
Predicting Online Item-Choice Behavior: A Shape-Restricted Regression Approach


Abstract
:1. Introduction
- We propose a shape-restricted optimization model for estimating item-choice probabilities from a user’s previous PV sequence. This PV sequence model exploits the monotonicity constraints to precisely estimate item-choice probabilities.
- We derive two types of PV sequence posets according to the recency and frequency of a user’s previous PVs. Experimental results show that the monotonicity constraints based on these posets greatly enhances the prediction performance of our PV sequence model.
- We devise constructive algorithms for transitive reduction specific to these posets. The time complexity of our algorithms is much smaller than that of general-purpose algorithms. Experimental results reveal that transitive reduction improves efficiency in terms of both the computation time and memory usage of our PV sequence model.
- We verify experimentally that higher prediction performance is achieved with our method than with the two-dimensional probability table and common machine learning methods, namely, logistic regression, artificial neural networks, and random forests.
2. Related Work
2.1. Prediction of Online User Behavior
2.2. Shape-Restricted Regression
3. Two-Dimensional Probability Table
3.1. Empirical Probability Table
3.2. Two-Dimensional Monotonicity Model
4. PV Sequence Model
4.1. PV Sequence
4.2. Operations Based on Recency and Frequency
4.3. Partially Ordered Sets
4.4. Shape-Restricted Optimization Model
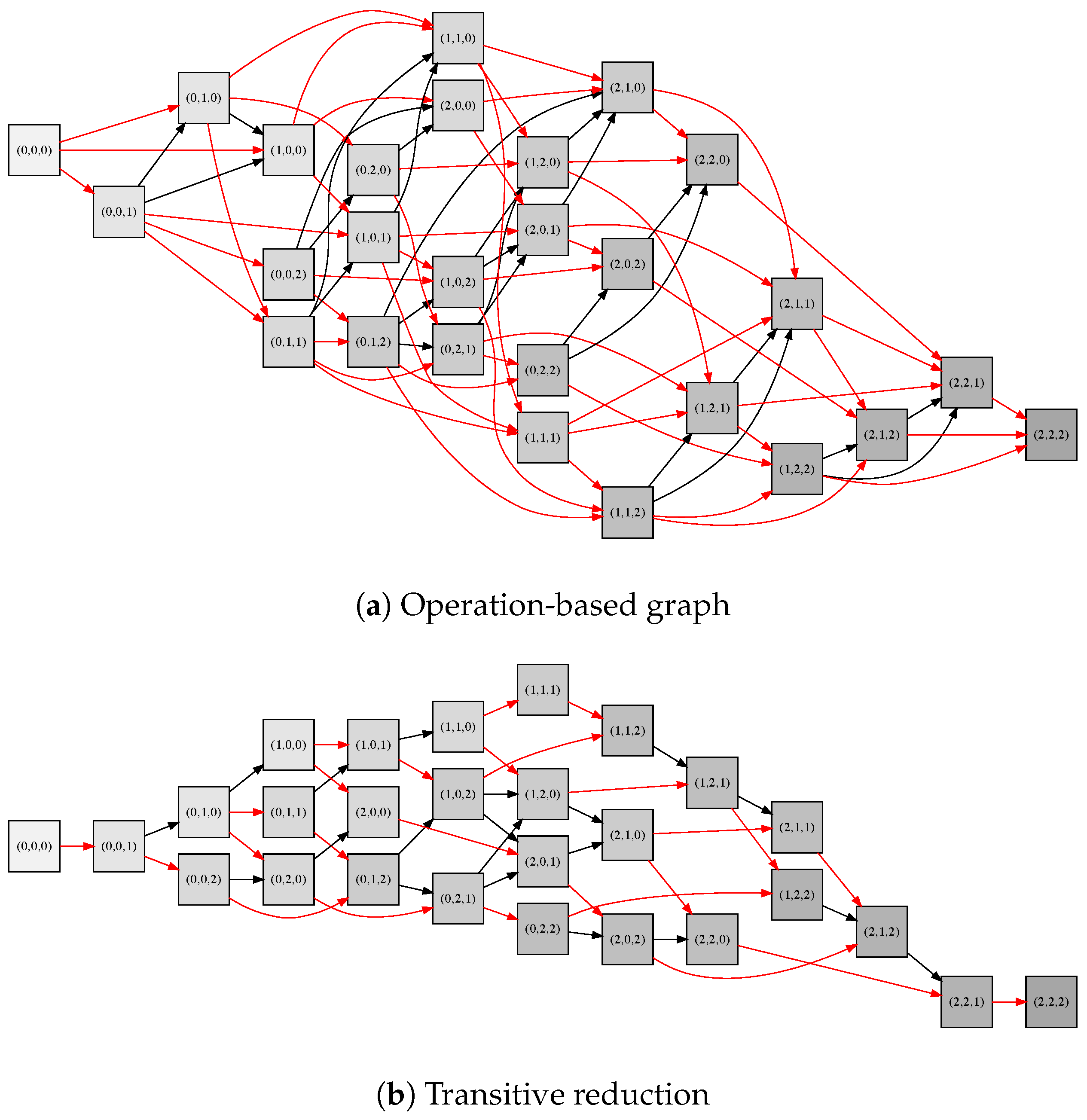
5. Algorithms for Transitive Reduction
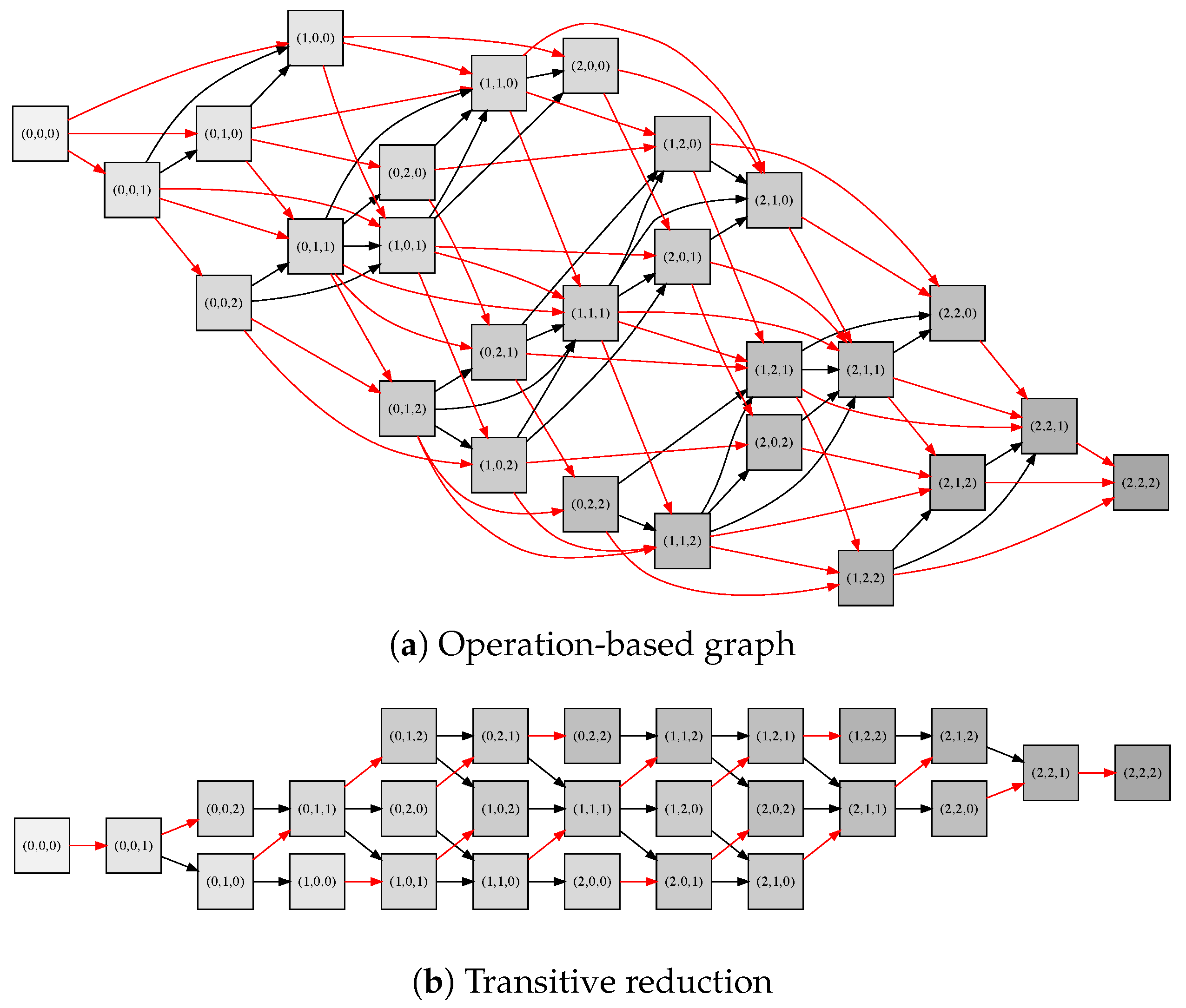
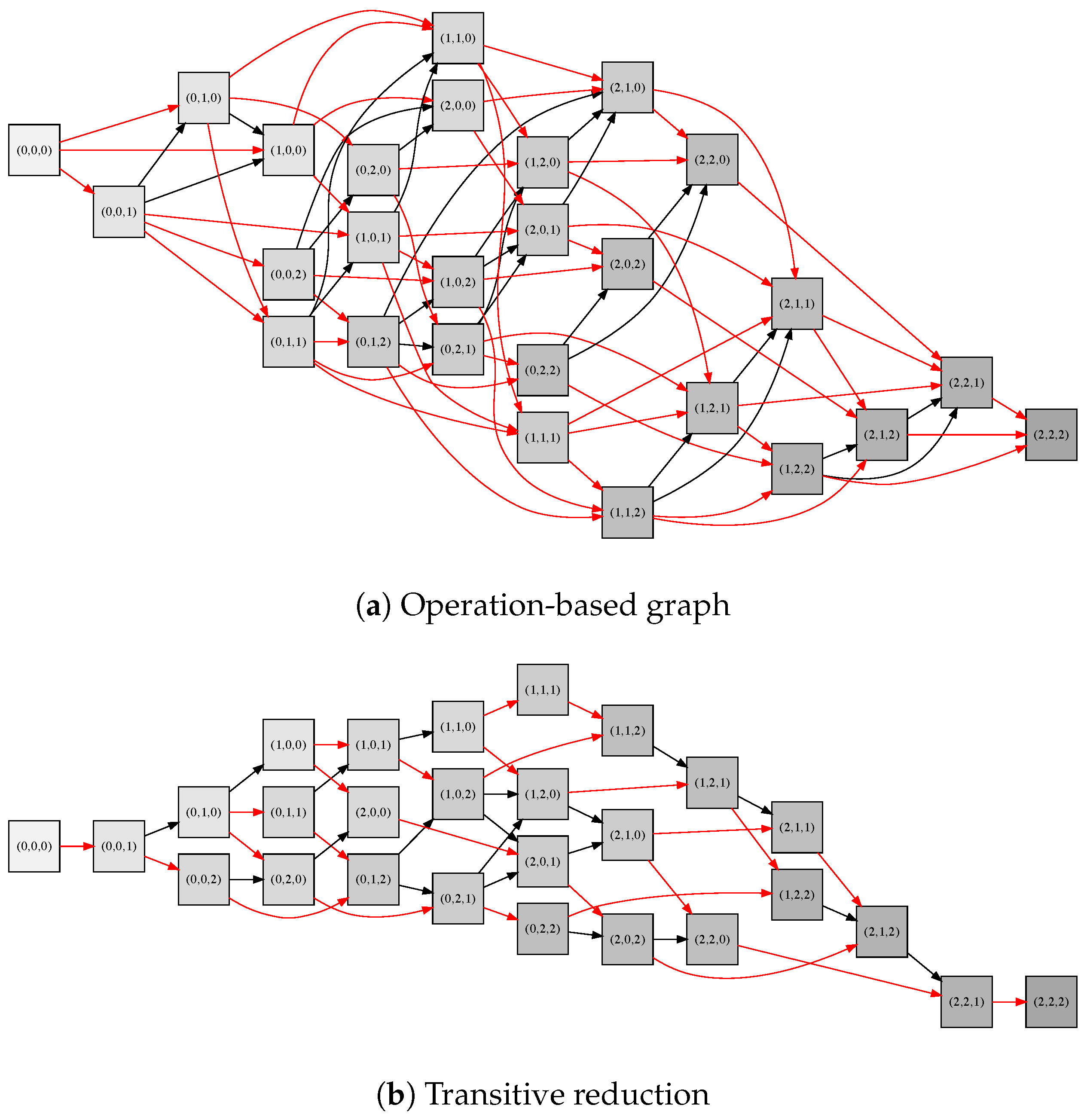
5.1. Transitive Reduction
5.2. General-Purpose Algorithms
- (C1)
- , and
- (C2)
- if satisfies , then .
- Step 1:
- An exhaustive directed graph is generated from a given poset .
- Step 2:
- The transitive reduction is computed from the directed graph using Lemma 2.
5.3. Constructive Algorithms
- (UM1)
- , or
- (UM2)
- there exists such that .
- (US1)
- there exists such that and for all , or
- (US2)
- there exists such that and for all .
6. Experiments
6.1. Methods for Comparison
6.2. Performance Evaluation Methodology
6.3. Effects of the Transitive Reduction
- Case 1 (Enumeration):
- All edges satisfying were enumerated.
- Case 2 (Operation):
- Case 3 (Reduction):
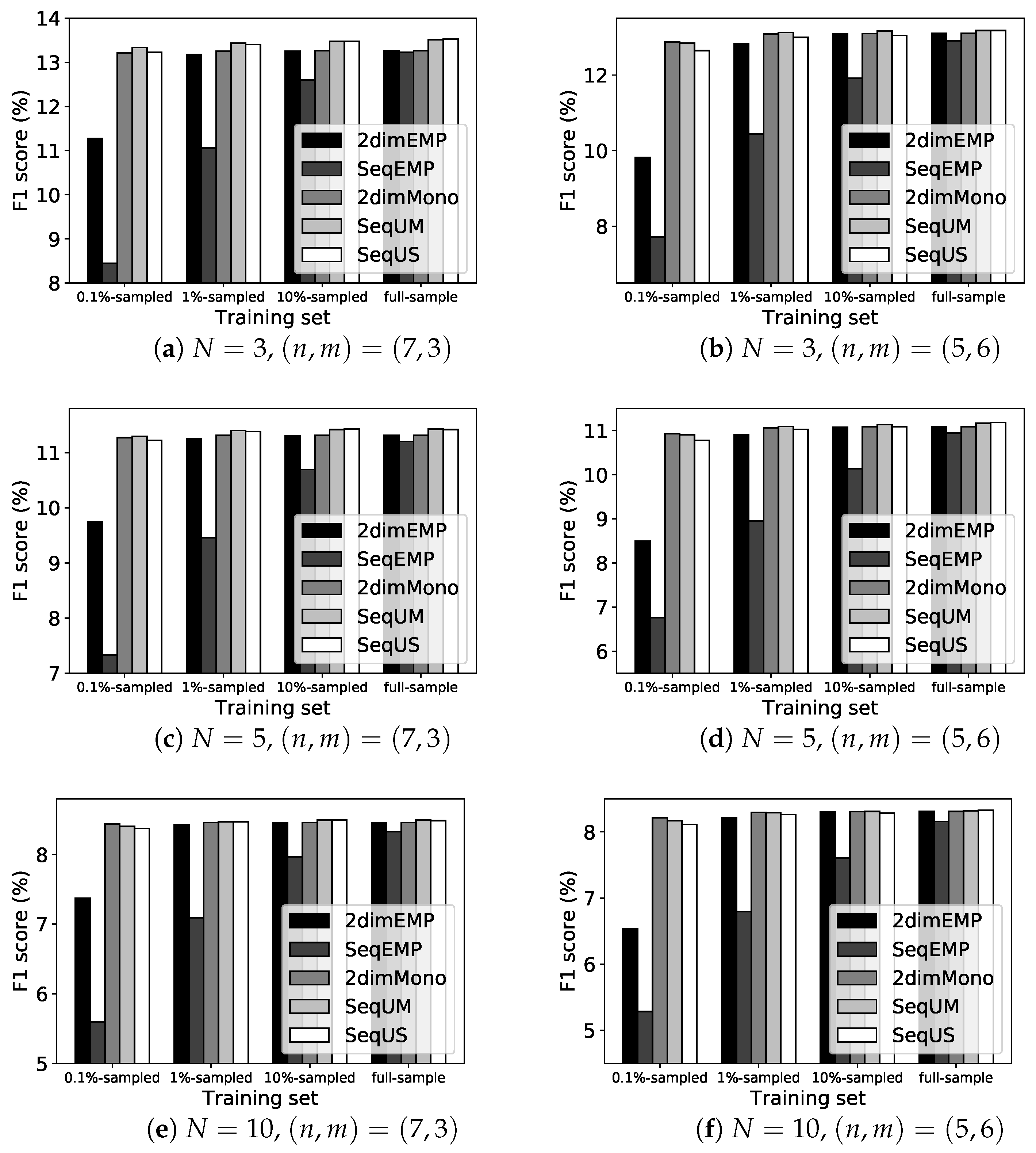
