
Adaptive Noise Exploration for Neural Contextual Multi-Armed Bandits
Abstract
1. Introduction
- We propose an adaptive dynamic noise exploration framework to address the general contextual bandit problem. Based on this framework, we develop two novel neural contextual multi-armed bandit algorithms: EAD and EAP.
- EAD algorithm: Adjust the variance of the added noise adaptively based on the arms’ selection frequencies and incorporate this adjusted noise into the rewards of the selected arms. With adaptive noise, these rewards are used to construct the loss function.
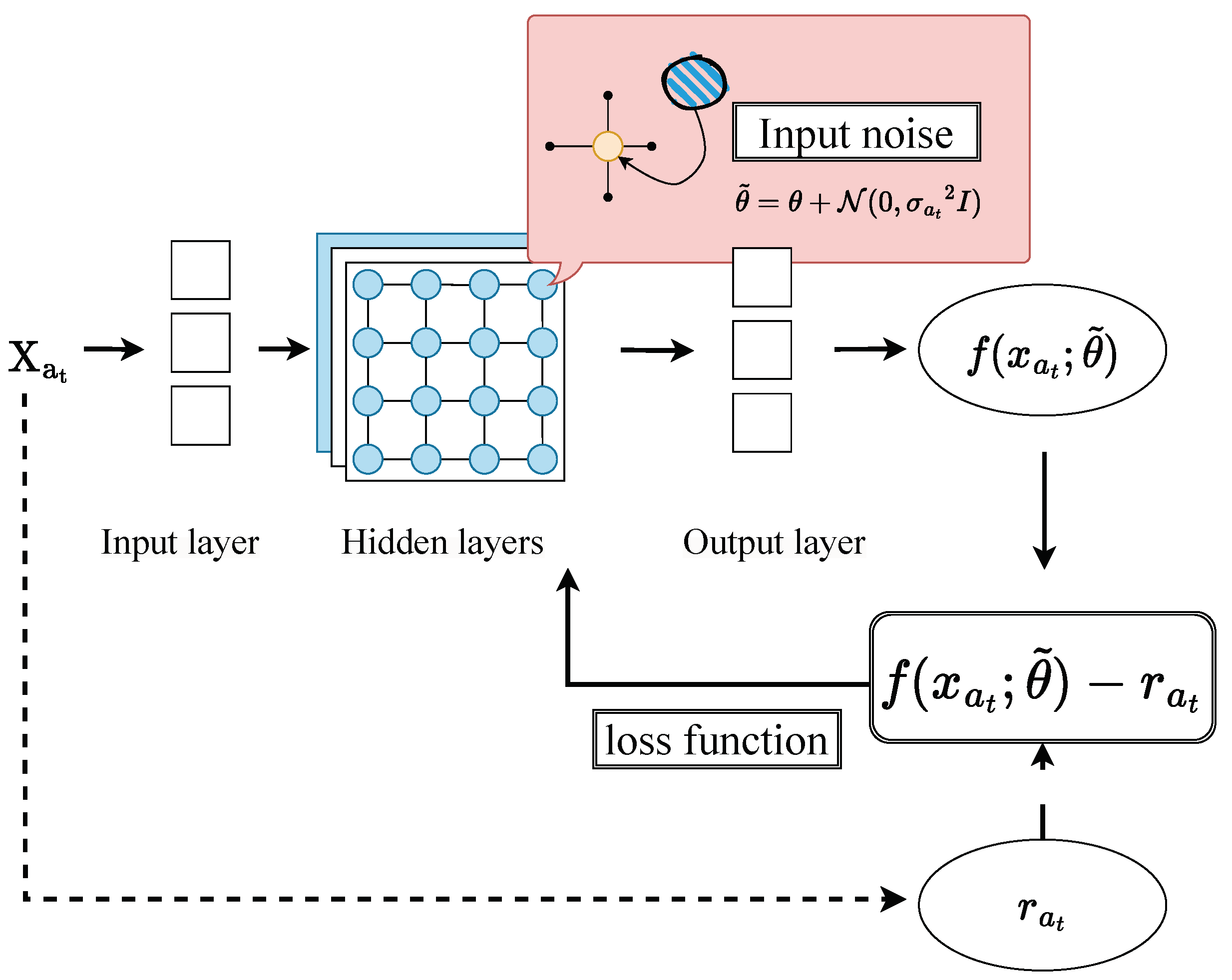
- EAP Algorithm: This algorithm introduces adaptive dynamic noise directly into the network parameters at the neural network’s hidden layers. Continuously interacting with the environment using these noisy parameters achieves more stable exploration.
- To validate the effectiveness of our framework, we conducted empirical evaluations on two recommendation system datasets and six classification datasets. Compared to existing baseline methods, our adaptive dynamic noise exploration strategies demonstrate significant advantages in improving long-term cumulative rewards and exploration time.
