Abstract
Video anomaly detection plays a crucial role in various fields such as surveillance, health monitoring, and industrial quality control. This research paper introduces a novel contribution to the field by presenting MaskedConv3D layers within a modified UNet architecture. These MaskedConv3D layers provide a unique approach to information propagation in three-dimensional video data by selectively masking temporal regions of convolutional kernels. By incorporating these layers into the skip connections of the UNet, the model gains the ability to infer missing information in the temporal domain based on the surrounding context. This innovative mechanism enhances the preservation of spatial and temporal details, addressing the challenge of effectively detecting anomalies in video data. The proposed methodology is evaluated on popular video datasets, showcasing its effectiveness in capturing intricate patterns and contexts. The results highlight the superiority of the modified UNet with MaskedConv3D layers compared to traditional approaches. Overall, this research introduces a novel technique for information propagation in video data and demonstrates its potential for advancing video anomaly detection.
1. Introduction
Video anomaly detection strives to recognise unusual patterns or occurrences deviating from standard or expected sequences within video data. This task is of critical importance as it facilitates the flagging of non-typical events that could potentially signify threats, irregularities, or uncommon circumstances. The implications of such a capability span numerous fields, from enhancing security via surveillance applications, improving health outcomes by identifying abnormal behavioural or physiological patterns, optimising traffic control through the detection of anomalies or accidents, to augmenting industrial processes by early identification of potential machinery malfunctions.
The advent of deep learning has fundamentally transformed the field of video anomaly detection, introducing innovative approaches that tackle previously insurmountable challenges. These algorithms leverage their intrinsic ability to learn complex, hierarchical representations directly from raw data, enabling the extraction of intricate patterns and contexts necessary for detecting anomalies in intricate video sequences.
Figure 1 illustrates the architecture of our proposed MaskedSkipUNet. On the left, a sequence of input video frames is processed by a series of 2D convolutional encoding blocks. The feature maps are then passed through a symmetric decoding path on the right, typical of UNet structures. Crucially, the yellow blocks interleaved between encoder and decoder levels represent our novel MaskedConv3D layers. These layers operate on the temporal dimension of the feature maps and apply a structured mask to the centre kernel, enabling selective feature suppression and inference of normal patterns. By placing these layers at skip connection points, we modulate the flow of information and prevent the direct copying of anomalous content from encoder to decoder, a limitation present in conventional UNets.
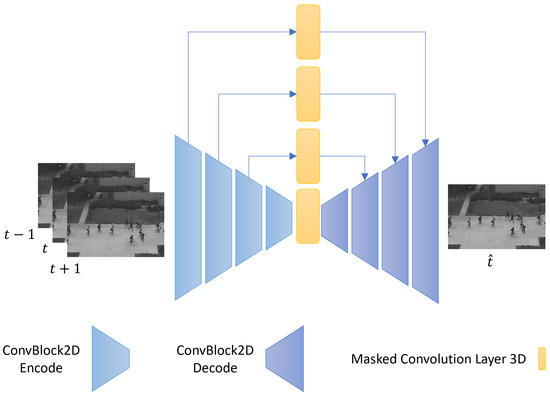
Figure 1.
This figure showcases the architecture of the proposed MaskedSkipUNet for video anomaly detection. The architecture is based on the UNet framework, augmented with MaskedConv3D layers inserted between the skip connections. These MaskedConv3D layers facilitate contextual inference by considering the temporal dimension and applying a user-defined zero mask to a subspace of the centre kernel.
Autoencoders (AEs) and Variational Autoencoders (VAEs) have significantly contributed to anomaly detection by accurately reconstructing input data and encoding it into a low-dimensional latent space, allowing anomalies to be identified as deviations from expected reconstructions or latent representations. However, this approach often results in small details within images and videos not being reconstructed well, leading to false positives when these details are misidentified as anomalies [1].
In the recent panorama of video anomaly detection, UNets have emerged as a potent architecture, demonstrating remarkable efficacy [2,3,4,5,6,7,8,9]. Unlike autoencoders and VAEs, which struggle to retain fine details, UNets leverage their skip connections to carry detailed spatial information from the encoder to the decoder, effectively preserving small details that are crucial for accurate reconstruction [10]. Originally conceived for biomedical image segmentation, UNets utilise a symmetric expanding path that helps recover spatial information lost during the contraction phase, allowing the model to effectively extract both high-level semantic information and low-level spatial information. This capability is particularly critical in applications where preserving detailed spatial contexts is vital, such as anomaly detection in videos.
The primary differentiator between UNets and autoencoders lies in the manner of information propagation. While both architectures comprise an encoding (contracting) and decoding (expanding) phase, UNets introduce additional “skip connections” that bridge the encoding and decoding paths at equivalent levels of hierarchy [11]. These connections allow the network to carry detailed spatial information from the encoder directly to the decoder, thereby facilitating the preservation and reconstruction of intricate spatial patterns often lost in the bottleneck of traditional autoencoders.
However, UNets have a significant limitation in that they can proficiently reconstruct anomalous samples as well as normal samples due to their skip connections from earlier layers. This proficiency can obstruct anomaly detection and is often resolved by designing large complexity around the UNet, as is later demonstrated in Section 5.1 (Figure 7).
In our research, we tackle the challenge of UNet’s anomaly reconstruction by implementing special convolution layers, the MaskedConv3D, between the skip connections. While several methodologies in the realm of anomaly detection focus on masking the image or data directly, our approach diverges significantly. Instead of operating on the image, we introduce masking at the convolutional layer level, resulting in a more nuanced and informed mechanism for anomaly identification. This strategic departure offers a unique lens through which anomaly detection can be more effectively understood and implemented. Our research presents several key innovations that distinguish it from existing methods:
- Unlike traditional approaches that mask the image or data directly, often requiring multiple random masks to account for unknown anomaly locations, our method masks at the convolutional layer level. This avoids the risk of obscuring critical normal features or missing anomalous ones. Moreover, by masking the kernel instead of the image, our approach enables efficient inference without requiring multiple masked versions of the input, significantly reducing computational overhead [12,13].
- Our research introduces MaskedConv3D layers that are strategically placed between the skip connections of the UNet architecture. By placing the MaskedConv3D layers between skip connections, we apply feature masking and feature inference on various granularities of detail. This addition tackles the challenge of UNet’s ability to reconstruct anomalies of various sizes [14,15].
- By implementing masked convolutions between skip connections, our method infers normal spatio-temporal features to be passed to the decoder. Instead of passing forward the anomalies across the reconstruction process [6,7], using MaskedConv3D layers means our model needs to infer normal features from surrounding spatio-temporal features.
Section 2 of this paper reviews existing methods in video anomaly detection, highlighting their strengths and limitations. In Section 3, we introduce our proposed MaskedSkipUNet architecture and explain its unique components, such as the MaskedConv3D layer. Section 4 describes the three datasets used for evaluation: the Ped2, CUHK Avenue, and ShanghaiTech datasets. In Section 5, we present the performance of the MaskedSkipUNet, demonstrating its advantages over other frame-based methods. Finally, Section 6 provides an evaluation of the effectiveness of the MaskedSkipUNet architecture by comparing it across various perumataions of architecture components. The source code is publicly available at https://github.com/demetrislappas/MaskedSkipUNet (accessed on 1 April 2025).
2. Related Work
Anomaly detection within video datasets presents a unique challenge, primarily due to the overwhelming prevalence of normal data. Consequently, training sets designated for anomaly detection are inherently biased towards normal samples [16,17,18]. To counteract this imbalance, certain strategies have been deployed, such as the generation of artificial anomalies. However, the efficacy of such methodologies remains questionable, given the inherent difficulty in simulating all potential real-world anomalies.
