
A Reconfigurable Framework for Hybrid Quantum–Classical Computing



Abstract
1. Introduction
2. Background and Related Work
2.1. Quantum Computing Fundamentals
2.2. Quantum Gates
- Hadamard Gate: A single-qubit gate that maps the basis state |0⟩ to and |1⟩ to , thus creating an equal superposition of the two basis states.
- RX, RY, and RZ Rotation Gates: These unitary operators rotate the state vector of a qubit around a given axis by a given angle. The RX gate is one of the rotation operators. It is a single-qubit rotation through angle radians around the x-axis. The RY gate is a single-qubit rotation through angle radians around the y-axis. Similarly, the RZ gate is a single-qubit rotation through angle radians around the z-axis.
- CNOT Gate: A universal two-qubit quantum gate that flips the state of the second qubit, the target qubit, if and only if the first control qubit is in the state |1⟩. A CNOT gate is used to entangle two qubits. Any quantum computation can be performed using only CNOT gates and single-qubit gates. The CNOT gate matrix can be derived from a unitary matrix by flipping the target states based on the control states.
2.3. Quantum Machine Learning
2.4. Related Work
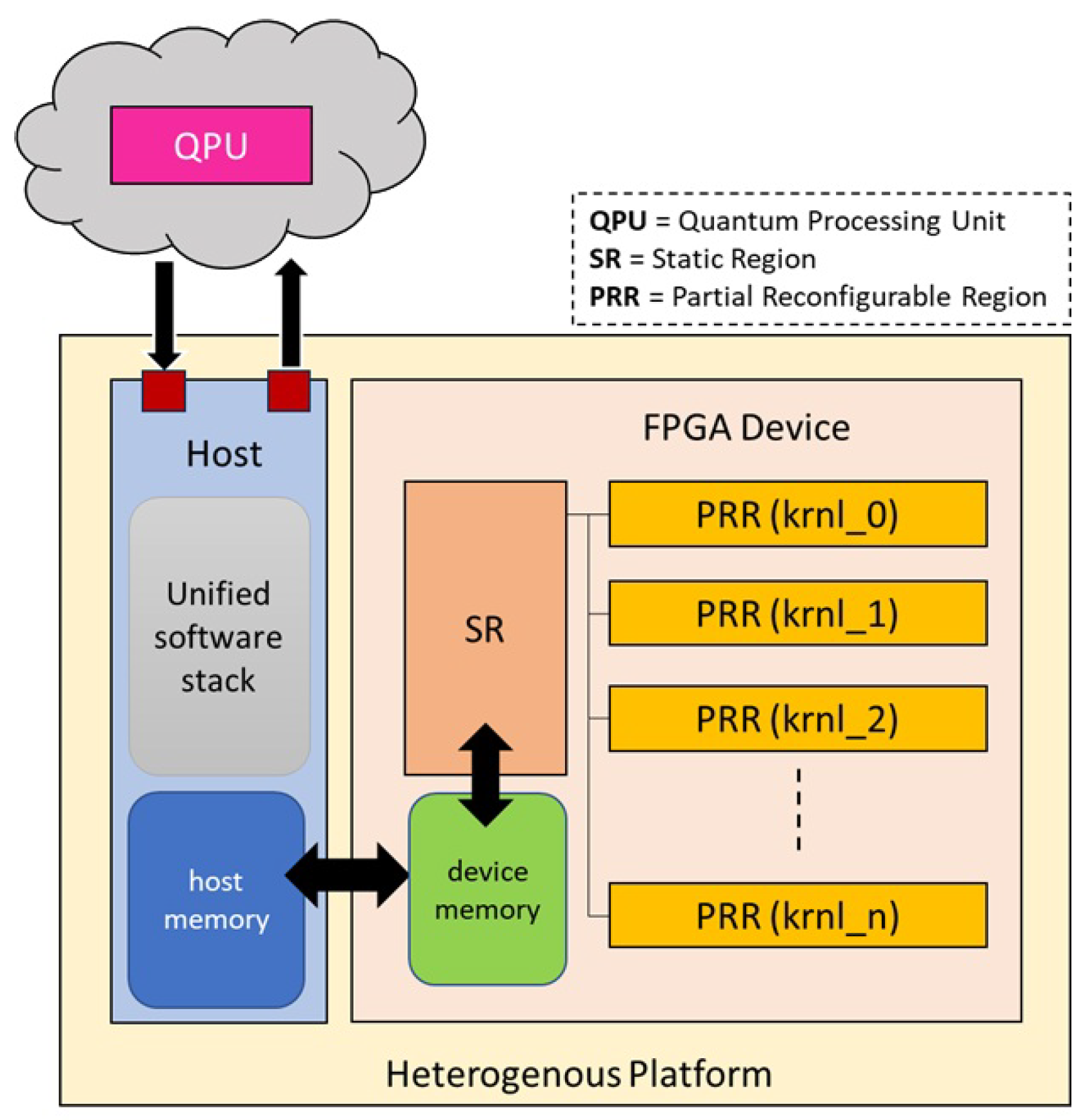
3. Proposed Framework
3.1. Quantum Machine Learning Task
3.1.1. Host Management and Unified Software
3.1.2. Quantum Circuit Generation
- Feature mapping layer:
- −
- Initializes qubits with Hadamard (H) gates for superposition.
- −
- Applies RY rotations for data encoding.
- −
- Parameters encode input features into quantum states.
- Real amplitude variational structure:
- −
- Builds on RealAmplitudes design with five variational layers.
- −
- Each layer implements alternating rotation blocks:
- *
- Three-axis rotations (RX, RY, RZ) for single-qubit operations.
- *
- Full entanglement pattern using CNOT gates between adjacent qubits.
- *
- All parameters initialized randomly from normal distribution N(0, 1).
- *
- Comprises (five layers × qubits × three rotations) trainable parameters.
3.1.3. Training: Forward Pass Function
- def forward(x, weights, circuit, input_params, weight_params):
- param_values = list(x) + list(weights)
- bound_circuit = circuit.assign_parameters(param_values)
- state = Statevector.from_instruction(bound_circuit)
- return state_to_probs(state.data)
3.1.4. Training: Gradient Computation and Loss Function
- are the circuit parameters.
- is a small perturbation ().
- is the quantum circuit prediction probability for the positive class (output from the quantum circuit after forward pass).
- is the actual label.
- is a small constant added for numerical stability to avoid .
