
Crude Oil and Hot-Rolled Coil Futures Price Prediction Based on Multi-Dimensional Fusion Feature Enhancement

Abstract
1. Introduction
- (1)
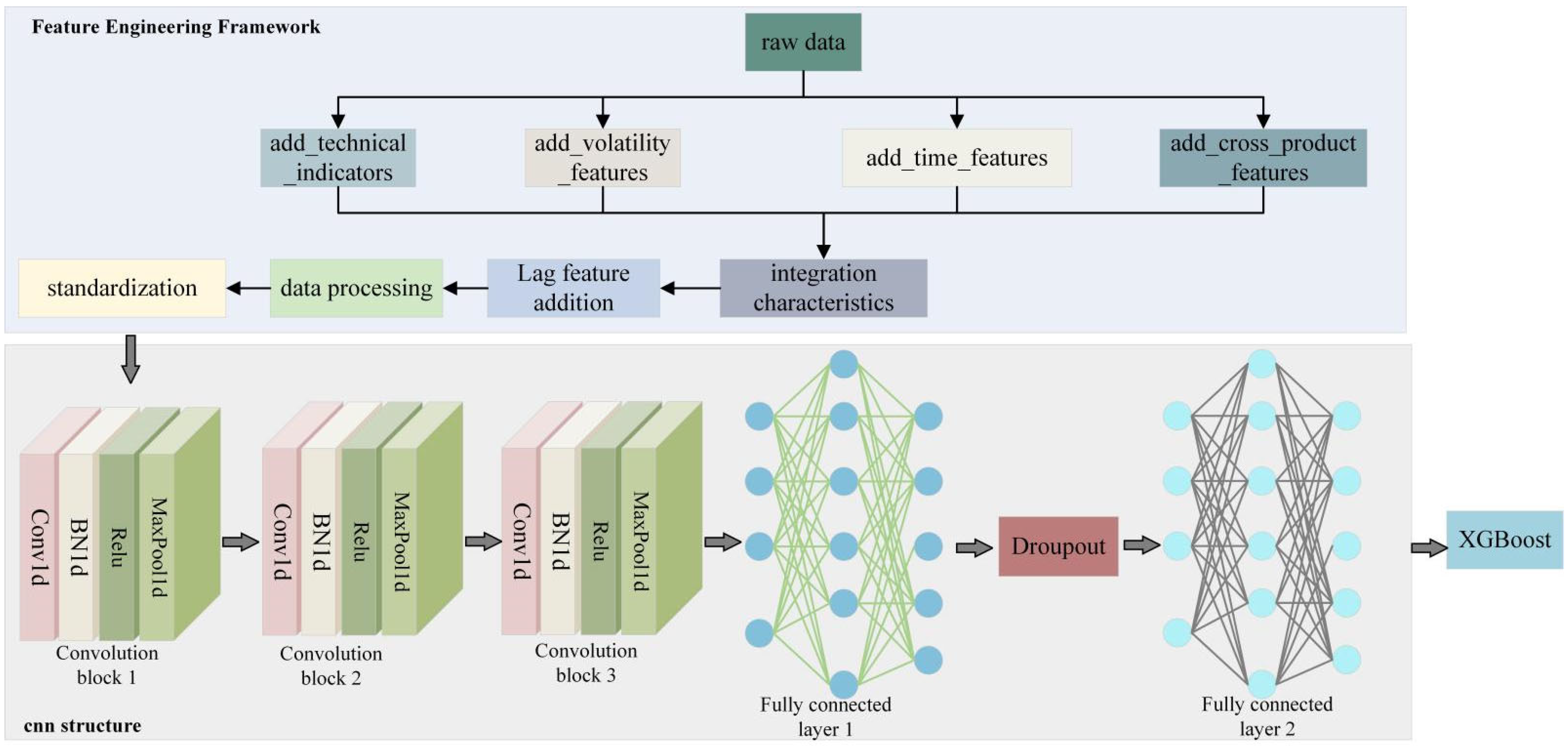
- The MDFFE forecasting method is designed to integrate technical indicators, volatility indicators, time characteristics, and cross-species linkage characteristics. This integration aims to uncover hidden information in the data and establish a solid foundation for the futures price forecasting system.