Unsupervised learning remains a favoured approach in this domain, typically involving the implementation of autoencoders (AEs) as a key mechanism [19,20,21,22,23,24,25,26]. AEs detect anomalies by evaluating the disparity between their initial input and the reconstructed output. They comprise an encoder, which maps normal data to a latent space, and a decoder, which recreates the original input.
The underlying rationale for this methodology is that normal data samples should exhibit minimal reconstruction errors when processed through an AE during inference. Given that the AE is unacquainted with anomalous samples, these samples are expected to yield substantial reconstruction errors when decoded.
Reconstruction remains a predominant method in numerous studies involving video anomaly detection [16,19,21,22,23,26]. Several approaches attempt to accommodate the temporal dimension by endeavouring to reconstruct complete sequences [21,23].
A significant challenge with AEs is their potential inability to reconstruct normal samples accurately enough to differentiate them from anomalies. Numerous techniques employ a UNet, an AE with skip connections between hidden layers that assist in reconstructing the original input from an earlier network layer [2,3,4,5,6,7,8,9]. Yet, skip connections present complications, as they make the decoder reliant not solely on the latent space for reconstruction but also on higher-dimensional features from the encoder’s earlier layers.
UNets might learn to reconstruct anomalous samples as proficiently as normal samples. This is attributed to the idea that a latent space is a fitting representation of data in a lower dimensional space, allowing anomaly detection to occur in the latent space without the need for reconstruction during inference. This is often combated by introducing extreme complexity within the UNet’s architecture. RHCrackNet [27] exemplifies an advancement in UNet-based architectures, focusing on static image segmentation, particularly for pavement crack detection. It incorporates feature fusion and enhancement modules to dynamically aggregate and refine multiscale information. Additionally, it employs a non-local attention mechanism to extract long-range spatial dependencies, addressing challenges such as background interference and weak crack continuity. These enhancements contribute to improved segmentation accuracy and robustness in static image applications.
A more innovative application of AEs/UNets in video anomaly detection involves their use for predicting subsequent frames [2,3,4,5,6,7,8,9,20,22,25,28,29]. This technique hypothesizes that a decoder, having learnt from an encoded sequence of normal frames, would struggle to generate the next frame from an encoded sequence of anomalous frames. The two-stream framework proposed by [29] employs context recovery with a spatio-temporal UNet for future frame prediction, combined with knowledge retrieval to enhance understanding of normality.
Several studies have aimed to encapsulate the significance of temporal dimensions by incorporating Transformers into their architecture, which span across a sequence of frames, facilitating an attention mechanism amongst them [2,8,25,30,31]. This approach appears plausible for capturing videos’ temporal characteristics, enabling an AutoEncoder/UNet to detect features unobtainable from a solitary frame.
Optical flow has also seen extensive application in video anomaly detection for capturing temporal features, as both an input feature and a predicted output feature [3,20,22,32,33,34]. Optical flow captures the perceived motion of pixels between consecutive frames, making it highly sensitive to motion-related anomalies. The Dual-Stream Anomaly Detection Network (DS-ADN) introduced in [34] uses optical flow data in combination with RGB information to enhance anomaly detection in traffic surveillance scenarios, employing a Multi-Scale Attention Fusion Module to better capture anomaly characteristics.
Existing supervised learning models have been utilised to augment AE/UNet performance by comparing the hidden features of the original input and the reconstructed output within the same pre-trained model [9]. This methodology bears similarity to the application of Generative Adversarial Networks (GANs) [2,3,5,20,25,31,35]. GANs consist of two models, a generator and a discriminator, that function in opposition. The generator strives to produce samples similar to ground truth data to deceive the discriminator, while the discriminator works to discern whether a sample is authentic or synthetic. In the context of anomaly detection, the AE/UNet generally acts as the generator, while the discriminator aims to identify discrepancies between the AE’s/UNet’s original input and the reconstructed output. This interplay aids the AE/UNet in improving the quality of its reconstructions to make them indistinguishable from the original input. The attention-guided generator with dual discriminator GAN (A2D-GAN) [35] is an example of such an approach, utilizing an encoder–decoder generator with self-attention and channel attention mechanisms, coupled with dual discriminators to enhance robustness against noise in real-time video anomaly detection.
A widely adopted strategy to prevent anomaly reconstruction is to include some form of memory within the hidden layers and/or latent space that references normal samples [4,6,19,23,26,33,36,37]. Memory modules in AEs/UNets concatenate linear combinations of learned memory vectors based on the input method. The underlying theory suggests that these modules will not be as efficient in forming linear combinations of anomalous vectors as they are with normal vectors in the latent space. This function is analogous to the role of the decoder, and one could argue that a more complex decoder might yield comparable results to a memory module.
An effective strategy for anomaly detection involves applying masking techniques to selectively obscure parts of the data, using the unmasked content to inpaint the masked areas, thereby detecting anomalies through discrepancies in reconstruction. In [12], the unsupervised SMAI method is introduced. It uses superpixel segmentation and an inpainting module to detect anomalies. During inference, frames are masked and inpainted, and discrepancies between the original and reconstructed areas identify anomalies. While effective for image-based anomaly detection, this approach is computationally intensive and time-consuming during inference. Additionally, the inpainting technique, primarily designed for images, poses challenges when extended to video anomaly detection.
The paper by Ristea et al. [14] uses masked convolutional layers in their self-supervised predictive convolutional attentive block (SSPCAB). The center area of the kernel is masked, and the convolution operation only considers input values from specific positions, ignoring others. While this is an innovative approach for feature extraction, it does not appear to utilise masked convolution layers to the best of their capabilities because they are only used in the first layer and the masked convolution only utilizes the corner pixels of a kernel. This limited usage restricts the network’s ability to fully exploit the advantages of masked convolution, particularly in capturing more nuanced spatio-temporal features and preventing the reconstruction of anomalies effectively. Furthermore, although [15] extends this approach with 3D masked convolutions to consider temporal dimensions, it still does not utilize these masked convolutional layers across the entire network effectively for anomaly detection. In our approach, we extend the use of MaskedConv3D layers throughout the UNet architecture, strategically inserting them between skip connections to infer normal spatio-temporal features across various granularities of detail and provide a more comprehensive anomaly detection solution.
3. Methodology
When dealing with video anomaly detection, classic UNet architectures can inadvertently become too proficient at reconstructing input features, including anomalies. This reconstruction efficiency of UNets, especially due to their skip connections, often leads to the undesired effect of anomalies being rendered indistinct from normal data. As a result, the anomalies can become less discernible, making detection more challenging.
In a traditional UNet setup, while the skip connections are crucial for preserving high-frequency details and mitigating the loss of information during the encoding process, they may also enable the accurate reconstruction of anomalies. This occurs because the detailed features from the encoder are directly carried over to the decoder, which may result in the anomalies being maintained in the output, thereby diminishing the model’s ability to differentiate between normal and anomalous patterns.
Incorporating the MaskedConv3D layer between these skip connections can alleviate these issues. The MaskedConv3D layer, considering the temporal dimension, works on a sequence of frames and applies a zero mask to a subspace of the centre kernel. This leaves the previous and next frames, as well as the boundary of the centre frame, intact, forming a sort of “hollow ball” around potential anomalies. This design forces the model to infer the reconstruction of this hollow space based on surrounding spatial and temporal information, rather than directly processing the anomalies themselves.