- Loss calculation: Implements parallel cross-entropy loss computation using optimized log-likelihood functions.
- Gradient computation: Accelerates stochastic gradient descent calculations through block processing.
- Weight updates: Performs parallel parameter updates using computed gradients and configurable learning rates.
4. Experimental Results
4.1. Experimental Setup
4.2. Dataset Generation and Pre-Processing
4.2.1. Dataset Selection and Initial Processing
4.2.2. Dimensionality Reduction via Principal Component Analysis (PCA)
4.2.3. Analysis of Variance Distribution
4.2.4. Quantum-Compatible Data Scaling
4.2.5. Binary Label Encoding
4.2.6. Dataset Splitting
4.3. Training, Testing, and Validation
4.4. FPGA Resource Utilization
4.5. Estimating Speedup for Larger-Scale Quantum Circuits
4.6. Complexity Considerations and Algorithm Classes
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chafii, M.; Bariah, L.; Muhaidat, S.; Debbah, M. Twelve Scientific Challenges for 6G: Rethinking the Foundations of Communications Theory. IEEE Commun. Surv. Tutor. 2023, 25, 868–904. [Google Scholar] [CrossRef]
- Beck, T.; Baroni, A.; Bennink, R.; Buchs, G.; Pérez, E.A.C.; Eisenbach, M.; da Silva, R.F.; Meena, M.G.; Gottiparthi, K.; Groszkowski, P.; et al. Integrating quantum computing resources into scientific HPC ecosystems. Future Gener. Comput. Syst. 2024, 161, 11–25. [Google Scholar] [CrossRef]
- Giortamis, E.; Romão, F.; Tornow, N.; Lugovoy, D.; Bhatotia, P. Orchestrating quantum cloud environments with qonductor. arXiv 2024, arXiv:2408.04312. [Google Scholar]
- Robledo-Moreno, J.; Motta, M.; Haas, H.; Javadi-Abhari, A.; Jurcevic, P.; Kirby, W.; Martiel, S.; Sharma, K.; Sharma, S.; Shirakawa, T.; et al. Chemistry beyond exact solutions on a quantum-centric supercomputer. arXiv 2024, arXiv:2405.05068. [Google Scholar]
- Schulz, M.; Ruefenacht, M.; Kranzlmüller, D.; Schulz, L.B. Accelerating hpc with quantum computing: It is a software challenge too. Comput. Sci. Eng. 2023, 24, 60–64. [Google Scholar] [CrossRef]
- Suchara, M.; Alexeev, Y.; Chong, F.; Finkel, H.; Hoffmann, H.; Larson, J.; Osborn, J.; Smith, G. Hybrid quantum-classical computing architectures. In Proceedings of the 3rd International Workshop on Post-Moore Era Supercomputing, Dallas, TX, USA, 11 November 2018. [Google Scholar]
- Xu, Y.; Huang, G.; Balewski, J.; Naik, R.; Morvan, A.; Mitchell, B.; Nowrouzi, K.; Santiago, D.I.; Siddiqi, I. QubiC: An Open-Source FPGA-Based Control and Measurement System for Superconducting Quantum Information Processors. IEEE Trans. Quantum Eng. 2021, 2, 1–11. [Google Scholar] [CrossRef]