2. Related Work
3. Problem Definition
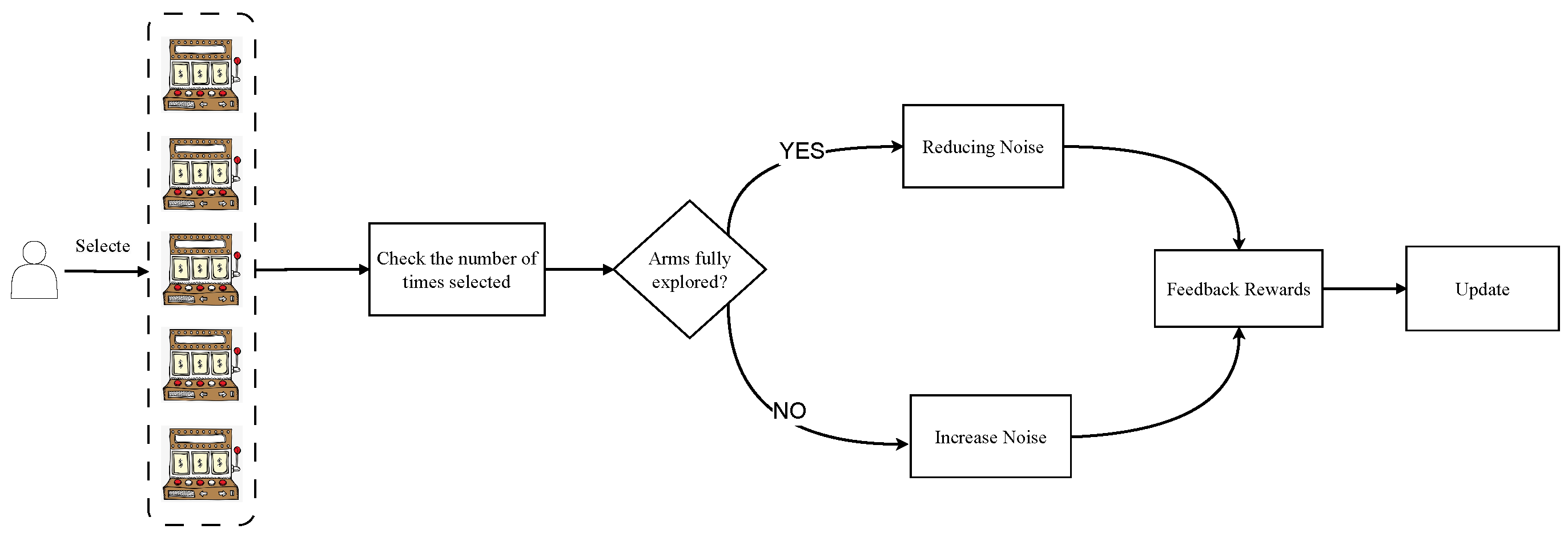
4. Proposed Method
4.1. Exploring Adaptive Noise in Decision-Making Processes
4.2. Exploring Adaptive Noise in Parameter Spaces
| Algorithm 1 Exploring Adaptive Noise in Parameter Spaces (EAD) |
|
| Algorithm 2 Exploring Adaptive Noise in Parameter Spaces (EAP) |
|
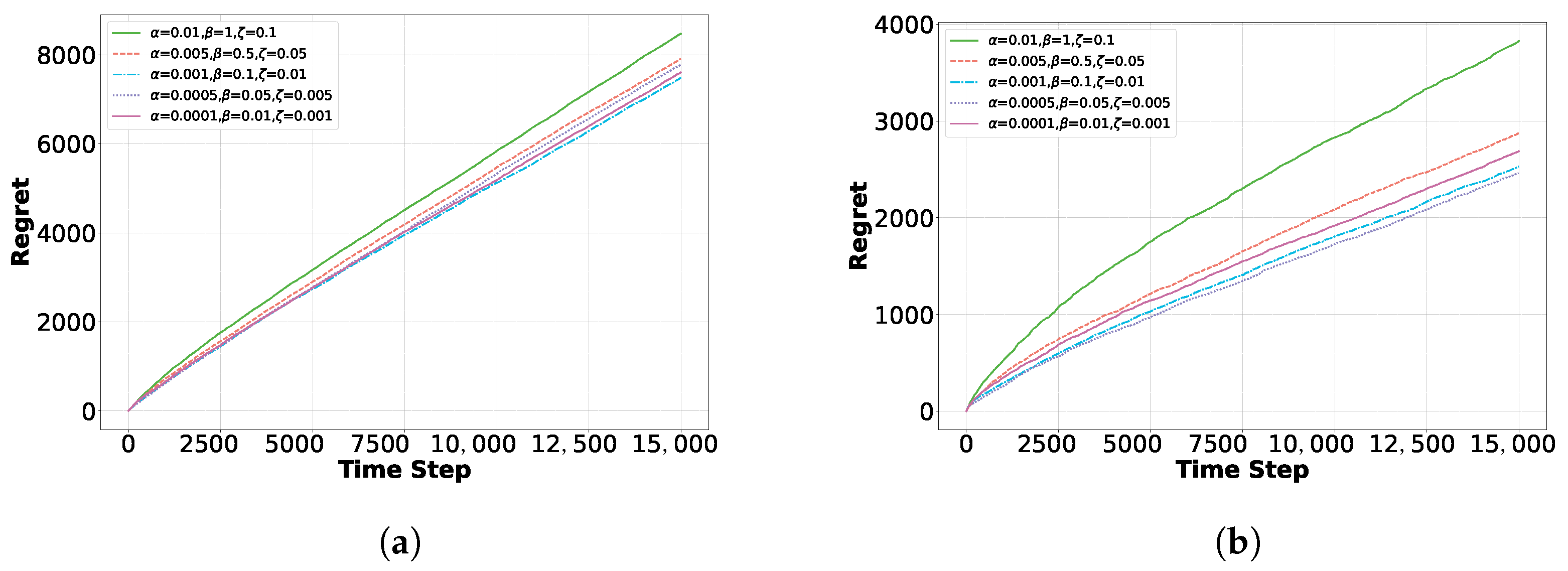