This approach is underpinned by the logic that the model should be able to reconstruct normal sequences using the information from the boundary and adjacent frames, while struggling to do the same for anomalous ones. Therefore, this method prevents anomalies from being inadvertently reconstructed and normalised, ensuring they stand out for detection.
3.1. MaskedConv2D
To facilitate a more tangible understanding of our methodology, we initially apply the concept of masked convolutional layers to a 2D image dataset as a proof of concept, before diving into the complexities of video anomaly detection with MaskedConv3D layers. Understanding the idea of a masked convolutional layer in 2D is easier prior to delving into the 3D variant. This approach underscores the versatility and adaptability of our technique.
A traditional Conv2D kernel, for instance a one, is made up of 49 weights, denoted by , where are identifiers for the rows and columns of the kernel, respectively. This kernel moves over an image, and the weights operate as multipliers for each corresponding pixel, establishing a linear combination between the weights and pixels. The outcome of this calculation is then linked to the central pixel position of the kernel, in our case .
If we were to momentarily employ a single Conv2D layer to depict the entire reconstruction procedure, it would be evident that a Conv2D layer, when trained solely on normal samples, would be proficient at reconstructing any image with near precision. This would hold for both normal and anomalous samples, with a graphic depiction of this scenario visible on the left side of Figure 2.
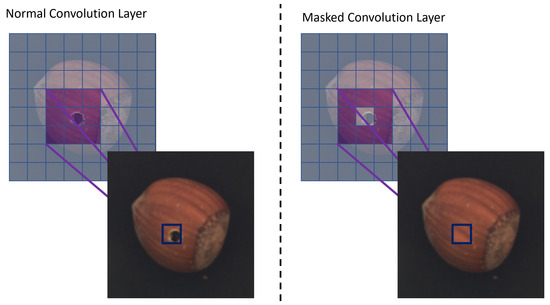
Figure 2.
This figure visually illustrates the impact of the MaskedConv2D layer in the reconstruction process. The left side shows the reconstruction using a traditional Conv2D layer, where both normal and anomalous samples are reconstructed with near precision. However, on the right side, with the application of the MaskedConv2D layer, the reconstruction is influenced by the surrounding pixels due to the zero-value mask. This leads to the preservation of normal patterns while making it more challenging to reconstruct anomalies.
We could envision that most of the kernel weights would have values close to zero and the central weight, , would have a value approximating 1, implying negligible reliance on the surrounding pixels’ information.
However, if we apply a mask to some of the central pixels of the kernel, assigning them zero values (as we do in our MaskedConv2D layer, shown in Figure 3), the central pixel would have to be deduced in the context of its surrounding pixels. In a two-dimensional space, these masked-out pixels form a sort of “ring”, a boundary within which the central pixel lies. The task of the MaskedConv2D layer then becomes figuring out the value of this central pixel based on the information from the pixels that exist outside this zero-value ring. This changes the operation of the layer from a simple linear combination of all pixels within the kernel to a process of spatial inference, where the values of the surrounding pixels provide cues to what the central pixel might be. Hence, a MaskedConv2D layer trained on normal data would find it difficult to infer anomalies from these boundary pixels and is more likely to substitute the anomaly with a pattern that resembles normal data. This phenomenon can be seen on the right side of Figure 2.
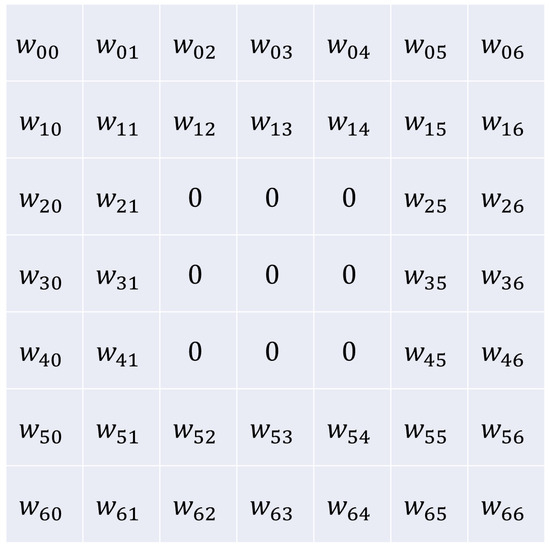
Figure 3.
This figure demonstrates the concept of weight masking in the MaskedConv2D layer. A traditional Conv2D kernel is depicted, where the central pixel weight is surrounded by zero-value weights. The zero mask creates a “ring” boundary around the central pixel, indicating that the MaskedConv2D layer infers the value of the central area based on the surrounding pixels. This spatial inference contributes to the detection of anomalies by preventing the reconstruction of anomalous patterns and enhancing the discernment between normal and anomalous data.
This presents a perspective not typically accounted for in traditional autoencoders. It is generally thought that the decoder will find it difficult to reconstruct anomalous samples, but this is not always the case. The encoder maps patterns to the latent space, and the decoder rebuilds these patterns. Ideally, normal and anomalous patterns would differ significantly, but if there is significant overlap between normal and anomalous samples, autoencoders may fall short. MaskedConv2D layers introduce the idea of extrapolating a normal pattern from its neighbouring patterns.
It is worth noting a key differentiator of our method. Whereas other methodologies might mask the image input directly [38,39], leading to a potential loss of information, our MaskedConv2D layer masks the convolutional kernels. This preserves the original data while altering the convolution operation, pushing the architecture to focus on the surrounding context rather than directly altered data.
3.2. MaskedConv3D
Following the explanation provided in Section 3.1, the concept of a MaskedConv3D layer should be relatively straightforward. The fundamental idea remains the same, but instead of establishing a boundary akin to a ring, as in 2D, a MaskedConv3D layer constructs a boundary resembling a hollow sphere in three dimensions. Extending the unique approach from MaskedConv2D, our 3D variant continues to mask the convolutional kernel instead of the volumetric video data, further differentiating our technique from mainstream practices. Given that the size of a Conv3D kernel is depicted as a three-dimensional array, encompassing temporal, height, and width dimensions, MaskedConv3D layers nullify only a subset of the temporal layers.
This approach utilises the information from previous and subsequent temporal frames to make educated guesses about the content of the current frame. To illustrate, let us assume a kernel size of , which consists of 27 weights, denoted by . In this case, are identifiers for the temporal dimension, rows, and columns of the kernel, respectively. Among these, only the weight would be set to zero. This example can be seen in Figure 4.
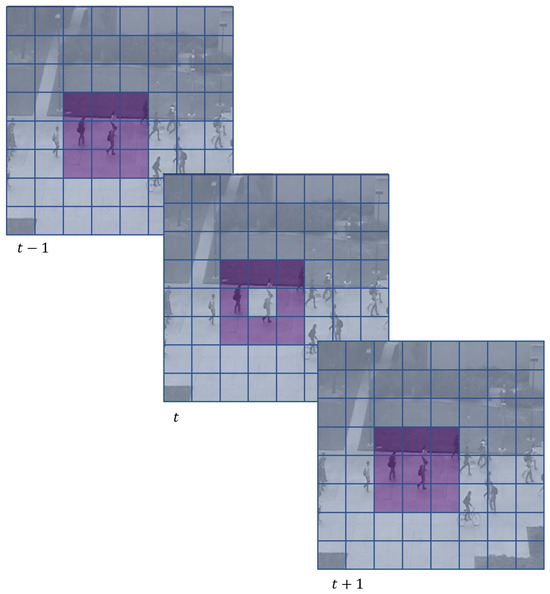
Figure 4.