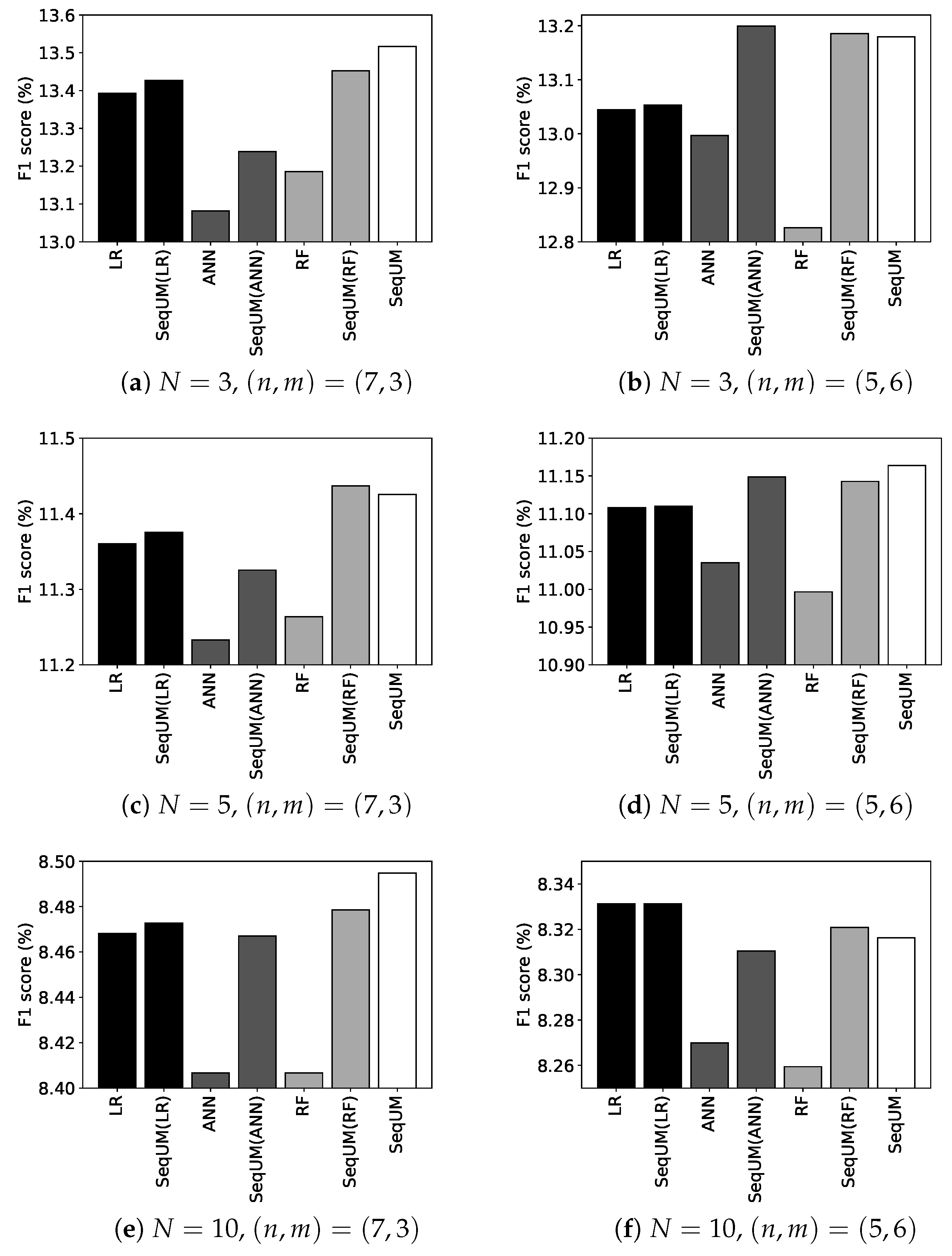
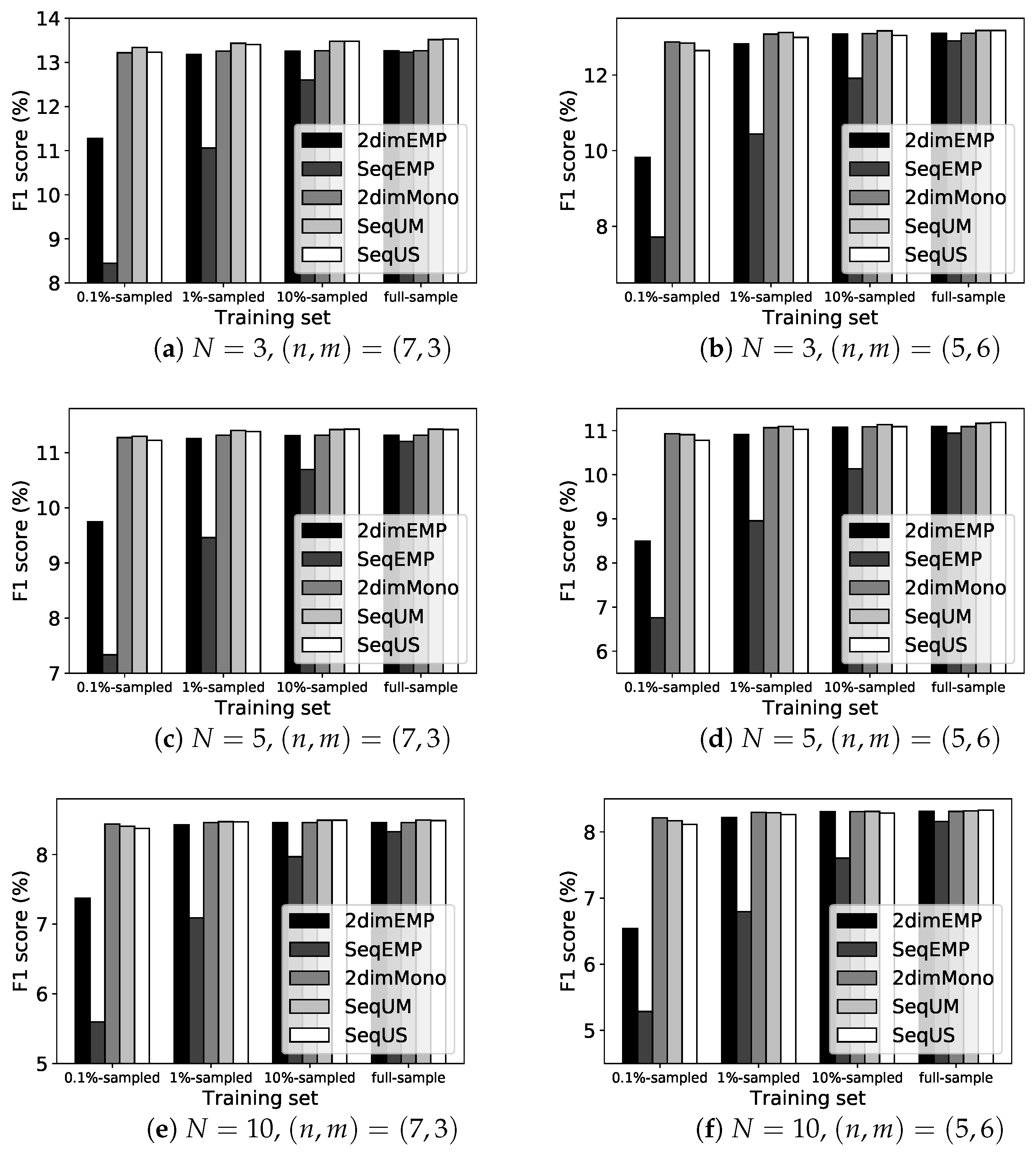
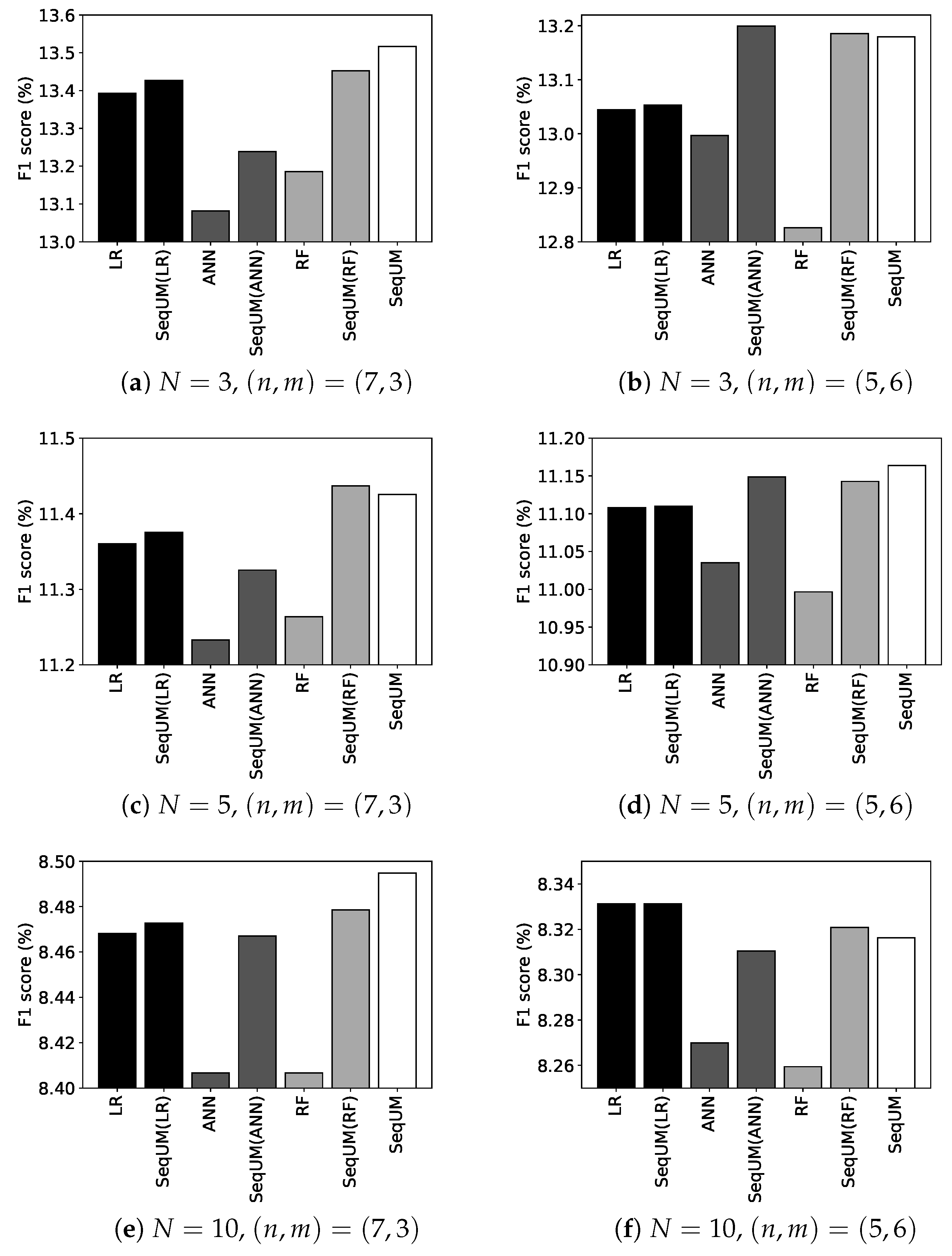
6.4. Prediction Performance of Our PV Sequence Model
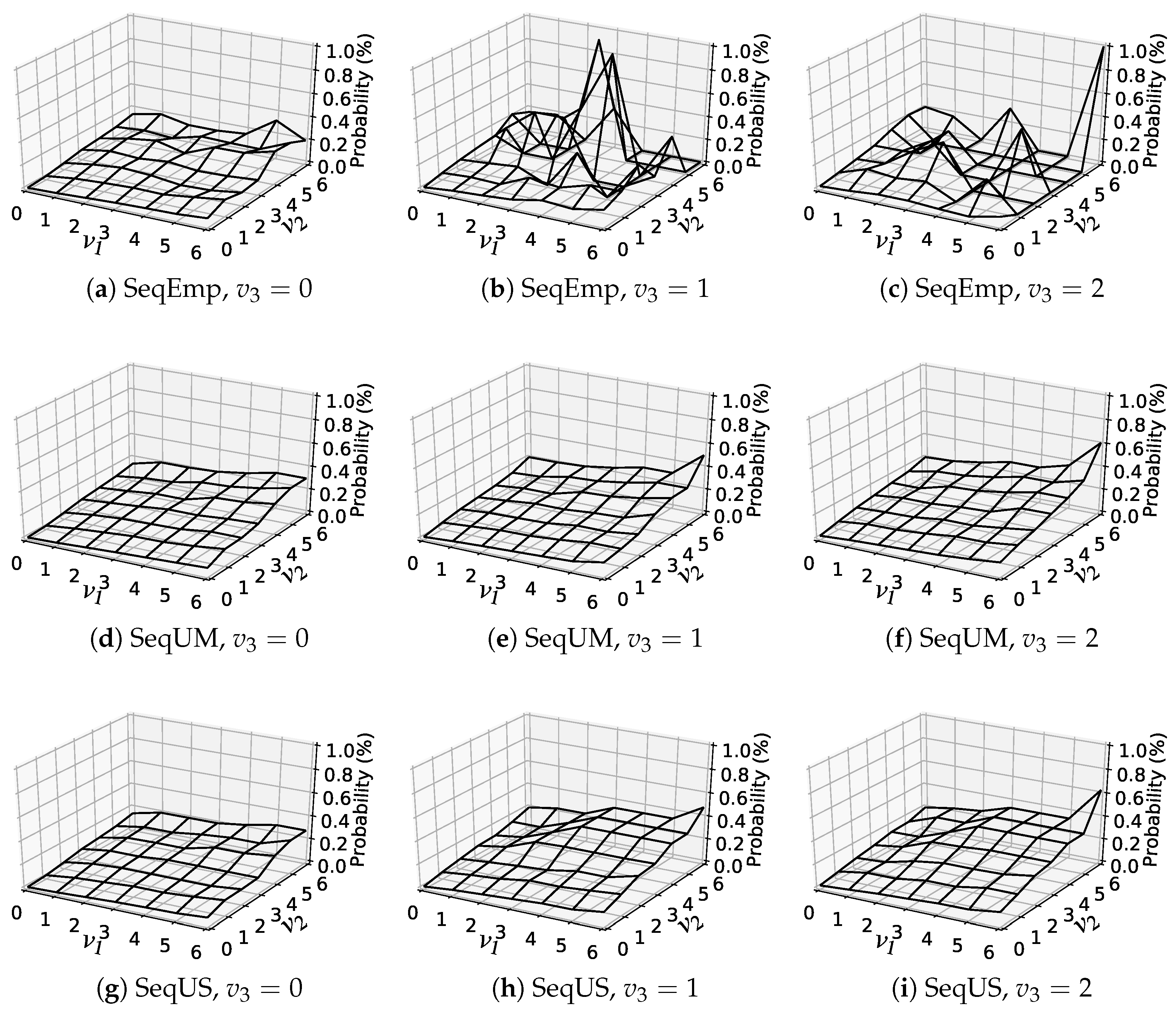
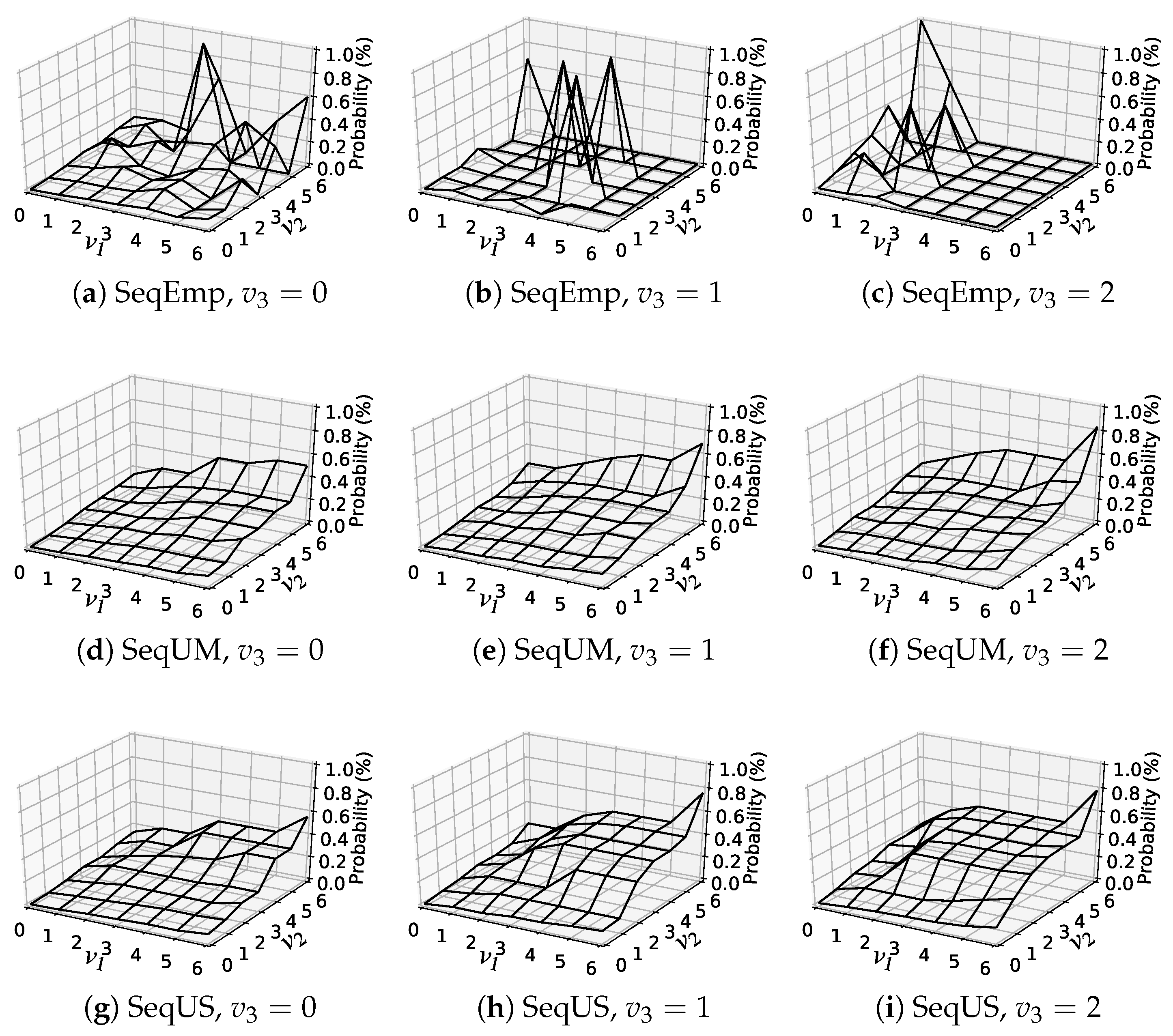
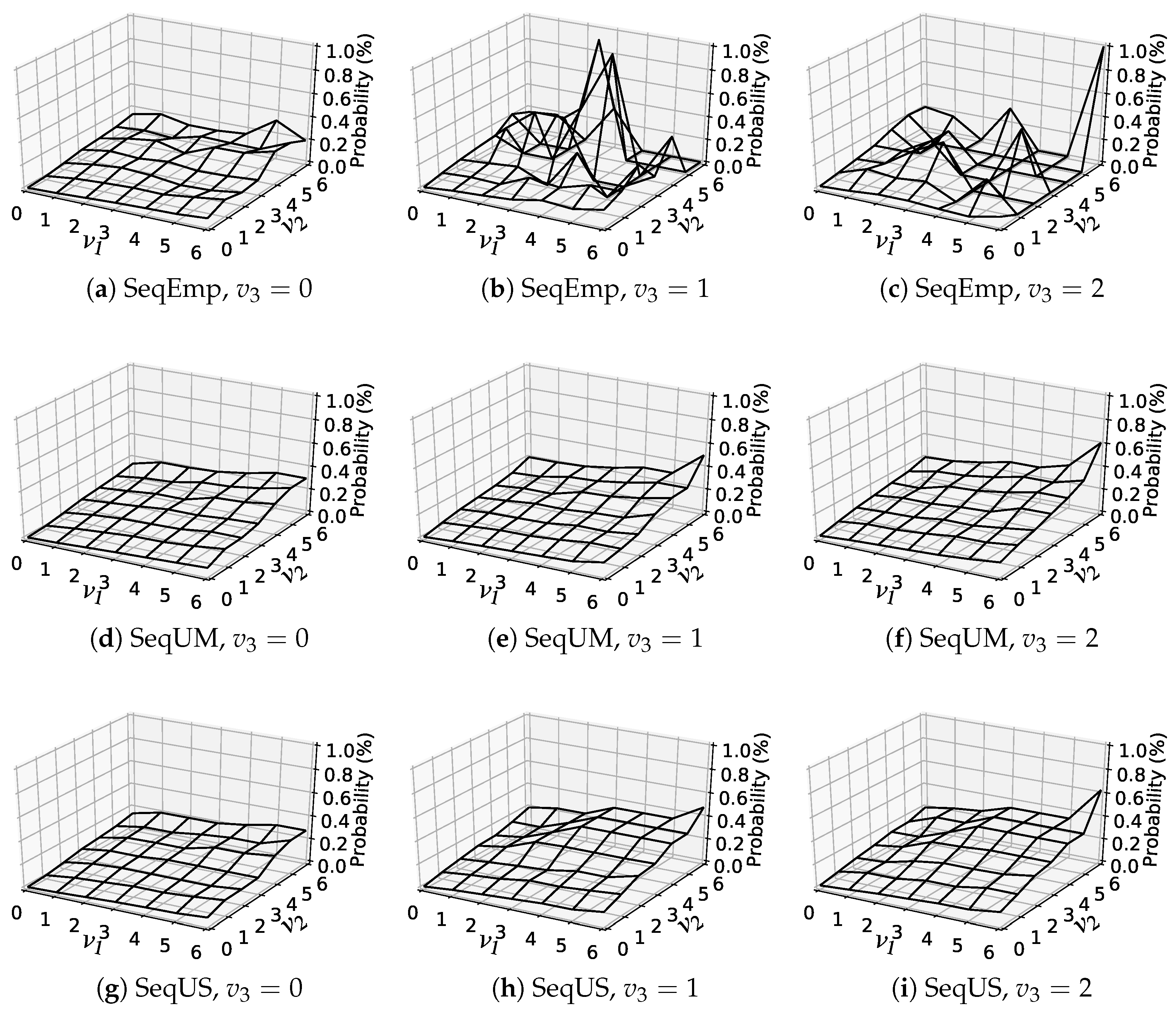
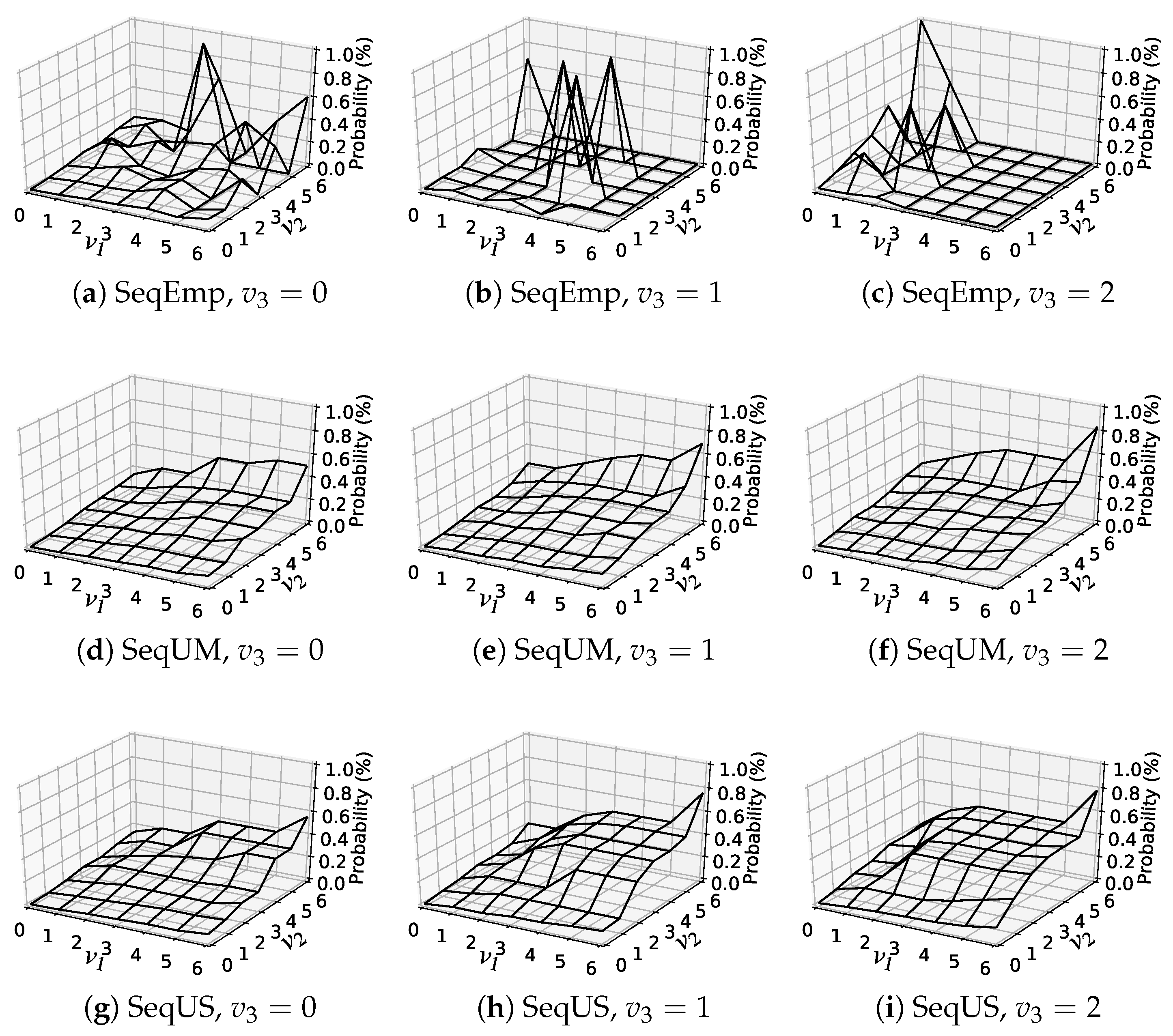
6.5. Analysis of Estimated Item-Choice Probabilities
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proofs
Appendix A.1. Proof of Theorem 3
Appendix A.1.1. The “Only if” Part
- Case 1:
- v = Up(u, s) for Some s ∈ [1, n]
- Case 2:
- v = Move(u, s, t) for Some (s, t) ∈ [1, n] × [1, n]
Appendix A.1.2. The “if” Part
- Case 1:
- Condition (UM1) Is Fulfilled
- Case 2:
- Condition (UM2) Is Fulfilled
Appendix A.2. Proof of Theorem 4
Appendix A.2.1. The “Only if” Part
- Case 1:
- v = Up(u, s) for Some s ∈ [1, n]
- Case 2:
- v = Swap(u, s, t) for Some (s, t) ∈ [1, n] × [1, n]
Appendix A.2.2. The “if” Part
- Case 1:
- Condition (US1) Is Fulfilled
- Case 2:
- Condition (US2) Is Fulfilled
Appendix B. Pseudocodes of Our Algorithms
Appendix B.1. Constructive Algorithm for (Γ,E UM * )
| Algorithm A1 Constructive algorithm for |
Input a pair of positive integers Output transitive reduction
|
Appendix B.2. Constructive Algorithm for (Γ,E US * )
| Algorithm A2 Constructive algorithm for |
Input: a pair of positive integers Output: the transitive reduction
|
References
- Turban, E.; Outland, J.; King, D.; Lee, J.K.; Liang, T.P.; Turban, D.C. Electronic Commerce 2018: A Managerial and Social Networks Perspective; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Kannan, P.; Li, H. Digital marketing: A framework, review and research agenda. Int. J. Res. Mark. 2017, 34, 22–45. [Google Scholar] [CrossRef]
- Ngai, E.W.; Xiu, L.; Chau, D.C. Application of data mining techniques in customer relationship management: A literature review and classification. Expert Syst. Appl. 2009, 36, 2592–2602. [Google Scholar] [CrossRef]
- Huang, T.; Van Mieghem, J.A. Clickstream data and inventory management: Model and empirical analysis. Prod. Oper. Manag. 2014, 23, 333–347. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Recommender Systems; Springer: Cham, Switzerland, 2016; Volume 1. [Google Scholar]
- Iwanaga, J.; Nishimura, N.; Sukegawa, N.; Takano, Y. Improving collaborative filtering recommendations by estimating user preferences from clickstream data. Electron. Commer. Res. Appl. 2019, 37, 100877. [Google Scholar] [CrossRef]
