

Insights into Image Understanding: Segmentation Methods for Object Recognition and Scene Classification



Abstract
1. Introduction
Main Contributions of the Paper
- i.
- An overview of the research advancements in deep learning-based image segmentation with focus on panoptic segmentation (PS) is presented.
- ii.
- The article draws attention to several interesting works towards PS that include Panoptic Feature Pyramid Network, Attention-guided network for PS, Seamless Scene Segmentation, Panoptic Deep lab, Unified panoptic segmentation network, and Efficient panoptic segmentation. A top-down approach to PS is discussed and suggested improvements in predicted outputs are highlighted.
- iii.
- Research efforts by leading companies supporting the bigger picture of developing computer vision models for PS are presented.
- iv.
- Performance metrics of both scene recognition and panoptic segmentation models are discussed. Several comparisons have been performed to measure the performance using different datasets under different metrics and highlight the potential benefits and challenges.
2. Literature Review
3. Panoptic Segmentation
3.1. Metrics for Panoptic Segmentation
3.2. Significant Advances in Panoptic Segmentation (PS) Achieved to Date
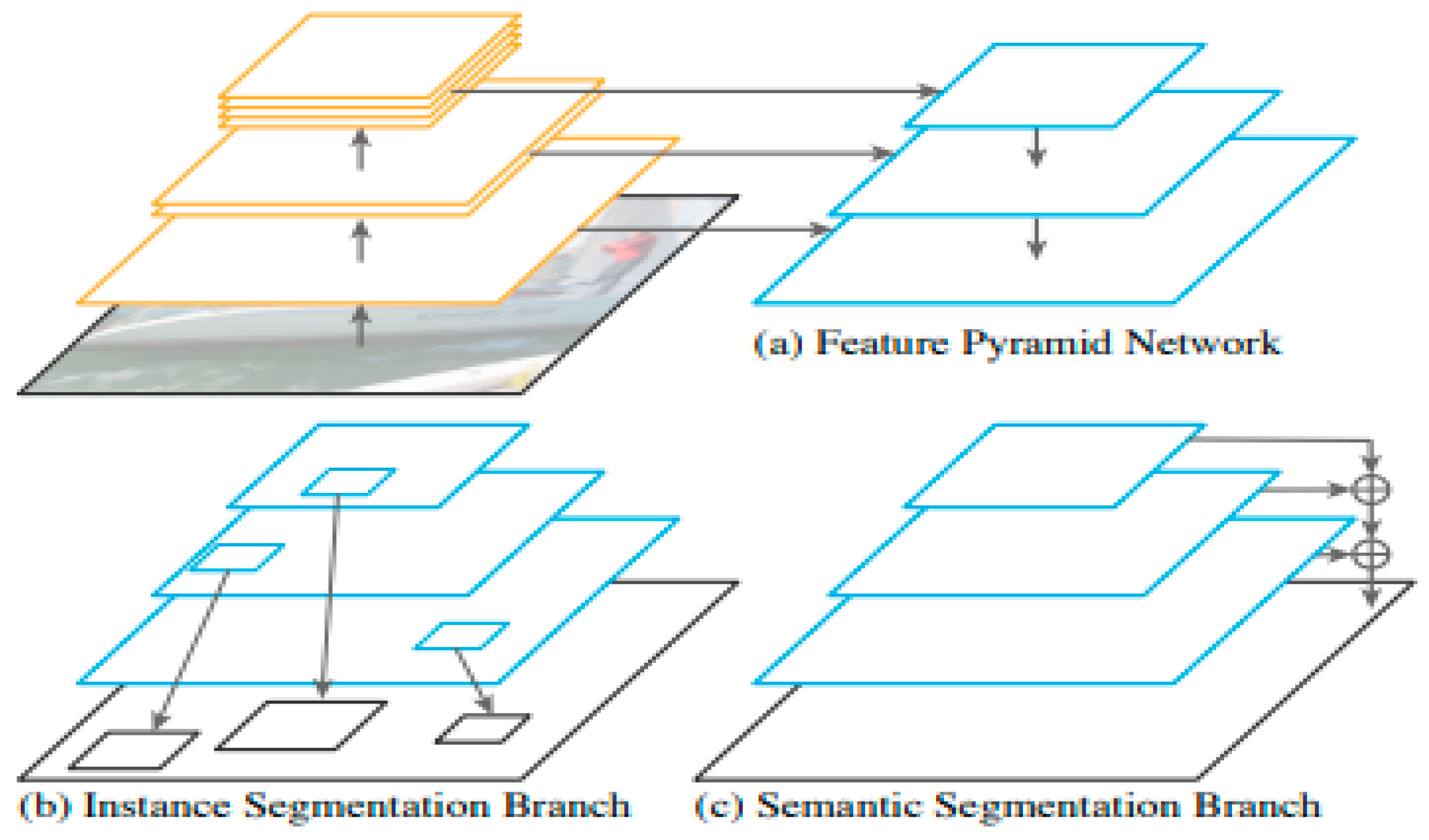
3.2.1. Panoptic Feature Pyramid Network
3.2.2. Attention-Guided Unified Network for Panoptic Segmentation
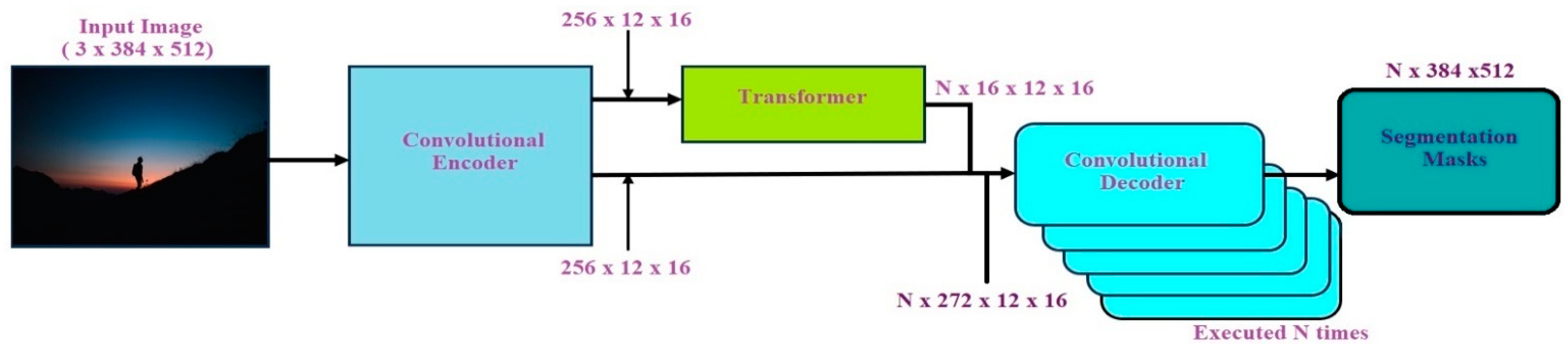
3.2.3. Panoptic DeepLab
3.2.4. Seamless Scene Segmentation
3.2.5. Unified Panoptic Segmentation Network
3.2.6. Efficient Panoptic Segmentation
3.3. Top-Down Approach to Panoptic Segmentation
3.3.1. Improvement in PS on Predicted Output Using Top-Down Approach
- i.
- Overlapping and Occlusion
4. Companies Developing Computer Vision Models for Panoptic Segmentation
4.1. Apple
- i.
- On-Device Panoptic Segmentation model
- ii.
- Fast Class-Agnostic salient-object segmentation
4.2. Facebook
4.3. Tesla
5. Publicly Available Datasets and Benchmarks
5.1. Datasets for Panoptic Segmentation
- i.
- COCO 2020 Panoptic Segmentation
- ii.
- Cityscapes Panoptic–Semantic Labeling
- iii.