This figure illustrates the concept of the MaskedConv3D layer used in the proposed MaskedSkipUNet architecture. The MaskedConv3D layer applies a zero mask to a subset of the temporal dimension in a 3D kernel. The kernel size and zero mask size are chosen analogous to the frame size. This creates a “hollow sphere” boundary around potential anomalies, allowing the model to infer the reconstruction of this space based on surrounding spatial and temporal information. The MaskedConv3D layer enhances anomaly detection by preventing anomalies from being inadvertently reconstructed and normalized, thereby improving their detectability within the video data.
The key is that, by leaving central pixels zero-weighted, the layer is required to draw on the three-dimensional spatial and temporal context it has at its disposal in order to infer its value. This is analogous to the way the 2D version leverages spatial context, but with the additional complexity of the temporal dimension, making the 3D version potentially more powerful for tasks involving video or other 3D data.
3.3. Architecture
Our approach employs a Conv2D UNet architecture, which is comprised of tailor-made ConvBlocks for the encoder and decoder, along with MaskedConv3D layers inserted amid the skip connections.
A ConvBlock is structured to include a multi-headed convolution, essentially meaning that it contains 3 Conv2D layers with “same” padding and respective kernel sizes of . These layers are then concatenated together on the channel dimension. Subsequently, a batch normalisation is performed, followed by the application of a ReLU activation function. The output is then restructured to reduce the height and width dimensions, and passed through a final Conv2D layer (also with “same” padding). The entire process is capped off with an additional batch normalisation and another ReLU layer. Figure 5 provides a visual representation of an encoder ConvBlock.
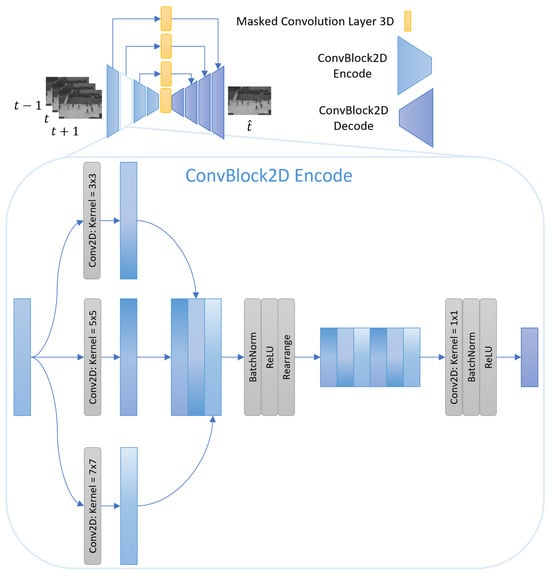
Figure 5.
This figure illustrates the architecture of the Encoder ConvBlock used in the proposed MaskedSkipUNet framework. The ConvBlock consists of three Conv2D layers with kernel sizes of 3, 5, and 7, respectively. The outputs of these layers are concatenated along the channel dimension and passed through batch normalization and ReLU activation. The resulting feature maps are then downsampled, followed by another Conv2D layer and additional batch normalization and ReLU layers.
The UNet architecture is composed of 8 of these ConvBlocks, with 4 each dedicated to the Encoder and Decoder. Skip connections are implemented between the layers, each of which traverses a MaskedConv3D layer before being concatenated with its corresponding layer. The encoder and decoder, which consist of Conv2D layers, treat each frame as an individual image, the temporal dimension is only considered during the MaskedConv3D layers. It is worth noting that this architecture largely mirrors a traditional UNet, with the key distinction being the introduction of the MaskedConv3D layers in the skip connections, lending a unique capacity for contextual inference to the framework. The appropriate kernel sizes and mask dimensions for the MaskedConv3D layers were selected through empirical experimentation to balance temporal context and reconstruction quality. A visual of the architecture can be seen in Figure 1.
3.4. Rationale Behind the Architecture
In our UNet architecture, the encoder operates as a spatio-feature extractor for each frame, unearthing a fresh layer of features at every ConvBlock. The MaskedConv3D layers, situated strategically between these ConvBlocks, serve a unique and vital role. As the features extracted by the encoder are passed through the skip connections, the MaskedConv3D layers replace these features, generating new ones by interpreting the context provided by the existing surrounding features. This stage is where the actual inference takes place and is also the primary site of novelty in our architecture.
Specifically, these MaskedConv3D layers contribute the key capability to detect anomalies—they do this by failing to accurately reconstruct the features from the surrounding context when presented with anomalous data. This failure is what signals the presence of an anomaly and differentiates the anomalous data from the normal.
Following this feature extraction and inference process, the decoder assumes its role in the framework, which is singularly focused on assembling these inferred features back together, ultimately yielding a reconstructed output.
In contrast to “Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection” [14], our proposed MaskedSkipUNet architecture uses MaskedConv3D layers not just as feature extractors, but as a mechanism to infer reconstruction based on surrounding spatio-temporal hierarchical features.
The MaskedSkipUNet architecture improves upon methods like “Superpixel Masking and Inpainting” [12]. By focusing the masking operation on the convolutional kernels rather than the frames themselves, MaskedSkipUNet sidesteps the computational burden of generating multiple masked copies of each frame. This kernel-based masking is not only computationally more efficient but also retains critical temporal and spatial information that could be lost when masking frames directly. Furthermore, the architecture incorporates a temporal dimension through its MaskedConv3D layers, an aspect that traditional inpainting methods are currently unable to address.
The MaskedConv3D layers in our model enable the model to leverage the temporal and spatial context surrounding anomalies, facilitating accurate detection and preserving normal patterns. By excluding the anomalies from direct reconstruction, the MaskedSkipUNet effectively distinguishes anomalies from normal frames, resulting in significantly improved anomaly detection accuracy. This difference in the application of masked convolutional layers underlines the unique approach of our proposed MaskedSkipUNet architecture in the field of video anomaly detection.
4. Datasets
In our experiments, we utilize both image and video datasets to demonstrate the adaptability and breadth of our methodology. Initially, experiments on the fairly simple MVTec dataset, which comprises high-resolution images, are used as proof of concept. Subsequently, to delve deeper into more intricate scenarios, we leverage three prominent video-based datasets: the Ped2 dataset, CUHK Avenue dataset, and the ShanghaiTech dataset. These video datasets, with their inherent complexity and diverse anomaly types, provide a comprehensive backdrop against which we rigorously evaluate our proposed model.
4.1. MVTec Dataset
The MVTec dataset [40] is a comprehensive and widely-used benchmark for evaluating machine vision algorithms. Comprising high-resolution images across a diverse array of industrial object categories like cables, screws, and pills, it is meticulously curated to emulate real-world industrial scenarios. This design makes the MVTec dataset an invaluable resource for gauging the robustness and generalizability of anomaly detection algorithms.
4.2. Ped2 Dataset
The Ped2 dataset [41] is renowned for its surveillance video clips, collected in a pedestrian area. The videos feature a range of anomalous events, such as people biking, skating, or moving in an irregular pattern. Each video has a frame resolution of and varies in length, allowing for a diverse set of samples.
4.3. CUHK Avenue Dataset
The CUHK Avenue dataset [42] is another significant surveillance video dataset collected from the avenue of the Chinese University of Hong Kong. The anomalies in this dataset typically consist of running people, loitering, and throwing objects, which are not common activities in the depicted setting. The videos have a frame resolution of , and the number of frames varies per video.
