

GPU Algorithms for Structured Sparse Matrix Multiplication with Diagonal Storage Schemes †

Abstract
1. Introduction
- We introduce GPU algorithms, for the first time, to multiply banded and structured sparse matrices, where the sparse matrices are stored as the CDM and HM schemes, respectively;
- Explore the performance of both the CDM and HM storage schemes in the multiplication of banded matrices with varying bandwidth and of structured sparse matrices with varying numbers of diagonals, respectively;
- Compare the performances of the proposed GPU algorithms with their CPU implementations.
2. Related Work
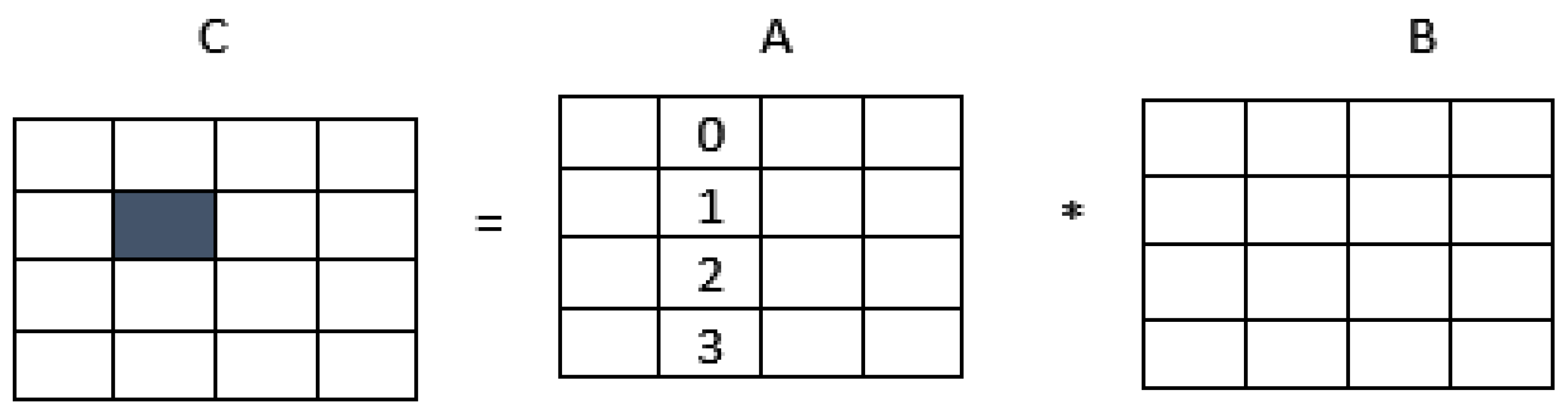
3. Storage Schemes
3.1. Diagonal Storage Scheme
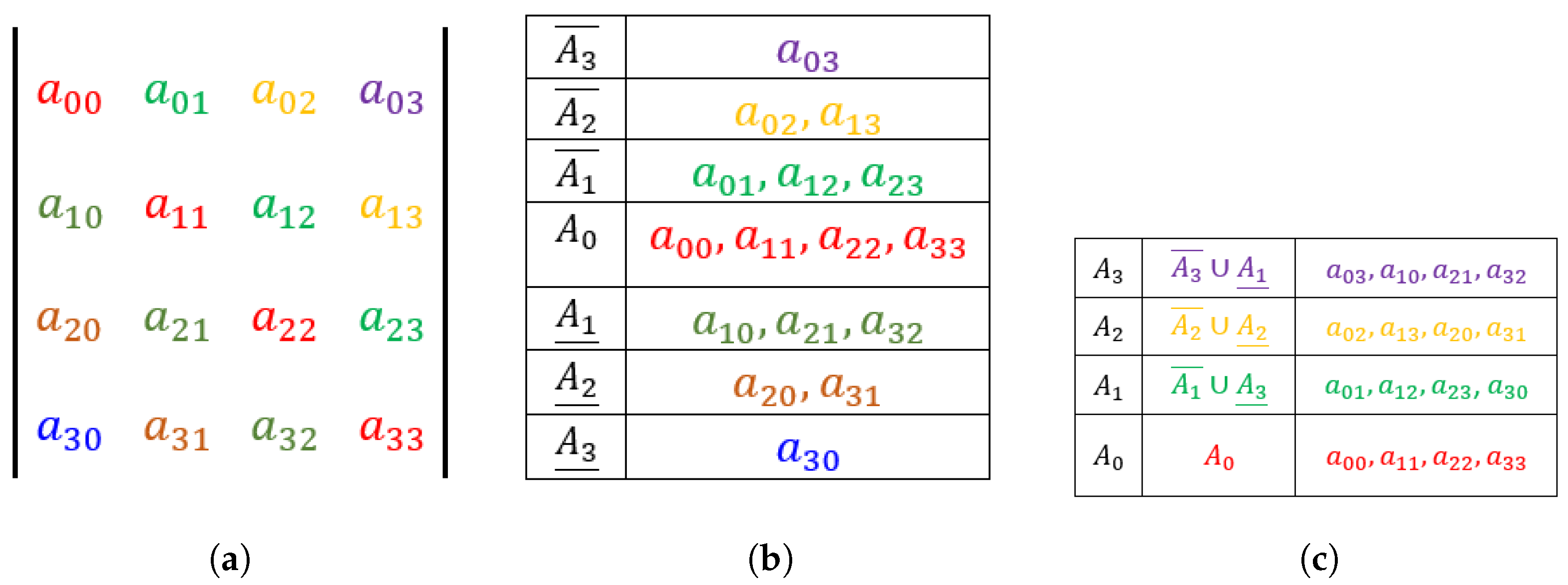
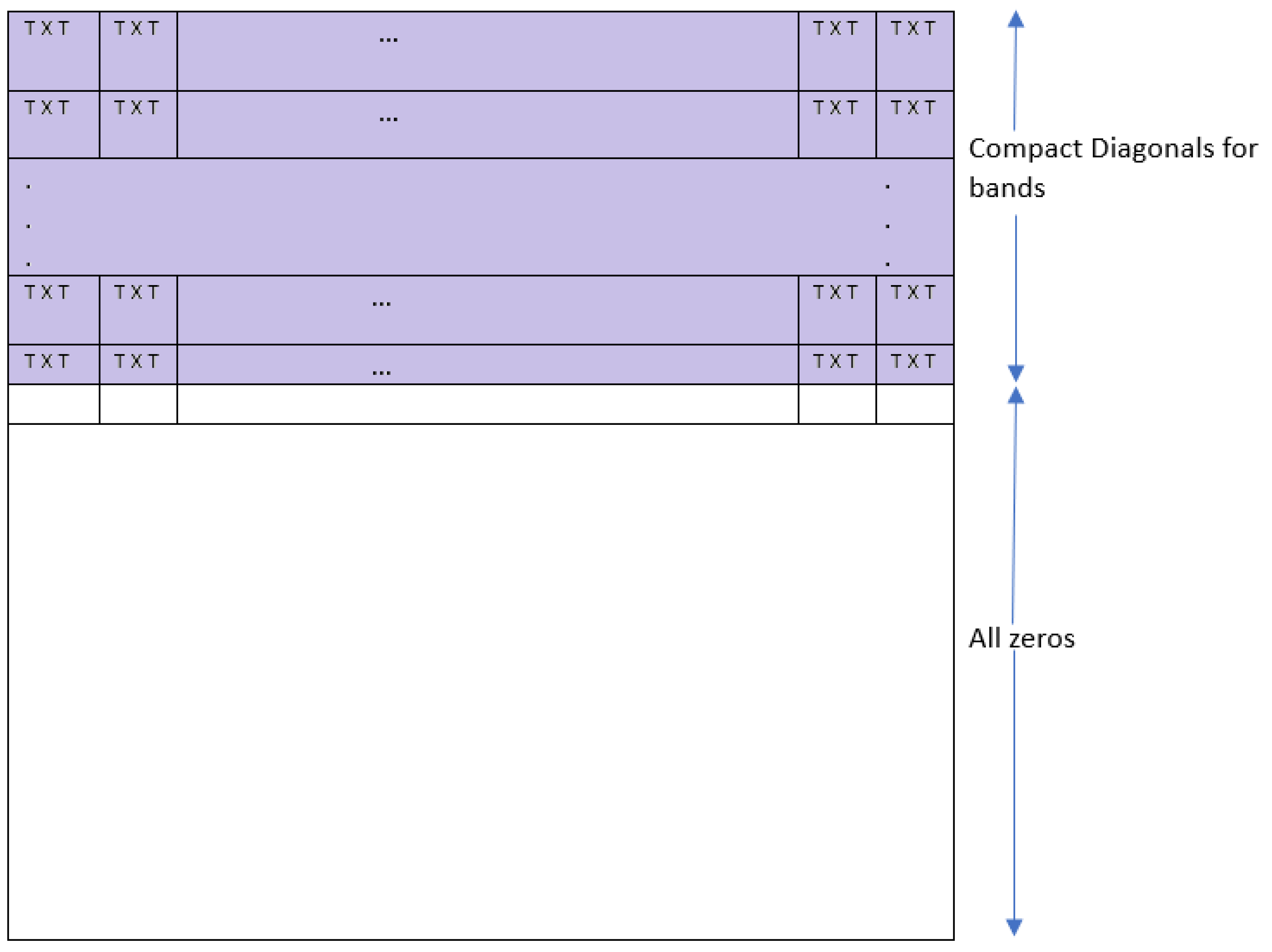
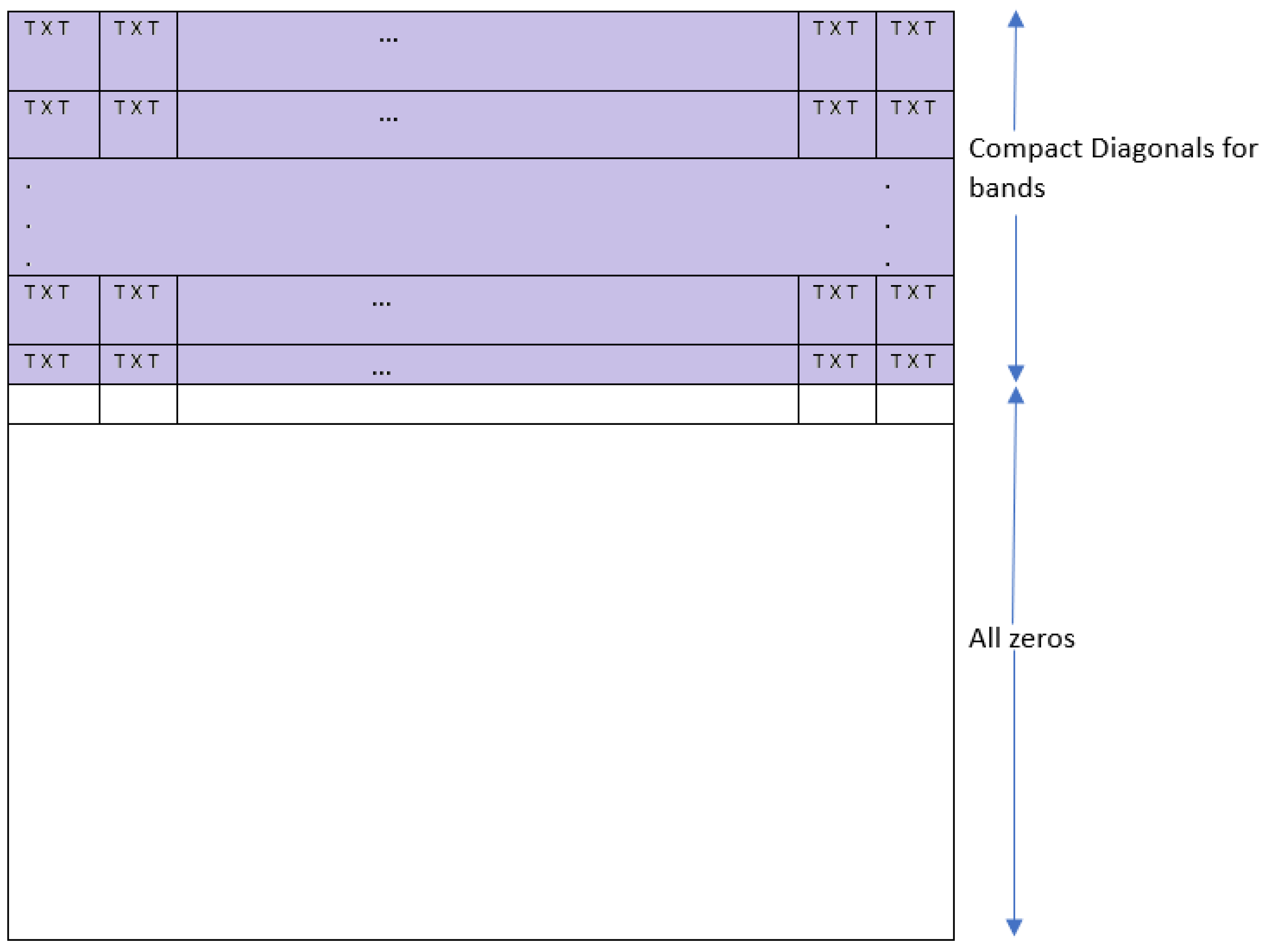
3.2. Compact Diagonal Storage Scheme
4. Compact Diagonal Matrix Multiplication
5. GPU Programming
6. Algorithms
6.1. Banded Matrix–Matrix Multiplication
- Integer representing the number of compact diagonals in X.
- List of integers of length , which is the list of the indices of the diagonals of X.
