
Using Epidemiological Models to Predict the Spread of Information on Twitter


Abstract
:1. Introduction
- “Ode systems-based models” that divide the population into different classes named according to the state in which various individuals find themselves, such as susceptible, infected, dead, recovered, etc. Each equation of the system describes the evolution of these classes;
- Stochastic models that use stochastic differential equation systems;
- Models with delay that use delayed differential equations in order to consider the incubation period of a virus.
2. Epidemiology-Based Information Spread Models
- S(t), i.e., susceptible class: the class of people who can be infected;
- I(t), i.e., infectious class: the class of people who are infected;
- R(t), i.e., recovered class: the class of people who have recovered from disease.
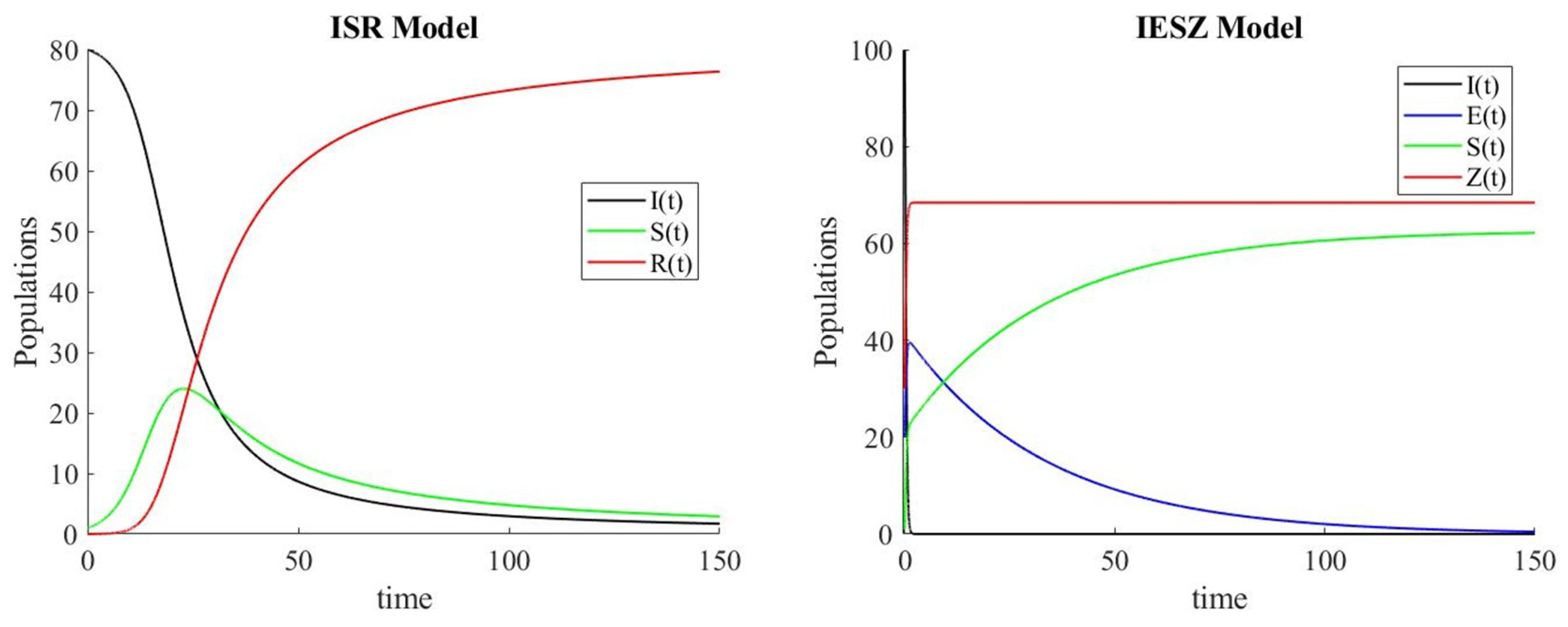
- I(t), i.e, ignorant class. This group plays the role the susceptible class, because its members are all users of the social network who can see the news, but they have not seen it yet, so they ignore it;
- S(t), i.e, spreader class. This group plays the role of the infectious class because its members are the users that spread the news, exactly as infected individuals can spread a disease during an epidemic;
- R(t), i.e, recovered class. This group plays the role of the recovered class, such as in the SIR model of epidemics; they are individuals who do not spread the news anymore.