- BDD100K Panoptic Segmentation
- iv.
- Mapillary Vistas v2.0
- v.
- Semantic KITTI Panoptic Segmentation
- vi.
- ScanNet
- vii.
- nuScenes
5.2. Comparison of Various Panoptic Segmentation Models
5.3. Datasets for Scene Recognition
- i.
- Scene-15
- ii.
- SUN-397
- iii.
- MIT Indoor-67 scenes
- iv.
- UIUC Sports-8
- v.
- Places
Limitations and Challenges of Scene Recognition Algorithms
- i.
- In early 2000, scene extractions from images were mainly carried out using the GAD’s. These descriptors utilized low-level image features such as the semantic typicality (this measure groups the natural real-world images in terms of their similarity into six different scene categories that include forests, coasts, rivers/lakes, plains, sky/clouds, and mountains, and categorizes a given image into one of those categories along side the nine local semantic concepts based on the frequency of image occurrence. Here, a archetypal categorial form of representation is learnt from each scene category and the “typicality measure” proposed is further evaluated (qualitatively and quantitatively) by incorporating a cross-validation on images containing 700 natural scenes. Furthermore, as typicality is a measure of uncertainty of predictions based on given annotations, and the nature of real-world images resembling an obscure nature, it is imperative to pay attention to the modeling of scene typicality after carrying out manual annotations [84]); a GIST (which is an abstract representation of a scene for activating the memory representations of different scene categories, such as sky, city, mountains, etc.); a census-transform histogram (CENTRIST) [59] (a visual descriptor for identifying the scene categories or the topological places by encoding the structural properties in an image and by suppressing the detailed textual information. It is inferred that the model proved to be successful for both datasets related to scene categories and the topological places and has been noticeably faster); etc. These GAD’s saw limited performance in scale for understanding the visual scene representations that are complex in nature.