- Bucklin, R.E.; Sismeiro, C. Click here for Internet insight: Advances in clickstream data analysis in marketing. J. Interact. Mark. 2009, 23, 35–48. [Google Scholar] [CrossRef]
- Fader, P.S.; Hardie, B.G.; Lee, K.L. RFM and CLV: Using iso-value curves for customer base analysis. J. Mark. Res. 2005, 42, 415–430. [Google Scholar] [CrossRef]
- Van den Poel, D.; Buckinx, W. Predicting online-purchasing behaviour. Eur. J. Oper. Res. 2005, 166, 557–575. [Google Scholar] [CrossRef]
- Chen, Y.L.; Kuo, M.H.; Wu, S.Y.; Tang, K. Discovering recency, frequency, and monetary (RFM) sequential patterns from customers purchasing data. Electron. Commer. Res. Appl. 2009, 8, 241–251. [Google Scholar] [CrossRef]
- Iwanaga, J.; Nishimura, N.; Sukegawa, N.; Takano, Y. Estimating product-choice probabilities from recency and frequency of page views. Knowl.-Based Syst. 2016, 99, 157–167. [Google Scholar] [CrossRef]
- Nishimura, N.; Sukegawa, N.; Takano, Y.; Iwanaga, J. A latent-class model for estimating product-choice probabilities from clickstream data. Inf. Sci. 2018, 429, 406–420. [Google Scholar] [CrossRef]
- Aho, A.V.; Garey, M.R.; Ullman, J.D. The transitive reduction of a directed graph. SIAM J. Comput. 1972, 1, 131–137. [Google Scholar] [CrossRef]
- Cirqueira, D.; Hofer, M.; Nedbal, D.; Helfert, M.; Bezbradica, M. Customer purchase behavior prediction in e-commerce: A conceptual framework and research agenda. In Proceedings of the International Workshop on New Frontiers in Mining Complex Patterns, Würzburg, Germany, 16 September 2019; Springer: Cham, Switzerland, 2019; pp. 119–136. [Google Scholar]
- Baumann, A.; Haupt, J.; Gebert, F.; Lessmann, S. Changing perspectives: Using graph metrics to predict purchase probabilities. Expert Syst. Appl. 2018, 94, 137–148. [Google Scholar] [CrossRef]
- Koehn, D.; Lessmann, S.; Schaal, M. Predicting online shopping behaviour from clickstream data using deep learning. Expert Syst. Appl. 2020, 150, 113342. [Google Scholar] [CrossRef]
- Moe, W.W.; Fader, P.S. Dynamic conversion behavior at e-commerce sites. Manag. Sci. 2004, 50, 326–335. [Google Scholar] [CrossRef]
- Montgomery, A.L.; Li, S.; Srinivasan, K.; Liechty, J.C. Modeling online browsing and path analysis using clickstream data. Mark. Sci. 2004, 23, 579–595. [Google Scholar] [CrossRef]
- Park, C.H.; Park, Y.H. Investigating purchase conversion by uncovering online visit patterns. Mark. Sci. 2016, 35, 894–914. [Google Scholar] [CrossRef]