- : the news spreading rate;
- : the recovery rate;
- k: the average number of connections among individuals;
- N: the population size.
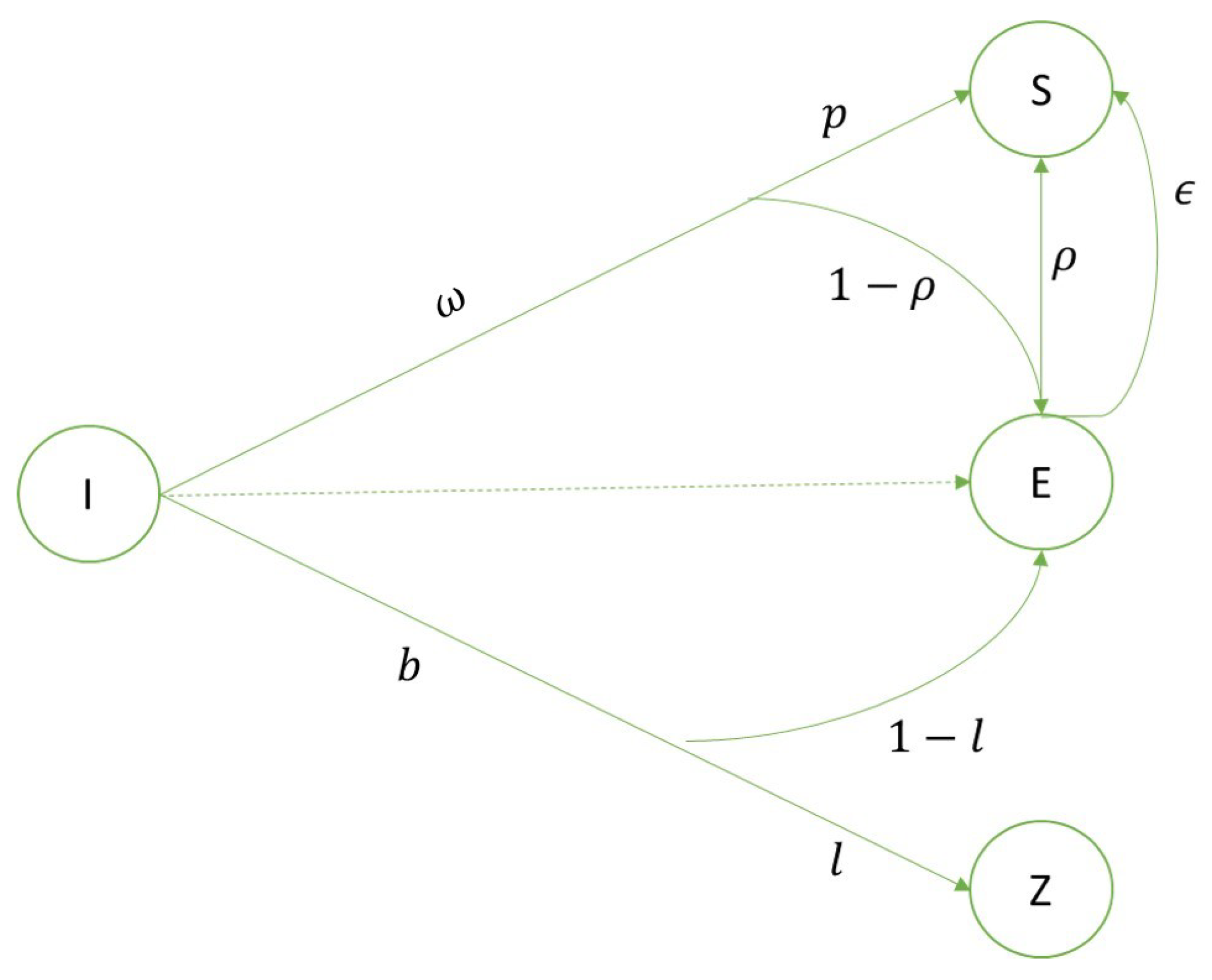
- I(t), i.e., ignorant class. As in the ISR model, this group represents the class of people that can see the news;
- E(t), i.e., exposed class. The class of people who have been exposed to the news but have not yet shared it;
- S(t), i.e., spreader class. The class of people who spread the news;
- Z(t), i.e., skeptic class. The class of people who saw the news but choose to ignore it.