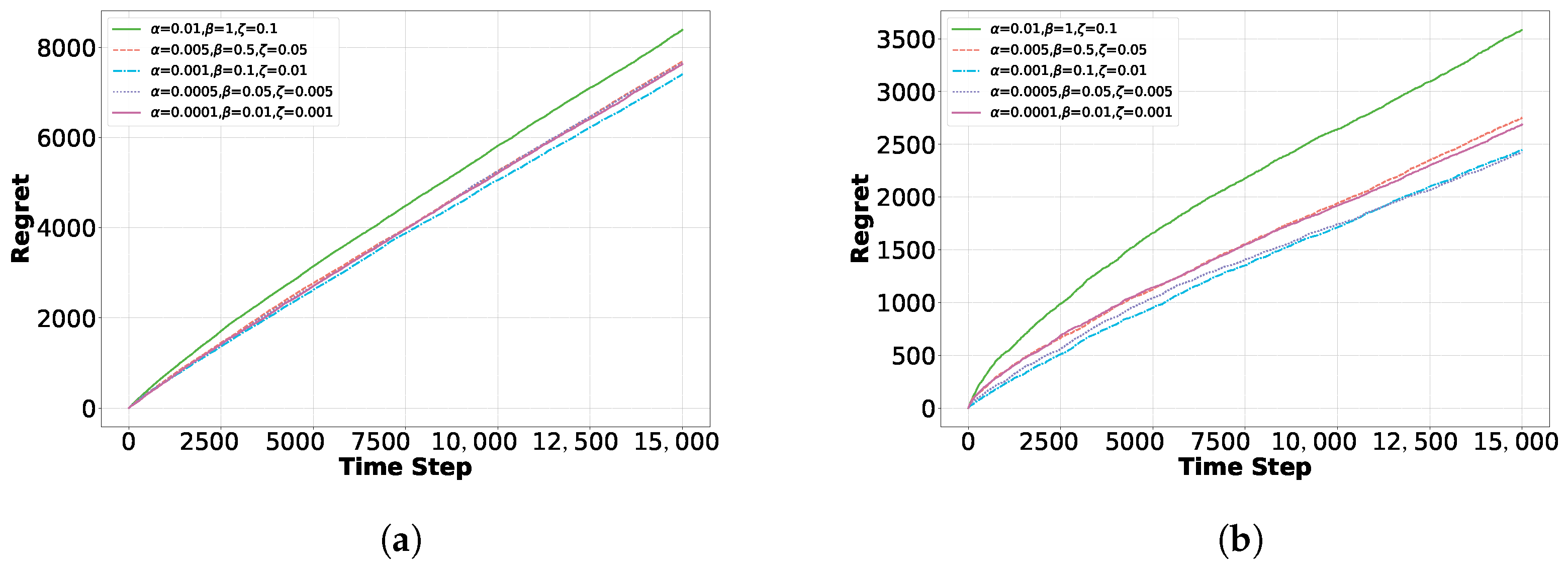
4.3. Real-World Application Analysis
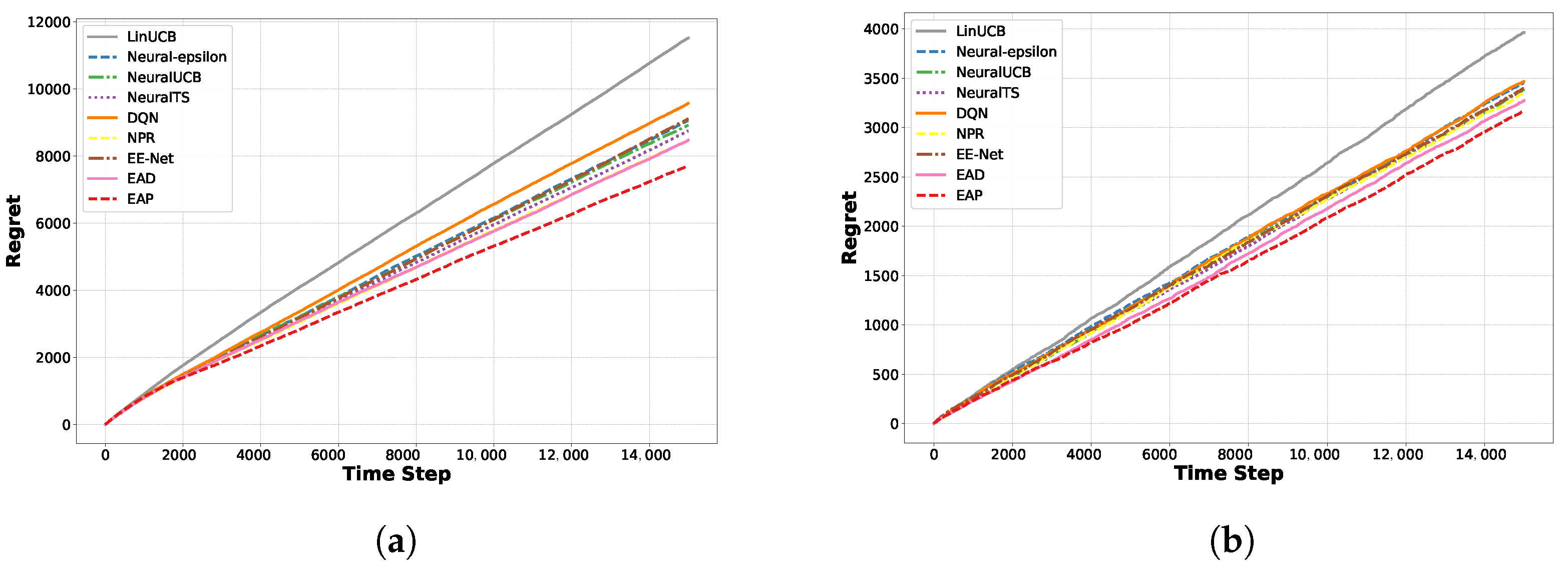
5. Experiments
- LinUCB [9]: This approach explicitly assumes a linear relationship between the reward and the arm’s context vector. Unknown parameters are estimated using ridge regression, which is integrated with the UCB strategy to select the arm.