- Sismeiro, C.; Bucklin, R.E. Modeling purchase behavior at an e-commerce web site: A task-completion approach. J. Mark. Res. 2004, 41, 306–323. [Google Scholar] [CrossRef]
- Dong, Y.; Jiang, W. Brand purchase prediction based on time-evolving user behaviors in e-commerce. Concurr. Comput. Pract. Exp. 2019, 31, e4882. [Google Scholar] [CrossRef]
- Zhang, Y.; Pennacchiotti, M. Predicting purchase behaviors from social media. In Proceedings of the International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1521–1532. [Google Scholar]
- Pitman, A.; Zanker, M. Insights from applying sequential pattern mining to e-commerce click stream data. In Proceedings of the 2010 IEEE International Conference on Data Mining Workshops, Sydney, Australia, 13 December 2010; pp. 967–975. [Google Scholar]
- Qiu, J.; Lin, Z.; Li, Y. Predicting customer purchase behavior in the e-commerce context. Electron. Commer. Res. 2015, 15, 427–452. [Google Scholar] [CrossRef]
- Li, Q.; Gu, M.; Zhou, K.; Sun, X. Multi-classes feature engineering with sliding window for purchase prediction in mobile commerce. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 1048–1054. [Google Scholar]
- Li, D.; Zhao, G.; Wang, Z.; Ma, W.; Liu, Y. A method of purchase prediction based on user behavior log. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 1031–1039. [Google Scholar]
- Romov, P.; Sokolov, E. RecSys challenge 2015: Ensemble learning with categorical features. In Proceedings of the 2015 International ACM Recommender Systems Challenge, Vienna, Austria, 16–20 September 2015; pp. 1–4. [Google Scholar]
- Yi, Z.; Wang, D.; Hu, K.; Li, Q. Purchase behavior prediction in m-commerce with an optimized sampling methods. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 1085–1092. [Google Scholar]
- Zhao, Y.; Yao, L.; Zhang, Y. Purchase prediction using Tmall-specific features. Concurr. Comput. Pract. Exp. 2016, 28, 3879–3894. [Google Scholar] [CrossRef]
- Jannach, D.; Ludewig, M.; Lerche, L. Session-based item recommendation in e-commerce: On short-term intents, reminders, trends and discounts. User Model. User-Adapt. Interact. 2017, 27, 351–392. [Google Scholar] [CrossRef]
- Vieira, A. Predicting online user behaviour using deep learning algorithms. arXiv 2015, arXiv:1511.06247. [Google Scholar]