- ii.
- To improve the performance, PFE gained prominence in the research community. It made use of the local features (aka. local visual descriptors), for example, histogram of oriented gradients, scale-invariant feature transform [85], bag-of-visual words, and local binary patterns, to name a few. Researchers utilized the bag-of-visual words framework before deep learning took the center stage and comprised of three different modules such as (i) feature extraction, (ii) code book learning, and (iii) coding processing. For any given image, the local features are extracted and are propagated to the code book learning module for extracting the visual words. This module uses k-Means clustering and extracts the k clusters by dividing the visual descriptors resembling the local features in terms of their Euclidean distances. Each cluster obtained represents a group of visual descriptors that share similar features whose center point is considered as the distinct visual word. This way all clusters containing the visual-words forms a code book. Finally, by incorporating all the learned features, the coding processing module predicts the contents of the entire image.
- iii.
- The SPL pattern learning aims at increasing the scene recognition accuracy as some scenes may have certain specific spatial layouts. One such spatial layout utilizes the randomized spatial partitions [67] by considering both classification and optimal spatial partition as one single problem. Here, an input image is partitioned into a pool of several partitions, each representing a different size and shape. This is further transformed into a histogram based representation of features consisting of an ordered pair p(Ii, θj) where Ii represents the level and θj represents the partitioned patterns. Another spatial layout presented in [88] make use of class-specific spatial layouts that are obtained from spatial partitions based on the convolutional-feature maps. There have been several customized modules found in the literature that support various spatial structures, for example, randomized spatial pooling [69] and spatial pyramid pooling [89], to name a few.
- iv.
- DRD is another way of independently extracting important regions or objects from the scenes. This is performed by using models such as deformable part based [90], and Object bank [70] to obtain the discriminative regions. However, to reduce the noisy features, important spatial pooling regions ISPR’s are used in identifying and locating the discriminative regions. It is noted that ISPRs make use of part filters to preserve the quality of image regions.
- v.
- OCA models the relationship among the diverse assignment of objects and scene categories and is considered the most challenging tasks among several scene recognition approaches. Here, the discriminative patch identification serve as the first step in carrying out the subsequent correlation analysis and this depends either on the pre-trained object detectors or on other practical region proposal methods. To analyze and understand the relationship between the diverse assignment of objects and scene categories, several probability models have been introduced in the literature. With the humungous information, OCA achieves a moderate recognition accuracy, and is considered the slowest in terms of the inference speed because of heavy computational load. It is to be noted that OCA can serve as an alternative in situations when object detection is needed for the task.
- vi.
- HDMs are considered as effective approaches to scene recognition. The intermediate layers in the CNN, on the one hand, capture the local features whereas the top layers capture the holistic features. In the end-to-end networks, multi-stage convolutional features should be considered for example the DAG-CNNs (directed acyclic graph CNNs) [75].
