1. Introduction
Scheduling is an important tool for manufacturers and production engineers since it deals with the allocation of human and machine resources to satisfy consumer demand. The objective is to monitor and optimize workloads, as well as to reduce production time and costs while adhering to all production constraints.
In traditional scheduling problems and models, job processing times are assumed to be a constant value. However, this hypothesis is not suitable for many realistic situations in which the job processing time may change owing to job deterioration and/or learning effect phenomena. Indeed, when the employees execute the same task repeatedly, they learn how to perform more efficiently. On the other hand, machines wear out after long periods of processing. Therefore, recent trends in scheduling theory have focused on modeling real-world production scheduling problems where human learning, as well as machine deteriorating effects, are taken into account when studying scheduling problems [
1,
2]. The learning effect [
3] is a natural human-oriented phenomenon appearing among operators after repeating similar tasks frequently. They gain experience and the execution time decreases accordingly. Ref. [
4] proposed the first modeling of this phenomenon with a learning curve and since then, multiple models have been proposed in the literature. Refs. [
3,
5] were among the pioneers that investigated the learning effect in scheduling problems, and this was continued in the literature in hundreds of studies with different machine configurations [
6,
7]. On the other hand, the deteriorating effect [
8,
9] is a machine-oriented phenomenon appearing after processing tasks are conducted on machines for a long time. The machine performances wear out and therefore additional delays are required to execute the production schedule. Refs. [
8,
10] seem to be the first to have investigated this effect in production scheduling. The interested reader can find extensive surveys of different scheduling models and problems involving deteriorating jobs in [
11,
12]. More recently, Ref. [
13] presented an updated survey of the results on scheduling problems with deteriorating jobs and time-dependent processing times. As for learning and/or deterioration effects, Ref. [
7] reviews the mathematical models for scheduling problems. It is worth noting that most proposed learning or deteriorating effects functions are either position-dependent, time-dependent, or sum-of-processing-times-dependent [
6,
13,
14].
To counter the deteriorating effect, increase machines’ availability, and reduce the overall production costs, maintenance activities should be planned along the production process [
15]. However, unavailability periods for machines appear since the maintenance activities may take up a potential production time that could otherwise be allocated to completing production tasks. Therefore, to compensate for this deficiency, maintenance tasks should be scheduled in an effective way to improve machine availability and minimize disruption to the production process [
16]. Ref. [
17] established that appropriate maintenance planning can preserve machine performance and save 20–30% of total operating costs.
Recently, maintenance strategies have moved towards a smart aspect. In fact, modern sensor, diagnosis, and prognostic and health management (PHM) technologies allow the ideal planning of interventions and reduce inopportune spending. Simply put, signals gathered from embedded sensors (or inspection information) are analyzed in order to continuously (or periodically) monitor the health state of the production system. Following that, the current state is inferred and the future progression till failure is predicted in order to estimate the time left before the occurrence of failure, known as the remaining useful life (RUL) [
18]. Then, the PHM outputs (i.e, RUL) are exploited in the decision making that concerns maintenance planning. The main advantage of this strategy, namely the decision making based on prognosis information, which is referred to as a post-prognostic decision (PPD) [
19], is that it maintains the system only when necessary, which reduces the cost of inopportune maintenance interventions.
The current PPD research on scheduling problems is focused on two main streams. First, the intent is to make the best PPD regarding maintenance planning. In order to improve maintenance planning, PHM findings are thus used [
20,
21,
22,
23]. On the other hand, the second stream looks into the issue of integrating production jobs and maintenance operations when making decisions. This can help to avoid production downtime and improve system availability by establishing the most appropriate integrated production and maintenance schedule [
16,
18,
24,
25,
26,
27].
Metaheuristics have emerged as a common solution approach for scheduling in industry and manufacturing due to the fact that most problems are computationally hard [
28]. Recently, bio-inspired metaheuristics, including evolutionary algorithms and swarm intelligence algorithms, have become increasingly popular [
29]. Evolutionary algorithms start with a set of random candidate solutions and iteratively generate descendant solutions until an acceptable one is found. Common metaheuristics in this category that have many applications in scheduling problems are genetic algorithms [
30,
31], the differential evolution algorithm [
32], and more recently, biogeography-based optimization (BBO) [
33]. Swarm Intelligence is an advanced artificial intelligence discipline that uses the behavior of living swarms such as ants, bees, butterflies, and birds to solve complex problems [
34]. Several metaheuristics in this category have been applied to solve scheduling problems such as Ant Colony Optimization (ACO) [
35], Particle Swarm Optimization (PSO) [
36], and more recently, Grey Wolf Optimization (GWO [
37]). The artificial bee colony (ABC) algorithm [
38], which has recently been introduced to formulate NP-hard problems, simulates the social behavior of bees when searching for promising food sources associated with higher nectar amounts. The ABC algorithm has been extensively applied to solve various flowshop scheduling problems [
39,
40,
41]. On the other hand, machine learning (ML) is an expansive field within artificial intelligence that has gained significant popularity due to its straightforward algorithms, enabling programs to learn patterns, behaviors, models, and functions. This acquired knowledge is then utilized to enhance future decision making and actions. ML can be categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning. In recent years, reinforcement learning (RL) methods have been applied to machine scheduling problems [
42]. It is noteworthy that among scheduling problems, jobshop scheduling, flowshop scheduling, unrelated parallel machine scheduling, and single-machine scheduling have emerged as the most extensively studied ones [
42].
While integrating maintenance decisions in production scheduling problems makes existing models and solution methods more realistic, it also increases their complexity. Furthermore, incorporating effects further increases the problem’s complexity. Additionally, while most research on deteriorating jobs and learning effects has focused on single-machine problems [
1], it is the multimachine problems that are more interesting and closer to real-world problems. Therefore, the intent of this paper is to explore the permutation flowshop scheduling problem (PFSP) with flexible maintenance under learning and deteriorating effects, through the perspective of reinforcement learning algorithms. In this regard, we propose two Q-learning (QL)-driven artificial bee colony (ABC) algorithms to solve the defined PFSP with only the learning effect and the defined PFSP with simultaneous consideration of learning and deteriorating effects. The main advantages of the proposed hybrid metaheuristic approaches are the following:
- 1.
To be close to realistic production workshops, we propose a novel interpretation of PHM outputs, where RULs and degradation values are estimated based on the operating conditions of machines during the processing of production jobs;
- 2.
The use of the QL algorithm, one of the major RL algorithms, to guide the search process in the employed bees phase of the ABC algorithms;
- 3.
The design of a new heuristic, named INEH, based on the hybridization of the NEH heuristic [
43] and maintenance insertion heuristic [
44] concepts, to generate initial solutions of good quality;
- 4.
A maintenance cost function to be optimized when readjusting maintenance emplacements after being perturbed in employed and onlooker bees phases;
The remainder of this paper is organized as follows. A literature review and the research gaps are given in
Section 2. The problem formulation and objective function are provided in
Section 3.
Section 4 details the proposed ABC-based solving approaches.
Section 5 discusses the performance analyses and presents our computational results. Finally, some conclusions and future works are discussed in
Section 6.
3. Integrated Problem Description and Effects Mathematical Models
In this section, we first describe the integrated permutation flowshop scheduling problem (PFSP) with flexible maintenance that we are dealing with. We focus on the variable duration of maintenance and job processing times due to learning and deteriorating effects. Furthermore, the assumptions made in this paper are provided. Finally, we discuss the most salient aspects of learning and deteriorating effects. The following notations are used for the remainder of this paper:
| J | indicates a set of production jobs to be processed. |
| j | indicates the index of a job in the set J (). |
| indicates the ith machine, i is used as the machine index (). |
| indicates the number of planned maintenance operations on machine i. |
| indicates the planned maintenance operation on machine i at the cth position, where c is used as the maintenance position indicator (). |
| indicates the normal processing time of job j on machine i. |
| is the time-dependent deteriorating processing time of job j on machine i, where t is its start time. |
| is the deteriorating index. |
| is the normal time of the cth maintenance on machine i. |
| is the position-dependent learning time of the cth maintenance on machine i. |
| is the learning index. |
| indicates the degradation of machine i after processing the job j. |
| indicates a subset of J with jobs where . |
| indicates the total completion time. |
3.1. The Integrated Scheduling of Production and Maintenance Problem
The PFSP is one of the most thoroughly studied scheduling problems in the operation research literature. Many production scheduling problems resemble a flowshop, and therefore, it has been extensively studied due to its application in industry [
68].
