2.1. Proximal Policy Optimisation Algorithm
This work was carried out using the baseline implementation of the Proximal Policy Optimisation (PPO) algorithm from
stable-baselines3 [
15]. This library is an updated version of
stable-baselines, which, in turn, is a fork of OpenAI’s original
Baselines library. It provides ‘reliable implementations of reinforcement learning algorithms in PyTorch’.
The PPO algorithm was originally proposed by Schulman et al. [
16] as a development of Schulman et al.’s earlier work on Trust Region Policy Optimisation [
17]. Both techniques are policy-based methods, in which the agent learns a policy
, which maps the current state
to a distribution over the action space. For problems with continuous action spaces, this is often a (potentially multivariate) Gaussian distribution. During training, the action to take is sampled according to this distribution. Following training, the mode of the distribution is taken to be the optimal action for use in evaluation.
Both methods limit how ‘far’ an update can shift the policy. In the typical implementation of PPO, this is achieved by maximising a surrogate objective function in the gradient ascent that includes a term to penalise changes in policy, effectively limiting the rate of change. This objective function is reproduced in Equation (
1). In practical implementations, the expected value is calculated across a batched sample of transitions.
The two key terms in this equation are the policy update probability ratio
and the advantage estimator,
. The probability ratio is defined as
so that, if the new policy,
, is more likely to choose action
in state
than the old policy,
, then the probability ratio is greater than 1. The advantage estimator represents an estimate of ‘how much better’ the overall reward is if a particular action
is taken, as opposed to choosing a random action distributed according to the policy. The loss function is maximised by having a probability ratio less than one when the advantage is negative, and greater than one when the advantage is positive. In effect, this means the new policy is more likely to result in advantageous actions.
The clipping term serves to penalise large changes to the existing policy, by limiting the overall increase in that can be achieved by generating extreme probability ratios. By taking a minimum of both the original and clipped values in the objective function, the clipping process does not mask extreme changes in the probability ratios that result in reduced probability of advantageous actions, or increased probability of disadvantageous actions.
2.2. Aircraft Model
The state of the aircraft model is composed of the following: the Cartesian position,
; the body-frame velocity,
; the vehicle attitude as a non-normalised quaternion,
(denoted in vector form in the order
); the body–axis angular rates,
. Using this state representation, the full six degree-of-freedom equations of motion of the aircraft are
For the work presented here, only the longitudinal terms, , are non-zero. Follow on work will consider the lateral motion of the aircraft.
The forces
and torques
on the vehicle are computed from parameterised curves representing the aerodynamic coefficients. These aerodynamic coefficients are resolved into dimensionalised forces and torques through equations of the forms:
These equations use the dynamic pressure of the fluid from the
term, where
is the air density and
is the freestream velocity. Alongside this is the coefficient itself
, and scaling terms,
S and
. Typical choices in aerospace, and those used for this model, are the main wing area for
S and the main wing mean aerodynamic chord for
. The coefficient terms are, typically, a function of the aerodynamic state of the aircraft and current control inputs.