6. Conclusions and Research Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Wang, Z.; Qiu, S.; Xu, J.; Zhao, H.; Fortino, G.; Habib, M. A selection framework of sensor combination feature subset for human motion phase segmentation. Inf. Fusion 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Cabria, I.; Gondra, I. MRI segmentation fusion for brain tumor detection. Inf. Fusion 2017, 36, 1–9. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 122017. [Google Scholar] [CrossRef] [PubMed]
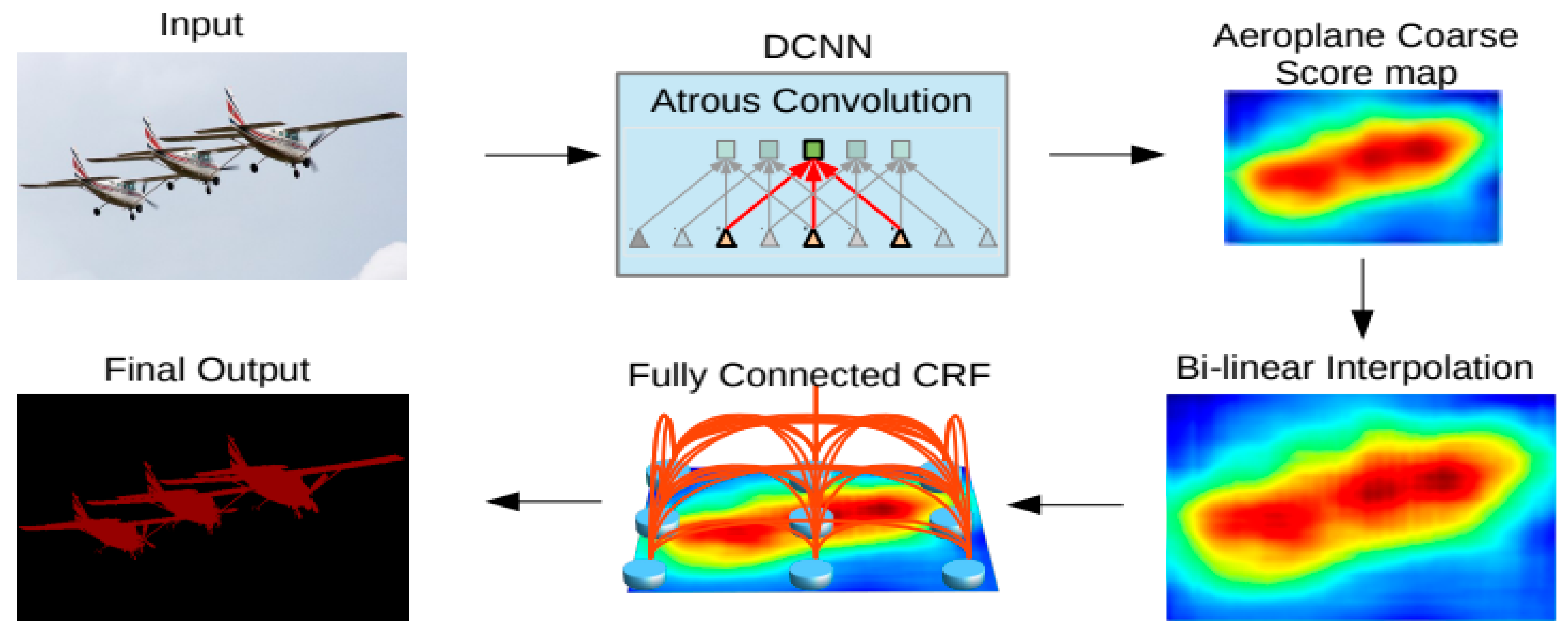
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Yao, J.; Fidler, S.; Urtasun, R. Describing the scene as a whole: Joint object detection, scene classification and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Xiong, Y.; Liao, R.; Zhao, H.; Hu, R.; Bai, M.; Yumer, E.; Urtasun, R. Upsnet: A unified panoptic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Liu, S.; Jia, J.; Fidler, S.; Urtasun, R. SGN: Sequential grouping networks for instance segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision e ECCV 2014; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8693. [Google Scholar]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Xie, L.; Lee, F.; Liu, L.; Kotani, K.; Chen, Q. Scene recognition: A comprehensive survey. Pattern Recognit. 2020, 102, 107205. [Google Scholar] [CrossRef]
- Hoiem, D.; Hays, J.; Xiao, J.; Khosla, A. Guest editorial: Scene understanding. Int. J. Comput. Vis. 2015, 112, 131–132. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Schwing, A.G.; Urtasun, R. Fully connected deep structured networks. arXiv 2015, arXiv:1503.02351. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. arXiv 2016, arXiv:1611.07709. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Neuhold, G.; Ollmann, T.; Bulo, S.R.; Kontschieder, P. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE Xplore: Piscataway, NJ, USA, 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. Youtube-8m: A large-scale video classification benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Computer Vision–ECCV 2008: 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008, Proceedings, Part I 10; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Leibe, B.; Cornelis, N.; Cornelis, K.; Van Gool, L. Dynamic 3D scene analysis from a moving vehicle. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007. [Google Scholar]
- Tighe, J.; Lazebnik, S. Finding things: Image parsing with regions and per-exemplar detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Tighe, J.; Niethammer, M.; Lazebnik, S. Scene parsing with object instances and occlusion ordering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Sun, M.; Kim, B.S.; Kohli, P.; Savarese, S. Relating things and stuff via object property interactions. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1370–1383. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 25 March 2024).
