1. Introduction
Speech Enhancement Algorithms (SEAs) are computational methods designed to improve the acoustic properties of speech signals that have been degraded by added noise or other distortions, thereby improving human perception [
1,
2]. It is widely known that additive noise is the most prevalent and influential type of noise in real-world environments. Therefore, SEAs are designed to process noisy signals, restore clean speech, improve speech quality and intelligibility, mitigate noise pollution, and reduce listener fatigue [
3]. In real-life scenarios, background noise often contaminates clean speech, resulting in noisy signals. Consequently, speech consistently includes unwanted degradation that creates a lower-quality signal for human listeners. This degradation leads to listener fatigue and significantly reduces the performance of speech recognition systems [
4]. SEAs have been developed to process noisy signals and restore the original speech signal by effectively performing noise suppression to ultimately improve the perceived quality for human listeners [
5]. Over the decades, several SEAs have been developed, significantly shaping modern audio processing technologies. In 1979, the spectral subtraction method was introduced [
6]. This method can estimate the noise from the silent portions of a signal and subtract it from the spectrum. It helps to reduce background noise and improve speech clarity, making it a foundational technique for many later advancements in telephony and audio applications. The Wiener filter, first developed in 1940 by Norbert Wiener, has been applied in the speech enhancement field to solve signal estimation problems for speech signals [
7]. This statistical filtering method minimizes the mean squared error between the original and enhanced signal, leading to improved speech quality in noisy environments, and has found use in VoIP applications and hearing aids.
In the 1980s, Kalman filters began to find applications in speech processing. First proposed in the 1960s by Rudolf Kalman [
8], the Kalman filter is a Bayesian recursive filter that can predict the optimal state of a speech signal, making it particularly useful in dynamically noisy environments such as live broadcasting and speech recognition systems. During the same period, Ephraim & Malah (1984) introduced an algorithm for estimating the Minimum Mean Square Error (MMSE) [
9]. This algorithm uses statistical modeling to suppress noise while preserving speech intelligibility, capitalizing on the major importance of the short-time spectral amplitude. This method has become a key component in hearing aids and noise suppression features in modern smart devices [
9]. The 1990s saw the emergence of subspace methods [
10], which decompose the speech signal into distinct components, allowing speech to be separated from noise without significantly affecting clarity. These methods have been widely used in robust speech recognition and forensic audio analysis. Additionally, statistical modeling-based methods [
11] that leverage Gaussian Mixture Models (GMMs) and Hidden Markov Models (HMMs) to predict clean speech based on previously recorded patterns have recently gained traction. These approaches have contributed to advancements in speech synthesis, assistive voice technologies, and speech-to-text conversion. These classical SEAs laid the groundwork for modern advancements, including deep learning-based speech enhancement techniques and Generative Adversarial Networks (GANs), which build upon these fundamental principles with more sophisticated data-driven approaches to noise suppression and speech quality improvement.
There are various criteria for classifying SEAs. Several studies have categorized SEAs based on the number of channels, distinguishing between single-channel and multi-channel approaches [
12,
13]. Other studies have classified SEAs into three basic categories according to different processing techniques: spectral-subtractive algorithms, methods based on statistical models, and optimization criteria [
6]. The latter category includes Wiener filtering (WF) [
14], Minimum Mean Square Error (MMSE) estimation [
9], deep learning algorithms [
15]), and subspace algorithms [
16].
A broad classification of SEAs can also be made based on processing domains, which can be divided into transform domain-based SEAs, time domain-based SEAs, and hybrid domain-based SEAs. Recently, there has been a growing trend toward speech enhancement models that combine the time and frequency (TF) domains [
17,
18,
19]. In transform domain-based SEAs, degraded speech is processed in the transform domain, whereas temporal SEAs operate in the time domain. Each processing domain offers its own advantages and disadvantages [
4]. Various discrete transforms have been used in SEAs, including the Discrete Fourier Transform (DFT) [
9,
20], Wavelet Transform (WT) [
21], Discrete Cosine Transform (DCT) [
22], Discrete Krawtchouk Transform (DKT), and Discrete Tchebichef Transform (DTT) [
14]. It is worth mentioning that different types of DCTs are utilized to improve speech quality, such as by reducing noise, extracting essential features, and enabling efficient compression. Each type has specific advantages that make it suitable for particular applications. DCT Type-II (DCT-II) [
23,
24] is considered the most widely used type, especially in Mel-Frequency Cepstral Coefficients (MFCCs), which play a crucial role in speech recognition and enhancement. It is known for its excellent energy compaction, making it highly effective for speech compression and denoising. On the other hand, the DCT Type-III (DCT-III) [
25], also referred to as Inverse DCT (IDCT), is essential for reconstructing speech signals after enhancement. It is often used in filtering bank-based speech processing to restore speech quality after noise suppression. Another important variant is DCT Type-IV (DCT-IV) [
26], which is commonly applied in sub-band coding and speech denoising. It provides a smoother spectral representation of speech signals, helping to reduce artifacts and improve overall clarity. Additionally, the Modified Discrete Cosine Transform (MDCT) [
27] is widely used for audio compression and real-time speech applications. Overall, these DCT-based techniques have greatly contributed to speech enhancement by improving noise reduction, compression efficiency, and speech intelligibility. Their continued relevance in modern deep learning-based SEAs highlights their lasting impact on the field. Each category of SEA can be implemented using specific transforms.
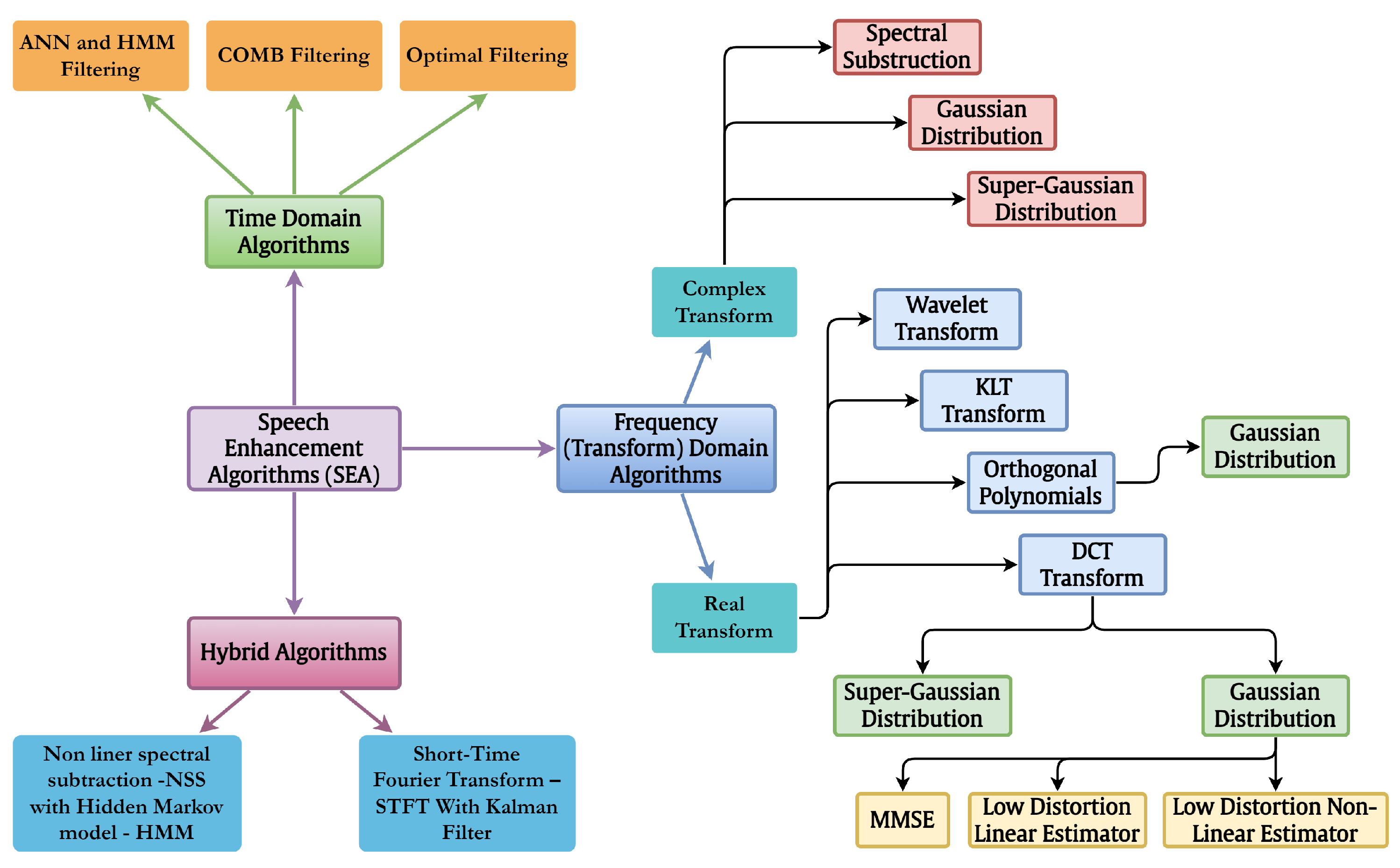
Figure 1 illustrates the different classes of SEA based on dedicated processing domains [
1].
