

A Computationally Efficient Method for the Diagnosis of Defects in Rolling Bearings Based on Linear Predictive Coding


Abstract
1. Introduction
- A novel fault diagnosis method, which combines LPC and an NN, is proposed and used for bearing vibration signals.
- The LPC-NN method is less time-consuming and computationally less expensive compared to other advanced techniques.
- Experimental results on the CWRU and the SUSU datasets demonstrate that LPC-NN outperforms modern competitive techniques, achieving 100% accuracy in most cases.
2. The Proposed LPC-NN Method
2.1. Linear Predictive Coding
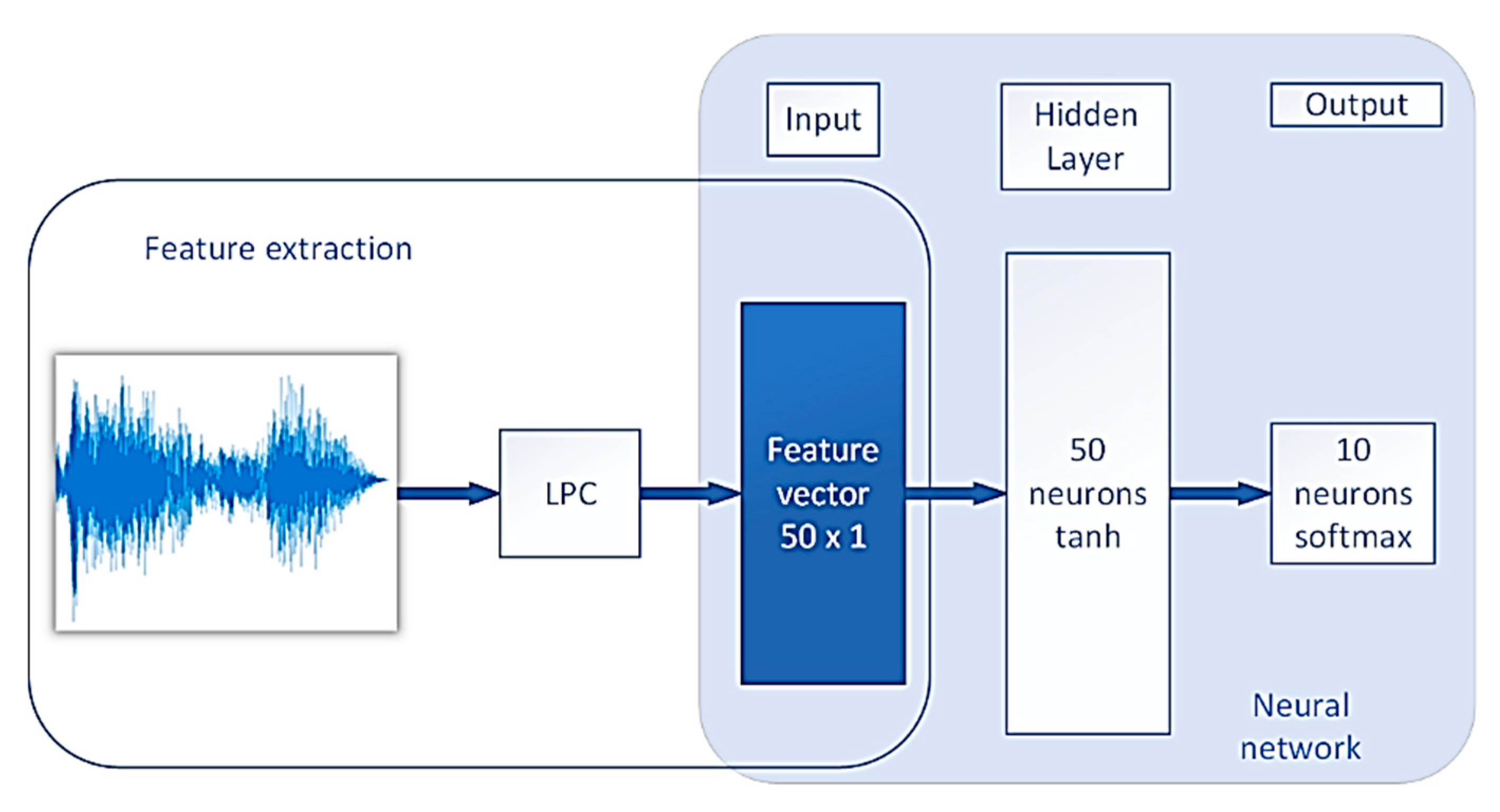
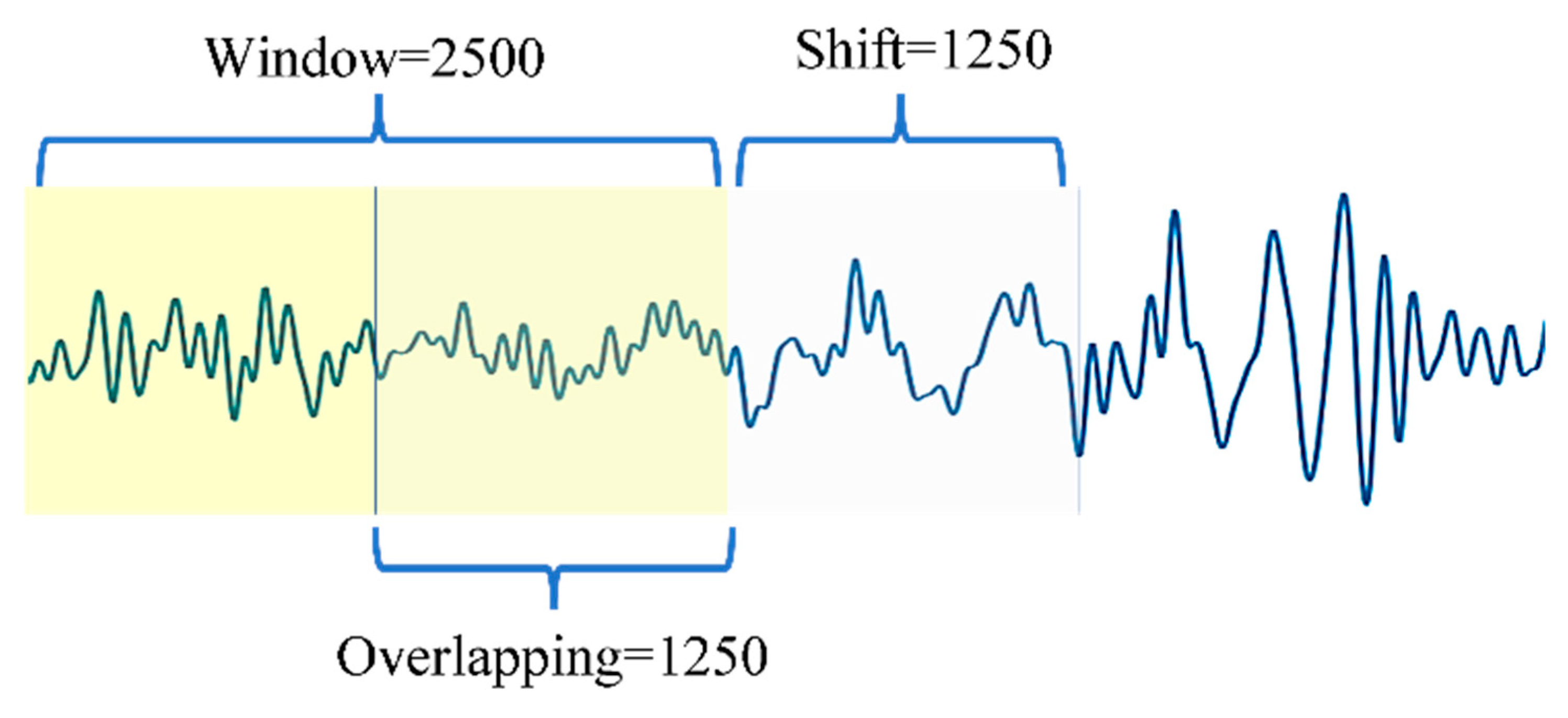
2.2. Feature Extraction
2.3. Proposed LPC-NN Method
3. Description of Datasets
- The CWRU dataset was provided by Case Western Reserve University’s Bearing Data Center [45] and has been used extensively in rolling bearing fault diagnosis. CWRU vibration data were collected using accelerometers, which were attached to the housing of a mechanism. This is the traditional approach for collecting diagnostic information from such technological processes.
