Abstract
Object detection in complex road scenes is vital for autonomous driving, facing challenges such as object occlusion, small target sizes, and irregularly shaped targets. To address these issues, this paper introduces DGSS-YOLOv8s, a model designed to enhance detection accuracy and high-FPS performance within the You Only Look Once version 8 small (YOLOv8s) framework. The key innovation lies in the synergistic integration of several architectural enhancements: the DCNv3_LKA_C2f module, leveraging Deformable Convolution v3 (DCNv3) and Large Kernel Attention (LKA) for better the capture of complex object shapes; an Optimized Feature Pyramid Network structure (Optimized-GFPN) for improved multi-scale feature fusion; the Detect_SA module, incorporating spatial Self-Attention (SA) at the detection head for broader context awareness; and an Inner-Shape Intersection over Union (IoU) loss function to improve bounding box regression accuracy. These components collectively target the aforementioned challenges in road environments. Evaluations on the Berkeley DeepDrive 100K (BDD100K) and Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) datasets demonstrate the model’s effectiveness. Compared to baseline YOLOv8s, DGSS-YOLOv8s achieves mean Average Precision (mAP)@50 improvements of 2.4% (BDD100K) and 4.6% (KITTI). Significant gains were observed for challenging categories, notably 87.3% mAP@50 for cyclists on KITTI, and small object detection (AP-small) improved by up to 9.7% on KITTI. Crucially, DGSS-YOLOv8s achieved high processing speeds suitable for autonomous driving, operating at 103.1 FPS (BDD100K) and 102.5 FPS (KITTI) on an NVIDIA GeForce RTX 4090 GPU. These results highlight that DGSS-YOLOv8s effectively balances enhanced detection accuracy for complex scenarios with high processing speed, demonstrating its potential for demanding autonomous driving applications.
1. Introduction
Object detection in complex traffic scenarios is paramount for the safety and efficacy of autonomous driving systems. Accurate, high-FPS identification of diverse road users and obstacles, particularly complex-shaped or occluded targets, is crucial for robust decision-making [1,2]. Key challenges include detecting small objects (often <322 pixels [3,4]), handling irregularly shaped targets (e.g., pedestrians and cyclists [5]), and those with significant occlusion [6], all while meeting demanding processing speeds (typically >30 FPS [7,8]). Addressing these interconnected issues is vital for dependable autonomous navigation [1].
While deep learning has significantly advanced object detection, traditional methods falter in such complexities. Two-stage algorithms (e.g., the R-CNN family [9,10]) achieve high accuracy but often at lower FPS, limiting their suitability for autonomous driving [1,11]. Conversely, single-stage detectors like SSD [12] and the You Only Look Once (YOLO) series [13,14,15] offer improved speed by performing classification and localization concurrently, making them more appropriate for high-FPS applications. The YOLO series is particularly recognized for balancing speed and accuracy [16], with the recent YOLOv8 demonstrating enhanced accuracy and adaptability [17,18], making it a strong baseline for challenging traffic environments [19].
This study enhances modern detection by specifically targeting small, occluded, and irregularly shaped objects in dynamic urban settings. We propose DGSS-YOLOv8s, an advanced model built upon the efficient YOLOv8s framework. Its core novelty is the synergistic integration of optimized techniques tailored to these challenges, aiming for competitive accuracy while maintaining high processing speed.
DGSS-YOLOv8s integrates the DCNv3_LKA_C2f module, an Optimized-GFPN structure, and the Detect_SA module, alongside an Inner-Shape IoU loss, to significantly enhance the detection of challenging targets and ensure high FPS. The main contributions are as follows. First, the DCNv3_LKA_C2f module (combining DCNv3 and LKA) improves feature representation for non-rigid objects with efficiency. Second, an Optimized-GFPN for the neck reduces latency and improves multi-scale feature fusion. Third, the Detect_SA module in detection heads captures global spatial dependencies with reduced complexity. Fourth, the Inner-Shape IoU loss, using shape-aware penalties [20] and adaptive inner bounding box overlap [21], improves regression for occluded and elongated objects.
DGSS-YOLOv8s is comprehensively evaluated on BDD100K [22] and KITTI [23] datasets, demonstrating superior performance in complex traffic scenarios. Section 2 reviews prior work. Section 3 details the DGSS-YOLOv8s architecture. Section 4 presents comparative benchmarking, and Section 5 concludes and outlines future research.
2. Related Works
Object detection, a cornerstone of computer vision significantly advanced by deep learning [16], is critical for autonomous driving. This application demands high accuracy and high Frames Per Second (FPS) to navigate complex traffic environments featuring occlusion, varying object scales (especially small objects) and irregular target geometries [1]. Recent efforts also focus on robustness to adverse conditions [24] and computational efficiency for on-vehicle deployment [25].
Early deep learning detectors included two-stage architectures like Faster R-CNN [10] and Cascade R-CNN [26], which achieved high precision but often at the cost of lower FPS, limiting their suitability for high-FPS systems [1,11]. Single-shot detectors, such as SSD [12] and RetinaNet [27] (using FPN [28]) offered improved speed. The You Only Look Once (YOLO) series [29] became prominent for its favorable speed–accuracy balance [16,30].
Modern detectors employ various techniques for complex scenes. Multi-scale feature fusion (e.g., FPN [28], PANet [31], BiFPN [32]) remains vital. Deformable Convolutions (DCNs), including DCNv3 (a key part of models like InternImage [33]), provide adaptive spatial sampling crucial for irregular shapes [33,34,35]. Attention mechanisms, such as Large Kernel Attention (LKA) [36] which efficiently captures long-range dependencies, are also integrated to enhance feature representation [37,38,39,40].