Formally, the PFSP can be described as follows. A set of n independent jobs needs to be processed on a set of m independent machines in the same order on the m machines. We assume that all jobs are available at time zero and no preemption is allowed. In order to ensure the system’s reliability and to prevent the occurrence of fatal breakdowns during the processing horizon, machines are monitored continuously by a PHM module. This module is able to predict, for each machine , the relative time before failure after processing a job j, noted as , and the resulting degradation value, , is then deduced. When the cumulative jobs degradation reaches a certain threshold, , a maintenance operation should be planned.
The resulting integrated sequence is denoted where represents the corresponding integrated sequence of n jobs and () flexible maintenance on machine . Then can be seen as a succession of blocks of jobs (subset of ) separated by maintenance operations ():
= , where .
The general assumptions of the integrated problem are given as follows:
At time zero, all jobs are available and ready for processing and no preemption is allowed;
Each machine can handle at most one action (production or maintenance) and each job can be processed by at most one machine;
Each production job j (maintenance operation ) requires a basic amount of processing time on each machine i, represented by ();
We fix the degradation value associated to job j after being processed on machine i, where .
The maximal authorized threshold degradation is fixed to 1 for all machines;
At least one maintenance intervention is performed on each machine and no maintenance intervention is performed after the processing of the last job;
After a maintenance intervention, the machine is recovered to an “As good as new” state.
3.2. Learning and Deteriorating Effects’ Mathematical Models
Due to the learning effect, we suppose that the maintenance durations will decrease gradually as they are scheduled later in the sequence. This is the position-dependent learning model (Equation (
1)). On the other hand, for the deteriorating effect, we suppose that the production job processing times will increase gradually over time. This is the time-dependent deteriorating model (Equation (
2)).
4. Proposed QL-Driven ABC-Based Solving Approaches
The ABC algorithm [
38] is a competitive bio-inspired algorithm that simulates the behavior of bee colonies when searching for promising food sources associated with higher nectar amounts. In the ABC algorithm, the food source represents a candidate solution to the problem and the nectar amount of a source corresponds to the quality, known as fitness, of the related solution. The ABC search process is conducted by three bee swarms, namely: employed, onlooker, and scout bees. A review of its fundamentals and some applications can be found in [
69]. In [
70], the ABC algorithm showed effective performances over the differential evolution (DE) algorithm, Particle Swarm Optimization (PSO), and evolutionary algorithm (EA). The main advantages of the ABC algorithm are its ability to balance exploitation and exploration, it having few control parameters, its fast convergence, its strong robustness, and its ease of being combined with other methods [
71]. It is also easy to implement compared to GA and Ant Colony Optimization (ACO) [
72].
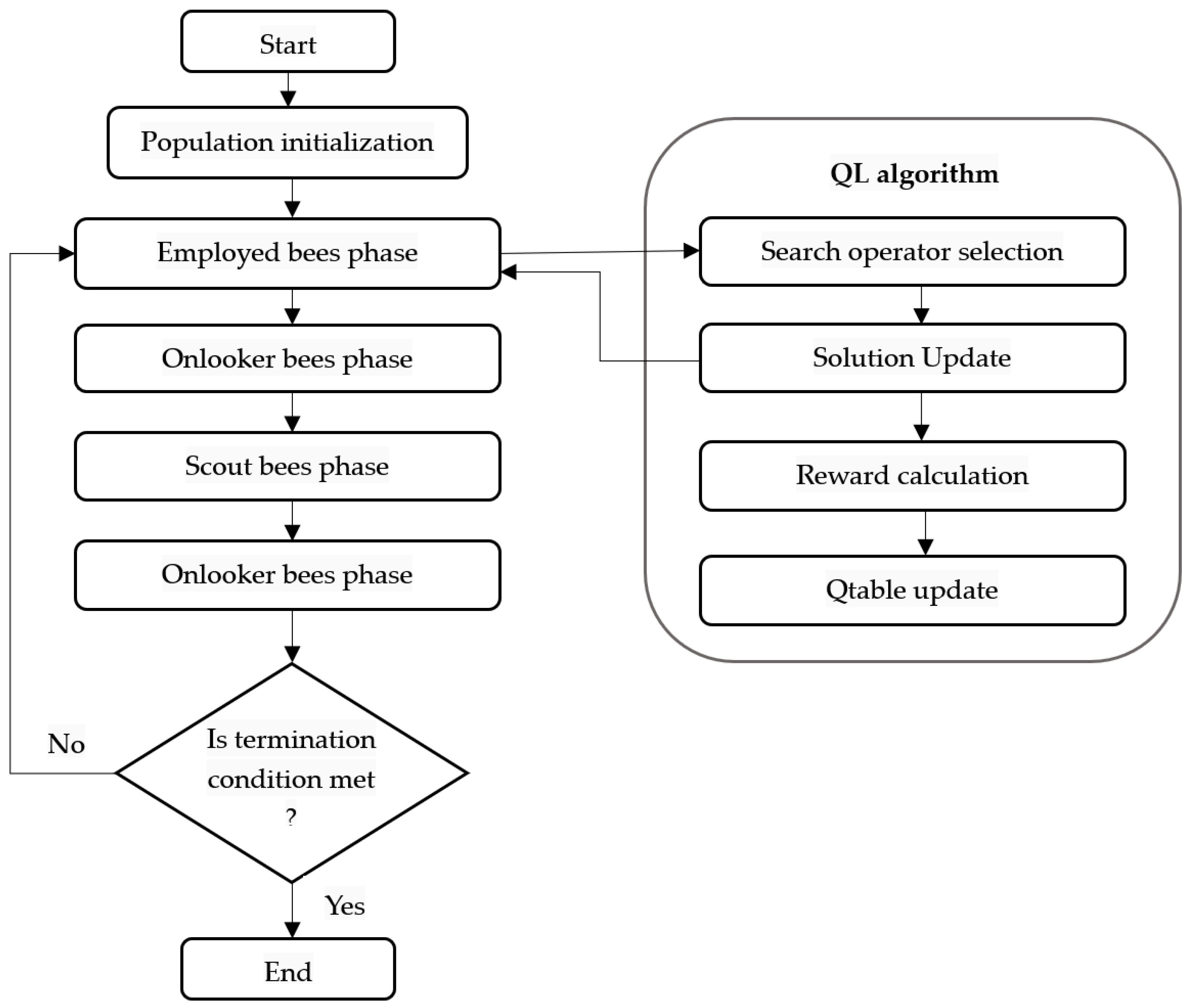
In an attempt to solve the integrated PFSP with a flexible maintenance problem under learning and deteriorating effects in a reasonable time, in this paper, we propose two efficient ABC algorithms enhanced with the RL mechanism. The first ABC algorithm, named IQABC-LE for Integrated QL-based ABC under Learning Effect, takes into account the learning effect. After generating the initial solutions, the search process of IQABC-LE starts with the employed bees phase, which applies an RL mechanism to drive the neighborhood exploitation of the associated solutions in order to update the search space with optimal solutions. After that, the onlooker bees select the best individuals from the search space to exploit their neighborhood for further optimization. To allow exploration of the search space, the scout bees randomly replace the solutions that have not been updated after a defined number of trials. The search process is iterated until a termination condition is met. The general scheme of the IQABC-LE algorithm is given in Algorithm 1 and its flow chart is indicated in
Figure 1. The second ABC algorithm, named IQABC-LDE for Integrated QL-based ABC under Learning and Deteriorating Effects, follows the same steps as IQABC-LE but also takes into account the deteriorating effect. The main features of the proposed algorithms are detailed in the sections below.
4.1. Food Source Representation and Evaluation
A suitable solution representation is based on the work of [
73]. A candidate solution
, i.e., food source, jointly specifies the production job sequence and the maintenance operations’ positions on each machine and is codded by a two-field structure. The first field is a vector S =
representing the production job order. The second field represents the scheduling of maintenance operations on each machine by a binary matrix
P of
size. An element
of
P indicates if a maintenance intervention is scheduled on machine
after job
j, and then
=1, or not, and then
=0. Let
and
represent a solution of an integrated flowshop scheduling problem with machines and jobs. Then, the execution order of the ten jobs and maintenance operations on the three machines is the following:
Machine 1: 1, 9, M, 3, 8, 5, M, 6, 7, 4, 2, M, 0.
Machine 2: 1, 9, 3, M, 8, 5, 6, M, 7, 4, 2, 0.