- Neural-Epsilon [32]: Utilizes a neural network to learn the reward function of pulling an arm. It selects the arm with the highest predicted reward with a probability of , i.e., , and randomly selects an arm with a probability of .
- NeuralUCB [13]: A neural network is employed to learn the reward function from the exploration strategy based on UCB.
- NeuralTS [14]: It uses a neural network to learn the reward function derived from the Thompson Sampling exploration strategy.
- NPR [5]: Utilizes a neural network to learn the reward function by exploring through the addition of perturbed rewards.
- DQN [33]: A reinforcement learning approach that combines deep learning and Q-learning leverages neural networks to approximate the Q-value function, enabling agents to efficiently learn optimal policies in high-dimensional state spaces.
- EE-Net [22]: A dual neural network architecture is adopted. One neural network learns the real reward function, and the other neural network learns the potential reward value, and the architecture combines the output of the two to make a comprehensive decision, so as to improve the effect of exploration and utilization.
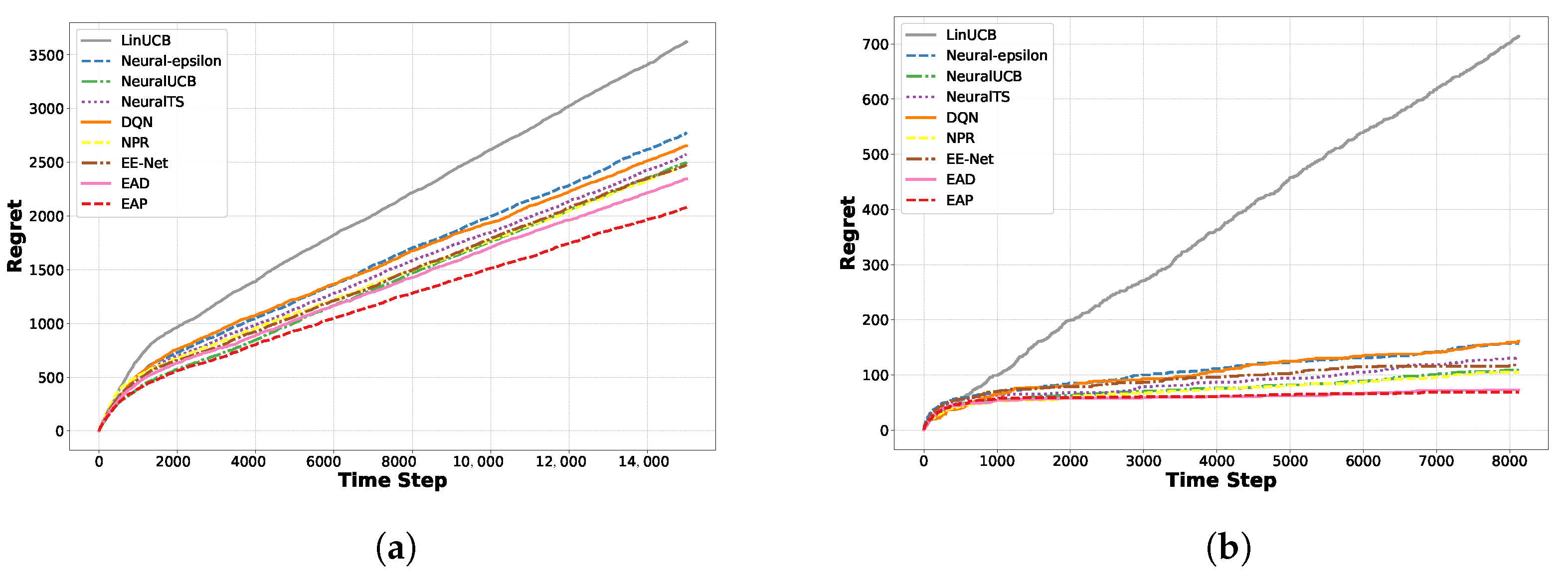
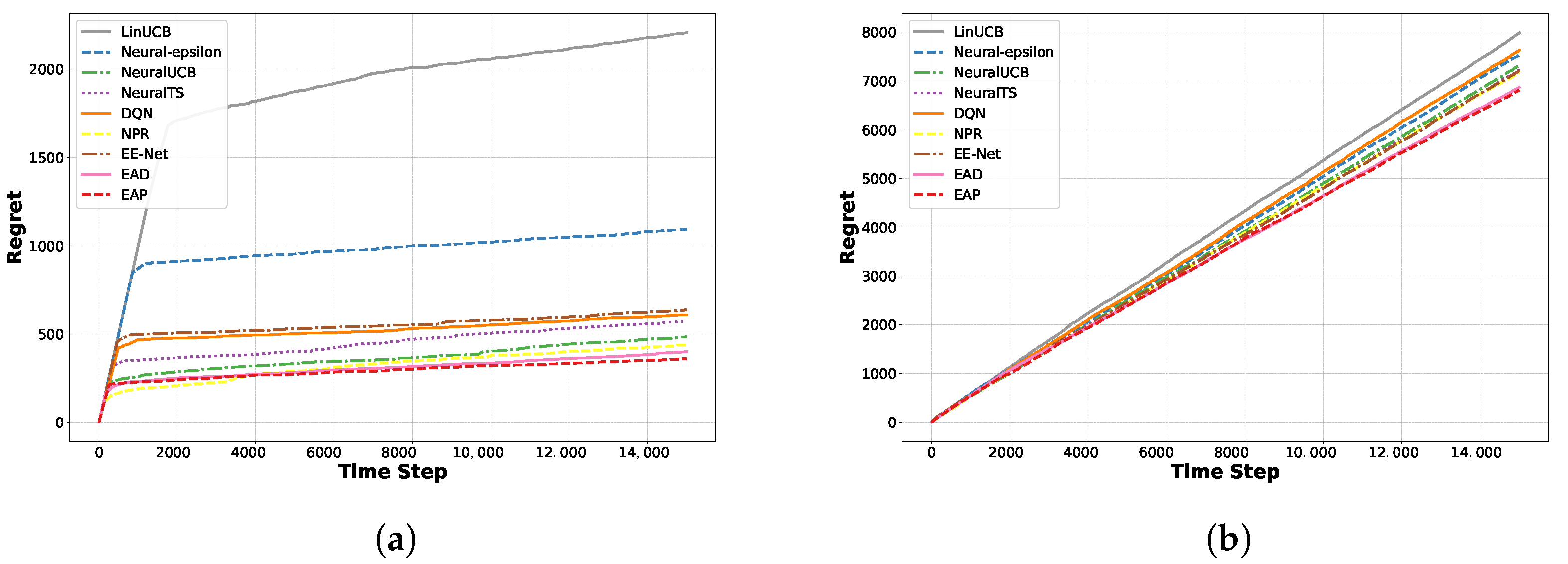
5.1. Experiments on the Recommendation Dataset
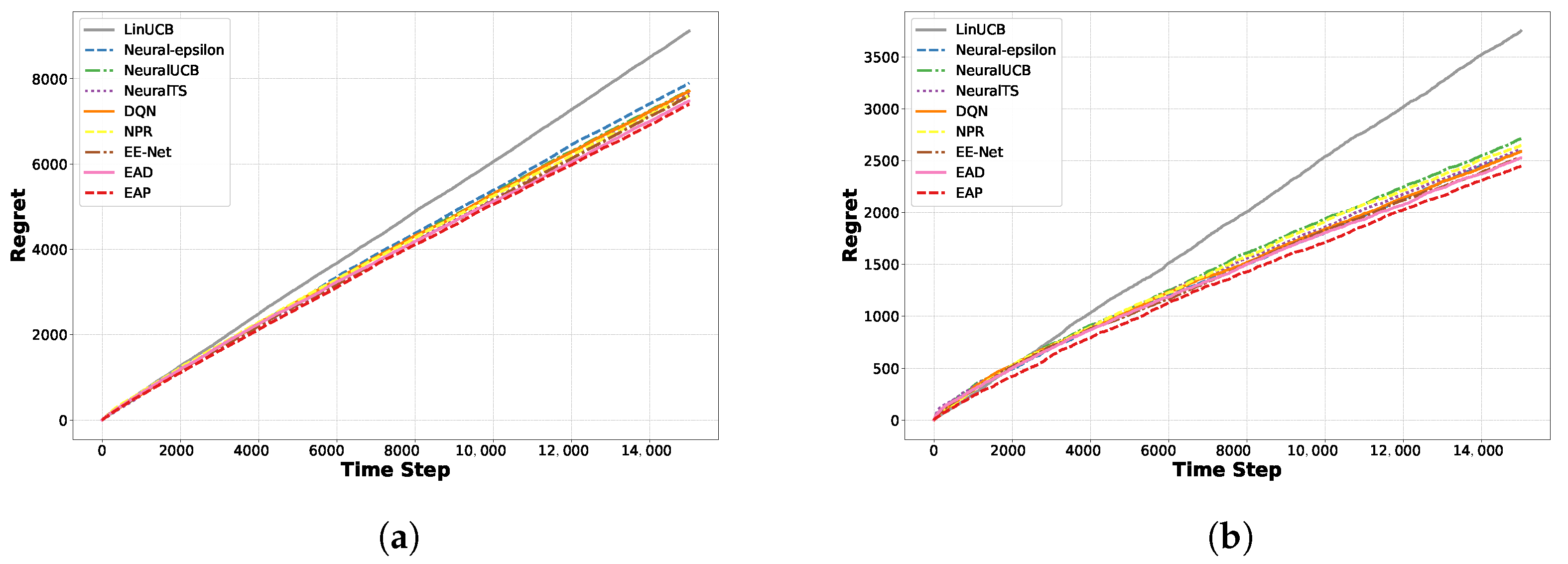
5.2. Regret Comparison Experiments on Classification Datasets
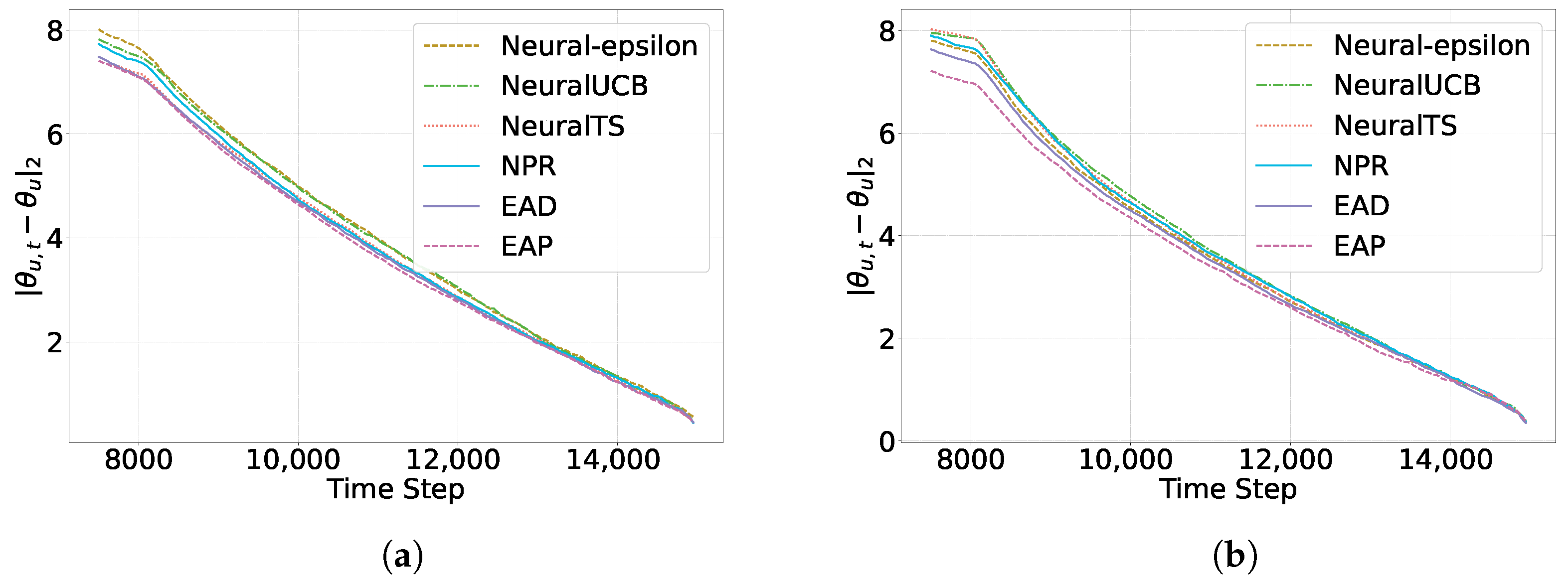
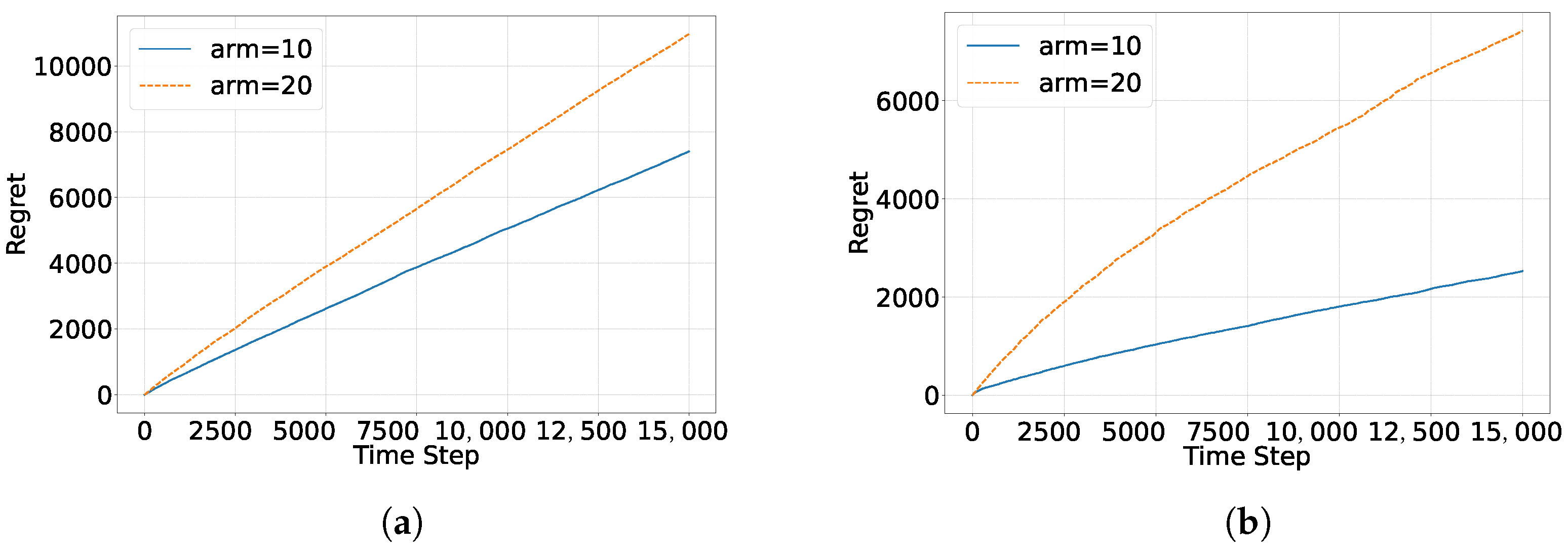
5.3. Scalability of the Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Yang, L. Constrained contextual bandit algorithm for limited-budget recommendation system. Eng. Appl. Artif. Intell. 2024, 128, 107558. [Google Scholar] [CrossRef]