While SOTA models like InternImage-H [33] achieve high accuracy on benchmarks (e.g., BDD100K [22]), their computational cost can be prohibitive for high-FPS deployment [41]. Similarly, top KITTI [23] performers often use multi-modal data (camera-LiDAR) or complex 3D processing [42,43], which pose practical challenges [44,45]. Thus, efficient, camera-only detectors remain crucial. This has driven innovation in fast detectors like the YOLO series (YOLOv5-YOLOv10 [15,18,46,47]) and others [2,48,49]. Our work, DGSS-YOLOv8s, builds on YOLOv8s, focusing on targeted enhancements for small, occluded, and irregularly shaped objects—critical for safety—while maintaining high FPS, unlike general-purpose SOTA models, which may not optimize for these specific challenging scenarios under demanding latency constraints.
Bounding box regression accuracy, especially for small and occluded objects, is another focus. Beyond standard IoU extensions [50,51], specialized losses like Shape-IoU [20] (shape/scale-aware) and Inner-IoU [21] (adaptive overlap quality) offer improved localization. However, concurrently addressing small size, irregular shape, occlusion, and strict high-FPS demands in an efficient, unified framework remains a significant challenge, motivating our proposed architectural enhancements.
3. Methodology
This section details the proposed DGSS-YOLOv8s model, including its overall architecture and the key modifications introduced to enhance detection performance in complex autonomous driving scenarios.
3.1. Architecture Overview
To address the challenge of road object detection in complex scenarios of autonomous driving, we propose the DGSS-YOLOv8s model. The model further optimizes the detection capability of irregularly shaped targets, occluded targets, and small targets based on YOLOv8s [18]. DGSS-YOLOv8s significantly improves the model’s performance in complex traffic scenarios by introducing three key modules, namely DCNv3_LKA_C2f, Optimized-GFPN, and Detect_SA, alongside a tailored loss function. Figure 1 illustrates the overall architecture of the DGSS-YOLOv8s model.
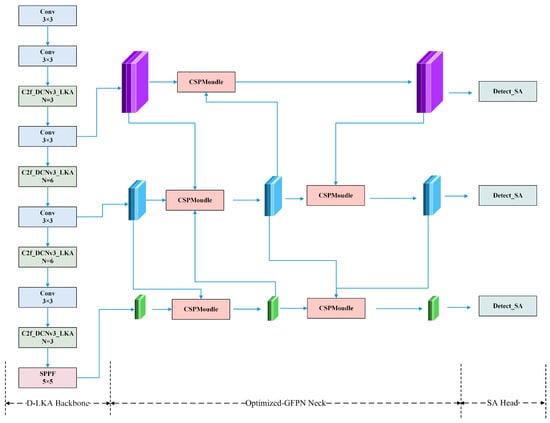
Figure 1.
Overview of architecture of DGSS-YOLOv8s.
3.1.1. DCNv3_LKA_C2f Module
While the YOLOv8s architecture employs C2f (CSP Bottleneck with 2 convolutions and faster) modules for multi-scale feature aggregation, their conventional convolutions have locality constraints that can limit modeling long-range spatial dependencies and handling irregularly shaped or occluded targets due to fixed sampling locations. Deformable Convolution v3 (DCNv3) [33] addresses fixed sampling by learning input-dependent offsets [34], allowing adaptive receptive fields crucial for object shape variations. This improves feature representation for complex objects and enhances computational efficiency through sparse sampling [33]. The mathematical description of DCNv3 is as follows:
where
- G denotes the total number of aggregation groups used to enrich the feature representation by partitioning the spatial aggregation process into multiple subspaces.
- represents the position-independent projection weights, which are shared within each group to reduce the number of parameters and computational complexity.
- is the modulation scalar of the k-th sampling point in the g-th group, normalized by the Softmax function to ensure gradient stability during the training process.
- is a sliced input feature map corresponding to a specific aggregation group.
- refers to the offset of the sampling position of the k-th grid in the g-th group, dynamically adjusting the position of the convolution kernel to adapt to the complex target shape.
To further enhance global feature capture, which is limited by traditional small receptive fields, we incorporate Large Kernel Attention (LKA) [36]. LKA efficiently achieves a large receptive field by decomposing a large kernel operation (e.g., into depth-wise, depth-wise dilated, and point-wise convolutions [36]), capturing long-range spatial dependencies with linear complexity. The synergy of DCNv3’s dynamic sampling and LKA’s large kernel advantage, termed DCNv3_LKA [52], improves detection performance in complex scenes. We fuse this DCNv3_LKA module into the bottleneck of C2f, as shown in Figure 2. The resulting DCNv3_LKA_C2f module alleviates the misdetection of complex and non-rigid targets and enhances global feature relationship modeling, especially for occluded objects, thereby reducing false negatives.