- The SUSU dataset [30] was provided by South Ural State University and obtained using a sensor mounted directly on the shaft. This method of mounting potentially provides increased sensitivity to defects.
3.1. The CWRU Dataset
3.2. The SUSU Dataset
- The motor rotation speed was constant at 1200 RPM.
- Data were obtained without load.
- The sampling frequency was 31175 Hz.
- The recorded signal length for each bearing condition was 64.1540 s.
4. Experimental Results
4.1. One-Load Experiment on CWRU Dataset
4.2. Performance Across Different Load Domains on CWRU Dataset
4.3. Comparison of Computational Costs on SUSU Dataset
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peng, B.; Bi, Y.; Xue, B.; Zhang, M.; Wan, S. A Survey on Fault Diagnosis of Rolling Bearings. Algorithms 2022, 15, 347. [Google Scholar] [CrossRef]
- Liu, F.; Gao, S.; Tian, Z.; Liu, D. A new time-frequency analysis method based on single mode function decomposition for offshore wind turbines. Mar. Struct. 2020, 72, 102782. [Google Scholar] [CrossRef]
- Qi, R.; Zhang, J.; Spencer, K. A Review on Data-Driven Condition Monitoring of Industrial Equipment. Algorithms 2023, 16, 9. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Z.; Wang, S.; Li, W.; Sarkodie-Gyan, T.; Feng, S. A hybrid deep-learning model for fault diagnosis of rolling bearings. Measurement 2021, 169, 108502. [Google Scholar] [CrossRef]
- Han, H.; Wang, H.; Liu, Z.; Wang, J. Intelligent vibration signal denoising method based on non-local fully convolutional neural network for rolling bearings. ISA Trans. 2022, 122, 13–23. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Ismail, F. An enhanced bispectrum technique with auxiliary frequency injection for induction motor health condition monitoring. IEEE Trans. Instrum. Meas. 2015, 64, 2679–2687. [Google Scholar] [CrossRef]
- Zhen, L.; Zhengjia, H.; Yanyang, Z.; Xuefeng, C. Bearing condition monitoring based on shock pulse method and improved redundant lifting scheme. Math. Comput. Simul. 2008, 79, 318–338. [Google Scholar] [CrossRef]
- Luo, G.Y.; Osypiw, D.; Irle, M. On-line vibration analysis with fast continuous wavelet algorithm for condition monitoring of bearing. J. Vib. Control 2003, 9, 931–947. [Google Scholar] [CrossRef]
- Wang, W.J.; McFadden, P.D. Early detection of gear failure by vibration analysis and calculation of the time-frequency distribution. Mech. Syst. Signal Process. 1993, 7, 193–203. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Snin, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. A 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Huang, N.E.; Wu, Z. A review on Hilbert-Huang transform: Method and its applications to geophysical studies. Rev. Geophys. 2008, 46, RG2006. [Google Scholar] [CrossRef]
- Parey, A.; Badaoui, M.; Guillet, F.; Tandon, N. Dynamic modelling of spur gear pair and application of empirical mode decomposition-based statistical analysis for early detection of localized tooth defect. J. Sound Vib. 2006, 294, 547–561. [Google Scholar] [CrossRef]