- : the contact rate between a member of the ignorant class and a member of the spreader class;
- b: the contact rate between a member of the ignorant class and a member of the skeptic class;
- p: the probability of transition from the ignorants class to the spreader class after a meeting between a member of the former class with a member of the latter class;
- l: the probability of transition from the ignorants class to the skeptic class;
- : the contact rate between a member of the exposed class and a member of the spreader class;
- : the transition rate from the exposed class to the spreader class;
- N: population size, which is the sum of the sizes of each class.
3. Data Acquisition and Parameter Estimation
| Algorithm 1 Constructing ISR vectors from Twitter data. |
|
- News popularity: the degree of popularity or attention received by the news;
- Time range: the duration of time taken into consideration;
- Number of tweets posted within the selected time range;
- The level of influence or popularity of users within the network who share the analyzed news.
3.1. Case Studies
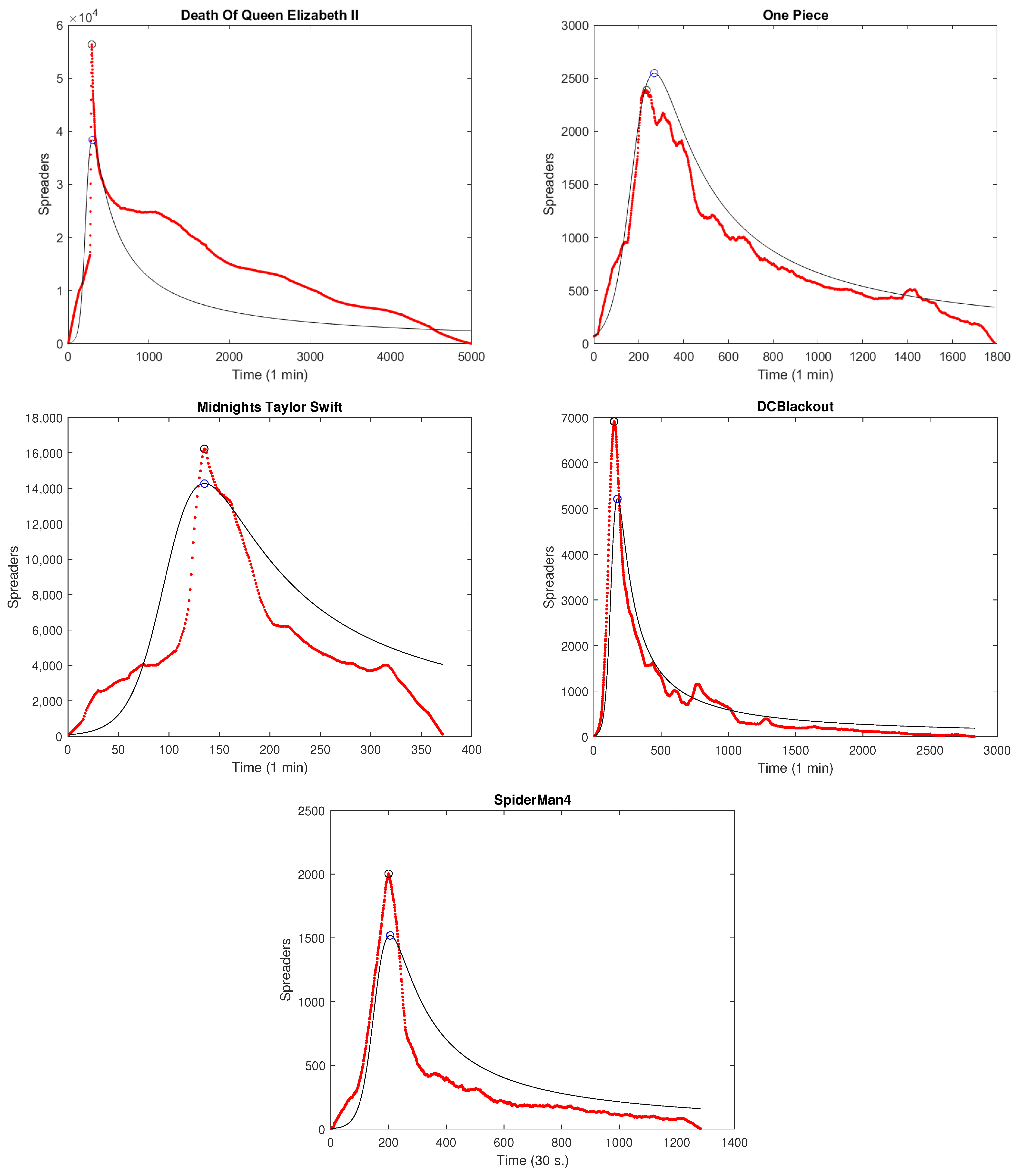
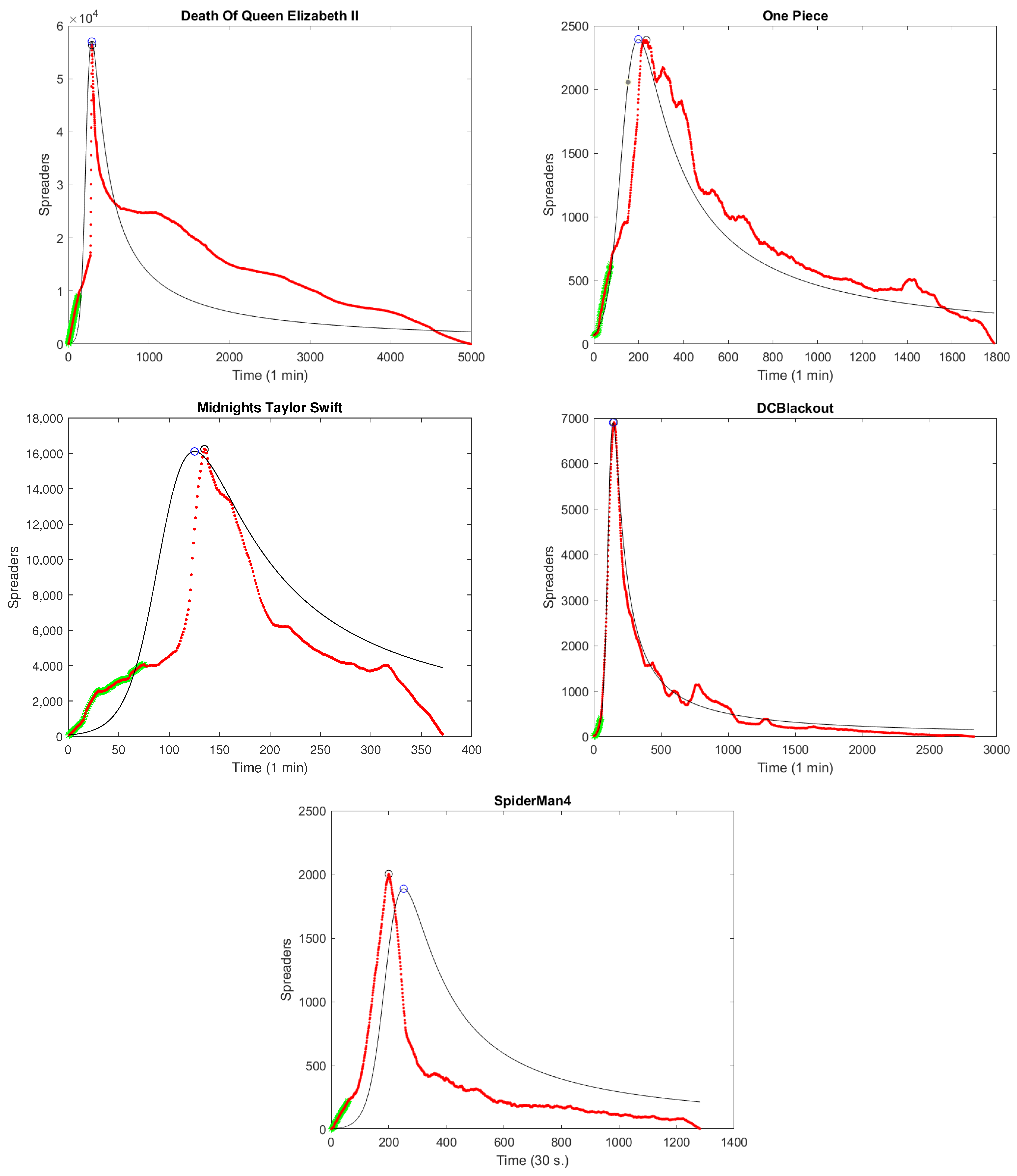
- The death of the Queen of the United Kingdom and other Commonwealth realms, Elizabeth II;
- The release of chapter number 1000 of the famous Japanese manga One Piece;