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef] [PubMed]
- Van Rijsbergen, C. Information Retrieval; Butterworths: London, UK, 1979. [Google Scholar]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Li, Y.; Chen, X.; Zhu, Z.; Xie, L.; Huang, G.; Du, D.; Wang, X. Attention-guided unified network for panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Porzi, L.; Bulo, S.R.; Colovic, A.; Kontschieder, P. Seamless scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Mohan, R.; Valada, A. EfficientPS: Efficient Panoptic Segmentation. arXiv 2021, arXiv:2004.02307v3. [Google Scholar] [CrossRef]
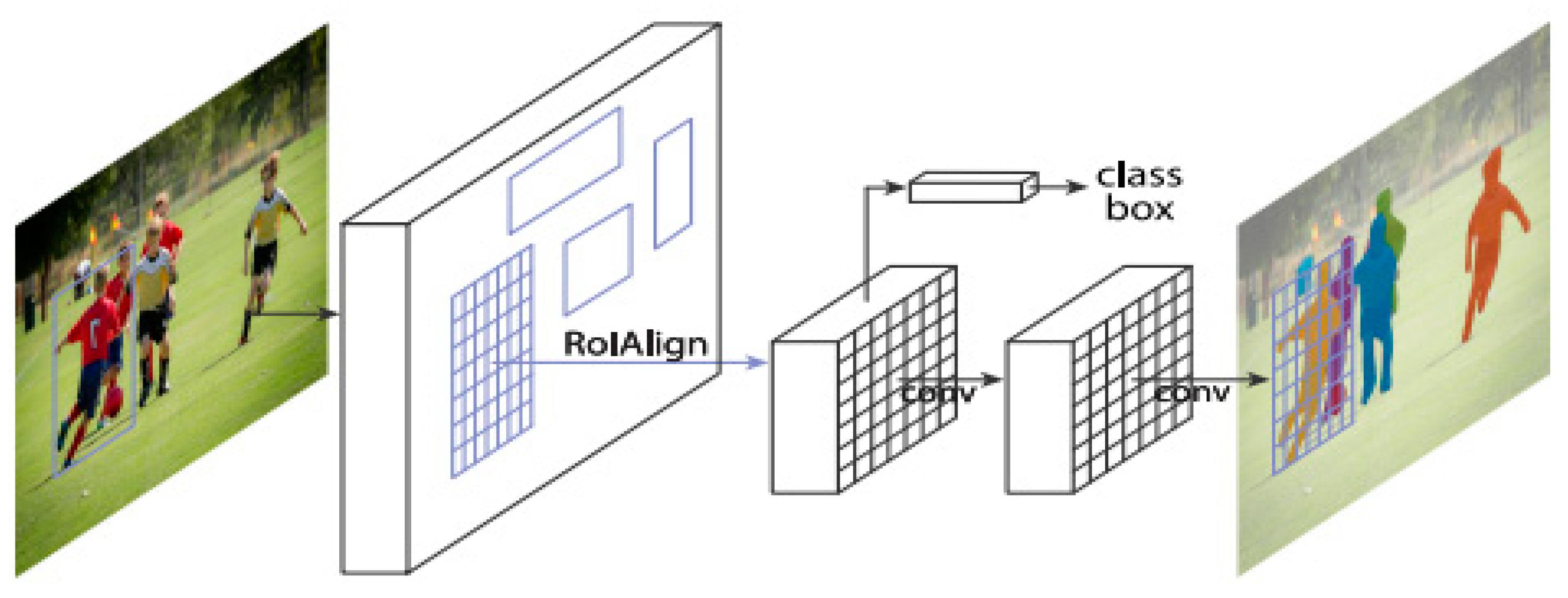
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, X.; Chen, D. A survey on deep learning-based panoptic segmentation. Digit. Signal Process. 2022, 120, 103283. [Google Scholar] [CrossRef]
- de Geus, D.; Meletis, P.; Dubbelman, G. Panoptic Segmentation with a Joint Semantic and Instance Segmentation Network. arXiv 2019, arXiv:1809.02110v2. [Google Scholar]
- Liu, H.; Peng, C.; Yu, C.; Wang, J.; Liu, X.; Yu, G.; Jiang, W. An End-To-End Network for Panoptic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- On-Device Panoptic Segmentation for Camera Using Transformers. October 2021. Available online: https://machinelearning.apple.com/research/panoptic-segmentation (accessed on 25 March 2024).
- Fast Class-Agnostic Salient Object Segmentation. June 2023. Available online: https://machinelearning.apple.com/research/salient-object-segmentation (accessed on 25 March 2024).
- Prakhar Bansal. Panoptic Segmentation Explained. Available online: https://medium.com/@prakhar.bansal/panoptic-segmentation-explained-5fa7313591a3 (accessed on 25 March 2024).