- Xia, Y.; Xie, Z.; Yu, T.; Zhao, C.; Li, S. Toward joint utilization of absolute and relative bandit feedback for conversational recommendation. User Model. User-Adapt. Interact. 2024, 34, 1707–1744. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S.; Yin, G. Reinforcement learning in healthcare: A survey. ACM Comput. Surv. 2021, 55, 5. [Google Scholar] [CrossRef]
- Aguilera, A.; Figueroa, C.A.; Hernandez-Ramos, R.; Sarkar, U.; Cemballi, A.; Gomez-Pathak, L.; Miramontes, J.; Yom-Tov, E.; Chakraborty, B.; Yan, X.; et al. mHealth app using machine learning to increase physical activity in diabetes and depression: Clinical trial protocol for the DIAMANTE Study. BMJ Open 2020, 10, e034723. [Google Scholar] [CrossRef] [PubMed]
- Jia, Y.; Zhang, W.; Zhou, D.; Gu, Q.; Wang, H. Learning Neural Contextual Bandits through Perturbed Rewards. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Saber, H.; Pesquerel, F.; Maillard, O.A.; Talebi, M.S. Logarithmic regret in communicating MDPs: Leveraging known dynamics with bandits. In Proceedings of the 15th Asian Conference on Machine Learning, İstanbul, Turkey, 11–14 November 2024; Yanıkoğlu, B., Buntine, W., Eds.; PMLR: Cambridge, MA, USA, 2024; Volume 222, pp. 1167–1182. [Google Scholar]
- Letard, A.; Gutowski, N.; Camp, O.; Amghar, T. Bandit algorithms: A comprehensive review and their dynamic selection from a portfolio for multicriteria top-k recommendation. Expert Syst. Appl. 2024, 246, 123151. [Google Scholar] [CrossRef]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time analysis of the multiarmed bandit problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Li, L.; Chu, W.; Langford, J.; Schapire, R.E. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 661–670. [Google Scholar]
- Zhang, X.; Xie, H.; Li, H.; CS Lui, J. Conversational contextual bandit: Algorithm and application. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 662–672. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Zhou, D.; Li, L.; Gu, Q. Neural contextual bandits with ucb-based exploration. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR: Cambridge, MA, USA, 2020; pp. 11492–11502. [Google Scholar]