- Jiang, X.; Wang, J.; Shi, J.; Shen, C.; Huang, W.; Zhu, Z. A coarse-to-fine decomposing strategy of VMD for extraction of weak repetitive transients in fault diagnosis of rotating machines. Mech. Syst. Signal Process. 2019, 116, 668–692. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, L.; Duan, L.; Li, T. Intelligent Fault Diagnosis of Rolling Element Bearings Based on HHT and CNN. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 292–296. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, X.; Zhao, W.; Liu, T. Rolling Bearing Fault Diagnosis Based on Optimized VMD Combining Signal Features and Improved CNN. World Electr. Veh. J. 2024, 15, 544. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhao, H.; Wang, F. A novel deep autoencoder feature learning method for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2017, 95, 187–204. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lu, N.; Xing, S. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal Process. 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Xu, Z.; Li, C.; Yang, Y. Fault diagnosis of rolling bearing of wind turbines based on the Variational Mode Decomposition and Deep Convolutional Neural Networks. Appl. Soft Comput. 2020, 95, 106515. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y. Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef]
- Saufi, S.R.; bin Ahmad, Z.A.; Leong, M.S.; Lim, M.H. Challenges and opportunities of deep learning models for machinery fault detection and diagnosis: A review. IEEE Access 2019, 7, 122644–122662. [Google Scholar] [CrossRef]
- Sun, T.; Gao, J. New Fault Diagnosis Method for Rolling Bearings Based on Improved Residual Shrinkage Network Combined with Transfer Learning. Sensors 2024, 24, 5700. [Google Scholar] [CrossRef]
- Chen, Z.; Cen, J.; Xiong, J. Rolling Bearing Fault Diagnosis Using Time-Frequency Analysis and Deep Transfer Convolutional Neural Network. IEEE Access 2020, 8, 150248–150261. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.; Deng, J.; Zhao, B.; Shi, Y.; Zhou, J.; Shao, S. LEFE-Net: A Lightweight Efficient Feature Extraction Network with Strong Robustness for Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2021, 70, 3513311. [Google Scholar] [CrossRef]
- Chu, W.C. Speech Coding Algorithms: Foundation and Evolution of Standardized Coders; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar] [CrossRef]
- Quatieri, T.F. Discrete-Time Speech Signal Processing: Principles and Practice; Pearson Education: London, UK, 2002; 781p. [Google Scholar]
- de Fréin, R. Power-Weighted LPC Formant Estimation. IEEE Trans. Circuits Syst. II Express Briefs 2020, 68, 2207–2211. [Google Scholar] [CrossRef]
- Jin, X.; Davis, M.; de Fréin, R. A Linear Predictive Coding Filtering Method for Time-Resolved Morphology of EEG Activity. In Proceedings of the 2021 32nd Irish Signals and Systems Conference (ISSC), Athlone, Ireland, 10–11 June 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Loparo, K.A. Bearing Vibration Dataset. Case Western Reserve University. Available online: https://engineering.case.edu/bearingdatacenter/download-data-file (accessed on 19 January 2025).
- Sinitsin, V.; Ibryaeva, O.; Sakovskaya, V.; Eremeeva, V. Dataset with Wireless Acceleration Sensor for Rolling Bearing Fault Diagnosis. Available online: https://github.com/susu-cm/bearings-dataset (accessed on 19 January 2025).