- : One-dimensional list of length containing the values of X.
| Algorithm 1:CUDA Algorithm for Banded Matrix–Matrix Multiplication |
 |
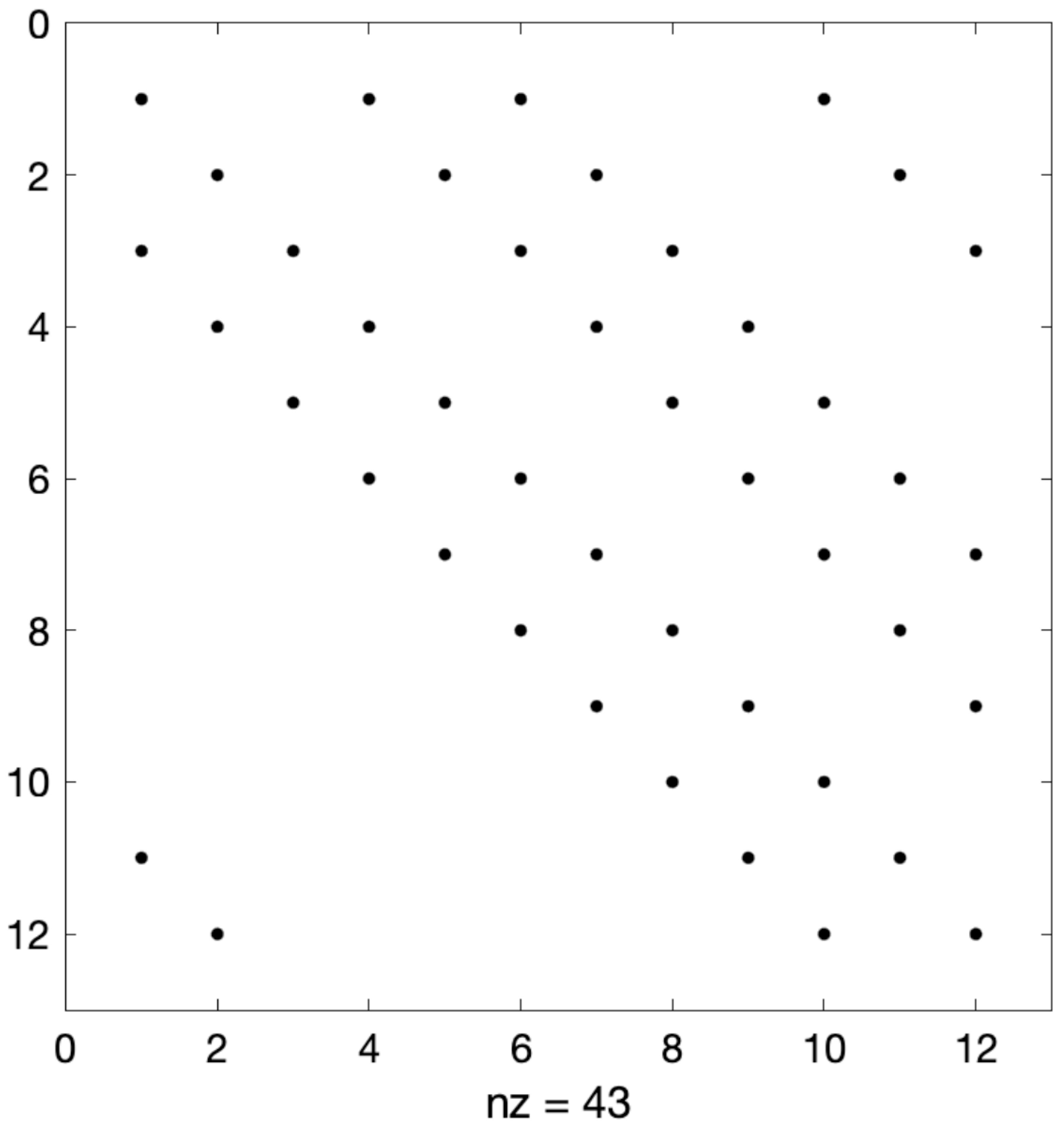
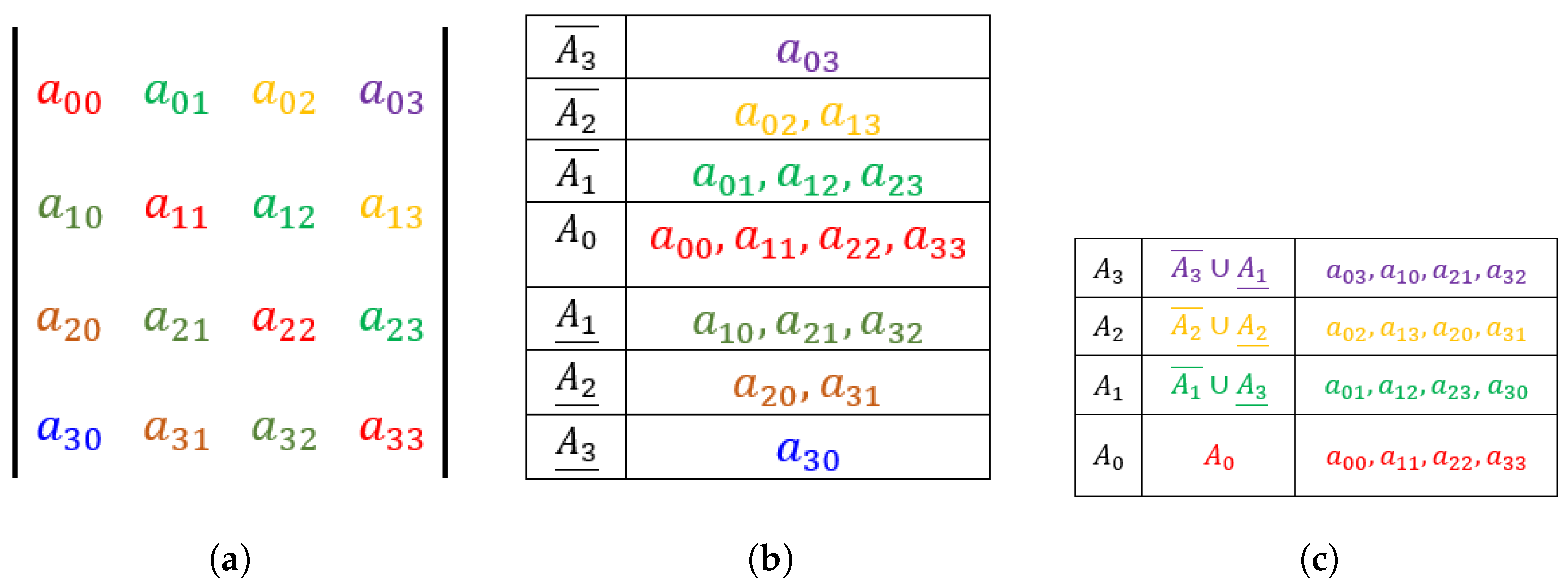
6.2. Structured Sparse Matrix–Matrix Multiplication
- An integer value that represents the number of HM diagonals in X. In structured sparse matrices, we know that only some of the diagonals have nonzeros. We will store those diagonals only.