3.1.2. Optimized-GFPN Module
Feature pyramid networks (FPNs) [28] and their variants (e.g., PANet [31], BiFPN [32], GFPN [53,54], etc.), although successful in multi-scale feature fusion, still have obvious limitations in complex traffic scenarios. The unidirectional information flow of FPNs restricts the adequate fusion of high-level semantic and low-level spatial information; especially when dealing with both long-range and close-range targets, the detection accuracy of the model tends to decrease. For example, PANet solves the problem of unidirectional information flow by introducing bottom-up paths, but the complex structure increases the computational overhead and reduces the real-time performance of the model. BiFPN improves the information flow, but the computational cost is high, which makes it difficult to satisfy the demand for real-time detection. Although GFPN performs well in multi-scale feature processing, especially in small object detection and contextual information integration, it is accompanied by increased computational complexity and design complexity challenges. To prioritize high FPS while maintaining strong multi-scale fusion, we designed Optimized-GFPN. Inspired by efficiency-focused designs like BiFPN [32], our Optimized-GFPN modifies the standard YOLOv8s neck structure by removing specific upsampling layers identified as potentially redundant through experimentation, directly reducing the computational graph depth and latency. It is shown in Figure 3. Meanwhile, CSPModule (Cross-Stage Partial module) is introduced in Optimized-GFPN to replace traditional 3 × 3 convolutional feature fusion operations. Following the Cross-Stage Partial Network (CSPNet) principle [14], this splits feature channels, processing only a portion and then merging, aiming to reduce computation while enriching feature representation diversity. Combined with the reparameterization mechanism (Rep convolution) [55] and Efficient Layer Aggregation Network (ELAN) [56], this streamlined architecture enhances fusion efficiency and detection accuracy while contributing positively to the overall model FPS.
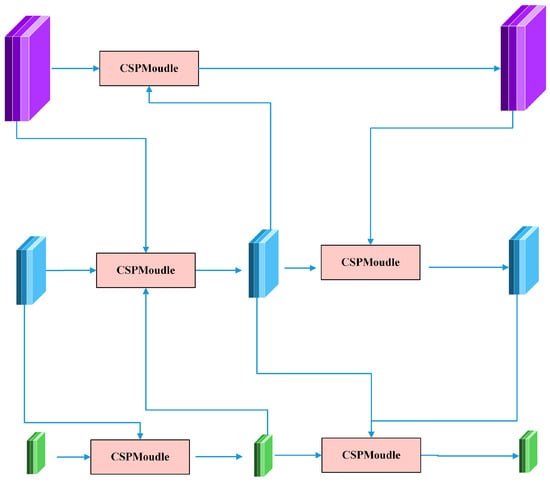
Figure 3.
Structural diagram of Optimized-GFPN.
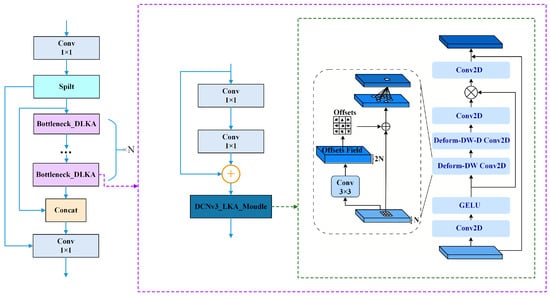
Figure 2.
Structural diagram of DCNv3_LKA_C2f.
The structure of CSPmodule is shown in Figure 4. The CSPmodule reduces redundant computations and improves the diversity of feature representations by splitting the input feature map into two parts, one subjected to the convolution operation and the other kept unchanged, and then merging the two parts of the feature map. Meanwhile, the Rep convolution in this module can make the model different at training time and inference time to improve efficiency.
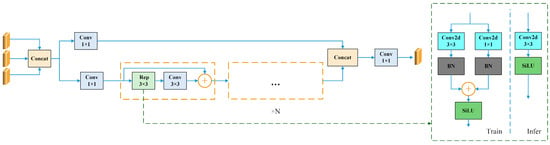
Figure 4.
Structural diagram of CSPmodule.
3.1.3. Detect_SA Module
Traditional detection modules mainly rely on local feature extraction, making it difficult to comprehensively capture the global information in an image, limiting the performance of the model in complex scenes. Although the Transformer architecture [40] performs well in capturing global contextual information, its typical Self-Attention (SA) mechanism is often limited in practical applications due to its high computational complexity and memory consumption. Specifically, standard SA exhibits quadratic complexity () with respect to the number of input tokens (N) [40], requiring large memory () for attention maps, and the accompanying Feed-Forward Network (FFN) layers also contribute significantly to parameters and computation [57], hindering high-FPS applications on high-resolution inputs. These factors—quadratic computational cost, large memory footprint, and expensive FFN layers—are the primary limitations that Detect_SA aims to overcome for real-time applications. To address these limitations while still benefiting from global context modeling, we constructed the Detect_SA module by integrating the Memory-efficient Self-Attention module [58] in the detection header of YOLOv8s. Our Detect_SA implementation achieves efficiency by employing grouped query attention combined with a bottleneck structure using 1 × 1 convolutions to reduce channel dimensions before the SA computation and notably omitting the large FFN typical in Transformer blocks. Figure 5 illustrates the schematic structure of Detect_SA. The Memory-efficient Self-Attention module retains the global context-capturing capability of the Self-Attention layer while reducing the computational complexity and memory footprint by removing the FFN part and introducing 1 × 1 convolution [58]. Specifically, 1 × 1 convolution is used to reduce the number of input channels, making Self-Attention a bottleneck layer with smaller input/output channels, followed by restoring the channel dimensions through 1 × 1 convolution. To further enhance the expressive power of the model, the module also contains an additional bypass 1 × 1 convolution for retaining the uncompressed residual information.
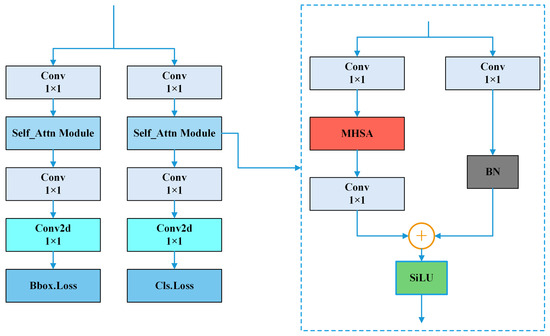
Figure 5.