- Yang, Y.; Shen, Z.; Zhu, X.; Wang, Z.; Zhang, G.; Zhou, J.; Jiang, X.; Deng, C.; Liu, S. FPGA-based electronic system for the control and readout of superconducting quantum processors. Rev. Sci. Instruments 2022, 93, 074701. [Google Scholar] [CrossRef]
- Branchini, B.; Conficconi, D.; Sciuto, D.; Santambrogio, M.D. The Hitchhiker’s Guide to FPGA-Accelerated Quantum Error Correction. In Proceedings of the 2023 IEEE International Conference on Quantum Computing and Engineering (QCE), Bellevue, WA, USA, 17–22 September 2023; Volume 02, pp. 338–339. [Google Scholar] [CrossRef]
- Moawad, Y. Architectures and Optimisations for FPGA-Based Simulation of Quantum Circuits. Ph.D. Thesis, University of Glasgow, Glasgow, UK, 2025. [Google Scholar]
- Mahmud, N.; El-Araby, E.; Caliga, D. Scaling reconfigurable emulation of quantum algorithms at high precision and high throughput. Quantum Eng. 2019, 1, e19. [Google Scholar] [CrossRef]
- Bach, N.H.; Vu, L.H.; Tran, D.L.; Dao, T.T.; Luu, T.T.H.; Nguyen, D.N. Re-structuring CNN using quantum layer executed on FPGA hardware for classifying 2-D data. In Proceedings of the 2024 9th International Conference on Integrated Circuits, Design, and Verification (ICDV), Hanoi, Vietnam, 6–7 June 2024; pp. 143–147. [Google Scholar] [CrossRef]
- Pushpak, S.N.; Jain, S. An Implementation of Quantum Machine Learning Technique to Determine Insurance Claim Fraud. In Proceedings of the 2022 10th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 13–14 October 2022. [Google Scholar]
- Nikoloska, I.; Simeone, O. Training hybrid classical-quantum classifiers via stochastic variational optimization. IEEE Signal Process. Lett. 2022, 29, 977–981. [Google Scholar] [CrossRef]
- Wani, J.; Allamsetty, T.K.; Gherde, R.; Agarwal, V. HLS Implementation of Quantum Shor’s Algorithm Using Matrix Pruning. In Proceedings of the 2022 Second International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 21–22 April 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, E.; Davis, J.J.; Cheung, P.Y. A PYNQ-based framework for rapid CNN prototyping. In Proceedings of the 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; p. 223. [Google Scholar]
- IBM Quantum. Qiskit: An Open-Source Framework for Quantum Computing. 2021. Available online: https://zenodo.org/records/8190968 (accessed on 5 April 2025). [CrossRef]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Mavroeidis, V.; Vishi, K.; Zych, M.D.; Jøsang, A. The Impact of Quantum Computing on Present Cryptography. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 405–414. [Google Scholar] [CrossRef]
- Misra, S.; Rani, P. Quantum Machine Learning: A Comprehensive Overview and Analysis. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024. [Google Scholar]