- The release of singer Taylor Swift’s new album, Midnights;
- The DCBlackout [10] rumor, which is related to an interruption of communication in Washington, D.C., due to Black Lives Matter Movement manifestations;
- The rumor related to the release of the movie Spiderman 4 on 3 May 2024 with the participation of the leading actor in other Spiderman movies from 2002 and 2007, Tobey Maguire. The rumor was spread by a user who used the name “Tobey Maguire” as his Twitter name and the same profile photo as the actor.
3.2. Parameter Estimation
- Choice of a lower bound and an upper bound for the parameters to be optimized, i.e., , and k in the (1), and, possibly, the starting number of individuals belonging to each class (, and );
- Choice of a random initial approximation (inside the interval identified by the lower and upper bounds) for the set of parameters to be optimized;
- Computation of the function to be minimized, which measures the error between the real data and the data computed by solving system (1) () with the built-in ode45 MATLAB function. This error is computed by considering the entire dataset of real data or a part of it (built as Algorithm 1) and the solution of the system computed using parameters previously described. Therefore, if I, S and R are the vectors of real data so that , and are the real numbers of ignorants, spreaders and recovered individuals at time , respectively, and , and are the corresponding data computed by solving system (1), we compute the function to be minimized using the following formula:where n is the total number of data points taken into consideration;
- Minimization of the obtained error by means of the built-in lsqnonlin MATLAB function and gain of the optimized parameters;
- Use of the optimized parameters to solve the ODEs system (1) in order to obtain a good approximation of the real data.
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SIR | Susceptible infectious recovered model |
| ISR | Ignorants spreaders recovered model |
| IESZ | Ignorants exposed spreaders skeptic model |
| IESR | Ignorants exposed spreaders recovered model |
| ISI | Ignorants spreaders ignorants model |
| ISRI | Ignorants spreaders recovered ignorants model |
References
- Rastogi, S.; Bansal, D. A review on fake news detection 3T’s: Typology, time of detection, taxonomies. Int. J. Inf. Secur. 2023, 22, 177–212. [Google Scholar] [CrossRef] [PubMed]
- The Ji Village News Mathematical Modelling of Fake-News. Available online: https://www.haidongji.com/2018/07/23/mathematical-modeling-of-fake-news/ (accessed on 23 March 2022).