Structural diagram of Detect_SA.
Compared to incorporating a standard Transformer block (SA+FFN) with similar input/output dimensions, Detect_SA achieves global context modeling with significantly lower theoretical computational cost and memory footprint. While precise memory figures depend on implementation details and input size, the removal of the FFN and the use of bottlenecking substantially reduce parameters and intermediate activation storage compared to the standard SA’s memory for attention maps plus FFN costs [57]. This efficiency is crucial for maintaining high real-time FPS, as substantiated by the minimal FPS decrease observed in our ablation studies (detailed in Section 4.4), where adding this module yielded accuracy gains with only a modest impact on speed. This makes it suitable for efficient, high-FPS detection tasks in resource-constrained environments such as self-driving vehicles. Regarding adaptability, the core principles of Detect_SA (bottlenecking, grouped attention, FFN removal) are general and could potentially be adapted to other object detection architectures, particularly those using convolutional heads where inserting such an attention mechanism might enhance feature representation. However, seamless integration would require architectural adjustments specific to the target model (e.g., channel dimensions, connection points). Within the scope of this specific study on DGSS-YOLOv8s, we did not perform a direct head-to-head benchmark comparing Detect_SA against a standard SA module integrated into the same YOLOv8s detection head on datasets like COCO [4] or KITTI. Our evaluation focused on the overall impact of Detect_SA within the proposed DGSS-YOLOv8s architecture via ablation studies (Section 4.4), which demonstrate its positive contribution to accuracy with acceptable efficiency trade-offs for our target application.
3.2. Inner-Shape IoU Loss Function
While YOLOv8 employs Complete IoU (CIoU) [51] for bounding box regression, CIoU can overlook the influence of the bounding box’s own shape and scale. To address this, and to better handle varied overlap scenarios, especially for irregular and occluded targets, our proposed Inner-Shape IoU loss function integrates concepts from Shape-IoU [20] and Inner-IoU [21]. Shape-IoU introduces shape and scale factors for a more comprehensive regression, while Inner-IoU adaptively adjusts auxiliary bounding box scales based on IoU levels and focuses on internal overlap for improved convergence and generalization [20,21].
Our Inner-Shape IoU loss is defined as
Here, represents the loss component derived from Shape-IoU principles, which penalizes discrepancies in distance, shape, and scale between predicted and ground-truth boxes (as detailed in [20], incorporating considerations for its distance loss and shape loss , where the parameter is empirically set to 4). is derived from Inner-IoU concepts, focusing on the Intersection over Union of adaptively scaled auxiliary bounding boxes to refine regression for varying degrees of overlap (details in [21]).
The rationale for selecting this specific combination, Inner-Shape IoU, over other advanced IoU losses (like SIoU [59] or EIoU [60]) stemmed from an empirical investigation into addressing the key localization challenges in this work: irregular shapes and occlusion. By combining Shape-IoU’s sensitivity to bounding box geometry [20] with Inner-IoU’s adaptive mechanism [21], we aimed for a more comprehensive gradient signal for the specific complexities targeted by DGSS-YOLOv8s. Our experiments indicate that this combined approach improves convergence speed and enhances detection performance for complex-shaped objects compared to baseline losses.
4. Experiments and Results
The empirical validation of DGSS-YOLOv8s was performed through cross-dataset benchmarking protocols involving urban traffic perception benchmarks with multi-object complexity. This methodological section systematically elaborates on three critical experimental pillars: (a) data source specifications encompassing sensor modalities and annotation protocols; (b) hardware–software co-design strategies for deployment optimization; (c) comparative analysis of quantitative performance metrics against state-of-the-art baselines.
4.1. Datasets
The BDD100K [22] and KITTI [23] datasets were utilized as benchmarks for our object detection model. These datasets inherently present significant challenges for autonomous driving applications, such as object occlusion, small target sizes, and irregularly shaped targets (e.g., pedestrians, cyclists). A prominent issue identified was class imbalance, particularly a low ‘Cyclist’ proportion in KITTI, which can bias models against minority classes [61].
To mitigate these challenges, our comprehensive preprocessing strategy involved several steps. We first removed severely blurred images (with a Laplacian variance [62]) and duplicates to ensure data quality. Crucially, to address the class imbalance, we performed targeted 2× instance replication for the ‘Cyclist’ category, significantly improving its representation and ensuring a more balanced label distribution across the dataset. The dataset partitioning followed standard guidelines: BDD100K was split into 70% for training, 10% for validation, and 20% for testing, while KITTI used an 80% training, 10% validation, and 10% testing split.
Beyond preprocessing, data augmentation techniques (detailed in Section 4.2, Table 1), including Mosaic [14] and Copy-Paste [63], were extensively employed. These methods not only enhance model robustness but also help mitigate potential spatial biases observed in the datasets (e.g., bounding boxes predominantly clustering in the lower left due to a typical driving perspective). Our proposed model, specifically its DCNv3_LKA_C2f module and Inner-Shape IoU loss, is intrinsically designed to implicitly learn from and effectively handle these complexities and irregular object shapes present in the standard annotations of BDD100K and KITTI. While strong BDD100K performance suggests some generalization, thorough evaluation on diverse unseen data remains future work.

Table 1.
Data augmentation techniques and example parameters used during training.