4.4. ShanghaiTech Dataset
Lastly, the ShanghaiTech dataset [43] is a recently developed, large-scale dataset featuring surveillance video clips from a variety of scenarios, both indoor and outdoor. The anomalies in this dataset are diverse, including burglary, climbing, and fighting. Videos have a resolution of , with the number of frames varying per video.
5. Results
5.1. MVTec Dataset Findings
In our experimentation, we employed a specific subset of the MVTec dataset as our foundational testing ground, seeking to probe the effectiveness of masked convolutions embedded within skip connections. The structured yet challenging nature of this image dataset, especially juxtaposed against the intricacies of video anomaly detection, offered a controlled environment to rigorously ascertain the algorithm’s capability in anomaly recognition. With the MVTec dataset encompassing both defect-free and defective samples, it provided an ideal base to validate the efficiency and scalability of our method.
Figure 6 shows the Receiver Operating Characteristic (ROC) curves for the AutoEncoder, UNet, and MaskedSkipUNet, accompanying their specific AUC scores. With the UNet registering an 86.6% AUC, the MaskedSkipUNet, boasting a 93.8% AUC, only marginally surpasses the AutoEncoder’s score of 92.9%.
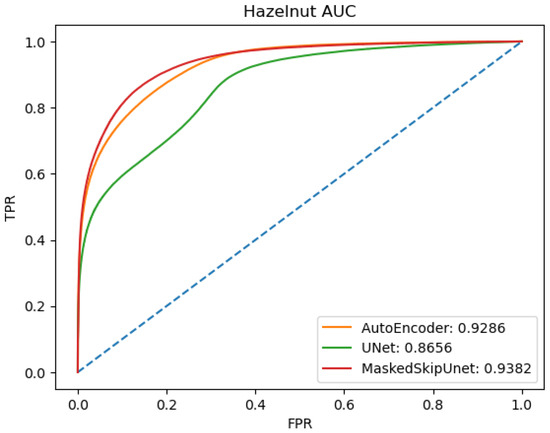
Figure 6.
Receiver Operating Characteristic (ROC) curves comparing the performance of AutoEncoder, UNet, and MaskedSkipUNet on the hazelnut category of the MVTec dataset. The AUC scores for each method are also provided, underlining the supremacy of MaskedSkipUNet in anomaly detection.
A more granular, qualitative examination further elucidates our conviction in advancing this methodology for the more complex domain of video anomaly detection. Figure 7 displays results from the hazelnut category of the MVTec dataset. Ground truth images are arrayed in the first column, displaying both regular and anomalous specimens. Successive columns illuminate the output produced by the AutoEncoder, UNet, and MaskedSkipUNet. The inherent differences in reconstructions, spanning from the blurring by the AutoEncoder to the precise detailing by the UNet are notable. The MaskedSkipUNet’s extrapolation of normal features is particularly compelling, as it seemingly leverages the contextual cues to supplant anomalous regions.
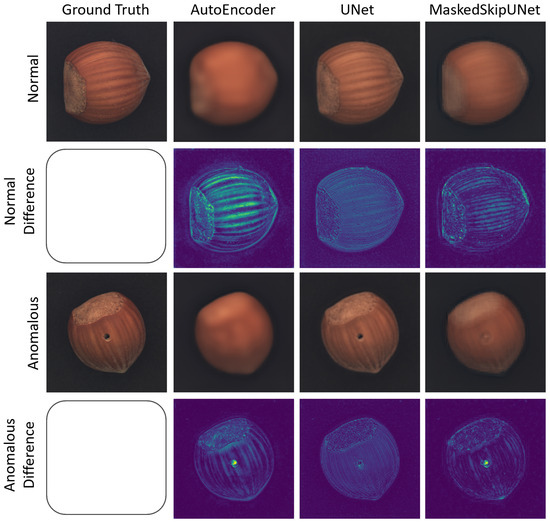
Figure 7.
Comparative analysis of anomaly reconstruction techniques on hazelnut samples from the MVTec dataset. The first column displays ground truth images, featuring both a normal and an anomalous sample. Subsequent columns show the output reconstructions from an AutoEncoder, UNet, and MaskedSkipUNet, respectively. The first row presents the ground truth and reconstructions of a normal sample, while the second row highlights the differences between the reconstructed and original ground truth of the normal sample. The third row showcases the ground truth and reconstructions of an anomalous sample, and the final row illustrates the discrepancies between the reconstructed and original ground truth of the anomalous sample. The figure demonstrates the varying capabilities of each algorithm in capturing details and reconstructing anomalies.
5.2. Video Anomaly Detection Results
In our evaluation, we follow the competitors as outlined in [37], and we additionally adopt a median window size of 17, as proposed in [28]. Since our method is not based on object detection, we compare it against other frame-based methods as in [37] and not against object detection-based methods [28,44,45,46]. Additionally, we assign an anomaly score to each frame in video anomaly detection by calculating the Euclidean distance at the pixel level between the original input and its reconstruction. We further divide this distance into patches of size and determine the frame score to be the highest mean value among these patches.
Frame-based methods focus on detecting anomalies at the individual frame level, which aligns with our approach. These methods are particularly suitable for surveillance video analysis, where temporal continuity may not always be guaranteed, and each frame’s independent analysis can provide valuable insights.
The competitors we consider include a variety of frame-based methods, each with its unique strengths and approaches to anomaly detection. These include methods leveraging memory-augmented deep autoencoders [36], contrastive learning [47], comprehensive regularisation in predictive networks [44], and more. By comparing our methodology with these established frame-based methods, we aim to demonstrate the robustness and effectiveness of our approach in detecting anomalies in surveillance videos.
Table 1 provides a comprehensive comparison of different methods in the field of video anomaly detection, evaluating their performance on the Ped2, Avenue, and ShanghaiTech datasets. Notably, our novel approach, the MaskedSkipUNet, demonstrates remarkable performance comparable to the current state of the art on the Ped2 dataset and surpasses the state of the art on the Avenue dataset. Specifically, the MaskedSkipUNet achieves an outstanding accuracy of 98.4% on the Ped2 dataset, matching the top-performing competitor. Moreover, on the Avenue dataset, our method achieves a remarkable accuracy of 91.2%, outperforming all other methods evaluated. These results exemplify the effectiveness and superiority of our approach in accurately detecting anomalies at the frame level. Our method sets the benchmark in anomaly detection on two out of three datasets. While we achieve a strong 76.0% accuracy on the ShanghaiTech dataset, its diverse and complex scenes present an ongoing challenge in the field of video anomaly detection.

Table 1.
This table presents a performance comparison of different methods for video anomaly detection. The table showcases the anomaly detection accuracy achieved by each method on the Ped2 and Avenue datasets. The MaskedSkipUNet architecture outperforms the existing state-of-the-art methods, demonstrating its effectiveness and superiority in frame-based video anomaly detection. The bold marked figures indicate the best performing scores.
While we acknowledge that object detection-based methods have been shown to attain better scores on these datasets, we argue that they may not be as effective in some practical use cases. Most object detection-based methods are only able to detect anomalies in objects they are trained to detect. This means they would not be able to predict anomalies in objects not detectable by the object detection models, limiting their applicability in real-world scenarios where anomalies could take many unpredictable forms.
6. Ablation Studies
We carried out a series of ablation studies to discern the individual contributions of various components in our proposed architecture, the MaskedSkipUNet. The following subsections detail the variants of the model (which can be seen in Figure 8) and their respective performances (which can also be seen in Table 2).