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Jain, P.; Bhosle, S. Analysis of vibration signals caused by ball bearing defects using time-domain statistical indicators. Int. J. Adv. Technol. Eng. Explor. 2022, 9, 700. [Google Scholar] [CrossRef]
- Sinitsin, V.; Ibryaeva, O.; Sakovskaya, V.; Eremeeva, V. Intelligent Bearing Fault Diagnosis Method Combining Mixed Input and Hybrid CNN-MLP Model. Mech. Syst. Signal Process. 2022, 180, 109454. [Google Scholar] [CrossRef]
- Thimmaraja, Y.G.; Nagaraja, B.G.; Jayanna, H.S. Speech enhancement and encoding by combining SS-VAD and LPC. Int. J. Speech Technol. 2021, 24, 165–172. [Google Scholar] [CrossRef]
- Vaidyanathan, P.P. The Theory of Linear Prediction; Morgan & Claypool: San Rafael, CA, USA, 2008; 198p. [Google Scholar] [CrossRef]
- Marple, S.L., Jr. Digital Spectral Analysis; Prentice Hall: Englewood Cliffs, NJ, USA, 1987. [Google Scholar]
- Abo-Zahhad, M.; Ahmed, S.M.; Abbas, S.N. A New EEG Acquisition Protocol for Biometric Identification Using Eye Blinking Signals. Int. J. Intell. Syst. Appl. 2015, 6, 48–54. [Google Scholar] [CrossRef]
- Rabiner, L.R.; Schafer, R.W. Digital Processing of Speech Signals; Prentice-Hall: Hoboken, NJ, USA, 1978; 512p. [Google Scholar]
- Vaseghi, S.V. Advanced Digital Signal Processing and Noise Reduction, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2000; pp. 227–262. [Google Scholar] [CrossRef]
- Huo, J.; Liu, L.; Liu, L.; Yang, Y.; Li, L. Selection of the Order of Autoregressive Models for Host Load Prediction in Grid. In Proceedings of the Eighth ACIS International Conference on Software Engineering, Artificial Intelligence, Networking, and Parallel/Distributed Computing (SNPD 2007), Qingdao, China, 30 July–1 August 2007; pp. 516–521. [Google Scholar] [CrossRef]
- Tang, Q.; Zhou, J.; Xin, J.; Yang, L.; Li, Y. Autoregressive Model-Based Structural Damage Identification and Localization Using Convolutional Neural Networks. KSCE J. Civ. Eng. 2020, 24, 2173–2185. [Google Scholar] [CrossRef]
- Myasnikov, E. Using UMAP for Dimensionality Reduction of Hyperspectral Data. In Proceedings of the 2020 International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russia, 6–9 October 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Chollet, F. Deep Learning with Python; Manning Publications: New York, NY, USA, 2017. [Google Scholar]