4.2. Implementation
To systematically evaluate DGSS-YOLOv8s’ road detection efficacy in vehicular environments, we established a reproducible experimental protocol with the following specifications:
- Hardware platform: Intel® Xeon® Silver 4214R CPU @2.40 GHz, 90 GB DDR4 RAM, NVIDIA GeForce RTX 4090 (24 GB GDDR6X Graphics Processing Unit (GPU)).
- Software stack:
- –
- PyTorch 1.11.0 + Torchvision 0.12.0 (CUDA 11.3 backend).
- –
- Ultralytics YOLOv8 reference implementation (v8.1.0) [18].
The learning regimen utilized a batch dimension of 8 over 200 training epochs. Input tensor dimensions were standardized to through bicubic interpolation, achieving an optimal trade-off between small-object preservation (>95% sub-50px targets retained) and edge deployment feasibility. Data augmentation strategies, detailed in Table 1, were applied during training to enhance model robustness and generalization against potential dataset shifts and variations encountered in real-world driving. All comparative analyses employed randomly initialized parameters under identical initialization seeds to eliminate pretraining bias. Network scaling strictly followed YOLOv8s’ original width/depth coefficients.
4.3. Measurement Index
Detection performance quantification adopted the orthogonal metric system:
where precision (P) and recall (R) follow the definitions in Equations (4) and (5). The frames-per-second (FPS) metric incorporated full pipeline latency measurements, including
- Tensor preprocessing (normalization + resizing);
- Inference computation;
- Non-maximum suppression (NMS) postprocessing.
The equation for Average Precision (AP) is shown in Equation (6):
The detection results were divided into True Positive (TP), False Positive (FP), True Negative (TN), and False Negative (FN). The equations for Average Precision (AP) and mAP are given in Equations (6) and (7), respectively. AP represents the mean accuracy for a specific object class, N denotes the total number of classes, mAP@50 represents the average AP across all classes at an Intersection over Union (IoU) threshold of 0.5, and mAP@50:95 spans IoU values from 0.5 to 0.95 with a step size of 0.05. Detection Evaluation Metrics:
Detection results were categorized as TP (correctly identified objects), FP (spurious detections), TN (accurately rejected backgrounds), and FN (missed targets).
Core metrics are defined as
Standard evaluation protocols include
- mAP@50: IoU threshold fixed at 0.5.
- mAP@50:95: Average over IoU thresholds [0.5, 0.95] with 0.05 increments [4].
4.4. Experimental of Ablation Analysis
To assess the efficacy of the newly introduced object detection improvements under traffic conditions, we performed a component-wise performance study through ablation experiments with imagery selected from the KITTI and BDD100K datasets. In comparative result matrices, the “✓” symbol denotes the deployment of our modular enhancements, benchmarked against the baseline YOLOv8s architecture. For rigorous performance validation, evaluation criteria included mAP@50, mAP@50:95, precision (P), recall (R), and frame rate (FPS) metrics [66]. Detailed outcomes are presented in Table 2 and Table 3.
Table 2.
Consequences of DGSS-YOLOv8s algorithm ablation on the KITTI dataset.
Table 3.
Consequences of DGSS-YOLOv8s algorithm ablation on the KITTI dataset.
Ablation studies (Table 2 and Table 3) confirm the efficacy of DGSS-YOLOv8s over the baseline YOLOv8s. On BDD100K, DGSS-YOLOv8s achieved a 50.2% mAP@50 (+2.4 points) and a 23.3% mAP@50:95 (+1.2 points). On KITTI, improvements were more substantial, with mAP@50 reaching 86.9% (+4.6 points) and mAP@50:95 increasing to 65.4% (+9.8 points). This enhanced detection capability was achieved with a moderate increase in parameters (from 11.2M to 13.2M), while maintaining high processing speeds of approximately 107 FPS (BDD100K) and 110 FPS (KITTI). The synergistic integration of the DCNv3_LKA_C2f module (for improved irregular object recognition), the Optimized-GFPN (for enhanced multi-scale fusion), the Detect_SA module (for efficient global context awareness), and the Inner-Shape IoU loss (for refined localization) collectively contributed to these advancements. These results validate the effectiveness of the proposed enhancements in balancing detection accuracy for complex scenarios with high computational efficiency, making DGSS-YOLOv8s a viable solution for demanding traffic perception tasks.
4.5. Algorithm Performance Analysis
Figure 6 and Figure 7 present comparative precision–recall (P-R) evaluations across BDD100K and KITTI datasets, visualizing per-class detection characteristics at mAP@50 thresholds for both baseline YOLOv8s and our enhanced DGSS-YOLOv8s. Visually, the P-R curves for DGSS-YOLOv8s consistently demonstrate a better precision–recall trade-off, positioned generally higher and further to the right compared to the baseline curves across both datasets, indicating improved performance across various operating points. On BDD100K (Figure 6), while performance varies across classes, the most notable visual improvement is seen for the ’Pedestrian’ category, where the curve for DGSS-YOLOv8s (see Figure 6b) is significantly elevated compared to YOLOv8s (see Figure 6a), visually underscoring the enhanced capability to reliably detect this challenging category while maintaining precision. On the KITTI dataset (Figure 7), this trend is even more pronounced for both ’Pedestrian’ and ’Cyclist’, with their P-R curves for DGSS-YOLOv8s (see Figure 7b) showing substantial upward shifts over the baseline (see Figure 7a), visually confirming enhanced detection reliability for these vulnerable road users.