- (2)
- An innovative lag feature design is implemented, addressing the common issue of data leakage during the model construction phase. This ensures the scientific rigor and dependability of the training process, making it more stringent and standardized. Consequently, it establishes a robust foundation for achieving precise predictions in the future.
- (3)
- A deep integration of convolutional neural networks (CNN) and extreme gradient boosting (XGBoost) is achieved. By leveraging the strong temporal feature extraction capabilities of CNN and the superior nonlinear mapping of XGBoost, an end-to-end prediction framework is developed. This framework incorporates a meticulously designed three-layer CNN structure and an adaptive weight fusion strategy. It maximizes the strengths of each model while mitigating their weaknesses, significantly enhancing prediction accuracy and reducing variability. This provides a solid basis for the accurate forecasting of futures prices.
2. Related Work
3. Multi-Dimensional Fusion Feature-Enhanced Prediction Method
3.1. Data Augmentation of Multi-Dimensional Feature Engineering
3.1.1. Technology Index
3.1.2. Fluctuation Index
3.1.3. Time Characteristics
3.1.4. Cross-Variety Linkage Characteristics
3.1.5. Lag Feature Design
3.2. Deep Fusion Module
3.2.1. Convolutional Neural Network Structure
3.2.2. Adaptive Weight Fusion Strategy
4. Experimental Results and Analysis
4.1. Data Set Introduction
4.2. Introduction of Evaluation Index
4.3. Model Configuration and Theory
4.4. Quantitative Analyses
4.5. Qualitative Analyses
4.6. Statistical Tests
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Li, H.; Ren, H.; Jiang, H.; Ren, B.; Ma, N.; Chen, Z.; Zhong, W.; Ulgiati, S. Shared responsibility for carbon emission reduction in worldwide “steel-electric vehicle” trade within a sustainable industrial chain perspective. Ecol. Econ. 2025, 227, 108393. [Google Scholar] [CrossRef]
- Chen, X.; Tongurai, J. Revisiting the interdependences across global base metal futures markets: Evidence during the main waves of the COVID-19 pandemic. Res. Int. Bus. Financ. 2024, 70, 102391. [Google Scholar] [CrossRef]
- Krekel, G.; Suer, J.; Traverso, M. Identifying the social hotspots of German steelmaking and its value chain. Sustain. Prod. Consum. 2024, 51, 222–235. [Google Scholar] [CrossRef]
- Derakhshani, R.; GhasemiNejad, A.; Amani Zarin, N.; Amani Zarin, M.M.; Jalaee, M.S. Forecasting copper prices using deep learning: Implications for energy sector economies. Mathematics 2024, 12, 2316. [Google Scholar] [CrossRef]
- Mensi, W.; Aslan, A.; Vo, X.V.; Kang, S.H. Time-frequency spillovers and connectedness between precious metals, oil futures and financial markets: Hedge and safe haven implications. Int. Rev. Econ. Financ. 2023, 83, 219–232. [Google Scholar] [CrossRef]
- Kumar, S.; Kumar, A.; Singh, G. Causal relationship among international crude oil, gold, exchange rate, and stock market: Fresh evidence from NARDL testing approach. Int. J. Financ. Econ. 2023, 28, 47–57. [Google Scholar] [CrossRef]
- Fiszeder, P.; Fałdziński, M.; Molnár, P. Attention to oil prices and its impact on the oil, gold and stock markets and their covariance. Energy Econ. 2023, 120, 106643. [Google Scholar] [CrossRef]
- Ben Ameur, H.; Boubaker, S.; Ftiti, Z.; Louhichi, W.; Tissaoui, K. Forecasting commodity prices: Empirical evidence using deep learning tools. Ann. Oper. Res. 2024, 339, 349–367. [Google Scholar] [CrossRef]