- Wu, Z.; Tan, B.H.; Duan, R.; Liu, Y.; Mong Goh, R.S. Neural modeling of buying behaviour for e-commerce from clicking patterns. In Proceedings of the 2015 International ACM Recommender Systems Challenge, Vienna, Austria, 16–20 September 2015; pp. 1–4. [Google Scholar]
- Moe, W.W. An empirical two-stage choice model with varying decision rules applied to internet clickstream data. J. Mark. Res. 2006, 43, 680–692. [Google Scholar] [CrossRef]
- Yeo, J.; Kim, S.; Koh, E.; Hwang, S.w.; Lipka, N. Predicting online purchase conversion for retargeting. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 591–600. [Google Scholar]
- Borges, J.; Levene, M. Evaluating variable-length Markov chain models for analysis of user web navigation sessions. IEEE Trans. Knowl. Data Eng. 2007, 19, 441–452. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph neural networks in recommender systems: A survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Huang, C.; Wu, X.; Zhang, X.; Zhang, C.; Zhao, J.; Yin, D.; Chawla, N.V. Online purchase prediction via multi-scale modeling of behavior dynamics. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2613–2622. [Google Scholar]
- Li, Z.; Xie, H.; Xu, G.; Li, Q.; Leng, M.; Zhou, C. Towards purchase prediction: A transaction-based setting and a graph-based method leveraging price information. Pattern Recognit. 2021, 113, 107824. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Li, Y.; Yao, L.; An, J.; Bai, L.; Lim, E.P. Face to purchase: Predicting consumer choices with structured facial and behavioral traits embedding. Knowl.-Based Syst. 2022, 235, 107665. [Google Scholar] [CrossRef]
- Sun, Y. E-commerce purchase prediction based on graph neural networks. In Proceedings of the 2022 International Conference on Information Technology, Communication Ecosystem and Management (ITCEM), Bangkok, Thailand, 19–21 December 2022; pp. 72–75. [Google Scholar]
- Matzkin, R.L. Semiparametric estimation of monotone and concave utility functions for polychotomous choice models. Econom. J. Econom. Soc. 1991, 59, 1315–1327. [Google Scholar] [CrossRef]
- Aıt-Sahalia, Y.; Duarte, J. Nonparametric option pricing under shape restrictions. J. Econom. 2003, 116, 9–47. [Google Scholar] [CrossRef]
- Chatterjee, S.; Guntuboyina, A.; Sen, B. On risk bounds in isotonic and other shape restricted regression problems. Ann. Stat. 2015, 43, 1774–1800. [Google Scholar] [CrossRef]
- Groeneboom, P.; Jongbloed, G. Nonparametric Estimation under Shape Constraints; Cambridge University Press: Cambridge, UK, 2014; Volume 38. [Google Scholar]