- A list of integers (of length ) that stores the indices of the diagonals of X. The first element of this array is 0 if the principal diagonal is dense. It stores the indices of the super diagonals first, followed by those of the subdiagonals. For superdiagonal indices, those are stored in ascending order. For subdiagonal indices, those are stored in descending order.
- : This is a one-dimensional array that stores the entries of X. The entries from the same diagonal are kept together according to their column indices.
- A list of integers (of length ) that stores the indices of the entries in for each diagonal of X.
- The multiplications between the principal diagonals of A and B contribute to the principal diagonal of C. Each multiplication can be described in the following way, with the left index 0 indicating the (principal) diagonal:
- The entries of A and B are from the i-th superdiagonal and -th subdiagonal, respectively. Each of the multiplications can be described in the following way: .
- The entries of A and B are from the -th subdiagonal and i-th superdiagonal, respectively. Each of the multiplications can be described in the following way: .
- Let and j be an entry from A and an index of a diagonal from B, respectively. If exists, then will be multiplied with , and this multiplication will contribute to .
- Let and j be an entry from the principle diagonal of A and an index of a diagonal from B, respectively. will be multiplied with (if it exists), and their multiplication will contribute to .
- Let be an entry from A. It can be multiplied with (if it exists), and the multiplication result will contribute to .
- Let and be an entry from A and an index of a diagonal from B, respectively. Assume and exist. Then, will be multiplied with , and the multiplication result will contribute to .
- Let and j be an entry from A and an index of a diagonal from B, respectively. Here, . If exists, then will be multiplied with , and the multiplication result will contribute to .
- Rule for matrix multiplication with coordinate matrix data structure: Let and be two matrices of size stored in a coordinate storage scheme. We want to compute . An element will be multiplied with , where , and will contribute to .
- Assume that we convert to matrix A stored in an HM structure. Let be an entry in . This element will be in the HM storage scheme.
| Algorithm 2:CUDA Algorithm for Structured Sparse Matrix–Matrix Multiplication |
 |
7. Experimental Results
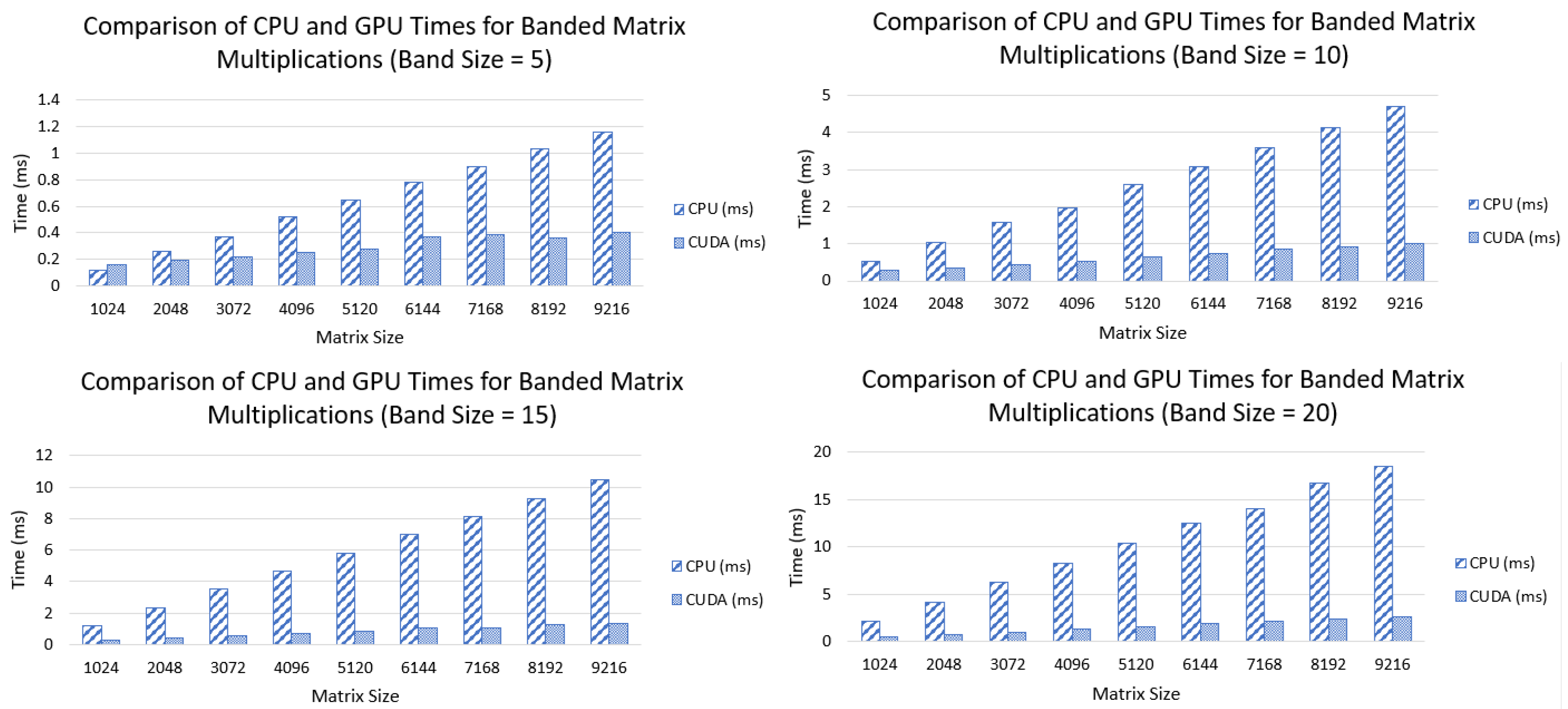
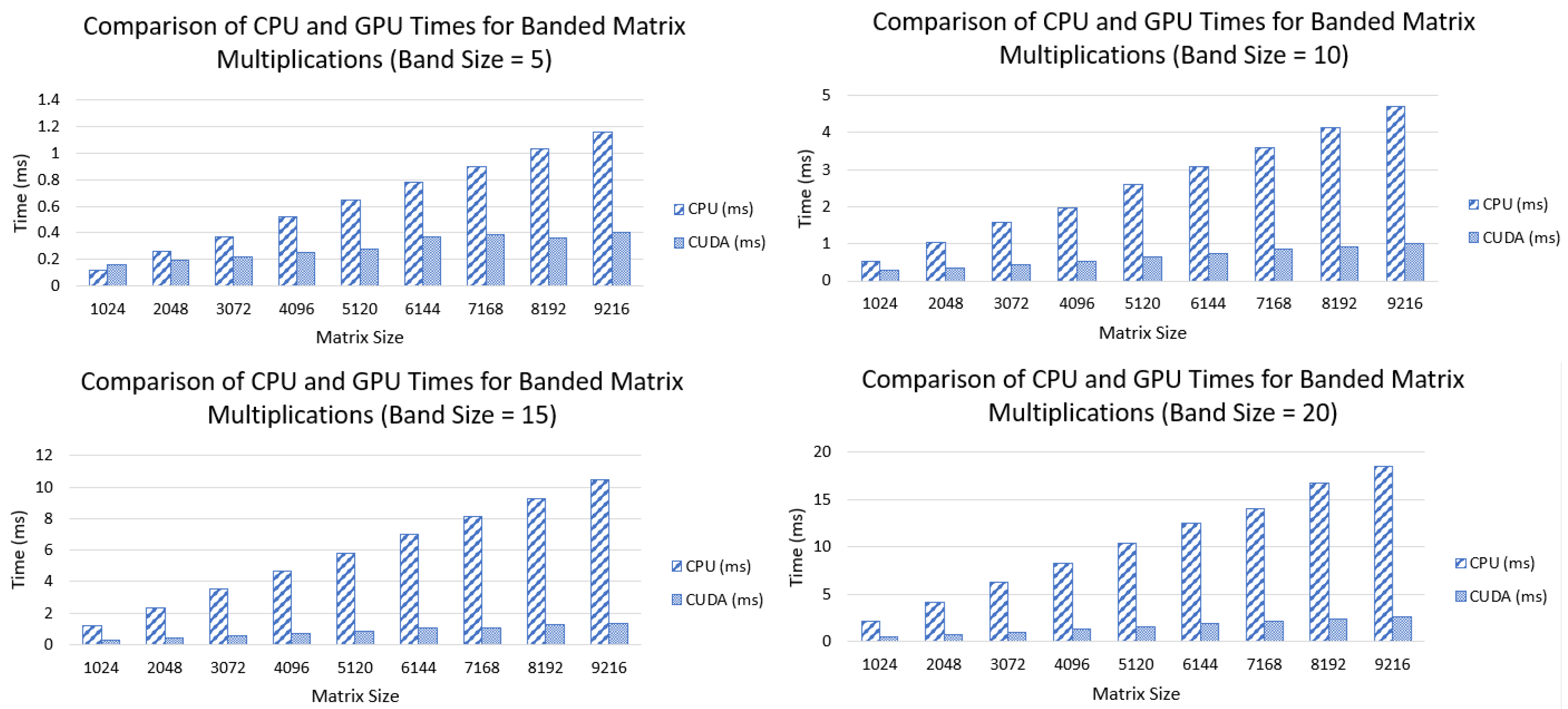
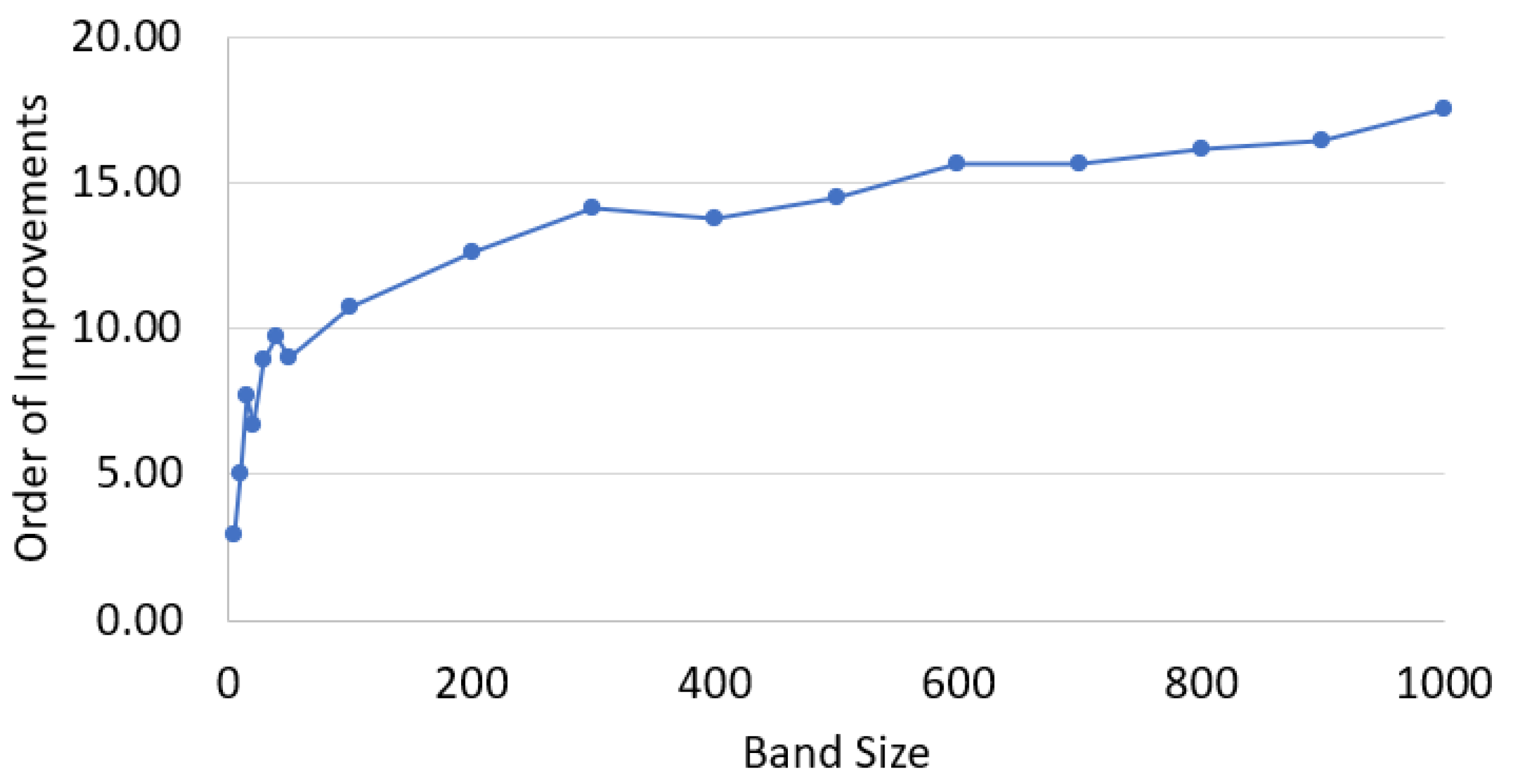
7.1. Banded Matrix Multiplication
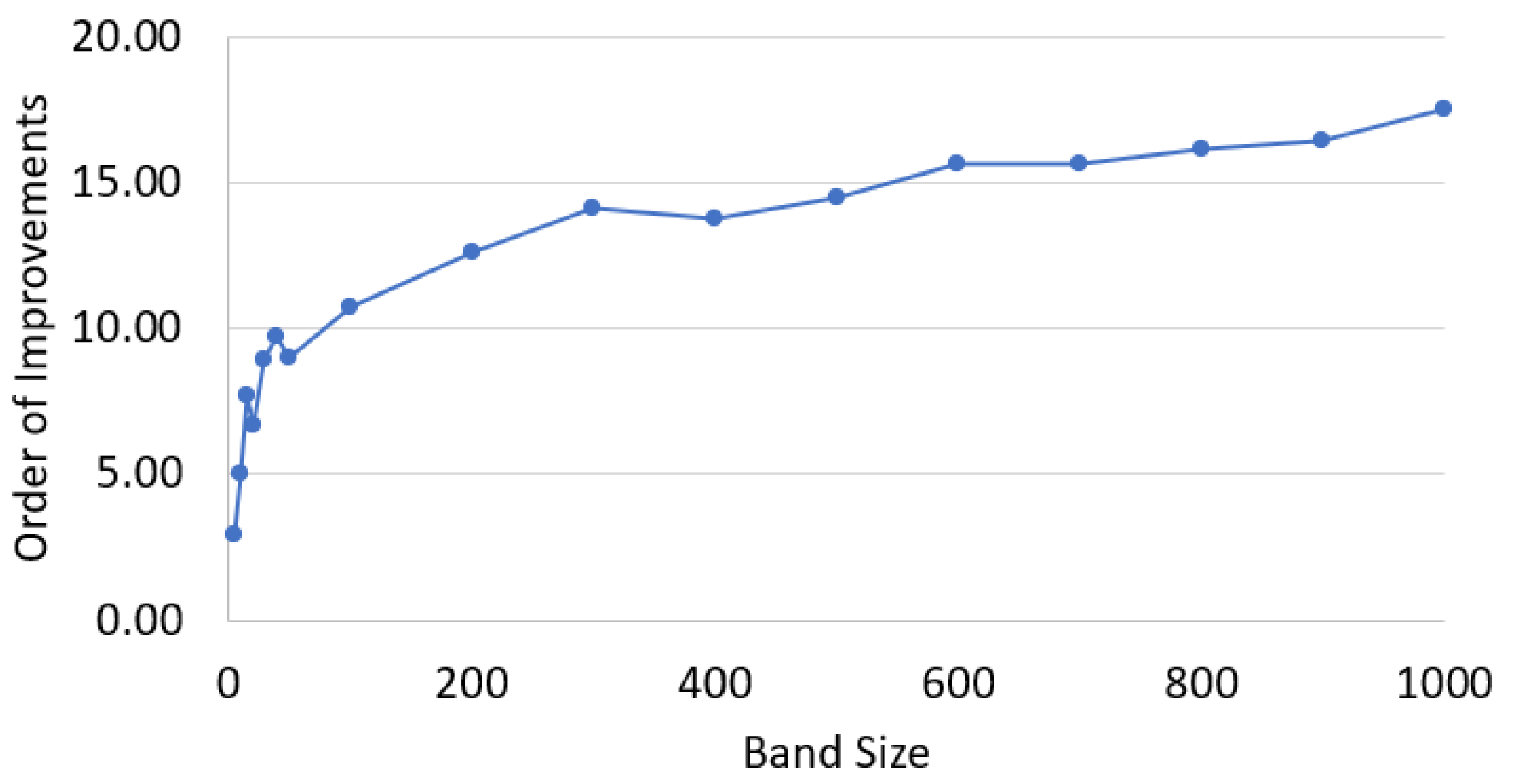
7.2. Structured Sparse Matrix Multiplication