- Using Panoptic Segmentation to Train Autonomous Vehicles. Mindy News Blog. December 2021. Available online: https://mindy-support.com/news-post/using-panoptic-segmentation-to-train-autonomous-vehicles/ (accessed on 25 March 2024).
- COCO 2020 Panoptic Segmentation. Available online: https://cocodataset.org/#panoptic-2020 (accessed on 25 March 2024).
- Cityscapes Dataset. Available online: https://www.cityscapes-dataset.com/dataset-overview/ (accessed on 25 March 2024).
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; Available online: https://arxiv.org/abs/1805.04687.pdf (accessed on 25 March 2024).
- Mapillary Vistas Dataset. Available online: https://www.mapillary.com/dataset/vistas (accessed on 25 March 2024).
- Cheng, X.; Lu, J.; Feng, J.; Yuan, B.; Zhou, J. Scene recognition with objectness. Pattern Recognit. 2018, 74, 474–487. [Google Scholar] [CrossRef]
- Semantic KITTI Dataset. Available online: http://www.semantic-kitti.org/dataset.html (accessed on 25 March 2024).
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; Available online: https://arXiv:1903.11027.pdf (accessed on 25 March 2024).
- Arnab, A.; Torr, P.H. Pixelwise instance segmentation with a dynamically instantiated network. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bai, M.; Urtasun, R. Deep watershed transform for instance segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chang, C.-Y.; Chang, S.-E.; Hsiao, P.-Y.; Fu, L.-C. Epsnet: Efficient panoptic segmentation network with cross-layer attention fusion. In Proceedings of the Asian Conference on Computer Vision, Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Xiao, Y.; Wu, J.; Yuan, J. mCENTRIST: A multi-channel feature generation mechanism for scene categorization. IEEE Trans. Image Process. 2014, 23, 823–836. [Google Scholar] [CrossRef]
- Meng, X.; Wang, Z.; Wu, L. Building global image features for scene recognition. Pattern Recognit. 2012, 45, 373–380. [Google Scholar] [CrossRef]
- Wu, J.; Rehg, J.M. CENTRIST: A Visual Descriptor for Scene Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1489–1501. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Togneri, R.; Sohel, F.A. A discriminative representation of convolutional features for indoor scene recognition. IEEE Trans. Image Process. 2016, 25, 3372–3383. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Rehg, J.M. Beyond the Euclidean distance: Creating effective visual codebooks using the histogram intersection kernel. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Gong, Y.; Wang, L.; Guo, R. Multi-scale order less pooling of deep convolutional activation features. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Gao, S.; Tsang, I.W.H.; Chia, L.T.; Zhao, P. Local features are not lonely—Laplacian sparse coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Xie, L.; Lee, F.; Liu, L.; Yin, Z.; Chen, Q. Hierarchical coding of convolutional features for scene recognition. IEEE Trans. Multimed. 2019, 22, 1182–1192. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, J.; Tian, Q.; Xu, C.; Lu, H.; Ma, S. Image classification by non-negative sparse coding, low-rank and sparse decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Jiang, Y.; Yuan, J.; Yu, G. Randomized spatial partition for scene recognition. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 730–743. [Google Scholar]
- Hayat, M.; Khan, S.H.; Bennamoun, M.; An, S. A spatial layout and scale invariant feature representation for indoor scene classification. IEEE Trans. Image Process. 2016, 25, 4829–4841. [Google Scholar] [CrossRef]
- Yang, M.; Li, B.; Fan, H.; Jiang, Y. Randomized spatial pooling in deep convolutional networks for scene recognition. In Proceedings of the IEEE Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Li, L.J.; Su, H.; Fei-Fei, L.; Xing, E. Object bank: A high-level image representation for scene classification and semantic feature sparsification. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–11 December 2010. [Google Scholar]