SEAs have garnered significant attention due to their wide range of applications. Numerous reviews and surveys have been conducted to examine different aspects of SEAs. For example, ref. [
28] investigated various techniques for speech de-reverberation and enhancement in noisy and reverberant environments. Two primary backbone Deep Neural Networks (DNNs) were compared, one operating in the time domain and the other in the frequency domain. In [
29], the authors conducted a literature survey that discussed challenges such as nonstationary noise and overlapping speech. These are common issues in real-world scenarios, where speech signals are often degraded. A comprehensive summary of speech enhancement techniques and their various applications was presented in [
29], focusing on traditional methods such as adaptive filtering and Wiener filtering as well as modern approaches such as deep learning-based techniques. Today, SEAs are integrated into various fields and applied in many practical applications, including telecommunications, hearing aids, speech recognition, and audio restoration. This paper aims to offer valuable insights for researchers and engineers, helping them to choose the most suitable approach based on the specific challenges of their acoustic environments.
In particular, this systematic literature review is designed to assist speech researchers and academics by identifying critical research gaps in this field and highlighting promising directions for future studies. Through an in-depth analysis of speech enhancement methodologies, this review draws attention to the field’s most impactful topics. Furthermore, it addresses recent challenges and uncovers current research gaps involving SEAs, providing valuable insights and guidance for future research trajectories.
2. Background
Speech enhancement aims to improve the quality and intelligibility of speech signals. However, achieving better speech quality does not necessarily guarantee higher intelligibility, as these two criteria are independent. Most SEAs focus on noise reduction by improving the quality of the speech signal, often at the expense of reducing intelligibility. The quality of a speech signal refers to its clarity, intelligibility, and naturalness, which determine how well a listener or automated system can perceive and understand the speech. Quality is influenced by factors such as background noise, distortion, bandwidth, and temporal continuity [
30]. High-quality speech signals exhibit minimal noise, reduced artifacts, and a well-preserved frequency spectrum, ensuring both naturalness and intelligibility [
31]. In speech enhancement, various algorithms aim to improve quality by suppressing noise and distortions while preserving key speech components, making the resulting signals more suitable for applications such as telecommunication, speech recognition, and assistive hearing devices. The human ear plays a vital role in speech perception, making certain sound properties essential for speech quality. The ear is most sensitive to frequencies between 1 kHz and 4 kHz, where speech intelligibility is highest; thus, speech enhancement should preserve this range [
32]. The ear also follows loudness perception patterns, meaning that speech should be balanced across frequencies in order to sound natural [
33]. Additionally, the auditory system can distinguish rapid sound changes, meaning that avoiding distortion of key speech cues is crucial when enhancing speech signals [
34]. Finally, binaural hearing helps with spatial awareness, enabling better speech perception in noisy environments [
35]. The human voice itself can sometimes be an unclean source signal, even before any external noise or distortions are introduced; for instance, this can happen due to speech disorders, medical conditions such as dysphonia or Parkinson’s disease, and stuttering, which can cause irregularities in voice production [
36]. Emotional states such as whispering, shouting, or crying also affect speech clarity and make it harder to process [
37]. Additionally, factors such as fatigue, dehydration, and aging can alter vocal quality, leading to hoarseness or instability [
38]. In multilingual settings, accents and pronunciation variations may introduce further complexity [
39]. Because of these natural variations, speech enhancement systems must adapt to intrinsic distortions in the human voice while preserving its unique characteristics. Interestingly, listeners can sometimes extract more information from a noisy signal than an enhanced one, especially when listening attentively; however, prolonged exposure to noisy signals can cause discomfort, prompting the development of methods that simultaneously enhance the quality and intelligibility of speech signals [
40]. Deep learning techniques such as Convolutional Neural Networks (CNNs) have been employed to analyze and process distorted speech signals. These approaches enhance speech quality while facilitating clearer and more accurate speech inputs, benefiting tasks such as automatic speech recognition as well as applications in noisy environments.
The design of a speech enhancement architecture should involve multiple standards, including an appropriate speech model, addressing different noise types, intelligibility improvement, and quality enhancement. One of the most crucial factors in any design is the mitigation of artifacts, including Musical Noise (MN), which is a common artificial distortion generated during speech enhancement or noise reduction processes. MN manifests as isolated tonal or harmonic elements resembling random musical notes, which can disrupt the listening experience [
9]. The process of speech degradation caused by background noise and the subsequent application of noise suppression techniques is depicted in
Figure 2. As speech signals travel from source to destination, they often encounter additive background noise in uncontrolled environments [
4]. Therefore, SEAs are an important optimization method for enhancing distorted signals and removing noise.
The critical challenge in developing highly effective SEAs lies in selecting suitable processing techniques for noise reduction and clarity improvement, along with accurately modeling the statistical properties of noise and speech. Techniques such as spectral subtraction and Wiener filtering are commonly employed for noise suppression. Additionally, the choice of an appropriate Probability Density Function (PDF) to model noise and speech signals significantly impacts the performance of such algorithms. There are different statistical PDFs for modeling these random signals, which can be stationary or nonstationary. For instance, different works have used Gaussian PDFs [
9,
30,
41]. These are widely used due to their simplicity, but may not accurately represent real-world noise in nonstationary environments. Suppressing nonstationary noise is a more complex task than suppressing stationary noise. To address this, more advanced PDFs use Laplacian [
20,
42] or Gamma [
43] distributions for more accurate noise modeling. Many studies have emphasized the importance of matching the PDF to the noise type in order to increase the algorithm’s accuracy. Techniques such as Deep Neural Networks (DNNs), Kalman filtering, Non-negative Matrix Factorization (NMF), and MMSE estimation further leverage statistical models to refine speech signals, demonstrating the critical role of PDF selection in achieving optimal results.
Significant advancements have been made in recent decades thanks to the availability of open-source resources, techniques, and measurements for building and evaluating SEAs. This study seeks to review and analyze recent existing research on SEAs while providing a comprehensive overview of their concepts, development, and challenges.
3. Method
The field of speech enhancement is of great interest due to its highly multidisciplinary nature and its relevance to many human-centric applications, including medical applications. Therefore, in this review we implement the idea of building a body of evidence and information on various SEA approaches. The survey conducted in this paper is divided into several stages, with each stage including specific elements of planning, conducting, and reporting to form the methodological framework. This systematic literature review is conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) protocol [
44,
45], which is useful for visualizing the relationship between the stages of the literature review process.