Machine 3: 1, 9, M
, 3, 8, 5, 6, M
, 7, 4, 2, 0.
| Algorithm 1: IQABC-LE() |
- Require:
Population size (PopSize), Onlooker bees percentage (onlook%), Number of generations (max_iterations), Abandonment number of trials (limit)
Begin ▹ Population initialization step for to alpha%PopSize do end for for to (PopSize-alpha%PopSize-1) do end for while do for 1 to PopSize do ▹ employed bees phase NeighborEbee← QL(Ebees[i]) ▹ Qlearning selection (Algorithm 3) if NeighborEbee ≥ Ebees[i] then Ebees[i]← NeighborEbee end if end for for i←1 to onlook%PopSize do ▹ onlooker bees phase Olook[i]← probaSelection(Ebees) Olook ← ILS(Olook[i]) if Olook ≥ Olook[i] then Ebees[i]←Olook end if end for for i←1 to PopSize do ▹ scout bees phase if CheckLimit(Ebees[i],limit)=True then Ebees[i]←RandomGeneration() end if end for end while Return Best Solution() End
|
The objective is to find a solution
that minimizes the amount of nectar (the measure of the quality of a solution), i.e., the best sequencing of jobs and maintenance operations to be processed for each machine in order to minimize the total completion time of the schedule,
, taking into account maintenance interventions planning under learning and deteriorating effects. Considering the learning and the deteriorating effects, and the fact that the total completion time
depends mainly on the sum of the job processing times and maintenance durations (see Formula (
3)), the
while considering the learning effect and both effects simultaneously are given by Formulas (
4) and (
5), respectively.
where:
refers to the total idle time of the last machine
m waiting for jobs arrival and
is the number of inserted maintenance activities on the last machine
m.
4.2. Initial Population Generation
To allow quality and diversity in the search space, we generated an initial population of candidate solutions at random and “seeded” it with some good ones. Therefore, in this work, we suggest the following three-step initialization procedure to generate an initial population of complete integrated solutions ():
Step 1. Firstly, we generated the first candidate food source of the initial population with a newly designed heuristic, named INEH, a greedy approximate heuristic based on the well-known NEH heuristic [
43], by modifying its second phase.
Step 2. Generate
PopSize production sequences using a modified NEH heuristic [
74]. To generate complete food sources, maintenance activities are scheduled using the PHM-based greedy heuristic of [
44]. In this heuristic, maintenance operations are inserted according to the current accumulated degradation of the machine estimated by the PHM module, starting from the first machine
to the last one
.
Step 3. The rest of the population is generated randomly with production sequences generated at random and maintenance operations inserted using the heuristic of [
44].
The main idea of the INEH heuristic is to build from scratch the sequence of production jobs and maintenance operations giving priority to jobs with higher processing times to be scheduled first. In the first phase, the jobs are ordered according to the LPT rule in a list
L. Then, a partial sequence is generated with the first job of
L. The second phase is an insertion procedure to iteratively construct a complete integrated sequence. This phase starts first, by scanning the current partial sequence, and maintenance operations are inserted when necessary with respect to the threshold
=1 on each machine. Then, by testing the second job of
L in all available positions of the integrated partial sequence. The position that yields the minimum makespan is chosen to be inserted, and the new partial integrated sequence overwrites the last one. This insertion step is repeated iteratively with the rest of the jobs. Detailed steps of the INEH heuristic are given in Algorithm 2.
| Algorithm 2: INEH Heuristic |
- Require:
A Set of production jobs
Begin Let L the list of ranked production jobs in decreasing order of total processing time (LPT rule). Insert the first job of L in the first position of the current partial empty sequence. Update L whileL not Empty do Insert maintenance operations in the appropriate positions of the current partial sequence with respect to the threshold Insert the first job of L in all the k+1 possible positions of the current partial sequence Evaluate all of k+1 resulting partial sequences Keep the best sequence as a new current partial sequence Update L end while Return Integrated sequence End
|
4.3. QL-Based Employed Bees Phase
RL studies the sequential decision process of interaction between the agent and the environment [
75]. Q-learning (QL) is one of the major RL algorithms that allows agents to learn an optimal policy through trial and error in an unknown environment. It does not rely on prior knowledge of the environment’s dynamics [
76]. The algorithm uses a value function called the
Q-
to estimate the expected cumulative reward for taking specific actions in certain states and following the optimal policy thereafter.
During the learning process, the agent explores the environment, taking actions and observing the resulting rewards and next states. These experiences are used to iteratively update the Q-values, which represent the estimated quality of actions in different states. The update process is guided by the Bellman equation, which relates the current Q-value to the expected future Q-values.
Motivated by the above consideration, this paper introduces the QL principle to the selection of neighborhood structures in order to guide the search process in the employed bees phase of the proposed IQABC algorithms. Employed bees are in charge of searching for new and hopefully better food sources. To this end, in the original ABC algorithm, each employed bee generates one new candidate solution in the neighborhood of the current solution in one food source. The new candidate replaces the old solution if it is better. In this paper, each employed bee is placed on a solution from the population and applies one of the neighborhood structures on it, to generate a new solution. The choice of the neighborhood structure is performed by the application of a QL algorithm. The new solution replaces the current one if its quality is better, otherwise, a non-optimization trials counter, nb_trials, is incremented.
4.3.1. Neighborhood Structures
Neighborhood structures are designed for further optimization of the initial solutions. Based on previous studies on scheduling, it has been found that the insert neighborhood is generally more effective for the PFSP [
77]. Furthermore, it is advised to incorporate complementary neighborhood structures to ensure a thorough exploration of the search space and enhance the effectiveness of the search process. Therefore, in this paper, insert and swap neighborhoods are used. These neighborhood structures allow the generation of new solutions by changing the execution order of production jobs. Additionally, a third type of neighborhood structure involving the shifting of maintenance tasks is utilized. Based on these neighborhoods, six local search operators are proposed as follows:
- 1.
Swap move on production jobs. It consists of swapping the positions of two production jobs selected randomly from the production sequence.
- 2.
Double swap move on production jobs. It consists of making two consecutive swap moves on the production sequence.
- 3.
Insert move on production. It consists of selecting a production job randomly and then inserting it into another randomly selected position in the production sequence.
- 4.
Double insert move on production jobs. It consists of making two consecutive insert moves.
- 5.
Right shift move on maintenance activities. It consists of selecting a maintenance operation in a selected machine and then shifting it to the right, i.e., after the next job in the sequence.
- 6.
Left shift move on maintenance activities. It consists of selecting a maintenance operation in a selected machine and then randomly shifting it to the left, i.e., before the previous job in the sequence.
4.3.2. Q-Learning Algorithm
In the proposed IQABC algorithms, a QL algorithm is used to guide the choice of the neighborhood structures in the employed bees phase. The states of the QL model are defined by the set of population individuals, while the six neighborhood structures indicate the set of actions. At each iteration, the QL agent observes the current solution (
s), selects an action (
a) (a neighborhood structure), which generates a new solution (
s’), and consequently, it receives a reward/penalty (
r) signal according to the quality of the generated solution (see Formula (
6)). The agent records its learning experience by a
Q-value (
Q(
s,a)), which is stored in a
Q-table. The update of the
Q-value is given in Formula (
7), where
is the Q-learning rate and
is the discount factor.
The action selection mechanism is implemented using an
-greedy strategy, where the agent can choose the best action considering the associated
Q-value (exploitation), or can select one action randomly (exploration) with an
probability. Thus, the e-greedy strategy enables both exploitation and exploration. That is, the agent has to exploit what it already knows to obtain a reward, but it also needs to explore in order to make better action selections in the future. The employed bees stage with the QL algorithm is recalled in Algorithm 3.
| Algorithm 3: QL-based Employed bees phase |
- Require:
Search space, Q-table of the population
Begin for Each solution S from the search space do ▹ S is the current state Generate a random number a if then Choose the best action (Neighbor structure ) associated with the best Q-value of the Q-table. else Choose the best action randomly end if Generate New Solution Sol’ using ▹ Sol’ is the next state end for r← 1+makespan()-makespan() ▹ reward formula Update the Q-value of the tuple ( , ) as specified in Formula ( 7) if makespan() ≤ makespan() then Replace with end if update the search space End
|
To implement the QL algorithm, we used the “pandas” python library. The Q-table is stored in a DataFrame structure, which is a two dimensional table where indexes (lines) point to food sources as represented in
Section 4.1, and columns refer to a defined list of neighborhood structures as presented in
Section 4.3.1.
4.4. Onlooker Bees Phase
Similar to the employed bees phase, the onlooker bees phase aims to enhance the intensification of the local search process. Firstly, the onlooker bees select candidate solutions from the employed bees stage according to the roulette wheel method. Then a local search heuristic borrowed from the iterated local search (ILS) algorithm [
78] with destruction and reconstruction procedures is applied to selected solutions for exploitation. The probability that a solution (
Sol) is allowed to be selected is defined in Formula (
8).
4.5. Scout Bees Phase
In the scout bees phase, candidate solutions that have not been updated after a defined number of trials, let this be limit, are abandoned and replaced by new random ones.