- Zuo, Z.; Wang, G.; Shuai, B.; Zhao, L.; Yang, Q.; Jiang, X. Learning discriminative and shareable features for scene classification. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Shi, J.; Zhu, H.; Yu, S.; Wu, W.; Shi, H. Scene Categorization Model using Deep Visually Sensitive features. IEEE Access 2019, 7, 45230–45239. [Google Scholar] [CrossRef]
- Lin, D.; Lu, C.; Liao, R.; Jia, J. Learning important spatial pooling regions for scene regions for scene classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Wu, R.; Wang, B.; Wang, W.; Yu, Y. Harvesting discriminative meta objects with deep CNN features for scene classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Yang, S.; Ramanan, D. Multi-scale recognition with DAG-CNNs. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Liu, Y.; Chen, Q.; Chen, W.; Wassell, I. Dictionary learning inspired deep network for scene recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Seong, H.; Hyun, J.; Kim, E. FOSNet: An End-to End Trainable Deep Neural Network for Scene Recognition. IEEE Access 2020, 8, 82066–82077. [Google Scholar] [CrossRef]
- Xie, G.; Zhang, X.; Yan, S.; Liu, C. Hybrid CNN and dictionary-based models for scene recognition and domain adaptation. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1263–1274. [Google Scholar] [CrossRef]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the IEEE International Conference on Computer Vision, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Quattoni, A.; Torralba, A. Recognizing Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Li, L.; Fei-Fei, L. What, where and who? Classifying events by scene and object recognition. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, L.; Wang, Y.; Zhang, B.; Qiao, Y. Weakly supervised PatchNets: Describing and aggregating local patches for scene recognition. IEEE Trans. Image Process. 2017, 26, 2028–2041. [Google Scholar] [CrossRef]
- Vogel, J.; Schiele, B. A semantic typicality measure for natural scene categorization. In Pattern Recognition, Proceedings of the 26th DAGM Symposium, 30 August–1 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 195–203. [Google Scholar]
- Amrani, M.; Jiang, F. Deep feature extraction and combination for synthetic aperture radar target classification. J. Appl. Remote Sens. 2017, 11, 042616. [Google Scholar] [CrossRef]
- Song, Y.; Zhang, Z.; Liu, L.; Rahimpour, A.; Qi, H. Dictionary reduction: Automatic compact dictionary learning for classification. In Computer Vision—ACCV 2016. ACCV 2016, Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Huang, Y.; Wu, Z.; Wang, L.; Tan, T. Feature coding in image classification: A comprehensive study. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 493–506. [Google Scholar] [CrossRef]
- Weng, C.; Wang, H.; Yuan, J.; Jiang, X. Discovering class-specific spatial layouts for scene recognition. IEEE Signal Process. Lett. 2017, 24, 1143–1147. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 33, 346–361. [Google Scholar]
- Pandey, M.; Lazebnik, S. Scene recognition and weakly supervised object localization with deformable part-based models. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Elharrouss, O.; Al-Maadeed, S.; Subramanian, N.; Ottakath, N.; Almaadeed, N.; Himeur, Y. Panoptic Segmentation: A Review. arXiv 2021, arXiv:2111.10250. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2001.05566v5. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Dataset | Back-Bone | PQ | PQST | PQTH | Comparison |
|---|---|---|---|---|---|---|
| Panoptic Feature Pyramid Network (FPN) [34] | COCO | R50-FPN×2 | 39.2 | 27.9 | 46.6 | On Cityscapes, the panoptic FPN comparison is performed with DIN [54] and it is inferred that panoptic FPN surpasses DIN with a 4.3-point PQ margin. Note: DIN is a substitute to region-based instance segmentation. It commences with pixelwise semantic segmentation and subsequently performs grouping to retrieve instances. |
| R50-FPN | 39.0 | 28.7 | 45.9 | |||
| R101-FPN | 40.3 | 29.5 | 47.5 | |||
| Cityscapes | R50-FPN×2 | 57.7 | 62.4 | 51.3 | ||
| R50-FPN | 57.7 | 62.2 | 51.6 | |||
| R101-FPN | 58.1 | 62.5 | 52.0 | |||
| Attention-guided unified network for Panoptic Segmentation (AUNet) [35] | COCO | ResNet-101-FPN | 45.2 | 31.3 | 54.4 | AUNet is compared with the leading bottom-up methods (such as DWT [55], SGN [8]) and Mask R-CNN. It is inferred that a consistent accuracy gain is achieved with MS-COCO, and thereby a new state-of-the-art can be further achieved. |