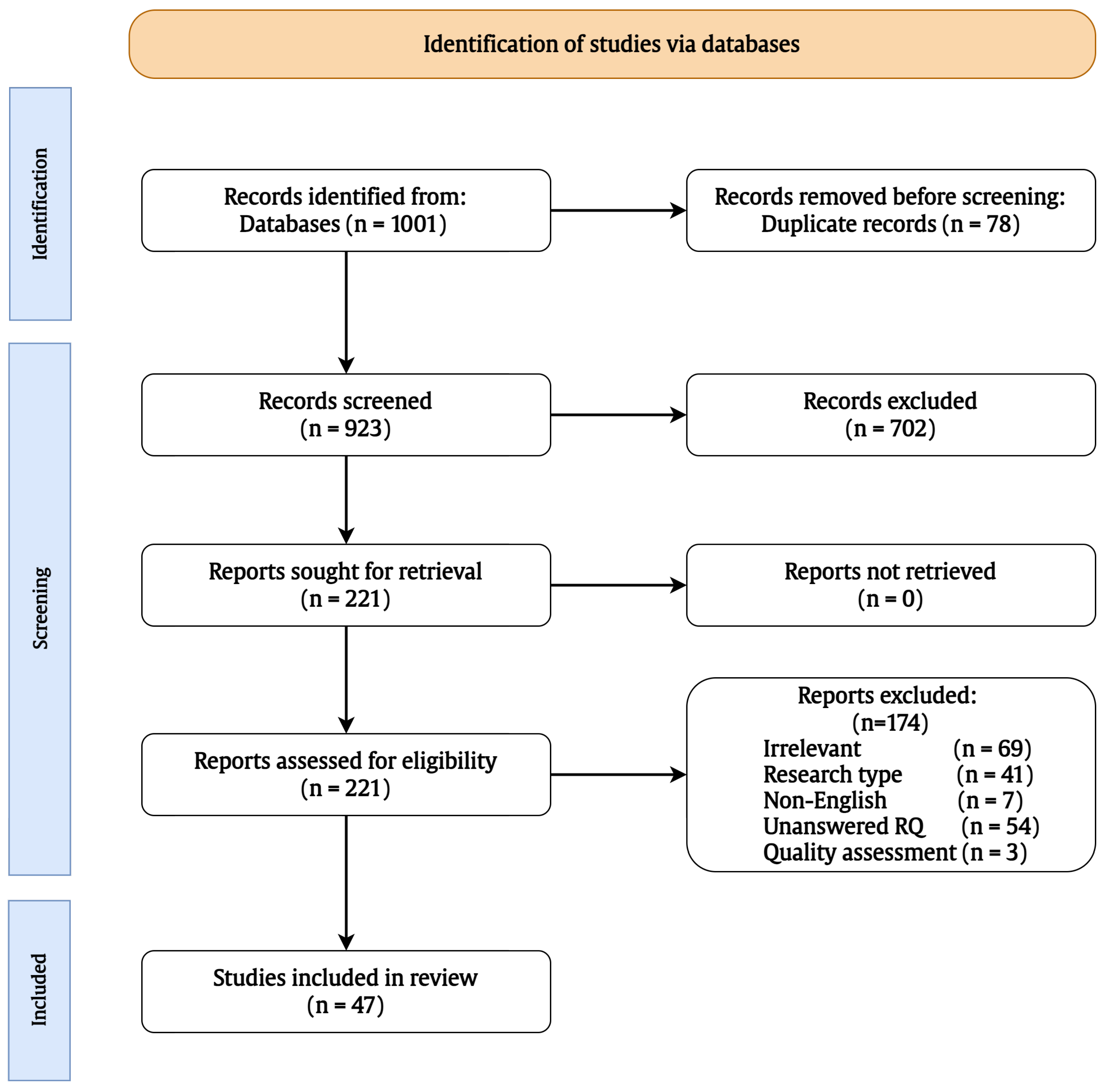
Figure 3 presents the PRISMA flowchart, which details the outcomes at each stage of the systematic review and visually summarizes the screening process while improving the quality and transparency of the SEA literature. First, the number of identified papers from the electronic database is recorded. The selection process of the systematic review is then carried out transparently by reporting the decisions made at each stage, including the number of studies. Reasons for including or excluding papers at the full-text stage are documented. The PRISMA flowchart, shown in
Figure 3, enhances the reliability and reproducibility of reviews by enabling researchers to understand and evaluate the methodology and findings. The workflow of the methodology is initiated by identifying research questions, followed by formulating and outlining the search strategy and developing criteria for the inclusion or exclusion of studies. Lastly, the procedures for quality assessment and data extraction are implemented. Data are extracted to obtain essential information from the selected papers included in the review. In this review, the extraction process was performed independently by two reviewers to ensure greater accuracy and reduce bias. All stages of the review are detailed in the following sections.
This work reviews the technologies used for speech enhancement processing. It explores the existing methods and techniques currently used in the field in addition to the potential challenges and limitations, providing insights about how methods for enhancing the quality of degraded speech can be improved. The following sections present the methodological steps and resources used to conduct this systematic review in comprehensive detail.
3.1. Research Questions (RQs)
Identifying and constructing the Research Questions (RQs) is the first and most essential process in any literature review. In this systematic literature review, RQs were developed by starting with the broad topic of Speech Enhancement Algorithms (SEAs), conducting preliminary research on specific issues related to SEAs, and narrowing down the focus within this field. The soundness of the potential questions was then evaluated by identifying the main challenges in existing SEAs. The following seven RQs were established to facilitate an in-depth examination of the field:
- RQ1:
What are the most commonly used recent research approaches in the field of SEAs?
- RQ2:
What are the main types of transform-based SEA used in the existing studies?
- RQ3:
What is the number of channels presented in the current works?
- RQ4:
What are the major models used to identify speech and noise signals?
- RQ5:
What are the well-known datasets used in existing papers?
- RQ6:
What are the most effective measurements for evaluating speech intelligibility and quality?
- RQ7:
What are the current limitations and challenges in the reviewed SEAs?
The construction of these RQs was formulated carefully. RQ1 aims to identify recent research topics and then conduct preliminary research on the field of SEAs, which is the subject of interest in this work. Then, the definition of essential issues that need to be addressed in this field is provided based on RQ2, RQ3, and RQ4. Specifically, RQ2 focuses on the recent types of transform-based SEAs, RQ3 highlights the number of channels presented in the current SEA, and RQ4 provides an overview of the major types of models for speech and noise signals. After that, RQ5 and RQ6 narrow the focus and scope of the research by demonstrating the most well-known datasets applied in the field and the most effective measures used for evaluating the intelligibility and quality of enhanced speech signals, respectively. Finally, RQ7 aims to investigate the current limitations and challenges in the reviewed studies on SEAs. The concept of RQ formulation has significant implications for our methodological process, and has been carefully implemented to guide researchers through these questions in order to provide broader benefits to the field of SEAs.
3.2. Search Strategy Based on Search Strings and Online Electronic Databases
After developing the research questions related to the SEA topic, the search strategy was performed by identifying specific categories and keywords that are commonly used in the related studies. The search process was then conducted across five electronic databases.
The first step in formulating a search strategy is to take the topic and break its terminology into discrete concepts (categories) and keywords. The following four concepts were formalized based on the literature review: Concept 1 is associated with the signal type (speech, noise, voice, and audio); Concept 2 is associated with the algorithm name (enhancement, improvement, noise reduction, and denoising); Concept 3 is associated with algorithm types (Wiener filtering, MMSE estimation, deep learning, spectral subtraction, and noise estimation); finally, Concept 4 is associated with the approach (system, technology, technique, method, and algorithm).
Then, a search string is formed by identifying primary keywords for each concept.
Table 1 outlines the defined concepts along with their corresponding keywords. These keywords are commonly used in research studies on SEA and are aligned with the research questions. The categories and their corresponding keywords were selected based on an extensive literature review. As shown in the table, different keywords were defined for the four categories, which are expressed using similar or related terms. A thorough search was formalized based on the identification of alternative synonyms, acronyms, and spellings which include variations of the major term. The defined keywords were then organized under the four distinct concepts and combined using the Boolean operator OR. Subsequently, the Boolean operator AND was applied to incorporate keywords across categories.
As a result of the above procedure, search strings were created from the keywords within each concept and Boolean operator. Boolean operators have the ability to link together two or more search conditions, allowing more complex search logics to be specified. The implemented procedure was as follows:
Concept 1: “Speech” OR “Voice” OR “Noise” OR “audio”
Concept 2: “Enhancement” OR “Improvement” OR “Noise Reduction” OR “Denoising”
Concept 3: “Wiener Filtering” OR “MMSE Estimation” OR “Deep Learning” OR “Spectral subtraction or Noise estimation”
Concept 4: “System” OR “Method” OR “Technology or Technique” OR “Algorithm”.