- Zurakowski, D.; Staffa, S.J. Statistical power and sample size calculations for time-to-event analysis. J. Thorac. Cardiovasc. Surg. 2023, 166, 1542–1547.e1. [Google Scholar] [CrossRef]
- Rios-Avila, F.; Maroto, M.L. Moving beyond linear regression: Implementing and interpreting quantile regression models with fixed effects. Sociol. Methods Res. 2024, 53, 639–682. [Google Scholar] [CrossRef]
- Xu, L.; Xu, H.; Ding, F. Adaptive multi-innovation gradient identification algorithms for a controlled autoregressive autoregressive moving average model. Circuits Syst. Signal Process. 2024, 43, 3718–3747. [Google Scholar] [CrossRef]
- Shyu, Y.W.; Chang, C.C. A hybrid model of memd and pso-lssvr for steel price forecasting. Int. J. Eng. Manag. Res. 2022, 12, 30–40. [Google Scholar] [CrossRef]
- Wu, S.; Wang, W.; Song, Y.; Liu, S. An EEMD-LSTM, SVR, and BP decomposition ensemble model for steel future prices forecasting. Expert Syst. 2024, 41, e13672. [Google Scholar] [CrossRef]
- Li, C.; Wu, C.; Zhou, C. Forecasting equity returns: The role of commodity futures along the supply chain. J. Futures Mark. 2021, 41, 46–71. [Google Scholar] [CrossRef]
- Khattak, B.H.A.; Shafi, I.; Khan, A.S.; Flores, E.S.; Lara, R.G.; Samad, M.A.; Ashraf, I. A systematic survey of AI models in financial market forecasting for profitability analysis. IEEE Access 2023, 11, 125359–125380. [Google Scholar] [CrossRef]
- Wang, J.; Zhuang, Z.; Feng, L. Intelligent optimization based multi-factor deep learning stock selection model and quantitative trading strategy. Mathematics 2022, 10, 566. [Google Scholar] [CrossRef]
- Kontopoulou, V.I.; Panagopoulos, A.D.; Kakkos, I.; Matsopoulos, G.K. A review of ARIMA vs. machine learning approaches for time series forecasting in data driven networks. Future Internet 2023, 15, 255. [Google Scholar] [CrossRef]
- Roy, A.; Chakraborty, S. Support vector machine in structural reliability analysis: A review. Reliab. Eng. Syst. Saf. 2023, 233, 109126. [Google Scholar] [CrossRef]
- Lang, G.; Zhao, L.; Miao, D.; Ding, W. Granular-Ball Computing Based Fuzzy Twin Support Vector Machine for Pattern Classification. IEEE Trans. Fuzzy Syst. 2025, 99, 1–13. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, S.; Xie, Y.; Zhu, T.; Fernandez, C. An improved particle swarm optimization-least squares support vector machine-unscented Kalman filtering algorithm on SOC estimation of lithium-ion battery. Int. J. Green Energy 2024, 21, 376–386. [Google Scholar] [CrossRef]
- Mahmoodi, A.; Hashemi, L.; Jasemi, M.; Mehraban, S.; Laliberté, J.; Millar, R.C. A developed stock price forecasting model using support vector machine combined with metaheuristic algorithms. Opsearch 2023, 60, 59–86. [Google Scholar] [CrossRef]
- Kuo, R.J.; Chiu, T.H. Hybrid of jellyfish and particle swarm optimization algorithm-based support vector machine for stock market trend prediction. Appl. Soft Comput. 2024, 154, 111394. [Google Scholar] [CrossRef]
- Yin, L.; Li, B.; Li, P.; Zhang, R. Research on stock trend prediction method based on optimized random forest. CAAI Trans. Intell. Technol. 2023, 8, 274–284. [Google Scholar] [CrossRef]
- Chou, J.S.; Chen, K.E. Optimizing investment portfolios with a sequential ensemble of decision tree-based models and the FBI algorithm for efficient financial analysis. Appl. Soft Comput. 2024, 158, 111550. [Google Scholar] [CrossRef]