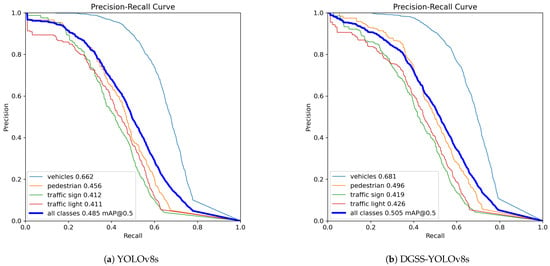
Figure 6.
P-R curve comparison on the BDD100K dataset.
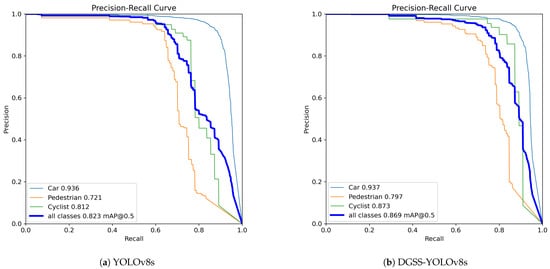
Figure 7.
P-R curve comparison on the KITTI dataset.
To further quantify the effectiveness of the proposed method, the results for per-class metrics are presented in Table 4 and Table 5. Table 4 shows that, in the BDD100K dataset, DGSS-YOLOv8s improves mAP@50 and mAP@50:95 across all categories by 2.0% and 1.2%, respectively. Specifically, the mAP@50 for the ‘vehicle’ class increased from 66.2% to 68.1%, while the mAP@50 for the ‘traffic sign’ and ‘traffic light’ classes increased by 0.7% and 1.5%, respectively. For the ‘pedestrian’ class, mAP@50 increased from 45.6% to 49.6%.
Table 4.
Performance metrics of YOLOv8 and DGSS-YOLOv8s for every class on the BDD100K Dataset (%).
Table 5.
Performance metrics of YOLOv8 and DGSS-YOLOv8s for every class on the KITTI dataset (%).
Table 5 indicates that in the KITTI dataset, DGSS-YOLOv8s achieved a 4.6% increase in mAP@50 and a 9.8% increase in mAP@50:95 across all categories. In particular, the “Cyclist” class saw its mAP@50 rise from 81.2% to 87.3%, while mAP@50:95 improved from 51.2% to 61.4%. The “Pedestrian” class experienced a 7.6% increase in mAP@50 and a 9.1% increase in mAP@50:95. These classes often involve objects that are more likely to be occluded and exhibit complex shapes in traffic scenarios. This demonstrates an overall improvement in model performance, particularly in detecting complex and occluded objects.
To further evaluate the effectiveness of the proposed method, we conducted experiments comparing the results with various traditional object detection networks (Table 6 and Table 7).
Table 6.
Experimental results comparing different algorithmic models on the BDD100K dataset.
Table 7.
Experimental results comparing different algorithmic models on the KITTI dataset.
Comparative analysis against other detectors (Table 6 and Table 7) highlights DGSS-YOLOv8s’s strong performance. On BDD100K, DGSS-YOLOv8s (51.3% mAP@50, 103.1 FPS) demonstrated significant speed advantages (5.3-8.4x) over traditional two-stage detectors like Faster R-CNN [10] with comparable accuracy and substantially higher mAP@50 (+17.4%) than earlier single-stage models like SSD [12]. Against recent SOTA models (e.g., YOLOv9 [46], YOLOv10 [47]), it offered significantly higher FPS (7.9–11.6% faster) with competitive mAP@50. On KITTI, DGSS-YOLOv8s (86.9% mAP@50, 102.5 FPS) substantially outperformed traditional detectors (e.g., +7.4% mAP@50, 4.3 × FPS vs. Faster R-CNN) and, notably, demonstrated both higher mAP@50 (+1.6% to +3.8%) and significantly higher FPS (7.3–12.4% faster) than YOLOv9 and YOLOv10.
Overall, DGSS-YOLOv8s achieved a compelling balance between high FPS and accuracy for challenging objects (small, occluded, irregular) in complex traffic scenarios. While not always achieving the absolute highest mAP (e.g., vs. YOLOv9 on BDD100K), its consistent high FPS across datasets, coupled with substantial accuracy gains in targeted areas (per ablation and per-class results in Table 2, Table 3, Table 4 and Table 5) underscores its novelty. This lies in the synergistic integration of modules, specifically enhancing the detection of difficult cases on an efficient baseline, which is crucial for practical autonomous driving deployment.
Furthermore, DGSS-YOLOv8s showed enhanced multi-scale target detection capabilities (Table 8), assessed using COCO metrics (small: <322 pixels). For small objects, AP-small reached 11.4% on BDD100K (+0.7% over YOLOv8s) and a significant 35.3% on KITTI (+9.7%). Corresponding AR-small improvements were also notable (+1.6% on BDD100K, +6.3% on KITTI), confirming robust detection efficacy for these critical targets.
Table 8.
Performance completion of YOLOv8s and DGSS-YOLOv8s algorithms for object detection of various sizes in BDD100K and KITTI.
4.6. Visualizations
To better understand the detection properties of DGSS-YOLOv8s, we provide several visualizations, including object detection results and gradient-based class activation mapping (Grad-CAM) [67].
- Object detection results: Figure 8 and Figure 9 present the detection result comparison between YOLOv8s and DGSS-YOLOv8s on the BDD100K and KITTI test datasets, respectively. Compared to YOLOv8s, DGSS-YOLOv8s demonstrates improved target localization in complex backgrounds, significantly reducing both false detections and misidentifications. Furthermore, DGSS-YOLOv8s can detect targets that YOLOv8s misses, including pedestrians in challenging backgrounds, occluded cyclists, and distant pedestrians. This demonstrates that DGSS-YOLOv8s offers enhanced performance in recognizing complex shapes, small objects, and occluded targets compared to YOLOv8s. However, it is important to note that DGSS-YOLOv8s cannot completely eliminate false positives and false negatives.