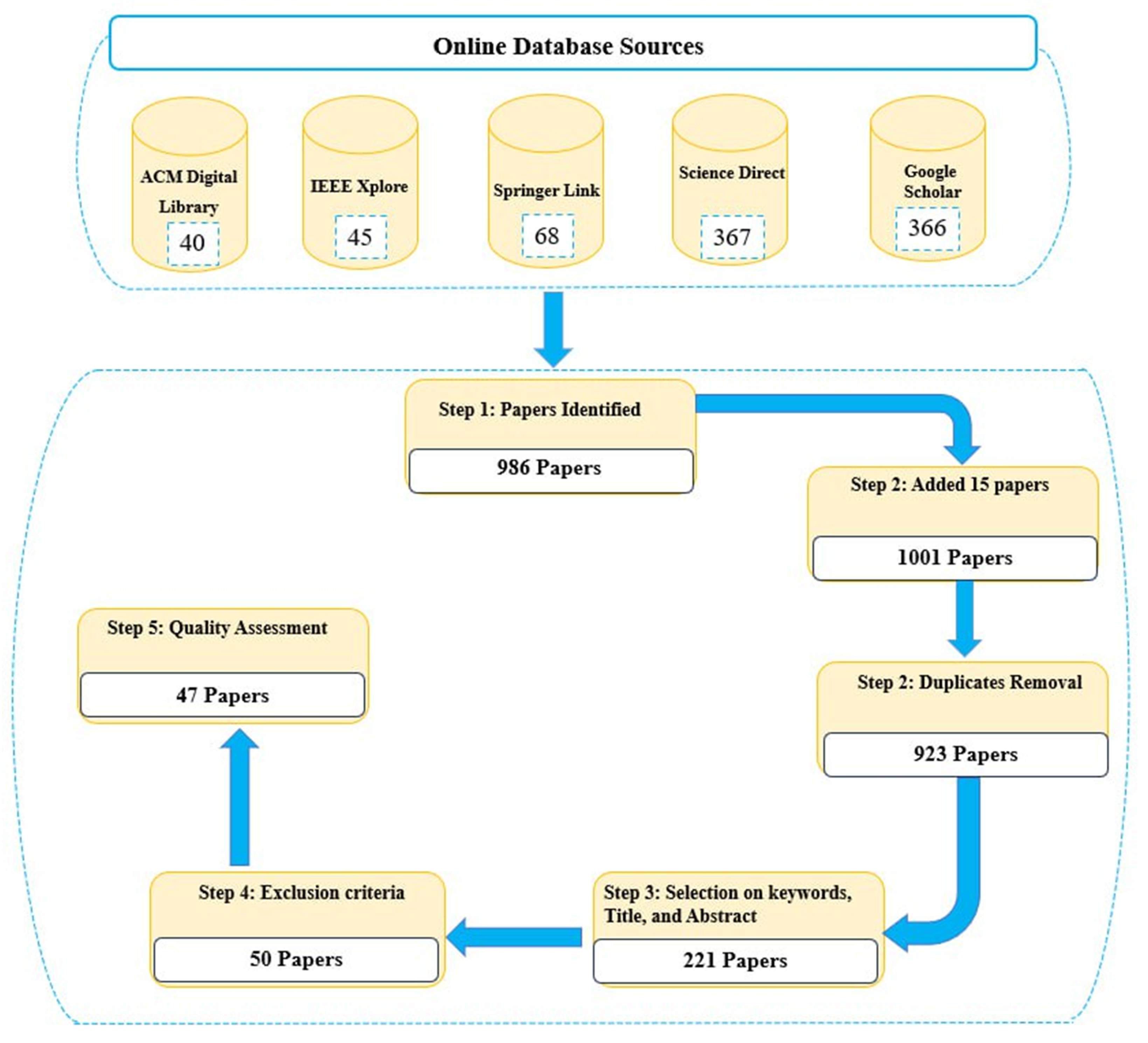
The resulting string was structured as (Concept 1) AND (Concept 2) AND (Concept 3) AND (Concept 4). The search results were subsequently retrieved and stored using Mendeley Reference Management software. Then, the search string including the keywords based on the categories and Boolean operators (logical operations) was entered into the search box of the selected electronic library database or search engine. Afterwards, the search process was conducted by retrieving articles from the five electronic databases used for data collection. The five sources cover many aspects of the reviewed research area and provide effective search engines that are easy to use and appropriate for automatic search [
46]. The list of libraries included SpringerLink, IEEE Xplore, ScienceDirect, ACM Digital Library, and Google Scholar. The aforementioned combinations of keywords based on Boolean expressions were used in the search process. The search engines mostly support logical operators and permit the use of parentheses to link multiple search conditions and define more complex logics. Parentheses are significant because they separate the specific elements of the search string in order to confirm that they are regarded as a group.
However, the details of the search step based on the defined search string sometimes need to be carefully checked to ensure the best results depending on the keyword combinations and the database being used. The complete documentation of the search strategy, including its details, is illustrated in
Table 2, which provides the name of the online electronic database (digital library), the date of the search, the combination(s) of keywords based on Boolean operators, and the number of studies retrieved (with and without filter). Therefore, the result is a documentary report containing all the details related to the search strategy, which helps in tracking the subsequent research phases.
3.3. Study Selection Based on Inclusion and Exclusion Criteria
Selection criteria aim to identify studies that provide direct evidence on the research topic. To minimize the potential for bias, selection criteria should be specified during the protocol definition phase and can be refined during the search process [
47]. In this systematic review we identified target study papers based on specific formalized criteria. These criteria, collectively known as the eligibility criteria, should be specified carefully when searching for papers, as they help to narrow down the scope of the relevant topic. The criteria used for exclusion and inclusion set the boundaries of this paper, and were evaluated based on the details mentioned in
Table 3. The first excluding step in this stage was to remove redundant papers, followed by screening the papers against the keywords and formulated research questions following the steps in [
46,
48]. Any paper that was not expected to provide an accurate answer to the research questions was excluded. Next, papers were assessed against the inclusion and exclusion criteria based on the title, abstract, and full text. Included studies were from peer-reviewed journals, conferences, and workshop papers. In the event of multiple versions of a selected paper, only the most recently updated version was included; all other versions were excluded.
Table 2 shows that the search string retrieved a total of 986 articles. In addition, fifteen papers were added from other surveys and overviews. Of 1001 papers, 78 were removed due to duplication, leaving 923 papers for further review. Subsequently, the retained papers were checked by authors based on the title, abstract, and keywords of the papers. The authors were considered the reviewers, and the number of retrieved records was 221. To assess the actual relevance of the studies, selection was performed on all potentially relevant studies by applying the set of inclusion and exclusion criteria. The criteria were applied to the retrieved records in order to assess them and make decisions about which retained papers were reviewed. The adopted exclusion and inclusion criteria are illustrated in
Table 3.
Based on [
47,
49], two researchers evaluated each paper and reached agreement about whether to include or exclude it. In cases of disagreement, the matter was discussed and resolved based on the predefined criteria. The applied criteria further reduced the number of research papers to 50.