- Zhao, J.; Lee, C.D.; Chen, G.; Zhang, J. Research on the Prediction Application of Multiple Classification Datasets Based on Random Forest Model. In Proceedings of the 2024 IEEE 6th International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 26–28 July 2024; IEEE: New York, NY, USA, 2024; pp. 156–161. [Google Scholar]
- Ping, W.; Hu, Y.; Luo, L. Price Forecast of Treasury Bond Market Yield: Optimize Method Based on Deep Learning Model. IEEE Access 2024, 12, 194521–194539. [Google Scholar] [CrossRef]
- Mienye, I.D.; Swart, T.G.; Obaido, G. Recurrent neural networks: A comprehensive review of architectures, variants, and applications. Information 2024, 15, 517. [Google Scholar] [CrossRef]
- Pathak, D.; Kashyap, R. Neural Correlate-Based E-Learning Validation and Classification Using Convolutional and Long Short-Term Memory Networks. Trait. Du Signal 2023, 40, 1457. [Google Scholar] [CrossRef]
- Wan, W.D.; Bai, Y.; Lu, Y.N.; Ding, L. A hybrid model combining a gated recurrent unit network based on variational mode decomposition with error correction for stock price prediction. Cybern. Syst. 2024, 55, 1205–1229. [Google Scholar] [CrossRef]
- Pan, H.; Tang, Y.; Wang, G. A Stock Index Futures Price Prediction Approach Based on the MULTI-GARCH-LSTM Mixed Model. Mathematics 2024, 12, 1677. [Google Scholar] [CrossRef]
- Wu, B.; Wang, Z.; Wang, L. Interpretable corn future price forecasting with multivariate time series. J. Forecast. 2024, 43, 1575–1594. [Google Scholar] [CrossRef]
- Zhang, Y.T.; Jin, C.T.; Li, Y. Stock Index Futures Price Prediction Based on VAE-ATTGRU Model. Comput. Eng. Appl. 2024, 60, 293–301. [Google Scholar]
- Wang, H.C.; Hsiao, W.C.; Liou, R.S. Integrating technical indicators, chip factors and stock news for enhanced stock price predictions: A multi-kernel approach. Asia Pac. Manag. Rev. 2024, 29, 292–305. [Google Scholar] [CrossRef]
- Farimani, S.A.; Jahan, M.V.; Fard, A.M.; Tabbakh, S.R.K. Investigating the informativeness of technical indicators and news sentiment in financial market price prediction. Knowl.-Based Syst. 2022, 247, 108742. [Google Scholar] [CrossRef]
- Marfatia, H.A.; Ji, Q.; Luo, J. Forecasting the volatility of agricultural commodity futures: The role of co-volatility and oil volatility. J. Forecast. 2022, 41, 383–404. [Google Scholar] [CrossRef]
- Aliu, F.; Asllani, A.; Hašková, S. The impact of bitcoin on gold, the volatility index (VIX), and dollar index (USDX): Analysis based on VAR, SVAR, and wavelet coherence. Stud. Econ. Financ. 2024, 41, 64–87. [Google Scholar] [CrossRef]
- Verma, S.; Sahu, S.P.; Sahu, T.P. Discrete wavelet transform-based feature engineering for stock market prediction. Int. J. Inf. Technol. 2023, 15, 1179–1188. [Google Scholar] [CrossRef]
- Wang, B. A research on resistance spot welding quality judgment of stainless steel sheets based on revised quantum genetic algorithm and hidden markov model. Mech. Syst. Signal Process. 2025, 223, 111881. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stages | Step and Method | Description |
|---|---|---|
| Data preprocessing and feature engineering | Function: data preprocessing (lookback) | |
| Extract multi-dimensional features | Includes technical indicators (MA/RSI/MACD/Bollinger Bands), volatility indicators (returns/volatility/amplitude), temporal features (trading session/intra-day minute), and cross-asset linkage features (price ratio/rolling correlation/volume ratio). | |
| Standardization | Standardize features and target variables to ensure data are on a consistent scale, improving model training efficiency and stability. | |