- Abdullah, S.; Wu, X. An epidemic model for news spreading on Twitter. In Proceedings of the 23rd IEEE International Conference on Tools with Artificial Intelligence, ICTAI, Boca Raton, FL, USA, 7–9 November 2011; Volume 2011, pp. 163–169. [Google Scholar]
- Cardone, A.; Díaz de Alba, P.; Paternoster, B. Influence of age group in the spreading of fake news: Contact matrices in social media. In Proceedings of the IEEE 16th International Conference on Signal Image Technology& and Internet Based Systems (SITIS), Dijon, France, 19–21 October 2022; pp. 515–521. [Google Scholar]
- D’Ambrosio, R.; Díaz de Alba, P.; Giordano, G.; Paternoster, B. A modified SEIR model: Stiffness analysis and application to the diffusion of fake news. In Computational Science and Its Applications, Proceedings of the 22nd International Conference, Malaga, Spain, 4–7 July 2022, Proceedings, Part I; Gervasi, O., Murgante, B., Hendrix, E.M.T., Taniar, D., Apduhan, B.O., Eds.; Springer: Cham, Switzerland, 2022; Volume 13375, pp. 90–103. [Google Scholar]
- D’Ambrosio, R.; Giordano, G.; Mottola, S.; Paternoster, B. Stiffness analysis to predict the spread out of fake information. Future Internet 2021, 13, 222. [Google Scholar] [CrossRef]
- Din, R.; Algehyne, E.A. Mathematical analysis of COVID-19 by using SIR model with convex incidence rate. Results Phys. 2021, 23, 103970. [Google Scholar] [CrossRef] [PubMed]
- He, H.; Peng, Y.; Sun, K. SEIR modeling of the COVID-19 and its dynamics. Nonlinear Dyn. 2020, 101, 1667–1680. [Google Scholar] [CrossRef]
- Lacitignola, D.; Diele, F. Using awareness to Z-control a SEIR model with overexposure: Insights on COVID-19 pandemic. Chaos Solit. 2021, 150, 111063. [Google Scholar] [CrossRef]
- Maleki, M.; Mead, E.; Arani, M.; Agarwal, N. Using an epidemiological model to study the spread of misinformation during the Black Lives Matter Movement. arXiv 2021, arXiv:2103.12191. [Google Scholar]
- Muhlmeyer, M.; Agarwal, S. Information spread in a social media age. In Modelling and Control; CRC Press: Boca Raton, FL, USA; Taylor and Francis Group: Boca Raton, FL, USA; London, UK; New York, NY, USA, 2021. [Google Scholar]
- Muhlmeyer, M.; Agarwal, S.; Huang, A. Modeling social contagion and information diffusion in complex socio-technical systems. IEEE Syst. J. 2020, 14, 5187–5198. [Google Scholar] [CrossRef]
- Muhlmeyer, M.; Huang, J.; Agarwal, S. Event Triggered Social Media Chatter: A New Modeling Framework. IEEE Trans. Comput. Soc. Syst. 2019, 6, 197–207. [Google Scholar] [CrossRef]
- Kevrekidis, P.G.; Cuevas-Maraver, J.; Drossinos, Y.; Rapti, Z.; Kevrekidis, G.A. Reaction-diffusion spatial modeling of COVID-19: Greece and Andalusia as case examples. Phys. Rev. E 2021, 104, 024412. [Google Scholar] [CrossRef]
- Martin, O.; Fernandez-Diclo, Y.; Coville, J.; Soubeyrand, S. Equilibrium and sensitivity analysis of a spatio-temporal host-vector epidemic model. Nonlinear Anal. Real World Appl. 2021, 57, 103194. [Google Scholar] [CrossRef]
- Song, P.; Xiao, Y. Analysis of a diffusive epidemic system with spatial heterogeneity and lag effect of media impact. J. Math. Biol. 2022, 85, 17. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Wang, F.; Xu, K. Modeling Information Diffusion in Online Social Networks with Partial Differential Equations; Springer: Cham, Switzerland, 2020; Volume 7. [Google Scholar]