- Guntuboyina, A.; Sen, B. Nonparametric shape-restricted regression. Stat. Sci. 2018, 33, 568–594. [Google Scholar] [CrossRef]
- Wang, J.; Ghosh, S.K. Shape restricted nonparametric regression with Bernstein polynomials. Comput. Stat. Data Anal. 2012, 56, 2729–2741. [Google Scholar] [CrossRef]
- Pardalos, P.M.; Xue, G. Algorithms for a class of isotonic regression problems. Algorithmica 1999, 23, 211–222. [Google Scholar] [CrossRef]
- Gaines, B.R.; Kim, J.; Zhou, H. Algorithms for fitting the constrained lasso. J. Comput. Graph. Stat. 2018, 27, 861–871. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R.J.; Hoefling, H.; Tibshirani, R. Nearly-isotonic regression. Technometrics 2011, 53, 54–61. [Google Scholar] [CrossRef]
- Han, Q.; Wang, T.; Chatterjee, S.; Samworth, R.J. Isotonic regression in general dimensions. Ann. Stat. 2019, 47, 2440–2471. [Google Scholar] [CrossRef]
- Stout, Q.F. Isotonic regression for multiple independent variables. Algorithmica 2015, 71, 450–470. [Google Scholar] [CrossRef]
- Altendorf, E.E.; Restificar, A.C.; Dietterich, T.G. Learning from sparse data by exploiting monotonicity constraints. In Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence, Edinburgh, UK, 26–29 July 2005; pp. 18–26. [Google Scholar]
- Schröder, B. Ordered Sets: An Introduction with Connections from Combinatorics to Topology; Birkhäuser: Basel, Switzerland, 2016. [Google Scholar]
- Warshall, S. A theorem on boolean matrices. J. ACM 1962, 9, 11–12. [Google Scholar] [CrossRef]
- Le Gall, F. Powers of tensors and fast matrix multiplication. In Proceedings of the 39th International Symposium on Symbolic and Algebraic Computation, Kobe, Japan, 23–25 July 2014; pp. 296–303. [Google Scholar]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Ludewig, M.; Jannach, D. Evaluation of session-based recommendation algorithms. User Model. User-Adapt. Interact. 2018, 28, 331–390. [Google Scholar] [CrossRef]
- Stellato, B.; Banjac, G.; Goulart, P.; Bemporad, A.; Boyd, S. OSQP: An operator splitting solver for quadratic programs. Math. Program. Comput. 2020, 12, 637–672. [Google Scholar] [CrossRef]
- Orzechowski, P.; La Cava, W.; Moore, J.H. Where are we now? A large benchmark study of recent symbolic regression methods. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018; pp. 1183–1190. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #PVs | Choice | |||||||