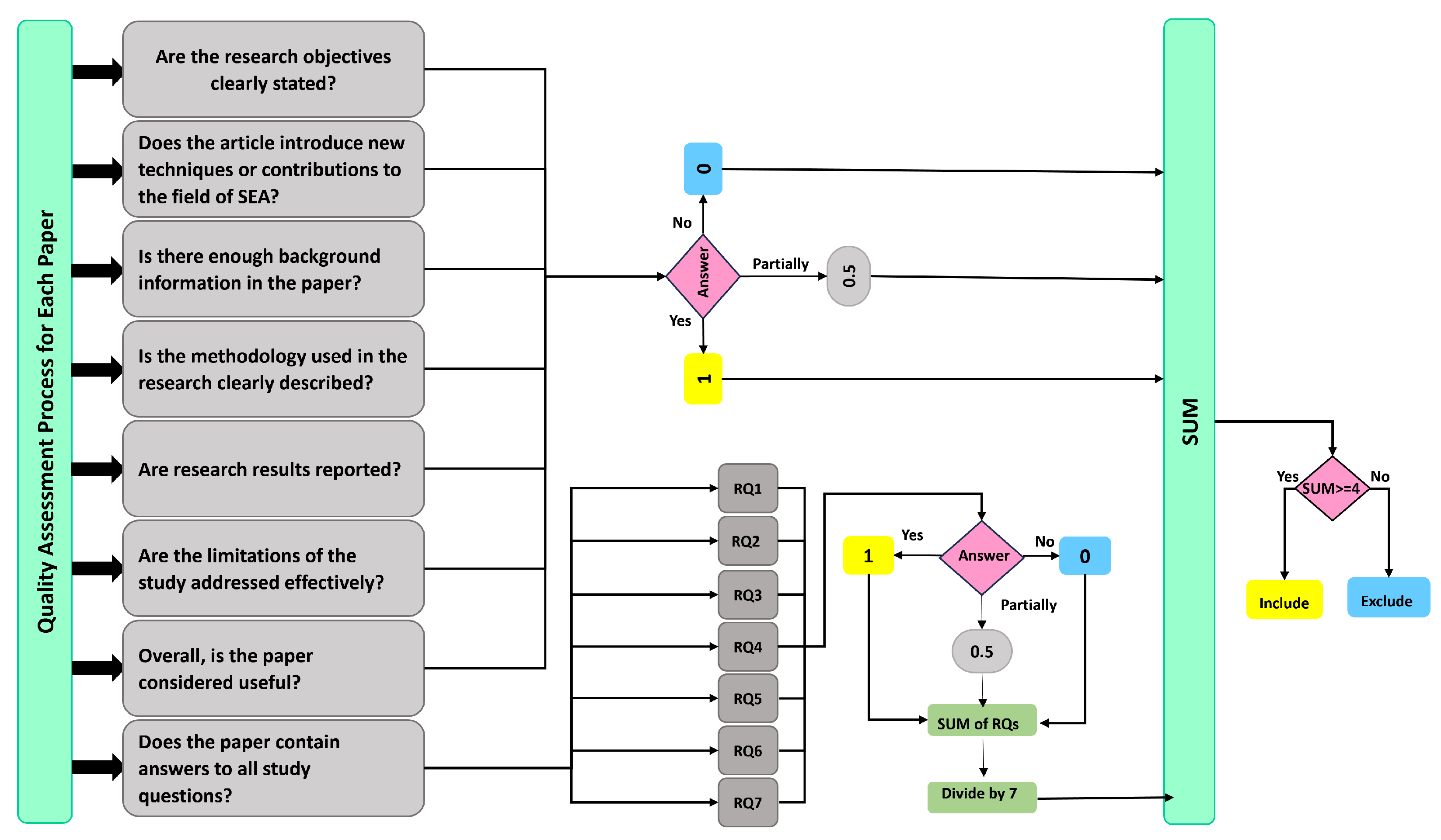
3.4. Quality Assessment (QA) Rules
In any systematic literature review, applying Quality Assessment (QA) rules is considered the last step in identifying the final list of candidate papers for inclusion. QA rules were applied to evaluate the quality of the research papers in accordance with the set research questions. Given the lack of standard empirically grounded QA rules suitable for use in such study designs, we implemented a scoring system to evaluate the quality of the papers eligible for inclusion in our systematic review based on the rules provided in [
50]. Following the study selection process, we applied eight additional criteria in order to improve the results. QA rules were applied to each nominated paper in order to assess the quality of its contents and select only those studies most relevant to our SEA topic. Using the procedure suggested in [
47], we checked the quality of each candidate paper for inclusion based on the following QA checklist:
- QA1.
Are the research objectives clearly stated?
- QA2.
Does the article introduce new techniques or contributions to the field of SEA?
- QA3.
Is there enough background information in the paper?
- QA4.
Is the methodology used in the research clearly described?
- QA5.
Does the paper contain answers to the research questions?
- QA6.
Are research results reported?
- QA7.
Are the limitations of the study addressed effectively?
- QA8.
Overall, is the paper considered useful?
Each question had three possible answers, with points being scored in the following way:
The study was marked with “Yes” if the answer to the QA item was positive, where “Yes” = 1.
The study was marked with “No” if the answer to the QA item negative, where “No” = 0.
The study was marked with “Partial” if it only partially answered the QA item, where “Partial” = 0.5.
The procedure for quality assessment is illustrated in
Figure 4. The QA score of the research studies was achieved by weighing their quality alongside the QA questions; a paper was selected if it had a quality score equal to or greater than four. The results are presented in
Table 4. Then, for each research study, the total score was computed based on a predefined threshold. If the total score was grater than or equal to four, the candidate study was included; on the other hand, if the score was less than four, the candidate study was excluded. Based on this procedure, three studies were excluded after implementing the quality assessment.
In the QA procedure, studies were scored based on the degree to which specific criteria were met. The steps are summarized as follows. First, the questions used for the assessment procedure were defined. A scale was then determined to assign ranks to the papers based on the list of quality assessment questions. The total score value was obtained after summing all the weights provided based on these questions. Afterwards, a threshold of four was set, with papers excluded if this threshold was not med. On this basis, three papers were excluded.
The final number of retained studies was 47. The excluded papers are highlighted in purple in
Table 4. All details of the QA answers for the retained papers are shown in
Table 4.
The full workflow of our systematic review after all methodological steps is depicted in
Figure 5.
4. Results and Discussion
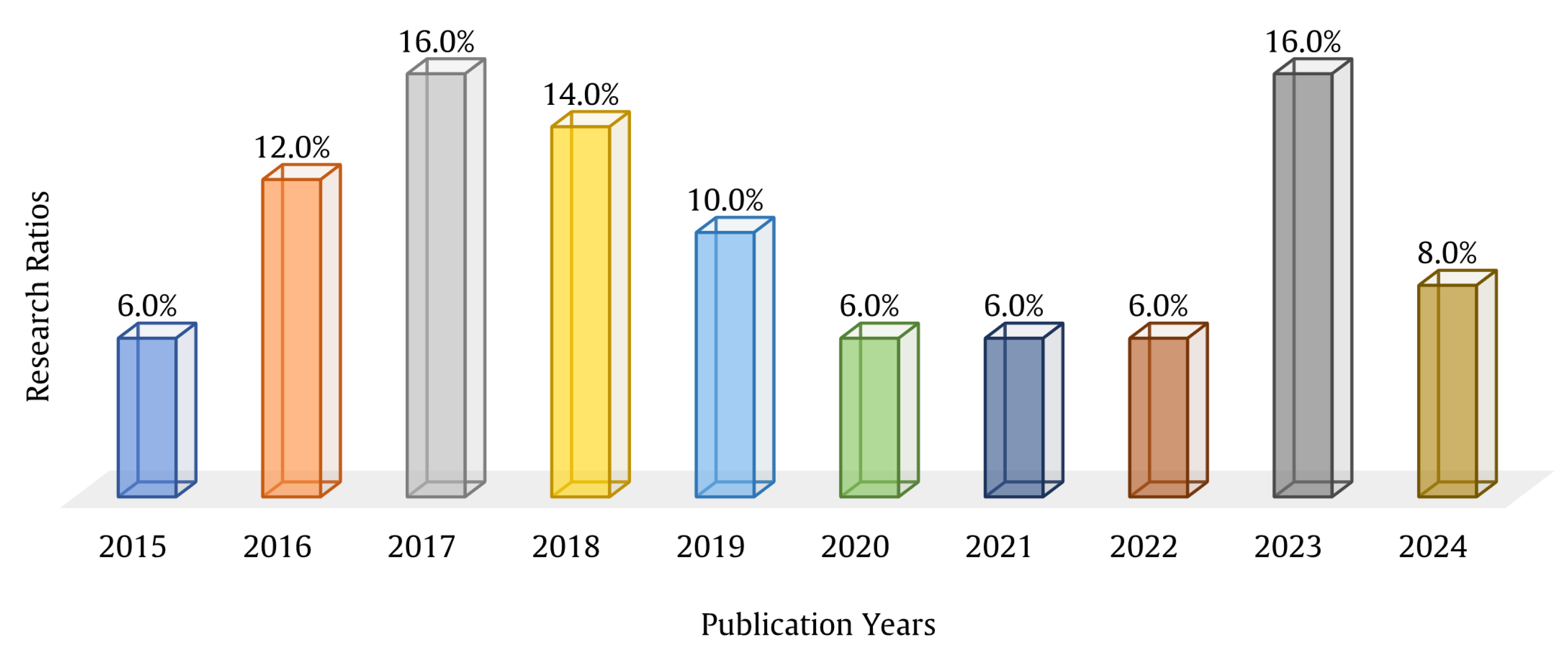
The aim of this stage is to discuss and accurately record information from the candidate studies. To reduce the chance of bias, the data extraction process is clearly defined. Various types of algorithms are used for speech enhancement, in which multiple transforms and techniques have been implemented. To cover the trends in the candidate articles, an overview of these studies according to their year of publication is provided based on the 50 papers retained after the exclusion step. The year-wise distribution of the collected studies is displayed in
Table 5. For more clarity and to provide a better understanding of trends in the SEA research area, the number of related research studies per year along with their percentage ratio is presented in
Figure 6.