| Data splitting | Divide data into training and testing sets based on the given lookback value, ensuring consistent data distribution during model training and testing. | |
| Returns | Returns training features, training targets, testing features, testing targets, feature scaler, and target scaler. | |
| CNN model construction | Class: CNN model | |
| Initialize network structure | Define input dimensions, convolutional layers, pooling layers, fully connected layers, and other network structures to build a CNN model for feature extraction and prediction. | |
| Forward propagation | Input data passes through convolutional layers, activation functions (e.g., ReLU), pooling layers, etc., to extract features and output prediction results. | |
| XGBoost model construction | Class: XGBoost model | |
| Initialize model | Set hyperparameters, including n_estimators, max_depth, learning_rate, etc., to initialize the XGBoost model for prediction. | |
| Train | Fit the model using training data to learn the nonlinear mapping relationship between features and target variables. | |
| Predict | Make predictions on new data and output the prediction results. |
| Model | Description | Key Parameters | Training Method |
|---|---|---|---|
| BiLSTMModel | Bidirectional long short-term memory network, used to capture both forward and backward dependencies. | Input dimension: 2100, hidden layer dimension: 64, output dimension: 1, and number of layers: 1. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| CNN | Convolutional neural network, used for feature extraction. | Input channels: 1, output channels: 16, kernel size: 3, and pooling window: 2. Output dimension: 1. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| CNNLSTM | A hybrid model combining CNN for feature extraction and LSTM for sequence modeling. | Input dimension: 2100, LSTM hidden layer dimension: 64, output dimension: 1, CNN layers: 2, and LSTM layers: 1. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| LSTM | Long short-term memory network, used for processing sequential data. | Input dimension: 2100, hidden layer dimension: 100, number of layers: 5, and output dimension: 1. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| CNNBiLSTMGRU | A hybrid model combining CNN, bidirectional LSTM, and GRU layers. | Input dimension: 2100, CNN layers: 2, bidirectional LSTM hidden layer dimension: 64, GRU hidden layer dimension: 64, and output dimension: 1. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| TransformerModel | A Transformer-based sequence model. | Input dimension: 2100, embedding dimension: 32, number of layers: 4, attention heads: 8, feed-forward dimension: 128, dropout: 0.1, and output dimension: 1. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| LSTMTransformer | A hybrid model combining LSTM and Transformer layers. | Input dimension: 2100, LSTM layers: 4, Transformer layers: 4, embedding dimension: 32, and output dimension: 1. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| CNNLSTMGRU | A hybrid model combining CNN, LSTM, and GRU layers. | Input dimension: 2100, CNN layers: 2, LSTM hidden layer dimension: 64, GRU hidden layer dimension: 64, and output dimension: 1. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| MDFFE | A hybrid model combining CNN for feature extraction and XGBoost. | CNN output dimension: 128, XGBoost parameters: number of trees: 200, max depth: 10, learning rate: 0.1, weight distribution: CNN 0.2, and XGBoost 0.8. | Optimizer: Adam, learning rate: 0.001, epochs: 50, batch size: 128, and seed: 666. |