- Zhang, W.; Zhou, D.; Li, L.; Gu, Q. Neural thompson sampling. arXiv 2020, arXiv:2010.00827. [Google Scholar]
- Zhang, H.; He, J.; Righter, R.; Shen, Z.J.; Zheng, Z. Contextual Gaussian Process Bandits with Neural Networks. In Proceedings of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS 2024), Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- Lin, Y.; Endo, Y.; Lee, J.; Kamijo, S. Bandit-NAS: Bandit sampling and training method for Neural Architecture Search. Neurocomputing 2024, 597, 127684. [Google Scholar] [CrossRef]
- Xu, P.; Wen, Z.; Zhao, H.; Gu, Q. Neural Contextual Bandits with Deep Representation and Shallow Exploration. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Ban, Y.; He, J. Local clustering in contextual multi-armed bandits. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2335–2346. [Google Scholar]
- Chaudhuri, A.R.; Jawanpuria, P.; Mishra, B. ProtoBandit: Efficient Prototype Selection via Multi-Armed Bandits. In Proceedings of the 14th Asian Conference on Machine Learning, Hyderabad, India, 12–14 December 2022; Khan, E., Gonen, M., Eds.; PMLR: Cambridge, MA, USA, 2023; Volume 189, pp. 169–184. [Google Scholar]
- Feng, Z.; Wang, P.; Li, K.; Li, C.; Wang, S. Contextual MAB Oriented Embedding Denoising for Sequential Recommendation. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Merida, Mexico, 4–8 March 2024; pp. 199–207. [Google Scholar]
- Gu, Q.; Karbasi, A.; Khosravi, K.; Mirrokni, V.; Zhou, D. Batched neural bandits. ACM/IMS J. Data Sci. 2024, 1, 1–18. [Google Scholar] [CrossRef]
- Ban, Y.; Yan, Y.; Banerjee, A.; He, J. EE-Net: Exploitation-Exploration Neural Networks in Contextual Bandits. In Proceedings of the Tenth International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Kveton, B.; Szepesvari, C.; Vaswani, S.; Wen, Z.; Lattimore, T.; Ghavamzadeh, M. Garbage in, reward out: Bootstrapping exploration in multi-armed bandits. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: Cambridge, MA, USA, 2019; pp. 3601–3610. [Google Scholar]