 Figure 8. Detection results of YOLOv8s and DGSS-YOLOv8s on BDD100K outputs.
Figure 8. Detection results of YOLOv8s and DGSS-YOLOv8s on BDD100K outputs. Figure 9. Detection results of YOLOv8s and DGSS-YOLOv8s on KITTI outputs.
Figure 9. Detection results of YOLOv8s and DGSS-YOLOv8s on KITTI outputs. - Grad-CAM Results: We utilized Grad-CAM [67] to visualize CNN decision-making mechanisms, enabling the distinguishing and pinpointing of critical image regions influencing prediction outcomes. This technique constructs coarse localization maps by analyzing gradient propagation from the final convolutional layer to object-related concepts. As demonstrated in Figure 10 and Figure 11, comparative analysis reveals DGSS-YOLOv8s’ superior attention allocation compared to the baseline model. Visualization outcomes distinctly indicate YOLOv8s’ inadequate focus on traffic elements, whereas our enhanced architecture exhibits optimized feature concentration—effectively reducing boundary ambiguities, emphasizing target-centric characteristics, and filtering irrelevant background data. Notably, in occlusion-intensive scenarios, the modified framework demonstrates improved detection consistency through better spatial reasoning. For small object detection tasks, DGSS-YOLOv8s successfully identifies and amplifies discriminative features, achieving precise characteristic extraction that translates to measurable accuracy improvements in complex traffic environments.
 Figure 10. Grad-CAM visualization of BDD100K.
Figure 10. Grad-CAM visualization of BDD100K. Figure 11. Grad-CAM visualization of KITTI.
Figure 11. Grad-CAM visualization of KITTI.
5. Conclusions
Accurate perception with high processing speed in surrounding environments, especially detecting small, occluded, or irregularly shaped objects, remains a critical bottleneck for safe and efficient autonomous driving systems. Effectively addressing these challenges requires balancing high detection accuracy with stringent computational constraints. To tackle challenges including object occlusion and non-standard geometries in demanding traffic environments, this study presented DGSS-YOLOv8s, an upgraded version of the YOLOv8s detection framework. The core contribution lies in the synergistic integration of four innovative elements: (1) the DCNv3_LKA_C2f component strengthens the recognition of non-standard object geometries; (2) the Optimized-GFPN architecture boosts multi-level feature integration; (3) the Detect_SA mechanism expands contextual understanding with high efficiency; and (4) the Inner-Shape IoU metric enhances localization for occluded and truncated objects. Comprehensive evaluations on the BDD100K and KITTI datasets demonstrated the framework’s advancements. The model showed mAP@50 improvements of 2.4% (BDD100K) and 4.6% (KITTI) over baseline YOLOv8s, with mAP@50:95 increasing by 1.2% and 9.8%, respectively. Significant progress appeared in vulnerable road user detection, including pedestrian recognition on BDD100K (mAP@50: 45.6% to 49.6%) and cyclist detection on KITTI (mAP@50: 81.2% to 87.3%). Notably, the solution enhanced small object detection (AP-small up by 9.7% on KITTI) while achieving high processing speeds exceeding 100 FPS (103.1 FPS on BDD100K, 102.5 FPS on KITTI). Visual analysis further corroborated component contributions. Future research will continue to optimize the algorithm structure and evaluate its generalization on diverse, unseen real-world datasets to further enhance detection performance in autonomous driving scenarios.
Author Contributions
Conceptualization, S.C.; methodology, K.Y. and S.C.; software, S.C.; validation, L.C.; formal analysis, K.Y. and S.C.; investigation, K.Y.; resources, L.C. and K.Y.; data curation, K.Y.; writing—original draft preparation, S.C.; writing—review and editing, K.Y.; visualization, S.C.; supervision, L.C.; project administration, L.C.; funding acquisition, K.Y. and L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Shanghai Municipal Commission of Science and Technology, and the project name ‘Scenario Factory, a working platform for the generation and processing of autonomous driving simulation scenarios’. The grant number is 220H1053500.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Boukerche, A.; Hou, Z. Object detection using deep learning methods in traffic scenarios. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Wu, B.; Iandola, F.; Jin, P.H.; Keutzer, K. Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 1–26 July 2017; pp. 129–137. [Google Scholar] [CrossRef]
- Tong, K.; Lyu, Y.; Li, Y.; Wu, Y.; Zhang, L. Deep learning-based small object detection: A survey and benchmark. Appl. Intell. 2023, 53, 15861–15883. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; Volume 8693, Lecture Notes in Computer Science; pp. 740–755. [Google Scholar] [CrossRef]
- Teixeira, F.; Georgiou, T.; Mylonas, P.; Lalas, A.; Chrysostomou, D.; Stivaros, S.; Aksoy, E. A Review on Vision-Based Pedestrian and Vehicle Detection Systems and Their Performance on Benchmark Datasets. Sensors 2021, 21, 7267. [Google Scholar] [CrossRef]
- Hosseini, P.; Rezghi, M.; Etemad, A.; Kasaei, S. Occlusion Handling in Generic Object Detection: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6018–6035. [Google Scholar]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Carvalho, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixao, T.M.; DeSouza, F.; et al. Self-Driving Cars: A Survey. Expert Syst. Appl. 2021, 175, 114816. [Google Scholar] [CrossRef]
- Liu, R.; Feng, Y.; Wang, X.; Wang, C.J. RT-BEV: A Real-Time Framework for Vision-Centric Bird’s-Eye-View Perception. In Proceedings of the 45th IEEE Real-Time Systems Symposium (RTSS), York, UK, 10–13 December 2024. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 23–19 October 2025; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Wong, C.; Yifu, Z.; Montes, D.; et al. ultralytics/yolov5: V6.2—YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML and Deci.ai integrations; Zenodo: Geneva, Switzerland, 2022. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D.M. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 June 2024).