- Grave, M.; Viguerie, A.; Barros, G.F.; Reali, A.; Andrade Roberto, F.S.; Coutinho Alvaro, L.G.A. Modeling nonlocal behavior in epidemics via a reaction-diffusion system incorporating population movement along a network. Comput. Methods Appl. Mech. Engrg. 2022, 401, 115541. [Google Scholar] [CrossRef] [PubMed]
- Hill, E.M. Modelling the epidemiological implications for SARS-CoV-2 of Christmas household bubbles in England. J. Theor. Biol. 2023, 557, 111331. [Google Scholar] [CrossRef] [PubMed]
- Omame, A.; Abbas, M.; Din, A. Global asymptotic stability, extinction and ergodic stationary distribution in a stochastic model for dual variants of SARS-CoV-2. Math. Comput. Simul. 2023, 204, 302–336. [Google Scholar] [CrossRef]
- Yang, J.; Shi, X.; Song, X.; Zhao, Z. Threshold dynamics of a stochastic SIQR epidemic model with imperfect quarantine. Appl. Math. Lett. 2023, 136, 108459. [Google Scholar] [CrossRef]
- Martcheva, M. An Introduction to Mathematical Epidemiology; Springer: Cham, Switzerland, 2015; Volume 61. [Google Scholar]
- Blanes, S.; Iserles, A.; Macnamara, S. Positivity-preserving methods for ordinary differential equations. ESAIM Math. Model. Numer. Anal. 2022, 56, 1843–1870. [Google Scholar] [CrossRef]
- Conte, D.; Guarino, N.; Pagano, G.; Paternoster, B. On the Advantages of Nonstandard Finite Difference Discretizations for Differential Problems. Numer. Anal. Appl. 2022, 15, 219–235. [Google Scholar] [CrossRef]
- Conte, D.; Guarino, N.; Pagano, G.; Paternoster, B. Positivity-preserving and elementary stable nonstandard method for a COVID-19 SIR model. Dolomites Res. Notes Approx. 2022, 15, 65–77. [Google Scholar]
- Conte, D.; Pagano, G.; Paternoster, B. Nonstandard finite differences numerical methods for a vegetation reaction-diffusion model. J. Comput. Appl. Math. 2023, 419, 114790. [Google Scholar] [CrossRef]
- Scalone, C. Positivity preserving stochastic θ-methods for selected SDEs. Appl. Numer. Math. 2022, 172, 351–358. [Google Scholar] [CrossRef]
- Cardone, A.; D’Ambrosio, R.; Paternoster, B. Exponentially fitted IMEX methods for advection–diffusion problems. J. Comput. Appl. Math. 2017, 316, 100–108. [Google Scholar] [CrossRef]
- Cardone, A.; Ixaru, L.G.; Paternoster, B.; Santomauro, G. Ef-Gaussian direct quadrature methods for Volterra integral equations with periodic solution. Math. Comput. Simul. 2014, 110, 125–143. [Google Scholar] [CrossRef]
- D’Ambrosio, R.; Moccaldi, M.; Paternoster, B. Numerical preservation of long-term dynamics by stochastic two-step methods. Discret. Contin. Dyn. Syst. Ser. B. 2018, 23, 2763–2773. [Google Scholar] [CrossRef]
- Frasca-Caccia, G.; Hydon, P.E. Numerical preservation of multiple local conservation laws. Appl. Math. Comput. 2021, 403, 126203. [Google Scholar] [CrossRef]
- Frasca-Caccia, G.; Hydon, P.E. A New Technique for Preserving Conservation Laws. Found. Comput. Math. 2022, 22, 477–506. [Google Scholar] [CrossRef]
- Ignatius, D. Modeling the Spread of Information on Twitter. Master’s Thesis, California State Polytechnic University, Pomona, CA, USA, 2018. [Google Scholar]
- Twitter Developer Option. Available online: www.developer.twitter.com (accessed on 7 December 2022).
- Tweepy Documentation. Available online: https://docs.tweepy.org/en/latest/ (accessed on 7 December 2022).