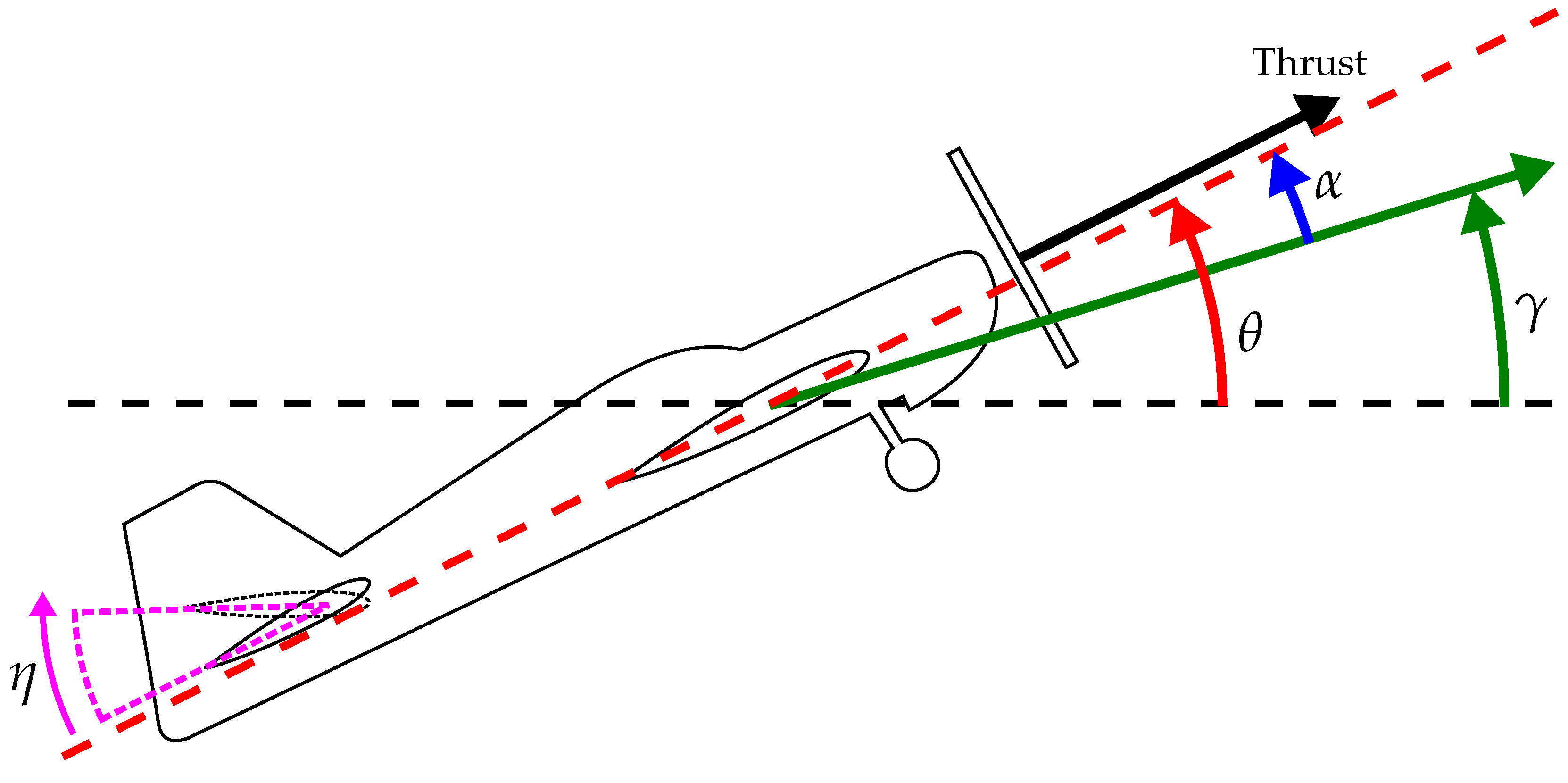
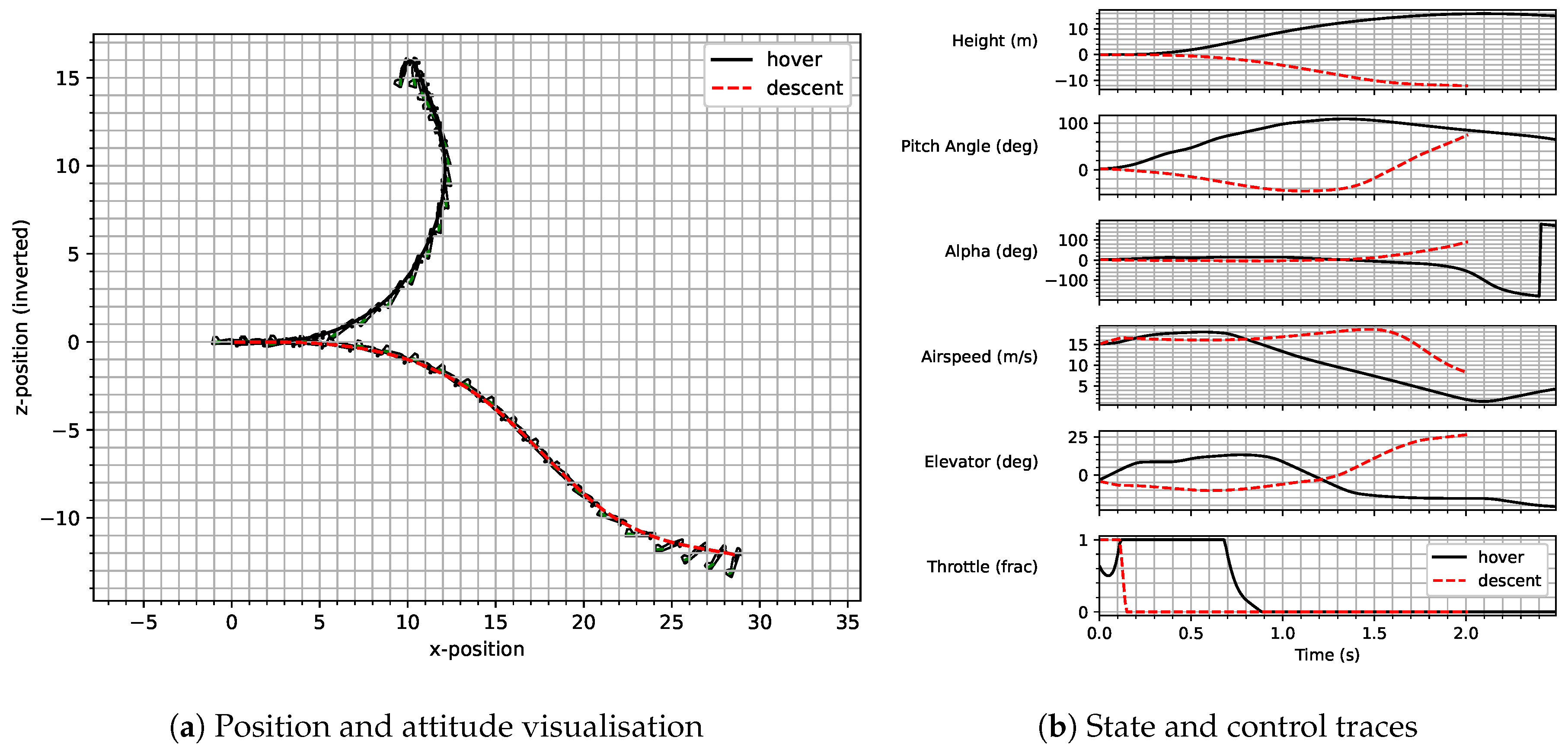
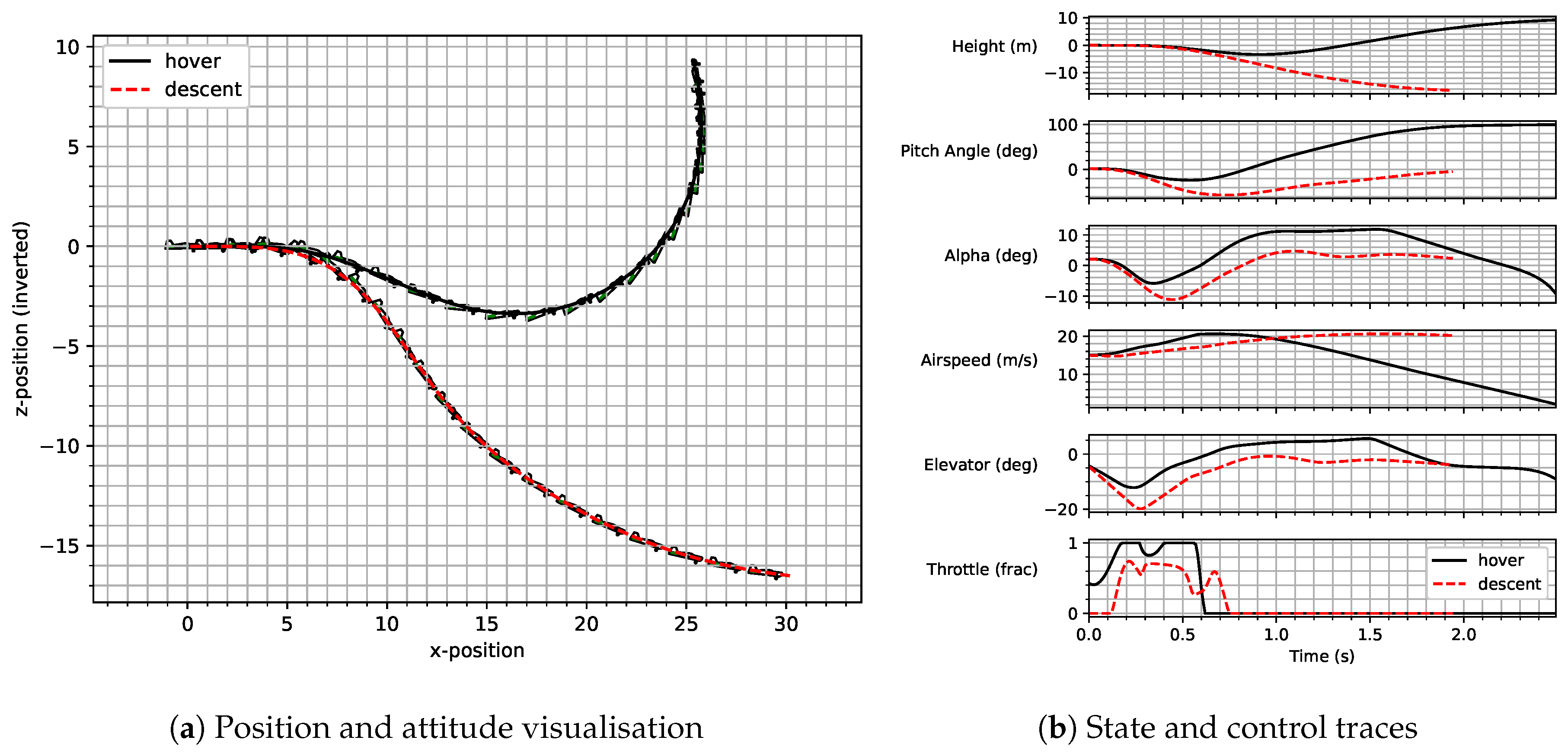
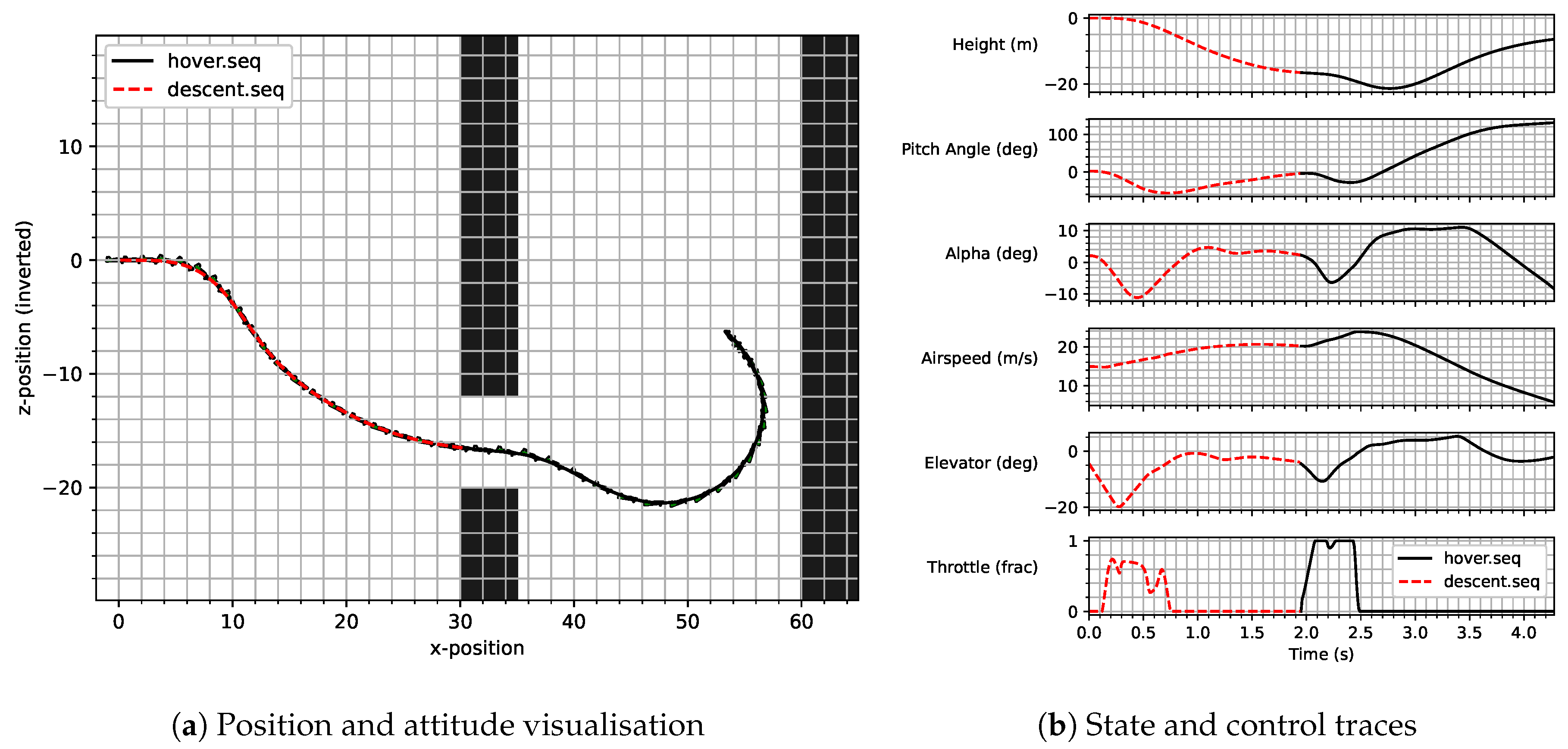
Figure 1 is a graphical representation of the various angles used in aircraft dynamics. The vehicle’s centre-of-mass is travelling along the green arrow, describing the flight path. The angle
is the angle between this direction of travel, and the horizon is the flight path angle. The angle between the horizon and the aircraft’s reference axis is the pitch angle, denoted by
, and the difference between the pitch and flight path angles provides the angle of attack, denoted by
. The angle of attack describes the angle between the oncoming airflow and the aircraft reference axis and is key for the modelling of the aerodynamic forces and moments. The elevator angle,
, is also shown.
The model used in this work is based on wind-tunnel data for the FMS Models MXS2 airframe (
https://www.fmshobby.com/products/fms-1100mm-mxs-v2-pnp-with-reflex, accessed on 24 November 2022), pictured in
Figure 2. The airframe was mounted in the University of Bristol’s 7′ × 5′ wind tunnel, with a load cell mounted internally (see
Figure 2a). Automated control inputs were generated by a set of Python scripts, which also recorded load cell data. The pitch and yaw traverse, and the tunnel airspeed, were controlled by the wind tunnel’s existing control system, which was manually provided with setpoints.
With the airframe mounted, the overall range available for the traverse was to 20 in angle of attack, and in sideslip. Data was gathered at indicated wind tunnel speeds of 10 m s−1 to m s−1 in m s−1 increments. The elevator, rudder and aileron were each deflected individually across a range of throttle settings at each tunnel speed and vehicle attitude, yielding a large dataset covering almost all of the conventional flight envelope and initial stages of the post-stall regime.