4.6. Readjustment Procedure for Maintenance Cost Minimization
The perturbations on the candidate solutions, through the neighborhood structures within the employed bees stage, and the local search heuristic within the onlooker bees phase may disturb the positions of the required maintenance interventions, which can either be advanced or delayed. In both cases, a maintenance cost needs to be considered. An early maintenance intervention is detected when the cumulative degradation caused by the production jobs scheduled before it is less than the threshold
. In this case, we define the maintenance cost as follows:
In the case of tardy maintenance intervention, i.e, when the cumulative degradation caused by the production jobs scheduled before it is greater than the threshold
, we define the maintenance cost as follows:
An optimal maintenance cost is reached when the cumulative degradation is equal to .
In this regard, we propose to apply a readjustment procedure (Algorithm 4) after the generation of new solutions in the employed and onlooker bees phase that browses complete solutions to detect early/tardy maintenance interventions and tries to readjust them in the appropriate positions that optimize the maintenance cost.
| Algorithm 4: Readjustment procedure |
- Require:
Sol (a returned solution with job permutation vector S and the associated maintenance matrix P), the cumulative machine degradation.
Begin for Each machine ) do for Each job j from S do if P[i,j]=1 then end if if then Insert the maintenance before or after j in order to minimize the maintenance cost. Update the matrix P with the maintenance emplacement. Remove the next maintenance: P[i,(next maintenance position)]. . end if end for end for End
|
4.7. Termination Condition
The termination condition of the proposed IQABC is a maximum number of iterations (max_iterations) of the algorithm or when the limit of the number of iterations without improving the best solution (stagnation) is reached.
5. The Computational Results and Analysis
In this section, the performance of the designed QL-driven ABC algorithms IQABC-LE and IQABC-LDE is demonstrated through numerical experiments on a well-designed test bed. The experiments are conducted in Python 3.9.5 on a personal computer with Windows 10 operating system, Intel i5 CPU (2.10 GHz), and 8-GB RAM.
In the following, we first describe how test data are generated. Secondly, to analyze the performance of our newly proposed algorithms, we conducted two sets of experiments. In the first set, the calibration process, and a comparison between IQABC without learning and deteriorating effects and a standard ABC were performed. In the second, we validated our IQABC algorithms with effects, namely IQABC-LE and IQABC-LDE, by comparing them with several representative algorithms. We ran, independently, all the algorithms five times on each instance. The complete details are reported in the next sections.
5.1. Data Generation
We used two types of data to assess our proposed methods. The first was about production, while the second was about PHM and maintenance data. For the first type, we ran our experiments on a set of 110 known Taillard instances [
79] of different sizes (n × m), with n ∈ {20,50,100,200} and m ∈ {5,10,20}. To complete the production data with the PHM data and the maintenance duration, we proceeded as follows:
For each instance, we generated three levels of machines’ degradation: (1) from the uniform distribution for job processing times below 20; (2) from the uniform distribution for job processing times between 20 and 50; and from the uniform distribution for job processing times above 50.
Each instance was tested twice, the first time with medium maintenance durations generated from the uniform distribution , designated as the first maintenance mode , and the second time with long maintenance durations generated from the uniform distribution , designated as the second maintenance mode .
It is challenging to make a fair comparison between our results and those of other authors. This difficulty arises from the fact that only a small number of authors have addressed the same problem with the same constraints and objectives, and even fewer with the same instances for comparison purposes. Therefore, to demonstrate the effectiveness of our newly proposed QL-driven ABC algorithms, we report the Average Relative Percentage Deviations (
ARPD) provided by each algorithm (after maintenance operations) with respect to the best-known solution for the Taillard instance without maintenance operations (see Equation (
9)). Taillard’s acceleration technique [
80] was applied to compute the makespan. It allows the CPU time to be reduced by calculating all the partial schedules in a given iteration in a single step.
where
is Taillard’s best-known solution and
is the returned value, and
R is the number of similar scaled instances running.
5.2. IQABC Features Analysis
For the first set of experiments, we undertook a sensitive performance analysis of our newly proposed algorithms IQABC by varying different parameters. These parameters were experimentally found to be good and robust for the problems tested. We chose a full factorial design in which all possible combinations of the following ABC factors were tested:
Population size PopSize: three levels (50, 70, and 100);
Onlooker bees percentage onlook%: three levels (20%, 30%, and 40%);
Abandonment number of trials limit: three levels (5, 10, and 50);
Number of iterations max_iterations: three levels (100, 150, and 200).
All the cited factors resulted in a total of 3 × 3 × 3 × 3 = 81 different combinations run on a set of
Taillard instances with
and
. The job processing times of the instances were generated uniformly in the interval
, and maintenance durations were generated according to the first maintenance mode (M1) described in
Section 5.1. Each instance was executed five times, which meant a total of 16,200 executions. The ARPD was calculated as a response variable. The resulting experiment was analyzed by means of a multifactor analysis of variance (ANOVA) technique [
81] with the least significant difference (LSD) intervals at the 95% confidence level.
Each parameter was set to its most adequate level as follows: PopSize = 70; onlook% = 40%; Limit = 5; and max_iterations = 200.
For the QL factors, namely the Q-learning index
, the discount factor
, and the probability for the QL mechanism
, based on the study of [
82], four typical combinations for the QL algorithm were tested:
C1: = 0.1, = 0.8, = 0.2;
C2: = 0.1, = 0.8, = 0.1;
C3: = 0.1, = 0.9, = 0.1;
C4: = 0.1, = 0.9, = 0.2.
After executing different experiments for each combination, we decided to keep the second combination, as it was able to report better results. Finally, the stagnation factor was set at 80% since a large number of convergence curves for multiple executions showed a stabilization of the results up to this value.
5.3. Performance Analysis of IQABC Algorithm without Learning and Deteriorating Effects
To prove the performance of the integrated QL-driven ABC algorithm without learning and deterioration effects (IQABC), we compared it with three different competing algorithms for the same problem and constraints without considering the learning and deteriorating effects. The comparative algorithms are: (1) a population-based metaheuristic, which is the ABC algorithm of [
54] with random neighborhood selection; (2) a unique solution-based metaheuristic, which is the Variable Neighbor Search (VNS) algorithm of [
83]; (3) and finally, INEH, our newly designed constructive heuristic. The comparison was carried out by means of 1100 runs of the test benchmark. The resulting ARPD values reported in
Table 1 were calculated based on the
value given in Formula (
3), with no consideration of the learning and deteriorating effects, and with respect to the first and second maintenance modes (
and
).
Table 1 shows that the INEH heuristic produces competitive ARPD results compared to the VNS metaheuristic, even though the INEH is a constructive method. In fact, for small instances (20x5, 20x10, 20x20), INEH achieves the best ARPD values: for Mode 1, an average of 16.76 against 20.90 for VNS; for Mode 2, an average of 19.14 for INEH against 22.59 for VNS. Nonetheless, it fails to reach the results obtained by the VNS algorithm for large instances (50x5–200x20): for Mode 1, an average of 9.60 against 8.03 for the VNS; and for Mode 2, an average of 12.59 for INEH against 8.71 for VNS. The great advantage of the INEH heuristic is its ability to obtain near-optimal solutions in a reasonable computation time (on average 6.99 time units (TU) compared to 3120.89 TU for VNS).