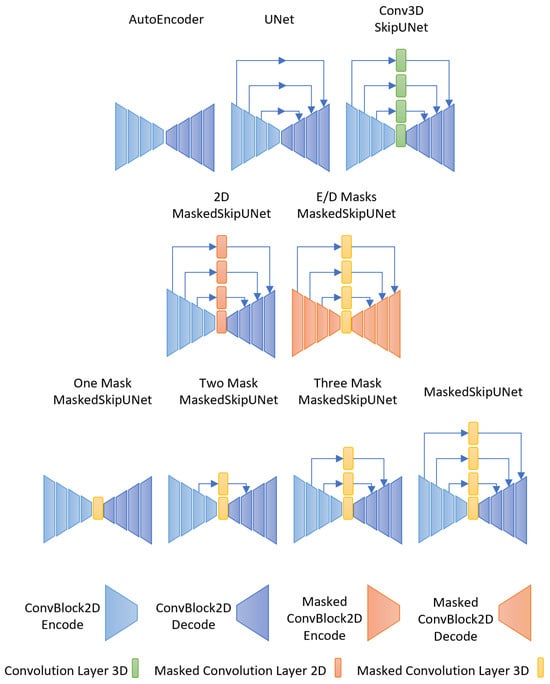
Figure 8.
Visual representations of the architectures evaluated in our ablation studies (Section 6). From the baseline AutoEncoder to our primary contribution, the MaskedSkipUNet, each variant elucidates the impact of incorporating or excluding specific components like skip connections, MaskedConv3D layers, and their interplay.
Table 2.
Ablation study results summarising the AUC scores attained by each model variant. The table underscores the influence of distinct architectural components on the anomaly detection performance, revealing the incremental benefits of MaskedConv3D layers and skip connections. The bold marked figures indicate the best performing score.
6.1. Comparative Analysis of Baseline and Skip Connection Variants
We explored three foundational variants of our MaskedSkipUNet architecture to understand their individual contributions to anomaly detection. The AutoEncoder, which uses only the encoder and decoder without any skip connections or MaskedConv3D layers, served as our baseline and achieved an AUC score of 87.1%. Adding skip connections to the AutoEncoder resulted in the UNet model, which surprisingly showed a decreased AUC score of 75.3%. This suggests that UNets may be more effective at reconstructing anomalies, thereby reducing their anomaly detection capabilities. Lastly, the Conv3D SkipUNet variant, which replaces MaskedConv3D layers with standard Conv3D layers, yielded a notable AUC score of 95.2%.
6.2. Impact of Dimensionality and Layer Types on Anomaly Detection
Two additional variants were examined to assess the impact of dimensionality and layer types on performance. The 2D MaskedSkipUNet, which replaces MaskedConv3D layers with MaskedConv2D layers, emphasized the importance of capturing the temporal dimension with an AUC score of 89.0%. On the other hand, the E/D Masks MaskedSkipUNet, which substitutes conventional Conv2D layers in both the encoder and decoder with MaskedConv2D layers, achieved a lower AUC score of 81.5%. This result indicates the effectiveness of standard Conv2D layers in feature extraction during both the encoding and decoding phases.
6.3. Incremental Benefits of Multiple MaskedConv3D Layers in MaskedSkipUNet
The “One Mask MaskedSkipUNet” incorporates a MaskedConv3D in the latent space without skip connections. Sequentially enhancing this setup, the “Two Mask MaskedSkipUNet” includes one MaskedConv3D skip connection and the “Three Mask MaskedSkipUNet” integrates two MaskedConv3D skip connections. Their performances are , , and AUC, respectively. Our primary contribution, the full-fledged “MaskedSkipUNet”, with a MaskedConv3D in the latent space and three MaskedConv3D skip connections, achieved the highest AUC score of . This progression underscores the incremental value of each MaskedConv3D layer introduced.
6.4. Discussion
The results from our ablation studies vividly illustrate the importance of each component in the MaskedSkipUNet architecture. In particular, the incorporation of MaskedConv3D layers, both in the latent space and as skip connections, proves crucial for optimising anomaly detection. While several methods mask the image directly and gauge the reconstruction error based on this altered input, our results highlight the advantage of masking at the convolution layer instead. This approach not only retains the original image data but also compels the model to develop a deeper understanding and sensitivity to anomalies, evident from our superior performance metrics.
Figure 9 visually compares the performance of each model variant on a frame from the Ped2 dataset, containing normal pedestrians and an anomalous cyclist. The AutoEncoder struggles to reconstruct both the cyclist and pedestrians, resulting in blurry outputs. The UNet achieves high-fidelity reconstructions for all subjects, including the anomaly, thereby failing to highlight it. Our proposed MaskedSkipUNet maintains sharp reconstructions of pedestrians while degrading the reconstruction of the cyclist, successfully isolating the anomaly. Other variants like the Conv3D SkipUNet and E/D Masks MaskedSkipUNet show partial effectiveness. Notably, as the number of MaskedConv3D layers increases from one to three, and ultimately to our final model with four, reconstructions of normal subjects improve, while the anomaly remains less visible, confirming the value of multiple masked layers.

Figure 9.
Reconstruction outputs from ablation models on a Ped2 frame with an anomalous bicycle and normal pedestrians. Underneath the title of each model is the reconstructed frame (top) and its pixel-wise difference from the original (bottom), illustrating the impact of each architectural variant on anomaly suppression.
7. Conclusions
In the evolving landscape of video anomaly detection, this research introduces a novel framework employing the innovative MaskedSkipUNet architecture. By strategically integrating MaskedConv3D layers within skip connections, we have enhanced the model’s prowess in identifying anomalies, particularly in complex surveillance footage. Our methodology’s robustness is evident from the empirical evaluations conducted on varied datasets, including prominent ones like Ped2, CUHK Avenue, and ShanghaiTech. Moreover, a preliminary exploration on a 2D image dataset establishes the versatility and adaptability of our approach as a precursor to its application on intricate video datasets.
Our findings shed light on the fundamental importance of masked convolutions, especially in preserving and emphasizing spatial details, vital for distinguishing anomalies. The MaskedSkipUNet, while built upon existing frameworks like UNet, carves a distinctive niche for itself by excelling in anomaly detection tasks where traditional methods falter.
Furthermore, our qualitative and quantitative results, underpinned by compelling visualizations, underscore the merits of our proposed architecture. The ability of MaskedSkipUNet to extrapolate normal features, even in the presence of anomalous regions, sets it apart, enabling more accurate anomaly predictions and reconstructions.
However, our approach is not without limitations. One notable drawback arises when anomalies are large in size. Since the model relies on reconstructing masked regions using surrounding spatio-temporal context, it performs best when anomalies are small and the surrounding context is largely normal. In scenarios involving large-scale anomalies or scenes where much of the surrounding content is also abnormal, the model may lack sufficient normal reference to accurately infer a normal reconstruction. This constraint could reduce the model’s effectiveness in highly dynamic environments or in scenes where the anomaly encompasses a substantial portion of the frame. Additionally, the datasets we consider do not include variations in weather conditions. To ensure robustness in outdoor deployments across different climates, appropriate preprocessing techniques would need to be applied before using our model, as discussed in [60,61].
Looking forward, future research could explore augmenting the MaskedSkipUNet architecture with diffusion-based mechanisms. Specifically, the reconstructed output from the model could be treated as a slightly less noisy version of the original input and recursively passed back into the MaskedSkipUNet. Training the model to refine its reconstructions across multiple iterations would allow it to gradually suppress anomalies treated as noise and recover finer normal details. This iterative refinement process could significantly improve the model’s sensitivity to subtle and low-contrast anomalies, making it better suited for real-world applications that demand high precision.