| Model | MAE↓ | RMSE↓ | MAPE↓ | R-Squared | SSE↓ |
|---|---|---|---|---|---|
| BiLSTMModel | 0.0806 | 0.0980 | 0.0842 | 0.5916 | 206.7034 |
| CNN | 0.0720 | 0.0838 | 0.0720 | 0.7019 | 150.8885 |
| CNNLSTM | 0.1403 | 0.1957 | 0.1475 | −0.6273 | 823.6530 |
| LSTM | 0.2427 | 0.3332 | 0.2592 | −3.7164 | 2387.2202 |
| CNNBiLSTMGRU | 0.1314 | 0.1665 | 0.1464 | −0.1782 | 596.3677 |
| TransformerModel | 0.1395 | 0.1689 | 0.1519 | −0.2123 | 613.5961 |
| LSTMTransformer | 0.2504 | 0.2831 | 0.2813 | −2.4046 | 1723.2487 |
| CNNLSTMGRU | 0.1298 | 0.1751 | 0.1288 | −0.3020 | 659.0109 |
| MDFFE | 0.0068 | 0.0084 | 0.0071 | 0.9970 | 1.5090 |
| CNN | FE | XGBoost | MAE↓ | RMSE↓ | MAPE↓ | R-Squared | SSE↓ |
|---|---|---|---|---|---|---|---|
| √ | × | × | 0.0720 | 0.0838 | 0.0720 | 0.7019 | 150.8885 |
| √ | √ | × | 0.0250 | 0.0376 | 0.0254 | 0.9353 | 44.6601 |
| √ | √ | √ | 0.0068 | 0.0084 | 0.0071 | 0.9970 | 1.5090 |
| Model | Target Model Mean Error | Comparison Model Mean Error | Mean Error Difference | T-Statistic | T-Test p-Value | Wilcoxon Statistic | Wilcoxon p-Value | Cohen d | T-Test Significance (α = 0.05) | Wilcoxon Significance (α = 0.05) |
|---|---|---|---|---|---|---|---|---|---|---|
| BiLSTMModel | 0.002752569 | 0.08062279 | −0.07787022 | −205.3164029 | 0 | 231,432 | 0 | −2.788792657 | Significant | Significant |
| CNN | 0.002752569 | 0.072012575 | −0.069260006 | −239.5481362 | 0 | 105,285 | 0 | −3.229293133 | Significant | Significant |
| CNNLSTM | 0.002752569 | 0.148733619 | −0.145981049 | −142.4923388 | 0 | 94,251 | 0 | −1.93765241 | Significant | Significant |
| LSTM | 0.002752569 | 0.230479288 | −0.227726718 | −164.3823637 | 0 | 23,563 | 0 | −2.239282064 | Significant | Significant |
| CNNBiLSTMGRU | 0.002752569 | 0.138434251 | −0.135681681 | −191.5883282 | 0 | 26,907 | 0 | −2.586981754 | Significant | Significant |
| TransformerModel | 0.002752569 | 0.127368013 | −0.124615444 | −226.0726834 | 0 | 70,486 | 0 | −3.069560968 | Significant | Significant |
| LSTMTransformer | 0.002752569 | 0.136183782 | −0.133431213 | −186.1417067 | 0 | 65,410 | 0 | −2.513974888 | Significant | Significant |
| CNNLSTMGRU | 0.002752569 | 0.111576971 | −0.108824401 | −166.9906497 | 0 | 116,873 | 0 | −2.252380018 | Significant | Significant |
| Source | sum_sq | df | F | PR (>F) |
|---|---|---|---|---|
| C (model) | 671.944528 | 8.0 | 7053.753944 | 0.0 |
| Residual | 2304.543389 | 193,536.0 | NaN | NaN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Gao, Z.; Li, Y.; Cai, Z.; Yu, J.; Qin, P. Crude Oil and Hot-Rolled Coil Futures Price Prediction Based on Multi-Dimensional Fusion Feature Enhancement. Algorithms 2025, 18, 357. https://doi.org/10.3390/a18060357
Tang Y, Gao Z, Li Y, Cai Z, Yu J, Qin P. Crude Oil and Hot-Rolled Coil Futures Price Prediction Based on Multi-Dimensional Fusion Feature Enhancement. Algorithms. 2025; 18(6):357. https://doi.org/10.3390/a18060357
Chicago/Turabian StyleTang, Yongli, Zhenlun Gao, Ya Li, Zhongqi Cai, Jinxia Yu, and Panke Qin. 2025. "Crude Oil and Hot-Rolled Coil Futures Price Prediction Based on Multi-Dimensional Fusion Feature Enhancement" Algorithms 18, no. 6: 357. https://doi.org/10.3390/a18060357
APA StyleTang, Y., Gao, Z., Li, Y., Cai, Z., Yu, J., & Qin, P. (2025). Crude Oil and Hot-Rolled Coil Futures Price Prediction Based on Multi-Dimensional Fusion Feature Enhancement. Algorithms, 18(6), 357. https://doi.org/10.3390/a18060357