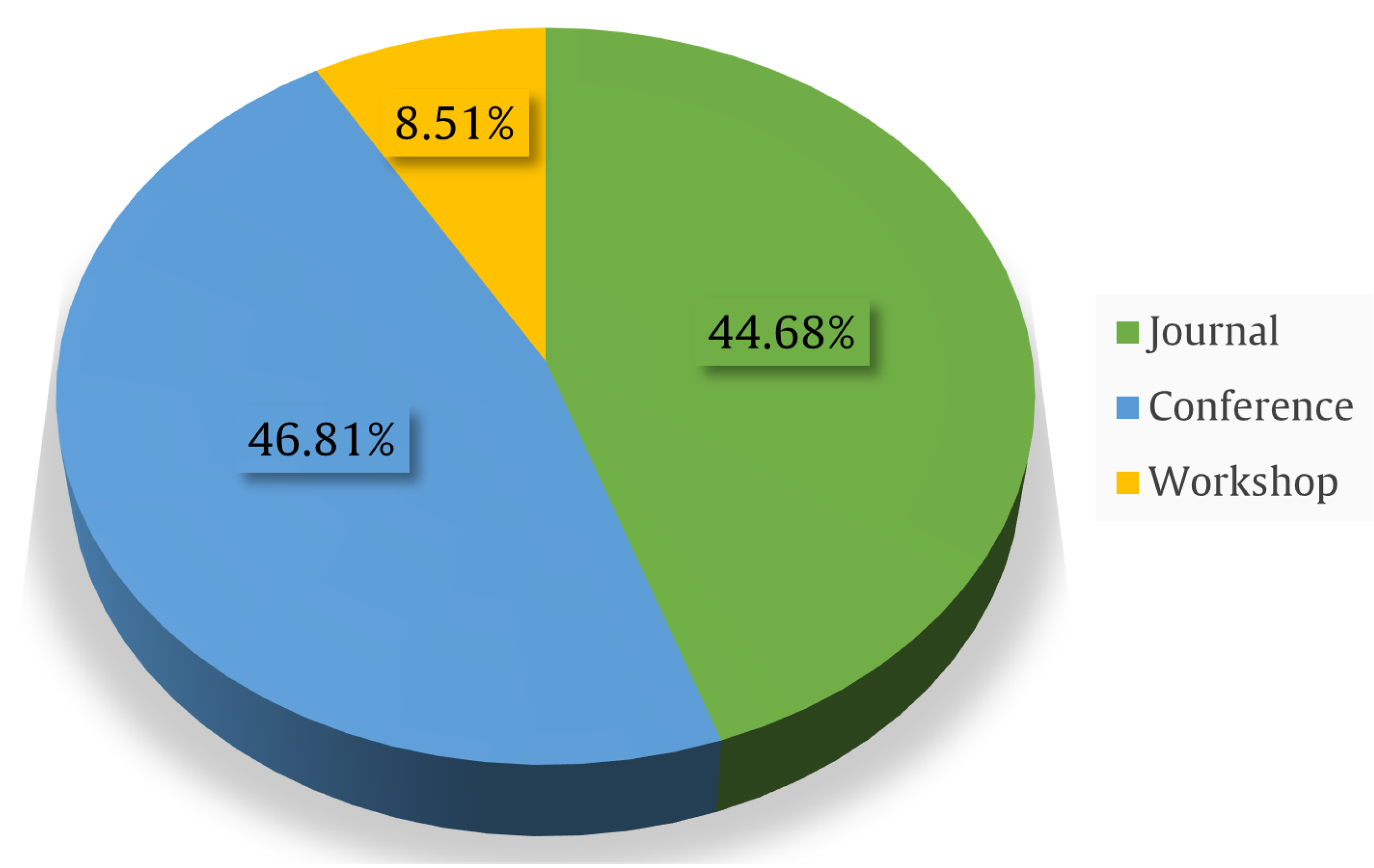
Figure 7 shows the collected papers divided according to their types and sources, with the average provided for each type of publication. A final total of 47 studies were retained. As presented in
Figure 7, 44.68% of the studies were published in journals, 46.81% were presented at conferences, and 8.51% were presented in workshops.
Table 6 shows that the majority of the 47 papers collected for the full review were indexed in Scopus and Web of Science. Specifically, 42 papers (89.4%) were indexed in Scopus and 39 papers (83.0%) in the Web of Science database, with a smaller subset of eight papers (17.0%) indexed in the Emerging Web of Science. This indicates that the majority of the collected literature is well-represented in established indexing platforms, which ensures a robust foundation for our systematic review. Overall, the dataset reflects a strong emphasis on credible and widely recognized sources. In this section, the research questions are answered in detail to achieve the objectives accurately and clearly.
Speech enhancement processes aim to recovers the desired clean speech of the damaged signal, with different approaches depending on the type of degradation and noise signal. Practically, this process remains challenging, specifically when dealing with high noise levels, nonstationary noise, and reverberation. Therefore, multiple approaches have emerged in recent years. Different types of SEA have been are adopted in the reviewed papers. It is worth noting that deep learning has recently attracted the attention of many researchers. The reviewed studies on SEAs investigate varied topics, including statistical based approaches, deep learning-based approaches, and hybrid methods that incorporate different approaches such as conventional speech enhancement and deep learning techniques. Specifically, topics such as phase-sensitive masks, harmonic regeneration, and time–frequency mask estimation have become popular. Hybrid approaches combining techniques such as Wiener filtering with neural networks are commonly used to improve voice intelligibility and lower noise in complex situations such as mobile communication, hearing aids, and drones. Among the 47 reviewed studies, several cover deep learning [
51,
53]. Nine of the retained studies were dedicated to DNNs [
52,
55,
64,
73,
76,
77,
80,
92,
96], while other studies presented CNNs for use in SEAs. CNNs are a class of deep neural architecture consisting of one or more pairs of alternating convolutional and pooling layers [
86]. In speech enhancement, long-term context is important for improving and understanding speech signals and processing continuous noise. RNNs can retain long-term context via modules such as LSTMs, making them better suited to handling long or complex signals. CNNs work well with short contexts, but require deeper networks or additional techniques such as dilated convolutions in order to simulate long-term effects. Therefore, RNNs were used in several of the reviewed studies. The SEA presented in [
15] utilizes a CNN and a Fully-Connected Neural Network (FCNN). Another study used a novel LSTM-based speech preprocessor for speaker diarization in a realistic mismatch scenario [
54]. To address the nonstationary of noise, one work used a Recurrent Neural Network (RNN)-based speech enhancement system to reduce wind noise [
84], while another used an equilibriated RNN for real-time enhancement [
94]. It is noteworthy that several studies were dedicated to hybrid speech enhancement algorithms. These dedicated hybrid forms of deep learning included RNN(LSTM)+CNN [
56] and CNN+RNN [
86] varieties. A different fundamental concepts using deep learning for speech processing was presented [
86]. These methods show that deep learning is becoming more sophisticated and adaptable in solving speech enhancement problems.
Another major approach is based on statistical models and optimization criteria, placing the problem of speech enhancement within a statistical and estimation framework. Among the retained studies, 18 out of 47 cover statistical approaches such as Wiener filtering (eight studies) [
66,
71,
78,
85,
89,
90,
91,
95], MMSE estimation (six studies) [
1,
3,
68,
72,
79,
97], or spectral subtraction (three studies) [
57,
67,
75]. Spectral subtraction is a classical speech enhancement method that estimates the noise spectrum during speech pauses and subtracts it from the noisy spectrum to obtain the estimated clean signal. This process can also be performed by multiplying the noisy spectrum using the gain function and combining it with the phase of the degraded speech signal. The final study in this category uses a wavelet denoising approach [
82]. Of the 47 reviewed papers, ten are dedicated to hybrid forms of speech enhancement: Wiener Deep Neural Network (WDNN) [
87,
93]; MMSE+DL [
60]; MMSE+Densely Connected Convolution Network (DCCN) [
59]; DL+MMSE [
61]; spectral subtraction with Wiener filter, CNN, and GNN [
63]; hybrid Wiener filter for 1D-2D [
88]; oblique projection and cepstral subtraction [
69]; Mel-Frequency Cepstral Coefficients (MFCC)+DNN [
83]; and WF generalized subspace+deep complex U-Net [
70]. A summary of the main types of algorithms used in SEAs is provided in
Table 7.