In conclusion, the MaskedSkipUNet heralds a promising leap forward in the domain of video anomaly detection. The foundation laid by this research paves the way for subsequent investigations and enhancements, driving the future evolution of this domain. As anomaly detection continues to hold paramount importance across numerous applications, from surveillance to industrial quality control, the strides made in this work ensure that our methodologies remain at the forefront of this ever-evolving discipline.
Author Contributions
Conceptualization, D.L.; methodology, D.L.; software, D.L.; validation, D.L., V.A. and D.M.; formal analysis, D.L.; investigation, D.L.; resources, D.L.; data curation, D.L.; writing—original draft preparation, D.L.; writing—review and editing, V.A. and D.M.; visualization, D.L.; supervision, V.A. and D.M.; project administration, D.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The source code is publicly available at https://github.com/demetrislappas/MaskedSkipUNet (accessed on 1 April 2025). The datasets used in this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| AE | AutoEncoder |
| AUC | Area Under the Curve |
| Conv2D | 2D Convolutional Layer |
| Conv3D | 3D Convolutional Layer |
| CUHK | Chinese University of Hong Kong |
| GAN | Generative Adversarial Network |
| MaskedSkipUNet | UNet architecture enhanced with MaskedConv3D layers in skip connections |
| ROC | Receiver Operating Characteristic |
| SHT | ShanghaiTech Dataset |
| SMAI | Superpixel Masking and Inpainting |
| SSPCAB | Self-Supervised Predictive Convolutional Attentive Block |
| UNet | U-shaped Convolutional Neural Network |
| VAE | Variational AutoEncoder |
References
- Zhou, C.; Paffenroth, R.C. Anomaly detection with robust deep autoencoders. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; Part F1296. pp. 665–674. [Google Scholar] [CrossRef]
- Yuan, H.; Cai, Z.; Zhou, H.; Wang, Y.; Chen, X. TransAnomaly: Video Anomaly Detection Using Video Vision Transformer. IEEE Access 2021, 9, 123977–123986. [Google Scholar] [CrossRef]
- Vu, T.H.; Boonaert, J.; Ambellouis, S.; Taleb-Ahmed, A. Multi-channel generative framework and supervised learning for anomaly detection in surveillance videos. Sensors 2021, 21, 3179. [Google Scholar] [CrossRef]
- Liu, Z.; Nie, Y.; Long, C.; Zhang, Q.; Li, G. A Hybrid Video Anomaly Detection Framework via Memory-Augmented Flow Reconstruction and Flow-Guided Frame Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13588–13597. [Google Scholar]
- Roy, P.R.; Bilodeau, G.A.; Seoud, L. Predicting Next Local Appearance for Video Anomaly Detection. In Proceedings of the 2021 17th International Conference on Machine Vision and Applications (MVA), Online, 25–27 July 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Szymanowicz, S.; Charles, J.; Cipolla, R. Discrete Neural Representations for Explainable Anomaly Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 148–156. [Google Scholar]
- Kim, Y.; Yu, J.Y.; Lee, E.; Kim, Y.G. Video anomaly detection using Cross U-Net and cascade sliding window. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 3273–3284. [Google Scholar] [CrossRef]
- Le, V.T.; Kim, Y.G. Attention-based residual autoencoder for video anomaly detection. Appl. Intell. 2022, 53, 3240–3254. [Google Scholar] [CrossRef]
- Wang, X.; Che, Z.; Jiang, B.; Xiao, N.; Yang, K.; Tang, J.; Ye, J.; Wang, J.; Qi, Q. Robust Unsupervised Video Anomaly Detection by Multipath Frame Prediction. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2301–2312. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Yong, B.X.; Brintrup, A. Do autoencoders need a bottleneck for anomaly detection? IEEE Access 2022, 10, 78455–78471. [Google Scholar] [CrossRef]
- Li, Z.; Li, N.; Jiang, K.; Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Superpixel Masking and Inpainting for Self-Supervised Anomaly Detection. In Proceedings of the British Machine Vision Conference, Virtual, 7–10 September 2020. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. Reconstruction by inpainting for visual anomaly detection. Pattern Recognit. 2021, 112, 107706. [Google Scholar] [CrossRef]
- Ristea, N.C.; Madan, N.; Ionescu, R.T.; Nasrollahi, K.; Khan, F.S.; Moeslund, T.B.; Shah, M. Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 13576–13586. [Google Scholar]
- Madan, N.; Ristea, N.C.; Ionescu, R.T.; Nasrollahi, K.; Khan, F.S.; Moeslund, T.B.; Shah, M. Self-supervised masked convolutional transformer block for anomaly detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 525–542. [Google Scholar] [CrossRef]
- Astrid, M.; Zaheer, M.Z.; Lee, S.I. Limiting Reconstruction Capability of Autoencoders Using Moving Backward Pseudo Anomalies. In Proceedings of the 2022 19th International Conference on Ubiquitous Robots (UR), Jeju, Republic of Korea, 4–6 July 2022; pp. 248–251. [Google Scholar] [CrossRef]
- Zaigham Zaheer, M.; Lee, J.H.; Astrid, M.; Lee, S.I. Old Is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14171–14181. [Google Scholar] [CrossRef]
- Astrid, M.; Zaheer, M.Z.; Lee, S.I. PseudoBound: Limiting the anomaly reconstruction capability of one-class classifiers using pseudo anomalies. Neurocomputing 2023, 534, 147–160. [Google Scholar] [CrossRef]
- Park, H.; Noh, J.; Ham, B. Learning memory-guided normality for anomaly detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14360–14369. [Google Scholar] [CrossRef]
- Saypadith, S.; Onoye, T. Video Anomaly Detection Based on Deep Generative Network. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Virtual, 22–28 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Deepak, K.; Chandrakala, S.; Mohan, C.K. Residual spatiotemporal autoencoder for unsupervised video anomaly detection. Signal Image Video Process. 2021, 15, 215–222. [Google Scholar] [CrossRef]
- Chang, X.; Zhang, Y.; Xue, D.; Chen, D. Multi-task learning for video anomaly detection. J. Vis. Commun. Image Represent. 2022, 87, 103547. [Google Scholar] [CrossRef]
- Chandrakala, S.; Shalmiya, P.; Srinivas, V.; Deepak, K. Object-centric and memory-guided network-based normality modeling for video anomaly detection. Signal Image Video Process. 2022, 16, 2001–2007. [Google Scholar] [CrossRef]
- Deepak, K.; Srivathsan, G.; Roshan, S.; Chandrakala, S. Deep Multi-view Representation Learning for Video Anomaly Detection Using Spatiotemporal Autoencoders. Circuits Syst. Signal Process. 2021, 40, 1333–1349. [Google Scholar] [CrossRef]
- Feng, X.; Song, D.; Chen, Y.; Chen, Z.; Ni, J.; Chen, H. Convolutional Transformer Based Dual Discriminator Generative Adversarial Networks for Video Anomaly Detection; Association for Computing Machinery: New York, NY, USA, 2021; Volume 1, pp. 5546–5554. [Google Scholar] [CrossRef]
- Massoli, F.V.; Falchi, F.; Kantarci, A.; Akti, Ş.; Ekenel, H.K.; Amato, G. MOCCA: Multilayer One-Class Classification for Anomaly Detection. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2313–2323. [Google Scholar] [CrossRef]