- Kveton, B.; Szepesvári, C.; Ghavamzadeh, M.; Boutilier, C. Perturbed-history exploration in stochastic multi-armed bandits. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2786–2793. [Google Scholar]
- Kveton, B.; Szepesvári, C.; Ghavamzadeh, M.; Boutilier, C. Perturbed-History Exploration in Stochastic Linear Bandits. In Proceedings of the Uncertainty in Artificial Intelligence, Virtual, 3–6 August 2020; PMLR: Cambridge, MA, USA, 2020; pp. 530–540. [Google Scholar]
- Kveton, B.; Zaheer, M.; Szepesvari, C.; Li, L.; Ghavamzadeh, M.; Boutilier, C. Randomized exploration in generalized linear bandits. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; PMLR: Cambridge, MA, USA, 2020; pp. 2066–2076. [Google Scholar]
- Janz, D.; Liu, S.; Ayoub, A.; Szepesvári, C. Exploration via linearly perturbed loss minimisation. arXiv 2023, arXiv:2311.07565. [Google Scholar]
- Audibert, J.Y.; Munos, R.; Szepesvári, C. Exploration–exploitation trade-off using variance estimates in multi-armed bandits. Theor. Comput. Sci. 2009, 410, 1876–1902. [Google Scholar] [CrossRef]
- Su, Y.; Lu, H.; Li, Y.; Liu, L.; Bi, S.; Chi, E.H.; Chen, M. Multi-Task Neural Linear Bandit for Exploration in Recommender Systems. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 5723–5730. [Google Scholar]
- Park, H. Partially Observable Stochastic Contextual Bandits. Ph.D. Thesis, University of Georgia, Athens, GA, USA, 2024. [Google Scholar]