Although the ABC metaheuristic of [
54] gave better solutions than the VNS algorithm, which is considered an efficient metaheuristic for the problem [
83,
84], the IQABC algorithm outperforms it, as can clearly be seen from
Table 1 for the two maintenance modes. This is proved by the employed bees’ local search procedures and the QL-driven neighborhood selection. To further verify the statistical significance of the difference in ARPD values between ABC and IQABC for the two maintenance modes, we performed a Friedman’s two-way analysis of variance test [
85]. The result summary in
Table 2 as well as the mean plots displayed in
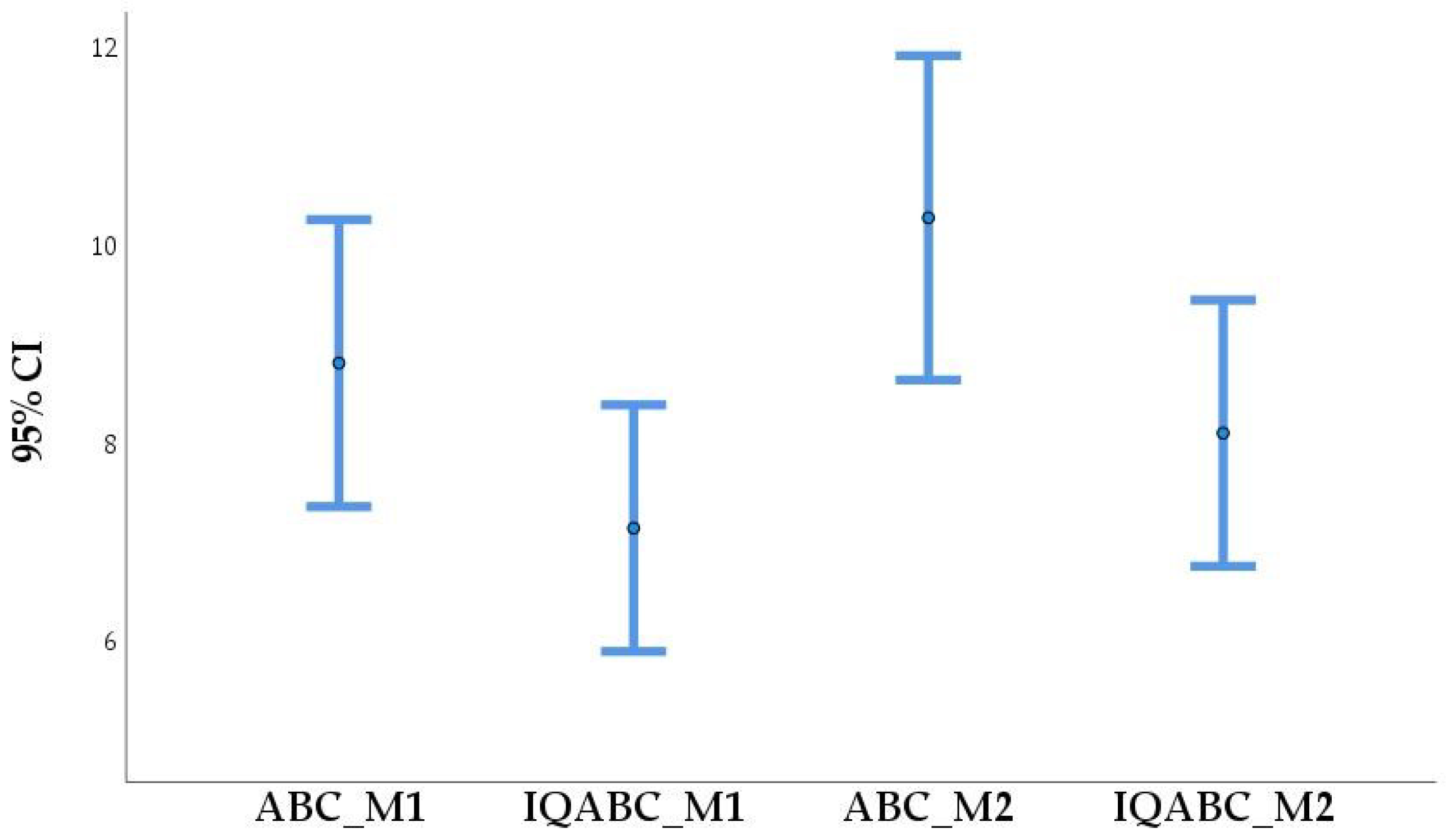
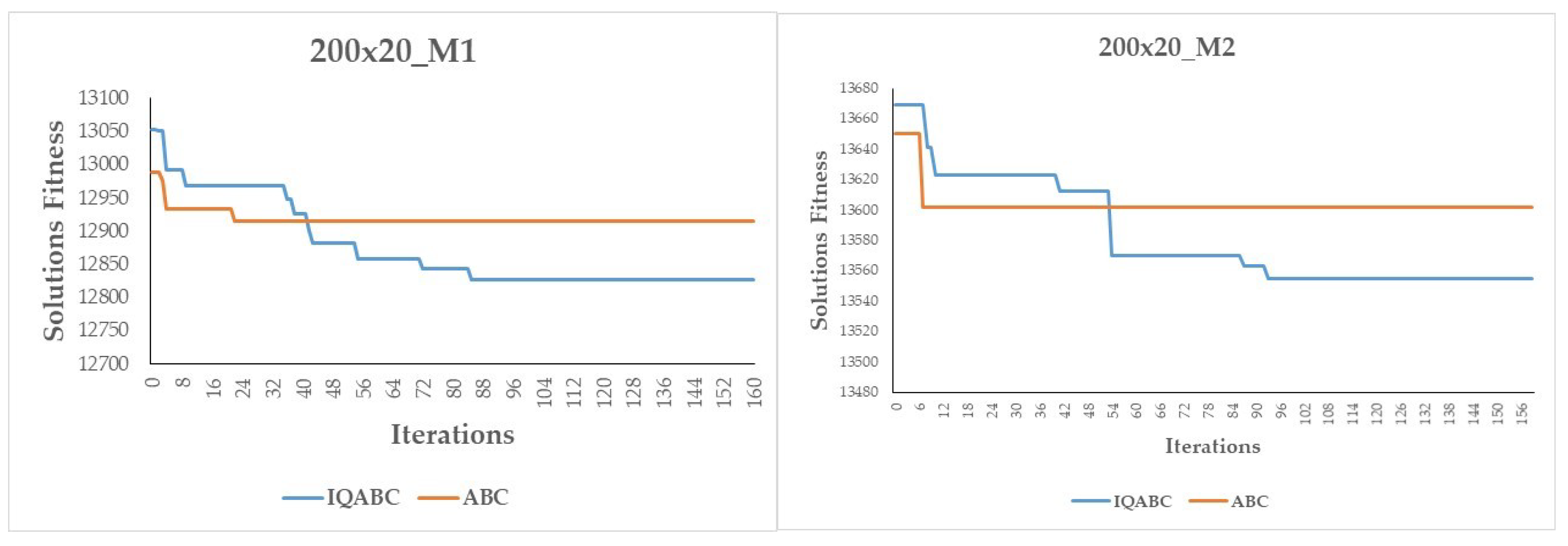
Figure 2 show the significant differences between IQABC and ABC. Therefore, the IQABC algorithm is significantly superior to the ABC, VNS, and INEH algorithms. However, the ABC and IQABC algorithms are population-based methods, which means an important amount of time is used to effectively explore the search space. Furthermore, the QL mechanism in the IQABC algorithm needs more time to learn optimal policies. Therefore, it is not meaningful to compare the running times of the IQABC and ABC algorithms with those of the VNS and INEH heuristics.
In
Figure 3,
Figure 4,
Figure 5 and