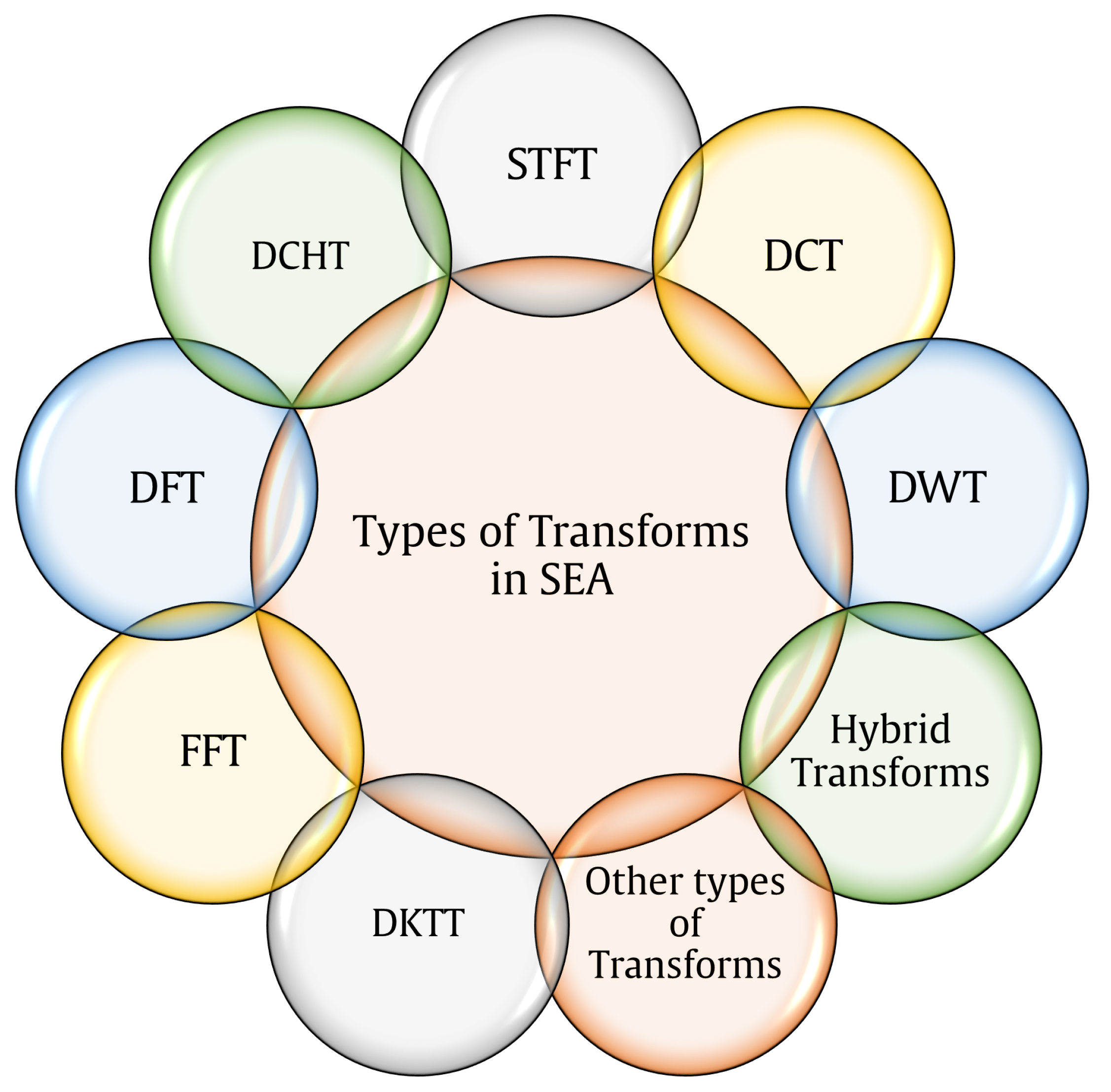
The main kinds of transform-based SEA adopted by the reviewed findings are indicted in this section. It is worth mentioning that the processing of speech enhancement can be applied in the time domain and frequency domain. However, discrete transforms have been recognized as a very useful tool in signal processing such as speech enhancement. In this approach, speech is viewed in transform domains, resulting in a massive shift in terms of robust ability to analyze the components of speech signals [
98]. Discrete transforms have different properties such as energy compaction and localization, which can be used to perform transform analysis in various practical applications. The significance of transforms in sequential data processing raises the possibility of using them in SEA research. Studies dedicated to SEAs include different types of transforms used in this field. As can be observed from
Figure 8, the main types of transforms used in the reviewed papers are as follows: nine studies used the Short-Time Fourier Transform (STFT) [
53,
60,
75,
78,
80,
84,
92,
94,
96]; five studies used the Fast Fourier Transform (FFT) [
57,
66,
67,
90,
93]; and three studies utilized the Discrete Cosine Transform (DCT) [
1,
72,
89]. In another technique presented by [
3,
97], the authors used the Discrete Krawtchouk–Tchebichef Transform (DKTT), a powerful transform that has high energy compaction and localization properties, to handle speech signal coefficients. Finally, one paper was dedicated to the Discrete Fourier Transform (DFT) [
56], another one used the Deep Complex Hybrid Transform (DCHT) [
15], and [
82] used the Wavelet Transform (WT). Additionally, some of the reviewed papers used more than one transform: FFT+DCT [
86], STFT+FFT [
71], DFT+STFT [
61], DFT+STFT [
51], DCT+DTCWPT+DWT [
95], STFT+DCT [
63], DFT+DCT+DWT [
88], STFT+WSST (Wavelet Synchro-Squeezing Transform) [
91], DFT+STFT [
79], and STFT+FFT [
87]. The main types of transforms used in SEAs are listed in
Table 8 along with their features.
The reviewed papers presented several main approaches that improve the performance of SEA in noisy environments based on the channel number. To answer this question, we focused on selected SEA studies that examined single channel-based speech enhancement and multi-channel-based speech enhancement. Single-channel SEA uses a single-channel speech signals; in this approach, signals can be collected by a single microphone. On the other hand, multi-channel SEA works on multiple channel signals, which helps to improve the degraded signal. The single-channel scenario is more common in real situations [
80]. The majority of studies focused on single-channel speech enhancement processing due to its simplicity and widespread use [
1,
51,
53,
54,
56,
57,
59,
60,
61,
62,
63,
64,
67,
69,
70,
71,
72,
80,
84,
86,
87,
88,
92,
94,
95]. Multi-frame filtering techniques are often used for single-microphone scenarios in combination with other methods, such as Wiener filtering or machine learning [
86]. Few of the retained studies addressed multi-channel approaches in SEA. These mostly addressed multi-channel scenarios based on different methods, including Wiener filtering, subspace projection, and multi-channel Wiener filters for spatial noise reduction [
66,
78,
79,
85].
Modeling of speech and noise signals has always been an issue due to environmental randomness. The evaluated publications used range of models for noise and speech signals. These models describe the variety of approaches used by researchers to address issues related to speech enhancement, such as Wiener filter and MMSE. As presented in the existing SEAs based on statistical approaches, the Probability Density Functions (PDF) introduced to model speech and noise transform coefficients are assumed to be either Gaussian or super-Gaussian functions. Because of these assumptions, the aforementioned PDF types provide high allowable mapping patterns for the speech and noise component distribution; however, this is not always the case in real situations. The most widely used model to represent noise signal is Gaussian, although it cannot represent the true situation due to the high number of different noise characteristics in various environments [
42]. Both speech and noise are assumed to obey random processes and are treated as random variables; thus, the basic models that represent speech or noise signals are Gaussian [
79,
87,
91,
93,
95], Laplacian [
1,
97], super-Gaussian [
3,
92], and Gaussian Mixture Model (GMM) [
78]. Other reviewed works were based on hybrid models: GMM+HMM [
86], Gaussian (noise) and Laplacian (clean speech) [
89], Gaussian+Laplacian (clean speech) and Gamma (noise) [
72], GMM+HMM [
54], and Gaussian+Gamma [
60].
Datasets are essential to advancing the development of SEA, as they provide results with scale, robustness, and confidence. They are a fundamental tool in speech analytics that provide the data from which analysts extract significant information, and can be used to conduct and identify trends in speech enhancement research. Speech signals under clean and noisy conditions are usually taken from different well-known databases to build a strong foundation of the proposed work. Based on the reviewed papers, some studies were adopted from the same datasets. The datasets adopted in the 47 included studies are listed in
Table 9 along with some brief details.