- Choppakatla, A. Quantum Machine Learning: Bridging the Gap Between Quantum Computing and Artificial Intelligence: An Overview. Int. J. Res. Appl. Sci. Eng. Technol. 2023, 11, 1149–1153. [Google Scholar] [CrossRef]
- Jiang, J.R. A Quick Overview of Quantum Machine Learning. In Proceedings of the 2023 IEEE 5th Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 27–29 October 2023. [Google Scholar]
- Maheshwari, D.; Sierra-Sosa, D.; Garcia-Zapirain, B. Variational quantum classifier for binary classification: Real vs synthetic dataset. IEEE Access 2021, 10, 3705–3715. [Google Scholar] [CrossRef]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef] [PubMed]
- Melnikov, A.; Kordzanganeh, M.; Alodjants, A.; Lee, R. Quantum machine learning: From physics to software engineering. Adv. Phys. X 2023, 8, 2165452. [Google Scholar] [CrossRef]
- Alexeev, Y.; Amsler, M.; Barroca, M.A.; Bassini, S.; Battelle, T.; Camps, D.; Casanova, D.; Choi, Y.J.; Chong, F.T.; Chung, C.; et al. Quantum-centric supercomputing for materials science: A perspective on challenges and future directions. Future Gener. Comput. Syst. 2024, 160, 666–710. [Google Scholar] [CrossRef]
- Suzuki, T.; Miyazaki, T.; Inaritai, T.; Otsuka, T. Quantum AI simulator using a hybrid CPU–FPGA approach. Sci. Rep. 2023, 13, 7735. [Google Scholar] [CrossRef]
- Belfore, L.A. A Scalable FPGA Architecture for Quantum Computing Simulation. arXiv 2024, arXiv:2407.06415. [Google Scholar]
- Pilch, J.; Długopolski, J. An FPGA-based real quantum computer emulator. J. Comput. Electron. 2019, 18, 329–342. [Google Scholar] [CrossRef]
- Bilgin, Y.; Tesfay, S.W.; Ipek, S.; Uğurdağ, H.F.; Durak, K.; Goren, S. PYNQ-based rapid FPGA implementation of quantum key distribution. In Proceedings of the 2021 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 483–488. [Google Scholar]
- Brassard, G.; Hoyer, P.; Mosca, M.; Tapp, A. Quantum amplitude amplification and estimation. Contemp. Math. 2002, 305, 53–74. [Google Scholar]
- McClean, J.R.; Boixo, S.; Smelyanskiy, V.N.; Babbush, R.; Neven, H. Barren plateaus in quantum neural network training landscapes. Nat. Commun. 2018, 9, 4812. [Google Scholar] [CrossRef]
- Wierichs, D.; Izaac, J.; Wang, C.; Lin, C.Y.Y. General parameter-shift rules for quantum gradients. Quantum 2022, 6, 677. [Google Scholar] [CrossRef]
- AMD PYNQ. Available online: https://www.pynq.io/ (accessed on 5 April 2025).
- AMD. AMD EPYC 7302—16-Core—3.0 GHz. Available online: https://www.exxactcorp.com/AMD-100-000000043-E198061333 (accessed on 5 April 2025).
- AMD Alveo™ U200 Data Center Accelerator Card. Available online: https://www.amd.com/en/products/accelerators/alveo/u200/a-u200-a64g-pq-g.html (accessed on 5 April 2025).