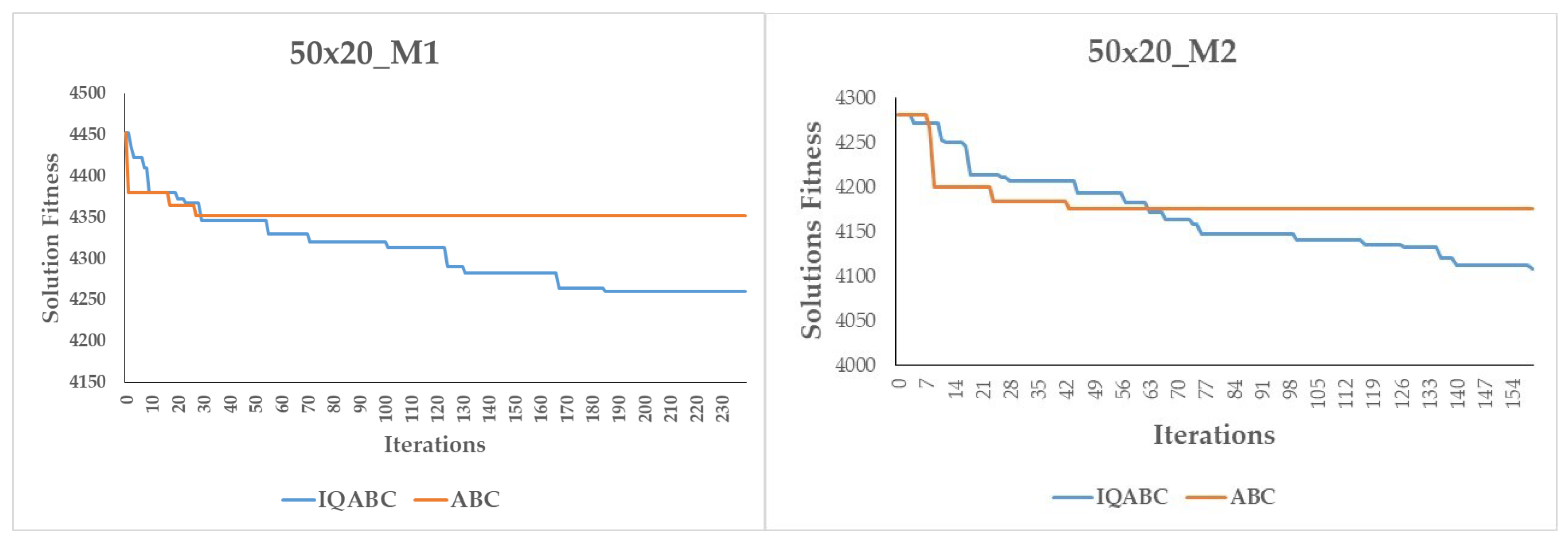
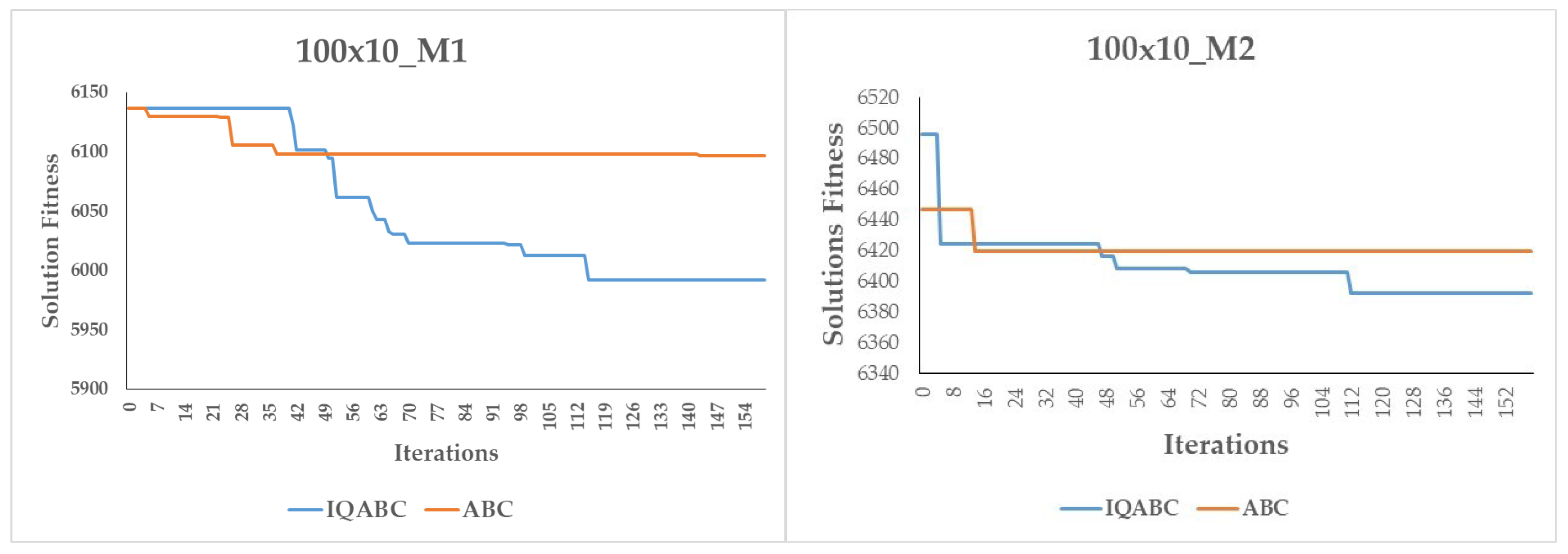
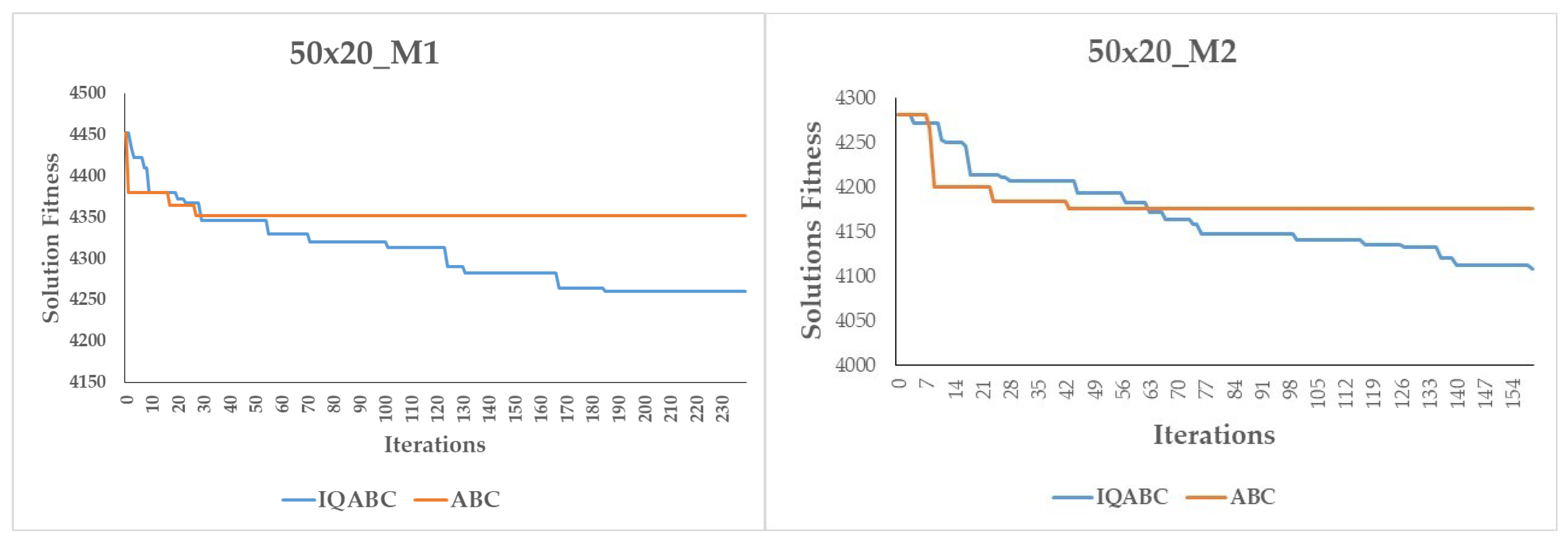
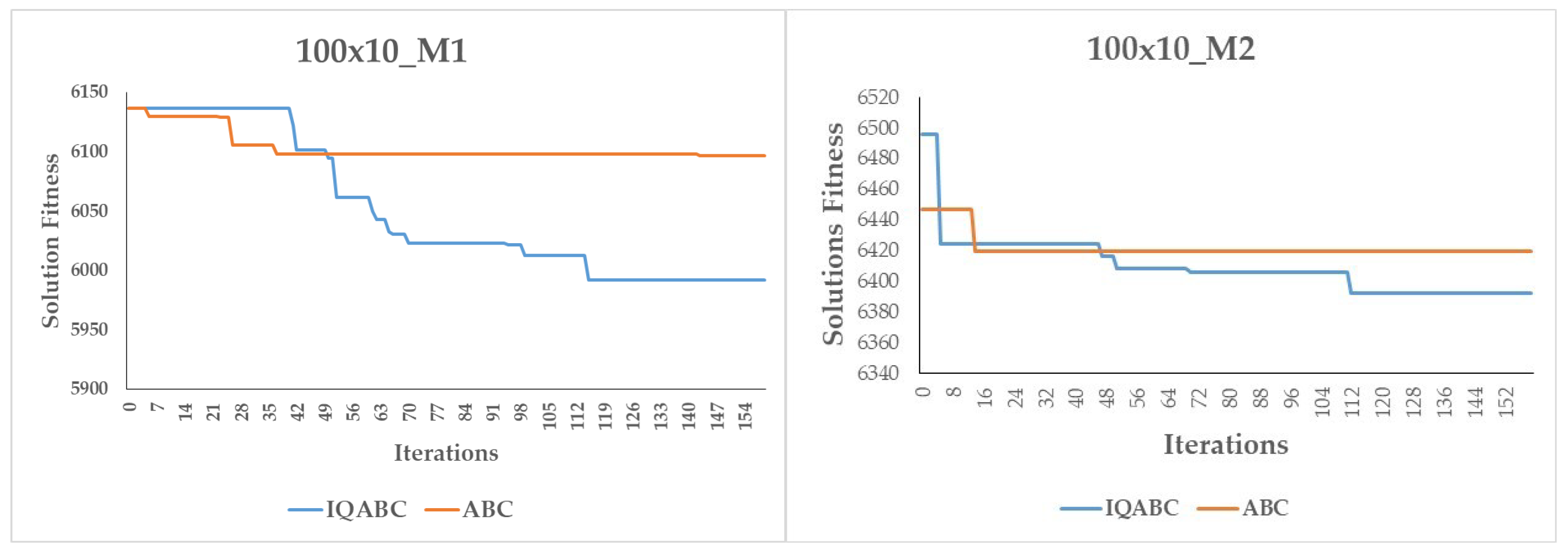
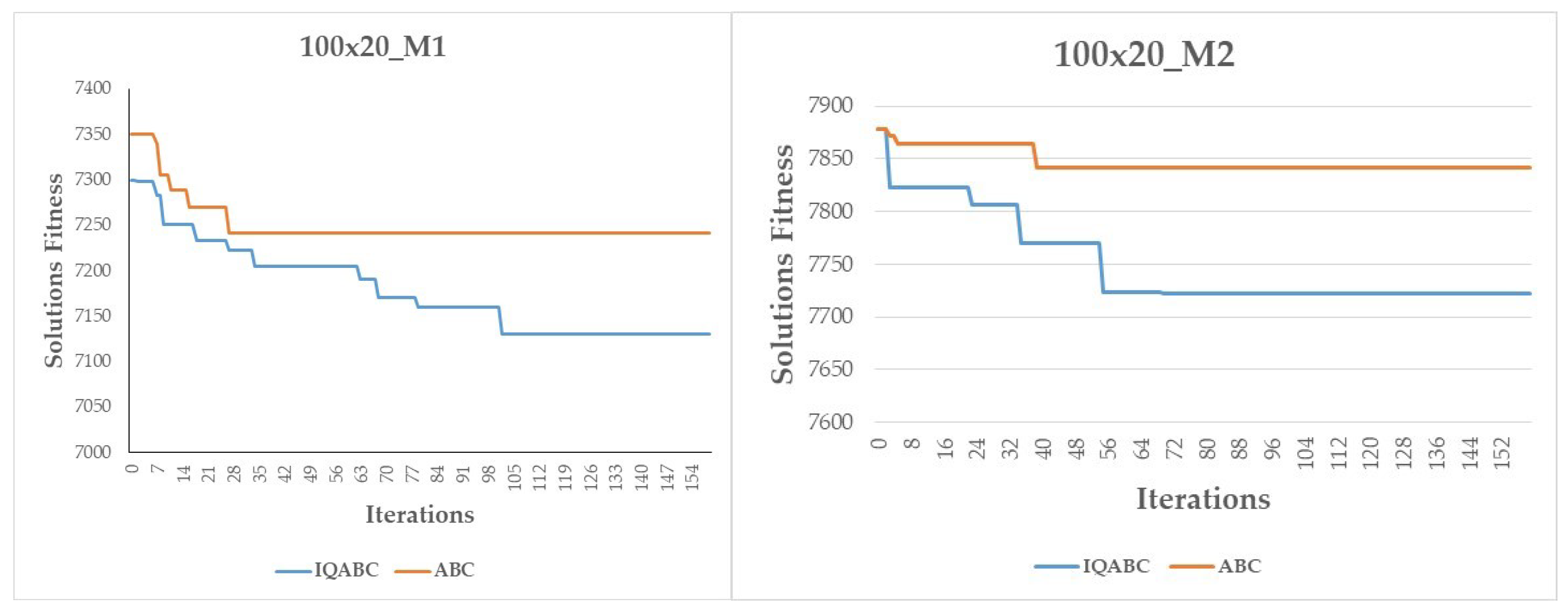
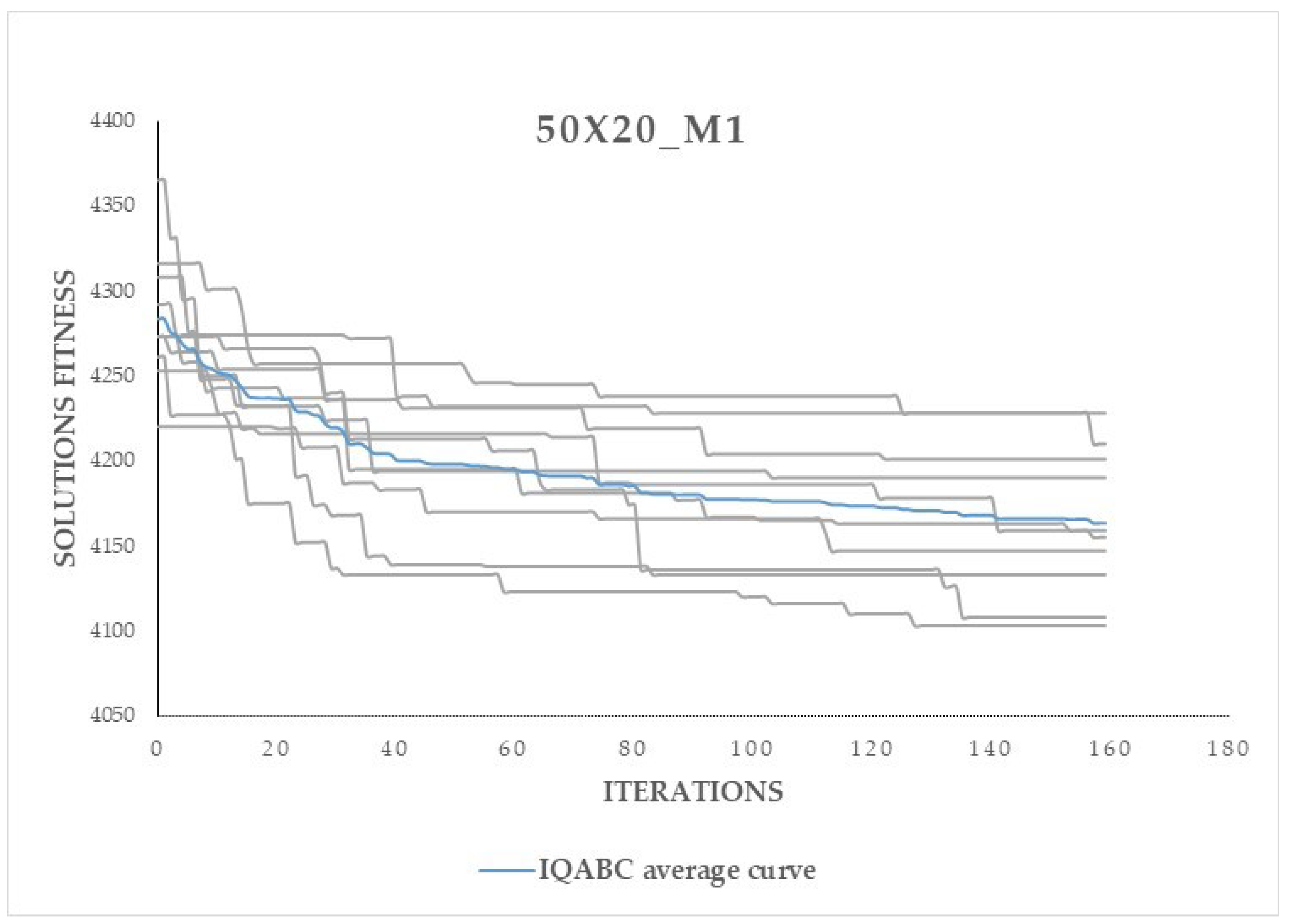
Figure 6, we also compare the convergence curves of the IQABC and ABC algorithms. We note that the ABC algorithm is more likely to become trapped in premature convergence, while the IQABC algorithm still finds better optimal solutions at a relatively more efficient rate, and the better results can be obtained at the final stage. We can conclude that the QL algorithm in the employed bees phase helps the IQABC algorithm to converge in a robust and efficient way. This conclusion is supported by the convergence curves of 10 trials on the instance 50x20_M1 as well as the average convergence curve in bold in
Figure 7.
It is important to note that high ARPD values do not reflect poor solution quality since they are calculated relative to the best-known Taillard solutions, without taking into account maintenance tasks and learning/deterioration effects. Therefore, the presented ARPD deviations (for all experiments) are much higher than they would be if they were calculated with respect to a more accurate lower bound that takes into account maintenance tasks and learning/deterioration effects.
5.4. Performance Analysis of the QL-Driven ABC Algorithm with Learning Effect
The performance of the first algorithm, namely the IQABC-LE, is proven through three scenarios and 1100 executions per scenario on the designed benchmarks completed with learning indexes (). First, we assume a small common learning rate among maintenance operators, so we generate small learning indexes (SF) from the uniform distribution . Then, assuming that the operators learn very quickly at the same rate, large learning indices (LF) are generated from the uniform distribution . Finally, we assume that the learning phenomenon is random and depends on the machine characteristics, so the learning indexes are generated from the uniform distribution per machine (FPM).
The execution results are compared with the ABC learning algorithm (ABC-LE) reported in [
54]. Indeed, the IQABC-LE algorithm implements a QL mechanism to guide the neighbor structure selection in the employed bees phase, instead of random selection as in ABC-LE. In addition, the IQABC-LE uses the INEH heuristic to generate one complete solution, while the ABC-LE algorithm applies the NEH heuristic [
43] to generate first, the production sequence, then, the maintenance heuristic[
44] to complete the solution with maintenance emplacements.