Datasets mentioned in the reviewed papers include CHiME-II and CHiME-III, which were used in [
51] to compare the performance of algorithms in various noise environments. CHiME-4 was used to evaluate the one-channel test in [
80]. Aurora-4 was used in [
51] to assess system performance in various noisy environments. Other datasets adopted in the reviewed studies include SPANZ [
70], BKB [
70], VCTK Corpus, which provides diverse English accents for speech enhancement tasks [
61], QUT [
61], VoiceBank-DEMAND [
94], IEEE Speech [
96], RSG-10(Noise), which provides random signal generation noise [
60], WSJO Corpus, AMI Corpus, and ADOS Corpus [
54]. These datasets are frequently used in SEA research. They offer a variety of settings for the testing and training phases of speech enhancement algorithms. Synthetic noise datasets are often used to assess model performance and replicate difficult acoustic conditions. In future studies, larger and more varied datasets could be used to improve robustness and generalizability.
It is necessary to assess SEA performance based on effectiveness metrics that provide meaningful and reliable procedures. The analyzed studies show that two principal criteria are used to measure the goodness of speech signals, namely, quality and intelligibility. Speech quality deals with speech clarity, nature of distortion, and amount of background noise, while speech intelligibility deals with the percentage of words that can be clearly understood. Good quality does not always guarantee high intelligibility, as they are independent of each other. Therefore, most SEAs improve quality at the expense of reducing intelligibility [
40,
106]. In general, there are two categories of speech quality assessment, namely, subjective and objective measures. Objective measurements are preferred, since they are dependent on a mathematical notion. Many metrics are commonly used in SEA evaluation, and every metric has its own strengths and weaknesses. Perceptual Evaluation of Speech Quality (PESQ) is considered the most important objective measure based on the reviewed studies. A total of 30 out of 47 studies used PESQ, constituting a majority of the reviewed papers.
Table 10 illustrates the most commonly used measurements, their abbreviations, a brief description, their percentage of use in the reviewed works, and which studies used them. The measurements mentioned in
Table 10 can be considered the most widely used in the field of speech enhancement.
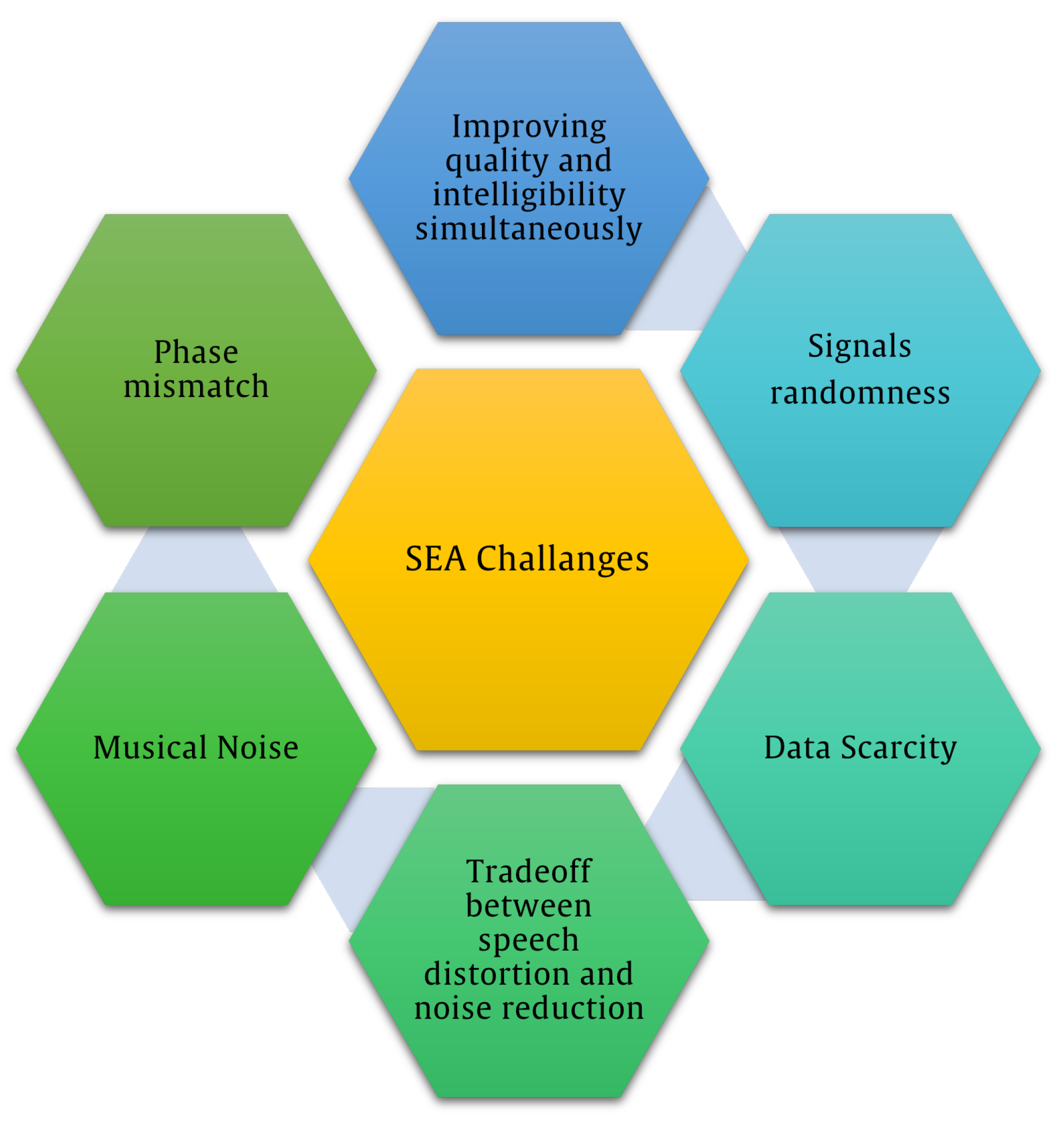
This section reviews the state-of-the-art approaches and previous findings related to speech enhancement problems based on the retained papers. Regardless of the successful SEA applications in various fields, many gaps and limitations still exist that should be addressed. The main concern of this research is focused on finding the significant issues that still need to be handled. The significant limitation that has been addressed in the retained papers is focusing on randomness of the signal, which has a great impact on subsequent speech and noise modeling. The nonstationarity of signals affects the statistical modeling of speech and noise signals [
1,
78,
97]. Therefore, the noise reduction performance of many SEAs depends on noise estimation and signal modeling, especially in complex environments [
61,
83,
96]. This issue is also related to another challenge caused by the surrounding environment in the form of simultaneous conversations and overlapping speech. This problem is termed the “cocktail party problem”, and happens when two or more people are talking at the same time [
48].
Data scarcity is another issue addressed in the current research. Using shared datasets is a cost-effective and feasible way to gradually advance a research field, allowing results to be analyzed and improved. The limited public availability of real-world noisy datasets for robust model training can affect the performance of SEAs in general [
56,
94]. Typically, SEAs work well for enhancing speech quality but poorly for enhancing intelligibility. Different articles show a tradeoff between quality and intelligibility when seeking to improve the overall performance and accuracy of the entire SEA system; therefore, some works tend to enhance both properties together [
1,
3,
51]. SEAs based on single-channel microphone environments aim to enhance the magnitude component in the time–frequency (TF) domain. On the other hand, the phase component of the input noisy signal is used without any processing. Accordingly, sound quality is damaged due to the mismatch between the estimated magnitude and the unprocessed phase spectra, causing perceptually disturbing artifacts that are sometimes referred to as phase mismatches [
51,
56,
72]. In general, SEAs based on neural networks aim to learn a noisy-to-clean transformation based on a supervised learning principle. Nevertheless, the trained networks may not be effective at handling the signal, and types of noise that were not present in the training data can cause domain mismatch between the training and test sets [
107]. Domain mismatch decreases model performance in testing environments that differ from the training data [
51,
76,
80,
92]. Many recent works aim to effectively mitigate this problem [
107]. In addition, the high computational complexity of deep learning models means that algorithms based on these models often require significant computational resources [
51,
76,
80,
92]. Although DL-based SEAs have made significant strides, challenges such as speech distortion and artifacts persist. These problems diminish perceived auditory quality as well as the accuracy of speech enhancement systems, particularly when employing lightweight models [
108]. Other issues include phonetic distortion [
61,
83,
92], musical noise [
69], and colored noise [
69,
96]. Therefore, it is important to address the balance between speech distortion and noise reduction, deal with speech and noise modeling in real situations, and increase quality and intelligibility simultaneously. The main challenges of SEA are shown in
Figure 9. It should be noted that this research focused on papers published between 2015 and 2024, providing an overview of recent challenges and trends in SEA research.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}