8. Summary and Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdullah, W.M.; Awosoga, D.; Hossain, S. Efficient Calculation of Triangle Centrality in Big Data Networks. In Proceedings of the 2022 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 19–23 September 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Gao, J.; Ji, W.; Chang, F.; Han, S.; Wei, B.; Liu, Z.; Wang, Y. A systematic survey of general sparse matrix-matrix multiplication. ACM Comput. Surv. 2023, 55, 1–36. [Google Scholar] [CrossRef]
- Kepner, J.; Gilbert, J. Graph Algorithms in the Language of Linear Algebra; SIAM: Philadelphia, PA, USA, 2011. [Google Scholar]
- Kepner, J.; Jananthan, H. Mathematics of Big Data: Spreadsheets, Databases, Matrices, and Graphs; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Shen, L.; Dong, Y.; Fang, B.; Shi, J.; Wang, X.; Pan, S.; Shi, R. ABNN2: Secure two-party arbitrary-bitwidth quantized neural network predictions. In Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022; pp. 361–366. [Google Scholar]
- Gholami, A.; Kim, S.; Dong, Z.; Yao, Z.; Mahoney, M.W.; Keutzer, K. A survey of quantization methods for efficient neural network inference. In Low-Power Computer Vision; Chapman and Hall/CRC: Boca Raton, FL, USA, 2022; pp. 291–326. [Google Scholar]
- Gundersen, G. The Use of Java Arrays in Matrix Computation. Master’s Thesis, University of Bergen, Bergen, Norway, 2002. [Google Scholar]
- Yang, W.; Li, K.; Liu, Y.; Shi, L.; Wan, L. Optimization of quasi-diagonal matrix–vector multiplication on GPU. Int. J. High Perform. Comput. Appl. 2014, 28, 183–195. [Google Scholar] [CrossRef]
- Benner, P.; Dufrechou, E.; Ezzatti, P.; Igounet, P.; Quintana-Ortí, E.S.; Remón, A. Accelerating band linear algebra operations on GPUs with application in model reduction. In Proceedings of the Computational Science and Its Applications–ICCSA 2014: 14th International Conference, Guimarães, Portugal, 30 June–3 July 2014; Proceedings, Part VI 14. Springer: Cham, Switzerland, 2014; pp. 386–400. [Google Scholar]
- Dufrechou, E.; Ezzatti, P.; Quintana-Ortí, E.S.; Remón, A. Efficient symmetric band matrix-matrix multiplication on GPUs. In Proceedings of the Latin American High Performance Computing Conference, Valparaiso, Chile, 20–22 October 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–12. [Google Scholar]
- Madsen, N.K.; Rodrigue, G.H.; Karush, J.I. Matrix multiplication by diagonals on a vector/parallel processor. Inf. Process. Lett. 1976, 5, 41–45. [Google Scholar] [CrossRef]
- Tsao, A.; Turnbull, T. A Comparison of Algorithms for Banded Matrix Multiplication; Citeseer: Vicksburg, MS, USA, 1993. [Google Scholar]