| ResNet-152-FPN | 45.5 | 31.6 | 54.7 | |||
| ResNeXt-152-FPN | 46.5 | 32.5 | 55.8 | |||
| Cityscapes | ResNet-50-FPN | 55.0 | 57.8 | 51.2 | ||
| ResNet-50-FPN | 56.4 | 59.0 | 52.7 | |||
| ResNet-101-FPN | 59.0 | 62.1 | 54.8 | |||
| Panoptic DeepLab [5] | Cityscapes | VGG-16 based LargeFOV | 40.3 | 49.3 | 33.5 | The design of Panoptic DeepLab is simple and requires only three loss functions while training and incorporates minimal parameters to a contemporary semantic segmentation model. |
| Mapillary Vistas | ResNet-101 | 65.5 | - | - | ||
| Seamless Scene Segmentation [36] | Cityscapes | ResNet-50-FPN | 59.8 | 64.5 | 53.4 | An effort to attain seamless scene segmentation involves the integration of semantic and instance segmentation methods, jointly operating on a sole network backbone. |
| Mapillary Vistas | ResNet-101-FPN | 37.2 | 42.5 | 33.2 | ||
| Unified panoptic segmentation network UPSNet [7] | COCO | ResNet-101-FPN | 46.6 | 36.7 | 53.2 | Three large datasets are used whose empirical results demonstrate that UPSNet attains SOTA performance with faster inference in comparison to other models. |
| Cityscapes | ResNet-101-FPN | 61.8 | 64.8 | 57.6 | ||
| UPSNet dataset: MR-CNN-PSP | ResNet-50-FPN | 47.1 | 49.0 | 43.8 | ||
| Efficient panoptic segmentation EPSNet [56] | COCO | ResNet-101-FPN | 38.9 | 31.0 | 44.1 | A one stage EPSNet is presented and achieves a significant performance on COCO dataset and outperforms other one stage approaches. Hence, EPSNet is notably faster than other existing PS networks. |
| Scene Recognition Types | Method | Feature Retrieval | Scene-15 | SUN-397 | Indoor-67 | Sports-8 |
|---|---|---|---|---|---|---|
| Global Attribute Descriptors | GIST [13] | GIST | 73.28 | - | - | 82.60 |
| LDBP [58] | LDBP | 84.10 | - | - | 88.10 | |
| mCENTRIST [57] | mCENTRIST | - | - | 44.60 | 86.50 | |
| CENTRIST [59] | CENTRIST | 83.88 | - | - | 86.22 | |
| Patch Feature Encoding | SPM [60] | SIFT | 81.40 | - | 34.40 | 81.80 |
| DUCA [61] | AlexNet | 94.50 | - | 71.80 | 98.70 | |
| HIK [62] | CENTRIST | 84.12 | - | - | 84.21 | |
| MOP-CNN [63] | AlexNet | - | 51.98 | 68.88 | - | |
| LScSPM [64] | SIFT | 89.75 | - | - | 85.31 | |
| NNSD [65] | ResNet-152 | 94.70 | 64.78 | 85.40 | 99.10 | |
| LR-Sc+ SPM [66] | SIFT | 90.03 | - | - | 86.69 | |
| Spatial Layouts Pattern Learning | RSP [67] | SIFT | 88.10 | - | - | 79.60 |
| S2ICA [68] | VGG-16 | 93.10 | - | 74.40 | 95.80 | |
| RS-Pooling [69] | AlexNet | 89.40 | - | 62.00 | - | |
| Discriminative Region Detection | Object Bank [70] | Object Filters | 80.90 | - | 37.60 | 76.30 |
| DSFL [71] | AlexNet | 92.81 | - | 76.23 | 96.78 | |
| VS-CNN [72] | AlexNet | 97.65 | 43.14 | 80.37 | 97.50 | |
| ISPRs [73] | HOG | 91.06 | - | 68.50 | 92.08 | |
| Object Correlation Analysis | SDO [50] | VGG-16 | 95.88 | 73.41 | 86.76 | - |
| MetaObject-CNN [74] | Hybrid CNN | - | 58.11 | 78.90 | - | |
| Hybrid Deep Models | DAG-CNN [75] | VGG-19 | 92.90 | 56.20 | 77.50 | - |
| Dual CNN-DL [76] | Hybrid CNN | 96.03 | 70.13 | 86.43 | - | |
| FOSNet [77] | SE-ResNeXt-101 | - | 77.28 | 90.37 | - | |
| Hybrid CNNs [78] | VGG-19 | - | 64.53 | 82.24 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammed, S.A.; Ralescu, A.L. Insights into Image Understanding: Segmentation Methods for Object Recognition and Scene Classification. Algorithms 2024, 17, 189. https://doi.org/10.3390/a17050189
Mohammed SA, Ralescu AL. Insights into Image Understanding: Segmentation Methods for Object Recognition and Scene Classification. Algorithms. 2024; 17(5):189. https://doi.org/10.3390/a17050189
Chicago/Turabian StyleMohammed, Sarfaraz Ahmed, and Anca L. Ralescu. 2024. "Insights into Image Understanding: Segmentation Methods for Object Recognition and Scene Classification" Algorithms 17, no. 5: 189. https://doi.org/10.3390/a17050189
APA StyleMohammed, S. A., & Ralescu, A. L. (2024). Insights into Image Understanding: Segmentation Methods for Object Recognition and Scene Classification. Algorithms, 17(5), 189. https://doi.org/10.3390/a17050189