syst. 2022, 42, 5265–5281. [Google Scholar]
- Huang, X.Y.; Lin, S.R.; Liu, N.A. A Review of Smoldering Wildfire: Research Advances and Prospects. J. Eng. Thermophys. 2021, 42, 512–528. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Zhu, M.X.; Liu, Z.Q.; Zhang, X.; Li, W.J.; Su, J.X. Review of Research on Video-Based Smoke Detection Algorithms. Comput. Eng. Appl. 2022, 58, 16–26. [Google Scholar]
- Wu, S.; Zhang, L. Using Popular Object Detection Methods for Real Time Forest Fire Detection. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 280–284. [Google Scholar]
- Al-Smadi, Y.; Alauthman, M.; Al-Qerem, A.; Aldweesh, A.; Quaddoura, R.; Aburub, F.; Mansour, K.; Alhmiedat, T. Early Wildfire Smoke Detection Using Different YOLO Models. Machines 2023, 11, 246. [Google Scholar] [CrossRef]
- Wan, Z.; Zhuo, Y.; Jiang, H.; Tao, J.; Qian, H.; Xiang, W.; Qian, Y. Fire Detection from Images Based on Single Shot MultiBox Detector. In Advances in Intelligent Systems and Computing, Proceedings of the The 10th International Conference on Computer Engineering and Networks, Singapore, 6 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 302–313. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A Small Target Object Detection Method for Fire Inspection. Sustainability 2022, 14, 4030. [Google Scholar] [CrossRef]
- Rahman, E.U.; Khan, M.A.; Algarni, F.; Zhang, Y.; Irfan Uddin, M.; Ullah, I.; Ahmad, H.I. Computer Vision-Based Wildfire Smoke Detection Using UAVs. Math. Probl. Eng. 2021, 2021, 5594899. [Google Scholar] [CrossRef]
- Sunkara, R.; Luo, T. No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Grenoble, France, 7 August 2022; pp. 443–459. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-Neck by GSConv: A Better Design Paradigm of Detector Architectures for Autonomous Vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- GitHub. Ultralytics/Yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite. Available online: https://github.com/ultralytics/yolov5 (accessed on 4 September 2023).
- GitHub. Ultralytics/Ultralytics: NEW—YOLOv8 in PyTorch > ONNX > OpenVINO > CoreML > TFLite. Available online: https://github.com/ultralytics/ultralytics (accessed on 4 September 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Details |
|---|---|
| Programming language | Python 3.8 |
| Operating system | Linux |
| Deep learning framework | Pytorch 1.11 |
| GPU | NVIDA Tesla V100 PCle |
| Acceleration Tool | CUDA11.3 |
| Training Parameters | Details |
|---|---|
| Epochs | 200 |
| Batchsize | 32 |
| Img-size | 640 × 640 |
| Optimization | SGD |
| Initial learning rate | 0.01 |
| Model | Precision | Recall | mAP50 | Params | Flops |
|---|---|---|---|---|---|
| Faster RCNN [21] | 0.388 | 0.728 | 0.801 | 136.69 | 369.72 |
| SSD [16] | 0.801 | 0.768 | 0.832 | 23.61 | 62.7 |
| YOLOv5s [28] | 0.853 | 0.879 | 0.874 | 7.06 | 16.5 |
| YOLOv8n [29] | 0.85 | 0.796 | 0.869 | 3.01 | 8.2 |
| FireDetector (Ours) | 0.852 | 0.871 | 0.902 | 2.87 | 14.8 |
| YOLOv8 | SPD-Conv | GSConv | Head | Precision | Recall | mAP50 | Params | FLOPs |
|---|---|---|---|---|---|---|---|---|
| √ | 0.85 | 0.796 | 0.869 | 3011043 | 8.2 | |||
| √ | √ | 0.848 | 0.844 | 0.891 | 3272163 | 11.7 | ||
| √ | √ | 0.86 | 0.836 | 0.894 | 2408131 | 7.0 | ||
| √ | √ | 0.859 | 0.821 | 0.889 | 2926692 | 12.4 | ||
| √ | √ | √ | 0.883 | 0.838 | 0.91 | 2882979 | 11.0 | |
| √ | √ | √ | 0.846 | 0.85 | 0.893 | 3187812 | 15.9 | |
| √ | √ | √ | 0.839 | 0.861 | 0.905 | 2519236 | 11.3 | |
| √ | √ | √ | √ | 0.852 | 0.871 | 0.902 | 2780356 | 14.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Li, Y.; Hu, T. ForestFireDetector: Expanding Channel Depth for Fine-Grained Feature Learning in Forest Fire Smoke Detection. Forests 2023, 14, 2157. https://doi.org/10.3390/f14112157
Sun L, Li Y, Hu T. ForestFireDetector: Expanding Channel Depth for Fine-Grained Feature Learning in Forest Fire Smoke Detection. Forests. 2023; 14(11):2157. https://doi.org/10.3390/f14112157
Chicago/Turabian StyleSun, Long, Yidan Li, and Tongxin Hu. 2023. "ForestFireDetector: Expanding Channel Depth for Fine-Grained Feature Learning in Forest Fire Smoke Detection" Forests 14, no. 11: 2157. https://doi.org/10.3390/f14112157
APA StyleSun, L., Li, Y., & Hu, T. (2023). ForestFireDetector: Expanding Channel Depth for Fine-Grained Feature Learning in Forest Fire Smoke Detection. Forests, 14(11), 2157. https://doi.org/10.3390/f14112157