- Vooturi, D.T.; Kothapalli, K.; Bhalla, U.S. Parallelizing Hines matrix solver in neuron simulations on GPU. In Proceedings of the 2017 IEEE 24th International Conference on High Performance Computing (HiPC), Jaipur, India, 18–21 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 388–397. [Google Scholar]
- Benner, P.; Dufrechou, E.; Ezzatti, P.; Quintana-Ortí, E.S.; Remón, A. Unleashing GPU acceleration for symmetric band linear algebra kernels and model reduction. Clust. Comput. 2015, 18, 1351–1362. [Google Scholar] [CrossRef]
- Kirk, D.B.; Wen-Mei, W.H. Programming Massively Parallel Processors: A Hands-On Approach; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Munshi, A.; Gaster, B.; Mattson, T.G.; Ginsburg, D. OpenCL Programming Guide; Pearson Education: London, UK, 2011. [Google Scholar]
- Volkov, V.; Demmel, J.W. Benchmarking GPUs to tune dense linear algebra. In Proceedings of the SC’08: Proceedings of the 2008 ACM/IEEE conference on Supercomputing, Austin, TX, USA, 15–21 November 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–11. [Google Scholar]
- Kurzak, J.; Tomov, S.; Dongarra, J. Autotuning GEMM kernels for the Fermi GPU. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 2045–2057. [Google Scholar] [CrossRef]
- Ortega, G.; Vázquez, F.; García, I.; Garzón, E.M. Fastspmm: An efficient library for sparse matrix matrix product on gpus. Comput. J. 2014, 57, 968–979. [Google Scholar] [CrossRef]
- Hossain, S.; Mahmud, M.S. On computing with diagonally structured matrices. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 24–26 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Eagan, J.; Herdman, M.; Vaughn, C.; Bean, N.; Kern, S.; Pirouz, M. An Efficient Parallel Divide-and-Conquer Algorithm for Generalized Matrix Multiplication. In Proceedings of the 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–11 March 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 0442–0449. [Google Scholar]
- Haque, S.A.; Choudhury, N.; Hossain, S. Matrix Multiplication with Diagonals: Structured Sparse Matrices and Beyond. In Proceedings of the 2023 7th International Conference on High Performance Compilation, Computing and Communications, Jinan, China, 17–19 June 2023; pp. 69–76. [Google Scholar]
- Barrachina, S.; Castillo, M.; Igual, F.D.; Mayo, R.; Quintana-Ortí, E.S. Solving dense linear systems on graphics processors. In Proceedings of the European Conference on Parallel Processing, Las Palmas de Gran Canaria, Spain, 26–29 August 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 739–748. [Google Scholar]
- Volkov, V.; Demmel, J. LU, QR and Cholesky Factorizations using Vector Capabilities of GPUs. 2008. Available online: https://bebop.cs.berkeley.edu/pubs/volkov2008-gpu-factorizations.pdf (accessed on 10 December 2023).
- Liu, C.; Wang, Q.; Chu, X.; Leung, Y.W. G-crs: Gpu accelerated cauchy reed-solomon coding. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 1484–1498. [Google Scholar] [CrossRef]