The comparison between the two algorithms is made according to the ARPD values, which are calculated on the basis of the
values given in Formula (
4).
The results presented in
Table 3,
Table 4 and
Table 5 clearly show the superiority of the IQABC-LE algorithm over the ABC-LE algorithm. An important note comparing the results of the IQABC algorithm when considering a learning effect and no effect, is the significant difference in ARPD values, which increasingly reinforce the need to take into account real constraints when studying scheduling problems.
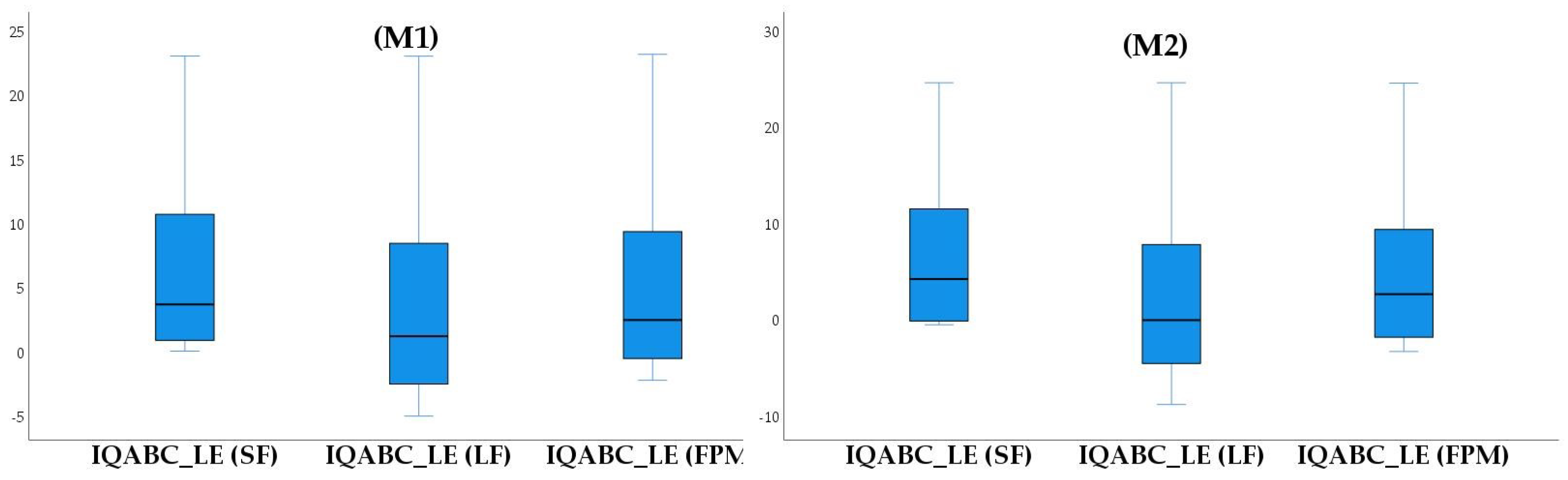
From
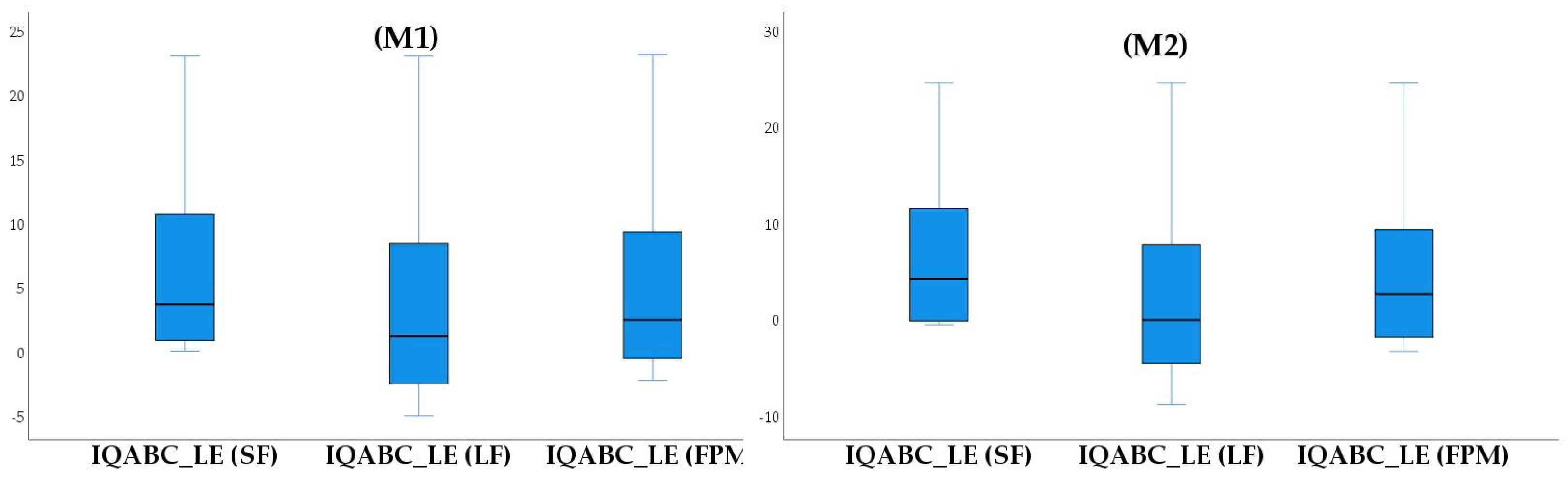
Figure 8, it can be seen that the IQABC-LE algorithm with large learning indexes (LF) optimizes the
very well compared to the small and random learning indexes. Consequently, it is of great importance for a workshop to improve the ability of its employees to learn.
5.5. Performance Analysis of the QL-Driven ABC Algorithm with Learning and Deteriorating Effects
In this section, the IQABC-LDE algorithm with a learning and deteriorating effect is evaluated on the designed benchmarks completed with random learning and deteriorating indexes generated from a uniform distribution
. The results of the 1100 executions are summarized in
Table 6 and compared to those of the ABC-LDE reported in [
54]. The ABC-LDE follows the same steps as the ABC-LE, with the addition of the deteriorating effect. The ARPD values reported in
Table 6 are calculated on the basis of the
values given in Formula (
5).
Once again, the IQABC-LDE is superior to the ABC-LDE, proving the effectiveness and robustness of the QL-based neighbor selection mechanism when combined with the ABC metaheuristic. As with the learning effect, we observe a significant difference in the results obtained with the IQABC algorithm if the learning and degradation effects are not taken into account, thus emphasizing the need to integrate these effects into the study. In fact, the deteriorating effect, as opposed to the learning effect, extends processing times. It is therefore important for manufacturers to implement an efficient maintenance strategy to prevent machines from deteriorating and additional delays.
6. Conclusions
We addressed the makespan PFSP with flexible maintenance under learning and deteriorating effects. The maintenance operations are inserted to prevent machine failures with an intelligent PHM-based policy. In addition, the learning effect on the maintenance duration is considered and modeled by a decreasing position-dependent function. On the other hand, the deteriorating effect is assumed to extend the job processing times over time. For the resolution, the well-known ABC algorithm, which has been successfully applied to solve the PFSP without learning and deterioration effects, is adapted to the problem with flexible maintenance, learning, and deteriorating effects in order to find a faster and near-optimal or optimal solution to the problem. To improve the local search in the ABC-employed bees phase, a QL algorithm, considered a common potential tool of the RL mechanism, is carefully integrated into the ABC metaheuristic. Furthermore, a newly designed heuristic, the INEH, is applied to enrich the search space with a high-quality complete solution. The adapted ABC algorithm with the new strategies is used to first solve the integrated PFSP with a learning effect (IQABC-LE) and then also with a deteriorating effect (IQABC-LDE). We conducted a comprehensive experimental study to evaluate the IQABC algorithm without considering the learning and deteriorating effects, the IQABC-LE and IQABC-LDE algorithms. The objective of evaluating these three algorithms is, on the one hand, to justify the significance of our study when we have considered the learning and deteriorating effects, and on the other hand, to prove the effectiveness and robustness of our newly proposed algorithms. For the latter purpose, the experimental results are compared with those of two existing and competitive metaheuristics in the literature: ABC and VNS. The computational results and comparisons demonstrate that the new strategies of the IQABC approach really improve its search performance and IQABC is a competitive approach for the considered problem. Moreover, the need to consider learning and deterioration effects for a more realistic and accurate study is also demonstrated and emphasized. For future work, we propose to integrate more realistic constraints such as the forgetting effect and human resource constraints in the study of the PFSP. We also expect to apply other recently introduced bio-inspired metaheuristics, such as BBO and GWO, to solve the studied scheduling problem, and compare the results with the ABC algorithm.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}