|---|---|---|---|---|---|---|---|---|
| User | Item | 1 April | 2 April | 3 April | 4 April | |||
| 1 | 0 | 1 | 0 | |||||
| 0 | 1 | 0 | 1 | |||||
| 3 | 0 | 0 | 0 | |||||
| 0 | 0 | 3 | 1 | |||||
| 1 | 1 | 1 | 0 | |||||
| 2 | 0 | 1 | 0 | |||||
| u | Operation | v | (UM1) | (UM2) |
|---|---|---|---|---|
| unsatisfied | — | |||
| satisfied | — | |||
| — | satisfied | |||
| — | unsatisfied |
| u | Operation | v | (US1) | (US2) |
|---|---|---|---|---|
| unsatisfied | — | |||
| satisfied | — | |||
| — | satisfied | |||
| — | satisfied |
| Abbreviation | Method |
|---|---|
| 2dimEmp | Empirical probability table (1) [11] |
| 2dimMono | Two-dimensional monotonicity model (2)–(5) [11] |
| SeqEmp | Empirical probabilities (6) for PV sequences |
| SeqUM | Our PV sequence model (7)–(9) using |
| SeqUS | Our PV sequence model (7)–(9) using |
| LR | -regularized logistic regression |
| ANN | Artificial neural networks for regression using |
| one fully-connected hidden layer of 100 units | |
| RF | Random forest of regression trees |
| Training | |||
|---|---|---|---|
| Pair ID | Start | End | Validation |
| 1 | 21 May 2015 | 18 August 2015 | 19 August 2015 |
| 2 | 31 May 2015 | 28 August 2015 | 29 August 2015 |
| 3 | 10 June 2015 | 7 September 2015 | 8 September 2015 |
| 4 | 20 June 2015 | 17 September 2015 | 18 September 2015 |
| 5 | 30 June 2015 | 27 September 2015 | 28 September 2015 |
| #Cons in Equation (8) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Enumeration | Operation | Reduction | ||||||||
| #Vars | SeqUM | SeqUS | SeqUM | SeqUS | SeqUM | SeqUS | ||||
| 5 | 1 | 32 | 430 | 430 | 160 | 160 | 48 | 48 | ||
| 5 | 2 | 243 | 21,383 | 17,945 | 1890 | 1620 | 594 | 634 | ||
| 5 | 3 | 1024 | 346,374 | 255,260 | 9600 | 7680 | 3072 | 3546 | ||
| 5 | 4 | 3125 | 3,045,422 | 2,038,236 | 32,500 | 25,000 | 10,500 | 12,898 | ||
| 5 | 5 | 7776 | 18,136,645 | 11,282,058 | 86,400 | 64,800 | 28,080 | 36,174 | ||
| 5 | 6 | 16,807 | 82,390,140 | 48,407,475 | 195,510 | 144,060 | 63,798 | 85,272 | ||
| 1 | 6 | 7 | 21 | 21 | 6 | 6 | 6 | 6 | ||
| 2 | 6 | 49 | 1001 | 861 | 120 | 105 | 78 | 93 | ||
| 3 | 6 | 343 | 42,903 | 32,067 | 1638 | 1323 | 798 | 1018 | ||
| 4 | 6 | 2401 | 1,860,622 | 1,224,030 | 18,816 | 14,406 | 7350 | 9675 | ||
| 5 | 6 | 16,807 | 82,390,140 | 48,407,475 | 195,510 | 144,060 | 63,798 | 85,272 | ||
| Time [s] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Enumeration | Operation | Reduction | ||||||||