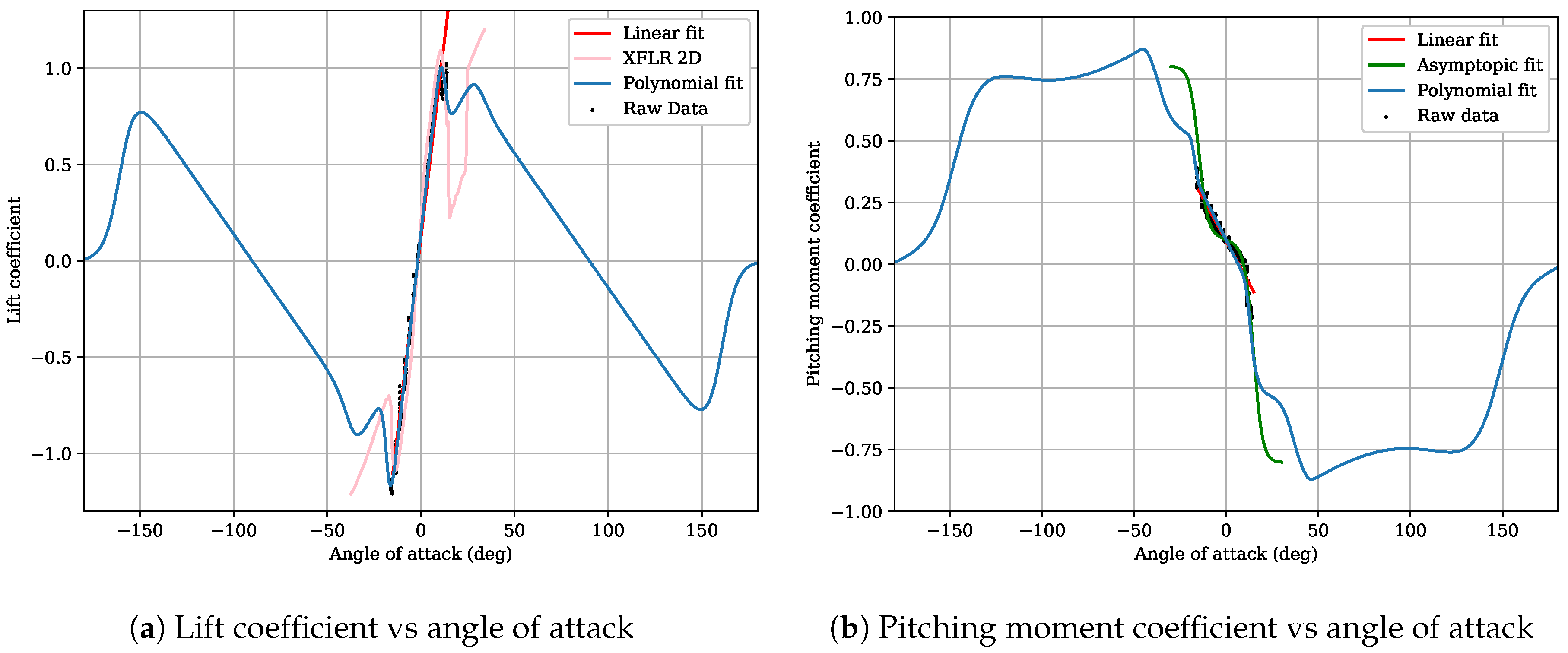
This data was then used to generate a set of parameterised curves to define the coefficients for the longitudinal model. These curves were extended with data from additional references to cover the full range of angle of attack from
through to 180
. The resulting curves for the lift and pitching moment coefficients are plotted in
Figure 3.
The longitudinal model has two control inputs available: elevator angle,
and throttle setting
.
Figure 1 shows the elevator angle, here defined as the angle to which the elevator is deflected upwards relative to its neutral position. Note that this definition of elevator angle is opposite in sense to convention, generating a positive pitching moment with a positive deflection. The wind tunnel data was used to generate a coefficient for the elevator that varied with throttle setting, airspeed and elevator angle. The throttle setting is mapped to the generated thrust, based on a two-dimensional polynomial incorporating the airspeed.
Along with the forces and torques exerted on the body, the mass and inertial properties of the body are required. A second airframe was fitted with necessary hardware for autonomous flight and used to make measurements of these properties. The resulting measurements are presented in
Table 1. In the work presented here, only a longitudinal model is used, so only the pitch inertia
and overall mass are needed.
These coefficient curves, thrust modelling and inertial data were used to implement the model using
pyaerso [
18]. This is an accessible Python interface to a simple flight dynamics modelling library implemented in Rust [
19]. It allows forces and moments to be calculated in Python, based on the current vehicle aerodynamic state, and to be transferred to dedicated, pre-compiled machine-code for the state propagation process. Wind and atmospheric density models can also be defined in Python, or a set of pre-built models can be selected from. This allows easy experimentation without the need to recompile software or manipulate aircraft model configuration files. It also means users are free to use arbitrary functions to define their models, rather than being limited to a set supported by the underlying dynamics code. The Python interface (
https://github.com/rob-clarke/pyaerso, accessed on 14 July 2023) and the underlying Rust library (
https://github.com/rob-clarke/aerso, accessed on 14 July 2023) are both available on GitHub under MIT licenses.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}