- Jiang, R.; Xie, T.; Li, A.; Hu, R. YOLOv8-Based Improved Model for Traffic Object Detection. Sensors 2023, 23, 6958. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S. Shape-IOU: More Accurate Metric considering Bounding Box Shape and Scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More Effective Intersection over Union Loss with Auxiliary Bounding Box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Song, C.; Kim, J. SJ+LPD: Selective Jittering and Learnable Point Drop for Robust LiDAR Semantic Segmentation under Adverse Weather. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Khan, M.A.; Al-Maadeed, S.A.; Bouridane, A. Advancing vehicle detection for autonomous driving: Integrating computer vision and machine learning for lightweight, real-time performance. Connect. Sci. 2024, 36, 2358145. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Parisapogu, S.A.B.; Narla, N.; Juryala, A.; Ramavath, S. YOLO based Object Detection Techniques for Autonomous Driving. In Proceedings of the 2024 Second International Conference on Inventive Computing and Informatics (ICICI), Bangalore, India, 11–12 June 2024; pp. 249–256. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar] [CrossRef]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. Internimage: Exploring large-scale vision foundation models with Deformable Convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14408–14419. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, C.; Xu, X.; Wang, L.; Zhan, D.; Chen, Z. A High-Resolution Feature Pyramid Network With Attention-Based Multi-Level Feature Fusion Module for Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Zhou, Y.; Wang, H.; Qiao, P.; Wan, W. Research on Deep Learning Detection Model for Pedestrian Objects in Complex Scenes Based on Improved YOLOv7. Sensors 2024, 24, 6922. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; NIPS: Grenada, Spain, 2017; pp. 5998–6008. [Google Scholar]
- Saha, S.; Xu, L. Vision Transformers on the Edge: A Comprehensive Survey of Model Compression and Acceleration Strategies. Neurocomputing 2024, 643, 130417. [Google Scholar] [CrossRef]
- Chen, Y.; Cai, G.; Song, Z.; Li, J.; Wang, X. LVP: Leverage Virtual Points in Multi-Modal Early Fusion for 3-D Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Wu, H.; Wen, C.; Shi, S.; Li, X.; Wang, C. Virtual Sparse Convolution for Multimodal 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 21654–21663. [Google Scholar]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef]
- Zhao, J.; Li, L.; Dai, J. A review of multi-sensor fusion 3D object detection for autonomous driving. In Eleventh International Symposium on Precision Mechanical Measurements; SPIE: Philadelphia, PA, USA, 2024; Volume 13178, p. 1317826. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Chen, L.; Wang, Z.; Liu, J.; Luo, H.; Han, X.; Tao, Q. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Tian, D.; Yan, X.; Zhou, D.; Wang, C.; Zhang, W. IV-YOLO: A Lightweight Dual-Branch Object Detection Network. Sensors 2024, 24, 6181. [Google Scholar] [CrossRef]
- Lv, Y.; Chen, B.; Zheng, Z.; He, Z.; Zhang, Z.; Shan, S. DETRs with Improved DeNoising Anchor Boxes for Real-Time Object Detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Azad, R.; Niggemeier, L.; Hüttemann, M.; Kazerouni, A.; Aghdam, E.K.; Velichko, Y.; Bagci, U.; Merhof, D. Beyond Self-Attention: Deformable Large Kernel Attention for medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 1287–1296. [Google Scholar] [CrossRef]
- Jiang, Y.; Tan, Z.; Wang, J.; Sun, X.; Lin, M.; Li, H. GiraffeDet: A heavy-neck paradigm for object detection. arXiv 2022, arXiv:2202.04256. [Google Scholar]
- Zhao, G.; Ge, W.; Yu, Y. GraphFPN: Graph Feature Pyramid Network for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2763–2772. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Hu, Y.H.; Chu, L.H.; Chen, X.Y.; Huang, L.Z.; Li, B. Demystifying Deep Neural Network Operators towards Better Network Designs. arXiv 2024, arXiv:2211.05781. [Google Scholar]
- Yu, H.; Wan, C.; Liu, M.; Chen, D.; Xiao, B.; Dai, X. Real-Time Image Segmentation via Hybrid Convolutional-Transformer Architecture Search. arXiv 2024, arXiv:2403.10413. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, X.; Lu, H. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. arXiv 2021, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Pech-Pacheco, J.L.; Cristobal, G.; Alvarez-Borrego, J.; Fernandez-Valdivia, J.J. Diatom autofocusing in brightfield microscopy: A comparative study. In Proceedings of the Proceedings 15th International Conference on Pattern Recognition. ICPR-2000, Barcelona, Spain, 3–7 September 2000; Volume 3, pp. 314–317. [Google Scholar] [CrossRef]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Istanbul, Turkey, 9–11 June 2021; Volume 34, pp. 13001–13008. [Google Scholar] [CrossRef]
- Zhao, R.; Tang, S.H.; Supeni, E.E.B.; Rahim, S.A.; Fan, L. Z-YOLOv8s-based approach for road object recognition in complex traffic scenarios. Alex. Eng. J. 2024, 106, 298–311. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).