- Smith, W.A.; Randall, R.B. Rolling Element Bearing Diagnostics Using the Case Western Reserve University Data: A Benchmark Study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Sassi, S.; Badri, B.; Thomas, M. Tracking Surface Degradation of Ball Bearings by Means of New Time Domain Scalar Indicators. Int. J. COMADEM 2008, 11, 36–45. [Google Scholar]
- Pradhan, M.K.; Gupta, P. Fault Detection Using Vibration Signal Analysis of Rolling Element Bearing in Time Domain Using an Innovative Time Scalar Indicator. Int. J. Manuf. Res. 2017, 12, 305–317. [Google Scholar] [CrossRef]
- Salem, A.; Aly, A.; Sassi, S.; Renno, J. Time-Domain-Based Quantification of Surface Degradation for Better Monitoring of the Health Condition of Ball Bearings. Vibration 2018, 1, 172–191. [Google Scholar] [CrossRef]
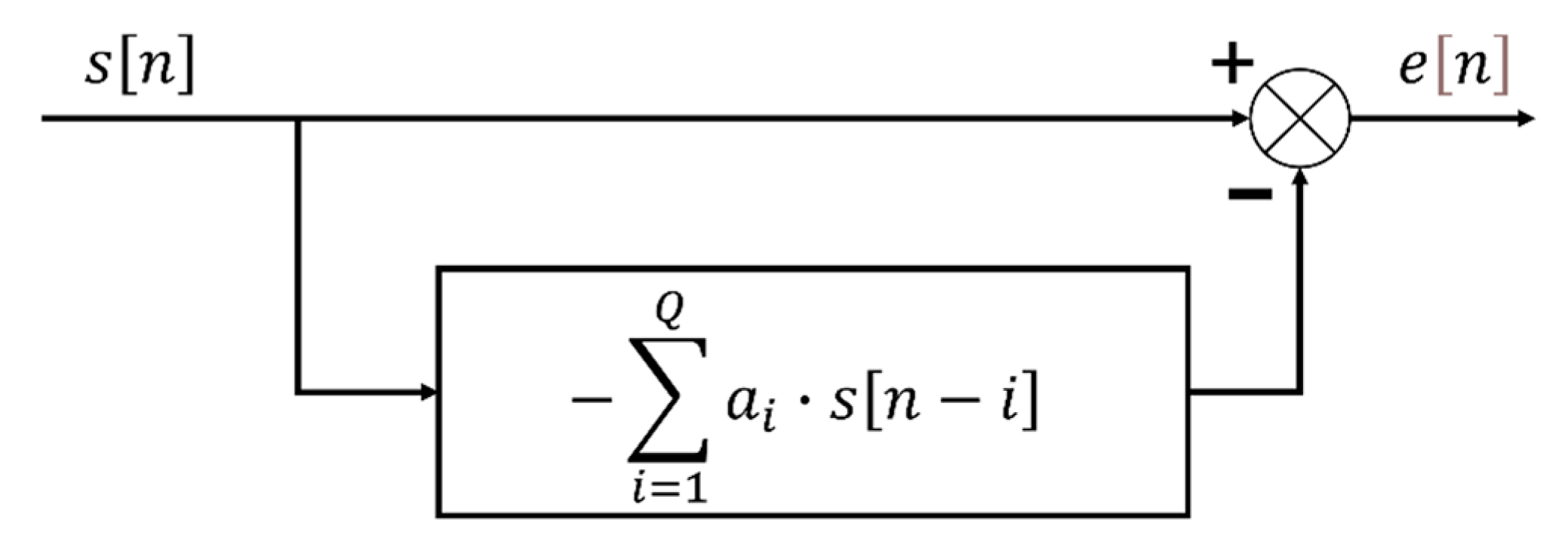












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Number | Fault Type | Diameter (Inches) |
|---|---|---|
| 0 (no faults) | None | None |
| 1 | Ball | 0.007 |
| 2 | Ball | 0.014 |
| 3 | Ball | 0.021 |
| 4 | Inner | 0.007 |
| 5 | Inner | 0.014 |
| 6 | Inner | 0.021 |
| 7 | Outer | 0.007 |
| 8 | Outer | 0.014 |
| 9 | Outer | 0.021 |
| Sub-Dataset | Number of Frames | Number of Training Frames | Number of Testing Frames |
|---|---|---|---|
| 1 | 1066 | 747 | 319 |
| 2 | 1258 | 881 | 377 |
| 3 | 1258 | 881 | 377 |
| 4 | 1260 | 883 | 377 |
| Entire dataset | 4842 | 3392 | 1450 |
| Class Number | Fault Type | Number of Training Frames | Number of Testing Frames |
|---|---|---|---|
| 0 (Normal) | None | 2155 | 920 |
| 1 | Ball | 2155 | 920 |
| 2 | Inner | 2155 | 920 |
| 3 | Outer | 2155 | 920 |
| 4 | Combined | 2155 | 920 |
| Parameter | Value | |
|---|---|---|
| Number of trials Number of LPC coefficients Number of neurons in hidden layer Number of epochs Patience Length of signal frame, s | 10 | |
| 50 | ||
| 50 | ||
| 500 | ||
| 100 | ||
| 0.208 | ||
| Sampling rate, Hz | CWRU | 12,000 |
| SUSU | 31,175 | |
| Sub-Dataset | Average Accuracy, % |
|---|---|
| 1 | 100 |
| 2 | 99.71 |
| 3 | 100 |
| 4 | 100 |
| Entire dataset | 100 |
| Sub-Dataset | CNN-gcForest [4], % | LPC-NN |
|---|---|---|
| 2 | 98.24 | 99.73 |
| 3 | 99.51 | 100 |
| 4 | 99.79 | 100 |
| Entire dataset | 99.2 | 100 |
| Class Label | Average Accuracy, % | Class Label | Average Accuracy, % | ||
|---|---|---|---|---|---|