| #Vars | SeqUM | SeqUS | SeqUM | SeqUS | SeqUM | SeqUS | ||||
| 5 | 1 | 32 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | ||
| 5 | 2 | 243 | 2.32 | 1.66 | 0.09 | 0.07 | 0.03 | 0.02 | ||
| 5 | 3 | 1024 | 558.22 | 64.35 | 3.41 | 0.71 | 0.13 | 0.26 | ||
| 5 | 4 | 3125 | OM | OM | 24.07 | 13.86 | 1.72 | 5.80 | ||
| 5 | 5 | 7776 | OM | OM | 180.53 | 67.34 | 9.71 | 36.94 | ||
| 5 | 6 | 16,807 | OM | OM | 906.76 | 522.84 | 86.02 | 286.30 | ||
| 1 | 6 | 7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ||
| 2 | 6 | 49 | 0.03 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 | ||
| 3 | 6 | 343 | 12.80 | 1.68 | 0.20 | 0.03 | 0.05 | 0.02 | ||
| 4 | 6 | 2401 | OM | OM | 8.07 | 4.09 | 2.12 | 2.87 | ||
| 5 | 6 | 16,807 | OM | OM | 906.76 | 522.84 | 86.02 | 286.30 | ||
| #Cons in Equation (8) | Time [s] | F1 Score [%], | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| #Vars | SeqUM | SeqUS | SeqUM | SeqUS | SeqEmp | SeqUM | SeqUS | ||||
| 3 | 30 | 29,791 | 84,630 | 118,850 | 86.72 | 241.46 | 12.25 | 12.40 | 12.40 | ||
| 4 | 12 | 28,561 | 99,372 | 142,800 | 198.82 | 539.76 | 12.68 | 12.93 | 12.95 | ||
| 5 | 6 | 16,807 | 63,798 | 85,272 | 86.02 | 286.30 | 12.90 | 13.18 | 13.18 | ||
| 6 | 4 | 15,625 | 62,500 | 76,506 | 62.92 | 209.67 | 13.14 | 13.49 | 13.48 | ||
| 7 | 3 | 16,384 | 67,584 | 76,818 | 96.08 | 254.31 | 13.23 | 13.52 | 13.53 | ||
| 8 | 2 | 6561 | 24,786 | 25,879 | 19.35 | 17.22 | 13.11 | 13.37 | 13.35 | ||
| 9 | 2 | 19,683 | 83,106 | 86,386 | 244.15 | 256.42 | 13.07 | 13.40 | 13.37 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nishimura, N.; Sukegawa, N.; Takano, Y.; Iwanaga, J. Predicting Online Item-Choice Behavior: A Shape-Restricted Regression Approach. Algorithms 2023, 16, 415. https://doi.org/10.3390/a16090415
Nishimura N, Sukegawa N, Takano Y, Iwanaga J. Predicting Online Item-Choice Behavior: A Shape-Restricted Regression Approach. Algorithms. 2023; 16(9):415. https://doi.org/10.3390/a16090415
Chicago/Turabian StyleNishimura, Naoki, Noriyoshi Sukegawa, Yuichi Takano, and Jiro Iwanaga. 2023. "Predicting Online Item-Choice Behavior: A Shape-Restricted Regression Approach" Algorithms 16, no. 9: 415. https://doi.org/10.3390/a16090415
APA StyleNishimura, N., Sukegawa, N., Takano, Y., & Iwanaga, J. (2023). Predicting Online Item-Choice Behavior: A Shape-Restricted Regression Approach. Algorithms, 16(9), 415. https://doi.org/10.3390/a16090415