- Liu, W.; Li, Z.; Wang, J.; Lu, Q. RHCrackNet: Refined Hierarchical Feature Fusion and Enhancement Network for Pixel-level Pavement Anomaly Detection. Big Data Mining Anal. 2025, 8, 880–896. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, Z.; Liu, J.; Li, C.; Song, L. OSIN: Object-centric Scene Inference Network for Unsupervised Video Anomaly Detection. IEEE Signal Process. Lett. 2023, 30, 359–363. [Google Scholar] [CrossRef]
- Cao, C.; Lu, Y.; Zhang, Y. Context Recovery and Knowledge Retrieval: A Novel Two-Stream Framework for Video Anomaly Detection. IEEE Trans. Image Process. 2024, 33, 1810–1825. [Google Scholar] [CrossRef]
- Ullah, W.; Hussain, T.; Ullah, F.U.; Lee, M.Y.; Baik, S.W. TransCNN: Hybrid CNN and transformer mechanism for surveillance anomaly detection. Eng. Appl. Artif. Intell. 2023, 123, 106173. [Google Scholar] [CrossRef]
- Li, G.; He, P.; Li, H.; Zhang, F. Adversarial composite prediction of normal video dynamics for anomaly detection. Comput. Vis. Image Underst. 2023, 232, 103686. [Google Scholar] [CrossRef]
- Cai, R.; Zhang, H.; Liu, W.; Gao, S.; Hao, Z. Appearance-Motion Memory Consistency Network for Video Anomaly Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 938–946. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, T.; Zhou, J.; Guan, J. Video anomaly detection based on spatio-temporal relationships among objects. Neurocomputing 2023, 532, 141–151. [Google Scholar] [CrossRef]
- Ji, Z.; Lv, W.; Hu, J.; Jin, Y.; Qiu, Z.; Huang, J. Dual-Stream Anomaly Detection Network for Real-World Traffic Scenarios. IEEE Trans. Intell. Transp. Syst. 2024, 25, 20779–20792. [Google Scholar] [CrossRef]
- Singh, R.; Sethi, A.; Saini, K.; Saurav, S.; Tiwari, A.; Singh, S. Attention-guided generator with dual discriminator GAN for real-time video anomaly detection. Eng. Appl. Artif. Intell. 2024, 131, 107830. [Google Scholar] [CrossRef]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; van den Hengel, A. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. arXiv 2019, arXiv:1904.02639. [Google Scholar]
- Sun, S.; Gong, X. Hierarchical Semantic Contrast for Scene-Aware Video Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22846–22856. [Google Scholar]
- Jiang, J.; Zhu, J.; Bilal, M.; Cui, Y.; Kumar, N.; Dou, R.; Su, F.; Xu, X. Masked Swin Transformer Unet for Industrial Anomaly Detection. IEEE Trans. Ind. Inform. 2023, 19, 2200–2209. [Google Scholar] [CrossRef]
- Huang, C.; Xu, Q.; Wang, Y.; Wang, Y.; Zhang, Y. Self-Supervised Masking for Unsupervised Anomaly Detection and Localization. IEEE Trans. Multimed. 2023, 25, 4426–4438. [Google Scholar] [CrossRef]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 FPS in MATLAB. In Proceedings of the 2013 IEEE International Conference on Computer Vision 2013, Sydney, NSW, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar] [CrossRef]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Moayed, Z.; Klette, R. Deep-anomaly: Fully convolutional neural network for fast anomaly detection in crowded scenes. Comput. Vis. Image Underst. 2018, 172, 88–97. [Google Scholar] [CrossRef]
- Liu, W.; Luo, D.L.; Gao, S. Future Frame Prediction for Anomaly Detection—A New Baseline. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, C.; Xie, Y.; Lin, S.; Yao, A.; Jiang, G.; Zhang, W.; Qu, Y.; Qiao, R.; Ren, B.; Ma, L. Comprehensive Regularization in a Bi-directional Predictive Network for Video Anomaly Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022; Volume 36, pp. 230–238. [Google Scholar] [CrossRef]
- Georgescu, M.I.; Ionescu, R.T.; Khan, F.S.; Popescu, M.; Shah, M. A Background-Agnostic Framework with Adversarial Training for Abnormal Event Detection in Video. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4505–4523. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Pang, G.; Chen, Y.; Singh, R.; Verjans, J.W.; Carneiro, G. Weakly-Supervised Video Anomaly Detection with Robust Temporal Feature Magnitude Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 4975–4986. [Google Scholar]
- Wang, Z.; Zou, Y.; Zhang, Z. Cluster Attention Contrast for Video Anomaly Detection; Association for Computing Machinery, Inc.: New York, NY, USA, 2020; pp. 2463–2471. [Google Scholar] [CrossRef]
- Nguyen, T.N.; Meunier, J. Anomaly Detection in Video Sequence with Appearance-Motion Correspondence. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wu, P.; Liu, J.; Shen, F. A Deep One-Class Neural Network for Anomalous Event Detection in Complex Scenes. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2609–2622. [Google Scholar] [CrossRef]
- Lu, Y.; Yu, F.; Reddy, M.K.K.; Wang, Y. Few-Shot Scene-Adaptive Anomaly Detection. In Proceedings of the Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 125–141. [Google Scholar]
- Chang, Y.; Tu, Z.; Xie, W.; Yuan, J. Clustering Driven Deep Autoencoder for Video Anomaly Detection. In Proceedings of the Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 329–345. [Google Scholar]
- Tang, Y.; Zhao, L.; Zhang, S.; Gong, C.; Li, G.; Yang, J. Integrating prediction and reconstruction for anomaly detection. Pattern Recognit. Lett. 2020, 129, 123–130. [Google Scholar] [CrossRef]
- Ramachandra, B.; Jones, M.; Vatsavai, R. Learning a distance function with a Siamese network to localize anomalies in videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Lv, H.; Chen, C.; Cui, Z.; Xu, C.; Li, Y.; Yang, J. Learning Normal Dynamics in Videos with Meta Prototype Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15425–15434. [Google Scholar]
- Yu, J.; Lee, Y.; Yow, K.C.; Jeon, M.; Pedrycz, W. Abnormal Event Detection and Localization via Adversarial Event Prediction. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 3572–3586. [Google Scholar] [CrossRef]
- Fang, Z.; Liang, J.; Zhou, J.T.; Xiao, Y.; Yang, F. Anomaly Detection with Bidirectional Consistency in Videos. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 1079–1092. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Gong, M.; Xie, Y.; Qin, A.K.; Li, H.; Gao, Y.; Ong, Y.S. Influence-Aware Attention Networks for Anomaly Detection in Surveillance Videos. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5427–5437. [Google Scholar] [CrossRef]
- Ning, Z.; Wang, Z.; Liu, Y.; Liu, J.; Song, L. Memory-enhanced appearance-motion consistency framework for video anomaly detection. Comput. Commun. 2024, 216, 159–167. [Google Scholar] [CrossRef]
- Liang, J.; Xiao, Y.; Zhou, J.T.; Yang, F.; Li, T.; Fang, Z. C2Net: Content dependent and independent cross-attention network for anomaly detection in videos. Appl. Intell. 2024, 54, 1980–1996. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Hu, E.; Wang, A.; Shiri, B.; Lin, W. VNDHR: Variational Single Nighttime Image Dehazing for Enhancing Visibility in Intelligent Transportation Systems via Hybrid Regularization. IEEE Trans. Intell. Transp. Syst. 2025; 1–15, early access. [Google Scholar] [CrossRef]
- Mishra, A.K.; Kumar, M.; Choudhry, M.S. Fusion of multiscale gradient domain enhancement and gamma correction for underwater image/video enhancement and restoration. Opt. Lasers Eng. 2024, 178, 108154. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).