- Larsen, E.S.; McAllister, D. Fast matrix multiplies using graphics hardware. In Proceedings of the 2001 ACM/IEEE Conference on Supercomputing, Denver, CO, USA, 10–16 November 2001; p. 55. [Google Scholar]
- Barrachina, S.; Castillo, M.; Igual, F.D.; Mayo, R.; Quintana-Orti, E.S. Evaluation and tuning of the level 3 CUBLAS for graphics processors. In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing, Miami, FL, USA, 14–18 April 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Cui, X.; Chen, Y.; Zhang, C.; Mei, H. Auto-tuning dense matrix multiplication for GPGPU with cache. In Proceedings of the 2010 IEEE 16th International Conference on Parallel and Distributed Systems, Shanghai, China, 8–10 December 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 237–242. [Google Scholar]
- Osama, M.; Merrill, D.; Cecka, C.; Garland, M.; Owens, J.D. Stream-K: Work-Centric Parallel Decomposition for Dense Matrix-Matrix Multiplication on the GPU. In Proceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, Montreal, QC, Canada, 25 February–1 March 2023; pp. 429–431. [Google Scholar]
- Matam, K.; Indarapu, S.R.K.B.; Kothapalli, K. Sparse matrix-matrix multiplication on modern architectures. In Proceedings of the 2012 19th International Conference on High Performance Computing, Pune, India, 18–22 December 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–10. [Google Scholar]
- Naumov, M.; Chien, L.; Vandermersch, P.; Kapasi, U. Cusparse library. In Proceedings of the GPU Technology Conference, San Jose, CA, USA, 20–23 September 2010. [Google Scholar]
- Bell, N.; Garland, M. Cusp: Generic Parallel Algorithms for Sparse Matrix and Graph computations, Version 0.3.0. 2012.
- Hoberock, J.; Bell, N. Thrust: A Parallel Template Library; GPU Computing Gems Jade Edition, 359; 2011. Available online: https://shop.elsevier.com/books/gpu-computing-gems-jade-edition/hwu/978-0-12-385963-1 (accessed on 10 December 2023).
- Gomez-Luna, J.; Sung, I.J.; Chang, L.W.; González-Linares, J.M.; Guil, N.; Hwu, W.M.W. In-place matrix transposition on GPUs. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 776–788. [Google Scholar] [CrossRef]
- Garland, M.; Kirk, D.B. Understanding throughput-oriented architectures. Commun. ACM 2010, 53, 58–66. [Google Scholar] [CrossRef]
- Haque, S.A.; Moreno Maza, M.; Xie, N. A Many-Core Machine Model for Designing Algorithms with Minimum Parallelism Overheads. In Parallel Computing: On the Road to Exascale; IOS Press: Amsterdam, The Netherlands, 2016; pp. 35–44. [Google Scholar]
- Davis, T. Florida Sparse Matrix Collection. 2014. Available online: http://www.cise.ufl.edu/research/sparse/matrices/index.html (accessed on 1 January 2023).