- Min, D.J.; Stolcke, A.; Raju, A.; Vaz, C.; He, D.; Ravichandran, V.; Trinh, V.A. Adaptive Endpointing with Deep Contextual Multi-Armed Bandits. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Langford, J.; Zhang, T. The Epoch-Greedy algorithm for contextual multi-armed bandits. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M.A. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Wu, J.; Wang, X.; Feng, F.; He, X.; Chen, L.; Lian, J.; Xie, X. Self-supervised graph learning for recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 726–735. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. ACM Trans. Interact. Intell. Syst. 2015, 5, 19. [Google Scholar] [CrossRef]
- Alami, R. Bayesian Change-Point Detection for Bandit Feedback in Non-stationary Environments. In Proceedings of the 14th Asian Conference on Machine Learning, Hyderabad, India, 12–14 December 2022; Khan, E., Gonen, M., Eds.; PMLR: Cambridge, MA, USA, 2023; Volume 189, pp. 17–31. [Google Scholar]






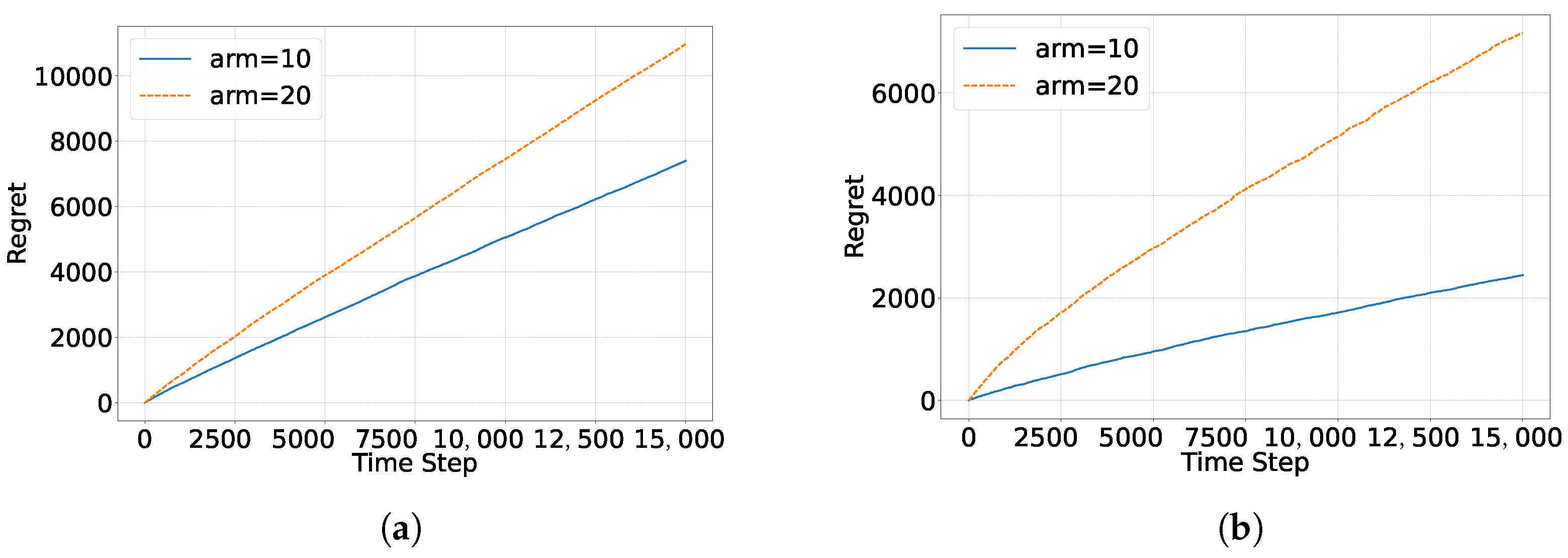

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MNIST | Mushroom | Shuttle | Covertype | Letter | MagicTelescope | |
|---|---|---|---|---|---|---|
| Number of attributes | 784 | 23 | 9 | 54 | 17 | 11 |
| Number of arms | 10 | 23 | 7 | 7 | 26 | 2 |
| Number of instances | 60,000 | 8124 | 60,000 | 581,012 | 20,000 | 19,020 |
| Number of rounds | 15,000 | 8124 | 15,000 | 15,000 | 15,000 | 15,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Shi, L.; Luo, J. Adaptive Noise Exploration for Neural Contextual Multi-Armed Bandits. Algorithms 2025, 18, 56. https://doi.org/10.3390/a18020056
Wang C, Shi L, Luo J. Adaptive Noise Exploration for Neural Contextual Multi-Armed Bandits. Algorithms. 2025; 18(2):56. https://doi.org/10.3390/a18020056
Chicago/Turabian StyleWang, Chi, Lin Shi, and Junru Luo. 2025. "Adaptive Noise Exploration for Neural Contextual Multi-Armed Bandits" Algorithms 18, no. 2: 56. https://doi.org/10.3390/a18020056
APA StyleWang, C., Shi, L., & Luo, J. (2025). Adaptive Noise Exploration for Neural Contextual Multi-Armed Bandits. Algorithms, 18(2), 56. https://doi.org/10.3390/a18020056