| Training Sub-Dataset | Test Sub-Dataset | Training Sub-Dataset | Test Sub-Dataset | ||
| 1 | 2 | 97.82 | 3 | 4 | 96.95 |
| 1 | 3 | 91.72 | 4 | 1 | 83.82 |
| 1 | 4 | 88.54 | 4 | 2 | 93.37 |
| 2 | 1 | 99.25 | 4 | 3 | 98.14 |
| 2 | 3 | 98.49 | All | 1 | 100 |
| 2 | 4 | 91.06 | All | 2 | 100 |
| 3 | 1 | 93.79 | All | 3 | 100 |
| 3 | 2 | 93.77 | All | 4 | 100 |
| Training Sub-Dataset | Predicted Sub-Dataset | TICNN | Ensemble TICNN | LPC-NN |
|---|---|---|---|---|
| 2 | 3 | 99.1 | 99.5 | 98.5 |
| 2 | 4 | 90.7 | 91.1 | 91 |
| 3 | 2 | 97.4 | 97.6 | 97.8 |
| 3 | 4 | 98.8 | 99.4 | 97 |
| 4 | 2 | 89.2 | 90.2 | 93.4 |
| 4 | 3 | 97.6 | 98.7 | 98.1 |
| Average accuracy | 95.5 | 96.1 | 96 | |
| Number of LPC Coefficients | Time, s | Average Accuracy |
|---|---|---|
| 12 | 2900 | 97.4 |
| 50 | 3200 | 98 |
| 100 | 2800 | 97.6 |
| Method | Average Accuracy, % | Time for Feature Extraction for Each Frame, Seconds | Time for Model Training, Seconds |
|---|---|---|---|
| TDSIs-NN | 76.8 | 0.038 | 25 |
| Hybrid MLP-CNN | 95.7 | 0.27 | 278 |
| LPC-NN | 98.3 | 0.00051 | 18 |
| TDSIs-NN | Hybrid CNN-MLP | LPC-NN | |
|---|---|---|---|
| Normal | 0.70 | 1.00 | 1.00 |
| Inner | 0.86 | 0.96 | 0.96 |
| Outer | 0.78 | 0.96 | 1.00 |
| Ball | 0.70 | 0.92 | 1.00 |
| Comb | 0.84 | 0.95 | 0.96 |
| Accuracy | 0.78 | 0.96 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammad, M.; Ibryaeva, O.; Sinitsin, V.; Eremeeva, V. A Computationally Efficient Method for the Diagnosis of Defects in Rolling Bearings Based on Linear Predictive Coding. Algorithms 2025, 18, 58. https://doi.org/10.3390/a18020058
Mohammad M, Ibryaeva O, Sinitsin V, Eremeeva V. A Computationally Efficient Method for the Diagnosis of Defects in Rolling Bearings Based on Linear Predictive Coding. Algorithms. 2025; 18(2):58. https://doi.org/10.3390/a18020058
Chicago/Turabian StyleMohammad, Mohammad, Olga Ibryaeva, Vladimir Sinitsin, and Victoria Eremeeva. 2025. "A Computationally Efficient Method for the Diagnosis of Defects in Rolling Bearings Based on Linear Predictive Coding" Algorithms 18, no. 2: 58. https://doi.org/10.3390/a18020058
APA StyleMohammad, M., Ibryaeva, O., Sinitsin, V., & Eremeeva, V. (2025). A Computationally Efficient Method for the Diagnosis of Defects in Rolling Bearings Based on Linear Predictive Coding. Algorithms, 18(2), 58. https://doi.org/10.3390/a18020058