- Deng, L. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Maćkiewicz, A.; Ratajczak, W. Principal components analysis (PCA). Comput. Geosci. 1993, 19, 303–342. [Google Scholar] [CrossRef]
- Cerezo, M.; Arrasmith, A.; Babbush, R.; Benjamin, S.C.; Endo, S.; Fujii, K.; McClean, J.R.; Mitarai, K.; Yuan, X.; Cincio, L.; et al. Variational quantum algorithms. Nat. Rev. Phys. 2021, 3, 625–644. [Google Scholar] [CrossRef]
- Waidyasooriya, H.M.; Hariyama, M.; Miyama, M.J.; Ohzeki, M. OpenCL-based design of an FPGA accelerator for quantum annealing simulation. J. Supercomput. 2019, 75, 5019–5039. [Google Scholar] [CrossRef]
- Choi, S.; Lee, K.; Lee, J.J.; Lee, W. Standalone FPGA-Based QAOA Emulator for Weighted-MaxCut on Embedded Devices. arXiv 2025, arXiv:2502.11316. [Google Scholar]
- Efthymiou, S.; Ramos-Calderer, S.; Bravo-Prieto, C.; Pérez-Salinas, A.; García-Martín, D.; Garcia-Saez, A.; Latorre, J.I.; Carrazza, S. Qibo: A framework for quantum simulation with hardware acceleration. Quantum Sci. Technol. 2021, 7, 015018. [Google Scholar] [CrossRef]
- Zoufal, C.; Lucchi, A.; Woerner, S. Quantum Generative Adversarial Networks for learning and loading random distributions. npj Quantum Inf. 2019, 5, 103. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Alveo U200 | CPU | |
|---|---|---|
| Processing System | Same as host | AMD EPYC 7302 (16-Core) |
| System Memory (GB) | 64 | 128 |
| System Frequency (MHz) | 300 | 3000 |
| FPGA Device | XCU200-2FSGD2104E | N/A |
| LUTs | 1182K | N/A |
| UltraRAM | 960 | N/A |
| DSP Slice | 6840 | N/A |
| No. of Qubits | CPU Time (s) | CPU Accuracy | FPGA Time (s) | FPGA Accuracy | Speedup |
|---|---|---|---|---|---|
| 8 | 1.38 | 99% | 0.27 | 98% | 5.11 |
| 9 | 1.53 | 90% | 0.27 | 95% | 5.67 |
| 10 | 1.67 | 86% | 0.30 | 99% | 5.57 |
| 11 | 1.86 | 98% | 0.34 | 99% | 5.47 |
| 12 | 2.03 | 91% | 0.34 | 93% | 5.97 |
| 13 | 2.17 | 88% | 0.36 | 96% | 6.03 |
| 14 | 3.12 | 78% | 0.4 | 99% | 7.8 |
| 15 | 3.34 | 76% | 0.4 | 96% | 8.35 |
| Resources Used | Utilization (%) | |
|---|---|---|
| LUT | 13,515 | 1.23 |
| REG | 12,000 | 0.66 |
| BRAM | 0 | 0 |
| URAM | 0 | 0 |
| DSP | 71 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pratibha; Mahmud, N. A Reconfigurable Framework for Hybrid Quantum–Classical Computing. Algorithms 2025, 18, 271. https://doi.org/10.3390/a18050271
Pratibha, Mahmud N. A Reconfigurable Framework for Hybrid Quantum–Classical Computing. Algorithms. 2025; 18(5):271. https://doi.org/10.3390/a18050271
Chicago/Turabian StylePratibha, and Naveed Mahmud. 2025. "A Reconfigurable Framework for Hybrid Quantum–Classical Computing" Algorithms 18, no. 5: 271. https://doi.org/10.3390/a18050271
APA StylePratibha, & Mahmud, N. (2025). A Reconfigurable Framework for Hybrid Quantum–Classical Computing. Algorithms, 18(5), 271. https://doi.org/10.3390/a18050271