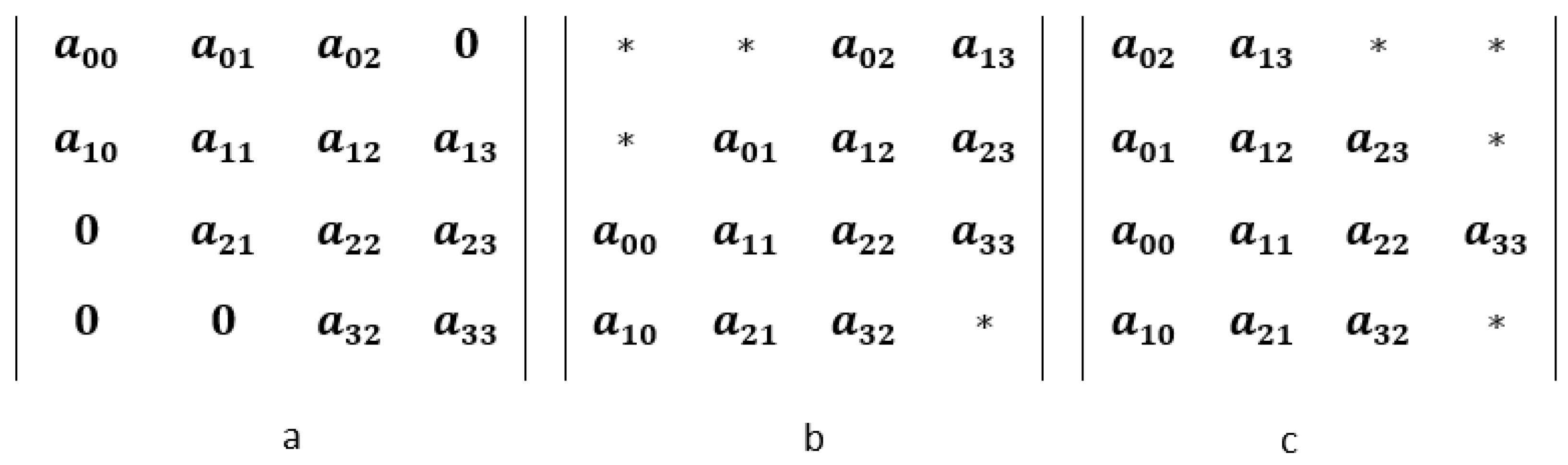


{kind=link}
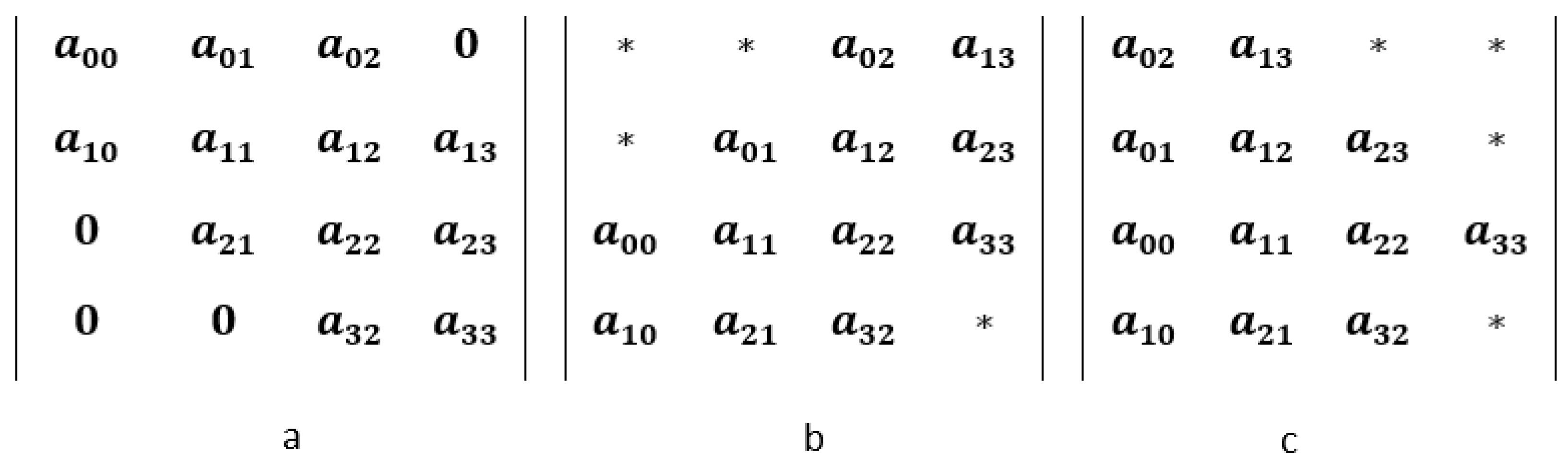{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Matrix | dgA, | dgB, | nzC | CPU | CUDA | Time |
|---|---|---|---|---|---|---|
| Size | nzA | nzB | (ms) | (ms) | Ratio | |
| 1000 | 9, 7446 | 5, 3968 | 33,824 | 4.33 | 0.16 | 27 |
| 2000 | 9, 15,003 | 15, 25,201 | 203,935 | 2.12 | 0.21 | 10 |
| 3000 | 29, 75,336 | 15, 39,207 | 990,791 | 11.66 | 0.39 | 30 |
| 4000 | 29, 97,958 | 35, 120,652 | 2,816,485 | 38.60 | 0.88 | 44 |
| 5000 | 59, 256,918 | 35, 150,005 | 6,625,325 | 99.52 | 1.89 | 52 |
| 6000 | 89, 473,743 | 75, 381,842 | 17,999,054 | 440.61 | 6.78 | 65 |
| 7000 | 99, 615,376 | 75, 451,559 | 23,585,358 | 560.69 | 8.92 | 63 |
| 8000 | 109, 767,508 | 35, 247,865 | 18,893,371 | 307.67 | 5.26 | 5 8 |
| 9000 | 59, 470,354 | 75, 593,612 | 24,161,386 | 444.00 | 7.09 | 63 |
| 10,000 | 109, 938,979 | 35, 310,455 | 24,738,090 | 365.51 | 6.34 | 58 |
| dgA, nzA | dgB, nzB | nzC | CPU | CUDA | Time |
|---|---|---|---|---|---|
| (ms) | (ms) | Ratio | |||
| 200, 1,746,454 | 200, 1,734,514 | 69,689,071 | 4812.40 | 66.62 | 72 |
| 300, 2,574,174 | 300, 2,599,683 | 76,317,794 | 11,031.72 | 141.86 | 78 |
| 400, 3,462,833 | 200, 3,499,657 | 75,463,181 | 19,733.96 | 241.23 | 82 |
| 500, 4,358,737 | 500, 4,372,825 | 75,504,513 | 31,817.91 | 358.39 | 89 |
| 600, 5,237,042 | 600, 5,233,209 | 75,281,188 | 46,549.84 | 468.83 | 99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haque, S.A.; Parvez, M.T.; Hossain, S. GPU Algorithms for Structured Sparse Matrix Multiplication with Diagonal Storage Schemes. Algorithms 2024, 17, 31. https://doi.org/10.3390/a17010031
Haque SA, Parvez MT, Hossain S. GPU Algorithms for Structured Sparse Matrix Multiplication with Diagonal Storage Schemes. Algorithms. 2024; 17(1):31. https://doi.org/10.3390/a17010031
Chicago/Turabian StyleHaque, Sardar Anisul, Mohammad Tanvir Parvez, and Shahadat Hossain. 2024. "GPU Algorithms for Structured Sparse Matrix Multiplication with Diagonal Storage Schemes" Algorithms 17, no. 1: 31. https://doi.org/10.3390/a17010031
APA StyleHaque, S. A., Parvez, M. T., & Hossain, S. (2024). GPU Algorithms for Structured Sparse Matrix Multiplication with Diagonal Storage Schemes. Algorithms, 17(1), 31. https://doi.org/10.3390/a17010031