- Koppelaar, H.; Nasehpour, P. Series Solution of High Order Abel, Bernoulli, Chini and Riccati Equations. Kyungpook Math. J. 2022, 62, 729–736. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Event | Date (d-m-y) | Duration | Scraped Tweets | Type | Hashtags |
|---|---|---|---|---|---|
| Death of Queen Elizabeth II | 8 September 2022 | 2 days | 485,011 | News | #queenelizabeth, #queenelizabethII, #RIPqueenelizabeth, #RIPqueenelizabethII, #godsavethequeen |
| One Piece | 1 March 2021 | 2 days | 16,537 | News | #onepiece |
| Taylor Swift’s Midnights | 21 October 2022 | 6 h | 106,716 | News | #MidnightsTaylorSwift |
| DCBlackout | 1 June 2020 | 2 days | 33,117 | Rumor | #DCBlackout |
| SpiderMan4 | 4 November 2022 | 10 h | 7341 | Rumor | #spiderman4 |
| Event | Estimated | Relative Error | ||
|---|---|---|---|---|
| Death of Queen Elizabeth II | 15 min | 292 | 302.63 | 0.0364 |
| One Piece | 2 min | 235 | 269.59 | 0.1472 |
| Taylor Swift’s Midnights | 15 min | 135 | 135.16 | 0.0012 |
| DCBlackout | 60 min | 150 | 175.09 | 0.1672 |
| SpiderMan4 | 30 s | 200 | 205.49 | 0.0275 |
| Event | Estimated | Relative Error | ||
|---|---|---|---|---|
| Death of Queen Elizabeth II | 124 | 292 | 289.00 | 0.0103 |
| One Piece | 75 | 235 | 199.06 | 0.1530 |
| Taylor Swift’s Midnights | 75 | 135 | 125.13 | 0.0731 |
| DCBlackout | 52 | 150 | 143.54 | 0.0431 |
| SpiderMan4 | 59 | 200 | 252.22 | 0.2611 |
| Event | |||
|---|---|---|---|
| Death of Queen Elizabeth II | 0.153463878328834 | 1.02393738655116 | 0.195770170416092 |
| One Piece | 0.198124671775847 | 0.532629600626445 | 0.113619513008026 |
| Taylor Swift’s Midnights | 0.444216647629681 | 0.823325900401598 | 0.125904515289138 |
| DCBlackout | 0.127744561954384 | 0.286654749230175 | 0.358841966601127 |
| SpiderMan4 | 0.410490456996288 | 1.106571906515240 | 0.100000063575436 |
| Event | |||
|---|---|---|---|
| Death of Queen Elizabeth II | 0.541078205848684 | 2.12886024675943 | 0.0592169183830037 |
| One Piece | 0.0919624956640816 | 0.271256024892648 | 0.32997392156807 |
| Taylor Swift’s Midnights | 0.119443419484832 | 0.17979093995445 | 0.512263317095459 |
| DCBlackout | 0.0469306748441707 | 0.0657201832547797 | 1.22327435650595 |
| SpiderMan4 | 0.041648371956623 | 0.07954719564129 | 0.815615022612782 |
| Event | Maximum Spreader Value | Approximated Maximum Spreader Value | Relative Error |
|---|---|---|---|
| Death of Queen Elizabeth II | 56,344 | 38,387.0 | 0.3187 |
| One Piece | 2387 | 2547.2 | 0.0671 |
| Taylor Swift’s Midnights | 16,230 | 14,266.0 | 0.1210 |
| DCBlackout | 6907 | 5214.5 | 0.2450 |
| SpiderMan4 | 2003 | 1517.2 | 0.2425 |
| Event | Initial Ignorants | Initial Spreaders | Maximum Spreader Value | Approximated Maximum Spreader Value | Relative Error |
|---|---|---|---|---|---|
| Death of Queen Elizabeth II | 51,403 | 1191 | 56,344 | 57,038.0 | 0.0123 |
| One Piece | 10,000 | 95 | 2387 | 2394.4 | 0.0031 |
| Taylor Swift’s Midnights | 11,264 | 654 | 16,230 | 16,112.0 | 0.0073 |
| DCBlackout | 10,000 | 26 | 6907 | 6900.7 | 0.0009 |
| SpiderMan4 | 10,000 | 36 | 2003 | 1887.3 | 0.0578 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castiello, M.; Conte, D.; Iscaro, S. Using Epidemiological Models to Predict the Spread of Information on Twitter. Algorithms 2023, 16, 391. https://doi.org/10.3390/a16080391
Castiello M, Conte D, Iscaro S. Using Epidemiological Models to Predict the Spread of Information on Twitter. Algorithms. 2023; 16(8):391. https://doi.org/10.3390/a16080391
Chicago/Turabian StyleCastiello, Matteo, Dajana Conte, and Samira Iscaro. 2023. "Using Epidemiological Models to Predict the Spread of Information on Twitter" Algorithms 16, no. 8: 391. https://doi.org/10.3390/a16080391
APA StyleCastiello, M., Conte, D., & Iscaro, S. (2023). Using Epidemiological Models to Predict the Spread of Information on Twitter. Algorithms, 16(8), 391. https://doi.org/10.3390/a16080391